
Abstract
This paper aims to contribute to the literature on subjective well-being by exploring the extent to which certain economic, social and institutional variables may affect the levels of well-being declared by individuals from different countries. To do this, we adopt a novel methodological approach based on frontier techniques in order to identify whether the maximum possible levels of well-being are achieved given the available resources. Specifically, the technique used to conduct the analysis is the stochastic nonparametric envelopment of data model, which combines the advantages of parametric methods and the flexibility of the nonparametric approach. This methodology has been adapted to deal with contextual variables by reformulating the original mathematical syntax of convex nonparametric least squares. Our empirical analysis is based on longitudinal information gathered from the World Values Survey for a set of 82 countries. Our results suggest that the most efficient countries in terms of well-being include mainly developing Latin American nations together with some European countries. Moreover, we find that several social indicators, such as the quality of government, the unemployment rate or different inequality indices, have a significant effect on the estimated efficiency measures.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The economics of happiness, life satisfaction or subjective well-being has become one of the most relevant fields of research in recent years,Footnote 1 with a growing number of applied studies reporting empirical associations between well-being indicators and multiple variables being published in the most prestigious economic journals (Dolan et al. 2008; Veenhoven 2012; MacKerron 2012). Actually, the use of aggregated self-report data on subjective well-being has been advocated by several renowned economists as an alternative measure of the increasingly complex welfare of societies whose citizens’ standards of education and health differ (Stiglitz et al. 2009). As a result, there is also an increasing body of literature focusing on assessing the potential influence of macroeconomic and social factors on such well-being indicators adopting a cross-national approach cross-national studies (e.g. Kahneman and Krueger 2006; Musikanski et al. 2017).
The recent development of international databases that provide information on the levels of life satisfaction or happiness of individuals, such as the World Values Survey (WVS), the European Social Survey (ESS) or the Gallup World Poll, has contributed notably to the development of this line of research (e.g. Schyns 1998; Veenhoven 2005, 2012; Exton et al. 2015). The methodological approaches used in the above studies differ in detail, although most are based on defining an equation where the dependent variable is a measure of the absolute level of well-being, and statistical and econometric techniques are used to identify explanatory variables significantly associated with this indicator (Powdthavee 2010). Although those variables might be very diverse, a recent study indicate that the most relevant ones are GDP per capita, healthy life expectancy at birth, social support (having someone to count on in times of trouble), freedom to make life choices, generosity and perceptions for corruption, since they can explain almost three-quarters of the variation in national average levels of well-being (Helliwell et al. 2016). However, other variables might also play a relevant role such as the level of unemployment (Di Tella et al. 2003), institutional quality (Ott 2010) or inequality (Schneider 2016) as well as the degree of participation that women have in the working and social life of the country (Mencarini and Sironi 2010).
In this paper, we adopt an alternative approach that has not been widely used in the literature so far, but has experienced remarkable growth in recent years. We are primarily concerned with exploring not the factors contributing to increasing individuals’ absolute levels of well-being but the efficiency with which individuals are able to reach their levels of subjective well-being, thus freeing resources that can be used for other purposes (Binder and Broekel 2012). This concept builds on the assumption that individuals’ well-being is the result of a combination of certain resources (i.e. income, health or education). Thus, an increase in such resources should lead to higher levels of satisfaction. However, not everyone is equally able to benefit from existing resources, even if they do have the same access to resources. Therefore, some individuals are intrinsically happier than others. Hence, there might be inefficiencies in the conversion process of resources into well-being, since some individuals might not be able to reach certain levels of satisfaction despite having a certain level of resources at their disposal. Alternatively, they might need more resources than other individuals to attain certain levels of well-being.
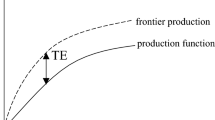
Accordingly, the frontier techniques that are commonly applied in the production theory literature can be used to estimate well-being efficiencies on the basis of Sen’s (1985) and Narayan et al.’s (2000) capability approach. In this framework, the most efficient units will be placed on the efficiency frontier, since they represent the best practice for converting resources into well-being. This frontier serves as a reference for evaluating the other units in the sample, and thus relative measures of inefficiency can be estimated as the distance to the frontier (Farrell 1957). Therefore, benchmark definition and empirical estimation are important practical issues. Frontiers can be estimated using different approaches generally classified as parametric or nonparametric methods.Footnote 2 Parametric methods assume a specific functional form of the production function that describes the process of translating the inputs into the maximum possible output, whereas nonparametric methods are based only on a set of axioms and estimate the relative efficiency of units through linear programming (e.g. data envelopment analysis—DEA—or free disposal hull—FDH—). Parametric and nonparametric approaches are frequently identified as competitors, but they are actually complementary since something must be sacrificed for something to be gained in their trade-off (Kuosmanen et al. 2015).
The methodology applied in the few previous studies that have attempted to estimate well-being efficiency measures has been mainly nonparametric (e.g. Binder and Broekel 2012; Debnath and Shankar 2014; Carboni and Russu 2015; Mizobuchi 2017a; Cordero et al. 2017), since this approach is more flexible and generalizable. However, it also has some limitations such as its poor discriminatory power when the sample size is small with respect to the total number of inputs and outputs included in the model. Besides, nonparametric methods are deterministic. Therefore, when using this approach it is not possible to recognize for inefficient units whether deviations from the frontier are due to technical inefficiency or to noise effects attributable to omitted variables, measurement errors or variations in individuals’ cultural and linguistic backgrounds. For instance, Exton et al. (2015) found that cultural bias possibly explains a variance of around 10 to 15% in subjective well-being scores around the world. Likewise, the empirical evidence suggests that differences in freedoms, trust and social capital across countries may also be important (Halpern 2010; Portela et al. 2013).
The main contribution of this work to this emerging line of research is to explore whether countries convert their available resources efficiently into subjective well-being using a novel approach known as stochastic semi-nonparametric envelopment of data (StoNED) (Kuosmanen and Kortelainen 2012). This method allows us to avoid the aforementioned drawbacks of nonparametric approaches. The main advantage of this method is that it can account for both inefficiency and noise in the deviations from the estimated function, i.e. analogously to stochastic frontier analysis (SFA), but within a flexible framework. Specifically, we use convex nonparametric least squares (CNLS, Hildreth 1954) to estimate the frontier. Besides, the proposed method can also be extended to account for the potential influence of contextual factors, such as country characteristics, regulations or the environment, that might affect the process of converting resources into well-being in the model (Johnson and Kuosmanen 2011).
In the context of this study, such factors are represented by several macroeconomic variables, social indicators and institutional factors related to quality of government and welfare-state policy. These factors have previously been found to have sizeable effects on individuals’ subjective well-being measures (see Helliwell and Huang 2008; Frey and Stutzer 2010), thus we are interested in exploring whether they may also affect well-being efficiency measures by using an extension of the StoNED approach. This method, known in the literature as stochastic semi-nonparametric envelopment of z variables data (StoNEZD), has not been applied previously in this framework, which makes this study clearly innovative.
The empirical analysis reported in this paper includes a sample of 82 countries with different levels of development from all continents. Data about subjective well-being was gathered from the World Values Survey (WVS), a global research project designed to provide a comprehensive measurement of all major areas of human concern, including data related to perceived well-being, counting variables such as life satisfaction and level of happiness. This information has been combined with data about multiple factors identified in previous literature as determinants of well-being collected from different international data sources such as the World Bank, the World Social Security Report, the World Economic Forum or the Freedom House Organization.
The remainder of this paper is structured as follows. Section 2 reviews previous literature on the use of frontier techniques in the well-being context. Section 3 describes the methodology applied in order to estimate measures of well-being efficiency. Section 4 explains the main characteristics of the dataset and the variables used in the empirical analysis study. Section 5 reports the main results, which it relates to the existing literature. Finally, the paper ends with some concluding remarks.
2 Previous Literature
Frontier techniques were originally developed for the analysis of production function, that is, to estimate how productive units maximize their output from a set of inputs or, alternatively, how they minimize the inputs used given a set of outputs. In the last 2 decades, however, we can identify a growing body of research using these methods in the well-being framework. Lovell et al. (1994) pioneered this approach to estimate the standard of living, the quality of life and the efficiency in transforming resources into achieved functioning. Since then, many empirical studies have adopted these techniques for similar purposes. They can be divided into studies interested in calculating objective indicators of welfare (housing, income, safety, healthy life expectancy, etc.) and studies focused on subjective measures of well-being or happiness (quality of life or life satisfaction).
In the first group, the most frequent approach is to calculate comprehensive measures of welfare that condense several dimensions or domains related to this concept into an overall index. In this way, complex and multidimensional issues can be assessed in an integrated manner in cross-country comparisons of actual living standards, making results easy to report and communicate. In this context, a key question is the selection of appropriate weights, since they determine the trade-offs between the multiple evaluated dimensions of well-being (Decancq and Lugo 2013). For this purpose, the use of frontier techniques, and, especially, linear programming techniques, is very useful because they assign weights endogenously from the actual data, thus avoiding the possibility of arbitrary selection. Specifically, this method assigns the most advantageous weights for each unit under evaluation, such that it is placed in the best possible relative position compared to the other units in the sample. As a result, some international organizations, such as the OECD, have recognised the usefulness of this approach for determining weights when constructing composite indicators of well-being or quality of life indices (see OECD 2008).
Hence, there are many empirical studies using DEA for several purposes, such as constructing composite human development indices (Mariano et al. 2015), deprivation (Zaim et al. 2001; Deutsch et al. 2003) or well-being (Mahlberg and Obersteiner 2001; Despotis 2005a, b; Murias et al. 2006, Jurado and Pérez-Mayo 2012; Reig-Martínez 2013; Guardiola and Picazo-Tadeo 2014, Mizobuchi 2014; Lorenz et al. 2017; Peiró-Palomino and Picazo-Tadeo 2018; Nissi and Sarra 2018), involving different economic, environmental and social factors.Footnote 3 Actually, the composite indicators are calculated in most cases using DEA with the benefit-of-the-doubt (BoD) principle (Cherchye et al. 2007). BoD consists of implementing DEA with the indicators (outputs) all being grouped into a single index along with a dummy input equal to 1. Thus it exclusively focuses on aggregating output measures and not on exploring the relationship between inputs and outputs. This approach can be used to interpret the weights as relative measures of importance associated with each domain.
Within the literature analysing subjective measures of well-being, we can also find some empirical studies constructing composite indicators using the BoD method (e.g. Bernini et al. 2013; Rogge and Van Nijverseel 2019). However, there is a more appealing approach in the recent literature, which explores how efficiently individuals or countries translate given resources into well-being. This line of research started with the work of Binder and Broekel (2012), who assessed relative happiness efficiency for a sample of British individuals using a robust nonparametric approach known as order-m (Cazals et al. 2002).Footnote 4 They went on to explore the potential influence of a set of individual characteristics on the efficiency score using a second-stage panel regression framework with fixed effects. Similarly, Cordero et al. (2017) also adopted a nonparametric order-m approach to estimate happiness efficiency measures for individuals from 26 OECD countries, albeit using the conditional nonparametric approach proposed by Daraio and Simar (2005) to incorporate the influence of a set of individual- and country-level contextual factors into their estimates. They found that the most efficient countries are in northern and central Europe, while transitional economies like the Russian Federation, China or Indonesia are among the worst performers in terms of well-being efficiency.
Likewise, there are other empirical studies using aggregated data at country or regional level. Debnath and Shankar (2014) applied DEA to calculate relative happiness efficiency measures for a sample of 130 countries considering several indicators of governance policies as input variables. They found that similar policies might affect happiness efficiency across countries differently. Similarly, they provide evidence demonstrating that developed countries are more inefficient in terms of happiness than developing countries. Mizobuchi (2017a) also uses DEA to estimate a happiness function for a sample of 36 countries considering several well-being dimensions and a set of socio-economic variables. One of the most relevant results is that the health factor explains the largest part of the cross-country variation in subjective well-being. Nikolova and Popova (2017) estimate well-being efficiencies for a sample of 91 countries over the 2009–2014 period using robust nonparametric techniques. They then apply second-stage panel data fixed effects regressions to examine the influence of several country-related institutional and social characteristics on efficiency measures. Their results show that countries with high-quality institutions where citizens perceive that they have the freedom to choose their way of life are more efficient in terms of well-being. Finally, Carboni and Russu (2015) apply DEA to assess the performance of the 20 Italian regions considering different dimensions of well-being and Malmquist indices to examine their evolution from 2005 to 2011. Their results indicate that northern regions outperform southern regions in terms of well-being efficiency, although none improved their well-being over the evaluated period.
To sum up, there is no previous work providing well-being efficiency measures that have accounted for the potential influence of noise or random effects on estimates, since all the above research adopts a fully nonparametric approach. Likewise, there is no previous study that has used the StoNEZD method to account for the influence of contextual factors. In the following section, we explain this methodology.
3 Methodology
In this study, we apply a novel approach, known as the StoNED method. This method combines the main advantages of parametric and nonparametric approaches. This model can be interpreted as the regression interpretation of data envelopment analysis (DEA), as proposed by Kuosmanen and Johnson (2010) combining the key advantages of both methods into a unified approach: the piecewise linear DEA-type nonparametric frontier with the probabilistic treatment of inefficiency and noise in stochastic models. Moreover, as we are interested in exploring the potential influence of a set of social and economic variables on efficiency levels, we apply an extension of this method known as StoNEZD (Johnson and Kuosmanen 2011). This approach incorporates an average effect of the operational context common to all the evaluated units. In the following, we introduce the key concepts of this framework.
In the production function framework, the technology is represented by a frontier production function \(f\left( x \right)\), which indicates the maximum output that can be produced with inputs \(\varvec{x}\). The observed output (\(y\)) may deviate from the frontier due to random noise (\(v\)), inefficiency (\(u > 0\)) and the effect of contextual factors (\(\varvec{z}\)). This model can be formally defined as follows:
According to this definition of the composite disturbance term, \(\varvec{\delta z}_{\varvec{i}} - u_{i}\) can be interpreted as the overall efficiency of a unit, where \(\varvec{\delta z}_{\varvec{i}}\) is the part of technical inefficiency explained by the contextual variables being identical for all firms, and \(u_{i}\) is the efficiency term that remains unexplained. Therefore, it is implicitly assumed that the exogenous variables only influence the distribution of the inefficiency scores, but they do not affect the location of the frontier.
The StoNEZD method estimates efficiency in two stages. In the first stage, the shape of the frontier is obtained by minimizing the squared residuals of a quadratic programming problem. This does not imply a priori any assumption about the functional form. However, it builds upon constraints like monotonicity and convexityFootnote 5:
where \(\varepsilon_{i}\) represent the residuals of the regression and the estimated coefficients \(\alpha_{i}\) and \(\varvec{\beta}_{\varvec{i}}\) characterize tangent hyperplanes to the unknown function \(f\left( {\varvec{x}_{\varvec{i}} } \right)\) at point \(x_{i} .\) Likewise, \(\varvec{\delta}\) represents the average effect of contextual variables \(\varvec{z}_{\varvec{i}}\) on performances and the term \(\varvec{\delta^{\prime}z}_{\varvec{i}}\) represents the portion of inefficiency that is explained by the contextual variables.
The parametric part of the regression equation containing the contextual variables is analogous to standard OLS. However, this approach avoids the potential bias and inconsistencies that may arise in the well-known two-stage approach, where DEA efficiency estimates are subsequently regressed on the contextual variables (see Wang and Schmidt 2002; Simar and Wilson 2007 for details), when the inputs are correlated with them. Using the StoNEZD method, the above \(\varvec{z}\) variables do not have to be uncorrelated with the explanatory variables (in this case, outputs \(y\)), because the syntax of the model is formulated so as to directly account for the environment. Hence, the frontier estimation explicitly takes into account the correlations between \(y\) and \(\varvec{z}\) (Johnson and Kuosmanen 2011). In our empirical analysis, the contextual factors are represented by social and economic factors that might be affecting the output (average level of well-being declared by individuals). Therefore, the fact that the StoNEZD approach can deal with such correlations is a major advantage with respect to the conventional two-stage model (Eskelinen and Kuosmanen 2013).
In a second stage, parametric techniques can be used to estimate the efficiency scores. In order to separate inefficiency from noise, we use the method of moments (Aigner et al. 1977), maintaining the assumptions of half-normal inefficiency and normal noise. In this method, the second and the third central moments can be estimated based on the distribution of the residuals:
The second moment is simply the variance of the distribution, and the third is a component of the skewness:
As the third moment depends exclusively on the parameter \(\sigma_{u}\), it can be written:
Subsequently, we estimate inefficiency measures of performance by using a well-known firm-specific estimator. Scores lower than one will indicate inefficiency and show the extent to which a country can increase the level of well-being given the current resources. The conditional expected value of the inefficiency can be computed using the conditional mean estimator \(E\left( {u_{i} |\hat{\varepsilon }_{i} } \right)\) and the formulation developed by Battese and Coelli (1988)Footnote 6:
where \({{\Phi }}\) is the cumulative distribution function of the standard normal distribution, with \(\mu_{*} = - \varepsilon_{i} \sigma_{u}^{2} /\sigma^{2}\) and \(\sigma_{*}^{2} = \sigma_{u}^{2} \sigma_{v}^{2} /\sigma^{2}\), and \(\varepsilon_{i} = \hat{\varepsilon }_{i} - \hat{\sigma }_{u} \sqrt {2/\pi }\) is the estimator of the composite error term.
Finally, it is worth mentioning that the StoNEZD estimator for \(\varvec{\delta}\) has some desirable properties, since it is shown to be statistically unbiased, consistent, asymptotically normally distributed, and converge at the standard parametric rate (\(n^{{{\raise0.7ex\hbox{$1$} \!\mathord{\left/ {\vphantom {1 2}}\right.\kern-0pt} \!\lower0.7ex\hbox{$2$}}}}\)) (see Kuosmanen et al. 2015; Yagi et al. 2018, for details). Therefore, standard techniques from regression analysis like t-tests or confidence intervals can be easily applied to test the statistical significance of the \(\varvec{\delta}\) effect.
4 Data and Variables
The data used in this study come from different sources. The measure of well-being was retrieved from the World Values Survey (WVS), an extensive dataset that provides information on multiple aspects regarding social and political life in many countries worldwide. Specifically, individuals interviewed in each country following a stratified random sampling procedure report their level of subjective well-being or life satisfaction on a scale of 1 to 10. This accounts for their feelings about their lives as a whole, including both economic and non-economic factors (Frey and Stutzer 2010). We use this information aggregated at country level as the output variable in our approach.Footnote 7 This measure of life satisfaction is thought to provide consistent and meaningful measures of well-being, which might be affected by multiple factors as reported by Frey (2008).
Since the WVS survey started in 1981, there have been six waves, covering the period 1981 to 2014.Footnote 8 Unfortunately, because most countries have only participated in some and not all of these waves, there are no longitudinal data covering the entire period. Thus, we have created a pooled dataset including as many country-years as possible. To do this, we calculated country-year means using data from different waves, assuming that the measures of subjective well-being have a high degree of stability over time (Headey and Wearing 1989; Ehrhardt et al. 2000). Subsequently, we averaged over the years to get a single period mean for each country.
Based on previous literature about the determinants of well-being (e.g. Helliwell et al. 2016), we selected three input variables representing the main resources that contribute to well-being (incomes, health conditions and educational level) and also fulfil the requirement of isotonicity (i.e. all other things being equal, more input implies an equal or higher level of output). Specifically, we have selected gross domestic product (GDP) per capita, life expectancy at birth and the average number of completed years of education for the population aged 25 and older.Footnote 9 These variables are similar to the ones used in other studies attempting to measure well-being efficiency at country level (e.g. Nikolova and Popova 2017). The first two indicators were retrieved from the World Bank Open Data section, while the last one was taken from the UNESCO Institute for Statistics.
As contextual variables, we selected several indicators reflecting the country’s economic and social context that have been previously identified in the literature as determinants of cross-country divergences in terms of subjective well-being. The economic indicators include the total public social protection expenditure, available from the World Social Security Report, as a proxy of welfare-state policies, and the unemployment rate and the Gini index, as proxies of economic inequality, both available from the World Bank Open Data section. The social indicators include the gender inequality index constructed by the World Economic Forum (Hausmann et al. 2006), an aggregate index representing the quality of governance, constructed as the mean of the six subcomponents from the Worldwide Governance Indicators (WGI) available through the World Bank (Langbein and Knack 2010; Kaufmann et al. 2014)Footnote 10 and an additional index representing civil liberties, measured on a one-to-seven scale, available from Freedom House Organization. Data for all these variables were not available for all the periods. Therefore, we collected data on the most recently available year, generally 2014. The summary statistics for all the variables included in our analysis are reported in Table 1.
Our final sample comprises 82 countries, including developed, transition and less-developed economies, for which data on all the aforementioned variables were available. All the continents are represented, as shown in the Table 6 in the Appendix reporting the raw measure of life satisfaction in each nation. In this regard, we can make a distinction between Eastern European countries, which have some common cultural and geopolitical characteristics, and other European countries. This division detects that the lowest average value of well-being is reported by Eastern European countries, which rank even lower than African countries. By contrast, we find that American countries have the highest average level of well-being, followed very closely by the other European countries and Australia, as the sole representative of Oceania. Figure 2, also included in the Appendix, shows a map with three colour-coded levels of subjective well-being (high, medium and low better), which illustrates this point more clearly. Here we find that the majority of the nations with the highest levels of well-being are on the American continent, although there are also a few examples in Europe (Iceland, Switzerland, Netherlands, Great Britain and the Scandinavian countries) and Asia (Qatar and Uzbekistan). On the contrary, the countries with the lowest levels were situated in Eastern Europe, Africa and also including some nations in Asia (Iraq, India, Bangladesh, Pakistan, South Korea and Hong Kong).
5 Results
In this section, we report the efficiency scores estimated with the methodology described in Sect. 3. First, we applied the StoNED method to obtain measures of well-being efficiency, i.e. considering the output variable and the three inputs only. Subsequently, we adopted the StoNEZD approach to calculate efficiency scores taking into account the effect of the contextual variables. Table 2 summarizes the main descriptive statistics for both specifications. In addition, Fig. 1 shows the histograms of efficiency estimates with both approaches.

Histograms of efficiencies for both specifications
In general terms, we observe that the distribution of efficiencies is quite similar in both models, with a high concentration around levels between 0.6 and 0.8, although dispersion is greater when the analysis includes contextual variables. In this case, the standard deviation is found to be higher and the differences between the maximum and minimum values wider. The mean inefficiency is relatively high in both models, although it is slightly higher in the second case (0.67 vs. 0.62). Therefore, well-being efficiency gains are still possible in many countries.
Nevertheless, the most interesting insights can be drawn by exploring the country rankings. Table 3 shows the efficiency scores for all 82 countries in the sample with both specifications, compared with the average levels of life satisfaction declared by individuals from each country (output). If we focus on top performers according to both rankings, we notice that most are developing countries where individuals state that they have relatively high life satisfaction levels (e.g. Puerto Rico, Colombia, Uzbekistan, Guatemala, Mexico or El Salvador). This could suggest that the consideration of inputs and contextual variables in the process of maximizing life satisfaction levels may not have a big influence on the performance of countries, as suggested by Cordero et al. (2017).
However, this claim only appears to be valid for relatively poor developing countries, where the input (income, health and education) values are frequently below average. Actually, we observe that several rich countries placed at the top of the life satisfaction rankings (e.g. Switzerland, Qatar, Canada, United States or Great Britain) are ranked much lower in both efficiency rankings taking into account their high input variable values. Likewise, there are some other important divergences between efficiency estimates and life satisfaction levels. For instance, we find that some African and Asian countries (e.g. Kyrgyzstan, Vietnam, Mali or Ethiopia), whose populations report life satisfaction levels very close to and even below average, rank high in terms of well-being efficiency. Similarly, there are also some countries with very low well-being efficiency values in the model including contextual factors, even though their citizens report life satisfaction levels close to the sample mean.
In order to summarize the above discrepancies, we calculated the Kendall and Spearman correlation coefficients between different rankings. From the values reported in Table 4, we find that there are significant differences between the output and both efficiency estimates. These differences are more relevant with respect to the estimates that take into account the contextual factors. Moreover, the maps in the Appendix (Figs. 2 and 3) are potentially very illustrative. In those figures we distinguish three different levels of life satisfaction and efficiency (high, medium and low) with different colours for each model. This underscores the fact that the colours for many countries change from one map to the other when inputs and contextual variables are included in the estimation of well-being efficiency measures.

Distribution of life satisfaction levels around the world

Distribution of efficiency scores around the world
The fact that the top performers are mainly Latin American countries is somewhat unexpected, especially taking into account that their economic and socio-political situation is characterized by a very unequal distribution of income, high levels of corruption and, in some cases, even high violence and crime rates. However, this result has also been identified in other studies (e.g. Debnath and Shankar 2014; Graham and Nikolova 2018). Some potential factors that could explain the higher levels of well-being reported by individuals from these nations are their slower pace of life, the important role played by family and interpersonal relations, a relative indifference to materialistic values or the quality of social life (Yamamoto 2016; Rojas 2018).
Finally, Table 5 reports the values of the \(\varvec{\delta}\) parameter estimated for each variable together with the respective t-statistic in order to examine the average effect of the social and economic indicator variables included as contextual variables in the model. As expected, we found a significant and positive sign for the unemployment rate, the Gini index and the gender inequality index. This indicates that lower levels of these indicators are associated with higher efficiencies. These results are consistent with previous findings in the literature analysing factors affecting well-being efficiency (Cordero et al. 2017), as well as other empirical studies exploring the determinants of the level of well-being declared by individuals (Verme 2011; Blanchflower et al. 2014). On the contrary, we identify a significant and negative sign for social expenditure, the quality of government and civil liberties, which implies that better performances are found to be better in terms of well-being efficiency for higher values of these indicators. These results corroborate the fact that countries with higher levels of well-being are characterized by having high quality institutions (Bjornskov et al. 2008, 2010) and allocate a large proportion of public spending to social policies (Pacek and Radcliff 2008).
6 Concluding Remarks
This paper constitutes a new contribution to the novel line of research focusing on measuring the subjective well-being efficiency of countries. This line of research consists of examining whether their individuals are able to achieve the maximum life satisfaction levels given their existing resources. In our empirical study, we have estimated an efficiency frontier for a sample of 82 countries of different sizes and levels of development, representing all the continents in the world. We applied a novel semi-nonparametric method (StoNED) to estimate well-being efficiency measures accounting for potential noise effects attributable to omitted variables or cultural bias. This represents a substantial advantage with respect to previous empirical studies found in the literature adopting a nonparametric approach, where such aspects could be confounded with inefficiency. In addition, our model also incorporates data about several contextual factors that might have an influence on country performance, such as economic conditions, social indicators or institutional factors, using an extension of the proposed method known as StoNEZD. This method, which has not been previously applied in this framework, allows us for exploring whether those factors affect wellbeing efficiency measures and the direction of this effect.
Our results show that there are some remarkable shifts in the ranking of countries according to the levels of well-being reported by citizens when information about input and contextual factors is taken into account. Thus, we find that there are countries in which well-being efficiency is relatively high despite individuals reporting below-average life satisfaction levels and vice versa, that is, nations whose well-being levels are high but should, according to their resources endowment and socioeconomic conditions, be higher. Nevertheless, we have found that most countries ranked as top performers in terms of well-being efficiency also report having high levels of life satisfaction. Many of these are developing Latin American countries, where individuals appear to be happy with their lives, even though they have to cope with an adverse social and economic context and poor institutions. This result is consistent with previous evidence found in other empirical studies estimating well-being efficiency measures (Debnath and Shankar 2014) and also with rankings focused only on life evaluations (Helliwell et al. 2016). Personality or cultural differences, as well as the ability of individuals to adjust to the existence of severe problems such as corruption or violence, are possible explanations (Graham 2011).
Finally, note that the use of the StoNEZD method has allowed us to test the statistical significance of the average effect of the contextual variables included in the model. The results suggest that efficiency gains could be achieved by increasing the level of social expenditure, enhancing the quality of government, promoting civil liberties, as well as reducing the unemployment rate and inequalities. These results are consistent with previous findings of studies focused on exploring the determinants of well-being at country level. Therefore, it seems to be a clear link between both lines of research. However, it would be interesting to explore in future studies whether these similarities are maintained or not when analyzing microdata at the individual level.
Notes
The literature on well-being is based on individuals’ self-reported data about life satisfaction, happiness or subjective well-being. Although there are significant differences between these constructs, we will use the words happiness, satisfaction and (subjective) well-being indistinctly throughout the paper (see, for example, Ferrer-i-Carbonell 2005). In any case, the focus of our study is on life satisfaction.
See Fried et al. (2008) for an overview of these methods.
The work of Mizobuchi (2017b), who applies corrected convex nonparametric least squares to construct composite well-being indicators incorporating sustainability concerns, can also be classed in this group.
Unlike other methods like DEA or FDH, this approach does not use data about all the units within the sample to build the frontier, but focusing on only some selected units with similar characteristics to the unit under evaluation.
Kuosmanen and Johnson (2010) show that this problem is equivalent to the standard (output-oriented, variable returns to scale) DEA model when a sign constraint on residuals is incorporated to the formulation (\(\varepsilon_{i}^{CNLS - } \le 0 \forall i\)) and considering the problem subject to shape constraints (monotonicity and convexity).
The first-, second-, third-, fourth-, fifth- and sixth-wave data were collected from 1981 to 1984, from 1990 to 1994, from 1995 to 1998, from 1999 to 2004, from 2005 to 2009 and from 2010 to 2014, respectively.
The WVS dataset also provides information about incomes, health status and educational level. However, these measures are based on the relative position of individuals with respect to people from the same country, and are thus considered as not providing an appropriate measure for a cross-country study.
References
Abdallah, S., Thompson, S., & Marks, N. (2008). Estimating worldwide life satisfaction. Ecological Economics, 65(1), 35–47.
Aigner, D., Lovell, C. K., & Schmidt, P. (1977). Formulation and estimation of stochastic frontier production function models. Journal of Econometrics, 6(1), 21–37.
Andor, M., & Hesse, F. (2014). The StoNED age: The departure into a new era of efficiency analysis? A Monte Carlo comparison of StoNED and the “oldies” (SFA and DEA). Journal of Productivity Analysis, 41(1), 85–109.
Battese, G. E., & Coelli, T. J. (1988). Prediction of firm-level technical efficiencies with a generalized frontier production function and panel data. Journal of Econometrics, 38(3), 387–399.
Bernini, C., Guizzardi, A., & Angelini, G. (2013). DEA-like model and common weights approach for the construction of a subjective community well-being indicator. Social Indicators Research, 114(2), 405–424.
Binder, M., & Broekel, T. (2012). Happiness no matter the cost? An examination on how efficiently individuals reach their happiness levels. Journal of Happiness Studies, 13(4), 621–645.
Bjornskov, C., Dreher, A., & Fischer, J. A. V. (2008). Cross-country determinants of life satisfaction: Exploring different determinants across groups in society. Social Choice and Welfare, 30, 119–173.
Bjornskov, C., Dreher, A., & Fischer, J. A. (2010). Formal institutions and subjective well-being: Revisiting the cross-country evidence. European Journal of Political Economy, 26(4), 419–430.
Blanchflower, D. G., Bell, D. N., Montagnoli, A., & Moro, M. (2014). The Happiness Trade-Off between Unemployment and Inflation. Journal of Money, Credit and Banking, 46(2), 117–141.
Carboni, O. A., & Russu, P. (2015). Assessing regional well-being in Italy: An application of Malmquist—DEA and self-organizing map neural clustering. Social Indicators Research, 122(3), 677–700.
Cazals, C., Florens, J. P., & Simar, L. (2002). Nonparametric frontier estimation: A robust approach. Journal of Econometrics, 106(1), 1–25.
Cherchye, L., Moesen, W., Rogge, N., & Van Puyenbroeck, T. (2007). An introduction to ‘benefit of the doubt’ composite indicators. Social Indicators Research, 82(1), 111–145.
Cordero, J. M., Salinas-Jiménez, J., & Salinas-Jiménez, M. M. (2017). Exploring factors affecting the level of happiness across countries: A conditional robust nonparametric frontier analysis. European Journal of Operational Research, 256(2), 663–672.
Daraio, C., & Simar, L. (2005). Introducing environmental variables in nonparametric frontier models: A probabilistic approach. Journal of Productivity Analysis, 24(1), 93–121.
Debnath, R. M., & Shankar, R. (2014). Does good governance enhance happiness: A cross nation study. Social Indicators Research, 116(1), 235–253.
Decancq, K., & Lugo, M. A. (2013). Weights in multidimensional indices of well-being: An overview. Econometric Reviews, 32(1), 7–34.
Despotis, D. K. (2005a). A reassessment of the human development index via data envelopment analysis. Journal of the Operational Research Society, 56(8), 969–980.
Despotis, D. K. (2005b). Measuring human development via data envelopment analysis: The case of Asia and the Pacific. Omega, 33(5), 385–390.
Deutsch, J., Ramos, X., & Silber, J. (2003). Poverty and inequality of standard of living and quality of life in Great Britain. In M. J. Sirgy, D. Rahtz, & A. C. Samli (Eds.), Advances in quality-of-life theory and research (pp. 99–128). Dordrecht: Kluwer.
Di Tella, R., MacCulloch, R. J., & Oswald, A. J. (2003). The macroeconomics of happiness. Review of Economics and Statistics, 85(4), 809–827.
Dolan, P., Peasgood, T., & White, M. (2008). Do we really know what makes us happy? A review of the economic literature on the factors associated with subjective well-being. Journal of Economic Psychology, 29(1), 94–122.
Ehrhardt, J. J., Saris, W. E., & Veenhoven, R. (2000). Stability of life- satisfaction over time. Journal of Happiness Studies, 1(2), 177–205.
Eskelinen, J., & Kuosmanen, T. (2013). Intertemporal efficiency analysis of sales teams of a bank: Stochastic semi-nonparametric approach. Journal of Banking & Finance, 37(12), 5163–5175.
Exton, C., Smith, C., & Vandendriessche, D. (2015). Comparing happiness across the world. OECD Statistics Working Paper 2015/4.
Farrell, M. J. (1957). The measurement of productive efficiency. Journal of the Royal Statistical Society: Series A (General), 120(3), 253–281.
Ferrer-i-Carbonell, A. (2005). Income and well-being: An empirical analysis of the comparison income effect. Journal of Public Economics, 89(5–6), 997–1019.
Frey, B. S. (2008). Happiness: A revolution in economics. Cambridge, MA: MIT Press.
Frey, B., & Stutzer, A. (2010). Happiness and economics: How the economy and institutions affect human well-being. Princeton, NJ: Princeton University Press.
Fried, H. O., Lovell, C. K., Schmidt, S. S., & Schmidt, S. S. (Eds.). (2008). The measurement of productive efficiency and productivity growth. Oxford: Oxford University Press.
Graham, C. (2011). Adaptation amidst prosperity and adversity: Insights from happiness studies from around the World. The World Bank Research Observer, 26(1), 105–137.
Graham, C., & Nikolova, M. (2018). Happiness and international migration in Latin America. In Helliwell, J. F., Layard, R., & Sachs, J. (Eds.), World Happiness Report 2018, New York (pp. 89–113).
Guardiola, J., & Picazo-Tadeo, A. J. (2014). Building weighted-domain composite indices of life satisfaction with data envelopment analysis. Social Indicators Research, 117(1), 257–274.
Halpern, D. (2010). The hidden wealth of nations. Cambridge: Polity.
Hausmann, R., Tyson, L. D., & Zahidi, S. (2006). The global gender gap report. Geneva: World Economic Forum.
Headey, B., & Wearing, A. (1989). Personality, life events, and subjective well-being: Toward a dynamic equilibrium model. Journal of Personality and Social Psychology, 57(4), 731–739.
Helliwell, J. F., & Huang, H. (2008). How’s your government? International evidence linking good government and well-being. British Journal of Political Science, 38, 595–619.
Helliwell, J. F., Huang, H., & Wang, S. (2016). The distribution of world happiness. In Helliwell, J. F., Layard, R., & Sachs, J. (Eds.), World Happiness Report 2016, New York (pp. 8–48).
Hildreth, C. (1954). Point estimates of ordinates of concave functions. Journal of the American Statistical Association, 49(267), 598–619.
Johnson, A. L., & Kuosmanen, T. (2011). One-stage estimation of the effects of operational conditions and practices on productive performance: Asymptotically normal and efficient, root-n consistent StoNEZD method. Journal of Productivity Analysis, 36(2), 219–230.
Jondrow, J., Lovell, C. K., Materov, I. S., & Schmidt, P. (1982). On the estimation of technical inefficiency in the stochastic frontier production function model. Journal of Econometrics, 19(2–3), 233–238.
Jurado, A., & Pérez-Mayo, J. (2012). Construction and evolution of a multidimensional well-being index for the Spanish regions. Social Indicators Research, 107, 259–279.
Kahneman, D., & Krueger, A. B. (2006). Developments in the measurement of subjective well-being. Journal of Economic Perspectives, 22, 3–24.
Kapteyn, A., Lee, J., & Tassot, C. (2015). Dimensions of subjective well-being. Social Indicators Research, 123(3), 625–660.
Kaufmann, D., Kraay, A., & Mastruzzi, M. (2014). Worldwide governance indicators. Washington, DC: World Bank.
Kuosmanen, T., & Johnson, A. L. (2010). Data envelopment analysis as nonparametric least-squares regression. Operations Research, 58, 149–160.
Kuosmanen, T., Johnson, A. L., & Saastamoinen, A. (2015). Stochastic nonparametric approach to efficiency analysis: A unified framework. In J. Zhu (Ed.), Data envelopment analysis. A handbook of models and methods (pp. 191–244). New York: Springer.
Kuosmanen, T., & Kortelainen, M. (2012). Stochastic non-smooth envelopment of data: Semi-parametric frontier estimation subject to shape constraints. Journal of Productivity Analysis, 38(1), 11–28.
Langbein, L., & Knack, S. (2010). The worldwide governance indicators: Six, one, or none? Journal of Development Studies, 46, 350–370.
Lorenz, J., Brauer, C., & Lorenz, D. (2017). Rank-optimal weighting or “How to be best in the OECD Better Life Index?”. Social Indicators Research, 134(1), 75–92.
Lovell, C. A. K., Richardson, S., Travers, P., & Wood, L. (1994). Resources and functionings: A new view of inequality in Australia. In W. Eichhorn (Ed.), Models and measurement of welfare and inequality (pp. 787–807). Heidelberg: Springer-Verlag.
MacKerron, G. (2012). Happiness economics from 35,000 feet. Journal of Economic Surveys, 26(4), 705–735.
Mahlberg, B., & Obersteiner, M. (2001). Remeasuring the HDI by data envelopment analysis. Interim Report 01-069. Laxenburg: International Institute for Applied Systems Analysis.
Mariano, E. B., Sobreiro, V. A., & do Nascimento Rebelatto, D. A. (2015). Human development and data envelopment analysis: A structured literature review. Omega, 54, 33–49.
Mencarini, L., & Sironi, M. (2010). Happiness, housework and gender inequality in Europe. European Sociological Review, 28(2), 203–219.
Mizobuchi, H. (2014). Measuring world better life frontier: A composite indicator for OECD Better Life Index. Social Indicators Research, 118, 987–1007.
Mizobuchi, H. (2017a). Measuring socio-economic factors and sensitivity of happiness. Journal of Happiness Studies, 18(2), 463–504.
Mizobuchi, H. (2017b). Incorporating sustainability concerns in the Better Life Index: Application of corrected convex non-parametric least squares method. Social Indicators Research, 131(3), 947–971.
Murias, P., Martinez, F., & De Miguel, C. (2006). An economic well-being index for the Spanish provinces: A data envelopment analysis approach. Social Indicators Research, 77(3), 395–417.
Musikanski, L., Polley, C., Cloutier, S., Berejnoi, E., & Colbert, J. (2017). Happiness in communities: How neighborhoods, cities and states use subjective well-being metrics. Journal of Social Change, 9(1), 3.
Narayan, D., Chambers, R., Shah, M. K., & Petesch, P. (2000). Voices of the poor. Crying out for change. New York: Oxford University Press for the World Bank.
Nettle, D. (2005). Happiness: The science behind your smile. Oxford: Oxford University Press.
Nikolova, M., & Popova, O. (2017). Sometimes your best just ain’t good enough: The worldwide evidence on well-being efficiency. IZA Institute of Labor Economics, Discussion Paper nº 10774.
Nissi, E., & Sarra, A. (2018). A measure of well-being across the Italian urban areas: An integrated DEA-entropy approach. Social Indicators Research, 136(3), 1183–1209.
OECD. (2008). Handbook on constructing composite indicators: Methodology and user guide. Paris: OECD Publishing.
Ott, J. C. (2010). Good governance and happiness in nations: Technical quality precedes democracy and quality beats size. Journal of Happiness Studies, 11, 353–368.
Pacek, A. C., & Radcliff, B. (2008). Welfare policy and subjective well-being across nations: An individual-level assessment. Social Indicators Research, 89(1), 179–191.
Peiró-Palomino, J., & Picazo-Tadeo, A. J. (2018). OECD: One or many? Ranking countries with a composite well-being indicator. Social Indicators Research, 139(3), 847–869.
Portela, M., Neira, I., & Salinas-Jiménez, M. (2013). Social capital and subjective well-being in Europe: A new approach on social capital. Social Indicators Research, 114, 493–511.
Powdthavee, N. (2010). How much does money really matter? Estimating the causal effects of income on happiness. Empirical Economics, 39(1), 77–92.
Reig-Martínez, E. (2013). Social and economic well-being in Europe and the Mediterranean Basin: Building an enlarged human development indicator. Social Indicators Research, 111(2), 527–547.
Rogge, N., & Van Nijverseel, I. (2019). Quality of life in the European Union: A multidimensional analysis. Social Indicators Research, 141(2), 765–789.
Rojas, M. (2018). Happiness in Latin America has social foundations. In Helliwell, J. F., Layard, R., & Sachs, J. (Eds.), World Happiness Report 2018, New York (pp. 115–145).
Schneider, S. M. (2016). Income inequality and subjective wellbeing: Trends, challenges, and research directions. Journal of Happiness Studies, 17(4), 1719–1739.
Schyns, P. (1998). Cross-national differences in happiness: Economic and cultural factors explored. Social Indicators Research, 43(1–2), 3–26.
Sen, A. (1985). Commodities and capabilities. In G. Hawthorn (Ed.), The standard of living: Lecture I, concepts and critiques. Oxford: Oxford University Press.
Simar, L., & Wilson, P. W. (2007). Estimation and inference in two-stage, semi-parametric models of production processes. Journal of Econometrics, 136(1), 31–64.
Stiglitz, J. E., Sen, A., & Fitoussi, J. P. (2009). Report of the Commission on the Measurement of Economic Performance and Social Progress (CMEPSP). Retrieved April 27, 2019 from http://www.stiglitz-senfitoussi.fr/en/documents.html.
Veenhoven, R. (2005). Inequality of happiness in nations: Introduction. Journal of Happiness Studies, 6, 351–355.
Veenhoven, R. (2012). Bibliography of happiness. (Section F ‘Happiness and Society’) World database of happiness. Erasmus University Rotterdam, Netherlands.
Verme, P. (2011). Life satisfaction and income inequality. Review of Income and Wealth, 57(1), 111–137.
Wang, H. J., & Schmidt, P. (2002). One-step and two-step estimation of the effects of exogenous variables on technical efficiency levels. Journal of Productivity Analysis, 18, 129–144.
Yagi, D., Chen, Y., Johnson, A. L., & Kuosmanen, T. (2018). Shape constrained kernel-weighted least squares: Estimating production functions for Chilean manufacturing industries. Journal of Business & Economic Statistics. https://doi.org/10.1080/07350015.2018.1431128.
Yamamoto, J. (2016). The social psychology of Latin American happiness. In M. Rojas (Ed.), Handbook of happiness research in Latin America. Berlin: Springer.
Zaim, O., Färe, R., & Grosskopf, S. (2001). An economic approach to achievement and improvement indexes. Social Indicators Research, 56, 91–118.
Acknowledgements
The authors would like to express their gratitude to the Spanish Ministry for Economy and Competitiveness for supporting this research through Grant ECO2017-83,759-P. Cristina Polo and Jose M. Cordero would also like to acknowledge the support and funds provided by the Extremadura Government (Grants GR18106 and IB16171).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Cordero, J.M., Polo, C. & Salinas-Jiménez, J. Subjective Well-Being and Heterogeneous Contexts: A Cross-National Study Using Semi-Nonparametric Frontier Methods. J Happiness Stud 22, 867–886 (2021). https://doi.org/10.1007/s10902-020-00255-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10902-020-00255-3