
Abstract
In this paper, a block-centered finite difference method is proposed to discretize the compressible Darcy–Forchheimer model which describes the high speed non-Darcy flow in porous media. The discretized nonlinear problem on the fine grid is solved by a two-grid algorithm in two steps: first solving a small nonlinear system on the coarse grid, and then solving a nonlinear problem on the fine grid. On the coarse grid, the coupled term of pressure and velocity is approximated by using the fewest number of node values to construct a nonlinear block-centered finite difference scheme. On the fine grid, the original nonlinear term is modified with a small parameter \(\varepsilon \) to construct a linear block-centered finite difference scheme. Optimal order error estimates for pressure and velocity are obtained in discrete \(l^\infty (L^2)\) and \(l^2(L^2)\) norms, respectively. The two-grid block-centered finite difference scheme is proved to be unconditionally convergent without any time step restriction. Some numerical examples are given to testify the accuracy of the proposed method. The numbers of iterations are reported to illustrate the efficiency of the two-grid algorithm.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the study of fluid flow in porous medium, it is well known that Darcy’s law is valid when the fluid velocity is low. When the velocity is high, a second-order term needs to be added, so the equation becomes nonlinear as suggested by Forchheimer [8]. The Darcy–Forchheimer equation takes the following form [1, 2, 8, 24]:
Equation (1) describes the nonlinear relationship between the Darcy velocity \(\mathbf {u}\) and the gradient of pressure \(\nabla p\). Here \(\mu \) and \(\rho \) denote the viscosity coefficient and the density of the fluid, respectively. The tensor function K represents the permeability tensor. The constant \(\beta \) denotes the Forchheimer number. The most important feature of Darcy–Forchheimer equation is that it combines the monotonicity of the nonlinear term and the non-degeneracy of the Darcy part.
In this paper, we consider the compressible Darcy–Forchheimer equation. The continuity equation governing the motion of the fluid is given by
where \(\phi \) is the porosity of the porous media and f is the source or sink term. If the fluid is compressible, it holds the following state equation,
where \(\rho =\rho _0 e^{C_F(p-p_0)}\). Then the governing equation (2) can be rewritten as
For the compressible fluid, the coefficient of compressibility \(C_F\) is of the order of \(10^{-8}\). Therefore, the term \(\dfrac{\partial \rho }{\partial p}\mathbf {u}\cdot \nabla p\) can be neglected as shown in [1, 2, 14].
Combining the velocity–pressure relation equation (1) with the governing equation (3), the two-dimensional nonlinear compressible Darcy–Forchheimer model describing high-speed non-Darcy flow in porous media is presented as follows.
where \(\varOmega \) is a porous media domain and the time interval \(J=(0,T]\). The notation \(|\cdot |\) represents the Euclidean norm, i.e., \(|\mathbf {u}|^2=\mathbf {u}\cdot \mathbf {u}\). For slightly compressible fluid, the density \(\rho \) depends on the pressure p, i.e., \(\rho =\rho (p)\). For simplicity we assume that the permeability tensor function \(K = \bar{k}I\), where \(\bar{k}\) is a positive constant and I is the unit matrix. The function \(g\in L^2(\partial \varOmega )\) is the flux through the boundary.
Considerable research has been done to study the incompressible Darcy–Forchheimer equation theoretically and numerically, such as [9] by Girault and Wheeler in 2008, [4] by Chaudhary and Cardenas et al. in 2011, [17, 19, 22, 23] by Rui et al. in 2012 and 2015. Recently, slightly compressible Darcy–Forchheimer model starts to receive a great deal of attention. In [1, 2], the authors analyzed the mathematical framework of the well productivity index for fast Forchheimer (non-Darcy) flows in porous media. In [12], the structural stability was established with respect to either the boundary data or the coefficients of the Forchheimer polynomials. In [13], the authors focused on qualitative properties of the solutions of generalized Forchheimer equations for slightly compressible fluids in porous media, subject to the flux condition on the boundary. In [18], the mixed finite element method was used to approximate the solution of the nonlinear system that describes the non-Darcy flow of a single-phase fluid in a porous media, and the optimal order error estimates were established for both pressure and momentum. In [14], the expanded mixed finite element method was used to solve slightly compressible Darcy–Forchheimer model with the initial boundary condition, and priori error estimates were given for the resulting degenerate parabolic equation for the pressure.
In this paper, we study the block-centered finite difference method [25,26,27], which is considered as the lowest order Raviart–Thomas mixed element method with proper quadrature formulation. The application of the finite difference enables us to approximate both the velocity and pressure with second-order accuracy. Moreover, the block-centered finite difference method transfers the saddle point system of the mixed element method into symmetric positive definite system.
The main difficulty of solving model (4) is to treat the strongly nonlinear term including p and \(|\mathbf {u}|\). To solve the nonlinear equations resulting from the block-centered finite difference scheme efficiently, we use two-grid method introduced by Xu [28, 29]. The idea is that we first produce a rough approximation of the solution on the coarse grid and then use it to obtain a linearized system on a fine grid. In this approach, solving a nonlinear problem on the fine grid is reduced to solving a linear system on the fine grid and a smaller nonlinear system on the coarse grid. As a result, the two-grid method has attracted many researchers due to its wide applicability, as shown in [3, 5,6,7, 10, 11, 16, 30].
In [19, 22], the method of averaging four subunits was used to construct the discretization scheme for the nonlinear term only involving \(\mathbf {u}\). In [20], this idea was adopted to approximate the nonlinear term of the model (4), eleven nodes would be needed on one partition unit, where six nodes are used for approximation of the pressure p and five nodes are used for approximation of the norm function \(|\mathbf {u}|\). In this paper, we only use two nodes, which is the fewest as possible, to construct the discretization scheme for the pressure p. To approximate the norm function \(|\mathbf {u}|\), we still use five nodes. It is proved that our scheme also preserves the monotonicity of the nonlinear term on the coarse grid. Moreover, our scheme greatly decreases the coupling degree of numerical scheme and hence greatly reduces the computational cost. On the fine grid, a linear system is constructed based on differentiable properties of the nonlinear term. However, one part of the original nonlinear term, namely the norm function \(|\mathbf {u}|\), does not have the continuous derivatives. To deal with this difficulty, we add a very small positive parameter \(\varepsilon \) to obtain a modified nonlinear term which is twice differentiable with bounded derivatives up to the second order. The modified norm function is only used for the partial derivative term with respect to \(\mathbf {u}\). Other parts still use the original nonlinear term to improve the accuracy of approximation scheme. We prove that the block-centered difference scheme preserves the monotonicity of the nonlinear operators on both coarse grid and fine grid. By using the monotonous property of nonlinear operators, we can get the optimal order error estimates for the approximation scheme of slightly compressible Darcy–Forchheimer model (4). The block-centered finite difference scheme is also be proved to be unconditionally convergent. The approach is different from that in [15]. The errors bounds in convergence estimates provide a principle of determining a proper meshsize H for the coarse grid and a proper parameter \(\varepsilon \) for the fine grid. Numerical experiments show that two-grid block-centered finite difference method is more efficient than the traditional iterative methods used in [17, 19].
The rest of the paper is organized as follows. In Sect. 2, the two-grid block-centered finite difference formulation is introduced for slightly compressible Darcy–Forchheimer model. The error estimates of two-grid algorithm are presented in Sect. 3. In Sect. 4, several numerical examples are presented to illustrate the algorithm’s accuracy and efficiency. In view of the number of iterations, the two-grid algorithm is more efficient than the traditional iterative method, without loss any accuracy. The conclusions and extensions are given in Sect. 5.
Throughout this paper we use C to denote a generic positive constant independent of the discretization parameters, which may have different values in different appearances.
2 Two-Grid Block-Centered Finite Difference Algorithm
In this section we introduce a two-grid algorithm, based on the block-centered finite difference approximation, for the nonlinear compressible Darcy–Forchheimer model (4).
For simplicity we use the following notations:
We assume that \(a_1, a_2(p), \alpha \) are continuous functions and
for some positive constants \(\underline{{a}}\) and \(\bar{a}\). Besides, the function \(a_2(p)\) is assumed to be twice differentiable with respect to p and have bounded derivatives.
Set \(0=t^0<t^1<\cdots <t^{N_t}=T\) and \(\varDelta t^k=t^k-t^{k-1}\). We assume the two-dimensional domain \(\varOmega \) is rectangular such that \(\varOmega =[b^x_1,b^x_2]\times [b^y_1,b^y_2]\).
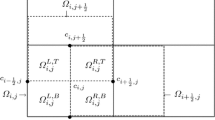
To construct the two-grid algorithm we have to define a regular coarse partition and a regular fine partition of \(\varOmega \) simultaneously. First we define the fine partition \(\varOmega _h=\varTheta _h^x\times \varTheta _h^y\) as follows:
Define
where \(i=1,\ldots ,n_x\) and \(j=1,\ldots ,n_y\).
Denote
where \(\theta ^k_{s,l}:=\theta (x_s,y_l,t^k)\) for a node-point \((x_s,y_l,t^k)\).
Let the discrete inner products and norms be defined as follows:
Next, we define a piecewise constant function \(\bar{q}\) on \((x_{i+1/2},y_j)\) and \((x_i\), \(y_{j+1/2})\) such that
For a pair of discrete functions \(\{V^x_{i+1/2,j}\}\) and \(\{V^y_{i,j+1/2}\}\), we give the definition of the interpolation operator \(\varvec{\Pi }\) as follows:
with
Let \(R(V^x,V^y)\) be the norm function for a vector \((V^x,V^y)\) such that
Then, define the square-root average operators \(Q^x\) and \(Q^y\) for \(\mathbf {V}=(V^x,V^y)\) as
It follows from direct calculations to (9) and (10) that
and
Then, we define
Let \(R_\varepsilon (V^x,V^y)\) be the norm function for a vector \((V^x,V^y)\) with a small positive parameter \(\varepsilon \):
We define \(N^x_\varepsilon (\bar{q},\mathbf {V})\) on \(\varOmega _{i+1/2,j}\) by replacing \(R(\cdot , \cdot )\) with \(R_\varepsilon (\cdot , \cdot )\) in \(N^x(\bar{q},\mathbf {V})\), and define \(N^y_\varepsilon (\bar{q},\mathbf {V})\) on \(\varOmega _{i,j+1/2}\) by replacing \(R(\cdot , \cdot )\) with \(R_\varepsilon (\cdot , \cdot )\) in \(N^y(\bar{q},\mathbf {V})\) as follows.
and
where
When constructing the two-grid algorithm we use a differentiable function \(N_\varepsilon ^x(\bar{p},\mathbf {u})\) (resp. \(N_\varepsilon ^y(\bar{p},\mathbf {u})\)) to replace \(N^x(\bar{p},\mathbf {u})\) (resp. \(N^y(\bar{p},\mathbf {u})\)). The reason is that the partial derivatives of \(N^x(\bar{p},\mathbf {u})\) and \(N^y(\bar{p},\mathbf {u})\) with respect to \(\mathbf {u}\) do not exist, when the velocity \(\mathbf {u}=(u^x,u^y)\) is zero. The key is to use \(\sqrt{\varepsilon ^2+(u^x)^2+(u^y)^2}\) to replace \(\sqrt{(u^x)^2+(u^y)^2}\). When \(\varepsilon \) is small enough, \(N_\varepsilon ^x(\bar{p},\mathbf {u})\) (resp. \(N_\varepsilon ^y(\bar{p},\mathbf {u})\)) is close to \(N^x(\bar{p},\mathbf {u})\) (resp. \(N^y(\bar{p},\mathbf {u})\)), and the partial derivative of \(N_\varepsilon ^x(\bar{p},\mathbf {u})\) (resp. \(N_\varepsilon ^y(\bar{p},\mathbf {u})\)) with respect to \(\mathbf {u}\) is also very close to that of \(N^x(\bar{p},\mathbf {u})\) (resp. \(N^y(\bar{p},\mathbf {u})\)), see Figs. 1 and 2 for the negligible differences.

Differences of \(\sqrt{\varepsilon ^2+(u^x)^2+(u^y)^2}\) and \(\sqrt{(u^x)^2+(u^y)^2}\) for \(h=0.1\) and \(\varepsilon =h^2\)

Differences of the partial derivative of \(\sqrt{\varepsilon ^2+(u^x)^2+(u^y)^2}\) and \(\sqrt{(u^x)^2+(u^y)^2}\) with respect to \(u^x\) for \(h=0.1\) and \(\varepsilon =h^2\)
Analogous to \(\varOmega _h\) we define a coarse grid \(\varOmega _H=\varTheta _H^x\times \varTheta _H^y\). We use \(H^x,H^y\) to denote the meshsizes in x and y directions of the coarse grid, respectively. Similarly we use \([d_H^{x}\theta ]\), \([D^x_{H}\theta ]\), \([d^y_{H}\theta ]\), \([D^y_{H}\theta ]\), \((\theta ,\omega )_M\), \((\theta ,\omega )_X\), \((\theta ,\omega )_Y\), \(\Vert \theta \Vert _M\), \(\Vert \theta \Vert _X\), \(\Vert \theta \Vert _Y\) to denote the finite difference operators, inner products and norms on the coarse grid, respectively. The norms and semi-norms of a discrete function on the coarse grid can be defined similarly. We also use notations \(X_m\) and \(Y_n\) such that
We define \(\hat{p}_H\) and \(\hat{\mathbf {u}}_H=(\hat{u}_H^x,\hat{u}_H^y)\) as the bilinear interpolation operator from the coarse grid \(\varOmega _H\) to fine grid \(\varOmega _h\) . Take \(\hat{\mathbf {u}}_H\) for example:
-
(i)
For each point \((x,y)\in (x_{m+1/2}, x_{m+3/2})\times (y_{n}, y_{n+1})\) with \(m=0,\ldots , N_x-1\) and \(n=1,\ldots , N_y-1\), we define \(\hat{u}_H^x(x,y)\) as the bilinear interpolation by using \(u^x_{m+1/2,n+1}\),\(u^x_{m+1/2,n}\), \(u^x_{m+3/2,n}\) and \(u^x_{m+3/2,n+1}\).
-
(ii)
For each point \((x,y)\in (x_{m+1/2}, x_{m+3/2})\times (y_{1/2}, y_{1})\) with \(m=0,\ldots , N_x-1\), we define \(\hat{u}_H^x(x,y)\) as the bilinear extrapolation by using \(u^x_{m+1/2,2}\), \(u^x_{m+1/2,1}\), \(u^x_{m+3/2,1}\) and \(u^x_{m+3/2,2}\).
-
(iii)
For each point \((x,y)\in (x_{m+1/2}, x_{m+3/2})\times (y_{Ny}, y_{Ny+1/2})\) with \(m=0,\ldots ,\) \(N_x-1\), we define \(\hat{u}_H^x(x,y)\) as the bilinear extrapolation by using \(u^x_{m+1/2,Ny}\), \(u^x_{m+1/2,Ny-1}\), \(u^x_{m+3/2,Ny-1}\) and \(u^x_{m+3/2,Ny}\).
Similarly, we can define \(\hat{u}_H^y(x,y)\) based on the values of \(u^y_{m,n+1/2}\) for \(m=1,\ldots , N_x\) and \(n=0,\ldots , N_y\), and define \(\hat{p}_H(x,y)\) based on the values of \(p_{m,n}\) for \(m=1,\ldots , N_x\) and \(n=1,\ldots , N_y\).
We are now ready to construct the two-grid block-centered finite difference algorithm in two steps.
Step 1 On the coarse grid \(\varOmega _H\) with meshsizes \(H^x\) and \(H^y\), the nonlinear block-centered finite difference schemes for \((U^x_{H})_{m+1/2,n}^{k}\), \((U^y_{H})_{m,n+1/2}^{k}\) and \((P_H)^k_{m,n}\) are as follows,
for \(m=1,\ldots , N_x-1\) , \(n=1,\ldots , N_y-1\) and \(k=1,\ldots ,N_t\).
Step 2 On the fine grid \(\varOmega _h\) with meshsizes \(h^x\) and \(h^y\), the linear block-centered finite difference approximation for \((U^x_{h})_{i+1/2,j}^{k}\), \((U^y_{h})_{i,j+1/2}^{k}\) and \((P_h)^k_{i,j}\) are as follows,
for \(i=1,\ldots , n_x-1\), \(j=1,\ldots , n_y-1\), \(k=1,\ldots ,N_t\) and a small positive parameter \(\varepsilon \), where
and
In the Step 1 on coarse grid, the fewest unknowns are used to construct the block-centered finite difference scheme. We have reduced the degree of coupling of \(P_H\) and \(\mathbf {U}_H\) as much as possible. Moreover, it brings the convenience to construct the scheme on the fine grid, in which the partial derivatives with respect to the unknowns are the essential parts.
This algorithm first produces a rough approximation of the solution and then uses it as the initial guess on the fine grid. With this method, solving a nonlinear equation on a fine grid is reduced to solving a nonlinear equation on a coarse grid together with solving a linear equation on a fine grid. This means that solving a nonlinear problem is not much more difficult than solving one linear problem, since the cost for solving the nonlinear problem on the coarse grid is relatively negligible.
3 Error Estimates
In this section, we present the optimal error estimates for the two-grid block-centered finite difference method for the slightly compressible Darcy–Forchheimer model (4).
According to Lemma 4.1 in [21], we have the following lemma.
Lemma 1
Suppose p is sufficiently smooth, then
where
The following lemma follows directly from Lemma 1.
Lemma 2
Suppose p is sufficiently smooth, then
where
Lemma 3
Suppose p and \(\mathbf {u}\) are sufficiently smooth, then
where
Proof
According to Lemma 4.2 in [19] and the Taylor expansion,
and
Therefore,
By Lemma 2, (26) and (25), we have
Similarly,
From the definitions of \(\bar{p}_{i+1/2,j}\) and \(\bar{p}_{i,j+1/2}\) in (7), we have
Thus, we get the following lemma by using Lemma 3, the Taylor expansion of \(a_2(p)\) and (29) and (30).
Lemma 4
Suppose p and \(\mathbf {u}\) are sufficiently smooth, then
From Lemma 4.4 in [19], Lemma 4.2 in [17] and (6), we can derive the following lemma.
Lemma 5
For any functions \(\mathbf {V}=(V^x,V^y)\) and \(\mathbf {W}=(W^x,W^y)\) we have
By referring to Lemma 4.6 in [19], Lemma 6 is given as follows.
Lemma 6
Let \(\{W^x_{i+1/2,j}\}\), \(\{W^y_{i,j+1/2}\}\), \(\{V^x_{i+1/2,j}\}\), \(\{V^y_{i,j+1/2}\}\), \(\varphi _{i,j}^x\), and \(\varphi _{i,j}^y\) be discrete functions with \(V_{1/2,j}^{x}=V_{i,1/2}^{y}=V_{n_x+1/2,j}^{x}=V_{i,n_y+1/2}^{y}=0\) and satisfy
where \(\psi ^x\) and \(\psi ^y\) are generic discrete functions. Then we have
Theorem 1
Let \(U_H^{x,k}\), \(U_H^{y,k}\), \(P_H^k\) be obtained by step 1 of two-grid finite difference algorithm. Suppose the solutions \(\mathbf {u}=(u^x,u^y)\) and p are sufficiently smooth, then there exists a positive constant C independent of H and \(\varDelta t\) such that
where
Proof
Denote
By (4), the definitions of operators \(D_H^x\) and \(D_H^y\), we have
From the first equation (16) in step 1 and (32),
According to the definition of \(\eta \) in (25),
By multiplying both sides of (35) by \((E^p+\eta )^k_{m,n}H_m^x H_n^y\) and summing up m and n, we have
It follows from Lemma 6 and (36) that
From (4) and the step 1 of two-grid algorithm (17) and (18), we obtain
Using Lemmas 2, 3, and 4 to (38) and (39), we get
Multiplying (40) and (41) by \(E^{x,k}_{m+1/2,n}H^x_{m+1/2} H^y_n\) and \(E^{y,k}_{m,n+1/2}H^x_{m} H^y_{n+1/2}\), respectively, and summing up m from 1 to \(N_x-1\) and n from 1 to \(N_y-1\), we arrive at
By Lemma 5 and the assumption (6) of \(a_2(p)\), we have
Applying the Cauchy–Schwarz inequality and the assumption for \(\alpha \), \(a_1\) in (6), we have
Multiplying (46) by \(2\triangle t^k\) and summing up k from 1 to \(N_t\), we have
Using Gronwall lemma, we get
Combing the definition of \(\eta \) in (25) and triangle inequality, the theorem holds. \(\square \)
In order to deduce the error estimates for Step 2 of the two-grid algorithm, we give the following useful lemmas.
Lemma 7
Suppose \(\{V^x_{i-1/2,j}\}\) and \(\{V^y_{i,j-1/2}\}\) are discrete functions with
For the discrete norms \(\Vert \cdot \Vert _x\) and \(\Vert \cdot \Vert _y\), we have the following inverse estimates.
where
We refer to Lemma 3.3 in [22] for the proof of Lemma 7.
Lemma 8
Assume \(\mathbf {V}=(V^x,V^y)\) is bounded by a positive constant C which is independent of any mesh grid parameters, we have
with \(i=1,\ldots , n_x\) and \(j=1,\ldots , n_y\).
Proof
Since
by combing (6), (49) and the boundedness of \(\mathbf {V}\), we deduce
Similarly,
Remark 1
By taking \(\varepsilon =O(h^2)\), we obtain
By referring to Lemma 3.8 in [22], we get Lemma 9 as follows.
Lemma 9
Suppose \({\mathbf {v}}\) is bounded, the modified nonlinear terms \(N_\varepsilon ^x(\bar{q},\mathbf {v})\) and \(N_\varepsilon ^y(\bar{q},\mathbf {v})\) are twice differentiable and have uniformly bounded second-order derivatives with respect to \(\mathbf {v}\).
Lemma 10
Suppose \(\mathbf {V}=(V^x,V^y)\) and \(\mathbf {W}=(W^x,W^y)\) are bounded, \(\{V^x_{i+1/2,j}\}\) and \(\{V^y_{i,j+1/2}\}\) are discrete functions with
Then, we have
Proof
It follows from the definition of \(L_\varepsilon ^x(\cdot ,\cdot )\) that
and
Subtracting (56) from (55), we have
Similarly,
The estimate (54) can then be obtained by applying Lemma 3.2 in [22] to (57) and (58).
Theorem 2
Let \(U_h^{x,k}\), \(U_h^{y,k}\), \(P_h^k\) be the approximation solutions obtained by step 2 of two-grid finite difference algorithm. Suppose the solutions \(\mathbf {u}=(u^x,u^y)\) and p are sufficiently smooth, then there exists a positive constant C independent of h and \(\varDelta t\) such that
Proof
Let
From the step 2 of two-grid algorithm (19)–(21), Lemmas 1, 2, 3, and 4,
Multiplying (59), (60), (61) by \(e^{x,k}_{i+1/2,j}h^x_{i+1/2} h^y_j\), \(e^{y,k}_{i,j+1/2}h^x_{i} h^y_{j+1/2}\), \((e^p+\eta )^k_{i,j}h_i^x h_j^y\) and summing over i and j, we get
Combining the definitions of \(L_\varepsilon ^x(\cdot ,\cdot )\) and \(L_\varepsilon ^y(\cdot ,\cdot )\) with Cauchy-Schwarz inequality, we have
From Theorem 1 and inverse inequality we know that \(P_H\), \(U_H^x\) and \(U_H^y\) are bounded.
Applying Taylor expansion to \(N_\varepsilon ^x(\bar{p},\mathbf {u})\) and \(N_\varepsilon ^y(\bar{p},\mathbf {u})\) and according to Lemmas 8 and 9, we obtain
Lemma 9 together with Cauchy–Schwarz inequality yield that
Using Lemma 10 and (6), we get
Therefore,
By the assumption of \(\alpha \), \(a_1\) in (6),
Multiplying (68) by \(2\triangle t^k\) and summing up k from 1 to \(N_t\), we have the following result from Lemma 7 and Theorem 1
Using Gronwall lemma, we have
Combing the definition of \(\eta \) in (25) and triangle inequality, the theorem establishes. \(\square \)
In the proofs of Theorems 1 and 2, it can be seen that there is no time step restriction for the optimal error estimates. The key reason is that we employed the monotonicity of the nonlinear operators on the coarse grid and the fine grid as shown in Lemmas 5 and 10, respectively.
4 Numerical Experiments
In this section we present some numerical experiments to illustrate the convergence property and efficiency of two-grid block-centered finite difference (tg-BCFD) method.
We consider the following slightly compressible Darcy–Forchheimer model with time interval \(J=(0,1]\).
For simplicity, the domains of Examples 1, 2, 3, and 4 are all chosen to be an unit square, i.e., \(\varOmega =[0,1]\times [0,1]\).
We first carry out the following two examples to verify the convergence rate of the tg-BCFD method.
Example 1
The analytical solutions of Darcy–Forchheimer model (71) with homogeneous Neumann boundary condition are given by
and functions f and q are computed correspondingly.
Example 2
The analytical solutions of Darcy–Forchheimer model (71) with inhomogeneous Neumann boundary condition are given by
and functions f, q and g are computed correspondingly.
In order to show the efficiency of tg-BCFD algorithm, we compare the numerical results of the algorithm with traditional block-centered finite difference (BCFD) method defined by (19)–(23) in [20] as follows for \(P^k_{i,j}\), \(U^{x,k}_{i+1/2,j}\), and \(U^{y,k}_{i,j+1/2}\).
where the piecewise constant function \(I_h q\) on \(\varOmega _{i,j}\) such that
with
For the coarse grid \(\varOmega _H\), we take uniform grids with mesh size \(H=\{\dfrac{1}{4}, \dfrac{1}{9}\), \(\dfrac{1}{16}, \dfrac{1}{25}\}\). According to Theorem 2, we use \(h=H^{3/2}\) as the mesh size of the fine grid \(\varOmega _h\). We take \(\varDelta t=O(h^2)\) and \(\varepsilon =10^{-4}\). When executing tg-BCFD algorithm and the traditional BCFD method (74), we choose \(eps=10^{-9}\) as the criterion of terminating iterations on the fine grid. As for the tg-BCFD method, we choose \(eps=10^{-3}\) as the criterion of terminating iterations on the coarse grid \(\varOmega _H\), because the correction capability of fine grid space is strong enough. The priori errors of tg-BCFD method in discrete \(L^2\) norms and \(L^\infty \) norms, convergence rates and the numbers of iterations are listed in Tables 1, 3 and plotted in Fig. 3. Those of BCFD method (74) are shown in Tables 2 and 4.

Log–log plots of errors. Left Top errors of p in discrete \(L^2\) norm; Left Bottom errors of p in discrete \(L^\infty \) norm; Right Top errors of \(\mathbf {u}\) in discrete \(L^2\) norm; Right Bottom errors of \(\mathbf {u}\) in discrete \(L^\infty \) norm
It can be observed from Tables 1, 3 and Fig. 3 that the tg-BCFD method have second-order accuracy in discrete \(L^2\) norms. These results are consistent with the error estimates in Theorem 2. In the last column of each table, the numbers of iterations on fine grid space are reported when \(t=1\). The computational cost on coarse grid of the tg-BCFD method is relatively negligible due to it’s weak iteration terminating condition and small number of node-points. The numbers of iterations for the tg-BCFD method are shown to be significantly less than those produced by the BCFD method (74) only on the last time level. In order to obtain the convergence rate, we choose \(\varDelta t=h^2\), which means the numerical experiments need large number of time levels (up to \(O(10^6)\) on the finest spatial grids). Seen from Tables 1, 2, 3, and 4, it is obvious that tg-BCFD method needs much less iterations compared with BCFD method.
Moreover, the results by using tg-BCFD method is without loss any accuracy comparing with the errors obtained by BCFD method (74). On the fine grid of tg-BCFD method, the resulting equations are linear and easy to be solved directly, but we still execute the iterative method just for obtaining the same errors as those by the BCFD method (74). It is shown that the resulting solution obtained by the tg-BCFD method still achieves asymptotically optimal accuracy.
In Examples 1 and 2, the errors in \(L^\infty \) norms are almost second-order accurate by using tg-BCFD method, though it has not been proved theoretically. Based on the experimental data, we can improve the results of Lemma 7 by using \(L^\infty \)-norm technique instead of inverse estimate method. Furthermore, the result of Theorem 2 can be rewritten as \(O(\varDelta t+\varepsilon +h^2+H^4)\). It will be our future work to obtain the error estimates in \(L^\infty \) norms.
Next, we use Example 1 to show the influence of \(\varepsilon \) on the errors. The re−esults when \(t=1\) are obtained by different values of \(\varepsilon \) listed in Tables 5, 6, 7, 8, and 9 and Fig. 4.

Log–log plots of errors in different values of \(\varepsilon \). Left Top errors of p in discrete \(L^2\) norm; Left Bottom errors of p in discrete \(L^\infty \) norm; Right Top errors of \(\mathbf {u}\) in discrete \(L^2\) norm; Right Bottom errors of \(\mathbf {u}\) in discrete \(L^\infty \) norm
Comparing with Table 1, one can see that the value of \(\varepsilon \) have an important influence on the errors of the tg-BCFD method. When \(\varepsilon \) is larger than \(O(h^2)\), it plays a leading role in errors of \(L^2\) norm and \(L^\infty \) norm (see Tables 5, 6, 7, and 8). In order to obtain the optimal error order, we should take \(\varepsilon =O(h^2)\) as shown in the proof of Theorem 2. In all examples, we choose the same value for parameter \(\varepsilon \) in order to obtain the convergence rates easily. Due to the smallest of mesh sizes used in all examples, \(\varepsilon \) is chosen as \(O(h^2)=10^{-4}\).
Finally, we solve the following two practical problems by using tg-BCFD method. The right-hand side function q, the injection and production flow rates at wells for f and the boundary conditions of slightly compressible Darcy–Forchheimer model (71) are listed as follows.
Example 3
Darcy–Forchheimer model (71) with homogeneous Neumann boundary condition:

Numerical pressure distribution and velocity quiver of Example 3 by tg-BCFD method
Example 4
Darcy–Forchheimer model (71) with inhomogeneous Neumann boundary condition:

Numerical pressure distribution and velocity quiver of Example 4 by tg-BCFD method
As shown in Figs. 5 and 6, the numerical pressure and velocity are reasonable and consistent with the physical phenomenon.
Next, we try to solve the Darcy–Forchheimer model (71) by tg-BCFD method on irregular domain such that \(y\in [0,1]\) and \(\varGamma \le x\le 0.875\) with \(\varGamma =0.56y(y-1)\).
Example 5
Darcy–Forchheimer model (71) with homogeneous Neumann boundary condition:
In order to use the tg-BCFD method on irregular domain, we replace a boundary point with the grid point inside the computational domain closest to this boundary point. Therefore, an approximation to curve boundary \(\varGamma \) with these grid points is obtained as boundary points forming the polygonal boundary. The approximation boundary condition is taken as zero boundary according to the curve boundary condition. Based on the numerical solutions on coarse grids, we use the proper second-order interpolation and extrapolation methods to get the initial iteration values on the fine grids, as in Fig. 7. Thus, a linear system is solved to obtain the numerical solutions of Darcy–Forchheimer model (71) in irregular domain.

Subdivision of irregular domain for Example 5 by tg-BCFD method. The irregular domain is given in black; the red polylines represent the approximate boundary; the green grids are mesh when \(h=1/64\) and the blue ones are mesh when \(H=1/16\)
The numerical solutions of pressure and velocity are given as in Figs. 8, 9.

Numerical pressure distribution of Example 5 by tg-BCFD method. Left \(\mathrm{t}=0.125\); Right \(\mathrm{t=1}\)

Numerical velocity distribution of Example 5 by tg-BCFD method. Left \(\mathrm{t}=0.125\); Right \(\mathrm{t}=1\)
Therefore, tg-BCFD method is useful and efficient for solving the nonlinear Darcy–Forchheimer model on both regular domain and irregular domain with smooth boundary.
5 Conclusions and Extensions
In this paper we apply a two-grid algorithm based on the block-centered finite difference discretization to solve the nonlinear Darcy–Forchheimer equations. The numerical procedure involves two steps: first solving a small nonlinear system on the coarse grid and then solving a linear system on the fine grid. When constructing the nonlinear scheme on coarse grid, we use the fewest possible nodal-points values of p and \(\mathbf {u}\) to construct the block-centered finite difference scheme. When constructing the linear scheme on fine grid, a small positive parameter \(\varepsilon \) is used to modify the original non-differentiable term in order to make it differentiable. It is proved that the modified nonlinear term still preserves the original property of the nonlinear term. The two-grid block-centered finite difference method is proved to be unconditionally convergent without any time step restriction by using the monotonicity of the discrete nonlinear operators. According to the theoretical analysis and numerical experiments, it is shown that solving such a large class of nonlinear equation will not be much more difficult than solving one single linearized equation, without sacrificing the order of accuracy of the fine grid solution. Moreover, it is clearly shown that \(H = O(h^{2/3})\) and \(\varepsilon =O(h^2)\) should be chosen to obtain asymptotically optimal approximation results in discrete \(L^2\) norms. Numerical experiments show that the errors in \(L^\infty \) norms are almost second-order accurate by using the two-grid block-centered finite difference method. If theoretical results in Lemma 7 could be improved by using the experimental results in \(L^\infty \) norms, the error bounds in Theorem 2 can be re-derived to be \(O(\varDelta t+\varepsilon +h^2+H^4)\), which will be our future work.
References
Aulisa, E., Ibragimov, A., Valko, P., Walton, J.: Mathematical framework of the well productivity index for fast Forchheimer (non-Darcy) flows in porous media. Math. Models Methods Appl. Sci. 19(8), 1241–1275 (2009)
Aulisa, E., Bloshanskaya, L., Hoang, L., Ibragimov, A.: Analysis of generalized Forchheimer flows of compressible fluids in porous media. J. Math. Phys. 50(10), 103102 (2009)
Bi, C., Ginting, V.: Two-grid finite volume element for linear and nonlinear elliiptic problems. Numer. Math. 108, 177–198 (2007)
Chaudhary, K., Cardenas, M.B., Deng, W., Bennett, P.C.: The role of eddies inside pores in the transition from Darcy to Forchheimer flows. Geophys. Res. Lett. 38(24), L24405 (2011)
Chen, L., Chen, Y.: Two-grid method for nonlinear reaction-diffusion equations by mixed finite element methods. J. Sci. Comput. 49, 383–401 (2011)
Chen, Y., Huang, Y., Yu, D.: A two-grid method for expanded mixed finite-element solution of semilinear reaction–diffusion equations. Int. J. Numer. Methods Eng. 57(2), 193–209 (2003)
Dawson, C.N., Wheeler, M.F., Woodward, C.S.: A two-grid finite difference scheme for nonlinear parabolic equations. SIAM J. Numer. Anal. 35, 435–452 (1998)
Forchheimer, P.: Wasserbewegung durch Boden. Z. Ver. Deutsch. Ing 45, 1782–1788 (1901)
Girault, V., Wheeler, M.F.: Numerical discretization of a Darcy–Forchheimer model. Numer. Math. 110, 161–198 (2008)
He, Y., Li, J.: Convergence of three iterative methods based on the finite element discretization for the stationary Navier–Stokes equations. Comput. Methods Appl. Mech. Eng. 198, 1351–1359 (2009)
He, Y., Wang, A.: A simplified two-level method for the steady Navier–Stokes equations. Comput. Methods Appl. Mech. Eng. 197, 1568–1576 (2008)
Hoang, L., Ibragimov, A.: Structural stability of generalized Forchheimer equations for compressible fluids in porous media. Nonlinearity 24(1), 1–41 (2010)
Hoang, L., Ibragimov, A.: Qualitative study of generalized Forchheimer flows with the flux boundary condition. Adv. Differ. Equ. 17, 511–556 (2012)
Kieu, Thinh T.: Analysis of expanded mixed finite element methods for the generalized forchheimer flows of slightly compressible fluids. Numer. Methods Partial Differ. Equ. 32, 60–85 (2016)
Li, B., Sun, W.: Uncontionally convergence and optimal error analysis for a Galerkin-mixed FEM for incompressible miscible flow in porous media. SIAM J. Numer. Anal. 51, 1959–1977 (2013)
Liu, W., Yin, Z., Li, J.: A two-grid algorithm based on expanded mixed element discretizations for strongly nonlinear elliptic equations. Numer. Algorithms 70, 93–111 (2015)
Pan, H., Rui, H.: Mixed element method for two-dimensional Darcy–Forchheimer model. J. Sci. Comput. 52, 563–587 (2012)
Park, E.J.: Mixed finite element method for generalized Forchheimer flow in porous media. Numer. Methods Partial Differ. Equ. 21, 213–228 (2005)
Rui, H., Pan, H.: A block-centered finite difference method for the Darcy-Forchheimer model. SIAM J. Numer. Anal. 5, 2612–2631 (2012)
Rui, H., Pan, H.: A block-centered finite difference method for slightly compressible Darcy–Forchheimer flow in porous media. J. Sci. Comput., accepted
Rui, H., Pan, H.: Block-centered finite difference methods for parabolic equation with time-dependent coefficient. Jpn. J. Ind. Appl. Math. 30, 681–699 (2013)
Rui, H., Liu, W.: A two-grid block-centered finite difference method for Darcy–Forchheimer flow in porous media. SIAM J. Numer. Anal. 53(4), 1941–1962 (2015)
Rui, H., Zhao, D., Pan, H.: A block-centered finite difference method for Darcy–Forchheimer model with variable Forchheimer number. Numer. Methods Partial Differ. Equ. 31(5), 1603–1622 (2015)
Ruth, D., Ma, H.: On the derivation of the Forchheimer equation by means of the averaging theorem. Transp. Porous Media 7(3), 255–264 (1992)
Weiser, A., Wheeler, M.F.: On convergence of block-centered finite difference for elliptic problems. SIAM J. Numer. Anal. 25, 351–375 (1988)
Wheeler, M.F., Xue, G., Yotov, I.: A multipoint flux mixed finite element method on distorted quadrilaterals and hexahedra. Numer. Math. 121, 165–204 (2012)
Wheeler, M.F., Yotov, I.: A multipoint flux mixed finite element method. SIAM J. Numer. Anal. 44, 2010–2082 (2006)
Xu, J.: A novel two-grid method for semilinear elliptic equations. SIAM J. Sci. Comput. 15, 231–237 (1994)
Xu, J.: Two-grid discretization techniques for linear and nonlinear PDEs. SIAM J. Numer. Anal. 33, 1759–1777 (1996)
Zhou, J., Hu, X., Zhong, L., Shu, S., Chen, L.: Two-grid methods for Maxwell eigenvalue problems. SIAM J. Numer. Anal. 52, 2027–2047 (2014)
Acknowledgements
The work of first author was supported in part by the AMSS-PolyU Joint Research Institute for Engineering and Management Mathematics, The Hong Kong Polytechnic University.
Author information
Authors and Affiliations
Corresponding author
Additional information
The work of the first author is supported by the National Natural Science Foundation of China Grant No: 11401289.
Rights and permissions
About this article

Cite this article
Liu, W., Cui, J. A Two-Grid Block-Centered Finite Difference Algorithm for Nonlinear Compressible Darcy–Forchheimer Model in Porous Media. J Sci Comput 74, 1786–1815 (2018). https://doi.org/10.1007/s10915-017-0516-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10915-017-0516-6