
Abstract
Objective
The current study proposes unique methods for apportioning existing census data in blocks to street segments and examines the effects of structural characteristics of street segments on crime. Also, this study tests if the effects of structural characteristics of street segments are similar with or distinct from those of blocks.
Methods
This study compiled a unique dataset in which block-level structural characteristics are apportioned to street segments utilizing the 2010 U.S. Census data of the cities of Anaheim, Santa Ana, and Huntington Beach in Orange County, California. Negative binomial regression models predicting crime that include measures of social disorganization and criminal opportunities in street segments and blocks were estimated.
Results
The results show that whereas some of the coefficients tested at the street segment level are similar to those aggregated to blocks, a few were quite different (most notably, racial/ethnic heterogeneity). Additional analyses confirm that the imputation methods are generally valid compared to data actually collected at the street segment level.
Conclusions
The results from the street segment models suggest that the structural characteristics from social disorganization and criminal opportunities theories at street segments may operate as crucial settings for crime. Also the results indicate that structural characteristics have generally similar effects on crime in street segments and blocks, yet have some distinct effects at the street segment level that may not be observable when looking at the block level. Such differences underscore the necessity of serious consideration of the issues of level of aggregation and unit of analysis when examining the structural characteristics-crime nexus.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Criminology has paid much attention to how crime varies across areas. Most of these studies have used Census defined boundaries (i.e., block, block group, or tract), and revealed that crimes are spatially concentrated within certain areas. Moreover, the structural characteristics of such areas have been found to affect the amount of crime and disorder. These structural characteristics include the level of concentrated disadvantage, racial/ethnic heterogeneity, residential instability, and economic inequality (Hipp 2007a; Sampson and Groves 1989; Warner and Pierce 1993). Yet, studies in the crime and place literature argue that the unit of analysis in relation to crime should be narrowed to smaller geographic units (i.e., buildings, addresses, clusters of addresses, block faces, or street segments) than these Census defined boundaries. Although a clear rule for the appropriate unit for studying crime has not been set, a considerable body of studies argues that the unit of analysis should be smaller (Oberwittler and Wikstrom 2009; Taylor 1997; van Wilselm 2009; Groff et al. 2009).
Small units of analysis are both theoretically and methodologically preferred. Theoretically, they better measure the physical and social environment of residents. Residents’ behaviors are influenced by physical and social environment only insofar as they can perceive these environments with their senses; these environments are arguably small (Oberwittler and Wikstrom 2009). Small units of analysis are methodologically preferred because they are less vulnerable to the risk of the aggregation bias. Aggregation bias, or the modifiable areal unit problem (MAUP), refers to bias that can affect the statistical results depending on the level of spatial aggregation employed. Because smaller units are more homogenous, they can more properly measure environmental characteristics. In sum, studies suggest that smaller units of analysis are better for the following reasons: (1) criminological theories (i.e., criminal opportunities and social disorganization) have direct relevance to understanding crime patterns at micro places; (2) it can minimize the aggregation in the analysis—hence, the risk of ecological fallacy is reduced; (3) spatial heterogeneity among the units of observation can be reduced relative to using larger units; and (4) policing strategies related to, and the policy implications from, such studies will be immediately actionable (Groff et al. 2010; Weisburd et al. 2012).
The census block is a small unit of analysis that has been widely used in studies of crime and place. According to Weisburd et al. (2012), the Census block is defined as the four block faces on a square street block. Census blocks have the advantage that they are the smallest geographic unit to which the U.S. Census Bureau aggregates data from all housing units. Studies revealed positive relationships between the number of robberies and presence of crime attractors and crime generators in and near a block (Bernasco and Block 2011; Kubrin and Hipp 2014), and property and violent crimes more frequently occur on blocks with certain structural characteristics such as higher renter occupancy, more liquor licenses, lower population density, and more crime on adjacent blocks (Raleigh and Galster 2014).
The street segment is another type of small unit of analysis that is frequently employed. Weisburd et al. (2004a) defined a street segment as both sides of a street between two intersections. Although existing studies have successfully revealed the importance of street segment as a unit of analysis and identified the crime patterns at street segments, the relationships between structural characteristics (i.e., poverty, residential instability, racial heterogeneity, etc.) of street segments and crime have been less explored. This is mostly due to the difficulty of data collection and measuring of structural characteristics of street segments; the few exceptions include a study that collected proxies for segment structural characteristics from a number of alternative sources, with some proxies admittedly better than others (Weisburd et al. 2012), and studies that evenly distributed the count data of a block and summed for each contiguous street segment (Smith et al. 2000; Rice and Smith 2002). The challenge for scholars then is whether to utilize segment-level measures with sometimes nontrivial measurement error, or whether for some measures a better strategy would be to impute data from another set of small units (such as blocks). If the spatial imprecision from relatively high-quality block-level data is less than the measurement error in certain segment-level measures that are not high quality, such imputation may be a better strategy. The present study explores the feasibility of this strategy.
Although street segments and blocks are both small units, street segments may be theoretically justified because we expect people to interact with others who live on the same street. There is less reason to expect residents on a block face to interact with people on the one behind them which is part of the block but less visible than the block across the street. Thus, a theoretical weakness of a block is that it assumes that people socially interact with others on the street behind them, but not with those who live across the street on the same street as them. However, studies have failed to assess whether the effects of structural characteristics of street segments are similar with (or distinct from) those at other small geographic units (i.e., Census block).The questions then are: (1) whether the theoretical justification of street segments over blocks are valid; (2) whether there exists a distinction between the two small units (street segments and blocks) in terms of structural characteristics, opportunities for crime, and thereby, patterns of crime; and (3) whether blocks are a reasonable approximation of street segments given abundance of data at the block level but difficulty of data collection at the street segment level.
To address these questions, the present study has four key goals. First, it proposes using an imputation strategy to assign Census demographic data from blocks to street segments (given the difficulty of collecting segment demographic data). Second, it compares two different imputation strategies for apportioning the block data to segments. Third, it examines the relationship of structural characteristics of street segments and crime. Fourth, by comparing the same models of two different units (street segments vs. blocks) this study evaluates if the structural characteristics distinctly affect crime depending on the small unit of analysis employed. The study uses data for small geographic units in the cities of Anaheim, Santa Ana, and Huntington Beach in Orange County, California.
Theoretical Background
Criminal Opportunities in Street Segments
Studies of crime and place frequently employ the theoretical frame emphasizing criminal opportunities. This opportunity approach suggests that different community environments create different criminal opportunities, the mixture of motivated offenders, potential victims, and the presence or absence of capable guardians (Cohen and Felson 1979; Felson 1987; Felson and Boba 2010). A major inquiry of this perspective is why some types of situational and contextual factors might increase/decrease crime events.
Crime pattern theory (Brantingham and Brantingham 1993) argues that crime occurs in certain patterns. These patterns are formed by routinized social, cultural, and economic activities over time, and spatially constructed by social and physical nodes, paths, and edges. Specifically, Brantingham and Brantingham (1984, 1995) describe how individuals’ behavior interacts with the built physical environment and land use characteristics to produce different patterns of opportunities for crime. They suggested that there should be more criminal opportunities in busier places resulting in more inflow of people due to the higher probability of having more potential offenders and victims present.
According to Brantingham and Brantingham (1995), the types of facilities present at places are the important factors in shaping of the number and type of people who are familiar with that place. Certain types of facilities (e.g., shopping centers, malls, schools, hotels, etc.) are seen to be crime generators because they draw a large number of people, some of whom may be potential offenders (Brantingham and Brantingham 1995). Thus, by attracting more people to a place, crime generators facilitate an increase of the number of potential offenders, as well as potential victims. Other facilities (e.g., drug markets, half-way houses, bars, etc.) are classified as crime attractors because they have reputations for criminal opportunities. Crime attractors are places that do not necessarily bring together large groups of people at the same time, but their function makes them well suited for motivated offenders to find attractive and weakly guarded victims or targets (Bernasco and Block 2011, p.35).
Previous studies have suggested that the theories of criminal opportunities are more applicable to micro places. Sherman et al. (1989) conceptualized the precise geographic place for understanding crime as “a fixed physical environment that can be seen completely and simultaneously, at least on its surface, by one’s naked eyes.” (p.31). Brantingham and Brantingham (1984, 1993) suggested that the mechanism of crime pattern theory is more plausibly theorized at the micro level. They argued that routine activities physically shape one’s activity space where people develop their awareness space. The awareness space is spatially and temporally limited because people know only limited area around their activity space. Therefore, it is more plausible to study criminal opportunities at micro places such as street segments.
Social Disorganization Theory
Social disorganization theory underpins many studies of crime and neighborhood. The intellectual starting point of the theory is that crime clusters in certain areas but not others. It argues that disorganized neighborhoods have lower levels of informal social control, which plays a key role in producing environments more favorable to crime. According to the theory, structural characteristics such as poverty, residential instability, and racial/ethnic heterogeneity are likely to have more crime producing influence (Shaw and McKay 1942). Specifically, such structural factors impede the sharing of common values and trust among residents, thus decreasing the ability to maintain informal social control—ability to regulate community itself (Bursik and Grasmick 1993; Bursik 1988; Kornhauser 1978; Kubrin and Weitzer 2003). Therefore, informal social control in the form of informal surveillance, communication, supervision, and intervention is thought to be the key mechanism intervening between social disorganization and crime.
Although numerous studies of social disorganization theory have tested the relationships between various structural characteristics and crime, less attention has been paid to the theoretical importance of the geographical aggregation employed, especially at the level of micro places. However, it is necessary to test the effects of various structural characteristics on crime at the level of micro places such as street segments for several reasons. First, as previous studies have suggested, the causal mechanisms of structural characteristics vary in spatial scale (see Hipp 2007b; Taylor 2015). That is, structural characteristics differ in their effects based on the level of aggregation employed. For example, Hipp (2007b) found that effects of racial/ethnic heterogeneity and economic resources can differ in their effects by the geographical level of aggregation. Lee et al. (2008)’s work on segregation also suggested that the social processes can vary by spatial scales.
Second, social disorganization theory is also applicable to understanding crime patterns at micro places. Barker (1963) coined the term “behavior setting” as a pattern of behavior and social environment to explain the relationship between people’s behavior in a particular situation and the structural characteristics. Wicker (1987) viewed street segments as small scale social communities (behavior settings) where people know each other, get familiar with others’ routines, develop and share their own norms on street segments. Moreover, street segments are as dynamic as other geographic units as people constantly move in and out and land use keeps changing (Taylor 1997). Therefore, street segments can be seen as communities that contain the characteristics of communities presented in social disorganization theory. Thus, “if the street segment can be seen as a type of ‘micro community,’ then social disorganization theory would seem to have direct relevance to the understanding of the criminology of place” (Weisburd et al. 2012 p.45). Scholars of criminology of place, however, have somewhat neglected the importance of social disorganization theory in empirical studies. A rare exception was a study attempting to collect proxy data in street segments for several social disorganization constructs (Weisburd et al. 2012). Therefore, a necessary next step is to test the effects of characteristics of social disorganization on crime at the street segment level.
Patterns of Crime and Structural Characteristics at Street Segments
Eck and Weisburd (1995) define micro places as specific locations within the larger social environments of communities and neighborhoods. Such micro places are defined as buildings or addresses, block faces, or street segments. A considerable body of literature finds that crime is not randomly distributed but rather spatially concentrated at these “micro” places regardless of the unit of analysis used (Eck et al. 2000; Eck and Weisburd 1995; Sherman et al. 1989; Sherman and Weisburd 1995; Taylor 1997; Taylor and Gottfredson 1986).
Among all definitions of micro places, the street segment is one of the most frequently employed units. Previous studies, mostly done by David Weisburd, Elizabeth Groff, and their colleagues, revealed a spatial concentration of crime at street segments (Groff and LaVigne 2001; Groff et al. 2010; Weisburd et al. 2004a, b; Weisburd et al. 2012), and the patterns of concentration are stable over time.
In addition to concentration and stability of crime patterns on street segments, studies have revealed that there is street-to-street variability of crime levels, which leads to an explanation of crime that may not be provided by studies using other units of analysis (i.e., block) (Weisburd et al. 2012; Groff et al. 2010). These findings suggest that within a geographic area, there is spatial heterogeneity of crime patterns across street segments, and, therefore individual street segments can have crime patterns that are unrelated to their immediately adjacent streets.
Moreover, Weisburd et al. (2012) found that the patterns of street-to-street variability are not only applicable to crime, but also to social structural characteristics. Specifically, they found strong evidence of spatial heterogeneity of social disorganization (i.e., residential property values, land use, racial heterogeneity, and physical disorder) and crime opportunities (i.e., public facility related crime generators and attractors, residential population, business related crime generators and attractors, police and fire stations as capable guardians, etc.) on nearby street segments. These findings suggest that data at the other units of analysis (e.g., block, block group, and tract) might be inappropriate to capture the effects of structural characteristics of small places and provide a basis for testing whether geographic patterns of characteristics of street segments are related to patterns of crime at street segments.
Thus, testing the underlying relationships between structural characteristics and crime at the street segment level is necessary for the following reasons: (1) the characteristics of places may encourage stability or change in crime; and (2) they would provide a basis for testing the direct relevance of crime pattern theory and social disorganization theory for understanding crime at street segments. More analysis of crime at the street segment level from a much more comprehensive set of data—including the characteristics of streets—are necessary. Moreover, it is important to examine whether the structural characteristics of street segments are distinct or similar compared to another small unit of analysis—blocks. To address this, the current study compares the same models at the street segment and block level to see if the structural characteristics of street segments have distinct or similar effects on crime compared to blocks.
In sum, the literature review points out that the existing research has successfully revealed the patterns of concentration and variability of crime as well as structural characteristics at the street segment level. Yet an intellectual gap still exists in that the effects of structural characteristics of street segments on crime have rarely been tested. The present study fills this gap by employing a unique method to apportion block level Census 2010 data to the street segment level, and tests the effects of structural characteristics on crime at the street segment- and block levels. This study poses the following research questions: (1) What are the effects of structural characteristics on crime when analyzed at the street-segment level? (2) Are these effects distinct from or similar with those analyzed at the block-level? and (3) Which and what types of structural characteristics predict crime better at which level?
Data and Methods
Street Segment and Apportioning Census Block Data
The units of analysis of this study are street segments and blocks. Block level data are derived from 2010 Census block data. The present study uses Census 2010 TIGER (Topologically Integrated Geographic Encoding and Referencing) line shape files to create street segments by splitting street lines at the points of intersections.Footnote 1 The study area is the cities of Anaheim, Santa Ana and Huntington Beach in Orange County, California. I selected these three cities based on the following reasons: (1) Anaheim and Santa Ana are the largest cities in Orange County, California, and they are very similar in many ways (i.e., population, racial composition, annual household income, etc.); and (2) Huntington Beach has dissimilar characteristics compared to the other two cities, therefore providing variety. Population of Anaheim, Santa Ana, and Huntington Beach is 336,265, 324,528, and 189,992 (Census 2010) respectively, and the annual household income of Anaheim and Santa Ana is $59,165 and $53,335, while that of Huntington Beach is $81,389 (2009-2013 American Community Survey 5-Year Estimates). Anaheim and Santa Ana have Hispanic/Latino dominant racial composition (52.8 and 78.2 % of total population, respectively), whereas Huntington Beach is a White dominant city (67.2 % of total population).
Although it is preferable to have data collected at the street segment level, such data are hard to obtain. Instead, the present study apportioned the Census data of blocks contiguous to each street segment in two ways: Simple Average (SA) and Segment Weighted Average (SWA). Using the information of relationships between street segments and blocks, the first method, SA, calculated the average values of Census data of blocks contiguous to the street segment, which takes following form:
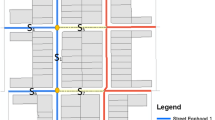
where \(N_{ }\) is the number of blocks associated with the street segment, and \(V_{j}\) is the value of the Census data for a given variable of block j associated with the street segment. As shown in Fig. 1, a hypothetical street segment is associated with two contiguous blocks (Block A and B).The SA method calculates the average values of these two blocks to apportion the data of the blocks to the street segment. For example, in Fig. 1, if the percent Hispanic/Latino in block A is 20.3 and that of block B is 15.6, the value of SA is calculated as (20.3 + 15.6)/2, which is 17.95. This means that when employing the SA method, the apportioned value of the percent Hispanic/Latino of this street segment is 17.95.

Associations between street segment, residential parcels, and blocks

Effects of average home values (logged) on burglary
The second method, SWA, utilizes the number of residential land use parcels contiguous to each street segment to refine these estimates. The decision to use the number of residential parcels to apportion the Census block data is based on the fact that Census respondents are typically a household member providing details of individuals residing in the unit. To get the number of contiguous residential parcels for the street segments, I used 2008 Southern California Association of Governments (SCAG) land use data which provide the parcel-level land use information in Southern California.
As shown in Fig. 1, a street appears as a centerline. This street center line is located in between the surrounding residential parcels residing in Census blocks. To properly capture the association between parcels and segments, I drew a 50 foot buffer around each street segment line so that each parcel can be linked to their associated street segment based on their proximity to (or intersections with) the segments. The buffer distance, 50 feet, has been set based on the Orange County Street Standard.Footnote 2
Through this process, I identified which parcels belong to which blocks based on their spatial locations. For example, in Fig. 1, a residential parcel, p1 has the block identification of block A because p1 has its centroid within block A, whereas parcel p13 has block identification of block B for the same reason. All residential parcels are associated with the contiguous street segment and the blocks they are located within. Next, I aggregated these residential parcels to the street segment and block level. As shown in Fig. 1, I ended up with segment/block combinations that refer to each side of the street. The entire process allowed me to compute the number of residential parcels contiguous to each street segment and the parcels’ associations with blocks on the sides of the street segment. For example, in Fig. 1, the street segment has 21 identified contiguous parcels among which 12 of them (p1–p12) are associated with block A while other 9 parcels (p13–p21) are associated with block B.
With this information, I apportioned Census data of blocks contiguous to the street segment by calculating the average values weighted by the number of residential parcels associated with a street segment and belonging to the block, which takes following form:
where SWA represents Segment Weighted Average of block data, \(P_{j }\) is the number of residential parcels within the block j associated with the street segment, and \(V_{j}\) is the value of the Census data for a given variable of j block. For example, in Fig. 1, if the percent Hispanic/Latino in block A is 20.3 and that of block B is 15.6, the value of segment weighted average is calculated as ((12*20.3) + (9*15.6))/(12 + 9) which is 18.28 percent. This means that when using the SWA method, the apportioned value of the percent Hispanic/Latino of this street segment is 18.28.Footnote 3
It is important to highlight the assumptions of these two approaches. Each of these approaches utilizes the data for a block and assumes homogeneity in distributing that data to all the segments that overlap the block. Whereas the SA method equally assigns that data to each overlapping segment (typically four), the SWA method weights the data by the number of residential units on each segment overlapping the block by utilizing land use parcels—these are smaller units that fall nicely within a block and are directly associated with a specific street segment. Given its geographical proximity and association with adjacent blocks, a street segment is not a completely separate line feature that just borders blocks, but can be considered as an overlapping unit containing characteristics similar to or different from those of the blocks. Therefore, the imputation method employed in the current study is attempting to use a more principled approach to impute information from blocks to segments. Additionally, a distinct characteristic of a street segment is that it consists of “both faces” of a street between two intersections. Thus, I imputed the Census data of the adjacent blocks into the street segment. Therefore, the SWA method addresses the nuanced geographical characteristic of a street segment (“both faces”) and the associations between street segments and blocks during the imputation process.
It is worth considering that these imputation methods will have difficulties in instances in which the structural characteristics of one street segment on a block are very different compared to other segments of the same block. Given that blocks are also very small geographic units, it may be reasonable to presume that very few blocks in a city will have substantially heterogeneous structural characteristics across segments. Furthermore, such heterogeneity would need to be systematically related to block characteristics to undermine the ability of these imputation methods to detect general patterns between structural characteristics and crime at the street segment level within a city (or cities). That is, imputed data are typically utilized to estimate general patterns, rather than estimate values for specific cases (in this case, segments). Nonetheless, I will return to this issue in the conclusion.
The total number of blocks is 8532 and that of street segments is 20,586 in the three cities (Anaheim, Santa Ana, and Huntington Beach). Of this total, I used only 5367 blocks—which have non-zero population —in the block-level models, with SA and SWA imputations for the street segment models. So, I restricted my analyses and my SA and SWA imputations to blocks with non-zero population. This decision was based on the fact that blocks with zero population will have missing values on the other socio-demographic variables. This decision eliminates the need to impute for missing socio-demographic data. Census data of 5376 blocks were imputed into 12,913 street segments contiguous to the blocks using the SA method, and into 12,762 segments using the SWA method. The number of street segments using the SWA method is less than SA because SWA method is based on the number of residential parcels within blocks. That is, the SWA method did not include the blocks with no residential land use parcels during the imputation of block values into street segments.
A limitation of the above imputation analyses is that I do not have a “gold standard” measure of the actual values in the segment for the Census measure. Therefore, to provide a more direct test of the validity of the two imputation methods, I constructed a measure of average home values based on data actually collected at the street segment level and included this measure in the models in place of the concentrated disadvantage measure. Given that I did not have such data for my three cities in the study site, I instead utilized land use parcel data from a city not in Orange County, but still in Southern California: the city of Long Beach in Los Angeles County, California. The data were derived from the Los Angeles County assessor office, and provide information of residential property value (home value) of each parcel. This allows me to calculate the average home values of street segments with actual street segment level data, and then to calculate the same values in blocks.Footnote 4 I then use the SA and SWA imputation methods to place the block data into segments, and compare the results to the actual segment values.
Dependent Variables
The dependent variables of this study are the number of crime incidents in 2010. Police agencies reported incident crime data with geographic information. Crime events were geocoded to latitude–longitude point locations using a geographic information system (ArcGIS 10.2).Footnote 5 Then, each crime point was aggregated to street segments and blocks. Crime events were classified into five Uniform Crime Reports Part 1 crime types: aggravated assault, robbery, burglary, motor vehicle theft, and larceny. This study excludes homicide because they are too rare on the street segments in 1 year to show variation across the street segments and blocks.
Previous studies have excluded crime incidents that occurred at intersections for the following reasons: (1) Because the events at intersections could be considered part of any one of the participating street segments, there is no clear method for assigning them to one or another; and (2) that incident reports at intersections differed dramatically from those at street segments (Weisburd et al. 2012; Weisburd et al. 2014; Groff et al. 2010). However, crime data for the current study show that characteristics of crime at intersections (about 1 % of all cases) are not different from those at street segments, thus dropping them might bias results as it would incorrectly assume these crime events did not occur. Instead of excluding all the crime incidents at intersections, I evenly distributed them to each contiguous street segment. For example, a typical intersection where two roads cross has four street segments. If a crime incident occurred on this intersection, each of four segments is given 0.25 of a crime incident.
Independent Variables
The structural characteristics at the street segment- and block-level are the independent variables of the current study. This study combines two data sets: (1) 2010 U.S. Census data, and (2) the Mint business data. To test the effects of social disorganization at the street segment or block level, the current study includes Census indicators of the three structural determinants of social disorganization as the independent variables. First, I constructed a concentrated disadvantage index, which is a factor score computed after a factor analysis of four measures: (1) % at or below 125 % of the poverty level; (2) % single-parent households; (3) average household income; and (4) % with at least a bachelor’s degree. The last two measures had reversed loadings in the factor score (Hipp 2010; Wo and Boessen 2016).Footnote 6 Second, to measure residential stability, this study utilizes the average length of residence. The present study accounted for the presence of racial/ethnic minorities in street segments or blocks as the percent African-American and the percent Latino/Hispanic. A Herfindahl index based on five racial/ethnic groups (white, African-American, Latino, Asian, and other races) was computed to capture the level of racial/ethnic heterogeneity which takes the following form:
where \(G_{j}\) represents the proportion of the population of racial/ethnic group j out of N groups. This study also accounted for population (log transformed) of the street segments and blocks and the percent occupied units is used to measure vacancies.
Based on the idea that land use characteristics and the physical environment are associated with crime opportunities, and that business facilities can be crime generators and crime attractors of places, the current study includes the number of employees of restaurants, schools, retail business, and the total number of employees. These measures were divided by 1000 for interpretation reasons. The measures of number of employees are used instead of the number of facilities because they are better proxy measures of (1) existence of the business facilities, (2) the size of the facilities, and (3) the magnitude of people moving in-and-out based on the assumption that larger business facilities tend to have more employees, thus more customers visiting the location. Also studies suggest that employees are expected to increase the number of suitable targets (Brantingham and Brantingham 1995). However, victims in one context may become capable guardians in another. To account for the effect of the presence of potential victims or guardians, this study uses the measures of the number of employees as estimates.
Data on the number of employees are derived from the Mint business data. Mint business data have information on business companies (what they do, who runs them, and their structure). Specifically, it provides addresses of companies, types of businesses by North American Industry Classification System (NAICS) code, the number of employees, year of establishment, the business revenues, and etc. In order to obtain the information of businesses, addresses of businesses in Sothern California were geocoded to latitude–longitude point locations using a geographic information system (ArcGIS 10.2) and then aggregated to street segments and blocks as done for the crime events.
Analytic Strategy
As shown in Table 1, since the dependent variables are counts of crime events in 2010 (aggravated assault, robbery, burglary, motor vehicle theft, and larceny), their distributions are not likely to be normally distributed. In many situations, researchers use negative binomial regression to estimates count models of crime (Hipp and Boessen 2013; Kubrin and Hipp 2014; Moore and Recker 2013; Stucky and Ottensmann 2009). Accordingly, this study used negative binomial regression that effectively deals with over-dispersion (Osgood 2000). I recognize that the structural characteristics and the distribution of crime can vary by three cities included in the models. Thus, I included fixed effects for cities (dummy variables of cities) to assess whether there are significant differences by cities.Footnote 7
Research has emphasized the spatial dependence of areas in relation to the distribution of crime (Anselin et al. 2000; Cohen and Tita 1999). This serves as an important reminder that areas do not exist and function in impermeable spheres of their own; rather, they coexist and mutually reinforce one another. Thus, it is important that ecological crime studies address potential spatial autocorrelation. To account for this, this study includes spatially lagged independent variables in the models. These measures were created based on an inverse distance function with a cutoff at 0.25 mile around the block (beyond which the areas have a value of zero in the W matrix).Footnote 8 The resulting spatial weights matrix (W) is row standardized. This matrix is multiplied by the matrix of values in the blocks for the variables of interests. As shown in Appendix Fig. 3, the 0.25 mile buffers of a street segment and the contiguous blocks are geographically very proximate and overlapping much each other. Therefore, it is plausible to think that the spatially lagged independent variables of blocks and segments are highly correlated. Effectively, I used SA method to construct the spatially lagged independent variables at the segment level. That is, the average values of the block level data were apportioned at the street segment level using the average of the buffer measures of blocks contiguous to the street segment.Footnote 9

Associations between 0.25 mile buffers of street segment and blocks
I checked the Moran’s I values of residuals from the negative binomial regression models including spatially lagged independent variables to assess if there is any additional spatial autocorrelation in the residuals and found no such evidence. The Moran’s I values of residuals in all models (SA, SWA, and block) were very small: always less than 0.03, which is a very small correlation. The Moran’s I values for the crime types ranged from 0.024 to 0.06 suggesting some spatial clustering of crime events, which effectively disappears after conditioning on the variables in the model.Footnote 10
Results
Results for Long Beach: Validation Tests
I begin by validating the two proposed imputation methods by comparing the correlations of the average home values between SA, SWA, and the actual street segment data of Long Beach, California. The correlations are very high. Specifically, the correlation between the two imputation methods (SA and SWA) was 0.99, while the correlations between the actual segment and SA, and SWA were 0.96 and 0.97 respectively. This implies that the imputed values using the two methods are very similar to the actual street segment data.
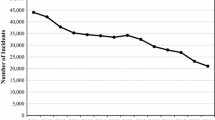
Next, I estimated models in which I included log transformed values of the average home values in the models in place of the concentrated disadvantage measure while including all other independent variables. I compare the model using the actual street segment data to those using the SA and SWA imputations for the property crime types in Table 1 and the violent crime types in Table 2. In terms of the average home values, only the results of property crime types are statistically significant. I visually display the statistically significant results by graphing the odds ratios in Fig. 2 for burglary, and Appendix Figs. 4 and 5 for larceny and motor vehicle theft.

Effects of average home values (logged) on larceny

Effects of average home values (logged) on motor vehicle theft
For all property crime types, I observe generally positive associations for average home values that level off at the higher level. This pattern is more evident for the results of motor vehicle theft. Importantly, the SWA and SA results are very similar to the models using the actual street segment data. In sum, given the high correlations and the results of the estimated models, the analysis confirms that the two imputation methods are generally valid compared to the data actually collected at the street segment level; and there is no substantial difference between the two methods.
Results for Anaheim, Santa Ana, and Huntington Beach
This study assesses whether there are distinct effects for the measures of structural characteristics in micro units, and compares the results across different levels of aggregation—SA, SWA and block. Table 3 presents the summary statistics for the variables used in the analyses. As shown in Table 3, means and standard deviations of crime incidents in segments are similar each other (SA and SWA), but different from blocks. This may suggest that the crime distribution in street segments has a distinct pattern from blocks. This is consistent with the findings of previous studies that there is a segment-to-segment variability of crime which may be weaker in other units of analysis (Weisburd et al. 2012; Groff et al. 2009). The coefficient of variance (the ratio of the standard deviation to the mean showing the extent of variability in relation to the mean) shows that the imputed segment variables using the SA and SWA methods have more variability than the block measures.
Next, I would like to present the results of the two imputation methods (SA and SWA). First, I turn to the relative quality of SA and SWA aggregating strategies by comparing the correlations between SA, SWA, and block data. The correlation results are presented in Table 4. Correlations between all three strategies are generally high. For example, the correlation of average length of residence between SWA and SA methods is 0.97. This implies that the imputed values using two strategies (SA and SWA) essentially are not different. Also, the correlations of SA-block and SWA-block ranged from 0.5 to 0.97 which means that the patterns of structural characteristics are generally stable regardless of unit of analyses employed. This seems reasonable because both blocks and street segments are small units that tend to overlap. Interestingly, the correlations between blocks and segments for the variables percent occupied units and percent black residents are relatively lower than other variables. An implication is that the relationships between these measures and crime may differ for street segments compared to blocks.Footnote 11
Next, I present the negative binomial regression results over three cities (Anaheim, Santa Ana, and Huntington Beach) for the property crime types in Table 5 and violent crime types in Table 6. These tables describe the results for separate analyses of the street segment measures using two forms of disaggregation (SA and SWA) and blocks. I turn first to the measures of structural characteristics derived from the social disorganization tenets. As shown in Tables 5 and 6, consistent with the findings of previous studies, concentrated disadvantage generally exhibits positive relationships with all types of crime regardless of the units of analysis used (SA, SWA, and block). Similar to the findings in previous studies, average length of residence as a measure of residential stability generally has a negative association with all types of violent and property crime. Specifically, as the average length of residence in street segments increases by a 1 year, there is a 3.6 % ([exp(−0.0371) − 1]*100 = −3.6) decrease in larceny when the SA method employed, with a 2.7 and a 1.45 % decrease in the SWA and block models respectively. A similar pattern is observed for the measure of vacancies—percent occupied units. A one percentage point increase in occupied units results in 1.2 % (SA) and 1.5 % (SWA) decrease in motor vehicle theft in street segments and 1 % decrease in blocks.
Surprisingly, for the racial/ethnic heterogeneity measure, the statistically significant coefficients of the street segment level models (both in SWA and SA) have the opposite direction compared to the effects in blocks. While the results of the block level models are consistent with the findings observed in previous studies (i.e., higher level of racial/ethnic heterogeneity predicts more crime), the results of street segment models show the opposite direction in general (higher level of racial/ethnic heterogeneity predicts less crime). For instance, a one standard deviation increase in racial/ethnic heterogeneity results in a 12 % ([exp (−0.6756*SD) −1]*100 = −12.04) decrease of burglary in streets when the SA method employed and a 11.6 % decrease using SWA. Likewise, a one standard deviation increase of racial/ethnic heterogeneity brings about 20.3 % (SA) and 21.1 % (SWA) decrease in motor vehicle theft in the segment.
This result suggests that the effects of racial/ethnic heterogeneity on crime at small units might vary by the units of analysis used. The findings of social disorganization measures confirm that there are some similar, but some distinct, effects of social disorganization on crime at the street segment level compared to the block level. An important implication is that social disorganization theory is applicable to explain the relationships between the structural characteristics and crime at micro places such as street segments.
Next, I turn to the effects of the measures derived from crime opportunities of place theory. As seen in Tables 5 and 6, the number of employees of businesses generally exhibit positive relationships with all types of property and violent crime on street segments and blocks. This supports the hypothesis that some types of businesses operate as crime generators as discussed above. For example, as shown in Tables 5 and 6, the effects of the number of retail employees at the street segment level (SA and SWA) are positively associated with all crime types. Specifically, a one person increase in retail employees in street segments results in about 3.86 % (SA) and 6.59 % (SWA) increase of robbery in street segment.
To compare the effect sizes of coefficients in the models of street segments and blocks, I calculated the ratios between the standardized coefficients of the SWA and block models (SWA/block). Standardizing the coefficients of the SWA and block models is more appropriate than comparing unstandardized coefficients given that the standard deviations differ for blocks and street segments. The ratios are reported in Table 7. In terms of social disorganization variables, greater effect sizes are generally observed when tested at the street segment level, except for the results of population. For example, the standardized coefficient of concentrated disadvantage index in the SWA model of burglary is 0.1, while that of block model is 0.036. For larceny, the standardized coefficients are 0.076 and 0.027 for SWA and block respectively. Therefore, the magnitude of effect size of SWA is about 2.8 times larger than that of blocks for burglary (Ratio = 2.79), and about 2.8 times as large for larceny (Ratio = 2.78). Likewise, the effect size of average length of residence on motor vehicle theft is nearly 2.7 times as larger when tested at the street segment level than the block level.
For the variables of the opportunities of place, the results are somewhat mixed. The effect sizes of the number of restaurant employees of the street segment are less than those of blocks for all crime types. For example, the effect of the number of restaurant employees on aggravated assault is 27 % less for street segments compared to the block model. In contrast, it is observed that the number of school employees has generally greater effects when the SWA strategy is used across all types of crime except for motor vehicle thefts. For example, effect size of the number of school employee on robbery in the SWA model is 93 % greater than that of the block model.
Next, I briefly describe the results of spatially lagged independent variables. The concentrated disadvantage index and percent black indicate significant and positive impacts on robbery no matter what unit of analysis is employed. Of the spatially lagged independent variables of criminal opportunities, the number of school employees is positively related with robbery in both of the segment and block models. For the types of property crime (burglary, larceny, and motor vehicle theft), percent occupied units have robustly negative relationships with all types of crime regardless of the units of analysis, while those of racial/ethnic heterogeneity have positive associations.
Finally, I employed a joint likelihood-ratio test to systematically determine whether the estimated coefficients in the two different models at the street segment level (SA and SWA) are statistically different from one another based on the \(\chi^{2}\) statistic. This assesses if the structural coefficient differences between the samples created by SA and SWA methods are significant. The result showed that the two data apportioning strategies do not have significant differences in all models in Tables 5 and 6 across all types of crime. Thus, the simpler approach appears to perform adequately, at least on these three cities.
Sensitivity Analysis
To check whether the SWA imputation method can be further enhanced, I employed additional weighting by adjusting for the mean number of residents per household, which is calculated by dividing the total block population by the number of households in the block. By doing this, I enhanced \(P_{j}\) in the Eq. (2), which takes following form:
where \(R_{j}\) is the mean number of residents per household in the block j, \(P_{j}\) is the number of residential parcels within block j associated with the street segment, and \(V_{j}\) is the value of the Census data for a given variable of j block. For example, in Fig. 1, block A has 12 residential parcels whereas block B has 9. If the percent Hispanic/Latino in block A is 20.3 and that of block B is 15.6, and if block A has a mean of 4 residents per housing unit, while block B has only 2, the value of the enhanced SWA is calculated as (4*12*20.3) + (2*9*15.6)/(4*12) + (2*9) which is 19.01. This means that when using the enhanced SWA method, the imputed value of the percent Hispanic/Latino of this street segment is 19.01 (Note that the value of the original SWA was 18.28).
To check the relative quality of SWA and the enhanced SWA methods, I calculated the correlations between them. The results are presented in Appendix Table 11. Correlations between the two different types of SWA strategies are very high. This implies that the imputed values using the two methods are not substantially different. The negative binomial regression results at the street segment level using the enhanced SWA method are presented in Appendix Table 12. I observed that the results are fairly similar to the original SWA. Finally, I employed a joint likelihood-ratio test to systematically determine whether the estimated coefficients in the two SWA models (SWA and the enhanced SWA) are statistically different from one another based on the \(\chi^{2}\) statistic. The result showed that the two data apportioning strategies do not have significant differences across all types of crime, suggesting little gain from this additional complication.
Discussion
This study attempted to verify the relationships between structural characteristics and crime at the street segment and block level. The primary contribution of the current study to the literature of crime and place is that it gives alternative ways to measure the structural characteristics of micro places (i.e., street segment) by using a more principled imputation of data of another small geographic unit of analysis (block). I have argued that this is reasonable because a block is also a small unit that has proximate geographic association with a street segment. The imputation methods employed in the current study do not just simply assign the block data to street segments assuming that a street segment is nested within a single block, but rather give each segment heterogeneous traits by imputing the structural characteristics of two or more different contiguous blocks into a street segment.
Scholars of crime and place emphasize that there are variations within larger units and therefore micro locations should be analyzed for understanding crime. Importantly, there is evidence that the patterns of crime in small places are tightly coupled with the structural characteristics of places (Weisburd et al. 2016; Weisburd et al. 2012). However, it is difficult to collect data at the street segment level, and the proxy measures employed in previous studies sometimes have limitations. This study therefore attempts to provide an alternative strategy by imputing relatively high quality data of another small unit (block) based on its unique and proximate geographic association with a street segment. In doing so, the current study contributes to the field of crime and place by advancing our understanding on the association between structural characteristics and crime in the micro places (i.e., street segment). A general question is whether the crude proxies that are collected specifically at the street segment level have more measurement error than the spatial measurement error introduced by the spatial imputation techniques utilized here. I believe that the current study contributes to the field by raising and trying to answer this question. Moreover, the sensitivity analysis using point level home value data attempts to do this, and found that the imputation methods work fine at least in the study area and for the home values as proxy measures of socioeconomic status of the places.
Whereas most of the results are quite similar regardless of the unit of analysis employed, a few were sometimes distinct. There were some unique patterns of crime in relation to structural characteristics when looking at the street segment level compared to the block level. This suggests that the issue of level of aggregation (unit of analysis) should be considered more seriously when examining the relationship between structural characteristics and crime. Although this suggestion is not completely new (Hipp 2007b), it has rarely been tested using street segment level data. Therefore, a major contribution of this study is to test the relationships between structural characteristics and crime at the street segment level, and compare them to the block level. In doing so, this study introduces unique methods to build a dataset of street segments by imputing Census block data to street segments. This provides a reasonable approach for estimating structural characteristics in street segments given the difficulty of actually collecting such data.
The results showed that some of the findings tested at the street segment level are consistent with the results when aggregating to blocks, whereas a few were quite different (e.g., racial/ethnic heterogeneity). For example, concentrated disadvantage has crime-enhancing effects across all types of crime no matter what unit of analysis is employed. The measure of residential stability (average length of residence) and the measure of occupied units are generally associated with lower crime rates. These measures of social disorganization tend to have greater impacts on crime in the segment models (SA and SWA) than in the block models. A notable implication is that the social disorganization perspective is important in understanding the criminology of place, reinforcing the suggestion of the previous studies (Smith et al. 2000; Rice and Smith 2002; Weisburd et al. 2012) that the existing literature focusing almost exclusively on criminal opportunities in small places might miss the patterns of social disorganization for better understanding crime.
The result of racial/ethnic heterogeneity is particularly interesting. For the property crime types, heterogeneity increases crime in the block models, whereas it decreases the crime in the street segment models. As shown in Table 2, given very high correlations of heterogeneity between segments and blocks (the patterns of heterogeneity in segments and blocks are very similar), this result supports that the relationship between heterogeneity and crime in street segment is unique and distinct from that of the block level. Although this result is somewhat striking because it reputes the traditional argument of the social disorganization perspective, it is not entirely new. Smith et al. (2000) also found that racial/ethnic heterogeneity was associated with less robbery in street segments (they referred to them as face blocks).
Racial/ethnic heterogeneity in street segments may function in a different way compared to blocks because of the appropriate scale of street segments. In social psychological literature, research on contact hypothesis emphasizes the potential benefits of diverse settings. Specifically, it argues that social propinquity between ethnically dissimilar others foster an identity that helps to reduce bias on diverse others, and thus build social ties and trust that transcends group boundaries. In other words, face-to-face social interactions among heterogeneous groups may be more conducive to develop knowledge-based trust and social ties among dissimilar groups if they have more opportunities for direct social interactions. (Gaertner et al. 1996; Pettigrew and Tropp 2006). Some empirical studies support that direct social interactions actually help build general trust among racially heterogeneous groups. In their study of neighborhoods in Detroit, Marschall and Stolle (2004) found that racial heterogeneity was positively related to trust among residents, and social interactions in heterogeneous places were more beneficial than more racially similar places.
These insights may be transferable to trust, social ties, and informal social control for understanding crime in street segments. Because of the proper spatial scale compared to blocks, residents in street segments may have more chances of direct social interactions to know others, diminish bias, and develop social ties and trust overarching ethically dissimilar groups. Such social ties and trust can help them have high level of informal social control to keep the community safe. This dynamic pattern may not be captured when analyzed at the block level. Therefore, an important implication is that researchers should pay more serious attention to level of aggregation issue particularly when testing the relationship between racial/ethnic heterogeneity and crime. Also, future research will want to explore the specific mechanism how racial/ethnic heterogeneity in street segments works different from blocks.
The results of the criminal opportunities measures are consistent with theoretical expectations. They exhibited strong effects in both the street segments and blocks models. This is consistent with previous studies that found various measures of retail and commercial businesses are associated with higher crime rates (Bernasco and Block 2011; Smith et al. 2000; Wilcox et al. 2004). Notably, these relationships were somewhat smaller at the street segment level compared to the block level. This implies that although criminal opportunities of street segments are important contexts for understanding the location of crime, using street segment as a unit of analysis is not necessarily the most effective choice to capture the patterns of criminal opportunities in the area. Overall, the results of this study reinforce the importance of incorporating land use characteristics to capture criminal opportunities when studying place and crime.
Although the imputation methods proposed in the current paper make homogeneity assumptions in imputing data from blocks into street segments, an important finding is the analysis that compares the SA and SWA imputed data to the gold standard data using point level residential home values. The correlations of these imputed data with the actual data were extremely high (above .96), and the models using the imputed average home values obtained very similar results to the models using the actual street segment data. This finding is consistent with the idea that the two imputation methods are valid for estimating structural characteristics in street segments given the difficulty of data collection at the street segment level. Also, I observed no substantial difference between the two methods, thus the simpler method was effectively preferable.
Although the results demonstrating effective imputation of home values from blocks to segments are important, it is worth acknowledging that such satisfactory performance may not occur for all possible measures. In general, the imputation techniques will work best when structural characteristics are more homogeneous with blocks, or at least do not exhibit systematic heterogeneity. It is plausible that residential property values on one side of a block are not substantially different from those on the other side of the same block, on average. For the same reason, we may expect to see similar patterns when the imputation methods employed for the measures of housing and residence related structural characteristics (i.e., average home values, average rent, percent home owners, percent occupied units, the number of housing units, percent single family housing units, etc.). Although it is not clear what types of measures might systematically vary across the segments within blocks, researchers would need to be alert to this possibility. Future work should explore collecting segment-level data to assess whether certain measures indeed vary consistently across segments within a block.
I acknowledge some limitations to this study. This study is designed as cross-sectional. A challenge with studying the relationships between structural characteristics and crime is the possibility of endogeneity. In other words, it is likely that the structural characteristics of the present can be affected by crime of the past. Indeed, Hipp (2010) found that neighborhoods with more crime are likely to experience changing structural characteristics (i.e., increasing levels of residential instability, concentrated disadvantage, a diminishing retail environment, and more African Americans) 10 years later. If this is a reciprocal relationship, an implication is that a cross-sectional design may actually find how crime affects structural characteristics rather than the reverse. To date, little is known about the relationship between the life course of crime hot spots and the actual life cycles of structural characteristics of street segments (or blocks). Therefore, future studies will want to utilize longitudinal data to capture and reflect: (1) how crime at the previous time point brings about changes in criminal opportunities and social disorganization at the current time point; and (2) How the changes of structural characteristics over time impact changes in crime. Such work can contribute to reveal the complexity of time–space convergence at small places that occurs from the characteristics of place, the structure of street network, and the routine activities of residents (Groff et al. 2009).
Also, for the SWA method, I did not distinguish between single and multi-family units when using residential parcels. Although counted as one, a multi-family unit often has more residential population compared to one unit of single family parcel. Yet, the sensitivity analysis of the enhanced SWA indirectly addressed this issue to some extent; and the results suggest that accounting for the number of housing units and residential population makes no substantial difference when imputing the block data to street segments. Another limitation is that although the models identify the effects of structural characteristics of street segments and blocks, the exact mechanisms bringing about such relationships are beyond the scope of the present study.
The findings have implications for public policy as law enforcement should consider hot spot policing, which has been found to be effective (Braga 2005; Braga et al. 2001; Sherman and Weisburd 1995; Weisburd and Green 1995). Since social disorganization and criminal opportunity measures at small places (street segments and blocks) are related to crime, it is reasonable to expect that crime will cluster at certain street segments and blocks as well as the surrounding areas. Therefore, law enforcement should consider increasing the number of patrol officers and the level of surveillance specifically targeting these places in order to reduce crime.
Conclusion
Although previous studies have provided valuable insight, they have typically not examined the relationships between crime and structural characteristics of street segments. The first contribution of the current study is to expand understanding regarding the nexus of structural characteristics and crime by testing this at the street segment level. Second, since the current study employs unique spatial techniques to apportion the block-level data to street segments, it provides an alternative method to construct data at the street segment level.
The results from the street segment models suggest that the structural characteristics from social disorganization and criminal opportunities on the street segments may operate as crucial settings for crime. I compared these findings with those of the block models and found that structural characteristics have generally similar effects on crime in street segments and blocks. However, I also found some distinct effects at the street segment level that may not be observable when looking at the block level. Moreover, the results reveal that theories of social disorganization as well as criminal opportunities are applicable to studying relationships between crime and structural characteristics of places (street segments and crime). Specifically, the effects of social disorganization measures are stronger in magnitude when tested at the street segment level, whereas criminal opportunity variables have greater effect sizes when tested at the block level. Such differences underscore the necessity of serious consideration of the issues of level of aggregation and unit of analysis when examining the structural characteristics-crime nexus.
Notes
This study excluded Amtrak/rail lines, shorelines, rivers, private streets, and highways. All other types of streets having address ranges in which addresses can be geocoded were included. There exist random breaks that often divide long street segments in Census TIGER line shape files. To deal with this issue, I dissolved the lines by the street names to remove all the random breaks before splitting the streets at intersections to get the street segments. A street segment is defined as a street from true intersection to intersection or when a street changes names without a true intersection. Although random breaks were removed by dissolving the street centerline file using street name, this process would not be a major concern for the data and analysis because for the most of cases, street names change when crossing intersections, which means it is very unusual that a street name just changes in the middle of a street.
The standard width of local streets in Orange County ranges from 40-56 feet, roadway shall be 50 feet, and parkway may be reduced to 5 feet.
For both of SA and SWA methods, each block was used multiple times to impute some of its characteristics to the street segments. For example, as shown in Fig. 1, a typical block (Block A) is associated with four street segments (a, b, c, and d) that border on the block. Therefore, in this case, the block was used four times for data imputation to the street segments. For the SWA method, some residential parcels (about 10 % of total 32,851), mostly those at the corners of the blocks, were double counted. Models using data in which the parcels are not inflated in the totals (spatially joining the parcels to the nearest street segment) were run and the results showed that the double-counting of parcels does not affect the overall findings.
Block-level estimates of housing values were not obtained by joining points to streets and then aggregating the street segment level data to blocks. Point-level data of home values were spatially joined to the street segments and blocks respectively.
Geocoding was done in ArcGIS 10.2 using a specific geocoding locator for Orange County using 2013 Census TIGER line shape file. The geocoding locater used the following parameters: spelling sensitivity = 75, minimum candidate score = 10, minimum match score = 10, side offset = 0, end offset 1 %, and Match if candidates tie = no. I used MapQuest open geocoding service and Google Earth Pro to geocode not matched incidents after the geocoding process using ArcGIS 10.2. Geocoding hit rates for crime incidents are 96.8 % (6038 of 5845) for Santa Ana, 96.8 % (9315 of 9621) for Anaheim, and 94.0 % (4725 of 5025) for Huntington Beach.
Census data provide only the percent single-parent households variable at block level. To have other variables for the concentrated disadvantage measure, I used an ecological inference technique. The variables used in the imputation model were: percent owners, racial composition, percent divorced households, percent households with children, percent vacant units, population density, and age structure (percent aged: 0–4, 5–14, 15–19, 20–24, 25–29, 30–44, 45–64, 65 and up). See (Kubrin and Hipp 2014).
To test whether the independent variables have similar or different relationships across 3 cities, I estimated separate models for each city employing three different aggregation strategies (SA, SWA, and Block). I present the results in Appendix Table 8, 9, and 10. The results show that the social disorganization components (i.e., concentrated disadvantage, average length of residence, and percent occupied) and the criminal opportunities measures (e.g., number of retail employees) have similar effects on crime at both of the street segment and block levels. The findings suggest that the effects of independent variables on crime are generally similar across the three cities. To systematically assess the difference of coefficients across three cities, I performed a series of joint tests on pairs of the cities. For example, I estimated a model with just Anaheim and Santa Ana, and included a dummy variable for one city (e.g., Anaheim) and included interactions between this city dummy variable and all other variables in the model. Given the large sample size and thus statistical power, I employ an information criterion rather than a \(\chi^{2}\) test. For all models, the Akaike Information Criterion (AIC) values were higher when allowing the coefficients to differ across the two cities compared to the model constraining them to be equal, suggesting that there are not systematic differences in the coefficients across cities. Thus, the three-city-pooled models presented in the current study are appropriate.
To empirically check whether distance matters for the spatially lagged independent variables, I ran the models with 0.5 mile buffer measures. I found no substantial difference between the models with 0.25 mile buffer measures and those with 0.5 mile buffers.
Including spatially lagged independent variables in the models is a conventional and valid way to account for spatial effects if theoretically justified. Anselin (2002) stated that it “does not require specialized estimation methods and ordinary least squares remains unbiased” (p.251). Florax and Folmer (1992) argued that omission of spatially lagged independent variables is an important cause for spatially correlated residuals. They empirically tested and revealed that the spatially dependent residuals can be remedied by incorporating the omitted spatially lagged predictor variables into the model. Many studies in the field address spatial dependence by including spatially lagged exogenous variables (Anselin 2003; Bernasco and Block 2011; Elffers 2003; Haberman and Ratcliffe 2015; Hipp 2010; Kubrin and Hipp 2014; Morenoff 2003; Sampson et al. 1999; Wo 2014; Wo and Boessen 2016). I follow the lead of these previous studies by including spatially lagged independent variables to account for spatial effects.
Although the Moran’s I values of residuals in all models were very small, the presence of spatial autocorrelation can affect the standard errors in the models. Nevertheless, ignoring correlated spatial errors will still yield consistent coefficient estimates (Anselin 1988: 59).
The lower correlations of percent black and percent occupied units are possibly the results of a “small numbers effect” impacting percentages. To check this, I restricted the data by dropping the extremely low values. I computed the correlations after excluding cases beyond the extreme 1 % of the distribution of each measure. In terms of percent occupied units, the correlation between SA and SWA increased from 0.64 to 0.90, and that of SWA and Block slightly increased from 0.50 to 0.66, while the correlation of SWA-Block remained unchanged. When it comes to the percent black measure, the correlations remained stable. Thus, it is somewhat true that the lower correlations are simply because of a small numbers effect (i.e., the result of percent occupied units between SWA and SA), but it still implies that the relationships between these measures and crime may differ for street segments compared to blocks.
References
Anselin L (1988) Spatial econometrics: methods and models. Springer, Boston
Anselin L (2002) Under the hood issues in the specification and interpretation of spatial regression models. Agric Econ 27(3):247–267
Anselin L (2003) Spatial externalities, spatial multipliers, and spatial econometrics. Int Reg Sci Rev 26(2):153–166
Anselin L, Cohen J, Cook D, Gorr W, Tita G (2000) Spatial analyses of crime. Crime Justice 4(2):213–262
Barker RG (1963) On the nature of the environment. J Soc Issues 19(4):17–38
Bernasco W, Block RL (2011) Robberies in chicago: a block-level analysis of the influence of crime generators, crime attractors, and offender anchor points. J Res Crime Delinq 48:33–57
Braga AA (2005) Hot spots policing and crime prevention: a systematic review of randomized controlled trials. J Exp Criminol 1:317–342
Braga AA, Kennedy DM, Waring EJ, Piehl AM (2001) Problem—oriented policing, deterrence, and youth violence: an evaluation of boston’s operation ceasefire. J Res Crime Delinq 38:195–226
Brantingham PJ, Brantingham PL (1984) Patterns in crime. MacMillan, New York
Brantingham PJ, Brantingham PL (1993) Environment, routine and situation: toward a pattern theory of crime. Adv Criminol Theo 5:259–294
Brantingham PJ, Brantingham PL (1995) Criminality of place. Eur J Crim Policy Res 3(3):5–26. doi:10.1007/BF02242925
Bursik RJ (1988) Social disorganization and theories of crime and delinquency: problems and prospects. Criminology 26:519–552
Bursik RJ, Grasmick HG (1993) Neighborhoods and crime: the dimensions of effective community control. Lexington Books, Boston
Cohen LE, Felson M (1979) Social change and crime rate trends: a routine activity approach. Am Sociol Rev 44(4):588–608
Cohen J, Tita G (1999) Diffusion in homicide: explaining a general method for detecting spatial diffusion processes. J Quant Criminol 15(4):451–493
Eck J, Weisburd D (eds) (1995) Crime and place: crime prevention studies (Vol. 4). Willow Tree Press, Monsey
Eck J, Gersh J, Taylor C (2000) Finding crime hot spots through repeat address mapping. In: Mollenkopf J, Ross T (eds) Analyzing crime patterns: frontiers of practice. Sage Publications, Thousand Oaks
Elffers H (2003) Analysing neighbourhood influence in criminology. Stat Neerl 57(3):347–367
Felson M (1987) Routine activities and crime prevention in the developing metropolis. Criminology 25(4):911–932. doi:10.1111/j.1745-9125.1987.tb00825.x
Felson M, Boba R (2010) Crime and everyday life, 4th edn. Sage Publications, California
Gaertner S, Rust M, Dovidio J, Bachman B, Anastasio P (1996) The contact hypothesis: the role of common ingroup identity on reducing intergroup bias among majority and minority members. In: Nye JL, Brower AM (eds) What’s social about social cognition?. Sage Publications, Newbury Park, pp 230–260
Groff E, LaVigne NG (2001) Mapping an opportunity surface of residential burglary. J Res Crime Delinq 38:257–278
Groff E, Weisburd D, Morris NA (2009).Where the action is at places: Examing spatio-temporal patterns of juvenile crime at places using trajectory analysis and GIS. In Weisburd, Bernasco & Bruinsma (Eds.), Putting crime in its place: units of analysis in spatial crime research. New York: Springer
Groff E, Weisburd D, Yang S-M (2010) Is it important to examine crime trends at a local “micro” level?: a longitudinal analysis of street to street variability in crime trajectories. J Quant Criminol 26(1):7–32. doi:10.1007/s10940-009-9081-y
Haberman CP, Ratcliffe JH (2015) Testing for temporally differentiated relationships among potentially criminogenic places and census block street robbery counts. Criminology 53(3):457–483. doi:10.1111/1745-9125.12076
Hipp JR (2007a) Income inequality, race, and place: does the distribution of race and class within neighborhoods affect crime rates? Criminology 48(3):683–723
Hipp JR (2007b) Block, tract, and levels of aggregation: neighborhood structure and crime and disorder as a case in point. Am Sociol Rev 72:659–680
Hipp JR (2010) A dynamic view of neighborhoods: the reciprocal relationship between crime and neighborhood structural characteristics. Soc Probl 57(2):205–230
Hipp JR, Boessen A (2013) Egohoods as waves washing across the city: a new measure of neighborhoods. Criminology 51:287–327
Kornhauser R (1978) Social sources of delinquency. University of Chicago Press, Chicago
Kubrin, CE, Hipp JR. (2014). Do fringe banks create fringe neighborhoods? Examining the spatial relationship between fringe banking and neighborhood crime rates. Justice Quart, 1–30. doi:10.1080/07418825.2014.959036
Kubrin CE, Weitzer R (2003) New directions in social disorganization theory. J Res Crime Delinq 40(4):374–402. doi:10.1177/0022427803256238
Lee BA, Reardon SF, Firebaugh G, Farrell CR, Matthews SA, O’Sullivan D (2008) Beyond the census tract: patterns and determinants of racial segregation at multiple geographic scales. Am Sociol Rev 73(5):766–791. doi:10.1177/000312240807300504
Marschall MJ, Stolle D (2004) Race and the city: neighborhood context and the development of generalized trust. Polit Behav 26(2):125–153. doi:10.1023/b:pobe.0000035960.73204.64
Moore MD, Recker NL (2013) Social capital, type of crime, and social control. Crime Delinq. doi:10.1177/0011128713510082
Morenoff JD (2003) Neighborhood mechanisms and the spatial dynamics of birth weight1. Am J Sociol 108(5):976–1017
Oberwittler D, Wikstrom H (2009) Why small is better: advancing the study of the role of behavioral contexts in crime causation. In Weisburd, Bernasco and Bruinsma (Eds.), Putting crime in its place: Units of analysis in spatial crime research. New York: Springer
Osgood DW (2000) Poisson-based regression analysis of aggregate crime rate. J Quant Criminol 16(1):21–43
Pettigrew TF, Tropp LR (2006) A meta-analytic test of intergroup contact theory. J Pers Soc Psychol 90(5):751
Raleigh E, Galster G (2014) Neighborhood disinvestment, abandonment, and crime dynamics. J Urban Affairs. doi:10.1111/juaf.12102
Rice KJ, Smith WR (2002) Socioecological models of automotive theft: integrating routine activity and social disorganization approaches. J Res Crime Delinq 39(3):304–336
Sampson RJ, Groves WB (1989) Community structure and crime: testing social disorganization theory. Am J Sociol 94(4):774–802. doi:10.1086/229068
Sampson RJ, Morenoff JD, Earls F (1999) Beyond social capital: spatial dynamics of collective efficacy for children. Am Sociol Rev 64(5):633–660. doi:10.2307/2657367
Shaw CR, McKay HD (1942) Juvenile delinquency and urban areas. Chicago University of Chicago Press, Chicago
Sherman L, Weisburd D (1995) General deterrent effects of police patrol in crime “hot spots”: a randomized, controlled trial. Justice Q 12(4):625–648. doi:10.1080/07418829500096221
Sherman L, Gartin P, Buerger M (1989) Hot spots of predatory crime: routine activities and the criminology of place. Criminology 27(1):27–56. doi:10.1111/j.1745-9125.1989.tb00862.x
Smith WR, Frazee SG, Davison EL (2000) Furthering the integration of routine activity and social disorganization theories: small units of analysis and the study of street robbery as a diffusion process. Criminology 38:489–524
Stucky TD, Ottensmann JR (2009) Land use and violent crime. Criminology 47:1223–1264
Taylor RB (1997) Social order and disorder of street blocks and neighborhoods: ecology, microecology, and the systemic model of social disorganization. J Res Crime Delinq 34(1):113–155. doi:10.1177/0022427897034001006
Taylor RB (2015) Community criminology: fundamentals of spatial and temporal scaling, ecological indicators, and selectivity bias. New York University Press, New York
Taylor RB, Gottfredson SD (1986) Enivronmental design, crime, and prevention: an examination of community dynamics. In: Reiss AJJ, Tonry M (eds) Communities and crime. University of Chicago Press, Chicago, pp 387–416
Van Wilselm, J (2009). Urban streets as micro contexts to commit violence In Weisburd, Bernasco & Bruinsma (Eds.), Putting crime in its place: Units of analysis in spatial crime research. (pp. 199–216). New York: Springer
Warner BD, Pierce GL (1993) Reexaming social disorganization theory using calls to the police as a measure of crime. Criminology 31(4):493–517. doi:10.1111/j.1745-9125.1993.tb01139.x
Weisburd D, Green L (1995) Policing drug hot spots: the jersey city drug market analysis experiment. Justice Q 12:711–735
Weisburd D, Bushway S, Lum C, Yang S-M (2004a) Trajetories of crime at places: a longitudinal study of street segments in the city of Seattle. Criminology 42(2):283–322. doi:10.1111/j.1745-9125.2004.tb00521.x
Weisburd D, Lum C, Yang S-M (2004b). The criminal careers of places: a longitudinal study (N. I. o. Justice/NCJRS, Trans.) (pp. 112). Rockville, MD: National Institute of Justice, US Department of Justice
Weisburd D, Groff ER, Yang S-M (2012) The criminology of place: Street segments and our understanding of the crime problem. Oxford University Press, New York
Weisburd D, Groff ER, Yang S-M (2014) Understanding and controlling hot spots of crime: the importance of formal and informal social controls. Prev Sci 15(1):31–43. doi:10.1007/s11121-012-0351-9
Weisburd D, Eck JE, Braga AA, Telep CW, Cave B, Bowers KJ, Bruinsma GJN, Gill C, Groff ER, Hibdon J, Hinkle JC, Johnson SD, Lawton B, Lum C, Ratcliffe JH, Rengert G, Taniguchi T, Yang S-M (2016) Place matters: criminology for the twenty-first century. Cambridge University Press, New York, NY.
Wicker AW (1987) Behavior settings reconsidered: Temporal stages, resources, internal dynamics, context. In: Stokels D, Altman I (eds) Handbook of environmental psychology. Wiley-Interscience, New York, pp 613–653
Wilcox P, Quisenberry N, Cabrera DT, Jones S (2004) Busy places and broken windows? Toward defining the role of physical structure and process in community crime models. Sociol Quart 45:185–207
Wo JC (2014) Community context of crime: a longitudinal examination of the effects of local institutions on neighborhood crime. Crime Delinq. doi:10.1177/0011128714542501
Wo JC, Hipp JR, Boessen A (2016). Voluntary organizations and neighborhood crime: a dynamic perspective. Criminology, http://onlinelibrary.wiley.com/doi/10.1111/1745-9125.12101/abstract
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kim, YA. Examining the Relationship Between the Structural Characteristics of Place and Crime by Imputing Census Block Data in Street Segments: Is the Pain Worth the Gain?. J Quant Criminol 34, 67–110 (2018). https://doi.org/10.1007/s10940-016-9323-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10940-016-9323-8