
Abstract
In this paper, we present a very fast Monte Carlo scheme for additive processes: the computational time is of the same order of magnitude of standard algorithms for simulating Brownian motions. We analyze in detail numerical error sources and propose a technique that reduces the two major sources of error. We also compare our results with a benchmark method: the jump simulation with Gaussian approximation. We show an application to additive normal tempered stable processes, a class of additive processes that calibrates “exactly” the implied volatility surface. Numerical results are relevant. This fast algorithm is also an accurate tool for pricing path-dependent discretely-monitoring options with errors of one basis point or below.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we introduce a fast Monte Carlo simulation technique for additive processes. In option pricing, Monte Carlo methods are attractive because they do not require significant modifications when the payoff structure of the derivative changes. We describe an efficient and accurate algorithm for Monte Carlo simulations of the process increments and we compute the prices of a class of discretely-monitoring path-dependent options. A process \(\{X(t)\}_{t\ge 0}\) is said to be an additive process, if it presents independent (but not-stationary) increments and satisfies \(X(0) = 0\) a.s.; stationarity is the main difference with Lévy processes (see e.g., Sato 1999).
Additive processes are becoming the new frontier in equity derivatives for their ability, on the one hand, to reproduce accurately market data, and on the other hand, to keep the process rather elementary (see e.g., Madan and Wang 2020; Carr and Torricelli 2021; Azzone and Baviera 2022a). In this paper, we show another advantage of additive processes: simulation schemes are as fast as standard (fast) algorithms for simulating the Black-Scholes model.
Up to our knowledge, the unique Monte Carlo (MC) scheme developed for a specific class of additive processes, Sato processes, has been introduced by Eberlein and Madan (2009). They generalize to this class of additive processes, a well-known jump simulation technique developed for Lévy processes, that can be found in many excellent textbooks (see e.g., Cont and Tankov 2003; Asmussen and Glynn 2007). It entails truncating small jumps below a certain threshold and then simulating the finite number of independent jumps; finally, the Asmussen and Rosiński (2001) Gaussian approximation (hereinafter GA) can be applied to substitute small jumps with a diffusive term: this has become a benchmark technique to compare numerical results.
In this paper, we propose a new MC technique for additive processes based on a numerical inversion of the cumulative distribution function (CDF). Monte Carlo simulation of additive processes is not straightforward because, in general, the CDF of process increments is not known explicitly. However, analytic expressions exist for the characteristic functions thanks to the celebrated Lévy-Khintchine formula (Sato 1999). Since the seminal paper of Bohman (1970), general methods have been developed for sampling from Fourier transforms and even some specific methods for some distributions (e.g. stable distributions) that do not require numerical inversion (Samorodnitsky and Taqqu 1994, Sect.1.7, p.41).
In the financial literature, these techniques have been developed specifically in the Lévy case, where it is possible to leverage on the stationary increments (see e.g., Glasserman and Liu 2010; Chen et al. 2012; Ballotta and Kyriakou 2014). These techniques are reliable and efficient: they build upon the characteristic function numerical inversion to obtain an estimation of the CDF. Specifically, we use the fast Fourier transform (FFT) method for the numerical inversion as proposed by Lee (2004) and then applied to MC option pricing in the studies of Chen et al. (2012) and Ballotta and Kyriakou (2014). Unfortunately, it is not trivial to extend these numerical methods to additive processes. Relative to this literature, our contribution lies in (i) extending to non-stationary processes these techniques and (ii) analyzing the three sources of error that arise in estimating derivative price expectations and showing how to improve the two largest ones.
Three are the main contributions of this paper. First, we propose a new Monte Carlo simulation technique for additive processes based on FFT. Second, we improve the two main sources of numerical error in existing techniques to accelerate convergence, using both a property of the Lewis formula in the complex plane and a spline method for CDF numerical inversion. Finally, we point out that the proposed technique is accurate and fast: (i) we compare it with traditional GA simulations showing that it is at least one and a half orders of magnitude faster whatever time horizon we consider and (ii) we observe that, when pricing some discretely-monitoring path-dependent options, the computing time has the same order of magnitude as standard algorithms for Brownian motions.
The rest of the paper is organized as follows. In Sect. 2, we overview the method and recall both Lewis (2001) formula for CDF and the error sources in the numerical approximation: we discuss the optimal selection of the integration path. In Sect. 3, we describe the proposed simulation method and present the other main error source in MC option pricing: the interpolation method in numerical inversion. We also discuss how to generalize the GA method for additives in an efficient way. Section 4 presents numerical results for a large class of pure-jump additive processes in the case of both European options (where analytic pricing methods are available), and some discretely-monitoring path-dependent options. Section 5 concludes. The main characteristics of the additive process that we use for the numerical analysis can be found in Appendix 1, a brief description of the algorithm in Appendix 2 and a comparison of simulated option prices with and without spline interpolation in Appendix 3.
2 Overview of the MC method for additive process
Pure jump asset pricing models based on additive processes have enjoyed remarkable popularity in recent years, at least for two main reasons. First, they allow a highly tractable closed-form approach with simple analytic expression for European options following Lewis (2001). This formula is computable as fast as the standard Black-Scholes one. Second, additive processes provide an adequate calibration to the implied volatility surface of equity derivatives, as well as they reproduce stylized facts as the time scaling of skew in volatility smile (see e.g., Azzone and Baviera 2022b).
In this section, we describe a third reason in favor of these models: they allow a simple, accurate, and fast numerical scheme for path-dependent option valuation. We extend to additive processes the preceding literature on Lévy processes’ simulation techniques and we discover that, thanks to this Monte Carlo scheme, it is possible to price efficiently exotic derivatives as Asian contracts or barrier options with discretely-monitored barriers, because we can focus only on monitoring dates.
The simulation of a discrete sample path of an additive process reduces to simulating from the distribution of the process increment between time s and time \(t>s\). Lévy process simulation is based on time-homogeneity of the jump process: the characteristic function of an increment is the same as the characteristic function of the process itself at time \(t=1\), re-scaled by the time interval \((t-s)\) of interest.
In this paper, we extend the preceding analysis to Lévy processes by i) presenting an explicit method for additive processes from their characteristic function and ii) analyzing the explicit bound for the total estimation bias. In the Lévy case, thanks to process time-homogeneity, the properties of the process characteristic function are immediately extended to its increments. For example, the characteristic function (also of increments) is analytic in a horizontal strip and the purely imaginary points on the boundary of the strip of regularity are singular points (cf. Lukacs 1972, th.3.1, p.12). This identification of process characteristic function and increments’ characteristic function is not anymore valid for additive processes. However, the present paper shows that the analyticity strip depends on time and that it is possible to build an efficient numerical scheme for additive processes. Let us point out that it is not trivial to extend to the non-stationary case of additive processes other advanced methods developed for simulating Lévy processes (see e.g., Kuznetsov et al. 2011; Ferreiro-Castilla and Van Schaik 2015; Boyarchenko and Levendorskiĭ 2019; Kudryavtsev 2019) or pricing path-dependent derivatives (see e.g., Jackson et al. 2008; Phelan et al. 2019).
Our method is based on three key observations. First, computing a CDF P(x) corresponds to pricing a digital option: this can be done efficiently in the Fourier space. This step can be crucial, as already highlighted by Ballotta and Kyriakou (2014) in the Lévy case, the standard Fourier formula with Hilbert transform presents some numerical instabilities due to the presence of a pole in the origin. They propose a regularization that leads to an additional numerical error. We propose a different approach that is based on the Lewis (2001) formula which presents two significant advantages. On the one hand, this technique is exact (thus, no numerical error is associated with it), and, on the other hand, it allows selecting the optimal integration path that reduces the numerical error in the discretization of the CDF.
Second, the Lewis (2001) formula for the CDF can be viewed as an inverse Fourier transform method that can be approximated with a fast Fourier transform (FFT) technique: Lewis-FFT computes multiple values of the CDF simultaneously in a very efficient way.
Finally, knowing the CDF approximation \({\hat{P}}\), we can sample from this distribution by inverting the CDF, i.e. by setting \(X ={\hat{P}}^{-1} (U)\), with U a uniform r.v. in [0, 1]. Thus, simulating a r.v. via a numerical CDF (i.e. coupling the discrete Fourier transform with a Monte Carlo simulation), requires a numerical inversion that is realized via an interpolation method. Following Glasserman and Liu (2010), due to its simplicity, a linear interpolation of the CDF is chosen in the existing financial literature (see e.g., Chen et al. 2012; Feng and Lin 2013). We propose the spline as interpolation rule because the computational cost is similar, while the bias associated with the two interpolation rules is significantly different: the upper bound of the bias can be estimated for a given grid step \(\gamma\), and, as we discuss in Sect. 3, it should be at least \(\gamma ^2\) smaller for the spline interpolation. In extensive numerical experiments we observe that, on the one hand, the error decreases even faster as a power of \(\gamma\) than predicted by the upper bound, thanks to the additional properties of the interpolated functions, and on the other hand, it becomes negligible for the grids that are selected in practice.
Due to these three main ingredients (Lewis formula, FFT and Spline interpolation) that play a crucial role in the proposed Monte Carlo simulation technique, we call the method Lewis-FFT-S. The algorithm is reported in Appendix 2.
The Lewis-FFT-S method extends the Eberlein and Madan (2009) technique to any additive process of financial interest, being significantly faster: we show that the proposed Monte Carlo is much faster than any jump-simulation method even considering the Asmussen and Rosiński (2001) Gaussian approximation. Analyzing in detail the numerical errors related to the methodology, we design an algorithm that increases both accuracy and computational efficiency. To the best of our knowledge, the proposed scheme is the first application in financial engineering of the MC simulation based on Lewis formula and FFT, when the underlying is governed by an additive process.
In the next subsection, we also recall explicit and computable expressions for the error estimates.
2.1 Lewis CDF via FFT
The proposed MC method simulates from the characteristic function of the additive increments. Due to the Lévy-Khintchine formula, the characteristic function
of an additive process \(\{f_t\}_{t\geq0}\) admits a closed-form expression. Furthermore, as already mentioned, according to (Lukacs (1972), th.3.1, p.12), the process characteristic function is analytic in a horizontal strip of the complex plane. Similarly to Lee (2004), we define \(p^-_t\ge 0\) and \(-(p^+_t +1) \le 0\), s.t. the characteristic function \(\phi _t\) is analytic when \(\Im (u) \in (-(p^+_t + 1), p^-_t)\).
We observe that for Lévy processes, the increment \(f_{t} - f_{s}\) has the same distribution as \(f_{\Delta }\), where \(\Delta =t-s\): the same property does not hold for additive processes, due to the time inhomogeneity. For an additive process, the characteristic function of an increment \(f_t - f_s\) between times s and \(t>s\) is
due to the independent increment property of additive processes.
Moreover, for all additive processes, a relevant property holds on the analytic strip of the characteristic function \(\phi _t\).
Theorem 2.1
\(p_t^+\) and \(p_t^-\) are non increasing for all additive processes.
Proof
From theorem 9.8 of (Sato 1999, p.52), we have that for any additive process the Lévy measure \(\nu _t(x)\) is a positive and non decreasing function of t for any x. Thanks to the Lévy Khintchine representation the characteristic exponent of an additive process, given its triplet \((\gamma _t,\,A_t,\,\nu _t)\), is (see e.g., Sato 1999, th.8.1 p.37)
where \(\gamma _t\) is the drift term and \(A_t\) the diffusion term. (Lukacs 1972, th.3.1, p.12) has proven that the characteristic function is analytical in an horizontal strip that includes the origin and is delimited by two points (if the strip is not the whole plane) on the imaginary axis. Hence, we evaluate the characteristic function in \(u=-i\,a\), with \(a\in {\mathbb {R}}\), and identify \(p_t^+\) and \(p_t^-\) as the extrema of the interval of a s.t. (1) is well defined, i.e. \(a\in (-p_t^-,p_t^++1)\). The integral \(\int _{\mathbb {R}}dx\, (e^{ax}-1-I_{|x|<1}\,a\,x)\nu _t(x)\) is the unique term that can diverge in (1).
First, we recall that \(\nu _t(x)\) is bounded for \(x\ne 0\) and \(\int _{{\mathbb {R}}}dx\,\min (|x|^2,1)\nu _t(x)<\infty\) (cf. Sato 1999, th.8.1 p.37). Then, for any \(Q>1\) the quantities i) \(\int _{-Q}^Qdx\, (e^{ax}-1-I_{|x|<1}\,a\,x)\nu _t(x)\), ii) \(\int _{-\infty }^{-Q} dx\,\nu _t(x)\) and iii) \(\int _{Q}^{\infty }dx\, \nu _t(x)\) are finite. Thus, we can recognize \(p_t^+\) and \(p_t^-\) from the set of a for which \(\int _{Q}^\infty dx\, e^{ax}\nu _t(x)\) and \(\int _{-\infty }^{-Q} dx\, e^{ax}\nu _t(x)\) converge.
Let us first prove the proposition for \(p_t^+\). Notice that \(p_t^+\) is unique because \(\int _{Q}^\infty dx\, e^{ax}\nu _t(x)\) is non decreasing in a and that \(p_t^+\ge -1\) because the origin is included in the analytical strip. Fix \(t>0\), there are three possible cases
-
1.
If \(\int _{Q}^\infty dx\, e^{ax}\nu _t(x)=\infty\) for any \(a>0\), then \(p_t^+=-1\);
-
2.
If \(\int _{Q}^\infty dx\,e^{ax}\nu _t(x)<\infty\) for any \(a>0\), then \(p_t^+=\infty\);
-
3.
If it exists \(\lambda _t^+\) s.t. \(\int _{Q}^\infty \, e^{ax}\nu _t(x)dx<\infty\) for any \(0<a<\lambda _t^+\) and \(\int _{Q}^\infty dx\, e^{ax}\nu _t(x)=\infty\) for any \(a>\lambda _t^+\), then \(p_t^+=\lambda _t^+-1\).
For any \(s<t\), we observe that \(\int _{Q}^\infty dx\, e^{ax}\nu _s(x) \le \int _{Q}^\infty dx \,e^{ax}\nu _t(x)\), thanks to the monotonicity of \(\nu _t(x)\) in t: let us consider the implications on the monotonicity of \(p_t^+\) in the three cases.
In case 1, \(p_t^+\le p_s^+\) because \(p_s^+\ge -1\) as emphasized above. In case 2, \(\int _{Q}^\infty dx\, e^{ax}\nu _s(x)\le \int _{Q}^\infty dx\, e^{ax}\nu _t(x)<\infty\) and then \(p_s^+=\infty\). In case 3, also \(\int _{Q}^\infty dx \,e^{ax}\nu _s(x)<\infty\) for any \(0<a<\lambda _t^+\) and then \(\lambda _t^+\le \lambda _s^+\), i.e. \(p_t^+\le p_s^+\). This proves the proposition for \(p_t^+\).
By repeating the same considerations for the integral \(\int _{-\infty }^{-Q}dx\, e^{ax}\nu _t(x)\) we can show that also \(p_t^-\) is non increasing in t \(\square\)
Thanks to the monotonicity of \(p^+_t\) and \(p^-_t\), we can easily identify the strip of regularity for any increment \(f_t - f_s\): its characteristic function \(\phi _{s,t}\) is analytic when \(\Im (u) \in (-(p^+_t + 1), p^-_t)\) for any \(s\in [0,t)\).
Lewis (2001) obtains the CDF, shifting the integration path within the characteristic function horizontal analyticity strip. The shift is \(- i \; a\) with a a real constant s.t. \(a \in (-p^-_t, p^+_t +1)\). Lewis deduces this formula using the properties of contour integrals in the complex plane.
The CDF P(x) of an additive process increment is (see e.g., Lee 2004, th.5.1)
where
The case with no shift (\(a=0\)) is the Hilbert transform: it has been considered in several studies in the financial literature on MC pricing (see e.g., Chen et al. 2012; Ballotta and Kyriakou 2014). In the Hilbert transform case, the singularity in zero in the integration should be taken into account as a Cauchy principal value; as already emphasized by Ballotta and Kyriakou (2014), the method could be not robust enough for applications in the financial industry: they have suggested a regularization technique that introduces an additional error source, while the Lewis method we consider here is exact (cf. also Fig. 2 for a comparison between the CDF error with Lewis formula and the Hilbert trasform method).
In the following, we focus on \(a > 0\): this is a default choice in the equity case because \(p_t^+\ge p_t^-\) is consistent with the negative equity skew (see e.g., Lee 2004, Section 7.4, p.26). We derive an approximation formula and its error bounds (in Sects. 2.2 and 3.1). Similar results hold for \(a<0\).
We approximate the Fourier transform with a discrete Fourier transform \({\hat{P}}(x)\)
where h is the step size in the Fourier domain and N is the number of points in the grid.
To implement the MC method, we need the CDF function for a large number of values in a regular grid with step size \(\gamma\). An algorithm that is computationally efficient is the fast Fourier transform (see Lee 2004, for a detailed analysis of the method in derivative pricing): it involves Toeplitz matrix–vector multiplication (see e.g., Press et al. 1992, ch.12) and relies on an additional requirement for N, whose simplest choice is \(N = 2^M\) with \(M\in {\mathbb {N}}\); hereinafter, we consider an N within this set. The main advantage of the method is that the computational complexity of the FFT is \(O(N \log _2 N)\) when computing one time-increment. Moreover, with an FFT, it holds the relationship
i.e., for a given number N of grid points, the step size in the Fourier domain h fixes the step size \(\gamma\).Footnote 1
2.2 CDF error sources
The numerical Fourier inversion is subject i) to a discretization error, because the integrand is evaluated only at the grid points, and ii) to a range error, because we approximate with a finite sum.
Assumption. \(\forall \, t>s\ge 0\) there exists \(B>0\), \(b>0\) and \(\omega >0\) such that, for sufficiently large |u|, the following bound for the absolute value of the characteristic function holds
Leveraging on the Assumption, we can estimate the explicit bound for the bias in terms of the step size h and the number of grid points N, as shown in the next proposition. The result in the next proposition improves the known bounds for numerical errors when computing the CDF (2), via a discrete Fourier transform, and indicates an optimal integration path that minimizes this error bound.
Proposition 2.2
If the Assumption holds, then
-
1.
The numerical error \(|P(x) - {\hat{P}}(x)|\) for the CDF is bounded by
$$\begin{aligned}&{{{\mathcal {E}}}}^{CDF}_{h, M} (x) = \frac{Be^{- x \, (p^+_t+1)/2 }}{\omega \pi } \Gamma \left[ 0,b \left( { N }\,h \right) ^\omega \right] \nonumber \\&\quad +\frac{e^{-\pi (p^+_t+1) /h}+e^{-\pi (p^+_t+1) /h- (p^+_t+1)\,x} \phi _{s,t}(-i \, (p^+_t+1))}{1-e^{-2\pi (p^+_t +1)/h}}\;\;, \end{aligned}$$(4)where \(\Gamma (z,u)\) is the upper incomplete gamma function and
$$\begin{aligned} \Gamma \left[ 0,b \left( { N }\,h \right) ^\omega \right] =O\left( ({ N }\,h)^{-\omega }e^{-b \, ({ N }\,h)^{\omega }}\right) \;\;; \end{aligned}$$ -
2.
The (optimal) bound holds selecting the shift a in (2) equal to \((p^+_t+1)/2\).
Proof
We bound the range and the discretization error separately.
First, we bound the CDF range error, i.e. the error we introduce considering the integral (2) in the range (0, Nh). Fix h, it exists \(N\in {\mathbb {N}}\) s.t.
The first inequality is due to \(|iu+a|>u\) for \(a>0\) and to the fact that \(|\phi _{s,t}(u-ia)|\le Be^{-b\; u^{\omega }}\) for sufficiently large values of u, thanks to the Assumption. Notice that in the range error the order of the exponential decay does not depend on a. Below, we prove that the choice of a determines the exponential decay of the discretization error: thus, its choice is crucial to get the optimal error bound.
Second, we bound the CDF discretization error.
By theorem 6.2 of Lee (2004), we have that for any \(a, \,p\) s.t. \(0<a<p<p_t^++1\)
where \(\phi _{s,t}(-i \, p)\) is well defined because \(0<p<p^+_t+1\).
We select a and p to minimize the discretization error. Notice that, for a sufficiently small h, the leading terms in the bound on the discretization error are \(e^{-2\pi a /h}\) and \(e^{-2\pi (p- a) /h-p\,x}\). Hence, for a given p the best choice of a is
This last quantity, for a sufficiently small h, is close to p/2 for any finite x. Thus, to minimize the discretization error, we select \(a=p/2\). Then, p can be chosen to its maximum value \(p^+_t+1\) and the upper bound becomes
With the selection of \(a=(p^+_t +1)/2\) and combining the bounds on the range and discretization errors, the thesis follows \(\square\)
The first term of \({{{\mathcal {E}}}}^{CDF}_{h, M} (x)\) accounts for the range error in the numerical inversion, while the second one accounts for the discretization error.Footnote 2 It is possible to prove, following the same steps of proposition 2.2, that in the \(a<0\) case the leading term in \({{{\mathcal {E}}}}^{CDF}_{M} (x)\) is \(\exp (-\pi p^-_t/h)\).Footnote 3 From this result, we can observe that it is convenient to use \(a>0\) if \(p_t^++1\ge p_t^-\) and \(a<0\) otherwise. In the financial literature, error estimations have been proposed when approximating a CDF via a discrete Fourier Transform (see e.g., Lee 2004; Chen et al. 2012; Ballotta and Kyriakou 2014). The bound in proposition 2.2 extends these results to the Lewis-FFT case, showing how to select the optimal integration path in the Lewis formula (2) to minimize the exponential decay of the error. Our approach eliminates the source of error originating from the pole in the origin (see e.g., Ballotta and Kyriakou 2014, eq.(4), p.1097), improving the CDF error. Moreover, selecting the optimal path, CDF error is even better than the one proposed by (Chen et al. (2012),th.2.1, p.14:6) deduced via the sinc expansion technique. The leading term in the discretization error in theorem 2.1 of Chen et al. (2012) goes as \(\max (e^{-\pi \,p_t^-/h},e^{-\pi \,(p_t^++1)/h})\), while, in our case, the error goes as the minimum of the two terms. Hence, we improve the discretization error of Chen et al. (2012) in all cases.Footnote 4
We desire to get a small approximation error increasing N and decreasing h. However, let us observe that, if one takes the limit \(h \rightarrow 0\) and \(N \rightarrow \infty\) keeping Nh fixed, then the range error bound does not decrease. Thus, our interest is to select \(h = h(N)\) so that the discretization and the range errors have about the same order. Expression (4) allows us to determine the size h and the number N such that the two sources of CDF error are comparable: we can impose that \(\exp (-\pi (p^+_t+1)/h) = \exp (-b\, (N \, h)^\omega )\), i.e. we select
We define
the error in this case. \({{{\mathcal {E}}}}^{CDF}_{M} (x)\) in (5) is the relevant estimation of the CDF error that we use in practice: with this selection of h, the total CDF error is \(O(N^{-\omega /(1+\omega )} ) \exp (-b N^{\omega /(1+\omega )})\) and decays almost exponentially as we increase N; moreover, the step size \(\gamma =2\pi /(h{ N }) = O(N^{-1/(1+\omega )})\).
3 The simulation method
Knowing the CDF approximation \({\hat{P}}\) in (3), we can sample from this distribution by inverting \({\hat{P}}\), i.e. by setting \(X ={\hat{P}}^{-1} (U)\), with U an uniform r.v. in [0, 1].
From the Fourier inversion, we obtain an estimate of \({\hat{P}}\) on a grid of N points with step \(\gamma\). As pointed out by (Glasserman and Liu 2010, Sect. 3, pp.1614-1615), an adequate inversion requires to impose that \({\hat{P}}\) is i) increasing and ii) inside the interval [0,1]. Thus, it is convenient to work with a subset of the grid of N points. We truncate the CDF between \(x_0<0\) and \(x_K>0\), such that the two conditions hold, and we consider the equally spaced grid (with step \(\gamma\)) \(x_0<x_1<...<x_K\) with \(K < { N }\).
Simulating a r.v. via a numerical CDF (i.e. coupling the Fourier transform with a MC simulation), requires a numerical inversion that is realized with an interpolation method. As already discussed in Sect. 2, differently from the existing financial literature (see e.g., Glasserman and Liu 2010; Chen et al. 2012; Feng and Lin 2013), the proposed method is based on spline interpolation. In the next subsection, we discuss the key idea behind this choice of the interpolation method.
3.1 Simulation error sources: truncation and interpolation
Besides numerical inversion error of the CDF, two are the error sources in the MC, when pricing a contingent claim: truncation and interpolation of the CDF.
Let us consider the expected value \({\mathbb {E}}V(f_t-f_s)\), with V(x) a derivative contract with a pay-off differentiable everywhere except in \(n_V\) points. It can be proven, similarly to (Chen et al. 2012, th.4.3, p.14:11), that the pricing errorFootnote 5 using the Lewis-FFT method with linear interpolation is
where p(x) is the probability density function of \(f_t-f_s\), \({\hat{p}}\) its estimation and
Three are the components of the bias error (6) when pricing a derivative: an error related to the numerical approximation of the CDF (7), a truncation error (8) and an interpolation error (9). Let us consider each error source separately.
First, the error related to the numerical approximation of the CDF in (7) is proportional to \({{{\mathcal {E}}}}^{CDF}_{M}(x_0)\): we have discussed in the previous section how to select the integration path and h in order to minimize it.
Second, we can always choose \(x_0\) and \(x_K\) s.t. the truncation error is negligible for all practical purposes. We select these points s.t. \({\hat{P}}(x_0)<10^{-10},\,1-{\hat{P}}(x_K)>10^{-10}\) (as suggested by Baschetti et al. 2022, eq.5). We notice that the range \((x_0,x_K)\) scales with \(\sqrt{t-s}\). In Fig. 1, as an example, we plot the one-day and one-year normalized probability density functions of the additive process used in the numerical experiments of Sect. 4. As expected, the one-day density is significantly more concentrated around zero than the one-year density when considering a constant x (on the right). Conversely, the ranges of the two densities look similar when considering the rescaled \(x/\sqrt{t-s}\) on the abscissa.Footnote 6 Moreover, to further improve the method accuracy (in particular when M is small), we introduce an exponential extrapolation for the CDF tail below \(x_0\) and above \(x_K\).

One-day and one-year normalized probability density functions of the additive process that we use in the numerical experiments of Sect. 4 with \(s=0\). On the right, we see that, as expected, the one-day density is significantly more concentrated around zero than the one-year density. Conversely, on the left, we see that the ranges of the two densities wrt to the rescaled \(x/\sqrt{t-s}\) are similar. Notice that both probability density functions have been divided by their respective maximum for visualization purposes
Finally, the bias associated with the linear interpolation, when computing the option value, is quadratic in the grid spacing \(\gamma\); this turns out to be the most significant source of error in most cases, as shown in the next section. It is well known that linear interpolation error goes as \(\gamma ^2\) (see e.g., Quarteroni et al. 2007, eq.(8.26), p.339). For this reason, in this paper, we propose a spline interpolation method. In this latter case, it is known that the bias goes, at least, as \(\gamma ^4\) as shown in Hall and Meyer (1976).
As already emphasized by (Glasserman and Liu 2010, Sect. 3, p.1615), to sample X from \({\hat{P}}(x)\) with a linear interpolation, after having generated U, a r.v. uniformly distributed in [0, 1], one should
-
1.
select the index j for which \({\hat{P}}(x_{ j-1}) \le U < {\hat{P}}(x_{ j})\);
-
2.
for each j determine the linear interpolation coefficients \(c_{0,j}^L\) and \(c_{1,j}^L\)
$$\begin{aligned} c_{0,j}^L:=\frac{ x_{ j} \, {\hat{P}}(x_{ j}) - x_{ j-1} \, {\hat{P}}(x_{ j-1})}{{\hat{P}}(x_{ j}) - {\hat{P}}(x_{ j-1})}\quad \text {and}\quad c_{1,j}^L:=\frac{\gamma }{{\hat{P}}(x_{ j}) - {\hat{P}}(x_{ j-1})}\;; \end{aligned}$$ -
3.
compute
$$\begin{aligned} X = c_{0,j}^L+c_{1,j}^L\, U\,\,. \end{aligned}$$
Let us discuss the computational cost of each step when sampling \({{{\mathcal {N}}}}_{sim}\) observations. The first step relies on a nearest neighborhood algorithm with an average computational cost proportional to \({{{\mathcal {N}}}}_{sim}\times \log _2{{{{\mathcal {N}}}}_{sim}}\) (see e.g., Cormen et al. 2001, p.11).Footnote 7 The second step cost is proportional to 6K. Finally, the last step is proportional to \({{{\mathcal {N}}}}_{sim}\).
Whereas step 1 is shared by both interpolation methods, steps 2 and 3 differ between spline and linear interpolations. In step 2, the additional computational cost of considering spline interpolation boils down to the cost of solving a \(K+1\)-dimensional linear system with a tridiagonal matrix to determine the spline coefficients \(\{c_{q,j}^S\}_{q=0}^3\), (cf. Quarteroni et al. 2007, ch.8), i.e. the cost is \(8 K-7\) (Quarteroni et al. 2007, ch.7, p.391). As for step 3, the cost of computing the spline interpolation of U is still proportional to \({{{\mathcal {N}}}}_{sim}\). It is clear that for a sufficiently large number of simulations \({{{\mathcal {N}}}}_{sim}\) and for \({{{\mathcal {N}}}}_{sim}>>K\), for both methods, the most relevant contribution in the computational cost is the one due to step 1, the nearest neighborhood algorithm.
We perform numerical experiments to compare linear and spline interpolation. We observe that, if the number of simulations is significantly above the grid dimension K, the spline interpolation is as expensive as the linear interpolation. Moreover, in table 1, we compare the computational cost of linear interpolation and spline interpolation. We consider a grid of size \(K=10^4\) and \({{{\mathcal {N}}}}_{sim}=10^5\). In this case, the spline cost is just 10% more than the linear one. The case considered in Table 1 is a particularly unfavorable situation, when comparing spline interpolation with linear interpolation: a large grid size \(K=10^4\) and a small number of simulations \({{{\mathcal {N}}}}_{sim}=10^5\). In this case steps 1, 2 and 3 computational times are comparable while, in practice, most of the computational costs are absorbed by the nearest neighborhood algorithm. For reasonable values of M (e.g. for \(M\le 15\)), the dimension of the grid K is always well below \(10^4\). Thus, for all values of K and \({{{\mathcal {N}}}}_{sim}\) (\({{{\mathcal {N}}}}_{sim}\ge 10^6\)) used in practice the incremental cost between Lewis-FFT (with linear interpolation) and Lewis-FFT-S (with spline interpolation) is negligible.
3.2 A simulation benchmark: the Gaussian approximation
In this subsection, we show how to generalize the GA method for additives in an efficient way, when a monotonicity property holds for the Lévy measure and then the ziggurat method (Marsaglia and Tsang 2000) can be applied.
A generic additive process may have an infinite number of jumps, most of them being small, over an arbitrary finite time horizon, making the simulation of such a process often nontrivial. Defining \(\nu _t\) the additive process jump measure (see e.g., Sato 1999, def.8.2, p.38), the jump measure of the additive process increment \(f_t-f_s\) is \(\nu _t-\nu _s\).
Eberlein and Madan (2009), in their study on simulation of additive processes, consider only a class of additive processes (Sato processes): their approach consists in discarding the small jumps that in absolute value are below a given threshold \(\epsilon\). It is well known, in the Lévy case, that such an approach is accurate only if there are not too many small jumps (see e.g., Cont and Tankov 2003). Alternatively, the small jump component of an additive process may be approximated by a Brownian motion (Asmussen and Rosiński 2001).
Once the jump measure of the increment (between time s and time \(t>s\)) is truncated, we have i) to draw a Poisson number of positive and negative jumps and ii) to simulate separately positive jumps from the probability density \(m^+_{s,t}\) and negative jumps from the probability density \(m^-_{s,t}\), where
To sample positive and negative jumps is extremely costly because often it is not possible to compute explicitly the integrals of \(m^+_{s,t}\) and \(m^-_{s,t}\).
When \(m^+_{s,t}(x)\) is non increasing in x and \(m^-_{s,t}(x)\) is non decreasing in x \(\forall s,t\) s.t. \(0\le s < t\), a faster methodology -for sampling from a known distribution without inverting numerically its integral- is available: the ziggurat method of Marsaglia and Tsang (2000). This method is applicable to probability density functions that are bounded and monotonic. We can apply the algorithm separately to negative and positive jumps. Notice that the density functions are bounded because we have truncated the small jumps. The ziggurat method covers a probability density with \(N_{ret}\) rectangles with equal area and a base strip. The base strip contains the tail of the probability density, it is built s.t. it has the same area of the rectangles. The method is composed of two building blocks: first, the rectangles with equal area are identified; second, the random variable is simulated either from a rectangle or from the base strip. Only in the latter case, an inversion of the integral is needed. \(N_{ret}\) is a key parameter because it controls the trade-off, in terms of computational time, between the inversion and the construction of the rectangles.
With respect to Eberlein and Madan (2009), to reduce the bias of the method, we also consider the Gaussian approximation of Asmussen and Rosiński (2001).
4 Numerical results
Financial applications provide an important motivation for this study. We show that the proposed Monte Carlo technique for additive processes can price path-dependent options fast and accurately. The computational time is comparable to the case with simple Brownian motion dynamics.
We are interested in simulating a discrete sample path of the process over a finite time horizon: we are only concerned about the values of an additive process on such a discrete-time grid. This arises from situations where only discrete values of the process are concerned as in Chen et al. (2012); Ballotta and Kyriakou (2014) (e.g., they consider discrete barrier, lookback, and Asian options).
The case of an additive normal tempered stable (ATS) is discussed in detail. ATS processes present several advantages: they calibrate accurately equity implied volatility surfaces and, in particular, they capture volatility skews (see e.g., Azzone and Baviera 2022a). We model the forward price at time t with maturity T as an exponential additive \(F_t(T)=F_0(T)e^{f_t}\), where \(f_t\) is the ATS process and \(F_0(T)\) is the forward price at time 0. The ATS characteristic function and Lévy measure are reported in Appendix 1 (cf. Eqs. (15-16)).
The Lewis-FFT-S method can be used for the ATS because, in the next proposition, we prove that the Assumption in Sect. 2.2 holds for this class of additive processes. Moreover, we prove that the Assumption holds for the two other classes of additive processes considered in the literature for option pricing: additive logistic processes (Carr and Torricelli 2021) and Sato processes (Carr et al. 2007).
Proposition 4.1
The Assumption (cf. Sect. 2.2) holds for
-
1.
ATS processes with \(\alpha \in (0,1)\);
-
2.
additive logistic processes ( Carr and Torricelli 2021);
-
3.
Sato processes with characteristic function \(\phi _{t}(u)\), for \(t=1\), that decays exponentially (Carr et al. 2007).
Proof
We prove the thesis for the ATS.
We observe that, by the condition (a) on \(g_1(t)\) and \(g_2(t)\) of theorem A.1, we have
is non increasing wrt t. Hence, thanks to the condition (a) on \(g_3(t)\) of theorem A.1
We have to show that, given s and t, there exists \(B>0\), \(b>0\), and \(\omega >0\) such that, for sufficiently large |u|, the Assumption holds for the characteristic function of ATS.
We choose \(\log (B)>\frac{1-\alpha }{\alpha }\left( \frac{t}{k_t} -\frac{s}{k_s}\right)\), \(0<b<\frac{(1-\alpha )^{1-\alpha }}{2^\alpha \alpha }\left( \frac{t}{k_t^{1-\alpha }} \sigma _t^{2\alpha }-\frac{s}{k_s^{1-\alpha }}\sigma _s^{2\alpha }\right)\) and \(0<\omega <2\alpha\).
Notice that it is possible to fix \(b>0\), because (11) holds. Moreover, the imaginary part of the exponent in (15) does not contribute to B, because the absolute value of the exponential of an imaginary quantity is unitary. For sufficiently large |u|, and for \(s<t\) \(|\phi _{t,s}(u-i\,a)|\) goes to zero faster than \(Be^{-b\; |u|^{\omega }}\) because \(\log \phi _{t,s}(u-i\,a)\) is asymptotic to
that is negative due to (11) for \(\alpha \in (0,1)\).
We prove the thesis for additive logistic processes.
Carr and Torricelli (2021) consider two additive logistic processes: the CPDA and the SLA. The characteristic function of an additive logistic process at time t is
where \({{{\mathcal {B}}}}\) is the beta function and \(\sigma _t>0\) is non decreasing. For the CPDA model \(c_t=1-\sigma _t\) and \(\sigma _t<1\) and for the SLA model \(c_t=1\) (cf. Carr and Torricelli 2021, prop.4.2).
For sufficiently large |u|,
where the asymptotic approximation follows from Stirling’s formula for the Gamma function \(\Gamma (\zeta )\) when \(\zeta \rightarrow \infty\) and \(\arg \zeta <\pi\) (see e.g. Abramowitz and Stegun 1948, p.257), and \(z_t(u)\) is a deterministic function. From this approximation, if \(t>s\), \(\log \left[ \phi _t(u-i\,a)/\phi _s(u-i\,a)\right]\) is asymptotic to
where the first inequality holds because \(\frac{\sigma _t|u|}{1+\sigma _ta}\) and \(\frac{\sigma _t|u|}{c_t-\sigma _ta}\) are non decreasing in t and positive and the second holds for sufficiently large |u|. Moreover, \({\hat{b}}>0\) because \(\sigma _t\) is non decreasing in t. Hence, we can set \(B>0\) and \(0<b<{\hat{b}}\) s.t.
for sufficiently large |u|.
Finally, we prove the thesis for Sato processes.
If \(\phi _1(u)\) decays exponentially as \(e^{-{\hat{b}}|u|^w}\), with \({\hat{b}}>0\), then \(\phi _t(u) =\phi _1(ut^\zeta )\) decays as \(e^{-{\hat{b}}|u|^w \,t^{\zeta \,w}}\). It is possible to select \(B>0\) and \(0<b<{\hat{b}}(t^{\zeta \,w}-s^{\zeta \,w})\) s.t. \(|\phi _{t,s}(u-i\,a)|=|\phi _t(u-i\,a) /\phi _s(u-i\,a) |<Be^{-b|u|^w}\) for \(t>s\) \(\square\)
A brief comment on Sato processes can be useful. Thanks to the self-similarity of the processes, if a condition on the characteristic function holds for \(t=1\) then it is satisfied also for all other time intervals.Footnote 8
In particular, for the numerical example, we focus on the power-law scaling ATS (see e.g., Azzone and Baviera 2022a, p.503) that is characterized by the parameters
where \({\bar{\sigma }}, {\bar{k}}, {\bar{\eta }} \in {\mathbb {R}}^+\), and \(\beta , \delta \in {\mathbb {R}}\). This model description has been shown to be particularly accurate for equity derivatives. Let us emphasize that, in the ATS case, \(p_t^+\ge p_t^-\), as shown in the next proposition, and then it is convenient to use \(a>0\) (cf. Sect. 2).
Proposition 4.2
For ATS processes with \(\alpha \in (0,1)\) we have that \(p_t^+\ge p_t^-\).
Proof
To identify \(p_t^+\) and \(p_t^-\), we apply the Lukacs theorem (cf. Lukacs 1972, th.3.1, p.12). At time t, the ATS characteristic function in Eq. (15) is analytic on the imaginary axis \(u=-i\,a\), \(a\in {\mathbb {R}}\) iff
By solving the second order inequality, we get
with \(g_1(t)\) and \(g_2(t)\) defined in (17). Hence, \(p^+_t:=-g_2(t)-1\) and \(p_t^-:=-g_1(t)\).
It holds that \(p^+_t\ge p_t^-\) because
\(\square\)
For all numerical experiments, we use the parameters reported in Table 2: these parameters are consistent with the ones observed in market data. Moreover, for simplicity, we consider the case with unitary underlying initial value and without interest rates nor dividends: these deterministic quantities can be easily added to simulated prices without any computational effort.Footnote 9
To evaluate the Lewis-FFT-S performances, we consider plain vanilla and exotic derivatives at different moneyness \(x=\log (S_0/\kappa )\), where \(\kappa\) is the strike price, and at different times to maturity. In the rest of the section, to ensure that we verify the performance of the method on options in a relevant range of moneyness x, we consider x in the range \(\sqrt{t}(-0.2,0.2)\), where t is the option time to maturity; deep out-of-the-money and in-the-money options are less informative on the method performances, as the option value is close to the intrinsic value.
In Sect. 4.1, we show how the Lewis-FFT-S (with spline interpolation) method significantly outperforms the method with linear interpolation for European options, where - thanks to the closed formula - we can easily verify the accuracy of the numerical method. In Sect. 4.2, we provide evidence that Lewis-FFT-S is extremely fast and it is less computationally expensive, by at least 1.5 orders of magnitude than the GA method. In Sect. 4.3, we price discretely-monitored Asian options, lookback options, and Down-and-In options with a time to maturity of five years. We also show that the Lewis-FFT-S is particularly efficient. The computational time needed to price path-dependent options with this method is just three times the computational time needed when using standard MC techniques for a geometric Brownian motion.
4.1 European options: accuracy
In the following, the Lewis-FFT-S performances are assessed for the ATS process. First, we compare the accuracy of Lewis method and Hilbert transform to compute the CDF. Second, we show that, when using linear interpolation the leading term in (6) goes as \(\gamma ^2\). Then, we improve the bound by considering spline interpolation (Lewis-FFT-S) and we discuss the excellent performances of the method for the ATS case. Thanks to FFT the Lewis-FFT-S is particularly fast: computational time has the same order of magnitude of standard algorithms that simulate Brownian motions. Thanks to the spline interpolation, Lewis-FFT-S is also particularly accurate, for \(10^7\) simulations and for any \(M>9\), the maximum observed error is 0.03 basis points (bp).
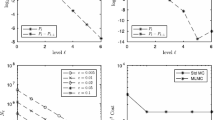
In Fig. 2, we compare the accuracy of the Lewis formula and the Hilbert transform method for inverting the CDF in terms of the mean absolute error (MAE) varying M s.t. \(N=2^M\). We consider the ATS case for the one month maturity and we invert the CDF on an interval \(x_0,\,x_K\). To investigate the potential instability of the Hilbert transform due to the pole in the origin, we consider both a small shift of \(0.01\cdot h\) in the FFT grid in the Fourier space and the case of a perfectly symmetric grid. The Lewis method is more accurate than the Hilbert transform method both in the case of a shift in the Fourier space (on the left) and in the symmetric case (on the right). The plotted results clearly indicate that the Hilbert method is highly unstable and even a slight shift in the Fourier space can result in a significant increase of the error, up to six orders of magnitude.

One-month mean absolute error (MAE) in the CDF (in log-scale) for the Lewis formula and Hilbert transform with a small shift of \(0.01\cdot h\) in the Fourier space (on the left) and in the case of a perfectly symmetric grid (on the right). The Lewis method is more accurate than the Hilbert method. The plotted results indicate that the Hilbert method is highly unstable and even a small shift in the Fourier space can result in a significant increase the error, up to six orders of magnitude
We do not desire a method that performs well either only OTM or only ITM. We want a MC that prices accurately options with any moneyness: for this reason, we consider 30 European call options with moneyness in a regular grid with range \(\sqrt{t}(-0.2,0.2)\).
Monte Carlo error is often decomposed into bias and variance (see e.g., Glasserman 2004, Sect.1.1.3, pp.9-18). In this paper, we aim to reduce the bias error, but it is relevant to take into account also the variance. For a large number of simulations, confidence intervals estimated via MC are directly linked to this quantity (see e.g., Glasserman 2004, ch.1, eq.(1.10), p.10). In our case, since we are considering the average error over 30 call options, the bias is assessed in terms of the maximum error in absolute value (MAX) wrt the exact price, while the variance is estimated with the average over the 30 MC standard deviations (SD). When the maximum error is below SD we can infer that the error on bias has been dealt with correctly. In all considered cases, SD is of the order of 0.1 bp and significantly above the Lewis-FFT-S error if \(M> 8\). We observe such a low SD because we are using \(10^7\) trials.
In Fig. 3, we plot the three terms that appear in the bias bound of Eq. (6) for an ATS with \(\alpha =2/3\) over a one-month time interval. The bound is for Lewis-FFT simulation with linear interpolation varying the number of grid points in the FFT via M s.t. \(N=2^M\). We plot the bounds on the error due to i) the truncation error (blue circles) in (8), ii) the linear interpolation of the CDF (red squares) in (9), and iii) the error related to the CDF approximation (green triangles) in (7). As we have already anticipated in Sect. 3.1, two are the most relevant error sources: the error originating from the CDF approximation and the one due to the interpolation. The error originating from the truncation is always negligible: at least ten orders of magnitude lower than interpolation error for every M. For the CDF approximation error, as explained in Sect. 2, we have suggested an optimal selection of the shift a in the Lewis-FFT approach. The term that we need to tackle is the interpolation one: for \(M>8\) the unique relevant bound is the one on the interpolation error that scales as \(\gamma ^2\) for all derivative contracts with pay-off differentiable everywhere except in a finite number of points (e.g. for \(M=10\) the interpolation error is 10 orders of magnitude above all other errors). Similar results hold \(\forall \alpha \in (0,1)\).

One-month European call option error bounds for an ATS (\(\alpha =2/3\)) simulated with Lewis-FFT and linear interpolation. We plot the bounds on the three error sources: (i) the truncation error (8) (blue circles), (ii) the error (9) due to the linear interpolation of the CDF (red squares) and (iii) the error (7) related to numerical CDF (green triangles). Let us emphasize that the truncation error is always negligible wrt the linear interpolation error (at least 10 orders of magnitude smaller for every M). Notice that, for \(M>8\) the unique significant term is the linear interpolation error (e.g. for \(M=10\), it is at least 10 orders of magnitude above all other errors) (colour figure online)
As discussed in Sect. 3.1, to reduce the CDF interpolation error, we consider the spline interpolation for the numerical inversion instead of the linear interpolation. With spline interpolation \({{{\mathcal {E}}}}\) should scale as \(\gamma ^4\) instead of \(\gamma ^2\). In Figs. 4 and 5, we plot the Lewis-FFT maximum error (MAX) for two different times to maturity: the error is for 30 European call options for different values of M using spline (blue circles) and linear (red squares) interpolation. We also plot SD, the average MC standard deviation, with a dashed green line. Notice that, for \(M>6\) the spline interpolation error is significantly below the linear interpolation error. Spline interpolation’s error improves significantly faster than the linear interpolation’s error: for M in the interval (6,10), the maximum error scales as \(\gamma ^2\) for the linear interpolation and as \(\gamma ^6\) for the spline interpolation. The observed behavior in the latter case -with an error that decreases much faster than \(\gamma ^4\)- is probably due to the monotonicity and boundness of the interpolated function (the CDF).

Maximum error for different values of M using Lewis-FFT-S (blue circles) and Lewis-FFT with linear interpolation (red squares). The maximum is computed over 30 call options (one-week maturity), with moneyness in the range \(\sqrt{t}\)(\(-\)0.2,0.2). We consider \(10^7\) simulations and \(\alpha =2/3\). Notice that, for \(M>6\) the spline interpolation error is significantly below the linear interpolation error. Spline interpolation’s error improves significantly faster than the linear interpolation’s error: for M in the interval (6,10) the maximum error scales, on average, as \(\gamma ^6\) for the spline interpolation and as \(\gamma ^2\) for the linear interpolation. Moreover, the maximum error becomes significantly lower than the average MC standard deviation (dashed green line) (colour figure online)

As Fig. 4 but for one-month maturity. Notice that, for \(M>6\) the spline interpolation error is significantly below the linear interpolation error. Also in this case, spline interpolation’s error improves significantly faster than the linear interpolation’s error: for M in the interval (6,10) the maximum error scales, on average, as \(\gamma ^6\) for the spline interpolation and as \(\gamma ^2\) for the linear interpolation
We also desire to estimate the method’s error with different metrics: besides MAX we consider the root mean squared error (RMSE) and the mean absolute percentage error (MAPE). In Table 3, we report the performances of the Lewis-FFT-S algorithm for \(10^7\) simulations. We consider two values of \(\alpha\) for the ATS: \(\alpha =1/3\) and \(\alpha =2/3\). The metrics are computed for 30 call options (one-month maturity) and moneyness in the range \(\sqrt{t}\)(\(-\)0.2,0.2). We observe that for \(M> 9\) the error is 0.03 bp or below whatever metric we consider.
The main result of this subsection is that, in the Lewis-FFT-S framework, a Monte Carlo with \(10^7\) simulations and \(M>9\) provides a very accurate pricing tool whatever time-horizon and \(\alpha \in (0,1)\) we consider.
4.2 European options: computational time
In this subsection, we emphasize that the proposed MC method is fast. We compare the Lewis-FFT-S computational cost both with the simplest possible dynamics for the underlying (geometric Brownian motion) and with the methodology that is often considered a benchmark for simulating jump processes (i.e. the simulation of jumps via the GA method). We prove that it is possible to speed up the simulation benchmark with the ziggurat method because the monotonicity conditions on \(m_{s,t}^+\) and \(m_{s,t}^-\) in (10) hold for the ATS and also for the additive logistic process.Footnote 10
Proposition 4.3
Consider \(m_{s,t}^+\) and \(m_{s,t}^-\) in (10). \(m_{s,t}^+\) is non increasing in x when \(x>0\) and \(m_{s,t}^-\) is non decreasing in x when \(x<0\) for
-
1.
ATS processes with \(\alpha \in (0,1)\);
-
2.
additive logistic processes.
Proof
We have to demonstrate that \(m^+_{s,t}(x)\) is non increasing in x and \(m^-_{s,t}(x)\) is non decreasing. We prove the thesis by showing that the derivative of \(\nu _t(x)\) wrt x is negative and non increasing in t for any \(x>0\) and is positive and non decreasing in t for any \(x<0\). Notice that if this holds then
is non-increasing in x and
is non decreasing in x.
We prove the thesis for the ATS.
Deriving \(\nu _t(x)\) in (16), we get
where \(C_2\) is a positive constant. The derivative of \(\nu _t(x)\) is non increasing in t for any \(x>0\) because
-
1.
\(g_3(t)\) is positive and non decreasing in t by condition 1 of theorem A.1;
-
2.
\(e^{x\, g_2(t)}\left( \alpha +\frac{s}{s/2+x\,g(t)}\right)\) is the combination of two non decreasing function in t for any \(x>0\);
-
3.
\(g_2(t)\) is negative and non decreasing and \((1-c \, x)e^{c\,x}\) is non decreasing for \(c<0\).
This proves the thesis for \(x>0\).
The same holds true for \(x<0\). Mutatis mutandis, by substituting \(g_2(t)\) with \(g_1(t)\), the proof is the same.
We prove the thesis for the logistic processes.
This entails showing that the derivative of the Lévy measure for the CPDA model and the SLA model is non increasing for \(x>0\) and non decreasing for \(x<0\). Let us first consider the CPDA. Its Lévy measure can be rewritten as
where \(a_t:=1/\sigma _t\), \(y:=x/\sigma _t\) and \(g(y):=e^{-y}/(y(1-e^{-y}))\).
We consider separately the positive and negative x. The derivative of \(\nu _t(x)\) for \(x>0\) is
where the equality is because \(\frac{\partial y}{\partial x}=a_t\). The mixed derivative is
where the first equality holds because \(\frac{\partial y}{\partial t}=\frac{a'_t y}{a_t}\).
The derivative of \(\nu _t(x)\) for \(x<0\) is
We can compute the mixed derivative
where the equality holds because \(\frac{\partial y}{\partial t}=\frac{a'_t y}{a_t}\) and the inequalities because \(a_t'<0\) and
Equations (13) and (14) prove the thesis for the CPDA process.
The Lévy measure for the SLA process can be rewritten as
Equation (13) proves the thesis for the SLA process if \(x>0\). Mutatis mutandis for the SLA process when \(x<0\), we get that
Hence, \(m_{s,t}^+\) is non increasing in \(x>0\) and \(m_{s,t}^-\) is non decreasing in \(x<0\) for both the CPDA and the SLA processes \(\square\)
In Table 4, we report the performances of the Lewis-FFT-S algorithm for \(10^7\) simulations. We consider the ATS with \(\alpha =1/3\) and \(\alpha =2/3\). For every choice of M, we register the computational time [s]. The metrics are computed for 30 call options (one-month maturity), with moneyness in the range \(\sqrt{t}\)(\(-\)0.2,0.2). We observe that for \(M> 9\) the maximum error is 0.03 bp or below.
We point out, that Lewis-FFT-S is considerably efficient. In our machine,Footnote 11 sampling \(10^7\) trials of a geometric Brownian motion takes approximately 0.08 s: just one-third of the Lewis-FFT-S computational cost (reported in Table 4).
In Fig. 6, we plot the computational time wrt the time to maturity in log-log scale for \(10^7\) simulations with Gaussian Approximation (blue squares) and Lewis-FFT-S (red circles). Time to maturity goes from one day to two years. To compare the two methods fairly, we need to select M for the Lewis-FFT-S and \(\epsilon\) for the Gaussian approximation s.t. the two methods provide similar errors. As above, for both methods, we price the 30 call options, with moneyness in the range \(\sqrt{t}\)(\(-\)0.2,0.2). For each time to maturity, we select M and \(\epsilon\) s.t. the maximum error (MAX) is between 1 bp and 0.1 bp, and s.t. the Lewis-FFT-S error is always below the GA error. Lewis-FFT-S computational time appears constant in the time to maturity, while GA computational time improves as the time to maturity reduces. However, GA is always more computationally expensive than Lewis-FFT-S by at least 1.75 orders of magnitude. This difference appears remarkable considering that we have verified that Lewis-FFT-S error is always below GA error.

Computational time wrt the time to maturity in log-log scale for \(10^7\) simulations with GA (blue squares) and Lewis-FFT-S (red circles) techniques. We price 30 European call options, with moneyness in the range \(\sqrt{t} (-0.2,0.2)\) with GA and Lewis-FFT-S. We consider times to maturity, between one day and two years. For each t, we select M and the threshold \(\epsilon\) s.t. the maximum error is between 1 bp and 0.1 bp and we require that the Lewis-FFT-S error is always below the GA error. The GA computational time improves as the time to maturity reduces because a lower number of jumps is involved, while the Lewis-FFT-S simulation depends weakly on the time horizon considered. We observe that GA is always more computationally expensive than Lewis-FFT-S by at least 1.75 orders of magnitude (colour figure online)
4.3 Discretely monitoring options
In this subsection, to give an idea of an application of the proposed MC, we price discretely-monitored (quarterly) Asian options, lookback options, and Down-and-In options with a time to maturity of five years.
Let us call L the Down-and-In barrier. The payoffs -Asian calls, lookback puts, and Down-and-In puts- we consider are respectively
where \(n=20\), \(0=t_0<t_1<...<t_i<...<t_n\) are the monitoring times, \(f_{t_i}\) is the process at time \(t_i\) for the logarithm of the underlying price, the strike price \(\kappa =S_0e^{-x}\) and x is the moneyness. For example, the process \(\{ f_t \}_{t\ge 0}\) can be modeled as a Brownian motion, in the simplest Black-Scholes case, or as an ATS process, as discussed in this paper. In both cases, we can simulate the paths of \(\{ f_t \}_{t\ge 0}\) by simulating the increments \(f_{t_i}-f_{t_{i-1}}\). Every increment of the ATS is simulated separately with the Lewis-FFT-S method. We point out that the procedure can be parallelized by leveraging on the independence of increments.
In Table 5, we report prices and MC standard deviation of Asian calls, lookback puts, and Down-and-In puts (with a barrier strike \(L=0.6\)). We simulate \(10^7\) paths of the ATS with \(\alpha =2/3\) and price the discretely-monitored (quarterly) path-dependent options with time to maturity of five years. We consider options with different moneyness in the range (\(-\)0.5,0.5), where \(0.5\approx 0.2\sqrt{t}\) for \(t=5\) years. We use \(M=13\) for the numerical CDF inversion. The method is very precise: the numerical error SD is of the order of one bp (or below) in all considered cases.
As pointed out in the previous subsection, the Lewis-FFT-S is also extremely efficient when pricing discretely-monitored path-dependent exotics: with an ATS, it takes only three times the computational cost that it takes with a standard Brownian motion.
5 Conclusions
In this paper, we propose the Lewis-FFT-S method: a new Monte Carlo scheme for additive processes that leverages on the numerical efficiency of the FFT applied to the Lewis formula for a CDF and on the spline interpolation properties when inverting the CDF. We present an application to the additive normal tempered stable process, which has excellent calibration features on the equity volatility surface (see e.g., Azzone and Baviera 2022a). This simulation scheme is accurate and fast.
We discuss in detail the accuracy of the method. In Fig. 3, we analyze the three-components of the bias error in (6). In this study, we have shown how to accelerate convergence by improving the two main sources of numerical error (6): the CDF error (7) and the interpolation error (9). First, we sharpen the CDF error considering the Lewis formula (2) for CDF and selecting the optimal shift that minimizes the error bound in the FFT. Second, we substitute the linear interpolation with the spline interpolation. In this way, the leading term in the interpolation error improves from \(\gamma ^2\) to at least \(\gamma ^4\). This improvement is particularly evident in Figs. 4, 5, where, for \(M>6\), the Lewis-FFT-S maximum error is significantly below the Lewis-FFT version of the method with linear interpolation and it appears to decrease as \(\gamma ^6\) in numerical experiments.
The Lewis-FFT-S is also fast. As discussed in Sect. 3.1, for a sufficiently large number of simulations, the increment in computational time due to spline interpolation is negligible. Moreover, as shown in Fig. 6, the proposed method is at least one and a half orders of magnitude faster than the traditional GA simulations, whatever time horizon we consider. Finally, we observe that, when pricing some discretely-monitoring path-dependent options, the computational time is of the same order of magnitude as standard algorithms for Brownian motions.
Notes
To avoid this constraint, one can consider the fractional fast Fourier transform (Chourdakis 2005) instead of the standard FFT. We have verified that the additional computational cost of the former method is not justified in the CDF simulation described in this paper.
It is possible also to obtain an error bound even when the Assumption does not hold. Equation (4) can be extended to the case where the characteristic function has an asymptotical polynomial decay \(|\phi _{s,t} (u-i\,a)| \le B \, |u|^{-b}\), with \(b>0\): in this case, the range error decays only as a power of u due to the polynomial decay of the characteristic function (see e.g., Ballotta and Kyriakou 2014, eq.(14), p.1099). However, in practice, when pricing exotic derivatives, the exponential decay of the characteristic function is a good reason for model selection.
In this case, the optimal shift is \(a=-p_t^-/2\).
Baschetti et al. (2022) point out that the symmetry in the real and imaginary components of the Hilbert transform allows to compute the CDF only N/2 times when the FFT grid size is N. This observation becomes relevant for situations where computing the characteristic function is computationally demanding. However, in the case of additive processes, characteristic functions are analytic and very fast to compute.
The upper bound on the bias \({{{\mathcal {E}}}}\) can be trivially extended to a payoff with a finite number n of monitoring times. The most relevant case, for \(n=1\), will be discussed in detail in Sect. 4.1.
In extensive numerical experiments, we have observed that when choosing \(x_0=-x_K\) and \(x_K\) the nearest point to \(5\sqrt{t-s}\) the above condition on \({\hat{P}}(x_0)\) and \({\hat{P}}(x_k)\) is always satisfied.
The computational cost estimation is for the merge sort algorithm. Since merge sort is a recursive algorithm it could be necessary, for memory efficiency, to recur to an insertion sort algorithm which computational cost is roughly proportional to \({{{\mathcal {N}}}}_{sim}^2\) (see e.g., Cormen et al. 2001, p.11).
Eberlein and Madan (2009) consider also some characteristic functions with polynomial decay; in this case, the considerations in note 3 hold.
We remind that, in this setting, the forward price \(F_0(T)\) is equal to the spot price \(S_0=1\).
Eberlein and Madan 2009, p.30 point out that -for Sato processes- the Lévy measure is decreasing in x for positive x and increasing in x for negative x.
We use MATLAB 2021a on an AMD Ryzen 7 5800 H, with 3.2 GHz.
We emphasize that we consider \(\alpha >0\). As discussed in Sect. 2.2, this is the relevant situation in practice when pricing exotic derivatives: the case with \(\alpha\) exactly equal to zero presents a power-law decay in the characteristic function.
Abbreviations
- \(\beta\) :
-
Scaling parameter of ATS variance of jumps
- \(\delta\) :
-
Scaling parameter of ATS skew parameter
- \({{{\mathcal {E}}}}\) :
-
Total error when pricing the derivative with payoff V(x)
- \(\eta _t\) :
-
ATS skew parameter
- \({\bar{\eta }}\) :
-
ATS constant part of skew parameter
- \(\epsilon\) :
-
Small jump threshold for GA
- \({{{\mathcal {E}}}}^{CDF}_{h, M}\) :
-
CDF error bound as a function of the grid size h and of M
- \({{{\mathcal {E}}}}^{CDF}_{ M}\) :
-
CDF error bound when h is s.t. the two sources of CDF error are comparable
- \(f_t\) :
-
The additive process at time t
- \(F_t(T)\) :
-
Forward price with maturity T at time t
- \(\phi _{s,t}\) :
-
Characteristic function of additive increment between s and t time to maturity
- \(\phi _{t}\) :
-
Characteristic function of additive process at time t
- \(\gamma\) :
-
Grid size in the CDF domain
- h :
-
Grid size in the Fourier domain
- \(k_t\) :
-
ATS variance of jumps parameter
- \({\bar{k}}\) :
-
ATS constant part of the variance of jumps
- K :
-
Dimension of the CDF interpolation grid
- \(\kappa\) :
-
Strike price
- L :
-
Down-and-In barrier strike
- \(m^+_{s,t}\) :
-
Probability density of positive jumps
- \(m^-_{s,t}\) :
-
Probability density of negative jumps
- M :
-
Integer number s.t. N is the number of grid points
- n :
-
Number of monitoring times in path dependent derivatives
- \(n_v\) :
-
Number of points in which V is not differentiable
- N :
-
Number of grid points \((N={ 2^M })\)
- \({{{\mathcal {N}}}}_{sim}\) :
-
Number of simulations
- \(\nu _t\) :
-
Jump measure of additive process
- P(x):
-
Model CDF of the increment between the times s and t
- \({\hat{P}}(x)\) :
-
Numerical approximation of the CDF of the increment between the times s and t
- \(p^-_t\) :
-
Upper bound of \(\phi _{t}\) strip of regularity
- \(p^+_t\) :
-
\(-(p^+_t+1)\) is the lower bound of \(\phi _{t}\) strip of regularity
- \({\bar{\sigma }}\) :
-
ATS diffusion parameter
- \(S_t\) :
-
Spot price at time t
- U :
-
Uniform r.v. in (0,1)
- V(x):
-
Derivative payoff
- \((x_0,x_K)\) :
-
Interval in which the CDF is interpolated
- a.s.:
-
Almost surely
- ATS:
-
Additive normal tempered stable process
- bp:
-
Basis point
- CDF:
-
Cumulative distribution function
- FFT:
-
Fast Fourier transform
- GA:
-
Gaussian approximation technique
- MAE:
-
Mean absolute error
- MAPE:
-
Mean absolute percentage error (in MC prices)
- MAX:
-
Maximum error (in MC prices)
- MC:
-
Monte Carlo
- ms:
-
Milliseconds
- nn:
-
Nearest neighborhood algorithm
- r.v.:
-
Random variable
- RMSE:
-
MC prices root mean squared errors
- SD:
-
Average standard deviation (in MC prices)
- s.t:
-
Such that
- wrt:
-
With respect to
References
Abramowitz M, Stegun IA (1948). Handbook of mathematical functions with formulas, graphs, and mathematical tables, vol. 55, US Government printing office
Asmussen S, Glynn PW (2007) Stochastic simulation: algorithms and analysis, vol. 57, Springer Science & Business Media
Asmussen S, Rosiński J (2001) Approximations of small jumps of Lévy processes with a view towards simulation. J Appl Probab 38(2):482–493
Azzone M, Baviera R (2022) Additive normal tempered stable processes for equity derivatives and power-law scaling. Quant Finance 22(3):501–518
Azzone M, Baviera R (2022b) Short-time implied volatility of additive normal tempered stable processes, Annals Oper Res, 1–34
Ballotta L, Kyriakou I (2014) Monte Carlo simulation of the CGMY process and option pricing. J Futur Mark 34(12):1095–1121
Baschetti F, Bormetti G, Romagnoli S, Rossi P (2022) The SINC way: a fast and accurate approach to fourier pricing. Quant Finance 22(3):427–446
Bohman H (1970) A method to calculate the distribution function when the characteristic function is known. BIT Numer Math 10(3):237–242
Boyarchenko S, Levendorskiĭ S (2019) SINH-acceleration: efficient evaluation of probability distributions, option pricing, and Monte Carlo simulations. Int J Theor Appl Finance 22(03):1950011
Carr P, Geman H, Madan DB, Yor M (2007) Self-decomposability and option pricing. Math Financ 17(1):31–57
Carr P, Torricelli L (2021) Additive logistic processes in option pricing. Finance Stochast 25:689–724
Chen Z, Feng L, Lin X (2012) Simulating Lévy processes from their characteristic functions and financial applications. ACM Transact Model Comput Simul (TOMACS) 22(3):1–26
Chourdakis K (2005) Option pricing using the fractional FFT. J Comput Finance 8(2):1–18
Cont R, Tankov P (2003) Financial modelling with jump processes, Chapman & Hall/CRC Financial Mathematics Series
Cormen TH, Leiserson CE, Rivest RL, Stein C (2001) Introduction to algorithms. MIT Press
Eberlein E, Madan DB (2009) Sato processes and the valuation of structured products. Quant Finance 9(1):27–42
Feng L, Lin X (2013) Inverting analytic characteristic functions and financial applications. SIAM J Financ Math 4(1):372–398
Ferreiro-Castilla A, Van Schaik K (2015) Applying the Wiener-Hopf Monte Carlo simulation technique for Lévy processes to path functionals. J Appl Probab 52(1):129–148
Glasserman P (2004) Monte Carlo methods in financial engineering, vol. 53, Springer Science & Business Media
Glasserman P, Liu Z (2010) Sensitivity estimates from characteristic functions. Oper Res 58(6):1611–1623
Hall CA, Meyer WW (1976) Optimal error bounds for cubic spline interpolation. J Approx Theory 16(2):105–122
Jackson KR, Jaimungal S, Surkov V (2008) Fourier space time-stepping for option pricing with Lévy models. J Comput Finance 12(2):1–29
Kudryavtsev O (2019) Approximate Wiener-Hopf factorization and Monte Carlo methods for Lévy processes. Theory Probab Appl 64(2):186–208
Kuznetsov A, Kyprianou AE, Pardo JC, Van Schaik K (2011) A Wiener-Hopf Monte Carlo simulation technique for Lévy process. Ann Appl Probab 21(6):2171–2190
Lee RW (2004) Option pricing by transform methods: extensions, unification and error control. J Comput Finance 7(3):51–86
Lewis AL (2001) A simple option formula for general jump-diffusion and other exponential Lévy processes, Available on SSRN, ssrn.com/abstract=282110
Lukacs E (1972) A survey of the theory of characteristic functions. Adv Appl Probab 4(1):1–37
Madan DB, Wang K (2020) Additive processes with bilateral gamma marginals. Appl Math Finance 27(3):171–188
Marsaglia G, Tsang WW (2000) The ziggurat method for generating random variables. J Stat Softw 5(8):1–7
Phelan CE, Marazzina D, Fusai G, Germano G (2019) Hilbert transform, spectral filters and option pricing. Ann Oper Res 282(1–2):273–298
Press WH, Teukolsky SA, Vetterling WT, Flannery BP (1992) Numerical recipes in C: the art of scientific computing. Cambridge University Press
Quarteroni A, Sacco R, Saleri F (2007). Numerical mathematics, vol. 37, Springer Science & Business Media
Samorodnitsky G, Taqqu M (1994) Stable non-Gaussian random processes: stochastic models with infinite variance. Chapman & Hall
Sato KI (1999) Lévy processes and infinitely divisible distributions. Cambridge University Press
Acknowledgements
We are grateful for the valuable comments from M. Fukasawa and C. Alasseur. We thank L. Ballotta, F. Baschetti, J. Blomvall, G. Bormetti, G. Consigli, G. Fusai, G. Germano, I. Kyriakou, O. Le Courtois, A. Pallavicini, R. Renò, and all participants to the conference on Intrinsic Time in Finance in Constance, to the QF workshop 2022 in Rome, to the ECSO-CMS conference 2022 in Venice, to the seminar at EDF R &D in Paris and to the Bayes financial engineering workshops 2022 in London.
Funding
Open access funding provided by Politecnico di Milano within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: The key features of the ATS process
In this appendix, we briefly recall the features of the ATS process that we use in the numerical experiments.
As in Azzone and Baviera (2022a), we model the forward at time t with maturity T as an exponential additive
where \(f_t\) is the ATS process.
At time t, the ATS characteristic function is
\(\sigma _t\), \(k_t\) are continuous on \([0,\infty )\) and \(\eta _t\) is continuous on \((0,\infty )\), with \(\sigma _t > 0\), \(k_t, \eta _t \ge 0\). As in the corresponding Lévy case, we define
with \(\alpha \in (0,1)\).Footnote 12
As proven by Azzone and Baviera (2022a) in proposition 2.2, the forward process \(F_t(T)\) is a martingale under the risk neutral measure.
The ATS jump measure is
with
and \(K_\nu (x)\) the modified Bessel function of the second kind (see e.g., Abramowitz and Stegun 1948, ch.9, p.376)
Moreover, we recall that a sufficient condition for the existence of ATS is provided in the following theorem (cf. Azzone and Baviera 2022a, th.2.1, p.503).
Theorem A.1
Sufficient conditions for existence of ATS There exists an additive process \(\left\{ f_t \right\} _{t\ge 0}\) with the characteristic function (15) if the following two conditions hold.
-
(a)
\(g_1(t)\), \(g_2(t)\), and \(g_3(t)\) are non decreasing, where
$$\begin{aligned} g_1(t)&:=(1/2+\eta _t)-\sqrt{\left( 1/2+\eta _t\right) ^2+ 2(1-\alpha )/(\sigma _t^2 k_t)} \nonumber \\ g_2(t)&:=-(1/2+\eta _t)-\sqrt{\left( 1/2+\eta _t\right) ^2+ 2(1-\alpha )/( \sigma _t^2 k_t)}\\ g_3(t)&:=\frac{ t^{1/\alpha }\sigma ^2_t}{k_t^{(1-\alpha )/\alpha }}\sqrt{\left( 1/2+\eta _t\right) ^2+ 2(1-\alpha )/( \sigma _t^2k_t)}\;\;; \nonumber \end{aligned}$$(17) -
(b)
Both \(t\,\sigma _t^2\,\eta _t\) and \(t\,\sigma _t^{2\alpha }\,\eta _t^\alpha \,/k_t^{1-\alpha }\) go to zero as t goes to zero \(\square\)
We point out that the boundaries of the strip of regularity of the characteristic function of the ATS \(p_t^++1\) and \(p_t^-\) are equivalent to \(g_1(t)\) and \(g_2(t)\), as shown in the proof of proposition 4.2.
Appendix 2: Simulation algorithm
A brief description of the Lewis-FFT algorithm follows

Appendix 3: European options errors: spline versus linear
In this appendix, we report the error between simulated and exact option prices strike-by-strike. In Table 6, we report the prices of 30 European options with exact method, Lewis-FFT-S MC and Lewis-FFT MC with linear interpolation for the 1-month maturity, \(\alpha =2/3\), and \(M=10\). Option prices are in percentage of the spot price. Errors of the Lewis-FFT-S are of the order of 0.01 bp. Morover, errors with spline interpolation are, on average, two orders of magnitude below errors with linear interpolation.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Azzone, M., Baviera, R. A fast Monte Carlo scheme for additive processes and option pricing. Comput Manag Sci 20, 31 (2023). https://doi.org/10.1007/s10287-023-00463-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10287-023-00463-1