
Abstract
In the paper we consider two types of utility functions often used in portfolio allocation problems, i.e. the exponential utility and the quadratic utility. We link the resulting optimal portfolios obtained by maximizing these utility functions to the corresponding optimal portfolios based on the minimum value-at-risk (VaR) approach. This allows us to provide analytic expressions for the risk aversion coefficients as functions of the VaR level. The results are initially derived under the assumption that the vector of asset returns is multivariate normally distributed and they are generalized to the class of elliptically contoured distributions thereafter. We find that the choice of the coefficients of risk aversion depends on the stochastic model used for the data generating process. Finally, we take the parameter uncertainty into account and present confidence intervals for the risk aversion coefficients of the considered utility functions. The theoretical results are validated in an empirical study.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The von Neumann–Morgenstern expected utility theory (see, von Neumann and Morgenstern (1944)) is often used to find the optimal portfolio weights. These weights represent the optimal fractions of wealth allocated to individual assets and lead to the maximum expected utility of future wealth. The future wealth or portfolio return is random implying that the expected utility depends on the parameters of the distribution used to model the data generating process of the underlying assets. An issue, which has to be addressed by the investor, is the choice of the functional form of the utility function. Typically, the analysis is constrained to the quadratic or exponential utilities [c.f., Tobin (1958), Bodnar et al. (2015)], which allow for explicit solutions of the portfolio problem. Other functions, like the power utility, require numerical techniques. Usually, most of the utility functions depend on an additional parameter referred to as a risk aversion coefficient. This parameter quantifies the investor’s attitude towards risk. Its choice is subjective and can be hardly justified by economic reasoning. In this paper, we argue that the risk aversion coefficient can be linked to the distribution used as a model for the data generating process and to the level of the value-at-risk (VaR) in which the investor is interested in or is required to report.
The quadratic utility function is commonly applied in portfolio theory because of its nice mathematical properties. First, an analytic solution is easy to obtain for the quadratic utility function. Second, Tobin (1958) showed that the Bernoulli principle is satisfied for the mean-variance solution only if one of the following two conditions is valid: the asset returns are normally distributed or the utility function is quadratic. Moreover, the quadratic utility presents a good approximation of other utility functions [see, e.g., Kroll et al. (1984), Brandt and Santa-Clara (2006), Levy and Levy (2014), Markowitz (2014)]. Levy and Markowitz (1979) considered the expected utility function in terms of the portfolio return and showed that it can be well approximated by a function of the mean and the variance of the portfolio return. For a portfolio with the weights \(\mathbf {w}=(w_1,\ldots ,w_k)^\prime \) such that \(\mathbf {w}^\prime \mathbf {1}=1\) where \(\mathbf {1}\) denotes the k-dimensional vector of ones, the quadratic utility is given by
where \(\mathbf {X}=(X_{1},\ldots ,X_{k})^\prime \) is the k-dimensional vector of asset returns and \(R_{\mathbf {w}}\) denotes the return of the portfolio with the weights \(\mathbf {w}\). The symbol \(\gamma _{quad}>0\) stands for the risk aversion coefficient.
The second utility function considered in the paper is the exponential utility given by
where \(\gamma _{exp}>0\) is the corresponding risk aversion coefficient. If the asset returns are multivariate normally distributed then the maximization of \(E(U_{exp}(R_{\mathbf {w}}))\) is equivalent to the so-called mean-variance utility function expressed as [cf. Ingersoll (1987), Okhrin and Schmid (2006, 2008)]
where \(\varvec{\mu }=E(\mathbf {X})\) and \(\varvec{\Sigma }=Var(\mathbf {X})\). Bodnar et al. (2013) compared the solutions resulting from maximizing \(E(U_{quad}(R_{\mathbf {w}}))\), \(E(U_{exp}(R_{\mathbf {w}}))\), and (3) and found that although they are mathematically equivalent, their stochastic properties appear to be different.
Note that the choice of the values for both \(\gamma _{quad}\) and \(\gamma _{exp}\) in practice is unclear. There are a few papers dealing with the estimation of the risk aversion coefficient from market data. For instance, Jackwerth (2000) derives the implied absolute risk aversion coefficient by estimating the risk-neutral and historical probabilities from option prices, while estimators relying on the realized volatility were suggested by Bollerslev et al. (2011). It is important to note, that the corresponding risk aversions characterize an aggregate and not an individual investor. The usual values of \(\gamma \)’s considered in empirical applications lie between 1 and 50 (for the quadratic utility) and the choice of the risk aversion coefficient is, usually, performed heuristically. In contrast, our approach is motivated by the financial interpretation of the solutions of the expected utility maximization problems based on the utilities (1) and (2).
The VaR-based regulation of the financial sector makes the VaR one of the central risk measures not only for funds but also for other investors [see, e.g., Bonaccolto et al. (2017)]. As a result the minimum-VaR portfolio of Alexander and Baptista (2002, 2004) became an appealing alternative to the classical mean-variance portfolio selection strategies. This is additionally supported by the good out-of-sample performance of these portfolios as documented by Alexander et al. (2009) and Durand et al. (2011). The authors show that using VaR as an additional constraint within a mean-variance portfolio strategy clearly reduce the impact of estimation risk in the parameters of asset returns. Furthermore, the resulting portfolios are more efficient compared to the portfolios without this constraint.
The idea of linking the risk aversion coefficient to the VaR level is not new and was recently popularized in Das et al. (2010) and Alexander and Baptista (2011). Generally it appears that the attitude towards risk can be easier specified by using the confidence level of VaR than by fixing abstract risk aversion coefficients. Das et al. (2010) impose a VaR constraint on the portfolio return and determine the implied risk aversion coefficient which leads to the targeted VaR of the portfolio. Alexander and Baptista (2011) derived an explicit expression for the implied risk aversion coefficient as a function of the VaR confidence level. This framework allows to incorporate the mental accounts and objectives of investors. Note that in both papers the authors assume Gaussian asset returns and the quadratic utility function.
In this paper, we extend the above mentioned paper by considering two different utility functions and elliptically distributed asset returns. More precisely we link the optimal portfolio obtained from a particular utility function to the minimum VaR optimal portfolio. The latter portfolio is determined by the significance level \(\alpha \), which can be fixed relying on the regulatory recommendations. This allows us to derive analytic expressions for \(\gamma _{quad}(.)\) and \(\gamma _{exp}(.)\) as functions of the VaR level. Thus, we quantify the investor’s attitude towards risk for different utilities and under different and more realistic distributional assumptions. The results of the empirical study justify the values of the risk aversion coefficients which are usually used in practice.
The rest of the paper is organized as follows. In Sect. 2, we present the main results of the paper. Here, the analytical expressions for \(\gamma _{quad}\) and \(\gamma _{exp}\) are presented under the assumption that the asset returns are multivariate normally distributed. In Sect. 3, these findings are extended to non-normal distributions. The influence of the parameter uncertainty is analyzed in Sect. 4, while the results of the empirical study are shown in Sect. 5. Concluding remarks are presented in Sect. 6. The “Appendix” contains the proofs of theoretical results.
2 Risk aversion for Gaussian returns
The results of this section are derived assuming that the asset returns are multivariate normally distributed, i.e. \(\mathbf {X}\sim \mathcal {N}_k(\varvec{\mu },\varvec{\Sigma })\), whereas the findings under a more general class of distributions are presented in the next section.
We consider two investors who aim to maximize the expected quadratic utility function given by
and the expected exponential utility function expressed as
respectively.
Merton (1969) proved that if the asset returns are multivariate normally distributed then the maximization of the expected exponential utility function is equivalent to the maximization of the mean-variance utility (3). The solution of (3) coincides with the Markowitz efficient frontier which is a parabola in the mean-variance space (Merton 1972) uniquely determined by the three parameters [cf. Bodnar and Schmid (2008b, 2009)), Font (2016)]
The quantities \(R_{\textit{GMV}}\) and \(V_{\textit{GMV}}\) are the expected return and the variance of the global minimum variance (GMV) portfolio [cf., Bodnar et al. (2017)] that determine the location of the parabola’s vertex in the mean-variance space, while s is the slope parameter of the parabola.
The maximization of the exponential utility function, i.e. (5), leads to the optimal portfolio with the weights
Similarly, the solution of (4) is given by
where \(\mathbf {A}=E(\mathbf {X}\mathbf {X}^\prime )\) and \(\mathbf {R}_{\mathbf {A}}=\mathbf {A}^{-1}-\frac{\mathbf {A}^{-1}\mathbf {1}\mathbf {1}^\prime \mathbf {A}^{-1}}{\mathbf {1}^\prime \mathbf {A}^{-1}\mathbf {1}}\). Bodnar et al. (2012) derived another expression for the weights of the optimal portfolio in the sense of maximizing the expected quadratic utility function expressed as
with [see, Bodnar et al. (2012, Theorem 1)]
In the next step we use another way of constructing an optimal portfolio on the efficient frontier which characterizes the investor’s attitude towards risk in a more natural way. A suitable candidate is the minimum VaR portfolio suggested by Alexander and Baptista (2002, 2004). The VaR at the confidence level \(\alpha \in (0.5,1)\) (\({\textit{VaR}}_\alpha \)) is defined as a portfolio loss satisfying
If \(\mathbf {X}\) is multivariate normally distributed then \(\textit{VaR}_\alpha \) is calculated implicitly and it is given by
where \(z_{\beta }=\Phi ^{-1}(\beta )\) is the \(\beta \)-quantile of the standard normal distribution. In practice, the values of \(\alpha \) are usually taken from the interval [0.95, 1). The VaR is a standard method of risk monitoring suggested by the Basel Committee on Banking Supervision. Alexander and Baptista (2002) went beyond taking of VaR for monitoring purposes, but use the VaR as a risk proxy in portfolio management. The optimization problem is given by
Alexander and Baptista (2002) proved that the solution of (11) lies on the efficient frontier and presented the expression for the weights of this portfolio. Additionally to a very concise and intuitive mathematical formulation of the problem, the minimum-VaR portfolios show a good out-of-sample performance as noted by Alexander et al. (2009) and Durand et al. (2011). The portfolios diminish the damaging impact of estimation risk and appear to be more efficient than the classical benchmarks.
Bodnar et al. (2012) restated the formula for the weights of the minimum VaR portfolio using the structure of (7):
The last expression implies that the VaR confidence level should be sufficiently high to guarantee that \(z_{1-\alpha }^2> s\) as was also originally identified in Alexander and Baptista (2002).
The above results can be summarized as follows:
-
It is important to note that all three solutions of the maximization problems in (4), (5) and (11) [cf. Bodnar et al. (2012)] lie on the Markowitz efficient frontier.
-
Equations (7), (9) and (12) show that all optimal portfolios have the same structure. Moreover, from (10) we conclude that the maximization of the expected quadratic utility function with the risk aversion coefficient \(\gamma _{quad}\) leads to the same portfolio as the maximization of the expected exponential utility function with the risk aversion coefficient \(\gamma _{exp}=\tilde{\gamma }_{quad}\) where the latter is given in (10).
The risk aversion coefficients \(\gamma _{quad}\), \(\gamma _{exp}\) and the \(\alpha \) value of VaR are related as obviously follows from (7), (9) and (12). Previously this idea was already exploited in Alexander and Baptista (2011) and Das et al. (2010) for Gaussian returns and quadratic utility function. From financial perspective the linkage is reasonable too, since investors can assess their attitude to risk using the confidence level of VaR in a more precise way, than by relying on an abstract risk aversion coefficient. This is additionally justified by the popularity of the VaR as a risk measure in the current regulatory laws.
The explicit relation depends on the parameters of the efficient frontier, \(R_{\textit{GMV}}\), s and \(V_{\textit{GMV}}\) only. Using (12) we are able to specify the closed-form expressions for risk aversion coefficients \(\gamma _{quad}\) and \(\gamma _{exp}\) used in (1) and (2), respectively, such that the corresponding portfolios coincide with the minimum VaR portfolio. Our results are summarized in the following theorem.
Theorem 1
Let \(\mathbf {X}\sim \mathcal {N}_k(\varvec{\mu },\varvec{\Sigma })\) and \(z_{1-\alpha }^2>s\). Then the implied risk aversion coefficients for the exponential and quadratic utility functions can be given in terms of the characteristics of the mean-variance efficient frontier and the confidence level of the VaR as follows:
The proof of Theorem 1 follows directly from the expressions for the weights given in (7), (9), and (12). Note that the expression in (14) coincides with equation (34) of Alexander and Baptista (2011), if the boundary for the portfolio return is appropriately selected. A semi-analytic expression for the implied risk aversion can also be found in Das et al. (2010) within a slightly different setup. For a given level of \(\alpha \) the investor attempts to minimize the most negative \(\alpha \dot{1}00\%\) of losses. Thus, \(\alpha \) reflects the risk attitude of the investor. If \(\alpha \) is large, then (s)he minimizes the extreme losses and, hence, the investor is very risk averse. If \(\alpha \) is small, then the investor cares about losses in general without paying particular attention to large losses. This implies that his risk aversion is moderate. In general it holds that both risk aversions are monotonously increasing in \(\alpha \).
At first sight, the dependence of the risk aversion on the characteristics of the efficient frontier appears to be surprising. However, this evidence is natural since the investor is averse to a particular amount of loss or of risk, implying non-constant \(\gamma \)’s. For a very risky portfolio the investor is more risk averse, than for a portfolio with a moderate risk. Moreover, the maximization of the expected quadratic utility function as well as of the expected exponential utility function leads to the portfolios which lie on the efficient frontier. As a result, the investor’s attitude towards risk depends on the position of the efficient frontier in the mean-variance space, which is fully determined by three parameters: \(R_{\textit{GMV}}\), \(V_{\textit{GMV}}\), and s.
3 Determination of the risk aversion coefficients for elliptically contoured distributed asset returns
We now extend the results of Sect. 2 to elliptically contoured (EC) distributions. This is a large class of multivariate distributions which includes the multivariate normal, Laplace and t distributions as special cases. This class has been already widely discussed in financial literature. For instance, Owen and Rabinovitch (1983) extended Tobin’s separation theorem, Bawa’s rules of ordering certain prospects to EC distributions. While Chamberlain (1983) showed that elliptical distributions imply the mean-variance utility functions, Berk (1997) argued that one of the necessary conditions for the validity of the capital asset pricing model (CAPM) is an elliptical distribution for the asset returns. Furthermore, Zhou (1993) extended findings of Gibbons et al. (1989) by applying their test to EC distributed returns. A further test for the CAPM under elliptical assumptions was proposed by Hodgson et al. (2002). The application of matrix variate elliptically contoured distributions in portfolio theory was initiated by Bodnar and Schmid (2008a) and Bodnar and Gupta (2009).
In this section, we restrict the discussion to the class of EC distributions for which the density function exists. The vector of asset returns \(\mathbf {X}\) is said to be elliptically contoured distributed if its density function is given by
where \(c_k>0\) is a constant which depends on the specific type of elliptically contoured distribution, i.e. on the function g(.) and the dimension of the vector \(\mathbf {X}\) only. Hereafter we use the shorthand notation \(\mathbf {X}\sim E_k(\varvec{\mu },\mathbf {D},g)\). The symbol \(\varvec{\mu }\) is the location vector, while \(\mathbf {D}\) denotes the dispersion matrix. If the second moment of \(\mathbf {X}\) exists then
i.e. \(\varvec{\mu }\) is the mean vector and the covariance matrix is proportional to \(\mathbf {D}\) with \(\omega =E(r^2)\) (see 16). The stochastic representation of the random vector \(\mathbf {X}\) is a convenient tool for simulation purposes. If the density function exists for all \(k \ge 1\) then the stochastic representation of \(\mathbf {X}\) is given by [cf. Fang and Zhang (1990)]
where \(\mathbf {Z}\sim \mathcal {N}_k(\mathbf {0}_k,\mathbf {I}_k)\) is independent of the scalar nonnegative random variable r. The symbol \(\mathbf {0}_k\) denotes the k-dimensional zero vector, while \(\mathbf {I}_k\) stands for the identity matrix of order k. Moreover, from (16) it holds that r fully determines the type of elliptical contoured distribution.
Using (16) we can calculate the expected quadratic utility and the expected exponential utility under the assumption that the asset returns follow an EC distribution. For the quadratic utility function it holds that
Consequently, the optimization problem based on (17) subject to \(\mathbf {1}^\prime \mathbf {w}=1\) is the same as the one in the case of the multivariate normally distributed asset returns. As a result, its solution is given by (9).
Similarly, using that \(R_{\mathbf {w}}|r \sim N(\varvec{\mu }^\prime \mathbf {w},r^2 \mathbf {w}^\prime \mathbf {D}\mathbf {w})\) for the exponential utility function we get
where the last identity is obtained observing that the conditional expectation is the moment generating function of the univariate normal distribution at point \(-\gamma _{exp}\). Hence,
where \(m_{r^2}(t)=E\left( e^{t r^2}\right) \) is the moment generating function of \(r^2\). As a result, the maximization of the expected exponential utility function is equivalent to
Lemma 1
Let \(\mathbf {X}\sim E_k(\varvec{\mu },\mathbf {D},g)\) with the moment generating function of \(r^2\) given by \(m_{r^2}(.)\). Then the solution of the optimization problem (19) is given by
where \(\tilde{\gamma }_{exp}\) is the solution with respect to \(\kappa \) of
with \(\psi (x)=\log \left( m_{r^2}(x)\right) \).
The results of Lemma 1 are appealing from a practical perspective. Although the maximization of the expected exponential utility function results in a challenging non-linear multivariate optimization problem, it can be simplified to an univariate one, for which the solution is determined by solving (21) with respect to \(\kappa \). This result continues to be true independently how large is the dimension of the constructed portfolio. Finally, we note that if the asset returns are multivariate normally distributed then \(r=1\) and, consequently, \(E(r^2)=1\), \(m_{r^2}(x)=e^x\), and \(\psi ^\prime (x)=1\). It follows from (21) that \(\kappa =\gamma _{exp}^{-1}\).
Next, we compare the solution of the maximization problems (4) and (5) under the assumption of elliptically distributed asset returns with the one obtained by minimizing the VaR at the confidence level \(\alpha \). In the case of elliptically contoured distribution, the VaR of the portfolio with weights \(\mathbf {w}\) is given by
where \(d_{1-\alpha }\) depends on k and g(.) only and it is independent of \(\mathbf {w}\). Minimizing \(\textit{VaR}_\alpha \) with respect to \(\mathbf {w}\) leads to the following expression for the weights
Using (22) we are able to specify the closed-form expressions for the risk aversion coefficients \(\gamma _{quad}\) and \(\gamma _{exp}\). It holds that
Theorem 2
Let \(\mathbf {X}\sim E_k(\varvec{\mu },\mathbf {D},g)\) with the moment generating function of \(r^2\) given by \(m_{r^2}(.)\) and let \(d_{1-\alpha }^2/E(r^2)>s\). Then
Additionally, \(\gamma _{exp}\) is the solution of
with \(\kappa =\frac{\sqrt{V_{\textit{GMV}}}}{\sqrt{d_{1-\alpha }^2/E(r^2)-s}}\).
The expression for the quadratic utility resembles the result under the Gaussian assumption, but for the exponential case the results appear to be more involved.
4 Estimation and inference procedure
In this section we deal with the problem of parameter uncertainty which has become a popular topic in finance recently [see, e.g., Kawas and Thiele (2017)]. The parameters of asset returns, i.e. \(\varvec{\mu }\) and \(\varvec{\Sigma }\), are unknown and have to be estimated from a sample. Replacing the population parameters with their sample counterparts in the above equations for the risk aversion coefficients we obtain their sample counterparts. In order to access the statistical properties of estimators we derive their stochastic representations.
Let \(\mathbf {X}_1,\ldots ,\mathbf {X}_n\) be a sample of asset returns used to estimate the parameters \(\varvec{\mu }\) and \(\varvec{\Sigma }\) by
Substituting \(\hat{\varvec{\mu }}\) and \(\hat{\varvec{\Sigma }}\) from (23) in (6), the estimators for the three parameters of the efficient frontier \(R_{\textit{GMV}}\), \(V_{\textit{GMV}}\), and s are obtained, namely,
Because \(\hat{\varvec{\mu }}\) and \(\hat{\varvec{\Sigma }}\) are random quantities, the estimated characteristics in (24) are random too. Assuming that the asset returns are iid and normal, Bodnar and Schmid (2008b, 2009) derived the exact distributions of \(\hat{R}_{\textit{GMV}}\), \(\hat{V}_{\textit{GMV}}\), and \(\hat{s}\). Let \(\phi (\cdot )\) be the density function of the standard normal distribution. By \(f_{\chi ^2_n}(\cdot )\) we denote the density of the \(\chi ^2\)-distribution with n degrees of freedom, while \(f_{F_{n_1,n_2,\lambda }}(\cdot )\) stands for the density of the non-central F-distribution with \(n_1\) and \(n_2\) degrees of freedom and the non-centrality parameter \(\lambda \). The symbol \(f_{N(\mu ,\sigma ^2)}(.)\) is used for the density function of the normal distribution with mean \(\mu \) and variance \(\sigma ^2\).
In the following lemma we summarize some results of Bodnar and Schmid (2008b, 2009). Particularly, we provide the exact joint and marginal distributions of \(\hat{R}_{\textit{GMV}}\), \(\hat{V}_{\textit{GMV}}\), and \(\hat{s}\).
Lemma 2
Let \(\mathbf {X}_1,\ldots ,\mathbf {X}_n\) be a random sample of independent vectors such that \(\mathbf {X}_i\sim \mathcal {N}_k(\varvec{\mu },\varvec{\Sigma })\) for \(i=1,\ldots ,n\) and \(n > k\). Let \(\varvec{\Sigma }\) be positive definite. Then it holds that
-
(a)
\(\hat{V}_{\textit{GMV}}\) is independent of \((\hat{R}_{\textit{GMV}},\hat{s})\).
-
(b)
\((n-1){\hat{V}_{\textit{GMV}}}/{V_{\textit{GMV}}} \sim \chi ^2_{n-k}\).
-
(c)
\(\frac{n(n-k+1)}{(n-1)(k-1)} \hat{s}\sim F_{k-1,n-k+1,n\,s}\).
-
(d)
\(\hat{R}_{\textit{GMV}}| \hat{s}=y \sim \mathcal {N}\left( R_{\textit{GMV}},\frac{1+\frac{n}{n-1}y}{n}V_{\textit{GMV}}\right) \).
-
(e)
The joint density function of \(\hat{R}_{\textit{GMV}}\), \(\hat{V}_{\textit{GMV}}\), and \(\hat{s}\) is given by
$$\begin{aligned} f_{\hat{R}_{\textit{GMV}},\hat{V}_{\textit{GMV}},\hat{s}}(x,y,z)&=\frac{n(n-k+1)}{(k-1)V_{\textit{GMV}}} f_{\chi ^2_{n-k}}\left( \frac{n-1}{V_{\textit{GMV}}}z\right) \\&\times f_{N(R_{\textit{GMV}},\frac{1+\frac{n}{n-1}y}{n}V_{\textit{GMV}})}(x)\\&f_{F_{k-1,n-k+1,n\,s}}\left( \frac{n(n-k+1)}{(n-1)(k-1)}y\right) . \end{aligned}$$
The application of the closed-form expressions for the risk aversion coefficients derived in Theorem 1 leads to the following estimators of these quantities given by
The formulas (25) and (26) show that the risk aversion coefficients can be estimated only if \(\hat{s}<z^2_{1-\alpha }\). Moreover, the corresponding population quantities can be interpreted if \(s<z^2_{1-\alpha }\) only. These two observations show that we are not able to derive the unconditional distributions of \(\hat{\gamma }_{exp}\) and \(\hat{\gamma }_{exp}\) but only the corresponding conditional distributions provided that \(\hat{s}<z_{1-\alpha }^2\). Following the approach of Bodnar et al. (2012) we first establish the conditional distributions of \(\hat{\gamma }_{quad}\) and \(\hat{\gamma }_{exp}\) given \(\hat{s}=s^*\) and generalize the results thereafter.
From Lemma 2 we obtain the following stochastic representations of \(\hat{R}_{\textit{GMV}}\) and \(\hat{V}_{\textit{GMV}}\) given \(\hat{s}=s^*\), denoted by \(\hat{R}_{\textit{GMV}}^*\) and \(\hat{V}_{\textit{GMV}}^*\). They are expressed as
where \(\xi _1 \sim N(0,1)\) and \(\xi _2 \sim \chi ^2_{n-k}\) are independently distributed. In Theorem 3 we establish the stochastic representations of \(\hat{\gamma }_{exp}\) and \(\hat{\gamma }_{quad}\) conditional on \(s^*=\hat{s}\). These quantities are denoted by \(\hat{\gamma }_{exp}^*\) and \(\hat{\gamma }_{quad}^*\).
Theorem 3
Let \(\mathbf {X}_1,\ldots ,\mathbf {X}_n\) be a random sample of independent vectors such that \(\mathbf {X}_i\sim \mathcal {N}_k(\varvec{\mu },\varvec{\Sigma })\) for \(i=1,\ldots ,n\) and \(n > k\). Let \(\varvec{\Sigma }\) be positive definite. Then it holds that
The results of Theorem 3 possess several interesting applications. First, for simulating \(\hat{\gamma }_{exp}^*\) and \(\hat{\gamma }_{quad}^*\) it is not necessary to generate n independent k-variate normally distributed random vectors. It is sufficient to simulate two independent random variables \(\xi _1\) and \(\xi _2\) from the well-known univariate distributions and then to apply the expressions of Theorem 3. Second, Theorem 3 is useful if one wants to derive the the densities of \(\hat{\gamma }_{exp}^*\) and \(\hat{\gamma }_{quad}^*\).
5 Extension to robust portfolio selection
Our results can be extended to the case where the investor solves
where u(.) is a utility function. If the distribution of asset returns is partially known then the portfolio selection problem (30) can be reformulated with robust optimization technique as follows [cf. Fabozzi et al. (2010)]
where the notation \(\mathbf {X}\sim (\varvec{\mu },\varvec{\Sigma })\) indicates that the distribution of \(\mathbf {X}\) belongs to the class of k-dimensional distributions with the mean vector \(\varvec{\mu }\) and the covariance matrix \(\varvec{\Sigma }\).
Let
denote the value of the inner minimization problem for given weights \(\mathbf {w}\). Popescu (2007) proved that (32) is equivalent to an optimization problem with univariate distributions with a given mean and variance, i.e.
Moreover, if \(V(\mathbf {w})\) is continuous, non-decreasing in \(\mu _{\mathbf {w}}\), non-increasing in \(\sigma ^2_{\mathbf {w}}\), and quasi-concave, then (31) is equivalent to the following quadratic optimization problem [cf. Popescu (2007)]
where \(\gamma \in [0,1]\). Moreover, if \(\mathbf {w}(\gamma )\) is the solution of (34) then \(V(\mathbf {w}(\gamma ))\) is continuous and unimodal in \(\gamma \).
Next we fix a portfolio \(\mathbf {w}\) and a confidence level \(\alpha \in (1/2,1]\). Fabozzi et al. (2010) argue that a robust version of VaR, denoted by RVaR, is given by
The application of Chebyshev’s inequality leads to [see Alexander and Baptista (2002, Section 3.2)]
where \(d_{1-\alpha }=d_{1-\alpha }(\mathbf {w})=1/\sqrt{1-\alpha }\). The solutions of the optimization problem (34) and
provide us the probabilistic interpretation of \(\gamma \). Following the proof of Theorem 1 we obtain
6 Empirical illustration
For illustration purposes we use monthly data for the MSCI Developed Markets Indexes (Australia, Austria, Belgium, Canada, Denmark, Finland, France, Germany, Hongkong, Ireland, Israel, Italy, Japan, Netherlands, New Zealand, Norway, Portugal, Singapore, Spain, Sweden, Switzerland, the UK, the US) and for the MSCI Emerging Markets Indexes (Brazil, Chile, China, Colombia, Czech Republic, Egypt, Greece, Hungary, India, Indonesia, South Korea, Malaysia, Mexico, Peru, Philippines, Poland, Russia, South Africa, Taiwan, Thailand, Turkey). The markets cover 23 and 21 countries respectively and the time span from June 2004 till March 2014, resulting in 117 observations. To assess the impact of the dimension we consider portfolios consisting of \(k = 2, 5, 10, 15, 21\) (or 23) assets. For simplicity we select the assets for the first part of the study in alphabetic order, e.g., when \(k=2\), the countries are Australia and Austria for developed markets and Brazil and Chile for emerging. The characteristics of the frontier are summarized in Table 1. As expected the variance of the GMV portfolio \(V_{\textit{GMV}}\) decreases with increasing k, but the return \(R_{\textit{GMV}}\) and the slope s increase. Furthermore, the return and variance of the global minimum variance portfolio are lower for the developed markets, compared to the emerging markets, which is consistent with our expectations.
6.1 Gaussian returns
The risk aversion coefficients \(\gamma _{quad}\) and \(\gamma _{exp}\) for Gaussian returns as functions of \(\alpha \) are shown in Fig. 1. In accordance with Theorem 1, note that these coefficients are monotonously increasing in \(\alpha \). Additionally, the coefficients are also increasing in k (the number of assets). Hence, if the size of the portfolio increases, then the minimum-VaR portfolio corresponds to a higher risk aversion coefficient. The same is observed by comparing the results for developed and emerging markets, where for the latter the implied risk aversion is lower despite of higher volatility. In general, for \(\alpha >0.95\) the risk aversion is high and the portfolio is close to the GMV portfolio. Even for small values of \(\alpha \) the risk aversion is much higher than the frequently used values from 1 to 10 for \(\gamma _{exp}\). This implies that if the investors are interested in the commonly used VaR at the 99% confidence level, then they are much more risk averse than typically assumed in empirical work.

The risk aversion coefficients \(\gamma _{quad}\) (top) and \(\gamma _{exp}\) (bottom) as functions of \(\alpha \) for portfolios consisting of the first k developed markets (left) and emerging markets (right)
In order to make the study robust to the choice of the indices we fix \(\alpha \) at 99% and sample 200 portfolios of different sizes from both pools of indexes. For each portfolio we compute the corresponding risk aversion coefficients and plot their histograms in Fig. 2. The result that the risk aversion coefficients increase in the number of assets still holds. Hence, this result is robust to using different sets of assets. Furthermore, small portfolios lead to systematically lower risk aversions compared to larger portfolios.

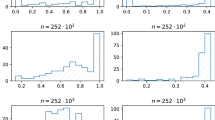
Histograms of risk aversion coefficients \(\gamma _{quad}\) (top) and \(\gamma _{exp}\) (bottom) for \(\alpha =0.99\) and portfolios consisting of \(k=2\) (left), \(k=5\) (middle) and \(k=15\) (right) randomly sampled emerging markets
6.2 Elliptical returns
To illustrate the theoretical results for elliptical distributions we concentrate on the multivariate Laplace distribution. This distribution is obtained assuming that \(r^2\) follows exponential distribution with intensity equal to 1. In a univariate framework the resulting distribution of \(X_i\) is the Laplace distribution with the density \(\frac{1}{2} \sqrt{\frac{2}{\lambda }} exp\left\{ -\sqrt{\frac{2}{\lambda }} |x_i-\mu _i|\right\} \). The \(1-\alpha \) quantile of this distribution is used as the \(d_{1-\alpha }\)-quantile in Theorem 2. Technical details on the multivariate Laplace distribution can be found in Eltoft et al. (2006), whereas Kotz et al. (2001) discuss the application of the multivariate Laplace distribution in portfolio theory. Alternatively, one may consider the multivariate t-distribution, which is very frequently applied in portfolio selection.
The Laplace distribution has heavier tails compared to the normal and thus is a reasonable alternative in financial applications. An explicit application of this distribution is technically demanding due to complex expressions for the density (see Eltoft et al. 2006). In our case, however, the stochastic representation allows us to work with r only. The corresponding risk aversion coefficients \(\gamma _{quad}\) and \(\gamma _{exp}\) as functions of \(\alpha \) are shown in Fig. 3. Similarly to the normal distribution, the risk aversion attains very high values even for modest levels of \(\alpha \). However, it is important to note that the values of the coefficients are lower than for the normal distribution. This implies that if we switch from the normal to a more heavy-tailed distribution the uncertainty about the future portfolio returns is partly captured by the new distribution. Particularly this is crucial for the minimum VaR portfolio, where we attempt to reduce the chances of large losses. Since the losses are partly taken into account by the new model, the investor becomes less risk averse within the new framework.

The risk aversion coefficients \(\gamma _{quad}\) (top) and \(\gamma _{exp}\) (bottom) as functions of \(\alpha \) for portfolios consisting of the first k developed markets (left) and emerging markets (right) assuming multivariate Laplace distribution for the returns
6.3 Estimation risk
With the next example we illustrate the simulated density functions of the sample risk aversions \(\hat{\gamma }_{quad}^*\) and \(\hat{\gamma }_{exp}^*\) by relying on Theorem 3. We use the same data as in the above examples and condition on \(s^*=\hat{s}\), where \(\hat{s}\) is obtained individually for each portfolio. We observe that the precision of the estimators is relatively high. Note that the number of assets has an opposite impact on the precision for the two risk aversions. While for the exponential utility the densities are narrower for small portfolios, they become wider for the quadratic utility (Fig. 4).

The conditional densities of \(\gamma _{quad}^*\) (top) and \(\gamma _{exp}^*\) (bottom) given \(s^*\) for portfolios consisting of the first k developed markets (left) and emerging markets (right) assuming multivariate normal distribution for the returns
7 Summary
In the paper we consider the exponential and quadratic utility functions which are frequently applied in portfolio management. Since the VaR plays a key role in monitoring risk, many investors follow the minimum VaR portfolio strategies. We link both approaches to obtain a functional relationships between the risk aversions and the level of VaR. The results are obtained assuming that the vector of asset returns is multivariate normally distributed and they are generalized to the class of elliptically contoured distributions. The latter is particularly important due to well known heavy-taildness of asset returns. Finally, we take the parameter uncertainty into account and give conditional stochastic representation of the empirical risk aversion coefficients. The theoretical results are validated in an empirical study.
References
Alexander GJ, Baptista AM (2002) Economic implication of using a mean-VaR model for portfolio selection: a comparison with mean-variance analysis. J Econ Dyn Control 26:1159–1193
Alexander GJ, Baptista AM (2004) A comparison of VaR and CVaR constraints on portfolio selection with the mean-variance model. Manag Sci 50:1261–1273
Alexander GJ, Baptista AM (2011) Portfolio selection with mental accounts and delegation. J Bank Finance 35:2637–2656
Alexander GJ, Baptista AM, Yan S (2009) Reducing estimation risk in optimal portfolio selection when short sales are allowed. Manag Decis Econ 30:281–305
Berk JB (1997) Necessary conditions for the CAPM. J Econ Theory 73:245–257
Bodnar T, Gupta AK (2009) Construction and inferences of the efficient frontier in elliptical models. J Jpn Stat Soc 39:193–207
Bodnar T, Schmid W (2008a) A test for the weights of the global minimum variance portfolio in an elliptical model. Metrika 67:127–143
Bodnar T, Schmid W (2008b) Estimation of optimal portfolio compositions for Gaussian returns. Stat Decis 26:179–201
Bodnar T, Schmid W (2009) Econometrical analysis of the sample efficient frontier. Eur J Finance 15:317–335
Bodnar T, Schmid W, Zabolotskyy T (2012) Minimum VaR and minimum CVaR optimal portfolios: estimators, confidence regions, and tests. Stat Risk Model 29:281–314
Bodnar T, Parolya N, Schmid W (2013) On the equivalence of quadratic optimization problems commonly used in portfolio theory. Eur J Oper Res 229:637–644
Bodnar T, Parolya N, Schmid W (2015) On the exact solution of the multi-period portfolio choice problem for an exponential utility under return predictability. Eur J Oper Res 246:528–542
Bodnar T, Mazur S, Okhrin Y (2017) Bayesian estimation of the global minimum variance portfolio. Eur J Oper Res 256:292–307
Bollerslev T, Gibson M, Zhou H (2011) Dynamic estimation of volatility risk premia and investor risk aversion from option-implied and realized volatilities. J Econom 160:235–245
Bonaccolto G, Caporin M, Paterlini S (2017) Log-robust portfolio management with parameter ambiguity. CMS 14:229–256
Brandt M, Santa-Clara P (2006) Dynamic portfolio selection by augmenting the asset space. J Finance 61:2187–2217
Chamberlain GA (1983) A characterization of the distributions that imply mean-variance utility functions. J Econ Theory 29:185–201
Das S, Markowitz H, Scheid J, Statman M (2010) Portfolio optimization with mental accounts. J Financ Quant Anal 45:311–334
Durand RB, Gould J, Maller R (2011) On the performance of the minimum VaR portfolio. Eur J Finance 17:553–576
Eltoft T, Kim T, Lee T-W (2006) On the multivariate Laplace distribution. IEEE Signal Process Lett 13:300–303
Fabozzi FJ, Huang D, Zhou G (2010) Robust portfolios: contributions from operations research and finance. J Ann Oper Res 176:191–220
Fang KT, Zhang YT (1990) Generalized multivariate analysis. Science Press, Springer, Beijing, Berlin
Font B (2016) Bootstrap estimation of the efficient frontier. CMS 13:541–570
Gibbons MR, Ross SA, Shanken J (1989) A test of the efficiency of a given portfolio. Econometrica 57:1121–1152
Hodgson DJ, Linton O, Vorkink K (2002) Testing the capital asset pricing model efficiency under elliptical symmetry: a semiparametric approach. J Appl Econom 17:617–639
Ingersoll JE (1987) Theory of financial decision making. Rowman & Littlefield Publishers, Lanham
Jackwerth JC (2000) Recovering risk aversion from option prices and realized returns. Rev Financ Stud 13:433–451
Kawas B, Thiele A (2017) Log-robust portfolio management with parameter ambiguity. CMS 14:229–256
Kotz S, Kozubowski T, Podgórski K (2001) The Laplace distribution and generalizations: a revisit with applications to communications, economics, engineering, and finance. Birkhäuser, Boston
Kroll Y, Levy H, Markowitz HM (1984) Mean-variance versus direct utility maximization. J Finance 39:47–61
Levy H, Levy M (2014) The benefits of differential variance-based constraints in portfolio optimization. Eur J Oper Res 234:372–381
Levy H, Markowitz HM (1979) Approximating expected utility by a function of mean and variance. Am Econ Rev 69:308–317
Markowitz H (2014) Mean-variance approximations to expected utility. Eur J Oper Res 234:346–355
Merton RC (1969) Lifetime portfolio selection under uncertainty: the continuous time case. Rev Econ Stat 50:247–257
Merton RC (1972) An analytic derivation of the efficient portfolio frontier. J Financ Quant Anal 7:1851–1872
Okhrin Y, Schmid W (2006) Distributional properties of portfolio weights. J Econom 134:235–256
Okhrin Y, Schmid W (2008) Estimation of optimal portfolio weights. Int J Theor Appl Finance 11:249–276
Owen J, Rabinovitch R (1983) On the class of elliptical distributions and their applications to the theory of portfolio choice. J Finance 38:745–752
Popescu I (2007) Robust mean-covariance solutions for stochastic optimization. Oper Res 55:98–112
Tobin J (1958) Liquidity preference as behavior towards risk. Rev Econ Stud 25:65–86
von Neumann J, Morgenstern O (1944) Theory of games and economic behavior. Princeton University Press, Princeton
Zhou G (1993) Asset-pricing tests under alternative distributions. J Finance 48:1927–1942
Acknowledgements
The authors thank Professor Rüdiger Schultz and an anonymous Reviewer for their helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
The authors appreciate the financial support of the German Science Foundation (DFG), projects BO3521/2 and OK103/1, “Wishart Processes in Statistics and Econometrics: Theory and Applications”. The first author is partly supported by the German Science Foundation (DFG) via the Research Unit 1735 ”Structural Inference in Statistics: Adaptation and Efficiency”.
Appendix
Appendix
Proof of Lemma 1
First, we note that \(\log (m_{r^2}(.))\) is an increasing function since \(\log (.)\) and \(m_{r^2}(.)\) are both increasing. Using this result we show that the solution of (19) lies on the efficient frontier in the mean-variance space [cf., Alexander and Baptista (2004, Definition 6)].
We prove the last statement by contradiction. Let \(\tilde{\mathbf {w}}\) be the solution of (19), but the portfolio with the weights \(\tilde{\mathbf {w}}\) does not lie on the efficient frontier. Then there exists a portfolio \(\tilde{\mathbf {w}}_0\) on the efficient frontier such that \(E(R_{\tilde{\mathbf {w}}_0}) \ge E(R_{\tilde{\mathbf {w}}})\) and \(Var(R_{\tilde{\mathbf {w}}_0}) \le Var(R_{\tilde{\mathbf {w}}})\) with at least one inequality being strict. Then
which implies that
The last equality contradicts the assumption that the portfolio with the weights \(\tilde{\mathbf {w}}\) maximizes the expected exponential utility function.
Hence, the weights of the optimal portfolio in the sense of maximizing the expected exponential utility are given by
Substituting the last equality in (19) leads to
which has to be maximized with respect to \(\kappa \). Let \(\psi (x)=\log \left( m_{r^2}(x)\right) \). Setting the derivative of (38) equal to zero leads to
Hence, \(\kappa \) is the solution of
This completes the proof. \(\square \)
Proof of Theorem 2
The equality for \(\gamma _{quad}\) follows from Theorem 1 and the fact that the expression for the weights of the minimum VaR portfolio in case of elliptically contoured distributions can be obtained from the expression for the case of normally distributed asset returns by replacing \(z_{1-\alpha }^2\) with \(d_{1-\alpha }^2/E(r^2)\). This follows from the fact that the weights of the portfolio maximizing the expected quadratic utility do not depend on the type of the underlying elliptically contoured distribution. The second result follows from (22) and Lemma 1. \(\square \)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Bodnar, T., Okhrin, Y., Vitlinskyy, V. et al. Determination and estimation of risk aversion coefficients. Comput Manag Sci 15, 297–317 (2018). https://doi.org/10.1007/s10287-018-0317-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10287-018-0317-x
Keywords
- Risk aversion
- Exponential utility
- Quadratic utility
- Elliptically contoured distributions
- Laplace distribution
- Parameter uncertainty