
Abstract
The cloud computing is established as the technology that provides all the need oriented and the use dependent IT resources that has been used very frequently for the business information systems. In relation to the terms of integration of all the decentralized information systems, the cloud systems have been providing an approach for stable solution. But the data security has been found to be a major challenge in the using of cloud systems and being a main reason as to why the companies avoid cloud service usage. The main question that is faced is the manner in which the cloud systems are used for the integration of such decentralized information systems that are to be designed and based on the technology and the organization to ensure privacy of law of that of the cloud user that may be guaranteed. Today there is a lot of attention that is being received from the academic as well as the perspective of the industry by means of an in depth cloud computing resource. There are several issues of security like availability, confidentiality and integrity. The experts have been studying the anonymous authentication for the data archiving to the clouds. In the conditions in which there is a communication that is achieved without penalty or fear, an anonymous authentication will be important. This has been needed by the organizations for protecting all their vital data from that of their industrial espionage. From among the techniques of authentication that has been attributed to a decentralized mechanism it may appear to be efficient. For this work, a trust-based secure and anonymous authentication for multiple attributes is make use of. The Recursive Best First Search (RBFS) algorithm will be used for finding the optimal weights from among the trust partners.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
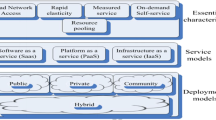
Cloud computing paradigm enables ubiquitous, on demand network with shared pool of computing resources which may be provisioned with minimal management. According to proponents, the upfront costs of infrastructure of the companies can be avoided using cloud computing and their prime focus will be on the projects that will differentiate their businesses as opposed to the infrastructure. The proponents further claim that cloud computing permits the enterprises to be able to get all their applications to be able to run faster having some improved manageability and minimum maintenance. These proponents will enable IT to be more rapid in adjusting the resources for meeting the business demands that are unpredictable and fluctuating. So the cloud computing is not a highly demanded utility or service owing to the advantages of the high power computing, cost of services, availability, accessibility, high performance and scalability.
Using the internet, the computation as well as the storage may be outsources by that of the users to the servers in case of cloud computing [1]. As the users are able to maintain all the resources on-side with no issues. There are several types of services that are provided by the cloud by making use of applications like the Microsoft online or Google Apps, the infrastructures like the Nimbus, the EC2 of Amazon, the Eucalyptus and the platforms for helping the developers to write applications and for example the Windows Azure and the Amazon’s S3. In most cases the data that is highly sensitive will be stored in the cloud like the social networks or medical records. So in case of cloud computing, privacy and security are critical issues.
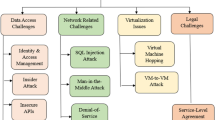
In relation to the cloud computing, the various critical aspects in security is obtained along with the difficulty from all the experiences which have been reported by the early adopters and from the researchers that analyse the experiment using the platforms of service providers and the technologies that have been associated to this. The security will be the greatest inhibitors for the adoption and also an important concern in the cloud computing. Using cloud computing is the modern manner in which the access to the using of computing resources on the Internet we find some security risks as well as some vulnerability from that of the conventional Internet that will include the confidentiality, integrity and availability. Further the new concerns are put forth by the cloud computing that include the moving and the storing in the cloud with chances of residing in other countries having different regulations. There are several types of regulations that are faced having partially or completely revealed even it had stayed inside the borders of the nation. There is also a chance of this data being transferred to that of a third party which makes use of other purposes for the other purposes like advertisements leading to security hassles. For preserving the integrity of the data which has been sorted in the cloud, it will be insured without any downloading but it may however prove itself to be costly more so when there it is a question of a large amount of data. Furthermore, the data is found to be dynamic and this can also be in the cloud or also anywhere else that it can be appended or updated [2].
There are several security issues that are the challenges in the cloud computing as it can encompass various technologies like the networks and the databases, their operating systems, resource scheduling, concurrent control, transaction management, virtualization and memory management. All these are very critical as the provider of cloud service which will ensure the users who are not facing any type of loss or theft of data that can result in a great loss that depends on the data sensitivity of all the data that is stored in the cloud. The malicious user can also pretend as being legitimate for the users and the infecting of the cloud.
The Data at rest will be a major issue in that of cloud computing as the users are able to store all their private, sensitive and their common data that can be accessed by anyone at any place. The data theft is one of the most common issue that is faced by the providers of cloud services in recent times. Aside from this certain providers of cloud services do not even provide to their own server owing to the effectiveness of cost and the flexibility. At the same time there are some incidents like that of the data loss that can result in a serious problem. For instance, the server can also shut down suddenly and result in the loss to the users. Also, there are natural disasters that can result in the data getting damaged or even corrupt. So the physical location of data may also be considered to an issue of security in that of cloud computing.
As there are different servers that store data at the different servers which are located at various other places, the data availability is an important concern because of some factors like that of efficiency of bandwidth and the partial unavailability of cloud for one cloud. It is also assured by the provider of cloud service where the computing resources are fully usable and also available at most situations. There is also an inaccessibility for computing the resources owing to a natural disaster or a denial of service.
There is another vital aspect in security of cloud computing for protecting privacy of data. This will be a shared environment that make sue of a sharing infrastructure thus having the risk of disclosure and unauthorized access. It is a huge challenge to be able to share the cloud computing resources by means of protecting the privacy of the customers. For delivering a secure multi-tenancy in the isolation of cloud computing, it is important to ensure that the data of the customer is separated from the data of the others. There can also be some data transfer among countries that may have some different regulations as well as legal implications. The data privacy of the customers and their security is ensured by means of data anonymity [3].
The user will have to be able to authenticate oneself even before beginning a transaction and they should also be assured that the outsourced data has not been tampered by the cloud. There is also a need for the privacy of the user to ensure the user identity will not be revealed to the remaining users of the cloud. The user will also be able to be accounted for by the cloud for the outsourced data and at the same time the cloud may also be accountable for the services which have been provided. The verification of the user validity for storing the data has also been done and other than that of the technical solutions that can ensure the privacy and security there will also be a need for the enforcement of law.
One more important concern here is the efficient search on that of the encrypted data and for this the cloud should not be aware of any query and the query of the records will have to be satisfied or else returned. This will have to be done by means of the searchable encryption [4, 5]. These encrypted keywords will be sent to the cloud and can also result in sending this to the cloud even without the knowledge of their actual keywords for the purpose of search. The main problems of the keywords are that they have been associated for a search that may be enabled and be present in the data records. On searching using an appropriate key word, the accurate records will return.
For this a major challenging issue is accountability that can involve some technical problems along with enforcement of law. Both in case of the cloud and the users the operations which have been performed or requested should not be refused. It is also quite crucial to have the transactions or the logs that are performed and it can be an issue that is significant for deciding on whether the information volume has to be present in this log. Access control [6] has been gaining a lot of importance and a large amount of the stored data will have accessibility to an authentic service. The access control of such sensitive information will have to be made carefully that may be health related and the important documents that are in the Dropbox or the Google docs or even the personal information which are available in social networking. Further, in case of the online social networking, the access control has been gaining importance in which the personal information for the members has been stored and with the pictures and the videos have been shared with that of the selected groups of their communities.
There is an algorithm of approximation used in Branch and Bound for finding a solution that is upper bound at the time of a search for pruning.
There is an artificial algorithm belonging to the heuristic search algorithm which is the Recursive Best-First Search (RBFS). The frontier nodes have been expanded and problem specific information has been used for the estimation of preferring one node over that of the other [6]. The RBFS memory’s complexity is O(db), in which d denotes the depth of its search and b being the branching factor. However, for the purpose of continuing its current path to the extent possible the f-cost will be kept in track by the RBFS for the best alternative available from that of a particular ancestor in the current node passed on as the argument for its recursive function. These nodes have been expanded in the order of first best in case of a function of evaluation which is not monotonic.
The identity of the entity has been recognized using the trust [7] along with the confidence on that of its behaviour and as the entity’s judgement has been based on its experiment it is a subjective behaviour. The actual degree of trust has been measured using a trust degree or a trust value. A trust obtained from entities with a direct interaction is a direct trust. A Trust obtained that of a trustworthy third party having direct contact with its designated one is an indirect or a recommended trust and an important way to obtain this from the unknown entities is a recommended trust.
This paper has been dealing with the following: the distributed access control for the data stored in the cloud in which only authorized users will gain access. The identity of the users will be protected and in the decentralized architecture, there are many KDCs for the key management and data not accessed by the users that are revoked once it is done. No stale information is written back by any writer who has the attributes and the keys which have been revoked.
The main aim of this study will be anonymous authentication mechanism. The literature related to the work has been discussed in Sect. 2, methods and techniques discussed in Sect. 3, the results that are obtained have been elaborated in Sect. 4 and the conclusion has been detailed completely in Sect. 5.
2 Literature survey
An Anonymous authentication had been supported by the novel as well as decentralized scheme of access control for the storage of data proposed by Ruj et al. [1] in which the authenticity of the user is verified. The replay as well as the support creation have been created in this scheme and the revocation of user is addressed. Unlike that of the other schemes of access control, this proposed scheme of authentication access control which is robust and also decentralized for the purpose of clouds which are centralized and the computation, the communication as well as the overhead storage will be compared to the centralized approaches.
There are many techniques for the anonymous authentication that was proposed by Patil and Katraj [8] for the purpose of data that is stored in the cloud and before the storing of data the series and tis authenticity has been verified by the cloud without knowledge of the identity of the user. The paper further has the added feature of access control and the replay attacks have been prevented by the creation of such schemes. Furthermore, such schemes will be duly decentralized and are also robust when compared to the other schemes of access control which have been designed for the clouds that have been decentralized. Such a computation, communication as well as overheads of storage are compared to a centralized approach and the aim of this paper will be to cover the issues of security in the cloud.
The Organizations will be able to outsource all sensitive data which is stored in the remote servers by means of using a paid facility known as the Storage-as-a-service (Saas) that has been offered by the Cloud Service Providers (CSPs). The data and its owner are being benefitted by the scheme of cloud based storage from the several facilities that are offered by that of the CSP and there is an indirect mutual trust which is duly enabled among them. There is a different authentication technique as well as the algorithms for the security of cloud which has been now presented in this paper.
There are several trust models that have been evaluated by Li and Ping [9] that had been used in case of the large as well as distributed environment along with that of a new model of cloud for the solving of the issues in security for the cross-cloud environment in which any user will be able to choose from among various providers of service and resources in an environment that is heterogeneous which will be able to cooperate. This is a model that is domain based and one of the domains of cloud providers has been divided into a similar domain along with a trust agent who is set. There are two different roles for the cloud customers that has been distinguished along with the varying strategies which are designed completely for them. In case of this proposed model, being similar to the computation or the storage, the trust recommendation will be treated as a type of service of clouds. The identity and the behaviour authentication has been achieved using the model. These results for the study has shown that such a trust relationship will be able to be constructed safely and efficiently in the environments of cross-clouds.
There are two critical methods that explore the issue in the authentication of the cloud computing along with the calculation of reputation and trust for the management which are the CSPs and the Sensor Network Providers (SNPs). There is a completely new and innovative authenticated Trust and Reputation Calculation and Management (ATRCM) system that is used for the CC-WSN integration which was put forth by Zhu et al. [10]. By means of a consideration for that of the authenticity of the SNP and the CSP the needs of the Cloud Service User (CSU) and the CSP, the CSP and the SNP’s cost, along with the service and its reputation, these following functions have been achieved by means of this proposed TRCM system: (1) the malicious impersonation attacks that are authenticated by that of the CSP and the SNP for avoiding service; (2) to be able to calculate and further manage the trust and the reputation relating to that of the service of the CSP and also the SNP and (3) to ensure help to the CSU and select the needed CSP and further assist the CSP in the choice of an appropriate SNP. The ATRCM and its effectiveness has been the result of the in depth analysis along with the design and the results of such an evaluation of functionality has been followed with the analysis of system security.
The main concerns from the viewpoint of the user is the privacy and security information. The servers and the cloud users will not be present in this domain relating to the users of cloud computing. Owing to this issue of privacy and data security, there is also a need for access control. Generally, in cloud, the access control will be centralized in the environment and only one single key distribution centre is given with the centralized cloud system and the symmetric key approach algorithm will be used. There are Multiple key distribution centres that are available in such decentralized cloud systems and so it has been used for generally avoiding any leakage of keys for the hostile users. The Attribute Based Encryption algorithm had been used by Usha and Sangeetha [11] in order to hide the users’ attributes and for providing an anonym control. For this system, the user authenticity will be confirmed by that of the cloud without the user knowledge and an added feature for such access control will be present in this method which only the valid users will be able to encrypt the information that is stored from its cloud server. A Trust-Extended Authentication Mechanism (TEAM) that has a decentralised authentication scheme had been proposed by Chuang and Lee [12] for a vehicle-to-vehicle network of communication and the concept of such trust relationships that are transitive had been adopted by the TEAM for enhancing the authentication of performance of procedure it will need only a few spaces of storage. The requirements of security like its anonymity, location privacy, replay attack and its resistance, forgery, mutual authentication, problem of synchronization, fast detection of errors, not having verification tables, attack resistance of man-in-the-middle and a session key agreement have been satisfied.
There is a new depth-first branch and the bound algorithm that was presented by Malone and Yuan [13] that was able to identify some better solutions and had ultimately converged into the optimal Bayesian network on its completion. The algorithm had not only been able to enhance the runtime for finding an optimal network structure that is up to about 100 times compared to the currently existing techniques and the optimality of these solutions had also been proved to be about 10 times faster in certain cases.
The algorithms for the prediction of the size of the Expanded Search Tree (EST) of that of the Depth first Branch and Bound algorithms (DFBnB) that are used for the tasks of optimization had been proposed by Lelis et al. [14]. In solving such problems that are combinatorial a prediction algorithm was implemented over that of the graphical techniques like the Markov or the Bayesian networks. These proposed techniques further extend to the DFBnB based approaches that have been provided by the Knuth-Chen schemes that were designed and further applied for the prediction of the size of the EST for the backtracking of search algorithms. Some good predictions have been found to be superior to the schemes of proposals of empirical results.
There are two simple techniques that had been put forth by Hatem et al. [15] that helped in the enhancing of the RBFS and its performance at the same time maintaining its advantages over that of the IDA. For the rectification of issues in this the RBFSCR was also proposed, in which the first technique will help in the binding of the RBFS regeneration overhead. By means of this it has been proved that there is a performance improvement for optimal as well as suboptimal searches and this can further yield a better space in the heuristic search. The RBFSCR will be the first linear space and a best first search that is robust enough for solving the problem of varying operator costs.
Almeida et al. [16] had presented another dynamic approach to adaptation of multi-cloud applications that are supported by that of the Branch-and-Bound (the B&B) algorithm for optimizing the process of adaptation while choosing of the services that are to be deployed in this application. Wu et al. [17] had also proposed resource allocation based algorithms for the SaaS providers that have to minimized the cost of infrastructure and the violations of Service Level Agreement (the SLA). These proposed algorithms have been designed in a manner in which that the SaaS providers can manage all the dynamic changes to the customers and the mapping of customer requests for the parameters of the infrastructure levels and the handling of the virtual machines and their heterogeneity.
Tang et al. [18] had proposed and also investigated a model of cross-layer resource allocation for the Cloud-Radio Access Network (C-RAN) for minimizing this system and its power consumption within the Baseband Unit (BBU) pool, the fiber links with the Remote Radio Heads (RRHs). Another decision model for an optimal allocation of the source servers to their physical target servers considering real-world constraints were presented by Speitkamp and Bichler [19]. This central model has been proved to be one Non-deterministic Polynomial (NP)-hard problem. So aside from being an exact solution method there is also a heuristic that has been presented for addressing some large scale projects of server consolidation. Additionally, there is also a method of pre-processing for the load data of the server that has introduced the permitting of the quality of service levels and their consideration.
For this type of a literature, that has summarized many anonymous authentication mechanisms, cloud algorithms, cloud services and trust models, most such data that is stored in the cloud is very sensitive. The security and the privacy are in this way very important problems in cloud computing. An efficient search based on the encrypted data is also considered an important concern in that of clouds. The work further proposed new schemes of decentralized access control for that of the secure storage of data in clouds which can support anonymous authentication. …This anonymous authentication will be the procedure of being able to accept the client without any details. Therefore, the cloud server will not be aware of the client’s details that can provide security to clients in concealing details from the rest of the clients in cloud. The access control in that of clouds has been gaining attention owing to the fact that only authorized users can get access to its valid service.
3 Methdology
The section also details a Depth first Branch and Bound Search algorithm (DFBBS), the Recursive Best-First Search (RBFS) and the trust model.
3.1 Depth first Branch and Bound Search algorithms (DFBB)
As it has been expected, the application of a depth-first search [10] may not be straightforward and for this there may be improvements needed with a new heuristic function along with a repairing strategy and duplicate detection.
3.2 Reverse order graph
This inefficiency will be addressed using a key improvement in finding some optimal parents in the sparse parent graphs. For any candidate parent set as is U for X, it will have to find its optimal parents by means of scanning through that of the parents X and also find its first subset of the U as its optimal parents. This scan can be got by means of removing all the non-candidate based variables V\U and will be implemented by using the bit vectors and the bitwise operations. This is further achieved through using Depth-first search. These bit vectors that are used in the previous scans for the search stack are also stored. As and for every step in this order the search will begin from their bit vectors that are on top of a stack and will remove only a single variable for finding its optimal parents. Furthermore, the depth first search will make it imperative that only the O(n2) bit vectors are stored at any time. The other methods of search may need some exponential bit vectors for being used within the same strategy that is incremental. However, this forward order graph has not been very amenable towards the above scan as the variables have been added as their candidate parents when the search gets deeper.
3.3 Branch and Bound
The depth first search and its efficiency has been improved to a significant extent by means of pruning and an ideal solution that was identified until now will be in an upper bound one for an optimal solution. of the depth-first search can be significantly improved by pruning.

In case a lower bound h that is on the cost from its current search node it can estimate the goal and calculate a lower bound for the cost of the solution that makes use of its current path for the node and if a lower bound will be worse than that of the upper bound solution and its current path does not result in any better solution.
3.4 Recursive Best-First Search (RBFS)
The RBFS and the recursive implementation of the depth-first search which is similar and the difference is a better condition used in backtracking assuring an expansion of nodes for its best first order. This also works by means of maintaining on its recursion stack of the complete path for the expansion of its current node and all of its immediate siblings of the nodes in the same path with its best node below every sibling [20]. Every time there is a current node that has a higher cost than that of the other nodes there will be a backing up of an algorithm with a deep common ancestor and a search down will continue to its new path. This RBFS will consider the search space as on tree and will explore this. The pseudo code for this is as below:

The arguments in this will be a node n that will have to be explored and also a bound B which will represent its best f value for that of an unexplored node. every child node that is generated will be given an f value and an usual \( g\left( {n_{i} } \right) + h\left( {n_{i} } \right) \) , and also an F value, that represents the best known f value for the node that is below \( {\text{n}}_{i} \) which has still not expanded and the F value for this child node is generated for the very first time by means of comparing parent’s f with that of its parent’s backed-up value F. In case \( {\text{f(n) < F(n) }} \) then it is taken.
3.5 Trust model
The cloud entities belonging to the customers and the providers is ensured in the cross applications and for this the nodes are grouped into two the customers and servers and the different trust strategies that have been designed for them. On the basis of an independent single-cloud platform, the trust domains are established. Both the independence of nodes as well as the manageability of the domains will be considered by the trust choice and their update strategies. So the trust recommendation had been managed and also treated as one single type of cloud service. There are two cloud roles that are now differentiated in case of this model: the client and server or the customer and provider. The Clients are considered as those enterprises or the individuals that shoes for using the cloud services and the resources that belong to such similar providers will be part of the same trust domain and each such domain will be set as its trust agent.
3.5.1 The cloud data privacy trust
The trust [10] will deal with the sensory data which has been stored in the cloud assessed by the others. Based on the feedback on the earlier Privacy Level Agreements (PLAs) relating to the service the sensory data was assessed by the others relating to every service from the CSP to the CSU in history stored on the TCE database in Fc2. As the CSU normally is sensitive about the privacy of data the cloud data privacy and its trust value (the \( T_{c2} \)) will be presented by the TCE as per the Eq. (1).
3.5.2 The cloud data transmission trust
The trust will be in respect to if the transmission of data which is from the CSP to the CSU is found to be successful. Making use of the feedback from the earlier SLAs relating to the service, along with a success number (the \( S_{c3} \)) and the failure number (the \( F_{c3} \)) of such data transmission of every service from the CSP to that of the CSU in history on the TCE database, the transmission trust (the Tc3) shown by TCE as in Eq. (2).
The basic realization framework for the new model is shown in Fig. 1.

Realization mechanism [9]
A general trust decision process [9] for this model will be as below: firstly, to look out for the corresponding value of its special trading partner in a local trust table (for the customer is the customer trust table and further for the provider will be a domain trust table). In case there is a value that exceeds its threshold an entity will agree to continue this transaction or else the transaction is suspended. In case there is no corresponding record that is found, then the entity broadcasts the trust request inside certain familiar domains and the original trust for the counterparty is calculated by means of making use of the received trust of recommendation and its corresponding factor of recommendation. There were two factors causing an update of the trust: one will be the time and the other will be the re-evaluation of the trust after every transaction. The time influence will be continuous and the transactions will be leaping. Therefore, the model will adopt several strategies for its evaluation. Contrastingly, this will count on the evaluation of the transaction of the previous time than that of the data of history cooperation. For reevaluating this trust after that of each transaction, in case it is the first time, the customer increases one of the records in the customer trust table for storing the trust of the new provider and at the same time it will update its recommendation service trust of the providers that had offered the recommended trust or else it will replace the old trust with that of the new one.
3.6 Depth first Branch and Bound Search algorithms (DFBBS) with trust model
The steps for DFBBS based trust is given as:

3.7 Recursive Best-First Search (RBFS) based trust model
The pseudo code for RBFS based trust is given as:

4 Results and discussion
The Result table and the graph for the accuracy of the trust and Transaction Success Ratio have been shown as per Tables 1, 2 and as per Figs. 2, 3. There are two evaluation factors that have been set up using experiments. The trust accuracy and the transaction success rate where the former implies a ratio for obtaining the trust value with a trust mechanism for the total evaluations and the latter is the ratio of the success transactions for that of the ideal transaction numbers.

Trust accuracy for DFBB search trust model

Transaction success ratio for DFBB search trust model
Table 1 and Fig. 2 shows that the trust accuracy of DFBB search trust model performs better by 1.03% and by 2.1% than RBF search trust model and trust model at 5% of malicious inputs respectively. The trust accuracy of DFBB search trust model performs better by 2.4% and by 5.99% than RBF search trust model and trust model at 25% of malicious inputs respectively. The trust accuracy of DFBB search trust model performs better by 12.2% and by 21.3% than RBF search trust model and trust model at 50% of malicious inputs respectively.
Table 2 and Fig. 3 shows that the transaction success ratio of DFBB search trust model performs better by 1.1% and by 1.1% than RBF search trust model and trust model at 5% of malicious inputs respectively. The transaction success ratio of DFBB search trust model performs better by 4.94% and by 8.8% than RBF search trust model and trust model at 25% of malicious inputs respectively. The transaction success ratio of DFBB search trust model performs better by 7.9% and by 9.3% than RBF search trust model and trust model at 50% of malicious inputs respectively.
5 Conclusion
The access control has been gaining attention in the clouds being very crucial with a large amount of such sensitive information stored in the cloud. The RBFS in general will be an algorithm of heuristic search that will expand the frontier nodes of the best and the first order that stack-based backtracking as opposed to the choosing from its Open list; the DFBBS based trust model will be also used and the results of this study prove that this DFBB search trust model will perform better by 1.03% and also by about 2.1% than the RBF search trust model along with the trust model at about 5% of malicious inputs and the accuracy of this trust of the DFBB was better by about 2.4% and further by about 5.99% than that of the RBF search trust model and the trust model at about 25% of the malicious inputs. The accuracy of trust accuracy of the DFBB search trust model has performed better by about 12.2% and further by about 21.3% than that of the RBF search trust model and the trust model at about 50% of the malicious inputs.
Change history
21 December 2022
This article has been retracted. Please see the Retraction Notice for more detail: https://doi.org/10.1007/s10586-022-03926-3
References
Ruj, S., Stojmenovic, M., Nayak, A.: Decentralized access control with anonymous authentication of data stored in clouds. IEEE Trans. Parallel Distrib. Syst. 25(2), 384–394 (2014)
Wang, C., Wang, Q., Ren, K., Lou, W.: Ensuring data storage security in cloud computing. In: 2009 17th International Workshop on Quality of Service, IWQoS (2009)
Younis, M.Y.A., Kifayat, K.: Secure cloud computing for critical infrastructure: a survey. In: Liverpool John Moores University, Technical Report, pp. 599–610 (2013)
Li, J., Wang, Q., Wang, C., Cao, N., Ren, K., Lou, W.: Fuzzy keyword search over encrypted data in cloud computing. In: IEEE INFOCOM, pp. 441–445 (2010)
Kamara, S., Lauter, K.: Cryptographic cloud storage. In: Financial Cryptography Workshops, ser. Lecture Notes in Computer Science, vol. 6054, pp. 136–149. Springer (2010)
Krishna, C.M.S.R., Samuel, G.J.: Decentralized access control with Anonymous authentication of data stored in cloud (2016)
Kallem, S.R.: Artificial Intelligence Algorithms, IOSR. J. Comput. Eng. (IOSRJCE) 6(3), 1–8 (2012)
Patil, M.T., Katraj, P.: A survey on different techniques used in decentralized cloud computing. Int. J. Sci. Eng. Appl. 116(18), 11–17 (2016)
Li, W., Ping, L.: Trust model to enhance security and interoperability of cloud environment. Cloud Comput. 5931, 69–79 (2009)
Zhu, C., Nicanfar, H., Leung, V.C., Yang, L.T.: An authenticated trust and reputation calculation and management system for cloud and sensor networks integration. IEEE Trans. Inf. Forens. Secur. 10(1), 118–131 (2015)
Usha, S., Sangeetha, P.: Multiple attribute authority based access control and anonymous authentication in decentralized cloud. Bonfring Int. J. Data Min. 6(3), 24–29 (2016)
Chuang, M.C., Lee, J.F.: TEAM: trust-extended authentication mechanism for vehicular ad hoc networks. IEEE Syst. J. 8(3), 749–758 (2014)
Malone, B., Yuan, C.: A depth-first branch and bound algorithm for learning optimal Bayesian networks. In: Graph Structures for Knowledge Representation and Reasoning, pp. 111–122. Springer, Cham (2014)
Lelis, L.H., Otten, L., Dechter, R.: Predicting the size of depth-first branch and bound search trees. In: IJCAI, pp. 594–600, (2013)
Hatem, M., Kiesel, S., Ruml, W.: Recursive best-first search with bounded overhead. In: AAAI, pp. 1151–1157 (2015)
Almeida, A., Dantas, F., Cavalcante, E., Batista, T.: A branch-and-bound algorithm for autonomic adaptation of multi-cloud applications. In: Cluster, Cloud and Grid Computing (CCGrid), 2014 14th IEEE/ACM International Symposium on, pp. 315–323. IEEE (2014)
Wu, L., Garg, S.K., Buyya, R.: SLA-based resource allocation for software as a service provider (SaaS) in cloud computing environments. In: Proceedings of the 2011 11th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing, pp. 195–204. IEEE Computer Society (2011)
Tang, J., Tay, W.P., Quek, T.Q.: Cross-layer resource allocation with elastic service scaling in cloud radio access network. IEEE Trans. Wirel. Commun. 14(9), 5068–5081 (2015)
Speitkamp, B., Bichler, M.: A mathematical programming approach for server consolidation problems in virtualized data centers. IEEE Trans. Serv. Comput. 3(4), 266–278 (2010)
Sharma, D., Dubey, S.K.: Comparative study of RBFS & ARBFS algorithm. IOSR J. Comput. Eng. 10(5), 105–110 (2013)
Author information
Authors and Affiliations
Corresponding author
Additional information
This article has been retracted. Please see the retraction notice for more detail: https://doi.org/10.1007/s10586-022-03926-3"
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Usha, S., Tamilarasi, A. RETRACTED ARTICLE: A trust based security framework with anonymous authentication system using multiple attributes in decentralized cloud. Cluster Comput 22 (Suppl 2), 3883–3892 (2019). https://doi.org/10.1007/s10586-018-2478-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-018-2478-3