
Abstract
In this article, we propose and study a new class of semiparametric mixture of regression models, where the mixing proportions and variances are constants, but the component regression functions are smooth functions of a covariate. A one-step backfitting estimate and two EM-type algorithms have been proposed to achieve the optimal convergence rate for both the global parameters and the nonparametric regression functions. We derive the asymptotic property of the proposed estimates and show that both the proposed EM-type algorithms preserve the asymptotic ascent property. A generalized likelihood ratio test is proposed for semiparametric inferences. We prove that the test follows an asymptotic \(\chi ^2\)-distribution under the null hypothesis, which is independent of the nuisance parameters. A simulation study and two real data examples have been conducted to demonstrate the finite sample performance of the proposed model.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Finite mixture of regression models, also known as switching regression models in econometrics, have been widely applied in various fields, see, for example, in econometrics (Wedel and DeSarbo 1993; Frühwirth-Schnatter 2001), and in epidemiology (Green and Richardson 2002). Since Goldfeld and Quandt (1973) first introduced the mixture regression model, many efforts have been made to extend the traditional parametric mixture of linear regression models. For example, Young and Hunter (2010), and Huang and Yao (2012) studied models which allow the mixing proportions to depend on the covariates nonparametrically; Huang et al. (2013) proposed a fully nonparametric mixture of regression models by assuming the mixing proportions, the regression functions, and the variance functions to be nonparametric functions of a covariate; Cao and Yao (2012) suggested a semiparametric mixture of binomial regression models for binary data.
In this article, we propose a new semiparametric mixture of regression models, where the mixing proportions and variances are constants, but the component regression functions are nonparametric functions of a covariate. Compared to traditional finite mixture of linear regression models, the newly proposed model relaxes the parametric assumption on the regression functions, and allows the regression function in each component to be an unknown but smooth function of covariates. Compared to the fully nonparametric mixture of regression models proposed by Huang et al. (2013), our new model improves the efficiency of the estimates of the mean functions by assuming the mixing proportions and variances to be constants, which are also presumed by the traditional mixture of linear regressions. The new model is more challenging to estimate due to the existence of both global parameters and local parameters. The comparison of our paper to Huang et al. (2013) is similar to the comparison between semiparametric regression and fully nonparametric regression. Although the parametric parts of our model have stronger assumption than the nonparametric parts of Huang et al. (2013), they can provide more homogeneous model and more efficient estimate. Therefore, the proposed semiparametric model can combine the good properties of both parametric models and nonparametric models.
Our new model is motivated by a US house price index data, which is also used by Huang et al. (2013). The data set contains the monthly change of S&P/Case-Shiller House Price Index (HPI) and monthly growth rate of United States Gross Domestic Product (GDP) from January 1990 to December 2002, see Fig. 3a for a scatter plot. Based on the plot, it can be seen that there are two homogeneous groups and the relationship between HPI and GDP are different in different groups. In addition, it is clear that the relationship in each group is not linear. Therefore, the traditional mixture of linear regression models can not be applied. In Fig. 3b, we added the two fitted component regression curves based on our new model, and it is clear that the new model successfully recovered the two-component regression curves. In addition, the observations were classified into two groups corresponding to two different macroeconomic cycles, which possibly explains that the impact of GDP growth rate on HPI change may be different in different macroeconomic cycles.
We will show the identifiability of the proposed model under some regularity conditions. To estimate the unknown smoothing functions, we propose both a regression spline based estimator and a local likelihood estimator using the kernel regression technique. To achieve the optimal convergence rate for both the global parameters and the nonparametric functions, we propose a one-step backfitting estimation procedure. The asymptotic properties of the one-step backfitting estimate are investigated. In addition, we propose two EM-type algorithms to compute the proposed estimates and prove their asymptotic ascent properties. A generalized likelihood ratio test is proposed for testing whether the mixing proportions and variances are indeed constants. We investigate the asymptotic behavior of the test and prove that its limiting null distribution follows a \(\chi ^2\)-distribution independent of the nuisance parameters. A simulation study and two real data applications are used to demonstrate the effectiveness of the new model.
The rest of the paper is organized as follows. In Sect. 2, we introduce the new semiparametric mixture of regression models and the estimation procedure. In particular, we propose a regression spline estimate and a one-step backfitting estimate. A generalized likelihood ratio test is also introduced for some semiparametric inferences. In Sect. 3, we use a Monte Carlo study and two real data examples to demonstrate the finite sample performance of the proposed model and estimates. We conclude the paper with a brief discussion in Sect. 4 and defer the proofs to the Appendix.
2 Estimation procedure and asymptotic properties
2.1 The semiparametric mixture of regression models
Assume \(\{(X_i,Y_i),\,i=1,\ldots ,n\}\) are a random sample from the population (X, Y). Let Z be a latent variable with \(P(Z=j)=\pi _j\) for \(j=1,\ldots ,k\). Suppose \(E(Y|X=x,Z=j)=m_j(x)\) and conditioning on \(Z=j\) and \(X=x\), Y follows a normal distribution with mean \(m_j(x)\) and variance \(\sigma _j^2\). Then, without observing Z, the conditional distribution of Y given \(X=x\) can be written as
where \(\phi (y|\mu ,\sigma ^2)\) is the normal density with mean \(\mu \) and variance \(\sigma ^2\). In this paper, we only considered the case when X is univariate. The estimation methodology and theoretical results discussed can be readily extended to multivariate X, but due to the “curse of dimensionality”, the extension is less applicable and thus omitted here. Throughout the paper, we assume that k is fixed, and therefore, refer to (1) as a finite semiparametric mixture of regression models, since \(m_j(x)\) is a nonparametric function of x, while \(\pi _j\) and \(\sigma _j\) are global parameters. If \(m_j(x)\) is indeed linear in x, model (1) boils down to a regular finite mixture of linear regression models. When \(k=1\), then model (1) is a nonparametric regression model. Therefore, model (1) is a natural extension of the finite mixture of linear regression models and the nonparametric regression model.
Huang et al. (2013) studied a nonparametric mixture of regression models (NMR),
where \(\pi _j(\cdot )\), \(m_j(\cdot )\), and \(\sigma _j^2(\cdot )\) are unknown but smooth functions. Compared to model (2), model (1) improves the efficiency of the estimates of \(\pi _j\), \(\sigma _j\) and \(m_j(x)\) by assuming the mixing proportions and variances to be constants, which are also presumed by the traditional mixture of linear regressions. We will demonstrate such improvement in Sect. 3. However, the new model (1) is more challenging to estimate than model (2) due to the existence of both global parameters and local parameters. In fact, we will demonstrate later that the model estimate of (2) is an intermediate result of the proposed one-step backfitting estimate. In this article, we will also develop a generalized likelihood ratio test to compare the proposed model with model (2) and illustrate its use in Sect. 3.
Identifiability is a critical issue in many mixture models. Some well known results of identifiability of finite mixture models include: mixture of univariate normals is identifiable (Titterington et al. 1985), and finite mixture of linear regression models is identifiable provided that covariates have a certain level of variability (Hennig 2000). Based on Theorem 1 in Huang et al. (2013) and Theorem 3.2 in Wang et al. (2014), we can get the following result on the identifiability of model (1).
Proposition 1
Assume that
-
(1)
\(m_j(x)\) are differentiable functions, \(j=1,\ldots ,k\).
-
(2)
One of the following conditions holds:
-
(a)
For any \(i\ne j\), \(\sigma _i\ne \sigma _j\);
-
(b)
If there exists \(i\ne j\) such that \(\sigma _i=\sigma _j\), then \(\Vert m_i(x)-m_j(x)\Vert +\Vert m_i'(x)-m_j'(x)\Vert \ne 0\) for any x.
-
(a)
-
(3)
The domain \(\mathscr {X}\) of x is an interval in \(\mathbb {R}\).
Then, model (1) is identifiable.
2.2 Estimation procedure and asymptotic properties
2.2.1 Regression spline based estimator
We first introduce a regression spline based estimator, which uses the regression spline (Hastie et al 2003; de Boor 2001) to transfer the semiparametric mixture model to a parametric mixture model. A cubic spline approximation for \(m_j(x)\) can be expressed as
where \(B_1(x),...,B_{Q+4}(x)\) is a cubic spline basis and Q is the number of internal knots. Many spline bases can be used here, such as a truncated power spline basis or a B-spline basis. In this paper, we mainly focus on the B-spline basis.
Based on the approximation (3), model (1) becomes
The log likelihood of the collected data \(\{(X_i,Y_i),i=1,..,n\}\) is
where \({{\varvec{\pi }}}=\{\pi _1,\ldots ,\pi _{k-1}\}^T\), \({{\varvec{\beta }}}=\{{{\varvec{\beta }}}_1,\ldots ,{{\varvec{\beta }}}_k\}^T\), \({{\varvec{\beta }}}_j=\left( \beta _{j1},\ldots ,\beta _{j,Q+4}\right) ^T\), and \({{\varvec{\sigma }}}^2=\{\sigma _1^2,\dots ,\sigma _k^2\}^T\). The parameters \(({{\varvec{\pi }}},{{\varvec{\beta }}},{{\varvec{\sigma }}}^2)\) can be estimated by the traditional EM algorithm for mixtures of linear regression models.
The estimation method based on the regression spline approximation is easy to implement, and therefore, will be used as an initial value for our other estimation procedures.
2.2.2 One-step backfitting estimation procedure
In this section, we propose a one-step backfitting estimation procedure to achieve the optimal convergence rates for both the global parameters and the nonparametric component regression functions.
Let \(\ell ^*({{\varvec{\pi }}},{{\varvec{m}}}(\cdot ),{{\varvec{\sigma }}}^2)\) be the log-likelihood of the collected data \(\{(X_i,Y_i),i=1,..,n\}\). That is,
where \({{\varvec{\pi }}}=\{\pi _1,...,\pi _{k-1}\}^T\), \({{\varvec{m}}}(\cdot )=\{m_1(\cdot ),...,m_k(\cdot )\}^T\), and \({{\varvec{\sigma }}}^2=\{\sigma _1^2,...,\sigma _k^2\}^T\). Since \({{\varvec{m}}}(\cdot )\) consists of nonparametric functions, (4) is not ready for maximization. Next, we propose a one-step backfitting procedure. First, we estimate \({{\varvec{\pi }}}\), \({{\varvec{m}}}\) and \({{\varvec{\sigma }}}^2\) locally by maximizing the following local log-likelihood function:
where \(K_h(t)=h^{-1}K(t/h)\), \(K(\cdot )\) is a kernel density function, and h is a tuning parameter.
Let \(\tilde{{{\varvec{\pi }}}}(x)\), \(\tilde{{{\varvec{m}}}}(x)\), and \(\tilde{{{\varvec{\sigma }}}}^2(x)\) be the maximizer of (5), which are in fact the model estimates of (2) proposed by Huang et al. (2013). Note that, in (5), the global parameters \({{\varvec{\pi }}}\) and \({{\varvec{\sigma }}}^2\) are estimated locally. To improve the efficiency, we propose to update the estimates of \({{\varvec{\pi }}}\) and \({{\varvec{\sigma }}}^2\) by maximizing the following log-likelihood function:
which, compared to (4), replaces \(m_j(\cdot )\) by \(\tilde{m}_j(\cdot )\).
Denote by \(\hat{{{\varvec{\pi }}}}\) and \(\hat{{{\varvec{\sigma }}}}^2\) the solution of maximizing (6). We can then further improve the estimate of \({{\varvec{m}}}(\cdot )\) by maximizing the following local log-likelihood function:
which, compared to (5), replaces \(\pi _j\) and \(\sigma _j^2\) by \(\hat{\pi }_j\) and \(\hat{\sigma }_j^2\), respectively.
Let \(\hat{{{\varvec{m}}}}(x)\) be the solution of (7), and we refer to \(\hat{{{\varvec{\pi }}}}\), \(\hat{{{\varvec{m}}}}(x)\), and \(\hat{{{\varvec{\sigma }}}}^2\) as the one-step backfitting estimates. In Sect. 2.2.4, we show that the one-step backfitting estimates achieve the optimal convergence rate for both the global parameters, and the nonparametric mean functions. In (7), since \(\hat{\pi }_j\) and \(\hat{\sigma }_j^2\) have root n convergence rate, unlike \(\tilde{{{\varvec{m}}}}(x)\), \(\hat{{{\varvec{m}}}}(x)\) does not need to adjust the uncertainty of estimating \(\pi _j\) and \(\sigma _j^2\). Therefore, \(\hat{{{\varvec{m}}}}(x)\) can have better estimation accuracy than \(\tilde{{{\varvec{m}}}}(x)\) proposed by Huang et al. (2013).
2.2.3 Computing algorithms
In this section, we propose a local EM-type algorithm (LEM) and a global EM-type algorithm (GEM) to perform the one-step backfitting.
Local EM-type algorithm (LEM)
In practice, we usually want to evaluate unknown functions at a set of grid points, which in this case, requires us to maximize local log-likelihood functions at a set of grid points. If we simply employ an EM algorithm separately for different grid points, the labels in the found estimators may change at different grid points, and we may not be able to get smoothed estimated curves (Huang and Yao 2012). Next, we propose a modified EM-type algorithm, which estimates the nonparametric functions simultaneously at a set of grid points. Let \(\{u_t,t=1,\ldots ,N\}\) be a set of grid points where some unknown functions are evaluated, and N be the number of grid points.
Step 1: modified EM-type algorithm to maximize \(\varvec{\ell _1}\) in (5)
In Step 1, we use the modified EM-type algorithm of Huang et al. (2013) to maximize \(\ell _1\) and obtain the estimates \(\tilde{{{\varvec{\pi }}}}(\cdot )\), \(\tilde{{{\varvec{m}}}}(\cdot ),\) and \(\tilde{{{\varvec{\sigma }}}}^2(\cdot )\). Specifically, at the \((l+1)\mathrm{th}\) iteration,
E-step Calculate the expectations of component labels based on estimates from the lth iteration:
M-step Update the estimates
for \(x\in \{u_t,t=1,\ldots ,N\}\). We then update \(\pi _j^{(l+1)}(X_i)\), \(m_j^{(l+1)}(X_i),\) and \(\sigma _j^{2(l+1)}(X_i)\), \(i=1,\ldots ,n\), by linear interpolating \(\pi _j^{(l+1)}(u_t)\), \(m_j^{(l+1)}(u_t),\) and \(\sigma _j^{2(l+1)}(u_t)\), \(t=1,\ldots ,N\), respectively.
Note that in the M-step, the nonparametric functions are estimated simultaneously at a set of grid points, and therefore, the classification probabilities in the the E-step can be estimated globally to avoid the label switching problem (Celeux et al. 2000; Stephens 2000; Yao 2012, 2015; Yao and Lindsay 2009).
Step 2: EM algorithm to maximize \(\varvec{\ell _2}\) in (6)
In Step 2, given \(\tilde{m}_j(x)\) from Step 1, a regular EM algorithm can be used to maximize \(\ell _2\) and update the estimates of \({{\varvec{\pi }}}\) and \({{\varvec{\sigma }}}^2\) as \(\hat{{{\varvec{\pi }}}}\) and \(\hat{{{\varvec{\sigma }}}}^2\). At the \((l+1)\)th iteration,
E-step Calculate the expectations of component labels based on the estimates from the lth iteration:
M-step Update the estimates
The ascent property of the above algorithm follows from the theory of the ordinary EM algorithm.
Step 3: Modified EM-type algorithm to maximize \(\varvec{\ell _3}\) in (7)
In Step 3, given \(\hat{{{\varvec{\pi }}}}\) and \(\hat{{{\varvec{\sigma }}}}^2\) from Step 2, we would then maximize \(\ell _3\) to find the estimates \(\hat{{{\varvec{m}}}}(x)\). At the \((l+1)\)th iteration,
E-step Calculate the expectations of component labels based on estimates from the lth iteration:
M-step Update the estimate
for \(x\in \{u_t,t=1,...,N\}\). Similar to Step 1, we update the estimates at a set of grid points first, and then update \(m_j^{(l+1)}(X_i)\), \(i=1,\ldots ,n\), by linear interpolating \(m_j^{(l+1)}(u_t)\), \(t=1,\ldots ,N\).
Global EM-type algorithm (GEM)
To improve the estimation efficiency, one might further iterate Step 1 to Step 3 until convergence. Next, we propose a global EM-type algorithm (GEM) to approximate such iteration, but with much less computation. At the \((l+1)\)th iteration,
E-step Calculate the expectations of component labels based on estimates from the lth iteration:
M-step Simultaneously update the estimates
for \(x\in \{u_t,j=1,\ldots ,N\}\). We then update \(m_j^{(l+1)}(X_i)\), \(i=1,...,n\) by linear interpolating \(m_j^{(l+1)}(u_t)\), \(t=1,\ldots ,N\).
2.2.4 Asymptotic properties
Next, we investigate the asymptotic properties of the proposed one-step backfitting estimates and the asymptotic ascent properties of the two proposed EM-type algorithms.
Let \({{\varvec{\theta }}}=({{\varvec{m}}}^T,{{\varvec{\pi }}}^T,({{\varvec{\sigma }}}^2)^T)^T\), \({{\varvec{\beta }}}=({{\varvec{\pi }}}^T,({{\varvec{\sigma }}}^2)^T)^T\), then \({{\varvec{\theta }}}=({{\varvec{m}}}^T,{{\varvec{\beta }}}^T)^T\). Define
and let
Define
Under further conditions defined in the Appendix, the consistency and asymptotic normality of \(\hat{{{\varvec{\pi }}}}\) and \(\hat{{{\varvec{\sigma }}}}^2\) are established in the next theorem.
Theorem 1
Suppose that conditions (C1) and (C3)|(C10) in the Appendix are satisfied, then
where \(B=E\{I_\beta (X)\}\), \(\Sigma =Var\{\partial \ell ({{\varvec{\theta }}}(X),Y)/\partial {{\varvec{\beta }}}-\varpi (X,Y)\}\), \(\varpi (x,y)=I_{\beta m}\varphi (x,y)\), and \(\varphi (x,y)\) is a \(k\times 1\) vector consisting of the first k elements of \(I_\theta ^{-1}(x)\partial \ell ({{\varvec{\theta }}}(x),y)/\partial {{\varvec{\theta }}}\).
Based on the above theorem, we can see that the proposed one-step backfitting estimator of the global parameters have achieved the optimal square root n convergence rate.
The next theorem gives the asymptotic property of \(\hat{{{\varvec{m}}}}(\cdot )\).
Theorem 2
Suppose that conditions (C2)|(C10) in the Appendix are satisfied, then
where \(f(\cdot )\) is the density of X, \(\Delta _m(x)\) is a \(k\times 1\) vector consisting of the first k elements of \(\Delta (x)\) with
Based on the above theorem, we can see that \(\hat{{{\varvec{m}}}}(x)\) has the same asymptotic properties as if \({{\varvec{\beta }}}\) were known, since \(\hat{{{\varvec{\beta }}}}\) has faster convergence rate than \(\hat{{{\varvec{m}}}}(x)\).
The asymptotic ascent properties of the proposed EM-type algorithms are provided in the following theorem.
Theorem 3
-
(i)
For the modified EM-type algorithm (Step 1) to maximize \(\ell _1\), given condition (C2),
$$\begin{aligned} \liminf _{n\rightarrow \infty }n^{-1}\left[ \ell _1({{\varvec{\theta }}}^{(l+1)}(x))-\ell _1({{\varvec{\theta }}}^{(l)}(x))\right] \ge 0 \end{aligned}$$in probability, for any given point \(x\in \mathscr {X}\), where \(\ell _1(\cdot )\) is defined in (5).
-
(ii)
For the modified EM-type algorithm (Step 3) to maximize \(\ell _3\), given condition (C2),
$$\begin{aligned} \liminf _{n\rightarrow \infty }n^{-1}\left[ \ell _3({{\varvec{m}}}^{(l+1)}(x))-\ell _3({{\varvec{m}}}^{(l)}(x))\right] \ge 0 \end{aligned}$$in probability, for any given point \(x\in \mathscr {X}\), where \(\ell _3(\cdot )\) is defined in (7).
-
(iii)
For the GEM algorithm, we have
$$\begin{aligned} \liminf _{n\rightarrow \infty }n^{-1}\left[ \ell ^*({{\varvec{m}}}^{(l+1)}(\cdot ),{{\varvec{\pi }}}^{(l+1)},{{\varvec{\sigma }}}^{2(l+1)})-\ell ^*({{\varvec{m}}}^{(l)}(\cdot ),{{\varvec{\pi }}}^{(l)},{{\varvec{\sigma }}}^{2(l)})\right] \ge 0 \end{aligned}$$in probability, for any given point \(x\in \mathscr {X}\), where \(\ell ^*(\cdot )\) is defined in (4).
2.3 Hypothesis testing
Huang et al. (2013) proposed a nonparametric mixture of regression models where mixing proportions, means, and variances are all unknown but smooth functions of a covariate. Compared to Huang et al. (2013), our model can be more efficient by assuming the mixing proportions and variances to be constants. Then, a natural question to ask is whether or not the mixing proportions and variances indeed depend on the covariate. This amounts to testing the following hypothesis:
Next, we propose to use the idea of the generalized likelihood ratio test (Fan et al. 2001) to compare model (1) with model (2).
Let \(\ell _n(H_0)\) and \(\ell _n(H_1)\) be the log-likelihood functions computed under the null and alternative hypothesis, respectively. Then, we can construct a likelihood ratio test statistic
Note that this likelihood ratio statistic is different from the parametric likelihood ratio statistics, since the null and alternative are both semiparametric models, and the number of parameters under \(H_0\) or \(H_1\) are undefined. The following theorem establishes the Wilks types of results for (13), that is, the asymptotic null distribution is independent of the nuisance parameters \({{\varvec{\pi }}}\) and \({{\varvec{\sigma }}}\), and the nuisance nonparametric mean functions \({{\varvec{m}}}(x)\).
Theorem 4
Suppose that conditions (C9)–(C13) in the Appendix hold and that \(nh^{4}\rightarrow 0\) and \(nh^2\log (1/h)\rightarrow \infty \), then
where \(r_K=[K(0)-0.5\int K^2(t)dt]/\int [K(t)-0.5K*K(t)]^2 dt\), \(\delta =r_K(2k-1)|\mathscr {X}|[K(0)-0.5\int K^2(t)dt]/h\), \(|\mathscr {X}|\) denotes the length of the support of X, and \(K*K\) is the 2nd convolution of \(K(\cdot )\).
Theorem 4 unveils a new Wilks type of phenomenon, and provides a simple and useful method for semiparametric inferences. We will demonstrate its application in Sect. 3.
3 Examples
3.1 Simulation study
In this section, we use a simulation study to investigate the finite sample performance of the proposed regression spline estimate (Spline), the one-step backfitting estimate using local EM-type algorithm (LEM), and the global EM-type algorithm (GEM), and compare them with the traditional mixture of linear regressionss estimate (MLR), and the nonparametric mixture of regression models (NMR, Huang et al. 2013). For the regression spline, we use \(Q=5\), where Q is the number of internal knots. For LEM, GEM and NMR, we use both the true value and the regression spline estimate as initial values, denoted by (T) and (S), respectively.
We conduct a simulation study for a two-component semiparametric mixture of regression models:
The covariate X is generated from the one-dimensional uniform distribution in [0, 1], and the Gaussian kernel is used in the simulation. The sample sizes \(n=200\) and \(n=400\) are conducted over 500 repetitions.
The performance of the estimates of the mean functions \({{\varvec{m}}}(x)\) is measured by the square root of the average squared errors (RASE),
where \(\{u_t,t=1,\ldots ,N\}\) are a set of grid points at which the unknown functions are evaluated. In our simulation, we set \(N=100\). To compare between model (1) and the nonparametric mixture of regression models proposed by Huang et al. (2013), we also report the RASE of \(\pi \) and \(\sigma ^2\), denoted by RASE\(_\pi \) and RASE\(_{\sigma ^2}\), respectively.
Bandwidth plays an important role in the estimation of \({{\varvec{m}}}(\cdot )\). There are ways to calculate the theoretical optimal bandwidth, but in practice, data driven methods, such as cross-validation (CV), are popularly used. Please see Zhang and Yang (2015) and the reference therein for the application and properties of cross-validation. Let \(\mathscr {D}\) be the full data set, and divide \(\mathscr {D}\) into a training set \(\mathscr {R}_l\) and a test set \(\mathscr {T}_l\). That is, \(\mathscr {R}_l\cup \mathscr {T}_l=\mathscr {D}\) for \(l=1,...,L\). We use the training set \(\mathscr {R}_l\) to obtain the estimates \(\{\hat{{{\varvec{\pi }}}},\hat{{{\varvec{m}}}}(\cdot ),\hat{{{\varvec{\sigma }}}}^2\}\), then consider a likelihood version CV, which is defined by
In the simulation, we set \(L=10\) and randomly partition the data. We repeat the procedure 30 times, and take the average of the selected bandwidths as the optimal bandwidth, denoted by \(\hat{h}\). In the simulation, we consider three different bandwidths, \(\hat{h}\times n^{-2/15}\), \(\hat{h}\), and \(1.5\hat{h}\), which correspond to under-smoothing (US), appropriate smoothing (AS), and over-smoothing (OS), respectively.
Tables 1 and 2 report the average of RASE\(_\pi \), RASE\(_m\), and RASE\(_{\sigma ^2}\), for \(\pi _1=0.5\) and \(\pi _1=0.7\), respectively. All the values are multiplied by 100. From Tables 1 and 2, we can see that LEM, GEM, and the regression spline estimates give better results than the mixture of linear regressions estimate. Compared to NMR, model (1) improves the efficiency of the estimation of mixing proportions and variances, and provides slightly better estimates for the mean functions. In addition, both LEM and GEM provide better results for the mean functions than the regression spline estimate when the sample size is small. We further notice that LEM(S) and GEM(S) provide similar results to LEM(T) and GEM(T). Therefore, the spline estimate provides good initial values for other estimates.
From Tables 1 and 2, LEM and GEM have similar performance in terms of model fitting. However, in terms of computation time, GEM has an absolute advantage over LEM. For example, on a personal laptop with an i7-3610QM CPU and 8GB of RAM, the average calculation time (in s) for each repetition when \(n=200\) is 0.072 and 0.017 for LEM and GEM, respectively, and 0.105 and 0.028 when \(n=400\).
Next, we test the accuracy of the standard error estimation and the confidence interval construction for \(\pi _1\), \(\sigma _1\) and \(\sigma _2\) via a conditional bootstrap procedure. Given the covariate \(X=x\), the response \(Y^*\) can be generated from the estimated distribution \(\sum _{j=1}^k\hat{\pi }_j\phi (Y|\hat{m}_j(x),\hat{\sigma }_j^2)\). For the simplicity of presentation, we only report the results for GEM(T). We apply the proposed estimation procedure to each of the 200 bootstrap samples, and further obtain the confidence intervals.
Table 3 reports the results from the bootstrap procedure. SD contains the standard deviation of 500 replicates, and can be considered as true standard errors. SE and STD contain the mean and standard deviation of the 500 estimated standard errors based on the conditional bootstrap procedure. In addition, the coverage probability of the 95% confidence intervals based on the estimated standard errors are also reported. From Table 3 we can see that the bootstrap procedure estimates the true standard error quite well, since all the differences between the true value and the estimates are less than two standard errors of the estimates. The coverage probabilities are satisfactory for \(\pi _1\), but a bit low for \(\sigma _1\) and \(\sigma _2\), especially for over-smoothing bandwidth.
We also apply the bootstrap procedure to investigate the point-wise coverage probability of the mean functions, at a set of evenly distributed grid points. Table 4 shows the results of the 95% confidence interval for the two-component mean functions. From the table, we can see that the mean function of the first component tends to have higher coverage probability than the second component, especially for over-smoothing bandwidth. In addition, the coverage probability is generally lower than the nominal level for over-smoothing bandwidth.
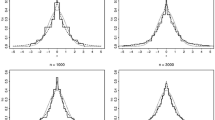
Next, we assess the performance of the testing procedure proposed in Sect. 2.3. Under the null hypothesis, the mixing proportion \(\pi _1\) and variances \(\sigma ^2_1\) and \(\sigma ^2_2\) are constants. We compute the distribution of T with \(n=200\) and \(n=400\) via 500 repetitions, and compare it with the \(\chi ^2\)-approximation. The histogram of the null distribution is shown in Fig. 1, where the solid line corresponds to a density of the \(\chi ^2\)-distribution with degrees of freedom \(\delta \) defined in Theorem 4. Figure 2 shows the Q-Q plot for the two cases. From Figs. 1 and 2, the finite sample null distribution is quite close to a \(\chi ^2\)-distribution with degrees of freedom \(\delta \), especially for the case of \(n=400\).

Histogram of \(T_n\) and \(\chi ^2\)-approximation of \(T_n\): a \(n=200\), b \(n=400\)

Q–Q plot: a \(n=200\), b \(n=400\)
3.2 Real data applications
Example 1 (The US house price index data) In this section, we illustrate the proposed methodologies with an empirical analysis of US house price index data (sample size \(n=141\)) that are introduced in Sect. 1. GDP is a well known measure of the size of a nation’s economy, as it recognizes the total goods and services produced within a nation in a given period, and HPI is known as a measure of a nation’s average housing price in repeat sales. It is believed that the housing price and GDP are correlated, and so it is of interest to study how GDP growth rate helps to predict HPI change.

a Scatterplot of US house price index data; b estimated mean functions with 95% confidence intervals and a clustering result
First, a two-component mixture of nonparametric regression models is fitted to the data. For real data sets, we use Monte-Carlo cross-validation (MCCV) (Shao 1993) to select the bandwidths. In MCCV, the data are randomly partitioned into disjoint training subsets with size \(n(1-p)\) and test subsets with size np, where p is the percentage of data used for testing. The procedure is repeated for 100 times, and we take the average as the selected bandwidth. For estimation and testing purpose, we use MCCV with \(p=10\%\), and the selected bandwidth is 0.030. Figure 3b contains the estimated mean functions and their 95% point-wise confidence intervals through the conditional bootstrap procedure, and the 95% confidence interval for \(\pi _1\), \(\sigma _1\) and \(\sigma _2\) are (0.347, 0.518), (0.009, 0.020) and (0.004, 0.008), respectively. Figure 3b also reports the hard-clustering results, denoted by dots and squares, respectively, for the two components. The hard-clustering results are obtained by maximizing classification probabilities \(\{p_{i1},p_{i2}\}\) for all \(i=1,\ldots ,n\). It can be checked that the dots in the lower cluster are mainly from Jan 1990 to Sep 1997, while the squares in the upper cluster are mainly from Oct 1997 to Dec 2002, when the economy experienced an internet boom and bust. In addition, it can be seen that in the first cycle of lower component, GDP growth has an overall positive impact on HPI change. However, in the second cycle of the upper component, GDP growth has a negative impact on HPI change, if GDP growth is smaller than 0.3; when GDP growth is larger than 0.3, it then has a similar positive impact on HPI change as the first cycle.
To examine whether the mixing proportions and variances are indeed constant, we apply the generalized likelihood ratio test developed in Sect. 2.3. The p-value is 0.331, and shows that model (1) is more appropriate for the data. To evaluate the prediction performance of the proposed model and compare it to the NMR model proposed by Huang et al. (2013), in Table 5, we use MCCV with repetition time 500 to report the average and standard deviation of the mean squared prediction error (MSPE) evaluated at the testing sets. It can be seen that the prediction performance of model (1) is slightly better than that of the NMR model (Huang et al. 2013).

a Scatterplot of NO data; b estimated mean functions with 95% confidence intervals and a clustering result
Example 2 (NO data) This data set gives the equivalence ratio, a measure of the richness of the air-ethanol mix in an engine against the concentration of nitrogen oxide emissions in a study using pure ethanol as a spark-ignition engine fuel. The data set contains 99 observations and is presented in Hurvich et al. (1998). Figure 4a shows the scatter plot of the data, which clearly indicates two different nitrous oxide concentration dependencies, with no clear linear trend. As a result, a two-component mixture of nonparametric regression models is fitted to the data.
Similar to the above example, the selected bandwidth is 0.091 based on MCCV with \(p=10\%\). The confidence intervals for parameter estimates are (0.395, 0.608), (0.005, 0.012), (0.025, 0.053) for \(\pi _1\), \(\sigma _1\) and \(\sigma _2\), respectively. Figure 4b contains the estimated mean functions and their 95% point-wise confidence intervals through the bootstrap procedure. The p-value of the generalized likelihood ratio test is 0.219, indicating that model (1) is the preferred model. Table 5 reports the average and standard deviation of MSPE evaluated at the testing sets based on MCCV. Based on Table 5, the new model has better prediction performance than the NMR model.
4 Discussion
Motivated by a US house index data, in this article, we proposed a new class of semiparametric mixture of regression models, where mixing proportions and variances are constants, but the component regression functions are smooth functions of a covariate. The identifiability of the proposed model is established and a one-step backfitting estimation procedure is proposed to achieve the optimal convergence rate for both the global parameters and the nonparametric regression functions. The proposed regression spline estimate is simple to calculate and can be easily extended to some other semiparametric and nonparametric mixture of regression models (Young and Hunter 2010; Huang et al. 2013; Huang and Yao 2012). But it requires more research to derive the asymptotic results for such regression spline based estimators for mixture models. A generalized likelihood ratio test has been proposed for semiparametric inferences.
When the dimension of the predictors is high, due to the curse of dimensionality, it is unpractical to estimate the component regression functions fully nonparametrically. Therefore, it is our interest to further extend the proposed mixture of nonparametric regression models to some other nonparametric or semiparametric models, such as mixture of partial linear regression models, mixture of additive models, and mixture of varying coefficient partial linear models.
In this paper, we assume that the number of components is known. However, in some applications, it might be infeasible to assume a known number of components in advance. Therefore, more research is needed to select the number of components for the proposed semiparametric mixture model. One possible way is to use AIC or BIC to choose the number of components. However, it is not clear how to define the degree of freedom for a semiparametric mixture model. Similar to Huang et al. (2013), one might also fit a mixture of linear regression using local data and choose the number of components based on traditional AIC or BIC. In addition, as one reviewer pointed out that when the number of components, k, is too large, the variance of model parameter estimates may be very large and the asymptotic results might not hold for the finite-sample setting. In this case, one might use a bootstrap procedure to estimate the standard errors of parameter estimates. Furthermore, it will be also interesting to investigate whether there are any minimax properties of the proposed estimation procedure.
References
Cao, J., Yao, W. (2012). Semiparametric mixture of binomial regression with a degenerate component. Statistica Sinica, 22, 27–46.
Celeux, G., Hurn, M., Robert, C. P. (2000). Computational and inferential difficulties with mixture posterior distributions. Journal of the American Statistical Association, 95, 957–970.
de Boor, C. (2001). A practical guide to splines. New York: Springer.
de Jong, P. (1987). A central limit theorem for generalized quadratic forms. Probability Theory and Related Fields, 75, 261–277.
Fan, J., Zhang, C., Zhang, J. (2001). Generalized likelihood ratio statistics and Wilks phenomenon. The Annuals of Statistics, 29, 153–193.
Frühwirth-Schnatter, S. (2001). Markov chain Monte Carlo estimation of classical and dynamic switching and mixture models. Journal of American and Statisical Association, 96, 194–209.
Goldfeld, S. M., Quandt, R. E. (1973). A Markov model for switching regressions. Journal of Econometrics, 1, 3–6.
Green, P. J., Richardson, S. (2002). A Markov model for switching regression. Journal of American and Statistical Association, 97, 1055–1070.
Hastie, T., Tibshirani, R., Friedman, J. (2003). The elements of statistical learning, data mining, inference and prediction. New York: Springer.
Hennig, C. (2000). Identifiablity of models for clusterwise linear regression. Journal of Classification, 17, 273–296.
Huang, M., Yao, W. (2012). Mixture of regression models with varying mixing proportions: a semiparametric approach. Journal of the American Statistical Association, 107, 711–724.
Huang, M., Li, R., Wang, S. (2013). Nonparametric mixture of regression models. Journal of American Statistical Association, 108, 929–941.
Hurvich, C. M., Simonoff, J. S., Tsai, C. L. (1998). Smoothing parameter selection in nonparametric regression using an improved Akaike information criterion. Journal of the Royal Statistical Society, Series B, 60, 271–294.
Shao, J. (1993). Linear models selection by cross-validation. Journal of the American Statistical Association, 88, 486–494.
Stephens, M. (2000). Dealing with label switching in mixture models. Journal of Royal Statistical Society, Series B, 62, 795–809.
Titterington, D., Smith, A., Makov, U. (1985). Statistical analysis of finite mixture distributions. New York: Wiley.
Wang, S., Yao, W., Huang, M. (2014). A note on the identifiability of nonparametric and semiparametric mixtures of GLMs. Statistics and Probability Letters, 93, 41–45.
Wedel, M., DeSarbo, W. S. (1993). A latent class binomial logit methodology for the analysis of paired comparison data. Decision Sciences, 24, 1157–1170.
Yao, W. (2012). Model based labeling for mixture models. Statistics and Computing, 22, 337–347.
Yao, W. (2015). Label switching and its simple solutions for frequentist mixture models. Journal of Statistical Computation and Simulation, 85, 1000–1012.
Yao, W., Lindsay, B. G. (2009). Bayesian mixture labeling by highest posterior density. Journal of American Statistical Association, 104, 758–767.
Young, D. S., Hunter, D. R. (2010). Mixtures of regressions with predictor-dependent mixing proportions. Computational Statistics and Data Analysis, 54, 2253–2266.
Zhang, Y., Yang, Y. (2015). Cross-validation for selecting a model selection procedure. Journal of Econometrics, 187, 95–112.
Acknowledgments
The authors thank the editor, the associate editor, and reviewers for their constructive comments that have led to dramatic improvement of the earlier version of this article. Xiang’s research is supported by NSF of China Grant 11601477 and Zhejiang Provincial NSF of China Grant LQ16A010002. Yao’s research is supported by NSF Grant DMS-1461677 and also funded by Department of Energy, Award no. 10006272.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix
In this section, the brief proofs of Theorems 1, 2 and 4 are presented, and please refer to the supplement file for more detailed proof. The conditions required by Theorems 1, 2, 3 and 4 are listed below. They are not the weakest sufficient conditions, but could easily facilitate the proofs.
Technical conditions
-
(C1)
\(nh^4\rightarrow 0\) and \(nh^2\log (1/h)\rightarrow \infty \) as \(n\rightarrow \infty \) and \(h\rightarrow 0\).
-
(C2)
\(nh\rightarrow \infty \) as \(n\rightarrow \infty \) and \(h\rightarrow 0\).
-
(C3)
The sample \(\{(X_i,Y_i), i=1,\ldots ,n\}\) are independently and identically distributed from f(x, y) with finite sixth moments. The support for x, denoted by \(\mathscr {X}\in \mathbb {R}\), is bounded and closed.
-
(C4)
\(f(x,y)>0\) in its support and has continuous first derivative.
-
(C5)
\(|\partial ^3\ell ({{\varvec{\theta }}},X,Y)/\partial \theta _i\partial \theta _j\partial \theta _k|\le M_{ijk}(X,Y)\), where \(E(M_{ijk}(X,Y))\) is bounded for all i, j, k and all X, Y.
-
(C6)
The unknown functions \(m_j(x)\), \(j=1,\ldots ,k\), have continuous second derivative.
-
(C7)
\(\sigma _j^2>0\) and \(\pi _j>0\) for \(j=1,\ldots ,k\) and \(\sum _{j=1}^k\pi _j=1\).
-
(C8)
\(E(X^{2r})<\infty \) for some \(\epsilon <1-r^{-1}\), \(n^{2\epsilon -1}h\rightarrow \infty \).
-
(C9)
\(I_\theta (x)\) and \(I_m(x)\) are positive definite.
-
(C10)
The kernel function \(K(\cdot )\) is symmetric, continuous with compact support.
-
(C11)
The marginal density f(x) of X is Lipschitz continuous and bounded away from 0. X has a bounded support \(\mathscr {X}\).
-
(C12)
\(t^3K(t)\) and \(t^3K'(t)\) are bounded and \(\int t^4K(t)dt<\infty \).
-
(C13)
\(E|q_\theta |^4<\infty \), \(E|q_m|^4<\infty \), where \(\frac{\partial \ell (\theta (X),Y)}{\partial \theta }=q_{\theta }\), and \(\frac{\partial \ell (\theta (X),Y)}{\partial m}=q_{m}\).
Proof of Theorem 1
Define \(\hat{{{\varvec{\beta }}}}^*=\sqrt{n}(\hat{{{\varvec{\beta }}}}-{{\varvec{\beta }}})\), where \(\hat{{{\varvec{\beta }}}}\) maximizes \(\ell _2({{\varvec{\beta }}})\) in (6). Let
Since \(\hat{{{\varvec{\beta }}}}\) maximizes \(\ell _2\), it is easy to see that \(\hat{{{\varvec{\beta }}}}^*\) maximizes
where \(A_n=\sqrt{\frac{1}{n}}\sum _{i=1}^n\frac{\partial \ell (\tilde{{{\varvec{m}}}}(X_i),{{\varvec{\beta }}},Y_i)}{\partial {{\varvec{\beta }}}}\) and \(B_n=\frac{1}{n}\sum _{i=1}^n\frac{\partial ^2 \ell (\tilde{{{\varvec{m}}}}(X_i),{{\varvec{\beta }}},Y_i)}{\partial {{\varvec{\beta }}}\partial {{\varvec{\beta }}}^T}.\) It can be easily seen that \(B_n=-B+o_p(1)\) with \(B=E\{I_\beta (X)\}\), therefore, by quadratic approximation lemma,
Define \(R_{1n}=\sqrt{\frac{1}{n}}\sum _{i=1}^n \frac{\partial ^2 \ell ({{\varvec{m}}}(X_i),{{\varvec{\beta }}},Y_i)}{\partial {{\varvec{\beta }}}\partial {{\varvec{m}}}^T}(\tilde{{{\varvec{m}}}}(X_i)-{{\varvec{m}}}(X_i))\), then \(A_n=\sqrt{\frac{1}{n}}\sum _{i=1}^n\frac{\partial \ell ({{\varvec{m}}}(X_i),{{\varvec{\beta }}},Y_i)}{\partial {{\varvec{\beta }}}}+R_{1n}+O_p(\sqrt{\frac{1}{n}}\Vert \tilde{{{\varvec{m}}}}-{{\varvec{m}}}\Vert _\infty ^2)\). Let \(\varphi (X_t,Y_t)\) be a \(k\times 1\) vector whose elements are the first k entries of \(I_\theta ^{-1}(X_t)\frac{\partial \ell ({{\varvec{\theta }}}(X_t),Y_t)}{\partial {{\varvec{\theta }}}}\). From assumption (C1), we know that \(O_p\{n^{1/2}[\gamma _nh^2+\gamma _n^2\log ^{1/2}(1/h)]\}=o_p(1)\), where \(\gamma _n=(nh)^{-1/2}\). By similar argument as the proof of Theorem 2 in Huang et al. (2013), it can be shown that \(\tilde{{{\varvec{\theta }}}}(X_i)-{{\varvec{\theta }}}(X_i)=\frac{1}{n}f^{-1}(X_i)I^{-1}_\theta (X_i)\sum _{t=1}^n\frac{\partial \ell ({{\varvec{\theta }}}(X_i),Y_t)}{\partial {{\varvec{\theta }}}}K_h(X_t-X_i)+O_p\{\gamma _nh^2+\gamma _n^2\log ^{1/2}(1/h)\}\). Since \({{\varvec{m}}}(X_i)-{{\varvec{m}}}(X_t)=O(X_i-X_t)\),
It can be shown that \(E[\frac{1}{n}\sum _{i=1}^n\frac{\partial ^2 \ell ({{\varvec{m}}}(X_i),{{\varvec{\beta }}},Y_i)}{\partial {{\varvec{\beta }}}\partial {{\varvec{m}}}^T}f^{-1}(X_i)K_h(X_i-X_t)]=I_{\beta m}(X_t)\). Let \(\varpi (X_t,Y_t)=I_{\beta m}(X_t)\varphi (X_t,Y_t)\), and \(R_{n3}=-n^{-1/2}\sum _{j=1}^n\varpi (X_t,Y_t)\), then \(R_{n2}-R_{n3}\overset{P}{\rightarrow }0\), and therefore
given \(nh^4\rightarrow 0\). Let \(\Sigma =\mathrm{Var}\{\frac{\partial \ell ({{\varvec{\theta }}}(X),Y)}{\partial {{\varvec{\beta }}}}-\varpi (X,Y)\}\), then Var\((A_n)=\Sigma \). It can be easily seen that \(E(A_n)=0\), therefore by (14),
\(\square \)
Proof of Theorem 2
Define \(\hat{{{\varvec{m}}}}^*=\sqrt{nh}(\hat{{{\varvec{m}}}}(x)-{{\varvec{m}}}(x))\), where \(\hat{{{\varvec{m}}}}(x)\) maximizes (7). It can be shown that
where
Notice that
where \(S_n=\sqrt{\frac{h}{n}}\sum _{i=1}^n\frac{\partial \ell ({{\varvec{\theta }}}(x),Y_i)}{\partial {{\varvec{\theta }}}}K_h(X_i-x)\). Since \(\sqrt{n}(\hat{{{\varvec{\beta }}}}-{{\varvec{\beta }}})=O_p(1)\) and \(\frac{1}{n}\sum _{i=1}^n\frac{\partial ^2 \ell ({{\varvec{m}}}(x),{{\varvec{\beta }}},Y_i)}{\partial {{\varvec{m}}}\partial {{\varvec{\beta }}}^T}K_h(X_i-x)=-f(x)I_{\beta m}^T(x)+o_p(1)\), then \(D_n=\sqrt{n}(\hat{{{\varvec{\beta }}}}-{{\varvec{\beta }}})\sqrt{h}\frac{1}{n}\sum _{i=1}^n\frac{\partial ^2 \ell ({{\varvec{m}}}(x),{{\varvec{\beta }}},Y_i)}{\partial {{\varvec{m}}}\partial {{\varvec{\beta }}}^T}K_h(X_i-x)=-\sqrt{h}f(x)I_{\beta m}^T(x)+o_p(1).\) Thus, from (15), \(\hat{{{\varvec{m}}}}^*(x)=f(x)^{-1}I_m(x)^{-1}S_n+o_p(1)\). Let \(\Lambda (u|x)=E[\frac{\partial \ell ({{\varvec{m}}}(x),{{\varvec{\beta }}},Y)}{\partial {{\varvec{m}}}}|X=u]\), it can be shown that
where \(\nu _0=\int K^2(t)\mathrm{d}t\). To complete the proof, let \(\Delta (x)=I_m^{-1}(x)\left[ \frac{1}{2}\Lambda ''(x|x)\right. \left. +f^{-1}(x)f'(x)\Lambda '(x|x)\right] \kappa _2h^2\), and \(\Delta _m(x)\) be a \(k\times 1\) vector whose elements are the first k entries of \(\Delta (x)\), then
\(\square \)
Proof of Theorem 4
Since \(\hat{{{\varvec{\beta }}}}\) has faster convergence rate than \(\hat{{{\varvec{m}}}}(\cdot )\), \(\hat{{{\varvec{m}}}}(\cdot )\) has the same asymptotic properties as if \({{\varvec{\beta }}}\) were known. Therefore, in the following proof, we study the property of \(\hat{{{\varvec{m}}}}(\cdot )\) assuming \({{\varvec{\beta }}}\) to be known.
Define \(\frac{\partial \ell (\theta (X_i),Y_i)}{\partial \theta }=q_{\theta i}\), \(\frac{\partial ^2\ell (\theta (X_i),Y_i)}{\partial \theta \partial \theta ^T}=q_{\theta \theta i}\) and similarly, define \(q_\mathrm{mi}\), \(q_\mathrm{mmi}\) and so on. Let \(\tilde{{{\varvec{\theta }}}}\) be the estimator under \(H_1\) (Huang et al. 2013), and \(\hat{{{\varvec{m}}}}\) be the estimator under \(H_0\) (model (2.1). From previous proof, we have
By (18) and (19), we can obtain that
and so,
By similar argument as Fan et al. (2001), it can be shown that under conditions (C9)–(C12), as \(h\rightarrow 0\), \(nh^{3/2}\rightarrow \infty \),
Therefore, \(T=\mu _n+W_n/2\sqrt{h}+o_p(h^{-1/2})\), where \(\mu _n=\frac{(2k-1)|\mathscr {X}|}{h}[K(0)-0.5\int K^2(t)dt]\),
It can be shown that Var\((W_n)\rightarrow \zeta \), where \(\zeta =2(2k-1)Ef^{-1}(X)\int [2K(t)-K*K(t)]^2dt\). Apply Proposition 3.2 in de Jong (1987), we obtain that
and completes the proof.\(\square \)
About this article

Cite this article
Xiang, S., Yao, W. Semiparametric mixtures of nonparametric regressions. Ann Inst Stat Math 70, 131–154 (2018). https://doi.org/10.1007/s10463-016-0584-7
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10463-016-0584-7