
Abstract
This study examined a behavioral intervention package to promote the use of target vocalizations alongside speech-generating device (SGD) mands. Six minimally verbal children with autism spectrum disorder participated, including three with no prior SGD experience. During baseline, SGD responses resulted in access to a preferred item and there was no reinforcement for vocalizations. In Phase I of intervention, responses that included target vocalizations were differentially reinforced with a highly preferred target item and, following a delay, responses without vocalizations produced an easy distractor trial and access to a lesser-preferred item. Three participants increased vocalizations with these procedures alone. For two of these participants, closer approximations or full words were modeled and differentially reinforced during a secondary intervention phase, resulting in an increase in closer matches for one of them. The third did not require this intervention, but a second target was introduced successfully. Although the remaining three participants responded minimally to Phase I, vocalizations increased to high levels for two of these three participants after a vocal model was added and faded during Phase II. Independent SGD maintained throughout all phases of the study for all participants, and participants generalized the use of vocalization responses when the SGD was not present.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Around 20% of individuals with autism spectrum disorder (ASD) have limited or no speech and are considered minimally verbal or functionally non-speaking (Armstrong and Jokel 2012). Augmentative and alternative communication (AAC) systems, such as speech-generating devices (SGDs), are tools that can be used in combination with systematic instruction to improve functional communication skills and may also have the potential to increase vocal speech (Blischak et al. 2003; Schlosser and Wendt 2008). Despite this fact, parents, teachers, and clinicians often believe that the implementation of AAC will delay vocal speech development (Romski and Sevcik 1997; Schlosser and Wendt 2008; Sigafoos et al. 2003). These beliefs may persist because (a) collateral gains in speech development may occur more slowly than AAC gains (Brady et al. 2015), and (b) AAC intervention alone may not facilitate large gains in vocal speech for individuals with limited vocal imitation skills (Gevarter et al. 2013; Schlosser and Wendt 2008). For those with limited echoic skills, the addition of intervention components that target vocalization may be necessary to see speech gains (Brady et al. 2015; Gevarter et al. 2016). Although early vocalizations for such learners may consist of word approximations (e.g., “bub” for “bubble”), using approximations in combination with AAC can help build a reinforcement history for vocalization and promote the functional use of an AAC system that can be understood by a wider range of listeners (Gevarter et al. 2016).
One intervention component that has been successful for increasing the vocalization rates of AAC users is delaying the reinforcement of AAC responses. Delay to reinforcement has typically been used in combination with additional methods such as vocal prompting and differential reinforcement. For instance, Carbone et al. (2010) used delay to reinforcement, time delay, and vocal prompts to increase the vocalization rates of children with ASD and developmental disabilities during manual sign mand training. Picture Exchange Communication (PECS; Frost and Bondy 2002) studies have suggested that vocalization increases may be most likely to occur during Phase IV when a listener delays reinforcement and the use of a vocal model after a PECS response (Charlop-Christy et al. 2002; Ganz and Simpson 2004; Tincani 2004). Tincani et al. (2006) described a functional relationship between increased vocalization rates and a PECS Phase IV package that included delay to reinforcement, a vocal model, and differential reinforcement. Greenberg et al. (2014) reported similar findings. Ragliani et al. (2017) also saw increases in targeted vocalizations using reinforcer delay, differential reinforcement, and increases in PECS response effort.
In a study by Gevarter et al. (2016), three of four participants with ASD began emitting target vocal approximations with SGD responses following the use of different combinations of reinforcer delay, differential reinforcement, and prompting. These strategies were evaluated as they were simple in nature and were successful elements in prior research with PECS and sign. Rather than using differential reinforcement with a full extinction component (which might lead to adverse reactions or discontinued interest in using an SGD), responses that included an SGD activation and a targeted vocalization resulted in more immediate, high-quality reinforcement. Two participants met mastery criterion with the combination of reinforcer delay and differential reinforcement alone, and one met criterion after fading a vocal model prompt. Participants generalized vocalizations to contexts where the SGD was absent, demonstrating that vocalizations were not solely under the stimulus control of SGD outputs. In line with findings reported by Roche et al. (2014), such results suggested that if full vocal words were established, it may be possible to fade out SGDs.
Although the Gevarter et al. (2016) study extended much of the prior research with lower-tech AAC formats, it had several limitations. First, the study did not continue to measure independent SGD responding during intervention. Additionally, participants had similar echoic profiles, and all had prior SGD experience. Prompting used during the second phase of intervention was also not rapidly faded and may have delayed responding for at least one participant. Finally, all participants used only vocal approximations of the target word and data on the use of closer vocal approximations were not collected.
For individuals with ASD, shaping is a common approach for increasing successive vocal approximations of a target word (Ross and Greer 2003). Shaping involves the systematic differential reinforcement of closer approximations of a targeted response (Skinner 1957). For instance, a response of “buh” might initially be reinforced as a mand for bubbles, but if “bub” emerged, differential reinforcement of “bub” would be implemented (placing “buh” on extinction). Research has supported shaping vocalizations for individuals with ASD and related disabilities (Bourret et al. 2004; Lovaas et al. 1973; Sloane et al. 1968). Shaping can also be used in combination with echoic and partial echoic prompts when a closer approximation is not yet in repertoire (Bourret et al. 2004). To determine whether it is possible to shape successive approximations that have not spontaneously emerged during SGD instruction, research could first examine the use of partial or full echoic prompts (i.e., vocal models) combined with differential reinforcement of a closer approximation.
Given the limitations of the Gevarter et al. (2016) study, extension and replication are needed to determine how a variety of behavioral strategies (e.g., differential reinforcement, reinforcer delay, and echoic prompting) can best be applied for learners with a range of limited echoic skills and varying prior AAC experience. Single subject designs can be used to demonstrate how different variations of procedures may benefit different learner groups. Such research could begin to elucidate guidelines for individualizing interventions in clinical practice. The first aim of the current study was, therefore, to determine whether a combination of reinforcer delay and differential reinforcement, applied during SGD instruction, would increase targeted vocalizations of children with ASD and varying echoic profiles and SGD experience. Secondly, the study sought to determine the effectiveness of supplemental methods (e.g., vocal modeling) for increasing vocalization rates or the use of closer approximations. Finally, the study aimed to determine whether SGD responding maintained during intervention, and whether vocalization responses generalized to contexts where the SGD was absent.
Methods
Participants
Five males and one female were recruited from a private preschool that serves children with ASD and related disabilities. An institutional review board approved the study and parental consent was obtained for each participant. All participants had independent diagnoses of ASD, confirmed via records review. The Childhood Autism Rating Scale Second Edition (CARS-2; Schopler et al. 2010) was also administered. Participants were not required to have experience using an SGD but needed to be limited in their use of spontaneous vocal mands and have delays in communication as assessed by the Vineland Adaptive Behavior Scales (Sparrow et al. 2005). Participants also needed to demonstrate a delay in vocal imitation skills as assessed via Group 1 scores on the Early Echoic Skills Assessment (EESA; Esch 2008) from the Verbal Behavior Milestones Assessment and Placement Program (VB-MAPP; Sundberg 2008). Group 1 on the EESA assesses the ability to vocally imitate 25 simple (e.g., “up”) and reduplicated (e.g., “mama”) syllables. About a month prior to recruitment, school speech-language pathologists administered the EESA to all preschool students. Each child had three opportunities to imitate a presented sound. Responses closest to the sound presented were scored, and individuals received one point for exact imitations and 0.5 points for partial imitations (e.g., recognizable, but missing sounds). To meet criteria, scores could range from 0 to 20 on Group 1. This threshold is the minimum score needed to pass Level 1 echoic skills (0–18 months of age) in the VB-MAPP (Sundberg 2008). An aim of this study was to include participants scoring both in the lower and higher ranges of this 0–20 score range.
Based on these assessments, six children met inclusion criteria (see Table 1 for full assessment information). Participants included Daniel, a 4.5-year-old Asian American male; Jaelyn, a 3.6-year-old Hispanic female; Keith, a 3.9-year-old Hispanic male; Stephen, a 5.0-year-old African-American male; Timothy, a 3.6-year-old African-American male; and Tyquan, a 5.3-year-old African-American male. Daniel, Stephen, and Jaelyn scored within the lower range on the EESA Group 1 (scores of 0–6), and Keith, Timothy, and Tyquan scored on the higher range (scores of 10–18). Jaelyn, Stephen, and Keith had previous experience with non-electronic picture selection AAC systems, and Daniel, Tyquan, and Timothy had experience using a GoTalk9.
Setting and Interventionists
The study took place in speech therapy rooms and a technology room at the participants’ preschool. The lead author, a board certified behavior analyst at the doctoral level, served as the interventionist for all participants.
Materials
Preferred Stimuli
One highly preferred item or activity was selected for each participant based upon a two-stage preference assessment (Green et al. 2008). Parents and teachers suggested highly preferred items including toys, activity materials, food, or drinks that participants were not already requesting via an SGD. For each participant, five items were assessed using a multiple stimulus without replacement format (DeLeon and Iwata 1996). The assessment was repeated three times and rank orders were computed. The highest preferred item was used as the target SGD response, and the lowest preferred item (still selected) was used for differential reinforcement. Preferred items and the programmed vocal output for each target were as follows: David-Oreo cookie (“oreo”); Jaelyn-gummy bear (“gummy”), Keith-fruit loop (“loop”), Stephen-yogurt (“yogurt”); Timothy-YouTube videos on iPhone (“i-phone”), and Tyquan-potato chip (“chip”). We did not ask school staff to restrict the use of items throughout the day, but we did ensure that these items were not added to SGDs used outside of training.
Speech-Generating Device (SGD)
A GoTalk1 SGD (i.e., SGD with one slot for a picture and one programmable voice output button) with a photograph of the child’s preferred item was created for Jaelyn, Keith, and Stephen, all of whom had no prior SGD experience. This was done since SGD instruction for learners at this stage might first focus on teaching the physical response required rather than require discrimination between multiple pictures. For Daniel, Timothy, and Tyquan, a GoTalk1 button with the target item was placed inside a TalkBook4, which also included GoTalk1 buttons for three other nontarget items (i.e., photographs of target items for other participants). These participants had prior SGD experience, and SGD instruction for learners at this phase might focus on teaching new vocabulary items. The researcher recorded all vocal outputs on the devices. The outputs selected were all one-word common labels for the item. In this study, unlike Gevarter et al. (2016), the target words were not selected based on reported prior use of particular phonemes. This was a limitation of the previous study, as it was unclear whether systematic targeted word selection was necessary.
Dependent Measures and Data Collection
During all sessions, the interventionist used a trial-based data sheet to code SGD responses and vocalizations according to the definitions described below. The coder transcribed vocal approximations emitted (e.g., wrote me if the child emitted “me” for “gummy”).
Independent and Prompted Target Vocalizations
The primary dependent measure was the percentage of trials that included independent target vocalizations. Independent target vocalizations occurred when a participant vocally emitted either the full target word, or an approximation of the target word during a trial, without an interventionist-provided vocal model (i.e., an independent vocalization could occur after SGD output but not after instructor’s echoic model). Vocalizations were prompted if they occurred within 6 s of the interventionist’s vocal speech model (i.e., during Phase II). For graphing purposes, the percentage of prompted vocalizations plus the percentage of independent vocalizations was summed during Phase II. Independent and prompted target vocalizations were coded into the sub-categories below.
Any Approximation of Target Word
Any approximation of the target word included a vocalization with at least one phoneme from the target word. For instance, “g” or “m” would be acceptable approximations for “gummy” but “p” would not.
Closer Approximations
For participants who participated in the Phase II to establish closer approximations, approximations of the targeted word that were closer to the target word (i.e., contained more correct phonemes) than the most commonly used approximation in Phase I were recorded. For example, “ip” was a closer approximation of “chip” than “gi.” Transcriptions of the approximations used in prior phases were used to determine how often closer approximations were utilized prior to Phase II to establish closer approximations.
Full Words
Full-word vocalizations required a correct initial sound and all the same sounds and number of syllables as the target word, with an allowance that one non-initial phoneme could be replaced with an alternative sound (e.g., “i-pone” counted as a full word, but “pone” did not). This allowance was due to the fact that, developmentally, preschoolers would not be expected to have all speech sounds in their repertoires and certain substitutions or deletions are developmentally appropriate (Bernthal et al. 2017).
Independent Correct SGD Responses
The percentage of independent correct SGD responses was a secondary measure. Independent correct SGD responses were defined as activating the full augmented voice output associated with the targeted preferred item by pressing the targeted button within 6 s of item presentation, without any prompting from the instructor. The requirement for a full voice output excluded repetitive pressing of the button.
Inter-observer Agreement
All sessions were videotaped and 33% of sessions for each participant were selected for inter-observer agreement (IOA). Videos rather than in situ IOA were used because these allowed for a more accuracy in coding (i.e., could amplify volume and replay-specific trials). For each participant, at least one session from each phase was randomly selected. An independent, trained observer (a graduate student in applied behavior analysis with masters in special education) watched the videotaped sessions and collected data using the same data sheets used by the interventionist. Training was conducted by reviewing definitions using specific examples of the participants’ targeted words (e.g., describing what would and would not count as an approximation of “gummy” based upon operational definitions) and practicing coding using videos not selected for IOA. Agreement was determined on a trial-by-trial basis for both SGD responses and vocalization responses. For vocalizations, observers needed to agree whether a response occurred was prompted or independent, and was an approximation or full word. IOA was calculated for each session by dividing the number of agreements by the sum of agreements and disagreements and multiplying by 100. Average IOA for SGD responses were as follows: Daniel 98.6% (90–100%), Jaelyn 95% (90–100%), Keith 100%, Timothy 96.7% (80–100%), Tyquan 98.8% (90–100%), and Stephen 95% (90–100%). Average IOA scores for vocalization were as follows: Daniel 98.6% (90–100%), Jaelyn 95% (90–100%), Keith 100%, Timothy 96.7% (80–100%), Tyquan 95% (90–100%), and Stephen 92.9% (80–100%).
Procedures
Table 2 provides a summary of procedures across phases.
Baseline
Baseline was designed to approximate opportunities for requesting that may occur when (a) a learner with no prior SGD experience is taught to activate an SGD with only one icon, or (b) a learner with prior SGD experience is introduced to a new target vocabulary item within a field of icons. During baseline and all subsequent phases, the appropriate SGD (GoTalk1 or TalkBook 4) was available (presented in table) and the preferred target item was presented behind the SGD just beyond reach or held up by the interventionist. The interventionist only started a session if the participant appeared interested in the target item (e.g., reaching, looking, and coming to table). Sessions were postponed if an establishing operation did not appear to be in place (e.g., the participant walked away or sought out other items).
A trial began when the SGD was present and the interventionist presented the preferred item. Any independent SGD response that occurred within 6 s of preferred item presentation was immediately reinforced with the highly preferred item. For instance, if the child activated an SGD button with a chip symbol within 6 s, the child immediately received a chip. If no response occurred within 6 s or an incorrect SGD response occurred, the correct SGD response was physically prompted and reinforced (e.g., researcher prompted child to press chip and then provided a chip). SGD prompting of the SGD was used as this phase was intended to replicate a typical SGD intervention without programmed intervention for vocalization. Vocalizations were not prompted or reinforced during baseline. If the participant initiated a target vocal word or approximation without an SGD response (e.g., said “gi” for chip), the vocalization was ignored and the SGD response (e.g., pressing chip) was physically prompted and reinforced.
For each session, participants were given ten opportunities to request with the SGD. After the preferred item was delivered, participants were given about 20 s to play with it or the amount of time it took to consume an edible. After the item was removed or the edible consumed, the interventionist immediately re-presented the item or presented an additional edible to begin the next trial. If a participant initiated a request (e.g., pressed chip prior to the interventionist holding up a chip), these initiations also counted as trials. As it was sometimes difficult to judge when an edible had been fully consumed, participants with edible target items were more likely to initiate trials (i.e., there was an establishing operation for requesting once item was consumed).
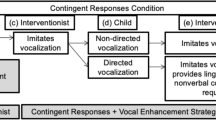
Intervention Phase I: Differential and Delayed Reinforcement
This phase was standardized across participants. Trials were presented identically to baseline (i.e., SGD present, preferred item placed behind SGD or held up, and the interventionist waited 6 s for a response), but the immediacy and quality of reinforcement were differentially applied based upon whether the learner’s initial response included an independent target vocalization. Procedures for the initial responses that included target vocalizations, and those that did not, are described below.
Initial Responses with Independent Target Vocalizations
If during the 6-s initial delay the participant emitted the full vocal word with or without an SGD response (e.g., said “chip” with or without pressing chip) or made a response that included both a target vocal approximation and an independent SGD response (e.g., said “gi” right before, during, or immediately after pressing chip), the targeted item (e.g., chip) was immediately provided. If the participant used a target vocal approximation without a correct SGD response (e.g., said “gi” but did not press chip), the interventionist prompted the SGD response, and the targeted item (e.g., chip) was provided.
Initial Responses Without an Independent Target Vocalization
Reinforcer delay and differential reinforcement were used when an SGD response occurred without a targeted vocalization during the initial 6 s (e.g., pressed chip, but did not emit any phonemes in “chip”), or there was neither an SGD response nor a target vocalization during the initial 6 s. If the initial SGD response was incorrect (e.g., pressed nontargeted item), or no response occurred, the interventionist first prompted a correct SGD response prior to implementing a reinforcer delay. Following an independent or prompted SGD response with no target vocalizations, the researcher waited up to 6 s for a target vocalization. If the participant made an independent target vocalization during the reinforcer delay, the interventionist delivered the highly preferred item. If there were no target vocalizations during the delay, the interventionist presented a simple distractor trial (e.g., clap your hands) and then delivered the previously selected lesser-preferred item. The participant could play with the lesser-preferred item for up to 20 s (or time to consume edible), but if he/she did not interact with it after 5 s, a new trial began.
Mastery Criteria for Phase I and Moving to Phase II
All participants could meet mastery criteria for Phase I in one of two ways: (a) four consecutive sessions with 90% independent vocalizations (any approximation of target word or full word) or (b) four out of five consecutive sessions with 90% independent vocalizations (any approximation of target word or full word) provided that the low score did not fall below 80%. The second criterion was an option because in related pilot work there were sometimes minimal drops in performance when the motivating operation for a specific item may have been moderately reduced based upon factors beyond the researcher’s control (e.g., teacher changed snack time). Phase II to increase rates was introduced when mastery criteria for Phase I was not met. This was determined to be the case when (a) independent vocalizations did not show an increase in level or trend after three sessions, or (b) independent vocalizations did not continue to show an increasing trend after five sessions. Phase II to establish closer approximations was introduced when a participant mastered Phase I using vocal approximations only.
Phase II to Increase Rates
Participants who did not show increasing trends, or whose rates leveled following an increase, participated in this phase (i.e., Daniel, Keith, Stephen). This phase was also implemented at a latter point for Jaelyn when Phase II to establish closer approximations was unsuccessful (see Results). Procedures were identical to Phase I, except that in cases where the distractor trial would have been implemented (i.e., when no targeted vocalization occurred during reinforcer delay), the instructor now provided a vocal model and waited an additional 6 s for an imitated vocalization to occur. Prompted target vocalizations (i.e., those occurring within 6 s of vocal model) initially resulted in access to the highly preferred item. Thus, an example initial trial at Phase II would be as follows (a) present preferred item (e.g., oreo) and SGD and wait 6 s; (b) if an SGD response but no target vocalization occurs, wait an additional 6 s; (c) if there is still no target vocalization, provide a vocal model of target item (e.g., say “oreo”); and (d) if participant makes a target vocalization following model (e.g., says “o–o”), reinforce with highly preferred item (i.e., oreo). If the participant did not make a targeted vocalization following the model, the distractor trial (e.g., “clap hands”) was delivered, and the response resulted in access to the lower-preferred item. If a participant used target independent or prompted vocalizations on three consecutive trials, the prompt was removed for subsequent trials (i.e., returning to Phase I procedures) until the end of the session or until the participant did not vocalize for a subsequent set of three trials (at which point the prompt was reintroduced).
If the participant had not consistently used a specific target approximation during Phase I, the echoic model was the full-target word (e.g., “oreo” for Daniel and “loop” for Keith). If the participant had started to primarily use one target approximation during Phase I, the model provided was the most commonly used approximation during Phase I. Thus, “u” was used as a model for Stephen because he had been commonly using this approximation in around 60% of trials during Phase I. Phase II continued until participants met a mastery criterion of three sessions with 80% of trials including any approximation of the targeted word (prompted or independent). Following mastery, participants returned to Phase I. Mastery criterion was lower than Phase I, as Phase II procedures were intended to be faded rapidly to return to Phase I.
Phase II to Establish Closer Approximations
This phase, which utilized modeling (i.e., echoic prompts) and differential reinforcement of closer approximations, was implemented for participants who met mastery criterion with Phase I using any approximation of the target word (i.e., Jaelyn, Tyquan). This phase was also briefly used for one session with Timothy for a second target that was introduced after he mastered the use of a full-target word during Phase I. Procedures were identical to Phase II for increasing rates except the vocal model presented was a closer approximation or full-target word, and only responses that included closer approximations or the full target resulted in access to the highly preferred item. Specifically, if there were no vocalizations or only a lesser approximation (i.e., the response reinforced in Phase I) during the initial 6 s of a trial, the instructor implemented a reinforcer delay. If no closer approximation occurred during the reinforcer delay, the instructor modeled a closer approximation or full word, and the participant was given an additional 6 s to imitate. Imitated closer approximations/full target words initially resulted in access to the highly preferred item. Thus, an example initial trial at this phase would be as follows (a) present preferred item (e.g., chip) and SGD and wait 6 s; (b) if an SGD response with only a lesser approximation occurs (e.g., pressed chip and said “gi”), wait an additional 6 s; (c) if there is still no closer approximation, provide a model of the closer approximation (e.g., say “ip”); and (d) if participant makes a closer approximation following model (e.g., says “ip”), reinforce with highly preferred item (i.e., chip). If the participant did not use a closer approximation, a distractor trial was delivered and the response resulted in access to the lower-preferred item. Criterion for fading out the model was the same as Phase II for increasing rates (i.e., fade out after three trials with prompted or independent closer approximations or full words). To meet mastery and return to Phase I, 80% of trials needed to include a prompted or independent closer approximation or full word.
For this phase, the vocal model selected was based on the existing approximation(s) that used during Phase I or baseline and informal echoic probes of additional phonemes in the target word. For instance, a model of “ip” was used for Tyquan’s target “chip” to try to improve upon his Phase I response of “gi” since probes indicated he could imitate a “p” sound but not “ch.” For Jaelyn, the partial echoic “ummy” was used for “gummy” (a closer approximation than her Phase I “me”). For Timothy’s second word, the full echoic “monster” was used.
Generalization Probes
Generalization probes were conducted during baseline and intervention for all participants and consisted of opportunities to vocally request the highly preferred item when the SGD was not present. A probe session consisted of five trials in which the preferred item was present but out of reach and/or held up by the interventionist. The interventionist reinforced target full-word responses or target vocal approximations by immediately providing access to the item. If the participant did not emit a target vocalization within 6 s of the presentation of the item, the interventionist gave him or her the item.
For any participant who mastered the use of a target full-word vocalization with the SGD present, extended Phase I generalization probe sessions replaced sessions with the SGD (i.e., given that participant used full vocal word, the SGD was not necessary). These probes included ten trials, and Phase I differential reinforcement procedures were used (i.e., if the participant did not vocalize the full target word, the distractor trial and lower-preferred item were utilized).
Maintenance
Based on scheduling possibilities, probes were conducted at 2 and 4 weeks or 1 and 3 weeks after intervention. Maintenance sessions mirrored Phase I procedures. Because Jaelyn went on vacation while she was still in Phase II, rather than conduct maintenance checks, Phase II to increase rates was reintroduced.
Procedural Integrity
We created a procedural integrity checklist for each phase. An independent trained observer (a graduate student in applied behavior analysis with a masters in special education) watched randomly selected sessions on video and used the appropriate checklist to score appropriate use of materials, prompting, delays, and reinforcement delivery. Training was conducted by reviewing the procedures and checklist for each phase and practicing using videos not selected for integrity checks. The observer collected procedural integrity data for 33% of sessions per participant, with at least one session from each phase per participant. Integrity was calculated by dividing the number of steps correctly implemented by the total number of steps and multiplying by 100. Mean scores were: Daniel 98.3% (90–100%), Jaelyn 100%, Keith 100%, Timothy 100%, Tyquan 99.4% (90–100%), and Stephen 97.1% (90–100%).
Experimental Design
We used two implementations of a multiple baseline design across participants (Baer et al. 1968) to evaluate the effects of the intervention. Although baseline and intervention for all participants were run concurrently, we initially grouped participants in sets of three based upon their EESA scores in order to make decisions regarding the staggering of intervention Phase I. Participants with scores from 10 to 18 (Keith, Timothy, Tyquan) were grouped together, and participants with scores from 0 to 6 (Daniel, Jaelyn, Stephen) were grouped together. The first participants to begin intervention were then selected based upon stable baseline patterns. Subsequent participants entered intervention when the following criteria were met: (a) his or her baseline data stabilized (i.e., no more than 10% difference in scores for last four sessions), and (b) the prior participant’s intervention data indicated an experimental effect for at least two sessions. Each participant could receive up to 12 intervention sessions. Two to three sessions occurred per week. Although intervention staggering decisions were based upon EESA score groupings, in order to clearly depict functional relationships, we graphed participant data in groups based upon the initial success with Phase I. Visual analysis can be used to determine the effects of Phase I in Figs. 1 and 2. Figure 1 allows for an analysis of Phase II to establish closer approximations, and Fig. 2 allows for an analysis of Phase II to increase rates.

Percentage of trials with target vocalizations for participants who mastered Phase I. BL baseline, PII phase II closer approximations, PI Phase I

Percentage of trials with target vocalizations for participants who required Phase II to increase rates
Results
Independent and Prompted Vocalizations
Figure 1 (participants who mastered the initial Phase I) and Fig. 2 (participants who did not master the initial Phase I) show the percentage of responses that included independent target vocalizations (any approximation of the target word, closer approximations, and full-target words) during all phases and the percentage of responses that included independent or prompted responses during Phase II. Generalization probe data are also included.
Baseline
During baseline, participants independently emitted any approximation of the target word during 0–40% of trials (M = 5%). Keith, Timothy, Stephen, and Daniel had low and stable baseline rates (0–10%) of any approximation of the target word and did not use the full word. Tyquan occasionally used a vocal approximation of “gi” for “chip” during early baseline sessions (starting at 40% on the first session), but the response appeared to extinguish during baseline when not reinforced. Jaelyn emitted the sound “m” (target word “gummy”) at variable rates during baseline. Although her repetitive “m” sound presented more like vocal stereotypy than an intentional vocal approximation, based upon the operational definition, it was recorded as a target vocalization. Following mastery of a full vocal word (see intervention Phase I), a single baseline probe for a second preferred item was conducted for Timothy. During baseline for the second word “monster,” Timothy used an approximation of “tonta” on 100% of trials.
Intervention Phase I
As illustrated in Fig. 1, there was a functional relationship between Phase I procedures and increases in vocalizations for Jaelyn, Timothy, and Tyquan. Timothy began using the full vocal target word (M = 97%), and Jaelyn and Timothy increased their use of any approximations of the targeted word (M = 87%). For Timothy, an extended Phase I with multiple generalization probes (i.e., no SGD present) was implemented. He continued to us the target word “iphone” with 100% accuracy. Jaelyn started frequently using the approximation “me” for “gummy.” Unlike Jaelyn’s use of “m” continuously during baseline, her use of “me” during intervention appeared to show elements of intentionality rather than vocal stereotypy (e.g., distinct use of the single phoneme either before or after the SGD responding coordinated with eye contact). Tyquan regularly emitted “gi” for “chip.”
Figure 2 displays data for Keith, Daniel, and Timothy. During intervention Phase I, Keith and Daniel did not show increasing trends in any approximations of the targeted word. Keith also began to show variable interest in his preferred item (i.e., session not conducted on a day he showed no interest). Although Stephen did show an increase in responding in Phase I (M = 58%), he appeared to plateau. Stephen primarily used the sound “uh” for “yogurt” but also attempted to use nontargeted sounds (e.g., “m”) at inconsistent rates, demonstrating a potential difficulty with acquiring a discriminated vocal approximation. Thus, there was not a clear functional relationship between Phase I procedures and increased responding for these participants.
Phase II to Establish Closer Approximations
Phase II with modeling and differential reinforcement of closer approximations or full target words had mixed results, as illustrated in Fig. 1. Tyquan rapidly began to imitate “ip” during Phase II, and the prompt was quickly faded, with the independent use of “ip” maintained in the return to Phase I. For Timothy, one Phase II session was conducted with his second target word, and he independently used the full word “monster” 70% of the time. When Phase I was reintroduced, he maintained “monster” at 100% rates. Jaelyn had less initial success with modeling and differential reinforcement of a closer approximation. On the first session of Phase II, Jaelyn used the closer approximation of “ummy” following the model of “ummy,” but on subsequent Phase II sessions she did not use any closer approximations, and her rate of “me” (initial approximation in Phase I) began to decrease. Because of the decreasing trend in any target vocal approximation, a decision was made to implement Phase II to increase rates for any approximation of the targeted word. As Phase II to establish a closer approximation had extinguished “me” without establishing a replacement closer approximation, during the Phase II to increase rates of any approximation, the “me” approximation was once again accepted. Jaelyn began to utilize “me” again (primarily following a prompt), but she then went on a vacation. When she returned and Phase II was continued, she often waited for the prompt before vocalizing, but in addition to saying “me” on some trials, she also began to say “gummy” after the vocal model. Upon returning to Phase I, Jaelyn independently used either “me” or “gummy” 90–100% of the time (primarily using “me,” but with one session where she used “gummy” 100% of the time).
Phase II for Increasing Rates
Figure 2 demonstrates the results of Phase II for increasing rates for Daniel, Keith, and Stephen. There was an experimental effect across two of three participants (Daniel and Keith). Daniel quickly began using any approximation of the targeted word with minimal to no prompting (primarily using the vocal approximation of “o–o” for “oreo”) and maintained a 100% rate of independent responding in a return to Phase I (meeting mastery criterion). Stephen’s rate of responding also increased from Phase I (using “uh” for “yogurt”). When Phase I was reintroduced, he met mastery criterion. During Phase II, Keith’s rates of any approximation of the target word did not increase with prompting, and he began to show increasing signs that he had lost interest in his preferred item. During attempts at further sessions, he showed no interest in his targeted item (e.g., reaching for lesser-preferred item, walking away, and rejecting the item when it was offered freely as an establishing operation probe). Thus, a decision was made to discontinue intervention.
Independent Correct SGD Responses
Table 3 lists the percentage of independent SGD responses on the first baseline session and the average and range of percentages for independent SGD responses for baseline, intervention, and maintenance for each participant. Across participants and phases, the percentage of independent SGD responses remained relatively high and stable. Jaelyn, Keith, and Tyquan had lower first session independent response rates (30–60%) but showed quick improvements by the second session following the use of minimal prompting during the first baseline session. Keith’s use of the SGD dropped during Phase II as he appeared to lose interest in his preferred item. Tyquan also had a brief decrease in SGD performance during Phase II to establish closer approximations, but it increased when Phase I was reintroduced.
Generalization Probes
Data from generalization probes can be found in Figs. 1 and 2. Only Jaelyn and Tyquan used any vocal approximation of the target word when the SGD was not present during baseline. Their responses were similar to the vocal approximations used when the SGD was present during baseline. Keith did not receive additional probes (no success with intervention). For all other participants, vocalizations used when the SGD was present generalized when it was not present (all having final generalization probe scores of 100%).
Maintenance
All participants who participated in maintenance probes maintained independent target vocalizations with and without the SGD present at rates of 90–100%. Keith did not participate in this phase as intervention was discontinued. Jaelyn did not participate in this phase as her vacation disrupted intervention (intervention was continued after her return).
Discussion
Replicating findings from Gevarter et al. (2016), five of six participants increased their use of vocalizations during an SGD intervention that included strategies targeting vocal speech. An experimental effect for Phase I (reinforcer delay plus differential reinforcement) was established across three participants (see Fig. 1). Phase II to establish closer approximations (i.e., added modeling with differential reinforcement of a closer approximation), used for these three participants, showed mixed results. One participant mastered a closer approximation, a second did not acquire a closer approximation initially but began to inconsistently use the full word toward the end of intervention, and the third quickly began using the full word for a second target. For the remaining three participants, for whom minimal to no effects were observed during Phase I, an effect for Phase II to increase rates (addition and rapid fading of echoic prompts) was established across two participants (see Fig. 2). One participant did not show increases in vocalization rates; however, intervention was discontinued when he appeared to lose interest in his preferred item. All five successful participants continued to use their SGDs at stable rates and generalized vocalizations when the SGD was not present. Four participants who participated in follow-up sessions maintained vocalizations and SGD responding. Below, we discuss specific findings in light of limitations, future research, and practice implications.
One important finding from this study is that vocalization rates improved for individuals with very low echoic skills. For instance, Daniel, who scored a 0 on the EESA, began using a specific vocalization of “o–o” for “oreo.” Stephen, who scored a 6 on the EESA, began using a vocal approximation of “uh” for “yogurt.” For both of these participants, Phase II to increase rates (i.e., addition of echoic prompts) was needed to reach mastery; however, prompts were rapidly faded. While this may indicate that some individuals with very low echoic skills may benefit from instructor-modeled prompts, Jaelyn, who scored a 6 on the EESA, began using “me” for “gummy” during Phase I without any prompts. These results replicate findings from the Gevarter et al. (2016) study in which two participants with EESA scores between 6 and 9 were successful without additional prompting, and one with an EESA score of 2 was successful after prompting was added. Although these findings are encouraging, there are limitations. This study did not specifically probe participants’ abilities to produce isolated phonemes in target words prior to intervention, and it is possible that phonemes used were already in repertoire. Thus, it remains unclear if these procedures would be fully effective at eliciting completely novel responses. Additionally, the decision to specifically prompt the “uh” sound for yogurt that Stephen had used during Phase I may have led to overgeneralization of this response. Following the study, his teacher reported that Stephen began to indiscriminately use “uh” as a mand for a variety of items. While partial echoic prompting may be necessary for some individuals (Bourret et al. 2004), it could have negatively impacted Stephen’s ability to discriminate between speech sounds applied in different contexts. Further research should explore the benefits of adding instructor-modeled full echoic versus partial echoic prompts, and the introduction of secondary targets could be used to assess whether individuals have acquired discriminated approximations. Alternatively, replication of methods involving “speech sound practice” (Brady et al. 2015) should be considered. In the Brady et al. study, prior to SGD instruction, participants were provided with instructor models of speech sounds that would be emitted in target SGD responses, and participants’ imitations of these models were prompted and reinforced. Clinically, prompts can be considered for individuals with very low echoic skills, but may not be necessary for all. Data collection and monitoring to determine modifications is key. Finally, given the time constraints of this study, we were unable to apply modeling and differential reinforcement of closer approximations across participants who required Phase II to increase rates. Determining the effectiveness of these procedures for a range of learners is a critical next step.
With regard to participants with higher echoic profiles (scores 10–18 on the EESA), two of the three participants met mastery criterion during Phase I. The third did not show success, and intervention was discontinued. Notably, Timothy and Tyquan, who had the highest overall EESA scores, had the most success with the intervention as a whole. Of note, Timothy, the participant who began to use the full word during Phase I, had the lowest score on the CARS-2 with only mild ASD symptoms present (he did have an independent ASD diagnosis). In addition, although he did not vocalize any phonemes in his target word “iphone” during baseline, on the first baseline session he attempted to initiate with the vocal word “play.” During intervention, it anecdotally appeared that Timothy’s overall echoic skills had improved since his initial EESA assessment (e.g., he started to spontaneously imitate more of the instructor’s words that were unrelated to intervention, such as “hi” and “bye”). It is unclear, however, whether these characteristics were related to his success. Further research is needed with individuals with a wider range of ASD symptoms and vocal imitation skills to determine how these predict success. Continued EESA probes during intervention could also be considered in research and practice.
Another interesting finding was that for Tyquan, who had the highest EESA score (18), the introduction of an SGD intervention that did not provide specific reinforcement for vocalizations (i.e., the baseline phase of this study) appeared to extinguish an existing vocal approximation (replacing it with the SGD response). Although his decreasing trend of responding with “gi” for “chip” during baseline could be considered a limitation of this study, the fact that responding stabilized at low rates following the decreasing trend supports the idea that extinction may have occurred. Examining unintentional vocalization extinction effects that could occur during SGD instruction (and the ability to reverse these effects) has important clinical implications. The fact that the vocal approximation rapidly re-emerged and increased in rate once both SGD responding and vocal approximations were reinforced provides support for the reinforcement of multiple topographies. While this pattern was only seen in one participant with regard to targeted vocalizations, Timothy’s early use of the nontargeted but related term “play” during baseline (which discontinued in additional baseline sessions) might also have indicated extinction. Research could attempt to replicate these findings with participants who have existing vocal approximations (i.e., reinforce SGD responses instead of existing vocal approximations, and if extinction occurs, see whether effects can be reversed via differential reinforcement). Clinically, practitioners should monitor whether existing vocal topographies are replaced by AAC responses and aim to reinforce the use of both modalities.
Important implications also arise from the fact that SGD responding continued to maintain at high stable rates throughout intervention and follow-up. This finding provides support for multimodal intervention packages and indicates that the response effort required to make both an SGD response along with a vocalization was not too high for the majority of participants. It is further promising that two of the five participants for whom the intervention was successful did not have prior SGD experience. While these findings suggest that some individuals with ASD can simultaneously work on developing AAC and vocal skills, there are several limitations and cautions to consider. First, this study examined simple SGD skills (e.g., requesting one preferred item from either a field-of-one or a field-of-four). It is possible that new SGD users who are being introduced to a more advanced system may need to demonstrate success with AAC use prior to targeting vocalizations. Additionally, the fact that new SGD users rapidly began using correct SGD responses during baseline with minimal prompting (i.e., high proficiency early on) may indicate that these participants may not be representative of all new SGD users. Successful participants in this study who did not have prior SGD experience did have experience with non-electronic picture-based systems, and following baseline, some participants also began participating in another study aimed at teaching iPad-based SGD responding during play (vocalization was not targeted in that study). These additional experiences could have impacted overall proficiency with the GoTalk. Finally, the fact that one participant with no prior SGD experience appeared to lose interest in his preferred item could indicate that the response effort of producing both an SGD response and a vocalization may have been too high for the given preferred item. Alternatively, satiation may have led to this decreased interest, as evidenced by the fact that he refused his preferred item when offered it freely. In the study by Gevarter et al. (2016), there was a similar concern for one participant.
Based upon these findings and limitations regarding SGD use and experience, future research should explore: (a) methods to increase vocalizations paired with more advanced SGD displays and alternative communicative functions (e.g., when navigating through a dynamic display; when using an SGD to tact), (b) the inclusion of participants with no AAC experience (i.e., no non-electronic picture-based system experience), and (c) methods aimed at increasing the motivating operations for preferred items used in SGD/vocalization mand training. Clinically, when implementing multimodal interventions, practitioners should record data on both modalities during assessment and intervention. If initial proficiency with SGD responding is limited or not increasing, it may be more appropriate to focus on increasing SGD responding prior to focusing on vocalization. Additionally, even if an individual is able to vocalize approximations for some words, if he or she does not have the speech sounds for others, SGD responding alone should continue to be reinforced for those words so as to not extinguish functional responses. Practitioners should also consider established methods for increasing motivating operations in general (e.g., limiting access outside of intervention, using a response class of preferred items that have the same vocal label).
Though limited, the findings regarding the application of modeling with differential reinforcement of a closer approximation also provide important suggestions for research and practice. Although we did not establish a functional relationship between these procedures and the use of closer approximations, Tyquan’s data provide preliminary support for the fact that this procedure may be appropriate to integrate during SGD instruction for some individuals. Additionally, it appeared that Timothy also may have benefited from a rapid modeling and differential reinforcement procedure to improve his articulation of “monster” (from “tonta” to “monster”), but with such a short implementation, conclusions are limited. In contrast to Timothy and Tyquan, Jaelyn’s data indicate the possibility of short-term negative effects of attempting to elicit a closer approximation too early (i.e., extinguishing existing approximations without a replacement). Despite the initial decrease in vocal approximations for Jaelyn using these procedures, it was promising that we are able to reverse these effects. Additionally, Jaelyn did begin to use the full word “gummy” both prompted and independently at variable rates toward the end of the study. While we could not rule out external reasons such as time or increased motivation (Jaelyn had returned from a vacation when she began to use “gummy”), prior research has demonstrated that the effects of differential reinforcement on vocalizations can be gradual and may lead to the initial inconsistent rates of closer approximations (Bourret et al. 2004). While we could have extended the Phase II to establish closer approximations, there was a concern that Jaelyn would have lost interest in her preferred item as she was starting to show negative reactions (e.g., whining) when her responses were not reinforced (despite the fact that she still received a lower quality reinforcer for an alternative response). A more extensive process for selecting targeted approximations based upon consistent use of speech sounds in the natural environment (see Brady et al. 2015) could have been employed. Alternatively, closer approximations could have been broken down more discretely (e.g., reinforcing mouth openings prior to “me”). Additionally, more formal methods for selecting the most appropriate models to use in combination with differential reinforcement should be considered.
From the clinical perspective, when proceeding to differentially reinforce additional successive approximations (i.e., implementing a full shaping intervention) general guidelines for shaping should be applied. For instance, shaping could be considered when the individual begins to spontaneously use a closer approximation during SGD instruction. If a closer approximation does not emerge spontaneously and prompting is needed, prior to implementing Phase II procedures from this study, it would be appropriate to consult with a speech-language pathologist (i.e., to select developmentally appropriate approximations), and to continue to monitor successful imitations of the prompt (with the understanding that it may be appropriate to return to accepting lesser approximations if modeling/differential reinforcement is not successful).
Finally, maintenance and generalization findings are promising. The ability to generalize vocal approximations when the SGD is absent has several applications. For instance, individuals can initiate with vocalizations when the SGD is unavailable, when with familiar learning partners, and when an alternative or additional response may assist in communication repair. Having an alternative response may also prevent learners from resorting to challenging behaviors for repair (Keen 2003). These findings also suggest that the vocalizations acquired can function as mands, independent of the echoic element that may still in part control responding when the SGD is present (e.g., imitating the SGD output). Such results replicate those of Gevarter et al. (2016), and support findings by Roche et al. (2014) regarding the systematic fading of an SGD to promote spontaneous speech. Timothy’s rapid acquisition of a second word might also suggest that effects may generalize across words. Future research should look at other areas of generalization (across listening partners, in more naturalistic contexts, etc.) Similarly, while the maintenance results were promising, more long-term distal measures are needed.
Overall, findings provide further support for multimodal communication intervention packages with behavioral components. The methods used in this study are simple in nature and could be easily applied by parents, teachers, and clinicians. Research that continues to demonstrate ways in which both AAC responses and vocalization skills can be simultaneously targeted may help to increase earlier adoption of AAC systems that enable functional communication responses and promote early vocal speech development.
References
Armstrong, E. S., & Jokel, A. (2012). Language outcomes for preverbal toddlers with autism. Studies in Literature and Language, 4, 1–7.
Baer, D. M., Wolf, M. M., & Risley, T. R. (1968). Some current dimensions of applied behavior analysis. Journal of Applied Behavior Analysis, 1, 91–97.
Bernthal, J. E., Bankson, N. W., & Flipsen, P. (2017). Articulation and phonological disorders: Speech sound disorders in children (8th ed.). Boston, Massachusetts: Pearson.
Blischak, D., Lombardino, L., & Dyson, A. (2003). Use of speech-generating devices: In support of natural speech. Augmentative and Alternative Communication, 19, 29–35.
Bourret, J., Vollmer, T. R., & Rapp, J. T. (2004). Evaluation of a vocal mand assessment and vocal mand training procedures. Journal of Applied Behavior Analysis, 37, 129–144.
Brady, N. C., Storkel, H. L., Bushnell, P., Barker, R. M., Saunders, K., Daniels, D., et al. (2015). Investigating a multimodal intervention for children with limited expressive vocabularies associated with autism. American Journal of Speech-Language Pathology, 24, 438–459.
Carbone, V. J., Sweeney-Kerwin, E. J., Attanasio, V., & Kasper, T. (2010). Increasing the vocal responses of children with autism and developmental disabilities using manual sign mand training and prompt delay. Journal of Applied Behavior Analysis, 43, 705–709.
Charlop-Christy, M. H., Carpenter, M., Le, L., LeBlanc, L. A., & Kellet, K. (2002). Using the picture exchange communication system (PECS) with children with autism: Assessment of PECS acquisition, speech, social-communicative behavior, and problem behavior. Journal of Applied Behavior Analysis, 35, 213–231.
DeLeon, I. G., & Iwata, B. A. (1996). Evaluation of a multiple-stimulus presentation format for assessing reinforcer preferences. Journal of Applied Behavior Analysis, 29, 519–533.
Esch, B. E. (2008). Early echoic skills assessment. In M. L. Sundberg (Ed.), Verbal behavior milestones assessment and placement program: The VB-MAPP (p. 24). Concord, CA: AVB Press.
Frost, L., & Bondy, A. (2002). The picture exchange communication system: Training manual. Newark, DE: Pyramid Educational Products.
Ganz, J. B., & Simpson, R. L. (2004). Effects on communicative requesting and speech development of the picture exchange communication system in children with characteristics of autism. Journal of Autism and Developmental Disorders, 34, 395–409.
Gevarter, C., O’Reilly, M. F., Kuhn, M., Mills, K., Ferguson, R., & Watkins, L. (2016). Increasing the vocalizations of individuals with autism during intervention with a speech-generating device. Journal of Applied Behavior Analysis, 49, 17–33. https://doi.org/10.1002/jaba.270.
Gevarter, C., O’Reilly, M. F., Rojeski, L., Sammarco, N., Lang, R., Lancioni, G. E., et al. (2013). Comparing communication systems for individuals with developmental disabilities: A review of single-case research studies. Research in Developmental Disabilities, 34, 4415–4432. https://doi.org/10.1016/j.ridd.2013.09.017.
Green, V. A., Sigafoos, J., Didden, R., O’Reilly, M., Lancioni, G., Ollington, N., et al. (2008). Validity of a structured interview protocol for assessing children’s preferences. In P. G. Grotewell & Y. R. Burton (Eds.), Early childhood education: Issues and developments (pp. 87–104). New York: Nova Science Publishers.
Greenberg, A. L., Tomaino, M. E., & Charlop, M. H. (2014). Adapting the picture exchange communication system to elicit vocalizations in children with autism. Journal of Developmental and Physical Disabilities, 26, 35–51.
Keen, D. (2003). Communicative repair strategies and problem behaviours of children with autism. International Journal of Disability, Development and Education, 50, 53–64.
Lovaas, O. I., Koegel, R., Simmons, J. Q., & Long, J. S. (1973). Some generalization and follow-up measures on autistic children in behavior therapy. Journal of Applied Behavior Analysis, 6, 131–165.
Ragliani, R. R., Ayres, K. M., Whiteside, E., & Ringdahl, J. E. (2017). Picture exchange communication system and delay to reinforcement. Journal of Developmental and Physical Disabilities. https://doi.org/10.1007/s10882-017-9564-y.
Roche, L., Sigafoos, J., Lancioni, G. E., O’Reilly, M. F., Schlosser, R. W., Stevens, M., et al. (2014). An evaluation of speech production in two boys with neurodevelopmental disorders who received communication intervention with a speech-generating device. International Journal of Developmental Neuroscience, 38, 10–16.
Romski, M. A., & Sevcik, R. A. (1997). Augmentative and alternative communication for children with developmental disabilities. Mental Retardation and Developmental Disabilities Research Reviews, 3, 363–368.
Ross, D. E., & Greer, R. D. (2003). Generalized imitation and the mand: Inducing first instances of speech in young children with autism. Research in Developmental Disabilities, 24, 58–74.
Schlosser, R. W., & Wendt, O. (2008). Effects of augmentative and alternative communication intervention on speech production in children with autism: A systematic review. American Journal of Speech-Language Pathology, 17, 212–230.
Schopler, E., Van Bourgondien, M. E., Wellman, G. J., & Love, S. R. (2010). Childhood autism rating scale (2nd ed.). Los Angeles, CA: Western Psychological Services.
Sigafoos, J., Didden, R., & O’Reilly, M. F. (2003). Effects of speech output on maintenance of requesting and frequency of vocalizations in three children with developmental disabilities. Augmentative and Alternative Communication, 19, 37–47.
Skinner, B. F. (1957). Verbal behavior. New York: Appleton-Century-Crofts.
Sloane, H. N., Johnston, M. K., & Harris, F. R. (1968). Remedial procedures for teaching verbal behavior to speech deficient or defective young children. In H. N. Sloane & B. D. MacAulay (Eds.), Operant procedures in remedial speech and language training (pp. 77–101). Boston: Houghton Mifflin.
Sparrow, S. S., Cicchetti, D. V., & Balla, D. A. (2005). Vineland adaptive behavior scales (2nd ed.). Circle Pines, MN: American Guidance Service.
Sundberg, M. L. (2008). Verbal behavior milestones assessment and placement program: The VB-MAPP. Concord, CA: AVB Press.
Tincani, M. (2004). Comparing the picture exchange communication system and sign language training for children with autism. Focus on Autism and Other Developmental Disabilities, 19, 152–163.
Tincani, M., Crozier, S., & Alazetta, L. (2006). The picture exchange communication system: Effects on manding and speech development for school-aged children with autism. Education and Training in Developmental Disabilities, 41, 177–184.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical Approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards.
Informed Consent
Informed consent was obtained from all individual participants included in the study.
Additional information
The first author was a professor at Manhattanville College (Purchase, NY) and the second author was a graduate student at Manhattanville College when data collection for the study occurred.
Rights and permissions
About this article

Cite this article
Gevarter, C., Horan, K. A Behavioral Intervention Package to Increase Vocalizations of Individuals with Autism During Speech-Generating Device Intervention. J Behav Educ 28, 141–167 (2019). https://doi.org/10.1007/s10864-018-9300-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10864-018-9300-4