
Abstract
Risk terrain modelling (RTM) is emerging as an effective approach for predicting how and where crimes concentrate within cities and regions. However, in its previous applications there is a tendency to overestimate the influence of external environmental risks and preventive factors. Most studies applying RTM have investigated factors associated with the characteristics of the urban setting, whilst only a limited number have focused on identifying the risks associated with the availability and the characteristics of potential targets for criminals. This study uses RTM to identify the spatial risk and protective factors related to residential burglaries in the city of Milan, Italy. Factors considered are the neighbourhood- and target-related contextual factors, the exposure to crime and potential mitigating strategies. The results show that when the place and target of the offence are intrinsically related a target-oriented approach to select factors is useful for increasing the understanding of why some locations are most likely to experience future crimes. Indeed, the peculiarities of the target itself are integral to understan both the decision-making of criminals and the overall level of crime risk. Related policy implications are discussed.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Evaluating or predicting the criminal risks inherent to different areas within cities is an emergent strategy for effectively preventing and counteracting criminal behaviours (Braga et al. 1999; Braga and Weisburd 2010; Chainey et al. 2008; Chainey and Ratcliffe 2005; Lersch and Hart 2011; Sherman and Weisburd 1995). The basic premise of such methods is that crime is not randomly distributed across space and time, but, rather, tends to cluster within specific places and at specific times irrespective of the designated unit of analysis (Eck and Weisburd 1995; Weisburd et al. 2009). This has substantial implications for crime forecasting and police resource allocation models, which aim to develop successful crime prevention programs within specific places (Caplan et al. 2011; Dugato 2013; Favarin 2018; Johnson 2010; Kennedy et al. 2011).
Several methods of crime risk forecasting have been developed and implemented. Some are focused on examining previous crime patterns and regularities in order to identify hot areas where there is an increased likelihood of future crime (Chainey et al. 2008). From a traditional hot spot analysis, this approach evolved towards more complex mathematical algorithms and simulations capable of modelling crime diffusion and replication across time and space (Bowers et al. 2004; Mohler et al. 2011; Rosser et al. 2017). However, despite their increased sophistication, such techniques remain predominantly focused on data and information about prior crimes. An alternative and complementary stream of research is a risk assessment that shifts the analytical focus away from actual crimes and instead onto the vulnerability and attractiveness of a specific area from the criminal’s perspective (Perry et al. 2013). To achieve this goal, these techniques factor in an analysis of the risk heterogeneity of a given setting in which crimes occur (Moreto et al. 2014). The central point of contention is that criminogenic risk is ordinarily a by-product of the manifold socio-economic and environmental factors that characterise a particular milieu (Caplan et al. 2011; Caplan and Kennedy 2016; Eck and Weisburd 1995). Consequently, any analyses of the distribution of crime events within a city must take into consideration the various risk factors that can influence both the severity and the longevity of criminal activities (Caplan et al. 2015; Moreto et al. 2014).
Risk terrain modelling (RTM) is a methodological approach to territorial risk assessment based on these aforesaid considerations. It was originally developed by Caplan and Kennedy (2010), but has undergone significant development and refining in the interim (Caplan and Kennedy 2016). RTM combines data on prior victimisation and territorial risk factors to explain crime concentration. In conjunction with pinpointing high-risk areas, the principal contribution of this approach is that it affords the identification of factors that determine risk. The rationale behind this approach is that the likelihood of a crime is determined by several contextual factors that either generate or hinder criminal opportunities. Of course, such a proposition both pre-dates and is already well-established outside of RTM. In fact, its theoretical antecedents lie in the seminal theories of environmental criminology, which purport that crime opportunities are not randomly distributed across places. Rather, concentrations of criminal events in delimitated areas are ordinarily called crime hot spots, and defined as areas which have “a greater than average number of criminal events [...] or where people have a higher than average risk of victimisation” (Eck et al. 2005, 2). Previous literature has demonstrated how a large portion of crimes committed in an urban setting are concentrated in specific areas, and, moreover, that this remains stable across time (Andresen et al. 2016; Andresen and Malleson 2011; Bennett 1995; Braga et al. 2010; Johnson and Bowers 2004; Townsley et al. 2000; Weisburd et al. 2012, Weisburd et al. 2004). Such stability is primarily due to the presence of contextual factors that act as crime generators, attractors or facilitators (Brantingham and Brantingham 1995).
Setting out from this well-established knowledge, the RTM approach has the additional merit of providing a step-by-step methodological blueprint for scholars and practitioners to produce a territorial risk assessment by collecting, evaluating and visualising those features at a territorial level. Moreover, by virtue of providing more effective predictions of crime events and stressing the merits of long-term solutions focused on reducing the structural causes of crime, the RTM approach can help to develop current policing strategies around crime concentration. The effectiveness of the RTM approach has been continually demonstrated through its various applications to different crime types across several countries. More specifically, studies have shown how this approach is flexible enough to both adapt to different contexts and backgrounds, and effectively forecast high risk areas for a wide variety of crime types, such as burglary (Moreto 2010; Moreto et al. 2014), robbery (Dugato 2013), violent crimes (Drawve et al. 2016a; Drawve, Drawve et al. 2016b; Kennedy et al. 2016), homicide (Dugato et al. 2017), shootings (Caplan et al. 2011) and terrorism (Onat and Gul 2018). Moreover, comparative studies also verify that RTM is equally, if not sometimes more, effective and reliable in crime forecasting than other methods based on hot spots analysis (Caplan et al. 2011; Drawve 2016; Dugato 2013; Ohyama and Amemiya 2018).
Although there is undoubtedly an increasing number of researchers adopting an RTM approach, there is a relative dearth of studies which have introduced specific target-based risk factors as a component of the risk. So far, most studies applying RTM have investigated those factors associated with the environment and landscape of different urban settings, such as land use, proximity to public transport or other facilities, and measures of social disorganisation (Caplan and Kennedy 2011). All these factors refer mainly to the structural composition of an area, whilst only a limited number of studies have focused on identifying the risk factors associated specifically with targets. Caplan et al. (2013) rightly argued that assessing an area’s vulnerability in relation to contextual factors is insufficient for correctly predicting the future location of crime. Other factors, such as exposure to crime or the presence of risk-mitigation strategies, must be considered. We agree with this conclusion, stressing that in analysing the contextual factors, crucial elements to be considered are also the presence and the characteristics of potential targets for criminals (Fig. 1).

Components of the crime risk
The presence of targets is more relevant in those scenarios where targets are mobile (i.e. street robberies, homicides, vehicle thefts, etc.). This issue has been implicitly included in previous studies by considering the facilities that attract a high number of potential targets and victims in a given place (Gerell 2018). This assumption sounds plausible enough, and, as such, it could prove to be useful to overcome problems associated with availability of data. Indeed, information about people’s or vehicle’s movements are rarely collected and, if they are collected, hard to access. However, when the targets of crimes are places themselves (e.g. houses, banks, shops, etc.) then the issue of differentiating their specificities becomes more relevant. Whilst some scholars have taken this aspect into consideration, they ordinarily include these features within the overall analysis of the contextual factors without a clear distinction. Even though this approach is plausible, this article advocates for the importance of differentiating between the vulnerability that is intrinsically connected with the characteristics of the targets and the one that is generated by the surrounding area itself. Especially when the target and the location of a crime are coincident as is the case for residential burglaries (Fig. 1).
This discrimination has practical implications in terms of risk reduction policies. Understanding how these two latter contextual factors combine in defining the overall vulnerability is crucial for accurately estimating the preferences and choices of the criminals and, consequently, defining better targeted interventions.Footnote 1
In this study, we apply the RTM approach to investigate residential burglaries in the city of Milan (Italy) taking into consideration the characteristics of the potential targets as a specific subcategory of the contextual factors in order to produce a better understanding of the micro dynamics related to the areas’ vulnerabilities. The results confirm that those specific features, in conjunction with other factors, improve the identification of the areas with a higher probability of future burglaries.
The article is organised as follows: the first section reviews knowledge about factors that can help in the prediction of residential burglaries. The second section discusses both the methodology utilised to define the risk map and the data used in the study. The third section delineates the results of the study, whilst the final section underscores the key implications emerging from the study for future research and policy-makers.
The Risk and Protective Factors of Residential Burglaries
Previous literature has highlighted several risk factors that impact upon the occurrence of residential burglaries. Specifically, these risks are related to the characteristics of the offender, the target, the location and the time frame in which crimes occur. Moreover, several authors have stressed how the location of prior instances of victimisation also constitutes an important risk factor for further victimisations.
Traditionally speaking, burglaries have been studied from a qualitative and ethnographic approach. At first, scholars were primarily interested in understanding the decision-making processes of the offenders and the choices of their targets, which, ultimately, led to a focus on describing the characteristics of offenders and targets (Bennett and Wright 1984; Cromwell et al. 1991b; Cromwell et al. 1991a; Rengert and Wasilchick 1985; Walsh 1986; Wright et al. 1995). More recently, quantitative research has begun to investigate the spatio-temporal patterns of burglaries in different urban settings, alongside identifying the potential social and environmental risk factors in order to design effective prevention strategies. Despite continued research interest in target selection (Bernasco 2006; Bernasco et al. 2015; Bernasco and Nieuwbeerta 2005; Bernasco and Ruiter 2014; Ruiter 2017; Vandeviver et al. 2015), the focus of these studies is invariably on the characteristics of the location where burglaries occur, the time frame in which crimes happen, and the influence of prior victimisation on criminal activity (Johnson 2013; Johnson et al. 2007; Johnson and Bowers 2004; Montoya et al. 2016; Moreto et al. 2014; Jerry H. Ratcliffe 2002; Townsley et al. 2000). Hence, there has been a notable shift in the field from more qualitative, offender-oriented and macro approaches to studying burglaries towards more quantitative, location-oriented and micro approaches. This transition has ultimately led to a more comprehensive understanding of the dynamics of both commercial and residential burglaries.
Offender Characteristics
Ethnographic studies conducted with burglars (e.g. interviews, field observation) have tended to focus on the process of target selection itself, rather than on the specific characteristics of offenders (Bennett and Wright 1984; Cromwell et al. 1991b; Cromwell et al. 1991a; Rengert and Wasilchick 1985; Walsh 1986; Wright et al. 1995; Wright and Decker 1994). Nevertheless, scholars have investigated specific features of offenders, such as gender, age, ethnicity and the level of expertise in conducting residential burglaries, as possible risk factors (Bernasco and Nieuwbeerta 2005; Shover 1991; Wright et al. 1995).
Target Characteristics
Qualitative studies have hitherto investigated the processes of target selection and, hence, the related characteristics of the targets. More recently, a distinct strand of geographical criminological research has applied a discrete spatial choice frameworkFootnote 2 to study the preferences of burglars when selecting targets (Bernasco 2006; Bernasco et al. 2015; Clare et al. 2009; Townsley et al. 2016; Townsley et al. 2015; Vandeviver et al. 2015). Both structural features and the demographic characteristics of the inhabitants represent important information for understanding what kinds of houses are more likely to fall victim to residential burglaries.
For instance, there is extensive agreement over the fact that burglars prefer to target unoccupied homes (Caplan and Kennedy 2011; Cohen and Cantor 1980; Homel et al. 2014; Mustaine 1997; Shover 1991; Tseloni et al. 2002), and therefore premises that display signs of possible occupancy are less likely to be the victim of residential burglaries. Indeed, dogs, alarms, the presence of a vehicle outside the house, milk on the doorstep or lights being on inside a house are all deterrents for some offenders, particularly novices (Buck et al. 1993; Clare 2011; Nee and Meenaghan 2006; Snook et al. 2011; M. Taylor and Nee 1988). Households inhabited by homemakers, old people and infants are less prone to domestic burglaries, because they are ordinarily occupied by someone (Dugato et al. 2015; Lister and Wall 2008; Wilcox et al. 2007). On the contrary, families composed of only one member or tenants are more at risk of burglary (Dugato et al. 2015; Shover 1991). The same is true of households inhabited by commuting workers (people that travel every morning to go to work) (Bruce et al. 1998).
Research has shown that burglars are more prone to target single-family dwellings than other types of houses/apartments (Bernasco and Nieuwbeerta 2005), whilst it is also proven that detached or semi-detached houses increase the likelihood of being selected by burglars (Kleemans 1996), although, one should note, Vandeviver et al. (2015) found conflicting results. Moreover, houses with multiple floors present fewer escape routes than ground floor premises (Beavon et al. 1994; Bennett and Wright 1984). Residential units with doors and windows on the ground floor that are accessible from the street, such as most single-family houses, present a higher risk of victimisation compared to apartments located on higher floors (Bernasco and Nieuwbeerta 2005).
Furthermore, studies have tested the real estate values of residential units as a proxy for the richness of an area (Bernasco and Nieuwbeerta 2005), whilst family income has been adopted as an indirect proxy for target attractiveness (Rountree and Land 2000). Research has produced discordant findings, as some burglars appear to be attracted to wealthy targets, while others are not. Indeed, research has shown that burglars either seem to prefer low-income houses in dilapidated neighbourhoods that can be easily entered (Evans 1989) or well-maintained houses where the goods to be stolen are economically rewarding (Bowers and Johnson 2005; Budd 1999).
Neighbourhood Characteristics
Studies have demonstrated how the surrounding environment is especially important for understanding the risk of victimisation for a target. Residential burglaries are not immune to the effects that contextual factors play in crime occurrence. Over the years, studies have examined the characteristics of the areas (e.g. neighbourhood, census tract, street segment) in which domestic burglaries have occurred. A summary of these risk factors is presented below.
Demographic Composition of the Neighbourhood
On the one hand, densely populated areas have more people that can informally control the territory, on the other hand they also include more potential targets. The presence of foreigners, young males, illiterates and unemployed people in a neighbourhood is also likely to increase the risk of potential victimisation (Hipp 2011; Kubrin and Herting 2003; Sorenson 2003; Weisburd et al. 2012).
Social Disorganisation
Residences located in disadvantaged neighbourhoods are subject to high crime rates due to low levels of socioeconomic status, collective efficacy and informal surveillance, and high levels of residential mobility (Bernasco and Nieuwbeerta 2005; Capowich 2003; Ratcliffe and Mccullagh 1998; Rountree and Land 2000).
Proximity to the Offender’s Residence
In line with the assumptions of crime pattern theory (Brantingham and Brantingham 1993, Beavon et al. 1994), burglars do not travel far from their homes to commit crimes. Research has shown that proximity to the offender’s residence is a key risk factor for domestic burglaries (Bernasco 2010; Bernasco and Nieuwbeerta 2005; Moreto et al. 2014; Vandeviver et al. 2015).
Proximity to Pawn Shops
Burglars want to discard stolen property as quickly as possible. For this reason, the proximity of pawn shops where offenders can sell stolen goods has been identified as a risk factor in previous research (Alpert et al. 2001; Clarke 1999; Fass and Francis 2004; Moreto et al. 2014).
Proximity to Public Transportation
Public transportation provides a means through which to access and exit the neighbourhood more easily (Caplan and Kennedy 2011). This explains why it is often used as a proxy for the accessibility of an area, and why it is often positively correlated with crime events (Moreto et al. 2014; Yu 2011).
Type of Land Use
Residential land use is a crucial risk factor if one considers that burglary can only occur within residences (Caplan and Kennedy 2011; Moreto 2010). However, previous literature has also stressed the importance of mixed land use as either a risk or prevention factor. Having said this, there is a controversial relationship between mixed land use (i.e. a combination of residential and commercial buildings in a given area) and crime. Several studies have demonstrated how mixed lands are more likely to experience higher crime rates, because of the weaker social ties between their residents (Groff and McCord 2011; Roncek 2000; Weisburd et al. 2012) and a lack of social control (Taylor 1997; Wilcox et al. 2004). Conversely, the presence of bars, theatres and cinemas can also enhance the vitality of an area which is otherwise empty during the evening/night, and thus have a positive effect on reducing crime (Jacobs 1961). Other studies which have investigated the relationship between land use and crime have invariably found a negative relationship between mixed land use and different crime types (Browning et al. 2010; Kinney et al. 2008; Montoya et al. 2016).
Time Frame and Exposure to Prior Victimisation
Selecting targets for residential burglaries has been shown to be dependent on the time frame. For example, burglars have different strategies for committing domestic burglaries in the daylight compared to when it is dark (Coupe and Blake 2006). In addition, offenders are more likely to burgle unoccupied homes, and, as such, are willing to wait for specific periods in which people are not at home to commit the burglary (Caplan and Kennedy 2011; Cohen and Cantor 1980; Homel et al. 2014; Mustaine 1997; Shover 1991; Tseloni et al. 2002). Indeed, research has identified specific hours of the day, days of the week and months of the year in which domestic burglaries are more likely to occur. The assumption here is that when the resident is absent there is an increased likelihood that a burglary will take pace (e.g. during the work day or summer holidays) (Caplan and Kennedy 2011; Farrell and Pease 1994; Shover 1991).
In addition, burglaries are more likely to occur in the period immediately after the first occurrence of victimisation (Anderson et al. 1995; Polvi 1990; Polvi et al. 1991). That is to say, repeat burglaries are more likely to occur in the seven day period after the original crime (for a review see Farrell 1995). According to qualitative interviews conducted with offenders, burglars usually return to the same house because they know the property and want to steal additional goods (Bennett 1995; Kleemans 2001). Recently, with the development of advanced GIS techniques and more sophisticated statistical methods, several authors have begun to study the spatio-temporal patterns of victimisation and repeat victimisation of domestic burglaries by taking into account these dynamics (Bowers and Johnson 2005; Johnson et al. 2007; Johnson and Bowers 2004; Ratcliffe 2002; Townsley et al. 2000). There is widespread agreement in the field concerning the fact that prior victimisation plays a central role in explaining the presence of residential burglaries in urban settings. Interviews with offenders confirm that burglars are disposed to return to a house they have previously robbed (Bennett 1995; Kleemans 2001), whilst quantitative work demonstrates that previous hot spot areas increase the risk of future victimisation (Farrell 1995; Farrell and Pease 1993; Farrell et al. 1995; Townsley et al. 2000; Weisburd et al. 2012; Matthews et al. 2001; Wells et al. 2012; Youstin et al. 2011).
Risk Mitigation Strategies
Previous literature indicates that burglars take into account the presence of police forces when offending; hence, why proximity to police stations is a potential prevention factor (Capowich 2003; Rengert and Wasilchick 1985; Weisburd et al. 2012). In addition, private security measures (e.g. alarms, dogs, locks, external lights) can also act as mitigation strategies to contrast residential burglaries (Buck et al. 1993; Wright and Decker 1994; Farrell 1995; Tseloni et al. 2017). According to a recent study, a combination of multiple anti-burglary security devices increases the protection capabilities of a residence 20 times compared to one with no security (Tseloni et al. 2017).
The Present Study
The purpose of this study is to combine the risk factors highlighted in the literature in an innovative RTM analysis considering at the same time the neighbourhood- and target-related contextual factors, the exposure to crime and potential mitigating strategies. This study analyses residential burglaries recorded in the city of Milan, Italy.Footnote 3 Although the choice of this city is primarily driven by the availability of data, several additional features make it a suitable case study. Indeed, Milan is the second largest city in Italy and has the typical urban structure of the main European cities (Dugato 2013; Favarin 2015, 2018). Moreover, Milan has one of the highest rates of residential burglary in Italy (Comune di Milano 2015). At this juncture, residential burglary constitutes one of the biggest concerns in Italy. In fact, this specific crime type has experienced a dramatic growth in recent years (+127% reported domestic burglaries), which is consistent with trends across most European countries. There are manifold causes for this increase. Chief among them is the recent economic and social crisis affecting many European countries, and the low clearance rate characterising this crime type (Bernasco 2014; Dugato et al. 2015). These factors are unlikely to be overcome at the local level alone, and instead point to the necessity of focusing more on preventive modes of intervention.
Data and Method
RTM is the method applied by this study to investigate the vulnerabilities that expose specific areas of Milan as the places of residential burglaries. The construction of the risk map for residential burglaries comprises several steps: (1) identification of the potential risk and protective factors; (2) operationalisation of each factor; (3) selection of the appropriate model type to identify the relevant factors; (4) assessment of the relative importance of each factor in determining the risk of crime. These latter steps are conducted by defining the nature of the association between each factor and the residential burglaries that occurred in the previous year (2013). The subsequent steps consist of: (5) constructing the final risk map; (6) evaluating its predictive power by looking at the reported crimes that occurred in 2014 (Caplan and Kennedy 2010).
Data
For the purposes of this analysis, data on residential burglaries were used both to define the outcome of the model (dependent variable) and to include previous victimisation as a potential risk factor (exposure). The presence of law enforcement stations estimate the level of formal control (risk mitigation strategies). The contextual risk and protective factors are divided into features of the physical and social backcloth of the neighbourhoods and the characteristics of the potential targets of the crime (i.e. the residential houses and their inhabitants).
Residential Burglary Data
Data on residential burglaries occurring in Milan between 2012 to 2014, including both attempted and completed crimes, are provided by the Italian Ministry of the Interior. On average, about 70% of the registered burglaries were geocoded for the years 2012–2014.Footnote 4
Exposure to Prior Victimisation
To investigate the effect of the repeated victimisation of specific buildings upon the overall risk of an area, we divided prior occurrences of crime into two subgroups: the first one includes crime counts in repeatedly victimised buildings (c.d. repeat victimisation); the second includes crime counts in buildings that were victimised only once (c.d. single victimisation).
Risk Mitigation Strategies
Information on the location of Police stations (Polizia di Stato and Carabinieri) was obtained from Pagine Gialle, and subsequently double-checked via the websites of law enforcement organisations.Footnote 5 All 75 Police stations were successfully geocoded using the reported address.
Area’s Vulnerabilities
-
i)
Target characteristics
-
Demographic composition and characteristics of the inhabitants. Data was retrieved from the Italian 2011 General Population and Housing Census, and collected at the census tract level (N = 6079) at the most detailed level of disaggregation available. Data was collected for: Commuting peopleFootnote 6; Percentage of people above the age of 70; Percentage of illiterates; Percentage of people with a university degree or an equivalent qualification; Percentage of homemakers; Percentage of people below the age of 5; Percentage of families composed of only one member; Percentage of tenant families.
-
Type and quality of housing units. Data on the number of housing units was provided by CERVED, an Italian information provider, at the census tract level. Housing units were divided into four categories: apartments of high quality; apartments of medium quality; apartments of low quality; and detached houses.
-
Height of the buildings Information about the height of buildings was retrieved from the Italian 2011 General Population and Housing Census, and collected at the census tract level. For the purposes of this analysis, two measures were considered: the percentage of buildings with one floor, and the percentage of buildings with four or more floors.
-
House values. Information about average real estate values was provided by the Italian Real Estate Market Observatory (OMI). OMI categorises the Milan Municipality into 54 OMI areas, within which real estate values are considered to be relatively homogeneous.
-
ii)
Neighbourhood characteristics
-
Mixed land use. The mixed land is operationalised as the density of business activities in a given area. Data on the number of business activities was provided by CERVED at the census tract level.
-
Stations. Data on the location of metro stops (N = 90) was obtained as GIS shapefiles from the geodatabase of the Milan Municipality.Footnote 7
-
Pawn shops. Data on the location of pawn shops was obtained from Pagine Gialle, a company which publishes telephone directories of businesses or institutions categorised by product or service. All of the 51 listed pawn shops were successfully geocoded using the reported address.
-
Demographic composition and characteristics of the neighbourhoods: Data was retrieved from the Italian 2011 General Population and Housing Census, and collected at the census tract level. Data was collected for: Population density; Percentage of people unemployed; Percentage of foreigners; Percentage of young males.
Operationalisation of the Factors
To the best of the authors’ knowledge, all previous research applying RTM has used a continuous grid with squared cells as the unit of analysis. Indeed, this type of grid is undoubtedly the most expedient for studying US cities, which are normally organised around a regular street network, or several un-built environments (i.e. sea, land or forests). However, most European cities are characterised by an irregularly shaped urban fabric, consisting of a dense system of narrow streets with only a few long and wide roads, which requires irregularly shaped census tracts. Therefore, following Birch et al. (2007), this study argues that an hexagonal grid is more appropriate than a squared one in modelling irregular shapes. This is because hexagons are closer in shape to circles than squares are: they have a shorter perimeter than squares of equal area, and thus reduce the potential bias from edge effects (Krebs 1998). Moreover, some parts of a square are farther from its centroid than any part of a hexagon of equal area (Birch et al. 2007). This serves to reduce the potential bias deriving from incorrect allocation of census tract characteristics to each of the hexagonal cells. Therefore, for the purposes of this analysis, Milan is modelled as a continuous grid of equally sized hexagonal cells of 2500 square metres (N = 71,440) (Fig. 2).

Hexagonal and square grid in comparison with the census tracts in Milan (fictitious values)
Moreover, the hexagons that do not intersect with any buildings are removed from the sample as well as all those hexagons that only contain non-residential buildings (e.g. universities, train stations, hospitals, prisons). Detailed information about the areas of the city covered by buildings was retrieved from Milano Geoportale. This data, which is publicly available as GIS shapefiles, reports the perimeter of all the buildings in Milan (N = 213,076), which was digitalised through a flight tracking conducted in 2012. This information allows the author to excise from the analysis those areas which do not contain any potential targets for burglars, and thus improves the precision of the estimates. Focusing only on those cells with available targets serves to limit the estimation sample, which, in turn, helps to reduce biases from having excessive “structural zeros” in the crime counts, without any loss of information. As a matter of fact, residential burglaries can only take place where residential buildings are located. This allows for a reduction of bias when estimating the regression coefficients that would otherwise show large distortions if all the hexagonal cells were included in the analysis. This strategy, ultimately, restricts the analysis to 38,323 hexagons, covering 53.6% of the total area of the city. Only 958 burglaries (4.58% of the total) took place in the 33,117 excluded hexagons during the period of 2012 to 2014. It is safe to assume that these numbers are due to either a margin of geocoding error or those crimes reported in non-built premises (i.e. tents, shacks or caravans).
The data about risk and protective factors were available in two different formats: dots and polygon. Point data about residential burglaries, for each of the three years analysed, were aggregated and counted within each hexagon. Data on other specific factors available at a point level (i.e. stations, police stations and pawn shops) were operationalised by considering buffers of 100 and 200 m around each location to test their possible areas of influence. All the other information was only available at a polygonal level, namely census tracts or OMI areas. This data was assigned to the hexagons that had their centroid included in the perimeter of that polygon. Demographic variables were processed as ratios at the census tract level. This method requires assuming that the demographic composition of each census is homogeneous across the hexagons it contains. Similarly, the average real estate value, available for 54 OMI areas, was assigned to the hexagons contained in each area. A slightly different approach was utilised for the assignation of the housing units: for each of the four variables provided at the census tract level, the number of units was spread among the hexagons that had their centroid included in the perimeter of that tract, using as a weight the extent of built area in each hexagon. This method is underpinned by the assumption that the buildings within each census tract are of approximately the same height so that the number of housing units in each hexagon is solely dependent on the extent of the built area. The same methodology was adopted to allocate the business activities to the hexagonal cells. The number of business activities in each census tract was spread among the hexagons that had their centroid included in the perimeter of that tract, using as a weight the extent of the built area of each hexagon. In this case, it was necessary to assume that business activities were homogeneously spread among the buildings of each census tract.
Model Selection and Identification of Relevant Factors
The analysis was performed using a step-wise backward selection process to determine the final model type. Starting from the full model, each variable was removed and the Bayesian Information Criteria (BIC) score recalculated. After each iteration, the specification with the lowest BIC score was selected as the new candidate model. This process was repeated until no addition of any variable led to a lower BIC score. Two different model specifications were tested: one Poisson and one negative binomial.Footnote 8 In order to measure the presence of multicollinearity, the variance inflation factor (VIF) and associated tolerance (1/VIF) was calculated for each of the explanatory variables (Hamilton 2013, 203). A tolerance value below 0.1 suggests the presence of significant collinearity with another variable. Tolerance values ranged from 0.51 to 0.98 in the final model, and thus suggest an absence of multicollinearity.
Ultimately, the negative binomial was selected as the best model specification. The backward selection process led to the exclusion of some factors (i.e. illiterates, unemployed, tenant families, children below the age of 5, percentage of buildings with one floor, percentage of buildings with four floors or more). Furthermore, a distance proximity of 100 m emerged as the most appropriate operationalisation of the spatial proximity to metro stations, pawn shops and police stations. Table 1 presents the variables included in the analysis with descriptive statistics at hexagonal level, information on the source, year and original level of aggregation. The last column of Table 1 gives information about the inclusion or exclusion of each variable in the final model(s) based on the results of the selection process.
Construction and Assessment of the Final Risk Map
Once the regression coefficients of the negative binomial are estimated, the predicted number of crimes in each hexagonal cell can be computed. For each of the 38,323 cells analysed, the predicted crime counts were calculated as \( \mathit{\exp}\left({\hat{\beta}}_0+\sum \limits_{i=1}^n{X}_i{\hat{\beta}}_0\right) \). This value was used to assign a risk score to each cell. The observations were divided into 10 equal classes, using as intervals the deciles of the distribution of predicted values. Scores of 10 and 9 are deemed to be very high and high respectively.
The validity of the risk score was then tested by using as an estimation sample the crime counts of 2013, and confronting the resulting risk scores with the crime occurrences registered in 2014. In particular, the results of the final model have been compared to the ones obtained by the other specifications of the model. In order to compare the predictive efficacy and accuracy of the different maps this study applies the predictive accuracy index (PAI) and the recapture rate index (RRI). The first one, developed by (Chainey et al. 2008), has as numerator the percentage of crimes correctly predicted and as denominator the percentage of the areas of the city identified as risky. The higher the value, the higher the accuracy of the model in predicting crime events. The second metric (RRI) proposed by Levine (2008) assesses the reliability of the forecasting power over time and is determined as the ratio having as denominator the PAI considering the recorded crimes used to define the model (Measured PAI) and as numerator the PAI calculated using the crime data in a subsequent time period (Predicted PAI).
Results
The first finding emerging from the analysis concerns the identification of relevant risk and protective factors and their relative importance in determining the risk of future residential burglaries. Table 2 reports the results of five different negative binomial regression models.Footnote 9 The first one is a model that includes only information about exposure to crime; the second model adds the influence of the risk mitigation strategies; the third and the fourth models incorporate the contextual factors, divided into neighbourhood and target characteristics. The last model is the full one resulting from the stepwise backward selection process. This latter model was the one used to construct the final risk map.
Focusing on the full model, the first interesting set of findings centres on the effect of previous victimisation. As expected, the presence of houses burgled in the previous year increases the likelihood of future similar crimes, and thus suggests a significant level of stability within risky areas. However, in contradistinction to what was expected, the presence of a single-victimised house has a higher effect on the overall level of risk than a multi-victimised dwelling. There are two potential reasons for this unexpected finding. First, previous research has demonstrated how repeat victimisation patterns usually occur in shorter time frames than those accounted for in this analysis (i.e. one year) (Bowers and Johnson 2005). Therefore, it is likely that a house that has been victimised several times over a single year has already endured its “chain” of consequential victimisation. Conversely, some of the single-victimised houses may only be at the beginning of this “chain”, and thus are at a higher risk of future crime. Second, the focus of this analysis is on defining the risk of an area (i.e. the cells) as opposed to a single target. Therefore, although repeated instances of prior victimisation are undoubtedly important for defining the risk of a specific house, the clustering of single instances of victimisation may be emblematic of more widespread risk in the entire area.
Regarding mitigation strategies and neighbourhood characteristics: proximity to a police station reduces the likelihood of a crime, as does a high number of commercial activities, whereas high residential density, which serves as a proxy for crowded apartment buildings, entails a lower level of informal control. This underscores the relevance of formal and informal control in the decision-making process of criminals. As hypothesised, the proximity to pawn shops and stations are significantly associated with the risk of residential burglaries. It is interesting to note that the mixed land use factor changes the sign of its association, becoming negative as expected, only when target characteristics are included into the model.
Most of the target characteristics included in the final model confirm the original hypotheses about their respective associations with residential burglaries. Specifically, the factors suggest that a higher probability of vacant targets during the daylight (i.e. a low commuting people exchange ratio, a high number of one-person households) is associated with an increased likelihood of future crimes. Similarly, a low number of homemaker residents reduces the risk by incrementing the control over the targets. The attractiveness of the targets as a risk factor is also confirmed by the positive effect of the average house value within each cell.
With respect to the type of residential premises, it appears that, if all other variables remain constant, the presence of detached houses and apartments of low quality significantly increase the likelihood of future burglaries. The greater attraction of these targets to criminals can be explained by considering two distinct motivations. On the one hand, detached houses are ordinarily more accessible and harder to safeguard than apartments, whilst, on the other hand, poor apartments are less likely to be adequately protected by their inhabitants. This is also confirmed by the negative impact upon risk of high quality apartments where it is not uncommon to find janitors and private or shared security systems.
The results were then used to construct a final predictive risk map for the 2014 residential burglaries using the 2013 crime data. The other factors were kept constant assuming a substantial level of stability for these social and structural features. Figure 3 shows the cells that scored the highest risk values. Specifically, 10% of the residential cells considered to be at very high risk, which corresponds to about 5% of the overall city area, are classified as zones at very high risk (red), whilst the following 10% as at high risk (orange). The comparison map shows the cells according to the actual number of burglaries recorded in 2014 (blue-scale).

Final risk map (full model) and actual residential burglaries in 2014
Table 3 provides, for each of the classes of risk values identified, a summary of the statistics about residential burglaries that occurred in 2014, which were used to evaluate the predictive effectiveness of the final risk map. The results show that more than half (53.37%) of the crimes recorded in the following year occurred in those areas defined as risky, with roughly one in three burglaries (34.13%) taking place in zones at a higher risk. Moreover, all the other statistics confirm the validity of the map in predicting areas where the likelihood of future burglaries is likely to be higher.
The results of the final model (full model) were compared with the ones obtained excluding the target and neighbourhood characteristics respectively. This permits isolating the effects of the different contextual factors in the evaluation of the predictive power of these models. In all cases, 10% of cells identified as the most likely sites of future residential burglaries were considered to calculate the predictive accuracy index (PAI) and the recapture rate index (RRI).
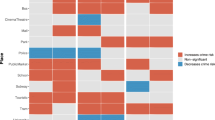
While the target model seems slightly more accurate but less consistent than the other two, all three specifications show almost equivalent results (Table 4). These minimal differences may suggest that the characteristics of the target and the neighbourhood bring the same informative contribution to the predictive effectiveness of the model. However, this consideration is proved wrong by observing Fig. 4 where the cells identified as at very high risk by both the target and neighbourhood models are coloured in red, whereas the cells in the riskiest decile for one of the two models only are coloured in green for the target model and blue for the neighbourhood model. The map shows that only 58.67% of the residential cells considered to be at very high risk by the target model are also considered as very high risk by the neighbourhood model. This suggests that the two sets of variables identified different sub-dimensions of the areas’ vulnerability.

Comparison of the very high risk areas identified by the target model, the neighbourhood model or both models
Conclusion
This study has demonstrated that when the place and target of the offence are intrinsically related a target-oriented approach to selecting factors is useful for significantly increasing the probability of correctly identifying the locations of future crimes. These findings contrast with the observed tendency in the academic literature to overestimate the influence of external environmental risks and preventive factors and, ultimately, overlook how the specificities of the target itself are integral to understanding both the decision-making of criminals and the overall level of crime risk.
Caplan and colleagues schema for assessing the likelihood of a future crime purports that three elements require evaluation: the exposure to crime; the presence of risk-mitigation strategies; and the vulnerability of the area, defined by the environmental factors attracting or facilitating crime (Caplan et al. 2013; Kennedy et al. 2016). This study suggests that in this latter category scholars should look specifically at information related to the attractiveness of a target when using RTM, or other territorial risk assessment strategies, to analyse residential burglaries or other similar crimes, such as shoplifting or bank robbery. Vulnerability is indeed defined both by internal specificities of the targets and by the external influence of surroundings features.
Moreover, the findings of this study are also relevant for practitioners and policy makers. Identifying the specific characteristics that make targets more vulnerable or attractive is crucial for designing more effective policies and interventions. In the short-term, including target features affords a higher level of predictive effectiveness, which, in turn, increases the possibility of identifying less stable crime concentrations. Ultimately, this will help to reduce crime concentrations and prevent further crime. In the long term, focusing the analytical gaze upon the specific features that make some targets more attractive to criminals than others can develop academic inquiry beyond looking at only the most common modus operandi, and help to develop more complex target-specific countermeasures. One especially important point concerns how including the characteristics of targets within the model may change the association with specific environmental factors emerging in the previous model (e.g. mixed land use). What this suggests is the importance to look at both target and place characteristics. Academic considerations notwithstanding, the most pertinent finding from a policy perspective is that an incorrect indication of causality between crime risk and certain contextual factors may lead to ineffective interventions, which, ultimately, fail to engage with the real roots of the crime threat.
It is instructive to point out that this research is not without its limitations. Firstly, some potentially relevant factors were excluded from the study due to the lack of reliable data. To cite an example, relevant neighbourhood factors, such as precise information about the structure of the street network of the city or about the patrolling activities of law enforcement were simply not available. Moreover, information about the specific security systems adopted by each target was missing. This study assumes that these aforesaid features can be partially accounted for via the quality of the houses. Whilst the authors consider this assumption to be plausible, it does not fully compensate for this lack of information. Future research should attempt to overcome these limitations and to test the relevance of the target characteristics in relation to other crime types.
Notes
It is worth noting that the distinction between target and neighbourhood characteristics is not always clear-cut. As an example, in analysing residential burglaries a high rate of unemployed inhabitants in a block could be a protective endogenous factor (i.e. the houses are less likely to be vacant during the day), but the same variable considered for surrounding blocks can be seen as a risk factor (i.e. due to the presence of potential offenders). Hence, the decisions should be driven by the aims of the analysis, specific assumptions, particular knowledge of the researchers or the characteristics of the data available.
“The approach is rooted in the micro-economic theory of random utility maximisation (RUM) and enables studying the choice behaviour of decision-makers selecting one alternative from a larger set of exhaustive and mutually exclusive alternatives” (Vandeviver et al. 2015).
The definition of residential burglary is the one specified in Art.624-bis of the Italian Criminal Code.
A total of 20,921 burglaries are successfully geocoded as point data (i.e. 6166 in 2012, 7356 in 2013, 7399 in 2014).
Polizia di Stato: https://questure.poliziadistato.it; Arma dei Carabinieri: http://www.carabinieri.it
People moving in and out of the census tract during the day for either work or study. This measure is computed, for each census tract, as the ratio: (resident population + people coming in - people going out)/(resident population).
Milano Geoportale: https://geoportale.comune.milano.it/sit
This method differs slightly from the one applied by the RTMDx software (Caplan and Kennedy 2016), although the basic approach of empirically selecting the relevant factors is the same. The decision of not using the RTMDx software was mainly driven by its current limitation in considering only risk or protective factors geocoded as point data.
To assess the potential effect of spatial dependence, we calculated the Moran’s I to test the spatial autocorrelation of our dependent variable and for the residuals of the models. The result are very close to 0 in all the cases suggesting that the autocorrelation of the dependent variable is negligible and that the residuals are spatially uncorrelated. These tests suggest that spatial dependence is not a relevant issue in our dataset and does not seriously affect the results obtained.
References
Alpert, G. P., Flynn, D., & Piquero, A. R. (2001). Effective community policing performance measures. Justice Research and Policy, 3(2), 79–94.
Anderson, D., Chenery, S., & Pease, K. (1995). Biting back: Tackling repeat burglary and car crime. Home Office Police Research Group London.
Andresen, M. A., & Malleson, N. (2011). Testing the stability of crime patterns: Implications for theory and policy. Journal of Research in Crime and Delinquency, 48, 58–82.
Andresen, M. A., Linning, S. J., & Malleson, N. (2016). Crime at places and spatial concentrations: exploring the spatial stability of property crime in Vancouver BC, 2003–2013. Journal of Quantitative Criminology, 33(2), 255–275.
Beavon, D. J. K., Brantingham, P. L., Brantingham, P. J. (1994). The influence of street networks on the pattering of propery offences. In R. V. Clarke (Ed.), Crime prevention studies (2:115–48). Monsey: Criminal Justice Press.
Bennett, T. (1995). Identifying, explaining, and targeting burglary “hot spots”. European Journal on Criminal Policy and Research, 3(3), 113–123.
Bennett, T., Wright, R. (1984). Burglars on burglary: Prevention and the offender. Aldershot: Gower.
Bernasco, W. (2006). Co-offending and the choice of target areas in burglary. Journal of Investigative Psychology and Offender Profiling, 3(3), 139–155.
Bernasco, W. (2010). A sentimental journey to crime: effects of residential history on crime location choice. Criminology, 48(2), 389–416.
Bernasco, W. (2014). Residential burglary. In G. Bruinsma & D. Weisburd (Eds.), Encyclopedia of criminology and criminal justice (pp. 4381–4391). Springer: New York.
Bernasco, W., & Nieuwbeerta, P. (2005). How do residential burglars select target areas? A new approach to the analysis of criminal location choice. British Journal of Criminology, 45, 296–315.
Bernasco, W., & Ruiter, S. (2014). Crime location choice. In G. Bruinsma & D. Weisburd (Eds.), Encyclopedia of criminology and criminal justice (pp. 691–99). Springer: New York.
Bernasco, W., Johnson, S. D., & Ruiter, S. (2015). Learning where to offend: effects of past on future burglary locations. Applied Geography, 60(Supplement C), 120–129.
Birch, C. P. D., Oom, S. P., & Beecham, J. A. (2007). Rectangular and hexagonal grids used for observation, experiment and simulation in ecology. Ecological Modelling, 206(3), 347–359.
Bowers, K. J., & Johnson, S. D. (2005). Domestic burglary repeats and space-time clusters. European Journal of Criminology, 2, 67–92.
Bowers, K. J., Johnson, S. D., & Pease, K. (2004). Prospective hot-spotting: the future of crime mapping? British Journal of Criminology, 44(5), 641–658.
Braga, A. A., & Weisburd, D. (2010). Policing problem places: Crime hot spots and effective prevention. Oxford: Oxford University Press.
Braga, A. A., Weisburd, D., Waring, E. J., Green, L., Spelman, W., & Gajewski, F. (1999). Problem-oriented policing in violent crime places: a randomized controlled experiment. Criminology, 37(3), 541–580.
Braga, A. A., Papachristos, A. V., & Hureau, D. M. (2010). The concentration and stability of gun violence at micro places in Boston, 1980–2008. Journal of Quantitative Criminology, 26(1), 33–53.
Brantingham, P. L., & Brantingham, P. J. (1993). Environment, routine, and situation: toward a pattern theory of crime’. In R. V. Clarke & M. Felson (Eds.), Routine activity and rational choice: advances in criminological theory, vol. 5. New Brunswick: Transaction.
Brantingham, P., & Brantingham, P. (1995). Criminality of place. European Journal on Criminal Policy and Research, 3(3), 5–26.
Browning, C. R., Byron, R. A., Calder, C. A., Krivo, L. J., Kwan, M.-P., Lee, J.-Y., & Peterson, R. D. (2010). Commercial density, residential concentration, and crime: land use patterns and violence in neighborhood context. Journal of Research in Crime and Delinquency, 47(3), 329–357.
Bruce, M. A., Roscigno, V. J., & McCall, P. L. (1998). Structure, context, and agency in the reproduction of black-on-black violence. Theoretical Criminology, 2(1), 29–55.
Buck, A. J., Hakim, S., & Rengert, G. F. (1993). Burglar alarms and the choice behavior of burglars: a suburban phenomenon. Journal of Criminal Justice, 21(5), 497–507.
Budd, T. (1999). Burglary of domestic dwellings: findings from the British crime survey. In Home Office statistical bulletin. London: Home Office.
Caplan, J. M., & Kennedy, L. W. (2010). Risk terrain modeling manual. Newark: Rutgers Center on Public Security.
Caplan, J. M., & Kennedy, L. W. (Eds.). (2011). Risk terrain modeling compendium. Newark: Rutgers Center on Public Security https://www.amazon.com/Risk-Terrain-Modeling-Compendium-Caplan/dp/1463700997.
Caplan, J. M., & Kennedy, L. W. (Eds.). (2016). Risk terrain modeling: Crime prediction and risk reduction. Oakland: University of California Press.
Caplan, J. M., Kennedy, L. W., & Miller, J. (2011). Risk terrain modeling: brokering criminological theory and GIS methods for crime forecasting. Justice Quarterly, 28, 360–381.
Caplan, J. M., Kennedy, L. W., & Piza, E. L. (2013). Joint utility of event-dependent and environmental crime analysis techniques for violent crime forecasting. Crime & Delinquency, 59(2), 243–270.
Caplan, J. M., Kennedy, L. W., Barnum, J. D., & Piza, E. L. (2015). Risk terrain modeling for spatial risk assessment. City, 17(1), 7.
Capowich, G. E. (2003). The conditioning effects of neighborhood ecology on burglary victimization. Criminal Justice and Behavior, 30(1), 39–61.
Chainey, S., & Ratcliffe, J. (2005). GIS and crime mapping. New York: Wiley.
Chainey, S., Tompson, L., & Uhlig, S. (2008). The utility of hotspot mapping for predicting spatial patterns of crime. Security Journal, 21, 4–28.
Clare, J. (2011). Examination of systematic variations in burglars’ domain-specific perceptual and procedural skills. Psychology, Crime & Law, 17(3), 199–214.
Clare, J., Fernandez, J., & Morgan, F. (2009). Formal evaluation of the impact of barriers and connectors on residential burglars’ macro-level offending location choices. Australian & New Zealand Journal of Criminology, 42(2), 139–158.
Clarke, R. V. (1999). Hot products: Understanding, anticipating and reducing demand for stolen goods. Police Research Series paper 112. London: Great Britain Home Office, Policing and Reducing Crime Unit Research, Development and Statistics Directorate.
Cohen, L. E., & Cantor, D. (1980). The determinants of larceny: an empirical and theoretical study. Journal of Research in Crime and Delinquency, 17(2), 140–159.
Coupe, T., & Blake, L. (2006). Daylight and darkness targeting strategies and the risks of being seen at residential burglaries. Criminology, 44(2), 431–464.
Cromwell, P. F., Marks, A., Olson, J. N., & Avary, D.’. A. W. (1991a). Group effects on decision-making by burglars. Psychological Reports, 69(2), 579–588.
Cromwell, P. F., Olson, J. N., & Avary, D.’. A. W. (1991b). Breaking and entering: An ethnographic analysis of burglary. Thousand Oaks: Sage.
di Milano, C. (2015). Milano - I Numeri Del Comune. Rapporto Ubers 2015. Urbes. Milan: ISTAT.
Drawve, G. (2016). A metric comparison of predictive hot spot techniques and RTM. Justice Quarterly, 33(3), 369–397.
Drawve, G., Moak, S. C., & Berthelot, E. R. (2016a). Predictability of gun crimes: a comparison of hot spot and risk terrain modelling techniques. Policing and Society, 26(3), 312–331.
Drawve, G., Thomas, S. A., & Walker, J. T. (2016b). Bringing the physical environment back into neighborhood research: the utility of RTM for developing an aggregate neighborhood risk of crime measure. Journal of Criminal Justice, 44, 21–29.
Dugato, M. (2013). Assessing the validity of risk terrain modeling in a European City: preventing robberies in Milan. Crime Mapping, 5(1), 63–89.
Dugato, M., Caneppele, S., Favarin, S., & Rotondi, M. (2015). ‘Prevedere i furti in abitazione’. Transcrime Research in Brief. Serie Italia. Trento: Transcrime - Università degli Studi di Trento, Università Cattolica del Sacro Cuore.
Dugato, M., Calderoni, F., & Berlusconi, G. (2017). Forecasting organized crime homicides: Risk terrain modeling of camorra violence in Naples, Italy. Journal of Interpersonal Violence. https://doi.org/10.1177/0886260517712275.
Eck, J. E., & Weisburd, D. (1995). Crime places in crime theory. In J. E. Eck & D. Weisburd (Eds.), Crime and place. Monsey: Willow Tree.
Eck, J. E., Chainey, S., Cameron, J. G., Leitner, M., & Wilson, R. E. (2005). Mapping crime: Understanding hot spots. Washington, D.C.: U.S. Department of Justice - National Institute of Justice.
Evans, D. J. (1989). Geographic analysis of residential burglary. In D. J. Evans & D. T. Herbert (Eds.), The geography of crime (pp. 86–107). London: Routledge.
Farrell, G. (1995). Preventing repeat victimization. Crime and Justice, 19, 469–534.
Farrell, G., & Pease, K. G. (1993). Once bitten, twice bitten: Repeat victimisation and its implications for crime prevention. Police Research Group Crime Prevention Unit paper no. 46. London: Home Office.
Farrell, G., & Pease, P. (1994). Crime seasonality: domestic disputes and residential burglary in Merseyside 1988–90. The British Journal of Criminology, 34(4), 487–498.
Farrell, G., Phillips, C., & Pease, K. (1995). Like taking candy: why does repeat victimization occur? British Journal of Criminology, 35(3), 384–399.
Fass, S. M., & Francis, J. (2004). Where have all the hot goods gone? The role of pawnshops. Journal of Research in Crime and Delinquency, 41(2), 156–179.
Favarin, S. (2015). Testing and explaining crime concentrations outside the U.S.: The City of Milan. Milan: Università Cattolica del Sacro Cuore.
Favarin, S. (2018). This must be the place (to commit a crime): Testing the law of crime concentration in Milan, Italy. European Journal of Criminology. https://doi.org/10.1177/1477370818757700.
Gerell, M. (2018). Bus stops and violence, are risky places really risky? European Journal on Criminal Policy and Research. https://doi.org/10.1007/s10610-018-9382-5.
Groff, E. R., & McCord, E. S. (2011). The role of neighborhood parks as crime generators. Security Journal, 25, 1–24.
Hamilton, L. C. (2013). Statistics with STATA: version 12, 8th edn. Belmont: Cengage.
Hipp, J. R. (2011). Spreading the wealth: the effect of the distribution of income and race/ethnicity across households and neighborhoods on City crime trajectories. Criminology, 49(3), 631–665.
Homel, R., Macintyre S., & Wortley, R. 2014. How house burglars decide on targets: A computer-based scenario approach. In B. Leclerc & R. Wortley (Eds.), Cognition and crime: Offender decision making and script analyses (pp. 26–47). Crime Science Series. London: Routledge.
Jacobs, J. (1961). The death and life of great American cities. New York: Random House.
Johnson, S. D. (2010). A brief history of the analysis of crime concentration. European Journal of Applied Mathematics, 21(4–5), 349–370.
Johnson, D. (2013). The space/time behaviour of dwelling burglars: Finding near repeat patterns in serial offender data. Applied Geography, 41(Supplement C), 139–146.
Johnson, S. D., & Bowers, K. J. (2004). The stability of space-time clusters of burglary. British Journal of Criminology, 44, 55–65.
Johnson, S. D., Bernasco, W., Bowers, K. J., Elffers, H., Ratcliffe, J., Rengert, G., & Townsley, M. (2007). Space–time patterns of risk: a cross national assessment of residential burglary victimization. Journal of Quantitative Criminology, 23(3), 201–219.
Kennedy, L. W., Caplan, J. M., & Piza, E. (2011). Risk clusters, hotspots, and spatial intelligence: risk terrain modeling as an algorithm for police resource allocation strategies. Journal of Quantitative Criminology, 27(3), 339–362.
Kennedy, L. W., Caplan, J. M., Piza, E. L., & Buccine-Schraeder, H. (2016). Vulnerability and exposure to crime: applying risk terrain modeling to the study of assault in Chicago. Applied Spatial Analysis and Policy, 9(4), 529–548.
Kinney, J. B., Brantingham, P. L., Wuschke, K., Kirk, M. G., & Brantingham, P. J. (2008). Crime attractors, generators and detractors: land use and urban crime opportunities. Built Environment, 34(1), 62–74.
Kleemans, E. R. (1996). Strategische Misdaadanalyse En Stedelijke Criminaliteit. Een Toepassing van de Rationele Keuzebenadering Op Stedelijke Criminaliteitspatronen En Het Gedrag van Daders, Toegespitst Op Het Delict Woninginbraak. Faculteit Bestuurskunde, Enschede, the Netherlands: Universiteit Twente.
Kleemans, E. R. (2001). Repeat burglary victimization: results of empirical research in the Netherlands. Crime Prevention Studies, 12, 55–68.
Krebs, C. J. (1998). Ecological methodology (2nd edn.). Menlo Park: Pearson.
Kubrin, C. E., & Herting, J. R. (2003). Neighborhood correlates of homicide trends: an analysis using growth-curve modeling. The Sociological Quarterly, 44(3), 329–350.
Lersch, K. M., & Hart, T. C. (2011). Space, time, and crime (3rd edn.). Durham: Carolina Academic Press.
Levine, N. (2008). The “hottest” part of a hotspot: Comments on “the utility of hotspot mapping for predicting spatial patterns of crime”. Security Journal, 21(4), 295–302.
Lister, S. C., & Wall, D. S. (2008). Deconstructing distraction burglary: An ageist offence? In SSRN scholarly paper ID 1085050. Rochester, NY: Social Science Research Network https://papers.ssrn.com/abstract=1085050.
Matthews, R., Pease, C., & Pease, K. (2001). Repeated Bank robbery: Themes and variations’. In G. Farrell & K. Pease Repeat victimization. Crime prevention studies, vol. 12 (pp. 153–64). . Monsey: Criminal Justice Press.
Mohler, G. O., Short, M. B., Brantingham, P. J., Schoenberg, F. P., & Tita, G. E. (2011). Self-exciting point process modeling of crime. Journal of the American Statistical Association, 106(493), 100–108.
Montoya, L., Junger, M., & Ongena, Y. (2016). The relation between residential property and its surroundings and day- and night-time residential burglary. Environment and Behavior, 48(4), 515–549.
Moreto, W. D. (2010). Risk factors of urban residential bulrgary. RTM Insights, Research Brief Series Dedicated to Shared Knowledge, 4, 1–3.
Moreto, W. D., Piza, E. L., & Caplan, J. M. (2014). “A plague on both your houses?”: Risks, repeats and reconsiderations of urban residential burglary. Justice Quarterly, 31(6), 1102–1126.
Mustaine, E. E. (1997). Victimization risks and routine activities: a theoretical examination using a gender-specific and domain-specific model. American Journal of Criminal Justice, 22(1), 41.
Nee, C., & Meenaghan, A. (2006). Expert decision making in burglars. British Journal of Criminology, 46(5), 935–949.
Ohyama, T., & Amemiya, M. (2018). Applying crime prediction techniques to Japan: A comparison between risk terrain modeling and other methods. European Journal on Criminal Policy and Research. https://doi.org/10.1007/s10610-018-9378-1.
Onat, I., & Gul, Z. (2018). Terrorism risk forecasting by ideology. European Journal on Criminal Policy and Research. https://doi.org/10.1007/s10610-017-9368-8.
Perry, W. L., McInnis, B., Price, C. C., Smith, S. C., & Hollywood, J. S. (2013). Predictive policing: The role of crime forecasting in law enforcement operations. Santa Monica: RAND.
Polvi, N. (1990). Repeat victimization. Journal of Police Science and Administration, 17, 8–11.
Polvi, N., Looman, T., Humphries, C., & Pease, K. (1991). The time course of repeat burglary victimization. The British Journal of Criminology, 31(4), 411–414.
Ratcliffe, J. H. (2002). Aoristic signatures and the Spatio-temporal analysis of high volume crime patterns. Journal of Quantitative Criminology, 18(1), 23–43.
Ratcliffe, J. H., & Mccullagh, M. J. (1998). Identifying repeat victimization with GIS. The British Journal of Criminology, 38(4), 651–662.
Rengert, G., & Wasilchick, J. (1985). Suburban burglary: A time and a place for everything. Springfield: Thomas.
Roncek, D. W. (2000). Schools and crime. In V. Goldsmith, P. G. McGuire, J. H. Mollenkopf, & T. A. Ross (Eds.), Analyzing crime patterns: Frontiers of practice (pp. 153–165). Thousand Oaks: Sage.
Rosser, G., Davies, T., Bowers, K. J., Johnson, S. D., & Cheng, T. (2017). Predictive crime mapping: arbitrary grids or street networks? Journal of Quantitative Criminology, 33(3), 569–594.
Rountree, P. W., & Land, K. C. (2000). The generalizability of multilevel models of burglary victimization: a cross-city comparison. Social Science Research, 29(2), 284–305.
Ruiter, S. (2017). Crime location choice. The Oxford Handbook of Offender Decision Making, 6, 398.
Sherman, L. W., & Weisburd, D. (1995). General deterrent effects of police patrol in crime “hot spots”: a randomized, controlled trial. Justice Quarterly, 12(4), 625–648.
Shover, N. (1991). Burglary. Crime and Justice, 14, 73–113.
Snook, B., Dhami, M. K., & Kavanagh, J. M. (2011). Simply criminal: predicting burglars’ occupancy decisions with a simple heuristic. Law and Human Behavior, 35(4), 316–326.
Sorenson, D. W. M. (2003). The nature and prevention of residential burglary: A review of the international literature with an eye toward prevention in Denmark. Copenhagen: Justitsministeriet.
Taylor, R. B. (1997). Social order and disorder of street blocks and neighborhoods: ecology, microecology, and systematic model of social disorganization. Journal of Research in Crime and Delinquency, 34(1), 113–155.
Taylor, M., & Nee, C. (1988). The role of cues in simulated residential burglary-a preliminary investigation. British Journal of Criminology, 28, 396.
Townsley, M., Homel, R., & Chaseling, J. (2000). Repeat burglary victimisation: spatial and temporal patterns. The Australian and New Zealand Journal of Criminology, 33(1), 37–63.
Townsley, M., Birks, D., Bernasco, W., Ruiter, S., Johnson, S. D., White, G., & Baum, S. (2015). Burglar target selection: a cross-national comparison. Journal of Research in Crime and Delinquency, 52(1), 3–31.
Townsley, M., Birks, D., Ruiter, S., Bernasco, W., & White, G. (2016). Target selection models with preference variation between offenders. Journal of Quantitative Criminology, 32(2), 283–304.
Tseloni, A., Osborn, D. R., Trickett, A., & Pease, K. (2002). Modelling property crime using the British crime survey: what have we learnt? British Journal of Criminology, 42(1), 109–128.
Tseloni, A., Thompson, R., Grove, L., Tilley, N., & Farrell, G. (2017). The effectiveness of burglary security devices. Security Journal, 30(2), 646–664.
Vandeviver, C., Neutens, T., van Daele, S., Geurts, D., & Beken, T. V. (2015). A discrete spatial choice model of burglary target selection at the house-level. Applied Geography, 64(Supplement C), 24–34.
Walsh, D. (1986). Victim selection procedures among economic criminals: The rational choice perspective’. In D. B. Cornish & R. V. Clarke (Eds.), The reasoning criminal: Rational choice perspectives on offending (pp. 39–52). New York: Springer.
Weisburd, D., Bushway, S., Lum, C., & Yang, S.-M. (2004). Trajectories of crime at places: a longitudinal study of street segments in the city of Seattle. Criminology, 42(2), 283–322.
Weisburd, D., Bruinsma, G. J. N., & Bernasco, W. (2009). Units of analysis in geographic criminology: Historical development, critical issues, and open questions. In D. Weisburd, G. J. N. Bruinsma, & W. Bernasco (Eds.), Putting crime in its place: Unit of analysis in geographic criminology (pp. 3–31). New York: Springer.
Weisburd, D., Groff, E. R., & Yang, S.-M. (2012). The criminology of place. Street segments and our understanding of the crime problem. New York: Oxford University Press.
Wells, W., Wu, L., & Ye, X. (2012). Patterns of near-repeat gun assaults in Houston. Journal of Research in Crime and Delinquency, 49(2), 186–212.
Wilcox, P., Quisenberry, N., Cabrera, D. T., & Jones, S. (2004). Busy places and broken windows? Toward defining the role of physical structure and process in community crime models. Sociological Quarterly, 45(2), 185–207.
Wilcox, P., Madensen, T. D., & Tillyer, M. S. (2007). Guardianship in context: implications for burglary victimization risk and prevention. Criminology, 45(4), 771–803.
Wright, R., & Decker S. H. (1994). Burglars on the job: Streetlife and residential break-ins. Lebanon: UPNE.
Wright, R., Logie, R. H., & Decker, S. H. (1995). Criminal expertise and offender decision making: an experimental study of the target selection process in residential burglary. Journal of Research in Crime and Delinquency, 32(1), 39–53.
Youstin, T. J., Nobles, M. R., Ward, J. T., & Cook, C. L. (2011). Assessing the generalizability of the near repeat phenomenon. Criminal Justice and Behavior, 38(10), 1042–1063.
Yu, S.-S. V. (2011). Do bus stops increase crime opportunities? El Paso: LFB Scholarly.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Dugato, M., Favarin, S. & Bosisio, A. Isolating Target And Neighbourhood Vulnerabilities In Crime Forecasting. Eur J Crim Policy Res 24, 393–415 (2018). https://doi.org/10.1007/s10610-018-9385-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10610-018-9385-2