
Abstract
Choice of romantic partner is an enormously important component of human life, impacting almost every facet of day-to-day existence, however; the processes underlying this choice are remarkably complex and have so far been largely resistant to scientific explanation. One consistent finding is that, on average, members of romantic dyads tend to be more alike than would be expected by chance. Selecting for self-similarity is at least partially driven by phenotypic matching wherein couples share similar phenotypes, and preferences for a number of these traits are partly genetically influenced (e.g., education, height, social attitudes and religiosity). This suggests that genetically influenced preferences for self-similarity might contribute to phenotypic matching (and thus assortative mating), but it has never been studied in actual couples. In the present study, we use a large sample of twins to model sources of variation in self-similarity between partners. Biometrical modelling revealed that very little of the variation in the tendency to assortatively mate across 14 traits was due to genetic effects (7 %) or the shared environment of twins (0 %).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Choice of romantic partner is an enormously important component of human life, impacting almost every facet of day-to-day existence including physical and psychological well-being, economic decision-making and social interaction. The processes underlying this choice are remarkably complex and have so far been largely resistant to scientific explanation. Yet one finding remains more pervasive than any other: on average, members of romantic dyads tend to be more alike than would be expected by chance (Caspi et al. 1992; Klohnen and Mendelsohn 1998; Mascie-Taylor 1989; Plomin et al. 1977; Price and Vandenberg 1980; Watson et al. 2004; Zietsch et al. 2011). This is referred to as assortative mating and appears to be one of the few consistent patterns of human coupling. Age, religiosity and social attitudes correlate strongly between partners (i.e. r = 0.97, 0.72, 0.61, respectively: Zietsch et al. 2011), while intelligence (r = 0.40: Mascie-Taylor and Vandenberg 1988), attractiveness (r = 0.39: Feingold 1988), and education (r = 0.45: Zietsch et al. 2011) correlate moderately. Small correlations have also been observed between both the height and weight of romantic partners (r = ~0.20), while weak correlations exist for personality traits (Feingold 1988; Hatemi et al. 2010; Koenig et al. 2009; Martin et al. 1986; Price and Vandenberg 1980; Watson et al. 2004; Zietsch et al. 2011). Researchers have even identified moderate assortative mating across a range of psychiatric disorders (Agrawal et al. 2006; Dorret I. Boomsma et al. 2010; Grant et al. 2007; Krueger et al. 1998; Nordsletten et al. 2016).
Assortative mating can restructure the genetic and social environment in a multitude of ways. For instance, assortative mating can reshape the social environment by influencing the distribution of resources across society and increasing stratification of the economy (Schwartz 2013). When spouses match based on income and educational attainment both resources and access to resources tend to become unevenly distributed. As a result, asymmetry occurs in the incentive to mate outside of one’s economic and educational sphere such that individuals high on the distribution stand to lose more by mating down comparative to individuals low on the distribution (Schwartz 2013). Moreover, assortative mating effectively moulds the genetic landscape, increasing homozygosity in the population (Lande 1977; Wilson 1973; Wright 1921) and additionally increasing genetic variance, primarily in subsequent generations following positive assortment (Bulmer 1971). These effects are caused by linkage disequilibrium between genes of like effect (Crow and Felsenstein 1982). Assortative mating can also produce genetic correlations between different traits such as height and intelligence (Keller et al. 2013) when both are linked to another trait (in this case overall attractiveness) for which there is assortative mating.
Despite how pervasive and consequential assortative mating is, its causes are not well understood. There is little evidence for convergence, whereby partners are not initially similar but become more similar over the course of the relationship (Caspi et al. 1992; Watson et al. 2004; Zietsch et al. 2011). This suggests that assortative mating must be largely due to initial choice. One cause of this initial choice assortment for which there is clear evidence is social homogamy—that is, couples meeting through similar social backgrounds (Nagoshi et al. 1987; Reynolds et al. 1996, 2000). However, statistical analyses of family data indicate that social homogamy cannot fully account for assortative mating, meaning that phenotypic matching—that is, selection of partners based on similarity in traits—must also play a role (Nagoshi et al. 1987; Reynolds et al. 1996, 2000; Zietsch et al. 2011).
What causes phenotypic matching, though, is not at all clear. Passive phenotypic matching can occur if individuals are more likely to meet because of their similarity on a certain trait. For example, many couples meet in the workplace, and people in the same workplace may also have more similar intelligence than a random pair of people, causing couples similarity for intelligence. However, there is evidence that people on average prefer self-similar traits in an ideal partner, and that these preferences are partly genetically influenced (e.g., education, height, social attitudes, religiosity; Heath and Eaves 1985; Zietsch et al. 2011). This suggests that genetically influenced preferences for self-similarity might contribute to phenotypic matching. However, it is has not been investigated whether there are in fact genetic influences on self-similarity of actual partner choices, as opposed to stated preferences. Additionally, there is substantial debate as to whether mate preferences are related to realised partner choice. For example, some research has shown that stated preferences are not predictive of choice in the context of a speed-dating paradigm (Eastwick et al. 2014; Kurzban and Weeden 2005; though see Li and Meltzer 2015; Li et al. 2013).
A previous study of twins and their spouses estimated genetic influences on partner choice across numerous traits at close to zero (Zietsch et al. 2011). Using data from over 27,000 individuals, Zietsch and colleagues (2011) investigated the similarity of identical twins’ partners when compared to non-identical twins’ across 14 different traits including height, education, income, social attitudes, and physical and personality measures. Identical twins’ partners were no more similar than non-identical twins’ partners indicating small or non-existent genetic effects on partner choice. It should be noted that the researchers also controlled for the influence of assortative mating on partner similarity between twin pairs by regressing twin’s own traits from partner traits. However, this study only aimed to investigate genetic variation in partner selection across numerous traits rather than genetic variation in selecting self-similar mates.
In the present study, we analyse this same data from a large sample of twins and their partners, for whom we have measures of height, body mass index (BMI), personality traits, social attitudes, religiosity, education, income, and age. For each trait in each twin, we calculate a score that represents the degree to which the twin’s partner is similar to the twin (with relevant statistical controls). We then use biometrical modelling to quantify the influence of genetic and environmental factors on variation individuals’ tendency to have a partner similar to themselves. The presence of a heritable component to the variation would suggest that genetic predisposition does play a role in people’s tendency towards phenotypic matching.
Methods
Participants
Two cohorts of twins were contacted for data collection, first in 1988 (see Heath et al. 1994) and then in 1990 (see Posner et al. 1996). Health and lifestyle questionnaire responses were collected from over 6,000 independent families. Available data for each measure in the questionnaire varied considerably, and twins provided information about their partners’ religiosity, educational attainment, income, and age, where partner information was missing. The use of twin-reported data for these variables increased data for twin’s partners by 110–180 %. For this study, we analysed the data regarding 11,357 twins and their partners (N = 6,397, see Table 1 for details). The Queensland Institute of Medical Research Human Research Ethics Committee approved this data collection. For further details regarding the sample, zygosity determination and data collection see Heath et al. (1994).
Measures
Availability of data for both members of a twin pair and each of their partners (henceforth referred to as complete sets) varied widely for different measures. However, incomplete sets were also used in the genetic modelling as their data contributed to the estimation of means, variance, and covariances using full information maximum likelihood.
Age, height and weight were self-reported and available for 2195, 439, and 426 sets, respectively. BMI was calculated based on self-reported height and weight.
Education was reported as highest level of education completed, ranging from (1) primary school/high school (8–10 years of education), (2) high school (11–12 years of education), (3) apprentice/diploma, etc., (4) technical/college, (5) university degree, and (6) university postgraduate. This was provided for 1794 complete sets. Yearly income was assessed using the following response options: (1) none, (2) <$5,000, (3) $5,000–$10,000, (5) $15,000–$25,000, (6) $25, 000, (7) $25,000–$35,000, (7) $35,000–$50,000, and (8) >$50,000. At the time of data collection, the average full time income was ~$25,000. Data for this question were available for 1197 complete sets.
Participants’ religiosity was indicated by frequency of church attendance (or other observances). 1765 complete sets were available with responses consisting of: (1) rarely, (2) once or twice a year, (3) every month or so, (4) once a week, and (5) more than once a week.
Participants’ social attitudes were scored based on responses to a list of topics (e.g. casual sex, immigration, birth control). Participants indicated whether they agreed or disagreed with each topic (0 or 2 depending on direction), or if they were uncertain (1). After an exploratory factor analysis of responses, 23 items were combined (absolute factor loadings >0.30) into a scale of conservative to liberal attitudes with scores ranging from 0 to 46 (for further detail see Zietsch et al. 2011). When three or fewer responses were missing, item scores were replaced with the mean. Participants with more than three missing responses were treated as missing. 441 complete sets were available for this scale.
To measure personality traits, participants were administered short versions of two commonly used personality inventories. Psychoticism, neuroticism, and extraversion scores were derived from 36 items (12 per trait) of the Eysenck Personality Questionnaire (EPQ-R; Eysenck et al. 1985). Harm avoidance (18 items), novelty seeking (19 items), reward dependence (12 items), and persistence (5 items) scores were derived from the revised Tridimensional Personality Questionnaire (TPQ; Cloninger et al. 1991). Items were presented as true/false and responses were summed. If > 25 % of responses of a scale were missing, the scale was treated as missing. Otherwise, missing responses were replaced with the mean. To maintain normality of the data, scores were transformed into arcsine values after being converted to a proportional scale (Freeman and Tukey 1950). Data for personality items ranged from 439 to 451 complete sets. Where both partners’ and twins’ reported data was available, correlations for religiosity, education, income, and age were 0.87, 0.84, 0.74 and 0.99, respectively (Zietsch et al. 2011).
Values three standard deviations above and below the mean were winsorised for all continuous variables in order to minimise departures from normality. As we analysed a measure of similarity between twins and their partners rather than scores on these measures themselves, we do not describe the original sample here. For sample descriptives, see Zietsch et al. (2011).
Partner Self-Similarity Scores
The aim of this study was to investigate the heritability of assortative mating on multiple traits. To do so, we required a measure of similarity between partners for each trait. However, simply taking the difference between a twin and their partner would be unsuitable given that many of the traits themselves vary due to familial influences (i.e. genetic and environmental variation shared between twins) and that the majority of traits are normally distributed within the population. Normally distributed traits will create differential likelihoods of finding a self-similar mate based on an individual’s own trait level. For example, it is more likely that individuals who are of average intelligence will find a partner similar in intelligence to them because this is the mode of possible partner intelligence. Likewise, extremely intelligent individuals will struggle to find someone who is similarly intelligent simply because there are fewer of these individuals in the population. Because many of the traits in the current study are heritable they will be shared more strongly between identical twins than non-identical twins and so too will the probability of matching with a self-similar mate. As a result, simply analysing the heritability of the partner self-similarity via a raw difference score would result in an estimate that is biased by the heritability of the trait on which twins are matching and estimates would to some extent reflect the familial effects on the traits themselves. For example, assume mating is completely random for height. A twin who is extremely tall will likely have a co-twin who is extremely tall (because of the heritability of height), and both twins are likely to have partners much shorter than themselves (and thus large twin-partner difference scores). The same would apply for extremely short twins. Comparing correlations between identical and non-identical twin pairs would therefore give the appearance of a heritable basis to self-similarity preferences for height despite all of the twins mating at random. To control for this effect, for each twin we calculated a partner self-similarity score that controlled for the extremity of the twin’s own phenotype. The method was as follows.
Firstly, scores on all traits were standardized separately by sex. This controls for sex effects so that the difference between twins and partners is relative to the average score of their sex. Thus, an average height male will not be dissimilar from an average sized woman despite actually being taller, whereas a taller than average male would be dissimilar from an average sized female. We then calculated a partner self-similarity score for each twin for each trait by calculating the absolute difference between the twin’s sex-standardized value and their partner’s sex-standardized value. By taking the absolute difference between a twin and their partner we measure only the difference between couples regardless of direction, such that a twin who is taller than average with an average height partner is equally similar as a twin who is shorter than average with an average height partner. This score was then regressed on the twin’s age (to control for any possible effects thereof). Then, to control for the extremity of the twin’s own phenotype, we regressed the residual of the age regression on the absolute value of the twin’s own standardised score. Regressing on the absolute score controls for the degree of a twin’s deviation from the sex standardized mean for the trait. The resulting score is essentially the degree of similarity between a twin and their partner that can’t be predicted by the extremity of the trait itself.
Simulation Testing
To confirm that simple difference scores would be problematic and to validate our measures of assortative mating, we ran a number of simulations to ensure that we were correct to control for phenotypic extremity and are still able to detect genetic effects on self-similarity partnering. We first generated a simulation to test the hypothesis that normally distributed traits might generate spurious estimates of heritability as described above. This involved firstly simulating a population of identical and non-identical twin pairs with correlated scores on a hypothetical variable. In this simulation, 10,000 pairs of identical twins and non-identical twins were generated with scores that correlated at r = ~0.70 and r = ~0.45, respectively (similar to twin correlations reported for multiple traits in Zietsch et al. 2011). We then generated scores for twin partners under random mating conditions (i.e. partner traits uncorrelated to the twin’s scores, r = ~0.00). We then calculated a difference score by taking the absolute difference between each twin and their partners (Fig. 1a), and tested the correlation of these difference scores within twin pairs. Over approximately one hundred simulated runs, identical twin similarity scores correlated more strongly (r = 0.12, p < 0.001) than that of non-identical twins, (r = 0.03, p < 0.001, respectively), despite mating completely randomly. This correlation would suggest 12 % of the variance in the similarity of twins to their partners is due to genetic effects, despite no preference for self-similarity. Thus any heritability estimates would actually be attributable to familial effects on the trait itself resulting in greater similarity between twins and their partners.

a Raw difference scores under random mating. b Controlled difference scores under random mating. c Raw difference scores under assortative mating. d Controlled difference scores under assortative mating
Controlling for this effect is the purpose of regressing out the extremity of the twins’ own scores from partner self-similarity as described earlier, so we checked that our method would work as planned. After regressing on the absolute value of the twins’ own scores (Fig. 1b), the twin pair correlations for partner self-similarity scores were no longer significant for both identical, r ~ 0.00, and non-identical twin pairs, r ~ 0.00, over one hundred simulations. This demonstrates that our method of controlling for familial effects on the twin’s phenotype is successful in removing spurious estimates of heritability for partner self-similarity preferences. Our method of control additionally improves the substantial negative skew in absolute difference scores between a twin and their partner.
We then ran another simulation to test that this method would not remove genuine genetic influences on self-similarity preferences. To do this, we again simulated 10,000 identical and non-identical twin pairs. For the purposes of simulating a genetic factor influencing assortment via preference, absolute difference scores between twins and their partners were now generated such that they were correlated within twin pairs more strongly in identical (r ~ 0.15) than in non-identical twin pairs (r ~ 0.07) in accordance with a modest genetic influence of ~15 % (Fig. 1c). As per the explanation above, this difference score was regressed on the absolute value of the twin’s own trait score and the residual of this regression was taken as the final index of similarity (Fig. 1d). Over a hundred simulations, this process retained the majority of similarity between identical twin pairs, r ~0.09, p < 0.001, which were more than twice the size of non-identical twin pair correlations, r ~0.04, p < 0.001, consistent with the presence of genetic influences and a heritability estimate of approximately 9 %.
In accordance with these successful simulations, we computed a controlled measure of partner self-similarity for each of the twin’s traits. Histograms of absolute partner differences and controlled partner differences can be seen in Supplemental Fig. 1 and demonstrate substantial variability in the degree of self-similarity between couples. We additionally checked that our measures of partner self-similarity were not simply reflecting Zietsch et al.’s (2011) measures of partner traits. Supplementary Table I shows that correlations between the two measures (self-similarity score and partner traits) were modest or null, confirming that we are measuring a unique aspect of mate-choice (i.e. self-similarity) independent of the previous study. Whereas Zietsch et al. (2011) conducted analysis on partner traits controlling for the twin’s own characteristics, we generate a measure of trait similarity between twins and their partners controlling for the extremity of the twins’ own traits.
Estimating Genetic and Environmental Influences on Assortative Mating
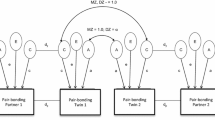
Using the classical twin design, we are able to partition variance in similarity scores into that caused by genetic factors, that due to shared environmental sources, and that due to any residual sources (Neale and Cardon 1992). Genetic causes of variation consist of additive effects (A: the sum effect of alleles across the genome) and nonadditive effects (D), which include interactions within and across genes (i.e. dominance and epistasis, respectively). The proportion of variance accounted for by additive effects constitutes the narrow-sense heritability of the trait (h 2). The sum of A and D indicates the broad-sense heritability (H 2) of the trait. Family environmental factors (C) include any non-genetic effect shared by the twins. This includes factors such as socioeconomic status of the household, the shared uterine environment, and parenting style, but mathematically is defined as any non-genetic effect that contributes to correlations between twins. As C and D are confounded in the classic twin design, only one can be estimated in a given model. Which is estimated is determined by preliminary analysis of twin correlations, and D is generally presumed to be present in the case that MZ correlations are more than twice that or DZ twin pairs. Finally, other sources of variation that are unshared between twins are included in an estimate of residual influences (E). These can be environmental influences not shared by the twins, chance biological effects such as mutations, any individual experiences of the twins, and, importantly, measurement error. These variance components are standardized so as to sum to 1. Accordingly, parameter estimates of A,C/D and E indicate the proportion of variance in a trait accounted for by each source.
Partitioning variation in a trait into these components is possible due to the identical segregating genes shared by identical (monozygotic: MZ) twins, compared with the 50 % of segregating genes shared by non-identical or dizygotic (DZ) twins. For instance, if additive genetic influences were underlying variation in a trait entirely, MZ twins would correlate at 1.0 and DZ twins at 0.5. If nonadditive genetic factors solely influenced trait variation, MZ twins would correlate at 1.0 and DZ twins (at most) at 0.25 (for a detailed explanation see Posthuma et al. 2003). Conversely, were shared environmental factors driving variation in a trait, both MZ and DZ twins would correlate at 1.0. If, however, residual sources were the only influence on variation in a trait, by definition neither MZ nor DZ twin pairs would correlate at all. Trait variance is typically the result of a combination of these factors. Structural equation modelling generates estimates of these influences which best match the observed data. The classical design has limited power to distinguish nonadditive and additive effects (Keller et al. 2010). Further, nonadditive genetic effects are confounded with shared environmental effects. Additionally, when nonadditive variance is not modelled, it is absorbed into estimates of additive genetic variance.
Statistical Analysis
All data preparation was conducted in SPSS Statistics, version 22.0 (IBM Corp 2013). Genetic modelling was executed using the statistical package OpenMx (Boker et al. 2011) in R (R Core Team 2014). OpenMx employs maximum-likelihood modelling, using a goodness-of-fit index that is distributed as Chi squared. We determined the optimal model for the data by systematically constraining parameters within the model (e.g. fixing them at zero, or equating different parameters), and comparing changes in Chi squared against changes in degrees of freedom. This allowed us to test hypothesis regarding those specific parameters, for instance whether MZ and DZ correlations are significantly different from each other.
Results
Estimating Genetic and Environmental Influences on Partner Self-Similarity
Consistent with previous research, we observed assortative mating on most traits (Table 2). We conducted preliminary testing on adjusted and unadjusted partner self-similarity scores for each trait, which revealed no significant mean differences among zygosity groups or between the sexes, indicating a similar degree of assortativity between males and females and their respective partners across every trait (see Supplementary Materials). In the case of several traits, variances differed significantly between males and females and between identical and non-identical twins. Twin pair correlations were also significantly different between MZ males and MZ females for religiosity (see Table 3), \(\chi_{2}^{2}\) = 10.23, p = 0.01. In these instances, we could see no reason that these differences were due to anything other than chance and these parameters were subsequently equated for further modelling.
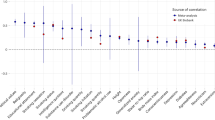
To investigate genetic effects on partner self-similarity scores, we first tested whether MZ twin pair correlations were greater than DZ twin pair correlations on our phenotype-controlled measure of self-similarity preference. This was not the case for any of the traits being investigated, indicating no significant genetic effects. As a result, subsequent modelling did not include estimates of D and instead modelled C. Across all traits, univariate ACE models revealed non-significant heritability estimates ranging from 0 to 17 % of variance in partner self-similarity scores (Table 4). Shared environmental effects were also negligible, with none reaching statistical significance across any of the traits.
We also estimated the influence of extremity on heritability by re-running the genetic analysis without regressing self-similarity scores on the extremity of twins’ own traits. It appears that our control had the expected effect of reducing the influence of phenotypic extremity, as familial estimates were higher than in our controlled measure for 8 of 14 traits. Estimates for the remaining traits were either the same (4) or slightly larger. Similar estimates are likely due to non-significant correlations of similarity scores between twins. The method of control only attempts to account for extreme phenotypes that are shared between twin pairs. If the twins are already uncorrelated, the control will have no effect and there would subsequently be no spurious variance estimates as a result. Subsequent analysis was therefore conducted using our phenotype controlled measure of self-similarity.
To investigate the possibility of genetic and environmental influences on an overall tendency towards self-similarity in partners (i.e. not specific to any one trait), we ran a multivariate model including our controlled measure of assortative mating on all traits. This allowed us to equate the influence of A and C to be equal across all of the traits to test if there is significant variation in the size of familial [i.e. genetic (A) and shared environmental effects (C)] effects between traits, while also providing an overall estimate of variance components on the tendency to assortatively mate (Table 4). No significant change in model fit was observed when estimates of A were equated across all traits, \(\chi_{13}^{2}\) = 0, p = 0.96, nor when C was equated across traits \(\chi_{13}^{2}\) = 2.8, p = 0.96. As A and C are partially confounded in the twin design, we have more power to detect A and C together than independently. When the contributions of both A and C were equated across traits (i.e. A equal across traits, C equal across traits) in the same model, no significant change in fit was observed, \(\chi_{26}^{2}\) = 24.9, p = 0.52. This indicates that genetic, shared environmental, and residual sources of variance are similar in magnitude for assortative mating on all of the traits we investigated. The final model shows small but significant familial influences on variation in assortative mating across the measured traits (accounting for 7 % of total variation).
Discussion
Modelling revealed non-significant, near-zero heritability across all 14 of the traits investigated in the study. Similarly, no significant effects of the shared environment were detected. Combined familial effects (i.e. A and C modelled together) did have a significant influence on self-similarity across several traits: more than 10 % of the variation in partner similarity on age, BMI, education, and income was accounted for by the combination of genes and the shared environment. Unfortunately, we lacked the statistical power to disentangle these effects clearly. In the case of religiosity, Verweij et al. (2014) have previously demonstrated a sizable genetic correlation between the trait itself and preferences for the trait in a potential partner, which may drive assortativity.
Biometrical modelling revealed that very little (7 %) of the variation in the tendency to assortatively mate across 14 traits was due to genetic effects when controlling for the extremity of twins’ own phenotypes. Shared environmental effects were also near-zero and non-significant. Confidence intervals indicated that genetic and shared environmental effects combined (i.e. familial effects) account for at least 5 % but no more than 9 % of the variance in assortative mating across all of the measured traits on average. In addition, we also quantified the degree to which familial influences may influence assortative mating via their effect on the twin’s phenotypes. At most this accounted for an additional 10 % of the estimated variance in any one trait. This leaves the majority of variation in assortative mating unexplained. It should be noted that estimates of residual variance contain measurement error, though for objectively measured traits such as age, height, and BMI, this is unlikely to have contributed much to estimates of residual variance.
The absence of significant genetic effects on variation in partner self-similarity mirrors previous research on mate choice (Lykken and Tellegen 1993; Zietsch et al. 2011). Zietsch et al. (2011) investigated the heritability of mate choice on the same traits investigated in this paper in the same sample of twins (where we investigate assortative mating on these traits) and found minimal, non-significant genetic effects. Though we used data from Zietsch et al.’s (2011) twin study of the heritability of mate-choice and found similar results we are confident that we have measured a novel aspect of partner choice in the present study. As reported in the Methods, the measures employed in this study were minimally, or otherwise not at all correlated with measures from the previous study (see Supplementary Materials). The apparent lack of genetic influence on variation in both assortative mating, and mating on these traits themselves, is surprising given that almost all studied behavioural traits across thousands of studies show substantial heritable variation (Polderman et al. 2015), including a range of mate preferences (Verweij et al. 2012; Verweij et al. 2014; Zietsch et al. 2015; Zietsch et al. 2012).
One explanation of the minimal heritability of mate choice, despite heritable mate preferences, may be that constraints of the mating market [e.g. an individual’s own mating value, the presence of ideal mates, or the number of competitors present (Penke et al. 2007)] limit the extent to which genetic influences on ideal partner preferences can be realised in an actual partner. However, individuals do tend to partner with those who are similar on a number of traits, which suggests that, to the extent that assortative mating is due to self-similarity preferences (as opposed to passive assortment), those preferences are being realised to some degree. As such, the fact that the vast majority (>90 %) of variance in partner self-similarity was accounted for by residual sources of variation may point to the relative importance of propinquity in driving assortative mating—that is, similar individuals are likely to inhabit similar environments and, as a result, are more likely to interact and ultimately pair with each other. On top of this effect, learned preferences based on past relationships, as well as simple chance effects, may also contribute to the dominant residual influence on variation in partner self-similarity.
The absence of shared environmental effects on assortative mating is also surprising. In this sample, and indeed generally, couples correlated strongly on social attitudes and religiosity. Religiosity and social values tend to be highly similar within the family and also show substantial variation due to the shared environment of the twins (Kendler and Myers 2009, respectively; Polderman et al. 2015). Anthropological evidence also suggests that parents influence the mate-choice of their offspring and could influence assortative mating by pushing for their child to partner with mates from, for example, a similar religious, social and economic background (for review see Buunk et al. 2008). Yet, the shared environment of the twins had a negligible impact on variation in assortative mating on these traits, suggesting minimal parental influences regarding similarity of these attitudinal variables in partnerships.
Crucially, this sample was limited in its power to disentangle genetic from shared environmental effects, given its small size; a larger sample and the addition of siblings in the twin model could potentially resolve this uncertainty by enhancing statistical power (Boomsma et al. 1999; Posthuma and Boomsmsa 2000). It should be noted that while genetic effects, if they exist, on variation in mate-choice must be small, they might nonetheless be meaningful over long periods of time. For example, Qvarnstrom et al. (2006) observed significant additive genetic variance in a large sample of birds accounting for less than 3 % of variation in mate choice. Given the multivariate nature of mate-selection, this may in fact represent a substantial proportion of variation relative to other contributing factors.
Additionally, variance in the shared environment may have been limited in this study. This research was conducted with an Australian population over 25 years ago, and given the environmental influences on variation in traits such as social attitudes and religiosity, a sample with more varied socio-cultural environments may yet reveal larger shared environmental influences on variation in partner self-similarity on these traits.
Assortative mating remains one of the most pervasive phenomena of partner choice in human beings. We have for the first time investigated genetic influences on variation in partner self-similarity across multiple traits and found no significant independent influence of genes or the shared environment. We did, however, observe significant familial effects accounting for a small amount of the variation in partner self-similarity overall. Given the importance of relationship partner choice and the influences of assortative mating on the genetic, financial and social landscape via economic and cultural stratification, further work should be undertaken to characterise the dominant non-familial causes of variation in individuals’ tendency to assortatively mate.
References
Agrawal A, Heath A, Grant J, Pergadia M, Statham D, Bucholz K, Madden P (2006) Assortative mating for cigarette smoking and for alcohol consumption in female Australian twins and their spouses. Behav Genet 36(4):553–566. doi:10.1007/s10519-006-9081-8
Boker SM, Neale MC, Maes HH, Wilde MJ, Spiegel M, Brick TR, Fox J (2011) OpenMx: an open source extended structural equation modelling framework: Psychometrika
Boomsma DI, Neale MC, Dolan CV (1999) A note on the power provided by sibships of sizes 2, 3, and 4 in genetic covariance odeling of a codominant QTL. Behav Genet 29(3):163–170
Boomsma DI, Saviouk V, Hottenga J-J, Distel MA, de Moor MHM, Vink JM, Willemsen G (2010) Genetic epidemiology of attention deficit hyperactivity disorder (ADHD Index) in adults (epidemiology of ADHD index). PLoS ONE 5(5):e10621. doi:10.1371/journal.pone.0010621
Bulmer MG (1971) The effect of selection on genetic variability. Am Nat 105(943):201–211. doi:10.1086/282718
Buunk AP, Park JH, Dubbs SL (2008) Parent-offspring conflict in mate preferences. Rev Gen Psychol 12(1):47–62. doi:10.1037/1089-2680.12.1.47
Caspi A, Herbener ES, Ozer DJ (1992) Shared experiences and the similarity of personalities: a longitudinal study of married couples. J Pers Soc Psychol 62(2):281–291. doi:10.1037/0022-3514.62.2.281
Cloninger CR, Przybeck TR, Svrakic DM (1991) The tridimensional personality questionnaire: U.S. normative data. Psychol Rep 69(3):1047–1057
Crow JF, Felsenstein J (1982) The effect of assortative mating on the genetic composition of a population. Soc Biol 29(1–2):22–35
Eastwick PW, Luchies LB, Finkel EJ, Hunt LL (2014) The predictive validity of ideal partner preferences: a review and meta-analysis. Psychol Bull 140(3):623–665. doi:10.1037/a0032432
Eysenck SBG, Eysenck HJ, Barrett P (1985) A revised version of the psychoticism scale. Personal Individ Differ 6(1):21–29. doi:10.1016/0191-8869(85)90026-1
Feingold A (1988) Matching for attractiveness in romantic partners and same-sex friends: a meta-analysis and theoretical critique. Psychol Bull 104(2):226–235. doi:10.1037/0033-2909.104.2.226
Freeman MF, Tukey JW (1950) Transformations related to the angular and the square root. Ann Math Stat 21(4):607–611. doi:10.1214/aoms/1177729756
Grant JD, Heath AC, Bucholz KK, Madden PAF, Agrawal A, Statham DJ, Martin NG (2007) Spousal concordance for alcohol dependence: evidence for assortative mating or spousal interaction effects? Alcohol Clin Exp Res 31(5):717–728. doi:10.1111/j.1530-0277.2007.00356.x
Hatemi PK, Hibbing JR, Medland SE, Keller MC, Alford JR, Smith KB, Eaves LJ (2010) Not by twins alone: using the extended family design to investigate genetic influence on political beliefs. Am J Polit Sci 54(3):798–814. doi:10.1111/j.1540-5907.2010.00461.x
Heath AC, Eaves LJ (1985) Resolving the effects of phenotype and social background on mate selection. Behav Genet 15(1):15–30. doi:10.1007/BF01071929
Heath AC, Cloninger CR, Martin NG (1994) Testing a model for the genetic structure of personality: a comparison of the personality systems of Cloninger and Eysenck. J Pers Soc Psychol 66(4):762. doi:10.1037/0022-3514.66.4.762
IBM Corp. (2013). IBM SPSS Statistics for Macintosh, Version 22.0. Armonk, NY: IBM Corp
Keller MC, Medland SE, Duncan LE (2010) Are extended twin family designs worth the trouble? A comparison of the bias, precision, and accuracy of parameters estimated in four twin family models. Behav Genet 40(3):377–393. doi:10.1007/s10519-009-9320-x
Keller MC, Garver-Apgar CE, Wright JC, Martin NG, Corley RP, Stallings MC, Zietsch BP (2013) The genetic correlation between height and IQ: shared genes or assortative mating? PLoS Genet. doi:10.1371/journal.pgen.1004329
Kendler KS, Myers J (2009) A developmental twin study of church attendance and alcohol and nicotine consumption: a model for analyzing the changing impact of genes and environment. Am J Psychiatry 166(10):1150–1155. doi:10.1176/appi.ajp.2009.09020182
Klohnen EC, Mendelsohn GA (1998) Partner selection for personality characteristics: a couple-centered approach. Pers Soc Psychol Bull 24(3):268–278. doi:10.1177/0146167298243004
Koenig LB, McGue M, Iacono WG (2009) Rearing environmental influences on religiousness: an investigation of adolescent adoptees. Personal Individ Differ 47(6):652–656. doi:10.1016/j.paid.2009.06.003
Krueger R, Moffitt T, Caspi A, Bleske A, Silva P (1998) Assortative mating for antisocial behavior: developmental and methodological implications. Behav Genet 28(3):173–186. doi:10.1023/A:1021419013124
Kurzban R, Weeden J (2005) HurryDate: mate preferences in action. Evolut Hum Behav 26(3):227–244. doi:10.1016/j.evolhumbehav.2004.08.012
Lande R (1977) The influence of the mating system on the maintenance of genetic variability in polygenic characters. Genetics 86(2):485–498
Li NP, Meltzer AL (2015) The validity of sex-differentiated mate preferences: reconciling the seemingly conflicting evidence. Evolut Behav Sci 9(2):89–106. doi:10.1037/ebs0000036
Li NP, Yong JC, Tov W, Sng O, Fletcher GJO, Valentine KA, Balliet D (2013) Mate preferences do predict attraction and choices in the early stages of mate selection. J Pers Soc Psychol 105(5):757–776. doi:10.1037/a0033777
Lykken DT, Tellegen A (1993) Is human mating adventitious or the result of lawful choice? A twin study of mate selection. J Pers Soc Psychol 65(1):56
Martin NG, Eaves LJ, Heath AC, Jardine R, Feingold LM, Eysenck HJ (1986) Transmission of social attitudes. Proc Natl Acad Sci USA 83(12):4364–4368. doi:10.1073/pnas.83.12.4364
Mascie-Taylor CGN (1989) Spouse similarity for IQ and personality and convergence. Behav Genet 19(2):223–227
Mascie-Taylor CGN, Vandenberg SG (1988) Assortative mating for IQ and personality due to propinquity and personal preference. Behav Genet 18(3):339–345. doi:10.1007/BF01260934
Nagoshi CT, Johnson RC, Ahern FM (1987) Phenotypic assortative mating vs. social homogamy among Japanese and Chinese parents in the Hawaii Family Study of Cognition. Behav Genet 17(5):477–485. doi:10.1007/BF01073114
Neale MC, Cardon LC (1992) Methodology for genetic studies of twins and families. Kluwer Academic Publishers, Boston
Nordsletten AE, Larsson H, Crowley JJ, Almqvist C, Lichtenstein P, Mataix-Cols D (2016) Patterns of nonrandom mating within and across 11 major psychiatric disorders. 73(4)
Penke L, Todd PM, Lenton AP, Fasolo B (2007) How self-assessments can guide human mating decisions. In: Geher G, Miller GF (eds) Mating intelligence: sex, relationships, and the mind’s reproductive system. Erlbaum, Mahwah, pp 37–75
Plomin R, DeFries JC, Roberts MK (1977) Assortative mating by unwed biological parents of adopted children. Science 196(4288):449–450. doi:10.1126/science.850790
Polderman TJC, Benyamin B, de Leeuw CA, Sullivan PF, van Bochoven A, Visscher PM, Posthuma D (2015) Meta-analysis of the heritability of human traits based on fifty years of twin studies. Nat Genet Adv Online Publ. doi:10.1038/ng.3285
Posner SF, Baker L, Heath A, Martin NG (1996) Social contact, social attitudes, and twin similarity. Behav Genet 26(2):123–133. doi:10.1007/BF02359890
Posthuma D, Boomsmsa DI (2000) A note on the statistical power in extended twin designs. Behav Genet 30:147–158
Posthuma D, Beem AL, de Geus EJC, van Baal GCM, von Hjelmborg JB, Iachine I, Boomsma DI (2003) Theory and practice in quantitative genetics. Twin Res 6(5):361–376. doi:10.1375/136905203770326367
Price RA, Vandenberg SG (1980) Spouse similarity in American and Swedish couples. Behav Genet 10(1):59–71. doi:10.1007/BF01067319
Qvarnstrom A, Brommer JE, Gustafsson L (2006) Testing the genetics underlying the co-evolution of mate choice and ornament in the wild. Nat 441(7089):84–86. doi:http://www.nature.com/nature/journal/v441/n7089/suppinfo/nature04564_S1.html
R Core Team (2014) R: a language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from http://www.R-project.org/
Reynolds CA, Baker LA, Pedersen NL (1996) Models of spouse similarity: applications to fluid ability measured in twins and their spouses. Behav Genet 26(2):73–88. doi:10.1007/BF02359886
Reynolds CA, Baker LA, Pedersen NL (2000) Multivariate models of mixed assortment: phenotypic assortment and social homogamy for education and fluid ability. Behav Genet 30(6):455–476. doi:10.1023/A:1010250818089
Schwartz CR (2013) Trends and variation in assortative mating: causes and consequences. Ann Rev Sociol 39:451–470. doi:10.1146/annurev-soc-071312-145544
Verweij KJH, Burri AV, Zietsch BP (2012) Evidence for genetic variation in human mate preferences for sexually dimorphic physical traits. PLoS ONE 7(11):e49294. doi:10.1371/journal.pone.0049294
Verweij KJH, Burri AV, Zietsch BP (2014) Testing the prediction from sexual selection of a positive genetic correlation between human mate preferences and corresponding traits. Evolut Hum Behav 35(6):497–501. doi:10.1016/j.evolhumbehav.2014.06.009
Watson D, Klohnen EC, Casillas A, Nus Simms E, Haig J, Berry DS (2004) Match makers and deal breakers: analyses of assortative mating in newlywed couples. J Pers 72(5):1029–1068. doi:10.1111/j.0022-3506.2004.00289.x
Wilson SR (1973) The correlation between relatives under the multifactorial model with assortative mating. Ann Hum Genet 37(2):189–204. doi:10.1111/j.1469-1809.1973.tb01826.x
Wright S (1921) Systems of mating. III. Assortative mating based on somatic resemblance. Genetics 6(2):144–161
Zietsch BP, Verweij KJH, Heath AC, Martin NG (2011) Variation in human mate choice: simultaneously investigating heritability, parental influence, sexual imprinting and assortative mating. Am Nat 177(5):605–616. doi:10.1086/659629
Zietsch BP, Verweij KJH, Burri AV (2012) Heritability of preferences for multiple cues of mate quality in humans. Evolution 66:1762–1772
Zietsch BP, Lee AJ, Sherlock JM, Jern P (2015) Variation in women’s facial masculinity preference is better explained by genetic differences than by previously identified context-dependent effects. Psychol Sci. doi:10.1177/0956797615591770
Acknowledgments
This study was funded by joint grants from the National Institutes of Health (Grant Numbers: AA07535, AA07728, AA10249, AA11998, MH31392) and the National Health and Medical Research Council (Australia, Grant Numbers: 941177 and 971232). James M. Sherlock is supported by an Australian Postgraduate Award. We also wish to thank Drew Bailey for integral input in developing a measure of the heritability of assortative mating.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of Interest
James M. Sherlock, Karin J. H. Verweij, Sean C. Murphy, Andrew C. Heath, Nicholas G. Martin, Brendan P. Zietsch declare no conflict of interests.
Ethical Approval
All research was conducted in accordance with the guidelines of the Queensland Institute of Medical Research Ethics Committee with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Additional information
Edited by Carol Van Hulle.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Sherlock, J.M., Verweij, K.J.H., Murphy, S.C. et al. The Role of Genes and Environment in Degree of Partner Self-Similarity. Behav Genet 47, 25–35 (2017). https://doi.org/10.1007/s10519-016-9808-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10519-016-9808-0