
Abstract
Stereoscopic video technologies have been introduced to the consumer market in the past few years. A key factor in designing a 3D system is to understand how different visual cues and distortions affect the perceptual quality of stereoscopic video. The ultimate way to assess 3D video quality is through subjective tests. However, subjective evaluation is time consuming, expensive, and in some cases not possible. The other solution is developing objective quality metrics, which attempt to model the Human Visual System (HVS) in order to assess perceptual quality. Although several 2D quality metrics have been proposed for still images and videos, in the case of 3D efforts are only at the initial stages. In this paper, we propose a new full-reference quality metric for 3D content. Our method mimics HVS by fusing information of both the left and right views to construct the cyclopean view, as well as taking to account the sensitivity of HVS to contrast and the disparity of the views. In addition, a temporal pooling strategy is utilized to address the effect of temporal variations of the quality in the video. Performance evaluations showed that our 3D quality metric quantifies quality degradation caused by several representative types of distortions very accurately, with Pearson correlation coefficient of 90.8 %, a competitive performance compared to the state-of-the-art 3D quality metrics.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the introduction of 3D technology to the consumer market in recent years, one of the challenges industry has to face is assessing the quality of 3D content and evaluating the viewer’s quality of experience (QoE). While several accurate quality metrics have been designed for 2D content, still there is room for improvement when it comes to 3D video quality assessment and reliability and accuracy of 3D quality metrics. Assessing the quality of 3D content is much more difficult than that of 2D content. In the case of 2D, there are well-known factors such as brightness, contrast, and sharpness that affect perceptual quality. In the case of 3D, depth perception changes the impact that the above factors have on the overall perceived 3D video quality. Although the effect of these factors on 2D video quality has been extensively studied, we have a limited understanding of how these factors affect 3D perceptual quality. In addition, other factors such as the scene’s depth range, display size and the technology used in 3D display (i.e., active or passive glasses, glasses-free auto-stereoscopic displays, etc.) - known as 3D quality factors - solely affect 3D video quality, while they have no effect on 2D video quality [10, 17, 35]. The study presented by Seuntiens [45] identifies some additional 3D quality factors such as “presence” and “naturalness” that also affect 3D perception. These factors are of particular interest nowadays, since they have potential relevance in the design and evaluation of interactive media. Chen et al. [14] suggest including two other 3D quality factors, “depth quantity” and “visual comfort”, in the overall quality of 3D content. It has been shown that 3D quality factors have closer correlation with the overall 3D video quality compared to 2D quality factors [11, 13]. Considering that the existing 2D quality metrics only account for 2D quality factors and ignore the effect of 3D quality factors such as depth and the binocular properties of the human visual system (HVS), using these metrics to evaluate the quality of 3D videos yields low correlation with subjective results [2, 6, 23, 30]. This has been verified by applying existing 2D quality metrics on the right and left views separately, and averaging the values over two views, then comparing the results with subjective evaluations [2, 6, 23, 30].
To account for the effect of 3D quality factors when evaluating the quality of 3D content, Ha and Kim [21] proposed a 3D quality metric that is based only on the temporal and spatial disparity variations. However, the proposed metric does not include the effect of 2D-associated quality factors such as contrast and sharpness. It is known that the overall perceived 3D quality is dependent on both 3D depth perception (3D factors) and the general picture quality (2D factors) [10, 17, 35]. In [21] the Mean Square Error (MSE) is used as a quality measure, which is known to have low performance in accurately representing the human visual system [51, 52]. Moreover, this method utilizes disparity information instead of the actual depth map, which may result in inaccuracies in the case of occlusions. In addition, when using disparity instead of depth, the same amount of disparity may correspond to different perceived depths, depending on the viewing conditions. Boev et al. categorized the distortions of 3D content to monoscopic and stereoscopic types and proposed separate metrics for each type of distortions [9]. In this approach, while the monoscopic quality metric quantitatively measures the distortions caused by blur, noise and contrast-change, the stereoscopic metric exclusively measures the distortions caused by depth inaccuracies. The main drawback of this approach is that it is unable to accurately measure the overall 3D quality, as it does not attempt to fuse the 2D and 3D associated factors into one index.
Considering that the ‘3D quality of experience’ refers to the overall palatability of a stereo pair, which is not limited to image impairments, some quality assessment studies propose to combine a measure of depth perception with the quality of the individual views. The study in [8] formulates the 3D quality as an efficient combination of the depth map quality and the quality of individual views. The depth map quality is evaluated based on the error between the squared disparities of the reference 3D pictures and that of the distorted one and the quality of each view is measured via structural similarity (SSIM) index [52]. Another group of researchers proposes to form a 3D quality index by combining the SSIM index of individual views and the Mean Absolute Difference (MAD) between the squared disparities of the reference 3D content and the distorted one [55]. In both methods presented in [8] and [55], the quality of the individual views is directly used to assess the overall 3D quality. However, when watching 3D, the brain fuses the two views to a single mental view known as cyclopean view. This suggests incorporating the quality of cyclopean view instead of that of individual views in order to design more accurate 3D quality metrics [15, 31]. To this end, Shao et al. [46] considered the binocular visual characteristics of HVS to design a full-reference image quality metric. In this approach, a left-right consistency check is performed to classify each view to non-corresponding, binocular fusion, and binocular suppression regions. Quality of each region is evaluated separately using the local amplitude and phase features of the reference and distorted views and then combined into an overall score [46]. In another work, Chen et al. propose a full-reference 3D quality metric, which assesses the quality of the cyclopean view image instead of individual right and left view images. In their approach the cyclopean view is generated using a binocular rivalry model [15]. The energy of Gabor filter bank responses on the left and right images is utilized to model the stimulus strength and imitate the rivalrous selection of cyclopean image quality. This work was later extended in [16] by taking into account various 2D quality metrics for cyclopean view quality evaluation and generating disparity map correspondences. The results of this study show that by taking into account the binocular rivalry in the objective 3D content quality assessment process, the correlation between the objective and subjective quality scores increases, especially in the case of asymmetrically distorted content [16]. Similarly, in the study by Jin et al. the quality of cyclopean view was taken into account in the design of a full-reference 3D quality metric for mobile applications, which is called PHVS-3D [31]. In this study the information of the left and right channels are fused using the 3D-DCT transform to generate a cyclopean view. Then, a map of local block dis-similarities between the reference and distorted cyclopean views is estimated using the MSE of block structures. The weighted average of this map is used as the PHVS-3D quality index. Although the proposed schemes in [15] and [31] take into account the quality of cyclopean view, they ignore the depth effect of the scene. The quality of cyclopean view on its own does not fully represent what is being perceived from watching a stereo pair as it only reflects the impairment associated with the cyclopean image. The overall human judgment of the 3D quality changes depending on the scene’s depth level [11, 13, 14, 45]. The impairments of 3D content are more noticeable if they occur in areas where depth level of the scene changes. Thus, a measure of depth quality in addition to the quality of cyclopean view has to be taken to account in the design of a 3D quality metric. One example of such approach is the full-reference PHSD quality metric proposed by Jin et al. [23]. Similar to PHVS-3D, PHSD fuses the information of the left and right views to simulate the cyclopean view and measure its quality. Then to take into account the effect of depth, the MSE between the disparity maps of the reference and distorted 3D content as well as the local disparity variance are incorporated. PHSD has been specifically designed for video compression applications on mobile 3D devices. Although PHSD has been proposed for evaluating the quality of 3D video, it does not utilize a temporal pooling strategy to address the effect of temporal variations of the quality in the video. The temporal pooling schemes map a series of fidelity scores associated to different frames to a single quality score that represents an entire video sequence [41]. Most of the existing full-reference stereoscopic quality metrics are either designed for 3D images or do not utilize temporal pooling.
In addition to the full-reference stereoscopic quality evaluation methods, there are also several no-reference stereoscopic quality assessment methods proposed in the literature that demonstrate competitive performance compared to full-reference metrics [12, 42]. Note that the no-reference quality metrics try to estimate the perceptual quality of distorted content without using the information of the reference 3D content. In one of the recent works, Chen et al. proposed a no-reference quality assessment method for natural stereopairs that employs the binocular rivalry to extract the 2D and 3D quality features and train a support vector machine to measure the quality of stereopairs [12]. In another work by Ryu and Sohn [42], the authors proposed a no-reference quality assessment framework for stereoscopic images by modeling the binocular quality perception in the context of blurriness and blockiness [42]. Even though the above-mentioned stereoscopic quality metrics algorithms are no-reference, they still demonstrate high performance when compared to some full-reference quality metrics for 3D images [12, 42].
In this paper, we propose a full-reference 3D quality metric, which combines the quality of the cyclopean view and the quality of depth map. In order to assess the degradation caused by 3D factors in the cyclopean view, a local image patch fusion method (based on HVS sensitivity to contrast) is incorporated to extract the local stereoscopic structural similarities. To this end, the information of the left and right channels is fused using the 3D-DCT transform. Then, we extract the local quality values using the structural similarity (SSIM) index to calculate the similarity between the reference cyclopean frame (fused left & right) and the distorted one. Moreover, the effect of depth on 3D quality of experience is taken into account through the depth map quality component by considering the impact of binocular vision on the perceived quality at every depth level. To this end, the variance of the disparity map and the similarity between disparity maps are incorporated to take to account the depth information in the proposed quality prediction model. HVS-based 2D metrics have been used in our design instead of MSE or MAD, as the former ones are reported to represent the perception of the human visual system more accurately [47, 51]. A temporal pooling strategy is used to address recency and the worst section quality effects. Recency effect refers to the high influence of the last few seconds of the video on the viewer’s ultimate decision on video quality. Worst section quality effect denotes the severe effect that the video segment with the worst quality has on the judgment of the viewers. The proposed metric can be tailored to different applications, as it takes into account the display size (the distance of the viewer from the display) and the video resolution. The performance of our proposed method is verified through extensive subjective experiments using a large database of stereoscopic videos with various simulated 2D and 3D representative types of distortions. Moreover the performance of our proposed scheme is compared with that of state-of-the-art 3D and 2D quality metrics in terms of efficiency as well as complexity.
The main contributions of this paper are summarized as follows: 1) Design and formulate quality measures for the cyclopean view and depth map and propose a 3D quality metric as a combination of these two quality measures that effectively predicts the quality of 3D content at the presence of different types of distortions, 2) Take into account the temporal quality effects, display size, and video resolution in the design of the 3D quality metric, 3) Create a large database of stereoscopic videos containing several different representative types of distortions that may occur during the multiview video compression, transmission, and display process, and 4) Verify the performance of the proposed quality assessment method through large-scale subjective tests and provide a comprehensive comparison with the state-of-the-art quality metrics.
The rest of this paper is organized as follows: Section 2 is dedicated to the description of the proposed metric, Section 3 describes our experiment setup, results and discussions are presented in Section 4, while Section 5 concludes the paper.
2 Proposed 3D quality metric
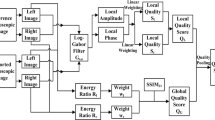
As mentioned in the Introduction section, the binocular perception mechanism of the human visual system fuses the two view pictures into a single so called cyclopean view image. In addition, the perceived depth, affects the overall perceptual quality of picture. Our proposed Human-Visual-system-based 3D (HV3D) quality metric takes into account the quality of the cyclopean view and the quality of the depth information. Cyclopean view quality component evaluates the general quality of cyclopean image, while the depth map quality component measures the effect of depth and binocular perception on the overall 3D quality. The cyclopean view is generated from the two view pictures (for the reference and distorted video) through the cyclopean view generation process. To mimic the binocular fusion of HVS, best matching blocks within the two views are found through a search process. These matching blocks are then combined in the frequency domain to generate the cyclopean view block. During the block fusion, Contrast Sensitivity Function (CSF) of HVS is taken into account through a CSF masking process. Then, the local similarities between the resulted cyclopean images are integrated into the overall cyclopean view quality component (Section 2.1). The depth map quality component is constructed by taking into account the quality of depth maps as well as the impact of depth variances (Section 2.2). As distortions can be perceived differently when there are different levels of depth present in a scene, depth map variances are computed as part of the depth map quality component of our method. The size of the blocks and geometry of the system structure in the depth map quality component are selected by considering the fovea visual focus in the HVS. Figure 1 illustrates the flowchart of the proposed framework and the following subsections elaborate on our proposed method.

Illustration of the proposed quality assessment technique
2.1 Quality of the cyclopean view – QCyclopean
To imitate the binocular vision and form the cyclopean view image we combine the corresponding areas from the left and right views. To this end, the luma information of each view is divided into m × m blocks. For each block of the left view, the most similar block in the right view is found, utilizing the disparity information. In our method, the depth map (or disparity map) is assumed to be available for the stereo views.
The depth map is either captured using a depth capturing device (e.g., a Kinect sensor), or generated by stereo matching techniques. There are many algorithms available in the literature for disparity map generation. We use the MPEG Depth Estimation Reference Software (DERS) [50] for dense disparity map generation. Note that we extract left-to-right disparity. The use of DERS for disparity map generation is suggested only when a dense disparity map is not available as an input. Note that in our cyclopean view generation scheme we need to find the best match to each block of pixels. However a dense disparity map provides the disparity value for each pixel. To address this problem, we approximate the disparity value of each block by taking the median of the disparity values of the pixels within that block. The depth information of each block has inverse relationship with its disparity value [33]. Having the disparity value per block, we can find the approximate coordinates of the corresponding block in the other view.
As Fig. 2 illustrates, A D is the approximate corresponding block for block A L in the right view, which has the same vertical coordinate as A L (illustrated as j in Fig. 2), but its horizontal coordinate differs from A L by the amount of disparity (illustrated as d in Fig. 2). Note that the A L and A D blocks are not necessarily the matching pair blocks that are fused by HVS since the position of A D is approximated based on the median of the disparity values of pixels within the block A L . In the case of occlusions, the median value does not provide an accurate estimate of the block disparity, and can result to a mismatch.

Selecting the best match: AD is the approximate corresponding block of AL in the right view + disparity; AR is the best match to AL within a search range
To find the most accurate matching block, we apply a matching block technique based on exhaustive search in a defined M × M search range around A D (see Fig. 2) using the Mean Square Error cost function. In Fig. 2, A R is the best match for A L within the search range. Note that the block size and search range are chosen based on the display resolution. For instance, in the case of HD resolution video we choose 16 × 16 block size and the search area of 64 × 64, since our performance evaluations have shown that these are the best possible sizes that significantly reduce the overall complexity of our approach while allowing us to efficiently extract local structural similarities between views.
The process of identifying matching blocks in the right view and the left view is done for both the reference and distorted stereo sets. Note that the distortions do not have any influence on the search results, since search is only performed on the reference video frames, and then the search results (i.e., the coordination of the best matching block) are used to identify matching blocks in the reference pair as well as the distorted pair.
In order to generate the cyclopean view, once the matching blocks are detected, the information of matching blocks in the left and right views needs to be fused. Here we apply the 3D-DCT transform to each pair of matching blocks (left and right views) to generate two m × m DCT-blocks, which contain the DCT coefficients of the fused blocks. The top level m × m DCT-block includes the coefficients of lower frequencies compared to the bottom one. Since the human visual system is more sensitive to the low frequencies of the cyclopean view [32], we only keep the m × m DCT-block corresponding to the lower frequency coefficients and discard the other ones. As a next step, we consider the sensitivity of the human visual system to contrast, which also affects the perceived image quality [7]. To take into account this HVS property, we need to prioritize the frequencies that are more important to the HVS. To this end, similar to the idea presented in [20], we utilize the proposed JPEG quantization tables. The JPEG quantization tables have been obtained from a series of psychovisual experiments designed to determine the visibility thresholds for the DCT basis functions. Based on this, the DCT coefficients that represent the frequencies with higher sensitivity to the human visual system are quantized less than the other coefficients so that the more visually important content is preserved during the course of compression. In our application, instead of quantizing the DCT coefficients we decided to scale them so that bigger weights are assigned to more visually important content. To achieve this, we adopt the 8 × 8 JPEG quantization table and create an 8 × 8 Contrast Sensitivity Function (CSF) modeling mask, such that the ratio among its coefficients is inversely proportional to the ratio of the corresponding elements in the JPEG quantization table. By applying the CSF modeling mask to the 3D-DCT blocks, the frequencies that are of more importance to the human visual system are assigned bigger weights. This is illustrated as follows:
where XC is our cyclopean-view model in the DCT domain for a pair of matching blocks in the right and left views, X represents the low-frequency 3D-DCT coefficients of the fused view, “.×” denotes the element-wise multiplication, and C is our CSF modeling mask. The elements of the CSF modeling mask are selected such that their average is equal to one. This guarantees that, in the case of uniform distortion distribution, the quality of each block within the distorted cyclopean view coincides with the average quality of the same view. Since the CSF modeling mask needs to be applied to m × m 3D-DCT blocks, for applications that require m to be greater than 8, cubic interpolation is used to up-sample the coefficients of the mask and create an m × m mask (in case m is less than 8, down-sampling will be used [3]).
Once we obtain the cyclopean-view model for all the blocks within the distorted and reference 3D views, the quality of the cyclopean view is calculated as follows:
where XC i is the cyclopean-view model for the i th matching block pair in the reference 3D view, XC’ i is the cyclopean-view model for the i th matching block pair in the distorted 3D view, IDCT stands for inverse 2D discrete cosine transform, N is the total number of blocks in each view, β 1 is a constant exponent, and SSIM is the structural similarity index [51, 52]. The value of β 1 is decided based on subjective tests presented in Section 3.
2.2 Quality of the depth map – QDepth
Depth information plays an important role in the perceptual quality of 3D content. The quality of the depth map becomes more important if there are several different depth levels in the scene. On the contrary, in a scene with a limited number of depth levels, the quality of the depth map plays a less important role in the overall 3D quality. This suggests considering the variance of depth map in conjunction with the depth map quality to reflect the importance of the depth map quality. However the variance of depth is required to be taken into account locally in the scene, as only a portion of the scene can be fully projected onto the eye fovea when watching a 3D display from a typical viewing distance. Figure 3 illustrates the relationship between the block size projected onto eye fovea and the distance of the viewer. As it can be observed, the length of a square block on the screen that can be fully projected onto the eye fovea is calculated as follows:
where K is the length of the block (in [mm]), d is the proper viewing distance from the display (in [mm]), and α is the half of the angle of the viewer’s eye at the highest visual acuity. The proper distance of a viewer from the display is decided based on the size of the display. The range of 2α is between 0.5 and 2° [26]. The sharpness of vision drops off quickly beyond this range. The length of the block (K) can be translated in pixel units as follows:
where k is the length of the block on the screen (in pixels), H is the height of the display (in [mm]), and h is the vertical resolution of the display.

Visual acuity of fovea, receptive field; relationship between the block size projected onto eye fovea and the distance of the viewer
The local disparity variance is calculated over a block size area that can be fully projected onto the eye fovea when watching a 3D display from a typical viewing distance. For calculating the local depth-map variance of the i th block (i.e., \( {\sigma}_{d_i}^2 \), an outer block of k × k is considered such that the m × m block is located at its centre (see Fig. 4 for the present embodiment), and \( {\sigma}_{d_i}^2 \) is defined as follows:
where M d is the mean of the depth values of each k × k block (outer block around the i th m × m block) in the normalized reference depth map. The reference depth map has been normalized with respect to its maximum value in each frame, so that the depth values range from 0 to 1. R j,l is the depth value of pixel (j,l) in the outer k × k block within the normalized reference depth map.

Block structures for calculating the variance of disparities
In our previous study on the relationship between the depth map quality and the overall 3D video quality, we verified that among the existing state-of-the-art 2D quality metrics, the Visual Information Fidelity (VIF) index of depth maps has the highest correlation with the mean opinion scores (MOS) of viewers [4]. It is also worth mentioning that the SSIM term in (2) compares the structure of two images only and does not take into account the effect of small geometric distortions [51]. The geometrical distortions are the source of vertical parallax, which causes severe discomfort for viewers (brain cannot properly fuse right and left view). The geometric distortions between right and left images (within the cyclopean view) are reflected in the depth map. Therefore, VIF is used to compare the quality of depth map of the distorted 3D content with respect to that of the reference one (see [47, 51] for more details on VIF) as follows:
where D is the depth map of the reference 3D view, D’ is the depth map of the distorted 3D view, VIF is the Visual Information Fidelity index, β 2 and β 3 are constant exponents, N is the total number of blocks, and \( {\sigma}_{d_i}^2 \) is the local variance of block i in the depth map of the 3D reference view. Note that the latter part in Eq. (6) performs a summation over the normalized local variances. The variance term is computed for each block according to (5) and normalized to the maximum possible variance value for all the blocks. The summation is then divided by N, the total number of blocks, to provide an average normalized local variance value in the interval of [0, 1].
2.3 Constructing the overall HV3D metric
Once the quality of the distorted cyclopean view and depth map is evaluated (see (2) and (6)), the final form of our HV3D quality metric is defined as follows:
where XC i is the cyclopean-view model for the i th matching block pair in the reference 3D view, XC’ i is the cyclopean-view model for the i th matching block pair in the distorted 3D view, IDCT stands for inverse 2D discrete cosine transform, N is the total number of blocks in each view, β 1 , β 2 , β 3 are the constant exponents, SSIM is the structural similarity index [51, 52], D is the depth map of the reference 3D view, D’ is the depth map of the distorted 3D view, VIF is the Visual Information Fidelity index, and σ 2 i is the local variance of block i in the depth map of the 3D reference view. The exponent parameters in HV3D (β 1 , β 2 , and β 3 ) are determined in the subsection 2.4.
Since different frames of a video have different influence on the human judgment of quality, the overall quality of a video sequence is found by assigning weights to frame quality scores, according to their influence on the overall quality. Subjective tests for video quality assessment have shown that subjects’ ultimate decisions on the video quality are highly influenced by the last few seconds of the video (recency effect) [34, 41, 43]. Moreover, the video segment with the worst quality highly affects the judgment of the viewers [43]. This is true mainly because subjects keep the most distorted segment of a video in memory much more than segments with good or fair quality [43]. Temporal pooling algorithms have been proposed that map a series of fidelity scores associated to different frames to a single quality score that represents an entire video sequence [41]. To address the recency and worst section quality effects, a temporal pooling strategy has been used in our study, which is discussed in subsection 2.5. The overall approach proposed in our study to evaluate the quality of 3D content is illustrated as a flowchart in Fig. 1. A MATLAB implementation of our metric is available online at our web site [19].
2.4 Constant exponents: β1, β2, and β3
To find the constant exponents for our HV3D quality metric and validate its performance, we performed subjective tests using two different 3D databases (one set for training and one set for validation).
To estimate the exponent constants of the proposed metric as denoted in the Eq. (7), all the terms were calculated for each video in the training dataset.To determine the best values for the exponent constants β 1 β 2 , and β 3 , we need to maximize the correlation between our HV3D indices and the MOS values of the training dataset. This can be formulated as follows:
where ρ is the Pearson correlation coefficient. We evaluate the correlation between HV3D and MOS vectors over a wide range of β i values and select the β i values that result in the highest correlation. The accuracy and robustness of the obtained exponents is further confirmed by measuring the correlation between MOS values and the HV3D indices of the validation video set (see Section 4).
2.5 Temporal pooling strategy
In our study, to address the recency and worst section quality effects we used the exponentially weighted Minkowski summation temporal pooling mechanism [22]. As shown in [41], the exponentially weighted Minkowski summation strategy outperforms some other existing temporal pooling methods, such as the histogram-based pooling, averaging, mean value of the last frames, and local minimum value of the scores in successive frames. The exponentially weighted Minkowski summation is formulated as follows:
where N f is the total number of frames, p is the Minkowski exponent, and τ is the exponential time constant that controls the strength of the recency effect. Higher values of p result in the overall score to be more influenced by the frame with largest degradation. In order to find the best values of p and τ, the Pearson correlation coefficient (PCC) is calculated for a wide range of these two parameters for the training video set.
Moreover, in order to adjust the proposed metric for the asymmetric video content where the overall quality of right and left view and their corresponding depth maps is not identical, the reference depth map and the base view for finding matching blocks (in the process of cyclopean view and depth map quality evaluation) are switched between the two views for every other frame. As a result, the overall 3D quality is not biased by the quality of one view or the eye dominance effect [5].
3 Experiment setup
This section provides details on the experiment setup, video sets used in our experiments, and the parameters of the proposed metric.
3.1 Data set
To adjust the parameters of our proposed scheme and verify its performance, we used two different video data sets (one training dataset and one validation dataset). The specifications of the training and validation video sets are summarized in Tables 1 and 2, respectively. These sequences are selected from the test videos in [30], the 3D video database of the Digital Multimedia Lab (DML) at the University of British Columbia (publicly available [19]), and sequences provided by MPEG for standardization activities and subjective studies [29]. These datasets contain videos with fast motion, slow motion, dark and bright scenes, human and non-human subjects, and a wide range of depth effects. Note that the test sequences adopted from [30] and [19] are naturally captured stereoscopic videos, i.e., they contain only two views captured using two side-by-side cameras. The MPEG sequences, however, are originally multiview sequences with several views per each video. For each of the multiview sequences, only the two views (i.e., one stereoscopic pair) which were recommended by MPEG in their Common Test Conditions are used [29].
For each video sequence, the amount of spatial and temporal perceptual information is measured according to the ITU Recommendation P.910 [38] and results are reported in Tables 1 and 2. For the spatial perceptual information (SI), first the edges of each video frame (luminance plane) are detected using the Sobel filter [48]. Then, the standard deviation over pixels in each Sobel-filtered frame is computed and the maximum value over all the frames is chosen to represent the spatial information content of the scene. The temporal perceptual information (TI) is based upon the motion difference between consecutive frames. To measure the TI, first the difference between the pixel values (of the luminance plane) at the same coordinates in consecutive frames is calculated. Then, the standard deviation over pixels in each frame is computed and the maximum value over all the frames is set as the measure of TI. More motion in adjacent frames will result in higher values of TI. Figure 5 shows the spatial and temporal information indexes of each test sequence, as recommended in [38]. In addition to spatial and temporal information, for each sequence shown in Tables 1 and 2, we also provide information about the scene’s depth bracket. The depth bracket of each scene is defined as the amount of 3D space used in a shot or a sequence (i.e., a rough estimate of the difference between the distance of the closest and the farthest visually important objects from the camera in each scene) [54]. Since the information regarding the objects/camera coordinates is not available for all of the sequences, we adopt the disparity to depth conversion method introduced in [53] (which takes into account the display size and distance of the screen from the viewer) to find the depth of each object with respect to the viewer. We report the approximate averaged-over-frames of depth difference between the closest and farthest visually important objects. The visually important objects are chosen based on our 3D visual attention model [18] which takes into account various saliency attributes such as brightness intensity contrast, color, depth, motion, and texture. It is observed from Tables 1 and 2 that the training and test videos have a similar distribution of properties (spatial and temporal complexity and depth bracket). This makes it possible to compute the required parameters in our proposed quality metric using the training video set and use the same ones for performance evaluations over the test video set.

Distribution of spatial and temporal information over the training (a) and test (b) datasets
In order to evaluate the performance of our proposed quality metric, in addition to the general distortions used by 2D quality metric studies [47, 51, 52] we take into account the distortions that may occur during 3D video content delivery and display. The suggested scheme for delivering 3D content is to transmit two or three simultaneous views of the scene and their corresponding depth maps, and synthesize extra views at the receiver end to support multiview screens [27]. In this process the delivered content might be distorted due to compression of views, compression of depth maps, or view synthesizing.
Once these distortions are applied to the content, the quality of videos is evaluated both subjectively and objectively using the HV3D metric and existing state-of-the-art 2D and 3D metrics. Note that the levels of distortions applied to the 3D content are such that they lead to visible artifacts which in turn allow us to correlate subjective tests - Mean Opinion Score (MOS) - with objective results.
The following types of distortions are applied to both training and validation 3D videos (seven different types of distortions applied to 16 original videos, which results in 208 distorted videos):
-
1)
White Gaussian noise: white Gaussian noise with zero mean and variance value 0.01 is applied to both right and left views. DERS is used to generate a new depth map for the distorted stereo pair [50].
-
2)
Gaussian low pass filter: a Gaussian low pass filter with the size 4 and the standard deviation of 4 is applied to both right and left views. Then DERS generated a new depth map for the distorted stereo pair [50].
-
3)
Shifted (increased) intensity: the brightness intensity of right and left video streams is increased by 20 (out of 255). Once more, a new depth map is generated for the distorted stereo pair using DERS [50].
-
4)
High compression of views (simulcast coding): the right and left views are simulcast coded using an HEVC-based encoder (reference software HM ver. 9.2) [24, 37, 49]. The low delay configuration setting with the GOP (group of pictures) size of 4 was used. The quantization parameter (QP) was set to 35 and 40 to investigate the performance of our proposed metric at two different compression-distortion levels with visible artifacts. A new depth map for the distorted stereo pair is generated using DERS [50].
-
5)
High compression of depth map: the depth map of one view (left view in our simulations) is compressed using an HEVC-based encoder (HM reference software ver. 9.2 [24, 37, 49]) with QPs of 25 and 45, and low delay profile with GOP size of 4. Then, the right view is synthesized using the decoded depth map and the original left view. View synthesis is performed using the view synthesis reference software (VSRS 3.5) [1]. Also, a new depth map for the synthesized view is generated using DERS [50]. The quality of the stereo pair including the synthesized right view and the original left view is compared with that of the reference one.
-
6)
High compression of 3D content (views and depth maps): the right and left view video sequences and their corresponding depth maps are encoded using an HEVC-based 3D video encoder (3D HTM reference software ver. 9 [24]) with random access high efficiency configuration. GOP size was set to 8 and QP values were set to 25, 30, 35, and 40 according to the MPEG common test conditions for 3D-HEVC [29].
-
7)
View synthesis: using one of the views of each stereo pair and its corresponding depth map, the other view is synthesized via VSRS and a new stereo pair is generated [1]. As a result, two sets of distorted stereo pairs are formed where the synthesized view once was the left view and once the right one. Then, new depth maps are generated for these distorted stereo pairs using DERS [50].
In our study, capturing artifacts (such as window violation, vertical parallax, depth plane curvature, keystone distortion, or shear distortion) are not considered, as our proposed quality metric is a full-reference metric and requires a reference for comparison. In other words, it is assumed that the 3D video content and the corresponding depth map sequences are already properly captured and the goal is to evaluate the perceived quality when other processing/distortions are applied. Distortions introduced during 3D content acquisition using rangefinder sensors are not considered in our experiments. In addition, we did not take into account the effect of crosstalk, as the amount of crosstalk depends on the 3D display technology used. We assume that the display imposes the same amount of crosstalk to both reference and distorted 3D content. To design a quality metric that takes into account the effect of crosstalk, the information about the amount of crosstalk at different intensity level for different 3D display systems is required.
After applying the seven above-mentioned distortions (at different levels) to the 16 stereo videos, we obtain 208 distorted stereo videos.
3.2 Subjective test setup
The viewing conditions for subjective tests were set according to the ITU-R Recommendation BT.500-13 [39]. The evaluation was performed using a 46” Full HD Hyundai 3D TV (Model: S465D) with passive glasses. The peak luminance of the screen was set at 120 cd/m2 and the color temperature was set at 6500 K according to MPEG recommendations for the subjective evaluation of the proposals submitted in response to the 3D Video Coding Call for Proposals [28]. The wall behind the monitor was illuminated with a uniform light source (not directly hitting the viewers) with the light level less than 5 % of the monitor peak luminance.
A total of 88 subjects participated in the subjective test sessions, ranging from 21 to 32 years old. All subjects had none to marginal 3D image and video viewing experience. They were all screened for color blindness (using Ishihara chart), visual acuity (using Snellen charts), and stereovision acuity (via Randot test – graded circle test 100 s of arc). Subjective evaluations were performed on both training and validation data sets (see Tables 1 and 2).
Test session started after a short training session, where subjects became familiar with video distortions, the ranking scheme, and test procedure. Test sessions were set up using the single stimulus (SS) method where videos with different qualities were shown to the subjects in random order (and in a different random sequence for each observer). Each test video was 10 s long and a four-second gray interval was provided between test videos to allow the viewers to rate the perceptual quality of the content and relax their eyes before watching the next video. There were 11 discrete quality levels (0–10) for ranking the videos, where score 10 indicated the highest quality and 0 indicated the lowest quality. Here, the perceptual quality reflects whether the displayed scene looks pleasant in general. In particular, subjects were asked to rate a combination of “naturalness”, “depth impression” and “comfort” as suggested by [25]. After collecting the experimental results, we removed the outliers from the experiments (there were seven outliers) and then the mean opinion scores (MOS) from the remaining viewers were calculated. Outlier detection was performed in accordance to ITU-R BT.500-13, Annex 2 [39].
3.3 Assigning constant exponents and pooling parameters
To find the constant exponents in Eq. (7), the two quality components were calculated for the videos in the training set. Note that in our experiment, a block size of 64 × 64 was chosen for measuring the variance of disparity. In this case, the 3D display has resolution of 1080 × 1920 (HD), its height is 773 mm, the appropriate viewing distance is 3000 mm, and the value of 2α in Eq. (4) is equal to 0.88° which is consistent with the fovea visual focus.
Then, the exponent values that result in the highest correlation between the HV3D metric and the MOS values corresponding to the training distorted video sets are selected (see Eq. (8)). The selected constant exponents are β 1 = 0.4, β 2 = 0.1, and β 3 = 0.29.
In order to find the Minkowski exponent parameter (p) and the exponential time constant (τ) for temporal pooling (see Eq. (9)), the Pearson Correlation Coefficient (which measures the accuracy of a mapping) is calculated for a wide range of these two parameters over the training video set. In other words, these parameters are exhaustively swept over a wide range to enable us find the highest stable maximum point in the accuracy function. Extensive numerical evaluations show that the effect of slight changes in the selected pooling parameters is negligible in the overall metric performance. The same performance evaluations have shown that p = 9 and τ = 100 result in the highest correlation between the subjective tests and our quality metric results.
4 Results and discussion
In this section we evaluate the performance of each component of the HV3D quality metric (cyclopean view and depth map quality terms) as well as its overall performance over the validation data set. The performance of HV3D is also compared with that of state-of-the-art 2D and 3D quality metrics. The performance of HV3D quality metric is discussed in the following subsections.
4.1 Contribution of quality components of HV3D metric
In order to investigate the contribution of the cyclopean view and depth map quality components of HV3D quality metric (see Eq. 7) in predicting the overall 3D QoE, the correlation between each quality component and the MOS values over the validating dataset is studied by calculating the Spearman rank order correlation coefficient (SCC), the Pearson correlation coefficient (PCC), and the Root-Mean-Square Error (RMSE). While PCC and RMSE measure the accuracy of the 3D QoE prediction by quality components, SCC measures the statistical dependency between the subjective and objective results. In other words Spearman ratio assesses how well the relationship between two variables can be described using a monotonic function, i.e., it measures the monotonicity of the mapping from each quality metric to MOS. In addition, to measure the consistency of mapping from each quality metric component to MOS, outlier ratios (OR) are calculated [23]. Table 3 shows SCC, PCC, RMSE, and OR for cyclopean view and depth map quality components of HV3D. As it is observed, the quality components of the proposed metric demonstrate high correlation with Mean Opinion Score (MOS). In the following subsection the overall performance of HV3D as a hybrid combination of the two quality components is analyzed.
4.2 Overall performance of the HV3D metric
To prove the efficiency of the HV3D quality metric, its performance is compared with that of the state-of-the-art 3D quality metrics using the validation dataset. We compare our proposed quality metric against Ddl1 [8], OQ [55], CIQ [15], PHVS-3D [31], and PHSD [32]. Note that the parameters of PHVS-3D [31] and PHSD [32] are originally customized for 3D mobile applications. For a fair comparison these parameters are updated for 3D HD screen. In addition, we follow what is considered common practice in evaluating 3D quality metrics and compare the performance of the HV3D against several 2D quality metrics including PSNR, SSIM [52], VIF [47], VQM [36], and MOVIE [44]. To this end, the quality of the frames of both views is measured separately using these 2D quality metrics and then the average quality over the frames from both views is calculated. In order to perform a comprehensive evaluation on the performance of the proposed method, in addition to full-reference 3D and 2D quality metrics, we also include a no-reference quality metric proposed by Ryu and Sohn [42] in our experiments. Table 4 provides an overview on the 3D quality metrics used in our experiments.
Figure 6 shows the relationship between the MOS and the resulting values from each quality metric for the entire validation set and all 7 different distortions (as described in Section 3). A logistic fitting curve is used for each case to clearly illustrate the correlation between subjective results (MOS) and the results derived by each metric. The logistic fitting curve is formulated as follows [40]:
where x denotes the horizontal axis (quality metric) and y represents the vertical axis (MOS) in each diagram and a, b, and c are the fitting parameters. Figure 6 shows that our HV3D objective metric demonstrates strong correlation with the MOS results.

In order to evaluate the statistical relationship between each of the quality metrics and the subjective results, PCC, SCC, RMSE, and OR are calculated for different quality metrics over the entire validation dataset and is illustrated in Table 5. As it is observed, the performance of our HV3D in quantifying the quality of the entire validation dataset in the presence of the 7 representative types of distortions is superior to other objective metrics in terms of accuracy, monotonicity, and consistency. In particular, Pearson correlation coefficient between our metric and MOS is 90.8 %, Spearman correlation ratio is 91.3 %, and RMSE is 6.43. As it is observed the hybrid combination of the cyclopean view and depth map quality components has improved the correlation between the quality indices and MOS values (see Tables 3 and 5).
4.3 Performance of HV3D in the presence of different types of distortions
To evaluate the performance of the proposed metric in predicting the quality of the content in the presence of different types of distortions, the statistical relationship between HV3D indices and MOS values is analyzed separately per each type of distortion.
Table 6 shows the PCC and SCC values for various quality metrics and different types of distortions over the validation dataset. As it is observed the HV3D quality metric either outperforms other quality metrics or its performance is quite comparable in predicting the quality of distorted 3D content. The results in Table 6 show superior performance of our proposed quality metric specifically for 3D video coding and view synthesizing applications. Note that in the case of simulcast video compression the performance of our quality metric is slightly lower than the 3D video compression case. This is due to the low quality of depth maps generated from the compressed stereo videos in the simulcast coding scenario (in 3D video coding the coded version of reference depth maps are available).
4.4 Effect of the temporal pooling
The performance evaluations demonstrated in Table 5 presents statistical comparison between HV3D and various 2D and 3D quality metrics. Except VQM [36], MOVIE [44], and HV3D, the rest of the metrics in Table 5 have been originally designed for assessing the quality of images and do not take into account the temporal aspect of video content. To address this, the exponentially weighted Minkowski pooling mechanism [22] is used in conjunction with image quality metrics to convert a set of frame quality scores to a single meaningful score for a video instead of averaging the scores over the frames. Note that the parameters of the exponentially weighted Minkowski pooling are optimized for each quality metric separately (using the training set), to achieve the highest PCC with the MOS scores.
The PCC and SCC values between the MOS and different quality metrics before and after applying the temporal pooling are reported in Table 7. As it is observed temporal pooling in general tends to improve the performance of the metrics. This improvement is more substantial in the case of the quality metrics such as PSNR and SSIM that have lower assessment performance at the presence of distortions with more temporally variant visual artifacts such as 3D compression, view synthesis, and depth map compression.
It is observed from Table 7 that, in general, temporal pooling does not have a significant impact on the performance of different quality metrics (maximum effect occures for PSNR, which is an increase in SCC of 2.53 % and an icrease in PCC of 2.07 %). The reason is that the distortions added to the original videos in Section 3.1 (which are the common artifacts that occur during compression, transmission, and display of 3D content) are not highly variant over time. For this reason, the video database contains videos in which distortion densities do not change drastically from frame to frame. As a result, the visual quality of different parts of the videos does not vary significantly over time. In order to investigate the effect of temporal pooling when distortions are highly variant in time, we perform additional tests using a new set of videos containg time-variant distortions. Note that simulcast compression, depth map compression, 3D video compression, and view synthesis distortions are not applied on each frame independently and are almost visually consistent over the entire video sequence. For that reason, we do not consider these distortions in this experiment. The types of artifacts that are considered are the ones which show spiky appearance in some frames and do not appear in the rest of frames. The following distortions are considered in our additional experiment:
-
1)
White Gaussian noise: white Gaussian noise with zero mean and variance value varying temporally from 0.01 to 0.08 is applied to both right and left views; DERS is used to generate a new depth map for the distorted stereo pair [50]. The variance value for each frame is selected randomly between 0.01 and 0.08.
-
2)
Gaussian low pass filter: a Gaussian low pass filter with the size LG and standard deviation of SG is applied to both right and left views. Then, DERS is used to generate a new depth map for the distorted stereo pair [50]. LG and SG vary randomly in the interval of [3–15] for each frame.
-
3)
Shifted (increased) intensity: the brightness intensity of the right and left frames is increased by randomly selecting pixel values from [10–50] (out of 255). A new depth map is generated for the distorted stereo pair using DERS [50].
-
4)
JPEG compression of the views: both views are compressed using JPEG compression with the quality factor randomly selected from the range [1–100] for each frame.
Subjective experiments (similar to the ones explained in Section 3.2, for the 4 × 8 above test videos and 16 subjects) are performed to evaluate the performance of different metrics before and after temporal pooling. Table 8 shows the results of this experiment. It is observed that temporal pooling implies a much stronger effect in the case that distortions densities are highly variant in time. In particular, the maximum effect introduced by temporal pooling occures for PSNR, which is a 10.23 % increase in SCC and 9.44 % in PCC. Moreover, the average improvements in Table 7 due to temporal pooling are 0.79 % for SCC and 1.09 % for PCC, while the improvements in Table 8 are 5.85 % for SCC and 4.68 % for PCC.
4.5 Sensitivity of our method to constant exponents
The method we presented in this paper is based on training our quality model using a training video set and then testing it over a validation video set. For these kinds of approaches to be convincing, it is necessary to study the robustness of the algorithm against the changes in the parameters that are used in the design.
In order to evaluate the robustness of the proposed quality metric to the constant exponents, β 1 , β 2 , and β 3 , we first choose a set of optimal parameters e.g., the ones reported in Section 3.3. Then, we evaluate the PCC values when the exponents are slightly changed.
Over a wide range of β1, β2, and β 3 , we observed that the rate of change (derivative) of PCC is not significant. In particular, these parameters are swept over the intervals 0.35 ≤ β 1 ≤ 0.45, 0.05 ≤ β 2 ≤ 0.15, and 0.25 ≤ β 3 ≤ 0.35. Over these intervals, the PCC does not degrade significantly. Minimum PCC value for this set of intervals is 0.8533 (corresponding to SCC value of 0.8572) which occurs at β 1 = 0.45, β 2 = 0.15, and β 3 = 0.35.
4.6 Complexity of HV3D
Identifying matching areas over the right and left views is considered to be one of the most computationally complex procedures in the HV3D implementation. As explained in Section 2.1, to model the cyclopean view for each block within one view, the matching block within the other view is detected through an exhaustive search. As illustrated in Fig. 2, A R is the matching block for A L , which is found by performing an exhaustive search around A D . To reduce the complexity of HV3D, instead of performing a full search, the disparity map is used to find the matching areas within two views. To this end, for each block in the left view, we assume that the horizontal coordinate of the matching block in the right view is equal to the coordinate of the block in the left view plus the disparity of the block in the left view. This approximation as shown in Fig. 2 is as if A D in the right view is chosen as the matching block for A L in the left view. Using this approach, which is called Fast-HV3D, the computational complexity is reduced significantly. The experimental results show that for “Fast-HV3D” method, PCC is 0.8865, SCC is 0.8962, RMSE is 6.73, and the outlier ratio is 0, which confirms that while the complexity of the Fast-HV3D quality metric is less than that of the original HV3D quality metric, its performance is almost similar (see Table 5).
Note that due to the use of the disparity information for modeling the binocular fusion of the two views in Fast-HV3D, the cyclopean view quality component will be slightly correlated to the depth map quality component. However, the disparity information is used in a different way in the two quality components. More specifically, the disparity information incorporated in the cyclopean view generation is only used to find the matching blocks and the goal is to fuse the two views to create the intermediate cyclopean image. However, the depth information used in the depth map quality component is directly used to consider: 1) the effect of smooth/fast variations of depth level, and 2) the effect of distortions on the depth map quality. In addition, please note that the depth map quality component does not utilize the image intensity values at all. The cyclopean view image is a 2D intermediate image, constructed by the fusion of the two views. The depth map specifies how much each object (within the cyclopean view) is perceived outside/inside the display screen.It is observed from Tables 3 and 5 that each quality component can predict the overall MOS to some extent. However, only the combination of the two components demonstrates very high accuracy.
Note that for the Fast-HV3D method, the performance of the metric is slightly less than regular HV3D, which is due to the usage of median disparity for each block and the resulting correlation between the two quality components.
The computational complexity of different algorithms is usually expressed by the complexity degree order, which is mathematically measured. Mathematical measurement of the computational complexity of various quality metrics in terms of complexity degree order is very difficult. Thus to compare the complexity of different quality metrics, we measure the simulation time for each metric. A comparative experiment was performed on a Win7-64bit Workstation, with Intel Core i7 CPU, and 18 GBs of memory. During the experiment, it was ensured that no other program was running on the machine. Each metric was applied to a number of frames, and the total simulation time was measured. Moreover the simulation time of each metric relative to that of PSNR was calculated as follows:
The average simulation times per one HD frame for different quality metrics, as well as the relative simulation time of each quality metric with respect to that of PSNR are reported in Table 9. As it is observed, the complexity of Fast-HV3D is 21.21 % less than that of HV3D in terms of simulation time. Although HV3D is 56.5 times more complex than PSNR in terms of simulation time, its complexity is still much less than that of other quality metrics such as PHSD, PHSD-3D or MOVIE, which are 453.43 to 4972.29 times more complex than PSNR. The relative simulation time versus the PCC value for different quality metrics is illustrated in Fig. 7. It is observed that the proposed HV3D quality metric and its fast implementation (Fast-HV3D) perform well, while their computational complexity is moderate.

Relative complexity of different metrics versus their PCC values
In summary, the performance evaluations and Spearman and Pearson correlation ratio analysis showed that our 3D quality metric quantifies the degradation of quality caused by several representative types of distortions very competitively compared to the state-of-the-art quality metrics. In our future work, we will improve the temporal pooling approach used in HV3D by including other factors such as motion, depth of the scene, and frame rate.
5 Conclusions
In this paper we proposed a new full-reference quality metric called HV3D for 3D video applications. Our approach models the human stereoscopic vision by fusing the information of the left and right views through 3D-DCT transform and takes to account the sensitivity of the human visual system to contrast as well as the depth information of the scene. In addition, a temporal pooling mechanism is utilized to account for the temporal variations in the video quality.
To adjust the parameters of the HV3D quality metric and evaluate its performance, we prepared a database of 16 reference and 208 distorted videos with representative types of distortions. Performance evaluations revealed that the proposed quality metric achieves an average of 90.8 % correlation between HV3D and MOS, outperforming the state-of-the-art 3D quality metrics. The proposed metric can be tailored to different applications, as it takes into account the display size (the distance of the viewer from the display) and the video resolution.
References
“View synthesis reference software (VSRS) 3.5,” wg11.sc29.org, March 2010
Banitalebi-Dehkordi A, Pourazad MT, Nasiopoulos P (2013) 3D video quality metric for 3D video compression. 11th IEEE IVMSP Workshop: 3D Image/Video Technologies and Applications, Seoul
Banitalebi-Dehkordi A, Pourazad MT, Nasiopoulos P (2013) 3D video quality metric for mobile applications. 38th International Conference on Acoustic, Speech, and Signal Processing, ICASSP, Vancouver
Banitalebi-Dehkordi A, Pourazad MT, Nasiopoulos P (2013) A study on the relationship between the depth map quality and the overall 3D video quality of experience. International 3DTV Conference: Vision Beyond Depth, Scotland
Banitalebi-Dehkordi A, Pourazad MT, and Nasiopoulos P (2014) “Effect of eye dominance on the perception of stereoscopic 3D video,” International Conference on Image Processing, ICIP
Banitalebi-Dehkordi A, Pourazad MT, Nasiopoulos P (January 2013) “A human visual system based 3D video quality metric,” ISO/IEC JTC1/SC29/WG11, Doc. M27745, Geneva, Switzerland
Barten PGJ (1999) “Contrast sensitivity of the human eye and its effects on image quality”, SPIE Press
Benoit A, Le. Callet P, Campisi P, Cousseau R (2008) “Quality assessment of stereoscopic images,” EURASIP Journal on Image and Video Processing, special issue on 3D Image and Video Processing, vol. 2008, Article ID 659024
Boev A, Gotchev A, Egiazarian K, Aksay A, Akar GB (June 2006) “Towards compound stereo-video quality metric: a specific encoder-based framework,” IEEE Southwest Symposium on Image Analysis and Interpretation, Denver, USA, pp. 218–222
Boev A, Hollosi D, Gotchev A, Egiazarian K (Jan 2009) “Classification and simulation of stereoscopic artefacts in mobile 3DTV content,” Electronic Imaging Symposium 2009, San Jose, USA
Boev A, Poikela M, Gotchev A, Aksay A (July 2010) “Modeling of the stereoscopic HVS,” Mobile 3DTV project report, available: http://sp.cs.tut.fi/mobile3dtv/results/
Chen M, Cormack LK, Bovik AC (September 2013) “No-reference quality assessment of natural stereopairs,” IEEE Transactions on Image Processing, vol. 22, no. 9
Chen W, Fournier J, Barkowsky M, Callet PL (2010) “New requirements of subjective video quality assessment methodologies for 3DTV,” in fifth International Workshop on Video Processing and Quality Metrics for Consumer Electronics, VPQM, USA
Chen W, Fournier J, Barkowsky M, Le Callet P (2012) Quality of experience model for 3DTV. SPIE Conference on Stereoscopic Displays and Applications, San Francisco
Chen MJ, Su CC, Kwon DK, Cormack LK, Bovik AC (2012) “Full-reference quality assessment of stereopairs accounting for rivalry,” 46th Annual Asimolar Conference on Signals, Systems, and Computers, United States
Chen M, Su C, Kwon D, Cormack L, Bovik AC (2013) Full-reference quality assessment of stereopairs accounting for rivalry. Signal Process Image Commun 28:1143–1155
Coria L, Xu D, Nasiopoulos P (January 2011) “Quality of experience of stereoscopic content on displays of different sizes: a comprehensive subjective evaluation,” IEEE International Conference on Consumer Electronics, ICCE, pp. 778–779, Las Vegas, NV, USA
Coria L, Xu D, Nasiopoulos P (Oct. 2012) “Automatic stereoscopic video reframing,” 3DTV-Con: The True Vision - Capture, Transmission and Display of 3D Video
3D video database at Digital Multimedia Lab, University of British Columbia, available at: http://dml.ece.ubc.ca/data/hv3d/
Egiazarian K, Astola J, Ponomarenko N, Lukin V, Battisti F, Carli M (2006) Two new full reference quality metrics based on HVS. International Workshop on Video Processing and Quality metrics, Scottsdale
Ha K, Kim M (2010) “A perceptual quality assessment metric using temporal complexity and disparity information for stereoscopic video,” 18th International Conference on Image Processing, ICIP
Hamberg and H. de Ridder (1999) “Time-varying image quality: modeling the relation between instantaneous and overall quality,” Society of Motion Picture & Television Engineers (SMTPE) Journal, Vol. 108, pp. 802–811
Hanhart P, De Simone F, Ebrahimi T (2012) “Quality assessment of asymmetric stereo pair formed from decoded and synthesized views,” In Quality of Multimedia Experience (QoMEX), 2012 Fourth International Workshop On, pp. 236–241
HEVC at HHI Fraunhofer: https://hevc.hhi.fraunhofer.de/
Hyunh-Thu Q, Callet PL, Barkowsky M (2010)“Video quality assessment: from 2D to 3D challenges and future trends,” IEEE 17th International Conference on Image Processing, (ICIP), pp. 4025–4028
Irwin DE (1992) “Visual memory within and across fixations,” Eye movements and Visual Cognition: Scene Preparation and Reading, 146–165
ISO/IEC JTC1/SC29/WG11 (January 2013) “3D-HEVC Test Model 3,” N13348, Geneva
ISO/IEC JTC1/SC29/WG11 (MPEG) (March 2011) Document N12036, “Call for proposals on 3D video coding technology,” 96th MPEG meeting, Geneva
ISO/IEC JTC1/SC29/WG11 (November 2011) “Common test conditions for HEVC- and AVC-based 3DV”, Doc. N12352, Switzerland
Jin L, Boev A, Pyykko SJ, Haustola T, Gotchev A “Novel stereo video quality metric,” Mobile 3DTV project report, available: http://sp.cs.tut.fi/mobile3dtv/results/
Jin L, Boev A, Gotchev A, Egiazarian K (2011) “3D-DCT based perceptual quality assessment of stereo video,” 18th International Conference on Image Processing, ICIP
Jin L, Boev A, Gotchev A, Egiazarian K (Sept. 2011) “Validation of a new full reference metric for quality assessment of mobile 3DTV content,” in 19th European Signal Processing Conference (EUROSIPCO 2011)
Kauff P, Atzpadin N, Fehn C, Müller M, Schreer O, Smolic A, Tanger R (2007) Depth map creation and image-based rendering for advanced 3DTV services providing interoperability and scalability. Signal Process Image Commun 22(2):217–234
Lee K, Park J, Lee S, Bovik AC (2010) Temporal pooling of video quality estimates using perceptual motion models. IEEE 17th International on Image Processing, ICIP, Hong Kong
Mai Z, Pourazad MT, Nasiopoulos P (Sept 2012) “Effect of displayed brightness on 3D video viewing”, IEEE International Conference on Consumer Electronics, ICCE, pp. 1–3, Berlin
Pinson MH, Wolf S (2004) A new standardized method for objectively measuring video quality. IEEE Trans Broadcast 50(3):312–322
Pourazad MT, Doutre C, Azimi M, Nasiopoulos P (2012) HEVC: The new gold standard for video compression: how does HEVC compare with H.264/AVC. IEEE Consum Electron Mag 1(3):36–46
Recommendation ITU P.910 (1999) “Subjective video quality assessment methods for multimedia applications,” ITU
Recommendation ITU-R BT.500-13 (2012) “Methodology for the subjective assessment of the quality of the television pictures”
Recommendation ITU-TJ.149 (2004) “Method for specifiying accuracy and cross-calibration of video quality metrics (VQM)”
Rimac-Drlje S, Vranjes M, Zagar D (2009) “Influence of temporal pooling method on the objective video quality evaluation,” in Broadband Multimedia Systems and Broadcasting, BMSB
Ryu S, Sohn K (April 2014) “No-reference quality assessment for stereoscopic images based on binocular qulaity perception,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 24, no. 4
Seshadrinathan K, Bovik AC (2011) “Temporal hysteresis model of time varying subjective video quality,” IEEE International Conference on Acoustic, Speech, and Signal Processing, ICASSP
Seshadrinathan K, Bovik AC (Febuary 2010) “Motion tuned spatio-temporal quality assessment of natural videos,” IEEE Transactions on Image Processing, vol. 19, no. 2
Seuntiens P (2006) “Visual experience of 3D TV,” Doctoral thesis, Eindhoven University of Technology
Shao F, Lin W, Gu SH, Jiang G, Srikanthan T (May 2013) “Perceptual full-reference quality assessment of stereoscopic images by considering binocular visual characteristics,” IEEE Transactions on Image Processing, vol. 22, no. 5
Sheikh HR, Bovic AC (Feb. 2006) “Image information and visual quality”, IEEE Transactions on Image Processing, Vol. 15, NO. 2
Sobel I (2014) “History and definition of the Sobel operator”
Sullivan GJ, Ohm J, Han WJ, Wiegand T (2012) Overview of the high efficiency video coding (HEVC) standard. IEEE Trans Circ Syst Video Technol 22(12):1649–1668
Tanimoto M, Fujii T, Suzuki K (2009)” Video depth estimation reference software (DERS) with image segmentation and block matching,” ISO/IEC JTC1/SC29/WG11 MPEG/M16092, Switzerland
Wang Z, Bovik AC (2009) Mean squared error: love it or leave it? IEEE Signal Process Mag 26(1):98–117
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13:600–612
Wang J, Silva MPD, Callet PL, Ricordel V (June 2013) “Computational model of stereoscopic 3D visual saliency,” IEEE Transactions on Image Processing, vol. 22, no. 6
Xu D, Coria LE, Nasiopoulos P (2012) Guidelines for an improved quality of experience in 3D TV and 3D mobile displays. J Soc Inf Disp 20(7):397–407. doi:10.1002/jsid.99
You J, Xing L, Perkis A, Wang X (2010) Perceptual quality assessment for stereoscopic images based on 2D image quality metrics and disparity analysis. International Workshop on Video Processing and Quality Metrics for Consumer Electronics, VPQM, Arizona
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was partly supported by Natural Sciences and Engineering Research Council of Canada (NSERC) under Grant STPGP 447339-13 and the Institute for Computing Information and Cognitive Systems (ICICS) at UBC.
Rights and permissions
About this article

Cite this article
Banitalebi-Dehkordi, A., Pourazad, M.T. & Nasiopoulos, P. An efficient human visual system based quality metric for 3D video. Multimed Tools Appl 75, 4187–4215 (2016). https://doi.org/10.1007/s11042-015-2466-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-015-2466-z