
Abstract
Forecast reconciliation is the post-forecasting process aimed to revise a set of incoherent base forecasts into coherent forecasts in line with given data structures. Most of the point and probabilistic regression-based forecast reconciliation results ground on the so called “structural representation” and on the related unconstrained generalized least squares reconciliation formula. However, the structural representation naturally applies to genuine hierarchical/grouped time series, where the top- and bottom-level variables are uniquely identified. When a general linearly constrained multiple time series is considered, the forecast reconciliation is naturally expressed according to a projection approach. While it is well known that the classic structural reconciliation formula is equivalent to its projection approach counterpart, so far it is not completely understood if and how a structural-like reconciliation formula may be derived for a general linearly constrained multiple time series. Such an expression would permit to extend reconciliation definitions, theorems and results in a straightforward manner. In this paper, we show that for general linearly constrained multiple time series it is possible to express the reconciliation formula according to a “structural-like” approach that keeps distinct free and constrained, instead of bottom and upper (aggregated), variables, establish the probabilistic forecast reconciliation framework, and apply these findings to obtain fully reconciled point and probabilistic forecasts for the aggregates of the Australian GDP from income and expenditure sides, and for the European Area GDP disaggregated by income, expenditure and output sides and by 19 countries.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Starting from Hyndman et al. (2011), regression-based forecast reconciliation has become an hot topic in the forecasting literature (van Erven and Cugliari 2015; Wickramasuriya et al. 2019; Wickramasuriya 2021; Panagiotelis et al. 2021; Jeon et al. 2019; Ben Taieb and Koo 2019; Ben Taieb et al. 2021; Panagiotelis et al. 2023; Wickramasuriya 2023). By forecast reconciliation, we mean a post-forecasting procedure (Di Fonzo and Girolimetto 2023) in which previously (and however) generated incoherent predictions (called base forecasts) for all the components of a multiple time series are adjusted in order to fulfill some externally given linear constraints. These reconciled forecasts are said to be coherent. In many real world applications, forecasts of a large collection of time series have a natural organization according to a hierarchical structure. More precisely, a system is classified as hierarchical when series are created by aggregating others in a tree shape. When the system is formed by a unique tree, then the collection is called “hierarchical time series” (Hyndman et al. 2011). On the other side, when various hierarchies share the same series at both the most aggregated and disaggregated levels (top and bottom level, respectively), we face a “grouped time series” (Hyndman et al. 2016).
In the field of forecast reconciliation, the bottom-up and top-down approaches are among the earliest and best known ones. Bottom-up forecasting (Dunn et al. 1976) uses only forecasts at the bottom level to obtain all the reconciled forecasts. In contrast, top-down forecasting (Gross and Sohl 1990) uses only the forecasts at the highest aggregated level. Having observed that neither forecasting approach uses all the available information, Hyndman et al. (2011) developed a regression-based reconciliation approach consisting in (i) forecasting all the series with no regard for the constraints, and (ii) using then a regression model to optimally combining these (base) forecasts in order to produce coherent forecasts. This approach has witnessed a continuous growth of the related literature (Hyndman et al. 2016; Athanasopoulos et al. 2020; Wickramasuriya 2021; Panagiotelis et al. 2023), that in most cases grounds on the so-called structural representation of a hierarchical/grouped time series (Athanasopoulos et al. 2009), in which the variables are classified either bottom if they belong to the most disaggregated level, or upper if they are obtained by summing the lower levels’ variables. In mathematical terms, upper and bottom variables are linked by an aggregation matrix, which describes how the upper series are obtained from the bottom ones (Hyndman et al. 2011). This representation is directly related to the hierarchical structure, where the series are naturally classifiable and an aggregation matrix may be obtained with little effort. Theoretical aspects for point and probabilistic forecast reconciliation have been developed using a structural representation by Panagiotelis et al. (2021) and Panagiotelis et al. (2023), respectively (see also Wickramasuriya 2021, 2023).
However, it can be shown (van Erven and Cugliari 2015; Wickramasuriya et al. 2019; Bisaglia et al. 2020; Di Fonzo and Girolimetto 2023) that reconciled forecasts may be obtained as the solution to a linearly constrained quadratic optimization problem,Footnote 1 that does not require any “upper and bottom” classification of the involved variables. This approach grounds on a zero-constrained representation of the linearly constrained multiple time series (Di Fonzo and Girolimetto 2023) describing the relationships linking all the individual series in the system. For a genuine hierarchical/grouped time series, where the top and bottom level variables are uniquely identified, it is easy to express the relationship between structural and zero-constrained representations. Wickramasuriya et al. (2019) show that the structural and the corresponding projection reconciliation approaches produce the same final reconciled forecasts. Unfortunately, given a zero-constrained representation of a linearly constrained multiple time series, finding the corresponding structural representation is not trivial (Di Fonzo and Girolimetto 2023), and one of the objective of the present paper is to fill this gap.
Most of the forecast reconciliation approaches proposed in the literature refer to genuine hierarchical/grouped time series, that do not take into account the full spectrum of possible cases encountered in real-life situations. As pointed out by Panagiotelis et al. (2021), “concepts such as coherence and reconciliation (...) require the data to have only two important characteristics: the first is that they are multivariate, and the second is that they adhere to linear constraints". Using a novel geometric interpretation, Panagiotelis et al. (2021) develop definitions and a formulation for linearly constrained multiple time series within a general framework and not just for simple summation hierarchical relationships. However, their results still ground on the structural representation valid only for genuine hierarchical/grouped time series, and this also holds for the probabilistic forecast reconciliation approach developed by Panagiotelis et al. (2023). Nevertheless, the point we wish to stress here is that when working with general linear constraints and many variables, the interchangeability between structural and zero-constrained representations, easy to recover for a genuine hierarchical/grouped time series, is no more always straightforward.
In this paper we address a number of open issues in point and probabilistic cross-sectional forecast reconciliation for general linearly constrained multiple time series. First, we introduce a general linearly constrained multiple time series by exploiting its analogies with an homogeneous linear system. Second, we show that the classical hierarchical representation for a multiple time series is a simple special case of the general representation. Third, we show that if it is possible to express a general linearly constrained multiple time series according to a “structural-like” representation, we can easily achieve the formulation for point and probabilistic regression-based reconciled forecasts using a linear combination matrix, with elements in \({\mathbb {R}}\), that is the natural extension of the aggregation matrix used in the structural reconciliation approach, with elements only in \(\{0,1\}\). When the distinction between bottom and upper variables is no longer meaningful, we adopt a classification involving free and constrained variables, respectively, and show how to obtain a structural-like representation, possibly using well known linear algebra techniques, such as the Reduced Row Echelon Form and the QR decomposition (Golub and Van Loan 1996; Meyer 2000).
The remainder of the paper is structured as follows. In Sect. 2, we present the notation and the main results about the point forecast reconciliation for a genuine hierarchical/grouped time series and in the general case. We define the structural-like representation for a general linearly constrained multiple time series by distinguishing between free and constrained variables, instead of bottom and upper, and use this result in the probabilistic forecast reconciliation framework set out by Panagiotelis et al. (2023). In Sect. 3, we show how to obtain the linear combination matrix for the structural-like representation in a computationally efficient wayFootnote 2. Two empirical applications are presented in Sect. 4. First, we extend the forecast reconciliation experiment for the Australian GDP originally developed by Athanasopoulos et al. (2020) and Bisaglia et al. (2020), to obtain both point and probabilistic GDP forecasts simultaneously coherent with their disaggregate counterpart forecasts from income and expenditure sides. Second, point and probabilistic forecasts are obtained for the European Area GDP from income, expenditure and output sides, geographically disaggregated by 19 component countries, where the large number of series and constraints makes a full row rank zero-constraints matrix difficult to build. Section 5 contains conclusions.
2 Cross-sectional forecast reconciliation of a linearly constrained multiple time series
Let \(\varvec{x}_t\) be a n-dimensional linearly constrained multiple time series such that all the values for \(t=1,\ldots\) (either observed or not) lie in the coherent linear subspace \({\mathcal {S}}\in {\mathbb {R}}^n\), \(\varvec{x}_t \in {\mathcal {S}}\; \forall t>0\) (Panagiotelis et al. 2021), which means that all linear constraints are satisfied at time t. These constraints can be represented through linear equations and grouped as a (rectangular) linear system. Following Meyer (2000) and Leon (2015), let \(x_{1,t}, \dots , x_{n,t}\) be the observations of n individual time series at a given time \(t = 1,\ldots , T\). An homogeneous linear system of p equations in the n variables present in \(\varvec{x}_t\) can be written as
where the \(\gamma _{ij}\)’s are real-valued coefficients. This system can be expressed in matrix form as
where \(\varvec{\Gamma }\in {\mathbb {R}}^{(p \times n)}\) is the coefficient matrix
Expression (1) is called “zero-constrained representation” of a linearly constrained multiple time series (Di Fonzo and Girolimetto 2023).
2.1 Forecast reconciliation of a genuine hierarchical time series

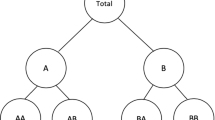
A simple three-level hierarchical structure for a linearly constrained multiple time series
In Fig. 1 it is shown a simple, genuine hierarchical time series (Athanasopoulos et al. 2009; Hyndman et al. 2011; Athanasopoulos et al. 2020; Hyndman and Athanasopoulos 2021), that can be seen as a particular case of a linearly constrained multiple time series. This hierarchical structure is defined only by simple summation constraints,
that can be easily transformed into a zero-constrained representation \(\varvec{\Gamma }\varvec{x}= \varvec{0}_{(8 \times 1)}\), with \(\varvec{x}=\left[ a_1 \; a_2 \; a_3 \; b_1 \; b_2 \;b_3 \;b_4 \;b_5 \;\right] ' = \left[ \varvec{a}' \quad \varvec{b}'\right] '\), and
such as the \(\gamma _{i,j}\)’s coefficients are only -1, 0 and 1, and \(\varvec{a}= \varvec{A}\varvec{b}\).
In general, let \(\varvec{b}_t = \begin{bmatrix} b_{1,t}&\dots&b_{n_b,t} \end{bmatrix}'\in {\mathbb {R}}^{(n_b \times 1)}\) and \(\varvec{a}_t = \begin{bmatrix} a_{1,t}&\dots&a_{n_a,t} \end{bmatrix}'\in {\mathbb {R}}^{(n_a \times 1)}\), \(t = 1,\ldots , T\), with \(n = n_a + n_b\), be the T vectors containing the bottom and the aggregated series, respectively, of a hierarchy. All series can be collected in the T vectors
where \(\varvec{P}\in \{0,1\}^{(n \times n)}\) is a permutation matrix used to appropriately re-order the original vector \(\varvec{x}_t\). If the classification as upper or bottom of the single time series in \(\varvec{x}_t\) is known in advance, we assume \(\varvec{x}_t = \varvec{y}_t = \left[ \varvec{a}_t' \quad \varvec{b}_t'\right] '\), i.e. \(\varvec{P}= \varvec{I}_n\) (no permutation of the original vector is needed). Moreover, also the linear combination (aggregation) matrix \(\varvec{A}\in \{0,1\}^{(n_a \times n_b)}\) describing the summation constraints linking the upper time series to the bottom ones, \(\varvec{a}_t = \varvec{A}\varvec{b}_t\), is assumed known in advance. Thus the “structural representation” is simply given by (Athanasopoulos et al. 2009)
where \(\varvec{S}\in \{0,1\}^{(n\times n_a)}\) is the structural (summation) matrix.
Suppose now we have the vector \({\widehat{\varvec{y}}}_h = \begin{bmatrix}{\widehat{\varvec{a}}}_h'&{\widehat{\varvec{b}}}_h' \end{bmatrix}'\in {\mathbb {R}}^{(n\times 1)}\) of unbiased and incoherent (i.e., \({\widehat{\varvec{y}}}_h \ne \varvec{S}{\widehat{\varvec{b}}}_h\)) base forecasts for the n variables of the linearly constrained series \(\varvec{y}_t\) for the forecast horizon h. Hyndman et al. (2011) use the structural representation (3) to obtain the reconciled forecasts \({\widetilde{\varvec{y}}}_h\) as
where \(\varvec{W}\) is a \((n\times n)\) p.d. matrix assumed known and \({\widehat{\varvec{y}}}_h\) (\({\widetilde{\varvec{y}}}_h\)) is the vector containing the base (reconciled) forecasts at forecast horizon h. Some alternative matrices \(\varvec{W}\) have been proposed in the literature for the cross-sectional forecast reconciliation caseFootnote 3:
-
identity (ols): \({\widehat{\varvec{W}}}_{\textrm{ols}} = \varvec{I}_n\) (Hyndman et al. 2011),
-
series variance (wls): \({\widehat{\varvec{W}}}_{\textrm{wls}} = \varvec{I}_{n} \odot {\widehat{\varvec{W}}}_{\textrm{sam}}\) (Hyndman et al. 2016),
-
MinT-shr (shr): \({\widehat{\varvec{W}}}_{\textrm{shr}}={\widehat{\lambda }} {\widehat{\varvec{W}}}_{\textrm{wls}} +(1-\) \({\widehat{\lambda }}) {\widehat{\varvec{W}}}_{\textrm{sam}}\) (Wickramasuriya et al. 2019),
-
MinT-sam (sam): \({\widehat{\varvec{W}}}_{\textrm{sam}}=\frac{1}{T} \sum _{t=1}^{T} {\widehat{\varvec{e}}}_{t} {\widehat{\varvec{e}}}_{t}^{\prime }\) is the covariance matrix of the one-step ahead in-sample forecast errors \(\widehat{{\textbf{e}}}_{t}\) (Wickramasuriya et al. 2019),
where the symbol \(\odot\) denotes the Hadamard product, and \({\widehat{\lambda }}\) is an estimated shrinkage coefficient (Ledoit and Wolf 2004).
The structural representation (3) may be transformed into the equivalent zero-constrained representation \(\varvec{a}_t - \varvec{A}\varvec{b}_t = \varvec{0}_{(n_a \times 1)}\), that is (Wickramasuriya et al. 2019)
\(\varvec{C}\in \{-1,0,1\}^{(n_a \times n)}\) is a full row-rank zero constraints matrix used to obtain the point reconciled forecasts according to the projection approach (van Erven and Cugliari 2015; Wickramasuriya et al. 2019; Di Fonzo and Girolimetto 2023):
Structural and zero-constrained representations can be interchangeable depending on which of the two is more convenient to use, allowing for greater flexibility in the calculation of the reconciled forecasts. For, the zero-constrained representation appears to be less computational intensive: in equation (4) two matrices must be inverted, one of size (\(n\times n\)) and the other (\(n_b \times n_b\)), whereas only the inversion of an (\(n_a \times n_a\)) matrix is required in formula (6).
2.2 The general case: zero-constrained and structural-like representations
In the hierarchical/grouped cross-sectional forecast reconciliation there is a natural distinction between upper and bottom time series that leads to the construction of the matrix \(\varvec{C}\) as in (5), where the first \(n_a\) columns refer to the upper and the remaining \(n_b\) (\(=n-n_a\)) to the bottom variables, respectively. The time series in these two sets are categorized logically: all those related to the last level belong to the second group, the rest to the first. Most of the forecast reconciliation approaches proposed in the literature refer to genuine hierarchical/grouped time series and its structural representation. However, these do not take into account the full spectrum of possible cases encountered in real life situations. For a general linearly constrained multiple time series \(\left( \varvec{x}_t, \; t=1,\ldots ,T\right)\), the classification between upper and bottom variables might not be meaningful, prompting us rather to look for two new sets: the constrained variables, denoted as \(\varvec{c}_t\in {\mathbb {R}}^{(n_c \times 1)}\), and the free (unconstrained) variables, denoted as \(\varvec{u}_t\in {\mathbb {R}}^{(n_u \times 1)}\), with \(n = n_c + n_u\), such that \(\varvec{y}_t = \varvec{P}\varvec{x}_t = \left[ \varvec{c}_t' \quad \varvec{u}_t'\right] '\), and
In this general framework, \(\varvec{A}\in {\mathbb {R}}^{(n_c \times n_u)}\) is the linear combination matrix associated to the linearly constrained multiple time series \(\varvec{x}_t = \varvec{P}'\varvec{y}_t\), that can be thus expressed via the “structural-like representation”
where \(\varvec{S}\in {\mathbb {R}}^{(n_c \times n_u)}\) is the structural-like matrix.Footnote 4 It is worth noting that a full-rank zero-constraints matrix \(\varvec{C}\in {\mathbb {R}}^{(n_c \times n)}\) like in expression (5) may be easily obtained by expression (8) and used for the full-rank zero constrained representation \(\varvec{C}\varvec{y}_t = \varvec{C}\varvec{P}\varvec{x}_t = \varvec{0}_{(n_c\times 1)}\). Therefore, even for a general, possibly not genuine hierarchical/grouped, linearly constrained multiple time series, either the structural (4) or the projection (6) approaches may be used to perform the point forecast reconciliation of incoherent base forecasts.

A general linearly constrained structure: two hierarchies sharing only the same top-level series
A simple example of a linearly constrained multiple time series that cannot be expressed as a genuine hierarchical/grouped structure is shown in Fig. 2. In this case the variable X is at the top of two distinct hierarchies, that do not share the same bottom-level variables. The aggregation relationships between the upper variables X and A, and the bottom ones A1, A2, B, C, and D are given by:
In this case, both the zero-constrained and the structural-like representations are found in a rather straightforward manner. We consider \(\left\{ A2, B, C, D\right\}\) as free variables, such that \(\varvec{y}_t = \varvec{x}_t\) (i.e., \(\varvec{P}= \varvec{I}_4\)), with \(\varvec{c}_t = \begin{bmatrix} x_{{X},t}&x_{{A},t}&x_{{A1},t} \end{bmatrix}'\) and \(\varvec{u}_t = \begin{bmatrix} x_{{A2},t}&x_{{B},t}&x_{{C},t}&x_{{D},t} \end{bmatrix}'\). Thus, the coefficient matrix of the zero-constrained representation (1) is
It is immediate to check that the system of linear constraints (9) may be re-written as
that is \(\varvec{C}\varvec{x}_t = \varvec{0}_{(3 \times 1)}\), where
The structural-like representation of the general linearly constrained multiple time series in Fig. 2 is then \(\varvec{y}_t = \varvec{S}\varvec{u}_t\), with \(\varvec{S}= \left[ \varvec{A}' \quad \varvec{I}_3 \right] '\).
It should be mentioned, however, that for medium/large systems (with many constraints and/or variables), manually operating on the constraints could be time-consuming and challenging. In Sect. 3 we will show a general technique to derive the linear combination matrix \(\varvec{A}\) from a general zero-constraints matrix \(\varvec{\Gamma }\).
2.3 Probabilistic forecast reconciliation for general linearly constrained multiple time series
So far we have dealt with only point forecasting, but if one wishes to account for forecast uncertainty, probabilistic forecasts should be considered, as they - in the form of probability distributions over future quantities or events - measure the uncertainty in forecasts and are an important component of optimal decision making (Gneiting and Katzfuss 2014).
Representation (8) states that \(\varvec{y}_t\) lies in an n-dimensional subspace of \({\mathbb {R}}^n\) spanned by the columns of \(\varvec{S}\), called “coherent subspace” and denoted by \({\mathcal {S}}\) (Panagiotelis et al. 2023). Now, let \({\mathscr {F}}_{{\mathbb {R}}^{n_u}}\) be the Borel \(\sigma\)-algebra on \({\mathbb {R}}^{n_u}\), \(\left( {\mathbb {R}}^{n_u}, {\mathscr {F}}_{{\mathbb {R}}^{n_u}}, \nu \right)\) a probability space for the free variables, and \({s}: {\mathbb {R}}^{n_u} \rightarrow {\mathbb {R}}^n\) a continuous mapping matrix. Then a \(\sigma\)-algebra \({\mathscr {F}}_{{\mathcal {S}}}\) can be constructed from the collection of sets \({s}({\mathcal {B}})\) for all \({\mathcal {B}} \in {\mathscr {F}}_{{\mathbb {R}}^{n}}\).
Definition 1
(Coherent probabilistic forecast for a linearly constrained multiple time series) Given the triple \(\left( {\mathbb {R}}^{n_u}, {\mathscr {F}}_{{\mathbb {R}}^{n_u}}, \nu \right)\), we define a coherent probability triple \(\left( {\mathcal {S}}, {\mathscr {F}}_{{\mathcal {S}}}, \breve{\nu }\right)\) such that \(\breve{\nu }({s}({\mathcal {B}}))=\nu ({\mathcal {B}})\), \(\forall {\mathcal {B}} \in {\mathscr {F}}_{{\mathbb {R}}^{n_u}}\).
In order to extend forecast reconciliation to the probabilistic setting, let \(\left( {\mathbb {R}}^{n}, {\mathscr {F}}_{{\mathbb {R}}^{n}}, {\widehat{\nu }}\right)\) be a probability triple characterizing base (incoherent) probabilistic forecasts for all n series, and let \(\psi : {\mathbb {R}}^{n_u} \rightarrow {\mathbb {R}}^n\) be a continuous mapping function defined by Panagiotelis et al. (2023) as the composition of two transformations, \({s} \circ {g}\), where \({g}: {\mathbb {R}}^n \rightarrow {\mathbb {R}}^{n_u}\) is a continuous function corresponding to matrix \({\varvec{G}}\) in equation (4).
Definition 2
(Probabilistic forecast reconciliation for a linearly constrained multiple time series) The reconciled probability measure of \({\widehat{\nu }}\) with respect to \(\psi\) is a probability measure \({\widetilde{\nu }}\) on \({\mathcal {S}}\) with \(\sigma\)-algebra \({\mathscr {F}}_{{\mathcal {S}}}\) such that
where \(\psi ^{-1}({\mathcal {A}})=\left\{ {\varvec{x}} \in {\mathbb {R}}^{n}: \psi ({\varvec{x}}) \in {\mathcal {A}}\right\}\) is the pre-image of \({\mathcal {A}}\).
We consider two alternative approaches to deal with probabilistic forecast reconciliation according to the above definitions: a parametric framework, where probabilistic forecasts are produced under the assumption that the density function of the forecast errors is known, and a non-parametric framework, where no distributional assumption is made.
2.3.1 Parametric framework: Gaussian reconciliation
A reconciled probabilistic forecast may be obtained analytically for some parametric distributions, such as the multivariate normal (Yagli et al. 2020; Corani et al. 2021; Eckert et al. 2021; Panagiotelis et al. 2023; Wickramasuriya 2023). In particular, if the base forecasts distribution is \({\mathcal {N}}({\widehat{\varvec{y}}}_h, \varvec{W}_h)\), then the reconciled forecasts distribution is \({\mathcal {N}}({\widetilde{\varvec{y}}}_h, {\widetilde{\varvec{W}}}_h)\), with
The covariance matrix \({\widetilde{\varvec{W}}}_h\) deserves special attention. In the simple case assumed by Wickramasuriya et al. (2019), it is \(\varvec{W}_h = k_h\varvec{W}\), where \(k_h\) is a proportionality constant, and the reconciled covariance matrix reduces to (see Appendix A):
However, the proportionality assumption along the forecast horizons h may be too restrictive, and computing \(k_h\) cannot be an easy task. Thus, three alternative formulations of \({\varvec{W}}_h\), already shown in Sect. 2.1, have been proposed in the forecast reconciliation literature:
-
diagonal covariance matrix: \(\varvec{W}_h = {\widehat{\varvec{W}}}_{\textrm{wls}}\) (Corani et al. 2021; Panagiotelis et al. 2023);
-
sample covariance matrix: \(\varvec{W}_h = {\widehat{\varvec{W}}}_{\textrm{sam}}\) (Panagiotelis et al. 2023);
-
shrinkage covariance matrix: \(\varvec{W}_h = {\widehat{\varvec{W}}}_{\textrm{shr}}\) (Athanasopoulos et al. 2020).
2.3.2 Non-parametric framework: joint bootstrap-based reconciliation
When an analytical expression of the forecast distribution is either unavailable, or relies on unrealistic parametric assumptions, the empirical evaluation of the results may be grounded on reconciled samples (Jeon et al. 2019; Yang 2020; Panagiotelis et al. 2023). At this end, we extend theorem 4.5 in Panagiotelis et al. (2023), originally formulated for genuine hierarchical/grouped time series, to the case of a general linearly constrained multiple time series. This theorem states that, if \(\left( {\widehat{\varvec{y}}}^{[1]}, \ldots , {\widehat{\varvec{y}}}^{[L]}\right)\) is a sample drawn from an incoherent probability measure \({\widehat{\nu }}\), then \(\left( {\widetilde{\varvec{y}}}^{[1]}, \ldots , {\widetilde{\varvec{y}}}^{[L]}\right)\), where \({\widetilde{\varvec{y}}}^{[\ell ]}:=\psi \left( {\widehat{\varvec{y}}}^{[\ell ]}\right)\) for \(\ell =\) \(1, \ldots , L\;\), is a sample drawn from the reconciled probability measure \({\widetilde{\nu }}\) as defined in (10). According to this result, reconciling each member of a sample obtained from an incoherent distribution yields a sample from the reconciled distribution. As a consequence, coherent probabilistic forecasts may be developed through a post-forecasting mechanism analogous to the point forecast reconciliation setting. For this purpose, the bootstrap procedure by Athanasopoulos et al. (2020) is applied:
-
1.
appropriate univariate models \(M_i\) for each series in the system are fitted based on the training data \(\{y_{i,t}\}_{t=1}^T\), \(i = 1,\dots ,n\), and the one-step-ahead in-sample forecast errors are stacked in an \((n \times T)\) matrix, \({\widehat{\varvec{E}}}=\left\{ {\widehat{e}}_{i, t}\right\}\);
-
2.
\({\widehat{\varvec{y}}}^{[l]}_{i,h} = f_i\left( M_i, {\widehat{e}}_{i, h}^{[l]}\right)\) is computed for \(h = 1,\dots ,H\) and \(l = 1,\dots , L\), where \(f(\cdot )\) is a function of the fitted model and its associated error, \({\widehat{\varvec{y}}}^{[l]}_{i,h}\) is a sample path simulated for the \(i-\)th series, and \({\widehat{e}}_{i, h}^{[l]}\) is the \((i, h)-\)th element of an \((n\times H)\) block bootstrap matrix containing H consecutive columns randomly drawn from \({\widehat{\varvec{E}}}\);
-
3.
the optimal reconciliation formula, either according to the structural approach (4) or the projection approach (6), is applied to each \({\widehat{\varvec{y}}}^{[l]}_{h}\).
3 Building the linear combination matrix \({\textbf{A}}\)
In the previous section, we limited ourselves to introduce the linear combination matrix \(\varvec{A}\) in expression (7), in line with the novel classification distinguishing between free (unconstrained) and constrained variables. In this section we propose two ways of building such a matrix in practice.
First, consider the simple case where there are no redundant constraints (\(n_c = p\)) and the first \(n_c\) columns of \(\varvec{\Gamma }\) are linearly independent, so that \(\varvec{y}_t = \varvec{x}_t = \Big [\varvec{c}_t' \quad \varvec{u}_t'\Big ]'\) and \(\varvec{\Gamma }\varvec{y}_t = \varvec{0}_{(n_c\times 1)}\). This homogeneous linear system can be written as
where \(\varvec{\Gamma }_c\in {\mathbb {R}}^{(n_c \times n_c)}\) contains the coefficients for the constrained variables, and \(\varvec{\Gamma }_u\in {\mathbb {R}}^{(n_c \times n_u)}\) those for the free ones. Thanks to its non-singularity, \(\varvec{\Gamma }_c\) can be used to derive the equivalent zero-constrained representation:
where
In practical situations, mostly if many variables and/or constraints are involved, categorizing variables as either constrained or free may be a challenging taskFootnote 5: the goal is to identify a valid set of free variables with invertible coefficient matrix \(\varvec{\Gamma }_c\).
3.1 General (redundant) linear constraints framework
When n is large, it is not always immediate to find a set of non-redundant constraints, so the method shown in expression (12) may be hardly applied in several real-life situations. We propose to overcome these issues by employing standard linear algebra tools, like the Reduced Row Echelon Form or the QR decomposition (Golub and Van Loan 1996; Meyer 2000), that are able to deal with redundant constraints and do not request any a priori classification of the single variables entering the multiple time series.
3.1.1 Reduced Row Echelon Form (rref)
A matrix is said to be in rref (Meyer 2000) if and only if the following three conditions hold:
-
it is in row echelon form;
-
the pivot in each row is 1;
-
all entries above each pivot are 0.
The idea is then very simple: classify as constrained the variables corresponding to the pivot positions of the rref representation coefficient matrix, while the remaining columns form the linear combination matrix \(\varvec{A}\). Usually a rref form is obtained through a Gauss-Jordan elimination (more details in Meyer 2000). So, let \(\varvec{Z}\in {\mathbb {R}}^{(n_c\times n)}\) be the rref of \(\varvec{\Gamma }\) deprived of any possible null rows, then a permutation matrix \(\varvec{P}\) can be obtained starting from the pivot columns of \(\varvec{Z}\), such that
where \(\pi _c(i)\), \(i = 1,\ldots , n_c\), is the position of the i-th pivot column (i.e., one of the columuns that identify the constrained variables) and \(\pi _u(j)\), \(j = 1,\ldots , n_u\), is the position of the j-th no-pivot column (i.e., one of the columns associated to the free variables). Then, the linear combination matrix \(\varvec{A}\) can be extracted from the expression
Additional examples can be found in the online appendix.
3.1.2 QR decomposition
Given the \((p \times n)\) coefficient matrix \(\varvec{\Gamma }\) of the zero-constrained representation (1), \(\varvec{\Gamma }= \varvec{Q}\varvec{R}\varvec{P}\) is a QR decomposition with column pivoting (Lyche 2020), where \(\varvec{Q}\in {\mathbb {R}}^{(p \times p)}\) is a square and orthonormal matrix (\(\varvec{Q}'\varvec{Q}= \varvec{Q}\varvec{Q}'=\varvec{I}_p\)), \(\varvec{P}\in \{0,1\}^{(n \times n)}\) is a permutation matrix, and \(\varvec{R}\in {\mathbb {R}}^{(p \times n)}\) is an upper trapezoidal matrix (Anderson et al. 1992, 1999) such that
where \(\varvec{R}_{c}\in {\mathbb {R}}^{(n_c \times n_c)}\) is upper triangular, and \(\varvec{R}_{u}\in {\mathbb {R}}^{(n_c \times n_u)}\) is nonsingular (Golub and Van Loan 1996). Applying this decomposition to the homogenous system (1), we obtain
that is equivalent to (Meyer 2000)
Due to the non-singularity of \(\varvec{Q}\), \(\varvec{z}= \varvec{0}_{(p \times 1)}\) is the unique solution to the homogenous system \(\varvec{Q}\varvec{x}= \varvec{0}_{(p \times 1)}\) (Lyche 2020). Then, the homogeneous system (1) representing a general linearly constrained time series may be re-written asFootnote 6\(\big [ \varvec{R}_c \quad \varvec{R}_u\big ]\varvec{y}_t = \varvec{0}_{(n_c\times 1)}\). Finally, from (12) we obtain
where \(\varvec{R}_c\) is invertible by construction (Golub and Van Loan 1996). It is worth noting that the Pivoted QR decomposition generates a permutation matrix \(\varvec{P}\) that “moves” the free variables in \(\varvec{x}_t\) to the bottom part of the re-ordered vector \(\varvec{y}_t\), that is \(\varvec{P}\varvec{x}_t = \varvec{y}_t = \big [\varvec{c}_t' \quad \varvec{u}_t'\big ]'\).
It should be noted that in both cases (QR and rref), \(\varvec{P}= \varvec{I}_n\) if the first \(n_c\) columns of \(\varvec{\Gamma }\) are linearly independent. This means that both algorithms start by assuming as constrained and free the variables as they appear in \(\varvec{x}\), whose ordering is then changed only if it is not feasible for the constraints operating on the multivariate time series in equation (1).
4 Empirical applications
In this section we present two macroeconomics applications involving general linearly constrained multiple time series which do not have a genuine hierarchical/grouped structure. In the first case, in the wake of Athanasopoulos et al. (2020), we forecast the Australian GDP from income and expenditure sides, for which Bisaglia et al. (2020) already provided a full row-rank \(\varvec{C}\) matrix. The second application concerns the European GDP disaggregated by three sides (income, expenditure and output) and 19 member countries. In this case, building a full row-rank zero constraints matrix is not an easy task, so we use a QR decomposition (Sect. 3.1). Detailed informations on the variables in either dataset are reported in the online appendix.
4.1 Reconciled probabilistic forecasts of the Australian GDP from income and expenditure sides
Athanasopoulos et al. (2020) first considered the reconciliation of point and probabilistic forecasts of the 95 Australian Quarterly National Accounts (QNA) variables that describe the Gross Domestic Product (GDP) at current prices from the income and expenditure sides, interpreted as two distinct hierarchies. In the former case (income), GDP is the top level aggregate of a hierarchy of 15 lower level aggregates with \(n_a^I = 6\) and \(n_b^I = 10\), whereas in the latter (expenditure), GDP is the top level aggregate of a hierarchy of 79 time series, with \(n_a^E = 27\) and \(n_b^E = 53\) (for details, Athanasopoulos et al. 2020; Bisaglia et al. 2020; Di Fonzo and Girolimetto 2022, 2023).
Considering these two hierarchies as distinct yields different GDP forecasts depending on the considered disaggregation (either by income or expenditure). The fact that the two hierarchical structures describing the National Accounts share only the same top-level series (GDP), prevents the adoption for the whole set of \(n=95\) distinct variables of the original structural reconciliation approach proposed by Hyndman et al. (2011). However, it is possible to use the results shown so far for a general linearly constrained multiple time series. The homogeneous constraints valid for the variables are described by the following \((33 \times 95)\) matrix \(\varvec{\Gamma }\) (Bisaglia et al. 2020):
where \(\varvec{A}^I \in \{0,1\}^{(5 \times 10)}\) and \(\varvec{A}^E \in \{0,1\}^{(26 \times 53)}\) are the aggregation matrices for the income and the expenditure sides, respectively, and \(\varvec{\Gamma }\) has already full row-rank. A structural-like representation of the multiple time series that incorporates both sides’ accounting constraints may be obtained by transforming \(\varvec{\Gamma }\) through, for example, the QR technique described in Sect. 3.1. This operation results in a \((33 \times 95)\) matrix \(\varvec{C}= \left[ \varvec{I}_{33} \; -\varvec{A}\right]\), where \(\varvec{A}\) is the \((33 \times 62)\) linear combination matrix shown in Fig. 3, and \(\varvec{S}= \left[ \varvec{A}' \quad \varvec{I}_{62}\right] '\) is the structural-like matrix (see Sect. 2.2).

Linear combination matrix \(\varvec{A}\) for the Australian GDP from income and expenditure sides
We perform a forecasting experiment as the one designed by Athanasopoulos et al. (2020). Base forecasts from \(h = 1\) quarter ahead up to \(h = 4\) quarters ahead for all the 95 separate time series have been obtained through simple univariate ARIMA models selected using the auto.arima function of the R-package forecast (Hyndman and Khandakar 2008). The first training sample is set from 1984:Q4 to 1994:Q3, and a recursive training sample with expanding window length is used, for a total of 94 forecast origins. Finally the reconciled forecasts are obtained using three reconciliation approaches (ols, wls and shr, see Sect. 2.1) through the R package Foreco (Girolimetto and Di Fonzo 2023).
In Athanasopoulos et al. (2020) the probabilistic forecasts of the Australian quarterly GDP aggregates are separately reconciled from income \(\big ({\widetilde{X}}_{GDP}^I\big )\) and expenditure \(\big ({\widetilde{X}}_{GDP}^E\big )\) sides. This means that the empirical forecast distributions \({\widetilde{X}}_{GDP}^I\) and \({\widetilde{X}}_{GDP}^E\) are each coherent (see Sect. 2.3) within its own pertaining side with the other empirical forecast distributions, but in general \({\widetilde{X}}_{GDP}^I \ne {\widetilde{X}}_{GDP}^E\) at any forecast horizon. This circumstance could confuse the user, mostly when the difference between the empirical forecast distributions is not negligible, as shown in Fig. 4, where the GDP empirical forecast distributions from income and expenditure sides for 2018:Q1 are presented along with their fully reconciled counterparts through the shr joint bootstrap-based reconciliation approach (see Sect. 2.3.2).Footnote 7

Australian GDP empirical one-step-ahead forecast distributions for 2018:Q1, shr joint bootstrap-based reconciliation approach. Empirical Cumulative Distribution Function (left), and Smoothed density (right)
4.1.1 Point and probabilistic forecasting accuracy
To evaluate the accuracy of the point forecasts we use the Mean Square Error (MSE)Footnote 8:
where \({\tilde{e}}_{i,j,t+h} = \left( {\tilde{y}}_{i,j,t+h} - {y}_{i,j,t+h}\right)\) is the the h-step-ahead forecast error using the approach j to forecast the i-th series, \(j = 0\) denotes the base forecast (i.e., \({\tilde{y}}_{i,0,t+h} = {\widehat{y}}_{i,t+h}\)), and t is the forecast origin. To assess any improvement in the reconciled forecasts compared to the base ones, we use the MSE-skill score:
The accuracy of the probabilistic forecasts is evaluated using the Cumulative Rank Probability Score (CRPS, Gneiting and Katzfuss 2014):
where \({\hat{P}}_i(\omega )=\displaystyle \frac{1}{L} \displaystyle \sum _{l=1}^{L} {\textbf{1}}\left( x_{i,l} \le \omega \right)\), \(\varvec{x}_{1}, \varvec{x}_{2}, \ldots , \varvec{x}_{L}\in {\mathbb {R}}^{n}\) is a collection of L random draws taken from the predictive distribution and \(\varvec{z}\in {\mathbb {R}}^{n}\) is the observation vector. In addition, to evaluate the forecasting accuracy for the whole system, we employ the Energy Score (ES), that is the CRPS extension to the multivariate caseFootnote 9:
4.1.2 Results
Table 1 shows the MSE and CRPS-skill scores for the GDP point and probabilistic reconciled forecasts. Table 2 presents the MSE and ES-skill scores for all 95 Australian QNA variables from both income and expenditure sides. The ‘Income’ and ‘Expenditure’ panels, respectively, reproduce the results found by Athanasopoulos et al. (2020). The ‘Fully reconciled’ panels show the skill scores for the simultaneously reconciled forecasts. For the point forecasts, all the reconciliation approaches improve forecast accuracy compared to the base forecasts. In detail, shr is almost always the best approach for the one-step-ahead forecasts, whereas wls is competitive for \(h\ge 2\). Looking at the probabilistic reconciliation results in Table 1, it is worth noting that for GDP ols outperforms both wls and shr, whatever side and framework (parametric or not) is considered. However, when all 95 variables are considered (Table 2), shr and wls approaches almost always show the best performance. In the Gaussian framework, these results are confirmed for the income side, whereas shr performs poorly when we look at the expenditure side (either fully reconciled or not).
In Fig. 5 are shown the results obtained by the non-parametric Friedman test and the post hoc “Multiple Comparison with the Best” (MCB) Nemenyi test (Koning et al. 2005; Kourentzes and Athanasopoulos 2019; Makridakis et al. 2022) to determine if the forecasting performances of the different techniques are significantly different from one another. In general, wls always falls in the set of the best performing approaches. For the bootstrap-based probabilistic reconciled forecasts of the expenditure side variables, wls and shr significantly improves in terms of MSE and CRPS compared to the base forecasts. This result is confirmed in the remaining cases as well.

MCB Nemenyi test for the fully reconciled forecasts of the Australian QNA variables at any forecast horizon. In each panel, the Friedman test p-value is reported in the lower right corner. The mean rank of each approach is shown to the right of its name. Statistical differences in performance are indicated if the intervals of two forecast reconciliation approaches do not overlap. Thus, approaches that do not overlap with the blue interval are considered significantly worse than the best, and vice-versa
In conclusion, when income and expenditure sides are simultaneously considered for both point and probabilistic forecasts, forecast reconciliation succeeds in improving the base forecasts of GDP and its component aggregates, while preserving the full coherence with the National Accounts constraints.
4.2 Reconciled probabilistic forecasts of the European Area GDP from output, income and expenditure sides
In this section, we consider the system of European QNA for the GDP at current prices (in euro), with time series spanning the period 2000:Q1-2019:Q4. This system has many variables linked by several, possibly redundant, accounting constraints, such that it is difficult to manually build a system of non-redundant constraints.

Linear combination matrices \(\varvec{A}\) for the European Area GDP: output side in panel (a), income side in panel (b), expenditure side in panel (c)
The National Accounts are a coherent and consistent set of macroeconomic indicators that are used mostly for economic research and forecasting, policy design, and coordination mechanisms. In this dataset, GDP is a key macroeconomic quantity that is measured using three main approaches, namely output (or production), income and expenditure. These parallel systems internally present a well-defined hierarchical structure of variables with relevant economic significance, such as Final consumption, on the expenditure side, Gross operating surplus and mixed income on the income side, and Total gross value added on the output side. In the EU countries, the data is processed on the basis of the ESA 2010 classification and are released by Eurostat.Footnote 10 We consider the 19 Euro Area member countries (Austria, Belgium, Finland, France, Germany, Ireland, Italy, Luxembourg, Netherlands, Portugal, Spain, Greece, Slovenia, Cyprus, Malta, Slovakia, Estonia, Latvia, and Lithuania) that have been using the euro since 2015. In Fig. 6 we have represented the aggregation matrices describing output, income, and expenditure constraints, respectively: in panel (a), matrix \(\varvec{A}_{\textrm{O}}\) for the output side, in panel (b) matrix \(\varvec{A}_{\textrm{I}}\) for the income side, and in panel (c) matrix \(\varvec{A}_{\textrm{E}}\) for the expenditure side. The zero-constraints coefficient matrix describing the QNA variables for a single country can thus be written as
where \(\varvec{K}_{\textrm{E}}\), \(\varvec{K}_{\textrm{I}}\) and \(\varvec{K}_{\textrm{O}}\), respectively, are the following \((13 \times 15)\), \((3 \times 15)\) and \((1 \times 15)\) matrices:
This disaggregation is common for almost all European countries, the only differences being related to the presence/absence of an aggregate measuring the statistical discrepancy in each accounting side.Footnote 11 The \((361 \times 720)\) matrix describing the accounting relationships for the whole EA19 QNA by countries and accounting sides can be written as follows:
where \(\otimes\) is the Kronecker product, and the top-left portion of \(\varvec{\Gamma }\) refers to the European Area aggregates as a whole. In order to proceed with the calculations, it is necessary to eliminate the columns related to null variables (e.g., the statistical discrepancy aggregate for the countries/sides where it is not contemplated, see footnote 11). Then, to eliminate possible remaining redundant constraints, we apply the QR decomposition (Sect. 3.1). Finally, we obtain the linear combination matrix \(\varvec{A}\), which refers to 311 free and 358 constrained time series, and the full rank zero-constraints matrix \(\varvec{C}= \begin{bmatrix} \varvec{I}_{358}&-\varvec{A}\end{bmatrix}\).
A rolling forecast experiment with expanding window is performed using ARIMA models to produce the individual series’ base forecasts. The first training set is set from 2000:Q1 to 2009:Q4, which gives 40 one-step-ahead, 39 two-step-ahead, 38 three-step-ahead and 37 four-step-ahead ARIMA forecasts, respectively. The used reconciliation approaches are ols, wls and shr, and the forecast accuracy is evaluated through MSE, CRPS and ES indices, as described in Sect. 4.1.
4.2.1 Results
Table 3 shows the MSE indices for point forecasts, and the ES indices for probabilistic nonparametric (bootstrap) and parametric (Gaussian) forecasts, respectively. The rows of the table are divided into three parts: the first row shows the results for GDP, the second to fourth rows the National Accounts’ divisions (income, expenditure, or output sides), while the remaining rows correspond to the 19 countries and EA19. All forecast horizons are considered.Footnote 12

MCB Nemenyi test for the fully reconciled forecasts of the European Area QNA variables at any forecast horizon. In each panel, the Friedman test p-value is reported in the lower right corner. The mean rank of each approach is shown to the right of its name. Statistical differences in performance are indicated if the intervals of two forecast reconciliation approaches do not overlap. Thus, approaches that do not overlap with the blue interval are considered significantly worse than the best, and vice-versa

CRPS-skill scores of the one-step-ahead GDP non-parametric joint bootstrap probabilistic reconciled (wls) forecasts for the 19 Euro Area countries
When only GDP is considered, any reconciliation approach consistently outperforms the base forecasts, both in the point and probabilistic cases. The wls approach confirms a good performance when we look at the income, expenditure, and output sides, while ols shows the worst performance. When the parametric framework is considered, shr is worse than the base forecast for the income side. At country level, ols is the approach that overall shows the worst performance, with many relative losses in the accuracy indices higher than 30%. It is worth noting that all reconciliation approaches always perform well for the whole Euro Area (EA19). Overall, in this forecasting experiment wls appears to be the most performing reconciliation approach, showing no negative skill score, and improvements higher than 20% and 10% for nonparametric and parametric probabilistic frameworks, respectively.
Figure 7 shows the MCB Nemenyi test at any forecast horizon, distinct by expenditure side and income and output sides, respectively. The results just seen are further confirmed by this alternative forecast assessment tool: it clearly appears that the wls approach almost always significantly improves compared to the base forecast, in terms of both point and probabilistic forecasts.
Finally, a visual evaluation of the accuracy improvement obtained through wls forecast reconciliation, although limited to a single forecast horizon, is offered by Fig. 8, showing the European map with the CRPS skill scores for the one-step-ahead GDP non-parametric probabilistic reconciled forecasts. It is worth noting that only for two countries (Greece and Portugal) a decrease is registered (\(-3.3\)% and \(-4.9\)%, respectively). In all other cases, improvements in the forecasting accuracy are obtained, with Germany and Lithuania leading the way with about 18%. Furthermore, the improvement in the forecasting accuracy for the \(EA19-GDP\) is 24.2%, the highest throughout the whole Euro Area.
5 Conclusions
Producing and using coherent information, disaggregated by different characteristics useful for different decision levels, is an important task for any practitioner and quantitative-based decision process. At this end, in this article we aimed to generalize the results valid for the forecast reconciliation of a genuine hierarchical/grouped time series to the case of a general linearly constrained time series, where the distinction between upper and bottom variables, which is typical in the hierarchical setting, is no longer meaningful.
Two motivating examples have been considered, both coming from the National Accounts field, namely the forecast reconciliation of quarterly GDP of (i) Australia, disaggregated by income and expenditure variables, and (ii) Euro Area 19, disaggregated by the income, output and expenditure side variables of 19 component countries. In both cases, the structure of the time series involved cannot be represented according to a genuinely hierarchical/grouped scheme, so the standard forecast reconciliation techniques fail in producing a “unique” GDP forecast, either point or probabilistic, making it necessary to solve this annoying issue.
We have shown that using well known linear algebra tools, it is always possible to establish a formal connection between the unconstrained GLS structural approach originally developed by Hyndman et al. (2011), and the projection approach to reconciliation dating back to the work by Stone et al. (1942), and then applied to solve different reconciliation problems (Di Fonzo and Marini 2011; van Erven and Cugliari 2015; Wickramasuriya et al. 2019; Di Fonzo and Girolimetto 2023). We propose a new classification of the variables forming the multiple time series as free and constrained, respectively, that can be seen as a generalization of the standard bottom/upper variables classification used in the hierarchical setting. Furthermore, we show techniques for deriving a linear combination matrix describing the relationships between these variables, starting from the coefficient matrix summarizing the (possible redundant) constraints linking the series.
The application of these findings to both point and probabilistic reconciliation techniques proved to be easy to implement and powerful, resulting in significant improvements in the forecasting accuracy of GDP and its components in both forecasting experiments.
Notes
This approach dates back to the seminal paper by Stone et al. (1942) on the least squares adjustment of noisy data with accounting constraints (Byron 1978, 1979). Recent applications to the reconciliation of systems of seasonally adjusted time series are provided by Di Fonzo and Marini (2011, 2015).
The procedures used in this paper are implemented in the R package FoReco (Girolimetto and Di Fonzo 2023). A complete set of results is available at the GitHub repository: https://github.com/danigiro/mtsreco.
Dealing with the uncertainty in base forecasts, and their error covariance matrices, is of primary interest to establish characteristics and properties of the reconciled forecasts. This topic is left to future research.
Unlike the structural (summation) matrix in (3), that describes the simple summation relationships valid for genuine hierarchical/grouped time series, and has only elements in \(\{0,1\}\), in expression (8) \(\varvec{S}\) consists of real coefficients, appropriately organized to highlight the links between constrained and free variables.
The issue of defining a valid set of free variables is studied by Zhang et al. (2023) in the framework of hierarchical/grouped reconciliation with immutable forecasts.
Possible null rows, present if \(\varvec{\Gamma }\) is not full-rank, are removed.
Note that the naive practice of averaging GDP forecasts from different sides yields a single forecast, that is though inconsistent with the component variables from both sides.
The Mean Absolute Scaled Error (MASE) leads to the same conclusions (see the online appendix).
An alternative to the Energy Score is the Variogram Score (Scheuerer and Hamill 2015), considered in the online appendix, that leads to similar conclusions.
Further information can be found at https://ec.europa.eu/eurostat/esa2010/ and https://ec.europa.eu/eurostat/web/national-accounts/data/database.
For 14 countries (Belgium, France, Germany, Italy, Luxembourg, Netherlands, Spain, Greece, Slovenia, Cyprus, Malta, Slovakia, Latvia, and Lithuania), the expenditure, income and output statistical discrepancies are not present. A statistical discrepancy aggregate is present in the output QNA of Portugal and in the expenditure QNA of Finland, Estonia and Austria. Ireland is the only country where a statistical discrepancy aggregate is present in all accounting sides.
A disaggregated analysis by forecast horizon is reported in the online appendix.
References
Anderson E, Bai Z, Bischof C, Blackford S, Demmel J, Dongarra J, Du Croz J, Greenbaum A, Hammerling S, McKenney A et al. (1999) LAPACK Users’ Guide: Third Edition. Software, Environments, and Tools. Society for Industrial and Applied Mathematics
Anderson E, Bai Z, Dongarra J (1992) Generalized QR factorization and its applications. Linear Algebra Appl 162–164:243–271. https://doi.org/10.1016/0024-3795(92)90379-O
Athanasopoulos G, Ahmed RA, Hyndman RJ (2009) Hierarchical forecasts for Australian domestic tourism. Int J Forecast 25(1):146–166. https://doi.org/10.1016/j.ijforecast.2008.07.004
Athanasopoulos G, Gamakumara P, Panagiotelis A, Hyndman RJ, Affan M (2020) Hierarchical forecasting. In: Fuleky P (ed) Macroeconomic forecasting in the era of big data, vol 52. Springer International Publishing, Cham, pp 689–719. https://doi.org/10.1007/978-3-030-31150-6_21
Ben Taieb S, Koo B (2019) Regularized regression for hierarchical forecasting without unbiasedness conditions. In: Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, Anchorage AK USA, pp 1337–1347. ACM
Ben Taieb S, Taylor JW, Hyndman RJ (2021) Hierarchical probabilistic forecasting of electricity demand with smart meter data. J Am Stat Assoc 116(533):27–43. https://doi.org/10.1080/01621459.2020.1736081
Bisaglia L, Di Fonzo T, Girolimetto D (2020) Fully reconciled GDP forecasts from income and expenditure sides. In: Pollice A, Salvati N, Schirripa Spagnolo F (eds) Book of short papers SIS 2020, 951–956. Pearson
Byron RP (1978) The estimation of large social account matrices. J R Stat Soc A (General) 142(3):405. https://doi.org/10.2307/2982515
Byron RP (1979) Corrigenda: the estimation of large social account matrices. J R Stat Soc A (General) 142(3):405. https://doi.org/10.2307/2982515
Corani G, Azzimonti D, Augusto JPSC, Zaffalon M (2021) Probabilistic reconciliation of hierarchical forecast via Bayes’ rule. Mach Learn Knowled Discover Databases 12459:211–226. https://doi.org/10.1007/978-3-030-67664-3_13
Di Fonzo T, Girolimetto D (2022) Fully reconciled probabilistic GDP forecasts from Income and Expenditure sides. In: Balzanella A, Bini M, Cavicchia C, Verde R (eds) Book of short papers SIS 2022, 1376–1381. Pearson
Di Fonzo T, Girolimetto D (2023) Cross-temporal forecast reconciliation: optimal combination method and heuristic alternatives. Int J Forecast 39(1):39–57. https://doi.org/10.1016/j.ijforecast.2021.08.004
Di Fonzo T, Marini M (2011) Simultaneous and two-step reconciliation of systems of time series: methodological and practical issues. J R Stat Soc C 60(2):143–164. https://doi.org/10.1111/j.1467-9876.2010.00733.x
Di Fonzo T, Marini M (2015) Reconciliation of systems of time series according to a growth rates preservation principle. Stat Methods Appl 24(4):651–669. https://doi.org/10.1007/s10260-015-0322-y
Dunn DM, Williams WH, Dechaine TL (1976) Aggregate versus subaggregate models in local area forecasting. J Am Stat Assoc 71(353):68–71. https://doi.org/10.1080/01621459.1976.10481478
Eckert F, Hyndman RJ, Panagiotelis A (2021) Forecasting swiss exports using Bayesian forecast reconciliation. Eur J Oper Res 291(2):693–710. https://doi.org/10.1016/j.ejor.2020.09.046
Girolimetto D, Di Fonzo T (2023) FoReco: forecast reconciliation. R package v0.2.6. https://danigiro.github.io/FoReco/
Gneiting T, Katzfuss M (2014) Probabilistic forecasting. Annual Rev Stat Appl 1(1):125–151. https://doi.org/10.1146/annurev-statistics-062713-085831
Golub GH, Van Loan CF (1996) Matrix computations. Johns Hopkins University Press, Baltimore
Gross CW, Sohl JE (1990) Disaggregation methods to expedite product line forecasting. J Forecast 9(3):233–254. https://doi.org/10.1002/for.3980090304
Hyndman RJ, Ahmed RA, Athanasopoulos G, Shang HL (2011) Optimal combination forecasts for hierarchical time series. Computat Stat Data Anal 55(9):2579–2589. https://doi.org/10.1016/j.csda.2011.03.006
Hyndman RJ, Athanasopoulos G (2021) Forecasting: principles and practice (3rd ed). Melbourne: OTexts. https://otexts.com/fpp3/
Hyndman RJ, Khandakar Y (2008) Automatic time series forecasting: the forecast package for R. J Stat Softw 27: 1–22. https://doi.org/10.18637/jss.v027.i03
Hyndman RJ, Lee AJ, Wang E (2016) Fast computation of reconciled forecasts for hierarchical and grouped time series. Computat Stat Data Anal 97:16–32. https://doi.org/10.1016/j.csda.2015.11.007
Jeon J, Panagiotelis A, Petropoulos F (2019) Probabilistic forecast reconciliation with applications to wind power and electric load. Eur J Oper Res 279(2):364–379. https://doi.org/10.1016/j.ejor.2019.05.020
Koning AJ, Franses PH, Hibon M, Stekler H (2005) The M3 competition: statistical tests of the results. Int J Forecast 21(3):397–409. https://doi.org/10.1016/j.ijforecast.2004.10.003
Kourentzes N, Athanasopoulos G (2019) Cross-temporal coherent forecasts for Australian tourism. Ann Tour Res 75:393–409. https://doi.org/10.1016/j.annals.2019.02.001
Ledoit O, Wolf M (2004) A well-conditioned estimator for large-dimensional covariance matrices. J Multivar Anal 88(2):365–411. https://doi.org/10.1016/S0047-259X(03)00096-4
Leon SJ (2015) Linear algebra with applications, 9th edn. Pearson, Boston
Lyche T (2020) Numerical linear algebra and matrix factorizations. Springer, New York
Makridakis S, Spiliotis E, Assimakopoulos V (2022) M5 accuracy competition: results, findings, and conclusions. Int J Forecast 38(4):1346–1364. https://doi.org/10.1016/j.ijforecast.2021.11.013
Meyer CD (2000) Matrix analysis and applied linear algebra. Society for Industrial and Applied Mathematics, Philadelphia
Panagiotelis A, Athanasopoulos G, Gamakumara P, Hyndman RJ (2021) Forecast reconciliation: a geometric view with new insights on bias correction. Int J Forecast 37(1):343–359. https://doi.org/10.1016/j.ijforecast.2020.06.004
Panagiotelis A, Gamakumara P, Athanasopoulos G, Hyndman RJ (2023) Probabilistic forecast reconciliation: properties, evaluation and score optimisation. Eur J Oper Res 306(2):693–706. https://doi.org/10.1016/j.ejor.2022.07.040
Scheuerer M, Hamill TM (2015) Variogram-based proper scoring rules for probabilistic forecasts of multivariate quantities. Mon Weather Rev 143(4):1321–1334. https://doi.org/10.1175/MWR-D-14-00269.1
Stone R, Champernowne DG, Meade JE (1942) The precision of national income estimates. Rev Econ Stud 9(2):111. https://doi.org/10.2307/2967664
van Erven T, Cugliari J (2015) Game-theoretically optimal reconciliation of contemporaneous hierarchical time series forecasts. In: Antoniadis A, Poggi JM, Brossat X (eds) Modeling and stochastic learning for forecasting in high dimensions, vol. 217, pp 297–317. Cham, Springer International Publishing. https://doi.org/10.1007/978-3-319-18732-7_15
Wickramasuriya SL (2021) Properties of point forecast reconciliation approaches. https://doi.org/10.48550/arXiv.2103.11129
Wickramasuriya SL (2023) Probabilistic forecast reconciliation under the gaussian framework. J Bus Econ Stat. https://doi.org/10.1080/07350015.2023.2181176
Wickramasuriya SL, Athanasopoulos G, Hyndman RJ (2019) Optimal forecast reconciliation for hierarchical and grouped time series through trace minimization. J Am Stat Assoc 114(526):804–819. https://doi.org/10.1080/01621459.2018.1448825
Yagli GM, Yang D, Srinivasan D (2020) Reconciling solar forecasts: probabilistic forecasting with homoscedastic Gaussian errors on a geographical hierarchy. Sol Energy 210:59–67. https://doi.org/10.1016/j.solener.2020.06.005
Yang D (2020) Reconciling solar forecasts: probabilistic forecast reconciliation in a nonparametric framework. Sol Energy 210:49–58. https://doi.org/10.1016/j.solener.2020.03.095
Zhang B, Kang Y, Panagiotelis A, Li F (2023) Optimal reconciliation with immutable forecasts. Eur J Oper Res 308(2):650–660. https://doi.org/10.1016/j.ejor.2022.11.035
Acknowledgements
The authors acknowledge financial support from project PRIN2017 “HiDEA: Advanced Econometrics for High-frequency Data”, 2017RSMPZZ.
Funding
Open access funding provided by Università degli Studi di Padova.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendix A: Derivation of equation (11)
Appendix A: Derivation of equation (11)
Denote \(\varvec{W}_h = k_h\varvec{W}\), where \(k_h\) is a proportionality constant and \(\varvec{W}\) is the p.d. covariance matrix used in the point forecast reconciliation formula (4). Then:
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Girolimetto, D., Di Fonzo, T. Point and probabilistic forecast reconciliation for general linearly constrained multiple time series. Stat Methods Appl 33, 581–607 (2024). https://doi.org/10.1007/s10260-023-00738-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10260-023-00738-6