
Abstract
Pearson residuals are a widely used tool for model diagnostics of count time series. Despite their popularity, little is known about their distribution such that statistical inference is problematic. Squared Pearson residuals are considered for testing the conditional dispersion structure of the given count time series. For two popular types of Markov count processes, an asymptotic approximation for the distribution of the test statistics is derived. The performance of the novel tests is analyzed and compared to relevant competitors. Illustrative data examples are presented, and possible extensions of our approach are discussed.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The analysis and modeling of count time series, i.e., of quantitative time series having the range \(\mathbb {N}_0=\{0,1,\ldots \}\), has become a popular area in research and applications; see the books by Davis et al. (2016) and Weiß (2018). An important step during model fitting is diagnostic checks with regard to the considered candidate model, to find out, e.g., a possible misspecification of the model order or the dispersion structure. In the present paper, we are concerned with the latter task, i.e., the aim is to detect a misfit of the (conditional) variance of the actual data-generating process (DGP) \((X_t)_{\mathbb {Z}}\). In this context, we speak about overdispersion (underdispersion) if the DGP has more (less) variance than captured by the fitted model. If concentrating on the marginal dispersion of a stationary DGP, the use of an appropriate type of dispersion index is quite common among practitioners. For example, to check for a marginal equidispersion, Fisher’s dispersion index might be used, which is defined as the quotient of the (sample) variance to the mean, i.e., as \(I=\sigma ^2/\mu \) or \(\hat{I}=S^2/\bar{X}\), respectively. The distribution of \(\hat{I}\) for count time series data was analyzed by Schweer and Weiß (2014), among other works.
If also considering the conditional dispersion structure, statistics based on the (standardized) Pearson residuals appear as a reasonable choice (Harvey and Fernandes 1989; Czado et al. 2009; Jung and Tremayne 2011; Jung et al. 2016; Weiß 2018). Let the candidate model (depending on some parameter vector \({\varvec{\theta }}\in \mathbb {R}^m\)) have the conditional mean \(E[X_t\ |\ X_{t-1},\ldots ;\ {\varvec{\theta }}]\) and variance \(V[X_t\ |\ X_{t-1},\ldots ;\ {\varvec{\theta }}]\). Inserting the estimated parameter \(\hat{{\varvec{\theta }}}\) into these functions of \({\varvec{\theta }}\), the Pearson residuals are defined as
Note that these residuals are computed from the same set of data that was used for parameter estimation.
Assuming that the type of candidate model was chosen adequately, the “true” Pearson residuals \(R_t({\varvec{\theta }})\) have mean 0, variance 1, and they are serially uncorrelated. So it is natural to also analyze the estimated Pearson residuals \(R_t(\hat{{\varvec{\theta }}})\) for these properties. For example, Harvey and Fernandes (1989) suggest to “check on whether the sample variance of the residuals is close to 1. A value greater than 1 indicates overdispersion relative to the model that is being fitted.” (p. 413). This conclusion, however, has to be done with some caution. In a recent work, Weiß et al. (2019) did a comprehensive simulation study and showed that statistics based on Pearson residuals offer a good potential for detecting certain misspecifications, but a decision for or against the actual candidate model is difficult because of considerable deviations from the above target values even under model adequacy. Comparing the distributions of statistics based on either \(R_t({\varvec{\theta }})\) or \(R_t(\hat{{\varvec{\theta }}})\), they also showed that main parts of these deviations are caused by estimation uncertainty. Therefore, in this work, we aim at capturing the effect of the estimated parameters on the residuals’ distribution for certain types of count process model. To the best of our knowledge, such derivations have only been done for classical regression models up to now, e.g., by Pierce and Schafer (1986) and Cordeiro and Simas (2009).
Remark 1
Pearson residuals are very popular in practice, also because they are universally applicable in some sense: As long as the conditional mean and variance required for (1) can be computed for the considered model, the Pearson residuals can be used for checking the model adequacy. On the other hand, because of their general definition, they do not use further model properties beyond conditional mean and variance. Therefore, it might be possible to define alternative (and perhaps refined) types of residuals for specific model classes. As an example, Jung et al. (2016) define “component residuals” for the so-called INAR model (to be defined in Sect. 2), which allow to infer on the parts of the INAR recursion separately. Similarly, Zhu and Wang (2010) define residuals being tailor-made for the so-called INARCH model (see Sect. 2). If being concerned with such types of DGP (under the null), it is certainly recommended to also apply these (and further) diagnostic tools in addition to the Pearson residuals.
Furthermore, if not only the null model is specified but also the class of alternative models, this information might be used for constructing a hypothesis test, e.g., in the spirit of Sun and McCabe (2013), who consider INAR models based on the Katz family of distributions. But as mentioned before, here, our focus is on the widely applicable Pearson residuals, which we investigate analytically for certain INAR and INARCH models, and where possible extensions (e.g., to different model classes) are also briefly discussed. Furthermore, our simulation study (Sect. 4) shows that the considered tests show a rather good performance despite the general nature of the Pearson residuals.
Let the computed residuals \(R_t\) be indexed by \(t=1,\ldots ,n\). Since our focus is on the conditional dispersion structure, we consider the statistics
where \(\bar{R}\, =\, \frac{1}{n}\,\sum _{t=1}^n R_t\). For an adequately chosen model type, both statistics in (2) should take a value “close to 1.” For the two types of Markov count process described in Sect. 2, the aim is to derive closed-form formulae providing an asymptotic approximation to the distribution of (2). This is done in Sect. 3, where we also analyze these asymptotics and illustrate their application with some real-data examples. The finite-sample performance of the asymptotic approximations and the power of the dispersion tests implied by (2) are investigated in Sect. 4. Sect. 5 outlines possible extensions of our approach, and Sect. 6 provides concluding remarks on the residual-based dispersion tests.
2 Markov count processes
The computation of conditional mean and variance, as required for calculating the Pearson residuals (1), is particularly simple if being concerned with a pth-order Markov process. Certainly, the computation is also possible for many further processes, for example, Hidden-Markov processes, see p. 112 in Weiß (2018). But in the present work, we restrict on count-data Markov chains i.e., \(p=1\)), where the distribution of \(X_t\) only depends on the previous observation \(X_{t-1}\). Many models for count-data Markov chains have been proposed in the literature (Weiß 2018), where especially such having a conditional linear autoregressive (CLAR(1)) structure are widely used in practice, i.e., where the conditional mean is of the form \(E[X_t\ |\ X_{t-1}] = \alpha \,X_{t-1}+\beta \) (see Grunwald et al. 2000). Two popular instances of CLAR(1) models are INAR(1) and INARCH(1) model (integer-valued autoregressive (conditional heteroscedasticity)); see McKenzie (1985), Ferland et al. (2006) and Weiß (2018).
The INAR(1) model is defined by the recursion \(X_t\, =\, \alpha \circ X_{t-1} + \epsilon _t\) with \(\alpha \in (0;1)\), where the innovations \(\epsilon _t\) are i. i. d. count random variables satisfying \(E[\epsilon _t]=\mu _{\epsilon }>0\) and \(V[\epsilon _t]=\sigma _{\epsilon }^2>0\). The involved binomial thinning operation “\(\circ \)” (Steutel and van Harn 1979) is defined by requiring that \(\alpha \circ X|X\, \sim Bin (X,\alpha )\), where X is a count random variable. Conditional mean and variance are given by
which are both linear functions of \(X_{t-1}\). A Poi-INAR(1) model assumes Poisson-distributed innovations, say \(\epsilon _t\sim Poi (\beta )\) with \(\mu _{\epsilon }=\sigma _{\epsilon }^2=\beta \). Then also the observations \(X_t\) are Poisson-distributed, now \(X_t\sim Poi (\mu )\) with \(\mu =\sigma ^2=\frac{\beta }{1-\alpha }\). In this case, the parameter vector \({\varvec{\theta }}\) is given by \((\beta ,\alpha )\).
The INARCH(1) model assumes that the conditional mean is linear in the previous observation, i.e.,
whereas the conditional variance follows from the chosen conditional distribution of \(X_t\) given \(X_{t-1}\). If choosing a Poisson distribution, i.e., if \(X_t\,\sim \,Poi (\alpha \cdot X_{t-1} + \beta )\), then we obtain the Poi-INARCH(1) model satisfying \(V_t=M_t=\alpha \cdot X_{t-1} + \beta \). The two-dimensional parameter vector \({\varvec{\theta }}\) is again commonly chosen as \((\beta ,\alpha )\). Note that the unconditional distribution of \(X_t\) is not Poisson, actually, we have \(I=1/(1-\alpha ^2)>1\) (overdispersion) and \(\mu =\frac{\beta }{1-\alpha }\).
Remark 2
There are many ways of estimating the model parameters of a Poi-INAR(1) or INARCH(1) model, respectively. In this work, the main aim is to obtain closed-form formulae for the asymptotic distribution of the residual-based dispersion tests (2), enabling a detailed analysis of these asymptotics (to be done in Sect. 3). For this reason, we decided to use moment estimators, which are easy to compute by simple formulae (in exactly the same way for both models!), and for which explicit expressions for the asymptotic distribution are readily available, see Weiß and Schweer (2016). These moment estimators use the empirical mean \(\bar{X}\), variance \(\hat{\gamma }(0)\), and first-order autocovariance \(\hat{\gamma }(1)\), and they estimate \(\alpha \) by \(\hat{\rho }(1)=\hat{\gamma }(1)/\hat{\gamma }(0)\) as well as \(\beta \) by \(\bar{X}\big (1-\hat{\rho }(1)\big )\).
But other types of estimators might be used as well for computing the Pearson residuals, e.g., maximum likelihood (ML) estimators as this was done in the simulation study by Weiß et al. (2019). Then, however, it is not possible anymore to find closed-form formulae for the asymptotics of (2), because both the ML estimators themselves as well as their asymptotic distribution can only be computed numerically. In addition, one has to be aware that the Pearson residuals based on ML estimators will behave differently (not necessarily worse) than those based on moment estimators in some situations. This was observed by Weiß et al. (2019); see the last paragraph of their Sect. 3, where deviations in the dispersion structure also affected the mean and autocorrelation of the ML-based residuals. Since the asymptotics for an ML-based implementation of (2) are not explicitly available, hypothesis testing is only possible based on a bootstrap implementation. But this causes a considerable amount of additional computational efforts, whereas the moment-based implementation of (2) only requires to evaluate a few formulae. Nevertheless, we also did some simulation experiments regarding such bootstrap implementations, and these are presented in Sect. 5.
3 Approximating the squared Pearson residual’s distribution
Let \(X_0,\ldots ,X_n\) be the available time series, which is assumed to originate from a Markov count DGP. These data are used to estimate the DGP’s model parameter vector \({\varvec{\theta }}\) on the one hand, and to compute the Pearson residuals \(R_1,\ldots ,R_n\) according to (1) on the other hand. Then, we compute the statistics (2) to check the adequacy of the fitted model’s dispersion structure. For this purpose, we need to approximate the distribution of the statistics (2) under the null hypothesis of having fitted the correct type of model to the data. Our approach for doing this is as follows. Since \(\bar{R}^2\) is expected to produce values being very close to zero, the values of \(S_R^2\) and \(\mathrm{MS}_R\) will usually nearly coincide; also see the examples and simulations as follows. Hence, we approximate the distribution of the empirical variance \(S_R^2\) by the one of \(\mathrm{MS}_R = \frac{1}{n}\,\sum _{t=1}^n R_t(\hat{{\varvec{\theta }}})^2\). The latter, in turn, is derived in two steps. First, we derive an asymptotic approximation for the joint distribution of \(\frac{1}{n}\,\sum _{t=1}^n R_t({\varvec{\theta }})^2\) (mean of squared “true” residuals) and \(\hat{{\varvec{\theta }}}\). Then, in analogy to Weiß et al. (2017), we approximate \(\mathrm{MS}_R\) linearly in \(\hat{{\varvec{\theta }}}-{\varvec{\theta }}\) by
see Appendix A.1. This general expression is finally adapted to the considered types of DGP and used to compute an asymptotic approximation for the distribution of \(\mathrm{MS}_R\). The results obtained for a Poi-INAR(1) DGP are presented in Sect. 3.2, the ones for a Poi-INARCH(1) DGP in Sect. 3.2. The detailed derivations are provided by Appendices A and B, respectively. Since it is not clear in advance that our approximation approach works successfully in practice, its performance has to be checked with simulations, which is done later in Sect. 4.
3.1 Approximation for Poi-INAR(1) DGP
For the Poi-INAR(1) DGP with conditional mean \(M_t=\alpha \, X_{t-1} + \beta \) and variance \(V_t=\alpha (1-\alpha )\, X_{t-1} + \beta \), which was briefly surveyed in Sect. 2, the statistic \(\mathrm{MS}_R\) from (2) is computed as
see (3). In Appendix A.1, we show that (5) implies the following linear approximation for \(\mathrm{MS}_R(\hat{\beta },\hat{\alpha })\):
This approximation allows us to separate the randomness of the residuals from the one of the estimated parameters. The required moment
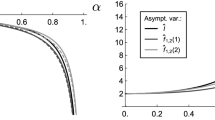
can be computed numerically as \((1-\alpha )^{-1}\,\sum _{x=0}^M \frac{x}{\alpha \, x + \mu }\, p_x\) with M sufficiently large, where the marginal probabilities \(p_x = P(X_{t-1}=x)\) are from the \(Poi (\mu )\)-distribution. For \(\alpha \rightarrow 0\), we have \(E\big [\frac{X_{t-1}}{V_t}\big ]\rightarrow 1\).
(7) immediately implies the following approach for bias correction,
where bias approximations for \(E\big [\hat{\alpha }-\alpha \big ], E\big [\hat{\beta }-\beta \big ]\) are to be inserted. For the case of the moment estimators used here (Sect. 2), such bias formulae are provided by Weiß and Schweer (2016).
To derive an approximate distribution for (7), we need the following result.
Theorem 1
Let \((X_t)_{\mathbb {Z}}\) be a Poi-INAR(1) process with \(\mu =\frac{\beta }{1-\alpha }\), and let \(\hat{\beta },\hat{\alpha }\) be moment estimators of \(\beta ,\alpha \); see Sect. 2. Then,
is asymptotically normally distributed with mean \({\varvec{0}}\) and covariance matrix \({\varvec{\Sigma }}=(\sigma _{ij})_{i,j=1,2,3}\), where
The proof of Theorem 1 is given in Appendix A.3. The covariances \(\sigma _{22},\sigma _{23},\sigma _{33}\) have first been derived by Freeland and McCabe (2005).
Next, we combine the linear approximation (7) with Theorem 1 and derive the following normal approximation (see Appendix A.4).
Theorem 2
Let \((X_t)_{\mathbb {Z}}\) be a Poi-INAR(1) process with \(\mu =\frac{\beta }{1-\alpha }\), and let \(\hat{\mu },\hat{\alpha }\) be moment estimators of \(\mu ,\alpha \); see Sect. 2. Then, the distribution of the linear approximation (7) for \(\mathrm{MS}_R(\hat{\beta },\hat{\alpha })\) can be approximated by a normal distribution with mean 1 and variance \(\sigma _{\mathrm{MS}_R}^2/n\), where
A plot of approximate bias and standard deviation (SD) of \(\mathrm{MS}_R\), as implied by (8) and Theorem 2, is shown in Fig. 1 (where we set \(n=1\)). It becomes clear that the actual marginal mean \(\mu \) has only little effect on these approximations, whereas the effect of the dependence parameter \(\alpha \) is very strong. Note that for \(\alpha \rightarrow 0\), we have \(E\big [\frac{X_{t-1}}{V_t^2}\big ]\rightarrow 1/\mu \). So the limiting value of \(\sigma _{\mathrm{MS}_R}\) for \(\alpha \rightarrow 0\) is given by \(\sqrt{2}\), which can also be recognized from Fig. 1b.

Approximate bias in (a) and SD in (b) of \(\mathrm{MS}_R\) for Poi-INAR(1) DGP (setting \(n=1\)), plotted against \(\alpha \) for different mean levels \(\mu \)
In applications, the normal distribution implied by Theorem 2, together with the bias-corrected mean (8), can now be used to approximate the true distribution of both statistics \(\mathrm{MS}_R\) and \(S_R^2\) from (2) under the null hypothesis of a Poi-INAR(1) DGP. The performance of this approximation is investigated in Sect. 4, where results from a simulation study are presented.
Example 1
Let us consider a time series of monthly counts (Jan. 1987 to Dec. 1994, so 96 observations) of claims caused by burn-related injuries in the heavy manufacturing industry, which was presented in Example 2.5.1 by Freeland (1998) as an illustration for the Poi-INAR(1) model. Under this assumption, together with the moment estimates \(\hat{\mu }\approx 8.604\) and \(\hat{\alpha }\approx 0.452\), we compute 95 Pearson residuals, see (6), where both \(\mathrm{MS}_R\) and \(S_R^2\) take the value \(\approx 1.310\). Following Harvey and Fernandes (1989), this indicates that the data exhibit more variation than captured by the Poi-INAR(1) model. But does 1.310 constitute a significant deviation from 1?
The same data were also analyzed in Schweer and Weiß (2014) by using Fisher’s dispersion index, and they ended up with a “quite narrow decision” against the Poi-INAR(1) model. Let us complement this result by a residual-based test concerning the alternative \(\mathrm{MS}_R,S_R^2>1\). Using the asymptotics of (8) and Theorem 2 (and plugging-in the above moment estimates instead of the unknown model parameters), we approximate the mean and standard deviation of \(\mathrm{MS}_R\) as 0.971 and 0.177, respectively. On a 5%-level, the critical value computes as 1.263, so we actually have a “less narrow” decision (P value 0.028) against the Poi-INAR(1) model than in Schweer and Weiß (2014).
3.2 Approximation for Poi-INARCH(1) DGP
For the Poi-INARCH(1) DGP, conditional mean and variance are equal to each other, both given by \(M_t=\alpha \, X_{t-1} + \beta \), see Sect. 2. So this time, the statistic \(\mathrm{MS}_R\) from (2) is computed as
see (4). In Appendix B.1, we again use (5) to derive the following linear approximation of \(\mathrm{MS}_R(\hat{\beta },\hat{\alpha })\):
Like before, this approximation allows us to separate the randomness of the residuals from the one of the estimated parameters. The required moment
can be computed numerically as \(\sum _{x=0}^M \frac{x}{\alpha \, x + \beta }\, p_x\) with M sufficiently large. The marginal probabilities \(p_x=P(X_{t-1}=x)\) can be approximated based on the invariance equation of the INARCH(1) model; see Sect. 3.3 in Weiß et al. (2017) or Remark 2.1.3.4 in Weiß (2018). For \(\alpha \rightarrow 0\), we have \(E\big [\frac{X_{t-1}}{V_t}\big ]\rightarrow 1\).
Like in the INAR(1) case, (10) would also imply a bias correction, namely
where bias approximations for \(E\big [\hat{\alpha }-\alpha \big ], E\big [\hat{\beta }-\beta \big ]\) are to be inserted. For the case of the moment estimators used here (Sect. 2), such bias formulae are provided by Weiß and Schweer (2016). But our simulations to be presented in Sect. 4 show that this time, the bias correction does not work satisfactorily.
To derive an approximate distribution for (10), we again proceed in a stepwise manner and first derive the following result.
Theorem 3
Let \((X_t)_{\mathbb {Z}}\) be a Poi-INARCH(1) process with \(\mu =\frac{\beta }{1-\alpha }\), and let \(\hat{\beta },\hat{\alpha }\) be moment estimators of \(\beta ,\alpha \); see Sect. 2. Then,
is asymptotically normally distributed with mean \({\varvec{0}}\) and covariance matrix \({\varvec{\Sigma }}=(\sigma _{ij})_{i,j=1,2,3}\), where
The proof of Theorem 3 is given in Appendix B.3. The covariances \(\sigma _{22},\sigma _{23},\sigma _{33}\) have first been derived by Weiß (2010).
Next, we combine the linear approximation (10) with Theorem 3 and derive the following normal approximation (see Appendix B.4).
Theorem 4
Let \((X_t)_{\mathbb {Z}}\) be a Poi-INARCH(1) process with \(\mu =\frac{\beta }{1-\alpha }\), and let \(\hat{\mu },\hat{\alpha }\) be moment estimators of \(\mu ,\alpha \); see Sect. 2. Then, the distribution of the linear approximation (10) for \(\mathrm{MS}_R(\hat{\beta },\hat{\alpha })\) can be approximated by a normal distribution with mean 1 and variance \(\sigma _{\mathrm{MS}_R}^2/n\), where
A plot of approximate bias and SD of \(\mathrm{MS}_R\), as implied by (11) and Theorem 4, is shown in Fig. 2 (where we set \(n=1\)). The dependence parameter \(\alpha \) has again a very strong effect on these quantities, but in contrast to Fig. 1 for a Poi-INAR(1) DGP, they are also notably influenced by the marginal mean \(\mu \) this time. The limiting value of \(\sigma _{\mathrm{MS}_R}\) for \(\alpha \rightarrow 0\) again equals \(\sqrt{2}\), which can also be recognized from Fig. 2b.

Approximate bias in (a) and SD in (b) of \(\mathrm{MS}_R\) for Poi-INARCH(1) DGP (setting \(n=1\)), plotted against \(\alpha \) for different mean levels \(\mu \)
In applications, the normal distribution implied by Theorem 4 can now be used to approximate the true distribution of both statistics \(\mathrm{MS}_R\) and \(S_R^2\) from (2) under the null hypothesis of a Poi-INARCH(1) DGP. The performance of this approximation is investigated in Sect. 4, where results from a simulation study are presented. There, also the possible bias correction using (11) is investigated.
Example 2
Jung and Tremayne (2011) presented a time series of counts of iceberg orders (per 20 min for 32 consecutive trading days in 2004, so 800 observations) with respect to the Deutsche Telekom shares traded in the XETRA system of Deutsche Börse. These overdispersed data were also analyzed by Weiß (2015), where a Poi-INARCH(1) model turned out to be a reasonable candidate modelFootnote 1. So we compute the 799 (squared) Pearson residuals under this model assumption, see (9), where we have the moment estimates \(\hat{\mu }\approx 1.406\) and \(\hat{\alpha }\approx 0.635\). Both \(\mathrm{MS}_R\) and \(S_R^2\) take the value \(\approx 1.088\), which is rather close to 1. But because of the large sample size, we have a significant though narrow violation of the null hypothesis on a 5%-level, because the P value equals 0.049 (with bias correction: 0.043). This goes along with the results in Weiß (2015), who finally preferred another model for these data.
Example 3
Recalling Example 1, the claims counts time series requires a model with more variation than provided by a Poi-INAR(1) model, and such a model is given by the Poi-INARCH(1) model (also see the conclusions in Schweer and Weiß (2014)). Proceeding as in Example 2, we compute \(\mathrm{MS}_R\) and \(S_R^2\) as \(\approx 1.050\), so again only a small exceedance of 1. But this time, the sample size is much smaller, and the critical value on a 5%-level becomes rather large, namely 1.239 (with bias correction: 1.238). Also the P value 0.365 (with bias correction: 0.363) shows that there is no contradiction against a Poi-INARCH(1) model for the claims counts data.
4 Results from a simulation study
We conducted a simulation study, the aim of which was twofold: to check the finite-sample performance of the approximations for mean and variance of \(\mathrm{MS}_R\) and \(S_R^2\) derived in Sect. 3, and to investigate size and power of the diagnostic tests based on \(\mathrm{MS}_R\) and \(S_R^2\). For each considered scenario, we simulated \(10^5\) replications. As a general result, it turned out that the difference between \(\mathrm{MS}_R\) and \(S_R^2\) from (2) was virtually negligible. For example, if we observed a difference in power at all, this difference was very small and followed a regular pattern. Since \(S_R^2 = \mathrm{MS}_R - \bar{R}^2\ < \mathrm{MS}_R\), \(\mathrm{MS}_R\) lead to equal or slightly better power if an upper-sided test against overdispersion is done, and \(S_R^2\) lead to equal or slightly better power if a lower-sided test against underdispersion is done. So to save some space, the summarizing tables collected in Appendix C are restricted to \(\mathrm{MS}_R\) only.
The first part of our simulations refers to a hypothetical Poi-INAR(1) model, i.e., the Pearson residuals and the asymptotics for \(\mathrm{MS}_R\) are computed as described in Sect. 3.1. The results in Table 1 for the marginal means \(\mu \in \{2,5\}\) and the autocorrelation parameters \(\alpha \in \{0.25,0.5,0.75\}\) show a negative bias for \(\mathrm{MS}_R\), but this bias is captured quite well by the asymptotic approximation (8), at least for sample size \(n\ge 250\). An analogous conclusion applies to the standard errors of \(\mathrm{MS}_R\), where the approximation quality slightly deteriorates with increasing \(\alpha \). In practice, these approximations are used for testing the hypothetical Poi-INAR(1) model, in analogy to Example 1. So the performance of such a test (size & power) is crucial for applications. This is investigated for diverse alternative scenarios: We use upper-sided tests to uncover overdispersion as generated by an NB-INAR(1) DGP in Table 2 or by a ZIP-INAR(1) DGP as in Table 3, and lower-sided tests to uncover underdispersion as generated by a Good-INAR(1) DGP in Table 4. Here, the INAR(1) innovations follow a negative binomial or zero-inflated Poi-or Good distribution, respectively; for background information on these distributions, see Weiß (2018). As a competitor, we use the \(\hat{I}\)-test relying on the sample dispersion index as derived by Schweer and Weiß (2014).
The size values in Table 2 (columns \(I=1\); replicated in Table 3) for the \(\mathrm{MS}_R\)-test are always very close to the nominal 5%-level, whereas those of the \(\hat{I}\)-test are either somewhat larger than 5% for \(\alpha =0.25\), or smaller than 5% for \(\alpha =0.75\). Also concerning the lower-sided tests, see Table 4, the size values the \(\mathrm{MS}_R\)-test are usually more close to the 5%-level than those of the \(\hat{I}\)-test. In particular, with only few exceptions, the \(\mathrm{MS}_R\)-test has better power values than the \(\hat{I}\)-test, both for under- and overdispersion, and also for the case if overdispersion is actually caused by an excessive number of zeros. So we can give a clear recommendation for using the \(\mathrm{MS}_R\)-test instead of the \(\hat{I}\)-test in the INAR(1) case.
The second part of our simulation study refers to a hypothetical Poi-INARCH(1) DGP, see Sect. 3.1. Here, we do not consider the dispersion index as a competitor, because it is known to perform poorly for such INARCH processes. Instead, we consider the \(\widehat{C}_{1;2}\)-test proposed by Weiß et al. (2017), and we also use the parametrizations given there, i.e., \(\mu \in \{2.5,5\}\) and \(\alpha \in \{0.2,0.4,0.6,0.8\}\). Table 5 compares the simulated means and standard errors with the asymptotic approximations implied by (11) and Theorem 4. While the approximation of the standard errors works rather well, especially for \(\mu =5\), the mean approximation is not satisfactory: In most cases, the simulated bias is clearly stronger, but for \(\mu =2.5\) and \(\alpha =0.8\), we also find the opposite deviation. For this reason, we did not further use the bias correction when executing the \(\mathrm{MS}_R\)-test in the INARCH(1) case. The size values of the \(\mathrm{MS}_R\)-test (without bias correction) are given in Table 6 (column “\(\theta =1\)”). Most often, they are reasonably close to the nominal 5%-level, and in case of a notable deviation (essentially for \(T=100\) or \(\mu =2.5\), \(\alpha =0.8\)), the \(\mathrm{MS}_R\)-test is conservative. This differs from the \(\widehat{C}_{1;2}\)-test, the size of which often exceeds the 5%-level, especially for large \(\alpha \).
For power analysis, we use an alternative DGP with additional conditional variation, namely the same NB-INARCH(1) process as in Weiß et al. (2017):
The corresponding power values in Table 6 show that the \(\mathrm{MS}_R\)-test has better power values in most cases despite its tendency to being conservative. The advantage to the \(\widehat{C}_{1;2}\)-test is particularly large for a highly correlated process (\(\alpha =0.8\)). So taking all results together, we clearly recommend the \(\mathrm{MS}_R\)-test for uncovering a misfit of the DGP’s dispersion structure.
5 Possible extensions
In view of their good performance, as demonstrated in Sect. 4, it appears to be a promising direction for future research to extend the residual-based dispersion tests also to other relevant types of count process. This could be done in two ways. On the one hand, analogous asymptotic approximations could be derived for different types of DGP. For example, if appropriately parametrized, the non-Markovian Poi-INMA(1) process (a moving-average-type process) has the same formulae for 1-step-ahead conditional mean and variance as the Poi-INAR(1) process, see (3). Hence, we also get the same formulae for the test statistic and its linear approximation, namely (6) and (7), respectively. So it remains to compute an asymptotic result analogous to Theorem 1, where the asymptotics derived by Aleksandrov and Weiß (2019) constitute a starting point. Another idea could be to consider models for bounded counts, i.e., having a finite range of the form \(\{0,\ldots ,N\}\) with some \(N\in \mathbb {N}\), like the finite Markov chains binomial AR(1) or INARCH(1); see Weiß (2018) for details and references. These processes, however, have slightly different expressions for the conditional variance (if choosing the model parameters to match the conditional mean), thus also the expressions for the residuals slightly differ from the ones discussed in this article. For \(N\rightarrow \infty \), these formulae converge to those of the respective Poisson counterpart.
A second solution for doing residual-based tests for count DGPs could be based on a parametric bootstrap implementation (regarding the respective hypothetical model for the DGP). This would allow to consider further types of DGP, such as higher-order INAR and IN(G)ARCH models or Hidden-Markov models, or to use different estimation approaches for computing the residuals, e.g., ML instead of moment estimators. To get an idea about the performance of such a bootstrap implementation, we did a simulation experiment for the Poi-INAR(1) case, by comparing the above asymptotic approximation with the parametric bootstrap scheme described in Jentsch and Weiß (2018). Since the bootstrap implementation requires much more computing time, we did only 5 000 Monte Carlo replicates this time (and always 500 bootstrap replicates). The results are summarized in Table 7, where the columns “asym” refer to the asymptotic approximation and are taken from Table 2, and where the columns “boot” contain the new simulation results. Although showing more fluctuations, the sizes for this upper-sided bootstrap test are close to the 5%-level, and the power values regarding an NB-INAR(1) DGP agree quite well with those of the asymptotic approximation (with some deterioration for increasing \(\alpha \)). It should be noted, however, that the lower-sided bootstrap test suffers from oversizing, especially for \(\alpha =0.75\) (see Table 8), so further refinements would be required here.
In addition, we also combined the above bootstrap implementation (Poi- against NB-INAR(1) DGP) with ML-based residuals; also recall the discussion in Remark 2. This, however, caused a further increase in computing time because of the numerical optimizations required for each simulation and each bootstrap run. The obtained simulation results are summarized in Table 9. Again, the sizes show a bit more fluctuations than in the case of the asymptotic implementation based on moment estimators (see Table 7), but are sufficiently close to 0.050. The ML-based power values are nearly the same as those obtained using moment estimators for the low autocorrelation level \(\alpha =0.25\), but they become more and more superior with increasing \(\alpha \). This result appears plausible in view of a better performance of the ML estimators than the moment estimators for highly correlated INAR(1) processes; see the discussion in Weiß and Schweer (2016). So if the computational burden caused by the ML-based bootstrap implementation can be managed, this type of residual-based dispersion test seems to be even more powerful in detecting neglected dispersion than the more simple moment-based implementation.
6 Conclusions
For doing model diagnostics with respect to the conditional dispersion structure of the given count time series, we used statistics based on the squared Pearson residuals. To allow for hypothesis testing, we derived asymptotic approximations for the distribution of the test statistics under the null of a Poi-INAR(1) or INARCH(1) DGP. The simulations demonstrated that the resulting tests show a very good performance for uncovering diverse over- and underdispersion scenarios. Although we concentrated on Poi-INAR(1) and INARCH(1) DGPs (and computed the residuals based on moment estimators), we also argued that extensions to other types of count processes (or to other types of estimators) are possible (e.g., based on an appropriate bootstrap implementation). A more detailed study of such extensions and their performance should be done in a future research.
References
Aleksandrov, B., Weiß, C.H.: Parameter estimation and diagnostic tests for INMA(1) processes. In: TEST (2019) (forthcoming)
Cordeiro, G.M., Simas, A.B.: The distribution of Pearson residuals in generalized linear models. Comput. Stat. Data Anal. 53(9), 3397–3411 (2009)
Czado, C., Gneiting, T., Held, L.: Predictive model assessment for count data. Biometrics 65(4), 1254–1261 (2009)
Davis, R.A., Holan, S.H., Lund, R., Ravishanker, N. (eds.): Handbook of Discrete-Valued Time Series. CRC Press, Boca Raton (2016)
Ferland, R., Latour, A., Oraichi, D.: Integer-valued GARCH processes. J. Time Ser. Anal. 27(6), 923–942 (2006)
Freeland, R.K.: Statistical analysis of discrete time series with applications to the analysis of workers compensation claims data. Ph.D. thesis, University of British Columbia, Canada (1998). https://open.library.ubc.ca/cIRcle/collections/ubctheses/831/items/1.0088709
Freeland, R.K., McCabe, B.P.M.: Asymptotic properties of CLS estimators in the Poisson AR(1) model. Stat. Probab. Lett. 73(2), 147–153 (2005)
Grunwald, G., Hyndman, R.J., Tedesco, L., Tweedie, R.L.: Non-Gaussian conditional linear AR(1) models. Aust. N. Z. J. Stat. 42(4), 479–495 (2000)
Harvey, A.C., Fernandes, C.: Time series models for count or qualitative observations. J. Bus. Econ. Stat. 7(4), 407–417 (1989)
Ibragimov, I.: Some limit theorems for stationary processes. Theory Probab. Appl. 7(4), 349–382 (1962)
Jentsch, C., Weiß, C.H.: Bootstrapping INAR models. Bernoulli (2018). (forthcoming)
Johnson, N.L., Kemp, A.W., Kotz, S.: Univariate Discrete Distributions, 3rd edn. Wiley, Hoboken (2005)
Jung, R.C., Tremayne, A.R.: Useful models for time series of counts or simply wrong ones? AStA Adv. Stat. Anal. 95(1), 59–91 (2011)
Jung, R.C., McCabe, B.P.M., Tremayne, A.R.: Model validation and diagnostics. In: Handbook of Discrete-Valued Time Series, pp. 189–218 (2016)
McKenzie, E.: Some simple models for discrete variate time series. Water Resour. Bull. 21(4), 645–650 (1985)
Pierce, D.A., Schafer, D.W.: Residuals in generalized linear models. J. Am. Stat. Assoc. 81(4), 977–986 (1986)
Schweer, S., Weiß, C.H.: Compound Poisson INAR(1) processes: Stochastic properties and testing for overdispersion. Comput. Stat. Data Anal. 77, 267–284 (2014)
Steutel, F.W., van Harn, K.: Discrete analogues of self-decomposability and stability. Ann. Probab. 7(5), 893–899 (1979)
Sun, J., McCabe, B.P.M.: Score statistics for testing serial dependence in count data. J. Time Ser. Anal. 34(3), 315–329 (2013)
Weiß, C.H.: The INARCH(1) model for overdispersed time series of counts. Commun. Stat. Simul. Comput. 39(6), 1269–1291 (2010)
Weiß, C.H.: A Poisson INAR(1) model with serially dependent innovations. Metrika 78(7), 829–851 (2015)
Weiß, C.H.: An Introduction to Discrete-Valued Time Series. Wiley, Chichester (2018)
Weiß, C.H., Schweer, S.: Bias corrections for moment estimators in Poisson INAR(1) and INARCH(1) processes. Stat. Probab. Lett. 112, 124–130 (2016)
Weiß, C.H., Gonçalves, E., Mendes Lopes, N.: Testing the compounding structure of the CP-INARCH model. Metrika 80(5), 571–603 (2017)
Weiß, C.H., Scherer, L., Aleksandrov, B., Feld, M.: Checking model adequacy for count time series by using Pearson residuals. J. Time Ser. Econ. (2019) (forthcoming)
Zhu, F., Wang, D.: Diagnostic checking integer-valued ARCH($p$) models using conditional residual autocorrelations. Comput. Stat. Data Anal. 54(2), 496–508 (2010)
Acknowledgements
The authors thank the two referees for highly useful comments on an earlier draft of this article. The iceberg order data of Example 2 were kindly made available to the second author by the Deutsche Börse. Prof. Dr. Joachim Grammig, University of Tübingen, is to be thanked for processing of it to make it amenable to data analysis. We are also very grateful to Prof. Dr. Robert Jung, University of Hohenheim, for his kind support to get access to the data. The first author was funded by the IFF 2018 of the Helmut Schmidt University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Proofs for Poi-INAR(1) DGP
1.1 Linear approximation for squared residuals
Before turning to the specific case of a Poi-INAR(1) DGP, let us first consider the general case described in the beginning of Sect. 3, i.e., Let \(M_t=E[X_t\ |\ X_{t-1},X_{t-2},\ldots ]\) and \(V_t=V[X_t\ |\ X_{t-1},\ldots ]\) depend on some parameter vector \({\varvec{\theta }}\), then
where \(M_t({\varvec{\theta }})\) and \(V_t({\varvec{\theta }})\) denote the conditional mean and variance, respectively, as functions of \({\varvec{\theta }}\). To derive a linear approximation for the statistic \(\mathrm{MS}_R(\hat{{\varvec{\theta }}})\), we consider a first-order Taylor approximation of the function \(\mathrm{MS}_R({\varvec{\theta }})\) in \({\varvec{\theta }}\). The first-order partial derivative in \(\theta _i\) equals
The means of the summands are
where the first equation used that \(E\big [(X_t-M_t)^2\ |\ X_{t-1},\ldots \big ] = V_t\). This is used to conclude that
Thus, the linear Taylor approximation
together with Slutsky’s lemma, implies the linear approximation (5).
Now, consider the special case of a Poi-INAR(1) DGP, i.e., \({\varvec{\theta }}=(\beta ,\alpha )\). According to (5), we require the partial derivatives of \(V_t=\beta +\alpha (1-\alpha )\,X_{t-1}\), which equal \(\frac{\partial }{\partial \alpha }\,V_t=(1-2\alpha )\,X_{t-1}\) and \(\frac{\partial }{\partial \beta }\,V_t=1\). Thus, it follows that
This implies the linear approximation (7). Note that \(E\big [\frac{1}{V_t}\big ]\) can be rewritten as \(\frac{1}{\beta }\big (1-\alpha (1-\alpha )\,E\big [\frac{ X_{t-1}}{V_t}\big ]\big )\).
1.2 Joint distribution of residuals and moments
In order to prepare the asymptotic results to be derived for Sect. 3, we use a central limit theorem (CLT) for the four-dimensional vector-valued process \(({\varvec{Y}}_t)_{\mathbb {Z}}\) given by
with \(\mu (k) := E[X_t X_{t-k}]\). Note that the Poi-INAR(1) process is \(\alpha \)-mixing with exponentially decreasing weights, and it has existing moments of any order (Weiß and Schweer 2016). So the CLT by Ibragimov (1962) can be applied to \(\frac{1}{\sqrt{T}} \sum _{t=1}^T {\varvec{Y}}_t\). The following lemma summarizes the resulting asymptotics.
Lemma 1
Let \((X_t)_{\mathbb {Z}}\) be a Poi-INAR(1) process with \(\mu =\frac{\beta }{1-\alpha }\), \(\mu (k)=\mu (\alpha ^k+\mu )\) and
Then, \(\frac{1}{\sqrt{n}} \sum _{t=1}^n {\varvec{Y}}_t\) is asymptotically normally distributed with mean \({\varvec{0}}\) and covariance matrix \(\tilde{{\varvec{\Sigma }}} = (\tilde{\sigma }_{ij})\), where
The expressions for \(\tilde{\sigma }_{11},\ldots ,\tilde{\sigma }_{33}\) can be found in Theorem 2.1 of Weiß and Schweer (2016).
1.2.1 Proof of Lemma 1
Note that the conditional variance and the conditional mean are related to each other in several ways, namely:
We first need to calculate some conditional moments. Obviously, we have \(E\left[ X_t^2\ |\ X_{t-1}\right] =V_t+M_t^2\). Since for Poisson and binomial variates, factorial moments take a particularly simple form, we shall use the falling factorials \((x)_{(k)}=x\cdots (x-k+1)\) in the sequel. We have
where we used the moment formulae from Johnson et al. (2005), page 110, and the following simplification
Analogously, we get for the fourth conditional moment
We are now in a position to compute the asymptotic covariances required for Lemma 1. The CLT by Ibragimov (1962) implies that
where we used that \(E\left[ \frac{(X_t-M_t)^2}{V_t}\right] =1\) and
Here, we used formulas (A.7) and (A.6) for the conditional moments.
For the next covariance, we need
So it follows that
Now, let us take a look at
thus the last infinite sum vanishes. And the terms inside the first infinite sum can be calculated in the following way:
Note that (A.9) also holds for \(k=0\), see (A.8). So we get
Now, let us look at
where we used (A.6) and (A.7) for the conditional moments, and \(M_t=V_t+\alpha ^2 X_{t-1}\). This will be used for
Now, let us take a look at the terms inside the infinite sum.
The above relationship can be viewed as a recurrence. Let us define \(g_k:= E\left[ \tfrac{(X_t-M_t)^2}{V_{t}}\cdot X_{t+k}^2 \right] \) with
according to (A.11). Then, the first-order linear difference equation
has the unique solution given by
If we insert (A.14) into Eq. (A.12), we get
Together with \(g_0\) according to (A.11), it follows that
Now, we have to calculate \(\tilde{\sigma }_{03}\). For this purpose, we start with
Then,
where
Furthermore,
Thus, using that \(\alpha \mu +\mu ^2=\alpha (\mu +\mu ^2)+(1-\alpha )\mu ^2\), we obtain
where we used (A.10) and (A.12) in the last step. Plugging-in \(\tilde{\sigma }_{01}, \tilde{\sigma }_{02}\) from Lemma 1 as well as (A.15), it follows that
So the proof of Lemma 1 is complete.
1.3 Proof of Theorem 1
We use the Delta method the same way as described in the proof of Corollary 1 in Weiß et al. (2017), page 599. Let \({\varvec{g}}:\mathbb R^4\rightarrow \mathbb R^3\) be defined as
where
Then, the Jacobian of \({\varvec{g}}\) is given by
such that
We need to calculate the covariance matrix \({\varvec{\Sigma }}=\mathbf D \tilde{\varvec{\Sigma }}\mathbf D ^{\top }\) with \(\tilde{\varvec{\Sigma }}\) from the previous Lemma 1. The components \(\sigma _{22},\sigma _{23},\sigma _{33}\) are provided by Weiß and Schweer (2016), page 127. Furthermore, it obviously holds that \(\sigma _{11}=\tilde{\sigma }_{00}\). Then,
Finally,
1.4 Proof of Theorem 2
Using Theorem 1 and the Cramer–Wold device with
it follows for the linear approximation (7) that
converges to the normal distribution with mean 0 and variance \(\sigma _{\mathrm{MS}_R}^2={\varvec{l}}{\varvec{\Sigma }}{\varvec{l}}^{\top }\), where \({\varvec{\Sigma }}\) is the covariance matrix from Theorem 1. After tedious calculations, the variance simplifies to
The proof is complete.
Proofs for Poi-INARCH(1) DGP
1.1 Linear approximation for squared residuals
We proceed in the same way as in Appendix A.1. To apply the linear approximation (5) to the special case of a Poi-INARCH(1) DGP, we require the partial derivatives of \(V_t=M_t=\beta +\alpha \,X_{t-1}\), which equal \(\frac{\partial }{\partial \alpha }\,V_t=X_{t-1}\) and \(\frac{\partial }{\partial \beta }\,V_t=1\). Thus, it follows that
This implies the linear Taylor approximation (10). Note that \(E\big [\frac{1}{M_t}\big ]\) can be rewritten as \(\frac{1}{\beta }\big (1-\alpha \,E\big [\frac{ X_{t-1}}{M_t}\big ]\big )\).
1.2 Joint distribution of residuals and moments
The Poi-INARCH(1) process satisfies the same mixing and moment conditions as stated for the Poi-INAR(1) process in Appendix A.2. So again, we can use a CLT in the same way as described in Appendix A.2 for the vectors from Eq. (A.1). Note that in the INARCH(1) case, \(V_t\) equals \(M_t\).
Lemma 2
Let \((X_t)_{\mathbb {Z}}\) be a Poi-INARCH(1) process with \(\mu =\frac{\beta }{1-\alpha }\), \(\mu (k)=\frac{\mu \,\alpha ^k}{1-\alpha ^2}+\mu ^2\) and
Then, \(\frac{1}{\sqrt{n}} \sum _{t=1}^n {\varvec{Y}}_t\) is asymptotically normally distributed with mean \({\varvec{0}}\) and covariance matrix \(\tilde{{\varvec{\Sigma }}} = (\tilde{\sigma }_{ij})\), where
The expressions for \(\tilde{\sigma }_{11},\ldots ,\tilde{\sigma }_{33}\) can be found in Theorem 2.2 of Weiß and Schweer (2016).
1.2.1 Proof of Lemma 2
The proof is done in complete analogy to the proof of Lemma 1 in Appendix A.2. For computing conditional moments, we use that the conditional distribution of \(X_t\) given \(X_{t-1}\) is \(Poi (M_t)\), so we use the formulae for Poisson moments in Johnson et al. (2005). Like in Appendix A.2, using that \(E\big [\tfrac{(X_t-M_t)^2}{M_t}\big ]=1\), we get
To compute \(\tilde{\sigma }_{01}\), we first need
Then, like in Appendix A.2, it follows that
The terms inside the infinite sum can be calculated as
So we get
Now, let us look at
This will be used for
We can rewrite the terms inside the infinite sum as
This relationship can be viewed as a recurrence, where \(1+\beta +\alpha \beta =1+\mu (1-\alpha ^2)\). Defining \(g_k= E\left[ \frac{(X_t-M_t)^2}{M_t}\cdot X_{t+k}^2 \right] \) with
according to (B.5), we have the first-order linear difference equation
It has the unique solution
which also holds for \(k=0\). Thus,
All the terms without the power k can be added together:
So we can further calculate
So it remains to calculate \(\tilde{\sigma }_{03}\). First,
Then, like in Appendix A.2, we have
Here,
Thus, it follows that
Comparing with (B.2) and (B.6), and using that
it follows that
Plugging-in \(\tilde{\sigma }_{01},\tilde{\sigma }_{02}\) from Lemma 2 as well as (B.9), we obtain
This completes the proof of Lemma 2.
1.3 Proof of Theorem 3
The proof follows the same steps as in Appendix A.3, and the required matrix \(\mathbf D \) can be directly taken from page 599 in Weiß et al. (2017):
Then, we calculate the covariance matrix \({\varvec{\Sigma }}=\mathbf D \tilde{\varvec{\Sigma }}\mathbf D ^{\top }\) with \(\tilde{\varvec{\Sigma }}\) from the previous Lemma 2. The components \(\sigma _{22},\sigma _{23},\sigma _{33}\) are provided by Weiß and Schweer (2016), page 129, or by Weiß et al. (2017), page 599. Furthermore, it obviously holds that \(\sigma _{11}=\tilde{\sigma }_{00}\). Then,
Finally,
1.4 Proof of Theorem 4
Using Theorem 3 and the Cramer–Wold device with
it follows for the linear approximation (10) that
converges to the normal distribution with mean 0 and variance \(\sigma _{\mathrm{MS}_R}^2={\varvec{l}}{\varvec{\Sigma }}{\varvec{l}}^{\top }\), where \({\varvec{\Sigma }}\) is the covariance matrix from Theorem 3. After tedious calculations, the variance simplifies to
Tables
See Tables 1, 2, 3, 4, 5, 6, 7, 8 and 9.
Rights and permissions
About this article

Cite this article
Aleksandrov, B., Weiß, C.H. Testing the dispersion structure of count time series using Pearson residuals. AStA Adv Stat Anal 104, 325–361 (2020). https://doi.org/10.1007/s10182-019-00356-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10182-019-00356-2