
Abstract
We describe several analytical results obtained in four candidates social choice elections under the assumption of the Impartial Anonymous Culture. These include the Condorcet and Borda paradoxes, as well as the Condorcet efficiency of plurality voting with runoff. The computations are done by Normaliz. It finds precise probabilities as volumes of polytopes and counting functions encoded as Ehrhart series of polytopes.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Lepelley et al. (2008, p. 382) state:
Consequently, it is not possible to analyze four candidate elections, where the total number of variables (possible preference rankings) is 24. We hope that further developments of these algorithms will enable the overcoming of this difficulty.
Normaliz (Bruns et al. 2018) is a software tool that (in particular) may be used for the computation of volumes and Ehrhart series of rational polytopes. In the 20 years of its existence it has found numerous applications. For these, as well for its connections to several computer algebra systems see Bruns et al. (2018). One of the driving forces for the improvements of Normaliz in the past years was the desire to solve the problems raised by Schürmann (2013), that is to compute the volumes and Ehrhart series of certain polytopes related to social choice.
We believe that the recent development in the algorithms of Normaliz have (partially) solved the problem raised by Lepelley, Louichi and Smaoui. Brandt et al. (2016, p. 388) write:
To the best of our knowledge, Normaliz is the only program which is able to compute polytopes corresponding to elections with up to four alternatives.
This remark applies to the computation of Ehrhart series. For volume computations one has other choices; see Remark 4. For a very recent preprint in the same spirit as Brandt et al. (2016), see Brandt et al. (2019).
The model underlying all the election schemes discussed in this paper assumes that every voter has a linear ranking of the candidates. For n candidates there are \(N=n!\) such orders. The election profile is the collection of the N numbers \((v_1,\dots ,v_N)\) where \(v_i\) is the number of voters that have decided for the i-th ranking. The election scheme then ranks the candidates based on the profile. The first person in this ranking is declared winner and the last is the loser of the election.
In this paper we present several results of our own computational experiments with four candidates elections under the assumption of the Impartial Anonymous Culture (IAC) (Gehrlein and Fishburn 1976) [the (IAC) assumes that all election profiles have the same probability for a fixed number of voters]. The background of these experiments, motivated by social choice theory and its connection with the polytope theory, may be found in Gehrlein and Lepelley (2011, 2017), Lepelley et al. (2008), Schürmann (2013) or Wilson and Pritchard (2007). For discrete convex geometry we refer the reader to Bruns and Gubeladze (2009).
The Condorcet winner is a candidate who is preferred by a majority of voters in all pairwise comparisons with the other candidates. Condorcet observed that a Condorcet winner need not exist: pairwise comparison is not transitive. This phenomenon is called the Condorcet paradox. As an introductory example we discuss this paradox whose (IAC) probability of \(331/2048\approx 16.2\%\) for four candidates has been known for quite a while (Gehrlein 2001). This probability and almost every other we present is actually the limit of the probabilities for a finite number k of voters as k goes to infinity.
If the ideal result of an election is the Condorcet winner, provided such exists, then the conditional probability with which the Condorcet winner is selected as the winner of an election is a strong quality measure for the election scheme. This probability is called the Condorcet efficiency. In Gehrlein and Lepelley (2011), it has been studied extensively by Gehrlein and Lepelley. Therefore we continue with the Condorcet efficiency of plurality voting (see Schürmann 2013) and complement it by the Condorcet efficiency of plurality elections with runoff. While plurality voting has Condorcet efficiency \(74.3\%\), a runoff ballot of two candidates increases it to \(91.2\%\). The gain is substantial and justifies runoff ballots that are part of many voting procedures (in this introduction we content ourselves with approximate probabilities; precise rational numbers will be given later on).
Another problem discussed in Schürmann (2013) is “plurality versus runoff”, namely the probability of \(75.5\%\) that the plurality winner also wins the runoff.
Next follows a discussion of the four types of antisymmetric relations between four candidates that can arise from comparisons in majority, and their probabilities. As we will see, the case (i) of a linear order is the most likely one by far. The other three cases, namely that (ii) there exists a Condorcet winner, but not a loser, (iii) a loser, but not a winner, and (iv) neither a winner, nor a loser, have small probabilities \(< 10\%\).
We conclude the list of voting outcomes with the Borda paradoxes. The strict Borda paradox occurs if the outcome of the pairwise majority comparison is a linear order and the plurality outcome completely reverses it. For four candidates its conditional probability is approximately \(0.156\%\). The strong Borda paradox [also known as the Condorcet loser paradox (Brandt et al. 2016)] has two variants, namely (i) that the Condorcet loser wins the plurality, and (ii) that the Condorcet winner is the last in plurality. As to be expected, their conditional probabilities are considerably larger, namely about \(2.268\%\) and \(2.379\%\). Though one would intuitively expect that these probabilities agree, they are not equal.
All these events are discussed together with their defining inequalities in Sect. 2. We would like to point out that Normaliz not only computes the volumes of the polytopes in all cases, but also their Ehrhart series, and therefore precise numbers of election profiles that represent the events under discussion, depending on the number of voters. We give the complete numerics only for the Condordet paradox, but all data can be obtained by request from the authors.
Ehrhart series (see Sect. 3) are more easily to compute for closed polytopes than for the ones that arise if one excludes ties. However, in many cases the Ehrhart series of the semiopen polytope can be computed from that of its closure (and conversely). The crucial condition is that all inequalities, except the sign conditions, defining the semiopen polytope are strict, and they are satisfied with equality by the election profile in which every preference order has the same number of voters; see Theorem 5. This follows from a variant of Ehrhart reciprocity [for example, see Bruns and Gubeladze (2009, Th. 6.51)]. From the Ehrhart series of the semiopen polytope one can also read the minimal number of voters that can realize the event under consideration; see Remark 8.
Normaliz can do all computations in dimension 24 (the number of preference orders for four candidates), but the the computation times range from seconds (for the Condorcet paradox) to a few days (for the Condorcet efficiency of the runoff scheme) on a fast machine that allows 32 parallel threads (see Sect. 5.3 for the technical details). Schürmann (2013) made the elegant observation that many computations can be enormously accelerated if one uses the symmetry that is inherent in many polytopes. Only two of the polytopes discussed in this paper do not allow this approach, namely linear order and (consequently) the strict Borda paradox. Symmetrization, which requires the computation of weighted Ehrhart series, shrinks computation times from days to hours, minutes, or even tenths of seconds, depending on the example. Symmetrization is discussed in Sect. 4, and all relevant computation data are listed in Sect. 5.
The reader who is interested in a deeper understanding of the mathematics and algorithms of Normaliz is refereed to the articles by Bruns and Koch (2001), Bruns and Ichim (2010), Bruns et al. (2011, 2016, 2017) and Bruns and Söger (2015).
2 Polytopes in four candidates elections and their volumes
2.1 Voting schemes and volumes of rational polytopes
We briefly sketch the connection between rational polytopes and social choice, referring the reader to Gehrlein and Lepelley (2011), Lepelley et al. (2008), Schürmann (2013) or Wilson and Pritchard (2007) for details and a more extensive treatment. As an introductory example we first consider the well-known Condorcet paradox. The polytopes \({{\mathscr {P}}}\) associated to it and to other voting events are semiopen: \({{\mathscr {P}}}\) is the bounded set of solutions of a system of linear equations and inequalities in which some of the inequalities may be strict.
Consider an election in which each of the k voters fixes a linear preference order of n candidates. In other words, voter i chooses a linear order \(j_1\succ _i\dots \succ _i j_n\) of the candidates \(1,\dots ,n\). There are \(N=n!\) such linear orders that we list lexicographically. The election profile is the N-tuple \((v_1,\dots ,v_N)\) in which \(v_p\) is the number of voters that have chosen the preference order p. Then \(v_1+\dots +v_N=k\), and \((v_1,\dots ,v_N)\) can be considered as a lattice point in the positive orthant \({{\mathbb {R}}}_+^N\) of \({{\mathbb {R}}}^B\), more precisely, as a lattice point in the simplex
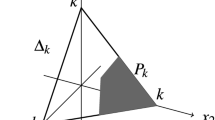
where \(A_k\) is the hyperplane defined by \(v_1+\dots +v_N=k\), and \({{\mathscr {U}}}^{(n)}={{\mathscr {U}}}_1^{(n)}\) is the unit simplex of dimension \(N-1\) naturally embedded in N-space (\({{\mathscr {U}}}^{(n)}\) is the convex hull of the unit vectors; see Fig. 1).

The unit simplex in \({{\mathbb {R}}}^3\)
As mentioned in the introduction, the further discussion is based on the Impartial Anonymous Culture (IAC). It assumes that all lattice points in the simplex \({{\mathscr {U}}}_k^{(n)}\) have equal probability of being the outcome of the election.
We fix a specific outcome \(v=(v_1,\dots ,v_N)\). By the majority rule candidate j beats candidate \(j'\) in the election with profile v if
As the Marquis de Condorcet (1785) observed, the relation “beats” is nontransitive in general, and one must ask for the probability of Condorcet’s paradox, namely an outcome without a Condorcet winner, where candidate j is a Condorcet winner if j beats all other candidates \(j'\). The Condorcet winner will sometimes be denoted \(CW \) in the following. Given the number k of voters, let \(p_{CW }^{(n,j)}(k)\) denote the probability that candidate j is the Condorcet winner, and \(p_{CW }^{(n)}(k)\) the probability that there is a Condorcet winner at all. By symmetry and by mutual exclusion, \(p_{CW }^{(n)}(k)=n\cdot p_{CW }^{(n,j)}(k)\).
Now, if we assume that the number k of voters is very large, then we are mainly interested in the limit
Let us fix candidate 1. It is not hard to see that the \(n-1\) inequalities (2.1) for \(j=1\) and \(j'=2,\dots ,n\) constitute homogeneous linear inequalities in the variables \(v_1,\dots ,v_N\). Together with the sign conditions \(v_i\ge 0\) they define a semi-open subpolytope \({{\mathscr {C}}}^{(n)}_k\) of \({{\mathscr {U}}}_k^{(n)}\). Then
where \(\overline{\phantom {C}}\) denotes closure and \({{\mathscr {C}}}^{(n)}={{\mathscr {C}}}_1^{(n)}\). For the validity of (2.2) note that we work with the lattice normalized volume in which the unit simplex has volume 1.
In the case of two candidates, Concordet’s paradox cannot occur (if one excludes draws), and for three candidates the relevant volume is not hard to compute, even without a computer (see Gehrlein and Fishburn 1976).
The situation changes significantly for four candidates since \({{\mathscr {C}}}^{(4)}\) has dimension 23 and 234 vertices. From now on we will simplify our notation and omit often the superscript (4) when dealing with four candidates. As a subpolytope of \({{\mathscr {U}}}\), \({{\mathscr {C}}}\) is cut out by the inequalities \(\lambda _i(v)>0\), \(i=1,2,3\) whose coefficients are in the first 3 rows displayed in Table 1. For the assignment of indices the preference orders are listed lexicographically, starting with \(1\succ 2 \succ 3\succ 4\) and ending with \(4\succ 3 \succ 2\succ 1\).
Normaliz computes
in less than a second (the combinatorial data of all polytopes discussed and the computation times are listed in Sect. 5). It follows that \(p_CW =1717/2048\approx 0.8384\). This value was first determined by Gehrlein (2001).
2.2 Plurality rule and runoff
A very simple way out of the dilemma that there may not exist a Condorcet winner is plurality voting: candidate j is the plurality winner if j has more first places in the preference orders of the voters than any of the other \(n-1\) candidates. A problem discussed in Schürmann (2013) is plurality voting versus plurality runoff. It goes as follows. In the first round of the election the two top candidates in plurality are selected, and in the second round the preference orders are restricted to these two candidates. In order to model this situation by inequalities one must fix an outcome of the first round of plurality voting, for example we may assume that candidate 1 is the winner of the first round and candidate 2 is placed second after the first round. The chosen outcome gives rise to \(n-1\) inequalities. Then the n-th inequality expresses that 1 is also the winner of the second round. The volume of the corresponding polytope gives the probability of this event. By mutual exclusion and symmetry, we must multiply the volume by \(n(n-1)\) in order to obtain the probability for the event that the winner of the first plurality round wins after runoff.
As a subpolytope of \({{\mathscr {U}}}\), the polytope \({{\mathscr {Q}}}\) is defined by the inequalities in Table 2.
The volume is
The total probability of the event that the winner of the first plurality round wins after runoff is
Therefore, the probability of the failure of the winner of the first round to win the runoff is
in accordance with the results of Schürmann (2013) for a similar model. This computation was first performed by De Loera et al. (2013), where LattE Integrale (Baldoni et al. 2013) was used for the volume computation.
2.3 Condorcet efficiency
The last problem discussed in Schürmann (2013) is the Condorcet efficiency of plurality voting. It is the conditional probability that the Condorcet winner, provided that such exists, is elected by plurality voting, as \(k\rightarrow \infty \) (similarly one defines the Condorcet efficiency of other voting schemes). Therefore one must compute the probability of the event that candidate j is both the Condorcet winner and the plurality winner. By symmetry, one can assume \(j=1\). The semi-open polytope \({{\mathscr {E}}}_k^{(n)}\), whose lattice points represent this expected outcome, is cut out from \({{\mathscr {C}}}_k^{(n)}\) by \(n-1\) further inequalities saying that 1 has more first places than any of the other \(n-1\) candidates. Thus one obtains
as the Condorcet efficiency of plurality voting where \({{\mathscr {E}}}^{(n)}={{\mathscr {E}}}_1^{(n)}\).
The extra three inequalities \(\lambda _i(v)>0\), \(i=4,5,6\), given in the last three lines of Table 1 increase the complexity of the polytope \({{\mathscr {E}}}\) enormously in comparison to \({{\mathscr {C}}}\). Nevertheless, Normaliz computes the volume in moderate time. We have obtained
so that the Condorcet efficiency of plurality voting turns out to be
in perfect accordance with Schürmann (2013).
Remark 1
Schürmann (2013) used variants of the polytopes \({{\mathscr {Q}}}\) and \({{\mathscr {E}}}\). Our choices (which are demanding slightly more computational resources) avoid inclusion–exclusion calculations that would come up in Sect. 3.
It is interesting to compare the Condorcet efficiency of plurality voting to the the Condorcet efficiency of the runoff voting scheme. In other words, given that there exists a Condorcet winner, what is the probability that she or he is at least second in plurality?
As above, let us assume that candidate 1 is the Condorcet winner. Then there are n possible cases. The first case is when candidate 1 is the plurality winner as well, and this case was studied above. The other \(n-1\) cases are associated to the event that candidate j wins or ties candidate 1 in plurality (where \(j\ne 1\)), while candidate 1 wins the plurality voting against all other candidates. By symmetry, these \(n-1\) cases are identical and yield the same volume. The n cases are mutually disjoint and exhaust all the possibilities (disjointness is important in Sect. 3 for avoiding complicated inclusion–exclusion calculations). The semi-open polytope \({{\mathscr {F}}}_{1,j}^{(n)}\), whose lattice points represent the outcome of the cases \(j=2,\ldots ,n\), is cut out from \({{\mathscr {C}}}_k^{(n)}\) by the closed condition that candidate j wins against or ties with candidate 1 in plurality and by \(n-2\) inequalities saying that 1 has more first places than the remaining \(n-2\) candidates. Thus one obtains
as the Condorcet efficiency of the runoff, where \({{\mathscr {F}}}^{(n)}={{\mathscr {F}}}_{1,2}^{(n)}\). In fact, there are n choices for the candidate that is simultaneously the Condorcet and the plurality winner, and there are \(n(n-1)\) choices for the pair of candidates (A, B) in which A is the plurality winner and B is the CW, but only second in plurality.
As a subpolytope of \({{\mathscr {U}}}\), the polytope \({{\mathscr {F}}}\) is defined by the inequalities in Table 3, where the last line should be interpreted as \(\overline{-\lambda _4}(v)\ge 0\), expressing the condition that candidate 1 does not beat candidate 2 in plurality.
The volume is
Finally, the Condorcet efficiency of the runoff is
2.4 Condorcet classification
In this subsection we classify the asymmetric relations between four candidates given by the majority rule. To the best of our knowledge the computations of the probabilities of the classes is new.
Let us first outline a duality argument that will be used several times below. Consider an election profile \(v=(v_1,\dots ,v_N)\) for n candidates, where \(N=n!\), the N preference orders \(\pi _1,\dots ,\pi _N\) are listed in some order, and \(v_i\) is the number of voters of \(\pi _i\). Each preference order has an inverse \(c(\pi )\) that ranks the candidates in inverse order relative to \(\pi \): the inverse order to \(1 \succ 2 \succ 3\succ 4\) is \(4\succ 3 \succ 2\succ 1\) etc. The assignment \(\pi \rightarrow c(\pi )\) defines a permutation of the sequence \(1,\dots ,N\), sending i to the index of \(c(\pi _i)\). The induced permutation of the coordinates of \({{\mathbb {R}}}^N\) is called inversion of preference orders. It inverts all comparisons in majority. In particular it turns a Condorcet winner into a Condorcet loser, and conversely.
The results of the n candidates elections may be classified in two main categories:
-
(A)
There exists a Condorcet winner. As seen above, in the case of four candidates elections the results fall into this category with probability
$$\begin{aligned}P(\exists \text { Condorcet Winner})=1717/2048\approx 0.8384.\end{aligned}$$ -
(B)
There exists no Condorcet winner. For four candidates elections the results fall into this category with probability
$$\begin{aligned}P(\not \exists \text { Condorcet Winner})=1-1717/2048=331/2048\approx 0.1616.\end{aligned}$$
We refer the reader to Gehrlein and Lepelley (2011, Section 3.2.1) or Gehrlein and Lepelley (2010) for a discussion of the three candidates situation. Note that in the three candidates scenario the event that there exists a linear order on the result of the majority voting is the same as the event that there exists a Condorcet winner, since the other two candidates are automatically ordered. This no longer true for four or more candidates. Even if a Condorcet winner exists, the remaining candidates need not to be linearly ordered. Therefore, we need to further refine our classification. Precise results for small numbers of voters would have to take into account ties between the candidates. For simplicity we neglect ties in our classification that applies only if the number of voters goes to infinity.
We discuss the case of four candidates in detail:
-
(A)
Assume that a Condorcet winner (CW) does exist. This situation must be split into two subcategories:
-
(1)
The result of the majority voting defines a linear order of the candidates. This further implies (independently of the number of candidates n) that there also exists a Condorcet loser (CL).
-
(2)
There exist no linear order on the result of the majority voting. In the (particular) case of four candidates elections this is equivalent to saying that there exists a cycle of length three among the lower candidates (i.e., the three candidates Condorcet Paradox) or that there exists no Condorcet loser.
-
(1)
-
(B)
Now assume the case that a Condorcet winner does not exist. This situation must also be split into two subcategories:
-
(1)
There exists a cycle of order three among the candidates and a Condorcet loser. Inversion of preference orders turns this case into (A2). In particular they have the same probability.
-
(2)
There exists a cycle of length four among the candidates or (equivalently) there exists no Condorcet loser. This condition defines only 4 of the 6 relations between the candidates, but it easy to check that all 4 possibilities for the remaining 2 relations are equivalent up to a renaming of the candidates.
-
(1)

Oriented graphs representing the Condorcet classes of four candidates with respect to the relation given by the majority rule
The four cases of the classification are illustrated by their directed graphs in Fig. 2. In order to compute the probabilities of the 4 classes, we consider the polytope \({{\mathscr {T}}}\) which corresponds to the event that candidate 1 beats candidates 2, 3, 4, candidate 2 beats candidates 3, 4 and candidate 3 beats candidate 4. In other words, \({{\mathscr {T}}}\) represents the linear order. As a subpolytope of \({{\mathscr {U}}}\), the polytope \({{\mathscr {T}}}\) is defined by the inequalities in Table 4 (note that \(\beta _i=\lambda _i\) for \(i=1,2,3\)). We have obtained
Since a set of 4 elements admits 24 possible linear orders, the probability to have a linear order on the result of the majority voting is
It follows that the probability that a Condorcet winner does exists, and still there exist no linear order on the result of the majority voting is
By the duality argument observed in the case (B1) the probability that a Condorcet loser does exists, but no Condorcet winner, is
as well. The probability of the remaining class (B2), the existence of a 4-cycle, is
As a test for the correctness of the algorithm, we have nevertheless computed the probability of a 4-cycle directly. To this end, we consider the polytope \({{\mathscr {K}}}\) corresponding to the event that candidate 1 beats candidate 2, candidate 2 beats candidate 3, candidate 3 beats candidate 4 and candidate 4 beats candidate 1. As a subpolytope of \({{\mathscr {U}}}\), the polytope \({{\mathscr {K}}}\) is defined by the inequalities in Table 5.
We have obtained
Since a set of 4 elements admits 6 possible cycles of length four among the elements (if we fix one element there are 6 possible linear orders among the remaining three elements), one obtains exactly the same probability for the class (B2) that was computed indirectly above.
2.5 Borda paradoxes
In this subsection we study a family of voting paradoxes, first introduced by Chevalier de Borda (1781). To the best of our knowledge all volume computations in this subsection are new.
The strict Borda paradox appears in a voting situation when there is a complete reversal of the ranking of candidates given by the majority voting and plurality voting. In order to model this situation by inequalities one must first assume that there exists a linear order on the result of the majority voting that involves all n candidates, say \(1,\dots ,n\) in this order (there are n! possible outcomes). The chosen outcome gives rise to
inequalities. Then one must add \(n-1\) inequalities expressing that the order was completely reversed by the plurality voting. The volume of the corresponding polytope gives the probability of this event. By mutual exclusion and symmetry, we must multiply the volume by n! and then take the conditional probability under the hypothesis that such a linear order exists.
As a subpolytope of \({{\mathscr {U}}}\), the polytope \({{\mathscr {B}}}_{{St }}\) is defined by the inequalities in Table 6. Note that the first six inequalities describe the event that the result of the majority voting yields a linear order. We have obtained
Finally, conditioned by the assumption that there exists a linear order on the result of the majority voting, we get the probability of the strict Borda paradox for large numbers of voters,
Remark 2
(a) The inequalities defining the strict Borda paradox have an obvious property, which we only state since it does not hold in the case of the strong Borda paradox discussed below: it does not matter if one considers the inequalities in Table 6 or the inequalities defined by the same linear forms multiplied by \(-\) 1. In fact, the multiplication by \(-\) 1 reverses the linear order on the candidates both for majority and plurality, and thus amounts to a renaming of the candidates.
(b) One may ask, as in Gehrlein and Lepelley (2010), what happens if the negative plurality rule is used instead of the plurality rule. The negative plurality rule requires the voters to cast a vote against their least preferred candidate. It is not difficult to see that inversion of the preference orders as discussed in Sect. 2.4 above, maps an event representing the strict Borda paradox for plurality to an event representing the strict Borda paradox for negative plurality. Therefore no new computation is necessary.
(c) With the notation used in Gehrlein and Lepelley (2010, Formula 19), we have
We note that the probability of observing the strict Borda paradox in four candidates elections (under the Impartial Anonymous Culture hypothesis) is significantly smaller than the probability of observing the strict Borda paradox in three candidates elections, which was computed in Gehrlein and Lepelley (2010, Formula 19) and is \(1/90\approx 0.0111\).
The strong Borda paradox is the voting situation in which there is an inversion between the winner or the loser from the majority voting to plurality voting. Under the name Condorcet loser paradox it is intensively studied in Brandt et al. (2016). It appears that de Borda was primarily concerned with the outcome that plurality voting might elect the majority voting loser (Chevalier de Borda 1781). In the following we say that the strong Borda paradox occurs if the Condorcet loser is the winner of the plurality voting. Let us assume that candidate 1 is the Condorcet loser. Next, by assuming that 1 wins the plurality we obtain \(n-1\) new inequalities. Each candidate may fulfill these conditions, so by symmetry the result must be multiplied by n. Finally, the conditional probability has to be computed.
As a subpolytope of \({{\mathscr {U}}}\), the polytope \({{\mathscr {B}}}_{{Sg }}\) is defined by the inequalities in Table 7.
One gets
Combined with the previous computations, we obtain the probability of the strong Borda paradox for large numbers of voters:
(we have used that the probability that there exists a Condorcet loser equals the probability that there exists a Condorcet winner).
The situation when the Condorcet winner is the loser of the plurality voting presents also interest, in which case we say that the reverse strong Borda paradox appears. This situation is easy to model: we simply have to multiply the linear forms of Table 7 by \(-\) 1. In other words, as a subpolytope of \({{\mathscr {U}}}\), the polytope \({{\mathscr {B}}}_{{SgRev }}\) is defined by the inequalities \(\ \beta _1,\beta _2,\beta _4,-\beta _{10},-\beta _{11},-\beta _{12}\). Its volume is given by
Combined with the previous computations, we get the probability of the reverse strong Borda paradox for large numbers of voters
The difference between the two forms of the strong Borda paradox may seem surprising, but there is less symmetry than one might assume naively: preference reversal turns the Condorcet winner into the Condorcet loser and conversely, but such exchange does not exist between the plurality winner and the plurality loser. Already the minimal number of voters that can realize the paradoxa differ; see Remark 8(d).
Remark 3
(a) Again one may ask what happens if the negative plurality rule (NPR) is used for the strong Borda paradox (BP) and its reverse variant. In total we then have 4 variants. But the 2 new variants are isomorphic to those considered above via the inversion of preference orders:
In fact, the inversion of preference orders turns an event representing the strong Borda paradox for plurality into an event for the reverse strong Borda paradox with negative plurality. Similarly it exchanges the events within the other pair.
(b) With the notation used in Gehrlein and Lepelley (2010, Formula 20), we have
We note that the probability of observing the strong Borda paradox in four candidates elections under the plurality rule (respectively the negative plurality rule) is smaller, but still of the same magnitude, with the probability of observing the strong Borda paradox in three candidates elections under the plurality rule (respectively the negative plurality rule), which was computed in Gehrlein and Lepelley (2010, Formula 20) and is \(4/135 \approx 0.0296\) (respectively \(17/540 \approx 0.0315\)).
Remark 4
After the initial submission of this paper, Lepelley informed us by e-mail that several volume computations in El Ouafdi et al. (2018) can also be done by a combination of the software packages LattE (Baldoni et al. 2013) and lrs (Avis 2018). The authors obtained precisely the same results as we. This is a good test for the correctness of all algorithms involved.
In addition to LattE and lrs the El Ouafdi et al. (2018) also used the descent algorithm of Normaliz (Bruns and Ichim 2018) that was developed after the submission of this paper.
3 Computations of Ehrhart series and quasipolynomials arising in four candidates elections
While the probability for very large numbers of voters of a certain type of election result, for example the Condorcet paradox, can be computed as the volume of a polytope (or the sum of such volumes), one can use the polyhedral method also to find the exact number of election profiles of the given type for a specific number k of voters. For example, if \({{\mathscr {C}}}\) is the semiopen polytope defined by the condition that candidate 1 is the Condorcet winner, then the number of election profiles for k voters with Condorcet winner 1 is
The function \(E({{\mathscr {C}}},k)\) is called the Ehrhart function of \({{\mathscr {C}}}\). The best approach to its computations uses the generating function
This Ehrhart series is the power series expansion of a rational function at the origin. It is computed as a rational function, and in the following we will always represent Ehrhart series in the form numerator/denominator. The numerator is a polynomial with integer coefficients. The denominator can always be written as a product of d terms \(1-t^g\), \(d=\dim {{\mathscr {P}}}+1\):
Note that in general there exists no canonical representation in this form; see Bruns et al. (2016, Section 4) for a brief discussion of this problem. If \({{\mathscr {P}}}\) is closed, then \(h_0=1\), and the denominator can be chosen in such a way that all \(h_i\) are nonnegative. In the semiopen case such a representation may not exist. The theory of Ehrhart series is developed in several books, for example in Bruns and Gubeladze (2009). For a treatment under the aspect of social choice we refer the reader to Lepelley et al. (2008).
For closed polytopes \({{\mathscr {P}}}\), the Ehrhart function \(E({{\mathscr {P}}},k)\) itself is given by a quasipolynomial \(q_{{\mathscr {P}}}\) for all \(k\ge 0\). Roughly speaking, this means that \(q_{{\mathscr {P}}}(k)\) is a polynomial whose coefficients depend periodically on k. The period is a divisor of the least common multiple of the exponents g in the factors \(1-t^g\) in the denominator. In the Normaliz output the period is always exactly the least common multiple. In the semiopen case one has \(E({{\mathscr {P}}},k)=q_{{\mathscr {P}}}(k)\) only for sufficiently large k. More precisely, if r is the degree of \(E_{{\mathscr {P}}}(t)\) as a rational function, then \(E({{\mathscr {P}}},r)\ne q_{{\mathscr {P}}}(r)\), but \(E({{\mathscr {P}}},k)= q_{{\mathscr {P}}}(k)\) for all \(k>r\).
For \(n=4\) the Ehrhart series of \({{\mathscr {C}}}\) has the numerator
The Ehrhart series of \({\overline{{{\mathscr {C}}}}}\) has the numerator
Both have the same denominator
Numerator and denominator are coprime, but in general one cannot find a coprime representation if one insists on a denominator that is a product of terms \(1-t^g\).
If we write the numerator of \({\overline{{{\mathscr {C}}}}}\) as \(\sum _{i=0}^{40} a_it^i \), then the numerator of \({{\mathscr {C}}}\) is \(\sum _{i=0}^{40} a_{40-i}t^{i+1}\): up to a shift in degree, they are palindromes of each other. This rather unexpected relationship is not an accident, and is explained by the following theorem.
Theorem 5
Let \(\lambda _1,\dots ,\lambda _m\) be linear forms on \({{\mathbb {R}}}^d\), and let \({\mathbf {1}}\in {{\mathbb {R}}}^d\) be the vector with the entry 1 at all coordinates. Suppose that \(\lambda _i({\mathbf {1}})=0\) for all \(i=1,\dots ,m\). Set \(C=\{x\in {{\mathbb {R}}}^d_+: \lambda _i(x)\ge 0,i=1\dots ,m\}\), and
Define the he semiopen polytope \({{\mathscr {P}}}\) by
If \(\dim {{\mathscr {P}}}=d-1\) (the maximal dimension), then the following hold:
-
(1)
\(J=I-{\mathbf {1}}\), where J is the set of lattice points in D and I is the set of interior lattice points of C.
-
(2)
$$\begin{aligned} E_{{{\mathscr {P}}}}(t)=(-1)^d\,t^{-d}E_{{{\overline{{{\mathscr {P}}}}}}}(t^{-1}). \end{aligned}$$
-
(3)
Suppose that
$$\begin{aligned} E_{{{\overline{{{\mathscr {P}}}}}}}(t)=\frac{h_0+h_1t\dots +h_st^s}{(1-t^{g_1})\cdots (1-t^{g_d})}. \end{aligned}$$Then the Ehrhart series of \({{\mathscr {P}}}\) has the numerator polynomial
$$\begin{aligned} h_st^w+\dots +h_0t^{w+s} ,\qquad w=\sum _{i=1}^d g_i-d-s, \end{aligned}$$over the same denominator.
Proof
The crucial observation is (1). Since \(\dim {{\mathscr {P}}}=d-1\), the interior of C is
For lattice points \(x\in {{\mathbb {Z}}}^d\) these inequalities amount to \(x_i\ge 1\) and \(\lambda _j(x)\ge 1\). Thus x belongs to the interior of C if and only if \(x-{\mathbf {1}}\) satisfies the inequalities \(x_i\ge 0\) for \(i=1,\dots ,d\), and \(\lambda _j(x)>0\) for \(j=1,\dots ,m\). This proves \(J=I-{\mathbf {1}}\).
By Ehrhart reciprocity (for example, see Bruns and Gubeladze 2009, Th. 6.51) the Ehrhart series of the interior of \({{\overline{{{\mathscr {P}}}}}}\) is \((-1)^dE_{{{\overline{{{\mathscr {P}}}}}}}(t^{-1})\). In view of (1) we have to multiply this series by \(t^{-d}\) to obtain the Ehrhart series of \({{\mathscr {P}}}\). This gives (2).
Part (3) is now an elementary transformation. \(\square \)
Remark 6
(a) The condition \(\lambda _i({\mathbf {1}})=0\) in Theorem 5 is equivalent to the natural assumption that it only depends on the differences \(v_i-v_j\) whether a voting profile \((v_1,\dots ,v_d)\) belongs to the event defined by the inequalities.
(b) We have formulated Theorem 5 for the grading by total degree. It can easily be generalized to other gradings.
In the case of our polytopes we have \(d=24\). So, for \({{\mathscr {C}}}\) we obtain \(\sum _{i=1}^d g_i-d-s=65-24-40=1\), as observed. Theorem 5 is applicable to all polytopes in Sect. 2 with the exception of \({{\mathscr {F}}}\). Nevertheless we have computed both Ehrhart series in each case since the comparison is an excellent test of the Normaliz algorithm. For \({{\mathscr {F}}}\) the formula in Theorem 5 does indeed not hold.
The Ehrhart quasipolynomials of \({{\mathscr {C}}}\) and \({\overline{{{\mathscr {C}}}}}\) have period 4. Moreover, they are equal for an odd number of voters k and have the same expression
(for \(k\equiv 1,3 \text { mod }4\)), where
Let us reformulate this result in terms of probabilities. With the notation introduced at the beginning of Sect. 2, we have
where
Since
we get
This is exactly the same formula as the one computed first by Gehrlein Gehrlein (2001). For the case of even k we set
and
then we get
To the best of our knowledge the above formula for an even number of voters has not been computed before our computations with Normaliz.
In Fig. 3 we present the graph of \(p_{CW }^{(4)}(k)\) and in Fig. 4 we present the graph of \(p_{CW }^{(4)}(k^2)\) for \(k=0,\ldots ,48\). The difference between the values of \(p_{CW }^{(4)}\) for even and odd numbers of voters is due to the fact that in the case of an even number of voters ties do occur. The graphs are drawn using the software package R, see R Core Team (2013).

Probabilities for a small number of voters

Probabilities for a large number of voters
Remark 7
With the notation used in Gehrlein and Lepelley (2011, Formula 1.27 and 1.29), we have
For the other eight polytopes, since the numerators of the Ehrhart series are very long, we only list the denominators for a representation similar to the one given above for \({{\mathscr {C}}}\) and \({\overline{{{\mathscr {C}}}}}\) (with non-coprime numerators):
The denominators have 24 factors. All computed data is available and will be provided by the authors on request.
The reciprocity between \(E_{{\mathscr {P}}}(t)\) and \(E_{{{\overline{{{\mathscr {P}}}}}}}(t)\) in Theorem 5 can be recast into a relation between the Ehrhart quasipolynomials. In terms of quasipolynomials, Ehrhart reciprocity says \(q_{{relint }{{\overline{{{\mathscr {P}}}}}}}(k)=(-1)^{d-1}q_{{{\overline{{{\mathscr {P}}}}}}}(-k)\) for all \(k\ge 1\) (for example, see Bruns and Gubeladze 2009, Th. 6.51), and in view of Theorem 5 this implies
It follows that under the conditions of Theorem 5 one has \(E({{\mathscr {P}}},k)=q_{{\mathscr {P}}}(k)\) for all \(k>-d\), and therefore for all \(k>0\).
Remark 8
(a) In Table 8 we summarize the essential data of the numerators of the Ehrhart series of the polytopes (with the exception of \({{\mathscr {F}}}\)), according to the notations introduced in Theorem 5. The last column represents the period of the associated Ehrhart quasipolynomials.
(b) The numerator of \({\overline{{{\mathscr {F}}}}}\) is a polynomial of degree 1386 whereas the numerator of \({{\mathscr {F}}}\) has degree 1389. They are not related by Theorem 5, so the Ehrhart series must be computed separately by Normaliz. The Ehrhart quasipolynomials of \({{\mathscr {F}}}\) and \({\overline{{{\mathscr {F}}}}}\) have period 120.
(c) The number w in Table 8 is the smallest number of voters that can realize the respective election outcome since it is the initial degree of the Ehrhart series, i.e., the lowest exponent of t that appears in the Ehrhart series (when written as a power series). It is also the coefficient of the smallest power of t in the numerator polynomial of the Ehrhart series when written as a rational function. In fact, one obtains the series expansion by multiplying the numerator polynomial with the power series expansion of 1 / q(t) where q is the polynomial in the denominator, and this power series has constant coefficient 1.
Future versions of Normaliz may contain a function that allows the computation of the initial degree without the computation of the full Ehrhart series. The latter is much more difficult.
(d) The values of w can be checked by elementary arguments, independently from the Ehrhart series computation. We explain it for the strong Borda paradox. Let candidate A be the plurality winner. Then he has got more first places, say m, than any of the three other candidates. On the other hand, he is the Condorcet loser, and therefore must be behind any of the other candidates in at least \(m+1\) preference orders. Another candidate, for example B, gets first place in at least one of these \(m+1\) preference orders. Then \(m>1\), so \(m\ge 2\). For the total number of voters k it follows that \(k \ge 2m+1\ge 5\). The strong Borda paradox can indeed be realized with 5 voters; see Table 9 where the numbers in the last lines indicate the number of voters that have the preference ranking above them. Note that the same argument works for any number of candidates, with the exception of the three candidates situation where the minimal number of voters is 7. Similarly one can see that, for four candidates elections, the strict Borda paradox needs 9 voters, whereas the reverse strong Borda paradox requires only 3 of them, as shown in Table 9.
4 The exploitation of symmetry
The elegant approach of Schürmann Schürmann (2013) for the computation of the volumes of \({{\mathscr {C}}}\) and variants of \({{\mathscr {Q}}}\) and \({{\mathscr {E}}}\) uses the high degree of symmetries of these polytopes. Suppose that a polytope \(P\subset {{\mathbb {R}}}^d\) is defined by the sign inequalities \(x_i\ge 0\), \(i=1,\dots ,d\), and further inequalities \(\lambda _i(x)\ge 0\) (or \(>0\)). If certain variables \(x_{i_1},\dots ,x_{i_u}\) occur in all of the linear forms \(\lambda _i\) with the same coefficient (that may depend on i), then any permutation of them acts as a symmetry on the corresponding polytope, and the variables \(x_{i_1},\dots ,x_{i_u}\) can be replaced by their sum \(y_j=x_{i_1}+\dots +x_{i_u}\) in the \(\lambda _i\) (the polytopes may have further symmetries). The substitution can be used for a projection into a space of much lower dimension, mapping the polytope P to a polytope Q (this requires that the grading affine hyperplane \(A_1\) is mapped onto an affine hyperplane by the projection). Instead of counting the lattice points in kP one counts the lattice points in kQ weighted with their number of preimage lattice points in kP. This amounts to the consideration of a weighted Ehrhart function
The polynomial f is easily determined by elementary combinatorics: if \(y_j\), \(j=1,\dots ,m\), is the sum of \(u_j\) variables \(x_i\), then
The theory of weighted Ehrhart functions has recently been developed in several papers; see Baldoni et al. (2011, 2012) and Bruns and Söger (2015). In Schürmann (2013), only the leading form of the polynomial f is used. Integration of the leading form with respect to Lesbesgue measure yields the volume.
In the case of the Condorcet polytope \({{\mathscr {C}}}\) for four candidates the symmetrization yields a polytope of dimension 7: there are two groups of 6 variables each that can be replaced by their sums, and 6 groups of two variables each. We leave it to the reader to spot them. Fortunately Normaliz finds them automatically. The polynomial f, also computed automatically, is
in this case. Among our polytopes, only \({{\mathscr {T}}}\) and \({{\mathscr {B}}}_{{St }}\) do not allow any symmetrization.
Before Version 3.2.0 of Normaliz called its offspring NmzIntegrate behind the scenes for the symmetrized computation of volumes and weighted Ehrhart series. From version version 3.3.0 on, NmzIntgerate is included in Normaliz itself and no longer exist as a separate program. The algorithmic approach of NmzIntegrate is developed in Bruns and Söger (2015). For polynomial arithmetic Normaliz uses CoCoALib by Abbott et al. (2018).
5 Computational report
In this section we want to document the use of Normaliz and computations performed with it during the preparation of this work.
5.1 Use of Normaliz
Normaliz is distributed as open source under the GPL. In addition to the source code, the distribution contains executables for the major platforms Linux, Mac and Windows. We include some details on the use of Normaliz in order to show that the input files have a transparent structure and that the syntax of the execution command is likewise simple.
The polytope \({{\mathscr {C}}}\) has the following input file:

The first line amb_space 24 sets the ambient space to
\({{\mathbb {R}}}^{24}\). The 3 excluded_faces represent the strict inequalities \(\lambda _i>0\), \(i=1,2,3\) of Table 1 (the input type of non-strict inequalities is inequalities). The keyword nonnegative indicates that all 24 coordinates are to be taken nonnegative, whereas total_degree defines the grading in which each coordinate has weight 1. HilbertSeries indicates that we want to compute the Hilbert series. The last two lines NoExtRaysOutput and NoSuppHypsOutput suppress output data that do not interest us for the Hilbert series. Let us suppose the file is called Condorcet.in.
In Normaliz the simplest command for the computation is

Depending on the installation, it may be necessary to prefix normaliz or Condorcet by a path. Often one adds the option -c to get terminal output showing the progress of the computation. If one is only interested in the volume, one replaces HilbertSeries by Multiplicity or Volume (without any explicit computation goal, Normaliz would compute both the Hilbert series and Hilbert basis by default). The number of parallel threads can be limited by adding the option -x\(=<\)N> to the command line where <N> stands for the number of threads.
The computation results are contained in Condorcet.out. We display the relevant part:

The volume we are interested in is called multiplicity because of its algebraic interpretation. Hilbert series is followed by the numerator polynomial of the rational function. The denominator is \((1{-}t)(1{-}t^2)^{14}(1{-}t^4)^9\). The Hilbert quasi-polynomial is printed by residue classes modulo the period. All coefficients must be divided by the common denominator.
As will be apparent from the terminal output (obtained with -c on the command line or Verbose in the input file), Normaliz successfully tries symmetrization. One should note that Normaliz does automatic symmetrization only if the cone D defined by image \({{\mathscr {Q}}}\) has dimension \(\le 2\dim (C)/3\) where C is the cone over the polytope \({{\mathscr {P}}}\) to be computed. The bound has been introduced since one cannot expect a saving in computation time if the dimension does not drop enough. However, the user can force Normaliz to use symmetrization.
Remark 9
(a) Normaliz has an input type strict_inequalities. While it seems a natural choice and will yield the same results as excluded_faces, its use for the computations of this paper is not advisable since the algorithmic approach does not (yet) allow symmetrization, and even for cases without symmetrization it is usually significantly slower than excluded_faces.
(b) A graphical interface called jNormaliz (Almendra and Ichim 2018) is also available in the Normaliz package. For its use Java must be installed on the system.
5.2 Overview of the examples
The columns of Table 10 contain the values of characteristic numerical data of the examples studied, namely: \(\#\)vertices is the number of the vertices of the polytope, and \(\#\)supp the number of its support hyperplanes. \(\#\)Hilb is the size of the Hilbert basis of the Ehrhart cone over the polytope [see Bruns and Ichim (2010) for more details]. These data are invariants of the polytope.
The last two columns list the number of simplicial cones in the triangulation and the number of components of the Stanley decomposition [see Bruns et al. (2016) for details on these numbers]. These data are not invariants of the polytope. The information is included to show the complexity of the computations if symmetrization is not used. Normaliz can do all computations without symmetrization, but then some of them will take days, even those with a high degree of symmetry. The size of the lexicographic triangulation depends on the order in which the extreme rays are processed. The polytopes in the table above are defined by their support hyperplanes, and therefore Normaliz first computes the extreme rays from them. Moreover, bottom decomposition, see Bruns et al. (2017), is used automatically if the ratio of the largest degree among the generators and the smallest is \(\ge 10\). This further influences the data contained in the last two columns.
Of all our polytopes, only \({{\mathscr {T}}}\) and \({{\mathscr {B}}}_{{St }}\) cannot be symmetrized. The combinatorial data of the symmetrized polytopes are contained in Table 11.
We remark that, for Hilbert basis computations, the dual algorithm of Normaliz (see Bruns and Ichim 2010) is much faster than the primal algorithm for the examples of this paper, and all computations run in a few seconds. This is by no means always the case (see Bruns et al. 2016).
5.3 Hardware characteristics
Almost all computations were run on a compute server with operating system CentOS 7.3, 4 Intel Xeon E5-2660 at 2.20 GHz (a total of 32 cores) and 192 GB of RAM. With the exception of \({{\mathscr {B}}}_{{St }}\), all computations were also done on a standard laptop with operating system Ubuntu 16.04, an Intel i5-4200M CPU at 2.5 GHz and 12 GB RAM. In parallelized computations we have limited the number of threads used to 30. In Tables 12 and 14, 4x and 30x indicates parallelization with 4 and 30 threads, respectively. As the large examples below show, the parallelization scales efficiently; see also Table 13. The version that we have used exchanges data via files. The laptop has an SSD, but the server has only hard disks, and it is not a local hard disk of the machine, but the files must go through the NFS, the network file system.
Normaliz needs relatively little memory. All computations mentioned in this paper run stably with \(< 0.5\) GB of RAM for each thread used.
5.4 Volumes
Table 12 contains the computation times for the volumes of the studied polytopes, as obtained with version 3.2.1. Since version 3.5.2 Normaliz has a second algorithm for the computation of volumes that is very often significantly faster. It was developed after the submission of this paper; see Bruns and Ichim (2018).
The input for all these examples is given in the form of inequalities. When one runs Normaliz on such examples, it first computes the extreme rays of the cone and uses them as generators. This small extra time is also included in the reported times below (it is also apparent and not surprising that small examples profit from a small number of parallel threads).
In order to measure the parallelization we have run the volume computation of \({{\mathscr {E}}}\) with varying number of threads. Table 13 shows that Normaliz is very efficiently parallelized.
Remark 10
The volume of the polytope \({{\mathscr {C}}}\) was first computed by Gehrlein (2001). The volumes of variants of the polytopes \({{\mathscr {Q}}}\) and \({{\mathscr {E}}}\) had been computed by Schürmann (2013) with LattE integrale (Baldoni et al. 2013). This information was very useful for checking the correctness of Normaliz.
5.5 Ehrhart series and quasipolynomials
The experimental times obtained for computation of Ehrhart series and quasipolynomials are contained in Table 14. As above, the presented times include the time used by Normaliz for computing the extreme rays of the cone. Moreover, the Ehrhart quasipolynomials are computed from the Ehrhart series (see Bruns and Ichim 2010). This requires for some examples like \({{\mathscr {B}}}_{{St }}\) a significant extra time, which has likewise been included. We have also measured the parallelization for the Ehrhart series computation of \({{\mathscr {B}}}_{{St }}\); see Table 15. Somewhat surprisingly, the efficiency is \(>100\%\) for certain numbers of threads, an effect that can only be explained by the memory management of the system.
References
Abbott, J., Bigatti, A. M., & Lagorio, G. (2018). CoCoA-5: A system for doing Computations in Commutative Algebra. http://cocoa.dima.unige.it.
Almendra, V., & Ichim, B. (2018). jNormaliz: A graphical interface for Normaliz. www.math.uos.de/normaliz.
Avis, D. (2018). lrs: A revised implementation of the reverse search vertex enumeration algorithm. http://cgm.cs.mcgill.ca/~avis/C/lrs.html.
Baldoni, V., Berline, N., De Loera, J. A., Dutra, B., Köppe, M., Moreinis, S., Pinto, G., Vergne, M., & Wu, J. (2013). A user’s guide for LattE integrale v1.7.2, 2013. Software package LattE is available at http://www.math.ucdavis.edu/~latte/.
Baldoni, V., Berline, N., De Loera, J. A., Köppe, M., & Vergne, M. (2011). How to integrate a polynomial over a simplex. Mathematics of Computation, 80, 297–325.
Baldoni, V., Berline, N., De Loera, J. A., Köppe, M., & Vergne, M. (2012). Computation of the highest coefficients of weighted Ehrhart quasi-polynomials of rational polyhedra. Foundations of Computational Mathematics, 12, 435–469.
Brandt, F., Geist, C., & Strobel, M. (2016). Analyzing the practical relevance of voting paradoxes via Ehrhart theory, computer simulations, and empirical data. In Proceedings of the 2016 international conference on autonomous agents and multiagent systems (pp. 385–393).
Brandt, F., Hofbauer, J., & Strobel, M. (2019). Exploring the no-show paradox for condorcet extensions using Ehrhart theory and computer simulations. In Proceedings of the 18th International Conference on Autonomous Agents and Multiagent Systems (AAMAS). IFAAMAS.
Bruns, W., & Gubeladze, J. (2009). Polytopes, rings and K-theory. Berlin: Springer.
Bruns, W., Hemmecke, R., Ichim, B., Köppe, M., & Söger, C. (2011). Challenging computations of Hilbert bases of cones associated with algebraic statistics. Experimental Mathematics, 20, 25–33.
Bruns, W., & Ichim, B. (2010). Normaliz: Algorithms for affine monoids and rational cones. Journal of Algebra, 324, 1098–1113.
Bruns, W., & Ichim, B. (2018). Polytope volume by descent in the face lattice and applications in social choice. Preprint arXiv:1807.02835.
Bruns, W., Ichim, B., Römer, T., Sieg, R., & Söger, C. (2018). Normaliz: Algorithms for rational cones and affine monoids. http://normaliz.uos.de.
Bruns, W., Ichim, B., & Söger, C. (2016). The power of pyramid decomposition in Normaliz. Journal of Symbolic Computation, 74, 513–536.
Bruns, W., & Koch, R. (2001). Computing the integral closure of an affine semigroup. Universitatis Iagellonicae Acta Mathematica, 39, 59–70.
Bruns, W., Sieg, R., & Söger, C. (2017). Normaliz 2013–2016. In G. Böckle, W. Decker, & G. Malle (Eds.), Algorithmic and experimental methods in algebra, geometry, and number theory (pp. 123–146). Cham: Springer.
Bruns, W., & Söger, C. (2015). Generalized Ehrhart series and integration in Normaliz. Journal of Symbolic Computation, 68, 75–86.
Chevalier de Borda, J.-C. (1781). Mémoire sur les élections au scrutin. Histoire de’Académie Royale Des Science, 102, 657–665.
De Loera, J. A., Dutra, B., Köppe, M., Moreinis, S., Pinto, G., & Wu, J. (2013). Software for exact integration of polynomials over polyhedra. Computational Geometry, 46, 232–252.
El Ouafdi, A., Lepelley, D., & Smaoui, H. (2018). Probabilities of electoral outcomes in four-candidate elections. Preprint https://doi.org/10.13140/RG.2.2.27775.87201.
Gehrlein, W. V. (2001). Condorcet winners on four candidates with anonymous voters. Economics Letters, 71, 335–340.
Gehrlein, W. V., & Fishburn, P. (1976). Condorcet’s paradox and anonymous preference profiles. Public Choice, 26, 1–18.
Gehrlein, W. V., & Lepelley, D. (2010). On the probability of observing Borda’s paradox. Social Choice and Welfare, 35, 1–23.
Gehrlein, W. V., & Lepelley, D. (2011). Voting paradoxes and group coherence. Berlin: Springer.
Gehrlein, W. V., & Lepelley, D. (2017). Elections, voting rules and paradoxical outcomes. Berlin: Springer.
Lepelley, D., Louichi, A., & Smaoui, H. (2008). On Ehrhart polynomials and probability calculations in voting theory. Social Choice and Welfare, 30, 363–383.
Marquis de Condorcet, N. (1785). Éssai sur l’application de l’analyse à la probabilité des décisions rendues à la pluralité des voix. Paris: Imprimerie Royale.
R Core Team. (2013). R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing. http://www.R-project.org/
Schürmann, A. (2013). Exploiting polyhedral symmetries in social choice. Social Choice and Welfare, 40, 1097–1110.
Wilson, M. C., & Pritchard, G. (2007). Probability calculations under the IAC hypothesis. Mathematical Social Sciences, 54, 244–256.
Acknowledgements
The authors like to thank Achill Schürmann for several test examples that were used during the development of Normaliz. They are also grateful to the anonymous referees for helpful comments. Bogdan Ichim was partially supported by a grant of Romanian Ministry of Research and Innovation, CNCS - UEFISCDI, project number PN-III-P4-ID-PCE-2016-0157, within PNCDI III.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Bruns, W., Ichim, B. & Söger, C. Computations of volumes and Ehrhart series in four candidates elections. Ann Oper Res 280, 241–265 (2019). https://doi.org/10.1007/s10479-019-03152-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10479-019-03152-y