
Abstract
Crop cultivar performance is a result of combined effects of genotype, environment and genotype × environment (G × E) interaction. To effectively generate reliable estimates of crop yield the magnitude and patterns of G × E in regional yield trials should be specified. This research aimed to (1) investigate existing possible mega-environments (ME) and suitability of test locations for winter wheat zoning, and (2) determine the role of climatic factors in clustering patterns of G × E. Winter wheat yield data from a three-year nationwide yield trial consisting of 24 genotypes grown in 24 test environments supplemented with 37 climatic factors were subjected to empirical and analytical analyses. Standard deviation-scaled genotype main effect and G × E interaction (SD-GGE) biplot methodology, factorial regression and partial least square regression were applied to both analyses. The combined ANOVA showed that the environmental effect was the main source of variation (83%), and the magnitude of G × E interaction was sixfold greater than genotype alone. The SD-GGE biplot confirmed non-repeatable patterns for grouping of test locations across years, indicating significant (P < 0.01) rank-change location-by-year interactions and existence of strong "crossover" G × E interactions. This led to the conclusion that the winter wheat growing region in Iran consists of a single but complex ME for grain yield, suggesting that high-yielding-and stable winter wheat genotypes should be developed for the entire region rather than genotypes adapted to specific agro-ecological regions. Precipitation (monthly and total) and temperature (minimum, maximum and average) accounted for 25.4% and 56.8% of total G × E.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Wheat (Triticum spp.) as the most diverse and widely consumed crop is the mainstay of global food security. Global demand for wheat is expected to grow rapidly in developing countries over the next decades due to high rates of population increase and income enhancement (Mohammadi 2018). Unpredictable environmental conditions in dryland areas caused by fluctuations in rainfall and temperature lead to highly variable yields and food insecurity (Sánchez-García et al. 2013; Hawkesford et al. 2013; Lobell and Gourdji 2012; Del Pozo et al. 2016). The most reliable way to address environmental variation is to choose promising genotypes over multiple locations and years (Malosetti et al. 2013; Yan 2015; Yan et al. 2000; Chairi et al. 2020). However, large yield trials and appropriate statistical methods are required for selection of promising lines, yield-based grouping of test locations and correct zoning of targeted regions (Navabi et al. 2006; Yan and Tinker 2006; Rozeboom et al. 2008).
Several empirical and analytical (biological) approaches are suggested for clustering of test environments in multi-environment trials (MET), including environmental factors (such as precipitation, temperature and soil) and genotypic trait information (Vargas et al. 2001; Motzo et al. 2001; Ramburan et al. 2012; Mohammadi et al. 2015).
Recently, the SD-GGE biplot has received increasing attention as it is an efficient method to fully explore MET data. The SD-GGE biplot is a standard deviation-scaled GGE biplot that explains variation due to G (genotype) and G × E interaction in more detail than the AMMI model and provides an easy and comprehensive solution for MET data analysis (Yan et al. 2007). It provides graphical displays of test environments, genotypes and their interaction based on principal component analysis (PCA) and presents a "which-wins-where" pattern for detecting mega-environment and crossover G × E interactions (Yan 2015). It allows investigation of test environments for selection of genotypes most adapted to target environments. The power of a test location for a representing target region (representativeness) and its ability to discriminate genotypes (discrimination ability) are the most important aspects of an ideal test location to be evaluated through multi-year and multi-location yield trials and outcomes must be repeatable across years (Yan et al. 2000).
Analytical models are required for enhancing the value of yield trials and understanding the causes of G × E interactions (Voltas et al. 2005; Yan and Hunt 2001). These models include some properties of trial sites regarding environmental factors such as precipitation, temperature, altitude, and latitude. Such models including factorial regression (FR; Denis 1988; van Eeuwijk et al. 1996) and partial least square (PLS) regression (Vargas et al. 2001) are based on a generalization of constrained-PCA (C-PCA) and are useful for studying G × E data with integration of some external factors (Amenta and D’Ambra 2001). The C-PCA integrates explanatory variables such as environmental factors into the G × E matrix data. For utilizing these methods, first the data matrix for the explanatory data is decomposed (external analysis) and then applied in PCA is to decompose the matrices (internal analysis).
The SD-GGE biplot methodology was applied to investigate G × E in grain yield data of winter wheat regional yield trials in Iran. The trials involved 24 winter wheat breeding lines and cultivars and 24 rainfed test environments across eight provinces that account for more than 60% of the rainfed winter wheat production area. Grouping of test environments through representativeness and discrimination ability was undertaken to explore the ecological grouping of test locations. Further analyses investigated the effects of climatic factors on G × E. The analysis presented in this research provides a basis for selection of superior winter wheat genotypes for cultivation in wide or narrow agro-ecological regions.
Materials and methods
Winter wheat genotypes and ecological regions
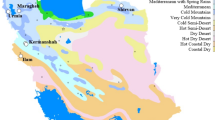
Twenty-four rainfed winter wheat genotypes consisting of 21 promising breeding lines and three current cultivars (Table 1) were evaluated at eight test locations (provinces) over three cropping seasons (2016–2017, 2017–2018, 2018–2019) (Table 2 and Fig. 1). The lines were representative of the national winter wheat breeding program for rainfed areas in Iran and were entries in the 24th Elite Regional Bread Wheat Yield Trial (ERBWYT).

Map of Iran showing winter wheat test locations and area grouping based on long-term rainfall using the geographical information system
Experimental design
The experimental design was a randomized complete blocks design with four replications at each location. The plot size was 7.2 m2 (6 rows, 6 m long, and 20 cm row spacing). The sowing density was 380 seeds per m2. The fertilizers used were 50 kg N ha−1 and 50 kg P2O5 ha−1 as basal application at planting. Herbicides were applied as a tank mixture of 2, 4-D and clodinafop-propargyl at tillering followed by hand weeding as required. No pest or disease control was necessary for the duration of the trials. Grain yields were measured as kg per plot, converted to yield per hectare (kg ha−1) for statistical analyses.
Climatic data collections
The climatic data collected from weather stations at each location included 37 parameters including monthly and total precipitation, and monthly temperature recordings on minimum, maximum and average during the growing period (October–June).
Data analysis
The yield data of 24 genotypes grown in 24 test environments were analyzed. Combined analysis of variance (ANOVA) and phenotypic and genetic correlations among test locations were conducted using the Meta-R package (Alvarado et al. 2015). The GEA-R package (Pacheco et al. 2015) was used in SD-GGE biplot analysis. The general model for the GGE biplot is:
where Yij is the grain yield of genotype i in environment j, μ is the grand mean, βj is the main effect of environment j, k is the number of principal components (PC); λk is the singular value of the kth PC; and αik and ηjk are the scores of genotype i and environment j, respectively, for the kth PC; and εij is the residual associated with genotype i in environment j.
In the SD-GGE biplot the cosine of the angle between vectors of two test locations indicates correlation; an acute angle shows a strong positive correlation whereas an obtuse angle indicates a negative correlation, and a right angle means no correlation. The projection of genotype or environment on the average tester coordinate (ATC) indicates average performance of genotype or desirability of test location (Yan et al. 2000). The distance between genotype and ATC is used to judge the genotype stability, whereas the angle between location vector and ATC assesses the representativeness of a test location. An acute angle shows more representativeness. A long vector for a test location shows greater discrimination. In SD-GGE biplot, the "which-wins-where" pattern shows a polygon view of G × E, in which the environments and genotypes are divided into several sections. The vertex genotype in each section is the one with the best mean performance across locations in that section.
To better understand the biological causes of G × E, multivariate partials least squares (PLS) regressions were performed as described by Aastveit and Martens (1986). The general model of PLS is based on the latent variable decomposition:
where T is a n × c matrix which giving the latent variable (also called scores) for the n observations; P and Q are, respectively, (p × c) and (l × c) orthogonal loading matrices; E and F are error terms assumed to be independent with random normal distributions.
To estimate the contribution of climatic variables to G × E, a factorial regression (FR) model was used as described by Denis (1988). The general model for FR is:
where μ, αi and βj are grand mean, G and E effects, respectively; zjk is kth climatic factor for environment j; and ξik represents the sensitivity of genotype i to kth climatic factor. The heterogeneity in the ξi’s for successive z1, zK variables account for G × E interaction, and the sum of multiplicative terms \(\sum\nolimits_{k + 1}^{K} {\xi_{ik} Z\gamma_{jk} }\) shows the interaction. The required number of climatic factors to optimally approximate the dimensionality can be detected using the Fischer F-test and Akaike's information criterion (AIC, Akaike 1974).
Results
ANOVA and variation in grain yield
The combined ANOVA for grain yield data showed that the effects of genotype, environment and G × E were highly significant (Table 3). The relative contribution of each treatment effect on variation in grain yield was determined according to the percentage of each treatment effect over the total effect. Environment (Y, L and Y × L) had the greatest impact on grain yield, accounting for 83% (27.7%, 29.0% and 26.3% corresponding to Y, L and Y × L effects) of the variation. G × E accounted for 7.5% of grain yield variability, whereas genotype contributed only 1.2%. The contribution of G × E was therefore about sixfold that of genotype alone, indicating a high G × E in these yield trials. The impact of each factor on grain yield variability could be ranked from high to low as: L (29%) > Y (27.7%) > Y × L (26.3%) > G × Y × L (3.9%) > G × L (2.9%) > G (1.2%) > G × Y (0.8%).
Genotypic mean yields varied from 1789 to 2181 kg/ha across environments. In the case of locations the yield levels ranged from 1346 (Arak) to 2553 kg/ha (Kermanshah). The mean yield in each cropping season was 2419 kg/ha (2016–2017), 1936 kg/ha (2017–2018) and 3303 kg/ha (2018–2019). The grain yield of genotypes varied among environments showing high G × E interaction. In addition to fixed environmental properties such as latitude, altitude and soil type that may influence G × E there were also the effects of climatic variables such as rainfall (amount and monthly pattern) and temperature which can be highly variable from year to year and location to location under dryland Mediterranean conditions. However, the poor temporal and spatial distribution of rainfall in the region (Fig. 2) is the main challenge for winter wheat productivity.

Monthly patterns of rainfall in eight test locations over three cropping seasons
The rainfall across environments during the growing period (October-June) varied from 189.7 mm at Ardabil in 2016–2017 (with a mean of 241 mm across years of study) to 782.5 mm at Kermanshah in 2018–2019 (mean of 599 mm rainfall). Given that about 400 mm of rainfall is required for successful crop production only 11 of 24 environments exceeded that level and consequently water stress conditions prevailed in more than of 50% of environments. Thus, some test environments were under severe drought conditions in different years.
Winter wheat mega-environments
Graphic analysis using the SD-GGE biplot for grain yield trials in single and multiple years provided an opportunity to identify possible mega-environments across the region. The which-wins-where pattern of the SD-GGE biplot showed several clustering patterns in the regional yield trials. A group of test locations sharing the same winner genotype is considered as a mega-environment (Gauch and Zobel 1997; Yan et al. 2000). Based on yearly SD-GGE biplots, the test locations were placed into groups, ranging from three in 2017–2018 and 2018–2019 to four in 2016–2017 (Fig. 3a–c).

SD-GGE biplot showing "which-wins-where" patterns of G × E interaction for 24 winter wheat genotypes in single-year (a 2016–2017; b 2017–2018; c 2018–2019) and multiple-year (d) trials
In 2016–2017, the eight test locations were divided into four clusters with the four best performers (Fig. 3a). The best genotype was G3 at Maragheh (MH7), Qamloo (QO7) and Arak (AK7). The second cluster included Kermanshah (KH7) and Zanjan (ZN7) with G7 as winner. The locations of Hamedan and Urmieh clustered in the same section with G9 as the best yielder. The Ardabil (AL7) location tended to separate in a single cluster with G21 as winner.
In the second year (2017–2018; Fig. 3b) there were three location clusters with three performer genotypes. G20 performed the best at Zanjan (ZN8), Qamloo (QO8), Arak (AK8) and Urmieh (UH8). G7 was winner at Kermanshah (KH8), Maragheh (MH8) and Hamedan (HN8). As in the first year Ardabil (AL8) clustered in a separate group with G24 being the winner.
The eight locations were divided by three winner genotypes in the third year (Fig. 3c); G5 was highest yielding at Kermanshah (KH9), Zanjan (ZN9) and Qamloo (QO9), whereas the best performers at Hamedan (HN9), Maragheh (MH9) and Ardabil (AL9) were G14 followed by G18; and G12 was the highest at Arak (AK9) and Urmieh (UH9).
Based on all data for 24 genotypes across 24 test environments (Fig. 3d), G3 performed the best in Kermanshah (KH7, KH9), Qamloo (QO7, QO8, QO9), Zanjan (ZN7, ZN8, ZN9), Maragheh (MH7, MH9) and Urmieh (UH7, UH8); G9 was first at Arak (AK7, AK8, AK9), Hamedan (HN7, HN9) and Ardabil (AL9); G8 performed well at Maragheh (MH8) and Hamedan (HN8), G4 at Urmieh (UH9) and Ardabil (AL7), and G14 at Ardabil (AL8). However, the grouping patterns varied from year to year reflecting large G × E interaction effects, leading to the conclusion that the GGE biplot analyses did not detect repeatable G × L interaction patterns across years. Thus, the winter wheat growing region in Iran appears to be a single but complex mega-environment.
Discrimination vs. representativeness of test locations
Discrimination power and representativeness of test locations are components of an ideal test location. Discriminative power was evaluated through vector length at each location whereas the representativeness was determined by the angle between the location vector and average tester coordinate (ATC). The ATC is the axis that passes from the biplot origin to the point representing the average of all locations (Yan et al. 2007). Thus, an ideal test location is a location with the longest vector (most discriminating) and the smallest angle with ATC (most representative). Among the eight locations in 2016–2017, the locations QO, AK, MH, KH, ZN were found as ideal test locations, and characterized as informative locations (Fig. 4a). Ardabil was identified as a non-informative location. In 2017–2018 the ideal test locations were MH, KH and UM (Fig. 4b); AL and ZN were not informative test locations. In 2018–2019, MH and AL showed relatively strong representativeness and discriminating ability (Fig. 4c). From the location positions on the biplot, no repeatable grouping pattern across years were observed, and the same locations in different years showed positive and negative PC1 scores, indicating crossover G × E interaction. Similar observations in the case of discrimination and representativeness of test location could be observed, as the same locations in different years expressed differences in discriminating ability and representativeness (Fig. 4d).

SD-GGE biplot showing representativeness and discrimination ability of test locations in single-year (a 2016–2017; b 2017–2018; c 2018–2019) and multiple-year (d) trials
Associations among test locations
The test locations Zanjan, Kermanshah, Qamloo, Maragheh and Arak were closely correlated in the 2016–2017 cropping season, as can be seen through the acute angles between their vectors. A similar pattern also observed between Hamedan and Urmieh. The Ardabil location was not associated with any other test location. In 2017–2018 the locations Zanjan, Qamloo and Arak as in the previous year kept their association in genotype ranking, and this pattern also occurred for Kermanshah and Maragheh as they showed consistent correlations. These two locations showed a positive correlation with Hamedan. Like the previous year, Ardabil did not associate with any other location.
The locations Zanjan and Qamloo were closely correlated in 2018–2019 and also showed a positive correlation with Kermanshah. Maragheh, Ardabil and Hamedan were also associated with each other in genotype rankings. Due to short vectors, Arak and Urmieh were not associated with other locations. In all three years a repeatable correlation was observed between Zanjan and Qamloo but this pattern was not observed between other locations.
Genetic and phenotypic correlation analyses (Fig. 5) between locations confirmed the relationships reported for test locations through the SD-GGE biplot. The most prominent genetic and phenotypic correlations were observed between Maragheh, Zanjan, Qamloo, Kermanshah, and Arak in the first cropping season. In second cropping season, positive relationships were observed among Qamloo, Zanjan, Urmieh and Arak. Similarly, significantly genetic and phenotypic correlations were observed between Maragheh and Kermanshah as well as between Ardabil and Hamedan. In the third cropping season Maragheh, Hamedan and Ardabil were positively associated, and a similar trend was observed between Qamloo and Zanjan.

Heatmap for genetic (above diagonal) and phenotypic (below diagonal) correlations between grain yields observed at different test locations in 2016–2017 (a), 2017–2018 (b) and 2018–2019 (c) cropping seasons
Mean yield and stability performance
The test locations that formed a mega-environment tended to change from year to year, thus leading to a conclusion that a grouping pattern was not consistent across years. This suggests that genotypes should be developed for high yield and stability across all environments rather than to breed genotypes with specific adaptation. Figure 6 shows the SD-GGE biplot ranking the 24 winter wheat genotypes for mean yield and stability performances across 24 test environments. Genotypes G3 and G9 produced the highest mean yield, followed by G17, G7 and G2; G8 ranked sixth followed by G22, G12, G13 and G9. All these genotypes expressed mean yields higher than the grand mean. Among them, G17 and G20 showed the highest stability as they were placed near to the ATC abscissa and had PC2 scores near to zero. Genotypes G24, G14 and G4 with highest contributions to G × E had yields less than the grand mean (Tables 4 and 5).
Climatic factors contributing to G × E interaction
Analytical methods FR and PLS regression were applied to investigate important environmental factors affecting G × E and grouping of test locations. Of 37 climatic variables applying to monthly rainfall and minimum, maximum and average temperatures, 23 were significantly (P < 0.01) influenced G × E according to F-tests. The validity of entered variables in the RF model was also confirmed by AIC (Table 6). These variables together explained 82.2% of total G × E interaction. Rainfall, and maximum, minimum and average temperatures accounted for 25.4%, 20.6%, 20.0%, and 16.2% of total G × E, respectively.
Among monthly rainfall variables, precipitation through March (4.1%), January (3.8%), April (3.5%), November (3.1%) and October (3%) significantly contributed to interaction variance. Maximum temperatures in November, February, January, October and April were significant and respectively, captured for 4.5%, 3.9%, 3.0%, 2.8%, and 2.8% of the total variation in G × E. Minimum temperatures in May, February, April, and June also significantly influenced G × E, accounting for 4.3%, 2.6%, 2.4%, 2.1%, and 2.1%, respectively. Average temperatures in November, March, October, January and February significantly contributed for 5.5%, 4.7%, 4.2%, 2.8% and 2.8% of total variation in G × E, respectively.
A biplot based on first and second PLS factors enriched by the 23 climatic factors was constructed (Fig. 7). The explanatory climatic factors that showed the highest contribution to interaction in factorial regression (Table 6) tend to show similar patterns in the PLS biplot, being placed further from the biplot origin indicative of high contributions to G × E. Test environments (KH9, UH9, KH7, HN9, ZN9, ZN8, MH9, UH7) located at the top of the biplot favored high values for rainfall through April, March, January, November, October and total rainfall, whereas the other environments (KH8, UH8, HN8, ZN8, QO8, QO7, AL7, AL8, AL9) located at the bottom tended to have high rainfall during May and February, and maximum temperatures in March, December and February; as well as minimum and average temperatures in March (Fig. 7).

SD-GGE biplot showing yield and stability analyses for 24 winter wheat genotypes (green) grown in 24 test environments (blue). (Color figure online)

PLS biplot representing X-scores for 24 winter wheat genotypes (numbers 1–24), Y-loadings of 24 rainfed test environments (red) enriched with the X-loadings of 23 climatic factors (green)s. (Color figure online)
The genotypes were clearly separated based on the first factor of the biplot, where genotypes G15, G16, G8, G3, G14 and G1 performed better in environments with high rainfall and temperature (corresponding to Kermanshah and Arak in all three years as well as to Hamedan and Urmieh in some years); whereas genotypes G4, G10, G21, G12, G5, G11 and G22 showed better adaptation to environments favored low temperatures (Maragheh and Qamloo in all three years as well as Zanjan and Ardabil in some years).
The PLS biplot clearly separated Maragheh and Qamloo from Karmanshah and Arak, showing differences in adaption of genotypes to these locations in their agro-climatic characteristics such as monthly rainfall distribution. For example, G13, G23, G6, G2, G22, G8, G18, and G3 favored high rainfall in April, March, January, November, October, whereas G14, G1, G9, G17, G15, and G16 favored higher rainfall in May and February. This indicated that monthly rainfall and its distribution led to significant G × E under rainfed conditions. Similar trends were observed for sensitivity of genotypes to monthly minimum and maximum temperatures. Genotypes G15, G16 G3, G18, G8, G14, and G1 were positively favored by higher temperatures, whereas G4, G10, G21, G12, G5, G11, and G22 positioned in the opposite side of the biplot, were negatively affected by higher temperatures. In general, the PLS biplot clearly separated environments in different groups with positively interactions with some specific climatic factors.
Discussion
Western and north-western Iran is the main region for rainfed winter wheat production. This region accounts for 54.7% of the total rainfed wheat area and 58.9% of total rainfed wheat production in the country. The region is defined as a cold highland area with wide variation in amount and monthly patterns of rainfall and minimum and maximum temperatures during the cropping season. The long-term rainfall in the area is 325 mm ranging from 235 (corresponding to Ardabil in the north) to 420 mm (corresponding to Kermanshah in the west). Cropping seasons with rainfall less than 300 mm are considered unfavorable for wheat production, although the monthly distribution of rainfall in dryland conditions is much more important than total rainfall. Wheat is most sensitive to drought during flowering and grain filling (May and June) and usually there is inadequate rainfall during that period; the period of stem elongation (March and April) is also important.
The highest mean yield in the three years study was recorded in 2018–2019, the year with highest rainfall (3303 kg/ha and 482 mm rainfall). This cropping season can be regarded as a favorable year in respect to rainfall. The 2016–2017 season with lowest rainfall, but with good monthly distribution was a moderate production year (2419 kg/ha and 314 mm rainfall); whereas 2017–2018 with moderate rainfall and the lowest productivity (1936 kg/ha and 386 mm rainfall) was more stressful due to insufficient precipitation at the critical growth stages. The latter two seasons can be regarded as unfavorable. Because of differences in productivity in unfavorable years it is obvious that wheat productivity is affected by climatic variables in addition to total rainfall. Factorial and PLS regression studies highlighted the importance of other climatic variables, especially monthly rainfall distribution. Rainfall during the critical growth stages in February, January, April, November and October contributed more to variation in grain yield than total rainfall. In addition, differences in minimum temperatures during the critical growth stages, particularly in May, February and April; and difference in maximum temperatures in November, February, January, October and April were also important and affected genotypes in different ways. Rainfall and minimum temperatures in June were also significant factors.
Environment accounted for 83% of the variation in grain yield. According to ANOVA and SD-GGE biplot, the G × E effect was sixfold greater than genotype effect. Such a pattern of interacting variance components indicates that the highest component of variation in dryland winter wheat regional yield trials was the environment. Similar results regarding the relative magnitude of genotype, environment and G × E were already reported (De Vita et al. 2010; Sánchez-García et al. 2012; Mohammadi et al. 2018). Highly significant interaction among environment (year, location, year × location interaction) and genotype leads to low yield stability. Thus, wheat breeders are advised to increase the number of genotypes in METs to identify the highest yielding, stable genotypes and minimize negative effects of G × E.
The "which-won-where" pattern of the SD-GGE biplot clearly showed a "crossover" pattern of location grouping in regional yield trials. Several location groups were distinguished each year. Clustering patterns showed poor repeatability across years, as most (but not all) locations showed changes in grouping across years. This instability in grouping could be due to the random nature of year-dependent factors caused by yearly variation in climatic variables (Navabi et al. 2006; Yan 2014; George and Lundy 2019). Yan (2014) defined this phenomenon as a type IV classification of regional yield trials. According to this kind of classification, the G × E interaction is dominated by genotype-by-location-by-year (G × L × Y) interaction, thus the target area cannot be meaningfully divided into distinct mega-environments. In our study, G × L × Y accounted for 3.9% of total variation and its size was threefold the genotype effect (1.2%) (Table 3). Furthermore, partitioning of G × E into its components indicated that G × L × Y was the largest source of interaction compared to G × L (2.9%) and G × Y (0.8%).
Based on the present results the target region is best represented as a single but complex mega-environment, suggesting that evaluation of winter wheat genotypes must occur over multiple locations and years. Thus, evaluation and selection of future varieties for dryland conditions must focus on genotypes with wide adaptation rather than genotypes adapted to specific regions. Similar recommendations were made by Navabi et al. (2006) in relation to spring wheat in Alberta when they found a lack of repeatability in the G × E interaction patterns over years. They suggested a single mega-environment with unpredictable "crossover" G × E interaction for spring wheat that did not support the previous classification of wheat growing areas in Alberta. Similarly, our results do not support the traditional classification of the winter wheat growing area in Iran which was based on empirical knowledge of the wheat growing area.
Clustering of locations for a target region has been subjected to several previous studies (George and Lundy 2019; Rakshit et al. 2012; Navabi et al. 2006; Mohammadi et al. 2010). George and Lundy (2019) pointed out that the cereal growing areas in California comprised a single but unstable mega-environment for grain yield in wheat. They concluded that the G × E interaction observed in California was primarily due to non-crossover G × E interaction and seasonal effects (i.e., G × Y and G × L × Y), with genotype effects generally dominating. Due to remarkable fluctuations in climatic conditions that cause unpredictable year effects, the recommended genotypes for the region should have high mean yield and stable performance. Our findings suggest that two outstanding breeding lines (G17 and G20) with the highest mean yield and stability across environments could be released for production in the entire region after further evaluation.
The mean productivity in the region has reached to 1517 kg/ha (Official statistics for Agriculture of Iran, 2019) and potential yield of newly developed winter wheat genotypes in regional yield trials is estimated to be 2100 kg/ha. This shows that wheat production in this region achieves about 70% of genetic yield potential. However, this gap is likely due to non-optimal cropping practices and lack of adoption of new varieties. The test location network included locations that are generally exposed to abiotic stress such as drought and cold that commonly occur in the Mediterranean rainfed conditions of western and north-western Iran.
Conclusion
Highly significant G × E interaction observed in the present trials was mostly explained by variation in monthly rainfall and temperatures from one location to another during critical growth periods. According to SD-GGE biplot analysis no repeatable G × L interaction patterns were identified, leading to the conclusion that the dryland winter wheat growing area in Iran is a single but complex mega-environment for grain yield. Thus, improvement in winter wheat grain yield will be best achieved by selecting genotypes with high mean yield and stable performance across the entire region that accounts for more than 60% of total rainfed wheat production in the country.
References
Aastveit H, Martens H (1986) ANOVA interactions interpreted by partial least squares regression. Biometrics 42:829–844
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Autom Control 19:716–723
Alvarado G, López M, Vargas M, Pacheco A, Rodríguez F, Burgueño J, Crossa J (2015) “META-R (Multi Environment Trial Analysis with R for Windows), Version 6.04.”, CIMMYT Research Data & Software Repository Network. https://data.cimmyt.org/dataset.xhtml?persistentId=hdl:11529/10201
Amenta P, D’Ambra L (2001) Generalized constrained principal component analysis. In: Borra S, Rocci R, Vichi M, Schader M (eds) Studies in classification, data analysis, and knowledge organization. Springer, Berlin, pp 137–144
Chairi F, Aparicio N, Serret MD, Araus JL (2020) Breeding effects on the genotype × environment interaction for yield of durum wheat grown after the Green Revolution: the case of Spain. Crop J 8:623–634
De Vita P, Mastrangelo AM, Matteu L, Mazzucotelli E, Virzi N, Palumbo M, Cattivelli L (2010) Genetic improvement effects on yield stability in durum wheat genotypes grown in Italy. Field Crops Res 119:68–77
Del Pozo A, Yáñez A, Matus I, Tapia G, Castillo D, Sanchez-Jardón L et al (2016) Physiological traits associated with wheat yield potential and performance under water-stress in a Mediterranean environment. Front Plant Sci 7:987
Denis JB (1988) Two-way analysis using covariates. Statistics 19:123–132
Gauch HG, Zobel RW (1997) Identifying mega-environments and targeting genotypes. Crop Sci 37:311–326
George N, Lundy M (2019) Quantifying genotype x environment effects in long-term common wheat yield trials from an agroecologically diverse production region. Crop Sci 59:1960–1972
Hawkesford M, Araus J, Park R, Calderini D, Miralles D, Shen T et al (2013) Prospects of doubling global wheat yields. Food Energy Secur 2:34–48
Lobell DB, Gourdji SM (2012) The influence of climate change on global crop productivity. Plant Physiol 160:1686–1697
Malosetti M, Bibaut JM, van Eeuwijk FA (2013) The statistical analysis of multi-environment data: modeling genotype-by-environment interaction and its genetic basis. Front Physiol 4:1–17
Mohammadi R (2018) Breeding for increased drought tolerance in wheat: a review. Crop past Sci 69:223–241
Mohammadi R, Haghparast R, Amri A, Ceccarelli S (2010) Yield stability of rainfed durum wheat and GGE biplot analysis of multi-environment trials. Crop Pas Sci 61:92–101
Mohammadi R, Farshadfar E, Amri A (2015) Interpreting genotype x environment interactions for grain yield of rainfed durum wheat in Iran. Crop J 3:526–535
Mohammadi R, Armion M, Zadhasan E, Ahmadi MM, Amri A (2018) The use of AMMI model for interpreting genotype x environment interaction in durum wheat. Exp Agric 54:670–683
Motzo R, Giunta F, Deidda M (2001) Factors affecting the genotype x environment interaction in spring triticale grown in a Mediterranean environment. Euphytica 121:317–324
Navabi A, Yang R, Helm J, Spaner DM (2006) Can spring wheat-growing mega-environments in the northern Great Plains be dissected for representative locations or niche adapted genotypes? Crop Sci 46:1107–1116
Pacheco A, Vargas M, Alvarado G, Rodríguez F, Crossa J, Burgueño J (2015) GEA-R (genotype x environment analysis with R for windows), Version 4.1. Mexico: CIMMYT. Retrieved from http://hdl.handle.net/11529/10203
Rakshit S, Ganapathy KN, Gomashe SS, Rathore A, Ghorade RB, Nagesh Kumar MV et al (2012) GGE biplot analysis to evaluate genotype, environment and their interactions in sorghum multi-location data. Euphytica 185:465–479
Ramburan S, Zhou M, Labuschagne M (2012) Integrating empirical and analytical approaches to investigate genotype x environment interactions in sugarcane. Crop Sci 52:2153–2165
Rozeboom KL, Schapaugh WT, Tuinstra MR, Vanderlip RL, Miliken GA (2008) Testing wheat in variable environments: genotype, environment, interaction effects, and grouping test locations. Crop Sci 48:317–330
Sánchez-García M, Alvaro F, Martín-Sánchez JA, Sillero JC, Escribano J, Royo C (2012) Breeding effects on the genotype x environment interaction for yield of bread wheat grown in Spain during the 20th century. Field Crops Res 126:79–86
Sánchez-García M, Royo C, Aparicio N, Martín-Sánchez A, Álvaro F (2013) Genetic improvement of bread wheat yield and associated traits in Spain during the 20th century. J Agric Sci 151:105–118
van Eeuwijk FA, Denis JB, Kang MS (1996) Incorporating additional information on genotypes and environments in models for two-way genotype by environment tables. In Kang MS, Gauch HG (eds) Genotype-by-environment interaction. CRC Press, Boca Raton
Vargas M, Crossa J, van Eeuwijk FA, Sayre K, Reynolds MP (2001) Interpreting treatment x environment interaction in agronomy trials. Agron J 93:949–960
Voltas J, Lopez-Corcoles H, Borras G (2005) Use of biplot analysis and factorial regression for the investigation of superior genotypes in multi-environment Trials. Eur J Agron 22:309–324
Yan W (2014) Crop variety trials: data management and analysis. Wiley-Blackwell, New York
Yan W (2015) Mega-environment analysis and test location evaluation based on unbalanced multiyear data. Crop Sci 55:113–122
Yan W, Hunt LA (2001) Interpretation of genotype x environment interaction for winter wheat yield in Ontario. Crop Sci 41:19–25
Yan W, Tinker NA (2006) Biplot analysis of multi-environment trial data: principles and applications. Can J Plant Sci 86:623–645
Yan W, Hunt LA, Sheng Q, Szlavnics Z (2000) Cultivar evaluation and mega-environment investigation based on GGE biplot. Crop Sci 40:596–605
Yan W, Kang MS, Ma B, Woods S, Cornelius PL (2007) GGE biplot vs. AMMI analysis of genotype-by-environment data. Crop Sci 47:643–655
Acknowledgements
This research (Grant Code: 0-15-15-005-950406) was funded by Dryland Agriculture Research Institute (DARI) of Iran. Special thanks to Dr. E. Mohammadi for making the GIS analysis. The authors thank all research assistants who directly or indirectly collaborated in carrying out this study. The authors also thank the reviewers and Associate Editor of Euphytica for comments and corrections to the manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest in the development and execution of this research.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Roostaei, M., Jafarzadeh, J., Roohi, E. et al. Grouping patterns of rainfed winter wheat test locations and the role of climatic variables. Euphytica 217, 183 (2021). https://doi.org/10.1007/s10681-021-02915-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10681-021-02915-8