
Abstract
In this work, the excitation source based glottal information is explored as a supplementary evidence for developing robust audio-visual speech recognition system. The commonly used audio feature mel-frequency cepstral coefficient (MFCC) manifest the vocal-tract information, but not about the excitation source information. We use the glottal information in together with MFCC and visual feature (lips movements) for our objectives. Iterative Adaptive Inverse Filtering (IAIF) method is used to estimate the glottal flow derivative (GFD), and standard mel-frequency cepstral processing approach is applied to obtain glottal mel-frequency cepstral coefficient (GMFCC). The DNN-HMM State Level Minimum Bayes Risk (DNN-HMM sMBR) is used to build the audio-visual speech recognition model. In our experimental analysis, we observe some English alphabet letters like ‘P’ and ‘B’ are confused by machine, when only MFCC or combination of MFCC and lip movements features are used. It may be due to the similar vocal-tract activities, or due to similar lips movements of sound units ‘p’ and ‘b’. The English letters ‘P’ and ‘B’ are distinguished when we include the glottal excitation information in together with vocal-tract and visual features. The conventional audio-visual feature; MFCC and lip movements information provides 82.76%, whereas the inclusion of GMFCC information increases the performance to 84.77%. These experimental observations reflect the usefulness of excitation source information for the development of a robust audio-visual speech recognition system. We also observed that the glottal excitation source information is robust to additive noise and found effective for audio-visual speech recognition system.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Automatic speech recognition (ASR) systems enable the machine to identify and recognize the sounds produced by humans. In noisy environments like market place, railway station and others, people use both speech and visual information like lips movements to recognize the spoken speech (Nandakishor & Pati, 2021). Some visemes (visual sound units) have similar lips movements (Bear & Harvey, 2017; Bozkurt et al., 2007). They create difficulty in viseme recognition task. Researchers prefer to use in together the audio features and visual information for speech recognition, particularly in unfavourable conditions (Lucey et al., 2005). This type of system is termed as audio-visual speech recognition system (Lucey et al., 2005; Nandakishor & Pati, 2021).

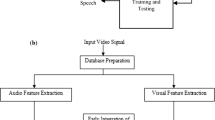
Block diagram of audio-visual speech recognition system
The general block diagram of audio-visual speech recognition system is shown in Fig. 1. The audio feature and the visual feature are concatenated directly to obtained the audio-visual features. This type of approach is called an early integration method (Nandakishor & Pati, 2021). The combined audio-visual feature is fed to a classifier for modeling the speech sounds. During testing phase, the audio-visual feature is obtained by following the same feature extraction process of the training phase. Then the combined audio-visual feature of unknown test utterances is fed to classifier for identifying the speech sound like letters, digits or phonemes.
Most of the audio-visual speech recognition systems use Mel-frequency cepstral coefficients (MFCC) (Noda et al., 2015; Debnath & Roy, 2022) as audio feature, and lip movements related visual features. In terms of source-filter model, speech is produced by exciting the time-varying vocal-tract system by a time-varying excitation source (Rabiner et al., 2013; Rabiner & Schafer, 2009). So, it is also interesting to explore the excitation source based audio information as a supplementary evidence for the development of robust audio-visual speech recognition system. The importance of excitation source information can be understood from the speech production mechanism. The speech sounds can be voiced and unvoiced sounds based on the excitation mode. During voiced speech production, the air is exhaled from the lungs through the trachea and it is interrupted by vibrating the vocal folds (Rabiner & Schafer, 2009) to produce quasi periodic speech signals, such as sound unit ‘b’. In case of producing the unvoiced sound like ‘p’, the air is constricted at high enough velocity resulting turbulence (Rabiner & Schafer, 2009). The sound units or phonemes (‘b’ and ‘p’) have same place of articulation and same manner of articulation, they are difficult to recognize by machine. These phonemes belong to bilabial plosive sounds (International Phonetic Association, 1999). It means they have same vocal-tract activities. Further, the bilabial plosive sounds while produced reflect similar kind of lip movements (Bozkurt et al., 2007). Due to same vocal-tract activities and same lips movements, the ASR system is not robust particularly in unfavourable conditions. In this case, the other component like excitation source information may be useful to differentiate between similar sound units because of its discriminative characteristics (Manjunath & Rao, 2015) and noise robustness (Yegnanarayana et al., 2005).

Speech signal, LP residual and GFD signal of a phoneme ‘b’ and b phoneme ‘p’
The excitation source signal is represented by linear prediction (LP) residual (Yengnanarayana & Satyanarayana Murthy, 2000; Mahadeva Prasanna Srinivasa & Yengnanarayana, 2006; Nandi et al., 2006) or the glottal flow derivative (GFD) signal derived from speech signal by several methods reported in Naylor et al. (2007), Thomas et al. (2012), Murthy and Yegnanarayana (2008), Drugman et al. (2012), Prathosh et al. (2013), Alku (1992), Alku and Vilkman (1996). We used the Wavesurfer for splitting/chopping the phoneme ‘b’ and ‘p’ portions from the wavfiles (sbwb3a.wav and pbwp8a.wav) of track 1 of 2nd CHiME database (Vincent et al., 2013). First we listened the speech wavfiles carefully and manually marked the timing of the phonemes with labels. Then automatically split the phoneme portion as wavfiles. The speech signal, LP residual and GFD signals of these wavfiles are shown in Fig. 2. In a recent work (Dutta et al., 2009), the iterative adaptive inverse filtering (IAIF) is found to be very effective in representation of the excitation source information for detection of spoofed speech. For our work objective, by a comparative study we select the GFD signal computed by using IAIF approach.
The rest of the paper is organized as follows: Sect. 3 provides literature review about the excitation source information for speech recognition task. Section 4 explains the excitation source features extraction process. The details about the database used for experimental studies are discussed in Sect. 5. Section 6 describes about the development of DNN-HMM based audio-visual speech recognition system. Experimental results analysis are discussed in Sect. 6.3. The summary and conclusion of the paper is presented in Sect. 7.
2 Literature survey
Several works related to Hidden Markov Model (HMM) based audio-visual speech recognition have been reported in Matthews et al. (1996), Dupont and Luettin (2000), Kaynak et al. (2004). As the machine learning algorithms advance, getting the facility of high computational resources and availability of large scale database, researchers more focus on deep neural networks (DNNs) approaches. Many works have been reported (Huang & Kingsbury, 2013; Thangthai et al., 2015; Meutzner et al., 2017) where the GMM model of conventional GMM-HMM is replaced by the deep nueral network to improve the performance of audio-visual speech recognizer. This type of model is known as hybrid model (Swietojanski et al., 2013). All of these reported works, used audio feature like MFCC or Relative Spectra Perceptual Linear Prediction (Rasta PLP). These features represent the vocal-tract information only. In literature survey of auido-visual speech recognition tasks, we have not found any work related to excitation source information.
However, the excitation source information has been explored as a supplementary feature in audio based speech recognition tasks. Some of the related works are reported in He et al. (1996), Chengalvarayan (1998), Manjunath and Rao (2015), Tripathi and Rao (2018). In He et al. (1996), authors derived an excitation source feature extracted from LP residual. To extract the excitation source feature, the LP residual is first converted to one-sided auto-correlation sequence and then mel ceptral analysis is applied to obtain the LP residual based cepstral feature. This feature is termed as residual cepstrum feature. Then this derived excitation source feature is combined together with vocal-tract feature that is linear prediction cepstral coefficients (LPCC) to improve the performance of the isolated word recognition system. The experiments are performed using ISOLATED Spoken Letter Database. By combining the vocal-tract feature (LPCC) with excitation source feature the recognition rate improved from 54.1 to 67.1% and from 68.7 to 70.2% for HMM and DTW based speech recognizer respectively.
In another work Chengalvarayan (1998), author developed an HMM based speech recognition system to recognize the name of various cities. The performance of the system is improved by combining the feature extracted from LP residual with LPCC feature. The LP residual is generated using \(10^{th}\) order LP analyzer. Then cepstral coefficients of the normalized LP residual is extracted and this feature is termed as extended feature (EXD) (Chengalvarayan, 1998). The baseline system that is HMM system developed using LPCC feature provides WER of 7.29% whereas the system developed using EXD feature and LPCC together gives 6.69% WER. The experimental results show the benefit of LP residual based excitation feature for speech recognition system.
Two excitation source features; Mel power differences of spectrum in sub-bands (MPDSS) feature and Residual Mel Frequency Cepstral Coefficient (RMFCC) feature are explored in addition to vocal-tract information to improve the performance of the phone recognizer (Manjunath & Rao, 2015). These excitation source features are extracted from LP residual (Manjunath & Rao, 2015). The performance of HMM based phone recognizer using MFCC, RMFCC and MPDSS are 58.45%, 35.74% and 14.93% respectively on TIMIT database. The system with RMFCC feature got better performance than MPDSS feature but less than MFCC feature. The best performance of 60.03% is observed when the vocal-tract feature MFCC is combined with excitation source feature RMFCC.
In another work Tripathi and Rao (2018), authors used a speech mode classifier (conversation, extempore and read mode) at front-end of the phone recognizer to improve the performance. The excitation source features; MPDSS and RMFCC are explored for development of speech mode classifier (SMC). The performance of SMC developed with MFCC is better than the excitation source features alone. The classification accuracy of RMFCC is more than MPDSS. The highest average classification accuracy of 97% is observed when the MFCC, RMFCC and MPDSS feature are fused together. The integration of SMC in phone recognizer improved by an accuracy of 11.8%.
From the literature, we know the excitation source features can be used to improve the performance of speech recognition system. As compare to speaker recognition task, the use of excitation source based features in speech recognition task is very limited. In these reported works, the excitation source information are extracted from LP residual signal. This motivate us to explore the other form of excitation feature like glottal source excitation information for developing the audio-visual speech recognition system.
3 Excitation source feature extraction
The excitation source signal like LP residual and GFD signal can be represented in compact form by using MFCC feature extraction method. The MFCC features extracted from the LP residual is termed as RMFCC features, similarly if it is extracted from GFD residual, then it is known as Glottal Mel Frequency Cepstral Coefficient (GMFCC) features.
3.1 Residual mel frequency cepstral coefficient
LP residual of the speech signal is obtained by applying inverse filtering on the speech signal (Yengnanarayana & Satyanarayana Murthy, 2000; Mahadeva Prasanna Srinivasa & Yengnanarayana, 2006; Nandi et al., 2006). In LP analysis, the speech sample s(n) is predicted as the linear weighted sum of the past speech samples. The predicted sample \({\hat{s}}(n)\) is given as
where p is the order of prediction, and \(\{a_{k}\}\) is the set of linear prediction coefficients.
The LP coefficients usually contains the vocal-tract information. Therefore, the excitation information can be obtained by eliminating the vocal-tract characteristics from speech sample and it is expressed by
where r(n) is known as LP residual of the speech signal. This residual signal represents the excitation source information.
LP residual signal is windowed into frames with duration of 25 ms with consecutive frame overlap by 10 ms. Discrete fourier transform is applied on each frame of LP residual to get LP residual spectrum. The LP residual spectrum is passed through a Mel-filter bank. Discrete cosine transform (DCT) is applied over the Mel-filtered LP residual spectrum to obtain cepstral coefficients. These cepstral coefficients are called RMFCC, as they are obtained by performing cepstral analysis over LP residual spectrum.
3.2 Glottal mel frequency cepstral coefficient
The speech signal is generated when vocal-tract system is excited by air passing through the opening of the vocal folds, called as glottis (Plumpe et al., 1999). The flow of air through glottis is known as glottal flow which is usually the excitation source in speech production mechanism. The output of the vocal-tract system is filtered by lip radiation, that is equivalent to first order differentiation (Plumpe et al., 1999). Therefore, the excitation signal can be represented as the derivative of the glottal flow. This glottal flow derivative signal is used as excitation source information in many speech recognition tasks (Plumpe et al., 1999).
The IAIF method is used for extracting the GFD signal. This method is an iterative process for refining the vocal-tract transfer function and glottal component. The glow flow signal is calculated by using an inverse filter to cancel the lip radiation and vocal-tract transfer function. This method consists of two iterations. In 1st iteration, the glottal flow is computed using 1st order linear predictive coding (LPC) analysis. In 2nd iteration, the higher order LPC analysis is used to generate more accurate glottal flow signal (Raitio et al., 2010; Phapatanaburi et al., 2022).

Processing steps for GMFCC feature extraction
As shown in Fig. 3, the GFD signal g(n) extracted from speech signal s(n) using IAIF method is further proceed on short segments. Short-term spectral analysis is carried out over 25 ms windows and overlapping by 20 ms. The overlapping enables to get the temporal characteristics of the speech sound units. The window size of 25 ms is sufficient to get good spectral resolution of the speech sounds. We used hanning window because it enhances the harmonics, smooth the edges and reduce the edge effect while applying the discrete fourier transform on the signal (Picone, 1993). The spectrum of GFD signal is obtained by calculating the discrete fourier transform of windowed GFD signal. Then Mel spectrum of the GFD signal is computed by passing the GFD spectrum through a set of band-pass filters. This set of filters is known as Mel-filter bank. DCT is applied to log scale of the Mel spectrum of GFD signal to extract the GMFCC coefficients.
4 Database description
For evaluating the performance of the proposed system, we use audio speech database of track 1 of the 2nd ‘CHiME’ Challenge database (Vincent et al., 2013). The structure of the utterances of this database follows the same structure of Grid database (Cooke et al., 2006) which is shown below.
<command(4)\(> <\)color(4)\(> <\)preposition(4)\(> <\)letter(25)\(> <\)digit(10)\(> <\)adverb(4)>
The number mentioned in the round bracket indicates the number of different commands, colors, prepositions, English letters, digits and adverbs which are mentioned in Table 1. The database belongs to 34 speakers (18 male, 16 female) (Vincent et al., 2013).
The audio signals were convolved with the binaural room impulse responses (BRIRs) to simulate room reverberation and small speaker movement. The audio speech signals were mixed with the background noise which was recorded from family living room. The addition of background noise to signals was done in controlled manner to get six different SNRs (− 6 dB, − 3 dB, 0 dB, 3dB, 6 dB and 9 dB) without rescaling the speech and noise signals.
This corpus consists of three data sets; (a) training set (b) development set and (3) test set. The training set has 500 utterances from each of 34 speakers. For each SNR level, development sets has 600 utterances and test set also consists 600 utterances at each SNR. All the speech data are provided at 16 bits and sampled at 16 kHz. The visual features are extracted from the video data of the Grid corpus.
5 DNN-HMM based audio-visual speech recognition system
The DNN-HMM based audio-visual speech recognition system is developed by using Kaldi speech recognition toolkit (Povey et al., 2011). This toolkit is used for both MFCC feature extraction process as well as for modeling the system.

Dimension of combined audio-visual feature
The MFCC features and GMFCC features are concatenated directly to obtained audio features, it is shown in Fig. 4. The dimension of both MFCC and GMFCC feature is 13. Hence the total dimension of the audio feature is 26. To extract visual features, first we converted the input videos to multiples image frames. Then the visual feature is extracted by calculating DCT of the gray-scale images which contain the mouth regions. The mouth regions are detected by the Viola–Jones algorithm (Viola & Jones, 2004). The number of frames per sec for audio and visual feature are not same. Therefore, in order to generate the same number of frames, 63-dimensional DCT visual features are interpolated. After that the audio-visual features are generated by combining the audio and visual feature at frame level. The total dimension of the audio-visual features is 89. The combined audio-visual features are converted to Kaldi features format and then feed to toolkit for modeling process.
Using the audio-visual feature, first we created a basic HMM model which is known as monophone HMM model. This monophone HMM model does not have any contextual information about the front and back of the phoneme that is neighbouring phonemes. After this training, the features are aligned with respect to the reference text transcription. This process is known as viterbi force alignment. Next step is to further extended the monophone model to context-dependent triphone HMM model (tri1) by the considering the context of neighbouring phonemes (left and right phonemes). In this context-dependent model process, we included the delta and delta-delta features for both the audio and visual features. After that we obtain the audio-visual features by concatenating them. The combined audio-visual features of the neighbouring frames (± 3 frames) are spliced. This is done to capture the dynamic information of the features. The dimension of the spliced feature is reduced to 40 using Linear Discriminative Analysis (LDA) and a new model (tri2) is generated. Then a speaker normalization method; Maximum Likelihood Linear Transform (MLLT) is applied to minimize the differences among the speakers. A more robust HMM model (tri3) is developed using speaker adaptation training (SAT) and feature-space Maximum Likelihood Linear Regression (fMLLR). The fMLLR technique is used to make the speaker-independent system (Povey & Saon, 2006; Rath et al., 2013).
DNN-HMM model is generally build by replacing the GMM model of tri3 HMM model (usually known as GMM-HMM model) with a feed-forward DNN model. The pre-training of the DNN is done by training the stack of Restricted Boltzmann Machines (RBM) using Contrastive Divergence. The weights updated during the pre-training process will be used in initializing the DNN parameters. This helps to reduce over fitting during fine-tuning. Fine-tuning of the DNN is done using Stochastic Gradient Descent (SGD) to minimize per-frame cross-entropy. The DNN is comprised of 6 hidden layers with sigmoid activation function and each layer has 2048 neurons. The output layers use a soft-max function. The sequence discriminative training method “state-level minimum Bayes risk (sMBR)” (Vesely et al., 2013) is applied to DNN-HMM. The sMBR training criteria is used to minimize the error, measured at state level between the features and word sequence of training utterances. We represented this system as DNN-HMM sMBR.
6 Experimental results and discussion
In order to select the best modeling method for this particular task, we compare HMM, DNN-HMM and DNN-HMM with sMBR using MFCC features. We also conducted a comparative analysis for selecting a suitable excitation source feature for development of audio-visual speech recognition system. After selecting the best excitation source feature and modeling technique, we develop a robust audio-visual speech recognizer.
6.1 Comparison of model performance
The performance comparison between various modeling techniques; HMM, DNN-HMM, DNN-HMM sMBR-1 and DNN-HMM sMBR-5 is conducted, particularly for speech recognition task. For conducting this experiment study, we develop audio based speech recognition systems using different models and MFCC features. In this experiment, we use the development set of track 1 of 2nd CHiME database. The accuracy of the system is determined by recognition rate of the keywords. We consider same keywords used in 2nd CHiME Speech Separation and Recognition Challenge. The keywords are the “letters” and “digits” present in the track 1 of 2nd CHiME database.
The experimental results are given in Table 2. We observed that DNN-HMM based system gives better performance than the HMM based system at every level of SNRs. The large relative performance improvement can be observed at very low SNR levels (− 6 dB and − 3 dB). This shows that the DNN-HMM based model works very well in the noisy condition also. A more clarity observation can be seen from Fig. 5.

Comparison of modelling techniques for speech recogntion system
The performance of the DNN-HMM based system is further improved when the sequence discriminative criteria that is “state-level minimum Bayes risk (sMBR)” is applied. The DNN-HMM sMBR-5 provides better performance than DNN-HMM sMBR-1 at every level of SNRs. The sMBR-1 and sMBR-5 represent state-level minimum Bayes risk training with 1 iteration and 5 iterations respectively. This shows that the system performance improves when the number of iterations increase from 1 to 5.
We also generated the phoneme sequences of test utterances by using the Kaldi function “ali-to-phones” to analyze the similar phonemes. The output phoneme level transcriptions are compared with the original reference transcriptions by using an optimal string matching algorithm “dynamic programming” to obtain the confusion matrix. From confusion matrix shown in Table 3, we observed that the consonant phonemes which have the similar place of articular and/or similar place of manner are confused each other. Those confused phonemes are {b and p}, {d and t}, {m and n} and {s and z}. From the literature survey (Manjunath & Rao, 2015; Tripathi & Rao, 2018), we understand this type of confusion can be reduced by considering the excitation source information along with vocal-tract features. This type of confusion is usually more happens in noisy condition (Manjunath & Rao, 2015). Therefore, it is important to select the robust excitation source feature in the development of automatic speech recognition system specially under unfavourable noisy environments.
6.2 Selection of robust excitation source feature
In this work, we conduct a comparative analysis between RMFCC and GMFCC features by using three different approaches; (a) similarity and discrimative measurement for similar phonemes using euclidean distance, euclidean similarity, cosine distance and cosine similarity (b) t-SNE (t-distributed stochastic neighbor embedding) plot for similar phonemes and (c) comparison of RMFCC and GMFCC features in context of letters and digits recognition in various SNR levels to examine the noise robustness.
The euclidean distance, euclidean similarity, cosine distance and cosine similarity between the similar phonemes are calculated. These distance measurement and similarity score are the proximity measurement between feature vectors in vector space. Euclidean distance between two vectors x and y is defined by below equation.
where \(x_{i}\) and \(y_{i}\) are the different points of the vector x and y respectively. and the euclidean similarity is calculated as
The smaller value of ED(x,y) and larger value of euclidean similarity ES(x,y) mean more closeness and similarity.
The cosine similarity and cosine distance are dependent on the angle between the two vectors. It measures the similarity in the direction or orientation of the vectors. The formulae of cosine similarity (CS(x,y)) and cosine distance (CD(x,y)) are given below
and
The CS(x,y) can be negative since Cos(\(\theta\)) value is in the range of -1 to 1. The negative or smaller value of CS(x,y) indicates less similarity.
To analysis the similarity of phonemes, the portions of 8 phonemes (‘b’, ‘p’, ‘d’, ‘t’,‘m’, ‘n’ and ‘z’) from the speech utterances of tract 1 of 2nd CHiME database (Vincent et al., 2013) are manually splitting using ‘WaveSurfer’. We calculated the value of ED(x,y) and CS(x,y) between feature vectors of similar phonemes using the RMFCC and GMFCC feature. The feature vectors of each phoneme is modeled with 4 Gaussian mixture model (GMM). This model gives mean, variance and weight parameters for each phoneme. Each phoneme has 4 mean vectors with corresponding weights. Each mean vector of phoneme model (scaled by corresponding weight) is compared with all 4 mean vectors (scaled by corresponding weights) of their corresponding similar phoneme model using euclidean and cosine distance and find the shortest distance. These four shortest distance values are normalized and calculated the mean value. The mean distance values of similar phoneme pairs are tabulated in Table 4. The similarity scores; ES(x,y) and CS(x,y) are also estimated in similar manner by finding largest similarity score between the mean vectors of mixture models of similar phoneme pair. The calculated similarity score values are given in Table 5. The values of distance calculated; ED(x,y) and CD(x,y) using RMFCC are less than the distances obtained by GMFCC whereas values of similarity score calculated; ES(x,y) and CS(x,y) using RMFCC are more than GMFCC. Smaller distance values and larger similarity scores between two sound units mean they are very close and similar to each other. This shows that GMFCC feature is more discriminative than RMFCC for similar sound unit classification.

t-SNE plot using RMFCC and GMFCC for a phoneme ‘b’ and ‘p’, b phoneme ‘d’ and ‘t’, c phoneme ‘m’ and ‘n’, d phoneme ‘s’ and ‘z’
We used t-SNE plot to visualize the distribution of RMFCC and GMFCC feature vectors for similar phoneme pairs. As compare to LP residual based excitation source features, the distributions of glottal based excitation source features for similar phonemes are less close to each others. We can see the more clarity from t-SNE plots of 4 similar phoneme pairs which are depicted in Fig. 6. These confusions in distributions of the phonemes like (‘p’ and ‘b’), (‘d’ and ‘t’), (‘m’ and ‘n’) and (‘s’ and ‘z’) may be due to additive background noise present in speech data and having similar acoustic characteristics. From this analysis, we observed that GMFCC excitation feature has more discriminatory information for speech sound classification.
We further conducted an experimental analysis to compare the performance of RMFCC and GMFCC feature for DNN-HMM ASR at different SNR levels. The recognition rate of keywords are showed in Table 6. The accuracy of speech recognizer is determined by the recognition rate of letters and digits.The average accuracy of the RMFCC based speech recognizer is 57.69% whereas the GMFCC based speech recognizer gives 72.46%. The GMFCC feature is more superior than RMFCC at high level SNR as well at low level SNR. This shows that that GMFCC feature is more robust than RMFCC feature for the speech recognition task. Therefore, we select the glottal based excitation source feature (GMFCC) in the development of audio-visual speech recognition system.
6.3 Performance analysis of audio-visual speech recognition system
The performance of the individual feature (MFCC, GMFCC and Visual) and combined features (MFCC + GMFCC, GMFCC + Visual, MFCC + Visual and MFCC + GMFCC + Visual) are analyzed and the results are given in Table 7. We observe that the MFCC feature gives better performance that is \(88.49\%\) at 3 dB SNR but the performance drastically decreases at − 6 dB and − 3 dB due to the background noise.

t-SNE plot using MFCC + Visual (V) and MFCC + GMFCC + Visual (V) for a phoneme ‘b’ and ‘p’, b phoneme ‘d’ and ‘t’, c phoneme ‘m’ and ‘n’, d phoneme ‘s’ and ‘z’

Performance of the proposed audio-visual speech recognition system for various features at different SNRs
At every level of SNRs, the performance of the MFCC feature is improved when it combines with GMFCC feature. This shows the robustness of glottal source excitation feature in noisy condition. However, the performance of the combination of MFCC and GMFCC can be further improved by including the visual features. At low SNR level, the recognition rate is greatly improved by combining the MFCC with visual feature. Similar observation is also seen while combining the GMFCC feature with visual feature. From Fig. 8, we can see the performance of the proposed speech recognizer is not much fluctuate after combining the vocal-tract feature, glottal excitation source feature and visual feature together. It means the proposed system is working fine at high SNR levels as well at low SNR levels. To accumulate all the benefits of vocal-tract information, glottal excitation information and visual feature, we combined all these features together and used in the development of a robust audio-visual speech recognition.
The average recognition rate of the audio-visual speech recognition system with (MFCC + Visual), (GMFCC + Visual) and (MFCC + GMFCC + Visual) are \(82.75\%\), \(79.77\%\) and \(84.77\%\) respectively. The average recognition rate is computed by taking the individual accuracy across different noise levels. The results are given in Table 7. The average recognition rate of the audio-visual speech recognition system developed using MFCC, GMFCC and Visual feature together is better than audio-visual speech recognition system using MFCC and visual feature together. This shows the benefit of using glottal excitation source information for automatic audio-visual speech recognition.
Under noisy condition or at low SNR levels, the classification of similar phonemes may get confuse due to similar vocal-tract characteristics, similar lip movements and distortion caused by surrounding acoustic noise. The excitation source feature together with vocal-tract feature and visual feature increase the discriminatory information for classifying the similar sound units. The details are visualised by using t-SNE plots for MFCC + Visual feature and MFCC + GMFCC + Visual feature in Fig. 7. From this figure, we observe that GMFCC feature is robust to noise degradation and found suitable for speech recognition task under noisy condition. The noise robustness behavior of this glottal excitation source feature may be due to noise suppression during the iterative process of IAIF approach (Drugmana et al., 2012).
We found English letter ‘B’ and ‘P’ are confused in recognition. The confused letters shown by red color and the correctly recognized letters are shown by black color in 4th column of Table 8. The issue of confusion in recognition is found when we use MFCC feature alone or combination of MFCC and visual feature. The proposed system is modelled at the phoneme level, therefore the recognized letters are formed by combination of phonemes or single phoneme. The letter ‘B’ has the effect of phoneme ‘b’ whereas the letter ‘P’ has the effect of phoneme ‘p’. These phonemes have same vocal-tract activities. Therefore, the only MFCC feature may be confused to detect these letters correctly under noisy condition. Even after adding the visual feature to MFCC feature, the issue is not able to overcome because both letters have same lip movements. The letter ‘P’ and ‘B’ are recognized accurately and distinguished properly after adding the glottal excitation feature to the vocal-tract feature and visual feature. This improves the performance of the proposed audio-visual speech recognition system.
7 Conclusion
In this work, we discuss about the usefulness of the excitation source information for audio-visual speech recognition system. The excitation source feature extracted from the glottal flow derivative signal (GMFCC) is more robust than excitation source information extracted from LP residual (RMFCC) for recognizing the speech sounds. Therefore, we explore the glottal excitation source information for development of audio-visual speech recognition system. In speech recognition task, the DNN-HMM based system with sMBR technique gives better performance than DNN-HMM model without sMBR technique and HMM model respectively. The combination of vocal-tract based features (MFCC) with the glottal excitation source feature (GMFCC) gives higher accuracy than the individual feature MFCC and GMFCC respectively. Since the visual feature is not corrupted by acoustic noise. Hence, the visual feature is combined to the vocal-tract and excitation features. The best average keywords recognition rate is found when the vocal-tract information, glottal excitation source and visual feature is combined together. From the experimental studies, we can conclude that the inclusion of glottal excitation source information with vocal-tract feature and visual feature is useful for audio-visual speech recognition system.
Data availability
The CHiME-2 database is available at Linguistic Data Consortium official website. This is not open source database, therefore authors cannot make the data available. The Grid database is available at zenodo website.
Code availability
Code will made available on reasonable request.
References
Alku, P. (1992). Glottal wave analysis with pitch synchronous iterative adaptive inverse filtering. Speech Communication, 11(23), 109–118.
Alku, P., & Vilkman, E. (1996). A comparison of glottal voice source quantification parameters in breathy, normal and pressed phonation of female and male speakers. IEEE Transactions on Audio, Speech and Language Processing, 48(5), 240–254.
Bear, H. L., & Harvey, R. (2017). Phoneme-to-viseme mappings: The good, the bad, and the ugly. Speech Communication, 95, 40–67.
Bozkurt, E., et al. (2007). Comparison of phoneme and viseme based acoustic units for speech driven realistic lip animation. In IEEE 15th signal processing and communications applications (pp. 1–4).
Chengalvarayan, R. (1998). On the use of normalized LPC error towards better large vocabulary speech recognition systems. In IEEE international conference on acoustics, speech and signal processing (ICASSP).
Cooke, M., et al. (2006). An audio-visual corpus for speech perception and automatic speech recognition. The Journal of the Acoustical Society of America, 120(5), 2421–2424.
Debnath, S., & Roy, P. (2022). Audio-visual speech recognition based on machine learning approach. International Journal of Advanced Intelligence Paradigms, 21, 3–4.
Drugman, T., et al. (2012). Detection of glottal closure instants from speech signals: A quantitative review. IEEE Transactions on Audio, Speech, and Language Processing, 20(3), 994–1006.
Drugmana, T., Bozkurtb, B., & Dutoita, T. (2012). A comparative study of glottal source estimation techniques. Computer Speech and Language, 26(1), 20–34.
Dupont, S., & Luettin, J. (2000). Audio-visual speech modeling for continuous speech recognition. IEEE Transactions on Multimedia, 2, 141–151.
Dutta, K., Singh, M., & Pati, D. (2009). Detection of replay signals using excitation source and shifted CQCC features. International Journal of Speech Technology, 24(9), 497–507.
He, J., Liu, L., & Palm, G. (1996). On the use of residual cepstrum in speech recognition. In IEEE international conference on acoustics, speech and signal processing (ICASSP) (Vol. 1, pp. 5–8).
Huang, J., & Kingsbury, B. (2013). Audio-visual deep learning for noise robust speech recognition. In International conference on acoustics, speech, and signal processing (ICASSP) (pp. 7596–7599).
International Phonetic Association. (1999). Handbook of the international phonetic association. Cambridge University Press.
Kaynak, M. N., et al. (2004). Analysis of lip geometric features for audio-visual speech recognition. IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans, 34(4), 564–570.
Lucey, S., et al. (2005). Integration strategies for audio-visual speech processing: Applied to text-dependent speaker recognition. IEEE Transactions on Multimedia, 7, 495–506.
Mahadeva Prasanna, S. R., & Yengnanarayana, B. (2006). Extraction of speaker-specific excitation information from linear prediction residual of speech. Speech Communication, 48(10), 1243–1261.
Manjunath, K., & Rao, K. S. (2015). Source and system features for phone recognition. International Journal of Speech Technology, 18(2), 257–270.
Matthews, I., Bangham, J. A., & Cox, S. (1996). Audiovisual speech recognition using multiscale nonlinear image decomposition. In International conference on spoken language processing (ICSLP) (pp. 38–41).
Meutzner, H., et al. (2017). Improving audio-visual speech recognition using deep neural networks with dynamic stream reliability estimates. In International conference on acoustics, speech and signal processing, (ICASSP).
Murthy, K. S. R., & Yegnanarayana, B. (2008). Epoch extraction from speech signals. IEEE Transactions on Audio Speech and Language Processing, 16(8), 1602–1613.
Nandakishor, S., & Pati, D. (2021). Analysis of Lombard effect by using hybrid visual features for ASR. In Pattern recognition and machine intelligence (PReMI’21).
Nandi, D., Pati, D., & Sreenivasa Rao, K. (2006). Implicit processing of LP residual for language identification. Computer Speech & Language, 41, 68–87.
Naylor, P. A., et al. (2007). Estimation of glottal closure instants in voiced speech using the DYPSA algorithm. IEEE Transactions on Audio, Speech and Language Processing, 15(1), 34–43.
Noda, K., et al. (2015). Audio-visual speech recognition using deep learning. Applied Intelligence, 42, 722–737.
Phapatanaburi, K., et al. (2022). Whispered speech detection using glottal flow-based features. Symmetry, 14(4), 777.
Picone, J. W. (1993). Signal modeling techniques in speech recognition. Proceedings of the IEEE, 81, 1215–1247.
Plumpe, M. D., Quatieri, T. F., & Reynolds, D. A. (1999). Modelling of glottal flow derivative waveform with application to speaker identification. IEEE Transactions on Speech and Audio Processing, 7(5), 569–586.
Povey, D., et al. (2011). The Kaldi speech recognition toolkit. In Proceedings of IEEE workshop on automatic speech recognition and understanding.
Povey, D., & Saon, G. (2006). Feature and model space speaker adaptation with full covariance gaussians. In Interspeech.
Prathosh, A., Ananthapadmanabha, T., & Ramakrishnan, A. (2013). Epoch extraction based on integrated linear prediction residual using plosion index. IEEE Transactions on Audio, Speech and Language Processing, 21(12), 2471–2480.
Rabiner, L. R., Juang, B.-H., & Yegnanarayana, B. (2012). Fundamentals of speech recognition. Pearson Education.
Rabiner, L. R., & Schafer, R. W. (2009). Digital processing of speech signals. Pearson Education.
Raitio, T., et al. (2010). HMM-based speech synthesis utilizing glottal inverse filtering. IEEE Transactions on Audio, Speech, and Language Processing, 19, 153–165.
Rath, S. P., et al. (2013). Improved feature processing for deep neural networks. In Interspeech.
Swietojanski, P. et al. (2013). Revisiting hybrid and GMM-HMM system combination techniques. In International conference on acoustics, speech, and signal processing (ICASSP).
Thangthai, K. et al. (2015). Improving lip-reading performance for robust audiovisual speech recognition using DNNs. In FAAVSP—the 1st joint conference on facial analysis, animation and auditory-visual speech processing (pp. 127–131).
Thomas, M. R., Gudnason, J., & Naylor, P. A. (2012). Estimation of glottal closing and opening instants in voiced speech using the YAGA algorithm. IEEE Transactions on Audio, Speech and Language Processing, 20(1), 82–91.
Tripathi, K., & Rao, K. S. (2018). Improvement of phone recognition accuracy using speech mode classiffication. International Journal of Speech Technology, 21(3), 489–500.
Vesely, K., et al. (2013). Sequence-discriminative training of deep neural networks. In Interspeech.
Vincent, E., et al. (2013). The second “CHiME” speech separation and recognition challenge: Datasets, tasks and baselines. In International conference on acoustics, speech, and signal processing (ICASSP) (pp. 126–130).
Viola, P., & Jones, M. J. (2004). Robust real-time face detection. International Journal of Computer Vision, 57, 137–154.
Yegnanarayana, B., Mahadeva Prasanna, M. S. R., Duraiswami, R., & Zotkin, D. (2005). Processing of reverberant speech for time-delay estimation. IEEE Transactions on Audio, Speech, and Language Processing, 13, 1110–1118.
Yengnanarayana, B., & Satyanarayana Murthy, P. (2000). Enhancement of reverberant speech using LP residual signal. IEEE Transactions on Speech and Audio Processing, 8(3), 267–281.
Funding
This work is funded by Ministry of Electronics and Information Technology (MeitY), Govt. of India under the project title “Development of Excitation Source Features Based Spoof Resistant and Robust Audio-Visual Person Identification System”. Award No: 12(5)/2015-ESD. Grant Recipient: Dr. Debadatta Pati
Author information
Authors and Affiliations
Contributions
The authors explore the benefit of glottal excitation source information for proposed audio-visual speech recognition system.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no Conflict of Interest.
Consent for publication
The authors give the consent to publisher for this article publication.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Nandakishor, S., Pati, D. Usefulness of glottal excitation source information for audio-visual speech recognition system. Int J Speech Technol 26, 933–945 (2023). https://doi.org/10.1007/s10772-023-10060-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-023-10060-x