
Abstract
Indentation is an old technique that emphasizes elements in source code using white spaces or tabs. But while this technique has been taught and applied for decades, evidence for its effectiveness is weak: up to 2022 relatively few experiments can be found – the present authors are only aware of one single experiment that revealed an effect of indentation and reported the effect size, but even in that experiment the effect of indentation was found to be weak. The situation changed recently, where an experiment was published that suddenly revealed a strong and large effect of indentation in control flows on reaction time. However, although the experiment provided an initial indication of a possible cause for the difference between indented and non-indented code (the length of the code that can be skipped in indented code), the evidence for this indicator was rather weak. The present paper presents a formal model on the differences in reading times (measured in terms of reaction times) between indented and non-indented code. Based on that model a controlled experiment on generated tasks was designed and executed on 27 participants (undergraduate students, PhD students, professionals). The experiment (again) confirms a strong (p < .001) and large (\(\eta _{p}^{2}\) = .198, \(\frac{M_{Non-Indented}}{M_{Indented}}\) = 2.13) effect of indentation. Furthermore, it confirms that the larger the skippable code is, the larger is the difference between reading time of indented and non-indented code (p = .001, \(\eta _{p}^{2}\) = .072). I.e., the experiment goes beyond the point “indented vs non-indented code” and explains the difference by revealing a factor that controls this difference. However, although the previous statements holds true for the whole sample in the experiment, this effect could only be shown for a subset of individual participants.
Similar content being viewed by others


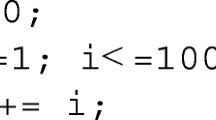
Avoid common mistakes on your manuscript.
1 Introduction
It is quite usual that software developers indent their code. The typical argument is that “indentation is used to format program source code to improve readability”Footnote 1, respectively indentation “helps better convey the structure of a program to human readers”Footnote 2. The use of indentation is wide-spread and integrated in tutorials for popular programming languages such as JavaFootnote 3, C++Footnote 4, or PythonFootnote 5Footnote 6. Also, modern IDEs such as IntelliJ, Eclipse, and Visual Studio support to indent code automatically either while or after entering code.
While the support for indentation, along with the common arguments about its benefits, is widespread, one easily forgets to ask for its evidence, especially taking into account that indentation is quite an old technique (the first study by Weissman can be found in 1974 Weissman 1974). It turns out that up to 2022 indentation is far from being exhaustively studied, respectively, the evidence for the positive effect of indentation is far from being clear and conclusiveFootnote 7: while we found 12 experiments in the literature (in 9 publications) that use indentation as a controlled factor, only one of themFootnote 8 shows an effect and reports the effect size.Footnote 9 And in case one considers newer works as most important one needs to keep in mind that a study from 2019 concluded that “indentation is indeed simply a matter of task and style, and do[es] not provide support for program comprehension” (Bauer et al. 2019, p. 163).
The situation changed in 2023 where an experiment by Morzeck et al. measured a strong (p < .001) and large (\(.4< \eta _{p}^{2} < .79\)) effect of indentation (non-indented code took between 142% and 269% more time to read) Morzeck et al. (2023). Although this can be considered as the first documented evidence for the large effect of indentation, we still see the need for a more detailed study on indentation for the following reasons.
First, since previous experiments hardly measured any indentation effect, there is the need to replicate the experiment (especially when considering that one finds in the literature an experiment which – according to those authors – replicated a previous experiment with different results, see Bauer et al. 2019). Second, even the experiment in 2023 followed the tradition of experimentation where hand-chosen code snippets were given to participants (a statement that holds true for all indentation experiments known to the present authors). I.e., we see the need to check, whether the experiment’s results are potentially caused by such hand-selected code examples. Additionally, the question still remains, what causes the difference between readability of indented and non-indented code, i.e., it is unclear what the underlying theory for the differences between indented and non-indented code is.Footnote 10
We strongly agree with Burnett’s “firmly believe in the importance of using theories” Association for Computer Machinery (2016) and our perspective is that empirical studies should not only focus on the description of a phenomenon (such as “there is a difference in the readability of indented and non–indented code”) but should give a theory about what factors influence such phenomenon. Additionally, we think such a theory should provide testable and quantifiable statements. I.e., instead of running experiments that rely on some externally given source code (most experiments on indentation used code snippets from textbooks), respectively instead of running experiments with hand-selected source codes (which is also the case in the experiment by Morzeck et al. 2023) we think it is desirable to define the kind of source code to be used in experiments upfront.
The reason for this consideration is plausible: it is known that different language constructs have different effects on readability, respectively understandability (see, for example, Ajami et al. 2019; Hanenberg and Mehlhorn 2021; Mehlhorn and Hanenberg 2022 among others). Consequently, when different source codes are used with different languages and language constructs, the different constructs have an effect and as long as such constructs are not controlled (and their effect is unknown), their contribution to the result remains unclear. Second, hand-chosen examples potentially suffer from an experimenter’s bias, and it remains unclear how experimental results can be applied to other source codes, respectively, to what extent experiment results depend on special characteristics of hand-chosen examples.
The present paper introduces a controlled experiment with the main focus on indentation and its effect on readability. Readability is measured in terms of reaction times of participants when reading indented or non-indented code. In contrast to previous experiments, the present one defines a theory on the readability differences between indented and non-indented code upfront which is then used for the experimental design: Instead of relying on given source codes from textbooks, the present paper defines a formal model of programs consisting of conditional statements and defines a metric on the indented and non-indented representations of these programs.Footnote 11 By that, the model describes differences in readability between the indented and non-indented representation of a given program. Based on the variables provided by this theory, an experiment is defined and executed on 27 participants (undergraduate students, PhD students, and professionals).
The main result of the experiment is that the model’s predictions match the measured results: the difference between reading time (measured in terms of reaction time) of indented and non-indented code can be explained by the underlying model. I.e., while (under the experimental settings) the effect of indentation on readability is strong (p\( <.001\)) and large (on average factor 2 under the experimental conditions), this is just one aspect of the experiment. From our perspective, it is more important that the underlying model expresses how differences between the reading times of indented and non-indented code are influenced by the underlying code: such differences can be explained by the code that can be skipped for indented code but which needs to be read in non-indented code.
Nevertheless, while the experiment (which was a repeated N-of-1 experiment) was able to give evidence of the factor that influences the differences in reading times between indented and non-indented code, this was not detected on individual participants. Instead, this effect was only observed on the whole sample.
2 Indentation
In text-based programming languages the term indentation decribes rules for source code elements that receive additional space in terms of white spaces or tabs in the beginning of some lines. In programming languages such as Java, such rules typically express (in addition to some other rules) that after each opening brace a new line follows, and the following lines receive additional space in the beginning up to the line that contains the closing brace.

Indented and non–indented Java code
Figure 1 illustrates a simple Java program that prints out “Hello, world” 10 times. In the indented version, additional white spaces appear before the method definition (and its closing braces) as well as each method body. Within the method body, the body of the for loop gets additional white spaces. In the non-indented code, no additional space appears in front of each line of code.
Different indentation styles have different indentation sizes, where the most popular ones are probably that a new indentation level starts with additional 2 or 4 white spaces. Additionally, different code styles suggest to add line breaks before opening braces, etc.
While for a number of programming languages these formatting styles are not connected to the semantics of a program, such statement does not hold for languages such as, for example, Python (where indentation describes to which code block a statement belongs). I.e., there are languages where the use of indentation is not an optional way of formatting source code but a necessity required by the language semantics.
Indentation looks quite simple and clear and different coding styles in comparable languages (such as Java, C, C++, C#, etc.) do not differ much. But one should not forget that there are several languages where coding styles in general or indentation guidelines in particular are not as well-established as for example the relationship between braces and indentation in the programming language Java. As a simple example, indentation guidelines in the data selection language SQL are not that well-established. Such statement holds for other data selection languages such as XQuery, etc. as well. Furthermore, there are programming languages such as Smalltalk (Goldberg and Robson 1983) where indentation rules are typically different.Footnote 12 And finally, in block-based languages such as ScratchFootnote 13 indentation is not a matter of white spaces, but a matter of distances (pixels or other units).
As already stated, one often finds statements that indentation positively influences the readability of programs, i.e., it is commonly assumed (and taught) that developers benefit from indentation - although the empirical foundation for that statement is rather weak (except one recent experiment that revealed large differences).
3 Related Work
The present paper proposes a readability model to explain differences in readability between indented and non-indented code and gives empirical evidence for the validity of the model. Hence, we consider works on indentation as well as on readability models as related. Although there are works that address the role of readability in software development (there are studies that give some evidence that time spent in understanding code is probably larger than any other activity in development, see for example Murphy et al. 2006 or Minelli et al. 2015), we do not focus on these works here.
3.1 Indentation
A list of experiments with the controlled factor indentation was already described by (see Morzeck et al. 2023). Instead of describing previous experiments here, we just refer to Morzeck et al. for a detailed description of each experiment. However, we use that list of experiments and describe them here (including the experiment by Morzeck et al.) from a slightly different perspective.
Table 1 lists all experiments known to us (including the present one) and describes for each experiment the following characteristics:
-
1.
what tasks were given to participants,
-
2.
what design was used (from the perspective of how many variables were considered),
-
3.
what kind of code was used,
-
4.
what programming language was used,
-
5.
how many participants were used,
-
6.
how many data points were collected (i.e., the sum of all data points collected on all participants),
-
7.
whether an effect was detected, and
-
8.
whether an effect size was reported.
For some experiments, our summary is not completely satisfying, because details in the corresponding publications are missing. For example, Albayrak and Davenport (experiment 11 in Table 1) report that they used a Java program with about 100 LOC, but what exact program was used is not described by the authors.
Up to 2022, 12 experiments can be found in the literature that focus on indentation.Footnote 14 Four of them reported an effect of indentation, but only one of them reports an effect size. If we follow the minimum requirements of research standards such as CONSORT (Moher et al. 2010) or APA JARS (Appelbaum et al. 2018) which consider the reporting of effect sizes as a minimum requirement for quantitative studiesFootnote 15, one experiment (the one by Albayrak and Davenport – experiment 11 in Table 1) remains as an indicator for the possible positive effect of indentation. Actually, the experiment by Miara et al. (experiment 9 in Table 1) could be considered as well: although Miara et al. do not report effect sizes, the paper contains a graphical illustratation of differences in means. Although this kinds of report is not very precise, it is at least to a certain extent a report of an effect size. Consequently, we use a question mark for that study to highlight that some information is given with respect to the effect size.Footnote 16
However, according to Bauer et al. their experiment (experiment 12 in Table 1) is a replication of Miara et al. (experiment 9 in Table 1) – and it was not possible to replicate the results. If we accept this as a replication, there are good reasons for not considering the experiment by Miara et al. as evidence for the (positive) effect of indentation.
In 2023, the experiment by Morzeck et al. (experiment 13 in Table 1) suddenly revealed not only a strong (p \(< .001\)), but also a large positive effect of indentation (\(\eta _{p}^{2}\) = .832, non-indented code required between 142% and 269% – on average 179% – more time to read). Morzeck et al. gave 20 participants 12 hand-selected, artificial pieces of code consisting of if-statements and printouts and measured the time required to identify the correct result. Each if-condition referred to a local variable in the code and compared it to an (integer) literal. Additional factors in the experiment were the level of skipping (how much code could be jumped over in the indented code), the existence of braces, and the participants’ background. While the background and braces did influence the dependent variable, there were interaction effects between skipping and the measured time - which indicated that the more code can be skipped in the indented code (by navigating to the appropriate next line), the larger the difference between indented and non-indented code. However, the experiment had three treatments for skipping (non skippable, mixed, skippable) and these reported differences did not hold for the latter two treatments. I.e., although to a certain extent a first indicator was found that skipping code might cause differences between indented and non-indented code reading time, the experiment was not able to reveal an effect for the different kinds of skipping.
Taking the large difference to previous experiment results into account, we see the need to discuss how the experiment design by Morzeck et al. (2023) differered from previous results.
Actually, all previous experiments differed in many facets:
-
1.
the programming languages were different (PL/I, Algol, Fortan, Pascal, and Java),
-
2.
the number of variables in the experiment were different (from one variable – indentation – such as in the experiment by Albayrak and Davenport 2010, up to four variables by Morzeck et al. 2023),
-
3.
the number of participants were different (20 up to 88),
-
4.
the number of data points were different (32 up to 420),
-
5.
the kinds of tasks and measurements were different (self-rating of participants, filling missing code snippets, questions on code (quiz), bug finding, and output detection),
-
6.
and the kind of code was different (textbook examples, functional code chosen by experimenters, artificial code chosen by experimenters).
All of these differences can cause differences in the results. We think that a combination of these effects can explain why previous experiments were not able to reveal differences between indented and non-indented code: the chosen code, the number of selected data points in combination with the given tasks (and the corresponding dependent variable).
Most experiments used textbook examples, such as Quicksort (used by Weissman, experiments 1 and 2 in Table 1) or Hangman (used by Kesler et al., experiment 10 in Table 1). The reason why we think that such examples are problematic for experiments is that they imply some algorithmic difficulty. I.e., participants in such experiments did not only need to understand the structure of the code (which is emphasized by indentation), but also the meaning of the code (while this meaning is not obvious). In case the effect of understanding some difficult code is much larger than identifying code structures, this implies that the effect of indentation can be hidden.
This alone does not need to be a problem for the experiment, because it can be compensated by a large number of selected data points (which means in traditional A/B experiments a large number of participants); it is a well-known phenomenon that the number of data points has a strong effect on the results of experiments:
-
“If the effect is small but the sample size very large, the p value will be statistically significant. Similarly, if the effect size is large and the sample size small, the p value will also be significant. Thus, given a big enough sample, even trivial effects can be statistically significant”, Kühberger et al. (2015, pp. 2–3),
-
“[...] if the null hypothesis is not rejected, it usually is because the N is too small.” Nunnally (1960, p. 643)
There are five experiments (including the present one) with more than 200 data points and four of them (except the one by Norcio and Kerst, experiment 8 in Table 1) were able to reveal an effect of indentation.Footnote 17 We do not argue that 200 data points are some special barrier that needs to be passed in order to reveal an indentation effect (especially one needs to take into account the number of different independent variables in an experiment as well as the effect in each experiment). But we think it illustrates why the first experiment by Weissman with only 32 selected data points was probably not able to detect an effect sof indentation.
Next, all three experiments by Weissman used self-ratings as dependent variable and did not show an effect. It could mean (in addition to the problem that the number of data points in all three experiments was low) that self-ratings are potentially problematic measures for revealing differences between indented and non-indented code. The experiment by Morzeck at al. also used self-ratings (in addition to the dependent variable reading time) in terms of the standardized NASA–TLX (Hart and Sraveland 1988) as a dependent variable. And while the results of the TLX were mostly in line with the results of the time measurements, there were still some differences. We think this is an indicator that one should be careful with human ratings as primary dependent variables (since there are a number of experiments in psychology that reveal that human ratings can be easily influenced, see, for example, Woolfolk et al. 1983; Loftus and Pickrell 1995; Proffitt et al. 2003 among many others).
Hence, we think that the reasons why Morzeck et al. were able to reveal a large difference between indented and non-indented code were that no code with algorithmic complexity was used, a large number of data points was collected, and that a measurement was used that did not depend on self-ratings.
3.2 Factors that Influence Readability and Comprehension
The present experiment was designed by excluding several factors where we will argue that each of these factors represents a confounding factor. However, instead of simply stating that something is a confounding factor, there is the need to point out that evidence for this statement can be found in the literature. Therefore, we will subsequently mention several studies that show an effect of some factors. We do not describe these studies (nor their results) in detail, because for the present work it is only relevant that effects were detected.
Morzeck et al. used local variables and within the if-conditions operators were used that compared the values with literals. However, from our perspective the use of local variables is a confounding factor (that we intentionally removed in the present experiment). A number of experiments can be found in the literature that point out that identifiers have an effect on the readability and comprehensibility of code (see for example Lawrie et al. 2006): not only the length of identifiers (see for example Hofmeister et al. 2019), but also their syntactical style (see for example Binkley et al. 2009, 2013). Although all previously mentioned studies differ with respect to their experimental design (including dependent variables) and their measured effect sizes, they give strong evidence for the effect of identifiers. Next, even if someone argues that identifiers should be included in the code, a direct follow up question is whether the variables of these identifiers should be statically or dynamically typed – and again, there is strong evidence in the literature that static typing has an effect on code comprehension (see for example Endrikat et al. 2014; Fischer and Hanenberg 2015).Footnote 18 While the previous mentioned experiments documented a positive effect of static typing, there are circumstances as well where the existence of static type annotations can also reduce the readability of code: the experiment by Hanenberg et al. showed that lambda expressions with static types reduce the readability of code in a very specific setting (Hanenberg and Mehlhorn 2021).Footnote 19
With respect to Boolean expressions, there is a larger variety of studies that show that the representation of Boolean expressions has an effect on participants. For example, a more recent survey revealed that students consider code with different representations of Boolean expressions as more readable than others, especially when method calls are involved (see Wiese et al. 2022). Ajami et al. gave evidence that the size of a Boolean expression and the presence of negations influences comprehension of Boolean expressions (Ajami et al. 2019). The same work also shows that there are differences in understandability between if-statements and loops – which is an essential information for the present work because both language constructs have an effect on the control flow of programs.
In the same context, there is evidence that specific language constructs or their occurance in APIs have an effect on code comprehension (see for example Uesbeck et al. 2016; Mehlhorn and Hanenberg 2022 among many others). Even the choice of keywords in programming languages have possibly an effect on comprehension – at least the intuitiveness of keywords has been tested and differences were detected (see Stefik and Siebert 2013; Lappi et al. 2023). And on a more coarse-grained level, not only specific language constructs, but whole languages have measureable effects on developers – at least there are indicators that some languages have a stronger tendency towards error-proneness than others (see Ray et al. 2014, 2017; Berger et al. 2019) which could be an indicator for differences in comprehensibility of code written in different languages.Footnote 20
3.3 Readability Models
Buse and Weimer presented a readability model (Buse and Weimer 2010) based on a machine learning approach which used subjective ratings of 120 human raters (each rates a source code’s readability on a 5-point Likert scale). The model consisted of 19 different features such as identifiers, identifier length, comments, assignments, etc. – indentation was also contained in the model. It turned out (based on a comparison Spearman’s rank correlation) that the model predicted the readability of code better than the average human rater (.71 in comparison to .55) and eight features were already able to explain 95% of the variance. However, according to the model, indentation correlated negatively with the readability, i.e., according to the model, the more indented the code is, the less readable is it – a result that at first glance looks like a contradiction to the here presented results. We still think that this negative correlation is caused by something else: the deeper nested code is, the harder it is to understand code. But in that case this does not mean that removing indentation would simplify code, because independent of whether or not the nesting is visualized by indentation, the nesting (and hence the code’s difficulty) remains.
Based on the work by Buse and Weimer, other readability models were created, whose technical approaches were comparable to Buse and Weimar (i.e., the use of machine learning approaches based on a manually generated training set). Scalabrino et al. (2016, 2018) introduced additional features that rely on textual characteristics such as the relationships between comments and identifiers and showed that the resulting model achieved a higher accuracy than the one by Buse et al.
Interestingly, the work by Buse and Weimar also showed that the resulting readability model hardly correlates with traditional software metrics such as cyclomatic complexity (see McCabe 1976) and emphasized that method length correlated much stronger with cyclomatic complexity.
4 Differences Between the Present Study and Existing Studies
As described in Section 3.1, we are aware of 13 studies that used indentation as a controlled factor. The present study uses indentation as a controlled factor as well. Still, it differs from most of the previous studies in a number of ways.
As already discussed, we think that the combination of algorithmic complexity in the code snippets, a too small number of data points, and the use of self-ratings was the reason why most studies did not find an effect of indentation. From our perspective, the study by Morzeck et al. already reduced these problems by using nested if-statements (in order to reduce the algorithmic complexity), a larger number of data points (240 collected data points distributed over 20 participants), and using time to completion, i.e. the time a participant required to give the correct answer, as a dependent variable (which is not based on self-ratings). However, we still see weaknesses in the study by Morzeck et al.
We see a weakness in the measurement. Morzeck et al. measured the time until the correct answer was given, i.e. time to completion was used an as approximator for reading time. This implies that in case an error was done, the participant has to think about potential reasons for this error – and the participant potentially repeats the whole task. In case a participant makes an error – and there might be multiple reasons why the participant makes an error (which might not only depend on the code representation alone) – the participant has to receive the feedback and find strategies to handle it. Our subjective impression was, that there are participants who repeat the whole task. Other participants started to guess what the answer is (in case there were branches where it was unclear to them whether or not they were executed). The problem is that the resulting measurement does not reflect on those different strategies – and also contains the time when the participant is just wondering why his answer was not correct. To reduce this problem, we changed the measurement in the present experiment: instead of measuring the time until a correct answer was given (time to completion), we measure the time a participant required to give an answer (reaction time). I.e., in the present work the reaction time is used as an approximator for the reading time. To ease the reading of the paper, we only make a distinction between the terms reaction time and reading time in the analysis section of the paper (to make the actual measurement explicit).
Another weakness is the code itself. Morzeck et al. had one characteristic in common with all previous studies: the code was hand-selected, i.e., the researchers chose pieces of code to be used in the experiment upfront. Although the degrees of freedom in the code is less than in other experiments (if-statements instead of textbook examples), the degree of freedom is still high. For example, what identifiers should be used or what operators in the Boolean expressions should be used is not prescribed – and it is known that both have an effect. In case someone replicates the experiment with some changes in the code and receives different results, it remains unclear whether such differences would be caused by the changes in the code. In other words, what is missing in the experiment is a precise model that describes what kind of code is tested in the experiment. To overcome this problem, we introduce in the present study a formal model for this code.
Additionally, we see a problem in the explanation of possible influencing factors on indentation. Morzeck et al. tried to explain the differences between the measured times with the code that can be skipped over. The idea was that the more code can be skipped, the larger is the difference between the time measurements. However, what can be considered as code to be skipped is relatively vague in the description by Morzeck et al. And, again, the code was hand-chosen. Again, there is the problem for possible replications to check whether or not some code can be considered as skippable or partially skippable code.
To overcome this problem, the present work introduces a formal model to describe the differences in readability between indented and non-indented code. Consequently, this model can be used to generate further code that can be used in replications and one can clearly test whether (or not) the model holds. This model only makes use of return statements and nested if-statements, where the conditions in the if-statements are just Boolean literals. The reason for reducing the model to these constructs lies in the previously described influence of different constructs on readability in general (see Section 3.2).
Finally – which is interesting from a practical perspective –we designed the experiment that tests the formal model as an N-of-1 experiment. Such kind of experiments can be executed on a single participant, i.e., it gives a single person the ability to rerun the study. However, we need to point out again that the second parameter of the experiment – which explains the differences between the measurements for indented and non-indented code – is only singnificant for the whole sample. I.e., although the N-of-1 experiment permits individuals (with relatively small effort) to experience the effect of indentation, it does not permit each individual to experience the effect of the parameter that controls the difference between indented and non-indented code.
5 Readability Model for Indented and Non-Indented Code
5.1 Discussion of Possible Effects of Indentation
While it is commonly assumed that indentation has a positive effect on readability (see for example the citations in the introduction), it is often not clearly articulated what exactly the effect should be or under what circumstances such an effect is assumed. However, in order to come up with a formal model that describes readability differences in indented and non-indented code, there is the need to discuss under what circumstances it is plausible that indentation has an effect – and under what circumstances it is plausible that indentation has no effect.Footnote 21
First, the effect of indentation probably depends on the kind of task given to developers. If a developer’s task is to count the number of lines of code or to count the number of classes and methods, indentation probably has a small or no effect. Likewise, if developers are asked to identify lines of code because of certain syntactical representation of that line (such as how often the phrase System.out.print can be found in a program), indentation has (probably) no effect.

Indented and non-indented Java code where the effect of indentation is probably large. Details are omitted (...) or abbreviated (print) to ease the presentation of the code
We think the situation is different for the code in Fig. 2 – as long as developers are asked “an appropriate” question. Asking what the program prints out when started with the parameter 8 probably reveals a large difference between the indented and non-indented code. Once developers are aware that i represents the parameter, and once they conclude that the first condition i>10 does not hold, they need to jump into the else branch of the first condition: While the identification of the else branch seems quite easy for the indented code, this is not the case for the non-indented code.
However, when asking what is printed out when started with the parameter 40 probably will not reveal larger differences between indented and non-indented code for the following reason: in both cases the program can be read from top to bottom without jumping over some lines. I.e., no matter whether or not the code is indented, the developer reads all lines up to line 8 and then gives the answer.
Based on the previous example, we think that indentation has a large effect, if some control flow in the code needs to be followed and where branches in the control flow can be skipped. Consequently, designing a model for the effect of indentation requires to consider language constructs that influence the control flow. However, one should not forget that different language constructs that influence the control flow have different difficulties. For example, if-statements and while-loops both permit to skip some parts of the code but a study by Ajami et al. gave first evidence that both constructs differ in terms of understandability (Ajami et al. 2019). The choice of the identifiers has an effect as well (see for example Lawrie et al. 2006; Binkley et al. 2009; Hofmeister et al. 2019) and it is plausible to assume that the position of identifiers in the program code has an effect on readability as well. When speaking about conditions (as they appear in if-statements we well as in loops) different Boolean expressions have different difficulties for readers as well (see Ajami et al. 2019).
5.2 Used Language in the Experiment
From the perspective of controlled experiments, the previously mentioned points (language constructs, identifier, identifier position, complexity of Boolean expressions) represent confounding factors, i.e., factors whose influence should be reduced as much as possible because they (potentially) cause deviations in an experiment. Furthermore, one needs to keep in mind (from the perspective of generalizability) that different programming languages do not necessarily provide the same language constructs that influence a program’s control flow.
Because of that, we think it is desirable (in order to reduce confounding factors) to reduce programs to very few of such language constructs. In our case, we decided to use only if-statements. To reduce the problem of identifiers, we waived the use of identifiers and used only literals instead. In order to reduce the problem of complexity of Boolean expressions, we decided not to use composed Boolean expressions. I.e., in the given experiment a program only consists of if-statements that do have a then- and else- branch where the Boolean expression in the condition is a Boolean literal (true or false). Inside a then- or else- branch only if-statements or return expressions appear where a return just returns an integer literal.

Kind of source code used in the experiment
Figure 3 illustrates the kind of source code that we used in the experiment. For such code, developers will be asked what the result of the code is. I.e., we reduce a program to an if-statement where the condition is either the literal true or false and where the body of each branch either consists of an if-statement or a return statement. The return statement just returns an integer literal to check whether a developer gives a correct answer to the question.
5.3 Formalized Model
Since the goal is to study the effect of indentation in a controlled way, there is the need to express what controlled means from the perspective of indentation and from the perspective of readability. In order to do so, we define the language used in the experiment and based on that we define a readability metric for indented and non-indented code.
Our model is based on a recursive data structure that represents an if-statement. Figure 4 describes the data structure as a context free grammar with a single production rule ifExpr and the terminal symbols if, true, false, else, and return.Footnote 22 The semantics of the language reduces an expression after finite steps to an integer literal (which is the returned value).

Syntax definition of language L, its semantics and readability functions read\(_{I}\), read\(_{NI}\), and diff
Based on the grammar, we define two different readability functions read\(_{I}\) (for indented code) and read\(_{NI}\) (for non–indented code) that operate on words of the language.
The function read\(_{I}\) defines that the if-condition needs to be read. In case the if-condition is fulfilled (if true), the if-statement needs to be read (+1) and the then-branch needs to be read. If the if-condition is not fulfilled (if false) the developer still needs to read the if-condition (+1) and jumps to else (+1) whose body needs to be read. After finite steps, a return is reached that needs to be read (+1).
The readability function read\(_{NI}\) is the readability model for non-indented code. In case the if-condition is fulfilled (if true), the condition needs to be read (+1) and the then-part needs to be read. This part of the function is the same as for read\(_{I}\). The result is different if the if-condition is not fulfilled (if false). In such situation the condition (+1), the else (+1), and the else-branch needs to be read. But additionally, the then-branch influences the result: for all if-statements in the then-branch two elements (if and else) need to be read in addition to their then- and else- branches (while their returns can be skipped).
The resulting numbers from the functions describe a readability index for the indented or non-indented code. Consequently, the function diff describes the readability differences between the indented and non-indented code. However, without any empirical evaluation it is unclear whether this formal model matches an observable phenomenon, i.e., actual measured differences between indented and non-indentedcode.
Table 2 illustrates an application of the model to Java code, i.e., additional literals such as {, }, and ; are considered. Applying each code example to the readability model leads to read\(_{I}\) = 4. Differences to read\(_{NI}\)(t) are caused by the outermost if-statement’s then-branch. While read\(_{I}\) ignores this branch, read\(_{NI}\) counts in this branch the number of then- and else-branches.
5.4 Implications and Interpretations
The goal of the proposed model is not to describe a complete (i.e., Turing complete) programming language. The model is just intended to make statements about nested if-statements. Additionally, the model does not take into account that there are sequences of statements. For example, the model does not take into account that two if-statements follow one another. And furthermore, the model gives expressions concrete values. For example, for indented as well as for non-indented code reading a return statement has the weight 1 and, in that way, has the same weight as reading an if-condition, or the else clause.
If we compare read\(_{I}\) and read\(_{NI}\), we see that under no circumstance for a given if-statement i the statement read\(_{NI}\)(i) < read\(_{I}\)(i) holds. Both values are only equal for a given term if either the topmost if-statement and all following if-statements in then-branches have the form iftruet else e, or if all then-branches that can be skipped just consist of return statements.
Actually, the proposed model reflects on a possible way how developers read a nested if-statement. It assumes that developers read the code from top to bottom.Footnote 23 As a consequence, both readability functions assume that one does not read any statement or expression following the actual return of a statement. While it is plausible to us that most developers will do that, we are aware that a developer’s reading strategy could be different.
For example, the code in Fig. 2 could be read in a different way. Instead of trying to find out what branches need to be skipped (reading from top to bottom), one could also try to find out from the bottom of the code where the else-branch starts. In such a case, one would rather first determine the inner if-statements in the top-most statement’s else-branch before recognizing that the inner if-statements is required as well.
Next, the model does not take into account that for example the identification of Boolean literals for a reader requires a different time than the identification of other literals (such as the keyword if or else). We are aware that keywords themselves have an effect on the understandability of code (see for example Stefik and Siebert 2013), but so far we are not aware of how large such (possible) differences are with respect to reading time.
6 Experiment Description
Again, so far the described languages and the resulting readability model is just the result of some plausible considerations. I.e., whether or not it has something to do with the reality cannot just be determined from the model. Instead, there is the need to test the model using empirical methods. And given that the model clearly describes the elements to be studied, the application of a controlled experiment seems appropriate.
6.1 Initial Considerations
The goal is to design a controlled experiment where code snippets (i.e. words of the proposed language) are shown to participants. But while it is relatively obvious for some variables how they can be controlled, it is not obvious for others.
The goal is to measure the reading time and we use the reaction time, i.e., the time a participant required to answer a question (independent of whether the result is correct) as an approximator for the reading time (this corresponds to, for example, the measurement performed in other experiments such as Hanenberg and Mehlhorn 2021). Additionally, we measure whether the answer given by the participant was correct.
However, there is the need to discuss what other factors should be controlled in the experiment.
Tasks
We already discussed tasks that could be given to developers in the previous section. However, while tasks such as asking for the lines of code or asking for the number of methods is a purely structural task (where the code does not have to be comprehended), we think that – considering that we concentrate on the control flow of programs – asking for the result of the program is reasonable. I.e., we can simply ask for programs such as the one given in Fig. 2 what the output of the program is. Such tasks also have the benefit that articulating the output is quite trivial and does not require any complex explanations by participants.
Code Format (Part I)
While the proposed language could be applied to different languagesFootnote 24, we still need to define what concrete language should be used. Languages can vary with respect to the concrete syntax (condition with or without brackets, optional brackets for the body of then- and else clauses, etc.). We decided to use Java’s syntax (which matches with respect to the if syntax other languages such as C, C++, C#, etc.).
Code Format (Part II)
A first (and rather obvious) factor is the use of new lines in the code, respectively the used code format. We decided that the code to be shown should contain opening and closing brackets for all if-statements independent of whether the then or else branch has more than one line of code.Footnote 25 An opening bracket is always in the same line as the corresponding if-statement. The else-branch consists of a closing bracket, the keyword else and an opening bracket. All brackets are followed by a new line. I.e., the code in Fig. 3 and Table 2 are illustrations of the code used in the experiment (but with less lines of code).
Lines of Code
Another rather obvious idea is to fix the lines of code. Actually, we do not think that the lines of code are an important issue for the distinction of indented and non-indented code: our readability model in Section 5 is based on the lines that have to be read (for indented code). However, a larger number of code lines can have other implications such as scrolling, etc. which is a confounding factor for the experiment. In order to get rid of potential effects caused by lines of code, we fixed the lines of code in the experiment to 29 LOC which corresponds to seven nested if-statements.Footnote 26
Syntax Highlighting
Actually, it is unclear whether or not syntax highlighting has a measurable effect (see, for example, Hannebauer et al. 2018) and even if it has, it is unclear whether it influences the result in an undesired way. However, in order to remove this potential threat, we decided to use no syntax highlighting in the experiment.
Integer Literals
Since the reaction time is used as a dependent variable (in addition to correctness), there is the need to check whether the participant identified the correct result. However, we are aware that the identification of the correct return statement is rather a matter of seconds – and in case the interaction between the experiment environment and the participant is too complex, there is the risk that the interaction hides the main effects. Due to this, the model already used integer literals in its language definition. If furthermore integer literals with single digits are used, participants can already put their fingers on the keyboard in the right position at the beginning of the experiment, which reduces the time for searching for the right keys on the keyboard.
Controlled Variation of Main Factors
The critical part for the experiment design is what and how independent variables should be chosen. Obviously, the goal is to compare the reading time required for indented code with the reading time required for non-indented code. But the formal model from Section 5.3 assumes that indented and non-indented code have different readability models: the assumption is that reading indented code just requires to read the necessary parts while the assumption for non-indented code is that all parts need to be read. Under the assumption that the model is correct, this means that differences in readability are not only a matter of whether or not the code is indented: it is also a matter of the code itself, i.e., what branches the code consists of and how they need to be followed (for the indented code). A first idea seems to be to use read\(_{NI}\) and read \(_{I}\) as independent variables. However, as explained in Section 5.4, the statement read\(_{NI}\)(t) \(\geqq \) read\(_{I}\)(t) holds for all if statements. I.e., it is not possible to combine arbitrary treatments of read\(_{NI}\) and read\(_{I}\). But it is possible to combine different treatments of read\(_{I}\) with different treatments of diff: the combination of read\(_{I}\) and diff determines read\(_{NI}\). Hence, we can choose read\(_{I}\) and diff independent of each other.Footnote 27 We decided to choose three different treatments for diff (0, 2, and 4) and three different treatments for read\(_{I}\) as well (4, 6, and 8). Hence, if we combine those treatment combinations with the factor technique (i.e. indented and non-indented), it gives a fair comparison with respect to indentation and the assumed readability model.
Between Subject / Crossover /
N-of-1 A typical design decision for experiments is to what extent treatment combinations should be tested on the same participant. Between subject experiments do not test different treatment combinations on different participants while crossover experiments vary treatment combinations on participants to some extent. N-of-1 trials give all participants all treatment combinations and permit to study the effect not only on all participants (if repeated on multiple participants) but on single participants as well (see Hanenberg and Mehlhorn 2021). Considering that asking for the result of a nested if-statement is rather a matter of seconds, and taking into account that variations between participants might be high, we decided to execute the experiment as an N-of-1 experiment with a fixed number of repetitions per treatment combination. In order to reduce possible period effects (see Hanenberg and Mehlhorn 2021; Kitchenham et al. 2003; Madeyski and Kitchenmam 2018), we tested possible unbalanced occurences of treatment combinations upfront following the approach proposed by Hanenberg and Mehlhorn (see Hanenberg and Mehlhorn 2021, pp. 20-22).
Kinds of Participants
We are aware of the long-lasting discussions about the possibility that different kinds of participants with different experience will lead to different results in experiments (see for example Höst et al. 2000; Svahnberg et al. 2008; Feigenspan et al. 2012; Siegmund et al. 2014; Feitelson 2015, 2022 among many others). Because of that, we decided to run the experiment on participants with different backgrounds. More precisely, we recruited undergraduate students, PhD students, and professionals as participants.
6.2 Experiment Layout
Following the previous discussion, the experiment was designed as a crossover experimentFootnote 28 where each participant receives 90 randomly generated code snippets. The experiment layout consists of the following parameters:
-
Dependent variables:
-
reaction time: The time until the participant responds to the question. This variable serves as an approximator of the reading time.
-
correctness: Whether the response was correct.
-
-
Independent variables:
-
indentation: The representation of the code with the two treatments indented and non-indented code. Indented code has four whitespaces for each level of indentation.
-
read \(_{I}\): The read\(_{I}\) value of the previously described readability model for indented code with three treatments (4, 6, and 8).
-
diff: The difference read\(_{NI}\) - read\(_{I}\) with three treatments (0, 2, and 4).
-
background: Three treatments (undergraduate students, PhD students, professionals).
-
-
Fixed variables:
-
given code: Java code consisting of 7 nested if-else-statements where each then/else-branch consists either of an if-statement or a return statement (29 lines of code).
-
code snippets: Initially randomly generated code snippets, each participant received the same snippets.
-
repetitions: For each participant, the experiment repeated each treatment combination of the independent variables indentation, read\(_{I}\), and diff fives times, i.e., in total all participants received 90 code snippets.
-
ordering: All participants received the same snippets in the same order.
-
-
Task: “What is the return value (single digit) of the given code?”
Taking the large number of variables and interactions into account, there are several hypotheses that can be tested that we do not explicitly write down here for presentation reasons. Still, it is obvious that we test whether the independent variables influence the dependent variables. However, considering that the goal of the present paper is to describe what causes the difference between indented and non-indented code, we especially focus on the interaction indentation*diff: we assume that an increase of diff increases the differences in the reaction times between indented and non-indented code.
6.3 Code Generation
The experiment is executed by an application that shows the code snippets to the participants and collects the data. The application also creates all possible statements consisting of seven nested if-conditions.
Since an if-condition can be represented as a binary tree (a node with two branches where we ignore the condition of the if-statement for a moment), and since the number of possible binary trees with n nodes can be computed by the Catalan number \(C_{n}=\frac{(2n)!}{(n+1)!n!}\)Footnote 29, there are \(C_{7}=429\) different statements consisting of 7 nested if-statement. Since each if-statement contains a Boolean condition, the number of possible true/false combinations for 7 if-statements is \(2^{7}=128\). I.e., there are \(C_{7}*2^{7}=429*128=54,912\) possible if-statements.
-
1.
The code generator generates all 54,912 if-statements and computes for each statement its read\(_{I}\) and read\(_{NI}\).
-
2.
Then, every statement s is kept where read\(_{I}\)(s)\(\,\epsilon \,\){4, 6, 8} and diff(s) \(\,\epsilon \,\){0, 2, 4}.
-
3.
Then, for each treatment combination five random statements are selected.
-
4.
Afterwards, all return statements contained in each statement receive a randomly chosen value between 1 and 9.
-
5.
The resulting 45 statements are used in the experiment with indentation.
-
6.
The steps 2–5 are repeated again and the resulting statements are used in the experiment without indentation.
-
7.
Finally, a sequence is generated from both sets of statements (indented and non-indented) and the sequence is randomly ordered.
The experiment used a seeded random number generator for generating the code (and doing the random ordering). I.e., for all participants, the experiment is the same (same tasks in the same order). The seed used in the experiment is not known to the participants.
The code for the training phase is generated in the same way as described above. The difference is, that participants were asked to enter a seed for the random generator manually. Since the input value is an integer, the chance is low that participants accidentally chose the seed used for the experiment.
6.4 Experiment Protocol
The experiment’s application was delivered to the participants and they executed it on their own machine. The participants were advised to use a 1920x1080 display resolution.
Participants were advised to train themselves using the given application. In order to start training, they had to enter a seed (which was used to generate the code). Afterwards, a training session started. The participants were told that they can stop training whenever they feel trained enough and that they can repeat the training as often as they like in case they do not feel trained enough.
In order to start the experiment, participants had to start the application without entering a seed (in that case, a predefined seed – not known to the participants – was used for the code generation).
The participants were permitted to take breaks between tasks – and they were explicitly told that they should take a short break in case they think it is required.
After the experiment, a csv-file was generated and the participants were asked to send it to the experimenter.
6.5 Measurements
The time measurement used in the experiment is the reaction time, i.e., the time starting from the moment code is shown to the participant until the moment when the participant pressed a key. This measurement is used as an approximator for the reading time. After a response is given, the tool shows the correct answer for the given task and tells the participant that the next code snippet will be shown after pressing a button. The time in between (when the correct answer is shown and the participant presses a button in order to get to the next ask) is not part of the measurement (but participants can use this time for a break).
An additional measurement is the correctness of the response. Therefore, we measured the answer given by the participant and compared it with the expected answer. In case, both are the same, the answer is considered correct, otherwise incorrect. Although one might argue that some answers are “more incorrect than others” (if, for example, the return of the first branch was expected, but the return of the last branch was provided), we do not make a more fine-grained distinction.
The experiment neither measured whether the participants took breaks, nor how many training tasks were done before the experiment.
The measurements were automatically done by the application provided to each participant.
6.6 Initial Testing of the Experiment Setup and Execution
In order to reduce potential carry-over effects, there is the need to test whether the treatment combinations were unbalanced in the experiment, i.e. whether certain treatment combinations occur more often than others in the beginning or the end of the experiment. Thereto, we followed the approach proposed by Hanenberg and Mehlhorn (see Hanenberg and Mehlhorn 2021, pp. 20-22) and checked the dependent variable task number (1-90) with the independent variables indentation, read\(_{I}\), and diff. None of the variables revealed a significant effect, nor did any interaction show a significant effect.Footnote 30
The experiment was executed on 27 volunteers in 2022 – 9 undergraduate computer science students (4th semester and above, age 21-26), 9 professional developers (age 26-39), and 9 PhD students (age 25-32). All participants were chosen based on purposive sampling (Patton 2014).
One participant (PhD student) was removed from the sample during the data collection phase, because this participant just repeated the training session (instead of doing the experiment). We found a different participant in order to have an equal number of participants for each background.

Interaction diagrams indentation*diff and indentation*background
6.7 Analysis
Again, the data on the reaction time was analyzed using an ANOVA, the number of errors were analyzed using a \(\chi { ^2}\) test (each using SPSS v27). The results are shown in Table 3.
With respect to the main dependent variable reaction time, all main factors indentation, read\(_{I}\), and diff were significant (with p < .001) and the interaction technique*diff (p < .001) was significant as well (in addition to the interactions indentation*read\(_{I}\) and indentation*background). Except of the variable background (that is described in more detail later on), all variables had an effect as expected: an increase of read\(_{I}\) or diff led to higher reaction times, and the effect of indentation was large: \(\frac{M_{Non-Indented}}{M_{Indented}}\) = 2.13, i.e., on average participants required 113% more time without indentation than with indentation.
Since the experiment mainly focuses on the interaction indentation*diff, we take a closer look into it. Figure 5 illustrates the interaction. An increase of diff leads to an increase of the reaction times in the non-indented as well as in the indented code. But the larger diff, the larger the differences of measured times between indented and non-indented code: for diff = 0 the ratio of means is \(\frac{M_{non-indented}}{M_{indented}}=1.75\), for diff = 2 it is \(\frac{M_{non-indented}}{M_{indented}}=2.10\), and for diff = 4 the ratio of means is \(\frac{M_{non-indented}}{M_{indented}}=2.45\). For diff = 0 the difference between indented and non-indented code is significant.Footnote 31
With respect to the variable background, it turned out that undergraduate students were the fastest in the experiment, followed by professionals, followed by PhD students. While their differences with respect to indented code was not large, their differences with respect to non-indented code was noteworthy (see Fig. 5): professionals required 22% more time than students (\(\frac{M_{professional_{non-indented}}}{M_{student_{non-indented}}}\) = 1.22), PhD students required 54% more time than students (\(\frac{M_{PhD\,student _{non-indented}}}{M_{student_{non-indented}}}\) = 1.54).
With respect to the dependent variable number of errors, all groups (undergraduate students, PhD students, professionals) made approximately the same number of errors (no significant difference in the \(\chi { ^2}\)-Test on errors and background). But these errors occurred (according to the \(\chi { ^2}\)-Test) with 17% significantly more often in non-indented code (\(\frac{\#Errors_{non-indented}}{N_{non-indented}}\) = .17) than in indented code (\(\frac{\#Errors_{indented}}{N_{indented}}\) = 3%), i.e., the number of errors in non-indented code is about 5.67 times higher than in indented code (\(\frac{\#Errors_{indented}}{\#Errors_{non-indented}}\) = 5.67). Table 4 illustrates (in addition to the \(\chi { ^2}\)-Test) the absolute number of errors for each background group. It turns out that the professionals had the lowest number of errors for indented code (less than 50% of the other groups) but they had the highest number of errors in non-indented code (more than 10% higher than the other groups). This difference is significant (but the evidence is not very strong with p = .04).
6.8 Analysis Per Participant
The experiment design follows the principle of an N-of-1 experiment where all participants receive a large number of code snippets with all treatment combinations which (in principle) permits to observe the same effects on individual participants. I.e., while the previous analysis was done on the whole sample, we repeat the previous analysis on each individual participant.Footnote 32
Table 5 describes the results for each individual participant. All participants were reactive to the variable indentation (<.001 for all participants). However, only a minority of these participants showed an effect on the interaction indentation*diff (see Table 6): 4/9 students, 3/9 professionals, and 6/9 PhD students. While for a number of participants it looks like that an increase of tasks would have revealed an interaction effect (such as for participant p7 whose interaction effect is p = .075), there are other subjects where even a larger increase of tasks probably would not have shown such an effect (such as for p4 whose interaction effect is with p = .738 non-significant). Furthermore, it is noteworthy how different the ratios \(\frac{M_{Non-Indented}}{M_{Indented}}\) are for the participants. While for some participants non-indented code required just about 50% more time (such as for the participants s5 and p4), there are others where it took more than 2 times longer to respond to the non-indented code (such as for participant p9).
6.9 Discussion So Far
So far, the experiment confirmed the large effect of indentation originally detected by Morzeck et al.: Morzeck et al. found that non-indented code took on average 179% more time to read, while in the present experiment it took on average 113% more time to read for non-indented code. Although one might argue that the differences between both experiments are quite large, one has to emphasize that the present experiment has additional controlled factors that the previous experiment by Morzeck et al. did not have.
Additionally, the present experiment had less lines of code (29 compared to 49) – and the results of the present experiment gives evidence that such difference in lines of code (which leads potentially to a larger number of lines of code that can be skipped) can increase the differences in means. And finally, one has to point out that the dependent variable used by Morzeck et al. was different to the variable applied here: Morzeck at al. used time to completion as an approximator for the reading time while the present experiment used reaction time (in addition to the dependent variable number of errors). We intentionally changed the dependent variable, because from our perspective time to completion is (in case of an error) a penalty for the non-indented group. Hence, from our perspective, despite the differences in mean differences (113% vs. 179%) the present experiment confirms the large effect of indentation: it is clear that from the readability perspective indentation is not just a matter of small percentages in comparison to non-indented code.
The goal of the present experiment was to go one step further. Instead of just measuring whether or not indentation has an effect, the goal was to determine what causes this effect. In other words: what other variables influence the difference between indented and non-indented code. Thereto, the present experiment started with a formal model that speculated on these differences. From this model the experiment (respectively the corresponding treatment combinations) were derived. The model assigned a readability score to a nested if-term and the function diff defined the difference between the indented and non-indented code. The experiment used different readability scores and their differences as independent variables (in addition to indentation and the participants’ background). And it turned out that the proposed diff metric was able to control the differences in the time measurements: linearly increasing the variable diff linearly increased difference in reaction times for indented and non-indented code.
However, three results of the experiment remain unsatisfying.
Background
First, the participant’s background had a rather surprising effect on the dependent variables. First, we expected that undergraduate students (who are probably not so familiar with reading code) would perform worst, followed by PhD students, followed by professional developers. However, it turned out that undergraduate students were the fastest, followed by professionals, followed by PhD students. With respect to the number of errors it turned out that undergraduate students and PhD student did a comparable number of errors (reading indented as well as non-indented code), but the professionals did less errors on the indented code, but more on the non-indented code. We think, there are multiple possible explanations for that (whose validity cannot be determined from the data). Possibly, professional developers are better in reading indented code (although it took them more time than students, they did less errors), but are just annoyed by non-indented code. It also could just mean that people who are less familiar with reading code (undergraduate students or PhD students) are more familiar with reading non-indented code (because these groups might be more often confronted with such kind of code).
Observations on Single Participants
Although the experiment was able to control the differences in reading time between indented and non-indented code on the whole sample, it turned out that only a subset of participants reacted on that model: only 13/27 participants revealed the interaction effect between indentation and diff. A closer look into each individual’s data seems to indicate that the sample size on each participant, i.e., 90 code snippets, was not sufficient – at least a number of participants revealed p-values that suggest that an increase of the code snippets per participant would reveal the same effect. However, there are participants (such as s8 and p4) who not even showed a tendency towards this interaction. Hence, we cannot exclude that there are participants for whom the interaction does not exist.
Restriction of the Model on diff = 0
The variable diff is intended to explain the differences between reading time of indented and non-indented code. While an increase of this variable led to an increase of this difference, there is one situation where the model does not fit the observed data, namely when diff = 0. In such case, the model assumes that there is no difference between the reading time of indented and non-indented code, but for diff = 0, there is still a noteworthy difference between the reading times: even in this situation the non-indented code required 75% more reading time (\(\frac{M_{non-indented_{diff=0}}}{M_{indentedt_{diff=0}}}=\frac{8.08}{4.62}=1.75\)). Consequently, while the proposed model explains differences quite well, it does not describe the situation well when (according to the model) there is no difference.
Hence, one can summarize that the model works well to explain differences in reaction time between indented and non-indented code, but there are still differences in situations where the model assumes that there are none.
7 Exploratory Analyses: Ad-hoc Modifications of the Model
The proposed model did not accurately explain the situation where diff = 0. While one could argue that it is simply up to future work to address this issue, we think that the underlying data set provides the ability to go one step further by changing the underlying model and compare it with the measurements. I.e., based on the observations, we perform an ad-hoc modification of the underlying model as an exploratory analysis and compare the modified model with the results.

Ad-hoc modification – read\(_{NI_{Ex1}}\), and diff\(_{Ex}\) and number of cases of diff\(_{\textbf {Ex}}\) in the sample
We see a possible reason for the differences at diff = 0 that non-indented readers still need to read the return statement (from which we originally assumed that it would be just skipped). If this is the case, there is the need to refine the original function read\(_{NI}\) – we call the new function read\(_{NI_{Ex}}\). Figure 6 illustrates the resulting function definition read\(_{{NI}_{Ex}}\).

Interaction diagrams indentation*diff\(_{\textbf {Ex}}\)
Considering the fact that we already have 90 treatment combinations, it is plausible to apply the new model to the existing data. However, the result is no longer a controlled experiment, because not all treatment combinations were randomly generated, and consequently not all treatment combinations are equally often contained in the experiment.
Figure 6 also contains how often each value of diff\(_{Ex}\) appeared in the sample of 90 tasks. For two combinations (diff\(_{Ex}\) = 3 and diff\(_{Ex}\) = 9) only few cases are contained and for diff = 8 there is no single case in the sample. Consequently, we remove them in the following analysis.
Table 7 contains the exploratory analysis of the ad-hoc modification. It turns out, that the results are comparable to the original study, except that the interaction i*read\(_{I}\) is no longer significant. Since the exploratory study was mainly motivated by the interaction effect of indentation and diff, we take a closer look into the interaction indentation*diff\(_{Ex}\) (see Fig. 7).
It turns out that the original problem – differences in indented and non-indented code for diff = 0 – is no longer present for diff\(_{Ex}\).Footnote 33 Again, the differences between indented and non-indented code become larger the higher the value for diff\(_{Ex}\). However, we also see an increase of the reaction time for the indented code: while for diff = 0 the time measurements of indented code are on average far below 5 seconds, they are on average far above 5 seconds for diff = 7.
8 Threats to Validity
External Validity - Artificial Code
The proposed model and reported experiment were intentionally designed to control factors as much as possible. Thereto, the code shown to the participants was completely generated and highly artificial. More precisely, the code just consisted of seven nested if-statements and return statements where the condition of each if-statement is a Boolean literal. This code is obviously no industrial code and we assume that effects on other code would be different. We assume that industrial code contains many more confounding factors that probably reduce the effect of indentation (and maybe even hide the effect of indentation).
Internal Validity and External Validity – Dead Code
The code in the experiment intentionally used Boolean literals in the conditions in order to reduce the confounding factor caused by reading (and finding) variable names. An implication of this is, that the code is a complicated way of expressing an integer literal (which is returned) and contains dead code – code that is never executed. This is an external threat (because hopefully dead code plays a rather minor role in industrial projects), but it is an internal threat as well: the readability model implies for indented code that only the relevant code will be read by participants. However, we assume that if someone studies code, one would probably also study dead code (in order to understand that this code will never be executed or in order to understand why the author of the code still kept such code).
Internal Validity - Dependent Variable
We see an internal threat in the use of the metric reaction time (in addition to number of errors). As discussed in Section 6.1, an alternative could have been to use the metric time to completion, where time is measured until the correct response is given. While the previous experiment by Morzeck et al. used time to completion as a response variable (and while some of the present authors applied time to completion in several other experiments, see for example the programming experiments reported in Stuchlik and Hanenberg 2011; Endrikat et al. 2014; Fischer and Hanenberg 2015 among others), we intentionally executed the experiment on reaction time. We did that because we assume that once a participant gets the feedback that his response is wrong, he would completely restart with the task. I.e., we believe that an error imposes an additional penalty for the time measurement on the technique that caused more errors.
Internal and External Validity - Code with Fixed Code Length
The experiment used a fixed code length of 29 lines of code. Bearing in mind that long method is an often articulated so-called code-smell (see Fowler 1999) whose occurrence is observed in industrial code (see for example Sharma and Spinellis 2018), it is worth considering to what extent methods of such length represent good code at all. Actually, this is an implication for the readability model: the less lines of code, the smaller will be (according to the model) the difference between indented and non-indented code. Consequently, while the experiment’s implication is that the differences in reaction time between indented and non-indented code can be controlled by varying values of the diff-function, it is worth noticing that this implies that the code length will increase as well.
Internal and External Validity – Classification of Participants
The study uses the education level as a classification for the participants’ background – and we should point out that the use of the education level is an often applied classification criterion.Footnote 34 The education level turned out to be a significant factor, but it was unclear to us how the results could be interpreted: we expected undergraduate students to be slowest in the experiment, followed by PhD students, followed by professional developers. However, undergraduate students were the fastest group. There are multiple possible reasons why these groups revealed rather unexpected results. One could be, that each group has a different attitude towards the participation in experiments (maybe undergraduate students are more willing to be fast, while PhD students are maybe more willing to provide correct answers). But it could also mean that the education level as a classification criterion is rather misleading (and possibly applying the same criterion to a different sample reveals different results).Footnote 35
Internal Validity – Exploratory Study
We ran the exploratory study on the existing data. Actually, the resulting study is no longer a controlled study. I.e., it is not the case that there is an identical number of measurements per treatment combination. Additionally, the treatment combinations are no longer randomly generated. Next, we excluded some values for diff from the analysis because the number of cases in the original set was too low. Actually, there is some arbitrariness in this decision, because we cannot clearly articulate under what circumstances the number of cases is too low. And finally, doing ad-hoc modifications on hypotheses because of given experimental results should in general be critically considered from an epistemological perspective (see for example Popper 1934): the danger is that authors do ad-hoc modifications in order to protect existing hypotheses. We think this was not the case in our situation. First, we clearly articulated that the ad-hoc modification was done ad-hoc (based on the experimental results). Second, we think that the modification we did was relatively small in the end: the original definition of diff already counted the if-statements that could be skipped. The add-hoc modification was that additionally the return statements should be counted. From our perspective, both models are still very similar and take the code into account that can be skipped while reading the indented code.
9 Summary and Discussion
The present work was motivated by the fact that the empirical foundation for indentation – although indentation has been taught and applied for decades – is quite weak: up to 2022 only one study could be found where evidence is given that indentation of source code has a positive effect.
In 2023, an experiment by Morzeck et al. (2023) measured a large positive effect of indentation, but it could not explain what factors influence the effect of indentation (but gave a first indicator that skippable code might be responsible for that). Based on that result, the present work focuses on variables that possibly influence the measured differences. Thereto, the present work introduces a formal model of the code to be used in the experiment including a readability metric for indented and non-indented code. Based on this model, a controlled experiment was constructed (by varying the parameters of the model in a controlled way) which revealed that the model was able to explain the differences in reading times (measured in terms of reaction times) between indented and non-indented code.
The result of the experiment revealed again a strong and large effect of indentation: on average, non-indented code required 113% more time to read - which confirms the findings by Morzeck et al. Additionally, non-indented code caused more errors in the responses (\(\frac{\#Errors_{indented}}{\#Errors_{non-indented}}\) = 5.67). However, we see the most important contribution in the controlled differences in reading times between indented and non-indented code. This was controlled by a factor that describes the code that can be skipped in indented code, but which still increases the reaction time for non-indented code (the variable diff): with an increasing diff, the ratios \(\frac{Non-Indented}{Indented}\) increased as well (from \(\frac{Non-Indented}{Indented}\) = 1.749 up to \(\frac{Non-Indented}{Indented}\) = 2.453). I.e., the present work describes an interaction effect between the variable diff and the variable indentation (with the treatments indented and non-indented) via a formal description and gives evidence for that interaction effect. I.e., the experiment does not only state that there is a difference between indented and non-indented code, but determines how the size of this difference can be controlled (by varying the branches that can be skipped in the indented code).
Still, it also turned out that the underlying model had its weakness: while the model assumed that there would not be a difference between the indented code and the non-indented code for diff = 0, the measurements still revealed such a difference. As a response to that, we proposed an ad-hoc modification of the model by simply proposing that even return statements should be counted in the code that can be skipped. In an exploratory study we tested the resulting model on the existing data and it turned out that the response variable no longer revealed a difference in the situation where the model also assumes no difference.
We see one additional contribution in the way how data is selected. The experiment is designed as an N-of-1 trial, which permits individuals to run the study. In other words, individuals can experience the studied effects on their own. We know from literature that developers have the tendency to rate their own personal experience higher than reading literature (see Devanbu et al. 2016). Although we consider this phenomenon as problematic (because personal experiences are probably not collected in controlled settings and there is the danger that personal experiences are biased), N-of-1 trials could potentially help: they permit an individual to study an effect in a controlled setting. This permits to analyze an individual’s result in a non-subjective way.
Having said this, the present experiment still has one facet that is not completely satisfying: while the effect of indentation was measurable on each individual, the interaction effect was only observable on the whole sample, respectively on 13 of 27 participants. We think that an increase of the sample size per participant (i.e., an increase of the number of repetitions per treatment combination) would increase the percentage of participants who reveal such interaction effect. We also think that even in the existing sample there were participants who were not reactive to the model. We can only speculate why this is the case. Maybe, there are individuals who read code in different ways than others, maybe some participants were frustrated to read non-indented code, maybe some participants were not concentrated well enough.
An additional (minor) result of the present work is that the background of participants was a significant effect in the experiment as well. However, the interpretation is unclear to us: undergraduate students required less time than professionals, who required less time than PhD students. This result is in contrast to experiments such as, for example, the one by El-Attar (2019) who found that professionals perform on average better on comprehension tasks. We do think that the distinction undergraduate student, PhD student, and professional probably hides a number of a personal qualifications and we think that this distinction – although the distinction students vs professionals is quite common in the literature (see for example Salman et al. 2015) – is probably not appropriate to find inherently people with homogenous characteristics.
The present experiment looks like a contradiction to the results by Buse and Weimer (2010) as well as Scalabrino et al. (2016, 2018), who constructed readability models using ML techniques. In both cases, it is documented that an increase in indentation decreases the readability. However, we do not think that it is a contradiction, but we think it is rather a matter of the terminology. It looks like both works use indentation as an indicator for nesting: in case the data in their training set is well-formatted code, indentation levels is the equivalent for nesting. And we agree that the deeper the code is nested, the more difficult it is to read. The model proposed here describes this as well: increasing the nesting increases the number of if-statements which for both – indented and non-indented code – leads on average to an increase in reading time.Footnote 36
We think that the present work might be criticized for the fact that the code shown to participants shows dead code (actually each code snippet is just a complicated form of returning an integer value). We do not think that such argument is strong, because reading (and re-reading) code (with conditionals) consists of reading different branches in code. I.e., one tries to determine under what conditions what branches of the code will be executed. In such case, one follows different branches in the code – which is exactly what is studied in the present experiment in a controlled way.
Finally, we would like to emphasize that the reading direction probably plays a major role. As explicitly mentioned in Section 5.4, the underlying model assumes that participants read the code from top to bottom: but for indented code, the assumption is that the participants read the code in a comparable way how the code is executed (i.e., where branches are – depending on some conditions – skipped), while it is assumed that readers of non-indented code read also those lines that can be skipped. Taking into account that the experiment gave strong evidence for the model, we think this assumption holds for the given code. However, Busjahn et al. (2015) gave evidence in their experiment that source code is typically not read from top to bottom. At first glance, it seems that the present work contradicts the work by Busjahn et al. However, we do not think that this is the case. Busjahn et al. used a number of source code that used procedural abstractions (i.e. named methods) as well as loops in their experiment. We think that it is plausible that both constructs encourage developers to read the code not from top to bottom.
10 Implications and Possible Follow-Up Studies
While we believe that it is desirable to measure the effect of indentation on source code that not only consists of nested if-statements, we do not think that the proposed model should just be applied to arbitrary source code in order to measure some average effect of indentation. Instead, we think the long-term goal of this line of research should be a formal model that describes the effect of code formatting in general, respectively the effect of indentation in particular by making those variables explicit that influence readability. And in order to achieve this, we think it is desirable to control more variables and to integrate more factors in the resulting model. We do not think that relieving controlled conditions would be helpful to achieve such goal.
As previously discussed, we think that reading directions do play a role. Hence, we think that future studies should try to control the reading direction and use this as an additional controlled variable. We would expect from studies where multiple lines of code are read more than once, that the effect of indentation is even stronger.
However, we also believe that procedural abstractions with good names reduce the effect of indentation. If, for example, a method is called is_prime_number and one would believe that the method name correctly describes its function, one probably does not look into the code in much detail. Consequently, we think that the effect of indentation in such methods is smaller, actually for comparable reasons as predicted in the present model: code that is skipped while reading reduces the resulting time measurements. Hence, for code that is hardly read by developers, indentation (probably) hardly plays a role.
Having said this, we think that it is worth studying what factors possibly cause a developer not to read code. If such factors become known, it is probably easier to develop stable theories on code readability.
Next, we think that possible future studies should also concentrate more on measurement techniques. Most known measurement techniques assume that participants are willing and motivated to participate in an experiment. But we are aware that unmotivated participants have a negative effect on the experiment results. We think that more research is required to make it possible to identify possibly outliers in an objective way.
Finally, we think the here presented work already has a practical implication for a field that is often not in the focus of empirical software engineering: teaching. While teaching programming, students are typically told to indent code without giving evidence for the effectiveness of indentation. We think that the reported experiment can provide such evidence to students; either in terms of giving students the paper to read, or simply by letting them execute the experiment – where the design as a N-of-1 experiment permits each single student to experience (and analyze) the experiment on their own.
11 Conclusion
The present paper studied differences in readability between indented and non-indented code. First, it gives strong evidence that this difference exists and that this difference is large. Second, the experiment gives strong evidence that this difference is influenced by the code that can be skipped (in the indented code): the larger this code, the larger the difference between reaction times of indented and non-indented code. I.e., a statement such as “the current experiment revealed on average an increase in reaction time of 113% for non-indented code” is true, but slightly misleading: The present experiment gave strong evidence that such difference can be varied by varying the code that can be skipped while reading the indented code, but which still requires to be read for non-indented code.
However, we need to point out that a variation of the code that can be skipped while reading indented code had only on the whole sample a significant effect – and only for about half of the individual participants (13/27). This probably points out that even in the present experiment (which is from our perspective highly controlled) not all factors are controlled. From our perspective this should motivate researchers to focus even more on controlled experiments in order to identify (and control) more factors that influence the readability of code.
Data Availability
A replication package of the experiment and the raw data of the experiment are public available currently under the link https://github.com/shanenbe/Experiments/tree/main/2023_Indentation/predecessors/hanenberg_et_al_2023. A remake of the experiment is available under https://github.com/shanenbe/Experiments/tree/main/2023_Indentation and can be executed online using the link https://htmlpreview.github.io/?https://raw.githubusercontent.com/shanenbe/Experiments/main/2023_Indentation/index.html. (The remake of the experiment is not identical to the here reported experiment, because the here reported one is a Java application which uses Java’s random number generator, while the remake is a JavaScript application that uses a different random number generator.)
Notes
Python is a slight exception in this list, because in Python indentation is also part of the language semantics.
It is a relatively well-studied phenomenon that software technologies are far from being exhaustively studied (see for example Tichy et al. 1995; Buse et al. 2011; Stefik et al. 2014; Kaijanaho 2015; Ko et al. 2015 among others). I.e. the statement “it is not exhaustively studied” is not a special characteristic of indentation.
The here mentioned remaining study is by Albayrak and Davenport (2010). Actually, there is another study by Miara et al. (1983) that showed an effect (with mixed results), but a replication of the study by Bauer et al. (2019) was not able to replicate the results, hence we do not count the publication by Miara et al. here as one of those studies that give evidence for the effect of indentation. We discuss this issue in more detail later on.
Morzeck et al. speculate that this difference could be caused by code that can be skipped while reading (Morzeck et al. 2023). Actually, the authors implemented the independent variable skippable in that experiment that turned out significant. However, a closer look revealed that only two of the three treatments led to different results. Hence, the evidence for the validity of this speculation is rather weak.
We intentionally reduce the question of indentation to nested if-statements, because we assume that indentation has different effects on different language constructs and different kinds of code.
This is probably caused by the fact that Smalltalk does not define control structures as explicit language constructs but makes use of object-oriented constructs in addition to lambda expressions to model loops and conditionals.
Actually, Morzeck et al. already describe that in the literature more experiments (such as in the article by Vessey and Weber 1984) are mentioned that seem to use indentation as a controlled factor (such as the experiments by Sime et al. 1977, 1999). However, a close look into these experiments reveals that it is rather questionable whether indeed indentation was a controlled factor. Because of that, we do not include these experiments here.
One should emphasize that it is hard to interpret quantitative results without knowing something about the effect size of an experiment.
But it should be mentioned that the study (which measured four levels of indentation in addition to one further variable) does not reveal clear results: while it looks seems as if indentation level 2 had an overall positive effect, it seems as if indentation level 4 reduced that positive effect (and possibly not even showed a difference to non-indented code) while the results of level 6 seemed to be somewhere in between. Since the paper does not report post-hoc tests, the previous estimations are only based on looking at the graphical representation of the results.
These four experiments include two experiments by Norcio, where no effect sizes were reported (experiments 6 and 7 in Table 1).
Actually, it is already an interpretation of the mentioned experiments that static typing improves comprehension, because in both experiments, developers had to write code with and without static types (with come other considered variables) by using a previously unknown API. Although the development time was measured in both experiments, we think it is plausible that the measured differences were caused by a different comprehensibilities of statically or dynamically typed APIs.
Another experiment that documented a negative effect of static type systems tested the possible effect of type casts (Stuchlik and Hanenberg 2011) - however, it is unclear to us, whether the measured effect can be interpreted as a negative effect on comprehension.
Actually, Morzeck et al. already deeply discuss possible effects of indentation. We still repeat those arguments here to understand the background for the formal model we introduce later on.
Actually, there are additional integer literals in the return statements, but since they do not play a role in our readability model, we neglect them here.
We are aware that there is evidence that the reading direction of source code in general is not top to bottom (see the work by Busjahn et al. 2015). However, we do not think that our assumption here is in contradiction to the results by Busjahn et al. – we discuss this issue in more detail in Sections 9 and 10.
A large number of languages (such as C, C++, C#, Java, Python) have if as a defined language construct to which the proposed language can be mapped to. Still, there are languages such as Smalltalk (Goldberg and Robson 1983) that do not have if as a language construct. For such languages it is not that obvious how to map the model to the language.
In programming languages such as Java brackets are optional and only necessary if more than one statement belongs to the body of the then or else branch. Although we are aware of the effects of brackets for the comparison of indented and non-indented code (see Morzeck et al. 2023), we still use it in the experiment, because in our experience brackets are just omitted in situations where a branch consists of a single line of code.
The result of 7 if-statements implies for the experiment, that no scrolling is necessary. Furthermore, 29 LOC are the result of the previously described use of new lines.
This statement is slightly simplified. Actually, this statement only holds if the code is long enough, i.e., if it contains sufficient if-statements. For example, with only one if-statment it is not possible to choose diff = 4. I.e., the upper limit of possible diff values is defined by the chosen LOC.
See Senn (2022) for a general introduction into crossover trials.
This statement holds for indentation (F(1, 72) = 1.711, p = .195), read\(_{I}\) (F(2, 72) = .286, p = .752), diff (F(2, 72) = .067, p = .935), indentation*read\(_{I}\) (F(2, 72) = .470, p = .627), indentation*diff (F(2, 72) = .035, p = .966), read\(_{I}\)*diff (F(2, 72) = .845, p = .501), and indentation*diff*read\(_{I}\) (F(4, 72) = .646, p = .631).
A post-hoc Tukey test reveals (with p < .001 for each comparison) that for each diff-value the comparison between non-indented and indented is significant. Simply running an ANOVA only on the data for diff = 0 reveals the same results (F(1, 792)=142.699, p < .001). Note, that even under the very conservative assumption that a Bonferroni correction should be applied, the result is still significant (because p < .001 and the number of diffs is three: .multiplying .001 with three still results in a p-value smaller than .01).
Of course, the analysis here will be done without the variable background, because each individual has the same background.
The ANOVA on the independent variables indentation, read\(_{I}\), and background reveals for the variable indentation F(1, 156) = .003, p = .956. One could argue that a correction of the p-value is required, which just even increases it, i.e., it does not change the statement that there is no significant effect.
We applied the education level before (see for example Uesbeck et al. 2016). Additionally, the application of such classification can be found manyfold in the literature (see for example the experiments mentioned by Falessi et al. 2018, pp. 455–457) and its applicability is still discussed (see for example Feldt et al. 2018).
One could assume that the classification based on years of experience might leads to better, or at least more plausible, results. In order to check whether the results are different we classified experience based on the years of experience in three groups (no experience = 0 years, medium experience < 5 years, experienced >= 5 years) and epeated the ANOVA described in Section 6.7, now with the additional variable experience_quantile. However, although the results are slightly different, they are still not plausible to us. Based on a Tukey post-hoc test on the significant variable experience_quantile (p = .001; \(\eta _{p}^{2}\) = .006) there was no significant difference between no experience (\(M_{no\,\text {exp}}\) = 8,440 ms) and experienced (\(M_{\text {exp}}\) = 8006 ms, p = .385), while there was a significant difference between medium experience (\(M_{med}\) = 9,125 ms) and experienced (p < .001). Again, medium experience was the slowest group. However, using the variable experience_quantile in the ANOVA does no longer reveal an interaction effect between technique and experience_quantile. All main variables in the experiment are comparable to the results reported in Section 6.7.
On average, deeply nested if-statments require to read more if-statements although there are situations where this is not the case (where the deeply nested code can be skipped).
References
Ajami S, Woodbridge Y, Feitelson DG (2019) Syntax, predicates, idioms - what really affects code complexity? Empir Softw Eng 24(1):287–328
Albayrak Ö, Davenport D (2010) Impact of maintainability defects on code inspections. In: Proceedings of the 2010 ACM-IEEE international symposium on empirical software engineering and measurement, ESEM ’10, New York, USA. Association for Computing Machinery
Appelbaum M, Cooper H, Kline R, Mayo-Wilson E, Nezu A, Rao S (2018) Journal article reporting standards for quantitative research in psychology: The apa publications and communications board task force report. Am Psychol 01:73:3–25
Association for Computer Machinery (2016) People of ACM – Margaret Burnett. https://www.acm.org/articles/people-of-acm/2016/margaret-burnett
Bauer J, Siegmund J, Peitek N, Hofmeister JC, Apel S (2019) Indentation: simply a matter of style or support for program comprehension? In: Proceedings of the 27th international conference on program comprehension, ICPC ’19, pp 154–164. IEEE Press
Berger ED, Hollenbeck C, Maj P, Vitek O, Vitek J (2019) On the impact of programming languages on code quality: a reproduction study. ACM Trans Program Lang Syst 41(4):1
Binkley Dave W, Davis Marcia, Lawrie Dawn J, Maletic Jonathan I, Morrell Christopher, Sharif Bonita (2013) The impact of identifier style on effort and comprehension. Empir Softw Eng 18(2):219–276
Binkley D, Davis M, Lawrie D, Morrell C (2009) To camelcase or under_score. In: The 17th IEEE international conference on program comprehension, ICPC 2009, Vancouver, British Columbia, Canada, May 17-19, 2009, pp 158–167
Buse RPL, Sadowski C, Weimer W (2011) Benefits and barriers of user evaluation in software engineering research. In: Proceedings of the 2011 ACM international conference on object oriented programming systems languages and applications, OOPSLA ’11, pp 643–656, New York, USA. Association for Computing Machinery
Buse RPL, Weimer WR (2010) Learning a metric for code readability. IEEE Trans Softw Eng 36(4):546–558
Busjahn T, Bednarik R, Begel A, Crosby M, Paterson JH, Schulte C, Sharif B, Tamm S (2015) Eye movements in code reading: relaxing the linear order. In Proceedings of the 2015 IEEE 23rd international conference on program comprehension, ICPC ’15, pp 255–265. IEEE Press
Devanbu PT, Zimmermann T, Bird C (2016) Belief & evidence in empirical software engineering. In: Proceedings of the 38th international conference on software engineering, ICSE 2016, Austin, TX, USA, May 14-22, 2016, pp 108–119
El-Attar M (2019) A comparative study of students and professionals in syntactical model comprehension experiments. Softw Syst Model 18(6):3283–3329
Endrikat S, Hanenberg S, Robbes R, Stefik A (2014) How do api documentation and static typing affect api usability? In: Proceedings of the 36th international conference on software engineering, ICSE 2014, pp 632–642, New York, USA, 2014. ACM
Falessi D, Juristo N, Wohlin C, Turhan B, Münch J, Jedlitschka Andreas, Oivo Markku (2018) Empirical software engineering experts on the use of students and professionals in experiments. Empir Softw Eng 23(1):452–489
Feigenspan J, Kästner C, Liebig J, Apel S, Hanenberg S (2012) Measuring programming experience. In: Beyer D, van Deursen A, Godfrey MW (eds) IEEE 20th international conference on program comprehension, ICPC 2012, Passau, Germany, June 11-13, 2012, pp 73–82. IEEE Computer Society
Feitelson DG (2015) Using students as experimental subjects in software engineering research - a review and discussion of the evidence. arXiv:1512.08409
Feitelson DG (2022) Considerations and pitfalls for reducing threats to the validity of controlled experiments on code comprehension. Empir Softw Eng 27(6):123
Feldt R, Zimmermann T, Bergersen GR, Falessi D, Jedlitschka A, Juristo N, Münch J, Oivo M, Runeson P, Shepperd M, Sjøberg DIK, Turhan B (2018) Four commentaries on the use of students and professionals in empirical software engineering experiments. Empir Softw Eng 23(6):3801–3820
Fischer Lars, Hanenberg Stefan (2015) An empirical investigation of the effects of type systems and code completion on api usability using typescript and javascript in ms visual studio. SIGPLAN Not 51(2):154–167
Fowler M (1999) Refactoring: Improving the Design of Existing Code. Addison-Wesley Longman Publishing Co., Inc, USA
Goldberg Adele, Robson David (1983) Smalltalk-80: The Language and Its Implementation. Addison-Wesley Longman Publishing Co., Inc, USA
Grogono P (1984) Programming in Pascal. Addison-Wesley series in computer science. Addison-Wesley
Hanenberg Stefan, Mehlhorn Nils (2021) Two n-of-1 self-trials on readability differences between anonymous inner classes (aics) and lambda expressions (les) on java code snippets. Empir Softw Eng 27(2):33
Hannebauer Christoph, Hesenius Marc, Gruhn Volker (2018) Does syntax highlighting help programming novices? Empir Softw Eng 23(5):2795–2828
Hart SG, Staveland LE (1988) Development of nasa-tlx (task load index): results of empirical and theoretical research. In: Hancock PA, Meshkati N (eds) Human mental workload, vol 52 of advances in psychology, pp 139–183. North-Holland
Hofmeister Johannes C, Siegmund Janet, Holt Daniel V (2019) Shorter identifier names take longer to comprehend. Empir Softw Eng 24(1):417–443
Höst Martin, Regnell Björn, Wohlin Claes (2000) Using students as subjects-a comparative study of students and professionals in lead-time impact assessment. Empir Softw Eng 5(3):201–214
Kaijanaho A-J (2015) Evidence-based programming language design: a philosophical and methodological exploration. University of Jyväskylä, Finnland, 11
Kernighan BW, Plauger PJ (1982) The Elements of Programming Style, 2nd edn. McGraw-Hill Inc, USA
Kesler TE, Uram RB, Magareh-Abed F, Fritzsche A, Amport C, Dunsmore HE (1984) The effect of indentation on program comprehension. Int J Man-Mach Stud 21(5):415–428
Kitchenham B, Fry J, Linkman S (2003) The case against cross-over designs in software engineering. In Eleventh annual international workshop on software technology and engineering practice, pp 65–67
Ko AJ, Latoza TD, Burnett MM (2015) A practical guide to controlled experiments of software engineering tools with human participants. Empir Softw Eng 20(1):110–141
Kühberger A, Fritz A, Lermer E, Scherndl T (2015) The significance fallacy in inferential statistics. BMC Res Notes 8(1):84
Lappi V, Tirronen V, Itkonen J (2023) A replication study on the intuitiveness of programming language syntax. Softw Qual J
Lawrie DJ, Morrell C, Feild H, Binkley DW (2006) What’s in a name? A study of identifiers. In: 14th International conference on program comprehension (ICPC 2006), 14-16 June 2006, Athens, Greece, pp 3–12. IEEE Computer Society
Loftus EF, Pickrell JE (1995) The formation of false memories. Psychiat Ann 25(12):720–725
Love LT (1977) Relating individual differences in computer programming performance to human information processing abilities. PhD thesis
Madeyski Lech, Kitchenham Barbara A (2018) Effect sizes and their variance for AB/BA crossover design studies. Empir Softw Eng 23(4):1982–2017
McCabe TJ (1976) A complexity measure. IEEE Tran Softw Eng SE–2(4):308–320
Mehlhorn N, Hanenberg S (2022) Imperative versus declarative collection processing: an RCT on the understandability of traditional loops versus the stream API in java. In 44th IEEE/ACM 44th international conference on software engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022, pp 1157–1168. ACM
Miara RJ, Musselman JA, Navarro JA, Shneiderman B (1983) Program indentation and comprehensibility. Commun ACM 26(11):861–867
Minelli R, Mocci A, Lanza M (2015) I know what you did last summer: an investigation of how developers spend their time. In: Proceedings of the 2015 IEEE 23rd international conference on program comprehension, ICPC ’15, pp 25–35. IEEE Press
Moher D, Hopewell S, Schulz KF, Montori V, Gøtzsche PC, Devereaux PJ, Elbourne D, Egger M, Altman DG (2010) Consort, explanation and elaboration: updated guidelines for reporting parallel group randomised trials. BMJ 340:2010
Morzeck J, Hanenberg S, Werger O, Gruhn V (2023) Indentation in source code: a randomized control trial on the readability of control flows in java code with large effects. In: Proceedings of the 18th international conference on software technologies (ICSOFT 2023). SITEPRESS
Murphy GC, Kersten M, Findlater L (2006) How are java software developers using the eclipse ide? IEEE Softw 23(4):76–83
Norcio AF (1982) Indentation, documentation and programmer comprehension. In: Proceedings of the 1982 conference on human factors in computing systems, CHI ’82, pp 118–120, New York, USA. Association for Computing Machinery
Norcio AF, Kerst SM (1983) Human memory organization for computer programs. J Am Soc Inf Sci 34(2):109–114
Nunnally J (1960) The place of statistics in psychology. Educ Psychol Meas 20(4):641–650
Patton MQ (2014) Qualitative Research & Evaluation Methods: Integrating Theory and Practice. SAGE Publications
Popper KR (1934) The Logic of Scientific Discovery. Hutchinson, London
Proffitt DR, Stefanucci J, Banton T, Epstein W (2003) The role of effort in perceiving distance. Psychol Sci 14(2):106–112
Ray B, Posnett D, Devanbu P, Filkov V (2017) A large-scale study of programming languages and code quality in github. Commun ACM 60(10):91–100
Ray B, Posnett D, Filkov V, Devanbu P (2014) A large scale study of programming languages and code quality in github. In: Proceedings of the 22nd ACM SIGSOFT international symposium on foundations of software engineering, FSE 2014, pp 155–165, New York, USA. Association for Computing Machinery
Salman I, Misirli AT, Juristo N (2015) Are students representatives of professionals in software engineering experiments? In: 2015 IEEE/ACM 37th IEEE international conference on software engineering, vol 1, pp 666–676
Scalabrino S, Linares-Vásquez M, Oliveto R, Poshyvanyk D (2018) A comprehensive model for code readability. J Softw Evol Process 30(6)
Scalabrino S, Vásquez ML, Poshyvanyk D, Oliveto R (2016) Improving code readability models with textual features. In 24th IEEE international conference on program comprehension, ICPC 2016, Austin, TX, USA, May 16-17, 2016, pp 1–10. IEEE Computer Society
Senn SS (2002) Cross-over Trials in Clinical Research. Statistics in Practice. Wiley
Sharma T, Spinellis D (2018) A survey on software smells. J Syst Softw 138:158–173
Shneiderman B, McKay D (1976) Experimental investigations of computer program debugging and modification. roc Hum Factors Ergon Soc Annu Meet 20(24):557–563
Siegmund Janet, Kästner Christian, Liebig Jörg, Apel Sven, Hanenberg Stefan (2014) Measuring and modeling programming experience. Empir Softw Eng 19(5):1299–1334
Sime ME, Green TRG, Guest DJ (1977) Scope marking in computer conditionals-a psychological evaluation. Int J Man-Mach Stud 9(1):107–118
Sime ME, Green TRG, Guest DJ (1999) Psychological evaluation of two conditional constructions used in computer languages. Int J Hum Comput Stud 51(2):125–133
Stefik A, Hanenberg S, McKenney M, Andrews A, Yellanki SK, Siebert S (2014) What is the foundation of evidence of human factors decisions in language design? an empirical study on programming language workshops. In: Proceedings of the 22nd international conference on program comprehension, ICPC 2014, pp 223–231, New York, USA. Association for Computing Machinery
Stefik Andreas, Siebert Susanna (2013) An empirical investigation into programming language syntax. ACM Trans Comput Educ 13(4)
Stuchlik A, Hanenberg S (2011) Static vs. dynamic type systems: an empirical study about the relationship between type casts and development time. In: Proceedings of the 7th symposium on dynamic languages, DLS ’11, pp 97–106, New York, USA. Association for Computing Machinery
Svahnberg M, Aurum A, Wohlin C (2008) Using students as subjects - an empirical evaluation. In Rombach HD, Elbaum SG, Münch J (eds) Proceedings of the second international symposium on empirical software engineering and measurement, ESEM 2008, October 9-10, 2008, Kaiserslautern, Germany, pp 288–290. ACM
Tichy WF, Lukowicz P, Prechelt L, Heinz EA (1995) Experimental evaluation in computer science: A quantitative study. J Syst Softw 28(1):9–18
Uesbeck PM, Stefik A, Hanenberg S, Pedersen J, Daleiden P (2016) An empirical study on the impact of c++ lambdas and programmer experience. In: Proceedings of the 38th international conference on software engineering, ICSE 2016, Austin, TX, USA, May 14-22, 2016, pp 760–771
Vessey I, Weber R (1984) Research on structured programming: an empiricist’s evaluation. IEEE Trans Softw Eng SE–10(4):397–407
Weissman LM (1974) A Methodology for Studying the Psychological Complexity of Computer Programs. PhD thesis. AAI0510378
Wiese E, Rafferty AN, Pyper J (2022) Readable vs. writable code: a survey of intermediate students’ structure choices. In: Proceedings of the 53rd ACM technical symposium on computer science education - volume 1, SIGCSE 2022, pp 321–327, New York, USA. Association for Computing Machinery
Woolfolk ME, Castellan W, Brooks CI (1983) Pepsi versus coke: labels, not tastes, prevail. Psychol Rep 52(1):185–186
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of Interest
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Communicated by: Alexandre Bergel.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hanenberg, S., Morzeck, J. & Gruhn, V. Indentation and reading time: a randomized control trial on the differences between generated indented and non-indented if-statements. Empir Software Eng 29, 134 (2024). https://doi.org/10.1007/s10664-024-10531-y
Accepted:
Published:
DOI: https://doi.org/10.1007/s10664-024-10531-y