
Abstract
Urban poverty is a complex phenomenon and people experiencing poverty suffer from various deprivations. Multidimensional poverty measurement has been one of the best indicators of this deprivation. In general, slum dwellers are considered homogenous groups, but it is not valid in multidimensional deprivation. This paper aims to find out the correlates of multidimensional poverty in slums. Spatiality and correlates of poverty in Varanasi City have been tapped using statistical modelling. The paper is based on primary data collected from 384 households through an interview schedule from 12 slums across three geographical zones of the city. The MPI index for slums, based on global MPI, was used to compute MPI for each geographical zone. Further ANOVA and hierarchical regression analysis were performed to find spatiality and correlates of multidimensional deprivation. The paper reveals that socio-religious categories, occupation and geographical location are significant determinants or at least correlates of multidimensional poverty in slums.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Poverty measurement is a crucial and complex issue in academia and policy planning. Traditional unidimensional approach to measure poverty in terms of income or consumption cannot capture the multiple factors contributing to poverty (Belhadj, 2011; Perry, 2002). Poverty can be defined much more broadly by considering poor people’s lack of education, health and other aspects of their standard of living (Alkire, 2007). Urban Poverty is a multidimensional phenomenon and people experiencing poverty suffer from various deprivations like lack of adequate housing and services, education and personal, security access to employment, social protection and lack of access to health (Bhasin, 2001; Sulaiman et al., 2014; Abd Manap et al., 2017; Ariyanto, 2023).
Various international organizations, agencies, economists, sociologists and geographers took the pain to identify parameters and indicators of poverty and the development of indexes such as the Physical Quality of Life Index (PQLI), Human Development Index (HDI), etc. (Jha & Tripathi, 2014; Morris, 1980; Narayana, 2009; Pandey et al., 2006; Sirgy et al., 2006). Hagerty et al. (2001) review 22 indexes of the last 30 years, but none of these indices except HDI has been computed for India. The Human Poverty Index (HPI) was the first such measure, which was replaced by the Multidimensional Poverty Index (MPI) in 2010 (Rahi, 2011). The MPI combines the incidence of poverty and the intensity of deprivation to measure acute poverty (Alkire & Santos, 2014). The incidence of poverty refers to the proportion of people who experience multiple deprivations, whereas the intensity of the deprivation refers to the average proportion of (weighted) deprivations they experience (Alkire et al., 2021; Khalaj & Yousefi, 2015). If everyone is deprived of all the considered indicators in society, the MPI would be 100 per cent based on available information for the household (Alkire & Santos, 2014).
It is also notable that, in general, slum dwellers are considered homogenous groups, but it is not the truth in the case of multidimensional deprivation. The economic condition and geographical attributes of cities are uneven and it also applies to slums in these cities. Therefore, one can see the variation in deprivation in the case of different social or marginal groups living in these slums. Furthermore, this variation is more prominent in the case of multiple deprivation or multidimensional poverty.
A poverty profile describes the pattern of poverty but is not predominantly concerned with explaining its causes. However, a satisfactory explanation of why some people are poor is essential to tackle the roots of poverty (Haughton & Khandker, 2009). The determinants or correlates of poverty have regional, community, household and individual characteristics (Fahad et al., 2023). Factors causing poverty, or at least the factors correlated to poverty, can be determined using these characteristics. Sociologists, political scientists and regional scientists point out that specific community attributes are empirical correlates of thriving communities and social and political structures play an essential role in economic development, inequality and poverty. (La Ferrara & Bates, 2001; Rupasingha & Goetz, 2007).
Spinks (2001) remarks that though all phenomena occur over time and thus have history, they also happen in space, at particular places and have a geographical attribute. Undoubtedly the two perspectives are linked, but over-attention to the former has occurred at the expense of geographical-based analysis. However, some crucial studies have emphasized spatial/location factors to determine poverty. The ‘spatial turn’ in urban sociology has directed attention to how spatial arrangements operate as constitutive dimensions of social phenomena and determine poverty and inequality (Gotham, 2003; Harvey, 1993; Löw & Steets, 2014). In this context, spatiality or locational correlates have evolved as a significant dimension of poverty. Location or Spatial effect has also been influential in poverty determination (Ong & Miller, 2005) and households in less endowed zones are likelier to be poor than those in more endowed regions, which depicts the spatial dimension of urban socio-economic inequality (Gounder, 2013; Nafees et al., 2022; Poon, 2009). Dinzey-Flores (2017) argues that it is vital to understand where inequality is located and how it is spatially distributed and spatial polarization or segregation of resources is responsible for this inequality.
Various studies found that household consumption, including demographic, social, housing characteristics, education, employment types, gender and location or geography, were the significant correlates of poverty (Gounder, 2013; Jamal, 2005). Xhafaj and Nurja (2014) presented two regression model, which shows that the household size, the educational level and gender of the household head and the zone (urban or rural) are variables that influence poverty. Researchers have established a relationship between poverty and social/religious/economic group in India (Dubey & Gangopadhyay, 1998; Meenakshi et al., 2000; Sundaram & Tendulkar, 2003; Shukla et al., 2010; Mukim & Panagariya, 2012; Panagariya & More, 2014; Arora & Singh, 2015). In other parts of the world, various studies have also found social, religious or racial determinants of poverty (HalimatusA’Diyah, 2015; Osmond & Grigg, 1978; Piazza, 2006). Borooah (2005) and Borooah et al. (2014) analyzed inequality and Poverty in India within the context of caste-based discrimination and found that at least one-third of the average income differences between Hindu and Scheduled Caste/Schedule Tribe (Socialy deprived population groups in India recognized by the Government of India; further referred as SC/ST) households were due to the unequal treatment of SC/ST or social discrimination. Panagariya and More (2014) argued that poverty rates among disadvantaged social groups and minorities had declined faster, but they accepted that Muslims have higher poverty rates, the highest in urban areas. While investigating the correlates of poverty, researchers also found various social, demographic and economic correlates. However, most scholars have used poverty as a binary variable (poor and non-poor) computed from household expenditure (Saunders et al., 2002). Jamal (2005) argued that using this binary variable may lose much of the information available about the actual relationship between expenditure and its explanatory factors. He recommended that the analysis be carried out with continuous expenditure variables rather than the poor or non-poor status. Therefore, in this study, the composite score of multidimensional poverty has been taken as a continuous dependent variable.
Further, it can be observed that most researchers did not try to find correlates of multidimensional poverty; instead, they used consumption poverty as a dependent variable (Sumarto et al., 2007). However, in the case of multidimensional poverty, it is necessary to be careful to find correlates of poverty without taking such socio-economic variable, which has already been used to calculate multidimensional poverty. Many scholars remarked that multidimensional poverty is decreasing, but the rate of decrease is not uniform across regions (Deaton & Dre’ze, 2002; Jayaraj & Subramanian, 2010; Khan et al., 2016). Alkire and Seth (2015) also found a substantial reduction in national poverty and each of its dimensions in India, but this has not been uniform across regions, castes, or religions. Kaibarta et al. (2022) also assessed the multidimensional poverty of urban poor households in an Indian City based on location, social groupings and length of stay.
Study area
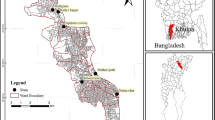
Varanasi (also known as Kashi or Banaras), with a continuous history dating back 3000 to 5000 years, is one of the oldest living cities in the world (Bansal et al., 2017; Gutschow, 2006; Singh et al., 2001) and is known as the cultural and spiritual capital of India (Singh, 2017). It is part of Varanasi Urban Agglomeration (VUA) and located on the left crescent-shaped bank of the Ganga River in the middle Ganga plain (Fig. 1). Varanasi joined the ‘million’ class city club in the 1991 census and in the 2011 census it records 1.2 million population. The overall population density of the town is 14,598 persons per sq. km. (i.e., 150 persons/ha). The urban poor and slum dwellers in Varanasi account for about 37.69% of the city population (Jha & Tripathi, 2014).

Location of Varanasi City
Initially, the city was the only place of pilgrimage just around the temple of Lord Shiva and later developed as a centre of religious, spiritual and educational activities. These activities have played a significant role in shaping the economic character of this city and it became a functional and commercial centre of eastern Uttar Pradesh and the western part of the adjoining state of Bihar. Apart from tourism and tourist-related activities, primary economic activities such as horticulture (for betel leaves and mangoes) and household industry (silk weaving and wooden toys) make Varanasi distinct because these undertakings have created a level of specialization such as banarasi paan and banarasi saree. Around 11% of the city population is engaged in manufacturing activities while the tertiary sector accounts for 6.80% of the total employment. The spinning and weaving industry employs about 51% of the total industrial workers, followed by metal industries employing 14% of the total workforce. (CDP, 2015). The morphology of the city shows a complex pattern with the areas that have the most religious heritage sites also having the most wholesale and retail outlets (CDP, 2015; Joshi, 1965).
Methodology
Data base
The paper is based mainly on primary data from 384 households collected through an interview from 12 slums of Varanasi city. The city has been divided into three geographical zones (Core, Middle and Outer) based on the morphological basis (Jha et al., 2019) and the same geographical zones have been considered for this study. These zones have been demarcated on the basis following criteria: Street Layout and Characteristics, Land Use as shown in Master Plan, pattern of settlements and functional Morphology of the city.
A total number of 78,253 slum households were included in the population. Based on Cochran’s (1963) formula for sample size, 384 slum households were included in the study, further divided equally among the three geographical zones. From each geographical zones, four slums were selected from different parts of the zone as sample slums to assess and analyze multidimensional Poverty (Fig. 2). From every sample slum, 32 households were chosen using systematic random sampling and every selected household was surveyed through a structured interview schedule. Informed consent was obtained from all the respondents in the study. The data collected from the field survey through the interview schedule were encoded and entered in SPSS 20 software for analysis.

Location of sample slums in Varanasi City
Indicators of multidimensional poverty index (MPI)
Jha and Tripathi (2018) designed Multidimensional Poverty Index for Slums based on lines of the versatile Methodology of global MPI developed by Alkire and Foster (2011), which can be readily adjusted to incorporate alternative indicators, cut-offs and weights that might be appropriate in local contexts. To measure the numerous deprivations of slum dwellers, 17 indicators belonging to three dimensions: education, health and living standard have been chosen (Table 1). Among 17 indicators, three belong to education; four belong to health; and the rest ten indicators belong to standard of living. Each person is assessed based on household achievements to determine if they are below the deprivation cut-off in each indicator and considered non-deprived and deprived accordingly. The deprivation of each person is weighted by the indicator’s weight.
Further, the three dimensions mentioned above are equally weighted, each receiving 1/3 weight. Again, the indicators within each dimension are also equally weighted. Thus, each indicator within education, health and living standard dimension receives 1/9, 1/12 and 1/30 weight, respectively. Each household is assigned a Composite Score of Poverty (C) according to their deprivations level in the component indicators. This deprivation score, also called the Composite Score of Poverty or C of each household, is calculated by taking a weighted sum of all deprivations so that the C for each household lies between 0 and 1. If the score is 1, the household or person is deprived in all component indicators; if the score is 0, the household or person is not deprived. Formally,
where Ii = 1 if the household is deprived in indicator i and Ii = 0 otherwise and wi is the weight attached to indicator i with \(\sum^{{\text{d}}}_{{{\text{i}} = {1}}} {\text{w}}_{{\text{i}}} = {1}\).
If the sum of the weighted deprivations is 33 per cent or more of possible deprivations, the person is considered to be multidimensionally poor. As discussed previously, the MPI combines two crucial pieces of information. Formally, the first component is called the multidimensional headcount ratio (H) and is expressed as:
where q is the number of multidimensionally poor people and n is the total population.
The second component, i.e., the intensity of Poverty (A), refers to the average deprivation score of multidimensionally poor people and can be expressed as:
where Ci (k) is the censored deprivation score of individual i and q is the number of multidimensionally poor people.
The MPI is the product of both and is expressed as:
Variables and statistical analysis
This study conducted one-way ANOVA and Post hoc tests to determine the spatial nature of multidimensional poverty. Further geographical zones were entered into the regression model as spatial or location predictors to determine the contribution of spatiality to poverty. Considering previous literature and the nature of multidimensional poverty, three independent variables were chosen for the hierarchical regression model. These included socio-religious category, occupation type of the head of the household and geographical zone as spatial/location variables. Notably, caste and religion were considered significant predictors in literature, but SC and ST were only found in the Hindu religion, whereas only the Other Backward Class (OBC) group was found in the Muslim community. Therefore, caste and religion were merged to run regression and produce valid results and a new variable (socio-religious category) was created. In this study, the composite score of multidimensional poverty denoted by Composite Score (Poverty) has been taken as a continuous dependent variable, as Jamal (2005) recommended.
Results
Based on the above methodology MPI for the slums in the different geographical zones in Varanasi city were computed (Table 2). The overall MPI for the slums of Varanasi City were also computed. For the computation of MPI, at first, the composite score of poverty was computed using seventeen indicators belonging to three dimensions, i.e., Education, Health and Standard of Living. Then censored composite scores followed by the Multidimensional Headcount ratio referred to as incidence of Poverty or H and Intensity of Poverty or A were computed using the formula mentioned earlier in the methodology section. The product of H and A were taken as MPI scores.
Spatiality
Poverty is multidimensional and one dimension of poverty is its spatiality, it can be seen that the Composite score of Poverty and MPI are different for each geographical zone. Geographical zones have been labelled as the moderate, high and impoverished zone by their MPI. To test if the mean composite score (Poverty) in different geographical zones is distinct in the population, the sample data were submitted to SPSS-20 for computing one-way ANOVA. The data was tested on the assumptions of one-way ANOVA, which indicated that there were no outliers in the data (box plot for values greater than 1.5 box-lengths from the edge of the box). The dependent variable, i.e., Composite score (Poverty), was normally distributed for the core, middle and outer geographical zone, as assessed by a normal Q-Q plot. The assumption of homogeneity of variances was violated, as assessed by Levene’s test for equality of variances (p = 0.035). The descriptive result of the Composite Score (Poverty) is shown in Table 3.
The composite score (Poverty) increased from the outer geographical region (n = 128, M = 0.432, SD = 0.210), to the core geographical region (n = 128, M = 0.483, SD = 0.175), followed by the middle geographical region (n = 128, M = 0.582, SD = 0.182). The composite score (Poverty) was found to be statistically significantly different for the different geographical regions, F(2, 381) = 20.614, p < 0.001. However, since, the assumption of homogeneity of variance was violated as assessed by Levene’s test for equality of variances (p = 0.035). Therefore, Welch ANOVA was also computed (Field, 2013) and the composite score (Poverty) was found to be significantly different for the different geographical zones, Welch’s F(2, 252.584) = 20.058, p < 0.001. In order to know which two groups differ significantly Post hoc test was computed and the results are presented in Table 4.
There was an increase in the composite score (Poverty) from the outer geographical zone (M = 0.432, SD = 0.210) to the core geographical zone (M = 0.483, SD = 0.175), a mean increase of 0.051, 95% CI [-0.006, 0.108], which was not statistically significant (p = 0.092). Again, the composite score (Poverty) increased from the middle geographical zone (M = 0.582, SD = 0.182) to the core geographical zone (M = 0.483, SD = 0.175), a mean increase of 0.099, 95% CI [0.046, 0.151], but it was statistically significant (p < 0.001). Similarly, the composite score (poverty) increased from the middle geographical zone (M = 0.582, SD = 0.182) to the outer geographical zone (M = 0.432, SD = 0.210), a mean increase of 0.150, 95% CI [0.092, 0.207], which was also statistically significant (p < 0.001).
The composite score (Poverty) for the middle geographical zone was statistically significant from the core and outer zone, but no significant difference was found between the core and outer zone. The group mean was statistically significantly different (p < 0.05) and it is concluded that Multidimensional Urban Poverty varies across geographical zones.
Correlates of multidimensional poverty
One of the objectives of this study is to find out the correlates of poverty. Multiple regression was computed in order to achieve the above objective. In this study, the independent variables were polytomous, so dummy variables were created. Table 5 shows the categorical variables, number of categories and respective dummy variables with reference categories for this regression model. The dependent variable, i.e., composite score (Poverty), is continuous.
A hierarchical multiple regression was run to determine if adding Occupation type followed by the Geographical Zones improved the composite score (Poverty) prediction over and above socio-religious group alone. There was independence of residuals, as assessed by a Durbin–Watson statistic of 1.465. There was no multicollinearity, as evaluated by tolerance values greater than 0.1. The assumption of normality was met, as assessed by Q-Q Plot. The model summary has been presented in Table 6 and complete details on each regression model have been enlisted in Table 7.
Model 1 indicates that the socio-religious category is one of the correlates of Multidimensional poverty (R2 = 0.110, F (2,381 = 23.443, p < 0.001). Further, in Model 2, the addition of Occupation (Government Service, Private worker and vendor) to the prediction of poverty (composite score) led to a statistically significant increase in R2 of 0.025, F(2, 379) = 5.573, p < 0.001. Model 2, which used the Socio-religious category and Occupation type to predict the composite score of poverty, was statistically significant, R2 = 0.135, F(4, 379) = 14.790, p < 0.001, adjusted R2 = 0.126 and proved the hypothesis, “Socio-religious category of the people and occupations are major determinants or correlates of multidimensional poverty”. In model 3, the addition of geographical zone (middle, core) to the prediction of poverty (composite score) led to a statistically significant increase in R2 of 0.99, F(2, 377) = 24.235, p < 0.001. In this final model, the socio-religious group (Muslim, Hindu Gen & OBC), Occupation type (Government service, Private service. worker and vendor) and Geographical Zone (core, middle) to predict composite score (Poverty) were statistically significant, R2 = 0.234, F(6, 377) = 19.151, p < 0.001, adjusted R2 = 0.221.
In Table 7, the coefficients (B) represent the difference in the composite score (Poverty) of being in the specified and the reference categories. On observing at B coefficient in Model 3, it can be seen that the socio-religious category is still a significant predictor, giving an increase of 0.135 points in the composite score for every household belonging to the Muslim socio-religious category than that of Hindu SC & ST category. There is no statistically significant evidence that Hindu General & OBC category achieves different composite scores (Poverty) to the reference category, i.e., Hindu SC & ST. The B coefficients for the occupation dummy variables can be interpreted similarly. There is no statistically significant evidence that the Private worker & vendor categories achieve different composite scores (Poverty) to Labour. However, Government service employees score significantly lower (− 0.110) than Labour (p < 0.05). Looking at the significant B coefficients, it is clear that both geographical zone dummy variables contribute statistically significantly to the composite score (p < 0.001). The final model indicates that middle and core geographical zone residents score more than outer zone residents. It is crucial to note that a high composite score reflects high deprivation results in poverty and vice-versa. Hence, it can be concluded from this model that households in the middle zone, having no one in government services and belonging to the Muslim socio-religious category, score the highest composite score leading to the highest deprivation and experiencing extreme poverty.
The regression equation for this study from regression model 3 can be expressed in the following form:
where B0 is the intercept (constant) and B1 to B4 are the slope coefficients (one for each variable). By substituting the values for B0 through B4, Composite Score (Poverty) can be predicted given that any household belongs to a specific socio-religious category, is engaged in a specific Occupation and is located in a specific geographical zone.
The above regression equation can predict a household’s composite score from a specific background. There are five terms in the regression equation for Model 3. There is the intercept, which is constant for all cases and there are nine regression coefficients: a coefficient for the Socio-religious group, a coefficient for occupation and two coefficients for the geographical zone, one for each zone. The intercept (constant) is 0.372 and this is the predicted composite score for the reference group, which is Socio-religious category = 0 (Hindu SC & ST), Occupation = 0 (Labour) and Geographical zone = 0 (Outer Zone). The coefficients represent the difference in composite scores between being in the specified category and being in the reference category. There is no interaction term, so the model assumes the effect of occupation and geographical zone are the same for all groups of the socio-religious category. For example, households located in the middle zone scored 0.155 higher than the outer zone regardless of the socio-religious category or occupation. Equally, whatever the geographical zone or socio-religious category, households with government service employees scored 0.110 less than any other household engaged in another job sector.
Table 8 shows that households in the Muslim socio-religious category worked as Labour or engaged in private service and vending and located in the middle zone scored the highest composite score and experienced the highest level of multidimensional poverty. By contrast, households belonging to either Hindu SC & ST or Hindu Gen & OBC socio-religious category, engaged in government service and located in the outer zone score the lowest composite score and experience the lowest level of multidimensional poverty.
Muslims, who resides in the middle zone and work as a labourer and private worker, were experiencing the highest level of multidimensional poverty. These slum dwellers were Muslim migrants and did not hold valid city citizenship documents; therefore, were lacking government support. Further, the slum dwellers are generally on private land without proper civic facilities. They did not develop household facilities such as toilet or kitchen because they are migrants and lives in tented houses. The educational attainments and indicators related to women were also low due to their orthodox religious beliefs. Therefore, it can be said that the segregation of resources, the socio-religious fabric and no access to government schemes are also the root cause of deprivation.
Discussion
The results presented a set of correlates of Multidimensional Poverty, including socio-religious category, occupation type and location of the settlement in the city. The study found that the socio-religious category is one of the significant correlates or predictors of poverty. This finding advocates that social geographies of Indian cities are shaped by socio-religious fabric. Similar findings have been reported by various scholars in India (Meenakshi et al., 2000; Mukim & Panagariya, 2012; Panagariya & More, 2014 Sundaram & Tendulkar, 2003; Thorat & Dubey, 2012). In other parts of the world, social/religious/racial determinants of poverty have been found in various studies, such as Osmond and Grigg (1978) found race as an important predictor of poverty.
This study also established the relationship between poverty and different socio-religious groups. The study suggests that Muslims are more deprived and poor than Hindus in slums. This deprivation can be seen across the dimensions and indicators. In Muslim community dominated slums, overall educational attainment is unsatisfactory and worst in females. Majority of muslim slum dwellers were migrants settle on private land with inadequate civic facilities and lacking household amenities. The health score were these muslim households was also very low because they do not believe in family planning due to religious beliefs and illiteracy. Panagariya and More (2014) also accepted that Muslims have higher poverty rates, which are highest in urban areas. Alkire and Seth (2015) found a substantial reduction in national Poverty (MPI) and each of its dimensions but also remarked that Muslims, the poorest subgroup in 1999, saw the most negligible reduction in poverty among religious groups.
Although some researchers found that distributional and deprivation outcomes are not ‘caste blind’ in general, therefore, households from the Scheduled Castes were more likely to be poor, than high-caste Hindu households (Borooah, 2005; Borooah et al., 2014). However, this study found no significant difference between Hindu general & OBC households and Hindu SC & ST households and therefore rejects the above argument. The main reason behind this finding can be identified as the similar living condition in slums, similar opportunities and challenges and similar economic status. This also indicates that social status is not as much powerful regarding economic and living standard as compared to rural areas. This is also a notable fact that SC & ST dwellers, usually resides in the core city, have more work opportunities than other castes and majority of them are employed in municipal corporation as sweepers and get more salary than their counterpart OBC & General slum dwellers, who are engaged in informal sector. This finding is similar to the argument of Panagariya and More (2014) that poverty rates among disadvantaged social groups are reducing faster, so the gap in poverty rates between them and the general population has declined.
The study further establishes that government service and poverty are negatively correlated. The main reason is the fixed salary and social security provided by the government. The households where at least one member was working in government and formal sector earns handsome salary than their counterparts working in informal sector. It is notable that gap between government/formal and informal sector is very huge regarding nature of Job, working hour, work condition, social security, medical and other benefits. Many researchers (Bhaumik & Chakrabarty, 2010; Gang et al., 2002; Hashmi et al., 2008; Saboor, et al., 2015) report similar conclusions that types of occupation or nature of job determine the household’s poverty level. Osmond and Grigg (1978), in their study in USA, found that the family head’s current employment status while Jamal (2005) found that occupation type or employment is the primary determinant of poverty in Pakistan. However, it is notable that this study did not find a significant negative correlation between poverty and private worker & vendor compared to Labour. This finding indicates that private workers and vendors in the city are not getting social security and sufficient income to afford a good lifestyle, so there is a need for skill development and social security schemes for slum dwellers.
The locational and spatial effect has also been instrumental in poverty determination (Ong & Miller, 2005; Spinks, 2001). In the present study, spatial variation can be seen very clearly across the geographical zones. The slum households located in middle zone were experiencing more multiple deprivation and poverty than core and outer zones. However, ANOVA test did not significantly differentiate poverty in core and outer zone, but final regression model differentiated each zone and reveals that residents of outer zone were less deprived. The location is not only important regarding their resident population, their connectivity to city center and working areas but also determine the polarization, segregation and distribution of resources. The present study also reveals very important fact that the location of slum households is the most dominant predictor of poverty. Many researchers focus on how spatial arrangements operate as constitutive dimensions of social phenomena and determine the level of poverty and inequality (Harvey, 1993; Smith, 1994; Soja, 2019). Spinks (2001) found that micro-level spatial inequality has facilitated polarisation between different urban spaces and their inhabitants in African cities. Similar findings were reported by other researchers (Poon, 2009; Kaibarta, 2022; Zhou et al., 2022) and their researches revealed that households in less endowed zones are more likely to be poor than those in more endowed regions. Researchers also found spatial variation in urban socio-economic inequality in different cities (Gounder, 2013). Thus, the findings of present study also re-establishes that the location of the slum household in the city is one of the most important predictors of multidimensional poverty.
Conclusion
The study presents a model for spatial and multidimensional deprivation in slums of Indian cities, which will be helpful to predict multidimensional poverty of slum households. The statistical analysis presents a regression model for Varanasi to predict multidimensional poverty and this model reveals that Muslim slum dwellers in the middle zone, employed as laborers and private workers, face the highest multidimensional poverty, whereas Hindu SC & ST or Hindu Gen & OBC households working in government service and located in the outer zone have the lowest multidimensional poverty levels. Inequality within the city is determined by the spatial polarization or segregation of resources, which plays a crucial role in shaping unequal distributions. The present study re-establishes the significance of location factor and space in poverty analysis and concludes that that socio-religious category, occupation and geographical location are significant determinants or at least correlates of poverty.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Abd Manap, N., Zakaria, Z., & Hassan, R. (2017). Investigation of poverty indicators for designing case representation to determine urban poverty. International Journal of Advances in Soft Computing and Its Applications, 9(2), 90–106.
Alkire, S. (2007). The missing dimensions of poverty data: Introduction to the special issue. Oxford Development Studies, 35(4), 347–359. https://doi.org/10.1080/13600810701701863
Alkire, S., & Foster, J. (2011). Counting and multidimensional poverty measurement. Journal of Public Economics, 95(7), 476–487. https://doi.org/10.1016/j.jpubeco.2010.11.006
Alkire, S., Kanagaratnam, U., & Suppa, N. (2021). The global multidimensional poverty index (MPI) 2021 (No. 51, pp. 1–39). Oxford Poverty and Human Development Initiative (OPHI).
Alkire, S., & Santos, M. E. (2014). Measuring acute poverty in the developing world: Robustness and scope of the multidimensional poverty index. World Development, 59, 251–274. https://doi.org/10.1016/j.worlddev.2014.01.026
Alkire, S., & Seth, S. (2015). Multidimensional poverty reduction in India between 1999 and 2006: Where and how? World Development, 72, 93–108. https://doi.org/10.1016/j.worlddev.2015.02.009
Ariyanto, K. (2023). Literature review: Urban poverty in a sociological perspective. Antroposen: Journal of Social Studies and Humaniora, 2(1), 24–32.
Arora, A., & Singh, S. P. (2015). Poverty across social and religious groups in Uttar Pradesh: An interregional analysis. Economic and Political Weekly, 50(52), 100–109.
Bansal, S., Pandey, V., & Sen, J. (2017). Redefining and exploring the smart city concept in indian perspective: Case study of Varanasi. In F. Seta, J. Sen, A. Biswas, & A. Khare (Eds.), From poverty, inequality to smart city. Springer. https://doi.org/10.1007/978-981-10-2141-1_7
Belhadj, B. (2011). A new fuzzy unidimensional poverty index from an information theory perspective. Empirical Economics, 40, 687–704. https://doi.org/10.1007/s00181-010-0368-5
Bhasin, R. (2001). Urban poverty and urbanization. Deep and Deep Publications.
Bhaumik, S., & Chakrabarty, M. (2010). Earnings inequality in India: Has the rise of caste and religion-based politics in India had an impact? In A. Shariff & R. Besant (Eds.), Handbook of Muslims in India (pp. 1–32). Oxford University Press.
Borooah, V. K. (2005). Caste, inequality and poverty in India. Review of Development Economics, 9(3), 399–414. https://doi.org/10.1111/j.1467-9361.2005.00284.x
Borooah, V. K., Diwakar, D., Mishra, V. K., Naik, A. K., & Sabharwal, N. S. (2014). Caste, inequality and poverty in India: A re-assessment. Development Studies Research. an Open Access Journal, 1(1), 279–294. https://doi.org/10.1080/21665095.2014.967877
CDP, 2015. City development plan for Varanas-2041. Capacity Building for Urban Development Project, Ministry of Urban Development. Retrieved from, https://openjicareport.jica.go.jp/pdf/12250312_03.pdf
Cochran, W. G. (1963). Sampling techniques (2nd ed.). John Wiley and Sons Inc.
Deaton, A. & Dreze, J. (2002). Poverty and inequality in India: A re-examination. Economic and Political Weekly, 37(36), 3729–3748.
Dinzey-Flores, Z. (2017). Spatially polarized landscapes and a new approach to urban inequality. Latin American Research Review, 52(2), 241–252.
Dubey, A. and Gangopadhyay, S., (1998). Counting the Poor: Where are the Poor in India? Department of Statistics, Government of India.
Fahad, S., Nguyen-Thi-Lan, H., Nguyen-Manh, D., Tran-Duc, H., & To-The, N. (2023). Analyzing the status of multidimensional poverty of rural households by using sustainable livelihood framework: Policy implications for economic growth. Environmental Science and Pollution Research, 30, 16106–16119. https://doi.org/10.1007/s11356-022-23143-0
Field, A. (2013). Discovering statistics using IBM SPSS Statistics: And sex and drugs and rock ‘n’ roll (4th ed.). Sage.
Gang, I. N., Sen, K., & Yun, M. S. (2002). Caste, Ethnicity and Poverty in Rural India. Retrieved from IZA Institute of labour economics website: https://www.iza.org/publications/dp/629/caste-ethnicity-and-poverty-in-rural-india
Gotham, K. F. (2003). Toward an understanding of the spatiality of urban poverty: The urban poor as spatial actors. International Journal of Urban and Regional Research, 27(3), 723–737. https://doi.org/10.1111/1468-2427.00478
Gounder, N. (2013). Correlates of Poverty in Fiji: An analysis of individual, household and community factors related to poverty. International Journal of Social Economics, 40(10), 923–938. https://doi.org/10.1108/IJSE-2012-0067
Gutschow, N. (2006). Benares: The sacred landscape of Vārānasī. Edition Axel Menges.
Hagerty, M. R., Cummins, R., Ferriss, A. L., Land, K., Michalos, A. C., Peterson, M., Sharpe, A., Sirgy, J., & Vogel, J. (2001). Quality of life indexes for national policy: Review and agenda for research. Bulletin of Sociological Methodology/bulletin De Méthodologie Sociologique, 71(1), 58–78. https://doi.org/10.1177/075910630107100104
Halimatusa’diyah, I. (2015). Zakat and social protection: The relationship between socio-religious CSOs and the government in Indonesia. Journal of Civil Society, 11(1), 79–99. https://doi.org/10.1080/17448689.2015.1019181
Harvey, D. (1993). From space to place and back again: Reflections on the condition of postmodernity. In J. Bird, B. Curtis, T. Putnam, G. Robertson, & L. Tickner (Eds.), Mapping the futures: Local cultures, global change. Routledge. https://doi.org/10.4324/9780203977781
Hashmi, A. A., Sial, M. H., Hashmi, M. H., & Anwar, T. (2008). Trends and determinants of rural poverty: A logistic regression analysis of selected districts of Punjab [with comments]. The Pakistan Development Review, 47(4), 909–923.
Haughton, J., & Khandker, S. R. (2009). Handbook on poverty + inequality. The World Bank.
Jamal, H. (2005). In search of poverty predictors: The case of urban and rural Pakistan. The Pakistan Development Review, 44(1), 37–55.
Jayaraj, D., & Subramanian, S. (2010). A Chakravarty-D’Ambrosio view of multidimensional deprivation: Some estimates for India. Economic and Political Weekly, 45(6), 53–65.
Jha, D. K., Harshwardhan, R., & Tripathi, V. K. (2019). Geographical zones of Varanasi City: Past to present. National Geographical Journal of India, 65(1), 46–55.
Jha, D. K., & Tripathi, V. K. (2014). Quality of life in slums of Varanasi city: A comparative study. Transactions, Journal of the Indian Institute of Geographers, 36(2), 171–183.
Jha, D. K., & Tripathi, V. K. (2018). Designing multidimensional poverty index for slums: Concept. Methodology and Interpretation, the Geographer, 65(1), 39–49.
Joshi, E. B. (1965). Uttar Pradesh district gazetteers Agra. Government of Uttar Pradesh.
Kaibarta, S., Mandal, S., Mandal, P., Bhattacharya, S., & Paul, S. (2022). Multidimensional poverty in slums: An empirical study from urban India. GeoJournal, 87(Suppl 4), 527–549. https://doi.org/10.1007/s10708-021-10571-7
Khalaj, S., & Yousefi, A. (2015). Mapping the incidence and intensity of multidimensional poverty in Iran urban and rural areas. The Journal of Spatial Planning, 18(4), 49–70.
Khan, A. U., Saboor, A., Ali, I., Malik, W. S., & Mahmood, K. (2016). Urbanization of multidimensional poverty: Empirical evidences from Pakistan. Quality & Quantity, 50, 439–469. https://doi.org/10.1007/s11135-014-0157-x
La Ferrara, E., & Bates, R. H. (2001). Political competition in weak states. Economics & Politics, 13(2), 159–184. https://doi.org/10.1111/1468-0343.00088
Löw, M., & Steets, S. (2014). The spatial turn and the sociology of built environment. In S. Koniordos & A. Kyrtsis (Eds.), Routledge handbook of European sociology (pp. 211–224). Routledge Handbooks Online.
Meenakshi, J. V., Ray, R., & Souvik, G. (2000). Estimates of poverty for SC, ST and female-headed households. Economic and Political Weekly, 35(31), 2748–2754.
Morris, M. D. (1980). The physical quality of life index (PQLI). Development Digest, 18(1), 95–109.
Mukim, M., & Panagariya, A. (2012). Growth, openness and the socially disadvantaged. In J. Bhagwati & A. Panagariya (Eds.), India’s reforms: How they produced inclusive growth. Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199915187.003.0005
Nafees, N. A., Iqbal, J., & Haq, Z. U. (2022). Assessing modified multidimensional poverty index and its demographic correlates in Khyber Pakhtunkhwa. Journal of Policy Research, 8(3), 1–10. https://doi.org/10.5281/zenodo.7075729
Narayana, M. R. (2009). Education, human development and quality of life: Measurement issues and implications for India. Social Indicators Research, 90(2), 279–293. https://doi.org/10.1007/s11205-008-9258-z
Ong, P. M., & Miller, D. (2005). Spatial and transportation mismatch in Los Angeles. Journal of Planning Education and Research, 25(1), 43–56. https://doi.org/10.1177/0739456X04270244
Osmond, M. W., & Grigg, C. M. (1978). Correlates of Poverty: The interaction of individual and family characteristics. Social Forces, 56(4), 1099–1120. https://doi.org/10.2307/2577513
Panagariya, A., & More, V. (2014). Poverty by social, religious and economic groups in India and its largest states: 1993–1994 to 2011–2012. Indian Growth and Development Review, 7(2), 202–230. https://doi.org/10.1108/IGDR-03-2014-0007
Pandey, M. D., Nathwani, J. S., & Lind, N. C. (2006). The derivation and calibration of the life-quality index (LQI) from economic principles. Structural Safety, 28(4), 341–360. https://doi.org/10.1016/j.strusafe.2005.10.001
Perry, B. (2002). The mismatch between income measures and direct outcome measures of poverty. Social Policy Journal of New Zealand, 19, 101–127.
Piazza, J. A. (2006). Rooted in poverty? Terrorism, poor economic development and social cleavages. Terrorism and Political Violence, 18(1), 159–177. https://doi.org/10.1080/095465590944578
Poon, F. B. (2009). Spatial inequality of urban poverty in Hong Kong. (Thesis). University of Hong Kong, Pokfulam, Hong Kong SAR. https://doi.org/10.5353/th_b4292997
Rahi, M. (2011). Human development report 2010: Changes in parameters and perspectives. Indian Journal of Public Health, 55(4), 272. https://doi.org/10.4103/0019-557x.92404
Rupasingha, A., & Goetz, S. J. (2007). Social and political forces as determinants of poverty: A spatial analysis. The Journal of Socio-Economics, 36(4), 650–671. https://doi.org/10.1016/j.socec.2006.12.021
Saboor, A., Khan, A. U., Hussain, A., Ali, I., & Mahmood, K. (2015). Multidimensional deprivations in Pakistan: Regional variations and temporal shifts. The Quarterly Review of Economics and Finance, 56, 57–67. https://doi.org/10.1016/j.qref.2015.02.007
Saunders, P., Bradshaw, J., & Hirst, M. (2002). Using household expenditure to develop an income poverty line. In Social policy and administration. Blackwell Publishers.
Shukla, R., Jain, S., & Kakkar, P. (2010). Caste in a different mould. Business Standard, New Delhi. Retrieved from, https://ssrn.com/abstract=3297408
Singh, R. P. (2017). Varanasi, the heritage capital of India: Valuing the Sacredscapes. In Book of abstracts, international seminar on Indian art heritage in a changing world: Challenges and prospects (Vol. 27, pp. 19–38).
Singh, R. P., Dar, V., & Rana, P. S. (2001). Rationales for including Varanasi as heritage city in the UNESCO World Heritage List. National Geographical Journal of India, 47(1–4), 177–200.
Sirgy, M. J., Michalos, A. C., Ferriss, A. L., Easterlin, R. A., Patrick, D., & Pavot, W. (2006). The quality-of-life (QOL) research movement: Past, present and future. Social Indicators Research, 76(3), 343–466. https://doi.org/10.1007/s11205-005-2877-8
Smith, D. (1994). Geography and social justice. Blackwell.
Soja, E. W. (2019). The city and spatial justice. In Public Los Angeles. https://doi.org/10.4000/BOOKS.PUPO.415
Spinks, C. (2001). A new apartheid? Urban spatiality, (fear of) crime and segregation in Cape Town, South Africa. Development Studies Institute, London School of Economics and Political Science. Retrieved from, https://www.files.ethz.ch/isn/138143/WP20.pdf
Sulaiman, J., Azman, A., & Khan, Z. (2014). Re-modeling urban poverty: A multidimensional approach. International Journal of Social Work and Human Services Practice, 2(2), 64–72. https://doi.org/10.13189/ijrh.2014.020209
Sumarto, S., Suryadarma, D., & Suryahadi, A. (2007). Predicting consumption poverty using non-consumption indicators: Experiments using Indonesian data. Social Indicators Research, 81(3), 543–578. https://doi.org/10.1007/s11205-006-0023-x
Sundaram, K. & Tendulkar, S. D. (2003). Poverty among social and economic groups in India in 1990s. Economic and Political Weekly, 38(50), 5263–5276.
Thorat, S., & Dubey, A. (2012). Has growth been socially inclusive during 1993–94–2009–10. Economic and Political Weekly, 47(10), 43–53.
Xhafaj, E., & Nurja, I. (2014). Determination of the key factors that influence poverty through econometric models. European Scientific Journal, 10(24). https://doi.org/10.19044/ESJ.2014.V10N24P%25P
Zhou, Q., Chen, N., & Lin, S. (2022). A poverty measurement method incorporating spatial correlation: A case study in Yangtze River Economic Belt, China. ISPRS International Journal of Geo-Information, 11(1), 50. https://doi.org/10.3390/ijgi11010050
Funding
No funding was received to assist with the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
Both authors contributed to the study’s conception and design. Material preparation, data collection, and analysis were performed by Dr DKJ. The first draft of the manuscript was written by Dr DKJ. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Ethical approval
Approval was obtained from the Departmental Research Committee, Department of Geography, Institute of Science, Banaras Hindu University, Varanasi, India. The procedures used in this study adhere to the tenets of the Declaration of Helsinki.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jha, D.K., Tripathi, V.K. Unveiling the complexity of urban poverty: Exploring spatial and multidimensional deprivation in slums of Varanasi, India. GeoJournal 88, 6561–6575 (2023). https://doi.org/10.1007/s10708-023-10986-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10708-023-10986-4