
Abstract
This paper presents a quantitative approach to evaluate the sustainability performance (SP) of an organization. A methodology is proposed based on principal component analysis (PCA), numerical taxonomy (NT), statistical, and cluster analysis. Related factors are determined considering sustainability dimensions, including social, economic, and environmental ones. A unique procedure is presented to commensurate the monetary factors. PCA is developed for multivariate analysis, which can rank annual records and determine factors' importance degree. NT is developed to verify and validate the results of PCA. The multivariate approach is able to rank the alternatives and simultaneously determine the importance degree of factors. An upstream oil and gas company is given as a case study. The statistical analysis showed direct relationships between the results of different analyses. In addition, the factors are categorized into two and four partitions to reduce dimensionality. The outcome-related factors are found to be of great importance for organizational SP. Furthermore, a descending SP in recent years was identified. To improve potential SP, operational planning for enhancing the performance of personnel is recommended. This paper provides intuition on the clusters obtained and why these factors affect the organizations' performance. The approach of this paper can be utilized for managers in the other industrial sectors who have access to company performance data and wish to analyze which factors are vital for company performance or hurting the company performance using the methodology presented in this paper.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Nowadays, sustainability is an inseparable topic for companies and organizations, especially in their survival and competition. Poor sustainability performance (SP) deprives managers of the stability they need for decision-making and disruption creation (Ding et al., 2016). This causes the organization to be unbalanced during a recession and takes it out of normalcy. Predetermined and anticipated decisions of managers to deal with such an atmosphere in a competitive world is of great importance. Organizational and management decisions play important roles in the overall performance of engineering, procurement, construction, and installation systems (Toutounchian et al., 2018). The ability to recover and return quickly after downturns is associated with the ability to cope with vulnerabilities. This ability will be enhanced if decision-making tools are used to deal with the effects of negative shocks.
Businesses need to identify the factors which affect their SP. More importantly, companies need to identify which elements to prioritize and accordingly manage their limited resources. Studying the key performance indicators (KPIs) of an organization in the past can help examine the SP. On the other hand, it will enable predictions about the organizational system behavior by assessing the past SP of an organization (Dev et al., 2020). Moreover, the past performance of the organization can also indicate its attention to KPIs. Based on an organization's past performance, it is possible to obtain comprehensive information about programs, identify challenges and make plans for the future. Hence, an organization’s performance in the past plays a significant role in its current and future performance.
Since the strategic definition for individual KPIs may disrupt the organization or have high costs, they can be clustered. The combination of KPIs also helps develop strategies to improve the organization's SP and inspire new thinking toward the organization's goals. Accordingly, practical operational, tactical, and strategic planning can be associated with each cluster instead of planning for each KPI. Therefore, it is essential to propose an integrated approach to continuously assess and improve the SP based on its previous performance. For this purpose, the identification and investigation of KPIs affecting the improvement of the SP should be attained. To specify a set of factors for measuring SP, their equilibrium to ensure various dimensions is necessary.
This paper aims to assess the SP of an organization through associated KPIs to improve its functional operating level and return to its normal condition during probable social, economic, and environmental downturns and crises. Dealing with sustainability under social, economic, and environmental dimensions, the research objectives are to evaluate annual SP ranking and to realize the importance degree of factors to be monitored.
With this background in mind, this paper examines these research questions:
-
1.
How can an integrated multivariate quantitative approach be proposed to assess the SP of an organization using annual historical data?
-
2.
What is the importance degree of effective KPIs in SP?
-
3.
What is the relationship between sustainability dimensions in terms of KPIs' classification?
This paper has addressed the aforementioned issue by introducing a simple-to-follow quantitative methodology with five phases and demonstrated a use case for an upstream oil and gas company. In the first phase, KPIs are determined concerning the sustainability dimensions. The second phase implies data gathering and scaling. A unique procedure is proposed for the monetary factors based on annual inflation rates (AIRs) and calculating consumer price indices (CPIs). Phase three develops principal component analysis (PCA) to achieve annual SP ranking and importance degree of KPIs simultaneously. In phase four, numerical taxonomy (NT) is developed to verify and validate the results of the developed PCA. Finally, phase five analyzes the results. Two quantitative methodologies are presented, for which the description of steps of data preparation, computation, and inference are provided. The main contributions of this paper can be highlighted and summarized as follows:
-
Proposing a simple-to-follow multivariate quantitative approach considering sustainability dimensions by synthesizing PCA, NT, clustering, and statistical analysis to assess SP;
-
Proposing a unique procedure to commensurate the monetary factors based on AIRs and CPIs;
-
Developing PCA which is capable of ranking annual SP and KPIs by defining utility functions;
-
Developing NT which can examine both positive and negative ideal values and integrate them for simultaneously evaluating the annual SP and KPIs;
-
Validating and implementing the proposed approach through application in a real-world case study.
The remainder of this paper is organized as follows. Section 2 reviews the related literature. Section 3 describes the proposed methodology. Section 4 deals with the case study and computational results. Verification and validation of the results are investigated in Sect. 5. Section 6 provides discussion and managerial insights. The conclusion is summarized in Sect. 7.
2 Literature review
Although many studies and efforts have been made to improve the SP of organizations, adverse events still occur due to recession and various crises (Azadeh et al., 2017). In times of crisis, organizations face significant threats to their financial, competitive, and survival potential (Pal et al., 2014). Azadeh et al. (2017) studied the performance of a production plant in crises considering management decisions using data envelopment analysis. Chen et al. (2019) proposed a mathematical formulation to capture favorable economic outcomes and environmental performance. Battisti et al. (2019) proposed an integrated approach to specify the role of learning in the performance of small enterprises using datasets in the period of financial crises. According to Alnajem et al. (2021), circular economy research exponentially increases with a 47.1% growth rate per year, and the sustainability topic has been one of the hotspots in recent years.
Many of the studies have tended to specify the organizational KPIs to assess SP. Hayami et al. (2015) found that the suppliers with fewer waste products (WP) desire to have better SP. Khan and Qianli (2017) examined the relationships between environmental and economic factors of the UK using time series data. Sabogal-De La Pava et al. (2021) considered the market value-added (VA) as a criterion to maximize the SP. Shan et al. (2021) studied the effect of economic and energy KPIs in limiting carbon emissions to evaluate SP. Pashapour et al. (2019) specified resilience-based factors to improve the performance of a petrochemical plant in terms of economics. Schwab et al. (2019) examined the effect of economic KPIs on the financial sustainability of a company in Swiss within business growth using quantitative and qualitative data. Ahmad, Muslija, et al. (2021) investigated the relationship between environmental sustainability and economic prosperity in 11 developing economies. D’Inverno et al. (2020) evaluated the performance of water utilities in Italy considering financial and economic factors, service quality, and environmental sustainability. D'Ambra et al. (2020) assessed the economic and social effects of carbon dioxide on sustainability. Singh and Misra (2021) proposed a framework to evaluate the safety performance of laborers by identifying and ranking key safety indicators in the Indian construction industry. Ahmad, Chandio, et al. (2021) examined dynamic interactions among sustainable development, air pollution, and energy investment in china using panel data in 27 provinces of China.
Some scholars have used annual data to evaluate the SP. Ahmad, Jan, et al. (2021) provided a model accompanying sustainability challenges by considering financial-based factors as inputs of production growth during 1997–2017. Brandenburg (2016) evaluated the trends of cost efficiency and SP using 8 years of data in European automotive industries. Ganda and Milondzo (2018) investigated the effect of carbon emissions on the SP of some African organizations. Salmanzadeh-Meydani and Fatemi Ghomi (2019) examined the causalities between economic growth and capital stock in Iran by the vector autoregression model. Forteza et al. (2017) examined the relationship among economic performance, accident rate, and site risk of Spanish companies using annual data. Hussain et al. (2021) evaluated financial development and economic openness on SP using annual data of Pakistan and performing time series methods.
Various studies have assessed the SP in the supply chain. Huo et al. (2018) investigated an organization's ability to improve economic and operational performance through the flexibility of the supply chain. Sabbaghnia et al. (2019) investigated reducing carbon emissions on the members’ profit in a supply chain. Das (2018) examined all three sustainability dimensions to determine their impacts on organizational performance in India. Arıkan et al. (2014) investigated the causalities between economic and environmental performance. Furthermore, most previous studies have focused on the economic dimension, while the social and environmental dimensions have still received less attention (Elfarouk et al., 2021). Moreover, the knowledge system that shapes companies' engineering, procurement, construction, and installation and encompasses their broad concepts and numerous complimentary ingredients have been neglected (Tseng et al., 2021). Even though there are many studies in terms of SP evaluation in the supply chain, the intra-organizational studies regarding the assessment of SP are limited and require more attention.
The literature determines that multiple-criteria decision-making method (MCDM) techniques considerably help to address and assess SP. Moreover, the application of MCDMs is closely interlinked to enable the managers of organizations to make better decisions. Solangi et al. (2020) applied Delphi and fuzzy analytical hierarchy process methods to evaluate the SP of electricity generation in Turkey. Although the application of PCA and NT exists in the literature (Azadeh et al., 2009, 2011; Pashapour et al., 2019; Shirali et al., 2013, 2016), the development to simultaneously ranking the alternatives and determining importance degree of variables has not taken adequate attention. Therefore, this paper contributes to the existing literature by developing PCA, and NT methodologies for the assessment in the context of SP, analyzing the results by utilizing statistical and clustering, and the application in a real-world case study.
3 Methodology description
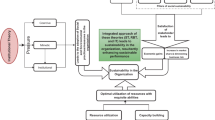
Figure 1 demonstrates the methodology proposed in this paper.

Proposed methodology
The nomenclatures for sets and indices are defined as follows:
-
\(I\) Set of input factors indexed by \(i \in \left\{ {1, 2, \ldots , a} \right\}\).
-
\(O\) Set of output factors indexed by \(o \in \left\{ {1, 2, \ldots , b} \right\}\).
-
\(F\) Set of financial-based factors indexed by \(f \in \left\{ {1, 2, \ldots , c} \right\}\).
-
\(U\) Set of non-financial-based factors indexed by \(u \in \left\{ {1, 2, \ldots , d} \right\}\).
-
\(V\) Set of all variables including input and output factors indexed by \( v \in \left\{ {1, 2, \ldots , m} \right\}\) where \(V = I \cup O = U \cup F\) and \(m = a + b = c + d\).
-
\(L\) Set of the reduced dimension of principal components (PCs) indexed by \( l \in \left\{ {1, 2, \ldots , p} \right\}\).
-
\(T\) Set of annual records indexed by \(t \in \left\{ {1, 2, \ldots , n} \right\}\).
3.1 Phase 1: Determining factors
The factors are categorized based on the sustainability dimensions. For the social dimension, the factors affecting the performance of personnel are considered. For the economic dimension, the outcome-based factors are specified, which mainly affect the sales and income. For the environmental dimension, pollution-based factors like different emissions are investigated.
Table 1 provides the extracted factors and their related dimensions in sustainability. Also, their input- and output-oriented nature and unit of measurements are given in this table. Output-oriented factors are positive criteria where the great values are favorable. In contrast, input-oriented factors are negative criteria where the small values are favorable.
3.2 Phase 2: Collecting and scaling data
The steps of this phase are as follows.
Step 1 Collecting annual data.
Raw annual data are collected from the studied organization as matrix \(D = \left[ {d_{tv} } \right]_{n \times m}\).
Step 2 Investigating commensurability of factors.
If factors are on the same scale, they are recorded without any changes. Otherwise, they are transformed to the same scale values. The unit of measurement for IV, EV, and VA are reported as million IRR. Therefore, the time value of money is considered, which is necessitated by the requirement of importance degree calculation.
Step 3 Transforming non-scale factors.
The AIR and CPI are applied for transforming monetary factors. CPI is a tool to measure the financial level of products and services to examine price changes and calculates as Eq. (1).
To apply Eq. (1), the CPI is considered 100 for the last period. Concerning a backward computation, Eq. (2) calculates the CPI for all periods.
Step 4 Determining commensurate matrix.
Equation (3) calculates the fixed value of financial factor \(f\) in period \(t\) (\({\text{FV}}_{tf}\)) based on its original value in period \(t\) (\({\text{OV}}_{{{\text{tf}}}}\)). Matrix \(D\) is transformed to the commensurate matrix \(X = \left[ {x_{tv} } \right]_{n \times m}\) by Eq. (4).
3.3 Phase 3: Developing PCA
In PCA, multidimensional factors are summarized into non-correlated components, linear combinations of the main factors. It has the following steps.
Step 1 Normalizing annual dataset.
Since the unit of measurement for various factors is different, they are normalized. Equations (5) and (6) apply for normalizing the input- and output-oriented factors, respectively. Matrix \(R = \left[ {r_{tv} } \right]_{n \times m}\) is obtained as a normalized matrix.
Step 2 Standardizing annual dataset.
For homogenizing factors, the standard data are considered with mean zero and unit variance as Eq. (7). Matrix \(S = \left[ {s_{tv} } \right]_{n \times m} = \left[ {S_{1} ,S_{2} , \ldots , S_{m} } \right]\) is a standardized matrix.
Step 3 Computing correlation coefficient matrix.
The covariance between factors \(j\) and \(k\) is calculated as Eq. (8). Covariance depends on the unit of measurements, while the correlation coefficient is a unit-free index. The Pearson's correlation coefficient is calculated as Eq. (9). Since \(S_{1}\), \(S_{2}\), …, \(S_{m}\) are standard, we have Eq. (10). Pearson's correlation coefficient matrix is asymmetrical as Eq. (11). The main diagonal of the matrix is \(+ 1\) because \({\text{Corr}}\left( {S_{j} ,S_{j} } \right) = E\left[ {S_{j} S_{j} } \right] = E\left[ {S_{j}^{2} } \right] = {\text{Var}}\left( {S_{j} } \right) = 1\).
Step 4 Calculating eigenvalues.
Equation (12) calculates eigenvalues from the matrix \(C\). Solving Eq. (12), \(m\) eigenvalues are obtained. They are arranged in decreasing order, \(\lambda_{1} , \lambda_{2} , \ldots , \lambda_{m}\) so that \(\sum\nolimits_{v = 1}^{m} {\lambda_{v} = m}\).
Step 5 Calculating eigenvectors and PCs.
Equation (13) calculates eigenvectors in which \(E_{v}\) is an \(m \times 1\) matrix as Eq. (14)
To avoid multiple solutions, a unit vector is considered by Euclidean norm as Eq. (15). These unit vectors are PCs in this methodology: \({\text{PC}}_{1} , \,{\text{PC}}_{2} , \ldots , \,{\text{PC}}_{m}\).
The first extracted PC accounts for the enormous possible variance in the dataset. The correlation between the two PCs is zero, and they are orthogonal. Generally, Eq. (16) is established among the coefficients of PCs.
Step 6 Reducing the number of PCs.
The variance explained by each PC is calculated as Eq. (17), where \(w_{v}\) can be considered as a weight criterion of the \(v\) th PC.
Three criteria are applied to reduce the number of PCs as follows.
-
Scree test: The eigenvalues are plotted in decreasing order of their values. The point at which the last significant drop or break occurs determines the number of PCs (Ledesma et al., 2015).
-
Kaiser rule: Those PCs whose eigenvalues are greater than one are considered.
-
Explained variance: The Pareto principle or 20/80 rule considers \(p\) first PCs to define 80 percent of variance.
Considering these criteria, the number of PCs is reduced to \(p\) where \(p < m\).
Step 7 Determining performance values.
Equation (18) calculates the performance value of record \(t\) for \({\text{PC}}_{l}\). \(n\) annual records regarding \(p\) PCs constitute matrix \(Y = \left[ {y_{tl} } \right]_{n \times p}\).
Step 8 Scores and annual ranking.
The total weighted performance of each annual record denotes the score of that record and is calculated as Eq. (19). The higher the \(z_{t}^{{{\text{PCA}}}}\), the better the annual record is. The ranking of annual records is made via these values.
Step 9 Importance degree of factors.
The influential factors are those that lead to the most score for the annual records and the most standard value. Therefore, the aggregation of record scores and standard values is applied for comparative measurement of factors as Eq. (20).
\(A_{v}^{{{\text{PCA}}}}\) is linearly normalized between − 1 and + 1 as Eq. (21), named the utility of each factor. The higher magnitude of the \(U_{v}^{{{\text{PCA}}}}\), the more influential the factor is.
3.4 Phase 4: Developing NT analysis
NT method is able to identify homogeneous states. In this method, factors are applied the same as the PCA. It has the following steps.
Step 1 Normalizing annual dataset.
Similar to step 1 of PCA analysis.
Step 2 Standardizing annual dataset.
Similar to step 2 of PCA analysis.
Step 3 Computing distance matrix.
The distance of every two annual records \(g\) and \(h\) for factor \(v\) is \(\left| {s_{gv} - s_{hv} } \right|\). Therefore, Euclidean distance of annual record \(g\) from \(h\) can be computed as Eq. (22). This is done to homogenize the annual records. Computing pairwise distances, the symmetrical distance matrix is obtained as \(Q = \left[ {q_{gh} } \right]_{n \times n}\).
Step 4 Calculating upper and lower bounds.
To calculate lower and upper bounds (\({\text{LB}},\,{\text{UB}}\)), vector \(q = \left[ {q_{t} } \right]_{n \times 1}\) is extracted from matrix \(Q\), where \(q_{t}\) is the minimum amount of the \(t\) th row in matrix \(Q\) as Eq. (23).
Equation (24) calculates the bounds. If all \(q_{t}\) are within the bounds, homogeneity is attained, and the next step is performed. Otherwise, cluster analysis should be made until all annual records become homogeneous. To do so, the records outside the bounds are removed. Again, the standard matrix is formed with these records removed. It repeats until the homogeneity is achieved.
Step 5 Positive and negative ideal values.
The positive and negative ideal values for each factor are as Eqs. (25) and (26), respectively.
Step 6 Distance from positive and negative ideal values.
The positive and negative distances of factor \(v\) for annual record \(t\) in the standard matrix are \(s_{v}^{{{\text{PIV}}}} - s_{tv}\) and \(s_{tv} - s_{v}^{{{\text{NIV}}}}\). Therefore, Euclidean distance of annual record \(t\) for all factors from positive and negative ideal values is calculated as Eqs. (27) and (28), respectively.
Step 7 Positive and negative growth levels.
Each annual record's positive and negative growth levels are calculated as Eqs. (29) and (30), respectively.
Since \(c_{t}^{{{\text{PIV}}}} ,c_{t}^{{{\text{NIV}}}} \ge 0\), \(\mathop {{\text{mean}}}\limits_{t \in T} \left\{ {c_{t}^{{{\text{PIV}}}} } \right\},\mathop {{\text{mean}}}\limits_{t \in T} \left\{ {c_{t}^{{{\text{NIV}}}} } \right\} \ge 0\). Also, \(\mathop {{\text{StDev}}}\limits_{t \in T} \left\{ {c_{t}^{{{\text{PIV}}}} } \right\},\mathop {{\text{StDev}}}\limits_{t \in T} \left\{ {c_{t}^{{{\text{NIV}}}} } \right\} \ge 0\). Hence, \(c^{{\text{PIV*}}} ,\,c^{{\text{NIV*}}} \ge 0\). Therefore, \(f_{t}^{{{\text{PIV}}}} ,\,f_{t}^{{{\text{NIV}}}} \ge 0\). \(f_{t}^{{{\text{PIV}}}}\) and \(f_{t}^{{{\text{NIV}}}}\) indicate the distance of annual record \(t\) from the best and the worst possible one, respectively. Therefore, the lower \(f_{t}^{{{\text{PIV}}}}\) and the higher \(f_{t}^{{{\text{NIV}}}}\) are desirable.
Step 8 Scores and annual ranking.
The scores of annual records are calculated as Eq. (31). The higher the \(z_{t}^{{{\text{NT}}}}\), the better the annual record is. The ranking of annual records can be obtained via these values.
Step 9 Importance degree of factors.
The aggregated comparative measurement and the utility of each factor in NT are obtained as Eqs. (32) and (33), respectively. The higher the magnitude of the \(U_{v}^{{{\text{NT}}}}\), the more influential the factor is.
3.5 Phase 5: Analyzing, validating, and verifying the results
The results are discussed in four categories:
-
First, the impact of dimension reduction in the proposed PCA is examined.
-
Second, extracted factors are clustered in different partitions.
-
Third, the annual SP is studied.
-
And finally, the importance degree of factors is evaluated.
To verify and validate the results of PCA, the annual ranking and importance degree of factors of the PCA and NT are compared. For this purpose, first, the existence of differences in the results is examined by a pairwise comparison test. If there is no significant difference, then the compatibility of the results is carried out. If it is high, it is concluded that the results of PCA are valid.
3.5.1 Pairwise comparison test
The statistical hypothesis is as follows:
where \(\mu_{{{\text{PCA}}}}\) and \(\mu_{{{\text{NT}}}}\) are the mean of annual ranking by PCA and NT, respectively. Since the scales obtained from PCA and NT methods for annual records are different, they cannot be used directly for pairwise comparison. Therefore, the annual ranking of records is evaluated. The Wilcoxon signed-rank nonparametric statistical test is applied with the following steps.
Step 1 Calculate \(\left| {R_{t}^{{{\text{PCA}}}} - R_{t}^{{{\text{NT}}}} } \right|\) and \({\text{sgn}} \left( {R_{t}^{{{\text{PCA}}}} - R_{t}^{{{\text{NT}}}} } \right) \) for \(t = 1, \ldots ,n\), where \(R_{t}^{{{\text{PCA}}}}\) and \(R_{t}^{{{\text{NT}}}}\) are ranking of PCA and NT for annual record \(t\) and \({\text{sgn}}\) indicates sign function.
Step 2 Omit \(\left| {R_{t}^{{{\text{PCA}}}} - R_{t}^{{{\text{NT}}}} } \right| = 0\) annual records. Let \(n_{r}\) the number of the reduced sample size.
Step 3 Order nonzero \(\left| {R_{t}^{{{\text{PCA}}}} - R_{t}^{{{\text{NT}}}} } \right|\) from smallest to largest.
Step 4 Rank so that the smallest \(\left| {R_{t}^{{{\text{PCA}}}} - R_{t}^{{{\text{NT}}}} } \right|\) is 1. For equal values, insert average rank. Let \(R_{t}^{W}\) denote the ranking.
Step 5 Calculate Wilcoxon test statistic as follows which is the sum of signed ranks:
Step 6 Compare \(W\) with the critical value of the Wilcoxon signed-rank test (Wilcoxon et al., 1970). For a two-tailed test, \(H_{0}\) rejects if \(\left| W \right| > W_{{\alpha ,n_{r} }}\).
3.5.2 Compatibility test
To evaluate the compatibility of PCA and NT results, Spearman's rank correlation coefficient is examined as Eq. (36).
4 Case study
The case study is an upstream oil and gas company in Iran. The main activities of such companies are contracting in engineering, procurement, construction, and installation in various projects for large offshore structures.
4.1 Data description
The data are reported based on Solar Hijri (SH) calendar in the organization. They cover 15 years from the first of 1382 SH (equals to March 21, 2003) to the end of 1396 SH (equals to March 20, 2018). Let \({\text{AR}}_{t}\) denote annual record \(t\). It should be noted that the total number of incidents is categorized into the NOI and the NOA. NOA implies intense incidents, and personnel needs more than four days' absence and even for several months.
To commensurate IV, EV, and VA, the time value of money was considered. The AIR of Iran is applied according to the report of the central bank of Iran.Footnote 1 Table 2 gives the AIR and calculated CPI for 15 periods. Thereafter, normalizing and standardizing are performed, but the corresponding values are not reported because of brevity.
4.2 Dimension reduction
Table 3 gives the correlation coefficient matrix. The eigenvalues of the correlation matrix in relation to PCA are as shown in Table 4. The higher the eigenvalue, the higher the explained variance of each PC is. Figure 2 illustrates the scree plot of eigenvalues. The scree plot is able to display how much each PC captures from the dataset. According to Table 4 and Fig. 2, the first four PCs comprise about 80 percent of data variability. The magnitudes of eigenvalues in these PCs are more than one. Therefore, the other 10 PCs are ignored according to the three criteria described in the proposed methodology. Table 5 introduces the coefficients of PCs.

Scree plot of eigenvalues
Figure 3 demonstrates the 2D loading plot of factors with PC1 and PC2. The value of a factor on each PC illustrates how much weight it has on each PC. EV and VA have the highest positive values and NOP, and IV have the highest negative values on PC1. The other point from the 2D loading plot is the angles between factors that specify how a factor is correlated. The factors are categorized into two groups according to their dispersion, schematically considering the first two PCs. Figure 4 displays the 3D loading plot of factors with PC1, PC2, and PC3. Like the 2D loading plot, schematically, considering the first three PCs, the factors are categorized into four groups according to their dispersion.

2D loading plot

3D loading plot
4.3 Performance values, annual ranking, and importance degree
Table 6 provides the performance values, scores, and annual ranking by PCA. Performance values of each annual record are obtained by multiplying standardized values of the dataset by eigenvectors of each PC. Consequently, the scores of PCA for each annual record are attained by multiplying weights of reduced PCs by performance values as Eq. (37). According to these scores, the annual records are ranked. Eventually, the utility and importance degree of factors are gained, as shown in Table 7.
4.4 Results of NT
Table 8 computes the distance matrix. The distance vector is the minimum distance of annual records given in the last row of the table. Figure 5 illustrates the line chart of the distance vector. Since all of the values of this vector are within the bounds, the homogeneity is confirmed.

Line chart of distance vector
Positive and negative ideal values are extracted, and subsequently, the Euclidean distance from these values and positive and negative growth levels are calculated for each annual record. Table 9 reports the results of the annual ranking from the NT. Eventually, Table 10 gives the utility and importance degree of factors for NT.
5 Verification and validation
The verification and validation of results are performed in different aspects:
-
1.
Categorizing factors in different groups,
-
2.
Investigating the annual SP,
-
3.
Assessing the importance degree of factors,
-
4.
Comparing the results of developed NT with traditional NT.
5.1 Cluster analysis
Based on PCA results, the factors were categorized into two and four partitions. In support of this, cluster analysis is applied. Table 11 shows the results of cluster analysis for both two and four partitions. The nearest neighbor method and the Euclidean distance have been utilized in cluster analysis. Figure 6 shows the dendrogram plot of this analysis. In this figure, line (a) and line (b) identify two and four partitions in clustering, respectively. Two partitions of cluster analysis are the same as the two extracted groups of Fig. 3. In addition, four partitions of cluster analysis are the same as the four determined groups of Fig. 4.

Dendrogram plot of cluster analysis
5.2 Comparison of results
It was shown that the first four PCs explain about 80 percent of data variability in PCA. Here, the effect of considering more PCs on the results is investigated. To do so, 90%, 99%, and 100% of data variability, which forms PC1–PC6, PC1–PC10, and PC1–PC14, respectively, are examined. Therefore, the annual ranking and the importance degree of factors by PCA are studied with different variabilities. On the other hand, the NT was performed in two modes: developed and traditional. Tables 12 and 13 give the annual ranking and importance degree of factors with different analyses. These findings express the results by PCA for 90%, 99%, and 100% variabilities are the same. Therefore, one of them is taken for pairwise comparison and compatibility tests. Figures 7 and 8 schematically compare the annual ranking and importance degree of factors by different analyses.

Comparison of annual ranking by different analyses

Comparison of importance degree of factors by different analyses
To statistically compare the results of different analyses, differences between the results are examined. In this paper, the level of significance is considered 95%. Table 14 contains the nonparametric stepwise Wilcoxon signed-rank test for annual ranking results by PCA with PC1-PC4 and developed NT. The Wilcoxon statistic is less than the critical value. Therefore, statistically, the null hypothesis is accepted.
Table 15 summarizes the results of all pairwise comparison tests by Wilcoxon signed-rank and Spearman's rank correlation. It is concluded that there is a direct relationship between the results of all pairwise analyses.
6 Discussion and managerial insights
Two quantitative methodologies are presented, for which the description of steps of data preparation, computation, and inference are provided. Comparable results on the importance degree obtained from the two methodologies increase the confidence in the results of the importance and rankings. Hypothesis testing procedures conduct the comparison of the results of the two methods. After dimensionality reduction to only the important ones, a company's performance is studied based on the clustered factors and ranks of the annual records. Concerning three introduced criteria to reduce the dimension of PCA, instead of 14 factors, the first four PCs can be used as new variables. The results of the Wilcoxon signed-rank test showed no statistically significant difference between the results of PCA with the first 4 PCs and those with more PCs. Spearman's results also showed a high correlation between the results. Therefore, the introduced criteria can reduce the computational complexity and ensure that dimensional reduction is desirable.
2D loading plot and 3D loading plot of PCA schematically categorized the factors in two and four different groups. Cluster analysis for two and four partitions showed precisely the same results. The first partition includes NOP, ECO, ESO, and EN, and the second one comprises NOA, NOL, and ENO, which are related to social and environmental dimensions of sustainability. Reducing workplace pollution can affect personnel performance. Workplace-related factors not only endanger the health of operators but also avoid them being active for several months. Therefore, the SP of the organization can be improved via environmental aspects and providing facilities for personnel. The third partition contains NOI, IV, and PR factors related to the social and economic dimensions of sustainability. NOI causes short-term interruption for personnel and production fluctuations. Thus, a short-term plan for personnel rest seems necessary for appropriate production. In addition, IV and PR are both related to production. Therefore, balancing imports and adapting with PR reduces costs such as inventory and improves the SP of the organization. Finally, the fourth partition encompasses WP, EV, ROI, and VA factors primarily related to the economic dimension of sustainability. All these factors are in the direction of the organization's outcomes and can guarantee the competitiveness and resiliency of the organization in the future. Increasing exports and reducing WP will improve VA and ROI. Therefore, improving these factors should be one of the priorities of the organization.
The annual ranking specified poor SP of organization in recent years. The management should make more efforts to improve it and also learn from lessons from partitioning the factors. EV and VA were identified as the most influential factors in the SP. Both of these factors are related to the economic dimension. Data on these factors indicated interconnected causality. The following remarks can help management to improve SP.
-
Proper marketing expedites the organization to improve EV.
-
Having a plan to reduce WP and using modern technology cause to increase PR.
-
Focusing on EV and IV along with NOP lead to balancing work-related NOI and NOA.
-
Paying attention to PR along with WP accelerates the VA and ROI.
7 Conclusion
This paper dealt with sustainability performance (SP) assessment via a multivariate quantitative approach. To do so, a five-phase methodology was proposed. Related factors were identified by considering sustainability dimensions. For monetary factors, a unique procedure was proposed to transform them. Principal component analysis (PCA) was developed so that it can simultaneously measure the annual SP and the importance degree of the factors. The utility function was defined to recognize the influential factors. Then, the traditional numerical taxonomy (NT) was expanded. The developed NT considers the distances of both positive and negative ideal values by integrating them for ranking. Moreover, it can rank annual records besides identifying the importance degree of factors by proposing a suitable utility function.
An upstream oil and gas company was investigated as a case study. The results derived from the two developed NT and PCA analyses were statistically compared. These analyses were made from four different aspects: (1) the impact of dimension reduction, (2) clustering of factors in different partitions, (3) the assessment of annual SP, and (4) the evaluation of the importance degree of factors.
Cluster analysis showed that the environmental factors affect only social factors related to the personnel. In addition to the environmental dimension, social-based factors influence the economic dimension, especially in production and imports. Also, economic factors have a high interaction in the financial output of the organization and create value-added. The correlation of developed NT with PCA is higher than that of traditional NT and PCA. Regarding the case of the oil and gas company, it can be concluded that the company SP in recent years has deteriorated. Exports value and value-added were identified as the most influential factors.
The paper's contributions are twofold: First, the methodology can be easily scaled to larger data sets which may consider a more significant number of performance factors than those considered in this paper. Second, it can be extended to different industries. The approach of this paper can be applied to other industry organizations to improve their SP. The impact of other factors can be investigated as other topics for future researches. Furthermore, the approach of this paper is extended simultaneous recognition of the importance of variables and alternatives. The knowledge in this paper will be helpful for further academic investigations into this topic and immediate industrial practice.
References
Ahi, P., Jaber, M. Y., & Searcy, C. (2016). A comprehensive multidimensional framework for assessing the performance of sustainable supply chains. Applied Mathematical Modelling, 40(23–24), 10153–10166.
Ahmad, M., Chandio, A. A., Solangi, Y. A., Shah, S. A. A., Shahzad, F., Rehman, A., & Jabeen, G. (2021). Dynamic interactive links among sustainable energy investment, air pollution, and sustainable development in regional China. Environmental Science and Pollution Research, 28(2), 1502–1518.
Ahmad, M., Jan, I., Jabeen, G., & Alvarado, R. (2021). Does energy-industry investment drive economic performance in regional China: Implications for sustainable development. Sustainable Production and Consumption, 27, 176–192.
Ahmad, M., Muslija, A., & Satrovic, E. (2021). Does economic prosperity lead to environmental sustainability in developing economies? Environmental Kuznets curve theory. Environmental Science and Pollution Research, 28(18), 22588–22601.
Alnajem, M., Mostafa, M. M., & ElMelegy, A. R. (2021). Mapping the first decade of circular economy research: A bibliometric network analysis. Journal of Industrial and Production Engineering, 38(1), 29–50.
Al-Tuwaijri, S. A., Christensen, T. E., & Hughes Ii, K. (2004). The relations among environmental disclosure, environmental performance, and economic performance: A simultaneous equations approach. Accounting, Organizations and Society, 29(5–6), 447–471.
Alves, J. A., Silva, L. T., & Remoaldo, P. C. C. (2015). The influence of low-frequency noise pollution on the quality of life and place in sustainable cities: A case study from Northern Portugal. Sustainability, 7(10), 13920–13946.
Anser, M. K., Usman, M., Godil, D. I., Shabbir, M. S., Tabash, M. I., Ahmad, M., Zamir,.A., & Lopez, L. B. (2021). Does air pollution affect clean production of sustainable environmental agenda through low carbon energy financing? Evidence from ASEAN countries. Energy and Environment.
Arıkan, E., Fichtinger, J., & Ries, J. M. (2014). Impact of transportation lead-time variability on the economic and environmental performance of inventory systems. International Journal of Production Economics, 157, 279–288.
Azadeh, A., Ghaderi, S., & Nasrollahi, M. (2011). Location optimization of wind plants in Iran by an integrated hierarchical data envelopment analysis. Renewable Energy, 36(5), 1621–1631.
Azadeh, A., Ghaderi, S., Omrani, H., & Eivazy, H. (2009). An integrated DEA–COLS–SFA algorithm for optimization and policy making of electricity distribution units. Energy Policy, 37(7), 2605–2618.
Azadeh, A., Salmanzadeh-Meydani, N., & Motevali-Haghighi, S. (2017). Performance optimization of an aluminum factory in economic crisis by integrated resilience engineering and mathematical programming. Safety Science, 91, 335–350.
Battisti, M., Beynon, M., Pickernell, D., & Deakins, D. (2019). Surviving or thriving: The role of learning for the resilient performance of small firms. Journal of Business Research, 100, 38–50.
Brandenburg, M. (2016). Supply chain efficiency, value creation and the economic crisis–An empirical assessment of the European automotive industry 2002–2010. International Journal of Production Economics, 171, 321–335.
Chen, W., Kucukyazici, B., & Saenz, M. J. (2019). On the joint dynamics of the economic and environmental performances for collective take-back systems. International Journal of Production Economics, 218, 228–244.
D’Inverno, G., Carosi, L., & Romano, G. (2020). Environmental sustainability and service quality beyond economic and financial indicators: A performance evaluation of Italian water utilities. Socio-Economic Planning Sciences, 100852.
Dal Pozzo, A., Guglielmi, D., Antonioni, G., & Tugnoli, A. (2018). Environmental and economic performance assessment of alternative acid gas removal technologies for waste-to-energy plants. Sustainable Production and Consumption, 16, 202–215.
D'Ambra, L., Crisci, A., Meccariello, G., Della Ragione, L., & Palma, R. (2020). Evaluation of the social and economic impact of carbon dioxide (CO2) emissions on sustainable mobility using a trend odds model. Socio-Economic Planning Sciences, 100817.
Das, D. (2018). Sustainable supply chain management in Indian organisations: An empirical investigation. International Journal of Production Research, 56(17), 5776–5794.
Dev, N. K., Shankar, R., & Swami, S. (2020). Diffusion of green products in industry 4.0: Reverse logistics issues during design of inventory and production planning system. International Journal of Production Economics, 223, 107519.
Ding, H., Liu, Q., & Zheng, L. (2016). Assessing the economic performance of an environmental sustainable supply chain in reducing environmental externalities. European Journal of Operational Research, 255(2), 463–480.
Elfarouk, O., Wong, K. Y., & Wong, W. P. (2021). Multi-objective optimization for multi-echelon, multi-product, stochastic sustainable closed-loop supply chain. Journal of Industrial and Production Engineering, 1–19.
Forteza, F. J., Carretero-Gomez, J. M., & Sese, A. (2017). Occupational risks, accidents on sites and economic performance of construction firms. Safety Science, 94, 61–76.
Ganda, F., & Milondzo, K. S. (2018). The impact of carbon emissions on corporate financial performance: Evidence from the South African firms. Sustainability, 10(7), 2398.
Goyal, S., Garg, D., & Luthra, S. (2021). Sustainable production and consumption: Analysing barriers and solutions for maintaining green tomorrow by using fuzzy-AHP–fuzzy-TOPSIS hybrid framework. Environment, Development and Sustainability, 1–47.
Hammad, A. W., Akbarnezhad, A., & Rey, D. (2017). Sustainable urban facility location: Minimising noise pollution and network congestion. Transportation Research Part E: Logistics and Transportation Review, 107, 38–59.
Hayami, H., Nakamura, M., & Nakamura, A. O. (2015). Economic performance and supply chains: The impact of upstream firms׳ waste output on downstream firms׳ performance in Japan. International Journal of Production Economics, 160, 47–65.
Huo, B., Gu, M., & Wang, Z. (2018). Supply chain flexibility concepts, dimensions and outcomes: An organisational capability perspective. International Journal of Production Research, 56(17), 5883–5903.
Hussain, A., Oad, A., Ahmad, M., Irfan, M., & Saqib, F. (2021). Do financial development and economic openness matter for economic progress in an emerging country? Seeking a sustainable development path. Journal of Risk and Financial Management, 14(6), 237.
Khan, S. A. R., & Qianli, D. (2017). Does national scale economic and environmental indicators spur logistics performance? Evidence from UK. Environmental Science and Pollution Research, 24(34), 26692–26705.
Król-Badziak, A., Pishgar-Komleh, S. H., Rozakis, S., & Księżak, J. (2021). Environmental and socio-economic performance of different tillage systems in maize grain production: Application of Life Cycle Assessment and Multi-Criteria Decision Making. Journal of Cleaner Production, 278, 123792.
Ledesma, R. D., Valero-Mora, P., & Macbeth, G. (2015). The scree test and the number of factors: a dynamic graphics approach. The Spanish journal of psychology, 18.
Ling-zhi, R., Xin-gang, Z., Yu-zhuo, Z., & Yan-bin, L. (2018). The economic performance of concentrated solar power industry in China. Journal of Cleaner Production, 205, 799–813.
Nishitani, K. (2011). An empirical analysis of the effects on firms’ economic performance of implementing environmental management systems. Environmental and Resource Economics, 48(4), 569–586.
Nishitani, K., & Kokubu, K. (2020). Can firms enhance economic performance by contributing to sustainable consumption and production? Analyzing the patterns of influence of environmental performance in Japanese manufacturing firms. Sustainable Production and Consumption, 21, 156–169.
Pal, R., Torstensson, H., & Mattila, H. (2014). Antecedents of organizational resilience in economic crises—an empirical study of Swedish textile and clothing SMEs. International Journal of Production Economics, 147, 410–428.
Pashapour, S., Bozorgi-Amiri, A., Azadeh, A., Ghaderi, S. F., & Keramati, A. (2019). Performance optimization of organizations considering economic resilience factors under uncertainty: A case study of a petrochemical plant. Journal of Cleaner Production, 231, 1526–1541.
Rahimi, M., Ghezavati, V., & Asadi, F. (2019). A stochastic risk-averse sustainable supply chain network design problem with quantity discount considering multiple sources of uncertainty. Computers and Industrial Engineering, 130, 430–449.
Sabbaghnia, A., Heydari, J., & Salmanzadeh-Mcydani, N. (2019). Optimization and coordination of a sustainable supply chain with emission reduction considerations. In 2019 15th Iran International Industrial Engineering Conference (IIIEC).
Sabogal-De La Pava, M. L., Vidal-Holguín, C. J., Manotas-Duque, D. F., & Bravo-Bastidas, J. J. (2021). Sustainable supply chain design considering indicators of value creation. Computers and Industrial Engineering, 107294.
Salmanzadeh-Meydani, N., & Fatemi Ghomi, S. (2019). The causal relationship among electricity consumption, economic growth and capital stock in Iran. Journal of Policy Modeling, 41(6), 1230–1256.
Schwab, L., Gold, S., & Reiner, G. (2019). Exploring financial sustainability of SMEs during periods of production growth: A simulation study. International Journal of Production Economics, 212, 8–18.
Shan, S., Ahmad, M., Tan, Z., Adebayo, T. S., Li, R. Y. M., & Kirikkaleli, D. (2021). The role of energy prices and non-linear fiscal decentralization in limiting carbon emissions: Tracking environmental sustainability. Energy, 234, 121243.
Shirali, G. A., Mohammadfam, I., Ebrahimipour, V., & Safety, S. (2013). A new method for quantitative assessment of resilience engineering by PCA and NT approach: A case study in a process industry. Reliability Engineering and System Safety, 119, 88–94.
Shirali, G. A., Shekari, M., & Angali, K. (2016). Quantitative assessment of resilience safety culture using principal components analysis and numerical taxonomy: A case study in a petrochemical plant. Journal of Loss Prevention in the Process Industries, 40, 277–284.
Singh, A., & Misra, S. C. (2021). Safety performance & evaluation framework in Indian construction industry. Safety science, 134, 105023.
Solangi, Y. A., Longsheng, C., Shah, S. A. A., Alsanad, A., Ahmad, M., Akbar, M. A., Ahmad, M., Akbar, M. A., Gumaei, A., & Ali, S. (2020). Analyzing renewable energy sources of a developing country for sustainable development: an integrated fuzzy based-decision methodology. Processes, 8(7), 825.
Taherdangkoo, M., Ghasemi, K., & Beikpour, M. (2017). The role of sustainability environment in export marketing strategy and performance: A literature review. Environment, Development and Sustainability, 19(5), 1601–1629.
Toutounchian, S., Abbaspour, M., Dana, T., & Abedi, Z. (2018). Design of a safety cost estimation parametric model in oil and gas engineering, procurement and construction contracts. Safety Science, 106, 35–46.
Tsao, Y.-C., Thanh, V.-V., Lu, J.-C., & Yu, V. (2018). Designing sustainable supply chain networks under uncertain environments: Fuzzy multi-objective programming. Journal of Cleaner Production, 174, 1550–1565.
Tseng, M.-L., Tran, T. P. T., Ha, H. M., Bui, T.-D., & Lim, M. K. (2021). Sustainable industrial and operation engineering trends and challenges Toward Industry 4.0: A data driven analysis. Journal of Industrial and Production Engineering, 1–18.
Wilcoxon, F., Katti, S., & Wilcox, R. A. (1970). Critical values and probability levels for the Wilcoxon rank sum test and the Wilcoxon signed rank test. Selected Tables in Mathematical Statistics, 1, 171–259.
Zhong, Y., & Wu, P. (2015). Economic sustainability, environmental sustainability and constructability indicators related to concrete-and steel-projects. Journal of Cleaner Production, 108, 748–756.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Salmanzadeh-Meydani, N., Ghomi, S.M.T.F., Haghighi, S.S. et al. A multivariate quantitative approach for sustainability performance assessment: An upstream oil and gas company. Environ Dev Sustain 25, 2777–2807 (2023). https://doi.org/10.1007/s10668-022-02112-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10668-022-02112-0