
Abstract
Runoff estimation is of immense importance in hydrological analysis for water resource planning and management. The developing countries cannot afford to establish a large number of gauging sites due to huge initial and operating expenditures. Hydrological modelling is an alternative solution to simulate the catchment response to extreme events under climate change for taking preventive measures. The hydrological models have their own leads and constraints, so because of limited hydrological data availability of the catchment, wavelet neural network (WNN), artificial neural network, adaptive neuro-fuzzy inference system, and Mike-11 Nedbor Afstromnings models were used in this study. These models were calibrated and validated using daily rainfall and runoff observations taken at Hamp Pandariya gauging station on Hamp river in the Chhattisgarh state of India. A comparative study of these models was carried out to investigate their performance, efficiency, and suitability for daily runoff simulation in Hamp Pandariya catchment and found suitable in simulating the hydrological response of the catchment and predicting runoff with a high degree of accuracy. The performance of these models was evaluated and compared with the aid of multiple goodness of fit criteria including coefficient of determinations (r2), Nash–Sutcliffe model efficiency index (NS), root mean square error, and water balance for model calibration and validation. These parameters indicated good agreement between observed and simulated runoff in terms of time to peak, discharge rate, daily and accumulated runoff volume, and shape of the hydrograph. The WNN was found the most appropriate model for future application due to Nash–Sutcliffe efficiency (NS) of 97% and 98% in calibration and validation, respectively, and the coefficient of determination as 99% both in calibration and validation.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The runoff simulation models offer a great prospect to comprehend the water resources systems at a catchment scale are substantial for water resources planning and management (Li et al., 2014). Runoff simulation plays a vital role in the management of reservoirs, appropriate planning for climatic extremes such as drought and flood hazards (Zahmatkesh et al., 2015). At any given spatial and temporal variations in explicit and implicit variables of watershed and precipitation characteristics, the relationship between rainfall and runoff is nonlinear and extremely complex (Kumar et al., 2019a, 2019b; Rezaie-Balf et al., 2017; Wu & Chau, 2011). The complex process of transformation of rainfall to runoff can be simulated through hydrologic models (Hadiani, 2015). The runoff simulation modelling methods can be broadly categorized into categories of theory-driven (conceptual) and data-driven (black box) approaches (Li et al., 2016). The theory-driven models express the different core sub-processes of the hydrological cycle in the catchment, which are not directly measurable for catchment (Solomatine & Dulal, 2003). The concomitant convolution of the theory-driven model, its prerequisite for hydrological data on spatial and temporal scales, less precision, and reliability induce the users to select data-driven models (Garcia-Pintado et al., 2015). The data-driven models are empirical and stochastic, which implicate scientific expression to state association between hydrological inputs. These expressions are assessed based on the analysis of concurrent input and outputs of the hydrological time series data and not on physical relationships between hydrological parameters. In comparison with the theory-driven models that deliberate all potential parameters affecting the catchment output, fewer parameters are required in developing the data-driven models (Rezaie-Balf et al., 2017). Data-driven models are often applied in the absence of sufficient data, efficient in time and cost responsive (Mengistu et al., 2016).
Mike-11 Nedbor Afstromnings model (NAM) is a theory-driven model that simulates the rainfall–runoff process at the catchment scale (Singh et al., 2014). Loliyana et al., (2015) applied the Mike-11 NAM model for Purna catchment in the Tapi basin and found it reasonably good in simulating annual hydrographs at daily time scales along with the prediction of water yield and flooding condition. Singh et al. (2014) used the Mike 11 NAM model for rainfall–runoff modelling in Vinayakpur intercepted catchment in the Chhattisgarh state of India and applied maximum and minimum simulated runoff for water resource management. Tiwari et al. (2016) used Mike-11 NAM for simulating daily runoff utilizing precipitation, potential evapotranspiration, and observed runoff in the Shipra river basin in Madhya Pradesh and found it sufficiently accurate for future predictions. Goyal et al., (2018) applied Mike-11 NAM for Narmada and Teesta river basins for evaluating the impact of changing the climate on the watershed hydrology and water yield using downscaled GCM climatic data. Artificial neural network (ANN) is amongst widely used data-driven models for runoff simulation and forecasting (Bhattacharya & Solomatine, 2003). Mukerji et al. (2009) applied ANN in the Ajay river basin up to Jamtara gauging site in Jharkhand India and found satisfactory results for flood forecasting. Raghuwanshi et al. (2006) applied ANN in the upper Siwane river in India and reported the model capabilities for estimation of runoff, sediment yield, missing data, and testing the accuracy of other models. Sudheer and Jain (2003) designed the data-driven algorithm for ANN rainfall–runoff models and reported that it could significantly reduce the effort and computational time required for runoff simulation. Senthil Kumar et al. (2005) compared different network types for ANN in rainfall–runoff modelling and found that the choice of the network type certainly has an impact on the model prediction accuracy. Jain et al. (2004) identified the physical process inherent in ANN rainfall–runoff models using a conceptual rainfall–runoff model and its application to understanding the process. Rajurkar et al. (2004) carried out modelling of daily rainfall–runoff relationships using ANN for two large size catchments in India and five other catchments used earlier by the World Meteorological Organization (WMO) for inter-comparison of the hydrological models. Senthil Kumar et al. (2013) applied ANN, fuzzy logic, and decision tree algorithm for modelling streamflow in the Kasol watershed in India and reported them suitable for runoff simulation. The Adaptive Neuro-Fuzzy Inference System (ANFIS) is another data-driven model, first proposed by (Jang, 1993), as a combination of an adaptive ANN and the fuzzy inference system (FIS). Lohani et al. (2006) applied FIS for modelling stage–discharge relationships and reported that the fuzzy logic-based approach can model the hysteresis effect (loop rating curve) more accurately than the ANN approach. Mukerji et al. (2009) applied ANFIS in the Ajay river basin up to Jamtara gauging site in Jharkhand India and found satisfactory results for flood forecasting. Jothiprakash and Magar (2012) compared the performance of the ANFIS model with other data-driven models for runoff simulation in the catchment. Ullah and Choudhury (2010) applied ANFIS for flood forecasting in the Barak river system in North-Eastern India and part of the Surma-Meghna river system with sufficient accuracy and reliability. Sehgal et al. (2014) found ANFIS sufficiently accurate for flood forecasting in two Indian rivers, Kamla and Kosi which vary widely in the catchment area and flow patterns. The very limited studies based on the coupling of the different data-driven models have reported improvement in the model efficiency and prediction results. Tiwari and Chatterjee (2010) applied WNN for daily discharge forecasting in the Mahanadi river basin and found it accurate and reliable. Maheswaran and Khosa (2012) applied WNN for monthly streamflow forecasting in the Cauvery river basin in India and found satisfactory results. Nayak et al. (2013) demonstrated the potential use of WNN for river flow modelling by developing a rainfall–runoff model for the Malaprabha basin in India. Ramana et al. (2013) applied WNN for monthly rainfall prediction of Darjeeling rain gauge station and found its performance better than ANN.
In developing countries like India, most of the catchments are still un-gauged (Swain & Patra, 2017) due to economic and social constraints (Jadhao & Tripathi, 2009). The Mahanadi river basin situated in the Chhattisgarh state of India is well known for paddy cultivation having a reckless increase in the human population, engulfing the agricultural land for urbanization and other land uses, hence producing immense stress on existing land and water resources (Asokan & Dutta, 2008). The amplified frequency of extreme rainfall events instigating potential flood hazards has increased during the last few decades in the Mahanadi river basin leading to huge loss of life and property (Jain et al., 2007). The rapidly shifting land use along with irregular frequency and intensity of rainfall is triggering exertion in the management of water resources in the Seonath sub-basin in the Chhattisgarh state of India (Galkate et al., 2014). Kumar et al. (2017) studied the impact of land-use changes in the upper Kharun catchment, Seonath sub-basin in the Chhattisgarh state of India, and reported that annual surface runoff has increased significantly by an expansion in built-up areas over the decades. Swain et al. (2018) applied the Soil and Water Assessment Tool (SWAT) over the Seonath sub-basin and found a poor correlation between observed and computed runoff. Since the earlier studies on runoff simulation in the Mahanadi and Seonath basins did not yield satisfactory results due to the non-availability of detailed spatial information on soil, topography, land use, and geology, the present study was carried out to compare four theory and data-driven conceptual models on sub-basin scales of Seonath basin. A novel approach for the coupling of data-driven models was conceded for the effective forecast of peak runoff with higher efficiency and consistency. The simulation results of theory-driven, data-driven, and coupled models were compared with observed runoff from the catchment to ascertain the best suited simulation model.
2 Methodology
2.1 Study area and data used
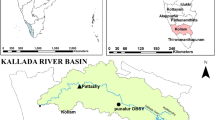
The Hamp Pandariya catchment is located in the Kawardha district of Chhattisgarh state, India. The basin extends between 22°11′30′′ and 22°30′30′′ north latitude to 81°06′00′′ and 81°28′30′′ east longitude. The catchment is an intercepted part of the Seonath river sub-basin and a part of the Mahanadi river basin. The Hamp river is a tributary of the Seonath river. The location of the Hamp Pandariya catchment in the Chhattisgarh state of India is shown in (Fig. 1). The daily rainfall data from 1980 to 2009 for three rain gauge stations (Bodla, Chirapani, and Pandariya) collected from the State Data Centre, Department of Water Resource, Chhattisgarh, have been used in the study. The daily potential evaporation collected from the Indian Meteorological Department at Raipur station was used as input in the models. The daily discharge data of the Pandariya gauging station from 1980 to 2009 were collected from the Department of Water Resource, Chhattisgarh. The 20-year (1980–1999) daily data of rainfall, runoff, and potential evaporation were used for model calibration and 10-year data (2000–2009) for model validation. The majority of the area in the catchment has fine mixed hyperthermic typic ustochrepts type of soil (northern and central) and fine loamy mixed hyperthermic typic ustochrepts on the eastern side. The majority of the area in the catchment lies under granitoid gneiss with the central part of the catchment being phyllite and some patches of laterite.

Hamp Pandariya catchment in Chhattisgarh state of India
2.2 Mike-11 NAM model
The NAM is a theory-driven model that functions by constantly accounting for moisture content in three different and mutually interrelated storages that represent overland flow, interflow, and base flow (Henriksen et al., 2003; Kumar et al., 2019a, 2019b). The physical processes applied in the NAM model are shown in Fig. 2a where fifteen different parameters are used to represent the surface, root zone, and groundwater characteristics (Table 1). The graphical representation and numerical goodness-of-fit measures were applied to evaluate the effectiveness of the calibration and validation process.

Structure of different models used for daily runoff simulation in Hamp Pandariya catchment
2.3 ANN model
The data-driven ANN model with feed-forward–backward propagation learning algorithm and sigmoid activation function was used for daily runoff simulation in Hamp Pandariya catchment. The model depends on both weights and activation function specified for neurons given in Eqs. 1 and 2 for an ANN. The ANN with supervised training comprises modified weight for input layers and threshold values by a data set consisting of input vectors can be seen in Fig. 2b. The time series of input data was normalized, and significant lags were identified based on auto-correlation, partial-autocorrelation, and cross-correlation function. The desired targets associated with each input vector were trained until certain model performance criteria were contented. The back-propagation algorithm gave the minimum error function in weight space when coupled with the method of gradient descent. The ANN model with an optimum number of neurons in the hidden layer was selected based on model performance indicators:
where x is the input parameter, and λ is sigmoid gain scale factor which is generally taken as one is given in Eq. (1):
where S is a set of training pairs, Ik is vector input to ANN, Ok is vector output from ANN, Q is the maximum number of training pairs, \(\varepsilon\) is the error associated in the input and output vector, and \({R}^{n}\) and \({R}^{p}\) are the unknown functions for the neural network to approximate given in Eq. (2):
where (ek) is the instantaneous error for kth training pair (Ik Ok,), \({y}_{k}\) is the change in the kth output layer, which is given in Eq. (3), and error for the entire set of training pairs S given by Ek is given in Eq. (4):
where βk is the instantaneous sum of square error of each output error (ejk), scaled by one half, \({E}_{k}\) is the sum of square error for kth layer, \({E}_{k}^{S}\) is the sum of the square error of the kth layer for the entire training set S given in Eq. (5):
where β is the mean square error computed over the entire training set S, and Q is the maximum number of training pairs.
The error calculated using Eq. (6) was used for computation of changes in weights for input to the hidden layer (\({z}_{ih}^{k+1})\) and hidden to the output layer (\({z}_{hj}^{k+1})\). The weights for the input, hidden and an output layer of the neural network were modified using Eqs. (7) and (8):
where \(\alpha\) is the rate of learning in the neural network, \({z}_{hj}^{k}\) is the weight of hidden to output for kth layer, \({z}_{ih}^{k}\) is the weight of hidden to input for kth layer, \(\delta {\varepsilon }_{k}\) is an error in the kth training layer, \(\delta {w}_{ih}^{k}\) is the rate of change of weight of the kth layer of input to the hidden layer, \(\delta {w}_{hj}^{k}\) is the rate of change of weight of the kth layer of output to the hidden layer, \({\xi }_{h}^{k}\) is the error in weight of the kth hidden layer, and \({X}_{i}\) is the weight of the hidden layer from previous input.
In the backpropagation algorithm, the learning rate (α) with an array change should be kept small for a smooth path in the weight space. The learning rate may be increased while maintaining stability by introducing a momentum term for hidden to the output layer (\(\mu \Delta {z}_{hj}^{k-1}\)) and input to the hidden layer \((\mu \Delta {z}_{ih}^{k-1})\) as given in Eqs. (9) and (10):
In standard back-propagation, learning rule without momentum (µ) = 0 and weights were not modified according to momentum, but in generalized delta rule with momentum (µ) > 0, weights assigned to input, hidden, and an output layer of the neural network were modified in accordance with momentum.
2.4 ANFIS model
ANFIS is a data-driven model with the synthesis of ANN and FIS which has the learning structure of a neural network with the human-inspired reasoning style of fuzzy systems. FIS is centred on the concept of fuzzy sets, which are set with no rigid boundary. The FIS comprises fuzzification of input variables, assessment of output for each rule, the combination of rule outputs, and defuzzification. In Takagi–Sugeno FIS, a fuzzy rule is created through a weighted linear combination of rigid inputs. The Takagi–Sugeno fuzzy rule applied using five-layer multilayer perceptron neural networks given by Jang (1993) is shown in Fig. 2c.
The output of the first layer \({Z}_{i}^{1}\) is given by Eqs. (11) and (12), where x or y is input, and αXi (or αYi-2) is a fuzzy set associated with the first layer of ANFIS.
The output (Zi1) can be computed using Eq. 13 for triangular membership function, (a) and (b) are factors that define the base of the triangle, while (c) defines the peak of the triangle, and (x) is the value of the input parameter.
In the second layer, the output from the first layer is multiplied to calculate the weight of the node \((w\) i) for the second layer and the sacking strength of the rule. The output \(({Z}_{i}^{2}\)) of the second layer is computed using Eq. (14).
In the third layer, the output from the second layer is normalized. The normalized weight \((\overline{w }\) i) for each layer and firing strength for each node (\({Z}_{i}^{3})\) is computed using Eq. (15)
In the fourth layer, pi, qi, and ri are the consequent parameter set and the ith node calculates the contribution of the ith rule (\({Z}_{i}^{4})\) in model output function based on the first-order Takagi–Sugeno method which is given in Eq. (16):
In the fifth layer, each node (fi) calculates the weighted final output (f) or Z5of the system using Eq. (17)
2.5 WNN model
Wavelet transform (WT) is a recently used tool for hydrological analysis which separates an input time series into shifted and scaled form of original wavelet. The input time series decomposes into multiple levels of details, with the interpretation of input time series in both time and frequency domains using a few coefficients (Rajaee et al., 2010). The WT is used for the analysis of irregular, asymmetric, and dynamic time series than normal time series (Ozger, 2010). The WT provides a flexible choice of mother wavelet as per the required characteristics of investigated time series (Adamowski & Sun, 2010). The discrete WT is usually preferred in hydrological time series decomposition (Rathinasamy & Khosa, 2012). The WT is used to obtain a comprehensive time scale depiction of localized and transient phenomena taking place at different time scales (Labat et al., 2000). The mother wavelet function \(\upxi (\mathrm{t})\) has finite energy which is given in Eqs. (18) and (19):
where \(\xi x,y(t)\) is a wavelet function, x is frequency parameter, and y is translation parameter. The frequency parameter (x) is a dilation for (a > 1) and contraction for (a < 1) of the wavelet function ξ (t) consistent with different scales. The translation parameter (y) is a temporal shift of function ξ (t).
The continuous wavelet transform (CWT) of time series f (t) given by (Rosso et al., 2004) can be expressed by Eq. (20):
where Wf(x, y) is the wavelet coefficient, and * is a complex conjugate of the wavelet function.
The WT looks for the level of resemblance amongst time series data and wavelet function at different scales to obtain wavelet coefficient\({W}_{f}(\mathrm{x},\mathrm{ y})\) for scalogram. The CWT produces huge data for all x and y. However, if frequency and translation parameters are selected based on powers of two, then the amount of data can be reduced considerably for more efficient data analysis. This discrete wavelet transformation (DWT) is given by (Mallat, 1989) shown in Fig. 2(d) and given in Eq. (21):
where m and n are the integers that control wavelet dilation and translation, respectively, x0 is a stated fine-scale step greater than 1, and y0 is a location parameter that must be greater than zero. The most common and simplest choice for parameters is x0 = 2 and y0 = 1.
For discrete-time series f (t), which occurs at different time t, the discrete wavelet transform is given in Eq. (22):
where Wf(m, n) is the wavelet coefficient for discrete wavelet of frequency x = 2 m and location y = 2 mn. The f (t) is a finite time series (t = 0, 1, 2,… N−1), and N is an integer power of 2 (N = 2 M); n is the time translation parameter, which changes in the range 0 < n < 2 M−m−1, where 1 < m < M.
2.6 Comparative evaluation of model performance
The various goodness of fit criteria, including coefficient of determination (r2), Nash–Sutcliffe coefficient (NS), and root mean square error (RMSE), were used to compare the performance of different models for runoff simulation. The coefficient of determination (r2) is defined as the square of the correlation between observed and simulated runoff from the above models which ranges between 0 and 1.
where \({Q}_{mi}\) is the measured runoff at time i, \({Q}_{si}\) is the simulated runoff at time i, \(\overline{{Q }_{m}}\) and \(\overline{{Q }_{S}}\) are the average of measured and simulated runoff, respectively. The Nash–Sutcliff efficiency (NS) is one of the most commonly used goodness of fit measures used to assess the predictive power of the hydrological model and ranges between −\(\infty\) and 1. The following equation can be used to compute the efficiency of the model:
The root mean square error (RMSE) is the standard deviation of residuals (prediction errors) and measures the distance of simulated runoff values from the regression line.
3 Application and data analysis
The modelling aids to acquire hydrological information required for the planning of water resources in a catchment. The measurement of runoff at a large scale is uneconomical and difficult; therefore, modelling becomes a prerequisite for the planning of water resources in the absence of such data. Because of limited data available for the catchment, theory and data-driven models with a novel coupling approach were attempted for daily runoff simulation in Hamp Pandariya catchment. The performance of runoff simulation models was used to identify the best model amongst them.
3.1 Analysis of meteorological data
The theory and data-driven models applied for runoff simulation in Hamp Pandariya catchment used Thiessen’s weighted rainfall which is given in Fig. 3a. The Thiessen’s weights for computation of weighted mean rainfall were assigned to each rain gauge station based on the area represented by the rain gauge station in the catchment. The Thiessen’s polygon was created using the “Create Thiessen Polygons tool” of Arc GIS 10.3 software based on a point feature representing the rain gauge station location in the catchment. The weights were assigned for three rain gauge stations, i.e., Chirapani (0.62), Pandariya (0.32), and Bodla (0.06), for computation of weighted mean rainfall for the catchment. The daily rainfall of each rain gauge station and the weighted mean is presented in Fig. 3b. The maximum daily rainfall observed at Pandariya RG was 165.90 mm, Bodla RG 143.40 mm, Chirapani RG 143.40 mm, and 118.67 mm for weighted mean rainfall. The daily potential evaporation used for runoff simulation modelling can be seen in Fig. 3c. The daily potential evaporation in catchment varies from 8.34 mm day−1 during May month to 2.13 mm day−1 during October months in the catchment. The statistical analysis of daily rainfall data at three rain gauge stations, daily weighted mean rainfall, and daily potential evaporation is given in (Table 2).

Daily meteorological data used for daily runoff simulation
3.2 Lag for input data to models
The delay in the hydrological process of runoff transformation from rainfall in the catchment can be taken care of by the identification of appropriate lag for the input data provided to the models. The appropriate lag for runoff in the models is identified based on autocorrelation, and partial autocorrelation showed that there was a significant relationship with the past two day’s runoff (Fig. 4a, b). The partial autocorrelation plot of observed runoff showed the correlation of the residuals after considering the lags in the observed runoff time series from the previous plot. The good partial autocorrelation of observed runoff was found significant up to the past three day’s runoff from the catchment. Therefore, based on the plot of autocorrelation and partial autocorrelation, the maximum lag for the observed runoff time series was identified as 3 days. The identification of lag between weighted mean rainfall and observed runoff based on cross-correlation is presented in Fig. 4c. The best cross-correlation between observed runoff and weighted mean rainfall was obtained without any lag to confirm that no lag is required between the observed runoff and weighted mean rainfall for runoff simulation in the catchment.

Auto-, partial and cross-correlation function for identification of time lag in days
3.3 Mike-11 NAM calibration and validation
The daily rainfall with observed and simulated runoff for calibration and validation using the Mike-11 NAM model is graphically presented in Fig. 5a, b, respectively. The optimized values of Mike-11 NAM model parameters were obtained in calibration through multiple iterations (Table 3). The maximum water content in surface storage (\({U}_{\mathrm{max}}\)), the maximum water content in the lower zone/root zone (\({L}_{\mathrm{max}}\)) and timing constant for base flow (\({CK}_{BF}\)) were found the most significant parameters for runoff simulation. The results of the Mike-11 NAM model with simulated annual runoff, annual groundwater recharge, overland flow, interflow, and base flow for calibration and validation are presented in Table 4.

Calibration and validation of NAM, ANN, ANFIS, and WNN models
3.4 ANN calibration and validation
The best ANN structure determined for runoff simulation is given in Eq. (28). There was no lag for Chirapani daily rainfall, lag of 2 days for Pandariya daily rainfall, lag of 5 days for Bodla daily rainfall, lag of 3 days for daily potential evaporation, and lag of one day for observed runoff were found suitable for the model. This ANN structure was then modified for the number of neurons in the hidden layer to optimize results based on obtained values of performance indices.
The daily observed and simulated runoff with corresponding weighted mean rainfall for calibration and validation of the ANN model is shown in Fig. 5c, d, respectively. The performance indices of the ANN model with the different number of neurons in the hidden layer can be seen in Table 5, which showed that structure 4–5–1 (4 input, 5 neurons, and 1 output) gave the best simulation of daily runoff from the catchment.
3.5 ANFIS calibration and validation
The ANFIS model had a similar number of neurons in the structure, with the same lags identified for inputs in the ANN model. The ANFIS architecture was then modified for radius based on subtractive clustering of input data sets to identify weights and the number of neurons in the hidden layer to optimize results given in (Table 6). The daily observed and simulated runoff with corresponding weighted mean rainfall for calibration and validation of the ANFIS model is presented in Fig. 5e, f, respectively. The ANFIS model structure with four neurons and radius 0.4 gave the best results for daily runoff simulation from the catchment.
3.6 WNN calibration and validation
The WNN model was similar to the ANN model in structure, with the same lags for inputs in the network of the ANN model. The number of neurons is varied from one to five at different levels of decomposition using Haar wavelet. The original mother wavelet was decomposed into corresponding details and approximation time series. The model performance indices encountered at different levels of wavelet decomposition with varying number of neurons observed are expressed in Table 7. The daily observed and simulated runoff with weighted mean rainfall for calibration and validation is presented in Fig. 5g, h. The Haar wavelet decomposition of level 4 with three neurons was found best for daily runoff simulation in calibration and validation based on performance indices.
3.7 Results and discussion of Mike-11 NAM, ANN, ANFIS, and WNN models
The statistical analysis of daily observed and simulated runoff during calibration (1980–1999) and validation (2000–2009) was used for comparative evaluation of the performance of different models and is presented in Table 8. The variance of the Mike-11 NAM model for simulated daily runoff reduced from 21.06% in calibration to 8.80% in validation. The decrease in the variance of the simulated runoff output from the model shows that the precision of the runoff estimates has increased from calibration to validation of the model. The Mike-11 NAM model performance indices, i.e. coefficient of determination (0.97), root mean square error (0.62), Nash–Sutcliffe efficiency (0.95), for runoff simulation in the Hamp Pandariya catchment of Seonath sub-basin were found superior as compared to the application of the same model in the Arpa catchment of Seonath sub-basin with Mike-11 NAM model performance indices, i.e. coefficient of determination (0.73), root mean square error (27.13), Nash–Sutcliffe efficiency (0.61) by Kumar et al., (2019a, 2019b). This illustrates that the Mike-11 NAM model when applied in the Hamp Pandariya catchment of the Seonath sub-basin has performed better for daily runoff simulation as compared to preceding studies made by Kumar et al., (2019a, 2019b). The Nash–Sutcliffe efficiency for the Mike-11 NAM model during calibration and validation was found as 0.82 and 0.95, respectively, which implies that the relative magnitude of the residual variance between the simulated runoff as compared to the measured runoff has decreased from calibration to validation. The percentage change in Mike-11 NAM model water balance shows a good volumetric match between measured and simulated runoff computed as 1.67 and -1.56% during calibration and validation, respectively. The Mike-11 NAM model water balance results agree with a similar study made by Teshome et al. (2020) for the Bina river basin in central India. The sensitivity analysis of Mike-11 NAM parameters was attained by manually changing the values of model parameters. The Mike-11 NAM model parameters obtained during calibration were increased and decreased by 10% and 20% on both sides (Teshome et al., 2020). The Mike-11 NAM model coefficient of determination, Nash–Sutcliffe model efficiency, and root mean square error were plotted against model parameters to obtain the most sensitive model parameters. The sensitivity analysis of Mike-11 NAM model parameters concluded that the maximum water content in surface storage (\({U}_{\mathrm{max}}\)), the maximum water content in the lower zone/root zone (\({L}_{\mathrm{max}}\)) and timing constant for base flow (\({CK}_{BF}\)) were the most significant Mike-11 NAM model parameters for daily runoff simulation in the catchment. The sensitivity analysis results were found analogous to a study made in the Vinayakpur catchment of Seonath sub-basin by Singh et al. (2014). The rugged terrain upstream of the catchment governs the surface water storage, and dominant agricultural land use in the central part of the catchment affects the runoff generation in the catchment. The base flow contribution to the streams significantly affects the runoff in the streams after the cessation of the rainy season. The theory-driven Mike-11 NAM model provides daily values of groundwater recharge, overland flow, interflow, and base flow; consequently, it has an advantage over data-driven models that provide only simulated runoff as model output. The Mike-11 NAM model simulated groundwater recharge and base flow given in Table 4 have decreased over the period which validates the impact of climate variability and land-use changes in the Hamp Pandariya catchment corroborating the analysis by Panda et al. (2013). The additional hydrological information obtained by the Mike-11 NAM model could be utilized for the assessment of different schemes of water resource management in the catchment such as groundwater recharge, base flow, and environmental flow in the river. The Mike-11 NAM model validation for Hamp Pandariya catchment provided better outcomes in terms of coefficient of determination (0.97), Nash–Sutcliffe model efficiency (0.95), and root mean square error (0.62) of simulated daily runoff, than SWAT model Nash–Sutcliffe efficiency (0.07) and the coefficient of determination (0.31) obtained for the same sub-basin by Swain et al. (2018). The SWAT model applied in the same sub-basin with the coefficient of determination (0.90), root mean square error (30.0), Nash–Sutcliffe efficiency (0.81) by Verma and Verma, (2019) and coefficient of determination (0.63), root mean square error (13.02), Nash–Sutcliffe efficiency (0.40) by Verma et al. (2020), clearly indicates that the Mike-11 NAM model performed better than SWAT model. The better performance of the Mike-11 NAM model than the SWAT model in the earlier studies made in the same sub-basin could be due to the non-availability of spatial database and creation of several reservoirs in the Seonath sub-basin which has modified the virgin flow of the river. The non-availability of regulated flow data of such reservoirs constructed in the sub-basin for input in the model is also a big deterrent in the routing of the flow of rivers in the SWAT model. Therefore, the rainfall–runoff modelling in the Hamp Pandariya catchment in the Seonath sub-basin with no reservoir yielded more realistic results than the SWAT model applied in earlier studies in the Seonath sub-basin (Table 9).
The optimized structure of ANN is given in Eq. (26) which has no lag for Chirapani daily rainfall, 2-day lag for Pandariya daily rainfall, 5-day lag for Bodla daily rainfall, 3-day lag for daily potential evaporation and one-day lag for the measured runoff. The ANN with 4–5–1 (4 input, 5 neurons and 1 output) has yielded the best simulation of daily simulated runoff from the catchment. The variance of the data-driven ANN model applied for daily runoff simulation in the catchment is improved from 19.62 to 8.86% during calibration and validation, respectively. The coefficient of correlation of simulated runoff from the ANN model for calibration and validation was computed as 0.97 and 0.98, respectively. Similarly, the Nash–Sutcliffe efficiency for predicting the performance of the ANN model during calibration and validation is 0.94 and 0.97, respectively. The ANN model was found more superior to the Mike-11 NAM model for simulating daily runoff from the catchment and requires less time for training as compared to Mike-11 NAM for simulating daily runoff from the catchment, which agreed with the outcomes of previous studies made by Kumar et al. (2017) in Arpa basin of the Seonath river in central India and Nayak et al. (2013) in Malaprabha basin of Southern India for the short-term and long-term dependence of streamflow. The ANN model yielded better goodness of fit of daily simulated runoff with measured runoff than Mike-11 NAM model could be due to anomalies in the precipitation due to climate changes studies made by Verma et al. (2016) in the Seonath sub-basin indicating an increasing trend of rainfall in monsoon season and decreasing trend of rainfall in the post-monsoon season. The short- and long-term changes due to climate change in the flow regime of the Seonath river basin studied by Verma and Dhiwar (2018) have important implications in rainfall–runoff modelling. The ANN has proven competencies and inherent learning mechanisms to capture such changes in the flow regimes over the long term which could be the reason for better performance than the Mike-11 NAM model for rainfall–runoff modelling in Hamp Pandariya catchment.
The ANFIS is a data-driven coupled model with a hybrid of ANN and FIS; therefore, the ANN structure was kept the same in the ANFIS model and modified only for radius based on subtractive clustering of input data sets to identify weights and the number of neurons in the hidden layer to optimize the results. The ANFIS model structure with four neurons with a radius of 0.4 gives the best results for daily runoff simulation from the catchment. The variance of daily simulated runoff improved from 19.25% in calibration to 8.21% in validation for the ANFIS model and was found higher than ANN model results. The ANFIS model overestimates the minimum simulated daily runoff of 0.24 m3/s and 0.41 m3/s for calibration and validation, respectively, which is opposite to ANN results which is in agreement with earlier studies made by Ghose et al. (2013) in the same sub-basin. However, the ANFIS model overestimates the maximum daily simulated runoff of 45.41 m3/s during calibration and underestimates for validation (25.27 m3/s) compared to the daily observed runoff from the catchment. These differences in the results of simulated runoff from ANN and ANFIS model may be due to different learning algorithms of feed-forward–backward propagation and radial basis function used, respectively, in these models (Kumar et al., 2019a, b). The root mean square error of simulated daily runoff from the ANFIS model for calibration and validation is 1.22 and 0.59, respectively. The Nash–Sutcliffe efficiencies from the ANFIS model were found as 0.92 and 0.95 for calibration and validation, respectively. The performance of the ANFIS model was better than the ANN model for daily runoff simulation in the catchment which is evident from the coefficient of determination (0.97), Nash–Sutcliffe model efficiency (0.95), and root mean square error (0.59) obtained for model validation. The results obtained from the ANFIS model were also following earlier similar studies made by (Lohani et al., 2006) in the upper catchment of Narmada river in central India as the model performance indices, i.e. coefficient of determination, Nash–Sutcliffe efficiency and root mean square error, for simulation of daily runoff from catchment were found almost similar to this study.
The WNN model was similar in model structure, with the same lags for inputs in the model as in ANN. The number of neurons was varied from one to five at different levels of decomposition using Haar wavelet. The Haar wavelet used by Tiwari et al. (2013) is mostly used for runoff simulation modelling. The Haar wavelet with the decomposition of level 4 with three neurons was found best for runoff simulation in calibration and validation based on different performance indices which is analogous to earlier studies made by Tiwari et al. (2013). The WNN model was found as the best model for daily runoff simulation amongst the different models used in this study which was evident from the variance of 18.39% in calibration to 7.39% in validation similar to results obtained by Nayak et al. (2013) in the Malaprabha basin in central India. The coefficient of correlation of simulated daily runoff from the WNN model for calibration and validation was found near to one which can be considered a close match. The Nash–Sutcliffe coefficient for model efficiency of simulated runoff from WNN model during calibration and validation was 0.97 and 0.98 which also propagated the superiority of this model over others. Therefore, it can be concluded that the coupling of wavelet transformation and ANN to develop the WNN model may be considered the best for simulation of daily minimum and maximum runoff from the catchment. The WNN model used only rainfall, potential evaporation, and observed runoff for daily runoff simulation from the catchment; compared to the SWAT model which requires huge information on meteorological data, land use, soil, the topography of the catchment is rarely available at varying spatial and temporal scales for the Indian catchments. Therefore, because of limited data availability for the catchment, the WNN model can be applied with sufficient accuracy and reliability for daily runoff simulation.
The better performance of the data-driven models than earlier used physically based distributed models for the same catchment pronounced that under non-availability of detailed spatial data and dependency of several parameters makes physically based model (like SWAT) more complex in the data-sparse regions of developing countries. The significant improvement of the goodness-of-fit measures confirmed the superiority of the ANN and ANFIS models for modelling rainfall–runoff relationships for Hamp Pandariya catchment. The supplementary escalation in model goodness-of-fit measures after coupling of ANN with wavelet functions was realized. The WNN model is suited for modelling nonlinear and non-stationary input with considerable changes over a while due to changes in the human environment system. This shows that coupling of data-driven models could be a better alternative to model complex rainfall–runoff relationships with limited spatial data which is a prerequisite for physically based distributed models. In the catchments where sufficient rainfall and runoff records are available, this coupled data-driven model can be used conveniently without much contemplation of complex hydrological processes. The long-term changes in flow regimes directly affect the management of water resources, agriculture, hydrology, and ecosystems. Hence, it is important to identify the changes in the magnitude of the temporal and spatial behaviour of discharge being imperative for suggesting suitable strategies for sustainable management of water resources, agriculture, environment, and ecosystems. The rainfall–runoff modelling is a prerequisite for the assessment of several complex hydrological processes such as vital environmental flow and long-term changes in the flow of the river system, which affects the human–environment system. The anthropogenic activities lead to land-use changes in the catchment, increasing compaction of the land surface which increases the runoff volumes and shortens the time of concentration into the streams. Climate change directly affects the precipitation and temperature which alternatively affects the runoff generation process in the catchment. Therefore, it can be concluded that this coupled data-driven model is appropriate to model the daily rainfall–runoff process in the catchment with limited input data availability for modelling under a considerable changing environment system.
3.8 Advantages of WNN model
The WNN model has a strong ability to apprehend non-stationary and nonlinear attributes embedded in the hydrological time series data and also capable to trace the implicit trend function of the hydrological cycle which is missing in Mike-11 NAM, ANN, and ANFIS models. The WNN increases the convergence speed of the model much faster than feed-forward back-propagation, radial basis function, and other learning algorithms resulting in less time for training and validation. The WNN has unique error detecting ability due to its adoption of wavelet-based input for model simulation as compared to ANN and ANFIS models. Therefore, the outlier data are easily detected and modified as per the past trend of the observed time series for better and reliable results from the modelling.
4 Conclusion
The main goal of this study was to recognize the capability of theory-driven and data-driven models for daily runoff simulation under the condition of limited data availability when SWAT model results were not found satisfactory for the Hamp-Pandariya sub-basin. The theory-driven Mike-11 NAM model entailed more time and operational understanding of model parameters for calibration and validation but provided important insight about supplementary hydrological processes like groundwater recharge, overland flow; interflow, and base flow which is absent in data-driven models. The additional hydrological information available from Mike-11 NAM can be used for water resource management in the catchment. The ANN and ANFIS model performed better than Mike-11 NAM in terms of model performance criteria and entails less time for calibration and validation. The ANN and ANFIS do not require any methodological acquaintance of the hydrological process for daily runoff simulation as compared to Mike-11 NAM which requires a proper understanding of the functions of each parameter in the model. The severe disadvantage of data-driven models is that it does not provide any information on the effect of other hydrological parameters on simulated runoff; thus, it remains discrete on hydrological explanations for any such deviations. Since data-driven models gave adequately good outcomes as compared to Mike-11 NAM, certain transformation was incorporated using the wavelet toolbox in MATLAB software to refine the inputs provided to ANN by transforming peaks and outliers data through model coupling in MATLAB software. This ensued in best model performance amongst all models used for runoff simulation from the catchment. Therefore, it can be concluded that under limited data availability WNN model can be a reliable tool for runoff simulation studies for water resource planning in the catchment.
References
Adamowski, J., & Sun, K. (2010). Development of a coupled wavelet transform and neural network method for flow forecasting of non-perennial rivers in semi-arid watersheds. Journal of Hydrology, 390(1–2), 85–91. https://doi.org/10.1016/j.jhydrol.2010.06.033
Asokan, S. M., & Dutta, D. (2008). Analysis of water resources in the Mahanadi River Basin, India under projected climate conditions. Hydrological Processes: an International Journal, 22(18), 3589–3603. https://doi.org/10.1002/hyp.6962
Bhattacharya, B., & Solomatine, D. P. (2003). Neural networks and M5 model trees in modeling water level-discharge relationship for an Indian river. In ESANN (pp. 407–412).
Galkate, R., Thomas, T., Jaiswal, R. K., & Singh, S. (2014). CS/AR-1/2014: Water availability study and supply demand analysis in Kharun sub-basin of Seonath basin in Chhattisgarh state. National Institute of Hydrology.
Garcia-Pintado, J., Mason, D. C., Dance, S. L., Cloke, H. L., Neal, J. C., Freer, J., & Bates, P. D. (2015). Satellite-supported flood forecasting in river networks: A real case study. Journal of Hydrology, 523, 706–724. https://doi.org/10.1016/j.jhydrol.2015.01.084
Ghose, D. K., Panda, S. S., & Swain, P. C. (2013). Prediction and optimization of runoff via ANFIS and GA. Alexandria Engineering Journal, 52(2), 209–220. https://doi.org/10.1016/j.aej.2013.01.001
Goyal, M. K., & Surampalli, R. Y. (2018). Impact of climate change on water resources in India. Journal of Environmental Engineering, 144(7), 04018054. https://doi.org/10.1061/(ASCE)EE.1943-7870.0001394
Hadiani, R. (2015). Analysis of rainfall-runoff neuron input model with artificial neural network for simulation for availability of discharge at bah Bolon watershed. Procedia Engineering, 125, 150–157. https://doi.org/10.1016/j.proeng.2015.11.022
Henriksen, H. J., Troldborg, L., Nyegaard, P., Sonnenborg, T. O., Refsgaard, J. C., & Madsen, B. (2003). Methodology for construction, calibration and validation of a national hydrological model for Denmark. Journal of Hydrology, 280(1), 52–71. https://doi.org/10.1016/S0022-1694(03)00186-0
Jadhao, A. K., & Tripathi, M. P. (2009). Prediction of runoff for small watershed using GIUH_CAL model and GIS approach in Chhattisgarh. International Journal of Agricultural Engineering, 2(2), 310–314.
Jain, A., Sudheer, K. P., & Srinivasulu, S. (2004). Identification of physical processes inherent in artificial neural network rainfall runoff models. Hydrological Processes, 18(3), 571–581. https://doi.org/10.1002/hyp.5502
Jain, S. K., Agarwal, P. K., & Singh, V. P. (2007). Mahanadi, Subernarekha and Brahmani Basins. In Hydrology and Water Resources of India (pp. 597–639). Springer, Dordrecht.https://doi.org/10.1007/1-4020-5180-8_13.
Jang, J. S. (1993). ANFIS: Adaptive-network-based fuzzy inference system. IEEE Transactions on Systems, Man, and Cybernetics, 23(3), 665–685. https://doi.org/10.1109/21.256541
Jothiprakash, V., & Magar, R. B. (2012). Multi-time-step ahead daily and hourly intermittent reservoir inflow prediction by artificial intelligent techniques using lumped and distributed data. Journal of Hydrology, 450, 293–307. https://doi.org/10.1016/j.jhydrol.2012.04.045
Kumar, A., Kumar, P., & Singh, V. K. (2019a). Evaluating different machine learning models for runoff and suspended sediment simulation. Water Resources Management, 33(3), 1217–1231. https://doi.org/10.1007/s11269-018-2178-z
Kumar, N., Tischbein, B., Kusche, J., Beg, M. K., & Bogardi, J. J. (2017). Impact of land-use change on the water resources of the Upper Kharun Catchment, Chhattisgarh, India. Regional Environmental Change, 17(8), 2373–2385. https://doi.org/10.1007/s10113-017-1165-x
Kumar, P., Lohani, A. K., & Nema, A. K. (2019b). Rainfall runoff modeling using Mike 11 NAM model. Current World Environment, 14(1), 27–36. https://doi.org/10.12944/CWE.14.1.05
Labat, D., Ababou, R., & Mangin, A. (2000). Rainfall-runoff relations for karstic springs. Part II: continuous wavelet and discrete orthogonal multiresolution analyses. Journal of Hydrology, 238(3–4), 149–178. https://doi.org/10.1016/S0022-1694(00)00322-X
Li, F., Zhang, Y., Xu, Z., Liu, C., Zhou, Y., & Liu, W. (2014). Runoff predictions in ungauged catchments in southeast Tibetan Plateau. Journal of Hydrology, 511, 28–38. https://doi.org/10.1016/j.jhydrol.2014.01.014
Li, Z., Huang, G., Wang, X., Han, J., & Fan, Y. (2016). Impacts of future climate change on river discharge based on hydrological inference: A case study of the Grand River Watershed in Ontario, Canada. Science of the Total Environment, 548, 198–210. https://doi.org/10.1016/j.scitotenv.2016.01.002
Lohani, A. K., Goel, N. K., & Bhatia, K. K. S. (2006). Takagi-Sugeno fuzzy inference system for modeling stage-discharge relationship. Journal of Hydrology, 331(1–2), 146–160. https://doi.org/10.1016/j.jhydrol.2006.05.007
Loliyana, V. D., & Patel, P. L. (2015). Lumped conceptual hydrological model for Purna river basin, India. Sadhana, 40(8), 2411–2428. https://doi.org/10.1007/s12046-015-0407-1
Maheswaran, R., & Khosa, R. (2012). Comparative study of different wavelets for hydrologic forecasting. Computers & Geosciences, 46, 284–295. https://doi.org/10.1016/j.cageo.2011.12.015
Mallat, S. G. (1989). A theory for multiresolution signal decomposition: The wavelet representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 11(7), 674–693.
Mengistu, D. T., Moges, S. A., & Sorteberg, A. (2016). RETRACTED: Revisiting systems type black-box rainfall-runoff models for flow forecasting application. Journal of Water Resource and Protection, 8(01), 65. https://doi.org/10.4236/jwarp.2016.81006
Mukerji, A., Chatterjee, C., & Raghuwanshi, N. S. (2009). Flood forecasting using ANN, neuro-fuzzy, and neuro-GA models. Journal of Hydrologic Engineering, 14(6), 647–652. https://doi.org/10.1061/(ASCE)HE.1943-5584.0000040
Nayak, P. C., Venkatesh, B., Krishna, B., & Jain, S. K. (2013). Rainfall-runoff modeling using conceptual, data driven, and wavelet based computing approach. Journal of Hydrology, 493, 57–67. https://doi.org/10.1016/j.jhydrol.2013.04.016
Ozger, M. (2010). Significant wave height forecasting using wavelet fuzzy logic approach. Ocean Engineering, 37(16), 1443–1451. https://doi.org/10.1016/j.oceaneng.2010.07.009
Panda, D. K., Kumar, A., Ghosh, S., & Mohanty, R. K. (2013). Streamflow trends in the Mahanadi River basin (India): Linkages to tropical climate variability. Journal of Hydrology, 495, 135–149. https://doi.org/10.1016/j.jhydrol.2013.04.054
Raghuwanshi, N. S., Singh, R., & Reddy, L. S. (2006). Runoff and sediment yield modeling using artificial neural networks: Upper Siwane River, India. Journal of Hydrologic Engineering, 11(1), 71–79. https://doi.org/10.1061/(ASCE)1084-0699(2006)11:1(71)
Rajaee, T., Mirbagheri, S. A., Nourani, V., & Alikhani, A. (2010). Prediction of daily suspended sediment load using wavelet and neurofuzzy combined model. International Journal of Environmental Science & Technology, 7(1), 93–110. https://doi.org/10.1007/BF03326121
Rajurkar, M. P., Kothyari, U. C., & Chaube, U. C. (2004). Modeling of the daily rainfall-runoff relationship with artificial neural network. Journal of Hydrology, 285(1–4), 96–113. https://doi.org/10.1016/j.jhydrol.2003.08.011
Ramana, R. V., Krishna, B., Kumar, S. R., & Pandey, N. G. (2013). Monthly rainfall prediction using wavelet neural network analysis. Water Resources Management, 27(10), 3697–3711. https://doi.org/10.1007/s11269-013-0374-4
Rathinasamy, M., & Khosa, R. (2012). Multiscale nonlinear model for monthly streamflow forecasting: A wavelet-based approach. Journal of Hydroinformatics, 14(2), 424–442. https://doi.org/10.2166/hydro.2011.130
Rezaie-Balf, M., Zahmatkesh, Z., & Kim, S. (2017). Soft computing techniques for rainfall-runoff simulation: local non-parametric paradigm vs. model classification methods. Water Resources Management, 31(12), 3843–3865. https://doi.org/10.1007/s11269-017-1711-9
Rosso, O. A., Figliola, A., Creso, J., & Serrano, E. (2004). Analysis of wavelet-filtered tonic-clonic electroencephalogram recordings. Medical and Biological Engineering and Computing, 42(4), 516–523. https://doi.org/10.1007/BF02350993
Sehgal, V., Sahay, R. R., & Chatterjee, C. (2014). Effect of utilization of discrete wavelet components on flood forecasting performance of wavelet based ANFIS models. Water Resources Management, 28(6), 1733–1749. https://doi.org/10.1007/s11269-014-0584-4
Senthil Kumar, A. R., Goyal, M. K., Ojha, C. S. P., Singh, R. D., & Swamee, P. K. (2013). Application of artificial neural network, fuzzy logic and decision tree algorithms for modelling of streamflow at Kasol in India. Water Science and Technology, 68(12), 2521–2526. https://doi.org/10.2166/wst.2013.491
Senthil Kumar, A. R., Sudheer, K. P., Jain, S. K., & Agarwal, P. K. (2005). Rainfall-runoff modelling using artificial neural networks: comparison of network types. Hydrological Processes: an International Journal, 19(6), 1277–1291. https://doi.org/10.1002/hyp.5581
Singh, A., Singh, S., Nema, A. K., Singh, G., & Gangwar, A. (2014). Rainfall-runoff modeling using MIKE 11 NAM model for Vinayakpur intercepted catchment, Chhattisgarh. Indian Journal of Dryland Agricultural Research and Development, 29(2), 1–4. https://doi.org/10.5958/2231-6701.2014.01206.8
Solomatine, D. P., & Dulal, K. N. (2003). Model trees as an alternative to neural networks in rainfall-runoff modelling. Hydrological Sciences Journal, 48(3), 399–411. https://doi.org/10.1623/hysj.48.3.399.45291
Sudheer, K. P., & Jain, S. K. (2003). Radial basis function neural network for modeling rating curves. Journal of Hydrologic Engineering, 8(3), 161–164. https://doi.org/10.1061/(ASCE)1084-0699(2003)8:3(161)
Swain, J. B., & Patra, K. C. (2017). Streamflow estimation in ungauged catchments using regionalization techniques. Journal of Hydrology, 554, 420–433. https://doi.org/10.1016/j.jhydrol.2017.08.054
Swain, S., Verma, M. K., & Verma, M. K. (2018). Streamflow estimation using SWAT model over Seonath river basin, Chhattisgarh, India. In Hydrologic Modeling (pp. 659–665). Springer, Singapore. https://doi.org/10.1007/978-981-10-5801-1_45.
Teshome, F. T., Bayabil, H. K., Thakural, L. N., & Welidehanna, F. G. (2020). Verification of the MIKE11-NAM model for simulating streamflow. Journal of Environmental Protection, 11, 152–167. https://doi.org/10.4236/jep.2020.112010
Tiwari, H. L., Balvanshi, A., & Chouhan, D. (2016). Simulation of rainfall runoff of Shipra River basin. International Journal of Civil Engineering and Technology, 7(6), 364–370.
Tiwari, M. K., & Chatterjee, C. (2010). A new wavelet-bootstrap-ANN hybrid model for daily discharge forecasting. Journal of Hydroinformatics, 13(3), 500–519. https://doi.org/10.2166/hydro.2010.142
Tiwari, M. K., Song, K. Y., Chatterjee, C., & Gupta, M. M. (2013). Improving reliability of river flow forecasting using neural networks, wavelets and self-organising maps. Journal of Hydroinformatics, 15(2), 486–502. https://doi.org/10.2166/hydro.2012.130
Ullah, N., & Choudhury, P. (2010). Flood forecasting in river system using ANFIS. In AIP Conference Proceedings, 1298(1), pp. 694–699. AIP.https://doi.org/10.1063/1.3516407.
Ramesh, V., Nema, M. K., Nema, A. K., & Sena, D. R. (2020). Hydrological modeling of a sub-basin of Mahanadi river basin using SWAT model. Indian Journal of Soil Conservation, 48(1), 1–10.
Verma, M. K., & Verma, M. K. (2019). Calibration of a hydrological model and sensitivity analysis of its parameters: A case study of Seonath river basin. International Journal of Hydrology Science and Technology, 9(6), 640–656. https://doi.org/10.1504/IJHST.2019.103444
Verma, M. K., Verma, M. K., & Swain, S. (2016). Statistical analysis of precipitation over Seonath river basin, Chhattisgarh, India. International Journal of Applied Engineering Research, 11(4), 2417–2423.
Verma, S., & Dhiwar, B. K. (2018). Analysis of short term and long term dependence of stream flow phenomenon in Seonath River Basin, Chhattisgarh. International Journal of Advanced Engineering Research and Science, 5(1), 237–369. https://doi.org/10.22161/ijaers.5.1.19
Wu, C. L., & Chau, K. W. (2011). Rainfall-runoff modeling using artificial neural network coupled with singular spectrum analysis. Journal of Hydrology, 399(3–4), 394–409. https://doi.org/10.1016/j.jhydrol.2011.01.017
Zahmatkesh, Z., Karamouz, M., & Nazif, S. (2015). Uncertainty based modeling of rainfall-runoff: Combined differential evolution adaptive metropolis (DREAM) and K-means clustering. Advances in Water Resources, 83, 405–420. https://doi.org/10.1016/j.advwatres.2015.06.012
Acknowledgements
The authors acknowledge the support of the State Hydrology Data Centre, Department of Water Resources, Chhattisgarh, India, for providing the necessary daily discharge data required for this study. The support by the Indian Meteorological Department, Raipur, Chhattisgarh, for meteorological data; National Bureau of Soil Survey and Land Use Planning, New Delhi, for soil data; and Geological Survey of India, Raipur, Chhattisgarh, for providing the lithological data of the catchment; is duly acknowledged. The authors are also thankful to unknown reviewers of the manuscript and the editor of the journal for the improvement of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest among the author and all author have their consent for the inclusion of their names in the manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Singh, G., Kumar, A.R.S., Jaiswal, R.K. et al. Model coupling approach for daily runoff simulation in Hamp Pandariya catchment of Chhattisgarh state in India. Environ Dev Sustain 24, 12311–12339 (2022). https://doi.org/10.1007/s10668-021-01949-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10668-021-01949-1