
Abstract
This paper deals with kriging-based interpolation of dosimetric data. Such data typically show some inhomogeneities that are difficult to take into account by means of the usual non-stationary models available in geostatistics. By including the knowledge of suspected potential sources (such as pipes or reservoirs) better estimates can be obtained, even when no hard data are available on these sources. The proposed method decomposes the measured dose rates into a diffuse homogeneous term and the contribution from the sources. Accordingly, two random function models are introduced, the first associated with the diffuse term, and the second with the unknown and unmeasured source contribution. Estimation of the model parameters is based on cross-validation quadratic error. As a bonus, the resulting model makes it possible to estimate the source activity. The efficiency of this approach is demonstrated on data simulated according to the physical equations of the system. The method is available to researchers through an R-package provided by the authors upon request.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Standard kriging assumes statistical invariance under translations in space, which means that linear combinations filtering trends are statistically homogeneous across the domain of interest. This is the case under the usual model in which the spatial function is the sum of a stationary random function and a polynomial drift. Another class of models in which this assumption holds is the IRFk model (Matheron 1973) in which only specific linear combinations of the variable have finite variance. This variance can then be computed on the basis of generalized covariances, allowing the calculation of the kriging predictor. This class of models emerges naturally when dealing with solutions of linear partial derivative equations with constant coefficients (Dong 1990).
The previous assumption, while most often reasonable (see Chilès and Delfiner 2012 or Wackernagel 2003), can be ruled out in several instances. A search for another form of homogeneity compatible with statistical inference is then needed. This is particularly difficult in the case of a unique realization, as opposed to cases where repeated measurements are available over time. Another particular class of non-stationary models, introduced by Sampson and Guttorp (1992), derives from a stationary random function by space deformation. The inference of this model is usually performed in the context of multiple realizations (Perrin and Meiring 1999). However, Fouedjio et al. (2015) introduced an inference method which can be used in the context of a unique realization.
In this paper, the spatial interpolation of dosimetric data is considered. Various methods have been applied to deal with geo-referenced radiometric measurements. A comparison was organized and proposed to the community in 2005 on the basis of gamma-dose rate data measured in Germany Dubois and Galmarini (2005). Another comparison of two geostatistical methods on gamma-dose temporal measurements in France was performed in 2015 (Warnery et al. 2015). Bayesian spatial prediction methods are advocated (Pilz and Spöck 2008) to take into account the uncertainty associated with the estimation of the parameters of the model. An example of dose exposure cartography within contaminated buildings by means of standard geostatistical methods is provided (Denoyers and Dubot 2014). Finally, one of our reviewers pointed out two more references, one (Kazianka 2013) in which copula-based interpolation is proposed, and a second (Elogne et al. 2008) in which the spartan spatial random field methodology is applied.
However, the situation addressed in this paper is somewhat different and also more specific. The main idea is the assumption that the presence of localized sources can produce many ’hot spots’. In the vicinity of those spots, the level of exposure increases abruptly; this situation requires a different handling. Furthermore, it is assumed that the locations of these potential sources are known beforehand, but not their actual activity.
The manuscript is organized as follows: the convolution model is introduced and motivated in the first section. It implies an affine relation between the source activity and the observed dose. Different treatments of the source activity are considered in the rest of the paper. The first proposition, detailed in the third section, is to consider source activity as deterministic and unknown. This point of view leads to the introduction of several additional drift functions; the geostatistical answer is known as kriging with external drift. The second proposition, presented in the fourth section, is to introduce a specific random function to model this activity. Then the observed dose is the sum of the contribution from these sources and of a homogeneous term, both modeled as random functions. The model inference is an interesting question, since no data on the source activity is available; it is discussed in the fifth section. Finally, the last section compares this new technique with the standard geostatistical approach (assuming a homogeneous variogram) on a 2D case study.
2 General Model
The variable of interest (the dose rate) is interpreted in the framework of the following model
where the term \(Y_{0}\) is due to diffuse contributions, resulting in an homogeneous term. Standard geostatistical second order models (models specified in terms of first order second moments, see Chilès and Delfiner (2012), Wackernagel (2003) or Cressie (1993) for more details) can be used for this term.
The second term is the contribution of the sources with support \(\varGamma \). The function \(\omega \) represents the source activity, and \(\phi \) is an attenuation function. \(\phi (x,y)\) can be viewed as the result at point x of a unit source located at location y. If the emissions are isotropic and the media is non-absorbing, then the fluxes through concentric spheres centered at y should be the same, implying a decrease of the signal proportional to the inverse of the squared distance to the source
The only assumption is that the particle and wave emission is isotropic, and the propagation is linear without absorption or decay. Other functions can be considered in the case of absorption by the media, as long as the form of this function is known beforehand. A more general function \(\phi _{\alpha }(x,y)\) can be used with an unknown exponent \(\alpha \) (which should also be estimated).
The function \(\omega \) is the source density. The product \(\omega (y)\, \hbox {d}y\) is interpreted as the effect of the sources within \(\hbox {d}y\) at a unit distance from y.
In this paper two modeling options are used to address the contribution of the sources:
-
1.
External drift. This approach can be considered when the domain \(\varGamma \) is the union of a limited number of small volumes located in \(y_k\). The contribution of the sources is then approximated by the discrete sum
$$\begin{aligned} \sum _{k}\phi (x,y_{k})\,\omega _{k} . \end{aligned}$$The coefficients \(\omega _{k}\) being unknown, this contribution will be handled by the external drift methodology (this methodology is fully described in Chilès and Delfiner 2012 or in Wackernagel 2003). That is, the kriging estimate \(Z^{*}\) is constrained to be unbiased for every possible set of weights \(\left\{ \omega _{k}\right\} \).
The external drift approach can deal with only a limited number of point contributions. In other words, the source must be discretized into a finite number of point sources, each one corresponding to a separate drift function (this will be clarified later in the paper). This approach may appear artificial, since the contribution of the sources is ’filtered out’ while computing the kriging predictor. But actually it can be shown to be equivalent to using a diffuse prior for the weights \(\omega _{k}\) in a Bayesian framework.
-
2.
Random function model. The density \(\omega \) is characterized by a random function model. This setting has several advantages that will be discussed further.
3 External Drift Approach
In this section the support \(\varGamma \) is assumed to be a collection of few isolated points at known locations \(y_k\). The model (1) then simplifies to
Since the coefficients \(\omega _{k}\) are unknown, a natural choice is to consider the functions \(\psi _{k}(x)=\phi (x,y_{k})\) as external drift functions
Here, no data point or estimation point should coincide with a putative source, so that \(\Vert x-y_{k}\Vert >0\). Then (2) can be written
The external drift methodology is well-established and is widely used, but considering its use in the context of many drift functions requires some particular attention to understanding its limitations.
3.1 Kriging with External Drift
When the model for \(Y_{0}\) is defined (the covariance, and the degree of a possible polynomial drift), kriging with external drift makes it possible to estimate Z over the domain of interest, given the measurements \(Z(x_{i});\, i=1,\ldots ,n\), and to compute the corresponding estimation variance. The unbiasedness conditions include the standard universality conditions
in which \(f_l\) are monomials, and the new conditions associated to the attenuation functions
There are some limitations to the number of drift functions that can be used in this methodology. Briefly, if K is the covariance matrix of \(Y_{0}\) at the data points (a matrix with coefficients \(k_{ij}=\hbox {cov}(Y_{0}(x_{i}),Y_{0}(x_{j}))\) and \(\varPhi ^{t}=(f_{l}(x_{i}),\psi _{k}(x_{i}))\) is the \(n \times p\) matrix giving the drift functions at data points, the matrix \(\varPhi ^{t}K^{-1}\varPhi \) should be invertible. This condition ensures that the drift coefficients can be estimated from the data with no ambiguity. This condition will no longer be satisfied with too many drift terms.
3.2 A Synthetic Example of the External Drift Method
The kriging with external drift approach is illustrated with a 1-D simulation, where 20 data points are sampled from the realization of a model including a stationary Gaussian random function with cubic covariance and a single source point. This simulation is represented in Fig. 1 together with the sampled data; the contribution of the source is highlighted.

Synthetic 1-D data generated by adding a Gaussian stationary random function (grey line) and a source term (solid line). The sum, shown as a dashed line, is sampled at 20 regularly spaced locations represented as black dots
In this illustrative example, three putative source locations are identified, with abscissa − 10, 0 (the true source) and 10. The three corresponding drift functions corresponding to the reciprocal of the squared distance to the 3 putative sources are shown in grey lines on Fig. 2.

The drift functions associated with the three putative sources (grey lines) which are assumed to be identified. For comparison, the simulated function is represented in black

Simulation (grey line) and kriging with various polynomial drift assessments. The inclusion of the 3 external drift functions (solid line) improves the interpolation (note that the overshoot between points at \(x=-\,2\) and \(x=+\,2\) is very accurately predicted: the grey and black lines are almost superposed)
First classical kriging interpolations are considered based on the true covariance, with polynomial drifts of various degrees (up to quadratic) and with the three external drift functions.
The results are shown in Fig. 3. The advantage of adding the information on the three possible sources is clear. In this example, it can be seen that kriging with external drifts is able to (1) distinguish the active source from the inactive ones, (2) interpret the data increase on both sides of the actual source to predict the bump in between, while kriging with various polynomial drifts produces a decrease towards the mean, and (3) predict fairly accurately the overshoot between the two central data points. Of course these good results were obtained using the correct basis functions (one of them is centered on the actual source location). They certainly would have been of lower quality if the putative sources were wrongly located, for instance.
4 Modeling Source Density as a Random Function
The situation seen in the previous paragraph, in which only 3 source points are considered, is certainly optimistic. In real situations, when considering continuous structures, such as pipes, reservoirs, etc, these structures are discretized and a large set of putative source points is generated; then the external drift method can no longer be applied. Hence some form of regularization is necessary to deal with the redundancy inherent to the short scale discretization of continuous structures. This can be achieved by a prior model for the density \(\omega \).
The density \(\omega \) is modelled as a second order random function, independent from the diffuse term Y and specified through its covariance and drift degree. Such characterization is sufficient to compute the optimal kriging weights.
Introducing the covariance of the diffusive term Y
the covariance of the dose rate Z is
If stationarity is not assumed for Y and \(\omega \), their mean \(m_{Y}(x)\) and \(m_{\omega }(y)\) are linked through
Assuming a linear space with basis \(f_{l};l=0,\ldots ,k\) for the drift of Y, and basis \(g_{l^{\prime }};l^{\prime }=1,\ldots ,k^{\prime }\) for the source density \(\omega \) (both are usually monomials, but the degree k and \(k^{\prime }\) may be different), the linear kriging estimate of \(Z(x_{0})\) on the basis of the data \(Z(x_{i});i=1,\cdots ,n\)
is unbiased if
This is ensured, whatever the coefficients of the means on their respective bases, if the kriging weights satisfy
So far, only point measurements have been considered. Note that, thanks to the linearity of the convolution linking the exposure to the source, there would be no difficulty in considering more general linear data. For example one can think of the dose accumulated along a trajectory recorded along time. Explicitly, if \(\tau \) is the time spent at location x along the trajectory T, the cumulative dose is
(a measure notation is used since the measuring device might even stop at some location). The point covariances must be derived
to account for the data Z(T) in this methodology.
4.1 Source Estimation
In the case of source estimation, the unbiasedness conditions are different from those used for the interpolation. Here
The right-hand side covariance in the kriging system does not involve the covariance of the diffuse term \(K_{Y}\), and is convoluted only once (as opposed to that of \(K_{Z}\) which is convoluted twice, as seen before)
Here, the condition to satisfy is
This leads to another set of unbiasedness conditions
5 Model Inference
Various strategies can be considered for the estimation of the covariance of \(Y_{0}\) (K matrix). The first strategy consists in using the observed covariance estimate without any correction in the kriging system. This covariance estimate is known to be biased, since the unknown drift term has not been filtered beforehand and therefore is still present in the naive estimate. This strategy is mainly relevant in case of repeated measurements, since the individual covariances \(\hbox {cov}(Z(x_{i}),Z(x_{j}))\) need to be estimated for every pair of data \((x_{i},x_{j})\), which is possible only in this case. The consequences of this bias will be briefly discussed in the next section.
The second strategy is based on filtering the data to get rid of the drift terms. Pseudo-maximum likelihood can then be considered.
The third strategy is based on minimization of the observed cross-validation error.
5.1 Using Biased Covariance
The naive use of the observed covariance of the data Z in the kriging system
is written as
It is shown in the “Appendix” that using this biased covariance in the kriging system does not affect the kriging weights, and thus the kriging interpolator, as long as the constraints imposed by the universality conditions (3) are fulfilled.
The price to pay, however, for this bias is the loss of an expression for the error variance.
5.2 Filtering the Drifts
An alternative is to select a parametric form \(K(\theta )\) for the covariance. Provided that the number of data points is large enough, a matrix G made of \(n-p\) vectors orthogonal to the p drift functions can be derived:
Accordingly, \(GZ=GY\) and the drifts present in the data will be filtered out automatically by the matrix G, providing centered linear combinations of the data. Their covariance is \(GK(\theta )G^{t}\). The coefficients \(\theta \) of the parametric model can then be estimated from the vectors GZ by least squares
The main benefit of this strategy is the possibility to get the kriging error variance. But the construction of the filtering matrix G might be problematic if the number of sources is very large.
5.3 Cross-Validation
The model including two random functions induces a more profound form of non-stationarity, which cannot be handled by the introduction of a few drift functions. The approach is based on estimating the performance of a model by leave-one-out cross-validation, and optimizing the model parameters according to the observed errors. The criterion is based on the quadratic error, but, since the chosen minimization algorithm does not involve derivatives, other criteria could be considered as well, such as the absolute deviation, for instance.
This approach is very flexible. Non-linear parameters, such as ranges, anisotropy direction, and the exponent of the attenuation, can be optimized in principle. The positivity on the variances is enforced by using parameters on the log scale. However, note that the parameter set leading to the minimum of the cross-validation error is not unique. For example, multiplying all the variances in the model by an arbitrary positive factor does not change the kriging weights, and hence the errors.
This problem can be mitigated either by adding appropriate constraints to the minimization or by adding penalty terms to the criteria. In the sequel, the latter approach has been used to force the overall variance to remain close to unity. The variances of the model components are then re-scaled in a second step so that the predicted error variances are correct on average.
The minimization task is performed using a function of the GNU gls library (Galassi 2019). Due to the possible non-convexity of the minimization problem, the optimum reached is generally only a local minimum, and it depends on the starting point of the algorithm. Therefore it is advisable to use plausible initial values.
6 Application Example
The synthetic data used in this section were generated by a physical simulator, with a geometry including two pipes placed 22 cm above the plane where measurements were taken. The simulator is the property of the EDF company, and we had access to only the resulting data.
The location and magnitude of the measurements are displayed in Fig. 4. The two solid lines represent the known pipes where the active sources are located. The data are available on a grid with a mesh of 10 cm. The information has been decimated to a grid with a mesh of 1 m to get 144 data used as measurements for all the estimation steps. The measurement values vary from 0 to 125.39 with a mean of 1044 and a variance of 40. The complete data set will be used only to evaluate the performances at the end of the procedure.

Location and magnitude of the data available as well as the two pipes where sources are located (black lines). The left figure shows the full simulation, with mesh of 10 cm and the right one shows the \((9\times 16)\) grid of data extracted for the exercise
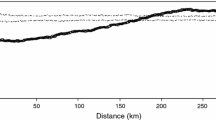
We first follow the traditional geostatistical procedure based on homogeneous models to interpolate the data, as described in Denoyers and Dubot (2014). This procedure is based on variogram modeling. In Fig. 5 we show the observed variogram calculated from the sampled data, together with a simple model with a geometric anisotropy, the structure being more continuous along y than along x.

Empirical variogram obtained along y (black colour) and along x (grey). The fitted model follows a geometric anisotropy described in the text
The following model was used to obtain the standard kriging interpolation
The new procedure requires two covariance models. In this exercise, the optimization algorithm is only used to estimate the variances of the different components, whereas the types, the ranges and the anisotropies have been defined beforehand. This limitation is mitigated by the introduction of many covariance components in the model for the diffuse term
The anisotropy coefficients \(a_i,b_i\) cover a triangular array with 9 terms as shown on Fig. 6. The diffusive term thus has 9 variances for the spherical components and one nugget term, while the covariance model for the source has 3 spherical variances plus a nugget term.

Triangular grid of covariance components \((a_i,b_i)\) included in the diffuse model (each dot represents the anisotropy of one component)
The set of 14 unknown variances are optimized by cross-validation as described in the previous paragraph. Some of the estimated variances happened to be negligible, and have been discarded from the final model, leaving only three terms for the diffuse covariance, and two for the source covariance.
The Fig. 7 compares the cross-validation performances of the new procedure to the one obtained with classical kriging. This first comparison is admittedly somewhat unfair, since the variances of the model used in the new procedure were optimized for these criteria, which was not the case for the standard model. The interpolation on the full grid shown later will provide a fair comparison.

Comparison of the leave-one-out cross-validation performances using the standard (left) and the new procedure (right). The data used here are the \(144=16\times 9\) sub-grid measurements
Next the estimation is performed with the two models on the original \(91\times 151\) data grid of 10 cm mesh. The error statistics are shown in Table 1. The advantage of the new method is not visible on the majority of points where the signal is close to zero, but shows up in the vicinity of the hot spots, which contributes mainly to the overall error variance. This is more apparent on the estimation maps (not shown) and on the Fig. 8 where a few profiles parallel to the X axis are represented. We can observe a substantial improvement in the highly exposed area.

The actual dose signal (solid lines, grey colour), the standard kriging interpolation (dashed lines) and the kriging with sources (mixed lines) along a few profiles. The dots represent the data points. At \(y=1\), the activity of the two sources is identified by the convolution model, and not by the standard kriging. At \(y=11\), the activity of the left source is almost perfectly identified by the new model
As stated previously, the method allows source estimation. However, this is a deconvolution problem known to be ill-posed. The use of a random function model, and thus of prior information, makes it possible to perform this inversion. In this application the source is discretized along the pipes at a step of 10 cm, generating 304 target points, and thus a highly overparametrized description. The Fig. 9 shows the resulting estimation.
The true density data were not available for comparison and in order to derive prediction errors. Nevertheless several comments can be issued concerning this figure. The first peak at \(y=1\) m observed on both pipes is associated to the first two hot spots seen on the original figure. The following negative estimate at approximately \(y=2\) m is obviously unrealistic and undesirable. Such an observation is very common in linear estimation, since no distributional constraint prevents linear interpolation from being negative. Only non-linear estimation could take care of such a constraint. The peak which can be seen on the first pipe beyond \(y=9\) m is compatible with the observed complete image. Finally, the peak at end of this line is possibly a side effect, which could have been reduced by extending the source line beyond \(y=15\) m.

Source density estimates
7 Conclusions
Dosimetric data interpolation is difficult in the presence of localized sources producing high spots, and requires a very dense sampling if standard interpolation methods are used. This remark applies to kriging, splines, radial basis function, or more generally any method making some assumption of homogeneity. When the locations of putative sources have been defined beforehand, more specialized models can be considered in which homogeneity does not hold.
In this paper we propose an approach based on modeling the unmeasured source density as an additional random function. The advantage is twofold: the benefit in terms of map precision is substantial, and the source density can be estimated, allowing contaminated sections to be accurately localized. The efficiency of the method is illustrated on simulated data for which the emission is isotropic, a favorable circumstance, since this is a basic assumption of our model. It remains to check that our very good performances are confirmed in a real case study.
Some extensions can be considered, such as handling of absorbing propagation media.
References
Chilès JP, Delfiner P (2012) Geostatistics. Modeling spatial uncertainty. Probability and Statistics. Wiley, Hoboken (ISBN) 978-0-470-18315-1
Cressie N (1993) Statistics for spatial data. Wiley, Hoboken
Denoyers Y, Dubot D (2014) Characterization of radioactive contamination using geostatistics. Nuclear Eng Int 59(716):16–18
Dong A (1990) Estimation géostatistique des phénomènes régis par des équations aux dérivées partielles. Doctoral thesis, 260 p., Ecole des Mines de Paris, CG. 35 rue St. Honoré, Fontainebleau
Dubois G, Galmarini S (2005) Introduction to the spatial interpolation comparison (SIC) 2004 exercise and presentation of the datasets. Appl GIS 1(2):09-1–09-11
Elogne S, Hristopulos D, Varouchakis E (2008) An application of spartan spatial random fields in environmental mapping: focus on automatic mapping capabilities. Stoch Environ Res Risk Assess 22:633–646
Fouedjio F, Desassis N, Romary T (2015) Estimation of space deformation model for non stationary random functions. Spatial Stat 13:45–61
Galassi M (2019) GNU scientific library reference manual (3rd Ed.) (ISBN) 0954612078
Kazianka H (2013) Spatialcopula: a matlab toolbox for copula-based spatial analysis. Stoch Environ Res Risk Assess 27:121–135
Matheron G (1973) The intrinsic random functions and their applications. Adv Appl Probab 5:439–468
Perrin O, Meiring W (1999) Identiability for non-stationary spatial structure. J Appl Probab 36:1244–1250
Pilz J, Spöck G (2008) Why do we need and how should we implement Bayesian kriging methods. Stoch Environ Res Risk Assess 22:621–632
Sampson P, Guttorp P (1992) Nonparametric estimation of nonstationary spatial covariance structure. J Am Stat Assoc 87:108–119
Wackernagel H (2003) Multivariate geostatistics: an introduction with applications. Springer, Berlin (ISBN) 3540441425
Warnery E, Ielsch G, Lajaunie C, Cale E, Wackernagel H, Debayle C, Guillevic J (2015) Indoor terrestrial gamma dose rate mapping in france: a case study using two different geostatistical models. J Environ Radioact 139:140–148
Author information
Authors and Affiliations
Corresponding author
Appendix A: Impact of Covariance Bias on Kriging
Appendix A: Impact of Covariance Bias on Kriging
Here, we demonstrated that using the biased covariance
affects neither the drift nor the dose estimates:
-
Drift coefficient estimation. Based on the \(\tilde{K}\) matrix, the weights \(\tilde{\varLambda }\) are obtained by
$$\begin{aligned} (K+\varPhi ww^{t}\varPhi ^{t})\,\tilde{\varLambda }\,=\,-\varPhi \tilde{\mu }. \end{aligned}$$Since \(\varPhi ^{t}\tilde{\varLambda }=I\) (universality condition), this gives
$$\begin{aligned} \tilde{\varLambda }=-K^{-1}\varPhi \,(\tilde{\mu }+ww^{t}), \end{aligned}$$(5)and finally
$$\begin{aligned} \varPhi ^{t}K^{-1}\varPhi (\tilde{\mu }+ww^{t})\,=\,-I. \end{aligned}$$But the Lagrange multiplier \(\mu \) of the true kriging system satisfies \(\varPhi ^{t}K^{-1}\varPhi \,\mu =-I\), so provided that the solution is unique, we identify \(\tilde{\mu }+ww^{t}=\mu \). Reporting in (5), we check that indeed \(\tilde{\varLambda }=\varLambda \). We conclude that despite the bias on the covariance, we get the correct kriging estimate of the drift. However, note that the apparent kriging variance
$$\begin{aligned} \tilde{\varLambda }^{t}\tilde{K}\tilde{\varLambda }=\varLambda ^{t}\tilde{K}\varLambda =\varLambda ^{t}(K+\varPhi ww^{t}\varPhi ^{t})\varLambda =\varLambda ^{t}K\varLambda +ww^{t}=\sigma _{K}^{2}+ww^{t}, \end{aligned}$$is not the correct one.
-
Interpolation. The perturbed kriging system is now
$$\begin{aligned} \left( \begin{array}{c@{\quad }c} K+\varPhi ww^{t}\varPhi ^{t} &{} \varPhi \\ \varPhi ^{t} &{} 0 \end{array}\right) \,\left( \begin{array}{c} \tilde{\varLambda }\\ \tilde{\mu } \end{array}\right) \ =\ \left( \begin{array}{c} K_{0}+\varPhi ww^{t}\varPhi _{0}^{t}\\ \varPhi _{0} \end{array}\right) . \end{aligned}$$We decompose the perturbed kriging matrix as follows:
$$\begin{aligned} \left( \begin{array}{c@{\quad }c} K+\varPhi ww^{t}\varPhi ^{t} &{} \varPhi \\ \varPhi ^{t} &{} 0 \end{array}\right) \,=\,\left( \begin{array}{c@{\quad }c} K &{} \varPhi \\ \varPhi ^{t} &{} 0 \end{array}\right) +\left( \begin{array}{c@{\quad }c} \varPhi ww^{t}\varPhi ^{t} &{} 0\\ 0 &{} 0 \end{array}\right) . \end{aligned}$$Then, provided that \(K^{-1}\) and \((\varPhi ^{t}K^{-1}\varPhi )^{-1}\) exist, we can write the perturbed kriging weights as the solution of
$$\begin{aligned} \left[ I+\left( \begin{array}{c@{\quad }c} K &{} \varPhi \\ \varPhi ^{t} &{} 0 \end{array}\right) ^{-1}\left( \begin{array}{c@{\quad }c} \varPhi ww^{t}\varPhi ^{t} &{} 0\\ 0 &{} 0 \end{array}\right) \right] \,\left( \begin{array}{c} \tilde{\varLambda }\\ \tilde{\mu } \end{array}\right)= & {} \left( \begin{array}{c} \varLambda \\ \mu \end{array}\right) +\, R, \end{aligned}$$(6)where \(\varLambda \) is the unperturbed kriging weights, and the vector R is given by
$$\begin{aligned} R\ =\ \left( \begin{array}{c@{\quad }c} K &{} \varPhi \\ \varPhi ^{t} &{} 0 \end{array}\right) ^{-1}\left( \begin{array}{c} \varPhi ww^{t}\varPhi _{0}^{t}\\ 0 \end{array}\right) . \end{aligned}$$It is not difficult to establish the following expression for the inverse of the kriging matrix (this formula is based on Schur complements)
$$\begin{aligned} \left( \begin{array}{c@{\quad }c} K &{} \varPhi \\ \varPhi ^{t} &{} 0 \end{array}\right) ^{-1}=\left( \begin{array}{c@{\quad }c} K^{-1}-K^{-1}\varPhi (\varPhi ^{t}K^{-1}\varPhi )^{-1}\varPhi ^{t}K^{-1}\ &{} \ K^{-1}\varPhi (\varPhi ^{t}K^{-1}\varPhi )^{-1}\\ \\ (\varPhi ^{t}K^{-1}\varPhi )^{-1}\varPhi ^{t}K^{-1} &{} -(\varPhi ^{t}K^{-1}\varPhi ) \end{array}\right) . \end{aligned}$$But since
$$\begin{aligned} (K^{-1}-K^{-1}\varPhi (\varPhi ^{t}K^{-1}\varPhi )^{-1}\varPhi ^{t}K^{-1})\,\varPhi ww^{t}\varPhi _{0}^{t}=0, \end{aligned}$$we get
$$\begin{aligned} R=\left( \begin{array}{c} 0\\ ww^{t}\varPhi _{0}^{t} \end{array}\right) . \end{aligned}$$We also have
$$\begin{aligned} \left( \begin{array}{c@{\quad }c} K &{} \varPhi \\ \varPhi ^{t} &{} 0 \end{array}\right) ^{-1}\left( \begin{array}{c@{\quad }c} \varPhi ww^{t}\varPhi ^{t}\ &{}\ 0\\ 0 \ &{} \ 0 \end{array}\right) \ =\ \left( \begin{array}{c@{\quad }c} 0 \ &{} \ 0\\ ww^{t}\varPhi ^{t}\ &{}\ 0 \end{array}\right) . \end{aligned}$$It follows that the first line of (6) implies \(\tilde{\varLambda }=\varLambda \).
The conclusion of this discussion is that the observed covariance can be used in place of the true covariance of \(Y_{0}\) in the interpolation of the dose rate and in the estimation of the drift coefficients. However the kriging variance will not be reliable, and we are not aware of any practical way to correct it.
Rights and permissions
About this article

Cite this article
Lajaunie, C., Renard, D., Quentin, A. et al. A Non-Homogeneous Model for Kriging Dosimetric Data. Math Geosci 52, 847–863 (2020). https://doi.org/10.1007/s11004-019-09823-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11004-019-09823-7