
Abstract
The use of the iris and periocular region as biometric traits has been extensively investigated, mainly due to the singularity of the iris features and the use of the periocular region when the image resolution is not sufficient to extract iris information. In addition to providing information about an individual’s identity, features extracted from these traits can also be explored to obtain other information such as the individual’s gender, the influence of drug use, the use of contact lenses, spoofing, among others. This work presents a survey of the databases created for ocular recognition, detailing their protocols and how their images were acquired. We also describe and discuss the most popular ocular recognition competitions (contests), highlighting the submitted algorithms that achieved the best results using only iris trait and also fusing iris and periocular region information. Finally, we describe some relevant works applying deep learning techniques to ocular recognition and point out new challenges and future directions. Considering that there are a large number of ocular databases, and each one is usually designed for a specific problem, we believe this survey can provide a broad overview of the challenges in ocular biometrics.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Several corporations and governments fund biometrics research due to various applications such as combating terrorism and the use of social networks, showing that this is a strategically important research area (Daugman 2006; Phillips et al. 2009). A biometric system exploits pattern recognition techniques to extract distinctive information/signatures of a person. Such signatures are stored and used to compare and determine the identity of a person sample within a population. As biometric systems require robustness against acquisition and/or preprocessing fails, as well as high accuracy, the challenges and the methodologies for identifying individuals are constantly developing.
Methods that identify a person based on their physical or behavioral features are particularly important since such characteristics cannot be lost or forget, as may occur with passwords or identity cards (Bowyer et al. 2008). In this context, the use of ocular information as a biometric trait is interesting regarding a noninvasive technology and also because the biomedical literature indicates that irises are one of the most distinct biometric sources (Wildes 1997).
The most common task in ocular biometrics is recognition, which can be divided into verification (1:1 comparison) and identification (1:n comparison). Also, recognition can be performed in two distinct protocols called closed-world and open-world. In the closed-world protocol, samples of an individual are present in the training and test set. The open-world protocol must have samples from different subjects both in the training and test sets. The identification process generally is performed on the closed-world protocol (except the open-set scenario, which has imposters that are only in the test set, i.e., individuals who should not match any subject in the gallery set), while verification can be performed in both, being the open-world most common protocol adopted in this setup. In addition to identification and verification, there are other tasks in ocular biometrics such as gender classification (Tapia and Aravena 2017), spoofing (Menotti et al. 2015) and liveness (He et al. 2016) detection, recognition of left and right iris images (Du et al. 2016), ocular region detection (Severo et al. 2018; Lucio et al. 2019), iris/sclera segmentation (Lucio et al. 2018; Bezerra et al. 2018), and sensor model identification (Marra et al. 2018).
Iris recognition under controlled environments at near-infrared wavelength (NIR) demonstrates impressive results, and as reported in several works (Bowyer et al. 2008; Phillips et al. 2008, 2010; Proença and Neves 2017, 2019) can be considered a mature technology. The use of ocular images captured in uncontrolled environments is currently one of the greatest challenges (Proença and Alexandre 2012; Rattani et al. 2016). As shown in Fig. 1, such images usually present noise caused by illumination, occlusion, reflection, motion blur, among others. Therefore, to improve the biometric systems performance in these scenarios, recent approaches have used information extracted only from the periocular region (Padole and Proença 2012; Proença and Neves 2018; Luz et al. 2018) or fusing them with iris features (Tan et al. 2012; Tan and Kumar 2013; Ahmed et al. 2016, 2017).

The term periocular is associated with the region around the eye, composed of eyebrows, eyelashes, and eyelids (Park et al. 2009, 2011; Uzair et al. 2015), as illustrated in Fig. 2. Usually, the periocular region is used when there is poor quality in the iris region, commonly in visible wavelength (VIS) images or part of the face is occluded (in face images) (Park et al. 2009; Luz et al. 2018). In the literature, regarding the periocular region, there are works that kept the iris and sclera regions (Luz et al. 2018; Proença and Alexandre 2012; De Marsico et al. 2017) and others that removed them Sequeira et al. (2016), Sequeira et al. (2017), Proença and Neves (2018).

Ocular components
Although there are several surveys in the literature describing ocular recognition methodologies (Wildes 1997; Bowyer et al. 2008; Ross 2010; Hake and Patil 2015; Nigam et al. 2015; Alonso-Fernandez and Bigun 2016b, a; De Marsico et al. 2016; Nguyen et al. 2017; Rattani and Derakhshani 2017; Lumini and Nanni 2017), such surveys do not specifically focus on databases and competitions. Table 1 summarizes the number of ocular databases/competitions described in these surveys.
One of the first surveys on iris recognition was presented by Wildes (1997), who examined iris recognition biometric systems as well as issues in the design and operation of such systems. Bowyer et al. (2008) described both the historical and the state-of-the-art development in iris biometrics focusing on segmentation and recognition methodologies. Addressing long-range iris recognition, the literature review described in Nguyen et al. (2017) presents and describes iris recognition methods at a distance system. Alonso-Fernandez and Bigun (2016b), Alonso-Fernandez and Bigun (2016a) surveyed methodologies focusing only on periocular biometrics, while Rattani and Derakhshani (2017) described state-of-the-art methods applied to periocular region, iris, and conjunctival vasculature recognition using VIS images. Nigam et al. (2015) described in detail methodologies for specific topics such as iris acquisition, preprocessing techniques, segmentation approaches, in addition to feature extraction, matching and indexing methods. Lastly, Omelina et al. (2021) recently performed an extensive survey regarding iris databases, describing properties of popular databases and recommendations to create a good iris database. The authors also made a brief description of some ocular competitions.
This work describes ocular databases and competitions (or contests) on biometric recognition using iris and/or periocular traits. We present the databases according to the images that compose them, i.e., NIR, VIS and Cross-Spectral, and multimodal databases. We also detailed information such as image wavelength, capture environment, cross-sensor, database size and ocular modalities employed, as well as the protocol used for image acquisition and database construction.
The main contributions of this paper are the following: (1) we survey and describe the types of existing ocular images databases and image acquisition protocols; (2) a detailed description of the applications and goals in creating these databases; (3) a discussion and description of the main and most popular ocular recognition competitions in order to illustrate the methodology strategies in each challenge; and (4) we drawn new challenging tasks and scenarios in ocular biometrics.
To the best of our knowledge, this is the first survey specifically focused on ocular databases and competitions. Thus, we believe that it can provide a general overview of the challenges in ocular recognition over the years, the databases used in the literature, as well as the best performance methodologies in competitions for different scenarios.
The remainder of this work is organized as follows. In Sect. 2, we detail the ocular databases separating them into three categories: NIR, VIS and cross-spectral, and multimodal databases. In Sect. 3, we present a survey and discussion of ocular recognition competitions using iris and periocular region information and describe the top-ranked methodologies. Sect. 4 presents recent works applying deep learning frameworks focusing on encoding and matching to iris/periocular recognition and other tasks regarding ocular biometrics (ocular preprocessing methods are beyond the scope of our review). Finally, future challenges and directions are pointed out in Sect. 5 and conclusions are given in Sect. 6.
2 Ocular databases
Currently, there are various databases of ocular images, constructed in different scenarios and for different purposes. These databases can be classified by VIS and NIR images and separated into controlled (cooperatives) and uncontrolled (non-cooperatives) environments, according to the process of image acquisition. Controlled databases contain images captured in environments with controlled conditions, such as lighting, distance, and focus. On the other hand, uncontrolled databases are composed of images obtained in uncontrolled environments and usually present problems such as defocus, occlusion, reflection, off-angle, to cite a few. A database containing images captured at different wavelengths is referred to as cross-spectral, while a database with images acquired by different sensors is referred to as cross-sensor. The summary of all databases cited in this paper as well as links to find more information about how they are available can be found at [www.inf.ufpr.br/vri/publications/ocularDatabases.html].
In this Section, the ocular databases are presented and organized into three subsections. First, we describe databases that contain only NIR images, as well as synthetic iris databases. Then, we present databases composed of images captured at both VIS and cross-spectral scenarios (i.e., VIS and NIR images from the same subjects). Finally, we describe multimodal databases, which contain data from different biometric traits, including iris and/or periocular.
2.1 Near-infrared ocular images databases
Ocular images captured at NIR wavelength are generally used to study the features present in the iris (CASIA 2010; Phillips et al. 2008, 2010). As even darker pigmentation irises reveal rich and complex features (Daugman 2004), most of the visible light is absorbed by the melanin pigment while longer wavelengths of light are reflected (Bowyer et al. 2008). Other studies can also be performed with this kind of databases, such as methodologies to create synthetic irises (Shah and Ross 2006; Zuo et al. 2007), vulnerabilities in iris recognition and liveness detection (Ruiz-Albacete et al. 2008; Czajka 2013; Gupta et al. 2014; Kohli et al. 2016), impact of contact lenses in iris recognition (Baker et al. 2010; Kohli et al. 2013; Doyle et al. 2013; Doyle and Bowyer 2015), template aging (Fenker and Bowyer 2012; Baker et al. 2013), influence of alcohol consumption (Arora et al. 2012) and study of gender recognition through the iris (Tapia et al. 2016). The databases used for these and other studies are described in Table 2 and detailed in this session. Some samples of ocular images from NIR databases are shown in Fig. 3.

One of the first iris databases found in the literature was created and made available by CASIA (Chinese Academy of Science). The first version, called CASIA-IrisV1, was made available in 2002. The CASIA-IrisV1 database has 756 images of 108 eyes with a size of \(320\times 280\) pixels. The NIR images were captured in two sections with a homemade iris camera (CASIA 2010). In a second version (CASIA-IrisV2), made available in 2004, the authors included two subsets captured by an OKI IRISPASS-h and CASIA-IrisCamV2 sensors. Each subset has 1200 images belonging to 60 classes with a resolution of \(640\times 480\) pixels (CASIA 2010). The third version of the database (CASIA-IrisV3), made available in 2010, has a total of 22, 034 images from more than 700 individuals, arranged among its three subsets: CASIA-Iris-Interval, CASIA-Iris-Lamp and CASIA-Iris-Twins. Finally, CASIA-IrisV4, an extension of CASIA-IrisV3 and also made available in 2010, is composed of six subsets: three from the previous version and three new ones: CASIA-Iris-Distance, CASIA-Iris-Thousand and CASIA-Iris-Syn. All six subsets together contain 54, 601 ocular images belonging to more than 1800 real subjects and 1000 synthetic ones. Each subset will be detailed below, according to the specifications described in CASIA (2010).
The CASIA-Iris-Interval database has images captured under a near-infrared LED illumination. In this way, these images are used to study the texture information contained in the iris traits. The database is composed of 2639 images, obtained in two sections, from 249 subjects and 395 classes with a resolution of \(320\times 280\) pixels.
The images from the CASIA-Iris-Lamp database were acquire by a non-fixed sensor (OKI IRISPASS-h) and thus the individual collected the iris image with the sensor in their own hands. During the acquisition, a lamp was switched on and off to produce more intra-class variations due to contraction and expansion of the pupil, creating a non-linear deformation. Therefore, this database can be used to study problems such as iris normalization and robust iris feature representation. A total of 16, 212 images, from 411 subjects, with a resolution of \(640\times 480\) pixels were collected in a single section.
During an annual twin festival in Beijing, iris images from 100 pairs of twins were collected to form the CASIA-Iris-Twins database, enabling the study of similarity between iris patterns of twins. This database contains 3183 images (400 classes from 200 subjects) captured in a single section with the OKI IRISPASS-h camera at a resolution of \(640\times 480\) pixels.
The CASIA-Iris-Thousand database is composed of 20, 000 ocular images from 1000 subjects, with a resolution of \(640\times 480\) pixels, collected in a single section by an IKEMB-100 IrisKing camera (IRISKING 2017). Due to a large number of subjects, this database can be used to study the uniqueness of iris features. The main source of intra-class variations that occur in this database is due to specular reflections and eyeglasses.
The last subset of CASIA-IrisV4, called CASIA-IRIS-Syn, is composed of iris images generated with iris textures automatically synthesized from the CASIA-IrisV1 subset. The generation process applied the segmentation approach proposed by Tan et al. (2010). Factors such as blurring, deformation, and rotation were introduced to create some intra-class variations. In total, this database has 10, 000 images belonging to 1000 classes.
The images from the ND-IRIS-0405 (Phillips et al. 2010) database were captured with the LG2200 imaging system using NIR illumination. The database contains 64, 980 images from 356 subjects and there are several images with subjects wearing contact lenses. Even the images being captured under a controlled environment, some conditions such as blur, occlusion of part of the iris region, and problems like off-angle may occur. The ND-IRIS-0405 is a superset of the databases used in the ICE 2005 (Phillips et al. 2008) and ICE 2006 (Phillips et al. 2010) competitions.
The ICE 2005 database was created for the Iris Challenge Evaluation 2005 competition (Phillips et al. 2008). This database contains a total of 2953 iris images from 132 subjects. The images were captured under NIR illumination using a complete LG EOU 2200 acquisition system with a resolution of \(640\times 480\) pixels. Images that did not pass through the automatic quality control of the acquisition system were also added to the database. Experiments were performed independently for the left and right eyes. The results of the competition can be seen in Phillips et al. (2008).
The ICE 2006 database has images collected using the LG EOU 2200 acquisition system with a resolution of \(640\times 480\) pixels. For each subject, two ‘shots’ of 3 images of each eye were performed per session, totaling 12 images. The imaging sessions were held in three academic semesters between 2004 and 2005. The database has a total of 59, 558 iris images from 240 subjects (Phillips et al. 2010).
The WVU Synthetic Iris Texture Based database, created at West Virginia University, has 1000 classes with 7 grayscale images each. It consists exclusively of synthetic data, with the irises being generated in two phases. First, a Markov Random Field model was used to generate the overall iris appearance texture. Then, a variety of features were generated (e.g., radial and concentric furrows, crypts and collarette) and incorporated into the iris texture. This database was created to evaluate iris recognition algorithms since, at the time of publication, there were few available iris databases and they had a small number of individuals (Shah and Ross 2006).
The WVU Synthetic Iris Model Based database also consists of synthetically generated iris images. This database contains 10, 000 classes from 5000 individuals, with degenerated images by a combination of several effects such as specular reflection, noise, blur, rotation, and low contrast. The image gallery was created in five steps using a model and anatomy-based approach (Zuo et al. 2007), which contains 40 randomized and controlled parameters. The evaluation of their synthetic iris generation methodology was performed using a traditional Gabor filter-based iris recognition system. This database provides a large amount of data that can be used to evaluate ocular biometric systems.
The Fake Iris Database was created using images from 50 subjects belonging to the BioSec baseline database (Fierrez et al. 2007) and has 800 fake iris images (Ruiz-Albacete et al. 2008). The process for creating new images is divided into three steps. The original images were first reprocessed to improve quality using techniques such as noise filtering, histogram equalization, opening/closing, and top hat. Then, the images were printed on paper using two commercial printers: an HP Deskjet 970cxi and an HP LaserJet 4200L, with six distinct types of papers: white paper, recycled paper, photographic paper, high-resolution paper, butter paper, and cardboard (Ruiz-Albacete et al. 2008). Finally, the printed images were recaptured by an LG IrisAccess EOU3000 camera.
The IIT Delhi Iris database consists of 1120 images, with a resolution of \(320\times 240\) pixels, from 224 subjects captured with the JIRIS JPC1000 digital CMOS camera. This database was created to provide a large-scale database of iris images of Indian users. In Kumar and Passi (2010), Kumar and Passi employed these images to compare the performance of different approaches for iris identification (e.g., Discrete Cosine Transform, Fast Fourier Transform, Haar wavelet, and Log-Gabor filter) and to investigate the impact in recognition performance using a score-level combination.
The images from the ND Iris Contact Lenses 2010 database were captured using the LG 2200 iris imaging system. Visual inspections were performed to reject low-quality images or those with poor results in segmentation and matching. To compose the database, the authors captured 9697 images from 124 subjects that were not wearing contact lenses and 12003 images from 87 subjects that were wearing contact lenses. More specifically, the images were acquired from 92 subjects not wearing lenses, 52 subjects wearing the same lens type in all acquisitions, 32 subjects who wore lenses only in some acquisitions and 3 subjects that changed the lens type between acquisitions (Baker et al. 2010). According to Baker et al. (2010), the purpose of this database is to verify the degradation of iris recognition performance due to non-cosmetic prescription contact lenses.
The ND Iris Template Aging database, described and used by Fenker and Bowyer (2012), was created to analyze the template aging in iris biometrics. The images were collected from 2008 to 2011 using an LG 4000 sensor, which captures images at NIR. This database has 22156 images, being 2312 from 2008, 5859 from 2009, 6215 from 2010 and 7770 from 2011, corresponding to 644 irises from 322 subjects. The ND-Iris-Template-Aging-2008-2010 subset belongs to this database.
All images from the ND TimeLapseIris database (Baker et al. 2013) were taken with the LG 2200 iris imaging system, without hardware or software modifications throughout 4 years. Imaging sessions were held at each academic semester over 4 years, with 6 images of each eye being captured per individual in each session. From 2004 to 2008, a total of 6797 images were obtained from 23 subjects who were not wearing eyeglasses, 5 subjects who were wearing contact lenses, and 18 subjects who were not wearing eyeglasses or contact lenses in any session. This database was created to investigate template aging in iris biometrics.
To investigate the effect of alcohol consumption on iris recognition, Arora et al. (2012) created the Iris Under Alcohol Influence (IIITD IUAI) database, which contains 440 images from 55 subjects, with 220 images being acquired before alcohol consumption and 220 after it. The subjects consumed approximately 200 ml of alcohol in approximately 15 min, and the second half of the images were taken between 15 and 20 min after consumption. Due to alcohol consumption, there is a deformation in iris patterns caused by the dilation of the pupil, affecting iris recognition performance (Arora et al. 2012). The images were captured using the Vista IRIS scanner at NIR wavelength.
The IIITD Contact Lens Iris (IIITD CLI) database is composed of 6570 iris images belonging to 101 subjects. The images were captured by two different sensors: Cogent CIS 202 dual iris sensor and VistaFA2E single iris sensor with each subject (1) not wearing contact lenses, (2) wearing color cosmetic lenses, and (3) wearing transparent lenses. Four lens colors were used: blue, gray, hazel and green. At least 5 images of each iris were collected in each lens category for each sensor (Kohli et al. 2013).
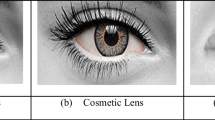
The images from the ND Cosmetic Contact Lenses database (Doyle and Bowyer 2014) were captured by two iris cameras, an LG4000 and an IrisGuard AD100, in a controlled environment under NIR illumination with a resolution of \(640\times 480\) pixels. These images are divided into four classes, (1) no contact lenses, (2) soft, (3) non-textured and (4) textured contact lenses. Also, this database is organized into two subsets: Subset1 (LG4000) and Subset2 (AD100). Subset1 has 3000 images in the training set and 1200 images in the validation set. Subset2 contains 600 and 300 images for training and validation, respectively (Doyle et al. 2013; Yadav et al. 2014; Severo et al. 2018). Both subsets have 10 equal folds of training images for testing purposes.
The ND Cross-Sensor-Iris-2013 database (Notre Dame 2013) is composed of 146550 NIR images belonging to 676 unique subjects, being 29986 images captured using an LG4000 and 116564 taken by an LG2200 iris sensor with \(640\times 480\) pixels of resolution. The images were captured in 27 sessions over three years, from 2008 to 2010, and in at least two sessions there are images of the same subject. The purpose of this database is to investigate the effect of cross-sensor images on iris recognition. Initially, this database was released for a competition to be held at the BTAS 2013 Conference, but the competition did not have enough submission.
The Database of Iris Printouts was created for liveness detection in iris images and contains 729 printout images of 243 eyes, and 1274 images of imitations from genuine eyes. The database was constructed as follows. First, the iris images were obtained with an IrisGuard AD100 camera. Then, they were printed using the HP LaserJet 1320 and Lexmark c534dn printers. To check the print quality, the printed images were captured by the Panasonic ET-100 camera using an iris recognition software, and the images that were successfully recognized were recaptured by an AD100 camera with a resolution of \(640\times 480\) pixels to create the imitation subset. Initially, images from 426 distinct eyes belonging to 237 subjects were collected. After the process of recognizing the printed images, 243 eyes images (which compose the database) were successfully verified (Czajka 2013).
The IIITD Iris Spoofing (IIS) database was created to study spoofing methods. To this end, printed images from the IIITD CLI (Kohli et al. 2013) database were used. Spoofing was simulated in two ways. In the first, the printed images were captured by a specific iris scanner (Cogent CIS 202 dual eye), while in the second, the printed images were scanned using an HP flatbed optical scanner. The database contains 4848 images from 101 individuals (Gupta et al. 2014).
The Notre Dame Contact Lenses 2015 (NDCLD15) database contains 7300 iris images. The images were obtained under consistent lighting conditions by an LG4000 and an IrisGuard AD100 sensor. All images have \(640\times 480\) pixels of resolution and are divided into three classes based on the lens type: no lens, soft, and textured. This database was created to investigate methods to classify iris images based on types of contact lenses (Doyle and Bowyer 2015).
The IIITD Combined Spoofing database was proposed to simulate a real-world scenario of attacks against iris recognition systems. This database consists of joining the following databases: IIITD CLI (Kohli et al. 2013), IIITD IIS (Gupta et al. 2014), SDB (Shah and Ross 2006), IIT Delhi Iris (Kumar and Passi 2010) and, to represent genuine classes, iris images from 547 subjects were collected. The CSD database has a total of 1872 subjects, with 9325 normal image samples and 11368 samples of impostor images (Kohli et al. 2016).
The Gender from Iris (ND-GFI) database was created to study the recognition of the subject’s gender through the iris, specifically using the binary iris code (which is normally used in iris recognition systems) (Tapia et al. 2016). The images were obtained at NIR wavelength by an LG4000 sensor and labeled by gender. The ND-GFI database contains a single image of each eye (left and right) from 750 men and 750 women, totaling 3000 images. About a quarter of the images were captured with the subjects wearing clear contact lenses. This database has another set of images that can be used for validation, called UND_V, containing 1944 images, being 3 images of each eye from 175 men and 149 women. In this subset, there are also images using clear contact lenses and some cosmetics (Tapia et al. 2016).
According to ISO (2011), an iris image has good quality if the iris diameter is larger than 200 pixels, and if the diameter is between 150 and 200 pixels, the image is classified as adequate quality. In this context, the images from the BERC mobile-iris database have irises with a diameter between 170 and 200 pixels, obtained at NIR wavelength with \(1280\times 960\) pixels of resolution. Using a mobile iris recognition system, the images were taken in sequences of 90 shots (Kim et al. 2016) moving the device at three distances: 15 to 25 cm, 25–15 cm, and 40–15 cm. In total, the database has 500 images from 100 subjects, which were the best ones selected by the authors of each sequence.
Raghavendra et al. (2016) created the Cataract Surgery on Iris database to analyze the impact of cataract surgery on the verification performance of iris recognition systems. The database contains 504 images belonging to 84 subjects who were affected by cataracts. The subjects’ ages vary from 50 to 80 years, being 34 males and 49 females. Three eye samples of each subject were collected before (24 h) and after (36–42 h) the surgery to remove the cataractous lens. The images were captured using a commercial dual-iris NIR device with a resolution of \(640\times 480\) pixels.
The Oak Ridge National Laboratory (ORNL) Off-angle database was created to study how the gaze angle affects the performance of iris biometrics (Karakaya et al. 2013; Karakaya 2016, 2018). This database encompasses 1100 NIR iris images from 50 subjects varying the angle acquisition from \(- 50^{\circ }\) to \(+ 50^{\circ }\) with a step-size of \(10^{\circ }\). The gender distribution consists of \(56\%\) male and \(44\%\) female subjects, and iris color of \(64\%\) with dark colors and \(36\%\) with light-colors. The images were collected by a Toshiba Teli CleverDragon series camera and have a resolution of \(4096\times 3072\) pixels.
The Meliksah University Iris Database (MUID) was collected to investigate the off-angle iris recognition. The authors developed an iris image capture system composed of two cameras to simultaneously capture frontal and off-angle samples. Thus, it is possible to isolate the effect of the gaze angle from pupil dilation and accommodation (Kurtuncu et al. 2016). In total, the database has 24360 NIR images from 111 subjects, 64 males and 57 females, with an average age of 26 years. The images were captured by two infrared-sensitive IDS-UI-3240ML-NIR cameras varying from \(- 50^{\circ }\) to \(+ 50^{\circ }\) angles with a step-size of \(10^{\circ }\) and have a resolution of \(1280\times 1024\) pixels. More details about the iris image acquisition platform are described in Kurtuncu et al. (2016).
The CASIA-Iris-Mobile-V1.0 database is composed of 11000 NIR images belonging to 630 subjects, divided into three subsets: CASIA-Iris-M1-S1 (Zhang et al. 2015), CASIA-Iris-M1-S2 (Zhang et al. 2016) and a new one called CASIA-IRIS-M1-S3. The images were captured simultaneously from the left and right eyes and stored in 8 bits gray-level JPG files. The CASIA-Iris-M1-S1 subset has 1400 images from 70 subjects with a resolution of \(1920\times 1080\) pixels, acquired using a NIR imaging module attached to a mobile phone. The CASIA-Iris-M1-S2 subset has images captured using a similar device. In total, this subset contains 6000 images from 200 subjects with a resolution of \(1968\times 1024\) pixels, collected at three distances: 20, 25 and 30 cm. At last, the CASIA-Iris-M1-S3 subset is composed of 3600 images belonging to 360 subjects with a resolution of \(1920\times 1920\) pixels, which were taken with a NIR iris-scanning technology equipped on a mobile phone.
The Open Eye Dataset (OpenEDS) was created to investigate the semantic segmentation of eyes components, and background (Garbin et al. 2019). This database is composed of 356649 eye images, being 12, 759 images with pixel-level annotations, 252, 690 unlabeled ones, and 91, 200 images from video sequences belonging from 152 subjects. The images were captured with a head-mounted display with two synchronized cameras under controlled NIR illumination with a resolution of \(640\times 400\) pixels.
2.2 Visible and cross-spectral ocular images databases
Iris recognition using images taken at controlled NIR wavelength environments is a mature technology, proving to be effective in different scenarios (Bowyer et al. 2008; Phillips et al. 2008, 2010; Proença and Alexandre 2012; Proença and Neves 2017, 2019). Databases captured under controlled environments have few or no noise factors in the images. However, these conditions are not easy to achieve and require a high degree of collaboration from subjects. In a more challenging/realistic scenario, investigations on biometric recognition employing iris images obtained in uncontrolled environments and at VIS wavelength have begun to be conducted (Proença and Alexandre 2005; Proença et al. 2010). There is also research on biometric recognition using cross-spectral databases, i.e., databases with ocular images from the same individual obtained at both NIR and VIS wavelengths (Hosseini et al. 2010; Sharma et al. 2014; Nalla and Kumar 2017; Algashaam et al. 2017; Wang and Kumar 2019a). Currently, many types of research have been performed on biometric recognition using iris and periocular region with images obtained from mobile devices, obtained in an uncontrolled environment and by different types of sensors (De Marsico et al. 2015; Raja et al. 2015; Rattani et al. 2016). In this subsection, we describe databases with these characteristics. Table 3 summarize these databases. Some samples of ocular images from VIS and Cross-spectral databases are shown in Fig. 4.

From top to bottom: VIS and Cross-spectral ocular image samples from the VISOB (Rattani et al. 2016), MICHE-I (De Marsico et al. 2015), UBIPr (Padole and Proença 2012), UFPR-Periocular (Zanlorensi et al. 2020a), CROSS-EYED (Sequeira et al. 2016, 2017), PolyU Cross-Spectral (Nalla and Kumar 2017) databases
The UPOL (University of Palackeho and Olomouc) database has high-quality iris images obtained at VIS wavelength using the optometric framework (TOPCON TRC501A) and the Sony DXC-950P 3CCD camera. In total, 384 images of the left and right eyes were obtained from 64 subjects at a distance of approximately 0.15 cm with a resolution of \(768\times 576\) pixels, stored in 24 bits (RGB) (Dobeš et al. 2004).
The UBIRIS.v1 database (Proença and Alexandre 2005) was created to provide images with different types of noise, simulating image capture with minimal collaboration from the users. This database has 1877 images belonging to 241 subjects, obtained in two sections by a Nikon E5700 camera. For the first section (enrollment), some noise factors such as reflection, lighting, and contrast were minimized. However, in the second section, natural lighting factors were introduced by changing the location to simulate an image capture with minimal or without active collaboration from the subjects. The database is available in three formats: color with a resolution of \(800\times 600\) pixels, color with \(200\times 150\) pixels, and \(200\times 150\) pixels in grayscale (Proença and Alexandre 2005).
The UTIRIS is one of the first databases containing iris images captured at two different wavelengths (cross-spectral) (Hosseini et al. 2010). The database is composed of 1540 images of the left and right eyes from 79 subjects, resulting in 158 classes. The VIS images were obtained by a Canon EOS 10D camera with \(2048\times 1360\) pixels of resolution. To capture the NIR images, the ISW Lightwise LW camera was used, obtaining iris images with a resolution of \(1000\times 776\) pixels. As the melanin pigment provides a rich source of features at the VIS spectrum, which is not available at NIR, this database can be used to investigate the impact of the fusion of iris image features extracted at both wavelengths.
The UBIRIS.v2 database was built representing the most realistic noise factors. For this reason, the images that constitute the database were obtained at VIS without restrictions such as distance, angles, light, and movement. The main purpose of this database is to provide a tool for the research on the use of VIS images for iris recognition in an environment with adverse conditions. This database contains images captured by a Canon EOS 5D camera, with a resolution of \(400\times 300\) pixels, in RGB from 261 subjects containing 522 irises and 11, 102 images taken in two sessions (Proença et al. 2010).
The UBIPr (University of Beira Interior Periocular) database (Padole and Proença 2012) was created to investigate periocular recognition using images taken under uncontrolled environments and setups. The images from this database were captured by a Canon EOS 5D camera with a 400mm focal length. Five different distances and resolutions were configured: \(501\times 401\) pixels (8m), \(561\times 541\) pixels (7m), \(651\times 501\) pixels (6m), \(801\times 651\) pixels (5m), and \(1001\times 801\) pixels (4m). In total, the database has 10, 950 images from 261 subjects (the images from 104 subjects were obtained in 2 sessions). Several variability factors were introduced in the images, for example, different distances between the subject and the camera, as well as different illumination, poses and occlusions levels.
The BDCP (Biometrics Development Challenge Problem) database (Siena et al. 2012) contains images from two different sensors: an LG4000 sensor that captures images in gray levels, and a Honeywell Combined Face and Iris Recognition System (CFAIRS) camera (Siena et al. 2012), which captures VIS images. The resolutions of the images are \(640\times 480\) pixels for the LG4000 sensor and \(750\times 600\) pixels for the CFAIRS camera. To compose the database, 2577 images from 82 subjects were acquired by the CFAIRS sensor and 1737 images belonging to 99 subjects were taken by an LG4000 sensor. Images of the same subject were obtained for both sensors (Smereka et al. 2015). The main objective of this database is the cross-sensor evaluation, matching NIR against VIS images (Rattani and Derakhshani 2017). It should be noted that this database was used only in Smereka et al. (2015) and no availability information is reported.
Sequeira et al. (2014b) built the MobBIOfake database to investigate iris liveliness detection using images taken from mobile devices under an uncontrolled environment. It consists of 1600 fake iris images obtained from a subset of the MobBIO database (Sequeira et al. 2014a). The fake images were generated by printing the original images using a professional printer in a high-quality photo paper and recapturing the image with the same device and environmental conditions used in the construction of MobBIO.
The images that compose the IIITD Multi-spectral Periocular database were obtained under a controlled environment at NIR, VIS, and night-vision spectra. The NIR images were captured by a Cogent iris Scanner sensor at a distance of 6 inches from the subject, while the night vision subset was created using the Sony Handycam camera in night vision mode at a distance of 1.3 meters. The VIS images were captured with the Nikon SLR camera, also at a distance of 1.3 meters. The database contains 1240 images belonging to 62 subjects, being 310 images, 5 from each subject, at VIS and night vision spectra, and 620 images, 10 from each subject, at NIR spectrum (Sharma et al. 2014).
Nalla and Kumar (2017) developed the PolyU Cross-Spectral database to study iris recognition in the cross-spectral scenario. The images were obtained simultaneously under VIS and NIR illumination, totaling 12, 540 images from 209 subjects with \(640\times 480\) pixels of resolution, being 15 images from each eye in each spectrum.
To evaluate the state of the art on iris recognition using images acquired by mobile devices, the Mobile Iris Challenge Evaluation (MICHE) competition (Part I) was created (De Marsico et al. 2015). The MICHE-I (or MICHEDB) database consists of 3732 VIS images obtained by mobile devices from 92 subjects. To simulate a real application, the iris images were obtained by the users themselves, indoors and outdoors, with and without glasses. Images of only one eye of each individual were captured. The mobile devices used and their respective resolutions are iPhone5 (\(1536\times 2048\)), Galaxy S4 (\(2322\times 4128\)) and Galaxy Tablet II (\(640\times 480\)). Due to the acquisition mode and the purpose of the database, several noises are found in images such as specular reflections, focus, motion blur, lighting variations, occlusion due to eyelids, among others. The authors also proposed a subset, called MICHE FAKE, containing 80 printed iris images. Such images were created as follows. First, they were captured using the iPhone5 the Samsung Galaxy S4 mobile devices. Then, using a LaserJet printer, the images were printed and captured again by a Samsung Galaxy S4 smartphone. There is still another subset, called MICHE Video, containing videos of irises from 10 subjects obtained indoor and outdoor. A Samsung Galaxy S4 and a Samsung Galaxy Tab 2 mobile devices were used to capture these videos. In total, this subset has 120 videos of approximately 15 seconds each.
The VSSIRIS database, proposed by Raja et al. (2015), has a total of 560 images captured in a single session under an uncontrolled environment from 28 subjects. The purpose of this database is to investigate the mixed lighting effect (natural daylight and artificial indoor) for iris recognition at the VIS spectrum with images obtained by mobile devices (Raja et al. 2015). More specifically, the images were acquired by the rear camera of two smartphones: an iPhone 5S, with a resolution of \(3264\times 2448\) pixels, and a Nokia Lumia 1020, with a resolution of \(7712\times 5360\) pixels.
Santos et al. (2015) created the CSIP (Cross-Sensor Iris and Periocular) database simulating mobile application scenarios. This database has images captured by four different device models: Xperia Arc S (Sony Ericsson), iPhone 4 (Apple), w200 (THL) and U8510 (Huawei). The resolutions of the images taken with these devices are as follows: Xperia Arc S (Rear \(3264\times 2448\)), iPhone 4 (Front \(640\times 480\), Rear \(2592\times 1936\)), W200 (Front \(2592\times 1936\), Rear \(3264\times 2448\)) and U8510 (Front \(640\times 480\), Rear \(2048\times 1536\)). Combining the models with front and rear cameras, as well as flash, 10 different setups were created with the images obtained. In order to simulate noise variation, the image capture sessions were carried out in different sites with the following lighting conditions: artificial, natural and mixed. Several noise factors are presented in these images, such as different scales, off-angle, defocus, gaze, occlusion, reflection, rotation and distortions (Santos et al. 2015). The database has 2004 images from 50 subjects and the binary iris segmentation masks were obtained using the method described by Tan et al. (2010) (winners of the NICE I contest).
The VISOB database was created for the ICIP 2016 Competition on mobile ocular biometric recognition, whose main objective was to evaluate methods for mobile ocular recognition using images taken at the visible spectrum (Rattani et al. 2016). The front cameras of 3 mobile devices were used to obtain the images: iPhone 5S at 720p resolution, Samsung Note 4 at 1080p resolution and Oppo N1 at 1080p resolution. The images were captured in 2 sessions for each one of the 2 visits, which occurred between 2 and 4 weeks, counting in the total 158, 136 images from 550 subjects. At each visit, it was required that each volunteer (subject) capture their face using each one of the three mobile devices at a distance between 8 and 12 inches from the face. For each image capture session, 3 light conditions settings were applied: regular office light, dim light, and natural daylight. The collected images were preprocessed using the Viola-Jones eye detector and the region of the image containing the eyes was cropped to a size of \(240\times 160\) pixels.
Sequeira et al. (2016), Sequeira et al. (2017) created the Cross-Spectral Iris/Periocular (CROSS-EYED) database to investigate iris and periocular region recognition in cross-spectral scenarios. CROSS-EYED is composed of VIS and NIR spectrum images obtained simultaneously with 2K\(\times 2\)K pixel resolution cameras. The database is organized into three subsets: ocular, periocular (without iris and sclera regions) and iris. There are 3840 images from 120 subjects (240 classes), being 8 samples from each of the classes for every spectrum. The periocular/ocular images have dimensions of \(900\times 800\) pixels, while the iris images have dimensions of \(400\times 300\) pixels. All images were obtained at a distance of 1.5 meters, under uncontrolled indoor environment, with a wide variation of ethnicity and eye colors, and lightning reflexes.
The Post-mortem Human Iris database was collected to investigate the post-mortem human iris recognition. Due to the difficulty and restriction in collecting such images, this database has only 104 images from 6 subjects. The images were acquired in three sessions with an interval of approximately 11 hours using the IriShield M2120U NIR and Olympus TG-3 VIS cameras.
The QUT Multispectral Periocular database was developed and used by Algashaam et al. (2017) to study multi-spectral periocular recognition. In total, 212 images belonging to 53 subjects were captured at VIS, NIR and night vision spectrum with \(800\times 600\) pixels of resolution. The VIS and NIR images were taken using a Sony DCR-DVD653E camera, while the night vision images were acquired with an IP2M-842B camera.
Regarding some ocular biometrics problems caused by substantial degradation due to variations on illumination, distance, noise, and blur when using single-frame mobile captures, Nguyen et al. (2020) created the VISOB 2.0 database. This database comprises multi-frame captures and has stacks of eye images acquired using the burst mode of two mobile devices: Samsung Note 4 and Oppo N1. It is the second version of the VISOB database and was used in the 2020 IEEE WCCI competition (Nguyen et al. 2020). The images were collected in two visits. At each visit, the subjects collected their own images under three lighting conditions in two sessions. The available subset of the VISOB 2.0 database (competition training set) has 75, 428 images of left and right eyes belonging to 150 subjects. The VISOB 2.0 can also be employed to investigate the probing fairness of ocular biometrics across gender (Krishnan et al. 2020).
The Iris Social Database (I-SOCIAL-DB) has 3286 VIS images from 400 subjects, being \(43.75\%\) male and \(56.25\%\) female. It is composed of images of public persons such as artists and athletes. This database was created by collecting 1643 high-resolution portrait images using Google Image Search. Then, the ocular regions were cropped as rectangles of \(350\times 300\) pixels. The binary masks for the iris region (created by a human expert) are also available. This database can be employed to evaluate iris segmentation and recognition under unconstrained scenarios.
The UFPR-Periocular database has VIS images acquired in unconstrained environments by mobile devices. These images were captured by the subjects themselves using their own smartphone models through a mobile application (app) developed by the authors (Zanlorensi et al. 2020a). In total, this database contains 33, 660 samples from 1122 subjects acquired during 3 sessions by 196 different mobile devices. The image resolutions vary from \(360\times 160\) to \(1862\times 1008\) pixels. The main intra- and inter-class variability are caused by occlusion, blur, motion blur, specular reflection, eyeglasses, off-angle, eye-gaze, makeup, facial expression, and variations in lighting, distance, and angles. The authors manually annotated the eye corners and used them to normalize the periocular images regarding scale and rotation. This database can also be employed to investigate gender recognition, age estimation, and the effect of intra-class variability in biometric systems. The UFPR-Periocular database, which includes the manual annotations of the eye corners, as well as information on the subjects’ age and gender, is publicly available for the research community.
Zanlorensi et al. (2020b) created the UFPR-Eyeglasses database to investigate intra-class variability and also the effect of the occlusion by eyeglasses in periocular recognition under uncontrolled environments. This database has 2270 images captured by mobile devices from 83 subjects with a resolution of \(256\times 256\) pixels. The subjects captured the images using the same mobile app used to collect the UFPR-Periocular database. This database can be considered a subset of the UFPR-Periocular database containing some additional images. The authors manually annotated the iris’s bounding box in each image and used it to perform scale and rotation normalization. The intra-class variations in this database are mainly caused by illumination, occlusions, distances, reflection, eyeglasses, and image quality. The UFPR-Eyeglasses database, which includes the authors’ manual annotations, is publicly available to the research community.
2.3 Multimodal databases
In addition to the databases proposed specifically to assist the development and evaluation of new methodologies for iris/periocular recognition, some multimodal databases can also be used for this purpose. Table 4 show these databases. As described in this subsection, most of these databases consist of iris images obtained at NIR wavelength. Figure 5 shows samples of ocular images from some multimodal databases.

The BioSec baseline database, proposed by Fierrez et al. (2007), has biometric data of fingerprint, face, iris and voice. Data were acquired from 200 subjects in two acquisition sessions, with environmental conditions (e.g., lighting and background noise) not being controlled to simulate a real situation. There are 3200 NIR iris images, being 4 images of each eye for each session, captured by an LG IrisAccess EOU3000 camera (Fierrez et al. 2007).
The BiosecurID multimodal database consists of 8 unimodal biometric traits: iris, face, speech, signature, fingerprints, hand, handwriting, and keystroking (Fierrez 2010). The authors collected data from 400 subjects in four acquisition sessions through 4 months at six Spanish institutions. The iris images were captured at NIR by an LG Iris Access EOU 3000 camera with a resolution of \(640\times 480\) pixels. Four images of each eye were obtained in each of the 4 sessions, totaling 32 images per individual and a final set of 12, 800 iris images.
The BMDB (multienvironment multiscale BioSecure Multimodal Database) (Ortega-Garcia 2010) has biometric data from more than 600 subjects, obtained from 11 European institutions participating in the BioSecure Network of Excellence (Ortega-Garcia 2010). This database contains biometric data of iris, face, speech, signature, fingerprint and hand, and is organized into three subsets: DS1, which has data collected from the Internet under unsupervised conditions; DS2, with data obtained in an office environment under supervision; and DS3, in which mobile hardware was used to take data indoor and outdoor. The iris images belong to the DS2 subset and were obtained in 2 sessions at NIR wavelength in an indoor environment with supervision. For the acquisition, the use of contact lenses was accepted, but glasses needed to be removed. Four images (2 of each eye) were obtained in each session for each of the 667 subjects, totaling 5336 images. These images have a resolution of \(640\times 480\) pixels and were acquired by an LG Iris Access EOU3000 sensor.
The goal of the Multiple Biometrics Grand Challenge (MBGC) (NIST 2010b) was the evaluation of iris and face recognition methods using data obtained from still images and videos under unconstrained conditions (Phillips et al. 2009). The MBGC is divided into three problems: the portal challenge problem, the still face challenge problem, and the video challenge problem (NIST 2010b). This competition has two versions. The first one was held to introduce the problems and protocol, whereas version 2 was released to evaluate the approaches in large databases (Phillips et al. 2009). The iris images were obtained from videos captured at NIR by an Iridian LG EOU 2200 camera (Hollingsworth et al. 2009). The videos present variations such as pose, illumination, and camera angle. The MBGC database has 986 iris videos from 268 eyes collected in 2008 (Hollingsworth et al. 2009).
The Q-FIRE database (Quality in Face and Iris Research Ensemble) has iris and face images from 195 subjects, obtained through videos at different distances (Johnson et al. 2010). This database has 28 and 27 videos of face and iris, respectively, captured in 2 sections, with varying camera distance between 5, 7, 11, 15 and 25 feet. The videos have approximately 6 seconds each and were captured at approximately 25 frames per second. A Dalsa 4M30 infrared camera equipped with a Tamron AF 70–300 mm 1:4.5–5.6 LD DI lens were used to capture iris videos. For distances of 15 and 25 feet, a Sigma APO 300-800mm F5.6 EX DG HSM lens was used. The most attractive distance of capture for iris is 5 (\(300\times 280\) pixels), 7 (\(220 \times \)200 pixels), and 11 (\(120\times 100\) pixels) feet since they respectively represent high, medium and low resolution, based on the number of pixels in the iris diameter. The images also have variations of illumination, defocus, blur, eye angles, motion blur, and occlusions (Johnson et al. 2010).
The NIR images from the ocular region (iris and periocular) of the FOCS database (NIST 2010a) were extracted from the MBGC database (NIST 2010b) videos, which were collected from moving subjects (Matey et al. 2006). These videos were captured in an uncontrolled environment presenting some variations such as noise, gaze, occlusion and lighting. The database has 9581 images (4792 left, 4789 right) with a resolution of \(750\times 600\) pixels from 136 subjects (Smereka et al. 2015).
Their system can recognize users from up to 3 meters (10 feet) using a system with an active search for iris, face or palmprint patterns. The images were taken using a camera with high resolution so that a single image includes regions of interest for both eyes and face traits. Information from the face trait such as skin pattern can also be used for multi-modal fusion. The database has 2567 images from 142 individuals and 284 classes with a resolution of \(2352\times 1728\) pixels.
The SDUMLA-HMT multimodal database contains biometric traits of iris, face, finger vein, gait, and fingerprint (Yin et al. 2011). All data belong to 106 subjects and were collected at Shandong University in China. The iris images were collected at NIR and under a controlled environment at a distance of 6 cm to 32 cm between the camera and the subject. In total, the authors collected 1060 iris images with \(768\times 576\) pixels of resolution, being 10 images (5 of each eye) from each subject (Yin et al. 2011).
Sequeira et al. (2014a) created the MobBIO database due to the growing interest in mobile biometric applications, as well as the growing interest and application of multimodal biometrics. This database has data from iris, face, and voice belonging to 105 subjects. The data were obtained using an Asus TPad TF 300T mobile device, and the images were captured using the rear camera of this device in 8 MP of resolution. The iris images were obtained at VIS and in two different illumination conditions varying eye orientations and occlusion levels. For each subject, 16 images (8 of each eye, cropped from an image of both eyes) were captured. The cropped images have a resolution of \(300\times 200\) pixels. Manual annotations of the iris and pupil contours are provided along with the database, but iris illumination noises are not identified.
The gb2s\(\mu \)MOD database is composed of 8160 iris, face and hand videos belonging to 60 subjects and captured in three sessions with environment condition variation (Ríos-Sánchez et al. 2016). Sessions 1 and 2 were obtained in a controlled environment, while session 3 was acquired in an uncontrolled environment. The iris videos were recorded only in sessions 1 and 2 with a NIR camera (850 nm) held by the subject himself as close to the face as possible capturing both eyes. The diameter of the iris in such videos is approximately 60 pixels. Ten iris videos were collected in two (5 in each session) for each one of the 60 subjects. Along with the videos, information such as name, ID card number, age, gender, and handedness are also available.
All databases described in this subsection contain iris and/or periocular subsets, however, some databases that do not have such subsets can also be employed for iris/periocular recognition. For example, the FRGC (Phillips et al. 2005) database, which is a database of face images, has already been used for iris (Tan and Kumar 2013) and periocular (Woodard et al. 2010; Park et al. 2011; Smereka et al. 2015) recognition in the literature.
3 Ocular recognition competitions
In this section, we describe the major recent competitions and the algorithms that achieved the best results in iris and/or periocular region information. Through these competitions, it is possible to demonstrate the advancement in terms of methodologies for ocular biometrics and also the current challenges in this research area.
The competitions usually provide a database in which the competitors must perform their experiments and submit their algorithms. Once submitted, the algorithms are evaluated with another subset of the database, according to the metrics established by the competition protocol. In this way, it is possible to fairly assess the performance of different methodologies for specific objectives.
In ocular biometrics including iris and periocular recognition, there are several competitions aimed at evaluating different situations, such as recognition in images captured at NIR and/or VIS wavelengths, images captured in an uncontrolled environment, images obtained with mobile devices, among others. For each competition, we describe the approaches that achieved the best results using fused information from iris and periocular region, and also the best performing methodologies using only iris information. Table 5 presents the main competitions held in recent years and the best results achieved, while Table 6 details the methodologies that obtained the best results in these competitions.
3.1 NICE: noisy iris challenge evaluation
The Noisy Iris Challenge Evaluation (NICE) competition contains two different contests. In the first one (NICE.I), held in 2008, the goal was the evaluation of methods for iris segmentation to remove noise factors such as specular reflections and occlusions. Regarding the evaluation of encoding and matching methods, the second competition (NICE.II), was carried out in 2010. The databases used in both competitions are subsets of UBIRIS.v2 (Proença et al. 2010), which contains VIS ocular images captured under uncontrolled environments.
Described by Proença and Alexandre (2012), the first competition aimed to answer: “is it possible to automatically segment a small target as the iris in unconstrained data (obtained in a non-cooperative environment)?” In total, 97 research laboratories from 22 countries participate in the competition. The training set consisted of 500 images, and their respective manually generated binary iris masks. The committee evaluated the proposed approaches using another 500 images through a pixel-to-pixel comparison between the original and the generated segmentation masks. As a metric, the organizers choose the following error rate based on pixel-level:
where n refers to the number of test images, w and h are respectively the width and height of these images, \(P_{i}(r,c)\) means the intensity of the pixel on row r and column c of the ith segmentation mask, \(G_{i}(r,c)\) is the actual pixel value and \(\otimes \) is the or-exclusive operator.
According to the values of \(E_{j}\), NICE.I’s best results are the following: 0.0131 (Tan et al. 2010), 0.0162 (Sankowski et al. 2010), 0.0180 (De Almeida 2010), 0.0224 (Li et al. 2010), 0.0282 (Jeong et al. 2010), 0.0297 (Chen et al. 2010), 0.0301 (Donida Labati and Scotti 2010), 0.0305 (Luengo-Oroz et al. 2010).
The second competition (NICE.II) evaluated only the feature extraction and matching results. Therefore, all the participants used the same segmented images, which were generated by the winner methodology in the NICE.I contest (Proença and Alexandre 2012), proposed by Tan et al. (2010). The main goal was to investigate the impact of noise presented inside the iris region in the biometric recognition process. As described in both competitions (Proença and Alexandre 2012), these noise factors have different sources, e.g., specular reflection and occlusion, caused by the uncontrolled environment where the images were taken. This competition received algorithms sent by 67 participants from 30 countries. The training set consists of 1000 images and their respective binary masks. The proposed methods had to receive a pair of images followed by their masks as input and generate an output file containing the dissimilarity scores (d) of which pairwise comparison with the following conditions:
-
1.
\(d(I, I) = 0\)
-
2.
\(d(I_{1}, I_{2}) = 0 \Rightarrow I_{1} = I_{2}\)
-
3.
\(d(I_{1}, I_{2}) + d(I_{2}, I_{3}) \ge d(I_{1}, I_{3})\).
The submitted approaches were evaluated using a new set of 1000 images with their binary masks. Consider \(IM = \{I_{1},...,I_{n}\}\) as a collection of iris images, \(MA= \{M_{1},...,M_{n}\}\) as their respective masks, and id(.) representing a function that identifies an image. The comparison protocol one-against-all returns a match set \(D^{I} = \{d^{i}_{1},...,d_{im}\}\) and a non-match set \(D^{E} = \ d^{e}_{1},...,d_{ek}\}\) of dissimilarity scores, where \(id(I_{i}) = id(I_{j})\) and \(id(I_{i}) \ne id(I_{j})\), respectively. The algorithms were evaluated using the decidability scores \(d'\) (Daugman 2004), which measure the separation level of two distributions. The following overlap area gives this decidability scores \(d'\):
where the means of the two distributions are given by \(\mu _{I}\) and \(\mu _{E}\), and the standard deviations are represented by \(\sigma _{I}\) and \(\sigma _{I}\).
The best results of NICE.II ranked by their \(d'\) scores are as follows: 2.5748 (Tan et al. 2012), 1.8213 (Wang et al. 2012), 1.7786 (Santos and Hoyle 2012), 1.6398 (Shin et al. 2012), 1.4758 (Li et al. 2012), 1.2565 (De Marsico et al. 2012), 1.1892 (Li and Ma 2012), 1.0931 (Szewczyk et al. 2012).
The winner method, proposed by Tan et al. (2012), achieved a decidability value of 2.5748 by fusing iris and periocular features. The fusion process was performed at the score level by the sum rule method. Therefore, for iris and periocular images, different features and matching techniques were used. The iris features were extracted with ordinal measures and color histogram and for the periocular ones, texton histogram, and semantic information. To compute the matching scores, the authors employed the following metrics: SOBoost learning, diffusion distance, chi-square distance, and exclusive OR operator.
Wang et al. (2012) proposed a method using only iris information. Their approach was ranked second in the competition, achieving a decidability value of 1.8213. The algorithm performed the segmentation and normalization of iris using the Daugman technique (Daugman 1993). Features were extracted by applying the Gabor filters from different patches generated from the normalized image. The AdaBoost algorithm computed a selection of features and the similarity.
The main contribution of NICE competitions was the evaluation of iris segmentation and recognition methods independently, as several iris segmentation methodologies were evaluated in the first competition and the best one was applied to generate the binary masks used in the second one, in which the recognition task was evaluated. Hence, the approaches described in both competitions can be fairly compared since they employed the same images for training and testing.
Although NICE.II was intended to evaluate iris recognition systems, some approaches using information from the periocular region were also included in the final ranking. The winning method fused iris and periocular information, however, it should be noted that some approaches that also fused these two traits achieved lower results than methodologies that used only iris features. Moreover, it would be interesting to analyze the best performing approaches in the NICE.II competition in larger databases to verify the scalability of the proposed methodologies, as the database used in these competitions was not composed of a large number of images/classes.
Some recent works applying deep Convolutional Neural Network (CNN) models have achieved state-of-the-art results in the NICE.II database using information from the iris (Zanlorensi et al. 2018), periocular region (Luz et al. 2018) and fusing iris/periocular traits (Silva et al. 2018) with decidability values of 2.25, 3.47, 3.45, respectively.
3.2 MICHE: mobile iris challenge evaluation
In order to assess the performance that can be reached in iris recognition without the use of special equipment, the Mobile Iris CHallenge Evaluation II, or simply MICHE-II competition, was held (De Marsico et al. 2017). The MICHE-I database, introduced by De Marsico et al. (2015) has 3732 images taken by mobile devices and was made available to the participants to train their algorithms, while other images obtained in the same way were employed for the evaluation.
Similarly to NICE.I and NICE.II, MICHE is also divided into two phases. MICHE.I and MICHE.II focused on iris segmentation and recognition, respectively. Ensuring a fair assessment and targeting only the recognition step, all MICHE.II participants used the segmentation algorithm proposed by Haindl and Krupicka (2015), which achieved the best performance on MICHE.I.
The performance of each algorithm was evaluated through dissimilarity. Assuming I as a set of the MICHE.II database and that \(I_{a}, I_{b} \in I\), the dissimilarity function D is defined by:
satisfying the following properties:
-
1.
\(D(I_{a}, I_{a}) = 0\)
-
2.
\(D(I_{a}, I_{b}) = 0 \Rightarrow I_{a} = I_{b}\)
-
3.
\(D(I_{a}, I_{b}) = D(I_{b}, I_{a})\).
Two metrics were employed to assess the algorithms. The first, called Recognition Rate (RR), was used to evaluate the performance in the identification problem (1:n), while the second, called Area Under the Curve (AUC), was applied to evaluate the performance in the verification problem (1:1). In addition, the methodologies were evaluated in two different setups: first comparing only images acquired by the same device and then using images obtained by two different devices (cross-sensor). The algorithms were ranked by the average performance of RR and AUC. The best results are listed in Table 7.
Ahmed et al. (2016), Ahmed et al. (2017) proposed the algorithm that achieved the best result. Their methodology performs the matching of the iris and the periocular region separately and combines the final score values of each approach. For the iris, they used the rubber sheet model normalization proposed by Daugman (1993). Then, the iris codes were generated from the normalized images with the 1-D Log-Gabor filter. The matching was computed with the Hamming distance. Using only iris information, an Equal Error Rate (EER) of 2.12% was reached. Features from the periocular region were extracted with Multi-Block Transitional Local Binary Patterns and the matching was computed with the chi-square distance. With features from the periocular region, an EER of 2.74% was reported. The outputs of both modalities (iris and periocular) were normalized with z-score and combined with weighted scores. The weights used for the fusion were 0.55 for the iris and 0.45 for the periocular region, yielding an EER of 1.22% and an average between RR and AUC of 1.00.
The best performing approach using only iris information was proposed by Raja et al. (2017). In their method, the iris region was first located through a segmentation method proposed by Raja et al. (2015) and then normalized using the rubber sheet expansion model (Daugman 2004). Each image band (red, green and blue) was divided into several blocks. The features were extracted from these blocks, as well as from the entire image, using a set of deep sparse filters, resulting in deep sparse histograms. The histograms of each block and each band were concatenated with the histogram of the entire image, forming the vector of iris features. The features extracted were used to learn a collaborative subspace, which was employed for matching. This algorithm achieved the third place in the competition, with an average between RR and AUC of 0.86 and with EER values of 0% in the images obtained by the iPhone 5S and 6.55% in the images obtained by Samsung S4.
This competition was the first to evaluate iris recognition using images captured by mobile devices and also to evaluate methodologies applied to the cross-sensor problem, i.e., to recognize images acquired by different sensors.
As in the NICE.II competition, one issue is the scalability evaluation of the evaluated approaches. Although the reported results are very promising, we have to consider them as preliminary since the test set used for the assessment is very small, containing only 120 images. As expected, the best results were attained using iris and periocular region information, however, some approaches that used only iris information achieved better results than others that fused iris and periocular region information.
3.3 MIR: competition on mobile iris recognition
The BTAS Competition on Mobile Iris Recognition (MIR2016) was proposed to raise the state of the art of iris recognition algorithms on mobile devices under NIR illumination (Zhang et al. 2016). Five algorithms, submitted by two participants, were eligible for the evaluation.
A database (MIR-Train) was made available for training the algorithms and a second database (MIR-Test) was used for the evaluation. Both databases were collected under NIR illumination. The images of the two irises were collected simultaneously under an indoor environment. Three sets of images were obtained, with distances of 20 cm, 25 cm, and 30 cm, and 10 images for each distance. The images from both databases were collected in the same session. The MIR-Train database is composed of 4500 images from 150 subjects, while MIR-Test has 12, 000 images from 400 subjects. All images are grayscale with a resolution of \(1968\times 1024\) pixels. The main sources of intra-class variation in the images are due to variations in lighting, eyeglasses and specular reflections, defocus, distance changes, and others. Differently from NICE.II, the segmentation masks were not provided in MIR2016, thus, the methodologies submitted included iris detection, segmentation, feature extraction, and matching.
For the evaluation, the organizing committee considered that the left and right irises belong to the same class; thus, a fusion of the matching scores of both irises was performed. All possible intra-class comparisons (i.e., irises from the same subjects) were implemented to compute the False Non-Match Rate (FNMR). From each iris class, two samples were randomly selected to calculate the False Match Rate (FMR). In total, 174, 000 intra-class and 319, 200 inter-class matches were used. In cases where intra- or inter-class comparisons could not be performed due to failure enrollment or failure match, a random value between 0 and 1 was assigned to the score. The classification of the participants was performed using the FNMR4 metric, but the EER and DI metrics were also reported. The FNMR4 metric reports the FNMR value when the FMR equals to 0.0001. The EER is the value when FNMR is equal to the FMR, and the DI value is the decidability index, as explained previously.
The best result was from the Beijing Bata Technology Co. Ltd. reporting FNMR4 = 2.24%, EER = 1.41% and DI = 3.33. The methodology, described in Zhang et al. (2016), includes four steps: iris detection, preprocessing, feature extraction, and matching. For iris detection, the face is found using the AdaBoost algorithm (Viola and Jones 2004) and eye positions are found by using Support Vector Machines (SVM). Next, to lessen the effect of light reflections, the irises and pupils are detected by the modified Daugmans Integro-Differential operator (Daugman 2004). In pre-processing, reflection regions are located and then removed using a threshold and shape information. Afterward, the iris region is normalized using the method proposed by Daugman (1993). Eyelashes are also detected and removed using a threshold. An improvement in image quality is achieved through histogram equalization. The features were extracted with Gabor wavelet, while Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) were applied for dimensionality reduction. The matching was performed using the cosine and Hamming distances, and the results combined.
The second place was achieved by TigerIT Bangladesh Ltd. with FNMR4 = 7.07%, EER = 1.29% and DI = 3.94. The proposed approach also made improvements in image quality through histogram equalization and smoothing. After pre-processing, the iris was normalized using the rubber sheet model (Daugman 2007). Features were then extracted with 2D Gabor wavelets, while the matching was performed employing the Hamming distance. This methodology was classified in second place since it obtained a higher FNMR4 value than the first one, but the EER and DI values were better than those reported by the winning algorithm of the competition.
The MIR2016’s main contribution is to be the first competition using NIR images acquired by mobile modules, in addition to the construction of a new database containing images from both eyes of each individual. Unfortunately, the competition did not have many participants and the proposed methodologies consist only of classical literature techniques.
3.4 VISOB 1.0 and VISOB 2.0 competitions on mobile ocular biometric recognition
The VISOB database was created for the VISOB 1.0 - ICIP 2016 Competition on mobile ocular biometric recognition, whose main objective was to evaluate the progress of research in the area of mobile ocular biometrics at the visible spectrum (Rattani et al. 2016). The front cameras of 3 mobile devices were used to obtain the images: iPhone 5S at 720p resolution, Samsung Note 4 at 1080p resolution and Oppo N1 at 1080p resolution. The images were captured in 2 sessions for each one of the 2 visits, which occurred between 2 and 4 weeks, counting in the total 158, 136 images from 550 subjects. At each visit, it was required that each volunteer (subject) capture their own face using each one of the three mobile devices at a distance between 8 and 12 inches from the face. For each session, images were captured under 3 light conditions: regular office light, offices lights off but dim ambient lighting still present (dim light) and next to sunlit windows (natural daylight settings). The collected database was preprocessed using the Viola-Jones eye detector and the region of the image containing the eyes was cropped to a size of \(240\times 160\) pixels.
The VISOB 1.0 competition was designed to evaluate ocular biometric recognition methodologies using images obtained from mobile devices in visible light on a large-scale database. The database created and used for the competition was VISOB (VISOB Database ICIP2016 Challenge Version) (Rattani et al. 2016). This database has 158, 136 images from 550 subjects, and is the database of images obtained from mobile devices with the largest number of subjects. The images were captured by 3 different devices (iPhone 5S, Oppo N1 and Samsung Note 4) under 3 different lighting classes: ‘daylight’, ‘office’, and ‘dim light’. Four different research groups participated in the competition and 5 algorithms were submitted. The metric used to assess the performance of the algorithms was EER.
In almost all competitions, participants submit an algorithm already trained and the evaluation is performed on an unknown portion of the database. On the other hand, VISOB 1.0 competitors submitted an algorithm that was trained and tested on an unknown portion of the database. Two different evaluations were carried out. In the first one (see Table 8), the algorithms were trained (enrollment) and tested for each device and type of illumination.
In the second evaluation, the algorithms were trained only with the images from the ‘office’ lighting class for each of the 3 devices. To assess the effect of illumination on ocular recognition, the tests were performed with the 3 types of illumination for each device. The results are shown in Table 9.
Raghavendra and Busch (2016) achieved an EER between 0.06% and 0.20% in all assessments, obtaining the best result of the competition. The proposed approach extracted periocular features using Maximum Response (MR) filters from a bank containing 38 filters, and a deep neural network learned with a regularized stacked autoencoders (Raghavendra and Busch 2016). For noise removal, the authors applied a Gaussian filter and performed histogram equalization and image resizing. Finally, the classification was performed through a deep neural network based on deeply coupled autoencoders.
All participants explored features based on the texture of the eye images, extracted from the periocular region. None of the submitted algorithms extracted features only from the iris. The organizing committee compared the performance of the algorithms using images obtained only by the same devices, that is, the algorithms were not trained and tested on images from different devices (cross-sensor). Thus, the main contributions of this competition were a large database containing images from different sensors and environments, along with the assessments on these different setups.
The second edition of this competition, called VISOB 2.0, was carried out at IEEE WCCI in 2020 (Nguyen et al. 2020). A new VISOB ’s subset with eye images from 250 subjects captured by two mobile devices: Samsung Note 4 and Oppo N1, was employed to compare the submitted approaches. This competition evaluated ocular biometrics recognition methods using stacks of five images in the open-world (subject-independent) protocol in different lighting conditions: Dark, Office, and Daylight. In the development (training) stage, the competitors were provided with stacks of images from 150 subjects. Regarding the subject-independent evaluation, the comparison of the submitted methods was performed employing samples from other 100 subjects that were not available in the training stage. The main idea of using multi-frame (stacks) captures for ocular biometrics is to avoid degradation in the images caused by variations in illumination, noise, blur, and user to camera distance. Two participants submitted algorithms based on deep representations and one based on hand-crafted features. Table 10 presents the results.
The rank 1 algorithm proposed by Zanlorensi et al. (2019) (UFPR) consists of an ensemble of ResNet-50 models (5 models, one for each image in the stack) pre-trained for face-recognition using the VGG-Face database. The authors had previously employed this method for cross-spectral ocular recognition achieving state-of-the-art results on the CROSS-EYED and the PolyU Cross-Spectral databases using iris and periocular traits. In this method, each ResNet-50 model was fine-tuned using the periocular images from VISOB 2.0. The only modification in the model was the addition of a fully connected layer containing 256 neurons at the top to reduce the feature dimensionality. The training was computed in the identification mode using a Softmax cross-entropy loss function as a prediction layer. Then, in the evaluation, the prediction layer was removed, and the final combined feature vector with a size of 1280 (\(5\times 256\)) was used to match samples by computing the cosine distance similarity. This algorithm’s best result was \(5.26\%\) of EER using images in the Office vs. Office lighting condition.
The second-place method (Bennet University) used Directional Threshold Local Binary Pattern (DTLBP), and wavelet transform for feature extraction (handcrafted features). Then, the Chi-square distance was employed to compute the similarity between the stack of images. This method’s best result was \(26.21\%\) of EER in the Office vs. Office lighting condition. Finally, the third approach employed the GoogleNet model pre-trained in the ImageNet database for feature extraction and euclidean distance to compute the similarity between the pairs of images. A Long Short Term Memory (LSTM) model using the euclidean distance scores as input was used to predict whether the pair of images is from the same subject or not. This method’s best result was 39.77 of EER in the Office vs. Office lighting condition.
To the best of our knowledge, VISOB 2.0 was the first competition to use multi-frame ocular recognition. The results show that comparison across different illumination was the most difficult for all methods. The open-world (subject-independent) protocol is a realistic scenario for applications in environments without restriction and prior knowledge of the subjects. Finally, the submitted algorithms’ performance shows that there is still room for improvement in this area.
3.5 Cross-eyed: cross-spectral iris/periocular competition
The first Cross-Eyed competition was held in 2016 at the 8th IEEE International Conference on Biometrics: Theory, Applications, and Systems (BTAS). The aim of the competition was the evaluation of iris and periocular recognition algorithms using images captured at different wavelengths. The CROSS-EYED database (Sequeira et al. 2016, 2017), employed in the competition, has iris and periocular images obtained simultaneously at the VIS and NIR wavelengths.
Iris and periocular recognition were evaluated separately. To avoid the use of iris information in the periocular evaluation, a mask excluding the entire iris region was applied. Six algorithms submitted by 2 participants, named HH from Halmstad University and NTNU from Norway Biometrics Laboratory, qualified. The final evaluation was carried out with another set of images, containing 632 images from 80 subjects for periocular recognition and 1280 images from 160 subjects for iris recognition.
The evaluation consisted of enrollment and template matching of intra-class (all NIR against all VIS images) and inter-class comparisons (3 NIR against 3 VIS images – per class). A metric based on Generalized False Accept Rate (GFAR) and Generalized False Reject Rate (GFFR) was used to verify the performance of the submitted algorithms. These metrics generalize the FMR and the FNMR, including Failure-to-enroll (FTE) and Failure-to-acquire (FTA), complying with the ISO/IEC standards (ISO 2006). Finally, to compare the algorithms, the GF2 metric (GFRR@GFAR = 0.01) was employed.
Halmstad University (HH) team submitted 3 algorithms. The approaches consist of fusing features extracted with Symmetry Patterns (SAFE), Gabor Spectral Decomposition (GABOR), Scale-Invariant Feature Transform (SIFT), Local Binary Patterns (LBP) and Histogram of Oriented Gradients (HOG). These fusions were evaluated combining scores from images obtained by the same sensors and also by different sensors. The evaluated algorithms differ by the fusion of different features: \(HH_1\) fusing all the features; \(HH_2\) fusing SAFE, GABOR, LBP and HOG; and \(HH_3\) fusing GABOR, LBP and HOG. The algorithms were applied only to periocular recognition, and the best performance was achieved by \(HH_1\), which achieved an EER of 0.29% and GF2 of 0.00%. More details can be found in Sequeira et al. (2016).
The Norwegian Biometrics Laboratory (NTNU) also submitted 3 algorithms, which applied the same approaches for feature extraction from iris and periocular traits. The iris region was located using a technique based on the approach proposed by Raja et al. (2015), and features were extracted through histograms resulting from the multi-scale BSIF, a bank of independent binarized statistical filters. These histograms were compared using the Chi-Square distance metric. Lastly, an SVM was employed to obtain the fusion and scores corresponding to each filter. The best approach achieved EER of 4.84% and GF2 of 14.43% in periocular matching, and EER of 2.78% and GF2 of 3.31% in iris matching.
In 2017, the second edition of this competition was held Sequeira et al. (2017). Similarly to the first competition, the submitted approaches were ranked by EER and GF2 values. Comparisons in periocular images were made separately for each eye, i. e., the left eyes were compared only with left eyes, and the same for the right eyes. The main difference was in the database used, as the training set consisted of the CROSS-EYED database and the test set was made with 55 subjects. As in the first competition, the matching protocol consisted of intra- and inter-class comparisons, in which all intra-class comparisons were performed and only 3 random images per class were applied in the inter-class comparisons. Results and methodologies of 4 participants were reported, being 4 participants with 11 algorithms for periocular recognition, and 1 participant with 4 algorithms for iris recognition. Two of these participants took part in the first competition, Halmstad University (HH) and Norwegian Biometrics Laboratory (NTNU). The other three competitors were IDIAP from Switzerland, IIT Indore from India, and an anonymous.
The best method using periocular information was submitted by \(HH_1\), which fused features based on SAFE, GABOR, SIFT, LBP and HOG. Their approach, similar to the one proposed in the first competition, reached EER and GF2 values of 0.82% and 0.74%, respectively. For iris recognition, the best results were attained by \(NTNU_4\), which was based on BSIF features and reported EER and GF2 values of 0.05% and 0.00%, respectively.
We point out two main contributions of these competitions: (1) the release of a new cross-spectral database, and (2) the evaluation of several approaches using iris and periocular traits with some promising strategies that can be applied for cross-spectral ocular recognition. Nevertheless, we also highlight some problems in their evaluation protocols. First, the periocular evaluation in the second competition only matches left eyes against left eyes and right eyes against right eyes using prior knowledge of the database. Another problem is the comparison protocol, which uses only 3 images per class in inter-class comparisons instead of all images without specifically reporting which ones were used. There is also no information on code availability, and details of the methodologies are lacking, limiting the reproducibility.
4 Deep learning in ocular recognition
Recently, deep learning approaches have won many machine learning competitions, even achieving superhuman visual results in some domains (LeCun et al. 2015). Therefore, in this section, we describe recent works that applied deep learning-based techniques focusing on encoding and matching, i.e., not covering iris preprocessing methods to ocular biometrics including iris, periocular and sclera recognition, gender and age classification, and subject-independent recognition.
4.1 Iris approaches
Liu et al. (2016) presented one of the first works applying deep learning to iris recognition. Their approach, called DeepIris, was created for recognizing heterogeneous irises captured by different sensors. The proposed method was based on a CNN model with a bank of Pairwise filters, which learns the similarity between a pair of images. The evaluation in verification protocol was carried out in the Q-FIRE and CASIA cross-sensor databases and reported promising results with EER of 0.15% and 0.31%, respectively.
Gangwar and Joshi (2016) also developed a deep learning method for iris verification on the cross-sensor scenario, called DeepIrisNet. They presented two CNN architectures for extracting iris representations and evaluated them using images from the ND-IRIS-0405 and ND Cross-Sensor-Iris-2013 databases. The first model was composed of 8 standard convolutional, 8 normalization, and 2 dropout layers. The second one, on the other hand, has inception layers (Szegedy et al. 2015) and consists of 5 convolutional layers, 7 normalization layers, 2 inception layers, and 2 dropout layers. Compared to the baselines, their methodology reported better robustness on different factors such as the quality of segmentation, rotation, and input, training, and network sizes.
To demonstrate that generic descriptors can generate discriminant iris features, Nguyen et al. (2018) applied distinct deep learning architectures to NIR databases obtained in controlled environments. They evaluated the following CNN models pre-trained using images from the ImageNet database (Deng et al. 2009): AlexNet, VGG, Inception, ResNet and DenseNet. Iris representations were extracted from normalized images at different depths of each CNN architecture, and a multi-class SVM classifier was employed for the identification task. Although no fine-tuning process was performed, interesting results were reported in the LG2200 (ND Cross-Sensor-Iris-2013) and CASIA-IrisV4-Thousand databases. In their experiments, the representations extracted from intermediate layers of the networks reported better results than the representations from deeper layers.
The method proposed by Al-Waisy et al. (2018) used left and right irises information for the identification task. In this approach, each iris was first detected and normalized, and then features were extracted and matched. Finally, the left and right irises matching scores were fused. Several CNN configurations and architectures were evaluated during the training phase and, based on a validation set, the best one was chosen. The authors also evaluated other training strategies such as dropout and data augmentation. Experiments carried out on three databases (i.e., SDUMLA-HMT, CASIA-IrisV3-Interval, and IIT Delhi Iris) reported a 100% rank-1 recognition rate in all of them.
Generally, an iris recognition system has several preprocessing steps, including segmentation and normalization (using Daugman’s approach (Daugman 1993)). In this context, Zanlorensi et al. (2018) analyzed the impact of these steps when extracting deep representations from iris images. Applying deep representations extracted from an iris bounding box without both segmentation and normalization processes, they reported better results compared to those obtained using normalized and segmented images. The authors also fine-tuned two pre-trained models for face recognition (i.e., VGG-16 and ResNet50) and proposed a data augmentation technique by rotating the iris bounding boxes. In their experiments, using only iris information, an EER of 13.98% (i.e., state-of-the-art results) was reached in the NICE.II database.
As the performance of many iris recognition systems is related to the quality of detection and segmentation of the iris, Proença and Neves (2017) proposed a robust method for inaccurately segmented images. Their approach consisted of corresponding iris patches between pairs of images, which estimates the probability that two patches belong to the same biological region. According to the authors, the comparison of these patches can also be performed in cases of bad segmentation and non-linear deformations caused by pupil constriction/dilation. The following databases were used in the experiments: CASIA-IrisV3-Lamp, CASIA-IrisV4-Lamp, CASIA-IrisV4-Thousand, and WVU. The authors reported results using good quality data as well as data with severe segmentation errors. Using accurately segmented data, they achieved EER values of 0.6% (CASIA-IrisV3-Lamp), 2.6% (CASIA-IrisV4-Lamp), 3.0% (CASIA-IrisV4-Thousand) and 4.2% (WVU).
In Wang and Kumar (2019a), Wang and Kumar claimed that iris features extracted from CNN models are generally sparse and can be used for template compression. In the cross-spectral scenario, the authors evaluated several hashing algorithms to reduce the size of iris templates, reporting that the supervised discrete hashing was the most effective in terms of size and matching. Features were extracted from normalized iris images with some deep learning architectures, e.g., CNN with softmax cross-entropy loss, Siamese network, and Triplet network. Promising results were reported by incorporating supervised discrete hashing on the deep representations extracted with a CNN model trained with a softmax cross-entropy loss. The proposed methodology was evaluated on a cross-spectral scenario and achieved EER values of 12.41% and 6.34% on the PolyU Cross-Spectral and CROSS-EYED databases, respectively.
Zanlorensi et al. (2019) performed extensive experiments in the cross-spectral scenario applying two CNN models: ResNet-50 Cao et al. (2017) and VGG16 Parkhi et al. (2015). Both models were first pre-trained for face recognition and then fine-tuned using periocular and iris images. The results of the experiments, carried out in two databases: CROSS-EYED and PolyU Cross-Spectral, indicated that it is possible to apply a single CNN model to extract discriminant features from images captured at both NIR and VIS wavelengths. The authors also evaluate the impact of representation extraction at different depths from the ResNet-50 model and the use of different weights for fusing iris and periocular features. For the verification task, their approach achieved state-of-the-art results in both databases on intra- and cross-spectral scenarios using iris, periocular, and fused features.
Wang and Kumar (2019b) proposed a deep learning-based approach for iris recognition composed of a residual network combined with dilated convolutional kernels, which optimizes the training process and aggregates contextual information from the iris images. The proposed method outperformed matching accuracy compared with classical and state-of-the-art approaches for iris recognition.
Ren et al. (2019) proposed a unified feature-level solution regarding intra-class variation in iris recognition caused by variations on illumination, eye angle, and eye gaze. Their method is composed of an encoder based on a trainable Locally Aggregated Descriptors (VLAD) and a deformable convolution. The authors performed extensive experiments on three iris databases showing that the proposed method outperformed state-of-the-art recognition approaches.
In Ren et al. (2020), the authors proposed a framework using CNN and graphical models to learn dynamic graph representations in order to solve occlusion that occurs in biometrics. Their approach consists of build feature graphs based on node representations generated by convolutional features re-crafted using a graph generator establishing connections among spatial parts. The authors stated that it is possible to adaptively remove the nodes representing the occluded parts using their similarities. Additionally, a novel strategy to measure the distances of nodes and adjacent matrices was proposed. Experiments using iris and face databases showed that the proposed framework can achieve promising results on occluded biometrics recognition.
Wei et al. (2019) proposed a method using adversarial strategy and sensor-specific information regarding the problem of cross-sensor iris recognition. Their approach consists of alleviating the degradation in the cross-sensor recognition by applying the adversarial strategy and weakening interference of sensor information. The method comprises three components: feature extractors containing sensor-specific information to narrow the distribution gap, an alignment feature distribution using Generative Adversarial Network (GAN), and a triplet loss function to reduce the discrepancy of images from different sensors. The authors validated their method on two cross-sensor iris databases.
4.2 Periocular approaches
Luz et al. (2018) designed a biometric system for the periocular region employing the VGG-16 model (Parkhi et al. 2015). Promising results were reported by performing transfer learning from the face recognition domain and fine-tuning the system for periocular images. This model was compared to a model trained from scratch, showing that the proposed transfer learning and fine-tuning processes were crucial for obtaining state-of-the-art results. The evaluation was performed in the NICE.II and MobBIO databases, reporting EER values of 5.92% and 5.42%, respectively.
Using a similar methodology, Silva et al. (2018) fused deep representations from iris and periocular regions by applying the Particle Swarm Optimization (PSO) to reduce the feature vector dimensionality. The experiments were performed in the NICE.II database and promising results were reported using only iris information and also fusing iris and periocular traits, reaching EER values of 14.56% and 5.55%, respectively.
Proença and Neves (2018) demonstrated that periocular recognition performance can be optimized by first removing the iris and sclera regions. The proposed approach, called Deep-PRWIS, consists of a CNNs model that automatically defines the regions of interest in the periocular input image. The input images were generated by cropping the ocular region (iris and sclera) belonging to an individual and pasting the ocular area from another individual in this same region. They obtained state-of-the-art results (closed-world protocol) in the UBIRIS.v2 and FRGC databases, with EER values of 1.9% and 1.1%, respectively.
Zhao and Kumar (2018) developed a CNN-based method for periocular verification. This method first detects eyebrow and eye regions using a Fully Convolutional Network (FCN) and then uses these traits as key regions of interest to extract features from the periocular images. The authors also developed a verification oriented loss function (Distance-driven Sigmoid Cross-entropy loss (DSC)). Promising results were reported on six databases both in closed- and open-world protocols, achieving EER values of 2.26% (UBIPr), 8.59% (FRGC), 7.68% (FOCS), 4.90% (CASIA-IrisV4-Distance), 0.14% (UBIRIS.v2) and 1.47% (VISOB).
Using NIR images acquired by mobile devices, Zhang et al. (2018) developed a method based on CNN models to generate iris and periocular region features. A weighted concatenation fused these features. These weights and also the parameters of convolution filters were learned simultaneously. In this sense, the joint representation of both traits was optimized. They performed experiments in a subset of the CASIA-Iris-Mobile-V1.0 database reporting EER values of 1.13% (Periocular), 0.96% (Iris) and 0.60% (Fusion).
4.3 Sclera approaches
In ocular biometrics using the sclera region, deep learning techniques are generally applied in the segmentation stage (Lucio et al. 2018; Das et al. 2019; Naqvi and Loh 2019; Wang et al. 2019), helping the recognition system by locating traits as the sclera itself and the iris. As described by Vitek et al. (2020a), the recognition is often performed using the segmented sclera vasculature by employing key-point and dense-grid descriptors as SIFT, SURF, ORB, and Dense SIFT. As the sclera is a relatively new ocular biometric trait, there are currently few deep learning-based approaches to perform person recognition (Rot et al. 2020; Maheshan et al. 2020).
Regarding segmentation methods, Lucio et al. (2018) proposed two approaches based on FCN and GAN to segment the sclera region. Experiments performed on two ocular databases demonstrated that the FCN model achieved better results on a single-sensor configuration. In contrast, for the cross-sensor scenario, the GAN model reached higher scores. Wang et al. (2019) presented the ScleraSegNet, which is based on the U-Net model. The authors also proposed and compared different embed attention modules in the U-Net model regarding learning discriminative features. Extensive experiments using three ocular databases showed that the channel-wise attention module was the most effective for performing the segmentation and that data augmentation techniques improved the generalization ability. Naqvi and Loh (2019) proposed a model for sclera segmentation employing a residual encoder and decoder network, called Sclera-Net. The authors also addressed sclera segmentation in images acquired by different sensors achieving promising results in this work. Recent competitions on sclera segmentation (Das et al. 2019; Vitek et al. 2020b) demonstrated that deep learning-based methods achieved the highest results, mainly models based on the U-Net and FCN architectures. The results reached in these competitions show that sclera segmentation is still an open and challenging problem.
Regarding the sclera recognition task based on deep learning methods, one of the first approaches found in the literature is the ScleraNET (Rot et al. 2020). In this work, the authors proposed a multi-task CNN model combining losses from the identity and gaze direction recognition. This model extracts vasculature descriptors and uses them to infer the identity of the subject. Promising results were achieved and compared with handcrafted-based methods. Maheshan et al. (2020) also proposed a method based on CNN for sclera recognition. The model comprises four convolutional layers, followed by a max-pooling layer and a fully connected layer at the top. The proposed model was evaluated and compared with the top 2 ranked algorithms in the SSRBC 2016 Sclera Segmentation and Recognition Competition (Das et al. 2016) reaching the higher scores.
4.4 Gender and age classification
Soft biometrics, such as gender and age classification, using ocular traits are tasks that have gained attention in research in recent years (Krishnan et al. 2020; Rattani et al. 2017b, 2018; Kuehlkamp and Bowyer 2019; Zanlorensi et al. 2020a). It can be used as primary biometric information to improve the accuracy of biometric systems (Rattani et al. 2017b). A few works in the literature employ ocular traits (iris and periocular region) using VIS images for gender and age estimation/classification based on deep learning techniques (Rattani et al. 2017a, 2018; Kuehlkamp and Bowyer 2019; de Assis Angeloni et al. 2019; Zanlorensi et al. 2020a).
Kuehlkamp and Bowyer (2019) performed extensive experiments using hand-crafted and deep-representations with iris and periocular traits for gender classification. The results sustain that gender prediction using periocular images is at least \(17\%\) more accurate than normalized iris images, regardless of the classifier (hand-crafted or deep representations). Krishnan et al. (2020) investigated the fairness of ocular biometrics methods using mobile images across gender. The evaluation employing the ResNet, LightCNN, and MobileNet models for periocular biometrics presented an equivalent verification performance for males and females. However, in gender classification, males outperformed females by a difference of \(22.58\%\).
Rattani et al. (2017a) investigated age classification using VIS ocular images acquired by mobile devices. The proposed method consists of a 6-layer CNN model comprising convolution, max-pooling, batch-normalization, and fully connected layers. Ages were grouped into 8 ranges, and a soft-max activation was employed to compute each group’s probability. Experiments conducted on a 5-fold cross-validation protocol using only the ocular region (both eyes, eyebrows, and periocular region) reported closer and promising results than full-face methods for age estimation, achieving an accuracy (\(\%\)) of \(46.97\pm 2.9\) against \(49.5\pm 4.4\), respectively. de Assis Angeloni et al. (2019) proposed a multi-stream CNN model using facial parts for age classification. The model consists of 4 streams, each one for the following traits: eyebrows, eyes, nose, and mouth. The proposed approach reached better results in accuracy than methods employing images from the entire face. Furthermore, an ablation study on the method reported that the eyes region was the most important trait to improve the entire approach accuracy.
In a recent work (Zanlorensi et al. 2020a), the authors proposed a multi-task learning network for periocular recognition using VIS images acquired by mobile devices. The CNN architecture was composed of a MobileNetV2 as a base model and 5 fully connected layers followed by soft-max layers for the following soft biometrics tasks: identity, age, gender, eye side, and smartphone model classification. The proposed multi-task model reached better results than several CNN architectures for verification and identification tasks on experiments conducted on closed- and open-world (subject-independent) protocols. Moreover, performing an ablation study, the authors stated that age, gender, and mobile device classification were critical components regarding the accuracy of the method for the identification task.
4.5 Subject-independent recognition
The term subject-independent comprises open-world, cross-dataset, and open-set protocols. There are samples from different subjects in the training and test (evaluation) stages in this scenario. It is generally employed in the evaluation of methods developed with representation learning. Regarding deep learning applications for ocular biometrics, the subject-independent evaluation is generally related to the method’s robustness, and it is evaluated for the verification task. Some works compared ocular (iris and periocular) biometric approaches on both subject-dependent (closed-world) and subject-independent (open-world) protocols showing that the latter is the most challenging (Zhao and Kumar 2018; Reddy et al. 2018; Zanlorensi et al. 2019; Proença and Neves 2019; Zanlorensi et al. 2020a). Furthermore, the results reached on VISOB 1.0 (subject-dependent) (Rattani et al. 2016) and VISOB 2.0 (Nguyen et al. 2020) (subject-independent) competitions sustains this statement.
The methodology proposed in Proença and Neves (2019) does not require preprocessing steps, such as iris segmentation and normalization, for iris verification. In this approach, based on deep learning models, the authors used biologically corresponding patches to discriminate genuine and impostor comparisons in pairs of iris images, similarly to IRINA (Proença and Neves 2017). These patches were learned in the normalized iris images and then remapped into a polar coordinate system. In this way, only a detected/cropped iris bounding box is required in the matching stage. The model’s input is a pair of images, and the output informs whether they are from the same subject or not. State-of-the-art results were reported in three NIR databases, achieving EER values of 0.6%, 3.0%, and 6.3% in the CASIA-Iris-V4-Lamp, CASIA-IrisV4-Thousand, and WVU, respectively, in the subject-independent (open-world) protocol.
Regarding ocular images captured in the VIS spectrum, Reddy et al. (2018) proposed a patch-based method employing deep learning networks. The model crops 6 overlapping patches from the ocular/periocular region and extracts features employing a small CNN network for each patch. For a given image pair, the matching is computed by a Euclidean distance between each patch’s features. The final score is then generated by combining the distances with the mean, median, and minimum of patches scores. Promising results were achieved in 3 VIS and 1 cross-spectral periocular databases.
Some works (Wang and Kumar 2019a; Zanlorensi et al. 2020a) evaluated the most employed CNN architectures for the verification task on the subject-independent setting. These approaches are generally based on Pairwise filters, Siamese, and Triplet networks. Regarding only these kinds of architectures, in Wang and Kumar (2019a), the Siamese model achieved better results than the Triplet network. On the other hand, in Zanlorensi et al. (2020a) the Pairwise filters network reached better results than the Siamese network. It is important to note that in both works (Wang and Kumar 2019a; Zanlorensi et al. 2020a), even in the subject-independent setting, the best results for the verification task were achieved employing CNN models using a soft-max layer in the training stage.
4.6 Final remarks
Regarding the works described in this section, we point out that some deep learning-based approaches for iris recognition aim to develop end-to-end systems by removing preprocessing steps (e.g., segmentation and normalization) since a failure in such processes would probably affect recognition systems (Zanlorensi et al. 2018; Proença and Neves 2017, 2019). Several works (Luz et al. 2018; Silva et al. 2018; Proença and Neves 2018; Zhao and Kumar 2018; Zhang et al. 2018) show that the periocular region contains discriminant features and can be used, or fused with iris and sclera information, to improve the performance of biometric systems. Furthermore, recent works on soft-biometrics for periocular recognition (Krishnan et al. 2020; Rattani et al. 2017b, 2018; Kuehlkamp and Bowyer 2019; Zanlorensi et al. 2020a) reported promising results and stated that this kind of information can be used to improve the accuracy of the biometric system. Finally, biometric systems evaluated in the subject-independent setting are still a challenging task since it is highly affected by the intra- and inter-class variability, especially in VIS images collected in unconstrained scenarios.
For completeness, there are several works and applications with ocular images using deep learning frameworks, such as: spoofing and liveness detection (Menotti et al. 2015; He et al. 2016), left and right iris images recognition (Du et al. 2016), contact lens detection (Silva et al. 2015), iris location (Severo et al. 2018), sclera and iris segmentation (Lucio et al. 2018; Bezerra et al. 2018), iris and periocular region detection (Lucio et al. 2019), gender classification (Tapia and Aravena 2017), iris/periocular biometrics by in-set analysis (Proença and Neves 2019), iris recognition using capsule networks (Zhao et al. 2019), and sensor model identification (Marra et al. 2018).
5 Challenges and future directions
In this section, we describe recent challenges and how approaches are being developed to address these issues. We also point out some future directions and new trends in ocular biometrics. The challenges and directions presented are as follows:
5.1 Scalability
The term scalability refers to the ability of a biometric system to maintain efficiency (accuracy) even when applied to databases with a large number of images and subjects. The largest NIR iris database available in the literature in terms of number of subjects is CASIA-IrisV4-Thousand (CASIA 2010), which has 20, 000 images taken in a controlled environment from 1000 subjects. In an uncontrolled environment and with VIS ocular images, the largest database is UFPR-Periocular (Zanlorensi et al. 2020a), which is composed of 33, 660 images from 1122 subjects. Although several proposed methodologies achieve high decidability index in these databases (Nguyen et al. 2018; Proença and Neves 2017, 2019; Rattani et al. 2016; Raghavendra and Busch 2016; Raja et al. 2016; Ahuja et al. 2016), indicating that these approaches have impressive and high separation of the intra- and inter-class comparison distribution, can we state that these methodologies are scalable? In this sense, it is necessary to research new methods as well as new databases with a larger number of images/subjects to evaluate the scalability of existing approaches in the literature.
5.2 Multimodal biometric fusion in the visible spectrum
The periocular region traits are most utilized when there is a poor quality image of the iris region or part of the face is occluded, which commonly occurs in uncontrolled environments at VIS wavelength (Park et al. 2009; Luz et al. 2018). A promising solution in such scenarios is the fusion of several biometric traits contained in the images, for example, iris, periocular, ear, and the entire face. In this way, there is still room for improvement in the detection/segmentation of biometric traits contained in the face region and also in algorithms for fusing features extracted from these traits into various levels, as feature extraction, matching score, and decision (R and J 2003).
There are few publicly available multimodal databases, and those available combine ocular modalities with other popular biometric traits, such as face or speech. Researchers aiming to evaluate the fusion of ocular biometric modalities against other less common modalities need to create their own database or build a chimerical one. In Lopes Silva et al. (2019), a protocol for the creation and evaluation of multimodal biometric chimerical databases is discussed. Although evaluation on chimeric databases is not an ideal condition, it may be an alternative to an initial/preliminary investigation (Lopes Silva et al. 2019).
5.3 Multi-session
Regarding real-world applications, databases containing images captured in more than one session in an uncontrolled environment can be used to analyze the robustness of biometric systems, as images obtained at distinctive sessions often present high intra-class variations caused by environmental changes, lighting, distance, and other noises such as occlusion, reflection, shadow, focus, off-angle, etc. Images obtained at different sessions are important for evaluating the variation of biometric traits through time and also the effect of imaging in different environments, e.g., indoor and outdoor environment, daylight (natural), office light (artificial), among others. Some studies (Rattani et al. 2016; Raghavendra and Busch 2016; Raja et al. 2016; Ahuja et al. 2016; Liu et al. 2016; Gangwar and Joshi 2016) show that images obtained in different sessions have a greater impact on the recognition of VIS images than of NIR images. This is because NIR images are generally obtained under controlled environments while VIS images are taken under uncontrolled environments and because the near-infrared spectrum best highlights the internal features of the iris (Liu et al. 2016; Gangwar and Joshi 2016; Rattani et al. 2016; Nalla and Kumar 2017; Nguyen et al. 2018).
5.4 Deep ocular representations
Several works have explored strategies by modifying and/or evaluating input images for iris feature extraction using CNN models (Liu et al. 2016; Gangwar and Joshi 2016; Proença and Neves 2017; Zanlorensi et al. 2018; Proença and Neves 2018, 2019; Zhao and Kumar 2018). Zanlorensi et al. (2018) showed that CNN models can extract more discriminating features from the iris region using images without classic preprocessing steps such as normalization and segmentation for noise removal. Proença and Neves (2018) demonstrated that by removing information from the eyeball region (iris and sclera), representations extracted from the periocular region yields better results in biometric systems and also that it is possible to train CNN models to define the region-of-interest automatically (i.e., ignoring the information contained in the eyeball region) in an implicit way. Recent works (Liu et al. 2016; Proença and Neves 2017, 2019) attained promising results by training CNN models to detect/learn similar regions in image pairs using Pairwise filters, that is, using a pair of iris images as input and a binary output informing if the images belong to the same class. Features extracted from these models generally achieve better results when compared to models trained for verification tasks, e.g., Triplet and Siamese networks (Wang and Kumar 2019a). Within this context, we can state that improvements can be made by exploring different approaches to feed the CNN models and also by exploring different architectures and loss functions.
5.5 Mobile cross-sensor images
Recently, some mobile (smartphones) ocular databases have been created (MICHE-I, VSSIRIS, CSIP and VISOB) to study the use of images from different sensors and environments in ocular biometrics. The images contained in these databases are captured by the volunteer himself in uncontrolled environments and have several variabilities caused by occlusion, shadows, lighting, defocus, distance, pose, gait, resolution, image quality (usually affected by the environment lighting), among others. Due to these characteristics, iris recognition using such images may not be reliable; thus some methodologies using periocular region information have been proposed (Ahuja et al. 2016; Ahmed et al. 2016; Aginako et al. 2017a; Ahuja et al. 2017). Another factor evaluated in these databases is the recognition using cross-sensor images, i.e., the matching of features extracted from images captured by different sensors. In this scenario, the largest database in terms of subjects is VISOB (Rattani et al. 2016) with 550 subjects and 158, 136 images captured using 3 different sensors. In terms of number of sensors, the largest database is CSIP (Santos et al. 2015) with 7 different sensors, however, it contains only 2004 images from 50 subjects. A next step may be to create a mobile ocular database containing a larger number of different sensor models (compared to existing ones) in different sessions. Such a database can be used to assess biometric systems regarding the noise signature of each camera, as well as the variations caused by the environments (sessions). It is essential that this database has a large number of subjects, e.g., at least 1000 (CASIA-IrisV4-Thousand).
5.6 Cross-spectral scenario
A recent challenge that still has room for improvement is the application of ocular biometric systems in a cross-spectral scenario/setting. The term cross-spectral refers to the matching of features extracted from images captured at different wavelengths, usually VIS images against NIR ones. Based on the configuration of the experiment, the feature extraction training step can be performed using images obtained at only one wavelength (VIS or NIR) or both (VIS and NIR). The challenge of this scenario is that the features present in NIR images are not always the same as those extracted in VIS images. We can mention some recent competitions and approaches that have been developed in this scenario (Sequeira et al. 2016, 2017; Nalla and Kumar 2017; Wang and Kumar 2019a; Zanlorensi et al. 2019).
5.7 Protocols: closed-world, open-world, and cross-dataset
Deep learning-based biometric systems consist of learning distinct features from traits. Those features can be used to generate a similar (or dissimilar) score to perform a verification task or can be fed to a classifier in order to perform an identification task. How learned features should be used is highly associated with the evaluation protocol. Ideally, experiments should be performed on different protocols such as closed-world, open-world, and cross-dataset to evaluate the robustness against different scenarios and the generalization ability of these models. Note that open-world and cross-dataset can also be reported as the subject-invariant protocol.
In the closed-world protocol, different samples from the same classes are present in the training and test sets, facilitating the use of supervised classifiers for the biometric identification task. This means that the system is not able to handle new classes. This type of system (closed-world) is usually evaluated with accuracy or recognition rate metrics.
The open-world protocol must have samples from different classes in the training and test sets. Within this protocol, the biometric system must provide a score to allow the calculation of similarity (or dissimilarity) from a pair of samples. The evaluation of open-world protocol is usually done with the biometric verification task. Although the verification process is often performed in a pair-wise fashion (1:1) and, by definition, in the verification task, the identity of the subject to be verified is known a priori, in biometric competitions this information is also used to generate scores from impostor pairs in order to emulate spoofing attacks (Proença and Alexandre 2012; Zhang et al. 2016; Rattani et al. 2016; Sequeira et al. 2016, 2017; De Marsico et al. 2017). The number of impostor pairs is often the absolute majority during the assessment, which makes open-world protocol very challenging. The evaluation of competitions using the open-world protocol are usually done by EER, AUC, or decidability.
Finally, the cross-dataset protocol consists of performing training and testing using data acquired with different devices (sensors). Therefore, two or more different databases are employed. This type of evaluation brings another kind of issues in real environments, for example, the influence of sensor quality and light spectrum sensitivity. Feature extraction methods should be robust enough to represent the samples under different conditions.
In our opinion, the closed-world protocol is the most challenging one, followed by open-world and closed-world, respectively. We emphasize that, in order to assess robustness and generalization ability, all protocols should be considered by future competitions.
5.8 Soft biometrics
Considering that several recent periocular databases have labeled soft-biometrics as age, gender, race, and eye color (Zanlorensi et al. 2020a; Rattani et al. 2016; Padole and Proença 2012), such information can be used to improve the biometric systems’ performance/accuracy. The few works found in the literature exploring this kind of information generally present promising improvements by using soft biometrics data for both the training and evaluation stage (Marra et al. 2018; Zanlorensi et al. 2020a). Recent research in this area aims to detect/classify these attributes (Krishnan et al. 2020; Rattani et al. 2017b, 2018; Kuehlkamp and Bowyer 2019; Zanlorensi et al. 2020a). With the advancement of these approaches, we believe that soft biometrics will increasingly become an alternative to improve biometric systems’ performance, serving as a pre-matching process to return the most likely matching samples.
6 Conclusion
This work presented a survey of databases and competitions for ocular recognition. For each database, we described information such as image acquisition protocols, creation year, acquisition environment, images wavelength, number of images and subjects, and modality. The databases were described and divided into three subsections: NIR, VIS and cross-spectral, and multimodal databases. Such databases included iris and periocular images for different applications such as recognition, liveness detection, spoofing, contact lens detection, synthetic iris creation, among others. We also presented recent competitions in iris and periocular recognition and described the approaches that achieved the best results. The top-ranked methodologies using only iris traits and also the better overall result (i.e., using both iris and periocular information) were detailed. Finally, we reviewed recent and promising works that applied deep learning frameworks to ocular recognition tasks.
We also described recent challenges and approaches to these issues, point out some future directions and new trends in the ocular biometrics. In this context, some research directions can be highlighted, for example, recognition using (1) images taken in an uncontrolled environment (Proença and Alexandre 2012; De Marsico et al. 2017; Rattani et al. 2016), (2) images obtained from mobile devices at the VIS wavelength (De Marsico et al. 2017; Rattani et al. 2016), and (3) cross-spectrum images (Wang and Kumar 2019a; Zanlorensi et al. 2019). Aiming to study the scalability of deep iris and periocular features and images obtained by smartphones, a very close real-world scenario, it may be interesting to create a database containing a larger number of devices/sensors and subjects compared with current databases (Kim et al. 2016; De Marsico et al. 2015; Raja et al. 2015; Santos et al. 2015; Rattani et al. 2016; Zanlorensi et al. 2020a), since the largest one in terms of sensors (CSIP) have only 2004 images captured from 50 subjects by 7 different devices and the largest database in terms of subject (UFPR-Periocular) have 33, 660 images captured from 1122 subjects by 196 different sensors (not cross-sensor). The application of machine learning techniques for segmentation, feature extraction, and recognition can still be greatly explored (De Marsico et al. 2016) since promising results have been achieved using them (Menotti et al. 2015; Gangwar and Joshi 2016; Liu et al. 2016; He et al. 2016; Du et al. 2016). Other directions that also deserve attention are ocular recognition at distance, liveness detection, multimodal ocular biometrics, and soft biometrics, which can be used to improve the performance of ocular biometric systems.
References
Abate AF, Barra S, Gallo L, Narducci F (2017) Kurtosis and skewness at pixel level as input for SOM networks to iris recognition on mobile devices. Pattern Recogn Lett 91:37–43
Abate A, Barra S, Gallo L, Narducci F (2016) Skipsom: Skewness & kurtosis of iris pixels in self organizing maps for iris recognition on mobile devices. 23rd ICPR. IEEE, Cancun, Mexico, pp 155–159
Aginako N, Castrillón-Santana M, Lorenzo-Navarro J, Martínez-Otzeta JM, Sierra B (2017a) Periocular and iris local descriptors for identity verification in mobile applications. Pattern Recogn Lett 91:52–59
Aginako N, Echegaray G, Martínez-Otzeta JM, Rodríguez I, Lazkano E, Sierra B (2017b) Iris matching by means of machine learning paradigms: a new approach to dissimilarity computation. Pattern Recogn Lett 91:60–64
Aginako N, Martinez-Otzerta JM, Sierra B, Castrillon-Santana M, Lorenzo-Navarro J (2016a) Local descriptors fusion for mobile iris verification. ICPR. IEEE, Cancun, Mexico, pp 165–169
Aginako N, Martinez-Otzeta JM, Rodriguez I, Lazkano E, Sierra B (2016b) Machine learning approach to dissimilarity computation: Iris matching. ICPR. IEEE, Cancun, Mexico, pp 170–175
Ahmed NU, Cvetkovic S, Siddiqi EH, Nikiforov A, Nikiforov I (2017) Combining iris and periocular biometric for matching visible spectrum eye images. Pattern Recogn Lett 91:11–16
Ahmed NU, Cvetkovic S, Siddiqi EH, Nikiforov A, Nikiforov I (2016) Using fusion of iris code and periocular biometric for matching visible spectrum iris images captured by smart phone cameras. In: International Conference on Pattern Recognition (ICPR). IEEE, Cancun, Mexico, pp 176–180
Ahuja K, Islam R, Barbhuiya FA, Dey K (2017) Convolutional neural networks for ocular smartphone-based biometrics. Pattern Recogn Lett 91(2):17–26
Ahuja K, Islam R, Barbhuiya FA, Dey K (2016) A preliminary study of CNNs for iris and periocular verification in the visible spectrum. In: International Conference on Pattern Recognition (ICPR). IEEE, Cancun, Mexico, pp 181–186
Al-Waisy AS, Qahwaji R, Ipson S, Al-Fahdawi S, Nagem TAM (2018) A multi-biometric iris recognition system based on a deep learning approach. Pattern Anal Appl 21(3):783–802
Algashaam FM, Nguyen K, Alkanhal M, Chandran V, Boles W, Banks J (2017) Multispectral periocular classification with multimodal compact multi-linear pooling. IEEE Access 5:14572–14578
De Almeida P (2010) A knowledge-based approach to the iris segmentation problem. Image Vis Comput 28(2):238–245
Alonso-Fernandez F, Bigun J (2016a) A survey on periocular biometrics research. Pattern Recogn Lett 82:92–105
Alonso-Fernandez F, Bigun J (2016b) Periocular biometrics: databases, algorithms and directions. In: International Conference on Biometrics and Forensics, IEEE, Limassol, Cyprus, pp 1–6
Arora SS, Vatsa M, Singh R, Jain A (2012) Iris recognition under alcohol influence: a preliminary study. In: IAPR International Conference on Biometrics (ICB). IEEE, New Delhi, India, pp 336–341
Baker SE, Bowyer KW, Flynn PJ, Phillips PJ (2013) Template aging in iris biometrics. Springer, London, pp 205–218
Baker SE, Hentz A, Bowyer KW, Flynn PJ (2010) Degradation of iris recognition performance due to non-cosmetic prescription contact lenses. Comput Vis Image Underst 114(9):1030–1044
Bezerra CS, Laroca R, Lucio DR, Severo E, Oliveira LF, Britto AS Jr, Menotti D (2018) Robust Iris Segmentation Based on Fully Convolutional Networks and Generative Adversarial Networks. In: Conference on Graphics, Patterns and Images (SIBGRAPI). IEEE, Parana, Brazil, pp 281–288
Bowyer KW, Hollingsworth K, Flynn PJ (2008) Image understanding for iris biometrics: A survey. Comput Vis Image Underst 110(2):281–307
CASIA (2010) Casia database. http://www.cbsr.ia.ac.cn/china/Iris%20Databases%20CH.asp
Cao Q, Shen L, Xie W, Parkhi OM, Zisserman A (2017) VGGFace2: a dataset for recognising faces across pose and age. CoRR arXiv 1710:08092
Chen Y, Adjouadi M, Han C, Wang J, Barreto A, Rishe N, Andrian J (2010) A highly accurate and computationally efficient approach for unconstrained iris segmentation. Image Vis Comput 28(2):261–269
Czajka A (2013) Database of iris printouts and its application: Development of liveness detection method for iris recognition. In: Internernational Conference on Methods Models in Automation Robotics (MMAR), IEEE, Miedzyzdroje, Poland, pp 28–33
Das A, Pal U, Ferrer MA, Blumenstein M (2016) SSRBC 2016: Sclera Segmentation and Recognition Benchmarking Competition. In: 2016 International Conference on Biometrics (ICB), pp 1–6
Das A, Pal U, Blumenstein M, Wang C, He Y, Zhu Y, Sun Z (2019) Sclera segmentation benchmarking competition in cross-resolution environment. In: 2019 International Conference on Biometrics (ICB), pp 1–7
Daugman J (1993) High confidence visual recognition of persons by a test of statistical independence. IEEE Trans Pattern Anal Mach Intell 15(11):1148–1161
Daugman J (2004) How iris recognition works. IEEE Trans Circuits Syst Video Technol 14(1):21–30
Daugman J (2006) Probing the uniqueness and randomness of iriscodes: results from 200 billion iris pair comparisons. Proc IEEE 94(11):1927–1935
Daugman J (2007) New methods in iris recognition. IEEE Trans Syst Man Cybern Part B 37(5):1167–1175
de Assis Angeloni M, de Freitas Pereira R, Pedrini H (2019) Age estimation from facial parts using compact multi-stream convolutional neural networks. In: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pp 3039–3045
Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L (2009) ImageNet: A large-scale hierarchical image database. In: IEEE conference on computer vision and pattern recognition. IEEE, Miami, FL, USA, pp 248–255
Dobeš M, Machala L, Tichavský P, Pospíšil J (2004) Human eye iris recognition using the mutual information. Optik Int J Light Electron Opt 115(9):399–404
Donida Labati R, Genovese A, Piuri V, Scotti F, Vishwakarma S (2020) I-social-db: a labeled database of images collected from websites and social media for iris recognition. Image and Vis Comput. https://doi.org/10.1016/j.imavis.2020.104058
Donida Labati R, Scotti F (2010) Noisy iris segmentation with boundary regularization and reflections removal. Image Vis Comput 28(2):270–277
Doyle JS, Bowyer KW (2015) Robust detection of textured contact lenses in iris recognition using BSIF. IEEE Access 3:1672–1683
Doyle JS, Bowyer KW, Flynn PJ (2013) Variation in accuracy of textured contact lens detection based on sensor and lens pattern. BTAS. IEEE, Arlington, VA, USA, pp 1–7
Doyle J, Bowyer K (2014) Notre dame image database for contact lens detection in iris recognition. http://www3.nd.edu/~cvrl/papers/CosCon2013README.pdf
Du Y, Bourlai T, Dawson J (2016) Automated classification of mislabeled near-infrared left and right iris images using convolutional neural networks. BTAS. IEEE, Niagara Falls, NY, USA, pp 1–6
Fenker SP, Bowyer KW (2012) Analysis of template aging in iris biometrics. In: IEEE Conference on Computer Vision and Pattern Recognition Workshops. IEEE, Providence, RI, USA, pp 45–51
Fierrez J et al (2010) BiosecurID: a multimodal biometric database. Pattern Anal Appl 13(2):235–246
Fierrez J, Ortega-Garcia J, Torre Toledano D, Gonzalez-Rodriguez J (2007) Biosec baseline corpus: a multimodal biometric database. Pattern Recogn 40(4):1389–1392
Galdi C, Dugelay J (2017) FIRE: Fast Iris REcognition on mobile phones by combining colour and texture features. Pattern Recogn Lett 91:44–51
Galdi C, Dugelay J (2016) Fusing iris colour and texture information for fast iris recognition on mobile devices. In: International Conference on Pattern Recognition (ICPR). IEEE, Cancun, Mexico, pp 160–164
Gangwar A, Joshi A (2016) DeepIrisNet: deep iris representation with applications in iris recognition and cross-sensor iris recognition. ICIP 57:2301–2305
Garbin SJ, Shen Y, Schuetz I, Cavin R, Hughes G, Talathi SS (2019) OpenEDS: Open Eye Dataset. CoRR abs/1905.03702:1–11. arXiv: 1905.03702
Gupta P, Behera S, Vatsa M, Singh R (2014) On Iris Spoofing Using Print Attack. In: International Conference on Pattern Recognition (ICPR). IEEE, Stockholm, Sweden, pp 1681–1686
Haindl M, Krupicka M (2015) Unsupervised detection of non-iris occlusions. Pattern Recogn Lett 57:60–65
Hake A, Patil P (2015) Iris image classification?: a survey. Int J Sci Res 4(1):2599–2603
He L, Li H, Liu F, Liu N, Sun Z, He Z (2016) Multi-patch convolution neural network for iris liveness detection. In: IEEE International Conference on Biometrics Theory, Applications and Systems (BTAS). IEEE, Niagara Falls, NY, USA, pp 1–7
Hollingsworth K, Peters T, Bowyer KW, Flynn PJ (2009) Iris recognition using signal-level fusion of frames from video. IEEE Trans Inf Forensics Secur 4(4):837–848
Hosseini MS, Araabi BN, Soltanian-Zadeh H (2010) Pigment melanin: pattern for iris recognition. IEEE Trans Instrum Meas 59(4):792–804 arXiv:0911.5462
IRISKING (2017) IrisKing. http://www.irisking.com/
ISO, Iec 19794–6, (2011) Information technology-biometric data interchange formats-part 6: Iris image data. Standard, International Organization for Standardization
ISO, Iec 19795–1, (2006) Biometric performance testing and reporting - part 1: Principles and framework. Standard, International Organization for Standardization
Jeong DS, Hwang JW, Kang BJ, Park KR, Won CS, Park D, Kim J (2010) A new iris segmentation method for non-ideal iris images. Image Vis Comput 28(2):254–260
Johnson PA, Lopez-Meyer P, Sazonova N, Hua F, Schuckers S (2010) Quality in face and iris research ensemble (Q-FIRE). In: IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS). IEEE, Washington, DC, USA, pp 1–6
Karakaya M (2016) A study of how gaze angle affects the performance of iris recognition. Pattern Recogn Lett 82:132–143. https://doi.org/10.1016/j.patrec.2015.11.001
Karakaya M (2018) Deep Learning Frameworks for Off-Angle Iris Recognition. In: 2018 IEEE 9th International Conference on Biometrics Theory, Applications and Systems (BTAS), pp 1–8. https://doi.org/10.1109/BTAS.2018.8698565
Karakaya M, Barstow D, Santos-Villalobos H, Thompson J (2013) Limbus impact on off-angle iris degradation. In: 2013 International Conference on Biometrics (ICB), pp 1–6
Kim D, Jung Y, Toh K, Son B, Kim J (2016) An empirical study on iris recognition in a mobile phone. Expert Syst Appl 54:328–339
Kohli N, Yadav D, Vatsa M, Singh R (2013) Revisiting iris recognition with color cosmetic contact lenses. In: International Conference on Biometrics (ICB), IEEE, Madrid, Spain, vol 1, pp 1–7
Kohli N, Yadav D, Vatsa M, Singh R, Noore A (2016) Detecting medley of iris spoofing attacks using DESIST. In: IEEE International Conference on Biometrics Theory, Applications and Systems (BTAS). IEEE, Niagara Falls, NY, USA, pp 1–6
Krishnan A, Almadan A, Rattani A (2021) Probing Fairness of Mobile Ocular Biometrics Methods Across Gender on VISOB 2.0 Dataset. In: International Conference on Pattern Recognition (ICPR). pp 229-243
Kuehlkamp A, Bowyer K (2019) Predicting Gender From Iris Texture May Be Harder Than It Seems. In: 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pp 904–912
Kumar A, Passi A (2010) Comparison and combination of iris matchers for reliable personal authentication. Pattern Recogn 43(3):1016–1026
Kurtuncu OM, Cerme GN, Karakaya M (2016) Comparison and evaluation of datasets for off-angle iris recognition. In: Carapezza EM (ed.), Sensors, and Command, Control, Communications, and Intelligence (C3I) Technologies for Homeland Security, Defense, and Law Enforcement Applications XV, International Society for Optics and Photonics, SPIE, vol 9825, pp 122–133
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436–444
Li P, Liu X, Xiao L, Song Q (2010) Robust and accurate iris segmentation in very noisy iris images. Image Vis Comput 28(2):246–253
Li P, Liu X, Zhao N (2012) Weighted co-occurrence phase histogram for iris recognition. Pattern Recogn Lett 33(8):1000–1005
Li P, Ma H (2012) Iris recognition in non-ideal imaging conditions. Pattern Recogn Lett 33(8):1012–1018
Liu N, Zhang M, Li H, Sun Z, Tan T (2016) DeepIris: Learning pairwise filter bank for heterogeneous iris verification. Pattern Recogn Lett 82:154–161
Lopes Silva P, Luz E, Moreira G, Moraes L, Menotti D (2019) Chimerical dataset creation protocol based on doddington zoo: a biometric application with face, eye, and ecg. Sensors 19(13):2968
Lucio DR, Laroca R, Severo E, Britto AS Jr, Menotti D (2018) Fully convolutional networks and generative adversarial networks applied to sclera segmentation. In: IEEE International Conference on Biometrics Theory, Applications and Systems (BTAS). IEEE, Redondo Beach, CA, USA, pp 1–7
Lucio DR, Laroca R, Zanlorensi LA, Moreira G, Menotti D (2019) Simultaneous iris and periocular region detection using coarse annotations. In: Conference on Graphics, Patterns and Images (SIBGRAPI). IEEE, Rio de Janeiro (Brazil), pp 178–185
Luengo-Oroz MA, Faure E, Angulo J (2010) Robust iris segmentation on uncalibrated noisy images using mathematical morphology. Image Vis Comput 28(2):278–284
Lumini A, Nanni L (2017) Overview of the combination of biometric matchers. Inf Fusion 33:71–85
Luz E, Moreira G, Junior LAZ, Menotti D (2018) Deep periocular representation aiming video surveillance. Pattern Recogn Lett 114:2–12
Maheshan MS, Harish BS, Nagadarshan N (2020) A convolution neural network engine for sclera recognition. Int J Interact Multimedia Artif Intell 6(1):78–83
Marra F, Poggi G, Sansone C, Verdoliva L (2018) A deep learning approach for iris sensor model identification. Pattern Recogn Lett 113:46–53
De Marsico M, Nappi M, Proença H (2017) Results from MICHE II: mobile iris challenge evaluation II. Pattern Recogn Lett 91:3–10
De Marsico M, Nappi M, Riccio D (2012) Noisy iris recognition integrated scheme. Pattern Recogn Lett 33(8):1006–1011
De Marsico M, Nappi M, Riccio D, Wechsler H (2015) Mobile Iris Challenge Evaluation (MICHE)-I, biometric iris dataset and protocols. Pattern Recogn Lett 57:17–23
De Marsico M, Petrosino A, Ricciardi S (2016) Iris recognition through machine learning techniques: a survey. Pattern Recogn Lett 82:106–115
Matey J, Naroditsky O, Hanna K, Kolczynski R, LoIacono D, Mangru S, Tinker M, Zappia T, Zhao W (2006) Iris on the move: acquisition of images for iris recognition in less constrained environments. Proc IEEE 94(11):1936–1947
Menotti D, Chiachia G, Pinto A, Schwartz WR, Pedrini H, Falcão AX, Rocha A (2015) Deep representations for iris, face, and fingerprint spoofing detection. IEEE Trans Inf Forens Security 10(4):864–879
NIST (2010a) Face and Ocular Challenge Series (FOCS). https://www.nist.gov/programs-projects/face-and-ocular-challenge-series-focs
NIST (2010b) Multiple biometric grand challenge (MBGC). https://www.nist.gov/programs-projects/multiple-biometric-grand-challenge-mbgc
Nalla PR, Kumar A (2017) Toward more accurate iris recognition using cross-spectral matching. IEEE Trans Image Process 26(1):208–221
Naqvi RA, Loh W (2019) Sclera-net: accurate sclera segmentation in various sensor images based on residual encoder and decoder network. IEEE Access 7:98208–98227. https://doi.org/10.1109/ACCESS.2019.2930593
Nguyen K, Fookes C, Jillela R, Sridharan S, Ross A (2017) Long range iris recognition: a survey. Pattern Recogn 72:123–143
Nguyen K, Fookes C, Ross A, Sridharan S (2018) Iris recognition with off-the-shelf CNN features: a deep learning perspective. IEEE Access 6:18848–18855
Nguyen H, Reddy N, Rattani A, Derakhshani R (2021) VISOB 2.0: The second international competition on mobile ocular biometric recognition. In: ICPR International Workshops and Challenge. Springer, Cham, pp 200-208
Nigam I, Vatsa M, Singh R (2015) Ocular biometrics: a survey of modalities and fusion approaches. Inf Fusion 26:1–35
Omelina L, Goga J, Pavlovicova J, Oravec M, Jansen B (2021) A survey of iris datasets. Image Vis Comput 108:104109. https://doi.org/10.1016/j.imavis.2021.104109
Ortega-Garcia J et al (2010) The multiscenario multienvironment biosecure multimodal database (BMDB). IEEE Trans Pattern Anal Mach Intell 32(6):1097–1111
Padole CN, Proença H (2012) Periocular recognition: analysis of performance degradation factors. In: IAPR international conference on biometrics (ICB). IEEE, New Delhi, India, pp 439–445
Park U, Jillela RR, Ross A, Jain AK (2011) Periocular biometrics in the visible spectrum. IEEE Trans Inf Forensics Secur 6(1):96–106
Park U, Ross A, Jain AK (2009) Periocular biometrics in the visible spectrum: a feasibility study. In: IEEE international conference on biometrics: theory, applications, and systems (BTAS). IEEE, Washington, DC, USA, pp 1–6
Parkhi OM, Vedaldi A, Zisserman A (2015) Deep face recognition. In: British machine vision conference (BMVC). BMVA Press, Swansea, UK, pp 1–12
Phillips PJ, Flynn PJ, Beveridge JR, Scruggs WT, O’Toole AJ, Bolme D, Bowyer KW, Draper BA, Givens GH, Lui YM, Sahibzada H, Scallan JA, Weimer S (2009) Overview of the multiple biometrics grand challenge. Advances in Biometrics. Springer, Berlin Heidelberg, Berlin, Heidelberg, pp 705–714
Phillips PJ, Scruggs WT, O’Toole AJ, Flynn PJ, Bowyer KW, Schott CL, Sharpe M (2010) FRVT 2006 and ICE 2006 large-scale experimental results. IEEE Trans Pattern Anal Mach Intell 32(5):831–846
Phillips P, Flynn P, Scruggs T, Bowyer KW, Chang J, Hoffman K, Marques J, Min J, Worek W (2005) Overview of the face recognition grand challenge. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, San Diego, CA, USA, vol 1, pp 947–954
Phillips PJ, Bowyer KW, Flynn PJ, Liu X, Scruggs WT (2008) The iris challenge evaluation 2005. In: IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS). IEEE, Arlington, VA, USA, pp 1–8
Proença H, Alexandre LA (2012) Toward covert iris biometric recognition: experimental results from the NICE contests. IEEE Trans Inf Forensics Secur 7(2):798–808
Proença H, Filipe S, Santos R, Oliveira J, Alexandre LA (2010) The UBIRISv.2: a database of visible wavelength iris images captured on-the-move and at-a-distance. IEEE Trans Pattern Anal Mach Intell 32(8):1529–1535
Proença H, Neves JC (2018) Deep-PRWIS: periocular recognition without the iris and sclera using deep learning frameworks. IEEE Trans Inf Forensics Secur 13(4):888–896
Proença H, Neves JC (2019) A reminiscence of mastermind: Iris/periocular biometrics by in-set CNN iterative analysis. IEEE Trans Inf Forensics Secur 14(7):1702–1712
Proença H, Alexandre LA (2005) UBIRIS: a noisy iris image database. In: Image Analysis and Processing (ICIAP). Springer, Berlin Heidelberg, Berlin, Heidelberg, pp 970–977
Proença H, Neves JC (2017) IRINA: iris recognition (even) in inaccurately segmented data. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Honolulu, HI, USA, vol 1, pp 6747–6756
Proença H, Neves JC (2019) Segmentation-less and non-holistic deep-learning frameworks for iris recognition. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, California, USA, pp 2296–2305
Ross A, Jain A (2003) Information fusion in biometrics. Pattern Recogn 24(13):2115–2125
Raghavendra R, Busch C (2016) Learning deeply coupled autoencoders for smartphone based robust periocular verification. In: IEEE International Conference on Image Processing (ICIP), IEEE, Phoenix, AZ, USA, vol 1, pp 325–329
Raghavendra R, Raja KB, Vemuri VK, Kumari S, Gacon P, Krichen E, Busch C (2016) Influence of cataract surgery on iris recognition: a preliminary study. In: 2016 International Conference on Biometrics (ICB), pp 1–8
Raja KB, Raghavendra R, Vemuri VK, Busch C (2015) Smartphone based visible iris recognition using deep sparse filtering. Pattern Recogn Lett 57:33–42
Raja KB, Raghavendra R, Venkatesh S, Busch C (2017) Multi-patch deep sparse histograms for iris recognition in visible spectrum using collaborative subspace for robust verification. Pattern Recogn Lett 91:27–36
Raja KB, Raghavendra R, Busch C (2016) Collaborative representation of deep sparse filtered features for robust verification of smartphone periocular images. In: IEEE International Conference on Image Processing, IEEE, Phoenix, AZ, USA, vol 1, pp 330–334
Rattani A, Derakhshani R (2017) Ocular biometrics in the visible spectrum: a survey. Image Vis Comput 59:1–16
Rattani A, Reddy N, Derakhshani R (2018) Convolutional neural networks for gender prediction from smartphone-based ocular images. IET Biometrics 7(5):423–430. https://doi.org/10.1049/iet-bmt.2017.0171
Rattani A, Derakhshani R, Saripalle SK, Gottemukkula V (2016) ICIP 2016 competition on mobile ocular biometric recognition. In: IEEE International Conference on Image Processing (ICIP) (2016) Challenge session on mobile ocular biometric recognition. IEEE, Phoenix, AZ, USA, pp 320–324
Rattani A, Reddy N, Derakhshani R (2017a) Convolutional neural network for age classification from smart-phone based ocular images. In: 2017 IEEE International Joint Conference on Biometrics (IJCB), pp 756–761
Rattani A, Reddy N, Derakhshani R (2017b) Gender prediction from mobile ocular images: A feasibility study. In: 2017 IEEE International Symposium on Technologies for Homeland Security (HST), pp 1–6
Reddy N, Rattani A, Derakhshani R (2018) Ocularnet: deep patch-based ocular biometric recognition. In: 2018 IEEE International Symposium on Technologies for Homeland Security (HST), pp 1–6
Ren M, Wang Y, Sun Z, Tan T (2020) Dynamic graph representation for occlusion handling in biometrics. Proc AAAI Conf Artif Intell 34(07):11940–11947
Ren M, Wang C, Wang Y, Sun Z, Tan T (2019) Alignment free and distortion robust iris recognition. In: 2019 International Conference on Biometrics (ICB), pp 1–7
Ross A (2010) Iris recognition: the path forward. Computer 43(2):30–35
Rot P, Vitek M, Grm K, Emeršič Ž, Peer P, Štruc V (2020) Deep sclera segmentation and recognition. Springer, Cham, pp 395–432
Ruiz-Albacete V, Tome-Gonzalez P, Alonso-Fernandez F, Galbally J, Fierrez J, Ortega-Garcia J (2008) Direct attacks using fake images in iris verification. In: European Workshop on Biometrics and Identity Management. Springer, Berlin Heidelberg, Berlin, Heidelberg, pp 181–190
Ríos-Sánchez B, Arriaga-Gómez MF, Guerra-Casanova J, de Santos-Sierra D, de Mendizábal-Vázquez I, Bailador G, Sánchez-Ávila C (2016) gb2s\(\mu \)MOD: a MUltiMODal biometric video database using visible and IR light. Inf Fusion 32:64–79
Sankowski W, Grabowski K, Napieralska M, Zubert M, Napieralski A (2010) Reliable algorithm for iris segmentation in eye image. Image Vis Comput 28(2):231–237
Santos G, Grancho E, Bernardo MV, Fiadeiro PT (2015) Fusing iris and periocular information for cross-sensor recognition. Pattern Recogn Lett 57:52–59
Santos G, Hoyle E (2012) A fusion approach to unconstrained iris recognition. Pattern Recogn Lett 33(8):984–990
Sequeira A, Chen L, Wild P, Ferryman J, Alonso-Fernandez F, Raja KB, Raghavendra R, Busch C, Bigun J (2016) Cross-Eyed-Cross-Spectral Iris/Periocular Recognition Database and Competition. In: 2016 International Conference of the Biometrics Special Interest Group (BIOSIG), IEEE, Darmstadt, Germany, vol 260, pp 1–5
Sequeira AF, Monteiro JC, Rebelo A, Oliveira HP (2014a) MobBIO: a multimodal database captured with a portable handheld device. In: International Conference on Computer Vision Theory and Applications (VISAPP), IEEE, Lisbon, Portugal, vol 3, pp 133–139
Sequeira AF, Murari J, Cardoso JS (2014b) Iris liveness detection methods in mobile applications. In: International Conference on Compute Vision Theory and Applications (VISAPP), IEEE, Lisbon, Portugal, vol 3, pp 22–33
Sequeira AF, Chen L, Ferryman J, Wild P, Alonso-Fernandez F, Bigun J, Raja KB, Raghavendra R, Busch C, de Freitas Pereira T, Marcel S, Behera SS, Gour M, Kanhangad V (2017) Cross-eyed 2017: Cross-spectral iris/periocular recognition competition. In: IEEE International Joint Conference on Biometrics. IEEE, Denver, CO, USA, pp 725–732
Severo E, Laroca R, Bezerra CS, Zanlorensi LA, Weingaertner D, Moreira G, Menotti D (2018) A benchmark for iris location and a deep learning detector evaluation. In: International Joint Conference on Neural Networks (IJCNN). IEEE, Rio de Janeiro, Brazil, pp 1–7
Shah S, Ross A (2006) Generating synthetic irises by feature agglomeration. In: International Conference on Image Processing (ICIP). IEEE, Atlanta, GA, USA, pp 317–320
Sharma A, Verma S, Vatsa M, Singh R, (2014) On cross spectral periocular recognition. In: IEEE International Conference on Image Processing (ICIP). IEEE, Paris, France, pp 5007–5011
Shin KY, Nam GP, Jeong DS, Cho DH, Kang BJ, Park KR, Kim J (2012) New iris recognition method for noisy iris images. Pattern Recogn Lett 33(8):991–999
Siena S, Boddeti VN, Vijaya Kumar BVK (2012) Coupled marginal fisher analysis for low-resolution face recognition. In: European conference on computer vision (ECCV). Springer, Berlin Heidelberg, Berlin, Heidelberg, pp 240–249
Silva P, Luz E, Baeta R, Pedrini H, Falcao AX, Menotti D, (2015) An approach to iris contact lens detection based on deep image representations. In: 28th SIBGRAPI Conference on Graphics Patterns and Images, IEEE, Salvador, Brazil, pp 157–164
Silva PH, Luz E, Zanlorensi LA, Menotti D, Moreira G, (2018) Multimodal feature level fusion based on particle swarm optimization with deep transfer learning. In: IEEE Congress on Evolutionary Computation (CEC). IEEE, Rio de Janeiro, Brazil, pp 1–8
Smereka JM, Boddeti VN, Vijaya Kumar BVK (2015) Probabilistic deformation models for challenging periocular image verification. IEEE Trans Inf Forensics Secur 10(9):1875–1890
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, Boston, MA, USA, pp 1–9
Szewczyk R, Grabowski K, Napieralska M, Sankowski W, Zubert M, Napieralski A (2012) A reliable iris recognition algorithm based on reverse biorthogonal wavelet transform. Pattern Recogn Lett 33(8):1019–1026
Tan T, He Z, Sun Z (2010) Efficient and robust segmentation of noisy iris images for non-cooperative iris recognition. Image Vis Comput 28(2):223–230
Tan CW, Kumar A (2013) Towards online iris and periocular recognition under relaxed imaging constraints. IEEE Trans Image Process 22(10):3751–3765
Tan T, Zhang X, Sun Z, Zhang H (2012) Noisy iris image matching by using multiple cues. Pattern Recogn Lett 33(8):970–977
Tapia J, Aravena C (2017) Gender classification from nir iris images using deep learning. Springer, Cham, pp 219–239
Tapia JE, Perez CA, Bowyer KW (2016) Gender classification from the same iris code used for recognition. IEEE Trans Inf Forensics Secur 11(8):1760–1770
Trokielewicz M, Czajka A, Maciejewicz P (2016) Post-mortem human iris recognition. In: 2016 International Conference on Biometrics (ICB), pp 1–6
University of Notre Dame (2013) Nd-crosssensor-iris-2013. https://cvrl.nd.edu/projects/data/#nd-crosssensor-iris-2013-data-set
Uzair M, Mahmood A, Mian A, McDonald C (2015) Periocular region-based person identification in the visible, infrared and hyperspectral imagery. Neurocomputing 149:854–867
Viola P, Jones MJ (2004) Robust real-time face detection. Int J Comput Vision 57(2):137–154
Vitek M, Rot P, Štruc V, Peer P (2020a) A comprehensive investigation into sclera biometrics: a novel dataset and performance study. Neural Comput Appl 32:17941–17955
Vitek M, et al. (2020b) Ssbc 2020: Sclera segmentation benchmarking competition in the mobile environment. In: 2020 International Joint Conference on Biometrics (IJCB), pp 1–10
Wang K, Kumar A (2019a) Cross-spectral iris recognition using CNN and supervised discrete hashing. Pattern Recogn 86:85–98
Wang K, Kumar A (2019b) Toward more accurate iris recognition using dilated residual features. IEEE Trans Inf Forensics Secur 14(12):3233–3245. https://doi.org/10.1109/TIFS.2019.2913234
Wang Q, Zhang X, Li M, Dong X, Zhou Q, Yin Y (2012) Adaboost and multi-orientation 2D Gabor-based noisy iris recognition. Pattern Recogn Lett 33(8):978–983
Wang C, He Y, Liu Y, He Z, He R, Sun Z (2019) Sclerasegnet: an improved u-net model with attention for accurate sclera segmentation. In: International Conference on Biometrics (ICB), pp 1–8
Wei J, Wang Y, Wu X, He Z, He R, Sun Z (2019) Cross-sensor iris recognition using adversarial strategy and sensor-specific information. In: 10th IEEE International Conference on Biometrics Theory, Applications and Systems, BTAS 2019, Tampa, FL, USA, September 23-26, 2019, IEEE, pp 1–8
Wildes RP (1997) Iris recognition: an emerging biometric technology. Proc IEEE 85(9):1348–1363
Woodard DL, Pundlik SJ, Lyle JR, Miller PE (2010) Periocular region appearance cues for biometric identification. In: IEEE Conference on Computer Vision and Pattern Recognition: Workshops (CVPRW). IEEE, San Francisco, CA, USA, pp 162–169
Yadav D, Kohli N, Doyle JS, Singh R, Vatsa M, Bowyer KW (2014) Unraveling the effect of textured contact lenses on iris recognition. IEEE Trans Inf Forensics Secur 9(5):851–862
Yin Y, Liu L, Sun X (2011) Sdumla-hmt: a multimodal biometric database. In: Sun Z, Lai J, Chen X, Tan T (eds) Biometric Recogn. Springer, Berlin, pp 260–268
Zanlorensi LA, Lucio DR, Britto AS Jr, Proença H, Menotti D (2019) Deep representations for cross-spectral ocular biometrics. IET Biometrics. https://doi.org/10.1049/iet-bmt.2019.0116
Zanlorensi LA, Luz E, Laroca R, Britto AS Jr, Oliveira LS, Menotti D (2018) The impact of preprocessing on deep representations for iris recognition on unconstrained environments. In: Conference on Graphics, Patterns and Images (SIBGRAPI). IEEE, Parana, Brazil, pp 289–296
Zanlorensi LA, Laroca R, Lucio DR, Santos LR, Britto Jr AS, Menotti D (2020a) UFPR-Periocular: a periocular dataset collected by mobile devices in unconstrained scenarios. arXiv preprint arXiv:2011.12427:1–12
Zanlorensi LA, Proença H, Menotti D (2020b) Unconstrained periocular recognition: using generative deep learning frameworks for attribute normalization. In: 2020 IEEE International Conference on Image Processing (ICIP), pp 1361–1365
Zhang Q, Li H, Sun Z, Tan T (2018) Deep feature fusion for iris and periocular biometrics on mobile devices. IEEE Trans Inf Forensics Secur 13(11):2897–2912
Zhang M, Zhang Q, Sun Z, Zhou S, Ahmed NU (2016) The BTAS*Competition on Mobile Iris Recognition. In: IEEE International Conference on Biometrics Theory, Applications and Systems (BTAS). IEEE, Nova York (USA), pp 1–7
Zhang Q, Li H, Zhang M, He Z, Sun Z, Tan T (2015) Fusion of face and iris biometrics on mobile devices using near-infrared images. In: Chinese Conference on Biometric Becognition (CCBR). Springer, Cham, pp 569–578
Zhang Q, Li H, Sun Z, He Z, Tan T (2016) Exploring complementary features for iris recognition on mobile devices. In: International Conference on Biometrics (ICB). IEEE, Halmstad, Sweden, pp 1–8
Zhao Z, Kumar A (2018) Improving periocular recognition by explicit attention to critical regions in deep neural network. IEEE Trans Inf Forensics Secur 13(12):2937–2952
Zhao T, Liu Y, Huo G, Zhu X (2019) A deep learning iris recognition method based on capsule network architecture. IEEE Access 7:49691–49701
Zuo J, Schmid NA, Chen X (2007) On generation and analysis of synthetic iris images. IEEE Trans Inf Forensics Secur 2(1):77–90
Acknowledgements
This work was supported by Grants from the National Council for Scientific and Technological Development (CNPq) (Grant Numbers 428333/2016-8, 313423/2017-2 and 306684/2018-2), and the Coordination for the Improvement of Higher Education Personnel (CAPES) (Social Demand Program), both funding agencies from Brazil.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zanlorensi, L.A., Laroca, R., Luz, E. et al. Ocular recognition databases and competitions: a survey. Artif Intell Rev 55, 129–180 (2022). https://doi.org/10.1007/s10462-021-10028-w
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10462-021-10028-w