
Abstract
This paper presents a noise reduction method based on binary mask thresholding function for enhancement in single channel speech patterns of mixed highly non-stationary noises with low (negative) input SNR. For this purpose, a mixed highly non-stationary noisy speech database is generated by using noise and clean speech database of AURORA and INDIC speech, respectively. Results are compared with widely used methods such as Daubechies13, Daubechies40, Symlet13, Coiflet5, Wiener, Spectral Subtraction, and log-MMSE for performance evaluation in terms of SNR, PESQ, and Cepstrum distance parameters. In comparison to other methods the proposed single-channel speech enhancement method shows satisfactory results and obtained significant improvement in speech quality and intelligibility.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
To communicate among humans, we need a fundamental mode that transfers ideas from person to person that is speech. If speech signal is transferred in a noisy medium then speech signal may be distorted. This kind of noise may be daily life noise patterns like vehicle, fan, machine gun, tank, factory, fighter plane etc. that create distortion in speech signal. The distorted speech may become meaningless. Hence, for enhancement of these noisy speech signals we need effective speech enhancement methods. There are various speech enhancement methods available in the literature (Lim and Oppenheim 1979; Loizou 2007; Weiss et al. 1974; Boll 1979; Wiener 1949; Hansen and Clements 1991; Ephraim and Malah 1984, 1985; Hazrati and Loizou 2012; Paliwal et al. 2011, 2012; Wojcicki and Loizou 2012). Some of these techniques are spectral subtraction, minimum mean square error (MMSE) based techniques, modulation channel based speech enhancement techniques, wiener filtering methods and wavelet transform based etc. The spectral subtractive algorithms were initially proposed by Weiss et al. (1974) in the correlation domain and later by Boll (1979) in the Fourier transform domain. After filtering, this spectral subtractive method generates isolated peaks (i.e. musical noise). The optimal filter that minimizes the estimation error is called the Wiener filter. Wiener filtering algorithms exploit the fact that noise is additive and one can obtain an estimate of the clean signal spectrum simply by subtracting the noise spectrum from the noisy speech spectrum (Wiener 1949). The main drawback of the iterative Wiener filtering approach was that as additional iterations were performed, the speech formants shifted in location and decreased in formant bandwidth (Hansen and Clements 1991). The wiener filter is the optimal complex spectrum estimator, not the optimal magnitude spectrum estimator. Ephraim and Malah proposed a MMSE estimator which is optimal magnitude spectrum estimator (Ephraim and Malah 1984). Unlike the Wiener filtering, the MMSE estimator does not require a linear model between the observed data and the estimator. But it assumes probability distributions of speech and noisy DFT coefficients. The DFT coefficients are statistically independent and hence uncorrelated. One drawback of this estimator is that it is mathematically tractable and it is not the most subjectively meaningful one. To overcome this problem a log-MMSE is derived by Ephraim and Malah (1985). Furthermore, some more efficient techniques are available in literature based on ideal binary mask (IdBM) (Hazrati and Loizou 2012). But modulation channel selection based method is more efficient for both quality and intelligibility improvement (Paliwal et al. 2011, 2012; Wojcicki and Loizou 2012).
Many researchers have been worked on speech enhancement using wavelet transform based methods. There are many algorithms given on various thresholding concepts for speech enhancement (Donoho 1995; Aggarwalet et al. 2011; Sanam and Shahnaz 2012; Tabibian et al. 2009; Bahoura and Rouat 2001; Zhao et al. 2011; Sheikhzadeh and Abutalebi 2001; Yi and Loizou 2004; Wang and Zhang 2005; Shao and Chang 2007). But quality and intelligibility of speech depends on the criterion adopted for masking threshold. A more efficient concept for threshold selection is adaptive thresholding (Johnson et al. 2007; Sumithra 2009; Sanam and Shahnaz 2012; Yu et al. 2007; Zhou 2010; Ghanbari and Reza 2006). A novel data adaptive thresholding approach to single channel speech enhancement is given by Hamid et al. (2013). In this paper complex signal were used in place of mixed speech signal. This complex signal was a combination of fractional Gaussian noise and noisy speech. A wavelet packet based binary mask method is given for mixed noise suppression (Singh et al. 2014, 2015). In this paper more than one noise and clean signal are mixed to generate noisy speech data for performance evaluation.
Over the past four decades, various single channel speech enhancement methods have been proposed for reduction/removal of one noise at one time but not analyzed for mixture of noises at same time. In this paper, a comparative study and implementation of speech enhancement techniques are presented for single channel Hindi speech patterns with mixed highly non-stationary noises. The mixed noises, we have taken as exhibition + pop music, restaurant + train, pop music + train + babble and pop music + babble + car. These four noise groups are used for quality and intelligibility evaluation of Hindi speech patterns. The well known and popular techniques like spectral-subtraction, wiener filtering, MMSE, p-MMSE, log-MMSE, ideal channel selection, modulation channel based method and wavelet transform based methods are implemented and their subjective and objective performances are analyzed to find out the optimal technique for Hindi speech enhancement in particular environmental condition (where more than one noise is present).
The paper is organized as follows; Sect. 2 presents the background of single channel speech enhancement techniques for noise reduction and binary mask function. Simulation conditions are given in Sect. 3. Section 4 shows the results and discussions. Finally, the conclusion is summarized in Sect. 5.
2 Noisy speech enhancement
A mixed highly non-stationary noisy single-channel Hindi speech signal can be modeled as the sum of clean speech and more than one additive background noises.
where, y(n), x(n) and n n (n) denote the noisy speech, clean speech and various additive background highly non-stationary noises, respectively.
2.1 Simulated algorithm
The motivation for the simulation of various speech enhancement algorithms is to enhance the noisy single-channel noisy speech patterns from mixed highly non-stationary signals. Eight commonly used speech enhancement algorithms are evaluated for enhancement in mixed noisy single-channel Hindi speech pattern. Wiener, Spectral Subtraction, log-MMSE and wavelet transform based method (Daubachies10, Daubachies40, Symlet18, Coiflet5, BiorSpline6.8) are implemented for comparative analysis. Wiener filtering method is an iterative method that is based on minimization of mean square error of the noisy speech (Wiener 1949). Spectral subtraction is a widely used frequency domain method for reduction of additive uncorrelated noises from a speech pattern (Boll 1979). Log-spectrum based MMSE is described by Ephraim and Malah (1985) after simple MMSE. This algorithm assumes a Gaussian model for the complex spectral amplitudes of both speech and noise. It gives the optimum estimate of the log-spectrum of the clean speech signal.
Wavelet is a mathematical function that is used to divide a given function into different scale components. It breaks the signal into a shifted and dilated version of a short term waveform called the mother wavelet. It has high frequency-resolution in low bands and low frequency-resolution in high bands. Hence, it is very helpful in various fields of signal processing and widely used for signal analysis. The wavelet transform W(s, τ) for a signal x(t) is defined as:
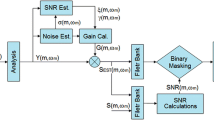
where s > 0 and τ ∊ R, x(t) is the input noisy speech signal. ψ(t) is mother wavelet function and satisfies the orthogonal condition. It is localized in time and frequency domain. In the mother wavelet S is scaling parameter and determining the width of the mother wavelet. τ is a translation parameter and gives the center of mother wavelet. The selection of an appropriate mother wavelet plays an important role in analysis and depends on the application. Various basis functions have been proposed, including Harr, Morlet, Maxican, Daubechies, bi-orthogonal etc. The Daubachies10, Daubachies40, Symlet18, Coiflet5, BiorSpline6.8 mother wavelets are used for decomposition of detailed and approximation coefficients in the proposed work. The five levels in wavelet decomposition are given in Fig. 1. The five level detailed coefficients are recovered for same number of samples as in input speech. Now these detailed coefficients D1–D5 are given to binary mask threshold function for removing noise coefficients. Block diagram of the proposed procedure is given in Fig. 2. The given binary mask decision is applied for all five levels detailed and approximated coefficients. After applying binary mask decision on coefficients we get denoised coefficients. Now these denoised detailed coefficients are added with approximated coefficients and Inverse Wavelet Transform (IWT) is obtained to get denoised speech signal.

Block diagram of wavelet decomposition up to five levels

Flow chart of the proposed method for enhancement of single-channel Hindi speech patterns
To obtain clean speech patterns from the noisy speech patterns, the estimated noise spectrum is subtracted from the noisy speech pattern, which is represented as:
where, n(f, t) denotes the noise, and x(f, t) and y(f, t) denotes the enhanced Hindi speech and noisy speech spectrum respectively. Where t, f indicates the frame index and channel or frequency bin index, respectively.
In Eq. 3, clean speech spectrum is computed by subtraction of estimated noise spectrum. The calculated noisy speech spectrum is accurate and very effective in terms of speech quality and intelligibility (Scalart and Filho 1996; Hu and Loizou 2007). The Eq. 4, priori SNR is calculated by using speech and noise signals (Feng 2015).
On the basis of this estimated noisy spectrum, a binary mask is constructed. A clean speech channel is selected on the basis of ideal binary mask. The ideal term is indicated that a priori information of the target signal is used. To calculate the binary mask SNR criterion is used as (Kim and Loizou 2010):
where, s(f, t), n(f, t) represent clean speech and noise signals respectively. The noise signal is calculated frame by frame. The binary mask (BM) is calculated by using SNR criterion. This is given as (Hazrati and Loizou 2012):
The value of threshold is set to −6 dB, which is located around the center of performance.
3 Simulation conditions
Wiener, Spectral Subtraction, log-MMSE and wavelet transform (Daubachies10, Daubachies40, Symlet18, Coiflet5, BiorSpline6.8) based method are compared with proposed method for performance evaluation. The clean speech pattern of Hindi language [taken from IIIT-H Indic speech database (Prahallad et al. 2012)] has been added with four different types of noise patterns [taken from NOIZEUS AURORA database (Hirsch and Pearce 2000)] for noisy speech generation. These four types of noises (pop music, babble, car, train, and restaurant) are added each other and with clean Hindi speech patterns at different levels of signal to noise ratio (SNR) ranging from −25 to −5 dB. These mixed noise patterns are exhibition + pop music, restaurant + train, pop music + train + babble and pop music + babble + car. These four mixed noise groups are used for quality and intelligibility evaluation of Hindi speech patterns in terms of performance measure parameters SNR, PESQ, SII and Cepstrum distance. All algorithms were implemented in MATLAB 7.1.
4 Results and discussion
With the aim of improving quality and intelligibility of mixed highly non-stationary noisy Hindi speech pattern, the four performance parameters are used and output values of those parameters are given in Tables 1, 2 and 3.
The output SNR values from various methods are given in Table 1. The maximum output SNR values given by coiflet5, BiorSpline6.8 and symlet18 wavelet transform at various levels of input SNR for all types of noises.
The higher values of PESQ parameter is given by BiorSpline6.8 wavelet transform at all level of input SNR values. These output PESQ values in Table 2 shows the maximum improvement of intelligibility and quality in enhanced Hindi speech pattern.
The lower Cepstrum distance value shows higher output PESQ values and maximum improvement in quality of speech. The Table 3 shows all output Cepstrum distance measure values and minimum values are given by BiorSpline6.8 wavelet transform.
MOS parameter is used for speech intelligibility measure. The results for MOS values are given in Table 4. The improvement in MOS is increased as input SNR level is increased. The improvement in intelligibility can also be compared on the basis of various spectrograms given in Fig. 3. The noisy and enhanced spectrograms of Hindi speech are given by different methods and clear spectrogram is given by BiorSpline6.8 wavelet transform. The maximum listening quality of the enhanced output spectrum is given by the proposed method.

Spectrograms of enhancement of single-channel speech (variation of frequency w.r.t. time): a clean, b mixed noisy speech (speech + pop music + babble + train), c Db10, d Db40, e Symlet18, f Coiflet5, g Bior 6.8, h Wiener, i Spectral Sub. j Log-MMSE
5 Conclusion
This paper presents a binary mask threshold function based BiorSpline6.8 wavelet transform method to enhance the speech quality and intelligibility of mixed highly non-stationary low SNR noises Hindi speech pattern. A comparative study is also done in this paper, which shows the performance of the conventional methods and wavelet based algorithms for enhancement in mixed noises single channel Hindi speech patterns. Wavelet domain methods show the higher improvement in quality and intelligibility measuring parameters in comparison to other spectral methods. The BiorSpline6.8 wavelets transform domain method give maximum improvement in speech quality and intelligibility parameters like PESQ and output SNR. BiorSpline6.8 wavelets transform method shows the maximum improvement in terms of performance measure parameters. In addition to that, the spectrograms also support same results and therefore the proposed method BiorSpline6.8 is more suitable for reduction of mixed highly non-stationary noises of negative SNR from noisy speech pattern in comparison to other speech enhancement methods.
References
Aggarwalet, R., et al. (2011). Noise reductions of speech signal using wavelet transform with modified universal threshold. International Journal of Computer Application, 20(5), 14–19.
Bahoura, M., & Rouat, J. (2001). Wavelet speech enhancement based on the teager energy operator. IEEE Signal Processing Letters, 8, 10–12.
Boll, S. F. (1979). Suppression of acoustic noise in speech using spectral subtraction. IEEE Transactions on Acoustics, Speech, and Signal Processing, 27(2), 113–120.
Donoho, D. L. (1995). De-noising by soft-thresholding. IEEE Transactions on Information Theory, 41, 613–627.
Ephraim, Y., & Malah, D. (1984). Speech enhancement using a minimum mean square error short time spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 32(6), 1109–1121.
Ephraim, Y., & Malah, D. (1985). Speech enhancement using a minimum mean square error log-spectral amplitude estimator. IEEE Transactions on Acoustics, Speech, and Signal Processing, 23(2), 443–445.
Feng, D., et al. (2015). Sparse HMM-based speech enhancement method for stationary and non-stationary noise environments. In IEEE international conference on acoustics, speech and signal processing (ICASSP), Australia.
Ghanbari, Y., & Reza, M. (2006). A new approach for speech enhancement based on the adaptive thresholding of the wavelet packets. Speech Communication, 48, 927–940.
Hamid, Md. E., et al. (2013). Single channel speech enhancement using adaptive soft-thresholding with bivariate EMD. In ISRN signal processing (Vol. 8).
Hansen, J., & Clements, M. (1991). Constrained iterative speech enhancement with application to speech recognition. IEEE Transactions on Signal Processing, 39(4), 795–805.
Hazrati, O., & Loizou, P. C. (2012a). Tackling the combined effects of reverberation and masking noise using ideal channel selection. Journal of Speech, Language, and Hearing Research, 55, 500–510.
Hazrati, O., & Loizou, P. (2012b). Tackling the combined effects of reverberation and masking noise using ideal channel selection. Journal of Speech, Language, and Hearing Research, 55, 500–510.
Hirsch, H. G., & Pearce, D. (2000). The Aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In ISCA ITRW ASR2000, Paris, France, September 18–20, 2000. http://www.utdallas.edu/~loizou/speech/noizeus/.
Hu, Y., & Loizou, P. C. (2007). A comparative intelligibility study of single-microphone noise reduction algorithms. Journal Acoustic Society of America, 22, 1777–1786.
Johnson, M. T., Yuan, X., & Ren, Y. (2007). Speech signal enhancement through adaptive wavelet thresholding. Speech Communication, 49(2), 123–133.
Kim, G., & Loizou, P. C. (2010). A binary mask based on noise constraints for improved speech intelligibility. In Interspeech ISCA, Japan.
Lim, J., & Oppenheim, A. V. (1979). Enhancement and bandwidth compression of noisy speech. Proceedings of the IEEE, 67(12), 1586–1604.
Loizou, P. C. (2007). Speech enhancement theory and practice. USA: CRC Press.
Paliwal, K. K., Schwerin, B., & Wojcicki, K. K. (2011). Role of modulation magnitude and phase spectrum towards speech intelligibility. Speech Communication, 53(3), 327–339.
Paliwal, K. K., Schwerin, B., & Wojcicki, K. (2012). Speech enhancement using a minimum mean-square error short-time spectral modulation magnitude estimator. Speech Communication, 54(2), 282–305.
Prahallad, K., Kumar, E. N., Keri, V., Rajendran, S., & Black, A. W. Interspeech-2012. (http://speech.iiit.ac.in/index.php/research-svl/69.html).
Sanam, T. F., & Shahnaz, C. (2012a). Teager energy operation on wavelet packet coefficients for enhancing noisy speech using a hard thresholding function. Signal Processing: An International Journal, 6(2), 22.
Sanam, T. F., & Shahnaz, C. (2012b). Enhancement of noisy speech based on a custom thresholding function with a statistically determined threshold. International Journal of Speech Technology, 15(4), 463–475.
Scalart, P., & Filho, J. (1996). Speech enhancement based on a priori signal to noise estimation. In Proceedings of IEEE international conference on acoustics, speech, signal processing (pp. 629–632).
Shao, Y., & Chang, C. (2007). A generalized time–frequency subtraction method for robust speech enhancement based on wavelet filter banks modeling of human auditory system. IEEE Transactions on Systems, Man, and Cybernetics, 37(4), 877–889.
Sheikhzadeh, H. & Abutalebi, H. R. (2001). An improved wavelet-based speech enhancement system. In EUROSPEECH (pp. 1855–1858).
Singh, S., Tripathy, M., & Anand, R. S. (2014). Single channel speech enhancement for mixed non-stationary noise environments. Advances in Signal Processing and Intelligent Recognition Systems, 64, 545–555.
Singh, S., Tripathy, M., & Anand, R. S. (2015). A wavelet based method for removal of highly non-stationary noises from single-channel hindi speech patterns of low input SNR. International Journal of Speech Technology, 18(2), 157–166.
Sumithra, A. (2009). Performance evaluation of different thresholding methods in time adaptivewavelet based speech enhancement. IACSIT, 1(5), 42–51.
Tabibian, S., Akbari, A., & Nasersharif, B. (2009). A new wavelet thresholding method for speech enhancement based on symmetric Kullback–Leibler divergence. In 14th international computer conference (CSICC) (pp. 495–500).
Wang, J., & Zhang, C. (2005). Noise reduction in speech based on bark scaled wavelet packet decomposition and teager energy operator. Signal Processing, China, 21, 44–47.
Weiss, M., Aschkenasy, E., & Parsons, T. W. (1974). Study and the development of the INTEL technique for improving speech intelligibility. Technical Report NSC-FR/4023, Nicolet Scientific Corporation.
Wiener, N. (1949). Extrapolation, interpolation and smoothing of stationary time series with engineering applications. Cambridge, MA: MIT Press.
Wojcicki, K., & Loizou, P. C. (2012). Channel selection in the modulation domain for improved speech intelligibility in noise. Journal of the Acoustical Society of America, 131(4), 2904–2913.
Yi, H., & Loizou, P. C. (2004). Speech enhancement based on wavelet thresholding the multitaper Spectrum. IEEE Signal Processing Letters, 12, 59–67.
Yu, G., Bacry, E., & Mallat, S. (2007). Audio signal denoising with complex wavelets and adaptive block attenuation. In Proceedings of IEEE international conference on acoustics, speech and signal processing (ICASSP) (Vol. 3, pp. 869–872).
Zhao, H., et al. (2011). An improved speech enhancement method based on teager energy operator and perceptual wavelet packet decomposition. Journal of Multimedia, 6(3), 308–315.
Zhou, B. (2010). An improved wavelet-based speech enhancement method using adaptive block thresholding. In IEEE international conference on acoustic, speech, signal processing (ICASSP).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Singh, S., Tripathy, M. & Anand, R.S. Binary mask based method for enhancement of mixed noise speech of low SNR input. Int J Speech Technol 18, 609–617 (2015). https://doi.org/10.1007/s10772-015-9305-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-015-9305-5