
Abstract
A novel image encryption algorithm in streaming mode is proposed which exhaustively employs an entire set of DNA complementary rules alongwith one dimensional chaotic maps. The proposed algorithm is highly efficient due to encrypting the subset of digital image which contains 92.125 % of information. DNA addition operation is carried out on this MSB part. The core idea of the proposed scheme is to scramble the whole image by means of piecewise linear chaotic map (PWLCM) followed by decomposition of image into most significant bits (MSB) and least significant bits (LSB). The logistic sequence is XORed with the decoded MSB and LSB parts separately and finally these two parts are combined to get the ciphered image. The parameters for PWLCM, logistic map and selection of different DNA rules for encoding and decoding of both parts of an image are derived from 128-bit MD5 hash of the plain image. Simulated experimental results in terms of quantitative and qualitative ways prove the encryption quality. Efficiency and robustness against different noises make the proposed cipher a good candidate for real time applications.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
With the ripening in the field of communication system, the multimedia data has also gained more importance over textual data. It is almost impossible to completely avoid the eavesdropping in broadcasted data over internet and satellite communication. Hence, data needs to be secure especially multimedia data which originated from sensitive organizations like military, medical etc. For images, the encryption in digital domain is a straight forward technique to convert into noise [39]. The standard ciphers are built for one dimensional binary bit stream which extracts a plain image bit by bit for encryption. Such types of techniques include AES [13], DES [14], Twofish [32] and BlowFish [1]. In the case of digital image, adjacent pixels often have similar gray-scale values and strong correlations, or image blocks have similar patterns, while for video data, consecutive frames are similar and most likely only few pixels would differ from frame to frame. Such an extremely high data redundancy of multimedia makes the conventional ciphers fail to obscure all visible information [18].
Commonly, two ways of image encryption are found: optical and digital encryption. The former adopts optical instrument to build physical systems for image encryption [22, 8, 43, 9, 33] which commonly relies on optics to randomize the frequency components in an image. The later one commonly takes advantage of a digital image and encrypts it either by an encryption algorithm in the form of software or a physical electronic device in the form of hardware. Most commonly employed encryption and security schemes are digital in nature since present communication systems are becoming entirely digital [2]. Thus among various digital image encryption techniques, the chaos-based image encryption method is believed to be good candidate for encryption purposes as chaotic systems are characterized by ergodicity, sensitive dependent on initial conditions and random like behaviors [6, 40, 11].
Recently, the characteristics of DNA computing such as massive parallelism, huge storage and ultra-low power consumption have been found [21]. Most of the researchers turned to use complementary rules of DNA to encrypt the data. DNA-based image encryption [36, 27, 42, 41] is one of the latest and most successful image encryption method. The fundamental idea of all DNA-based image encryption is categorized in two phases: first, using DNA theory to encode plain image pixels to a DNA sequence and using those rules to generate the key image. In the second phase, the encoded plain image pixels generated a key image based on DNA operation rules and form the cipher image [12].
Combining the benefits of both chaotic maps and DNA computing, many image encryption algorithms have been proposed by researcher which has some significant drawbacks such as A. Rehman [31] scheme lacks robustness against noise and have low efficiency due to calculation of new key for each block. Zhang et al. [41] is also not efficient and has no robustness against noise as encoded image is divided into blocks for addition with each other to achieve diffusion. In the same way, Liu et al. [27] transformed each nucleotide into its base pair for random time (s), which is pseudo random sequence by chebyshev map and is also less efficient.
In this paper, an image encryption algorithm is proposed which utilizes subset of an image to achieve diffusion in streaming mode under DNA addition operation. The selection of DNA complimentary rules for encoding and decoding both MSB and LSB parts and initial conditions and control parameter for PWLCM and logistic map are calculated from 128-bit hash of a plain image alongwith the use of common keys. The floating point Logistic sequence is converted into integer between 0 and 15 and then XORed with LSB and MSB separately. The usage of 1-D chaotic maps, streaming mode of encryption, simple mathematical operations like addition, XOR and MOD, selective data encryption alongwith MD5 hash are combined to achieve soaring efficiency. It also has the capability of encompassing the noisy factor that arises more often. The paramount advantage of this scheme is that it is capable to decrypt into original image despite the accumulation of noise due to noisy channel during transmission.
The rest of the paper is organized as follows: In Section 2, a brief description of the DNA rules and algebraic operation is provided. Section 3 is devoted to introduce the proposed method. In Section 4, discussion is made on the experimental results of the proposed cipher to demonstrate the validity. Concluding remarks of the paper are summarized in the final section.
2 Preliminaries
2.1 DNA rules for encoding and decoding of images
Knowledge of Deoxyribonucleic acid (DNA) sequences has become indispensable for basic biological research, and in numerous applied fields such as diagnostic, biotechnology, forensics, and biological systematics [20]. A single DNA sequence is comprised of four nucleic acid bases: A (Adenine), C (Cytosine), G (Guanine), and T (Thymine), where A and T, C and G are complementary pairs [20]. In the theory of binary system, 0 and 1 are complementary pair so 0 (00) and 3 (11) are complementary pair, 1 (01) and 2 (10) are also complementary pair. Four bases i.e., A, T, G, and C can be used to encode 01, 10, 00 and 11, respectively. In the total, the number of coding combination is 4! = 24. Because of the complementary relation between DNA bases, there are only eight kinds of coding combinations that can meet the Watson-Crick complement rule out of 24 kinds of coding combinations [35] shown in Table 1. In this paper, we use DNA code to encode the grayscale image. Each 8-bit pixel value of the grayscale image can be encoded into a nucleotide string whose length is 4 [34], for example if the first pixel value of the grayscale image is 167, its binary stream is [10100111]. By employing the DNA first encoding rule to encode the stream, the corresponding DNA sequence [CCGT] is attained. Whereas by decoding the above DNA sequence with the DNA encoding rule 1, we can get the original binary stream [10100111]. But the resultant binary sequence will be different if any other DNA encoding rule is used to decode the same DNA sequence as for instance, according to the sixth decoding rule, we get another binary sequence [00001101]. This is simple DNA encoding which is used to encode the least significant part of an image in our algorithm.
2.2 Addition and subtraction algebraic operations for DNA sequences
With the rapid progression in DNA computing, some biological and algebraic operations on DNA sequence are reported by researchers such as addition and subtraction operations [24]. These algebraic operations for DNA sequences are performed according to traditional addition and subtraction in the binary. Eight kinds of DNA addition rules and eight kinds of DNA subtraction rules exist in correspondence to eight kinds of DNA encoding combinations. The addition operation is performed to encrypt the DNA coding sequence and subtraction operation is used to decrypt it. For example, on two dataset of DNA sequences [TTGT] and [CGTA], one rule of addition operation is performed as shown in Table 2 in order to add them. Resultantly, a sequence [GAAT] is obtained. Likewise, the sequence [TTGT] can also be obtained by subtracting the sequence [GAAT] from [CGTA] under the subtraction operation. From Table 2, we can see that the base in each row or column is unique. This means that the results of addition and subtraction operation are unique. The algorithm of this paper uses these addition rules to substitute the most significant part of an image.
3 The proposed image encryption scheme
3.1 Generation of initial conditions
MD5 is a widely used cryptographic hash function that produces a 128-bit digest and it can expressed as a 32 digits hexadecimal number [26]. Even if there is only one bit difference between two images, their MD5 results will be completely different [27]. Presume that for each specific grayscale image: x 0, p x are the initial condition and control parameter for PWLCM, and y 0 is the initial condition for logistic map respectively, calculated by using 128-bit hash alongwith the common input keys. Furthermore, four numeric values are required for the selection of encoding and decoding rules for both most significant and least significant parts, calculated directly from MD5 hash. For this, first 24 hexadecimal values of hash are divided into three groups, h 1, h 2, h 3 and each h j is composed of 8 hexadecimal numbers where j = 1, 2, 3. For each group, we convert it into a floating decimal number d j ϵ(0, 0.0156) by Eq. (3.1):
The PWLCM system has attained peerless attraction in chaos research recently due to its simplicity in representation, good dynamical behavior as well as efficiency in implementation [27]. Among the lower dimensional maps, PWLCM has high invariant natural density [38] and its trajectory visits entire interval for every value of control parameter, hence more suitable for permutation process to accomplish it in less time. An image is permuted using PWLCM as is described in Eq. (3.2)
Suppose the common initial condition and control parameter for PWLCM are x 0 and p x the new numerical values can be generated by Eq. (3.3):
The Logistic map shown in Eq. (3.4) is in chaotic state for the control parameter 3.57 to 4.0 but the distribution density of the chaotic sequence is not uniform over the interval 0 to 1. To overcome this drawback, the logistic sequence described in [23] is transformed to get uniform distribution in the entire interval by applying Eq. (3.5) but this works only for the control parameter 3.99. Another numerical value is required for logistic map shown in Eq. (3.4), which can be calculated by using Eq. (3.6),
The proposed cipher requires four more numerical values in the range of 0 to 7 for the selection of DNA rules as shown in Table 3 in order to encode and decode LSB and MSB parts of an image. For this purpose, the last 32-bits or 8 hexadecimal values of MD5 are divided into four groups as q j1 q j2 q j3 q j4 where j = 1, 2, 3, 4.
3.2 Image encryption
In 1998, Fredrich proposed an architecture [17] for chaos based image encryption algorithm, since then most of the image encryption algorithms followed it. This architecture consists of two phases; confusion and diffusion. In the former phase, the sequence of information is changed and in later phase each piece of data is replaced by another symbol. The proposed image encryption algorithm also follows the same architecture by employing two chaotic sequences X and Y generated by PWLCM and logistic map respectively. In this paper, sequence X is used in position scrambling and Y is used to XOR with MSB and LSB parts after carrying out DNA addition operation on MSB part. Both confusion and diffusion phases are described in detail in the subsequent section as follows:
3.2.1 Confusion phase: using PWLCM system to generate confusion arrays
-
Step 1
Set the initial condition x ′0 and control parameter p ′ x , iterate the above Eq. (3.2) t + HW times, discard the former t values to avoid the transient effects to get sequence X = {x 1, x 2,...., x HW } where H and W are the height and width of an image.
-
Step 2
Sort X as
$$ \left[ lxly\right]= sort(X), $$where lx is the index values of sorted values ly in X
-
Step 3
Transform the 2-D image into 1-D array and rearrange the elements of I according to lx to get permuted image as shown in following Eq. (3.8),
$$ I^{\prime }(i)=I\left( lx(i)\right) $$(3.8)
3.2.2 Substitution phase for most significant part
It is well known fact that each bit at different position of a gray image carries a different amount of information that can be calculated using the formula given in Eq. (3.9) which shows that the higher four bits contains 92.125 % of information and the lower four contains only 5.875 % [7]. In Fig. 1, the underlying theme of the above stated fact is depicted visually in which each image is carrying zero information simultaneously at two bit planes or at four bit planes. It can be perceived visually that by keeping value of two bits as zero simultaneously at different positions, the loss in information will be at large scale at higher position as shown in Fig. 1a to d while 1e and 1f depict results of four bit planes of an image from least significant to most significant.

Information fading effect at different bits of gray image Lena
In the proposed algorithm, the selective diffusion operation is applied on most significant part of an image under DNA addition operation after encoding. So, the higher bit planes of an image are selected for substitution by adding with lower bit planes after encoding into DNA sequence under the DNA algebraic operation. For the diffusion process, first the permuted image I ′ is converted into binary image as I ′ ′ of size H × 8W and then split into two parts representing LSB and MSB of sizes H × 4W each and then encoded into DNA sequence according to Table 3 using the numerical value of s 1 and s 2 respectively, thereafter transformed into 1-D sequence of size H × 2W as,
The DNA addition is performed on L and R as,
After this, these parts L and R are decoded according to Table 3 using s 3 and s 4, we get,
Equation (3.4) is used to iterate (H × 4W) times with the initial condition y ′0 and control parameter μ = 3.99. To make the distribution of logistic sequence uniform, Eq. (3.5) is applied on Y and then converted it into integer numbers in the range of 0 to 15 as follows
Y ′ is divided into two groups as, Y 1 ′ = {y 1, y 2, …, y 2HW } and Y 2 ′ = {y 2HW + 1, y 2HW + 2, …, y 4HW } of size 2HW. At final stage, Y 1 ′ is XORed with MSB and Y 2 ′ with LSB.
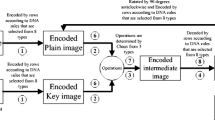
and finally both XORed parts are unified to get E as cipher image and the whole method is shown graphically in Fig. 2.

Schematic diagram of proposed cipher
3.3 Image encryption steps
Suppose that the size of the original grayscale image I is H × W, the complete encryption process consists of the following steps.
-
Input: Image I, the initial value x ′0 and control parameter p ′ x for PWLCM, the initial value y ′0 for logistic map.
-
Output: The encrypted image.
-
Step 1
Iterate Eq. (3.2) with new p ′ x and x ′0 get sequence X to permute the Image I according to the section 3.2.1 to form I ′.
-
Step 2
Generate new initial condition y ′0 and s j from 128-bit hash according to section 3.1.
-
Step 3
Split binary image I ′ into LSB and MSB part whereas the size of each is H × 4W, encode them using s 1 and s 2 to get L and M shown in Eq. (3.10).
-
Step 4
Perform DNA addition on L and M to get R and then decode both parts using s 3 and s 4 according to Table 1 to get L ′, R ′ respectively.
-
Step 5
Iterate Eq. (3.4) with y ′0 to get Y of size H × 4W and transform it into uniform distributed sequence according to Eq. (3.5), divide it into two sequences Y ′ i and Y ′2 as described in section 3.2.2.
-
Step 6
Convert floating point values of Y ′ l and Y ′2 into integer in the range of 0 to 15 using Eq. (3.13).
-
Step 7
XOR R ′ with Y ′ l and L ′ with Y ′2 and then combine XORed part to get cipher image.
3.4 Image decryption steps
Decryption process is similar to encryption in reverse order where first on LSB and MSB parts, XOR operation is performed then s 3 and s 4 are used to encode, DNA subtraction operation is applied at step 4. Finally s 1 and s 2 are used for decoding to get the original permuted image. Reversal of permutation is applied to get back an original image.
4 Simulation results and analysis
A good encryption scheme is satisfactory only when it is robust and possesses the attribute of resisting all sorts of known attacks, like brute force, statistical and differential attacks. Couples of tests and analysis have been made to ascertain the security of the proposed cryptosystem, including the most imperative ones like key space analysis, key sensitivity analysis, statistical analysis, differential analysis. The results of these tests demonstrate that the new scheme owns high security and efficiency. The results of each of these tests and the performance of the proposed cipher are elaborated and analyzed in detail in the subsequent section.
4.1 Key space
Quoting from [28]:
“A necessary, but usually not sufficient, condition for an encryption scheme to be secure is that the key space be large enough to preclude exhaustive search.”
The total number of different keys used in the encryption procedure integrated together to form the key space of a cryptosystem. If the key space of an encryption algorithm is large enough (more than 128-bit which is considered to be secure for most common cryptographic applications in view of the speed of present day computing machines) then the brute force attack on such algorithm becomes infeasible [29]. In this paper, the encryption algorithm consists of three key variables, (i) For PWLCM, initial value x o and control parameter p 0 with the precision 10− 16. (ii) Initial condition with precision 10− 16 of Logistic map.(iii) Eight DNA complementary rules for encoding and decoding. Thus, the total key space of the proposed system is S = (0.5 × 1016 × 1016) × 1016 × 28 = 2167, sufficiently larger than 2128 [16]. An image encryption algorithm with such a long key makes the brute force attack unworkable and infeasible.
4.2 Key sensitivity analysis
In secure encryption schemes, extreme key sensitivity is an essential factor. Chaotic maps have high sensitivity to initial value and control parameter. Both chaotic maps, i.e., logistic and PWLCM are highly sensitive to initial conditions and control parameter. The encrypted image of lena is shown in Fig. 3b with p x = 0.345678901234567 while Fig. 3c is the decrypted image with a key of only one bit difference p x = 0.345678901234568 that results in failure. By using the same key only, the original image can be decrypted as is shown in Fig. 3d.

Key sensitivity analysis for gray image Lena
It is obvious from the figures of the proposed scheme that the image can be correctly decrypted only when the encryption and decryption keys are even. Else, as long as there exists minute differences in the key, the original image can’t be extracted and the information of the original image cannot be reflected by the decrypted image. A swift change in the original image results a significant change in the ciphered image. The high sensitivity of the proposed algorithm demonstrates that it has sufficient ability of resisting exhaustive attack.
4.3 Resistance to statistical attack
Statistical analysis on cipher image is of crucial importance for a cryptosystem. Indeed, an ideal cipher should be robust against statistical attacks. In order to prove the security of the proposed image encryption scheme, following statistical tests are analyzed.
4.3.1 The gray histogram analysis
An Image histogram is a graphical representation that illustrates the number of pixels at each different intensity level found in that image. The histogram of the encrypted image should have uniform distribution and should be entirely different from that of the original image. The grayscale histograms of the plain-image and the cipher-image are plotted in Fig. 4. It is obvious from the simulation results that the primitive pixel grayscale values of the original image are concentrated within the specified region but they are relatively uniform after encryption.
From Fig. 4, we can see that the histograms of the cipher images are fairly uniform and entirely different from the respective histograms of the plain images, Lena and Pepper. The encrypted images cannot provide any statistical information of plain images to the attacker. In other words eliciting any information is quite impossible.

The histograms of the plain and encrypted images of Lena and Pepper
4.3.2 Auto correlation coefficient analysis
One of the mainstream tasks of an efficient image encryption algorithm is to reduce the correlation of adjacent pixels in order to make statistical attacks infeasible. Usually, there exists strong correlation among the adjacent pixels in the multimedia data. In this section, correlation coefficient of two adjacent pixels in original and encrypted images in all three directions i.e., horizontal, vertical and diagonal is calculated by random selection of 2,500 pairs of adjacent pixels by using the following formula [27].
where
In the above Eq. (4.1), x and y denote gray values of the two adjacent pixels in the image, N is the total number of pairs selected from the image for the calculation, E(x) and D(x) are the expectation and variance of x, respectively. Three images of first row of Fig. 5 demonstrate the strong correlation effect in adjacent pixels of plain image Lena in all three directions while images in the second of row of Fig. 5 reveal significant reduction of correlation effect in encrypted image of Lena in the corresponding directions (Vertical, Horizontal, Diagonal). Table 4 indicates the results of correlation coefficients of two adjacent pixels of encrypted images obtained from proposed system which are comparatively better than the Refs. [27] and [31]. The proposed method justifies the claim that no significant correlation exists between the original and its corresponding encrypted images.

Auto correlation analysis of plain and ciphered Lena in horizontal, vertical and diagonal directions
4.4 Information entropy analysis
The information entropy is considered amongst the most imperative feature of randomness. For measuring the strength of a cipher in symmetric cryptosystems, the information entropy is calculated as follows:
where P(m i ) is the emergence probability of m i . For any gray image, there are 28 states of information and for an ideal random image, the value of the information entropy of the encrypted image should tend to 8. The more closely it gets to the ideal value, the harder for the cryptosystem to divulge information. Equation (4.2) is used to compute the information entropy of the plain images and their corresponding cipher images. Table 5 lists the data pertinent to the comparison of the entropy of the proposed scheme and the comparable scheme Refs. [27] and [31]. It is notable that the obtained entropy value of four images encrypted by the proposed method is in close proximity to the theoretical value 8 which means that the ciphered images are very close to a true random source. It is further evident from the fact that the entropy values of the proposed scheme for different images are better than that of the compared scheme. Thus, the proposed algorithm is robust as the information leakage in the image enciphering process is exiguous.
4.5 Avalanche criterion
Avalanche effect is evident if, change of one bit in the plaintext causes significant difference in the cipher bits. Accordingly, for proving the claimed sensitivity to the plaintext, two cipher images are generated from two plain images with just one-pixel difference. The bits change rate of the cipher is 49.81 % i.e., very close to the ideal value of the avalanche criterion. Thus the change of one bit in the plaintext results in a drastic change in the ciphers bits, exhibiting a substantial avalanche effect. Figure 6 demonstrates the effect of one bit change in the plain text.

Avalanche effect (a) Plaintext difference (b) Ciphertext difference
4.6 Quantitative and qualitative analysis of NPCR and UACI
The discovery of differential cryptanalysis is usually attributed to Eli Biham and Adi Shamir [4, 5]. For obtaining meaningful relationship between the plain image and its cipher image, a cryptanalyst may make a slight change in the plain image such as modifying one pixel of the plain image. If this one minor change in the plain image leads to significant and unpredictable changes in the ciphered image then such differential cryptanalysis will become wasteful and defeasible. Quantitative and qualitative differential analysis on our proposed scheme shows great confusion and diffusion effect making the cipher image strongly robust against differential attacks. In image encryption, the cipher resistance to differential attacks is commonly analyzed via two widely used performance indices known as the number of pixels change rate (NPCR) and the unified averaged changed intensity (UACI). The NPCR concentrates on the absolute number of pixels which changes value in differential attacks while the UACI focuses on the averaged difference between two paired ciphertext images, when the difference between plaintext images is subtle (usually a single pixel).
NPCR score of a secure cipher should be very close to 100 % and UACI value shall be greater than 33 %. These two measurements can be mathematically defined by Eqs. (4.3) and (4.4) where L is the gray levels. Results reveal that the proposed algorithm is able to generate secure enough ciphertext against differential attacks by offering NPCR score over 99.60 % and UACI score over 33.40 %. Table 6 lists the correlation, NPCR and UACI of the proposed scheme and the comparable cryptosystems [27, 31] calculated between plaintext and encrypted images of Lena and Pepper. The mean and standard deviation for correlation, NPCR and UACI scores of 100 encrypted images of Lena are shown in Table 7.
Conventionally, a high NPCR/UACI score is usually interpreted as a high resistance to differential attacks, however it is not clear how high NPCR/UACI should be such that the image cipher indeed could have a high security level and can reflect true randomness of ciphertext. This problem is approached by Y. Wu et al. [37] who established a mathematical model for ideally encrypted images and then derived expectations, variances and hypothesis tests of NPCR and UACI (randomness tests) in order to yield qualitative results so as to test the quality of cipher to resist the differential attacks. To calculate NPCR qualitative score, under different significance level for different sizes of image, a critical NPCR score N * a is exhibited in Eq. (4.4). If the actual NPCR score of encrypted image is above N * a then it is considered to be a true random image like image. In addition, the two critical scores U * − α and U * + α extracted by Y. Wei et al. [17] under the α level of significance are shown in Eq. (4.6). If the actual UACI score of an encrypted image falls in the range of U * − α and U * + α , it is considered to be a random like image and consequently, the UACI test is passed. While the mean and Standard deviation of UACI can be calculated using the Eqs. (4.7) and (4.8), respectively.
In Table 9, NPCR and UACI scores of 500 encrypted images, generated by changing one bit of plaintext alongwith their means, standard deviation are calculated. It is noticeable that the qualitative results of our proposed image encryption algorithm are satisfying the high performance requirements. NPCR and UACI scores of the proposed method are up to mark and pass the randomness test at a threshold of 5 % percent under significance level α = 0.01 and α = 0.05 for NPCR and UACI. The work outperforms some previous methods for either high NPCR and UACI quantitative or qualitative scores as evident from comparison made in Table 9. Only one image of the proposed method failed to pass the qualitative test for α = 0.05. Thus, the proposed method demonstrates that the ciphertext image is true random-like. Actual scores of NPCR, UACI alongwith their mean and standard deviation are close to the ideal values.
4.7 Analysis of speed performance
Besides security consideration, EDT of the algorithm is also an important aspect for a good image cipher. In terms of computational complexity and speed performance, the algorithm is required to be fast enough so that it can be used efficiently in real time applications. Generally, EDT depends on the three factors i.e., Complexity of mathematical operations [25], Mode of operation (Block or Stream), No. of rounds required in the encryption process. In this section, speed performance of the proposed cryptographic system is analyzed. Time taken by the proposed cipher to encrypt/decrypt various different sized grayscale images have been measured. For improving speed, the above stated three measures are exercised in the proposed scheme. Fast and less complex integer operators DNA addition and subtraction (+and −), exclusive or (XOR) and modulus (mod) are employed in stream mode and one round of permutation and diffusion is enough to achieve the satisfactory result. The EDT is measured on Intel (R) Pentium 1,700 MHz with 2 GB RAM, running windows 7 Home Basic as operating system. The programming environment is MATLAB 7.13.
In Table 8, the EDT of the proposed algorithm is compared with the EDT of those reported in [31, 10, 15, 19] and it is observed that the operation speed of the proposed scheme is quite fast in comparison to the speed performance of the algorithms depicted in Table 8. They can barely appease any colossal performance requirement. In addition, with image size increasing, the time complexity of ours scheme increase linearly and attain a gain factor of 3.18 on average, relatively low to the described methods, which have multiplying factor of 3.62, 4.13, 6.19 and 8.64, respectively. Hence, the speed of our system is more stable and better for small size to large size images. Moreover, as the proposed cryptosystem indeed leads to a faster encryption speed so with such a speed, it is appropriate to be used for real time applications.
4.8 Robustness against noise and cropping
Robustness of cryptosystem against noise in a real world communication technology is one of the significant problems. When an image is transmitted electronically over the transmission channel, usually it gets infected with noise. A good encryption algorithm shall have the potential to immune such noise as a minor change in the encrypted image may induce a strong distortion in the decrypted image and thus might have the probability of not recuperating the original image. The method described in [31, 30] also have the same demerit as it does not allow to recover the image just because of an error in one pixel. A secure encryption scheme should consider the robustness against noise and shall be designed to avoid the propagation error in the decrypted image. The simulation results of the noise analysis for the proposed method depicted in Figs. 7 and 8 show that our algorithm is robust against salt & pepper noise and as well as Gaussian noise.

The encrypted images of Lena with 1–25 % of noise and their decrypted images

The encrypted images with Guassian noise and the decrypted images
The top row of Fig. 7 shows the encrypted images of Lena with different saturation of Salt & Pepper noise from 1 to 25 %. The bottom row of Fig. 7 shows the correspondent decrypted images which reflect that the proposed system is robust against noise even to one fourth of the disturbed pixel. Supplementary to above, statistically we have calculated the cross correlation, NPCR and UACI of decrypted images of Fig. 7e–h to plain image Lena of in Table 9. The fact dawns that our proposed system is not only robust against decrypting the noisy image but can also retain the high correlation and low UACI values. For better comprehension of the performance of the proposed cryptosystem, same level of Salt & Pepper noise (1–25 %) is added in the plain image shown in Fig. 3a and then the correlation, NPCR and UACI between the plain image Lena and noisy plain images are calculated. The statistical results of salt & pepper noise are shown in Table 10 while the comparative analysis of Table 11 reveals that proposed cipher is better than Ref. [27] for Gaussian noise. Hence our proposed system is not only able to decrypt the noisy encrypted image but still can also retain the high correlation and low UACI with pleasant visual quality of an image.
Likewise, an encryption algorithm should have the capability to immune the cropping effect as during transmission the data can be partially modified or lost due to some noisy system. If any part of an encrypted image gets damage during transmission, our system has the potential to recover it substantially. To validate this effect, we have cropped some part of the encrypted image Pepper as shown in Fig. 9a and its recovered image is shown in Fig. 9b. The simulation results demonstrate that the proposed image encryption scheme resists cropping effect effectively

Cropping effect in image Pepper
5 Conclusion
This paper puts forward a simple yet an efficient selective grayscale image encryption scheme based on combination of 1D chaotic systems and DNA encoding. By employing complete set of DNA rules for encoding and decoding of an image alongwith MD5 hash, the proposed work outperforms in terms of speed. To augment the efficiency of the proposed algorithm and to increase the ciphertext unpredictability, the half of the image containing maximum visual information is encrypted using quaternary DNA addition operation instead of binary. 128 bit hash of plain image is used to calculate initial conditions of PWLCM and Logistic map. In addition, it is also used to calculate control parameter of PWLCM and for selection of DNA rule. Simulation results justify the high resistance of the proposed cryptosystem against different attacks. Moreover, the light of encouraging Qualitative and Quantitative analysis show that the proposed method is strong to encrypt the digital grayscale images. The predominant advantage of this approach is robustness against noise and cropping effect. In a nut shell, the glaring feature of efficiency makes the algorithm feasible for image encryption in real time applications as in terms of efficiency, it outperforms the competitive image encryption algorithms.
References
Anderson R, Schneier B (1994) Description of a new variable-length key, 64 bit block cipher (Blowfish). In: Lecture notes in computer science. Springer, Berlin Heidelberg, pp 191–204
Behnia S, Akhshani A, Ahadpour S, Mahmodi H, Akhavand A (2007) A fast chaotic encryption scheme based on piecewise nonlinear chaotic maps. Phys Lett A 366:391–396
Behnia S, Akhshani A, Mahmodi H, Akhavan A (2008) A novel algorithm for image encryption based on mixture of chaotic maps. Chaos, Solitons Fractals 35:408–419
Biham E, Shamir A (1991) “Differential cryptanalysis of DES-like cryptosystems.” In: Proceedings of the 10th Annual International Cryptology Conference on Advances in Cryptology. Springer-Verlag
Biham E, Shamir A (1993) “Differential cryptanalysis of the Full 16-round DES.” In: Proceedings of the 12th Annual International Cryptology Conference on Advances in Cryptology. Springer-Verlag
Brown R, Chua LO (1996) Int J Bifurcat Chaos 6(2):219
Chang WC, Wong KW, Yu H, Zhu ZL (2012) An image encryption scheme using light weight bit level confusion and cascade cross circular diffusion. Opt Commun 285:2343–2354
Chen W, Chen X (2010) Space-based optical image encryption. Opt Express 18:27095–27104
Chen W, Chen X (2011) Optical image encryption using multilevel Arnold transform and non interferometric imaging. Opt Eng 50(11):117001
Chen G, Mao Y, Chui CK (2004) A symmetric image encryption scheme based on 3D chaotic cat maps. Chaos, Solitons Fractals 21:749–761
Corrochano EB, Mao Y, Chen G (2005) “Chaos-based image encryption.” In: Handbook of geometric computing. Springer, Berlin Heidelberg, pp 231–265
Enayatifar R, Abdullah AH, Isnin IF (2014) Chaos-based image encryption using a hybrid genetic algorithm and a DNA sequence. Opt Laser Eng 56:83–93
FIPS PUB 197 (2001) Advanced encryption standard. New York, NY
FIPS PUB 46 (1977) Data encryption standard
Francois M, Grosges T, Barchiesi D, Erra R (2012) A new image encryption scheme based on a chaotic function. Signal Process Image Commun 27:249–259
Françoisa M, Grosgesa T, Barchiesia D, Errab R (2012) A new image encryption scheme based on a chaotic function. Signal Process Image Commun 27:249–259
Fridrich J (1998) Symmetric ciphers based on two-dimensional chaotic maps. J Bifurcat Chaos 8:1259–1262
Furht B, Muharemagic E, Socek D (2005) Multimedia encryption and watermarking. Springer, New York
Gao T, Chen Z (2007) Image encryption based on a new total shuffling algorithm. Chaos, Solitons Fractals. doi:10.1016/j.chaos.2006.11.009
Gehani A, LaBean TH, Reif JH (2000) DNA based cryptography. DIMACS series in discrete mathematics. Theor Comput Sci 54:233–249
Head T, Rozenberg G, Bladergroen RS, Breek CKD, Lommerse PHM, Spaink HP (2000) Computing with DNA by operating on plasmids. Biosystems 57(2):87–93
Hennelly B, Sheridan JT. Optical image encryption by random shifting in fractional fourier domains. Opt Lett 28:269–271
Hui CG, Kai H, Yi D (2012) Image permutation scheme based on modified logistic map, IPCSIT 52
King OD, Gabroit P (2007) Binary templates for comma free DNA codes. Discret Appl Math 155:831–839
Kumar A, Ghose MK (2011) Extended substitution-diffusion based image cipher using chaotic standard map. Commun Nonlinear Sci Numer Simul 16:372–382
Liu HJ, Wang XY (2010) Color image encryption based on one-time keys and robust chaotic maps. Comput Math Appl 59(10):3320–3327
Liu H, Wang X, Kadir A (2012) Image encryption using DNA complementary rule and chaotic maps. Appl Soft Comput 12:1457–1466
Menezes AJ, van Oorschot PC, Vanstone SA (1997) Handbook of applied cryptography. CRC Press, Boca Raton
Patidara V, Pareekb NK, Purohita G, Sud KK (2011) A robust and secure chaotic standard map based pseudorandom permutation-substitution scheme for image encryption. Opt Commun 284(19):4331–4339
Pisarchik AN, Flores-Carmona NJ, Carpio-Valadez M (2006) Encryption and decryption of images with chaotic map lattices. Chaos 16(3):033118-1/6
Rehman A, Liao XF, Kulsoom A, Abbas SA. “Selective encryption for gray images based on chaos and DNA complementary rules”. Multimed Tools Appl. doi:10.1007/s11042-013-1828-7
Schneier B (1999) The two fish encryption algorithm: a 128 bit block cipher. J. Wiley, New York
Shi X, Zhao D (2011) Color image hiding based on the phase retrieval technique and Arnold transform. Appl Opt 50:2134–2139
Shiu HJ, Ng KL, Fang JF, Lee RCT, Huang CH (2010) Data hiding methods based upon DNA sequences. Inf Sci 180(11):2196–2208
Watson JD, Crick FHC (1953) A structure for DNA. Nature 171:737–738
Wei X, Guo L, Zhang Q, Zhang J, Lian S (2012) A novel color image encryption algorithm based on DNA sequence operation and hyper-chaotic system. J Syst Softw 85:290–299
Wu Y, Noonan JP, Agaian S (2011) “NPCR and UACI randomness tests for image encryption.” In: Cyber journals: multidisciplinary journals in science and technology, Journal of Selected Areas in Telecommunications (JSAT), pp 31–38
Xiao D, Liao XF, Deng SJ (2008) Parallel keyed hash function construction based on chaotic maps. Phys Lett A 372(26):4682–4688
Yang M, Bourbakis N, Li S (2004) Data-image-video encryption. IEEE Pot 23(3):28–34
Ye G (2010) Image scrambling encryption algorithm of pixel bit based on chaos map. Pattern Recogn Lett 31:347–354
Zhang Q, Guo L, Wei X (2010) Image encryption using DNA addition combining with chaotic maps. Math Comput Model 52:2028–2035
Zhang Q, Guo L, Wei X (2013) A novel image fusion encryption algorithm based on DNA sequence operation and hyper-chaotic system. Opt Int J Light Electron Opt 124:3596–3600
Zhu B, Liu S, Ran Q (2000) Optical image encryption based on multifractional Fourier transforms. Opt Lett 25(16):1159–1161
Acknowledgments
This work was supported in part by Natural Science Foundation Project of CQ CSTC under Grant No. 201440001 and National Natural Science Foundation of China under Grant No. 61070246.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kulsoom, A., Xiao, D., Aqeel-ur-Rehman et al. An efficient and noise resistive selective image encryption scheme for gray images based on chaotic maps and DNA complementary rules. Multimed Tools Appl 75, 1–23 (2016). https://doi.org/10.1007/s11042-014-2221-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-014-2221-x