
Abstract
Most geostatistical estimation and simulation methodologies assume the experimental data as hard measurements, meaning that the measures of a given property of interest are not associated with uncertainty. The challenge of integrating uncertain experimental data at the geostatistical estimation or simulation models is not new. Several attempts have been made, either considering the uncertain data as soft data or interpreting it as inequality constraints, based on the indicator formalism or decreasing the weight of soft data in kriging procedures. This paper presents a stochastic simulation methodology where the uncertain experimental data are modelled by a probability distribution at each sample location. Data values are firstly drawn, by stochastic simulation, at these locations prior to the simulation of the rest of the grid nodes. This method is also extended to the simulation of categorical uncertain data, as well as to the simulation with uncertain block support data. To illustrate the proposed methodology, an application to a real case study of pore pressure prediction of oil reservoirs is presented, as well as an upscaling problem.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Geostatistical methods of stochastic simulation are used for the spatial characterization of many physical phenomena, such as property distributions in hydrocarbon reservoirs or mineral deposits and allowing the assessment of the spatial uncertainty related with the property of interest simultaneously. When these methods are grounded on experimental data (e.g., measured chemical values, ore grades, porosity, and permeability), the experimental data are considered as hard data, with no uncertainty attached for the purpose of estimating histograms, variograms and for conditioning stochastic simulations. When the existing experimental information is uncertain, that is, it is not exact or should not be considered hard data, integration of this uncertainty into stochastic models when characterizing the spatial dispersion of the main properties of a spatial phenomenon is challenging. In fact, this challenge is not new, and it has been the object of several works, either to estimate local cumulative distribution functions (cdfs) with indicator cokriging with soft data (Journel 1986; Zhu and Journel 1993) or to estimate local cdfs for stochastic simulation, with the indicator formalism (Alabert 1987). The main limitation of these methods is related with the properties of using an indicator formalism to characterize continuous variables, in particular the cumbersome task of indicator covariance models estimation (Goovaerts 1997). These were among the first attempts to integrate uncertain data in geostatistical estimation and simulation algorithms. Srivastava (1992) with the probability field (P-Field) simulation introduced a different approach. Firstly, the uncertainty at any spatial location, which is characterized by a local cdf, can be guessed (expertize guess), or estimated (indicator kriging or multiGaussian kriging). P-Field simulation consists of a simulation of random fields and, consequently, a structured realization of a main variable is drawn from the local predefined cdfs. Although fast and simple, this algorithm contains some drawbacks of implementation (Pyrcz et al. 2001). Recently, new efforts have been made to simultaneously integrate hard and soft data into reservoir modelling using the Tau-model (Naraghi et al. 2015), multi-point statistics and multinomial logistic regression (Rezaee and Marcotte 2016) and collocated co-kriging and artificial neural networks (Moon et al. 2016).
This paper keeps one interesting part of the P-Field method: the characterization of uncertainty data with a pdf, prior to the stochastic sequential simulation of spatially correlated realizations. Once we define the uncertainty at the data location, through a local pdf, we propose to generate realizations of data values from the local probability distribution functions, defined at experimental sample data locations \(x_{{\beta }}\), previous to the simulation of entire grid of nodes. This new framework can be applied to continuous variables, categorical variables and block support data. The uncertain data of categorical variables (e.g., lithofacies, ore types) are considered a local probability to belong to each class and, after generating the data values at \(x_{{\beta }}\) with direct sequential simulation (DSS; Soares 2001), the entire grid of nodes is simulated with sequential indicator simulation (Alabert 1987). This approach is also extended to the simulation of block data with uncertain data defined at the block spatial support. Uncertain block data at experimental locations are firstly generated before the application of block sequential simulation (Liu and Journel 2009).
To illustrate the proposed methodology, two application examples are shown. The first is a one-dimensional application that deals with upscaling high-resolution well-log data into a coarser grid. The second is a real case study of pore pressure gradient prediction of oil reservoirs. The available dataset comprises six wells located within a model of 740,050 cells. Uncertain pore pressure well data, derived from mud weight, are used as conditioning local pdf for the stochastic simulation of uncertain data to obtain spatial uncertainty maps of pore pressure gradient as represented, for example, by variance models.
2 Stochastic Simulation with Uncertain Data
2.1 Simulation of Data Values with Local Distributions
Uncertainty of experimental data can be interpreted as a lack of accuracy and precision of measurements, that is, measurement errors. In this context, this is usually modelled in geostatistical practice by decreasing the weight of these samples in spatial interpolation or stochastic sequential simulation processes, for example, by increasing the nugget effect, or assuming the soft data as local means in simple kriging (Goovaerts 1997), or by adding an error in the diagonal of samples covariance matrix (Goovaerts 2006a, b; Kyriakidis 2004; Liu and Journel 2009; Monestiez et al. 2006).
In the framework of this study, uncertainty of a data measurement at a given location \(x_{{\beta }}\), say \(z(x_{{\beta }})\), is interpreted as a result of our lack of knowledge about the uncertain data (\(\beta )\) and it is modelled by a set of possible values z which can occur according to a probability distribution function \(F(z(x_{{\beta }})\).
Let us assume one knows some hard experimental data \(z(x_{{\alpha }})\) and also the pdf \(F(z(x_{{\beta }}))\) at another \(N_\mathrm{d}\) experimental sample locations associated with uncertain measurements of the same property. These experimental pdfs, referred here as local distributions, can be derived by expertize guesses (see case study, Sect. 3.1), or derived from auxiliary variables, such as inferred porosity from a secondary acoustic impedance model (Nunes et al. 2015).
The proposed method aims at integrating the uncertainty of data measurements—local distributions—in the framework of a stochastic sequential simulation. It consists of a sequential approach where, in a first step and before simulating the entire grid, the experimental data values located at \(x_{{\beta }}\) are firstly drawn from the local distributions, and in a second step the entire grid of nodes is sequentially simulated, conditioned to the previously simulated experimental data. The data values \(z(x_{{\beta }})\) drawn from \(F(z(x_{{\beta }}))\) must reproduce not only these local cfds, but also the spatial correlation as revealed by the spatial covariance.
The idea of generating a spatially correlated set of data values consists of two steps: calculating the local mean and variance at the experimental data location, conditioned to the neighborhood “hard” data \(z(x_{{\alpha }})\) and also to the values previously drawn from other uncertain data distributions; and, afterwards, generating the simulated values with the local distributions, centered at the local mean and variance, following the outline of direct sequential simulation (Soares 2001).
The simulated data values, as they come from distributions centered at simple kriging mean and variance, reproduce not only the spatial covariances (Journel 1994), but also the local distributions (Soares 2001). This is a development of a version of direct sequential simulation with joint probability distributions (Horta and Soares 2010), which can be summarized into two basic steps:
-
1.
The direct sequential simulation starts by generating first the \(N_\mathrm{d}\) values at the experimental sample data locations, \(x_{{\beta }} \quad =1\), ..., \(N_\mathrm{d}\), using the local distributions \(F(z(x_{{\beta }}))\). At a given sample location \(x_{{\beta }}\), the mean and variance of \(z(x_{{\beta }})\) are calculated by simple kriging based on the known “hard” data \(z(x_{{\alpha }})\) and previously simulated uncertain experimental data \(z^{\mathrm {l}}(x_{{\beta }})\). A value \(z^{\mathrm {l}}(x_{\mathrm {0}})\) at the experimental location \(x_{\mathrm {0}}\) is drawn from the local distribution \(F(z(x_{\mathrm {0}}))\) centered at the simple kriging estimate of local mean
$$\begin{aligned} z\left( {x_{0} } \right) *=\sum _\alpha {\lambda _{\alpha } \left( {x_{0} } \right) z\left( {x_{\alpha } } \right) } +\sum _\beta {\lambda _{\beta } \left( {x_{0} } \right) z^\mathrm{l}\left( {x_{\beta } } \right) } , \end{aligned}$$(1)and with a local variance identified with simple kriging variance where \(\lambda _{\alpha } \) and \(\lambda _{\beta } \) are, respectively, the kriging weights associated with the known “hard” data and the previously simulated uncertain experimental data.
-
2.
After a set of \(N_\mathrm{d}\) experimental sample data is generated from the local distributions, in a second stage, the direct sequential simulation methodology generates z(x) values on the entire grid of nodes conditioned to the simulated values at the experimental locations plus the eventual hard data \(\{{z}({x}_{{\alpha }}), \alpha =1,\ldots , {N}; {z}({x}_{{\beta }}), \beta =1, \ldots , N_\mathrm{d}\}\). For each realization, a new set of sample data is generated before the rest of the model is simulated.
2.2 Variogram Estimation
When only uncertain data are available, the variogram models must be estimated with that data. A simple solution consists on estimating the variogram with the average values of the distribution and perform a transformation a posteriori.
At any experimental well data location \(x_{{\beta }}\), one can calculate the average values \(z_{{v}}\) from the local distributions \(z_{v} \left( {x_{\beta } } \right) =\int _ {z\left( {x_{\beta ,u} } \right) d_{u} } \). The variogram of average values can be calculated as follows
and modeled. The a priori point variogram can be obtained with the following Markov–Bayes approximation
where C(0) and \(C_{{v}}\)(0) are the variances of the point and block values z(x) and \(z_{{v}}\)(x).
The variogram model (Eq. (3)) can be calibrated with an inverse procedure: experimental variograms \(\gamma _{{v}}(h)\)* can be calculated with simulated well data values by the exposed method, assuming the point variogram model of Eq. (3). A comparison between \(\gamma _{{v}}(h)\)* and \(\gamma _{{v}}(h)\) obtained with average values (Eq. (2)) allows the calibration of point variogram until a satisfactory match is reached.
2.3 Simulation of Categorical Variables with Uncertain Data
This approach can be extended to the simulation of categorical variables with uncertain experimental data. The spatial characterization of categorical variables has been the object of different geostatistical approaches. The more common are the simulation algorithms based on auxiliary Gaussian variables—truncated Gaussian, pluri-Gausssian simulations (Le Loc’h and Galli 1997)—and the sequential simulations algorithms based on an indicator variable or vector—the sequential indicator simulation (Alabert 1987) and the different versions of multi-point simulation (Mariethoz and Caers 2014). These are based on a simple idea: following a random path over all grid nodes to be simulated, a local probability to belong to different categories is estimated by indicator kriging (sequential indicator simulation) or using a reference image (stochastic simulation based on multi-point statistics, MPS). The indicator value is generated by Monte-Carlo based on those local probabilities.
In the context of this work, a further aim is the integration of uncertain data in the outline of the sequential indicator simulation algorithms. Let us define the indicator variable I(x) which can take, at the experimental hard data locations, the values “1” or “0” depending on the category to which the sample x belongs. For simplicity of demonstration, let us consider just two categories X and the complementary \(X^{\mathrm {c}}\). The indicator variable I(x) is
Define \(p(x)=\mathrm{prob}\{x\epsilon X\}\) as the probability of x belonging to X. p(x) has exactly the same meaning of I(x) but it can take any value between 0 and 1. At the uncertain data locations, a local probability distribution function of p(x) can be used to define the uncertainty. For example, Fig. 1 is a three-dimensional view of two lithofacies (center region of the reservoir) with different spatial continuity: a more continuous and predictable dispersion of both categories at the lower part and a more erratic dispersion of both lithofacies in the upper zone. Two samples with uncertain data of lithofacies, indirectly characterized/classified by well-log data, could be represented, for example, in the lower part of low uncertainty, by a lognormal distribution of p(x), and in the upper part of high uncertainty, by for example a bimodal distribution of p(x).

Three-dimensional view of two lithofacies with different spatial continuity: a more continuous and predictable dispersion of both categories at the upper part and a more erratic dispersion of both lithofacies in the lower zone
The outline described in Sect. 2.1 can be applied to the simulation of categorical variables with uncertain data, in two steps:
-
1.
First, in order to generate the \(N_\mathrm{d}\) values of \(p^{\mathrm {l}}(x)\) at the sample uncertain data locations \(x_{{\beta }}\), the use of direct sequential simulation with the local distributions of p(x), \(F(p(x_{{\beta }}))\), \(x_{{\beta }} \quad =1\), ..., \(N_\mathrm{d}\) is proposed. At a given sample location \(x_{\mathrm {0 }}\), the local mean and variance of \(p(x_{\mathrm {0}})\) are calculated by simple indicator kriging based on the known “hard” data \(I(x_{{\alpha }})\) and previously simulated uncertain experimental data \(I^{\mathrm {l}}(x_{{\beta }})\)
$$\begin{aligned} p\left( {x_{0} } \right) ^*=\sum _\alpha {\lambda _{\alpha } \left( {x_{0} } \right) I\left( {x_{\alpha } } \right) } +\sum _\beta {\lambda _{\beta } \left( {x_{0} } \right) I^\mathrm{l}\left( {x_{\beta } } \right) } . \end{aligned}$$(5)The local variance of \(p(x_{\mathrm {0}})\) is identified with the simple indicator kriging variance. A value \(p^{\mathrm {l}}(x_{\mathrm {0}})\) \(x_{\mathrm {0}}\) is drawn from the point distribution \(F(p(x_{\mathrm {0}}))\) centered at the simple indicator kriging estimate of local mean and with the local variance identified with simple indicator kriging variance, following the algorithm presented in Sect. 2.1. Finally, a simulated indicator value is generated by Monte Carlo based on the simulated \(p^{\mathrm {l}}(x_{\mathrm {0}})\) and one realization from a uniform pdf
$$\begin{aligned} I^\mathrm{l}(x_{0} )=0 \quad \mathrm{if} \; p^\mathrm{l}\left( {x_{0} } \right) <u\hbox { otherwise }I^\mathrm{l}(x_{0} )=1,\quad u \in U\left[ {0,1} \right] . \end{aligned}$$(6)\(I^{\mathrm {l}}(x_{\mathrm {0}})\) then becomes a data value for the next data node simulation.
-
2.
After a set of \(N_\mathrm{d}\) data sample values of p(x) is generated from the point distributions, in a second stage, the sequential indicator simulation, or MPS, generates \(I^{\mathrm {l}}(x)\) values on the entire grid of nodes conditioned to the simulated values at the experimental locations and to existent hard data \(\{I(x_{{\alpha }})\), \(_{\mathrm { }}\alpha =1\), N, \(I(x_{{\beta }})\), \(_{\mathrm { }}\beta =1, N_{\mathrm {d}}\)}. For each realization, a new set of sample data is generated before the rest of the image is simulated.
2.4 Block Sequential Simulation with Uncertain Data
The joint use of point and block support data for stochastic simulation of a point support Z(x) was proposed by Liu and Journel (2009). In this work, the authors interpreted uncertainty of data as an error. Hence, they approached the uncertain block data by adding to it an “error”, in a similar way as other authors have done before in Poisson kriging (Goovaerts 2006a, b, 2010; Kyriakidis 2004; Monestiez et al. 2006). At an experimental block data location \(v_{{\beta }}\), the block data \(D_\mathrm{{B}}(v_{{\beta }})\) are interpreted as the sum of the true value \(B(v_{{\beta }})\) plus an error R
As the uncertainty of block data is interpreted as an error, the idea of this method is to reduce the “weight” of block data in kriging procedure, by adding the variance of the error, \(\sigma ^{2}_{R,}\) to the diagonal of the block–block covariance matrix of the left hand side of kriging system
But in the context of this work, the uncertainty of block data is interpreted as a measure with some randomness and can be approached by a probability distribution function. Hence, the proposed method can be extended to direct block simulation with uncertain data, either with point or block local distributions.
In the first step, the uncertain block values are generated, at the experimental locations \(v_{{\beta }}\) based on the local block pdf \(F_\mathrm{{B}}(D(v_{{\beta }}))\) associated with uncertainty of block data. At the block location \(x_{\mathrm {0}}\), a simple block kriging (Liu and Journel 2009) is calculated with existing point data \(z(x_{{\alpha }})\) and with previously simulated block values \(D^{\mathrm {l}}_\mathrm{{B}}(v_{{\beta }})\)
To solve the block kriging system with block data, point–point, point–block, and block–block covariances need to be modeled.
In the case where the data uncertainty is defined not on the block but on the point pdf, block data are assumed as the average value of the points inside \(v_{{\beta }}\)
Hence, the simulated block value at the experimental locations is obtained as the average of simulated point values (method described in Sect. 2.1).
After a set of \(N_{\mathrm {d}}\) point data sample values and \(N_{\mathrm {B}}\) experimental block data is generated from the distributions \(F(z(v_{\mathrm {\beta )}})\) and \(F_{\mathrm {B}}(D(v_{{\beta }}))\), in the second step, the direct sequential simulation method generates z(x) values on the entire grid of nodes conditioned to the point and block simulated values at the experimental locations plus the eventual hard data \(\{z(x_{{\alpha }})\), \(_{\mathrm { }}\alpha =1\), N, \(z^{\mathrm {l}}(x_{{\beta }})\), \(_{\mathrm { }}\beta =1\), \(N_{\mathrm {d, }}D^{\mathrm {l}}_{\mathrm {B}}(v_{{\beta }})\), \(\beta =1\), \(N_{\mathrm {B}}\}\). As in the previous case, for each realization a new set of sample data is generated before the rest of the image is simulated.
3 Application Examples
This section illustrates two distinct application examples. The first example is a one-dimensional example that aims to show the accuracy of the proposed stochastic sequential simulation algorithm. The second one is a case study for inferring the pore pressure gradient by simultaneously integrating seismic processing velocities and uncertain well data.
3.1 One-Dimensional Synthetic Example
This one-dimensional example intends to reproduce the problem of upscaling high-resolution well-log data into a coarser scale (i.e., the reservoir grid). In geostatistical seismic inversion, an important step for the data conditioning is the upscaling of the original well-log data, with very high vertical resolution, into the inversion grid, normally at the seismic scale and, therefore, with lower vertical resolution than the original well-log data. However, in seismic reservoir characterization studies the upscaling procedure is often overlooked and tackled with simplistic and deterministic methodologies such as arithmetic or harmonic means of the original high-resolution well-log values located within a given cell. However, assigning an average value to a given cell may not be representative of the real behavior of the subsurface property and does not allow assessing the uncertainty associated with the upscaling procedure.
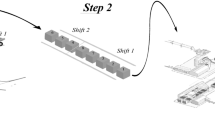
The proposed stochastic sequential simulation methodology may be used to assess the uncertainty related with the upscaling. One may consider the original high-resolution values located within a given coarse cell to build local point distributions, from where values are simulated using the proposed stochastic sequential simulation methodology (Fig. 2). With this upscaling approach, several realizations of the upscaled well-logs may be generated, allowing the assessment of the uncertainty related with the change of scale and assess its impact, for example, in geostatistical seismic inversion methodologies.

Point distributions built from the high-resolution well-log data samples of acoustic impedance within each coarser cell penetrated by the well
This one-dimensional example shows an example of upscaling a high-resolution acoustic impedance log into a reservoir model of 49 cells in the vertical directions. Figure 3 shows a set of 100 realizations of acoustic impedance using the point distributions shown in Fig. 2 built from the original well-log data. From this set of realizations, statistics such as the mean acoustic impedance model or the models corresponding to the 25, 50 and 75 quantiles (Fig. 4) may be computed.

Set of 100 realizations of acoustic impedance using the point distributions shown in Fig. 2

Set of 100 realizations of acoustic impedance using the point distributions shown in Fig. 3 with corresponding mean and quantiles: 25, 50 and 75 models
Each one of these realizations may be used as constraining data for geostatistical seismic inversion methodologies allowing the creation of different scenarios and assessing the impact of the resulting acoustic impedance models within the retrieved petro-elastic models.
3.2 Case Study: Gradient Pore Pressure Model with Uncertain Well Data
To illustrate the flexibility of the proposed stochastic sequential simulation methodology, this section comprises a real three-dimensional case study to infer the subsurface gradient pore pressure (GPP).
3.2.1 Dataset Description
The available dataset for this real case application comprises six wells and an initial GPP model derived from seismic processing velocities with 41 per 50 per 361 cells in i, j, k directions respectively (Fig. 5). Along with well positions the initial dataset contained the maximum and minimum values for expected GPP derived from the mud weight used during drilling.

3.2.2 Pore Pressure Gradient Prediction with Seismic Data
In this case, a study of gradient pore pressure prediction in petroleum reservoirs with uncertain data (Nunes et al. 2015) is performed. Abnormal pore pressure gradients can result in drilling problems such as borehole instability, stuck pipe, circulation loss, kicks, and blow-outs. Gradient pore pressure prediction is of great importance for risk evaluation in planning new wells in early stages of appraisal and production of hydrocarbons reservoirs, particularly in complex geological situations with high-pressure gradients. The knowledge of the local pore pressure risk helps preventing blow-outs and is crucial for planning the casing and mud weights and all the logistics associated with drilling in those situations.
Traditionally, pore pressure gradient prediction is based on existent relationships between seismic velocities (i.e., velocities inferred from velocity analysis during seismic processing) and the gradient pore pressure (Boer et al. 2006). This study proposes the following outline, summarized in these sequence of steps:
In a first step, a velocity volume resulting from velocity analysis during seismic processing and calibrated at the wells locations is transformed to gradient pore pressure using classical relations like, for example, Eaton’s equation (Eaton 1975)
The GPP volume results from the integration of geostatic and hydrostatic pressure gradients, GPG and GPH with the observed interval velocities (V), the normal compaction trend for interval velocity (\(V_{{N}})\) and the modeled exponent e. The exponent e, which measures the degree of sensitivity of the relationship between the velocity and GPP, after being calibrated at the well locations, is interpolated for all the study area (using, for example, kriging).
In a second step, the GPP volume obtained from (Eq. (11)) is calibrated with the very uncertain GPP values inferred at the well locations from the mud weights used during drilling. Commonly, the calibration is performed using values of GPP at the wells locations. The use of a mean value to predict extreme GPP values, the ones that may cause hazards, is problematic. However, one has not only an average value for GPP but also a range of values resulting from the lack of precision when measuring the mud weights used during drilling. The uncertain well data (i.e., the mud weights used during drilling) can and should be used to calibrate the GPP obtained from seismic velocities.
3.2.3 Integration of Uncertain Well Data in GPP Model
At the existing well locations, the available values of GPP can eventually be measured by resorting to repeat formation tester data but, most of the times, they are just inferred by the mud weight used during drilling operation. It is worthwhile noting that the value for the mud weight is often uncertain and only a range of expected values is normally available, resulting in very uncertain data. After the interpretation of GPP at the well samples’ locations, the uncertainty of this “soft” information is quantified by local probability distribution functions. These distribution functions can be any analytical cdf (e.g., triangular, truncated normal, beta) or experimentally built from the set of discrete GPP values at the wells locations derived from the mud weights. Usually, only lower and/or upper limits boundaries’ values of GPP are assumed for each sample along the well path.
GPP data interpreted as local “soft” data, with high uncertainty, can be the only available well data. The aim of this study is to take into account the uncertainty, as a probability distribution function, and implement the methodology described in Sect. 2.1 (i.e., to perform the stochastic simulation with the local cdf of GPP available at the well samples’ locations).
Assume one has \(N_{\mathrm {d}}\) well data points, with corresponding distribution functions \(F_{\mathrm {z}}(x_{{\alpha }})\), \(\alpha =1\), \(N_{\mathrm {d}}\) of the GPP variable. These distribution functions are derived from the values of mud weight used during drilling and represent the uncertainty of these measures. To propagate this uncertainty for the entire model simulation of GPP values for the regular grid of nodes \(x_{\mathrm {i}}\), \(i=1, N\) is needed.
The initial GPP volume derived exclusively from velocity models inferred during seismic processing and after the calibration of exponent e (Eq. (11)) is shown in Fig. 6. The only available well data have associated uncertainty. Triangular distributions (based on a maximum, minimum and mode values) were assumed for the point distributions of GPP along all the wells (Fig. 7). Two different regions are identified from the well data: the top with low GPP values and low uncertainty; the bottom region with high values and high uncertainty.

Vertical well section of the initial model of GPP. The location of the vertical section is shown in Fig. 5

Uncertain wells data. In each well, the mode is represented by the dark line. The minimum, Q25, Q75 and maximum are represented in light to dark tones. The spatial location of the wells is represented in Fig. 5

Vertical well section of the of the final simulated GPP model: a average model; b P90; c P50; d P10


Wells 1, 2, 3 (a) and 4, 5, 6 (b)—realizations of simulated well data values. The location of the vertical section is shown in Fig. 5
The proposed method, described in Sect. 2.1, can be summarized in the sequence of these two steps:
-
1.
Direct sequential simulation starts by first generating the \(N_{\mathrm {d}}\) values of GPP values at the well data location using the local distributions of Fig 7.
-
2.
After a set of \(N_{\mathrm {d}}\) well data GPP values is generated from the local distributions, in a second stage, the direct sequential simulation method generates GPP values on the entire grid of nodes, assuming the known velocity-based GPP cube as a local mean model (Fig. 6).
The initial GPP model derived from the velocity model generated during velocity analysis (Fig. 6) was used as a local mean model for the direct sequential simulation with point distributions. One could use the initial GPP model as an a priori trend model, instead of the simulation of GPP with local means, and simulate the residuals according to the same proposed methodology. At each cell penetrated by the available 5 wells, local distributions were generated based on the GPP values inferred from the mud weight used during drilling (i.e., uncertain soft data) (Fig. 7). Due to the lack of reliable data, these distributions were considered triangular based on the minimum, maximum and mode values as interpreted from the mud weight.
Fifty realizations of GPP following the proposed methodology were generated. First, the cells intersected by the wells are simulated taking into account the local point distributions and the initial GPP model derived from the seismic processing. Then, the rest of the cell grids are visited and simulated following the traditional direct sequential simulation procedure (Fig. 8) (Soares 2001). The experimental point distributions at the wells are well reproduced in different simulated models (Fig. 9).

Vertical well section of the of the GPP variance model showing the uncertainty areas of pore pressure. The location of the vertical section is shown in Fig. 5
Figure 10 depicts the variance of the 50 realizations and can be used to assess the spatial uncertainty associated with the GPP. The low spatial uncertainty/variance at the top, attached to the low GPP values, is derived from the low variance in the point distributions at the top, and the increasing uncertainty to the bottom zone of the high GPP values reflects an increased variance of the point distributions in that area.
4 Conclusions
This paper presents a new method of integrating uncertain “soft” data in stochastic simulations of continuous variables, categorical variables and block support data. The case study has shown the potential of the method with a new update approach of the GPP forecasting model. Integration of local distributions of “soft” data of pore pressure gradient, allowing the exploration of the uncertainty of data measurements, is the most important achievement of this new proposal. This method can be applied to any point distribution, either analytical or experimental distributions. Stochastic simulation with uncertain data may be directly integrated in the velocity model characterization by seismic inverse modelling (Azevedo et al. 2013).
References
Alabert F (1987) Stochastic imaging of spatial distributions using hard and soft information. Master’s thesis, Stanford University, Stanford, CA
Azevedo L, Nunes R, Soares A, Neto GS (2013) Stochastic seismic AVO inversion. 75th EAGE conference and exhibition, no. June 2013, pp 10–13
Boer LD, Sayers C, Nagy Z, Hooyman P, Woodward J (2006) Pore pressure prediction using well-conditioned seismic velocities. First Break 24:43–49
Eaton BA (1975) The equation for geopressure prediction from well logs. SPE paper #5544
Goovaerts P (1997) Geostatistics for natural resources evaluation. Oxford University Press, New York
Goovaerts P (2006a) Geostatistical analysis of disease data: visualization and propagation of spatial uncertainty in cancer mortality risk using Poisson kriging and p-field simulation. Int J Health Geograph 5:7
Goovaerts P (2006b) Geostatistical analysis of disease data: accounting for spatial support and population density in the isopleth mapping of cancer mortality risk using area-to-point Poisson kriging. Int J Health Geogr 5:52
Goovaerts P (2010) Combining areal and point data in geostatistical interpolation: applications to soil science and medical geography. Math Geosci 42:535–554
Horta A, Soares A (2010) Direct sequential co-simulation with joint probability distributions. Math Geosci 42(3):269–292. doi:10.1007/s11004-010-9265-x
Journel A (1986) Constrained interpolation and qualitative information. Math Geol 18(3):269–286
Journel A (1994) Modeling uncertainty: some conceptual thoughts. In: Dimitrakopoulos R (ed) Geostatistics for the next century. Kluwer Academic Pub., Dordrecht, pp 30–43
Kyriakidis P (2004) A geostatistical framework for area-to-point spatial interpolation. Geogr Anal 36(3):259–289
Le Loc’h G, Galli A (1997) Truncated PluriGaussian method: theoretical and practical points of view. In: Baafi et al (eds) Geostatiscs Wollongong ’96. Kluwer Pub., Dordrecht, pp 211–222
Liu Y, Journel A (2009) A package for geostatistical integration of coarse and fine scale data. Comput Geosci 35:527–547
Mariethoz G, Caers J (2014) Multi-point geostatistics: stochastic modeling with training images. Wiley, New York, p 376
Monestiez P, Dubroca L, Bonnin E, Durbec J, Guinet C (2006) Geostastistical modeling of spatial distribution of Balaenoptera physalus in the Northwestern Mediterranean Sea from sparse count data and heterogenous observation efforts. Ecol Model 193:615–628
Moon S, Lee GH, Kim H, Choi Y, Kim H (2016) Collocated cokriging and neural-network multi-attribute transform in the prediction of effective porosity: a comparative case study for the Second Wall Creek Sand of the Teapot Dome field, Wyoming, USA. J Appl Geophys 131(2016):69–83
Naraghi ME, Srinivasan S (2015). Integration of seismic and well data to characterize facies variation in a carbonate reservoir-the tau model revisited. In: Petrroleum Geostatistics 2015. European Association of Geoscientists and Engineers, EAGE, Biarritz, France, pp 243–247
Nunes R, Correia P, Soares A, Costa JFCL, Varalla LES, Neto GS, Silka MB, Barreto BV, Ramos TCF, Domingues M (2015) Gradient pore pressure modelling with uncertain well data. Petrol Geostat. EAGE Conference, Biarritz, France
Pyrcz MJ, Deutsch CV (2001) Two artifacts of probability field simulation. Math Geol 33(7):775–799
Rezaee H, Marcotte D (2016) Integration of multiple soft data sets in MPS thru multinomial logistic regression: a case study of gas hydrates. Stoch Environ Res Risk Assess 1–19. doi:10.1007/s00477-016-1277-8
Soares A (2001) Direct sequential simulation and cosimulation. Math Geol 33(8):911–926
Srivastava RM (1992) Reservoir characterization with probability field simulation. SPE Annual Technical Conference and Exhibition. Society of Petroleum Engineers, Washington, DC
Zhu H, Journel A (1993) Formating and integrating soft data: stochastic imaging via Markov–Bayes algorithm. In: Soares A (ed) Geostatistics Troia 92, vol 1. Kluwer Academic Pub., Dordrecht, pp 1–12
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Soares, A., Nunes, R. & Azevedo, L. Integration of Uncertain Data in Geostatistical Modelling. Math Geosci 49, 253–273 (2017). https://doi.org/10.1007/s11004-016-9667-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11004-016-9667-5