
Abstract
The paper presents an integrated model of artificial neural networks (ANNs) and non-dominated sorting genetic algorithm (NSGAII) for prediction and optimization of quality characteristics during pulsed Nd:YAG laser cutting of aluminium alloy. A full factorial experiment has been conducted where cutting speed, pulse energy and pulse width are considered as controllable input parameters with surface roughness and material removal rate as output to generate the dataset for the model. In ANN–NSGAII model, back propagation ANN trained with Bayesian regularization algorithm is used for prediction and computation of fitness value during NSGAII optimization. NSGAII generates complete set of optimal solution with pareto-optimal front for outputs. Prediction accuracy of ANN module is indicated by around 1.5 % low mean absolute % error. Experimental validation of optimized output results less than 1 % error only. Characterization of the process parameters in pareto-optimal region has been explained in detail. Significance of controllable parameters of laser on outputs is also discussed.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In laser beam cutting (LBC) process, thermal energy of highly focused laser beam is used for melting the sheet metal where molten material is blown out with the help of a high-pressure coaxial assist gas jet to complete the cut of desired contour (Steen 1991). Pulsed Nd:YAG laser cutting by virtue of its high laser beam intensity, low mean beam power, good focusing characteristics, very small pulse duration and shorter wavelength has become popular for precision cutting of thin sheet metals that require narrow kerf width, small heat affected zone (HAZ) and intricate cut profiles. The process is dependent on numbers of controllable process variables that bear complex nonlinear relationships with the output(s) or quality characteristics and optimisation of laser cutting process is essentially multi-objective in nature.
Optimisation of process parameters for pulsed Nd:YAG LBC have been carried out by researchers based on statistical design of experiment (DOE) methodologies such as Taguchi method (TM) (Dubey and Yadava 2008a, b; Sharma et al. 2010), response surface methodology (RSM) (Mathew et al. 1999), grey relational analysis(GRA) (Caydas and Hascalık 2008; Tsai and Li 2009; Li and Tsai 2009), and soft computing based techniques like genetic algorithm (GA) (Tsai et al. 2008). In TM, weighted effects of signal-to-noise (S/N) ratio of quality characteristics has been used as objective function for optimisation of kerf qualities during cutting of aluminium alloys (Dubey and Yadava 2008a, b) and nickel based super alloy (Sharma et al. 2010) plates. RSM has been used with weighted sum of separately developed regression models for each quality parameters as objective functions for optimisation of HAZ and kerf taper during cutting of carbon fibre reinforced plastic (CFRP) composites (Mathew et al. 1999). During GRA weighted sum of grey relational coefficients is used to compute grey relational grade to determine optimum solution during optimisation of surface roughness (Caydas and Hascalık 2008; Li and Tsai 2009), kerf quality (Tsai and Li 2009) and HAZ (Caydas and Hascalık 2008; Tsai and Li 2009; Li and Tsai 2009)while cutting St-37 steel (Caydas and Hascalık 2008), quad flat non-lead (QFN) strip (Tsai and Li 2009) and electronic printed circuit board (Li and Tsai 2009). Recently, hybrid approach of TM and RSM (Dubey and Yadava 2008a, b) has been incorporated for optimisation of pulsed Nd:YAG laser cutting process. Kernel learning provides a promising solution to nonlinear mapping. Liu and Zhu (2014) have presented a uniform framework for kernel self optimisation for kernel based feature extraction and recognition. The proposed hyperspectral imagery classification techniques have been evaluated successfully on two real datasets. Further Zhang et al. (2014) has developed an algorithm for optimising matrix mapping with data dependent kernel for feature extraction of image for classification. The method implements the algorithm without transforming matrix to vector and reduces the storage and computing burden. GA is derivative free stochastic optimisation method based loosely upon the concept of natural selection and natural genetics (Goldberg 2004). GA has been employed for different applications so far. Huang et al. (2007) have proposed an innovative watermarking scheme based on progressive transmission with GA. In the process both the watermark imperceptibility and watermark robustness requirements are optimised. Recently, Chen and Huang (2014) have proposed a co-evolutionary genetic watermarking scheme based on wavelet packet transform. Further it has been experimentally validated that, the proposed method can increase the capability to resist specific image processing method while keeping quality of the watermarked image acceptable. Takeyasu and Kainosho (2014) have devised the objective function to a scheme for international logistics problem which considers a reduced cost for the volume of lots and have successfully employed GA with a new selection method, Multi-step tournament selection method for solving the problem. Tsai et al. (2008) have employed GA for optimizing process parameters during laser cutting of QFN packages. In this work, the optimisation has been carried out using weighted sum of separately developed regression models for each quality parameters as objective functions. Balic et al. (2006) have designed a computer-aided, intelligent and GA based programming system for CNC cutting tools selection, tool sequences planning and optimisation of cutting conditions. Application of that method was found to reduce the total machining time by 16 % during turning operation of a rotational part. Saraç and Ozcelik (2012) has determined proper selection and crossover operators of GA through DOEs and the GA so developed is employed to obtain machine-cells and part-families in a cellular manufacturing system with the objective of maximizing the grouping efficacy. During comparative study with several well-known algorithms indicates that the proposed GA improves the grouping efficacy for 40 %.
It can be noted that, all the researches mentioned above have converted the multi-objective problem into single objective one before optimisation through weighted sum of S/N ratio/grey relational coefficients/regression models. But the assignment of weight factors in all the methods is often subjective in nature and produces only one particular optimum solution on the optimal front. However, it is necessary for a truly multi-objective optimization algorithm to generate a number of optimal solutions known as pareto-optimal solutions, with good diversity in objective and/or decision variable values. That will in turn help a user to select an optimum condition with corresponding operating parameter from the gamut of pareto-optimal solutions. Multi-objective genetic algorithm approach has been employed by Li et al. (2013) in the domain of feature fatigue for solving the feature addition problem. Validation of the proposed method using a smart phone case shows good performance in convergence. But, to the authors’ knowledge, no such effort has been made so far for determination of pareto-optimal solutions for a multi objective optimization problem (MOOP) of laser cutting process.
Non-dominated sorting genetic algorithm II (NSGAII), a soft computing technique developed by Deb et al. (2000) can be efficiently employed for such MOOP to obtain pareto-optimal solutions. But complex mathematical relationship between input and output variables of laser cutting often incurs significant error during formation of a closed form objective function. It can be suitably avoided on employing artificial neural networks (ANNs) for computation of objective function values. ANN is a soft computing technique, particularly popular for approximating complex nonlinear relationships between input–output process variables to any arbitrary degree of accuracy (Haykin 2006). Single hidden layer Back Propagation Neural Network (BPNN) is a popular variant of multilayer feed forward ANN. Conventional BPNN has been already employed by Yilbas et al. (2008) for classification of striation patterns of the laser cut surfaces and by Kuo et al. (2011) for prediction of depth, width and uniformity of cut. Quintana et al. (2011) have developed a reliable surface roughness monitoring application based on an ANN approach for vertical high speed milling operations. Geometrical cutting factors, dynamic factors, part geometries, lubricants, materials and machine tools were all considered as parameters during ANN modeling. Feng et al. (2014) have proposed a two stage backpropagation neural networks for investigating defects in LED chips. K-means clustering method is used for extracting the required feature values of the pad area and recognized by BPNN. The recognition rate obtained is 98.83 % and that indicates efficacy of the model. Ashhab et al. (2014) have modeled a combined deep drawing–extrusion process using ANN’s. The complex method constrained optimization is applied to the ANN model to find the inputs or geometrical parameters that will produce the desired or optimum values of total equivalent plastic strain, contact ratio and forming force. Narayanasamy and Padmanabhan (2012) have compared the regression and neural network modeling for predicting spring back of interstial free steel sheet during air bending process. It has been observed that the ANN modeling process has been able to predict the spring back with higher accuracy when compared with regression model. Xiong et al. (2014) have compared a neural network and a second order regression analysis for predicting bead geometry in robotic gas metal arc welding for rapid manufacturing. Better prediction performance is observed for neural networks. In a recent work, Jha et al. (2014) have compared performance of BPNN, genetic algorithm tuned neural network (GANN) and particle swarm optimization algorithm-tuned neural network (PSONN) for modeling of weld quality in electron beam welding of reactive material (Zircaloy-4). BPNN outperformed other two processes in most of the cases.
Wang and Cui (2013) have introduced a Levenberg Marquardt (LM) algorithm based auto associative neural network for monitoring tool wear. LM has improved the convergence accuracy and results indicate the proposed method is more accurate compared to gradient descent method. However, convergence accuracy of LM is not satisfactory during training and testing of small and noisy dataset. BPNN with Bayesian regularisation (BR) (MacKay 1992) is particularly useful for that purpose. But no application of it has been observed
Therefore, in the present work a trained ANN is coupled with NSGAII to develop an integrated ANN–NSGAII model where objective function values for NSGAII optimisation can be directly predicted by the trained ANN. The two-way traffic between ANN and NSGAII will eliminate the need for closed form objective function. On convergence that model will determine a pareto-optimal front with number of optimal solutions. That model has been employed on an experimental dataset for modelling and optimisation of material removal rate and surface roughness for pulsed Nd:YAG laser cutting of aluminium alloy sheet. Aluminium alloys are widely used in aeronautical and automotive industries but their highly reflective nature poses difficulty during laser cutting. Some attempts on optimisation of kerf quality (Dubey and Yadava 2008a, b), surface roughness and HAZ (Stournaras et al. 2009) for laser cutting of aluminium alloy have been taken up using TM. But no such study on soft computing application has been observed. Therefore, in present work optimisation of laser cutting of aluminium alloy has been carried out using ANN–NSGAII model. Required input/output data have been obtained from experimentation. A single hidden layer BPNN with BR has been used for ANN training purpose. Experimental details, selection of best ANN through training and testing, NSGAII optimisation and its validation have been detailed in subsequent sections. Finally, behaviour of the process parameters on output characteristics in pareto-optimal region has been also explained in detail.

Experimental setup
Experimental details
In the present investigation, experiment has been carried out using a 135 W pulsed Nd:YAG laser (Model JK-704, GSI Lumonics) machining system with CNC work table as shown in Fig. 1. Nitrogen is used as an assist gas. The controllable input process parameters considered are cutting speed (V), pulse energy (E) and pulse width (W). Focal length of lens (120 mm), nozzle diameter (1.5 mm), standoff distance (6.0 mm), assist gas pressure (6 bar) and spot diameter (0.24 mm) are kept constant throughout the experimentation while focus position is kept at the job surface. The Hindalco (India) made cold rolled AA1200 aluminium alloy sheet of thickness 1.22 mm has been used as job specimen.
The feasible range of input process parameters for complete through cutting has been obtained through an exhaustive set of pilot experiments. The numerical value of control factors at different levels for aluminium alloy sheets are furnished in Table 1.
27 experiments based on level 3 factor full factorial experiments have been conducted without replication. Replication in experimental run is carefully avoided as different output values with same set of input data generally leads to an erroneous ANN training.
In the present analysis, material removal rate (MRR) and surface roughness \((\hbox {R}_{\mathrm{a}})\) are analysed as two output quality characteristics. A 70 mm long cut has been produced with every setting of input parameters and the loss of mass was obtained by weighing the specimen before and after the cutting using Electronic Balance (Model Precisa XB220A, Switzerland). MRR (mg/min) is calculated by using the following formula (Dubey and Yadava 2008a, b):
Surface roughness of the cut edge profile is measuredwith Taylor Hobson Precision, Surtronic 3+ surface profilometer for a sampling length of 4 mm. No surface preparation was carried out for any of the surfaces. Surface roughness is obtained in terms of arithmetic mean value \((\hbox {R}_{\mathrm{a}})\). For each cutting, measurement of \((\hbox {R}_{\mathrm{a}})\) value has been repeated three times along sampling length and the average \((\hbox {R}_{\mathrm{a}})\) values are calculated. Out of 27 experimental datasets, 22 sets have been used for ANN training and the rest for ANN testing. Training and testing datasets are furnished in Table 2. Thus input vector (X) and output vector (D) for the present problem is given by,

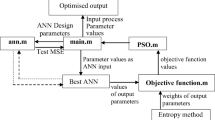
The logical flow diagram of integrated ANN–NSGAII model
Integrated ANN–NSGAII model
In the present work, an integrated ANN–NSGAII model has been devised which combines ANN and NSGAII for modelling and optimisation of the operational parameters of pulsed Nd:YAG laser cutting process. In that model, ANN initially develops an approximate relationship between input–output process parameters and predict the outputs for any given input parameters upto an appreciable degree of accuracy. That trained ANN is further used for estimation of objective function value during NSGAII optimisation. Here, introduction of ANN eliminates the need of closed form objective functions for optimisation and thereby reduces the chances to incur significant error during formation of complex mathematical relationship between input and output variables. Finally, NSGAII is employed to carry out multi-objective optimisation of process parameters. It is integrated with the trained ANN for estimation of objective function value. NSGA II generates a number of optimal solutions known as pareto-optimal solutions. That in turn helps a user to select an optimum condition with corresponding operating parameter from the gamut of pareto-optimal solutions.
Computation of training, prediction and optimisation phases in integrated ANN–NSGAII model is carried out by running a single program developed in MATLAB 7.0 environment using Pentium 4, 3 GHz and 512 MB PC. A logical flow diagram for the ANN–NSGAII model is given in Fig. 2. The present model works in two phases. In the training and prediction phase, ANN module determines the architecture with maximum prediction accuracy on training and testing a number of single hidden layer ANN architectures using BPNN with BR algorithm and designates as best ANN. Further, in optimisation phase, NSGAII subroutine sends initial population information to the ANN module in the main program. The best ANN generates the value of objective function corresponding to the initial population. The program control then switches back to the NSGAII subroutine and the cycle continues up to the point of appropriate convergence. Working of ANN and NSGAII for the present problem is furnished in some detail as follows.
Working of ANN module for training and prediction
Input vector (X) and output vector (D) in Eq. (2) consists nodes of input layer and output layer for present BPNN architecture respectively, as shown in Fig. 3. All the input, hidden and output nodes are interconnected by weights. All weights are initialized by generating random numbers before training. Each network is iterated for 1000 epochs during training. For better training performance, input and output data are normalised between 0 and 1 before actual application of the network and designated as \({\mathbf{X}}_{\mathrm{nor}}\) and \({\mathbf{D}}_{\mathrm{nor}}\) respectively. In all the cases, activation function of the hidden layer and output layer is sigmoidal and linear respectively. On forward pass computation generated output value (O) is compared with desired normalised output value \({\mathbf{D}}_{\mathrm{nor}}\) and their differences are computed as error. Present BPNN with BR model minimizes a term O, a linear combination of sum of the squared errors and sum of the squared weights. If the computed O satisfies convergence criterion, training stops. Otherwise, network weights are updated for next iteration through LM algorithm. LM algorithm ensures modelling of high nonlinearity in dataset through second order approximation of errors. In the present study, mean squared error (MSE) is computed at the point of convergence and considered as performance index for a network. MSE is calculated by,
In order to test generalization/prediction capability (Haykin 2006), the trained network is further fed with five sets of test input dataset that was not used (i.e. unknown to ANN) during training. The resulting ANN output is compared with corresponding known experimental output to determine the prediction error which is measured as MSE. This combined process of training and testing is carried out for different architectures of network by varying the number of hidden layer neurons, as a design parameter of the network, within a range of 4–11. The final network thus obtained then interfaces with NSGAII subroutine of the model for optimisation (Fig. 2).

Architecture of the back propagation networks
Objective function for present study
In the present multi-objective optimisation problem best cutting is ensured by maximum MRR and minimum surface roughness \((\hbox {R}_{\mathrm{a}})\) value along the length of cut. But as the program for NSGA II algorithm was meant for finding out the minima of a function, maximisation of a objective function f(x) is achieved by minimising—f(x). Therefore, the present optimisation problem can be given as,
The objective functions:
-
Minimise: \(-\)MRR (V, E, W)
-
Minimise: \((\hbox {R}_{\mathrm{a}})\) (V, E, W)
Subject to the constraints:
where, V, E, W is the laser cutting input parameters and MRR and \((\hbox {R}_{\mathrm{a}})\) represent the cut quality parameters as output.

Non-dominated sorting method
Optimisation with NSGAII
In the present work, an elitist non-dominated sorting GA (termed as NSGAII) (Deb 2002) has been employed for determination of pareto-optimal front for surface roughness and MRR. A schematic diagram of NSGAII has been shown in Fig. 4. In this elite preserving method, offspring population of size N, generated form genetic operators such as fitness scaling, selection, crossover and mutation, is combined with parent population N. Total 2N population is divided into number of non-dominated levels such as \(\hbox {L}_{1}, \hbox {L}_{2}, \hbox {L}_{3}\) etc based on principle of non dominations (Deb 2002). Each level contains a set of non-dominated solutions. Selection of best N solutions is carried out on including the solutions from non-dominated levels in ascending order. If inclusion of all solutions of last non-dominated level exceeds the population size N, solutions of the last level is sorted using the crowded tournament selection operator and remaining solutions of N are selected using descending order of magnitude of crowding distance. The new population of size N so created is again passed through genetic operators to create another new offspring population of size N. The computation stops if the average change in the fitness function value over stall generations is less than function tolerance and upon convergence best optimal solutions are obtained.
In the present problem a population of each of the N strings in population contains three substrings that indicate the constraining variables like V, E and W. The substring values of every string are therefore indicating values of V, E and W and sent to ANN module as input. The trained ANN upon prediction returns MRR and surface roughness as objective function values. Then computation continues following the above mentioned procedure.
NSGAII optimisation performance is closely dependent on proper selection of GA parameters such as, selection function, crossover fraction (p), mutation rate (m) and size of population (N). NSGAII conventionally employs crowding tournament selection for determination of non-dominated front. Elite count is kept 2 which include all solutions of first two non-dominated fronts as elites. Generally, crossover fraction (p) is kept near to 1.0 so that almost all the parents can participate in crossover. While, mutation rate (m) is kept to low value to avoid random search. However, in the present work near optimal GA parameters have been selected through the following steps:
-
(i)
Three levels have been suitably selected for each GA parameters p, m and N, within the range of 0.6–0.8, 0.01–0.02, 25–100 respectively as mentioned in Table 3.
-
(ii)
Initially, p is varied keeping m and N fixed at their mid values such as 0.015 and 50 respectively. Optimal solutions in each trial are compared with corresponding experimental output and absolute % errors so obtained are considered as measure of prediction accuracy. Table 3 indicates, optimisation with p \(=\) 0.7 have maximum prediction accuracy with minimum absolute % error of 0.58 and 0.26 % during prediction.
-
(iii)
Further, p and N values are fixed at 0.7 and 50. During testing m \(=\) 0.02 produces best prediction accuracy (Table 3).
-
(iv)
Finally, N is varied between 25 to 100 keeping p and m fixed at 0.7 and 0.02 respectively. It is observed that, increase in N will result substantial increase in optimisation time with comparatively insignificant improvement in prediction accuracy. Therefore, N \(=\) 25 is considered for the purpose.
Thus selected parameters for present work are p \(=\) 0.7, m \(=\) 0.02 and N \(=\) 25.
Set values/options for NSGAII operators in the present study are furnished below:
-
Size of populations (N): 25
-
Selection function: crowding tournament selection
-
Elite count: 2
-
Fitness function: rank scaling
-
Crossover function: two point
-
Crossover fraction (p): 0.7
-
Mutation function: adaptive feasible
-
Mutation rate (m): 0.02
Results and discussion
Performance of ANN module
ANN training and testing performance of each network is given in Table 4. Prediction capability being the primary objective of a trained ANN, best ANN architecture has been selected based on performance of a particular ANN during testing with test data. Figure 5 indicates best prediction performance by 3-6-2 network with minimum testing MSE of 3.05E\({-}\)04. Therefore, 3-6-2 network is considered as ANN with best prediction performance and employed further for interfacing with NSGAII for optimisation.
Prediction capability of the best ANN i.e. 3-6-2 network is assessed by calculating absolute % error in prediction for every test data after corresponding de-normalisation, as follows.
During testing with test data it is observed from Table 5 that 3-6-2 network can reduce mean absolute % error up to 1.03 and 1.58 % corresponding to surface roughness and MRR, respectively. Moreover, the maximum absolute % errors for them during ANN testing are 1.72 and 2.25 %. Order of magnitude of the errors indicates fairly good prediction accuracy of best ANN. This good prediction capability coupled with very negligible training time (9.57 s) has justified the use of ANN as a powerful tool for estimation of MRR and surface roughness of laser cutting for any combination of operational parameter setting.

Variation of training and prediction performances with hidden layer neurons

Pareto-optimal front obtained with NSGA II
Performance of NSGAII module
Optimisation has been carried out using trained best ANN (3-6-2 network) for computation of objective function value during iterations of NSGAII. Search ended after 118 generations (iterations) when average pareto-spread has reached assigned minimum value. Figure 6 indicates the pareto-optimal front for MRR and surface roughness with multiple pareto-optimal solutions that provides the user an opportunity to select a specific solution from them as per requirement.
Though the front has been developed with 18 pareto-optimal solutions as given in Table 6, any intermediate points can be directly obtained from it. the pareto-optimal front in Fig. 6 indicates –MRR values. That negative sign does not associated with physical value of MRR obtained but it only indicates maximisation of the MRR in algorithm. Therefore in Table 6 and in subsequent analysis absolute value of MRR has been considered.
From Fig. 6 and Table 6 it is observed that, the minimum surface roughness can be obtained as \(6.23\, \upmu \hbox {m}\) with V \(=\) 1.2 mm/s, E \(=\) 4.5 J and W \(=\) 0.5 ms and the corresponding MRR being 36.66mg/min. Figure 6 and Table 6 also indicates that, maximum MRR can be obtained is 57.494 mg/min with V \(=\) 1.8 mm/s, E \(=\) 6.8 J and W \(=\) 0.5 ms, the corresponding surface roughness being \(9.12\, \upmu \hbox {m}\).
Variation of the process parameters on surface roughness and MRR in pareto-optimal region have been studied using the pareto-optimal dataset in Table 6.

Variation of surface roughness and MRR with process parameters in pareto-optimal region a variation of surface roughness with cutting speed (mm/min), b variation of surface roughness with pulse energy (J), c variation of MRR with cutting speed (mm/min), d variation of MRR with pulse energy (J)

Surface roughness measured during experimental validation
Influence of process parameters on surface roughness
Figure 7a, b indicate variation of surface roughness with cutting speed and pulse energy in pareto-optimal region. It can be observed from Fig. 7a that surface roughness increases with cutting speed and relationship appears approximately parabolic in nature. This behaviour can be explained by the fact that the valleys and ridges of the cut surface are directly influenced by the overlap of two successive cuts. This overlap, in turn, decreases with increasing cutting speed eventually increasing surface roughness. Figure 7b indicates that, surface quality decreases linearly with increase in pulse energy and to obtain best surface quality pulse energy should be kept at the minimum operating level of 4.5 J. Higher level of pulse energy for a fixed pulse width and frequency would mean greater area of melting/ablation resulting in side burning and consequent poorer surface finish on the cut surface.
Pareto optimal solution indicates the selection of a minimum constant pulse width of 0.5 ms for obtaining minimum surface roughness as observed in Table 6. Pulse width is kept low as high pulse width accumulates more heat in every pulse to melt deeper grooves and produce large peak and valleys to end up with high surface roughness.
Influence of process parameters on MRR
Variation of MRR with cutting speed and pulse energy can be obtained on plotting the solutions of pareto-optimal zone and given in Fig. 7c, d. It is observed (Fig. 7c) that the maximum amount of material can be removed if the laser system is operated with highest cutting speed i.e. V \(=\) 1.8 mm/min. Figure 7d indicates that, maximum MRR can be obtained on operating with maximum pulse energy of E \(=\) 6.8J. Figure7c, d further indicate that MRR increases almost linearly with increase in cutting speed and pulse energy, respectively. Higher cutting speed means less overlap and hence more amount of space which contributes to material removal in each cut and thus MRR increases with higher cutting speed. With more applied energy (and hence higher peak power for a given pulse width) the cut will be more uniform across the depth as well as more material removal due to side burning. These two factors combine to yield higher MRR with increasing pulse energy.
Pareto optimal solution indicates the selection of a minimum constant pulse width of 0.5 ms for the entire front as observed in Fig. 6 and Table 6. Shorter pulse width results in high peak power (for a given pulse energy and frequency) resulting more uniform cut across the depth that promotes increase in MRR.
Validation of ANN–NSGAII model
Finally, accuracy of the optimal solutions obtained through ANN–NSGAII model is tested on comparing them with experimental data. Two solution points with (i) \(\hbox {MRR}=45.109\) mg/min, \(\hbox {Ra}=7.02\,\upmu \hbox {m}\) and (ii) \(\hbox {MRR}= 57.494\,\hbox {mg/min}\), \((\hbox {R}_{\mathrm{a}})=9.12\,\upmu \hbox {m}\) on the pareto-optimal front (Fig. 6) is randomly taken and considered for the validation with experimental data.
From Table 6 it can be observed that operational input parameter (V, E and W) values for solution points are (i) V \(=\) 1.5 mm/s, E \(=\) 4.5 J, W \(=\) 0.5 ms and (ii) V \(=\) 1.8 mm/s, E \(=\) 6.8 J, W \(=\) 0.5 ms respectively. The results of ANN–NSGAII optimisation model is validated on comparing with experimental output obtained using the aforesaid input parameter (V, E and W) values and experimental outputs obtained are (i) MRR \(=\) 45.066 mg/min, \((\hbox {R}_{\mathrm{a}})=7.06\,\upmu \hbox {m}\) and (ii) MRR \(=\) 57.696 mg/min, \((\hbox {R}_{\mathrm{a}})=9.13\,\upmu \hbox {m}\) respectively. Surface roughness profile obtained over sampling length during validation experiment is given in Fig. 8. The accuracy of ANN–NSGAII model is evaluated by calculating the absolute % error between outputs predicted by proposed model and experimental data and furnished in Table 7. It is observed that, the ANN–NSGAII model can predict optimized output with absolute % error of 0.499 and 0.096 % for MRR and surface roughness during comparison with first solution point and 0.063 and 0.350 % during comparisonwithsecond solution point. The fairly low errors indicate the accuracy of the model and validity of the characteristics explained above based on the optimal solutions.

Comparison of absolute % error between different ANN models during testing with testing input data of Surface Roughness \((\hbox {R}_{\mathrm{a}})\)

Comparison of absolute % error between different ANN models during testing with testing input data of Material Removal Rate
The level of accuracy obtained by present hybrid method may be due to several reasons. Conventionally a regression model developed from experimental dataset is used as objective function during optimisation which is very much susceptible to noise in dataset. But noise is unavoidable in an experimental dataset. Therefore, in the present work, conventional regression model is replaced with a BPNN with BR model as objective function, which is particularly suitable for modelling a noisy dataset (MacKay 1992). Prediction accuracy of a trained ANN is assessed by determination of absolute % error in prediction (Eq.(5)). Prediction accuracy of BPNN with BR has been compared with other popular feed forward ANN models such as gradient descent BPNN with adaptive learning rate (GDA), gradient descent BPNN with variable momentum (GDX), conjugate gradient BPNN with Fletcher-Reeves updates (CGF), BPNN with LM algorithm and Radial basis function networks (RBF). Figures 9 and 10 present a comparative study where prediction performance of BPNN with BR has been compared with all above mentioned models in terms of absolute % error and mean absolute % error for surface roughness and material removal rate. From figures it is clear that, BPNN with BR produces substantially higher prediction accuracy. Now, that accuracy in determination of objective function through BPNN with BR during iterations may lead to low % error during optimisaiton.

Comparative study of optimised output(s) obtained by different optimisation methods
Further, optimisation performance of ANN–NSAGAII has been compared with other relevant popular optimisation methods like weighted sum method of GA with ANN as objective function and conventional NSGAII with regression model as objective function. Comparative study has been presented in Table 8 and Fig. 11. It is clear from Fig. 11 that, pareto-optimal front for ANN–NSGAII is superior compared to conventional NSGAII. A solution point on pareto-optimal front of ANN–NSGAII is randomly considered (\((\hbox {R}_{\mathrm{a}})=7.02\,\upmu \hbox {m}\), MRR \(=\) 45.109 mg/min) and corresponding operational input parameter (V, E and W) values are V \(=\) 1.5 mm/s, E \(=\) 4.5 J, W \(=\) 0.5 ms. Experimental output corresponding to that input parameter setting is indicated in Fig. 11 and on comparing with it; ANN–NSGAII incurs absolute % error of 0.499 and 0.096 % for MRR and surface roughness respectively. The same operational input parameter values determine a solution point of \((\hbox {R}_{\mathrm{a}})=7.02\,\upmu \hbox {m}\) and MRR \(=\) 45.109 mg/min on pareto-optimal front of conventional NSGAII and ends up with an absolute % error of 1.08 and 0.31 % during validation. Weighted sum approach of conventional GA converts multi objective problem into single objective one and generates single optimal solution within objective space which may or may not be on the pareto-optimal front. Therefore, it is not assured that it will be among the best solution and closely match with actual experimental value. The optimised output obtained by weighted sum method of GA for the present problem also does not lie on pareto front (Fig. 11) and results a comparatively higher validation error (upto 2.11 %). That comparison clearly indicates the superior performance of ANN–NSGAII model in predicting optimised solution very close to actual experimental value. Therefore, inclusion of ANN models with superior prediction capability like BPNN with BR as objective function made NSGAII as an optimisation model with adequately high accuracy.
Computational analysis of ANN–NSGAII model
Present ANN–NSGAII model indicated in Fig. 2. Operate in two integrated phase. In phase I, selects best ANN through training and testing of different ANN architectures varying hidden layer neurons from 4 to 11. Individual training time for all architectures has been given in Table 9. Generally training time increases with increase in network complexity i.e. increase in number of hidden layer. But in Table 9 it can be observed that after 8 hidden layer neurons, training time of the network decreases with increase in network complexity. It may be due to over fitting of data. Table 4 indicates, in those cases network will perform well during training (i.e. low training MSE) but will lack in prediction capability (i.e. high testing MSE). However, total training time of all ANN under study has been found as 161.5 s (Table 9). In phase II best ANN (3-6-2 network) is employed as objective function during NSGAII optimisation.Optimisation completed with 996 iterations, 25,025 function counts, and optimisation time of 249.14 s. However, changing the epochs for ANN training, crossover fraction (p), mutation rate (m) and population size (N) for NSGAII, time for ANN training and optimisation time may vary. It has been observed that after 1000 epochs any increase in epoch number will only increase the training time without increasing the prediction capability. Therefore p, m and N have been varied to select a suitable combination as discussed in “Optimisation with NSGAII” section and Table 3. Variation in p and m does not results much variation in optimisation time but it affects prediction accuracy significantly. The increase in population size will only increase in optimisation time without significant increase in accuracy. Therefore, optimisation has been conducted with N \(=\) 25, p \(=\) 0.7 and m \(=\) 0.02 to get best optimisation time of 249.14 s (Table 9). Total computational time of the ANN–NSGAII model combining training, prediction and optimisation is also found to be 410.64s on a desktop Pentium IV, 3 GHz and 512 MB PC. High accuracy in prediction (less than 1 %) coupled with low computation time indicates suitability of the present ANN–NSGAII model in online application.
Analysis of variance
Finally, a popular statistical technique analysis of variance (ANOVA) is adopted for quantitative estimation of relative contribution of each control factor or parameter on measured response. It is expressed, in terms of F-ratio or in terms of percentage contribution (Montgomery 2001). Greater the F-ratio indicates more significant will be the factor. In the present work, ANOVA is employed for analyzing significance of controlling parameters V, E and W on MRR and surface roughness. ANOVA for MRR is given in Table 10. In 95 % confidence interval alpha is 0.05 and tabulated F-value for V, E and W is \(\hbox {F}_{0.05 }(2, 20) =3.49\). ANOVA test F-value for V, E and W are 36.87, 12.48 and11.97 which is much higher than corresponding tabulated F-value, i.e. 3.49. Moreover, as P-value of all the controlling parameters is less than 0.05 (alpha at 95 % confidence interval) the null hypothesis is rejected. Therefore all factors are considered as significant. Further, high F-ratio of 36.87 indicates cutting speed (V) as the most significant control factor with percentage contribution of 60.13 % for MRR while percentage contribution of other control factors on MRR are pulse width (19.52 %) and pulse energy (20.35 %). Table 10 also indicates ANOVA for surface roughness. ANOVA test F-value for V, E and W are 13.17, 12.13 and8.25 which is much higher than corresponding tabulated F-value, i.e. \(\hbox {F}_{0.05 }(2, 20) =3.49\). P values of all the parameters are less than 0.05. Therefore all the parameters are considered significant at 95 % confidence interval. Here all controlling parameters almost equally contribute in surface roughness and their percentage contributions on surface roughness in increasing order are: pulse width (24.59 %), pulse energy (36.15 %) and cutting speed (39.26 %).
Conclusion
In the present work, multi-objective optimisation of MRR and surface roughness for pulsed Nd:YAG laser cutting of thin sheet of aluminium alloy has been carried out using an integrated ANN–NSGAII model. The model completes training, prediction and multi-objective optimization by running a single program under MATLAB 7.0 environment with significantly small computational time. Best ANN shows high prediction capability and optimisation output results in negligible absolute % error (less than 1 %) during comparison of output with experimental results.
On the basis of the results obtained, the following conclusions can be made:
-
(i)
During process modelling, 3-6-2 network using BPNN with BR algorithm is considered as best ANN based on prediction capability.
-
(ii)
During multi-objective optimisation,NSGAII has developed complete pareto-optimal front instead of single optimal solutionproduced by conventional optimisation techniques.
-
(iii)
That pareto-optimal front indicates that, minimum surface roughness can be obtained is \(6.23\, \upmu \hbox {m}\) with the following conditions: V \(=\) 1.2 mm/s, E \(=\) 4.5 J and \(\hbox {W}=0.5\,\hbox {ms}\) respectively. Maximum MRR can be obtained is 57.494 mg/min with input parameter conditions of V \(=\) 1.8 mm/s, E \(=\) 6.8 J and W \(=\) 0.5 ms.
-
(iv)
In pareto-optimal region surface roughness increases in parabolic nature with cutting speed and linearly with increase in pulse energy. MRR increases almost linearly with cutting speed and pulse energy. Pulse width remains constant at lower limit of the operating range
-
(v)
Optimisation results predicted by ANN–NSGAII model showless than 1 % error of during experimental validation.
-
(vi)
Computational time of ANN–NSGAII is significantly small. Therefore good prediction and optimisation capability with low operational time indicates efficacy of model.
-
(vii)
Cutting speed has maximum influence on MRR and surface roughness.
-
(viii)
Present ANN–NSGAII model will be able to predict and optimise operational parameters of any experimental dataset with reasonable accuracy.
References
Ashhab, M. S., Breitsprecher, T., & Wartzack, S. (2014). Neural network based modeling and optimization of deep drawing–extrusion combined process. Journal of Intelligent Manufacturing, 25(1), 77–84.
Balic, J., Kovacic, M., & Vaupotic, B. (2006). Intelligent programming of CNC turning operations using genetic algorithm. Journal of Intelligent Manufacturing, 17(3), 331–340.
Caydas, U., & Hascalık, A. (2008). Use of the grey relational analysis to determine optimum laser cutting parameters with multi-performance characteristics. Opticsand Laser Technology, 40(7), 987–994.
Chen, Y. H., & Huang, H. C. (2014). Coevolutionary genetic watermarking for owner identification. Neural Computing and Applications. doi:10.1007/s00521-014-1615-z
Deb, K. (2002). Multi-objective optimisation using evolutionary algorithms. Singapore: Wiley.
Deb, K., Agarwal, S., Pratap, A., & Meyarivan, T. (2000). A fast elitist non-dominated sorting genetic algorithm for multi-objective optimisation: NSGA-II. In Proceedings of the Parallel Problem Solving from Nature VI (PPSN-VI), 849–858.
Dubey, A. K., & Yadava, V. (2008a). Optimization of kerf quality during pulsed laser cutting of aluminium alloy sheet. Journalof Material Processing Technology, 204, 412–418.
Dubey, A. K., & Yadava, V. (2008b). Multi-objective optimisation of laser beam cutting process. Optics and Laser Technology, 40, 562–570.
Feng, C., Kuo, J., Hsu, C. M., Liu, Z., & Wu, H. (2014). Automatic inspection system of LED chip using two-stages back-propagation neural network. Journal of Intelligent Manufacturing, 25(6), 1235–1243.
Goldberg, D. E. (2004). Genetic algorithms in search, optimisation and machine learning. Delhi: Pearson Education.
Haykin, S. (2006). Neural networks: A comprehensive foundation. Delhi: Pearson Education.
Huang, H. C., Pan, J. S., Huang, Y. H., Wang, F. H., & Huang, K. C. (2007). Progressive watermarking techniques using genetic algorithms. Circuits, Systems, and Signal Processing, 26(5), 671–687.
Jha, M. N., Pratihar, D. K., Bapat, A. V., Dey, V., Ali, M., & Bagchi, A. C. (2014). Knowledge-based systems using neural networks for electron beam welding process of reactive material (Zircaloy-4). Journal of Intelligent Manufacturing, 25(6), 1315–1333.
Kuo, C.-F. J., Tsai, W.-L., Su, T.-L., & Chen, J.-L. (2011). Application of an LM-neural network for establishing a prediction system of quality characteristics for the LGP manufactured by \(\text{ CO }_{2}\) laser. Optics and Laser Technology, 43(3), 529–536.
Li, M., Wang, L., & Wu, M. (2013). A multi-objective genetic algorithm approach for solving feature addition problem in feature fatigue analysis. Journal of Intelligent Manufacturing, 24(6), 1197–1211.
Li, C.-H., & Tsai, M.-J. (2009). Multi-objective optimization of laser cutting for flash memory modules with special shapes using grey relational analysis. Optics and Laser Technology, 41(5), 634–642.
Liu, X. F., & Zhu, X. (2014). Kernel-optimized based Fisher classification of hyperspectral imagery. Journal of Information Hiding and Multimedia Signal Processing, 5(3), 431–438.
MacKay, D. J. C. (1992). A practical Bayesian framework for back propagation networks. Neural Computation, 4(3), 448–472.
Mathew, J., Goswami, G. L., Ramakrishnan, N., & Naik, N. K. (1999). Parametric studies on pulsed Nd:YAG laser cutting of carbon fibre reinforced plastic composites. Journal of Material Processing Technology, 89–90, 198–203.
Montgomery, D. C. (2001). Design and analysis of experiments (5th ed.). New York: Wiley.
Narayanasamy, R., & Padmanabhan, P. (2012). Comparison of regression and artificial neural network model for the prediction of springback during air bending process of interstitial free steel sheet. Journal of Intelligent Manufacturing, 23(3), 357–364.
Quintana, G., Garcia-Romeu, M. L., & Ciurana, J. (2011). Surface roughness monitoring application based on artificial neural networks for ball-end milling operations. Journal of Intelligent Manufacturing, 22(4), 607–617.
Saraç, T., & Ozcelik, F. (2012). A genetic algorithm with proper parameters for manufacturing cell formation problems. Journal of Intelligent Manufacturing, 23(4), 1047–1061.
Sharma, A., Yadava, V., & Rao, R. (2010). Optimization of kerf quality characteristics during Nd:YAG laser cutting of nickel based superalloy sheet for straight and curved cut profiles. Optics and Lasers in Engineering, 48(9), 915–925.
Steen, W. M. (1991). Laser material processing. New York: Springer.
Stournaras, A., Stavropoulos, P., Salonitis, K., & Chryssolouris, G. (2009). An investigation of quality in \(\text{ CO }_{2}\) laser cutting of aluminum. CIRP Journal of Manufacturing Science Technology, 2(1), 61–69.
Takeyasu, K., & Kainosho, M. (2014). Optimization technique by genetic algorithms for international logistics. Journal of Intelligent Manufacturing, 25(5), 1043–1049.
Tsai, M.-J., & Li, C.-H. (2009). The use of grey relational analysis to determine laser cutting parameters for QFN packages with multiple performance characteristics. Opticsand Laser Technology, 41(8), 914–921.
Tsai, M.-J., Li, C.-H., & Chena, C.-C. (2008). Optimal laser-cutting parameters for QFN packages by utilizing artificial neural networks and genetic algorithm. Journalof Material Processing Technology, 208(1–3), 270–283.
Wang, G., & Cui, Y. (2013). On line tool wear monitoring based on auto associative neural network. Journal of Intelligent Manufacturing, 24(6), 1085–1094.
Xiong, J., Zhang, G., Hu, J., & Wu, L. (2014). Bead geometry prediction for robotic GMAW-based rapid manufacturing through a neural network and a second-order regression analysis. Journal of Intelligent Manufacturing, 25(1), 157–163.
Yilbas, B. S., Karatas, C., Uslan, I., Keles, O., Usta, Y., Yilbas, Z., et al. (2008). Wedge cutting of mild steel by \(\text{ CO }_{2}\) laser and cut-quality assessment in relation to normal cutting. Optics and Lasers in Engineering, 46(10), 777–784.
Zhang, D. L., Qiao, J., Li, J. B., Qiao, L. Y., Chu, S. C., & Roddick, J. F. (2014). Optimizing matrix mapping with data dependent kernel for image classification. Journal of Information Hiding and Multimedia Signal Processing, 5(1), 72–79.
Acknowledgments
The authors are thankful to all scientists and staff members of Centre for Laser Processing of Materials (CLPM), ARCI, Hyderabad, India, for kindly extending the facilities for conducting experiments on laser cutting and for providing useful advice and suggestions. Authors are also thankful to the Prof. Gautam Majumdar, Department of Mechanical Engineering, Jadavpur University for providing the facilities for post experimental measurements.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Chaki, S., Bathe, R.N., Ghosal, S. et al. Multi-objective optimisation of pulsed Nd:YAG laser cutting process using integrated ANN–NSGAII model. J Intell Manuf 29, 175–190 (2018). https://doi.org/10.1007/s10845-015-1100-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-015-1100-2