
Abstract
We propose an index of population diversity based on people’s birthplaces and decompose it into a size (share of immigrants) and a variety (diversity of immigrants) component. We show that birthplace diversity is largely uncorrelated with ethnic, linguistic or genetic diversity and that the diversity of immigrants relates positively to measures of economic prosperity. This holds especially for skilled immigrants in richer countries at intermediate levels of cultural proximity. We address endogeneity by specifying a pseudo-gravity model predicting the size and diversity of immigration. The results are robust across specifications and suggestive of skill-complementarities between immigrants and native workers.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
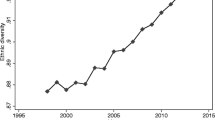
Population heterogeneity is increasing in virtually all advanced economies due to immigration. Foreign-born individuals now represent about 10 % of the workforce in OECD countries, a threefold increase since 1960 and a twofold increase since 1990. High-skill migration is growing even faster, with a twofold increase during the 1990s alone.Footnote 1 As a result, the diversity of the skilled workforce (measured as the likelihood that two randomly-drawn skilled workers have different countries of birth) in a typical OECD country has increased by more than 3 percentage-points (from 0.19 to 0.22) within just ten years.Footnote 2
What are the economic implications of higher diversity? Theory suggests that diversity has positive and negative economic effects. The former are due to complementarities in production, diversity of skills, experiences and ideas (think of a Dixit-Stiglitz production function). The latter arise from disagreements about public policies, animosity between different groups and conflict. The empirical literature has so far focused on ethnic and linguistic fractionalization, which were shown to exert negative effects on economic growth in cross-country comparisons (Easterly and Levine 1997; Collier 2001; Alesina et al. 2003, Forthcoming), with the possible exception of very rich countries (see Alesina and La Ferrara 2005, for a survey on these issues). Ashraf and Galor (2013a, b) focus on genetic diversity and show that it exhibits an inverse u-shaped relationship with income per capita. On balance the negative effects of diversity seem to dominate empirically. To put it differently, it has been relatively hard to empirically document the positive economic effects of diversity, which is the key objective of this paper.
We examine the relationship between population diversity in birthplaces and economic prosperity and specifically make four contributions. First, we construct and discuss the properties of a new index of birthplace diversity. We build indicators of diversity for the workforce of 195 countries in 1990 and 2000, disaggregated by education level, and computed both for the workforce as a whole and for its foreign-born component. Empirically, ethno-linguistic, genetic and birthplace diversity are almost completely uncorrelated. Conceptually, ethno-linguistic, genetic and birthplace diversity also differ as people born in different countries are likely to have been educated in different school systems, learned different skills, and developed different cognitive abilities. Intuitively, this may not be the case for people of different ethnic or genetic origins who were born, raised and educated in the same country.
Second, we investigate the relationship between birthplace diversity and economic development. We find that unlike ethnic/linguistic fractionalization, birthplace diversity remains positively related to long-run income after controlling for many covariates. This positive relationship is stronger for skilled migrants (workers with college education) in richer countries and economically meaningful. Increasing the diversity of skilled immigrants by 1 percentage-point raises long-run output by about 2 %.
Third, we make progress towards addressing endogeneity issues arising from selection on unobservables and reverse causality. We show that our results are unlikely to be explained by positive selection on unobservables. To address reverse causality, we specify a gravity model to predict the size and diversity of a country’s immigration using bilateral geographic/cultural variables. We confirm the robustness of our OLS findings in 2SLS models.
Fourth, we allow the effect of diversity to vary with bilateral cultural distance between immigrants and natives. We also investigate the effect of income per capita at origin. The productive effect of birthplace diversity is largest for immigrants from richer origin countries and for immigrants from countries at intermediate levels of cultural proximity. That is, the effect of diversity is inversely u-shaped in terms of cultural distance between immigrant and native workers. This suggests an optimal level of birthplace diversity in terms of cultural proximity.Footnote 3
The current empirical evidence linking income and productivity differences to birthplace diversity is growing rapidly but is still limited when it comes to cross-country evidence. Existing studies have focused mainly on the United States. Ottaviano and Peri (2006) construct a measure of cultural diversity for the period 1970–1990 using migration data on US metropolitan areas and find positive effects on the productivity of native workers as measured by their wages.Footnote 4 Peri (2012) finds positive effects of the diversity coming from immigration on the productivity of US states, a result he attributes to unskilled migrants promoting efficient task-specialization and adoption of unskilled-efficient technologies, and more so when immigration is diverse. Ager and Brückner (2013) study the link between immigration, diversity and economic growth in the context of the United States about a century ago, at a time now commonly referred to as “the age of mass migration” (Hatton and Williamson 1998).Footnote 5 They find that fractionalization increases output while polarization decreases it in US counties during the period 1870–1920. Cross-country comparisons include Andersen and Dalgaard (2011), who find positive effects of travel intensity on total factor productivity which they attribute to knowledge diffusion of temporary migrants, and Ortega and Peri (2014), who analyze the connection between income per capita and migration in a cross-section of countries. They focus on the growth effects of openness and diversity of trade vs. migration and find the share of immigration to be a stronger determinant of long run output than trade. In contrast, we focus on the effect of intrapopulation diversity, comparing birthplace to other dimensions of diversity (ethnic, linguistic, genetic) and demonstrate the positive effect of the diversity arising from skilled immigration on income per capita.
The rest of this paper proceeds as follows. Section 2 briefly discusses theoretical channels and related literature on diversity and economic performance. Section 3 explains the construction and analytical decomposition of our birthplace diversity index; we also explore its descriptive features and patterns of correlation with other diversity/fractionalization indices. In Sect. 4 we provide data sources, develop our empirical model, and describe OLS results for birthplace diversity in a range of empirical specifications. In Sect. 5, we discuss unobserved heterogeneity and reverse causality, showing that they are unlikely to explain our results. In Sect. 6, we augment our birthplace diversity index to include cultural distance and income at origin. Section 7 concludes.
2 The literature
People born in different countries are likely to have different productive skills because they have been exposed to different life experiences, different school and value systems, and thus have developed different perspectives that allow them to interpret and solve problems differently. We use the term “birthplace diversity” to designate the dimension of intrapopulation diversity arising from the heterogeneity in people’s birthplaces and posit that this source of diversity is more likely to capture skill complementarity effects than alternative dimensions of diversity (e.g., ethnic or linguistic fractionalization). Alesina et al. (2000) formalize the idea of skill complementarities using a Dixit-Stiglitz type production function where output increases in the variety of inputs and inputs can be interpreted as different type of workers. Their model thus allows for diversity to increase output without any counterbalancing costs. Lazear (1999a, b) proposes a model of teams of workers where diversity brings benefits via production complementarities from relevant disjoint information sets and also costs via barriers to communication; with decreasing marginal benefits and increasing marginal costs, this suggests that there is an optimal degree of diversity. A related argument, also brought forward by Lazear (1999b), is that diverse groups of immigrants tend to assimilate more quickly (in terms of learning the language of the majority) since they have stronger incentives to do so. Hong and Page (2001) see two sources for the heterogeneity of people’s minds: cognitive differences between people’s internal perspectives (their interpretation of a complex problem) as well as their heuristics (their algorithms to solve these problems). They show theoretically that, under certain conditions, a group of cognitively diverse but skill-limited workers can outperform a homogenous group of highly skilled workers. Fershtman et al. (2006) reach similar conclusions in a model where workers are heterogeneous in terms of status concerns.Footnote 6
Empirically, diversity is commonly measured by ethno-linguistic fractionalization (Easterly and Levine 1997; Alesina et al. 2003; Fearon 2003; Desmet et al. 2012) and ethno-linguistic polarization indices (Esteban and Ray 1994; Reynal-Querol 2002 and Montalvo and Reynal-Querol 2005). At a macro level, the costs of fractionalization have been established empirically in particular for ethno-linguistic diversity. These studies began with Easterly and Levine (1997), who show that ethnic fragmentation is associated with lower economic growth, especially in Africa. Collier (1999, 2001) adds that ethnic fractionalization is less detrimental in the presence of democratic institutions that mediate ethnic conflict. It is, however, unclear if this observation is not a corollary of higher income as shown in Alesina and La Ferrara (2005). Fearon and Laitin (2003) add that ethnic diversity alone is not sufficient to explain the outbreak of civil war. In a recent contribution, Arbatli et al. (2015) demonstrate the role of genetic intra-group diversity (independently of ethnic fractionalization and polarization) in explaining the incidence and severity of intrastate conflict. The authors establish a reduced form causal effect of genetic diversity on intrastate conflict and suggest this effect operates through the formation of ethnic groups, lower levels of interpersonal trust, and higher heterogeneity in policy preferences.
Putnam (1995), and Alesina and La Ferrara (2000, 2002) stress the role of trust, showing that individuals in racially diverse cities in the US participate less frequently in social activities and trust their neighbors to a lesser degree. The authors also find evidence that preferences for redistribution are lower in racially diverse communities. This also extends to the provision of productive public goods (Alesina et al. 1999). Alesina and Zhuravskaya (2011) stress the negative effect of ethnic segregation on the quality of government, while Alesina et al. (Forthcoming) highlight the detrimental effects of “ethnic inequality” (i.e., when economic inequality and ethnic diversity go hand-in-hand). Esteban et al. (2012) distinguish conflicts over public and private goods and find polarization to correlate positively with conflict on the former, and fractionalization to correlate positively with the latter (see also Esteban and Ray 2011). Ashraf and Galor (2013a) introduce a new dimension of diversity, intrapopulation genetic heterozygosity. Genetic diversity is found to have a long-lasting effect on population density in the pre-colonial era as well as on contemporary levels of development. More specifically, the authors find an inverted u-shaped relationship between genetic diversity and income/productivity. Ashraf and Galor (2011) find that cultural diversity (based on World Values Survey data) is positively correlated with contemporary development and suggest that cultural diversity facilitated the transition from agricultural to industrial societies, suggestive of the trade-off between beneficial forces of diversity expanding the production possibility frontier and detrimental ones leading to higher inefficiency and conflict.
At the micro level, empirical studies of diverse teams in the management and organization literature also find diversity to be a double-edged sword, with diversity (in terms of gender, education, tenure, nationality) being often beneficial for performance but also decreasing team cohesion and increasing coordination costs (see O’Reilly et al. 1989, and Milliken and Martins 1996). A study on airline industry productivity by Hambrick et al. (1996) finds that management teams heterogeneous in terms of education, tenure and functional background react more slowly to a competitor’s actions, but also obtain higher market shares and profits than their homogeneous competitors. In an experimental study, Hoogendoorn and van Praag (2012) set up a randomized experiment in which business school students were assigned to manage a fictitious business and increase outcome metrics like market share, sales and profits of their business. The authors find that more diverse teams (defined by parents’ countries of birth) outperform more homogeneous ones, but only if the majority of team members is foreign. Finally, Kahane et al. (2013) use data on team composition of NHL teams in the U.S. and find that teams with higher share of foreign (European) players tend to perform better. They attribute this finding both to skill effects (better access to foreign talent) and to skill complementarities among the group of foreign players; however, when players come from too large a pool of European countries, team performance starts decreasing.
Hjort (2014) analyzes productivity at a flower production plant in Kenya and uses quasi-random variation in ethnic team composition as well as natural experiments in this setting to identify productivity effects from ethnic diversity in joint production. He finds evidence for taste-based discrimination between ethnic groups, suggesting that ethnic diversity, in the context of a poor society with deep ethnic cleavages, affects productivity negatively. Brunow et al. (2015) analyze the impact of birthplace diversity on firm productivity in Germany. They find that the share of immigrants has no effect on firm productivity while the diversity of foreign workers does impact firm performance positively (as does workers’ diversity at the regional level). These effects appear to be stronger for manufacturing and high-tech industries, suggesting the presence of skill complementarities at the firm level as well as regional spillovers from workforce diversity. Parrotta et al. (2014) use a firm level dataset of matched employee-employer records in Denmark to analyze the effects of diversity in terms of skills, age and ethnicity on firm productivity. They find that while diversity in skills increases productivity, diversity in ethnicity and age decreases it. They interpret this as showing that the costs of ethnic diversity outweigh its benefits. Interestingly, they also find suggestive evidence that diversity is more valuable in problem-solving oriented tasks and in innovative industries. Ozgen et al. (2013) match Dutch firm level innovation survey data with employer/employee records and find that the diversity of immigrant workers increases the likelihood of product and process innovations. Boeheim et al. (2012) find further micro level evidence for the presence of production function complementarities using a linked dataset of Austrian firms and their workers during the period 1994–2005. Workers’ wages increase with diversity and the effect is stronger for white-collar workers and workers with recent tenure.
3 An index of birthplace diversity
We base our birthplace diversity measure on the Herfindahl-Hirschmann concentration index. Let \(s_{i}\) refer to the share in the total population of individuals born in country i with \(i=1,\ldots ,I\). In particular, \(i=1\) refers to natives.
The fractionalization index \(Div_{pop}\) may be expressed as:
This index measures the probability that two individuals drawn randomly from the entire population have two different countries of birth. It uses information on relative group sizes within a population to construct measures of diversity for the entire national population as well as by skill category; in particular, in the empirical analysis we distinguish between high-skill (for college educated workers) and low-skill diversity. It is important to stress that a key characteristic of the birthplace-diversity measures introduced in this paper is that they treat immigrants from the same country of origin as being identical to one another. The same problem characterizes other group-based measures like ethnic or linguistic fractionalization in which intragroup homogeneity is assumed for any given ethnic or linguistic group in a national population. In particular, unlike the genetic diversity measure of Ashraf and Galor (2013a), group-based fractionalization indices only pick up diversity that arises from intergroup rather than intragroup heterogeneity in individual traits. In particular, the index assumes that: (i) all groups are culturally equidistant one from another; and (ii) within a skill group, immigrants have the same characteristics as the average native of their origin country. We discuss these potentially important limitations in Sect. 5.1 on immigrants’ selection and Sect. 6 on group distance.
Our measure of \(Div_{pop}\) has two potentially independent margins that we intend to investigate empirically. First, the share of immigrants \((1-s_{1}) \), irrespective of their country of origin; and second, the diversity arising from the variety and relative size of immigrant groups (irrespective of their sizes relative to natives). We therefore decompose our diversity index into a component that we call \(Div_{between}\) (for “between natives and all immigrants”), which captures the first margin, and a \(Div_{within}\) component (for “within immigrant groups only”), which captures the second margin.
If all immigrants were born in one country \(i=2\) so that \(s_{1}+s_{2}=1\), then using (1) we can define:
This essentially calculates the \(Div_{pop}\) index assuming that all migrants can be grouped into one category \((1-s_{1})\)—thus excluding all diversity contributed by the fact that migrants tend to come from more than one origin country.
We rewrite (2) to include \(Div_{between}\) as follows:
We can now define
so that \(Div_{pop}\) is composed of two parts, \(Div_{between}\) and \(Div_{within}:\)
This decomposition does not separate clearly between size and variety effects: \(Div_{within}\) still depends on \(s_{1}\)—the share of natives—, since \(\sum _{i=2}^{I}s_{i}=(1-s_{1})\). We thus rewrite the \(Div_{within}\) component so that it does not depend on \(s_{1}\). We achieve this by defining \(s_{j}\) as the share of immigrants from country j in the total population of immigrants. It follows that \(s_{j}=\frac{s_{i}}{(1-s_{1})}\) where \(s_{1}\) is the share of natives (\(i=1)\).
We thus re-scale \(Div_{within}\) using (4):
and simplify to:
Our result has a very intuitive interpretation: since \(\sum _{j=1}^{J}\Big [s_{j}*(1-s_{j})\Big ]\) is basically (1) but applied to the population of immigrants, it is essentially a diversity index of immigrants only, irrespective of the natives. We thus define:
And rewrite (5)
where \((1-s_{1})^{2}\) has an intuitive interpretation as scale parameter for \(Div_{mig}\).
We can then rewrite (9) in terms of \(s_{mig}\), the share of immigrants (defined as foreign-born) and define \(s_{mig}=(1-s_{1})\):
We have thus an expression of \(Div_{pop}\) purely as a function of the relative size and diversity of immigration.
4 Empirical analysis
4.1 Birthplace diversity data
Our computation of birthplace diversity indices relies on the Artuc, Docquier, Ozden and Parsons (henceforth ADOP, 2015) data set which provides a comprehensive \(195\times 195\) matrix of bilateral migration stocks disaggregated by skill category (with or without college education) and gender for the years 1990 and 2000. Immigrants are defined as foreign-born individuals aged 25+ at census or survey date. The dataset is based on a comprehensive data collection effort in the host countries. For few destinations (and even fewer in our sample), official census information is not available. ADOP (2015) thus rely on a gravity model-based estimation of these cells.Footnote 7 In our sample, only 10 % of skilled immigrants are estimated based on this methodology.Footnote 8
Three caveats are in order. First, illegal immigration is not accounted for in most censuses, although in some cases (like in the US census) it is estimated. However, this limitation is mitigated by the fact that we use data on immigration stocks, not flows: most illegal migrants eventually become legalized or return to their country of origin. Second, immigrants who came as children are subsequently treated fully as immigrant workers (when aged 25+). However, these children then grow up, socialize and go to school in the host country, which puts a limit on the extent of variety in skills that they can contribute when they integrate the labor force. We address this issue in a robustness check. Third, a migrant is considered skilled independently of the location of college education, meaning that skilled migrants may be heterogeneous in terms of human capital quality. We partly address this issue by controlling for what we call “origin-effects” and review implications for our identification in Sect. 5.
4.2 Descriptive statistics and correlations
Table 1 shows that the bilateral correlation between ethnic, genetic and birthplace diversity measures is relatively weak. The correlation between ethnic fractionalization and \(Div_{mig}\) (all) is negative at \(-\)0.11 and close to zero for \(Div_{mig}\) (skilled).Footnote 9 Summary statistics and data sources can be found in the online appendix.
There is ample variation in country level birthplace diversity: Canada, Italy, Israel, Germany, Australia and the UK have high birthplace diversity of immigrants (\(Div_{mig}\)). The United States rank only 18th in a list of countries with the highest immigration diversity (0.92) due to relatively low diversity for unskilled immigration (0.84). Similarly low ranks can be observed for Germany (rank 27, at 0.90) and Australia (rank 28, at 0.90). In terms of \(Div_{mig}\) (skilled), however, the USA is very near the top (at 0.97). Countries with lowest overall immigration diversity are Pakistan, Bangladesh, Nepal, Syria and Iran (all lower than 0.5). Neighboring country effects seem to play a role: Ireland’s \(Div_{mig}\) (0.54 overall, 0.44 for the unskilled and 0.67 for the skilled) is still quite low due to dominant immigration from the UK. Switzerland, Austria or Australia follow similar patterns. Generally, such effects are more prevalent for \(Div_{mig}\) (unskilled). As a result, \(Div_{mig}\) (skilled) tends to be higher than \(Div_{mig}\) (unskilled). This is consistent with migrants’ self-selection being driven by net-of-migration-costs wage differentials, where low migration costs (due to short distances and high networks) mostly affect low-skill migration.Footnote 10
Table 2 shows some multivariate correlations between ethnic, linguistic and genetic diversity (ancestry-corrected), birthplace diversity and income per capita. Unlike all other dimensions of diversity, \(Div_{pop}\) is positively correlated with income per capita (at PPP), while ethnic and linguistic fractionalization are negatively correlated. Genetic diversity’s effect on income follows an inverted u-shape (Ashraf and Galor 2013a). When we include population birthplace diversity (\(Div_{pop}\)), coefficients on the other diversity variables change insignificantly. The inclusion of birthplace diversity, however, adds considerably to the predictive power of the model. We interpret this as indication that \(Div_{pop}\) is correlated with and jointly determined by many other factors, such as geography or the quality of institutions. Interestingly, this seems to be more an issue for the diversity of the unskilled population, and generally this is driven to a lesser extent by the variety than by the size of immigration. This point is further illustrated in models (6)–(8) where we use our decomposition analysis and separate \(Div_{pop}\) into \(Div_{between}\) and \(Div_{within}\). The productive effects of \(Div_{pop}\) clearly vary by skill level: \(Div_{pop}\) (unskilled) is mostly driven by \(Div_{between}\), but the association of \(Div_{pop}\) (skilled) with income per capita also clearly runs through \(Div_{within}\). Still, \(Div_{between}\) and \(Div_{within}\) are not independent from each other, as both depend on \(s_{mig}\) (see Eqs. 2 and 4 above). We thus proceed with a model that includes a large range of co-determinants of birthplace diversity and income and also separate the size (\(s_{mig}\)) and the variety (\(Div_{mig}\)) dimensions of birthplace diversity.
4.3 Model specification
To empirically investigate the relationship between birthplace diversity and economic development, we specify the following model where our dependent variable y is a country’s income per capita (GDP) at real PPP from the Penn World Tables 8 (Feenstra et al. 2013):Footnote 11
where \(\Delta _{k}\) is a vector of fractionalization/diversity measures, \(\Phi _{k}\) is a vector of climate and geography characteristics, \(X_{k}\) is a vector of disease environment indices, \(\Psi _{kt}\) is a vector of controls for institutional development, \(\Omega _{kt}\) is a vector of trade and origin effects, \(\Gamma _{kt}\) is a vector containing the country’s population size and schooling level, and \(\eta _{t}\) is a period fixed effect. We use indices s for skill groups (s = overall, skilled, unskilled), t for time periods (1990, 2000) and k for countries.
The results from our decomposition analysis as well as our initial correlation analyses point to the need to separate \(Div_{between}\) and \(Div_{within}\) further into their components, the share of immigrants, \(s_{mig}\), and the diversity of immigrants, \(Div_{mig}\). Thus we include the share and the diversity of immigrants evaluated at the means of the respective variables. To facilitate the interpretation we standardize both variables with a mean of zero and standard deviation of one. In the appendix we also test for interaction effects between size and variety.
Our baseline specification starts with a parsimonious model based upon Table 2 where we control for fractionalization/diversity indices (\(\Delta _{k}\)) only. We specifically include both ethnic and linguistic fractionalization (from Alesina et al. 2003) and genetic diversity (ancestry-adjusted) from Ashraf and Galor (2013a) since all three indices capture a potentially different productive margin of diversity.Footnote 12
We add more controls, going for increasingly stringent specifications incorporating first exogenous geographic/climatic controls only (our vector \(\Phi _{k}\)); we follow the literature on the geographical determinants of incomeFootnote 13 in including a landlockedness dummy (from Head et al. 2010), absolute latitude and share of population living within 100 km of an ice-free coast (both from Gallup et al. 1998), average temperature and precipitation (World Bank Group 2013), as well as a set of regional fixed effects for Latin America, Asia, Middle East and Northern Africa (MENA), and Sub-Saharan Africa. We then add the semi-exogenous geographical controls for the disease environment (\(X_{k}\)), which include malaria, yellow fever and tuberculosis incidence (all from World Bank 2013).
We further extend the model to account for endogenous variables that co-determine income and migration patterns. For institutional quality (\(\Psi _{kt}\)), we use the revised combined Polity-2 score from the Polity IV database (Marshall and Jaggers 2012). This index measures the degree of political competition and participation, the degree of openness of political executives’ recruitment and the extent of executives’ constraints (Glaeser et al. 2004). We also add dummies for British, French and Spanish ex-colonies as proxies for the origins of the legal system (Head et al. 2010).
Then comes our “trade and origin effects” vector, (\(\Omega _{kt}\)), which contains controls for the volume and structure of trade (namely real trade openness from PWT 8.0),Footnote 14 measures of trade diversity in imports and exports (based on Feenstra et al. 2005),Footnote 15 and also includes a weighted average of the GDP per capita (in PPP) of immigrants’ origin countries. The trade diversity indices are the goods market equivalents of \(Div_{mig}\), since import diversity is a proxy for variety in (imported) intermediary goods. Controlling for trade is also necessary since trade is determined by similar factors as migration (Ortega and Peri 2014). Surprisingly however, \(Div_{mig}\) and variables of trade openness/diversity are not much correlated (+.08 for trade openness, +0.12 for trade diversity). Last, the “origin-effects” variable captures the income at origin of the average representative immigrant and—while not a proxy for the selection of immigrants from each country of origin—correlates with immigrant groups’ ability to cover migration costs. Richer destination countries that draw on (relatively) richer source countries should be able to attract a wider range of immigrant groups and have higher immigrant diversity. Controlling for such origin-effects allows us to account for differences in migrant backgrounds (and skills) and focus on the pure (birthplace) diversity effect of immigration. Finally, we include a vector (\(\Gamma _{kt}\)) containing education as captured by years of education (Barro and Lee 2013) and population size (U.N. Population Division 2013).
We end up with a highly structured model and a short panel of 120 countries with data for 1990 and 2000. We made a significant effort to broaden our sample. The 120 countries reflect the intersection of the ADOP (2015) data, which is available for 190 countries and territories (195 origins, but no immigration data for five destinations), the PWT 8.0 data, which does not contain GDP data for 26 of those, the education data (Barro and Lee 2013) which is not available for 25 remaining countries and other data sources (primarily Alesina et al. 2003 and Ashraf and Galor 2013a) where missing data drops another 19 countries.Footnote 16 Our full sample does not differ systematically from a broader sample at the intersection of PWT 8.0 and ADOP (2015). Differences in sample means are small (not statistically significant) for most variables, with two exceptions: the sample mean for \(s_{mig}\) of skilled people is actually lower in our full sample than in the broader sample, and the sample mean for \(Div_{mig}\) is slightly higher (see the Online Appendix for details). This reflects the fact that we drop mainly small island states and territories that have very few skilled natives and correspondingly higher \(s_{mig}\) (skilled) as well as experience immigration from few large neighboring countries (leading to a lower \(Div_{mig}\)). Still, after these slight reductions of the sample size, our full sample still covers 90 % of all global migrants and 93.7 % of all skilled migrants.
4.4 OLS results
We estimate our model using an OLS estimator with standard errors clustered at the country level to account for serial correlation of standard errors. Our results are presented in Tables 3, 4 and 5. Table 3 shows the model estimated in a sample of 120 countries. In Table 4, we split our sample into sub-samples of rich and poor countries, establishing our main results. In Table 5 we analyze the stability of our main coefficients of interest by introducing groups of controls sequentially as described above.
Table 3 shows the full sample results for our two margins of birthplace diversity, \(s_{mig}\) and \(Div_{mig}\), and does so separately for each skill level (overall, high- and low-skill). We first report results for a parsimonious specification including only strictly exogenous covariates, namely climate and geography variables. Both the standardized size of immigration and its diversity correlate positively with income at the 1 % statistical significance level. We find similar results for the full model including all exogenous and endogenous covariates.Footnote 17 Coefficients for \(Div_{mig}\) (skilled) are somewhat higher than those for \(Div_{mig}\) (unskilled), but this difference is not statistically significant. Once we control for geographic variables (Michalopoulos 2012) ethnic and linguistic fractionalization converge towards zero. Genetic diversity shows the expected inverted u-shaped pattern (Ashraf and Galor 2013a). Trade openness (Frankel and Romer 1999), the quality of institutions (Acemoglu et al. 2001; Glaeser et al. 2004) and the level of education correlate positively with economic development. These findings are consistent with the argument that both the birthplace diversity of migrants as well as the share of immigrants relate positively to economic development.
Table 4 shows sub-sample results for rich and poor countries (above or below median GDP/capita in 1990). Given the theoretical arguments outlined in Sect. 2, we expect the birthplace diversity (\(Div_{mig}\)) of skilled workers to capture production function complementarities to a higher degree than other diversity indices. These complementarities should also be larger in countries closer to the technology frontier. Hence, our estimates for \(Div_{mig}\) (skilled) should be larger and more significant in a subset of rich economies relative to \(Div_{mig}\) (unskilled) and relative to estimates in a poor country subsample. This is exactly what we find. In the rich country subsample (column 2), our estimates for the standardized \(Div_{mig}\) (skilled) are now considerably magnified vis-a-vis the full sample and remain significant at the 1 % level. When we conduct a horse-race of skilled and unskilled \(Div_{mig}\) (column 4), we find that our results for \(Div_{mig}\) (skilled) continue to hold whereas the estimate of \(Div_{mig}\) (unskilled) is close to zero. In the poor country subsample (columns 5–8) we find no statistically significant results for birthplace diversity. These results are consistent with the view that the economic value of birthplace diversity is higher for countries closer to the technology frontier, particularly that diversity of skilled immigrants.Footnote 18 Interestingly, neither ethnic fractionalization nor linguistic or genetic diversity correlate robustly with income for these countries.
Our identification strategy is potentially exposed to omitted variables bias, since within-country variation in \(Div_{mig}\) is very low and is thus an insufficient basis for identification.Footnote 19 To address this concern at least partially, we specify in Table 5 a range of models that sequentially introduce our controls. We analyze the stability of our main coefficients of interest (on birthplace diversity of skilled immigrants) for rich countries (based on Table 4). Our estimates for \(Div_{mig}\) (skilled) are stable across specifications. The coefficient increases when going from model (1) to model (2), where we add a host of geography controls (including, most importantly, our set of regional fixed-effects). All subsequent model expansions do not substantially affect our coefficient estimates. In the last model (column 6) we add population size and education controls, two variables that are positively related to income and diversity. This slightly decreases the point-estimate for \(Div_{mig}\) as this likely takes out a small residual positive omitted variables bias. Interestingly, the relative stability of our \(Div_{mig}\) coefficient is not mirrored in our results for \(s_{mig}\) (skilled). Here, the coefficient varies substantially across specifications. This suggests that—as we discuss below—\(Div_{mig}\) is less likely to be affected by endogeneity issues than \(s_{mig}\).
To add more structure to the analysis, we follow Oster (2013) who proposes a simple heuristic to calculate bounding values for unbiased coefficients.Footnote 20 The results following this procedure indicate that any remaining omitted variables bias in our rich country subsample model is negative but relatively small, as Oster’s bounding values for unbiased coefficients are higher but in close proximity to our OLS estimates (see Table 5, column 6).Footnote 21
4.5 Robustness
4.5.1 Patenting activity
We extend our model to patent data in order to shed more light on the productivity effects of \(Div_{mig}\) (see Table 6). We define average patent intensity as the average number of patent applications per capita filed by country nationals and registered by national patent offices. We obtain this data from the World Intellectual Property Organization (2010) for the period 1995–2005 and construct this measure for 117 countries.Footnote 22 We apply our baseline model using all covariates on a year 2000 cross section. We find that the diversity of immigrants—in particular that of skilled immigrants—is robustly positively related to scientific innovation as measured by patenting activity. This holds both for measures of patent applications and patents granted per capita. These results hold also in our subsample of richer countries. We do not find similar effects for the diversity of unskilled workers. We take this as indication that the productivity-enhancing effect of variety in backgrounds and problem solving heuristics embedded in \(Div_{mig}\) partly works through innovation.
4.5.2 Total factor productivity
GDP/capita at PPP is our main dependent variable and we interpret the results for birthplace diversity as indicative of skill complementarities. Our interpretation implies that the effect of birthplace diversity should affect GDP/capita through total factor productivity (TFP). To test this proposition, we replace our measure of GDP by a measure of TFP per capita from the Penn World Tables 8 (Feenstra et al. 2013). Table 7 shows the results. In both the full sample as well as the rich country subsample, birthplace diversity of skilled immigrants remains positive and highly robust (at 1 %). This suggests that, consistently with an interpretation of the results in terms of skill complementarities, birthplace diversity affects income via total factor productivity.
4.5.3 Second-generation effects
Immigration flows are highly time persistent due to network effects. This means that our first-generation measure \(Div_{mig}\) could capture also second/third-generation effects of immigration, biasing our results. We thus construct a measure of \(Div_{mig}\) in 1960 based on data from Ozden et al. (2011) to obtain a lagged birthplace diversity index and add this new index and a lagged share of immigration to our model (see Table 8).Footnote 23 As can be seen in Column 2, the birthplace diversity of immigration in 1960 is positive but not significant while the size of immigration in 1960 is positive and significant when these lagged variables are entered independently of their contemporaneous values. Importantly, our main results for first-generation birthplace diversity and for immigration size remain positive and highly significant when past and present immigration size and diversity are entered jointly, with point-estimates which are barely affected. In particular, the magnitude of \(Div_{mig}\) remains virtually unchanged, despite the high positive correlation between \(Div_{mig}\) today and in the past (+0.66). This suggests that skilled diversity’s productive effects in high income countries—our main finding—operate primarily through first-generation effects. This finding is fully consistent with the theoretical arguments outlined in Sect. 2. The lack of significance of past diversity, on the other hand, is consistent with an interpretation in terms of compensating effects of birthplace and ethnic diversity (second-generation immigration being a mix of the two).
4.5.4 Children immigrants
Our measure of \(Div_{mig}\) counts all foreign-born workers as immigrants irrespective of the duration of their stay in their host country. Immigrants arriving in the destination country as children are—in terms of education and exposure to the destination country—probably closer to being native than foreign. We thus compute \(Div_{mig}\) and \(s_{mig}\) (skilled) at different age-of-entry thresholds, using data for a subset of 29 OECD destination countries from Beine et al. (2007). Table 9 shows that our estimates for birthplace diversity are robust to the exclusion of such special immigrant groups. We find somewhat lower estimates for these corrected birthplace diversity measures (the difference is not statistically significant), a fact that may be driven by attenuation bias due to counterfactual reclassification of young immigrants as natives.
4.5.5 Outliers and alternative fixed effects
Lastly we test the robustness of our results to the introduction of alternative regional fixed effects as well as to excluding outliers (see Table 10). More specifically, Australia, Canada and New Zealand have points-based immigration systems that select skilled immigrants according to labor market needs. The United States attracts a huge part of all skilled migrants in the world thanks to its large (pre and post tax) premium for skilled labor (Grogger and Hanson 2011). Controlling for these countries (in Column 3) or simply dropping them from the sample (in Column 4) does not affect our results. Likewise, this also holds for OPEC countries. In addition, we test robustness to alternative sets of fixed effects to establish robustness for our within-geographic region estimator.Footnote 24 Our results are fully robust to these modifications.
5 Identification
5.1 Unobserved heterogeneity
Our measures of \(Div_{pop}\) and \(Div_{mig}\) rely on the assumption that we cover representative individuals for the respective emigrant populations at different origins, and that immigrants across destinations are homogenous. Since we lack detailed information on these migrants (apart from education, gender and age-of-entry), we cannot exclude the possibility that migrants are positively self-selected from the home-country pool of skilled workers and also positively sort themselves to high-income destinations.Footnote 25
In a first step, we use the ADOP (2015) dataset to calculate the relative degree of selection per country of origin and destination based on observable skills. We calculate the distribution of educational attainment (% of skilled) for the natives of any origin country i from Barro and Lee (2013) and ADOP (2015) before emigration and immigration take place. We then calculate the share of skilled emigrants from origin i to any destination k and define:
where k is an index for destination country, j for origin country, and \(s_{mig\ jk}\) is the share of immigrants from origin j over all immigrants to destination k in year t. This index is a weighted average of immigrants’ skills relative to the skill distribution of their home countries’ native population. A value of 1 indicates that migrants from j to k are identical in terms of observed skills to non-migrants, a value above 1 signals positive selection. The index may reflect skill-selective policies in destination countries as much as it reflects the relative attractiveness of a destination country to skilled workers. Both aspects should be correlated with selection on unobservables, since both are proxies for the relative return to high skill, effort and risk taking attitudes. Clearly, our index of skill selection is at best an imperfect and noisy measure of the true degree of positive selection. Still, skill selection is positively correlated with income/capita at destination (+0.34), even more than our origin effects variable (+0.17) that accounts for destination countries’ over-sampling of immigrants from richer origins.
We proceed by adding the index of skill selection to our full model (Table 11, columns 2 and 3). The index and our origin effects variable both possess independent explanatory power in a parsimonious model (column 2). This serves as indicative evidence that the inclusion of these indices indeed mitigates the issue of migrant selection to some degree. Column 3 shows full model results, indicating that once we condition on the full set of controls, both indices lose their predictive power, while the coefficient on our key variable of interest \(Div_{mig}\) remains robustly estimated and statistically significant at the 1 % level. The estimate is slightly lower than in our base model, indicating the removal of a small positive bias in our estimate.
We extend this model by adding an interaction term to test whether our main results for the diversity of skilled immigrants vary with the observed level of skill selection. Table 11, column (4) shows the results. \(Div_{mig}\) continues to be estimated at the 1 % significance level, at even slightly higher magnitudes, while the interaction term is statistically indistinguishable from zero. We thus conclude that the effect of \(Div_{mig}\) on productivity is robust to measures of skill-selection on observables.
In a second step, we employ an alternative indirect measure of selection. We use data collected by Gallup market research reported in Espinova et al. (2011). These authors report an index of net migration potential that is based on surveys of close to 348.000 adults between 2007 and 2010 and available for 148 countries. The index is based on answers to the question “Ideally, if you had the opportunity, would you like to move permanently to another country [list of destination countries provided], or would you prefer to continue living in this country?” and is defined as the potential percentage increase in the destination country population. The index is thus effectively an indicator of immigration intentions as it gives the potential share of immigration if there were no constraints on migration. Besides the “usual suspects”, countries like Botswana and Malaysia make the TOP 20 due to their relative regional attractiveness. In addition to controlling for this index (Table 11, column 5), we regress it on actual immigration (\(s_{mig}\)) and in a separate model also on birthplace diversity (\(Div_{mig}\)). We add the residuals from these separate regressions to our full model (columns 6 and 7, respectively). These residuals can be interpreted as the degree to which existing constraints to immigration both at origin and destination countries are binding.Footnote 26 Constraints to emigration in the origin countries and constraints in destination countries both serve to increase the extent of migrants’ skill-selection. Throughout models (5)–(7), we find our estimates for \(Div_{mig}\) to remain robust at the 1 % level, albeit at slightly lower magnitudes. This suggests that our main OLS findings are robust to alternative indirect measures of selection.
In a third step, we use data provided by the OECD (2009) that capture the quality of education in a range of OECD and non-OECD countries based on standardized (PISA) test scores.Footnote 27 Figure A3 in the appendix shows the distribution of countries’ mean overall PISA score for high school students at age 15. We re-compute our \(Div_{mig}\) indices and exclude countries of origin with scores exceeding the OECD average (e.g. Finland, Hong Kong, Singapore). Countries that draw most heavily on such origins are—on average—more likely to attract above average talent and thus have a higher chance to benefit from “superstar” effects. Table 11, model (8) shows that the exclusion of these immigrants does not change our results.
Next, we use the full distribution of highly-skilled math- and science students (namely, the share of pupils per country in the highest sextile bracket of math and science skills worldwide—see appendix for more details). The quality of education around the world, especially outside the OECD, is remarkably poor.Footnote 28 Thus, very few countries have a deep pool of highly skilled individuals. We formalize this insight by calculating the maximum population in each country of origin that could theoretically be classified as “highly-skilled” in terms of mathematical skills. In essence, we apply the share of pupils in the top sextile of math skills today to the entire population born in a given country (before emigration and immigration), make very conservative assumptions (e.g., that the gap between rich and poor countries’ educational quality is stable over time) where we encounter missing data and compare that theoretical maximum of highly (math-) skilled people in each country with the stock of actual (subsequent) emigration. The appendix provides more details on the calculation. Given the very low numbers of highly skilled students outside the OECD, the emigrant stock of skilled workers of many countries in the world greatly exceeds even an optimistic hypothetical stock of highly math-skilled workers in these countries.Footnote 29 In other words, it is very unlikely for a rich country (with the possible exception of the mentioned top few destinations) to attract highly-skilled migrants without specializing on just a few countries with deep talent pools. Thus, for any not highly sought-after destination, more \(Div_{mig}\) necessarily implies less—not more—skill selection.
We test the robustness of our estimates for \(Div_{mig}\) by dropping all immigrants from origins with large pools of highly talented workers (i.e., with a ratio of math/science-talented workers / skilled emigrants \(>1\)) from our calculation of \(Div_{mig}\). We thus obtain a counterfactual index of birthplace diversity that disregards potential “high quality” immigrant groups (see Table 11, columns 9 and 10). Our estimates are very comparable in terms of magnitude and significance to our baseline \(Div_{mig}\) index. This suggests that the inclusion of immigrant groups with the highest likelihood for “superstar” backgrounds in our diversity index does not observably drive our results.
Overall, our baseline specification remains fairly robust to empirical and conceptual challenges to identification arising from the issue of selection on unobservables. Our main result for the diversity of skilled immigrants survives the introduction of an index of skill-selection based on observable skills as well as various adjustments to exclude immigrants from source countries that either possess deep “talent pools” (i.e., where the national average score on the standardized PISA test exceeds the cross-country OECD average) or that are not “highly-skilled constrained” (i.e., where the ratio of an imputed number of highly-talented workers in math/sciences skills to the overall number of skilled emigrants is larger than unity). It is therefore plausible that only a minor fraction of our overall effect can be explained by such selection. To the contrary, given that the pools of extra-ordinary high achievers (with high cognitive abilities in science and math fields) are relatively shallow, it seems that drawing skilled immigrants from a wide range of countries (and thus attaining a high \(Div_{mig}\)) is likely even correlated with a lower degree of selection of the best and the brightest.
5.2 Reverse causality
Richer countries could attract a larger flow of immigrants (resulting in a higher \(s_{mig}\)) coming from a wider range of origin countries (\(Div_{mig}\)) simply because they are richer. An initial descriptive analysis shows that the pure bilateral correlation with income, particularly for skilled immigrants, is higher for \(s_{mig}\) (+0.32) than for \(Div_{mig}\) (+0.23). This is even more prevalent in first differences: changes in \(s_{mig}\) between 1990 and 2000 are clearly positively associated with changes in income per capita (at 1 % level), but changes in diversity are not (the effect is close to zero and is not estimated precisely). Indirect effects from growth via \(s_{mig}\) to \(Div_{mig}\) appear also unlikely, since the correlation between a change in \(s_{mig}\) and a change in \(Div_{mig}\) is clearly negative (\(-\)0.36, significant at 5 %).
5.2.1 A gravity model of migration and diversity
We construct instruments for the share and diversity of immigration on the basis of a gravity model.Footnote 30 In order to mitigate the problem of violation of the exclusion restriction, we use only a very small subset of bilateral cultural and geographic variables. We thus specify a parsimonious gravity model for bilateral migration:
\(m_{jkst}\) is the bilateral immigration rate from origin country j to destination country k for immigrants of skill level s in year t expressed in terms of the population of destination country k. The choice of our model determinants follows the standard in the literature,Footnote 31 with destination population size in 1960 as a lagged measure (we also run and report a model excluding this variable), bilateral (geodesic) distance, common border, common official and ethnic minority languages (if language spoken by at least 9 % of population in both countries), time zone differences and common colonial history (all from CEPII, available from Head et al. 2010). We also add a vector of year (\(\eta _{t}\)) and origin-year fixed effects (\(\chi _{jt}\)) to account for multilateral resistance (Anderson and Van Wincoop 2003) that arises from time varying common origin shocks to migration which influence migrants’ locations decisions (Bertoli and Fernández-Huertas Moraga 2013).Footnote 32 We then predict bilateral migration using an OLS estimator following Frankel and Romer (1999) for the canonical log-transformation of the gravity equation and a PPML (pseudo-poisson maximum likelihood) estimator following Santos Silva and Tenreyro (2006) to avoid the bias arising from this log-transformation.Footnote 33
5.2.2 Instrumentation and identification
Table 12 shows results for our gravity models. Generally, the models have sufficiently high explanatory power and seem appropriately specified (keeping in mind that they are purposefully excluding potential determinants of destination countries’ productivity). All estimates on the migration determinants have the expected sign: destination country population in 1960 and bilateral distance enter negatively. Skilled migration is less constrained by migratory distance, as theory would predict, and is less affected by border-effects. The cultural proximity variables (common colonial relationship and common official/ethnic minority languages) both enter positively, as expected.
We construct instruments for our two main variables of interest, skilled birthplace diversity and the share of skilled immigration, using the predicted bilateral migration shares estimated from our PPML and OLS gravity models.Footnote 34 We turn to comparing our instruments for predicted diversity with actual \(Div_{mig}\) (see Appendix Fig. 2a). The correlation between actual and predicted diversity is strong, suggesting a priori a strong instrument. Furthermore, the instrument should be lower (higher) than actual diversity in richer (poorer) countries. This is exactly what we find (see Appendix Fig. 2b): a negative link between GDP per capita at destination and the difference between actual and predicted \(Div_{mig}\). We take this as indication that our gravity model yields an instrument which takes out at least a part of any small but endogenous component in the diversity-income relationship.
We report first-stage results in the online appendix. Throughout the models (which start with one instrumented variable and extend to up to three) we reject the null hypothesis of weak instruments both jointly (Kleibergen-Paap F-test) and individually (Angrist-Pischke F-tests), as these statistics exceed the strictest or (in model 3) second strictest Stock and Yogo (2005) critical values.Footnote 35
Two issues potentially affect the validity of our identification. First, bilateral omitted variables could be correlated with bilateral migration and also with destination country GDP/capita; for example bilateral trade with a rapidly growing trade partner such as China could affect the GDP (via TFP) of China’s neighboring trade partners. However, Hsieh and Ossa (2011) find that China’s productivity growth has only very small positive effects on neighbor countries’ TFP. We also account for such effects econometrically by including origin-year fixed effects. Our trade controls should adequately capture any residual aggregate bias. Second, relative bilateral geography variables (such as distance, common language or border contiguity) may be correlated with absolute (unilateral) geography variables, a point first raised in the context of trade gravity models by Rodriguez and Rodrik (2001). We account for that by including a very broad set of geography and disease variables into our second-stage baseline model, including the geographical fixed effects as suggested by these authors and conducting many robustness exercises on our geography variables. The inclusion of geography variables in our main model also served to remove an apparent negative omitted variables bias (see Table 5, column 2), suggesting that such an (unlikely) remaining bias from geography variables if any, may increase (not decrease) our \(Div_{mig}\) estimates.
5.2.3 2SLS results
Table 13 shows 2SLS results. We compare our baseline OLS specification in model (1) with alternative IV-specifications in models (2)–(4). In (2), we first instrument solely our main variable of interest, \(Div_{mig}\), assuming that any remaining endogeneity in our model (e.g., from \(s_{mig})\) is negligible. In (3) we relax this assumption and also instrument for \(s_{mig}\), before we also instrument for the diversity of imports in (4). We confirm our prior OLS findings on skilled \(Div_{mig}\) at the 5 % level in the first two models.Footnote 36 The IV estimates appear very stable and somewhat lower than our OLS estimates. This is closely in line with our expectation, namely that the OLS model suffers (if at all) from a small negative omitted variables bias and jointly also from a positive bias due to positive selection on unobservables. Our IV estimates confirm these inferences to a large extent. The slightly lower IV estimates suggest that the net effect of these two biases including measurement error is positive and relatively small (less than 10 % of the estimate).Footnote 37 When instrumenting for the share of immigration (model 3), our estimates for \(s_{mig}\) remain similar in magnitude but lose significance while \(Div_{mig}\) remains robust at the 5 % level. This suggests—in line with our discussion of omitted variables and selection—that establishing causality for \(s_{mig}\) is a bigger challenge than for \(Div_{mig}\).
In model (4), we go one step further and also instrument for the diversity of imports (\(Div_{imports}\)). We thus apply our gravity model of migration determinants to trade, following Frankel and Romer (1999). The strategy to obtain instruments from similar models is valid to the extent that the model determinants for migration and trade are estimated differentially. Table 12 shows that this is the case. Our \(Div_{mig}\) estimate remains remarkably robust, but the overall model is weakly identified since the instruments for the diversity of trade and migration are correlated. Needless to say, this approach is very demanding given the few degrees of freedom in our model and correlation structure between instruments. Remarkably, our estimate for \(Div_{mig}\) remains similar in magnitude but—as expected—loses some statistical significance (it remains significant at the 10 % level). The relative robustness of \(Div_{mig}\) in such a demanding model serves as indication that any endogeneity bias in our OLS model is small and unlikely to drive our main results.
6 Does cultural distance matter?
Our index assumes all groups to be equidistant from each other. We now expand this restrictive notion of diversity to allow different weights on closer or more distant groups and from richer and poorer countries of origin.
6.1 An augmented birthplace diversity index
We rely on Greenberg (1956) and expand our index by adding two group weights \(d_{jk}\) and \(e_{jk}\):
j is an index of immigrant groups, \(d_{jk}\) is a bilateral distance variable between immigrants j and natives k and \(e_{jk}\) is a unilateral weight capturing income at origin j. The augmented diversity index reduces to \(Div_{mig}\) when all groups are equidistant at \(d_{jk}=1\) and \(e_{jk}=1\).
In order to model distance we proceed as follows. For distance we use bilateral population-weighted genetic distance (Spolaore and Wacziarg 2009 and Cavalli-Sforza et al. 1994) for \(d_{jk}\) and a unilateral measure of GDP per capita (PPP) at origin (PWT 8.0) for \(e_{jk}\). We standardize these inputs for each destination and obtain vectors of genetic distance as well as GDP at origin that range from 0 (min) to 1 (max). We use GDP/capita in origin countries only (not GDP per capita distance) to avoid including our dependent variable in our regressor.
We specify a range of alternative functional forms for \(d_{jk}\) and \(e_{jk}.\) This allows us to create a limited set of alternative \(Div_{mig,augmented}\) indices that model different hypotheses (e.g., an index that over-weights immigrants from richer vs. poorer origins or an index that overweights closer or more distant immigrants). We then let these alternative indices run a “horse-race” by replacing our initial \(Div_{mig}\) index with these alternative specifications in our baseline model. We use a standard logistic function
where \(\theta \) is a parameter that ranges from \(-\)10 to +10 and \(x_{jk}\) takes on standardized values of genetic distance (for \(d_{jk}\)) and GDP/capita (for \(e_{jk}\)). The logistic function is convenient for our purpose. It can be centered on \(d_{jk}=1\) for groups at average genetic (income) proximity from the natives of a given country; it then converges to two bounds 0 and 2. In addition, by varying a single parameter \(\theta \), we can vary both the slope of the function and the spread between genetically closer (poorer) and more distant (richer) groups. We can then study a full range of alternative birthplace diversity indices and different income at origin using different combinations of \(\theta _{1}\) and \(\theta _{2}\) (applying to \(d_{jk}\) and \(e_{jk}\), respectively). Larger absolute values of \(\theta _{1}\) and \(\theta _{2}\) indicate a higher degree of relative over/under-weighting for cultural distance and for income at origin, respectively. Augmented diversity indices based on \(\theta _{1}>0\) ( \(\theta _{2}>0)\) overweight groups with higher genetic distance (richer origins).
6.2 Results
Table 14 shows coefficients for \(Div_{mig}\) (skilled). When holding GDP/capita at origin constant (at \(\theta _{2}=0\)), giving more weight to culturally closer immigrants (\(\theta _{1}<0\)) increases the predictive power of \(Div_{mig}\) slightly; however a very large weight diminishes the predictive power. In turn, overweighting culturally distant groups (and thus relatively underweighting closer groups) clearly diminishes the effect of \(Div_{mig}\) on income. This nonlinear, concave pattern for genetic/cultural distance appears to be stable (even to a large extent when varying income at origin). It suggests a trade-off between the productive costs and benefits of cultural distance. When holding genetic distance constant at (\(\theta _{1}=0\)), the effect of \(Div_{mig}\) increases linearly in income at origin, but with a very small gradient relative to that of cultural proximity and also not monotonically.
Second, we look at interaction effects. Moving from the center of Table 14 towards the lower left corner (thus overweighting culturally closer immigrant groups and also overweighting those from richer origins), the estimate on e.g., \(Div_{mig,augmented}\) \((\theta _{1}=-5;\theta _{2}=10)\) increases significantly (at 5 % level) vs. the simple baseline index \(Div_{mig}\). This increase is larger than any individual increase in either dimension (holding constant either \(\theta _{1}\) or \(\theta _{2}\) at zero). This suggests that a combination of culturally closer immigrants and richer origins (potentially a proxy for higher skills) can be particularly valuable.
7 Conclusion
We construct an index of population diversity based on people’s birthplaces. This new index, which we decompose into a size (share of foreign born) and a variety (diversity of immigrants) component, is available for 195 countries in 1990 and 2000 disaggregated by skill level. Our birthplace diversity measures are conceptually and empirically orthogonal to the various measures of diversity previously explored in the literature (such as ethnic, linguistic or genetic diversity). We find that the diversity of (and arising from) immigration relates positively to measures of economic prosperity. This holds especially for skilled immigrants in richer countries. Increasing the diversity of skilled immigration by 1 percentage-point point increases long run economic output by about 2 %.Footnote 38 These results are robust to our attempts to account for potential reverse causality and unobserved heterogeneity among skilled immigrants. They are also robust to accounting for immigrants’ age of entry or to second-generation effects.
Lastly, we extend our index of birthplace diversity and account for cultural distance between immigrants and natives. The productive effects of birthplace diversity appear to be largest for immigrants originating from richer countries and from countries at intermediate levels of cultural proximity. We interpret these findings as suggestive of the trade-offs between communication and social costs of diversity and benefits in terms of production function effects that arise from skill complementarities.
Notes
That is, a 17-% increase. 22 out of 27 OECD countries saw increases in the diversity of their skilled workforce between 1990 and 2000 (the only exceptions being Estonia, Greece, New Zealand, Poland and Slovakia).
This inverted u-curve for cultural proximity mirrors the results of Ashraf and Galor (2013a) on genetic diversity.
Bellini et al. (2013) apply the same methodology to European regions and find broadly consistent results for Europe as well.
See Laitin and Jeon (2013) for a recent overview of social psychology research on the effects of diversity.
See ADOP (2015) for more details.
We conduct a robustness check restricting our OLS and IV models to non-estimated observations only. The results (available upon request) remain virtually unchanged.
This also holds in first differences: the correlation between changes in size and diversity of skilled immigration 1990–2000 is low and even negative at \(-\)0.14.
See the online appendix for details on the definitions and sources for all variables.
Following Ashraf and Galor (2013a) we also include a squared term for genetic diversity.
We use the standard measure of trade volume: real trade openness (exports + imports) in percentage of GDP in real PPP prices. This indicator correlates most robustly with GDP growth (Yanikkaya 2003).
Typical countries that drop out of this sample are small island states or territories.
See the Online Appendix, Table 13, for a specification sequentially introducing covariates in a model of skilled birthplace diversity.
The difference in \(Div_{mig}\) (skilled) between the rich and poor country subsample is significant at the 1 % level (unlike the diversity of unskilled migrants).
Still, we obtain qualitatively similar results in our rich country subsample when using country fixed effects (see Appendix).
This test relies on the assumption that selection on observables from a basic model towards a full model is proportional to selection on unobservables.
See the Online Appendix Table 13 for a similar analysis for the full sample. It shows that the full sample model is relatively more susceptible to a remaining positive omitted variables bias than our main results for rich countries only.
The sample thus includes all countries with patenting activity as covered by WIPO (2010). Hence, our estimates are best interpreted as effect on the intensive margin of patenting.
Note that Ozden et al. (2011) do not provide a skill decomposition of immigration in 1960, we hence rely on diversity of immigrants of all skill groups.
In particular, we test for robustness to continental fixed effects as employed by Ashraf and Galor (2013a).
See Grogger and Hanson (2011) for a deeper discussion on such sorting across destinations.
In line with our priors, in a basic model as in Table 11, column (2), both indices hold independent explanatory power and correlate highly positively with income (available upon request).
See www.oecd-ilibrary.org (PISA 2009 results at a glance).
See Filmer et al. (2006), for an illustrative review of test score results. They report, among many other examples, that “the average science score among students in Peru [is] equivalent to that of the lowest scoring 5 % of US students”.
See the appendix for a simulation. The figures show that the vast majority of countries—even under the assumption that all high-ability math/science students had left—mostly sent non- highly math-skilled people abroad.
While the use of origin FE largely suffices to account for multilateral resistance in trade, Bertoli and Fernández-Huertas Moraga (2013) show this to hold for migration only under more restrictive distributional assumptions.
This bias is particularly salient with data that are heteroskedastic (e.g., due to many zero cells). Overall, the degree of OLS bias relative to PPML depends on the underlying features of the data.
To avoid violating the exclusion restriction via inclusion of a lagged measure of population size, we fully rely on the more parsimonious model excluding this variable.
As is well known, the Stock and Yogo (2005) critical values are are appropriate under homoskedasticity only. We report heteroskedasticity-robust clustered standard errors, which tend to be higher than those obtained under the assumption of homoskedasticity.
F-Tests on the excluded instruments and the joint instruments are well above the respective Stock and Yogo (2005) critical values.
Weak instruments could also drive this result. Note, however, that models 3 and 4 are still relatively strongly identified (Kleibergen-Paap exceeding or close to Stock Yogo 15 % maximal IV size critical value).
A one standard deviation increase in the birthplace diversity of skilled immigrants generates an increase of about 25 % in long run economic output.
References
Abramitzky, R., Boustan, L., & Eriksson, K. (2012). Europe’s tired, poor, huddled masses: Self-selection and economic outcomes in the age of mass migration. American Economic Review, 102(5), 1832–1856.
Abramitzky, R., Boustan, L., & Eriksson, K. (2013). Have the poor always been less likely to migrate? Evidence from inheritance practices during the age of mass migration. Journal of Development Economics, 102, 2–14.
Acemoglu, D., Johnson, S., & Robinson, J. (2001). The colonial origins of comparative development: An empirical investigation. American Economic Review, 91(5), 1369–1401.
Ager, P., & Brückner, M. (2013). Cultural diversity and economic growth: Evidence from the US during the age of mass migration. European Economic Review, 64, 76–97.
Alesina, A., Baqir, R., & Easterly, W. (1999). Public goods and ethnic divisions. Quarterly Journal of Economics, 114(4), 1243–1284.
Alesina, A., Devleeschauwer, A., Easterly, W., Kurlat, S., & Wacziarg, R. (2003). Fractionalization. Journal of Economic Growth, 8(2), 155–194.
Alesina, A., & La Ferrara, E. (2000). Participation in heterogeneous communities. Quarterly Journal of Economics, 115(3), 847–904.
Alesina, A., & La Ferrara, E. (2002). Who trusts others? Journal of Public Economics, 85(2), 207–234.
Alesina, A., & La Ferrara, E. (2005). Ethnic diversity and economic performance. Journal of Economic Literature, 43(3), 762–800.
Alesina, A., Michalopoulos, S., & Papaioannou, E. (Forthcoming). Ethnic inequality. Journal of Political Economy.
Alesina, A., Spolaore, E., & Wacziarg, R. (2000). Economic integration and political disintegration. American Economic Review, 90(5), 1276–1296.
Alesina, A., & Zhuravskaya, E. (2011). Segregation and the quality of government in a cross section of countries. American Economic Review, 101(5), 1872–1911.
Andersen, T., & Dalgaard, C.-J. (2011). Flows of people, flows of ideas, and the inequality of nations. Journal of Economic Growth, 16(1), 1–32.
Anderson, J., & Van Wincoop, E. (2003). Gravity and gravitas: A solution to the border puzzle. American Economic Review, 93(1), 170–192.
Arbatli, C., Ashraf, Q., Galor, O. (2015). The nature of conflict. NBER Working Paper No. 21079.
Artuc, E., Docquier, F., Özden, C., & Parsons, C. (2015). A global assessment of human capital mobility: The role of non-OECD destinations. World Development, 65, 6–26.
Ashraf, Q., & Galor, O. (2011). Cultural diversity, geographical isolation, and the origin of the wealth of nations. NBER Working Paper No. 17640.
Ashraf, Q., & Galor, O. (2013a). The out of Africa hypothesis, human genetic diversity and comparative economic development. American Economic Review, 103(1), 1–46.
Ashraf, Q., & Galor, O. (2013b). Genetic diversity and the origins of cultural fragmentation. American Economic Review, 103(3), 528–533.
Bandiera, O., Rasul, I., & Viarengo, M. (2013). The making of modern America: Migratory flows in the age of mass migration. Journal of Development Economics, 102(May), 23–47.
Barro, R., & Lee, J. (2013). A new data set of educational attainment in the world, 1950–2010. Journal of Development Economics, 104, 184–198.
Beine, M., Docquier, F., & Rapoport, H. (2007). Measuring international skilled migration: New estimates controlling for age of entry. World Bank Economic Review, 21, 249–254.
Beine, M., Docquier, F., & Özden, C. (2011). Diasporas. Journal of Development Economics, 95(1), 30–41.
Beine, M., Docquier, F., & Schiff, M. (2013). Migration, transfer of norms and home country fertility. Canadian Journal of Economics, 46(4), 1406–1430.
Bellini, E., Ottaviano, G., Pinelli, D., & Prarolo, G. (2013). Cultural diversity and economic performance: Evidence from European regions. In R. Crescenzi & R. Percoco (Eds.), Geography, institutions and regional economic performance, advances in spatial science (pp. 121–141). Berlin and Heidelberg: Springer Verlag.
Bertoli, S. (2010). Networks, sorting and self-selection of ecuadorian migrants. Annales d’Economie et de Statistique, 97–98, 261–288.
Bertoli, S., & Fernández-Huertas Moraga, J. (2013). Multilateral resistance to migration. Journal of Development Economics, 102, 79–100.
Boeheim, R., Horvath, G., Mayr, K. (2012). Birthplace diversity of the workforce and productivity spill-overs in firms. WIFO Working Papers No. 438.
Brunow, S., Trax, M., & Suedekum, J. (2015). Cultural diversity and plant-level productivity. Regional Science and Urban Economics, 53, 85–96.
Cavalli-Sforza, L. L., Menozzi, P., & Piazza, A. (1994). The history and geography of human genes. Princeton: Princeton University Press.
Collier, P. (1999). On the economic consequences of civil war. Oxford Economic Papers, 51, 168–183.
Collier, P. (2001). Ethnic diversity: An economic analysis of its implications. Economic Policy, 32, 129–166.
Desmet, K., Ortuño-Ortín, I., & Wacziarg, R. (2012). The political economy of ethnolinguistic cleavages. Journal of Development Economics, 97(2), 322–338.
Docquier, F., & Rapoport, H. (2012). Globalization, brain drain and development. Journal of Economic Literature, 50(3), 681–730.
Easterly, W., & Levine, R. (1997). Africa’s growth tragedy: Policies and ethnic divisions. Quarterly Journal of Economics, 112(4), 1203–1250.
Espinova, N., Ray, J., & Srinivasan, R. (2011). The world’s potential migrants. Gallup. Retrieved from, www.imi.ox.ac.uk/pdfs/the-worlds-potential-migrants. Accessed 23 March 2015.
Esteban, J., & Ray, E. (1994). On the measurement of polarization. Econometrica, 62(4), 819–851.
Esteban, J., & Ray, E. (2011). Linking conflict to inequality and polarization. American Economic Review, 101(4), 1345–1374.
Esteban, J., Mayoral, L., & Ray, E. (2012). Ethnicity and conflict: An empirical study. American Economic Review, 102(4), 1310–1342.
Fearon, J. (2003). Ethnic and cultural diversity by country. Journal of Economic Growth, 8(2), 195–222.
Fearon, J., & Laitin, D. (2003). Ethnicity, insurgency, and civil war. American Political Science Review, 97(1), 75–90.
Feenstra, R., Lipsey, R., Deng, H., Ma, A., & Mo, H. (2005). World trade flows: 1962–2000. NBER Working Paper No. 11040.
Feenstra, R., Inklaar, R., & Timmer, M. (2013). The next generation of the penn world table. Retrieved from, www.ggdc.net/pwt.
Felbermayr, G., Hiller, S., & Sala, D. (2010). Does immigration boost per capita income? Economics Letters, 107(2), 177–179.
Fershtman, C., Hvide, H., & Weiss, Y. (2006). Cultural diversity, status concerns and the organization of work. Research in Labor Economics, 24, 3–38.
Filmer, D., Hasan, A., Pritchett, L. (2006). A millennium learning goal: Measuring real progress in education. Center for Global Development Working Paper 97.
Frankel, J., & Romer, D. (1999). Does trade cause growth? The American Economic Review, 89(3), 379–399.
Frankel, J., Stein, E., & Wei, S. J. (1995). Trading blocs and the Americas: The natural, the unnatural, and the super-natural. Journal of Development Economics, 47(1), 61–95.
Gallup, J., Sachs, J., & Mellinger, A. (1998). Geography and economic development. In B. Pleskovic & J. E. Stiglitz (Eds.), Annual world bank conference on development economics. Washington, DC: The World Bank.
Glaeser, E., La Porta, R., & Shleifer, A. (2004). Do institutions cause growth? Journal of Economic Growth, 9(4), 271–303.
Greenberg, J. (1956). The measurement of linguistic diversity. Language, 32, 109–115.
Grogger, J., & Hanson, G. (2011). Income maximization and the selection and sorting of international migrants. Journal of Development Economics, 95, 42–57.
Hall, R., & Jones, C. (1999). Why do some countries produce so much more output per worker than others? Quarterly Journal of Economics, 114(1), 83–116.
Hambrick, D., Seung Cho, T., & Chen, M. J. (1996). The influence of top management team heterogeneity on firms’ competitive moves. Administrative Science Quarterly, 41(4), 659–684.
Hatton, T., & Williamson, J. (1998). The age of mass migration: Causes and economic impact. Oxford: Oxford University Press.
Head, K., Mayer, T., & Ries, J. (2010). The erosion of colonial trade linkages after independence. Journal of International Economics, 81(1), 1–14.
Hjort, J. (2014). Ethnic divisions and production in firms. Quarterly Journal of Economics, 129(4), 1899–1946.
Hong, L., & Page, S. (2001). Problem solving by heterogeneous agents. Journal of Economic Theory, 97(1), 123–163.
Hoogendoorn, S., & van Praag, M. (2012). Ethnic diversity and team performance: A field experiment. IZA Working Paper No. 6731.
Hsieh, C. T., & Ossa, R. (2011). A global view of productivity growth in China. NBER Working Paper 16778, September 2011.
Kahane, L., Longley, N., & Simmons, R. (2013). The effect of coworker heterogeneity on firm-level output: Assessing the impacts of cultural and language diversity in the National Hockey League. Review of Economics and Statistics, 95(1), 302–314.
Kali, R., Méndez, F., & Reyes, J. (2007). Trade structure and economic growth. Journal of International Trade & Econ Development, 16(2), 245–269.
Laitin, D. D., & Jeon, S. (2013). Exploring opportunities in cultural diversity. Mimeo: Stanford University.
Lazear, E. P. (1999a). Globalisation and the market for teammates. Economic Journal, 109(454), 15–40.
Lazear, E. P. (1999b). Culture and language. Journal of Political Economy, 107(6), 95–126.
Lewer, J. J., & Van den Berg, H. (2008). A gravity model of immigration. Economics Letters, 99(1), 164–167.
Marshall, M., & Jaggers, K. (2012). Polity IV project: Political regime characteristics and transitions, 1800–2012. Center for International Development and Conflict Management, University of Maryland.
Mayda, A. (2010). International migration: A panel data analysis of the determinants of bilateral flows. Journal of Population Economics, 23(4), 1249–1274.
McKenzie, D., & Rapoport, H. (2010). Self-selection patterns in Mexico-US migration: The role of migration networks. Review of Economics and Statistics, 92(4), 811–821.
Michalopoulos, S. (2012). The origins of ethnolinguistic diversity. American Economic Review, 102(4), 1508–1539.
Milliken, F. J., & Martins, L. L. (1996). Searching for common threads: Understanding the multiple effects of diversity in organizational groups. Academy of Management Review, 21(2), 402–433.
Montalvo, J., & Reynal-Querol, M. (2005). Ethnic polarization, potential conflict and civil war. American Economic Review, 95(3), 796–816.
OECD. (2009). OECD Programme for International Student Assessment (PISA), available from: https://pisa2009.acer.edu.au/.
O’Reilly, C., Caldwell, D., & Barnett, W. (1989). Work group demography, social integration, and turnover. Administrative Science Quarterly, 34(1), 21–37.
Oster, E. (2013). Unobservable selection and coefficient stability: Theory and validation. NBER Working Paper 19054.
Ortega, F., & Peri, G. (2009). The causes and effects of international migrations: Evidence from OECD countries 1980–2005. NBER Working Paper 14833.
Ortega, F., & Peri, G. (2014). Openness and income: The roles of trade and migration. Journal of International Economics, 92(2), 231–251.
Ottaviano, G., & Peri, G. (2006). The economic value of cultural diversity: Evidence from U.S. cities. Journal of Economic Geography, 6(1), 9–44.
Ozden, C., Parsons, C., Schiff, M., & Walmsley, T. (2011). Where on earth is everybody? The evolution of global bilateral migration 1960–2000. The World Bank Economic Review, 25(1), 12–56.
Ozgen, C., Nijkamp, P., & Poot, J. (2013). The impact of cultural diversity on firm: Evidence from dutch micro data. IZA Journal of Migration, 2, 18.
Parrotta, P., Pozzoli, D., & Pytlikova, M. (2014). Does labor diversity affect firm productivity? European Economic Review, 66, 144–179.
Peri, G. (2012). The effect of immigration on productivity: Evidence from US states. Review of Economics and Statistics, 94(1), 348–358.
Putnam, R. D. (1995). Bowling alone: America’s declining social capital. Journal of Democracy, 6(1), 65–78.
Reynal-Querol, M. (2002). Ethnicity, political systems, and civil wars. Journal of Conflict Resolution, 46(1), 29–54.
Rodriguez, F., & Rodrik, D. (2001). Trade policy and economic growth: A skeptic’s guide to the cross-national evidence. NBER Macroeconomics Annual, 15, 261–338.
Rodrik, D., Subramanian, A., & Trebbi, F. (2004). Institutions rule: The primacy of institutions over geography and integration in economic development. Journal of Economic Growth, 9(2), 131–165.
Sachs, J. (2003). Institutions don’t rule: Direct effects of geography on per capita income. NBER Working Paper No 9490.
Santos Silva, J., & Tenreyro, S. (2006). The log of gravity. The Review of Economics and Statistics, 88(4), 641–658.
Spolaore, E., & Wacziarg, R. (2009). The diffusion of development. Quarterly Journal of Economics, 124(2), 469–529.
Stock, J., & Yogo, M. (2005). Testing for weak instruments in linear IV regression. In Donald Andrews & James H. Stock (Eds.), Identification and inference for econometric models: Essays in honor of Thomas Rothenberg. New York, NY: Cambridge University Press.
Tinbergen, J. (1962). An analysis of world trade flows. In Jan Tinbergen (Ed.), Shaping the world economy. New York: Twentieth Century Fund.
U.N. Population Division. (2013). World population prospects: The 2013 revision. Retrieved from, http://www.esa.un.org/wpp.
World Bank Group (2013). World development indicators 2013. World Bank Publications, 2013.
World Intellectual Property Organization. (2010). World intellectual property indicators. Retrieved from, http://www.wipo.int/ipstats/en/statistics/patents/.
Yanikkaya, H. (2003). Trade openness and economic growth: A cross-country empirical investigation. Journal of Development Economics, 72(1), 57–89.
Author information
Authors and Affiliations
Corresponding author
Additional information
Our birthplace diversity dataset can be found at www.nber.org/data/population-birthplace-diversity/.
We thank the editor, Oded Galor, and three anonymous referees for excellent comments which greatly improved the paper. We are also grateful to Amandine Aubry, Simone Bertoli, François Bourguignon, Matteo Cervellati, Frédéric Docquier, Jesús Fernández-Huertas Moraga, Gordon Hanson, Frédéric Jouneau, Thierry Mayer, Lant Pritchett, Yona Rubinstein, Joao Santos-Silva, Jacques Silber, Sylvana Tenreyro, Nico Voigtlaender, Ekaterina Zhuravskaya, participants at the 5th AFD-World Bank Conference on Migration and Development, Paris, June 2012, the CEMIR conference at CESifo, Munich, December 2012, the NBER Economics of Culture and Institutions Meeting, Cambridge, April 2013, the 10th IZA Migration Meeting in Jerusalem, June 2013, the 4th TEMPO-CEPR Conference in Nottingham, September 2013, the NBER Conference on High Skill Immigration, October 2013, the workshop on “Deep Rooted Factors in Comparative Economic Development” at Brown University, May 2014, the CESifo workshop on “Demographic Changes and Long-Run Growth” in Venice, July 2014, and seminar audiences at PSE, Louvain, Geneva, Luxembourg, Milan, Hebrew University, Tel-Aviv, EUI, IDC, and the Kiel Institute for comments and suggestions. We also thank Quamrul Ashraf and Frédéric Docquier for sharing their data with us.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Alesina, A., Harnoss, J. & Rapoport, H. Birthplace diversity and economic prosperity. J Econ Growth 21, 101–138 (2016). https://doi.org/10.1007/s10887-016-9127-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10887-016-9127-6