
Abstract
Farmers may adapt to climate change by substituting away from the crops most severely affected. In this paper we estimate the substitution caused by a moderate change in climate in the US Midwest. We pair a 10-year panel of satellite-based crop coverage with spatially explicit soil data and a fine-scale weather data set. Combining a proportion type model with local regressions, we simultaneously address the econometric issues of proportion dependent variables and spatial correlation of unobserved factors. We find the change in expected crop coverage and then we link those changes to the expected changes from an estimated climate dependent yield equation. Ceteris paribus, we find that climate induced changes in yield are offset by land coverage changes for rice and cotton but they are strongly amplified for corn and soy.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Crop yields per acre (hereafter yield) for corn and soybeans in the US are forecasted to decrease by 30–46% before the end of the century, even under the slowest (B1) climate warming scenario (Schlenker and Roberts 2009). There are similar findings in Africa (Lobell et al. 2011) and China (Chen et al. 2016). In addition to the yield effect, there is also a crop coverage response to climate change. Crop coverage is the area of land used to produce a given crop in a given year. Farmers may grow crops that are better suited to the new weather conditions. That is, they increase or decrease the amount of land devoted to a particular crop. The coverage response effect may offset or reinforce the yield effect on crop production. Since farmers’ adaptation behavior is an important factor that affects crop production, in this paper, we study both crop yield and crop coverage in light of both weather and soil conditions along the Mississippi-Missouri river system, in order to project climate-related changes in crop production. This paper is the first to forecast the land coverage effects of projected climate change.Footnote 1
The dominant crop types along the Mississippi River are corn, soy, cotton and rice in the south and corn and soy in the colder north. Farmers grow crops with characteristics matching the landscape characteristics. As evidence, one sees cotton in the warmer, wetter south, wheat in drier regions, corn in the wetter parts of the Midwest, and so on. Based on temperature alone, coverage response to higher temperatures should result in the northward spread of cotton and rice, substitution of shorter-season crops (e.g., soy) for longer-season crops (e.g., corn), and the conversion of non-crop land in the south. However, soil properties are also a major determinant of which crops can be grown and the crop’s ultimate yield. If all crops suitable to local soils are negatively affected by warming, it is possible that farmers are left with no better alternative crop, not considering new technology or new crops being introduced into the region. That is, adaptation happens only when the substitution crop fits in the local soils and the current crop is harmed so much that it is less profitable than the substitution crop. We estimate the changes in crop coverage within the limits imposed by soil conditions.
Modern econometric studies of crop coverage began with Nerlove’s (1956) examination of crop share response to crop prices. His estimating equations are of the form that coverage is a function of lagged coverage, crop price, input prices and other variables. There is a large literature elaborating on this basic model, but it mostly focuses on the effect of price, cost, or risk of growing crops rather than changes in climate.
The major contribution of this paper is to project land use change on a 4 km square basis as a function of changes in climate. The other contributions of this paper are the methodological innovations, elaborated as follows. (1) We use a limited dependent variable regression with a ratio transformation function to simultaneously deal with the problems of that crop coverages are proportions and that our crop coverage data have many data points with zero coverage. There are previous researchers (Lichtenberg 1989; Wu and Segerson 1995) who use discrete choice models for crop share decisions. Berry’s logit (1994) is an appealing discrete choice model for shares that are not zero or one, because it is linear in the parameters and errors. However, Berry’s logit is not suitable for the data that have many zero data points as is the case in land use models over a large landscape. The model design in this paper satisfies the constraint of proportion dependent variable, has the advantage of linearity in parameters, and is good for the data with many zero points. (2) We use a local regression framework to address the problem of that land use may be correlated across space. A spatial error estimator can address the spatial correlation problem, but is not consistent in nonlinear regressions, like the limited dependent variable regression we use in this paper. The key problem is that the homoscedasticity assumption is violated by the spatial correlation in errors. Therefore, we use a local regression framework so that all parameters and the variances can vary across the landscape and account for unmeasured place specific phenomenon that would lead to spatial correlation. (3) We include the interaction terms of moisture and heat to address the fact that a dry warming is likely to be more harmful than warming with moisture. (4) Utilizing the fine-level panel data on weather and soil, we explicitly model the effects of weather and soil. Modeling the effect of weather is key for simulating the effects of climate change; and modeling the effect of soil allows us to estimate the changes in crop coverage within the limits imposed by soil conditions. In contrast, studies interested in price response use place fixed effects to account for these factors and so cannot shed light on the role of soil in climate change adaptation. (5) Since our focus is on climate, not on price, we can use year fixed effects to account for both price and non-price incentives to grow crops. In many countries (e.g., the United States and European Union), the incentive to grow crops in addition to the price is government payments. As these programs change year to year and have different marginal effects for different farmers, it is not possible to have a fully satisfactory treatment of the price variable. If the focus, as was Nerlove’s focus, is on price response, parsing the true incentive effects is a serious problem. However, since our focus is on climate, we use year fixed effects to account for both prices and government programs. The year fixed effects also would account for differences in input prices and any effects of variables that are common across space. For instance, the American biofuels program is also subsumed in the year fixed effects. In addition, many researchers (Just 1974; Chavas and Holt 1990; Lin and Dismukes 2007) think that the risk of growing a crop, perhaps the variance or lower semi-variance, is an important determinant of crop choices. Given that the risk of growing a crop can be taken as constant, which is a good approximation in a short time series, we use crop fixed effects to account for this factor.
As for estimating the effect of climate change on crop yield, recent literature, particularly Schlenker and Roberts (2009), worked at the county level and quantified the effects of weather on yield. The general tenor of their results is that high temperatures are very harmful to yields and so climate change projections for the United States result in large yield deficits in response to an increase in the number of hours of 29 °C plus temperatures for corn, 30 °C for soybeans, and 32 °C for cotton. Lobell et al. (2011) and Chen et al. (2016) did a similar analysis for Africa and China, respectively. These studies find that warmer climates negatively affect crop yield. Their work is noteworthy for the use of a great deal of spatial and temporal detail in their weather data, while the effects of soil are subsumed in the place fixed effects. Utilizing a much finer level of data and also a great deal of spatial and temporal detail in both weather and soil data, we explicitly model the effects of both weather and soil in the yield regression. It allows us to predict the crop yield losses to climate change, within the limits of soil conditions.
In this paper, we estimate the coverage response of corn, soy, cotton and rice to two climate change scenarios. We also estimate the change in yields implied by these same scenarios to see whether yield change and coverage change offset or reinforce each other. Like Schlenker and Roberts (2009), we find reductions in yield due to climate change. For corn and soybean, we find that coverage is also reduced; this exacerbates the yield loss and shifts the supply curves of corn and soybean further inward. For rice and cotton, we instead find increases in coverage; this compensates for yield loss and shifts the supply curves of rice and cotton back toward its original position.
The remainder of the paper is organized as follows. Section 2 summarizes the data on land use, soil conditions, weather, climate change scenarios, and crop yields for the states along the Mississippi-Missouri river corridor. Section 3 establishes the econometric system and presents the estimation results. Section 4 simulates crop coverage responses to climate change. Both Sects. 5 and 6 predicts crop production losses to climate change. Section 5 holds crop coverage fixed, while Sect. 6 considers both yield effect and coverage response. Section 7 concludes.
2 Data
Both yield and crop coverage are estimated as functions of weather, soil, and time trends or time fixed effects. Data on land cover, soil characteristics, weather, and climate change scenarios are matched on a 4 km by 4 km grid to create the primary data set. Data on crop yield are at the county level. The states included in the analysis are those along the Mississippi-Missouri river corridor for which there are at least 10 years of land cover data: Wisconsin, Iowa, Illinois, part of Missouri, Arkansas, and Mississippi.Footnote 2 Given that corn and soy are mainly grown in the three northern states (Wisconsin, Iowa, and Illinois), and rice and cotton are mainly grown in the southern states (Missouri, Arkansas, and Mississippi), the six states are divided into the groups of north and south accordingly. The summary statistics of all the variables for the two groups are presented in Table 1.
2.1 Crop Coverage
Land cover data is derived from the Cropland Data Layer (CDL) available annually from 2000 to 2010 (USDA NASS) for the six states.Footnote 3 They are divided into major crops, other crops, non-crop and wild, urban, and water bodies. The major crops include corn and soybean for Iowa, Wisconsin, and Illinois; and corn, soybean, rice, and cotton for Missouri, Arkansas, and Mississippi. The category of non-crop and wild land includes pasture, forest, improved pasture, etc. Conservation reserve lands should fall within this category as they do not have crops. We define agricultural land as the sum of major crops, other crops, and non-crop and wild land. Because urban and water bodies are very difficult to convert into crop land, we do not include them in discussion in this paper. Therefore, we define the share of major crops as the area of major crops divided by area of agricultural land.
Figure 1 shows the coverage shares of corn, soybean, rice, and cotton along the corridor. Corn grows mainly in the colder north, while soy crops are more widely distributed. Rice and cotton concentrate along the river in Missouri, Arkansas and Mississippi. For corn, the average percent coverage from 2002 to 2010 is 27.5% in the north (the three northern states: Wisconsin, Iowa, and Illinois), while it is only 5.5% in the south (the three southern states: Missouri, Arkansas, and Mississippi). For soy, the coverage is 20.9 and 29.4% in the north and the south, respectively. There is little cotton and rice in the north, while in the south, cotton takes 10.3% of the agricultural land and rice takes 11.8%.

Observed crop coverage along the Mississippi-Missouri River system. Notes: graphs display observed coverage shares for corn, soy, rice, cotton, and other land use, in the six states along the Mississipppi-Missouri river corridor. They are average shares over 2001–2010
2.2 Soil Characteristics
For soil data we focus on two types of variables, both derived from the USDA’s U.S. General Soil Map (STATSGO2). First, the underlying soil data include percent clay, sand, and silt, water holding capacity, pH value, electrical conductivity, slope, frost-free days, depth to water table, and depth to restrictive layer. Soil variable averages are spatially weighted from irregular polygons for each grid cell.
Second, we use a classification system generated by the USDA—land capability classFootnote 4 (LCC). A LCC value of one defines the best soil with the fewest limitations for production, and progressively lower LCC classifications signify more limitations on the land for agricultural production. The LCC integer scores increase incrementally to eight, where soil conditions are such that agricultural planting is nearly impossible. The use of LCC codes add explanatory power to the raw soil characteristics because these codes were assigned with knowledge of past yields that depend on characteristics not present in our data set. The spatial distribution of LCC levels is shown in Fig. 2. Together with Fig. 1, we see that prime agricultural soils are absent in southern Iowa and most parts of Wisconsin and so largely is the corn–soy complex. Similarly, more optimal soils hug the river in Missouri and Arkansas, and so do rice and cotton.

Distribution of land capabilty classification (LCC) levels. Notes: land capability class (LCC) one is the best soil, which has the fewest limitations. Progressively lower classifications lead to more limited uses for the land. LCC eight means soil conditions are such that agricultural planting is nearly impossible
2.3 Weather Variables
For weather data we use PRISM data processed by Schlenker and Roberts (2009) to a 4 km by 4 km spatial resolution, with a daily level of temporal resolution. The dataset includes both temperature (highs and lows) and precipitation. Two time periods of weather data are used for each crop year. (1) The planting season data are known by farmers before they actually plant. A cold wet spring, for instance, would delay planting and make a shorter season crop more desirable than a longer season crop. Compared to corn, soy is more tolerant of being planted late and more dependent on daylight hours, so it can make up time easily. When the planting season is late, farmers are more inclined to plant soy. (2) Past weather is used as a proxy for expected weather. We do not find much gain from including past weather beyond one season, though, in terms of predicting current weather, quite a few lags of past weather are statistically significant. For parsimony, we limit the lags of past weather to one.
Figure 3 shows the observed weather condition in the planting season (from April to June)Footnote 5 from 2002 to 2010 and the growing seasons (from April to November) from 2001 to 2009.Footnote 6 The observed temperatures are warmer in the south and the precipitation levels are larger. Monthly average temperature in the growing season ranges from 9 to 24 °C from the top of Wisconsin to the bottom of our study areas in Mississippi, a distance of 1600 km. Monthly average rainfall in a growing season is also variable across this landscape with a high of 17 cm and a low of 7 cm, highest in the southeast and lowest in the north.

Observed weather conditions
Degree days are calculated from daily highs and lows using a fitted sine curve to approximate the amount of hours the temperature is at or above a given threshold (Baskerville and Emin 1969). As in Schlenker and Roberts (2009), we bin the weather data into degree days at a given temperature and above. We draw on their work and other literature to reduce the number of bins to just those at critical thresholds. However, we expand the number of classifications of temperature to account for the month in which it occurs. We expect, for instance, that hot temperatures are not as harmful in autumn as they are in the middle of the growing season.
2.4 Climate Change Scenarios
Climate change scenarios are taken from Climate Wizard.Footnote 7 Two models are considered: (1) ensemble average, SRES emission scenario: A1B; and (2) ensemble average, SRES emission scenario: A2. Both models predict temperature and precipitation in change and in level for the end of the century (2080s). The comparison baseline is the average temperature and precipitation between 1961 and 1990.
Figure 4 shows the two climate change scenarios. The A1B model predicts a 4.1 °C increase in temperature on average in the north, and a 3.7 °C increase in the south. The A1B model also predicts a 1.35 cm increase in monthly precipitation in a planting season in the north, and a 0.65 increase in a growing season; while in the south the A1B model predicts a 0.22 cm decrease and a 0.243 cm decrease in a planting season and a growing season respectively. The A2 model predicts similar warming and drying pattern, but 0.6 °C warmer and 0.1 cm drier than A1B’s prediction.

Climate change scenarios. Notes: distribution is over 4 km squares for temperature change to 2080. Annual temperature change is from http://www.climatewizard.org/. Since it’s annual, the temperature changes in planting season and growing season are the same. Annual precipitation percent change is from the same source. We convert percent change to change by multiplying the observed precipitations in 2010 for the months in planting season and 2009 for the months in growing season
Future degree days are processed in two steps: first, future temperature highs and lows are generated by adding changes to original highs and lows; then the degree days are calculated based on the future highs and lows.
2.5 Yield Data
For the yield equations, the county-level data (1950–2010) of non-irrigated planted area and production on non-irrigated land is from USDA. Yield is defined as non-irrigated production divided by non-irrigated planted area for corn, soy, and cotton. For rice, non-irrigated planted area and production are not reported, because rice has to be irrigated. So for rice, yield is defined as total production divided by total planted area.
3 The Econometric System and Regression Results
In this section, we set up the econometric systems for crop coverage response and yield response to weather and soil characteristics. We also present the regression results, based on which we do the simulation under climate change scenarios in the next section.
3.1 Crop Coverage Response Equation
Within each of our 4 km grid cells, \( n \), we observe the fraction of land in year \( t \) that was allocated to crop (or other use) \( i \): \( S_{int} \). There are \( M \) crops. If we imagine that each hectare of our grid cells has a crop choice, then on that hectare the crop with the highest profit will be chosen. As a result, the fraction of the crop chosen in a grid cell will be a proportion type model.
where \( \varvec{X}_{{\varvec{int}}} \) is a vector of determinate factors of profit from planting crop \( i \) on plot \( n \) at year \( t \), \( \varvec{\beta}_{\varvec{i}} \) is a vector of coefficients and \( d_{int} \) is an error term. \( \phi \left( {} \right) \) is a suitable transformation with its domain on the unit interval. When all of the shares are strictly within the unit interval, using logit as the transformation and rearranging terms gives a linear estimation equation (Berry 1994): \( log\left( {S_{int} } \right) - log\left( {S_{0nt} } \right) =\varvec{\beta}_{\varvec{i}}^{{\mathbf{\prime }}} \varvec{X}_{{\varvec{int}}} + d_{int} \). To deal with the fact that many plots do not have a certain crop (i.e., many \( S_{int} \) are zeros), we instead use a ratio transformation and we get
In order to predict shares as a function of the independent variables, we sum the share ratio over \( S_{i} \) (recall that the shares sum to one) and solve for \( S_{0nt} \)
Substituting (3) into (2), we get
The estimation strategy is that first we estimate Eq. (2) by Tobit, accounting for the zero shares. Then we simulate \( d_{jnt} \) (\( j = 1, \ldots ,M \)) by taking draws from a left truncated normal distribution with mean 0, standard deviation \( \sigma_{jnt} \) and truncation at \( -\varvec{\beta}_{\varvec{i}}^{{\mathbf{\prime }}} \varvec{X}_{{\varvec{jnt}}} \). Finally, we calculate \( S_{int} \) for each draw and take the averages.
Because the scale of this study encompasses more than a 1000 km, some conditions that change across the landscape may not be accounted in our variables. This spatial correlation can induce heteroscedasticity, which would make straightforward tobit estimation inconsistent. We know of two feasible estimation strategies. One strategy is to estimate a linear probability model with a Spatial Error Model (SEM) correction for the errors. In the linear probability model, OLS would be consistent and the SEM would serve to produce the correct standard errors and a more efficient estimate of the coefficients. The limitation is that the prediction of shares is not guaranteed to be between 0 and 1. The other solution is to estimate local tobit models, each for only one county and its neighbors. The spatial correlation is taken care of because the coefficients and the variances are free to vary across the landscape. Neighbors of county \( i \) are defined to be counties whose centroids are within 70 km distance of the centroid of county \( i \). 70 km is chosen based on Moran’s I tests. The tests show that the spatial correlation in error decrease exponentially and beyond 70 km it is lower than \( 10^{ - 3} \). Within 70 km,Footnote 8 a county has 8 neighbors on average and each county has about 100 4 km grid cells. Therefore, each regression has about 900 observations.
Next, we consider what explanatory variables should be included. The Nerlovian adaptive price expectations model (Nerlove 1956) assumed that farmers have rational price expectations based on their information set, and described it in three equations. Braulke (1982) derived a reduced form from the three equations by removing the unobserved variables. Choi and Helmberger (1993) combined this reduced form and farmer’s demand functions. Based on their work, Huang and Khanna (2010) described the crop share as a function of the lagged share, climate variables, economic variables, risk variables, population density, and time trend. Hausman (2012) included most of these explanatory variables, and also futures prices, substitute crop share and crop yield. To follow the literature,Footnote 9 we include as explanatory variables lagged crop share, lagged substitute crop shares, weather in the current planting season and the last growing season, and soil conditions. We include the interaction term of heat and moisture to account for the possibility that dry warming is much more harmful than warming with moisture (Lobell et al. 2011). We also include year fixed effects to account for both output and input prices and government programs. This leads to the following specification:
where \( S_{int} \) is the fraction of land in year \( t \) that was allocated to crop \( i \), \( \varvec{SS}_{int - 1} \) is a vector of the coverage shares of crop \( i \)’s substitutes planted at grid cell \( n \) in year \( t - 1 \), and soy and corn are substitutes in the north and all four crops are substitutes in the south; \( \varvec{Soil}_{n} \) is a vector of soil conditions at grid cell \( n \), including percent clay, percent sand, percent silt, water holding capacity, pH, slope, electrical conductivity, frost-free days, depth to water table, and depth to restrictive layer, as well as LCC (Land Classification Code); \( \varvec{GDD}_{nt - 1} \) is a vector of degree days by month in the last growing season (April through November in year \( t - 1 \)), and the data are binned at 10, 15, 20, 25, 29, 30, and 32 °C, where 10 °C is degree days ≥ 10 °C, etc.; \( \varvec{PDD}_{nt} \) is a vector of degree days by month in the current planting season (April through June in year \( t \)), and the data are binned at 10 and 15 °C; \( \varvec{GP}_{nt - 1} \) is a vector of precipitation by month in the last growing season; \( \varvec{PP}_{nt} \) is a vector of precipitation by month in the current planting season; \( \varvec{PreDD}_{nt - 1} \) is a vector of interactions of the inverse of precipitation and the degree days at 32 °C and above in the same month, and all months in the last growing season are included. \( \mu_{t} \) and \( \varepsilon_{int} \) are the year fixed effect and the error term respectively. In sum, Eq. (5) describes the coverage ratio \( \left( {\frac{{S_{int} }}{{S_{0nt} }}} \right) \) as a function of lagged coverage shares of the crop of interest \( (S_{int - 1} ) \) and its substitutes \( (S_{int - 1} ) \), soil characteristics \( (\varvec{Soil}_{n} ) \), weather conditions \( (\varvec{GDD}_{nt - 1} ,\varvec{PDD}_{nt} ,\varvec{GP}_{nt - 1} ,\varvec{PP}_{nt} ,\varvec{PreDD}_{nt - 1} ) \), and common shocks that change along years \( (\mu_{t} ) \).
We run separate land use regression for each crop and each county. In sum, we have 766 sets of estimates (312 counties; 2 main crops for the northern states and 4 main crops for the southern states). We test the significance of soil, precipitation, and degree days. As shown in Table 2, soil and temperature are significant at the 1% significance level in 69 to 93% of the regressions. Precipitation is significant at the 1% significance level in 42 to 76% of the regressions. These results show that soil, precipitation and temperature are all important determinants of crop coverage.
“Appendix A” explores how a 1-degree change in temperature and a 1-cm change in precipitation affect crop coverage in both short run and long run. The results indicate that rice and cotton in the south spread toward the north, consistent with the fact that rice and cotton are heat-requiring crops; and farmers make different crop adaptations, even when facing same level of climate change, and the reason is soil. The results also indicate that it takes time for farmers to fully adjust crop coverage to weather shocks and 5 years is long enough for the farmers to complete the adaptation. Therefore, in the simulation for the climate change, we consider crop coverage response in 5 years.
3.2 Yield Equation
Yield is estimated at the county level as a function of weather, soil, and time trends. The estimation differs from Schlenker and Roberts (2009) in the use of the interaction term for hot and dry weather and in replacing the county fixed effects with soil variables. It leads to the following yield equation:
where \( Y_{ict} \) is yield of crop \( i \) per acre (abbreviated as yield) in county \( c \) in year \( t \); \( \varvec{Soil}_{c} \) is a vector of soil conditions in county \( c \), weighted by crop acre over grid cells; \( \varvec{DD}_{ct} \) is a vector of degree days in county \( c \) in year \( t \), weighted by crop acre over grid cells, and the data are binned at 0, 5, 10, 15, 20, 25, 29, 30, and 32 °C, where 10 °C is degree days > 10 and ≤ 15 °C; \( P_{ct} \) is precipitation in county \( c \) in year \( t \); \( PreDD_{ct} \) is interaction of the inverse of precipitation and the degree days at 32 °C and above, by year; \( \varvec{QT} \) is a vector of linear and quadratic time trends by state; \( \varepsilon_{ict} \) is the error term. In sum, Eq. (6) describes crop yield \( (Y_{ict} ) \) as a function of soil characteristics \( (\varvec{Soil}_{c} ) \), weather conditions (\( \varvec{DD}_{ct} ,P_{ct} ,(P_{ct} )^{2} ,PreDD_{ct} \)), and time trends (\( \varvec{QT} \)). Precipitation and its quadratic form are both in the model because of the non-linear relationship between yield and precipitation: When precipitation is low, additional rain or snow relives the drought and therefore increase yield; while when precipitation is high, additional rain or snow may harm the yield (Schlenker and Roberts 2009; Chen et al. 2016).
The individual coefficients are generally significant at the 95% level in the corn and soy equations and more sporadically significant for rice and cotton, presumably because of the much smaller sample size (about 20,000 county years for corn and soy, while only about 2000 county years for rice and cotton). The LCC variables for corn, soy, and cotton show a large advantage to better soils. For cotton in particular, LCC 2 yields less than half of LCC 1. In contrast, rice yields best in the lower rated soils, presumably because very wet soil is good for rice and deleterious for the other crops and so has a low LCC rating. An F-test shows that the soil variables are jointly significant in all crops.
The effect of extreme temperature on yield in this model comes from both the direct effect of the high temperature variable (degree days at 32 °C and above) and from the interaction term (degree days at 32 °C and above times the inverse of precipitation). The latter term accounts for the effect of hot and dry as opposed to just hot weather. The effects of increasing the degree days in the top temperature bin and the effect of increasing precipitation are given in Table 3. Starting with precipitation, the effect of another centimeter of water when there has been average precipitation is near zero for all crops. However, when there is another centimeter of water at minimum precipitation, yield increases by 5.8% for corn, 5.0% for soy, and 4.2% for cotton. Rice is usually irrigated and hence the effect is small and negative. The effects of another degree day in the top temperature bin, at average precipitation, are negative for all crops and strongest in corn with a 1% yield loss. However, when there is another degree day at minimum precipitation, the loss is 1.8% for corn, 1% for soy, 1.4% for cotton, and a slight gain for rice. These results on yield are similar to Schlenker and Roberts (2009) in that very hot weather is deleterious to crop yield.
The detailed regression results for the yield equations are available in “Appendix B”.
4 Crop Coverage Responses to Climate Change
Based on the estimation above, we simulate crop coverage response to the climate change A1B scenario. Figure 5 depicts the changes in the geographic distribution of crop coverage. The comparison is the A1B scenario for the late century (2080s) to the actual coverage in 2010.

Predicted crop coverage changes under the A1B scenario. Notes: a 20% change reported here means corn (for example) share increases from \( a \) to \( a + 0.2 \)
In the north, the average change for corn is a loss of 9.4 percentage points, starting from a base of 27.5% of the land being devoted to corn. In the figure, corn coverage decreases the most in northern and central Iowa and Illinois near the Mississippi River. These are the places with the highest coverage in corn in the baseline. These negative changes are partially offset by increases in coverage in northeastern Wisconsin. Given the sensitivity of corn to high heat, a hotter climate would be expected to move the corn growing area northward, as shown on the map. For soy, the loss in crop coverage in the A1B scenario is 6.3 percentage points, starting from a base of 20.9% coverage. The pattern follows that of corn; the ratio of soybeans to corn is close to three-quarters in the baseline and remains close to three-quarters in the A1B scenario in the north.
In the south, the change in climate removes most of the remaining corn from the landscape. Corn loses 4.5 percentage points from a base of 5.5% coverage. Soy is more suited to the hot and wet climate. It loses 14.9 percentage points from a base of 29.4% coverage. Rice and cotton coverage both increase in response to climate change. Rice gains 5.2 percentage points in coverage from a base of 10.3%. Cotton gains a half percentage point from a base of 11.8%. In terms of geographical distribution, the rice area gained is to the north of the cotton area gained. The likely reason that rice is positively influenced by the changed climate in that it is irrigated and not susceptible to damage in hot, dry weather.
“Appendix C” presents the same analysis for the climate change A2 and for temperature change only. We see that the A2 scenario has very similar effects on crop shares. Through comparing temperature change only to both temperature and precipitation changes, we conclude that for the Mississippi-Missouri river system, the major concern about climate change is warming, instead of drying.
5 Crop Production Losses to Climate Change with Crop Coverage Fixed
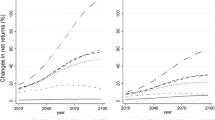
Figure 6 depicts production losses under the A1B scenario. These losses are predicted holding crop coverage fixed, so they show only the effect of lower yields on production. While Wisconsin gains corn and soy production, all other areas lose. Soy production is positively affected over a larger area compared to corn. The positive effect on soy production includes southwestern Wisconsin and northeastern Iowa. The production losses to both corn and soy are generally greater farther south. As shown in Table 4, the change in total production, holding crop coverage constant, is 20.3% for corn and 6.6% for soy in the north, while these numbers are 83.1% for corn and 58.9% for soy in the south. For rice and cotton in the south, there are production losses for both crops: 18.2% for rice and 59.0% for soy. In sum, only Wisconsin becomes a better climate for growing the major crops.

Crop production loss with coverage fixed under the A1B scenario
6 Crop Production Loss to Climate Change, Considering Both Yield Effect and Coverage Response
In this section, we answer the central question of the paper: what the production changes will be when farmers adapt to climate change by changing the land use for crops. In these estimates, both crop coverage and yield respond to climate change. These changes can be seen as a shift in the supply curve; prices and other conditions are held fixed. Table 4 and Fig. 7 provide the answer to this question.

Crop production loss with both yield effect and coverage response under the A1B scenario
Starting in the north, for corn (the first column of the table), 20.3% of production is lost due to the yield effect, and it is more than doubled when yield and crop coverage are both considered. For soybeans, loss from the yield and crop coverage effects together is five times the yield effect alone, despite soy suffering only minor yield effects. The use of the soy–corn rotation and the substitution away from corn is what leads to large coverage responses in soy in the north. Land uses that will increase as corn usage decreases include the major uses for 2010 other than corn and soy. The largest of these uses are grass, forest, wetlands, alfalfa and other hay. There are no other food crops with even 100,000 acres at present.
In the south, the coverage effect reinforces the production losses from the yield effect for corn and soybeans. In the case of corn, the A1B scenario nearly eliminates corn from the landscape; the production change through both effects is 1.1 times the yield effect. Soy is grown independently from corn in the south, unlike the north; both effects together reduce production by 1.3 times the yield effect alone. Because rice gains considerable coverage, it goes from a production loss when considering only yield loss to a production gain when considering both yield and coverage response. For cotton, the increase in coverage slightly mitigates the yield loss. Thus, adaptation by changing the crop landscape within the existing crop collection, particularly the increase in rice and cotton, is noticeable in affecting production changes when facing climate change.
7 Conclusion
This paper examines crop adaptation to climate change in the context of the six states along the Mississippi-Missouri river corridor. We consider the entire distribution of temperatures within each day and each 4 km grid cell. We also consider the soil conditions at the 4 km grid level. Based on the estimates of crop choices, we predict future crop share distribution under several climate change scenarios. We find that adaptation by changing crop choice offsets the production losses caused by lower yields for rice and cotton. For the main food crops, corn and soybeans, however these negative effects are reinforced.
In this paper we have dealt with changes in land use caused by climate. Government programs that are themselves partially a reaction to climate change, like the US Ethanol program, do by themselves induce land use change (Searchinger et al. 2008) For ethanol, these indirect land use changes partially offset the direct land use change from a hotter climate.
While this study shows that, ceteris paribus, the loss in food crop production from corn and soybeans will be exacerbated by substitution away from these crops to other uses, the underlying data on land use does not provide an obvious alternative. In the data pasture and minor crops are lumped together and there are no other food crops that use a substantial part of the landscape. With production losses as big as forecasted in this study, equilibration of the crop supply–demand system would require large changes in price or crops novel to this landscape. Price increases would draw land back into major crop production and might also increase yield through more input (mostly more fertilizer) and technology improvement. Should the equilibration be through price increases, then the quantity of food demanded, which would equal the quantity produced from this landscape, will fall. It is only through the introduction of crops new to this landscape that are more suited to the hot climate that food production can be restored to its current level.
Notes
There is currently insufficient land cover data to extend our analysis to other states.
The CDL is generated based on Resourcesat-1 AWiFS, Landsat 5 TM, and Landsat 7 ETM + satellites and has a ground resolution of 56 or 30 meters, depending on the year and sensors used (Mueller and Seffrin 2006).
LCC codes are based on physical measurements only. One reason why we don't reproduce it with our variables is that it is based on the soil series, which is categorical and we don't use. http://www.nrcs.usda.gov/wps/portal/nrcs/detail/national/about/history/?cid=nrcs143_021436.
Planting season and growing season vary across crops and regions. In the six states along the Mississippi-Missouri river corridor, the planting season is from April to May for corn, rice, and cotton, and from May to June for soybean. The harvest season is October for rice and corn, and November for cotton and soybean. Growing season is defined as the period between planting season (included) and harvest season (included).
We have ten year’s land use, soil and weather information from 2001 to 2010. Growing season weather enters regressions as a lag variable. For 2001, there is no lagged land use data or lagged weather data, so 2001 is dropped from the regressions. Regressions for 2002 to 2010 use the growing season weather from 2001 to 2009.
Source: http://www.climatewizard.org/.
We also tried 130 km to define neighbors in the regressions. It turns out to have smaller maximum likelihood and large minimum Chi square. So we choose 70 km for the regressions.
References
Askari H, Cummings JT (1977) Estimating agricultural supply response with the nerlove model: a survey. Int Econ Rev 18(2):257–292
Baskerville G, Emin P (1969) Rapid estimation of heat accumulation from maximum and minimum temperatures. Ecology 50:514–517
Berry ST (1994) Estimating discrete-choice models of product differentiation. RAND J Econ 25:242–262
Braulke M (1982) A note on the nerlove model of agricultural supply response. Int Econ Rev 23(1):241–244
Burke M, Emerick K (2016) Adaptation to climate change: evidence from US agriculture. Am Econ J Econ Policy 8(3):106–140
Chavas J-P, Holt MT (1990) Acreage decisions under risk: the case of corn and soybeans. Am J Agric Econ 72(3):529–538
Chen S, Chen X, Xu J (2016) Impacts of climate change on agriculture: evidence from China. J Environ Econ Manag 76(8):105–124
Choi J-S, Helmberger PG (1993) How sensitive are crop yields to price changes and farm programs? J Agric Appl Econ 25:237–244
Hausman C (2012) Biofuels and land use change: sugarcane and soybean acreage response in Brazil. Environ Resour Econ 51(2):163–187
Hornbeck R (2012) The enduring impact of the American dust bowl: short-and long-run adjustments to environmental catastrophe. Am Econ Rev 102(4):1477–1507
Huang H, Khanna M (2010) An econometric analysis of US crop yield and cropland acreage: implications for the impact of climate change. Denver, Colorado, pp 25–27
Just RE (1974) An investigation of the importance of risk in farmers’ decisions. Am J Agric Econ 56(1):14–25
Lichtenberg E (1989) Land quality, irrigation development, and cropping patterns in the northern high plains. Am J Agric Econ 71(1):187–194
Lin W, Dismukes R (2007) Supply response under risk: implications for counter-cyclical payments’ production impact. Appl Econ Perspect Policy 29(1):64–86
Lobell DB, Banziger M, Magorokosho C, Vivek B (2011) Nonlinear heat effects on African maize as evidenced by historical yield trials. Nat Clim Change 1(1):42–45
Mueller R, Seffrin R (2006) New methods and satellites: a program update on the NASS cropland data layer acreage program. In: Remote sensing support to crop yield forecast and area estimates, ISPRS archives, vol 36, no. 8, p W48
Nerlove M (1956) Estimates of the elasticities of supply of selected agricultural commodities. J Farm Econ 38(2):496–509
Nerlove M, Bessler DA (2001) Expectations, information and dynamics. Handb Agric Econ 1:155–206
Schlenker W, Roberts MJ (2009) Nonlinear temperature effects indicate severe damages to US crop yields under climate change. Proc Natl Acad Sci 106(37):15594–15598
Searchinger T et al (2008) Use of US croplands for biofuels increases greenhouse gases through emissions from land-use change. Science 319(5867):1238–1240
Wu J, Segerson K (1995) The impact of policies and land characteristics on potential groundwater pollution in Wisconsin. Am J Agric Econ 77(4):1033–1047
Acknowledgements
We are grateful to Michael Roberts and Wolfram Schlenker for sharing both their weather data and expertise. The remaining errors are those of the authors.
Funding
This project was funded by the Environmental Biosciences Institute at Berkeley and Illinois.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Crop Coverage Response to Unit Change in Weather
Table 5 and Fig. 8 summarize the crop coverage share changes for two scenarios in both short run and long run. In one scenario, daily temperature increases by one degree for all months in 2009 and 2010. In the other scenario, monthly precipitation decreases by 1 cm in all the months, and temperature increases as above. Table 5 shows that in the short run, 1-degree warming decreases corn and soy shares. With 1-degree warming, 1.6% less land (a 5% decrease) in the north and 4.3% less land (a 77% decrease) in the south is covered by corn; 1.2% less land (a 6% decrease) in the north and 0.3% less land (a 1% decrease) in the south is covered by soy. One degree warming increases rice share by 0.042 (a 40% increase in the south) and cotton share by 0.072 (a 61% increase in the south). It suggests that warming favors rice and cotton. Looking at corn and soy, dry warming decreases coverage more than warming alone in the north, but this pattern does not hold for corn in the south, which is wetter. Figure 8 shows that although the averages in share change are different in the scenarios with and without a change in precipitation, the difference is small and the share change patterns are similar. This indicates that a 1 cm change in precipitation is not large enough to have significant effects on crop adaptation.

Distribution of crop coverage changes with unit change in temperature and precipitation. x-axes are crop share changes. For example, 0.2 in the first panel means corn share increases from \( a \) to \( a + 0.2 \). SR stands for short run, which is the year when the weather change happens. LR stands for long run, which is 5 years after the weather change happens. For corn and soy, all six states are included. For rice and corn, only the three south states are included, because there is little rice and cotton in the north
Table 5 and Fig. 8 also show that the share changes of corn and soy in the long run are larger on average and the distributions have fatter tails. This indicates that it takes time for farmers to fully adjust crop coverage to weather shocks. The share changes of rice, cotton, and other land use in the long run are larger. We also check the crop share changes in 2020 and find that they are very similar to those in 2015. This suggests that 5 years is long enough for the farmers to complete the adaptation.
To illustrate how crop adaptation varies across landscapes, Fig. 9 maps out the long-run share changes for the 1-degree-warmer scenario and the 1-degree-warmer-and-1-centimeter-drier scenario, respectively. The findings are as follows. First, the two scenarios have similar land cover shifting patterns, which confirms the findings in Fig. 8. Second, rice and cotton in the south spread toward the north, which is expected, because the north becomes more suitable for rice and cotton. Third, the main crops, mainly rice and cotton, take land from minor crops and other uses in the south. This suggests that a 1-degree increase from current temperature is beneficial to rice and cotton. This is consistent with the fact that rice and cotton are heat-requiring crops. Last, but not at least, farmers make different crop adaptations, even when facing same level of climate change, and the reason is soil.

Crop coverage changes with unit change in weather. Notes A 20% change reported here means corn (for example) share increases from \( a \) to \( a + 0.2 \)
Appendix B: Full Regression Results of County Yield Equations by Crop
See Table 6.
Appendix C: Predicted Crop Coverage Changes Under the A2 Scenario
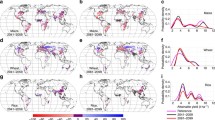
Figures 10 displays the spatial variations of crop adaptation under A2 model considering both temperature and precipitation changes. It is similar to the crop adaptation under A1B model, shown in Fig. 5 in the main text. The figures show that in the face of climate change, farmers, in general, will grow less corn and soy, more rice and cotton, and shift rice and cotton towards north.

Predicted crop coverage changes under the A2 scenario. Notes: a 20% change reported here means corn (for example) share increases from \( a \) to \( a + 0.2 \)
Figure 11 depicts the distributions of predicted crop share changes under climate change scenarios. Compared to Fig. 8, Fig. 11 has wider distributions, which is expected because the A1B and A2 scenarios have larger increases in temperature than a one-unit increase. It also shows that the four climate change scenarios lead to similar land use shifting patterns, which suggests that a drying climate within the predicted magnitude does not significantly worsen the growth condition for crops. Therefore, we conclude that for the Mississippi-Missouri river system, the major concern about climate change is warming, not drying.

Distribution of predicted crop coverage changes under climate change scenarios. Notes: x-axes are crop share changes. For example, − 0.5 in the first panel means corn share decreases from \( a \) to \( a - 0.5 \). For corn and soy, all six states are included. For rice and corn, only the changes in the three south states are included, because there is no rice and cotton in the north
Rights and permissions
About this article

Cite this article
Xie, L., Lewis, S.M., Auffhammer, M. et al. Heat in the Heartland: Crop Yield and Coverage Response to Climate Change Along the Mississippi River. Environ Resource Econ 73, 485–513 (2019). https://doi.org/10.1007/s10640-018-0271-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10640-018-0271-7