
Abstract
The rapid development of speech communication technology has made it possible for low bit-rate speech to become appropriate steganographic cover media. To incorporate data hiding into the low bit-rate speech codec, a novel steganography algorithm is proposed in this paper. By analyzing the encoding rule of fixed codebook vector, the way of transposing encoding locations of adjacent pulses is found to be suitable for data embedding with good imperceptibility. Based on encoding location transposition of adjacent pulses, the relationship between adjacent pulse locations is used to embed secret data while the fixed codebook search is being conducted during the encoding process of G.729 codec, which can maintain synchronization between data embedding and speech encoding. The experimental results demonstrate that the proposed steganography algorithm performs well in imperceptibility with a hiding capacity of 550 bits/s. Furthermore, the real-time and anti-detection performances are also satisfactory.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
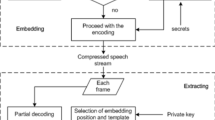
Nowdays increasingly great importance has been attached to the information security problem. To make the information transmission more secure and reliable, digital steganography, a technique of covert communication, has emerged and developed quickly. By embedding secret information into public digital media, steganography conceals both the information content and the information transmission behavior.
With the development of network and multimedia technology, low bit-rate codecs are widely applied to speech communication systems such as voice over Internet protocol (VoIP) service. As a result, steganography in low bit-rate speech streams has attracted interests of researchers [7, 9, 15]. Compared to the traditional steganography, the low bit-rate speech steganography has the following advantages. First, speech data is generated and transmitted in real time during the communication process, which improves steganography security by providing insufficient time to perform steganalysis. Second, the data volume of continuous speech communication is much greater than individual image or text, hence it is possible for large-scale secret information transmission. Third, speech data is hard to recognize from the enormous data over the Internet, let alone those with secret data embedded.
Due to the advantages of taking low bit-rate speech streams as covers to perform steganography, there have been some attempts in this area. For optionally regulating hiding capacity and imperceptibility, Tian et al. [13] proposed a dynamic ME method for VoIP steganography. By using Compounded Pseudorandom Sequence, a VoIP-based covert communication scheme was proposed in [14]. Liu et al. [6] improved the traditional LSB method and proposed the LSD (least significant digit) method. Inspired by the “Hamming + 1” scheme, Yan et al. [17] proposed a triple-layer steganography scheme for low bit-rate speech streams. To improve the security of the QIM (quantization index modulation) steganography in low bit-rate speech streams, a modified QIM steganography algorithm which selected the hiding positions randomly to adjust the embedding rate was proposed in [11]. Huang et al. [2] proposed a steganography algorithm based on the pitch period prediction process, which incorporated data hiding into G.723.1 codec. It is really an excellent work to combine data hiding with speech encoding, but the proposed algorithm can only be used in G.723.1 codec. To extend the application range of speech steganography in other low bit-rate codecs, we focus on incorporating data hiding into G.729 codec.
G.729 codec is one of the most representative low bit-rate codecs. Owing to the wide application of G.729 codec in a variety of speech communication systems, steganography aiming at G.729 codec has been explored. The abilities of parameters in the G.729 speech frame for carrying secret data were analyzed using a noisy resistance model in [8]. The study shows that the fixed codebook parameter is appropriate for data embedding. On this basis, Tian et al. took the fixed codebook parameters as cover data to design steganography algorithms [10, 12]. In [12], in order to solve the synchronization problem, some fields in the IP header were selected to embed the synchronization parameters. In [10], by introducing the notion of partial similarity value (PSV), an adaptive partial-matching steganography for VoIP was presented. Wu et al. [16] proposed a steganography algorithm to embed secret data into G.729 coding speech by adapting the techniques of covering code and the interleaving, which achieved high a hiding capacity. The fixed codebook parameter takes relatively more bits in G.729 speech frame, so it affords an approach to achieve high hiding capacity when being used to embed data. However, most of the steganography algorithms based on fixed codebook search process perform embedding by substituting the least significant bits (LSBs) of fixed codebook parameters. The way of direct substitution will cause large pulse displacements in the fixed codebook vector. Therefore, the imperceptibility remains to be improved.
In order to improve the imperceptibility of speech steganography in G.729 codec, a steganography algorithm for G.729 codec is presented in this paper. First, by analyzing the encoding rule, we prove that transposing encoding locations of adjacent pulses can reduce pulse displacements. Second, based on transposing encoding locations of adjacent pulses, a steganography algorithm is proposed by modifying the relationship between pulse locations, which incorporates data embedding into the fixed codebook search process in G.729 codec.
The rest of the paper is organized as follows. Section 2 analyzes the fixed codebook search process in G.729 codec. A novel speech steganography algorithm is presented in Section 3. Section 4 shows the experimental results. The conclusions are summarized in Section 5.
2 Analysis of fixed codebook search process in G.729 codec
ITU-T G.729 is a kind of speech compression technology based on conjugate structure algebraic code excited linear prediction (CS-ACELP) algorithm. For each speech frame of 10 milliseconds, G.729 codec extracts CELP parameters (linear prediction parameters, adaptive and fixed codebook parameters, adaptive and fixed codebook gains) and then encodes them for transmission. The fixed codebook vector is an important part of the exciting signal. It serves as an approximation to the residual signal after short-time and long-time predictions, which can provide a precise error compensation to help improving the speech quality.
2.1 Fixed codebook search process in G.729 codec
During G.729 encoding process, the fixed codebook vector is searched every subframe (a frame is divided into two subframes). The fixed codebook structure is shown in Table 1.
The fixed codebook vector c(n) contains four unit pulses.
Where δ(0) denotes the unit pulse.
When using the full search algorithm to search the fixed codebook vector, the search process is composed of four nested loops, with each nested loop searching for one pulse location. In order to get the optimal pulse location, the computation times needed are 23 × 23 × 23 × 24 = 8192. To decrease the computational complexity, G.729 adopts the centralized search algorithm. It simplifies the search process by restricting the entering times into the fourth nested loop. Let max3 and av 3 be the largest absolute correlation degree and the average correlation degree, respectively. The threshold thr 3 is calculated first:
kequals to 0.4. The last nested loop is effective only if the absolute correlation degree of the first three pulses c 3 is greater than thr 3. The block diagram of the centralized search algorithm is shown in Fig. 1.

The block diagram of the centralized search algorithm
N is the maximum search time of each subframe allowed. In the worst situation where N = 90, the total computation times in each subframe are 90 × 16 = 1440. Therefore, only 1440/8192 = 17.6 % of the codebook space is searched.
Though the centralized search algorithm decreases the computation complexity by non-exhaustive way, the fixed codebook vector obtained is just local optimal because of the restriction to the search range. Consequently, there are some redundancies in the fixed codebook parameters, to which minor modifications won’t cause significant loss of speech quality.
2.2 Fixed codebook vector encoding
The locations of the first three pulses τ 0, τ 1 and τ 2 are encoded with 3 bits respectively, with signs encoded to 1 bit respectively. The location of the fourth pulse τ 3 is encoded with 4 bits, with signs encoded with1 bit. Let C denote the fixed codebook parameter.
Where i j (j = 0, 1, 2, 3) denotes the pulse location. Let S denote the sign parameter.
Where s j = 1 denotes the sign is positive and s j = 0 denotes the sign is negative. Finally, transform C and S to binary format.
Two important theorems about transposing encoding locations of adjacent pulses in the fixed codebook vector are given below.
Theorem 1
Let τ a and τ b be any two adjacent pulses of the first three pulses in the fixed codebook vector. Transpose the encoding locations of τ a and τ b , the fixed codebook vector will remain unchanged or the two pulses τ a and τ b shift one unit respectively.
Proof
Take τ 0 and τ 1 for example. Assume that C ' and S ' are parameters obtained after transposing their encoding locations.
In the decoder, the locations and signs of τ 0 and τ 1 are obtained by decoding C ' and S '.
LSB (i)(C ') denotes the ith lowest bit of C '.
Then discuss the following two cases.
-
(1)
$$ \left\lfloor {i}_0/5\right\rfloor \ne \left\lfloor {i}_1/5\right\rfloor $$
Let c ' (n) be the fixed codebook vector decoded.
Known from Table 1, in this case i 0 + 1 doesn’t equal to i 1. Hence, compared to the original vector c(n), c ' (n) shifts one unit right at pulse τ 0 and one unit left at pulse τ 1. That is the two pulses shift one unit respectively.
-
(2)
$$ \left\lfloor {i}_0/5\right\rfloor =\left\lfloor {i}_1/5\right\rfloor $$
It is same to case (1):
But in this case i 0 + 1 equals to i 1. Hence, c ' (n) equals to c(n). That is the fixed codebook vector remains unchanged.
The cases of transposing the encoding locations of τ 1 and τ 2 are same to the cases above. □
Theorem 2
Transpose the encoding locations of τ 2 and τ 3 will make the total pulse displacements in the fixed codebook vector be three units at most.
Proof
Except for adding the jx bit while encoding i 3, it is same to the situation in Theorem 1. So the conclusions are directly given below.
-
(1)
$$ \left\lfloor {i}_2/5\right\rfloor \ne \left\lfloor {i}_3/5\right\rfloor $$
After transposing the encoding locations, let jx = 0. There are two cases:
-
a)
$$ {i}_3 \mod 5=3 $$
Compared to c(n), c ' (n) shifts one unit right at pulse τ 2 and one unit left at pulse τ 3.
-
b)
$$ {i}_3 \mod 5=4 $$
Compared to c(n), c ' (n) shifts one unit right at pulse τ 2 and two units left at pulse τ 3.
-
(2)
$$ \left\lfloor {i}_2/5\right\rfloor =\left\lfloor {i}_3/5\right\rfloor $$
After transposing the encoding locations, let jx stay the original value. Then the fixed codebook vector remains unchanged. □
Known from the two theorems above, the pulse displacements caused by transposing encoding locations of adjacent pulses are no more than three units. If the LSB of fixed codebook parameter is directly substituted, the pulse displacements will be five units. Therefore, transposing encoding locations of adjacent pulses in the fixed codebook vector introduces smaller displacements, which can be used to design speech steganography algorithm with better imperceptibility.
3 Steganography algorithm based on fixed codebook search process
With the guidance of incorporating data hiding into low bit-rate speech codec, in this section we propose a speech steganography algorithm based on the fixed codebook search process in G.729 codec.
In the fixed codebook vector, different pulses have different locations. The location relationship between adjacent pulses can be used to embed secret data. Let m 1 and m 2 be two secret bits. m 1 is embedded according to the location relationship between pulses τ 0 and τ 1, while m 2 is embedded according to the location relationship between pulses τ 2 and τ 3. The embedding rules are described below.
Pulse τ 3 is different from the first three pulses, which has 16 locations to choose and the location values are continuous between adjacent ones. Taking advantage of the parity of i 3, another one secret bit m 3 can be embedded.
Based on the embedding rules above, data embedding can be performed while the fixed codebook vector is encoded during the fixed codebook search process. The key problem is how to change the location relationship to satisfy embedding requirement.
Let τ j ' and τ j + 1 ' (j = 0, 2) be the pulses decoded after transposing the encoding locations of τ j and τ j + 1. Known from the two theorems described in Section 2.2, the new pulse locations i j ' and i j + 1 ' decoded with τ j ' and τ j + 1 ' are different from the original pulse locations i j and i j + 1. The influence of transposing encoding locations of adjacent pulses on the relationship of pulse locations is analyzed in two cases below.
-
(1)
$$ \left\lfloor {i}_j/5\right\rfloor \ne \left\lfloor {i}_{j+1}/5\right\rfloor $$
Table 1 shows that pulses τ j and τ j + 1 have different locations, that is i j ≠ i j + 1. Let’s assume i j < i j + 1. Because ⌊i j /5⌋ ≠ ⌊i j + 1/5⌋, in this case i j + 1 − i j ≥ 6. According to theorems 1 and 2, the pulse locations i j ' and i j + 1 ' decoded with τ j ' and τ j + 1 ' satisfy:
According to Eqs. (23) and (24), i j ' − i j + 1 ' ≥ i j + 1 − i j − 3 ≥ 3, that is i j ' > i j + 1 '. The case of i j > i j + 1 is same to the case of i j < i j + 1, except for i j − i j + 1 ≥ 3. So in this case i j + 1 ' − i j ' ≥ i j − i j + 1 + 2 ≥ 5, that is i j ' < i j + 1 '. As a result, after transposing encoding locations of τ j and τ j + 1, the relationship between i j ' and i j + 1 ' satisfies:
Hence we can draw the conclusion that transposing encoding locations of adjacent pulses can change the location relationship between adjacent pulses.
-
(2)
$$ \left\lfloor {i}_j/5\right\rfloor =\left\lfloor {i}_{j+1}/5\right\rfloor $$
According to theorems 1 and 2, in this case transposing encoding locations can’t change the location relationship between adjacent pulses. Hence only the parity of i 3 can be used to embed secret data.
3.1 Embedding procedure
The embedding procedure is described below.
-
Step 1:
Let M = (m 1, m 2, ⋅ ⋅⋅, m n ) be the secret bit stream to be embedded.
-
Step 2:
During the fixed codebook search process in each subframe, get the four pulses τ 0, τ 1, τ 2 and τ 3 in the fixed codebook vector. Let i 0, i 1, i 2 and i 3 be the pulse locations, s 0, s 1, s 2 and s 3 be the pulse signs.
-
Step 3:
According to the values of i 0 and i 1, there are two cases.
-
(1)
⌊i 0/5⌋ ≠ ⌊i 1/5⌋
Let m a (a ∈ [0, n]) be the secret bit to be embedded, i 0 ', i 1 ' and s 0 ', s 1 ' be the pulse locations and signs after m l being embedded. m a is embedded according to Eq. (26).
$$ \begin{array}{l}\left\{\begin{array}{l}{i}_0^{\prime }={i}_0,{s}_0^{\prime }={s}_0\hfill \\ {}{i}_1^{\prime }={i}_1,{s}_1^{\prime }={s}_1\hfill \end{array}\right.\kern2em if\ {m}_a=0,{i}_0>{i}_1\ or\ {m}_a=1,{i}_0<{i}_1\\ {}\left\{\begin{array}{l}{i}_0^{\prime }={i}_1-1,{s}_0^{\prime }={s}_1\hfill \\ {}{i}_1^{\prime }={i}_0+1,{s}_1^{\prime }={s}_0\hfill \end{array}\right.\kern1em if\ {m}_a=0,{i}_0<{i}_1\ or\ {m}_a=1,{i}_0>{i}_1\end{array} $$(26)-
(2)
\( \left\lfloor {i}_0/5\right\rfloor =\left\lfloor {i}_1/5\right\rfloor \)
No embedding is performed.
-
(1)
-
Step 4:
According to the values of i 2 and i 3, there are two cases.
-
(1)
$$ \left\lfloor {i}_2/5\right\rfloor \ne \left\lfloor {i}_3/5\right\rfloor $$
Let m b , m c (b, c ∈ [0, n]) be the secret bits to be embedded, i 2 ', i 3 ' and s 2 ', s 3 ' be the pulse locations and signs after m b and m c being embedded. m b and m c are embedded according to Eq. (27).
$$ \begin{array}{l}\left\{\begin{array}{l}{i}_2^{\prime }={i}_2,{s}_2^{\prime }={s}_2\hfill \\ {}{i}_3^{\prime }={i}_3+\left[7-2\cdot \left({i}_3 \mod 5\right)\right]\cdot \left|{i}_3 \mod 2-{m}_c\right|,{s}_3^{\prime }={s}_3\hfill \end{array}\right.\kern1.25em if\ {m}_b=0,{i}_2>{i}_3\ or\ {m}_b=1,{i}_2<{i}_3\\ {}\left\{\begin{array}{l}{i}_2^{\prime }={i}_3-{i}_3 \mod 5+2,\kern0.2em {s}_2^{\prime }={s}_3\hfill \\ {}{i}_3^{\prime }={i}_2+2-\left|{i}_2 \mod 2-{m}_c\right|,{s}_3^{\prime }={s}_2\hfill \end{array}\right.\kern6.4em if\ {m}_b=0,{i}_2<{i}_3\ or\ {m}_b=1,{i}_2>{i}_3\end{array} $$(27)-
(2)
$$ \left\lfloor {i}_2/5\right\rfloor =\left\lfloor {i}_3/5\right\rfloor $$
No embedding is performed.
-
(1)
-
Step 5:
Repeat Step 2 to Step 4 until all the secret data is embedded.
3.2 Extracting procedure
The extracting procedure is described below.
-
Step 1:
During G.729 decoder operates on each subframe, get the four pulses τ 0 ', τ 1 ', τ 2 ' and τ 3 ' after the fixed codebook vector being decoded. Let i 0 ', i 1 ', i 2 ' and i 3 ' be the pulse locations.
-
Step 2:
According to the values of i 0 ' and i 1 ', there are two cases.
-
(1)
$$ \left\lfloor {i}_0^{\prime }/5\right\rfloor \ne \left\lfloor {i}_1^{\prime }/5\right\rfloor $$
m a is extracted according to Eq. (28).
$$ {m}_a=\left\{\begin{array}{cc}\hfill 0\hfill & \hfill if\ {i}_0^{\prime }>{i}_1^{\prime}\hfill \\ {}\hfill 1\hfill & \hfill if\ {i}_0^{\prime }<{i}_1^{\prime}\hfill \end{array}\right. $$(28)-
(2)
$$ \left\lfloor {i}_0/5\right\rfloor =\left\lfloor {i}_1/5\right\rfloor $$
No extracting is performed.
-
(1)
-
Step 3:
According to the values of i 2 ' and i 3 ', there are two cases.
-
(1)
$$ \left\lfloor {i}_2/5\right\rfloor \ne \left\lfloor {i}_3/5\right\rfloor $$
m b is extracted according to Eq. (29).
$$ {m}_b=\left\{\begin{array}{cc}\hfill 0\hfill & \hfill if\ {i}_2^{\prime }>{i}_3^{\prime}\hfill \\ {}\hfill 1\hfill & \hfill if\ {i}_2^{\prime }<{i}_3^{\prime}\hfill \end{array}\right. $$(29)-
(2)
$$ \left\lfloor {i}_2/5\right\rfloor =\left\lfloor {i}_3/5\right\rfloor $$
No extracting is performed.
-
(1)
-
Step 4:
m c is extracted according to Eq. (30).
$$ {m}_c=\left\{\begin{array}{cc}\hfill 0\hfill & \hfill if\ {i}_3\hbox{'} \mod 2=0\hfill \\ {}\hfill 1\hfill & \hfill if\ {i}_3\hbox{'} \mod 2=1\hfill \end{array}\right. $$(30) -
Step 5:
Repeat Step 1 to Step 4 until all the secret data is extracted.
Let event A 1 denote that transposing operation can be used to perform embedding. Let event A 2 denote transposing operation is necessary for performing embedding. Let event A 3 denote that the parity of i 3 needs to be modified to perform embedding. The probabilities of the events are: P(A 1) = 7/8, P(A 2|A 1) = 1/2, P(A 3) = 1/2. Let C denote the average number of secret bits can be embedded per subframe.
The hiding capacity of the proposed algorithm is 2.75 × 2 × 100 = 550bits/s. According to the two theorems in Section 2.2, the average pulse displacements of the fixed codebook vector in each subframe can be calculated.
Define embedding rate as the average number of bits embedded per pulse displacement. The embedding rate of the proposed algorithm is C/S = 11/9. The embedding rate of directly using LSB substitution method to the fixed codebook parameters is just 0.4. Therefore, under the same embedding rate condition, the proposed algorithm has a better performance in imperceptibility by decreasing pulse displacements.
4 Experiments
To evaluate the effectiveness of the proposed steganography algorithm, we selected speech files of different lengths from the AN4 database [1] as steganography covers to conduct experiments. The speech files were divided into three groups which were defined as Sample-1, Sample-2 and Sample-3 in terms of their lengths. Sample-1 contained speech files with lengths no more than 2 s; sample-2 contained speech files with lengths between 2 and 4 s; sample-3 contained speech files with lengths more than 4 s. Each group contained 300 speech files, with half male and half female speakers. Each speech file was sampled at 8 kHz and quantized to 16 bits using the linear pulse code modulation (PCM).
In the experiments, G.729 codec operated at 8 kbps. To maximize the hiding capacity, each subframe is used to embed secret data. The proposed algorithm is evaluated in terms of three aspects: imperceptibility, real-time performance and security.
4.1 Imperceptibility
The waveforms and spectrograms of normal speech files (synthetic speech files with nothing embedded) and stego speech files (synthetic speech files with secret data embedded) are shown in Figs. 2 and 3. In both two figures, graphs (a)–(c) denote normal speech files and graphs (d)–(f) denote the corresponding stego speech files. Known from the two figures, there is nearly no difference between the normal speech files and the stego speech files in time domain and frequency domain. Therefore, the proposed algorithm has little influence on speech quality.

Waveforms of normal speech files and stego speech files

Spectrograms of normal speech files and stego speech files
When evaluating speech quality, objective evaluation methods are widely used for their advantages of convenience, flexibility and reliability. Objective evaluation methods can be divided into two groups: evaluation methods based on output only and evaluation methods based on input-output. A typical representative of the former is the evaluation method based on E-Model [4], which is a non-intrusive method. Because just using the output signal to evaluate speech quality, it has a good real-time performance. A typical representative of the latter is the perceptual evaluation speech quality (PESQ) method described in ITU-T P.862 Recommendation [3], which offers a high evaluation precision by comparing an original signal with a degraded signal and outputs a PESQ value as a prediction of the perceived quality. What concerned most in this paper is the quality of the stego speech file compared to the normal speech file, so we select the PESQ method to precisely reflect the difference in perceived qualities. The range of the PESQ value is −0.5 (worst) to 4.5 (best).
Figures 4, 5 and 6 show the PESQ values of 100 normal and stego speech files in three groups respectively. Table 2 shows the statistical results of the PESQ values for the three speech groups, where the negative change rate denotes deterioration in PESQ value and the positive one denotes amelioration. From the table, the average worsening change rates of PESQ values are 6.55, 6.47 and 6.60 %, respectively. The total average worsening change rate is 6.54 %. Though the PESQ values of stego speech files are slightly lower than that of normal speech files, it still remains at a normal level. Hence the stego speech files obtained by using the proposed algorithm have good perceived qualities.

PESQ values for Sample-1

PESQ values for Sample-2

PESQ values for Sample-3
The steganography algorithms proposed in [10] and [16] also perform data embedding in G.729 codec, they are representative research products published in recent years. In [10], fixed codebook vector is also taken as the cover data to embed secret data. In [16], parameters in fixed codebook vector and LSP (Line Spectrum Pair) are used to embed secret data together. Figure 7 shows the PESQ values for randomly selected 100 speech files of different lengths after being embedded using the proposed algorithm, the algorithm in [10] and the algorithm in [16]. The embedding rates of the proposed algorithm, the algorithm in [10] and the algorithm in [16] are 550 bits/s, 398 bits/s and 2.4kbits/s, respectively. Known from Fig. 7, the PESQ values of the proposed algorithm are around 3.5, indicating the perceived qualities of stego speeches are good. The PESQ values of the algorithm in [10] are around 3.2, so the proposed algorithm performs better than the algorithm in [10] in imperceptibility while achieving a higher hiding capacity. Though the embedding rate of the algorithm in [16] is much bigger than the proposed algorithm, the PESQ values of the algorithm in [16] is around 2.9, indicating a bad perceived qualities of stego speeches.

4.2 Real-time performance
To satisfy the real-time requirement, the latency caused by secret data embedding should be controlled in a small range. In order to test the influence of the proposed algorithm on the real-time performance of G.729 codec, we recorded the processing time of G.729 codec operating on each speech frame with and without secret data embedded on Intel Core 3.20 GHz computers with 4G DDR3 SD RAM.
The encoding time and decoding time of 100 speech frames are shown in Figs. 8 and 9. As is shown, the two curves in either figure are very close to each other. The average encoding and decoding time delays caused by the proposed algorithm are 0.185 and 0.093 ms respectively, which is negligible compared to the 15 ms time delay allowed in G.729 codec. Therefore, the proposed algorithm can satisfy the real-time requirement of G.729 codec well.

Encoding time of speech frames with and without data embedded

Decoding time of speech frames with and without data extracted
4.3 Security
The anti-detection performance is of great importance when considering the steganography security. We used the derivative mel-Frequency cepstral coefficients (DMFCC)-based steganalysis algorithm [5], an advanced algorithm based on Fourier spectrum statistics and mel-cepstrum coefficients, to detect the proposed algorithm. The LIBSVM Version 3.0 was used in our test. In the SVM-scale of LIBSVM, the lower and the upper is −1 and 1 respectively. The other parameters used are default values. In the SVM-train of LIBSVM, the svm_type is C-SVC, the kernel_type is RBF (radial basis function), the cost is 1000, the epsilon is 0.00001, and the other parameters used are default values.
The detection results are presented in Table 3. The average detection accuracies for the three groups of speech files are 51.10, 51.04 and 51.52 % respectively. This indicates the proposed algorithm can avoid being detected by the DMFCC-based algorithm.
Figure 10 shows the steganalysis results of the proposed algorithm and the algorithm in [10] using DMFCC-based algorithm at different detection window lengths. Know from Fig. 10, as the detection window becomes long, the detection accuracies of the two algorithms increase. This is because longer detection window means more speech frames are analyzed. But the average detection accuracies are around 51 % and the maximum accuracies are under 55 %, indicating the steganalysis algorithm is useless for the above two algorithms. The main reason is the two algorithms are performed in compressed domain, which have little impact on the time or transform domain.

Comparison of steganalysis results between the proposed algorithm and the algorithm in [10]
5 Conclusion
In this paper, a novel steganography algorithm for low bit-rate speech is proposed. Based on analyzing the fixed codebook search process in G.729 codec, we prove that transposing encoding locations of adjacent pulses in the fixed codebook vector causes small displacements. Then, the location relationship between adjacent pulses and the parity of the location value in the fourth pulse are used to perform embedding. The proposed steganography algorithm can attain a hiding capacity of 550 bits/s. Experimental results show that the proposed steganography algorithm outperforms the traditional steganography algorithms based on the fixed codebook in terms of imperceptibility. Meanwhile, the proposed steganography algorithm satisfies the real-time requirement well and can avoid being detected by the DMFCC-based steganalysis algorithm. The emphasis of future work will be put on how to apply the proposed algorithm to other codecs considering their characteristics.
References
An4 database (1991) http://www.speech.cs.cmu.edu/databases/an4/
Huang Y, Liu C, Tang S, Bai S (2012) Steganography integration into a low-bit rate speech codec. Inf Forensics Secur 7:1865–1875, IEEE Transactions on
ITU-T, Recommendation P (2001) 862-perceptual evaluation of speech quality (PESQ): an objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs. International telecommunication union-telecommunication standardization sector (ITU-T)
ITU-T, Recommendation G107 (2002) The E-Model, a computational model for use in transmission planning
Liu Q, Sung AH, Qiao M (2009) Temporal derivative-based spectrum and mel-cepstrum audio steganalysis. Inf Forensics Secur 4:359–368
Liu J, Zhou K, Tian H (2012) Least-significant-digit steganography in low bitrate speech. In: Proceedings of IEEE international conference on communications:1133–1137
Mazurczyk W (2013) VoIP steganography and its detection-a survey. ACM Comput Surv (CSUR) 46(2):20
Su Y, Huang Y, Li X (2006) Steganography-oriented Noisy Resistance Model of G.729a. In: Proceedings of IMACS multiconference:11–15
Tang S, Chen Q, Zhang W et al (2015) Universal steganography model for low bit-rate speech codec. Secur Commun Netw. doi:10.1002/sec.1183
Tian H, Jiang H, Zhou K, Feng D (2011) Adaptive partial-matching steganography for voice over IP using triple M sequences. Comput Commun 34:2236–2247
Tian H, Liu J, Li S (2014) Improving security of quantization-index-modulation steganography in low bit-rate speech streams. Multimedia Systems 20:143–154
Tian H, Zhou K, Jiang H, Huang Y, Liu J, Feng D (2009) An M-sequence based steganography model for voice over IP. In: Proceedings of the 44th IEEE international conference on communications, Dresden, Germany:1–5
Tian H, Zhou K, Feng D (2010) Dynamic matrix encoding strategy for voice-over-IP steganography. J Cent S Univ Technol 17:1285–1292
Tian H, Zhou K, Lu J (2012) A VoIP-based covert communication scheme using compounded pseudorandom sequence. Int J Adv Comput Technol 4(1):223–230
Wei Z, Zhao B, Liu B et al (2014) A novel steganography approach for voice over IP. J Ambient Intell Humaniz Comput 5(4):601–610
Wu Z, Cao H, Li D (2015) An M-sequence based steganography model for voice over IP. Chin J Electron 24(1):157–165
Yan S, Tang G, Sun Y, Gao X, Shen L (2014) A triple-layer steganography scheme for low bit-rate speech streams. Multimed Tools Appl 1–20. doi:10.1007/s11042-014-2265-y
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Yan, S., Tang, G. & Chen, Y. Incorporating data hiding into G.729 speech codec. Multimed Tools Appl 75, 11493–11512 (2016). https://doi.org/10.1007/s11042-015-2865-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-015-2865-1