
Abstract
The perception of emotional facial expressions may activate corresponding facial muscles in the receiver, also referred to as facial mimicry. Facial mimicry is highly dependent on the context and type of facial expressions. While previous research almost exclusively investigated mimicry in response to pictures or videos of emotional expressions, studies with a real, face-to-face partner are still rare. Here we compared facial mimicry of angry, happy, and sad expressions and emotion recognition in a dyadic face-to-face setting. In sender-receiver dyads, we recorded facial electromyograms in parallel. Senders communicated to the receivers—with facial expressions only—the emotions felt during specific personal situations in the past, eliciting anger, happiness, or sadness. Receivers mostly mimicked happiness, to a lesser degree, sadness, and anger as the least mimicked emotion. In actor-partner interdependence models we showed that the receivers’ own facial activity influenced their ratings, which increased the agreement between the senders’ and receivers’ ratings for happiness, but not for angry and sad expressions. These results are in line with the Emotion Mimicry in Context View, holding that humans mimic happy expressions according to affiliative intentions. The mimicry of sad expressions is less intense, presumably because it signals empathy and might imply personal costs. Direct anger expressions are mimicked the least, possibly because anger communicates threat and aggression. Taken together, we show that incidental facial mimicry in a face-to-face setting is positively related to the recognition accuracy for non-stereotype happy expressions, supporting the functionality of facial mimicry.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Imitation is a highly adaptive behavior. Throughout the lifespan, humans acquire new skills by imitating what they observe in others. Often, imitative behavior occurs as mimicry, i.e., unintentional and unconscious behaviors that match what was perceived (van Baaren et al. 2009). In social interactions people mimic movements, postures, vocalizations, and facial expressions (Chartrand and Lakin 2012), strengthening ties between individuals (Lakin et al. 2003), enhancing sympathy for the person being mimicked, advancing rapport, smoothing interactions (Chartrand and Bargh 1999; Chartrand and van Baaren 2009), and promoting prosocial behavior (Stel and Harinck 2011; Stel et al. 2008). Hence, mimicry helps to integrate individuals into a group and strengthens group coherence (Lakin et al. 2003).
An important possible function of mimicking facial expressions is to facilitate emotion recognition (Hess and Fischer 2013; Niedenthal et al. 2010b). Embodied simulation theories assume that perceiving an emotional expression triggers the simulation of the corresponding emotional state in the perceiver at neural and peripheral physiological levels, facilitating access to the emotional concept (Niedenthal et al. 2010b). Automatic facial mimicry represents the expressive part of emotion simulation (Goldman and Sripada 2005). More specifically, the facial feedback hypothesis (e.g., McIntosh 1996) proposes that mimicked facial expressions initiate feedback processes activating the corresponding emotional experience in the observer. This information helps to evaluate the emotional expression perceived in the partner. In line with this idea, interfering with facial mimicry impairs emotion recognition performance (Neal and Chartrand 2011; Oberman et al. 2007; Rychlowska et al. 2014). Likewise, Künecke et al. (2014) found that the amount of incidental facial muscle responses in response to emotional expressions was positively related to emotion recognition performance across individuals. However, some studies do not support the functionality of facial mimicry for emotion recognition (Blairy et al. 1999; Hess and Blairy 2001; Kosonogov et al. 2015). Kulesza et al. (2015) even found worse recognition performance, when participants actively mimicked facial expressions.
Facial mimicry might not be necessary (e.g., Bogart and Matsumoto 2010) but helpful for emotion recognition, at least in some conditions (Hess and Fischer 2013). It could be an efficient strategy for subtle differentiations rather than simple emotion categorizations (Hyniewska and Sato 2015; Sato et al. 2013), faster recognition (Niedenthal et al. 2001; Stel and van Knippenberg 2008), and for supporting difficult emotion recognition of low-intensity, non-stereotype facial expressions (Künecke et al. 2014).
In the present study, we investigated emotion recognition performance in a dyadic setting with facial electromyography (EMG) (Dimberg et al. 2002; Hess and Fischer 2013). Senders communicated emotions experienced during past personally salient events dominated by feelings of happiness, anger, or sadness by silently displaying the corresponding facial expression to the receiver. Participants rated facial expressions on three dimensions (anger, happiness, and sadness) and were instructed to achieve consensus with their partner. Thus, senders and receivers should consider each other as in-group members in a cooperative task, which should enhance facial mimicry (Bourgeois and Hess 2008; Fischer et al. 2012; Weyers et al. 2009). The emotional experiences in the personal situations and the resulting idiosyncratic expressions varied in intensity and were a mixture of basic and non-basic emotions, which rendered the emotion ratings sufficiently challenging, and rendered facial mimicry as an efficient means for good emotion recognition performance.
According to Hess and Fisher’s (2013) Emotion Mimicry in Context View, emotional expressions inherently communicate information about the expresser and his intentions. The interpretation of the emotional expression in a given context determines what and why the perceiver mimics. In the present setting, we expected that receivers would most strongly mimic happiness, to a lesser degree sadness, and least of all, anger. Smiles are usually mimicked regardless of context (e.g., Bourgeois and Hess 2008), presumably because they signal affiliative intent, their mimicry is socially expected, and entails no personal costs. In contrast, mimicry of sad expressions signals empathy with the sender and may entail further commitment; hence it is highly accepted, but potentially costly. Mimicking angry expressions in affiliative contexts is socially maladaptive and was therefore expected to occur weakly or rarely.
Although the amount of mimicry might differ with respect to emotion category, we expected facial mimicry to help recognizing all expressions shown here. Our experimental setting provided optimal conditions for mimicry as an efficient strategy for emotion recognition. In particular, emotion recognition of non-stereotype expressions, rated on continuous scales by receivers who resembled the senders in gender, age, and situational background (students) and who were highly motivated to achieve optimal rating agreement. Our study goes beyond previous research by measuring facial mimicry during an emotion recognition task in a dyadic face-to-face setting, which should provide a stronger test of the functional role of incidental facial mimicry for emotion recognition.
In separate actor-partner interdependence models (APIMs; Kenny et al. 2006) for each emotion category, we tested whether facial mimicry—measured with facial electromyogram (EMG)—occurred. Most importantly, we assessed whether the receivers’ own facial activity influenced their evaluation of the perceived facial expressions, leading to higher rating agreements between sender and receiver.
Method
Participants
Forty-two women were recruited through a listserve of Humboldt-Universität zu Berlin. We only tested female participants, in order to avoid cross gender effects (Hess and Bourgeois 2010), and since women appear to be emotionally more expressive and more responsive regarding facial mimicry (Stel and van Knippenberg 2008). Ages ranged from 18 to 36 years (M = 25.5, SD = 4.2). All participants reported normal or corrected-to-normal visual acuity. Most of them were right-handed (38/42) and native German speakers (35/42); non-native German speakers understood all instructions. A rating of familiarity (0 = not at all to 100 = very much) confirmed that senders and receivers in any given dyad had not known each other (M = .55, SD = 1.2, max = 4) before the experiment. Sympathy ratings (0 = not at all to 100 = very much) before the experiment were acceptable and did not differ between senders (M = 67.72, SD = 14.74) and receivers (M = 72.50, SD = 15.41). The ethics committee of the Department of Psychology of the Humboldt-Universität zu Berlin had approved the study. Informed consent was obtained from all participants.
Apparatus
Questionnaires and tasks were programmed with Inquisit Millisecond Software® (Draine 1998); stimuli were presented on 15 inch laptop screens. All ratings during the experiment were conducted via mouse click on visual analogue scales (from 0 = not at all to 100 = very much).
Pre-study
We piloted 27 abstract emotional situations with 20 participants in an online study; there were nine situations each written to elicit happy, angry, or sad emotions in varying intensities. Participants were instructed to remember specific situations in their lives with personal significance that matched the abstract situations in question, and to imagine these situations as vividly as possible. Autobiographical recall is a viable emotion elicitation technique which can adequately distinguish between discrete emotions (Lench et al. 2011). Participants were asked to rate their subjective feelings on the dimensions angry, happy, sad, neutral/detached, intensity of feeling, and how well they were able to imagine the situation in question. Then, participants provided a label for the situation and stated how many different situations they might have provided for the given abstract situation. Of 27 situations, we chose 12 that best distinguished between our target emotions happiness, anger, and sadness (Table 1). Additionally, we took into account how easily participants could imagine concrete personal situations.
Procedure
Participants of the experiment proper were randomly assigned to 21 sender-receiver dyads. The study consisted of three parts, of which only the first two will be reported here. In the first part, taking about 30 min, the senders completed a rating of emotional situations. The second part, starting after a 5-min break, was the emotion communication task; it took about 60–90 min, depending on how long it took the participants to imagine the situation and provide ratings.
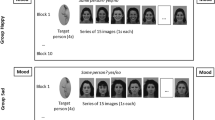
Figure 1 depicts the experimental setup. Participants were seated in an electrically shielded cabin. During emotional situations, only the senders’ EMG responses were measured; during the emotion communication task EMG recordings were taken from senders and receivers in parallel and senders were also video-recorded. Senders and receivers could easily see each other by looking over the small laptops in front of them.

Setup of the dyadic emotion communication task
The sender started first and worked on the emotional situations; half an hour later the receiver came in. After the application of EMG electrodes (for details see below) to both participants, they answered demographic questions and completed the Positive Affect Negative Affect Schedule (PANAS) (Watson et al. 1988) to assess mood. Positive and negative affect did not differ between senders and receivers.
Emotional Situations
In this task, the senders were instructed to recall and actively imagine personally experienced emotional situations corresponding to 12 different abstract situations (Table 1). The abstract descriptions of situations were presented in random order in the middle of the screen, with a light grey background and black Arial 40 point font. Descriptions were shown until senders indicated, by mouse click, to have recalled a specific personal situation matching the abstract description. After the screen went blank, participants should imagine the personal situation as vividly as possible including all arising feelings and emotions. When they felt their emotional re-experience to be at its maximum point, they pressed enter on the keyboard. After a 4 s post-stimulus interval, participants rated how well they had been able to imagine the personal emotional situation and were asked to label the situation freely but unambiguously. This was done for all 12 abstract situations. Following the labeling, participants rated their feelings according to three concrete emotions: “How angry are you?” (“Wie ärgerlich sind Sie?”), “How happy are you?” (“Wie sehr freuen Sie sich?”), and “How sad are you?” (“Wie traurig sind Sie?”).
As can be seen in Table 1, senders rated the situations according to the intended emotions (all β’s > .31). This was also true for the emotion communication task, which allowed investigating our hypothesis of emotion mimicry and recognition for predominantly angry, happy, and sad expressions.
Emotional Communication Task
Participants were informed that the sender recalled personal emotional situations and was trying to communicate her emotional experience by facial expression alone. Sender and receiver were encouraged to reach the best agreement possible in their ratings—but, of course, they did not know about each other’s ratings. Sitting face to face, sender and receiver (see setup Fig. 1) first rated the partner on familiarity and sympathy. Then, the sender tried to communicate to the receiver merely via facial expressions how she had felt in each of the 12 personal situations, indicated by the labels individually chosen for the personal emotional situations shown on the senders’ screen while the screen of the receiver was blank. As soon as the sender felt ready, she pressed enter, eliciting a short beep audible to both partners, and displayed the corresponding facial expression for 3 s. Then, a large red stop sign, presented for 2 s, on the sender’s screen indicated to return to a neutral expression. During the emotion communication, sender and receiver were required to maintain eye-contact. Next, both sender and receiver rated the sender’s facial expression for happiness, anger, and sadness. The 12 personal situations were repeated three times in random order. Hence, there were 36 emotional situation trials in total.
In order to neutralize emotional experience and expression, emotional situation trials alternated with vowel judgment trials. In these trials, the sender saw a fixation cross of 1 s duration, followed by one of five vowels (a, e, i, o, u) presented for 3.5 s, while the receivers’ screen was blank. During this time, the sender was asked to communicate the vowel to the receiver by silent lip movements. After another 500 ms the receiver indicated the vowel displayed, followed by the next emotional situation trial. Each vowel was shown seven times in random order, resulting in 35 vowel judgment trials. Figure 2 depicts the trial scheme for the emotional and vowel trials, respectively.

Trial schema for alternating emotional and vowel trials
After written and verbal instructions, there was a practice trial with one emotional situation and one vowel judgment. The experimenter made sure that participants had understood the task before they started.
EMG Recordings and Preprocessing
We simultaneously recorded facial muscle activity in senders and receivers with Ag/AgCl electrodes (4 mm diameter). Two electrodes each, placed according to Fridlund and Cacioppo (1986), measured activities of the left m. corrugator supercilii (corr; wrinkling the eye regions in smiling), m. orbicularis oculi (orbi; wrinkling the eye regions in smiling), and m. zygomaticus major (zyg; raising the lip corners in smiling); the ground electrode was placed in the middle of the forehead. Skin was prepared with abrasive peeling gel and alcohol, and the conductive gel was Neurgel®. Impedances were kept below 10 kΩ. EMG signals were acquired with two identical Coulbourn systems, including V75-04 bio-amplifiers (band-pass filtered at 8–10,000 Hz) and V76-24 4-channel contour following integrators (TC = 20 ms). The rectified and integrated EMG signals were sampled at 500 Hz with Brain Vision Recorder Software (Brain Products GmbH).
Continuous EMG data were notch-filtered at 50 Hz and visually inspected in Brain Vision Analyzer software (Brain Products GmbH). For the emotional situations, data were segmented into 11-s epochs with 1-s baselines preceding the mouse click indicating the recall of a personal situation. For the emotion communication task, we created 6-s segments with 1-s baselines preceding the button press indicating the start of emotion/vowel expressions. Single trial baseline-corrected data were exported for further analysis to the R Environment for Statistical Computing (R Core Team 2014).
We z-standardized the EMG separately for each muscle, task, and participant and averaged the activity over the 10- and 5-s segments for the emotion communication and emotional situation tasks, respectively. Finally, we created a Positive Expression Index (PosExp) by subtracting the corr activity from the mean of the orbi and zyg activity for each trial (Mauersberger et al. 2015). This measure accounts for the fact that facial expressions are muscle patterns rather than single muscle activations. High and low values in the PosExp indicate a more positive or a more negative facial expression, respectively, relative to the individual’s average expression.
Results
Intraclass Correlations
As a first step, we calculated the intraclass correlations (ICC) of the emotion ratings in order to make decisions surrounding the random effect structure in the following analyses. ICC indicates how much variance is explained by a grouping factor. We modeled Intercept-Only models with crossed random effects for dyad and situation for the emotion ratings, separately for happy, angry, and sad trials. All models were calculated with the lmer() function of the lme4 package (Bates et al. 2015) in R (R Core Team 2014). ICCs for emotion ratings by situation were .07 for happiness, .07 for anger, and .02 for sadness; ICCs by dyad were .36 for happiness, .32 for anger, and .38 for sadness. Since the amount of variance due to the dyad is considerable, and Kenny et al. (2006) suggest assuming non-independence if there are less than 25 dyads (p. 50), we included random effects for the dyad in all subsequent analyses. We neglected the factor situation in favor of simpler models.
Manipulation Checks
For manipulation checks, we first checked that senders did express emotions according to their ratings by predicting senders’ emotion ratings with their incidental PosExp activity. Second, we examined how well receivers performed in the emotion communication ratings, by predicting receivers’ emotion ratings with senders’ emotion ratings. Continuous predictors and dependent variables were standardized before entering analyses. Thus, the standardized β-coefficients can be interpreted as changes in units of SD of the dependent variable for a one-SD change in the predictor, controlling for the other predictors. For the explained variance, we report marginal and conditional R 2 (as suggested by Nakagawa and Schielzeth 2013) with the r.squaredGLMM() function of the MuMIn package (Barton and Barton 2015). The marginal R 2 is an approximation of the variance explained by the fixed effects only, whereas the conditional R 2 describes the variance explained by the fixed and random effects.
Three dyads had no data for one situation; however, there were enough trials per emotion from the other three situations. In one dyad, only 67% of all trials were recorded (all situations were presented twice, except situation 8 and 12, which were only presented once).
Senders’ ratings could be predicted by their PosExp activity for happy (β = .19, t = 3.27, p = .001, R 2(m) = .067, R 2(c) = .390), and angry trials (β = −.26, t = −4.92, p < .001, R 2(m) = .036, R 2(c) = .374). In sad trials the relationship was not significant: β = −.09, t = −1.60, p = .11, R 2(m) = .007, R 2(c) = .392. In principle, this provides the opportunity for the receivers to infer the senders’ ratings from their facial expressions.
Senders’ happiness ratings significantly predicted receivers’ happiness ratings (β = .85, t = 44.66, p < .001, R 2(m) = .705, R 2(c) = .746). This was also true for anger (β = .66, t = 22.95, p < .001, R 2(m) = .402, R 2(c) = .460) and sadness ratings (β = .61, t = 20.16, p < .001, R 2(m) = .347, R 2(c) = .433). This shows that receivers performed quite well in rating the senders’ facial expressions on the rating dimensions corresponding to the emotions in question (all βs > .61).
Average Mimicry Effects
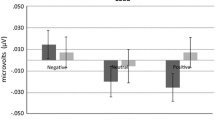
The following analyses address the influence of the emotions signaled by the senders on the receivers’ facial muscle activity, that is, mimicry. We conducted a repeated measure ANOVA of the PosExp EMG activity with factors emotion (happy, sad, angry) and role (sender, receiver) with the anova() function, based on Type III sums of squares and Satterwhite approximation for degrees of freedom (Kuznetsova et al. 2013). There was a significant effect of emotion, F (2, 1458) = 169.00, p < .001, with more activity in response to expressions of happiness, in comparison to expressions of anger (β = −.30, t = −15.49, p < .001) and sadness (β = −.31, t = −16.26, p < .001). Figure 3 depicts both senders’ and receivers’ PosExp activity in response to the different emotion trials. There was no main effect of role, but a significant interaction of emotion and role, F (2,1458) = 6.25, p = .002. Comparing senders’ and receivers’ PosExp activities within each emotion category revealed no differences in happy and sad, but in angry trials (β = −.31, t = −3.50, p < .001) (see Fig. 3) where the receivers’ PosExp activity was less pronounced than the senders’.

Senders’ and receivers’ average PosExp activity separately for each emotion. Error bars depict between standard-errors
Actor-Partner Interdependence Models
For modeling the relation between senders’ and receivers’ facial expressions and their ratings, we used APIMs (Kenny et al. 2006). Figure 4 illustrates the prototypical APIM for the present setting. Actor effects of senders (aS) and receivers (aR) indicate how their facial activity predicts their own emotion ratings. The receivers’ partner effect (pR) estimates the effect of the senders’ facial activity on the receivers’ emotion ratings, while the senders’ partner effect (pS) estimates the effect of the receivers’ facial activity on the senders’ ratings. Importantly, the correlation between senders’ and receivers’ EMG (rSR) indicates the similarity of their facial activities and, hence, the amount of mimicry. The residual covariance indicates the similarity of the senders’ and receivers’ ratings after accounting for all APIM effects. We separately estimated APIMs for categories of happy, angry, and sad facial expressions. Details on the construction and estimation of models are provided in the supplementary material (S1).

Actor-partner interdependence model (APIM) for the present setting. aS = sender’s actor effect; aR = receiver’s actor effect; pS = sender’s partner effect; pR = receiver’s partner effect; rSR = correlation of sender’s and receiver’s facial activity; cov(eS,eR) = residual covariance of sender’s and receiver’s rating not explained by the APIM
To test our hypotheses, we compared the full APIM shown in Fig. 4 with a restricted APIM without the parameter aR. If rSR is substantial and the model without aR fits worse, we can conclude that facial mimicry occurs and receivers use their facial expressions to signal agreement in emotion ratings to the senders. We conducted Chi square difference tests for the likelihood ratios (Δχ2) to compare these models. A significantly poorer model fit indicates that the full model describes the data better and thus aR is a meaningful predictor. For quantification of the explained covariance of senders’ and receivers’ ratings by actor and partner effects in the two competing models, we report marginal and conditional R 2 (Nakagawa and Schielzeth 2013).
Happiness APIM’s
For the happy trials, we found a significant effect of aR (see Table 2). The correlation between senders’ and receivers’ PosExp (rSR) was also significant, whereas aS and pR were not. The explained variance of the fixed effect was R 2(m) = .121, of fixed and random effects it was R 2(c) = .402. Excluding aR led to significantly poorer model fit (Δχ 2(1) = 8.65, p = .003) and smaller R 2(m) = .092 as well as R 2(c) = .353. Thus, receivers mimicked senders’ happiness expressions, which influenced their ratings (aR) and led to higher rating agreement, as expected. As can be seen in Table 2, when aR was not in the model, aS and pR became significant.
Anger APIM’s
The full anger model showed a significant aS and pR effect. The correlation between senders’ and receivers’ PosExp (rSR) was low, but significant (see Table 2). The aR and pS were not significant. The marginal R 2 was R 2(m) = .112, the conditional R 2 was R 2(c) = .337. When aR was fixed to zero, the p value indicated worse model fit (Δχ 2(1) = 3.48) p = .06, but R 2 dropped to a negligible value (R 2(m) = .112, R 2(c) = .334). This means, receivers’ little mimicry of anger did not influence their ratings or the agreement between senders’ and receivers’ ratings, which disconfirms our hypothesis.
Sadness APIM’s
In the sad trials, there was a significant effect of aR, pS, and rSR (see Table 2). Receiver effects were not significant. In the full model, effect size for fixed effects was R 2(m) = .148 and R 2(c) = .315 for fixed and random effects. Excluding aR did not affect fit (Δχ 2(1) = 2.42, p = .120) and R 2(m) = .145 as well as R 2(c) = .314 were slightly lower. This also disconfirms our hypothesis. Although receivers mimicked senders’ sad expressions, this mimicry did not affect receivers’ ratings or the agreement between senders’ and receivers’ ratings.
Discussion
We studied the contribution of facial mimicry to nonverbal face-to-face communication of emotions in a dyadic setting. A sender expressed her emotions about different personally experienced situations to a receiver with the intention of communicating predominantly happy, angry, or sad emotions. Senders and receivers rated each facial expression on these dimensions with the common aim of maximizing agreement between their ratings. Mimicry was measured with PosExp facial EMG. The contribution of mimicry to the accuracy of emotion ratings was assessed with APIMs.
Facial Mimicry and Emotion Recognition
The expected relation between facial activity and emotion ratings was only evident in happy trials. Receivers mimicked senders’ facial expressions to some extent. Additionally, receivers’ facial activity influenced their ratings, which in turn increased concordance between senders’ and receivers’ ratings. Although the APIMs do not imply causal relations per se, one might interpret this as a facial feedback mechanism within embodied simulation theories. Accordingly, the sender’s facial expression, interpreted as a relevant emotional signal, induces a corresponding emotion expression in the receiver, in turn, improving judgments about the perceived expression (Hess and Fischer 2013; Niedenthal et al. 2010a).
In the final models for happiness and anger, the sender’s PosExp activity influenced receiver’s ratings, indicated by a significant partner effect for the receiver. This reflects another potentially more visual-cognitive strategy for emotion recognition. Receivers might perceptually evaluate and rate the emotional expression without any influence of their own facial activity. Winkielman et al. (2015) suggested that an automated pattern-recognition strategy can be sufficient for emotion recognition under some conditions.
In addition to the predicted actor effect for the receivers, in happy trials there was also a significant partner effect for the senders. The higher the PosExp activity of the receivers, the higher the senders’ rating of their own happy expressions. When the senders perceived the receivers’ positive mimicry, they might, in turn, rate their own feelings more positively. The more the receiver was smiling back at the sender, the more positively she might have evaluated her own happiness expression.
In sum, the results suggest an active role of facial mimicry in recognizing happiness. This is in line with other studies claiming a functional role of facial mimicry for emotion recognition. Oberman et al. (2007) experimentally interfered with facial mimicry and found that recognition of happy expressions was mainly impaired. Although we measured incidental facial mimicry with facial EMG, we too found the strongest effect of mimicry for happiness.
Emotions or Intentions?
In contrast to our prediction, receivers’ facial activity did influence their ratings and senders’ and receivers’ rating agreement only in happy, but not in sad and angry trials. Especially in angry trials, mimicry was hardly present (see Fig. 3). These emotion-specific differences can be explained within the Emotion Mimicry in Context View (Hess and Fisher 2013), suggesting that in affiliative contexts, anger expressions are rarely mimicked since they signal potential threat. Mimicking anger expressions of one’s communication partner—without an external source of anger—might antagonize affiliative intentions and hence be socially maladaptive in most day-to-day encounters. Sadness mimicry signals empathy and might raise further expectations in the sender. These inherent meanings of angry and sad expressions might be internalized and overlearned and may have prevented or attenuated anger and sadness mimicry also in our study. Further, display rules may have contributed to the lack of anger mimicry. Safdar et al. (2009) reported that, compared to men, women show powerful expressions like anger less often but display powerless emotions like happiness and sadness more often. In our task, while female senders were asked to show angry expressions as often as happy and sad, female receivers might have been less susceptible to mimicking them in comparison to happy and sad expressions. Male participants, in contrast, might have shown more intense anger expressions and mimicry, but still less intense overall emotion expressions and mimicry (Stel and van Knippenberg 2008). We postulate that experimental manipulations where both persons have a common opponent at whom anger is directed may promote anger mimicry and when dyads have an intimate relation, this may promote sadness mimicry.
As opposed to the assumed basic emotion approach (Ekman et al. 1972), which interprets emotion expressions as readouts of inner states that can be modulated in social contexts, receivers’ facial responses might be better explained by the intentions that senders communicate with their expressions. In Fridlund’s (1994) Behavioral Ecological View, facial expressions are social tools in the service of communicating intentions. In this view, smiles communicate the willingness to be friends, anger expressions communicate the readiness to attack, and sadness expressions communicate the request to be taken care of. Instead of mimicking facial displays of basic emotions, receivers could have responded to these intentions with some of those responses inhibited by the presence of the sender. Possibly, participants reciprocated the friendship invitation by a positive expression, but reacted with bewilderment, fear, or even a neutral face to signal that they will not reciprocate the sender’s anger expression. Sadness expressions could trigger concern—an expression hard to differentiate from sadness with EMG recordings as was done in the present study.
Senders and receivers were instructed to send and rate senders’ facial expressions according to happiness, anger, and sadness. The basic emotion view predicts that the senders connect their inner emotional state with their facial expressions. However, as outlined above, it seems that perceivers responded to the communicative intentions of senders’ facial expression rather than mimicking a basic emotion expression. Thus, the Behavioral Ecological View explains the receivers’ facial responses more parsimoniously. Future research should strive to realize settings for which the Behavioral Ecological View and the Emotion Mimicry in Context View make contrasting predictions, including a rating of facial expressions on the outlined intention dimensions.
Limitations
Experimental control in the present study was weaker than in standard EMG experiments, where participants typically judge controlled visual stimuli presented on a computer screen. A large proportion of the variance in our data relates to random effects: differences between senders, receivers, and dyads as indicated by the relative size of marginal relative to conditional R 2. Nevertheless, our hypotheses regarding the fixed effects were testable and mostly confirmed. In the present study, receivers spontaneously responded to idiosyncratic expressions in a dyadic face-to-face situation. Although these expressions are less stereotyped and vary in their mixtures of basic emotions and intensities, they are still deliberately expressed, which might restrict the ecological validity of the communication situation. Another potential limitation is the small sample size of 21 dyads. We decided for a smaller sample size in favor of more trials, which is common in linear mixed-effect modeling and allowed for separate analyses for angry, happy, and sad trials. The results deserve a replication and extension with a larger sample. A third limitation is the lack of control for covariates, such as individual differences in empathy (Sonnby-Borgström 2002), emotion perception (Hildebrandt et al. 2015; Wilhelm et al. 2014), or emotion expression (Gunnery et al. 2012; Zaki et al. 2008). Furthermore, during the experiment, participants interacted only nonverbally, but body postures and movements, more implicit sources such as gaze, tears, pupil-dilation, eye blinks, blushing (Kret 2015), or even odor cues (de Groot et al. 2015) might also have communicated emotions and were then facially mimicked (Hess and Fischer 2014) or simulated on other neural and bodily levels.
Future studies could record additional physiological measures, such as electrodermal activity or body and head movements (Chartrand and Lakin 2012). Skin conductance responses could help distinguish between the negative emotions on the arousal dimension (Boucsein 2012). Similarly, synchrony of senders’ and receivers’ facial expressions might be an interesting measure (Boker et al. 2002; Ramseyer and Tschacher 2011) that is applicable to facial EMG. Although synchrony could be assessed from the present data, such an analysis was beyond the scope of the current research question.
Conclusion
We examined incidental facial mimicry measured with EMG in a dyadic face-to-face emotion communication task using state of the art modeling. Receivers predominantly mimicked senders’ happy expressions and to a lesser extent sad expressions. Importantly, receivers’ own facial activity influenced their ratings of the perceived emotion expressions and led to higher agreement with the senders’ ratings, but only for happy expressions. Thus, we provide new evidence in favor of a functional role of incidental facial mimicry for non-stereotype emotion recognition for happy expressions. Anger expressions, however, presumably signaling aggression rather than affiliation were not mimicked, although participants aimed for maximal recognition performance. Likewise, participants hardly mimicked sad expressions, which we also interpret to indicate potential further commitment. This underlines the importance of the intrinsic meaning of emotional expressions in a given context (Hess and Fischer 2013) and favors the view that facial expressions communicate intentions (Fridlund 1994). Our approach shows that including social interactions in emotion research (Fischer and van Kleef 2010) is feasible and can generate important empirical evidence relevant for current theories in facial mimicry and embodied cognition.
References
Barton, K., & Barton, M. K. (2015). Package ‘mumin’. Version, 1, 18. https://cran.r-project.org/web/packages/MuMIn/MuMIn.pdf.
Bates, D., Mächler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using LME4. Journal of Statistical Software. doi:10.18637/jss.v067.i01.
Blairy, S., Herrera, P., & Hess, U. (1999). Mimicry and the judgment of emotional facial expressions. Journal of Nonverbal Behavior, 23(1), 5–41. doi:10.1023/a:1021370825283.
Bogart, K. R., & Matsumoto, D. (2010). Facial mimicry is not necessary to recognize emotion: Facial expression recognition by people with moebius syndrome. Social Neuroscience, 5(2), 241–251. doi:10.1080/17470910903395692.
Boker, S. M., Rotondo, J. L., Xu, M., & King, K. (2002). Windowed cross-correlation and peak picking for the analysis of variability in the association between behavioral time series. Psychological Methods, 7(3), 338. doi:10.1037/1082-989X.7.3.338.
Boucsein, W. (2012). Electrodermal activity (2nd ed.). New York: Springer Science & Business Media. doi:10.1007/978-1-4614-1126-0.
Bourgeois, P., & Hess, U. (2008). The impact of social context on mimicry. Biological Psychology, 77(3), 343–352. doi:10.1016/j.biopsycho.2007.11.008.
Chartrand, T. L., & Bargh, J. A. (1999). The chameleon effect: The perception-behavior link and social interaction. Journal of Personality and Social Psychology, 76(6), 893–910. doi:10.1037/0022-3514.76.6.893.
Chartrand, T. L., & Lakin, J. L. (2012). The antecedents and consequences of human behavioral mimicry. Annual Review of Psychology. doi:10.1146/annurev-psych-113011-143754.
Chartrand, T. L., & van Baaren, R. (2009) Chapter 5 human mimicry. 41, 219–274. doi:10.1016/s0065-2601(08)00405-x.
de Groot, J. H., Smeets, M. A., Rowson, M. J., Bulsing, P. J., Blonk, C. G., Wilkinson, J. E., et al. (2015). A sniff of happiness. Psychological Science, 26(6), 684–700. doi:10.1177/0956797614566318.
Dimberg, U., Thunberg, M., & Grunedal, S. (2002). Facial reactions to emotional stimuli: Automatically controlled emotional responses. Cognition and Emotion, 6(4), 449–471. doi:10.1080/02699930143000356.
Draine, S. (1998). Inquisit [computer software]. Seattle, WA: Millisecond Software.
Ekman, P., Friesen, W. V., & Ellsworth, P. C. (1972). Emotion in the humanface: Guidelinesfor research and an integration offindings. New York: Pergamon.
Fischer, A. H., Becker, D., & Veenstra, L. (2012). Emotional mimicry in social context: The case of disgust and pride. Frontiers in Psychology, 3, 475. doi:10.3389/fpsyg.2012.00475.
Fischer, A. H., & van Kleef, G. A. (2010). Where have all the people gone? A plea for including social interaction in emotion research. Emotion Review, 2(3), 208–211. doi:10.1177/1754073910361980.
Fridlund, A. J. (1994). Human facial expression: An evolutionary view. San Diego, CA: Academic Press.
Fridlund, A. J., & Cacioppo, J. T. (1986). Guidelines for human electromyographic research. Psychophysiology, 23, 567–589. doi:10.1111/j.1469-8986.1986.tb00676.x.
Goldman, A. I., & Sripada, C. S. (2005). Simulationist models of face-based emotion recognition. Cognition, 94(3), 193–213. doi:10.1016/j.cognition.2004.01.005.
Gunnery, S. D., Hall, J. A., & Ruben, M. A. (2012). The deliberate Duchenne smile: Individual differences in expressive control. Journal of Nonverbal Behavior, 37(1), 29–41. doi:10.1007/s10919-012-0139-4.
Hess, U., & Blairy, S. (2001). Facial mimicry and emotional contagion to dynamic emotional facial expressions and their influence on decoding accuracy. International Journal of Psychophysiology, 40, 129–141. doi:10.1016/S0167-8760(00)00161-6.
Hess, U., & Bourgeois, P. (2010). You smile–I smile: Emotion expression in social interaction. Biological Psychology, 84(3), 514–520. doi:10.1016/j.biopsycho.2009.11.001.
Hess, U., & Fischer, A. (2013). Emotional mimicry as social regulation. Personality and Social Psychology Review, 17(2), 142–157. doi:10.1177/1088868312472607.
Hess, U., & Fischer, A. (2014). Emotional mimicry: Why and when we mimic emotions. Social and Personality Psychology Compass, 8(2), 45–57. doi:10.1111/spc3.12083.
Hildebrandt, A., Sommer, W., Schacht, A., & Wilhelm, O. (2015). Perceiving and remembering emotional facial expressions: A basic facet of emotional intelligence. Intelligence, 50, 52–67. doi:10.1016/j.intell.2015.02.003.
Hyniewska, S., & Sato, W. (2015). Facial feedback affects valence judgments of dynamic and static emotional expressions. Frontiers in Psychology, 6, 291. doi:10.3389/fpsyg.2015.00291.
Kenny, D. A., Kashy, D. A., & Cook, W. L. (2006). Dyadic data analysis. New York: Guilford Press.
Kosonogov, V., Titova, A., & Vorobyeva, E. (2015). Empathy, but not mimicry restriction, influences the recognition of change in emotional facial expressions. Quarterly Journal of Experimental Psychology, 68(10), 2106. doi:10.1080/17470218.2015.1009476.
Kret, M. E. (2015). Emotional expressions beyond facial muscle actions. A call for studying autonomic signals and their impact on social perception. Frontiers in Psychology, 6, 711. doi:10.3389/fpsyg.2015.00711.
Kulesza, W. M., Cisłak, A., Vallacher, R. R., Nowak, A., Czekiel, M., & Bedynska, S. (2015). The face of the chameleon: The experience of facial mimicry for the mimicker and the mimickee. The Journal of Social Psychology, 155(6), 590–604. doi:10.1080/00224545.
Künecke, J., Hildebrandt, A., Recio, G., Sommer, W., & Wilhelm, O. (2014). Facial EMG responses to emotional expressions are related to emotion perception ability. PLoS ONE, 9(1), e84503. doi:10.1371/journal.pone.0084053.
Kuznetsova, A., Brockhoff, P. B., & Christensen, R. H. B. (2013). Lmertest: Tests for random and fixed effects for linear mixed effect models (LMER objects of LME4 package). R package version, 2(6). http://www2.uaem.mx/r-mirror/web/packages/lmerTest/lmerTest.pdf.
Lakin, J. L., Jefferis, V. E., Cheng, C. M., & Chartrand, T. L. (2003). The chameleon effect as social cue: Evidence for the evolutionary significance of nonconscious mimicry. Journal of Nonverbal Behavior, 27(3), 145–162. doi:10.1023/A:1025389814290.
Lench, H. C., Flores, S. A., & Bench, S. W. (2011). Discrete emotions predict changes in cognition, judgment, experience, behavior, and physiology: A meta-analysis of experimental emotion elicitations. Psychological Bulletin, 37(5), 834–855. doi:10.1037/a0024244.supp.
Mauersberger, H., Blaison, C., Kafetsios, K., Kessler, C. L., & Hess, U. (2015). Individual differences in emotional mimicry: Underlying traits and social consequences. European Journal of Personality, 29(5), 512–529. doi:10.1002/per.2008.
McIntosh, D. N. (1996). Facial feedback hypotheses: Evidence, implications, and directions. Motivation and Emotion, 20(2), 121–147. doi:10.1007/BF02253868.
Nakagawa, S., & Schielzeth, H. (2013). A general and simple method for obtaining R2 from generalized linear mixed-effects models. Methods in Ecology and Evolution, 4(2), 133–142. doi:10.1111/j.2041-210x.2012.00261.x.
Neal, D. T., & Chartrand, T. L. (2011). Embodied emotion perception: Amplifying and dampening facial feedback modulates emotion perception accuracy. Social Psychological and Personality Science, 2(6), 673–678. doi:10.1177/1948550611406138.
Niedenthal, P. M., Augustinova, M., & Rychlowska, M. (2010a). Body and mind: Zajonc’s (re)introduction of the motor system to emotion and cognition. Emotion Review, 2(4), 340–347. doi:10.1177/1754073910376423.
Niedenthal, P. M., Brauer, M., Halberstadt, J. B., & Innes-Ker, Å. H. (2001). When did her smile drop? Facial mimicry and the influences of emotional state on the detection of change in emotional expression. Cognition and Emotion, 15(6), 853–864. doi:10.1080/02699930143000194.
Niedenthal, P. M., Mermillod, M., Maringer, M., & Hess, U. (2010b). The simulation of smiles (sims) model: Embodied simulation and the meaning of facial expression. Behavioral and Brain Sciences, 33(6), 417–433. doi:10.1017/S0140525X10000865.
Oberman, L. M., Winkielman, P., & Ramachandran, V. S. (2007). Face to face: Blocking facial mimicry can selectively impair recognition of emotional expressions. Social Neuroscience, 2(3–4), 167–178. doi:10.1080/17470910701391943.
R Core Team. (2014). R: A language and environment for statistical computing. R foundation for statistical computing (Version R version 3.1.2). Vienna, Austria. Retrieved from http://www.R-project.org/.
Ramseyer, F., & Tschacher, W. (2011). Nonverbal synchrony in psychotherapy: coordinated body movement reflects relationship quality and outcome. Journal of Consulting and Clinical Psychology, 79(3), 284. doi:10.1037/a0023419.
Rychlowska, M., Canadas, E., Wood, A., Krumhuber, E. G., Fischer, A., & Niedenthal, P. M. (2014). Blocking mimicry makes true and false smiles look the same. PLoS ONE, 9(3), e90876. doi:10.1371/journal.pone.0090876.
Safdar, S., Friedlmeier, W., Matsumoto, D., Yoo, S. H., Kwantes, C. T., Kakai, H., et al. (2009). Variations of emotional display rules within and across cultures: A comparison between canada, USA, and japan. Canadian Journal of Behavioural Science, 41(1), 1–10. doi:10.1037/a0014387.
Sato, W., Fujimura, T., Kochiyama, T., & Suzuki, N. (2013). Relationships among facial mimicry, emotional experience, and emotion recognition. PLoS ONE, 8(3), e57889. doi:10.1371/journal.pone.0057889.g001.
Sonnby-Borgström, M. (2002). The facial expression says more than words: Emotional “contagion” related to empathy? Lakartidningen, 99(13), 1438–1442. Retrieved from <Go to ISI>://WOS:000174751300002.
Stel, M., & Harinck, F. (2011). Being mimicked makes you a prosocial voter. Experimetal Psychology, 58(1), 79–84. doi:10.1027/1618-3169/a000070.
Stel, M., Van Baaren, R. B., & Vonk, R. (2008). Effects of mimicking: Acting prosocially by being emotionally moved. European Journal of Social Psychology, 38(6), 965–976.
Stel, M., & van Knippenberg, A. (2008). The role of facial mimicry in the recognition of affect. Psychological Science, 19(10), 984–985. doi:10.1111/j.1467-9280.2008.02188.x.
van Baaren, R., Janssen, L., Chartrand, T. L., & Dijksterhuis, A. (2009). Where is the love? The social aspects of mimicry. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 364(1528), 2381–2389. doi:10.1098/rstb.2009.0057.
Watson, D., Clark, L. A., & Tellegen, A. (1988). Development and validation of brief measures of positive and negative affect: The PANAS scales. Journal of Personality and Social Psychology, 54(6), 1063–1070. doi:10.1037/0022-3514.54.6.1063.
Weyers, P., Muhlberger, A., Kund, A., Hess, U., & Pauli, P. (2009). Modulation of facial reactions to avatar emotional faces by nonconscious competition priming. Psychophysiology, 46(2), 328–335. doi:10.1111/j.1469-8986.2008.00771.x.
Wilhelm, O., Hildebrandt, A., Manske, K., Schacht, A., & Sommer, W. (2014). Test battery for measuring the perception and recognition of facial expressions of emotion. Frontiers in Psychology, 5, 404. doi:10.3389/fpsyg.2014.00404.
Winkielman, P., Niedenthal, P., Wielgosz, J., Eelen, J., & Kavanagh, L. C. (2015). Embodiment of cognition and emotion. APA Handbook of Personality and Social Psychology, 1, 151–175. doi:10.1037/14341-004.
Zaki, J., Bolger, N., & Ochsner, K. (2008). It takes two: The interpersonal nature of empathic accuracy. Psychological Science, 19(4), 399–404. doi:10.1111/j.1467-9280.2008.02099.x.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Künecke, J., Wilhelm, O. & Sommer, W. Emotion Recognition in Nonverbal Face-to-Face Communication. J Nonverbal Behav 41, 221–238 (2017). https://doi.org/10.1007/s10919-017-0255-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10919-017-0255-2