
Abstract
A flexible procedure for the development of a multi-criteria composite index to measure relative vulnerability under future climate change scenarios is presented. The composite index is developed using the Weighted Ordered Weighted Average (WOWA) aggregation technique which enables the selection of different levels of trade-off, which controls the degree to which indicators are able to average out others. We explore this approach in an illustrative case study of the United States (US), using future projections of widely available indicators quantifying flood vulnerability under two scenarios of climate change. The results are mapped for two future time intervals for each climate scenario, highlighting areas that may exhibit higher future vulnerability to flooding events. Based on a Monte Carlo robustness analysis, we find that the WOWA aggregation technique can provide a more flexible and potentially robust option for the construction of vulnerability indices than traditionally used approaches such as Weighted Linear Combinations (WLC). This information was used to develop a proof-of-concept vulnerability assessment to climate change impacts for the US Army Corps of Engineers. Lessons learned in this study informed the climate change screening analysis currently under way.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
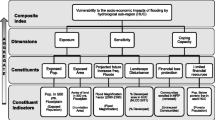
Identifying, measuring, and analyzing the level, extent, and spatial patterns of vulnerability has a rich and growing literature (Clark et al. 1998; Cutter et al. 2003; Turner et al. 2003; Ratick et al., 2009; Polsky et al. 2009; Preston et al. 2011; Ratick and Osleeb 2011; Perveen and Allen James 2011). While there are numerous variations, assessments often rely on a tripartite operational definition of vulnerability that involves measures of the exposure to the hazard, the sensitivity or susceptibility to the potential harm caused by the hazard, and the ability to cope with the harm. One key challenge to research examining vulnerability to climate change is in measurement—as the coupled biophysical and social systems that experience differential vulnerability require a wide variety of both data and expertise to accurately model, describe, and address those hazards (Turner et al. 2003; O’Neill et al. 2006).
In this paper, we present an approach to quantifying vulnerability to climate change by implementing and evaluating the multi-criteria Weighted Ordered Weighted Average (WOWA) procedure (Jiang and Eastman 2000; Liu 2006; Malczewski et al. 2003, Ratick et al., 2009, Ratick and Osleeb 2011). While the methods we present here are globally applicable, to illustrate the pros and cons of this approach at a relatively fine spatial scale, we focus on the context of a case study examining flooding vulnerability within the USA. Methodologically, we focus on one major issue relevant to the development of all composite indicators as aggregates of constituent indicators: trade-off, or the degree to which low constituent indicator values can average out, or compensate for, higher constituent values. High trade-off values occur when equally averaging all of the constituent indicators (a frequently utilized technique in the development of composite vulnerability indices) and can lead to implicitly optimistic assessments of vulnerability, potentially overlooking areas that are vulnerable because their high constituent indicator values have been averaged out (traded-off or compensated for) by lower values of other constituent indicators for those areas. This is a similar concept to making a type II error in hypothesis testing—rejecting a null hypothesis that is true. Alternately, choosing very low levels of trade-off, where low constituent indicator values cannot average out (trade-off or compensate for) higher values of other constituent indicators for an area, can lead to fairly pessimistic vulnerability assessments, perhaps highlighting areas as vulnerable that may not, in fact, be vulnerable.Footnote 1 This is similar concept to making a type I error in hypothesis testing—not rejecting a null hypothesis that is false.
The degree of trade-off used in constructing composite vulnerability indices is closely related to decision risk in making resource allocations in response to these assessments of vulnerability (Jiang and Eastman 2000). By controlling for trade-off, the WOWA aggregation process enables the assessment of the full range of vulnerability (from optimistic to pessimistic). These concepts are developed in Section 2.
We evaluate the WOWA composite index aggregation approach using six constituent indicators of future flood vulnerability (see Table 1). These indicators were selected as example proxy measures of both exposure and sensitivity to flooding events by the Institute for Water Resources (IWR) of the US Army Corps of Engineers (USACE); while this case study is US-specific, we employ it to illustrate the strengths and weaknesses of the approach presented in this paper. USACE also provided an initial set of subjective importance weights for each of the indicators that represent an expert assessment of the degree to which each indicator reflected and predicted vulnerability to flooding. The constituent indicators, and the derived composite vulnerability index, are measured across 204 Hydrologic Unit Code (HUC) areas in the continental USA. We use this case study to evaluate both (a) the effects of different trade-off levels with the WOWA approach and (b) the sensitivity of the composite vulnerability indices to changes in the expert assessments of importance weights using a Monte Carlo simulation approach. The methodology and lessons learned in this study can provide guidance to researchers seeking to conduct future index-based measurements of vulnerability across any spatial area, temporal scope, or scale.
2 The use of indicators in vulnerability assessments
Vulnerability assessments to climate change are frequently conducted using constituent indicators—quantitative measures that are used to represent the many factors associated with climate change impacts (Easterling and Kates 1995; Tzilivakis et al. 2015; de Bremond and Engle 2014). The indicators used in these assessments often represent three dimensions of vulnerability: exposure, sensitivity, and adaptive capacity (Barr et al. 2010; Yuan et al. 2015; Juhola and Kruse 2015). Sets of these indicators may be aggregated to create a composite index, a single comparable measure of vulnerability, in order to contrast varying degrees of vulnerability across all units of analysis (Clark et al. 1998; Cutter et al. 2003, Ratick et al. 2009). An ideal composite vulnerability index is impartial, intuitive to comprehend, and comparable across space and time (Rygel et al. 2006).
Composite vulnerability indices have been used in many contexts to perform climate vulnerability assessments. Recent global-scope indices range dramatically in terms of sector and spatial scale—for example, Vörösmarty et al. (2010) examine threats to fresh water supplies due to projected climate change using a global, grid-based approach, while Barr et al. (2010) and Juhola and Kruse (2015) examine the overall vulnerability of countries to climate change across different sectors. At a continental-scale, Tzilivakis et al. (2015) demonstrate the use of composite indices to assess the vulnerability of three ecosystem services—water, soil, and biodiversity—across 27 member states of the European Union. At the scale of individual countries, Monterroso et al. (2014) developed a methodology to assess the vulnerability of the agricultural sector in Mexico to climate change, using municipalities as the unit of analysis. Similarly, Sharma et al. (2015) recently developed a composite index to assess the vulnerability of forests in India to climate change.
There are a number of approaches to selecting the indicators used in a composite vulnerability index; however, for the purpose of this paper, we only highlight the most commonly used (see Füssel 2010 for a more detailed review of different approaches). One approach is to select relevant indicators based on a theoretical conceptual framework (Hahn et al. 2009; Kelly and Neil Adger 2000; O’Brien et al. 2004). Another approach is to gather a large set of indicators based on theory and practice and subsequently reduce the number to a core set that are relevant, comprehensive, and non-overlapping in the aspects of vulnerability that they measure through the use of methods such as factor analysis or correlation analysis (Clark et al. 1998; Cutter and Finch 2008; Ratick et al. 2009; Cutter et al. 2003; Adger et al. 2004). In this paper, we implement a hybrid approach in which measures of statistical overlap among indicators helped inform expert decision makers working from theoretical conceptual frameworks. Once indicator selection is performed, indicators are combined into a single index through a process called aggregation.
2.1 Aggregation and trade-off
There has been a growing interest in methods of data reduction and aggregation in recent years (Adger et al. 2004; Rygel et al. 2006; Ratick et al. 2009; Ratick and Osleeb 2011; Machado 2011). This can be partially attributed to the rapid growth of the information technology industry and the dissemination of vast quantities of data and information to end users, which can become so extensive that the supply of data or information can exceed the capacity to process it (Lin and Morefield 2011). Consequently, decision makers may accidentally ignore important data, focus on non-useful data, or become highly selective about which data to include in an analysis (Hwang and Lin 1999). When data reduction or aggregation methods are used effectively, the dimensionality of the data is reduced, information overload is mitigated, and decision makers are provided with the best and most useful information for the task at hand (Lin and Morefield 2011). While aggregation reduces the dimensions of the data and facilitates interpreting the results, care must be taken to ensure that important information is not obfuscated through the aggregation or data reduction technique selected.
The mathematical procedure used for aggregation has important implications for the interpretation of the final vulnerability assessment results. For example, averaging all indicators equally or applying different weights to each one can all produce different vulnerability index results, which in turn requires different interpretations (Adger et al. 2004; Ratick et al. 2009; Ratick and Osleeb 2011). While dozens of approaches are possible, there are at least six that are frequently encountered in the index-construction literature (see Table 2 and Machado 2011 for a summary). These are clustering-based approaches (i.e., statistical cluster analysis), Pareto frontier methods (i.e., Data Envelopment Analysis), the Weighted Linear Combination (WLC), spatially explicit aggregation techniques (i.e., multiplicative overlays), simple algebraic manipulations, and Ordered Weighted Averages (OWA). Of these, by far the most commonly used approach is the Weighted Linear Combination—having been employed across a wide range of sectors, countries, and scales (c.f. Clark et al. 1998; Hurd et al. 1999; Cutter et al. 2000; Wu et al. 2002; Cutter et al. 2003; Finch et al. 2010; López-Marrero and Yarnal 2010; Rinner et al. 2010; Cutter and Finch 2008). Here, we contrast the Weighted Linear Combination to the Weighted Ordered Weighted Average aggregation procedure to better illustrate advantages and drawbacks of each approach, using the context of the US case study to illustrate these in an applied case study.
2.1.1 The Weighted Linear Combination (WLC)
In the WLC, weights are assigned to each indicator and their weighted sum is calculated for each unit of analysis. The WLC weights are intended to reflect their relative importance, but the WLC is often used with equal weights for each constituent indicator. An example of the generic form for the construction of the weighted average is given in Eqs. (1) and (2) below (adapted from Ratick and Osleeb 2011):
Subject to:
where
I j = the composite WLC vulnerability index for HUC j
V i = a weight that reflects the relative importance (usually determined subjectively) of the constituent indicator (i) in the assessment of vulnerability
M ij = the physical measure of constituent indicator (i) in HUC j
A = the set of constituent indicators
J = the set of HUCs
The WLC has a number of benefits, including the ability to clearly identify the contribution of each indicator to the final score, its relative simplicity, and its wide use and acceptance in academic and policy literature. However, in cases where a single or many low indicator values offset or average out high indicator values, the WLC approach may not correctly identify at-risk areas or under-represent their true vulnerability. This concern, referred to as trade-off or compensation, can prove particularly challenging in vulnerability index construction where an implicitly optimistic assessment (type II errors, false negatives) may result in missed mitigation opportunities.
2.1.2 The (Weighted) Ordered Weighted Average (WOWA)
The OWA technique was first formally described by Yager (1988) and provides the equations upon which the method employed in this paper (the Weighted Ordered Weighted Average) was built. The OWA has found numerous applications in a wide variety of domains, including computer science and machine intelligence, business decision-making, and environmental protection (e.g., Yager and Kacprzyk 1997; Yager et al. 2011) as well as addressing decision problems with spatial dimensions using geographic information systems (GIS). The OWA functionality was built into the GIS-Idrisi software in the late 1990s (Eastman 1997) and implemented in the web-enabled CommonGIS system shortly thereafter (Rinner and Malczewski 2002). In application, the OWA helps mitigate the trade-off concern of the WLC by assigning weights based on the rank order of indicators in a given HUC (see Rinner et al. 2010; Yager 1988; Malczewski et al. 2003; Jiang and Eastman 2000). An OWA is obtained by first ordering (ranking) the indicator values in each HUC from largest to smallest. Next, order weights are applied to the attributes of each unit of analysis based on their position in this order—i.e., in our case, indicators with larger values after standardization would be weighted more heavily than those with lower values. These order weights allow the decision-maker to choose the degree of trade-off of low values for high values when aggregating the indicators to form the composite index.
In our implementation of the OWA, the degree to which trade-off is allowed to occur is measured by an ORness value (a derivative from the measures of ORness and ANDness in fuzzy sets [Yager 1988]). ORness ranges from 0 to 1, with 0.5 representing full trade-off. When ORness is equal to 0.5, the OWA yields the same results as the WLC. An ORness value of 0 has all the weight being applied to the constituent indicator with the smallest value in every HUC; an ORness value of 1 has all the weight being applied to the indicator with the largest value in each HUC. Limiting the range of ORness to between 0.5 to 1.0 can be interpreted as a range of measures from optimistic (allowing smaller values to compensate for larger values; ORness closer to 0.5) to pessimistic (not allowing smaller values to compensate for larger values; ORness closer to 1.0) assessments and related decision-making strategies (Malczewski et al. 2003).
Once an ORness value is selected, a nonlinear constrained optimization model is applied (Eqs. (3) and (4)) to find the OWA weights that maximize Shannon’s entropy measure (maximize dispersion) subject to the constraint that the weights adhere to the chosen OWA ORness level (Malczewski et al. 2003):
Subject to:
where
W k(i) = The order weight assigned to order k(i)
The use of the maximum dispersion measure provides a unique set of weights for any chosen ORness level that are the most equal across the constituent indicators, thereby using as much information as possible from each of the constituent indicators.
Using these order weights, the OWA composite index (CO j ) for each HUC j can be calculated following Eqs. (5) and (6) below. If index (k(i)j) represents the order of constituent indicator i for HUC j, and W k(i) represents the weight assigned to order k(i), then (adapted from Ratick and Osleeb 2011):
Subject to:
where
CO j = The composite ordered weighted average (OWA) index for HUC j
W k(i) = The order weight assigned to order k(i)
M k(i)j = The constituent indicator i (in order position k) for HUC j
A = The set of constituent indicators
J = The set of HUCs within the study area
The derivative of the OWA used in this paper, the WOWA, follows the same basic procedure as outlined above. However, before indicator ranks are calculated within each HUC j, a set of expert weights, or subjective weights representative of the importance of each constituent indicator, is first applied to each indicator value. This approach is preferable in some cases as it allows for both importance weighting (as in the WLC) as well as a control for trade-off (as in the OWA) within a single approach. Equation (9) in Section 3.4 below describes the incorporation of importance weights into the OWA (a step-by-step example can be found in Malczewski et al. 2003).
3 Methodology
Building on the approach outlined in Malczewski et al. (2003), our methodology for creating composite indices of the vulnerability of HUCs to floods under future scenarios of climate change consisted of the following steps. First, a set of six constituent vulnerability indicators was selected from a larger list by an expert panel made up of USACE scientists, decision makers, and consultants. Second, USACE engineers, scientists, and decision makers provided a subjective importance weight, representing their assessment of the degree to which the indicator reflected and predicted vulnerability to flooding. Third, the values for each indicator were standardized to facilitate the aggregation process, and the indicator values were aggregated for each Hydrological Unit Code (HUC-4) using the WOWA technique. Fourth, once the initial analysis was complete, a Monte Carlo sensitivity analysis was implemented by varying the importance weights to assess their influence on the results.
3.1 Data and study area
To estimate future climate change impacts, the constituent indicator data were projected into two future epochs: epoch 1 (2040–2060) and epoch 2 (2080–2100). Data sources included the EPA’s Integrated Climate and Land Use Scenarios (ICLUS) for IPCC’s A1B emissions scenario (Solomon et al. 2007), FEMA 500-year flood zones (Federal Emergency Management Agency, FEMA 2010), and the Coupled Model Intercomparison Project (CMIP3). Projections for many indicators were calculated based on anticipated changes in climate and climate variability using projections of precipitation and temperature changes from the output of 22 general circulation models (GCMs). Using these projections, two scenarios were selected: a wet and dry scenario, in which the 90th and 10th percentile of precipitation (and related measures) were used, respectively.
3.2 Indicator selection and importance weighting
Initially, a collection of 205 indicators relevant to flood risk were compiled from an exhaustive literature review. Over a series of meetings, this initial set of indicators was reduced by USACE engineers, scientists, decision makers, and consultants, who determined their relevance for quantifying exposure and sensitivity to future floods. Ultimately, a subset of six indicators was chosen, based on relevance, data availability, and through the use of correlation and factor analysis to reduce redundancy in the chosen constituent indicators in their measures of similar phenomena. Each of the six constituent indicators is summarized in Table 1.
USACE engineers and scientistsFootnote 2 then assigned weights to each indicator based on their relative importance to measuring vulnerability to future flooding. A weight of 1 was assigned to the least important constituent indicator, and a weight greater than or equal to 1 was assigned to the other indicators based on their relative importance by comparison. For example, if a constituent indicator is considered twice as important as the least important indicator, it would have been assigned a weight of 2. If an indicator was 50 % more important, it would have been assigned a weight of 1.5. The weights were then normalized to sum to 1.
Expert-based importance weights are subjective and may be influenced by a number of factors. These include the experience and degree of familiarity of the participants in the weighting activity, the goals that those participants had for the analysis, and their nuanced understanding of what comprises vulnerability. Recognizing this, the influence of the importance weights on the final results was examined using Monte Carlo simulation.
3.3 Data standardization
In order to compare the values of indicators (i.e., temperature; rainfall) measured in different units, a data standardization process must be employed. In our case, indicators that had negative values were first adjusted in preparation for standardization by adding the absolute value of its minimum over all HUCs (Eq. (7)):
where
M j is the modified constituent indicator value at HUC j,
I j is the constituent indicator value for HUC j, and
J is the set of all HUCs in the analysis.
Next, constituent indicators for which increasing values imply decreasing vulnerability were adjusted to account for this directionality by subtracting the constituent indicators values from the maximum value that the constituent indicator achieves over all scenarios and time periods (equation 8):
where:
D j is the direction-adjusted constituent indicator value for HUC j,
M j is the modified indicator value (with no negative values) produced from Eq. (7), or I j if that indicator did not have any negative values.
Table 3 describes some extant standardization approaches, each with strengths and weaknesses. We chose to standardize each constituent indicator to be no larger than 1 by dividing each constituent indicator’s value in each HUC by its maximum value over all the HUCs after Eqs. (7) and (8) are applied, in the scenarios and time periods analyzed.
3.4 WOWA Aggregation
The standardized constituent indicators were multiplied by their importance weights, yielding a weighted value. These importance weighted constituent indicator values were then aggregated for each HUC using the OWA procedure described in Section 2.1.2, Eqs. (5) and (6). We chose to test an ORness level of 0.5 (which gives each rank order the same weight, the equivalent of a Weighted Linear Combination) and is representative of an optimistic vulnerability assessment, as well as an ORness level of 0.7, representing a more pessimistic assessment. The ORness of 0.7 resulted in approximately 75 % of the weight being given to the largest 50 % of the indicators, due to the use of the maximum dispersion optimization described in Section 2.1.2, Eqs. (3) and (4).
Because constituent indicators were pre-weighted by their corresponding importance weights and then weighted again using the OWA weights, they need to be re-scaled to obtain a composite vulnerability index ranging from 0 to 1. This was accomplished for each scenario and time period using the rescaling formula in Eq. (9) (Jiang and Eastman 2000):
where
CO j is the composite WOWA vulnerability score for flooding in HUC j,
W k(i)j is the order weight assigned to order k(i) for HUC j,
V j is the importance weight for constituent indicator i, and
M ij is the value of constituent indicator i for HUC j.
Equation (9) results in a single value representing the composite vulnerability index value (CO j ) for each HUC j obtained using the importance weights and the OWA weights. It is applied to each HUC in each time interval within each scenario.
3.5 Sensitivity analysis
A Monte Carlo sensitivity analysis (Ratick and Schwarz 2009; Koller 2000) was conducted to determine the influence of the importance weights on the composite vulnerability indices for the HUCs, following a three-step procedure. First, the importance weights for each of the six indicators are randomly generated from a uniform distribution between 0 and 1, and normalized to sum to 1. Second, these weights are input into Eq. (9), using the OWA weights for an ORness value of 0.7, generating realizations of the composite vulnerability index for each of the 204 HUCs under these randomly generated importance weights. Third, this is repeated 1000 times to provide 1000 possible composite vulnerability index values for each HUC. The resultant average rank of each HUC in the average realizations is then compared to our findings in the original analysis. In this case, the average rank is used to contrast (a) the most likely WOWA outcome given no expert judgment to (b) our WOWA results given expert weightings—future research could examine the possibility of extreme changes to the WOWA results by examining other elements of the distribution (i.e., the likelihood of extreme vulnerabilities).
4 Results
4.1 WOWA Aggregation
The results of the case study are intended to demonstrate the types of information for decision-making that can result from the use of this composite index approach to vulnerability assessments, not as a validated measure of potential vulnerability in any of the HUCs. The resultant composite vulnerability index measures the projected vulnerability of each HUC when compared on these aggregated measures relative to the other HUCs. It does not provide a measure of the absolute vulnerability of each HUC to future floods. Using an example ORness of 0.7 together with the importance weights provided by USACE on the selected indicators, the resultant WOWA composite vulnerability index values (see Figs. 1, 2, 3, and 4) ranged from 0.20 to 0.89, with the most vulnerable cases being found (as expected) under the wet scenarios.

Resultant WOWA scores for each HUC under the dry scenario, epoch 1, ORness of 0.7

Resultant WOWA scores for each HUC under the dry scenario, epoch 2, ORness of 0.7

Resultant WOWA scores for each HUC under the wet scenario, epoch 1, ORness 0.7

Resultant WOWA scores for each HUC under the wet scenario, epoch 2, ORness 0.7
In this analysis, the two HUCs that had the highest average WOWA score across all time periods are shown in Fig. 5, broken down by their constituent indicator’s contribution after weighting. As Fig. 5 shows, both areas show higher vulnerability under the wet scenario than the dry scenario during both future epochs. However, in HUC 1507, the dry scenario reduces vulnerability less than it does in HUC 1810, largely due to the much larger exposed urban area in HUC 1507.

The indicator contributions for the two highest ranked HUCs (ORness = 0.7)
The results for these two HUCs when the analysis was performed using an ORness of 0.5 (equivalent to an equal-weights WLC) can be seen in Fig. 6. As expected, the total WOWA scores for both HUC 1507 and HUC 1810 (represented by the total height of each bar) are lower than with an ORness of 0.7. This is because larger values are no longer given larger weights in the rank-ordering of the OWA (all ranks are assigned equal weights when ORness = 0.5). This difference can be observed by comparing the flood frequency and urban area indicator contributions for HUC 1507 under both ORness options. Using the wet scenarios as an example, when ORness = 0.7 (Fig. 5), the majority of measured vulnerability is a result of the large urban area and flood frequency indicator values. Conversely, when ORness = 0.5 (Fig. 6), urban area and flood frequency contribute relatively less to the total index, as their values are no longer increased to account for trade-off.

The indicator contributions for the two highest ranked HUCs (ORness = 0.5)
4.2 Sensitivity
To analyze the results of the Monte Carlo sensitivity test of the importance weights, we first compared each HUC’s relative ranking based on its composite vulnerability index value under the given importance weights to that HUC’s average rank over all 1000 realizations. We then compared how often a HUC that is in the top 10 % of the most vulnerable HUCs during any epoch and scenario in our initial analysis remains in the top 10 % during the majority of the Monte Carlo random realizations.
The results of the sensitivity analysis can be seen in Figs. 7 and 8. As these figures illustrate, the randomization of importance weights had a relatively small impact on the resultant rank of the majority of HUCs. The r 2 fit between the observed and Monte Carlo realizations results ranged from 0.92 to 0.95. In all scenarios, the strongest agreements are seen in very-low vulnerability HUCs (i.e., those ranked closer to 204) and in vulnerable HUCs (i.e., those ranked closer to 1). This pattern is strongest in the relatively higher vulnerability HUCs within the dry scenario.

The relative rank of each HUC utilizing USACE expert weights compared to the average rank of each HUC over 1000 iterations utilizing random weights (wet scenario)

The relative rank of each HUC utilizing USACE expert weights compared to the average rank of each HUC over 1000 iterations utilizing random weights (dry scenario)
Table 4 focuses on the sensitivity of the most vulnerable HUCs, examining how frequently those HUCs identified as being in the top 10 % most vulnerable in the initial results remained in the top 10 % most vulnerable in the majority of the Monte Carlo random realizations. Using the wet scenario during the second epoch as an example:
-
36 HUCs were identified as being in the top 10 % of most vulnerable HUCs using both the USACE weights as well as in the majority of Monte Carlo iterations (true positives);
-
11 HUCs were identified as being in the top 10 % of most vulnerable HUCs using the USACE weights, but were not identified as vulnerable in the majority of iterations (false positives);
-
1 HUC was not identified as being in the top 10 % most vulnerable using the USACE weights, but was identified as vulnerable in the majority of iterations (false negative);
-
156 HUCs were not identified as vulnerable using either the USACE weights or in the majority of Monte Carlo iterations (true negatives).
A similar cross-tabulation was not constructed for the dry scenario, as in this cross-scenario analysis all of the most vulnerable HUCs were in the wet scenario (as expected for flooding vulnerability). This sensitivity analysis suggests that, in general, the importance weights selected by USACE engineers had a relatively small effect on the final index. This is supported by the very high r 2 value between the rank each HUC was assigned in our initial analysis and the average rank produced by the Monte Carlo iterations, though further research examining the distribution of variation across all iterations could provide deeper insights into this question.
To illustrate the importance of trade-off, the sensitivity analysis described above was performed again, this time using an ORness of 0.5, rather than 0.7. Because an ORness of 0.7 represents a more pessimistic decision-making strategy, it is anticipated that we should see fewer false negatives than in the case of ORness being equal to 0.5. This is borne out in the results. Comparing Tables 4 and 5 shows that in the 0.5 case there are a total of 10 false negatives across the two time epochs, while in the 0.7 case there is only a single false negative (i.e., one case in which a HUC was not identified as being in the top 10 % most vulnerable by our initial analysis, but would be in the top most vulnerable HUCs under random weights). This highlights a quality of the WOWA approach—as ORness increases from 0.5 to 1, subjective importance weights become less influential on the final index. In the extreme example (ORness = 1), only the importance weight assigned to the largest indicator in each HUC would influence the final result.
5 Discussion and conclusions
This paper contributes to the vulnerability assessment literature by presenting and evaluating a flexible approach to address one of the main challenges of constructing vulnerability indices: managing the trade-off, or the degree to which low constituent indicator values can average out, or compensate for, higher values. Our approach expands the ways in which importance weights and trade-off are incorporated into composite vulnerability indices by incorporating importance weights and applying ORness values in a WOWA aggregation process. Using this approach offers the option to implement one of the most commonly used approaches in building composite vulnerability indices (i.e., WLC if ORness = 0.5), but also provides a more informed decision-making process because a full range of outcomes (from more optimistic to pessimistic) of relative vulnerability can be explored by changing the degree of trade-off through the ORness values. In addition, a Monte Carlo sensitivity analysis can be used, as we demonstrate, to determine the effect of expert importance weights provided on the final composite vulnerability index.
However, there are many potential avenues for future research spurred from limitations to the WOWA methodology. Of primary concern is uncertainty (see below) and related robustness of solutions. Currently, the WOWA index-based approach suffers from at least four primary sources of uncertainty, all of which merit further research. These include (1) the spatial scale of analysis and related Modifiable Area Unit Problem (MAUP) concerns; (2) the importance of possible outliers in the distribution of all possible index values within robustness tests; (3) the calibration of the ORness parameter, and how to provide guidance to practitioners on its selection; and (4) the implications of the initial indicator selection and standardization processes. Many of these concerns are not unique to WOWA, also impacting other index-based approaches to estimating vulnerability.
Further, there are still fundamental challenges remaining to the interpretation and construction of all indices—i.e., unpacking the sources of differences between factual realities and perceptions of vulnerabilities in a world of limited capacity for measurement. However, to better understand these differences, it is critical that validation data are available—i.e., a historic analysis could examine if a difference between perceived and actual vulnerability after a disaster event was due to the optimism of decision makers, uncertainties in expert weightings, input data, the data selection process, or even stakeholder involvement (i.e., did a stakeholder choose different weights from experts?). These types of analyses are rapidly becoming more possible as computational capacity and standardized data stores become more prevalent.
The reduction of large sets of data into useful information for environmental decision-making is an ongoing methodological challenge. Despite the methodological limitations mentioned above, we present one approach to address this challenge and have provided a description of its capabilities as well as its potential advantages over other aggregation methods such as the WLC. Finally, although our case study focuses in the US, the relative ease of the WOWA procedure to provide comparable assessments under different ORness levels allows for such analysis to be easily incorporated into spatial decision support systems. This advantage facilitates the application of WOWA at other scales such as global vulnerability studies (subject to data availability), but also makes it particularly well suited for screening assessments, indicating where more detailed information needs to be developed at a finer spatial scale.
Notes
This holds true when higher values of constituent indicators and the final index values indicate higher levels of vulnerability; alternative definitions of vulnerability would result in differing interpretations.
USACE engineers and scientists are frequently involved in the decision-making process, but the parameters chosen were later made to be interactive for other groups of decision makers via a software platform.
References
Aceves-Quesada J, Diaz-Salgado J, López-Blanco J (2007) Vulnerability assessment in a volcanic risk evaluation in Central Mexico through a multi-criteria-GIS approach. Nat Hazards 40(2):339–356
Adger WN, Brooks N, Bentham G, Agnew M, Eriksen S (2004) New indicators of vulnerability and adaptive capacity. Norwich: Tyndall Centre for Climate Change Research. Vol 122
Alessa L, Kliskey A, Lammers R, Arp C, White D, Hinzman L, Busey R (2008) The arctic water resource vulnerability index: an integrated assessment tool for community resilience and vulnerability with respect to freshwater. Environ Manag 42(3):523–541
Ariza E, Jimenez JA, Sarda R, Villares M, Pinto J, Fraguell R, Fluvia M (2010) Proposal for an integral quality index for urban and urbanized beaches. Environ Manag 45(5):998–1013
Auerbach A (1981) The index of leading indicators: measurement without theory, twenty-five years later. NBER working paper series. National Bureau of Economic Research, Cambridge, MA
Barr R, Fankhauser S, Hamilton K (2010) Adaptation investments: a resources allocation framework. Mitig Adapt Strateg Glob Chang 15(8):843–858
Brooks N, Adger WN, Kelly PM (2005) The determinants of vulnerability and adaptive capacity at the national level and the implications for adaptation. Global Environ Change Part A 15(2):151–163
Clark GE, Moser SC, Ratick SJ, Dow K, Meyer WB, Emani S, Schwarz H (1998) Assessing the vulnerability of coastal communities to extreme storms: the case of Revere, MA., USA. Mitig Adapt Strateg Glob Chang 3(1):59–82
Cutter S, Boruff B, Shirley WL (2003) Social vulnerability to environmental hazards*. Soc Sci Q 84(2):242–261
Cutter S, Mitchell J, Scott MS (2000) Revealing the vulnerability of people and places: a case study of Georgetown County, South Carolina. Ann Assoc Am Geogr 90(4):713–737
Cutter S, Finch C (2008) Temporal and spatial changes in social vulnerability to natural hazards. Proc Natl Acad Sci 105(7):2301–2306
de Bremond A, Engle NL (2014) Adaptation policies to increase terrestrial ecosystem resilience: potential utility of a multicriteria approach. Mitig Adapt Strateg Glob Chang 19(3):331–354
Easterling W, Kates R (1995) Indexes of leading climate indicators for impact assessment. Clim Chang 31(2):623–648
Eastman JR (1997) Idrisi for Windows, version 2.0: tutorial exercises, Graduate School of Geography, Clark University, Worcester, MA
Esther H, Huggel C (2008) An integrated assessment of vulnerability to glacial hazards: a case study in the Cordillera Blanca, Peru. Mountain Res Dev 28(3–4):299–309
Federal Emergency Management Agency (FEMA) (2010). Impact of climate change on the National Flood Insurance Program. Thomas, W. and J.R. Kasprzyk. http://cedb.asce.org/cgi/WWWdisplay.cgi?272005
Finch C, Emrich C, Cutter SL (2010) Disaster disparities and differential recovery in New Orleans. Population Environ 31(4):179–202
Füssel, H-M (2010) How inequitable is the global distribution of responsibility, capability, and vulnerability to climate change: A comprehensive indicator-based assessment. Glob Environ Chang 20(4):597–611
Hahn MB, Riederer AM, Foster SO (2009) The livelihood vulnerability index: a pragmatic approach to assessing risks from climate variability and change—a case study in Mozambique. Glob Environ Chang 19(1):74–88
Hurd B, Leary N, Jones R, Smith J (1999) Relative regional vulnerability of water resources to climate change. JAWRA J Am Water Resource Assoc 35(6):1399–1409
Hwang MI, Lin JW (1999) Information dimension, information overload and decision quality. J Inf Sci 25(3):213–218
Jiang H, Eastman J (2000) Application of fuzzy measures in multi-criteria evaluation in GIS. Int J Geogr Inf Sci 14(2):173–184
Juhola S, Kruse S (2015) A framework for analysing regional adaptive capacity assessments: challenges for methodology and policy making. Mitig Adapt Strateg Glob Chang 20(1):99–120
Kelly PM, Adger WN (2000) Theory and practice in assessing vulnerability to climate change and facilitating adaptation. Clim Chang 47(4):325–352
Koller GR (2000) Risk modeling for determining value and decision making. CRC Press, Boca Raton
Lane Melissa E, Kirshen PH, Vogel RM (1999) Indicators of impacts of global climate change on US water resources. J Water Resour Plan Manag 125(4):194–204
Lin BB, Morefield PE (2011) The vulnerability cube: a multi-dimensional framework for assessing relative vulnerability. Environ Manag 48(3):631–643
Liu X (2006) Some properties of the weighted OWA operator. Systems, man, and cybernetics, part B: cybernetics. IEEE Transact 36(1):118–127
López-Marrero T, Yarnal B (2010) Putting adaptive capacity into the context of people’s lives: a case study of two flood-prone communities in Puerto Rico. Nat Hazards 52(2):277–297
Machado EA (2011) Assessing vulnerability to dengue fever in Mexico under global change. Ph.D. Dissertation, Clark University, Graduate School of Geography, Worcester, MA
Malczewski J, Chapman T, Flegel C, Walters D, Shrubsole D, Healy MA (2003) IS-multicriteria evaluation with ordered weighted averaging (OWA): case study of developing watershed management strategies. Environ Plann A 35(10):1769–1784
Monterroso A, Conde C, Gay C, Gomez D, Lopez J (2014) Two methods to assess vulnerability to climate change in the Mexican agricultural sector. Mitig Adapt Strateg Glob Chang 19(4):445–461
Moss R, Brenkert A, Malone EL (2002) Vulnerability to climate change: a quantitative approach. Prepared for the US Department of Energy. Available online: http://www.globalchange.umd.edu/data/publications/Vulnerability_to_Climate_Change.PDF
NOAA (2010) U.S. climate extremes index. Climate Services and Monitoring Division, Available online: http://www.ncdc.noaa.gov/extremes/cei/.
O’Brien K, Leichenko R, Kelkar U, Venema H, Aandahl G, Tompkins H, Javed A, Bhadwal S, Barg S, Nygaard L, West J (2004) Mapping vulnerability to multiple stressors: climate change and globalization in India. Global Environ Change Part A 14(4):303–313
O’Neill B, Crutzen P, Grübler A, Duong MH, Keller K, Kolstad C, Koomey J, Lange A, Obersteiner M, Oppenheimer M, Pepper W, Sanderson W, Schlesinger M, Treich N, Ulph A, Webster M, Wilson C (2006) Learning and climate change. Clim Pol 6:585–589
Perch-Nielsen S (2010) The vulnerability of beach tourism to climate change—an index approach. Clim Chang 100(3):579–606
Perveen S, Allen James L (2011) Scale invariance of water stress and scarcity indicators: facilitating cross-scale comparison of water resource vulnerability. Appl Geogr 31:321–328
Polsky C, Assefa S, Del Vecchio K, Hill T, Merner L, Tercero I, Pontius RG Jr (2009) he mounting risk of drought in a humid landscape: structure and agency in suburbanizing Massachusetts. In: Yarnal B, Polsky C, O’Brien J (eds) Sustainable communities on a sustainable planet: the human-environment regional observatory project. Cambridge University Press, Cambridge
Preston BL, Yuen EJ, Westaway RM (2011) Putting vulnerability to climate change on the map: a review of approaches, benefits and risks. Sustain Sci 6(2):177–202
Ratick S, Morehouse H, Klimberg R (2009) Creating an index of vulnerability to severe coastal storms along the north shore of Boston. Financial Model Appl Data Envelop Appl Appl Manage Sci 13:143–178
Ratick S, Schwarz G (2009) Monte Carlo simulation. Int Encyclo Human Geography 1:184–211
Ratick SJ, Osleeb J (2011) Creating an index to measure the vulnerability of populations susceptible to lead contamination in the Dominican Republic: evaluating composite index construction methods. GeoJournal: 1–14
Rinner C, Malczewski J (2002) Web-enabled spatial decision analysis using ordered weighted averaging (OWA). J Geogr Syst 4(4):385–403
Rinner C, Patychuk D, Bassil K, Nasr S, Gower S, Campbell M (2010) The role of maps in neighborhood-level heat vulnerability assessment for the city of Toronto. Cartogr Geogr Inf Sci 37(1):31–44
Rygel L, O’Sullivan D, Yarnal B (2006) A method for constructing a social vulnerability index: an application to hurricane storm surges in a developed country. Mitig Adapt Strateg Glob Chang 11(3):741–764
Sankarasubramanian A, Vogel RM (2001) Climate elasticity of streamflow in the United States. Water Resour Res 37:1771–1781
SDI (2010) Greenhouse Climate Response Index. Available online at: http://www.sdi.gov/lc_ghg.htm.
Sharma U, Patwardhan A (2008) Methodology for identifying vulnerability hotspots to tropical cyclone hazard in India. Mitig Adapt Strateg Glob Chang 13(7):703–717
Sharma J, Chaturvedi RK, Bala G, Ravindranath NH (2015) Assessing “inherent vulnerability” of forests: a methodological approach and a case study from Western Ghats, India. Mitig Adapt Strateg Glob Chang 4(20):573–590
Solomon S, Qin D, Manning M, Chen Z, Marquis M, Averyt KB, Tignor M, Miller HL (2007) Climate change 2007: the physical science basis. Contribution of working group I to the fourth assessment report of the intergovernmental panel on climate change. Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, p 996
Tzilivakis J, Warner D, Green A, Lewis KA (2015) Adapting to climate change: assessing the vulnerability of ecosystem services in Europe in the context of rural development. Mitig Adapt Strateg Glob Chang 20(4):547–572
Turner BL II, Kasperson RE, Matson PA, McCarthy JJ, Corell RW, Christensen L, Eckley N, Kasperson JX, Luers A, Martello ML, Polsky C, Pulsipher A, Schiller A (2003) A framework for vulnerability analysis in sustainability science. Proc Natl Acad Sci U S A 100(14):8074
Vörösmarty CJ, McIntyre PB, Gessner MO, Dudgeon D, Prusevich A, Green P, Glidden S, Bunn SE, Sullivan CA, Reidy Liermann C, Davies PM (2010) Global threats to human water security and river biodiversity. Nature 467(7315):555–561
Wood N, Burton C, Cutter SL (2010) Community variations in social vulnerability to Cascadia-related tsunamis in the US Pacific Northwest. Nat Hazards 52(2):369–389
Wu S, Yarnal B, Fisher A (2002) Vulnerability of coastal communities to sealevel rise: a case study of Cape May County, New Jersey, USA. Clim Res 22(3):255–270
Yager RR (1988) On ordered weighted averaging aggregation operators in multi-criteria decision making. IEEE Transact Syst Man Cybernetics 18:183–190
Yager RR, Kacprzyk J (1997) The ordered weighted averaging operators: theory and applications. Kluwer, Norwell, MA
Yager RR, Kacprzyk J, Beliakov G (2011) Recent developments in the ordered weighted averaging operators: theory and practice (studies in fuzziness and soft computing). Springer, Berlin
Yuan X-C, Wang Q, Wang K, Wang B, Jin J-L, Wei Y-M (2015) China’s regional vulnerability to drought and its mitigation strategies under climate change: data envelopment analysis and analytic hierarchy process integrated approach. Mitig Adapt Strateg Glob Chang 20(3):341–359
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Runfola, D.M., Ratick, S., Blue, J. et al. A multi-criteria geographic information systems approach for the measurement of vulnerability to climate change. Mitig Adapt Strateg Glob Change 22, 349–368 (2017). https://doi.org/10.1007/s11027-015-9674-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11027-015-9674-8