
Abstract
Landslides are a common geological hazard causing impairment of public works and loss of lives worldwide and in India, especially in the Himalayan region. The present study aims to map the landslide susceptibility for the Shillong Plateau region of India using different machine learning algorithms, namely artificial neural network (ANN), extreme gradient boosting (XGBoost), K-nearest neighbors (KNN), random forest (RF), and support vector machine (SVM) and provides insights into influential factors, with a focus on disaster risk reduction. For this purpose, the geospatial database containing 15 landslide conditioning factors related to regional geo-environmental settings and a landslide inventory with 1330 locations are prepared. The landslide susceptibility maps (LSM) reveal that the south-southeastern portion of Meghalaya, mainly slopes along the southern escarpment, are more susceptible to landslides. The model robustness is demonstrated using the area under the receiver operating characteristic curve (AUC), F1-score, kappa, and other statistical metrics. The XGBoost and RF machine learning models with AUC = 0.971 have shown the best performance, followed by SVM (0.958), KNN (0.951), and ANN (0.945), which is consistent with other applied statistical parameters and higher than the traditional MCDA methods. However, the problem of overestimation is observed in the case of ANN and XGBoost models. The generated LSMs will assist decision-makers and planners in identifying high-risk areas, prioritizing mitigation measures, and guiding regional development.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
One of the most common geological hazards, particularly in hilly areas, is landslides. These events affect the landscape and pose severe risks to vital infrastructure, including oil or gas pipelines, transmission lines for electricity, and transportation networks (Chen et al. 2017; Pham et al. 2017). Landslides are a complex phenomenon defined as rock, soil, or debris mass movement along slopes and associated with natural hazards, extreme weather events, or anthropogenic activity such as deforestation, earthquakes, rain, and road construction (Glade 2003; Youssef and Pourghasemi 2021). According to the Emergency Events Database (EM-DAT) maintained by the Centre for Research on the Epidemiology of Disasters (CRED), India is one of the most landslide-affected countries in Asia, second only to China (Guha-Sapir et al. 2017). In 2020–2021, India accounted for one of the highest numbers of landslide-related deaths in the world (CRED 2022). Approximately 0.42 million km2 (12.6%) of Indian landmass, including the Himalayan mountainous region in the north-northeast and the Western Ghats region, is highly vulnerable to landslide hazards (NDMA 2019). The Himalayan region, especially in the North Eastern Region (NER) of India, is geo-dynamically sensitive and subjected to frequent earthquakes and heavy monsoon rains, leading to severe landslides in recent years (Pham et al. 2017; NDMA 2019). With large-scale infrastructure developmental activities in the region, hazards like landslides are becoming a severe threat that requires immediate attention to mitigate and reduce the risk of associated disasters. In this regard, landslide susceptibility (LS) mapping is considered an imperative tool (Akgun 2012) that identifies highly vulnerable areas in terms of the probability of landslide occurrence based on factors such as past events and various other factors having the capacity to influence landslides. The landslide susceptibility maps (LSM) act as a tool for land use planners and decision-makers to select suitable areas for critical infrastructure and aid in preparing risk mitigation strategies (Pradhan and Lee 2010; Ozdemir and Altural 2013).
Landslide susceptibility studies (LSS) have gained significant attention throughout the world using geographic information systems (GIS) and remote sensing techniques over the last couple of decades (Kanungo et al. 2006; Pham et al. 2016; Sengupta et al. 2018; Zhang et al. 2019; Pokharel et al. 2021). However, the reliability of LSS is still a matter of concern as these studies are sensitive to various geo-environmental, anthropogenic, and other influencing factors, including the method used (Yilmaz 2009). There have been several LS models developed using different methodologies, such as inventory-based approaches (Akgun 2012), bivariate and multivariate methods (Chimidi et al. 2017; Zhu et al. 2018), multi-criteria decision analysis (MCDA) methods like analytical hierarchy process (AHP), analytic network process (ANP) (Kayastha et al. 2013; Ali et al. 2021), fuzzy-logic based approaches (Oh and Pradhan 2011; Agrawal and Dixit 2022a), probabilistic (Pourghasemi et al. 2014), and advanced machine learning (ML) methods (Pradhan 2013; Kavzoglu et al. 2014; Chen et al. 2018; Novellino et al. 2021; Jiang et al. 2023).
Advanced and sophisticated ML algorithms are increasingly being utilized for susceptibility studies due to their inherent ability to handle large datasets with non-linear spatial relationships, offer better precision and accuracy, and provide computational easiness compared to conventional statistical methods (Chen and Chen 2021). The artificial neural networks (ANN), Bayesian network (BN), boosted regression trees, decision trees (DT), Naïve Bayes (NB), logistic regression (LR), neuro-fuzzy inference system (ANFIS), random forest (RF), K-nearest neighbor (KNN), and support vector machine (SVM) are few of the popular ML algorithms in the field of landslide susceptibility assessment (Lee et al. 2007; Yilmaz 2010; Kavzoglu et al. 2014; Kim et al. 2018; Zhang et al. 2019; Adnan et al. 2020; Ghasemian et al. 2022; Wen et al. 2022). Convolutional neural networks (CNNs), a type of deep learning technique, have also been employed for landslide detection by several researchers (Meena et al. 2021; Wang et al. 2021; Huang et al. 2023; Jiang et al. 2023). Additionally, extreme gradient boosting (XGBoost), a relatively new ML technique, has been used to evaluate the susceptibility of various natural hazards (Pradhan and Kim 2020; Abedi et al. 2021; Pham et al. 2021; Hussain et al. 2022). Furthermore, some researchers have combined the outcomes of different susceptibility models using ensemble-based ML techniques to estimate LS (Kim et al. 2018; Di Napoli et al. 2020; Novellino et al. 2021). The advantages and disadvantages of various susceptibility models can be found in some of the published literature (e.g., Chacón et al. 2006; Dikshit et al. 2020; Shano et al. 2020).
For the Himalayan region, the use of ML algorithms in LSS has been mostly limited to the Shivalik Himalayas of the Uttarakhand and Central Himalayas (Kanungo et al. 2006; Chauhan et al. 2010; Ramakrishnan et al. 2013; Pham et al. 2016, 2017, 2019, 2020; Kumar et al. 2017; Peethambaran et al. 2019; Pokharel et al. 2021). However, for the NER of India in the Eastern Himalayas, only a few susceptibility studies are available, primarily relying on conventional statistical and MCDA approaches (Pandey et al. 2008; Ghosh and Carranza 2010; Balamurugan et al. 2016; Mondal and Mandal 2019; Agrawal and Dixit 2022a; Chanu and Bakimchandra 2022). It is evident from the above literature that at the regional scale, the assessment of LS using advanced data mining and ML algorithms is lacking in NER, India, and Meghalaya in particular. Furthermore, a search on the Scopus database using the keywords “landslide* OR landslide susceptibility” and “Meghalaya OR Shillong Plateau” yielded only 20 results, showing that the area has been understudied to date.
In the present study, five advanced ML algorithms, namely ANN, KNN, RF, SVM, and XGBoost, are adapted to perform the LSS of the Shillong Plateau region (Meghalaya) of NER, India. The region is prone to high seismicity and heavy rainfall and has numerous tectonic features (Agrawal et al. 2022), making it highly vulnerable to landslides. It is the first attempt to utilize ML algorithms for LSS in Meghalaya using GIS and remote sensing techniques. The generated LSMs may help the authorities and decision-makers to identify the landslide-vulnerable areas and plan for future development to accommodate urban sprawling with reduced risk of the concerned hazards in the region. To construct the LS model, the database of landslide inventory and various landslide conditioning factors (LCFs) are prepared and pre-processed (Pradhan and Lee 2010; Chen and Chen 2021). The discussion regarding the study area, data collection, pre-processing, and model development are made in the subsequent sections. R studio and ArcGIS 10.8 software are used for all the analysis and mapping purposes.
Study area and its geological setting
Meghalaya, situated in the NER of India, is considered as the study area for this study, as shown in Fig. 1. It is characterized by the Shillong Plateau, a significant landscape feature, and experiences torrential rainfall (Prokop 2014). It covers 22,429 km2 (0.68%) of India’s landscape and extends from 25.03 to 26.11°N and 89.82 to 92.80°E. The altitude in the study area ranges from 7 to 1962 m, with steep topographic relief and rugged terrain toward the southern portion, forming the southern escarpment along Dauki Fault (Agrawal et al. 2022).

Study area: its lithological and structural setting (1. Dauki, 2. Dhubri, 3. Dudhnai, 4. Kulsi Faults, 5. Barapani Shear Zone, 6. Umrangso, 7. Tluh, 8. Emangiri-Rewak Faults, 9. Dapsi Thrust, 10. Darugiri, 11. Chedrang, 12. Fulbari, 13. Samin Faults, 14. Eocene-Hinge Zone, 15. Kopili and 16. Oldham Faults; source: Bhukosh-Geological Survey of India)
Physiographically, Meghalaya can be divided into Garo Hill (covering the western part), Khasi Hills (in the center), and Jaintia Hills (covering the east-southeastern part). The region receives one of the highest rainfalls in the country, with a 30-year average ranging from 1234 to 7467 mm/year (Indian Meteorological Department; IMD), with the wettest area in the Khasi Hills. Rainfall is mainly concentrated between May and September, with sporadic showers throughout the year. The central southern part (Khasi Hills) receives the highest precipitation, with annual rainfall reaching as high as 12,000 mm in a year, about ten times the national average (IMD). This extreme variation in rainfall is primarily attributed to the southern escarpment, which acts as a barrier and enhances the orographic effect (Prokop 2014). The climate of the area is a monsoon-influenced humid subtropical climate (Cwa) as per the Köppen climate classification system, with temperature varying from 12 °C to 33 °C in the western portions and 2 °C to 24 °C in the central upland plateau. The area has a rich network of rain-fed streams forming tributaries of the Meghna and Brahmaputra rivers. Some of the major rivers are Bugi, Daring, Digaru, Kopili, Myntdu, Simsang, Umiam, Umkhri, and Umngot. The Khasi and Jaintia Hills have major urban centers, including Shillong, the capital city of Meghalaya, with a dense road network. The sprawling urban areas, dense roads, and heavy rainfall could intensify the damage associated with intensified landslides, putting the community and lifeline infrastructure at risk.
Geologically, the Shillong Plateau is the extension of the Indian Peninsular shield in the northeast with diverse lithological formations. It attained its current structural alignment during the Cenozoic Era. (Agrawal and Dixit 2022b). The area consists of Cenozoic era Quaternary sediments to the Archean-Paleoproterozoic eon gneissic complex (Strong et al. 2019). Various lithological formations such as Proterozoic (Paleo and Meso-proterozoic) (LI1), late Carboniferous-Permian (LI2), Mesozoic (Jurassic, Cretaceous) (LI3), Paleogene (Paleocene, Eocene, Oligocene) (LI4), tertiary Neogene (Pliocene, Miocene) (LI5) and Quaternary (Middle-late Pleistocene, Holocene-Meghalayan) (LI6) type of formations are present in the area (Fig. 1). As per Selby (1980), Quaternary sediments, siltstone, sandstone, and conglomerates of different eras are of low to medium strength against deformation/erosion and it covers ~ 37% area in the region. The Proterozoic formation consists of quartzite with phyllite interband, quartz, granulite, mica-gneiss, and others of Paleoproterozoic Mesoproterozoic eras, covering more than 50% of the landscape, are considered of high erosional resistance (Agrawal et al. 2022).
In addition, the study area is also characterized by a complex seismotectonic setting with numerous faults, thrust, and minor lineaments (Fig. 1) and has the potential for topographic amplification (Agrawal and Dixit 2022b; Gupta et al. 2022). The E-W trending Dauki Fault in the south is responsible for the plateau upliftment (Bilham and England 2001). Dhubri, Kopili, Oldham, and Umrangso Faults, Barapani shear zone, and Dapsi Thrust are other major tectonic features of the region (Kayal and De 1991). The area is in seismic zone V, which has a high seismic risk, according to the Indian Building Design Code (zone factor of 0.36 g; IS 1893–2016). From the perspective of geomorphological division, the study area consists of moderately to highly dissected Plateaus (~ 70%), moderately to highly dissected Hills and Valleys (~ 27%), alluvial flood Plain and Pediplain complex (~ 1%), and waterbodies (~ 1%) (Bhukosh-Geological Survey of India). The significant portion of Plateau margins along moderate to steep relief and along the steep slopes in the study area’s north, east, and south mainly consists of dissected hills and valleys (Fig. 2a). The study area comprises dense vegetation land (76.06%), light vegetation (including grass and shrub land; 17.25%), agricultural land (2.97%), built-up area (3.22%), bare-land (0.05%), and water surface (0.45%) (Fig. 2b). Due to these seismological and geological settings, along with heavy rainfall, landslides are frequent in the study area. The Khasi and Jaintia Hills regions are highly vulnerable to landslide occurrence. Several landslides, such as in the Jowai area (West Jaintia Hills), Sonapur in East Jaintia Hills, and the Mawlai-Umjapung area of East Khasi Hills districts, have occurred recently. Sonapur landslide, which first became active after the 1987 Chachar Earthquake along the NH-6 (earlier NH-44; Porowal and Dey 2010), has been reactivated during the monsoon seasons several times in the past.

a Geomorphology map of Meghalaya (GM1, moderately dissected hills and valleys; GM2, highly dissected plateau; GM3, moderately dissected plateau; GM4, pediment pediplain complex; GM5, alluvial-flood plains; GM6, waterbody; GM7, highly dissected hills and valley; Bhukosh-GSI). b Land use land cover map (LU1, dense vegetation; LU2, light vegetation including grass and shrub lands; LU3, agricultural land; LU4, built up area; LU5, bare lands; LU6, water surface)
Material and methods
Spatial database
Landslide inventory data
Preparing an inventory of past landslide data is the basis of any LSS (Pradhan 2013). A landslide inventory map helps to analyze the geospatial relationship between landslides and different landslide conditioning factors. The basic hypothesis of an LSS is that landslides will occur under similar settings as in the past (Guzzetti et al. 1999; Chen et al. 2017; Youssef and Pourghasemi 2021). By examining factors such as slope gradient, vegetation cover, and others in areas where landslides have previously occurred, LSS can identify areas with significant landslide susceptibility.
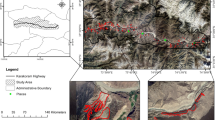
In this study, the locations of the past landslides were obtained from different sources such as the Bhukosh-Geological Survey of India (GSI) (www.bhukosh.gsi.gov.in) and Google Earth images. The collected landslides range from tens to thousands of square meters in area. Only data with an area of 100 m2 (10 × 10 m2) or more are retained for the study (Yilmaz 2010). As per Bhukosh-GSI, landslide events in the study region are mainly rainfall-induced, with a few exceptions. In this study, 1330 landslide locations are used (Fig. 3) and split randomly into training and testing datasets. Of these, 1054 landslides are associated with rock movement, 224 as debris slides (including 5 rock-cum-debris slides), and 50 as earth/soil slides, while two cannot be classified. Most of these landslides exhibit either shallow rotational or translational movement (GSI). The descriptive statistics of these landslides shows that 79.89% of past landslides have occurred in dense vegetation land, followed by light vegetation (16.95%), built-up areas (2.35%), and bare lands (0.42%). The training dataset was used to build the LS model based on different ML algorithms, and testing data was utilized during the model validation. Though there is no fixed ratio for the train-test split, the ratio of 70:30 is the most adopted one (Chen et al. 2018). Therefore, the training data was prepared using 70% of the total landslide inventory, and the remaining 30% was used for validation (Fig. 3).

Digital elevation model and landslide testing and training datasets
Landslide conditioning factors (LCF)
The occurrence of landslides in a region is often governed by various factors, including geo-environmental settings and the extent of anthropogenic activity. However, there are no fixed criteria for selecting the influencing factors for the LSS, and it often varies based on the region’s geo-environmental setting and data availability (Pradhan and Lee 2010). The geo-environmental setting refers to any location’s physical and environmental conditions, including factors such as topography, geology, hydrology, vegetation, climate, and human activities. Considering this, 15 LCFs are selected based on the available literature related to the study area and with similar geo-environmental settings (Dikshit et al. 2020; Pokharel et al. 2021). The selected LCFs include slope angle, aspect, elevation, distance from faults, distance from rivers, distance from roads, normalized difference vegetation index (NDVI), rainfall, plan curvature, stream power index (SPI), topography wetness index (TWI), lithology, geomorphology, land use land cover (LULC) and soil texture, listed in Table 1 (Agrawal and Dixit 2022a). The geospatial database of these LCFs with 10 m spatial resolution is prepared using GIS with UTM Zone 46N projected coordinate system and WGS 1984 datum (Ali et al. 2021).
Elevation, plan curvature, slope angle, and slope aspect are extracted using the digital elevation model (DEM) (Fig. 4a–d). The slope profile controls the shear force acting on soil or rock mass and water distribution, whereas the aspect affects the slope stability by impacting the amount of precipitation and solar radiation received (Yilmaz 2009; Pokharel et al. 2021). The plan curvature impacts the surface runoff dispersion and convergence and thus affects the slope stability (Pradhan and Lee 2010). The SPI and TWI are obtained based on Eqs. 1 and 2, using QGIS SAGA GIS tools (Fig. 4e and f).
where AS is the specific catchment area (m2) and β is the slope gradient.

a Slope (degree). b Aspect. c Plan curvature. d Elevation. e SPI. f TWI. g Distance from faults. h Distance from rivers. i Distance from roads. j Rainfall (mm/year). k NDVI. l Soil texture
SPI denotes the erosive power of a stream, and TWI represents the moisture content of the slope-forming material (Kavzoglu et al. 2014; Wang et al. 2021). Distances from faults, rivers, and roads are calculated using the Euclidean Distance tool in ArcGIS 10.8 based on faults data (Bhukosh-GSI), river, and road networks, respectively (Fig. 4g–i). The data source for these layers is listed in Table 1. The rainfall represents the climatological condition of a region and plays a vital role in a landslide. For the rainfall layer, the precipitation data for the last 30 years is obtained from IMD, and mean annual rainfall is used as an LCF (Fig. 4j). The NDVI is another critical factor signifying vegetation cover and health (Youssef and Pourghasemi 2021). It is calculated using high-resolution Sentinal-2 multispectral imagery (Eq. 3, Fig. 4k).
where NIR and R are near-infrared and red bands.
The lithological units present in a region also govern the landslide susceptibility. These units determine the geotechnical characteristics and effects of rock strength, permeability, resistance to weathering, and other properties (Youssef and Pourghasemi 2021). In the present study, the lithology of the study area is obtained from the Bhukosh-GSI database and grouped into six categories. The geomorphological units are derived from Bhukosh-GSI, which includes the following seven categories: moderately dissected hills and valleys (GM1), highly dissected plateau (GM2), moderately dissected plateau (GM3), pediment-pediplain complex (GM4), alluvial-flood plain (GM5), water bodies (GM6), and highly dissected hills and valley (GM7) (Fig. 2a). LULC is another important LCF adopted in many studies (Chen et al. 2017). The LULC map for the study area is extracted from the global LULC map provided by Esri (Gupta and Dixit 2022). The considered LULC classes are dense vegetation (LU1), light vegetation (grass and shrub land; LU2), agricultural land (including flooded vegetation; LU3), built area (LU4), bare land (LU5), and water surface (LU6) (Fig. 2b). The soil texture also influences the intensity and nature of slope movement by governing the geotechnical properties such as pore water pressure, cohesion, and permeability (Ghasemian et al. 2022). For this study, it is adapted from the FAO world soil map with the following soil type: loam (SO1), sandy loam (SO2), clay loam (SO3), and clay (SO4), as shown in Fig. 4l (Agrawal and Dixit 2022b).
Multicollinearity analysis
For any ML model, the multicollinearity between two or more input parameters may lead to erroneous results. Therefore, in the present study, the multicollinearity analysis among the selected LCFs is performed using indicators such as variance inflation factor (VIF) and tolerance (T) before the model training (Midi et al. 2010; Pham et al. 2016). A VIF value greater than 10 and tolerance < 0.1 indicates the problem of multicollinearity between LCFs (Chen et al. 2017; Chen and Chen 2021). The results are summarized in Table 1. For all the 15-LCFs, the VIF values remain less than 10, with the highest value of 5.449 and T remains greater than 0.18, indicating no multicollinearity problem in the dataset.
Data pre-processing
The selected LCF contains both numerical and categorical (discrete) datasets. The categorical variables include LULC, lithology, soil texture, and geomorphology. To make sense of an ML model, these discrete input variables first have to be encoded to numerical values. For this purpose, the one-hot encoding scheme is adopted in which multiple dummy variables are created. Each dummy variable corresponds to a feature class of a variable with binary representation. For example, if a landslide event is present in a discrete class of a variable, a value of 1 is encoded, and other classes are assigned 0. Therefore, 23 dummy variables are created in the present study. As the dataset contains variables of different scales, for instance, slope in degrees and elevation in meters, it is essential to normalize or standardize the dataset (Adnan et al. 2020). Therefore, the dataset was standardized with a mean of 0 and a standard deviation of 1 before the model training.
Landslide susceptibility modeling using machine learning algorithms
In the present study, five machine learning models: ANN, KNN, RF, SVM, and XGBoost, are used for comparative landslide susceptibility assessment. Among them, SVM, KNN, and RF are among the most widely used machine learning models in the field of LSS. The XGBoost, which is a tree-based boosting algorithm, is also getting traction in recent times. These models are discussed in detail in the following section, and the summarized methodology is shown in Fig. 5.

Adopted methodological approach for landslide susceptibility mapping
Extreme gradient boosting model (XGBoost)
The XGBoost is based on gradient-boosted regression tree (GBRT) algorithms, a powerful supervised ensemble machine learning approach (Chen and Guestrin 2016). The main advantage of extreme gradient boosting over other boosting techniques is that it can handle extensive sparse data and easy to implement. It offers scalability of various scenarios and high performance with minimal computational resources (Chen and Guestrin 2016). The XGBoost integrates several classification and regression tree models (CART) using gradient boosting to achieve better model precision. The XGBoost aims to minimize the objective function (i.e., the sum of the loss function and a regularization term), which helps to control overfitting. Mathematically, the objective function is given by Eq. 4 (Zhang et al. 2019).
where L is the differentiable loss function, which measures the difference between predicted value (\({\widehat y}_i\)) and target values (i.e., true value; \({y}_i\)) of the ith instance of the tth iteration, Ω is a penalty term (or regularization term) for model complexity, which can be expressed using Eq. 5. It is a function of the weights of the decision trees in the ensemble.
where wj is the optimal weight for the jth leaf and T is the number of leaves in a tree.
The second-order Taylor approximation can be applied for quick optimization, as in Eq. 6.
where gi and hi represent the first and second derivative of the loss function (i.e., the first term of Eq. 4), respectively.
In the present study, this algorithm is implemented using the xgboost package (Chen et al. 2022) in R 4.2 environment. The model training involves the tuning of several hyper-parameters: maximum tree depth (max_depth), number of boosting iterations (nrounds), shrinkage (η) controlling the learning rate, minimum loss reduction (γ) controlling the tree-split and preventing overfitting, and subsample which decides the sub-sample percentage for a tree (Table 2) and L2 regularization (Zhang et al. 2019). The optimal values of nrounds, max_depth, η, γ, and subsample are 600, 15, 0.05, 0.5, and 0.5, respectively, using the 10-fold repeated cross-validation and grid search method (Table 2).
Random forest (RF)
RF is an ensemble learning model which works on the bagging principle. It is a supervised machine learning model for non-parametric multivariate regression and classification of large datasets with numerical and/or categorical data (Catani et al. 2013). The RF uses multiple decision trees, generated by base decision trees using random samples from the training data (bootstrap samples), and gives the output based on the majority voting after combining individual tree’s decisions, i.e., aggregation (Huang et al. 2021). This bootstrap aggregation approach reduces the variance, thus improving the RF model’s performance and reducing the risk of overfitting.
The Breiman and Cutler’s randomForest package in the R 4.2 environment is used to develop the RF model for the present study (Liaw and Wiener 2022). The 10-fold repeated cross-validation approach with random search is adopted during model tuning. In RF, two prior parameters: the number of variables randomly sampled at each split (mtry) and the number of trees in the forest (ntree), should be optimized to minimize the out-of-bag error (Breiman 2001). The search range and optimal values of these parameters are mentioned in Table 2.
K-nearest neighbor (KNN)
The KNN is one of the simplest algorithms which perform the binary classification based on the k closest neighboring training elements in n-dimensional input space. It is a non-parametric and instance-based algorithm (Kala 2012). A distance metric used in the KNN tells about the closeness between given input samples and indicates the similarity and/or difference in variables (i.e., landslide conditioning factors) for any two samples. The more the similarity among variables, the lesser the feature distance between them will be. Moreover, the new class is assigned using a voting system to the new data point based on the predominant class in the neighboring instances (Marjanovic et al. 2009). The KNN model is developed using the e1071 package in R 4.2 (Meyer et al. 2022). The hyper-parameter tuned is the k value (Table 2) with Euclidean distance metric (Adnan et al. 2020). Using the 10-fold repeated cross-validation method, the optimal k value is obtained as 13, which is used to build the LS model.
Support vector machine (SVM)
SVM is another popular supervised machine learning method used widely in LSS (Pradhan 2013; Chen et al. 2017). It was developed by Vapnik (1999) based on statistical learning theory that can be used as a classifier and a regressor. This algorithm attempts to generate a decision surface separating two classes (e.g., landslide and non-landslide). It seeks an optimal hyper-plane with a maximum possible separation between any two classes (Kavzoglu et al. 2014) by solving the classification function in Eq. 7. The data points contiguous to the optimal plane are the support vectors.
where x = [x1, x2,……, xn] is the n input variables, yj = (y1, y2) is the output or target vector (1 and 0), α is the Lagrange multiplier, b is the offset from the origin of the decision surface, K(x, xi) is the kernel function that can be radial basis function (RBF), linear, sigmoid, or polynomial (Pradhan 2013; Yao et al. 2008). This study utilized the most popular RBF kernel (Wang et al. 2021). The svm library of the e1071 package (Meyer et al. 2022) is adopted in R 4.2 to develop the model. For the model training, the SVM involves several hyper-parameters such as gamma (γ), cost (C), and loss-function (ε), which must be tuned (Table 2). Based on the 10-fold cross-validation and grid search method of optimization (Kavzoglu and Colkesen 2009), the optimal value of γ, C, and ε are 0.01, 8, and 0.01, respectively (Table 2), which are used to build the SVM model.
Artificial neural network (ANN)
ANN attempts to mimic the neural system of the human brain for pattern recognition. The ANN is also known as a multilayer perceptron (MLP) which consists of a set of input neurons (input layer), fully connected one or more hidden layers, and an output layer (in the case of binary classification). The performance of an ANN model is sensitive to the number of hidden layers, the type of activation function, and the way weights are updated. After the random initialization, the back-propagation algorithm is used to update the connection weights between different nodes of various layers. Thus, ANN can draw a meaningful conclusion and identify trends from a large and complex data set, like landslide conditioning factors.
The present study uses the neuralnet package (version 1.44.2) in the R 4.2 environment to develop an ANN model for LSM (Fritsch et al. 2019; Günther and Fritsch 2010). The activation function logistic sigmoid and algorithm rprop + (resilient back-propagation with weight backtracking) yield faster convergence with better accuracy than simple back-propagation (Prasad et al. 2013) and are employed during the model generation. The input layer neurons were equal to the number of LCFs (including one-hot encoded ones) in the dataset. The learning rate and differentiable function for error calculation are set to 0.1 and “sse” (i.e., the sum of squared error), respectively. The optimal number of neurons in each hidden layer and epoch are obtained as 64, 32, and 150, respectively (Table 2).
Model performance evaluation
After model development, the prediction performance of susceptibility models should be evaluated using the dataset with known data points of landslide (true points) to which the model is not exposed earlier during the training phase (testing data). In the present study, the receiver operating characteristic (ROC) curve along with various statistical measures such as sensitivity (or recall), specificity, accuracy, kappa, and F1-score are employed (Eqs. 8–12) (Pham et al. 2016; Chen et al. 2018; Ghasemian et al. 2022). Sensitivity tells the predictive capability of a prediction model by comparing correctly classified landslide pixels with total landslide pixels. In contrast, specificity indicates the predictive capability of an LSM for predicting non-landslide pixels (true negative). Kappa statistics measure inter-rater reliability for binary classification (landslide or non-landslide) and evaluate the model’s reliability (McHugh 2012). A kappa value close to 1 indicates a reliable model. On the other hand, the F1-score combines sensitivity and precision into a single measure by taking their harmonic mean and giving balance emphasis to both (Agrawal and Dixit 2022a).
where TP is the number of landslides (true positive) classified correctly, FN is a false negative, i.e., the number of the actual landslides classified erroneously (as non-landslides), FP is false positive, i.e., non-landslide pixels (true negative; TN) classified as landslides, precision = TP/(TP + FP), PC is the proportion of pixels correctly classified (TP or TN), and Pexp is the expected agreements.
The ROC curve is one of the most popular techniques for model performance evaluation in LSSs. It compares the TP rate (i.e., sensitivity) with the FP rate (i.e., 1-specificity) by plotting the false positive rate on the x-axis and sensitivity on the y-axis (Youssef and Pourghasemi 2021). The area under the curve (AUC) is the main statistical indicator of the ROC curve and varies from 0.5 to 1, where high values suggest a good model performance (Yilmaz 2010).
Results and discussion
The landslide susceptibility modeling of Meghalaya is performed using five machine learning algorithms. For this purpose, 15 relevant factors influencing landslides are selected, and based on multicollinearity diagnostics, all of them show an absence of high collinearity (Table 1). Therefore, all 15 LCFs are employed for landslide susceptibility modeling. The results of each LS machine-learning model are discussed in the subsequent sections.
Landslide susceptibility modeling
Figure 6 shows the LSMs of Meghalaya developed using the five machine learning algorithms: ANN, KNN, RF, SVM, and XGBoost. The models were trained using 70% of landslide inventory data points consisting of both landslide (true positive) and non-landslide (true negative) events. The obtained susceptibility values vary from 0 to 1 where values close to 1 indicate a higher landslide susceptibility, and low values (0 or close to 0) indicate a lower one (Bragagnolo et al. 2020). The predicted landslide susceptibility values at any pixel in the study area are classified into five classes: (i) very low (0–0.24), (ii) low (0.25–0.49), (iii) moderate (0.50–0.74), (iv) high (0.75–0.89), and (v) very high (0.90–1.00) (Chen et al. 2018; Adnan et al. 2020). For all the models, more than 50% of the study area shows low to very low susceptibility for landslides (Fig. 6). However, the proportion of area under a susceptibility class varies from one model to another. The LSM produced using the XGBoost model shows the highest proportion of area (19.52%) under the very high susceptibility class, followed by ANN (16.70%) (Fig. 6). In comparison, the RF model resulted in the lowest proportion (3.44%) of very high LS areas (Fig. 6). This large variation in LS classes can be attributed to the difference in the relative importance of applied LCFs in each model. Since, in ANN and XGBoost, very high and very low LS classes dominate, and low, moderate, and high classes occupy the minimal area (Fig. 6), it suggests the problem of overestimation in the case of these two models as compared to other ML models.

Landslide susceptibility maps of Meghalaya and percentage distribution of different classes using different ML algorithms
The relative importance of different LCFs obtained during model training using different algorithms is shown in Fig. 7. The distance from roads is identified as the most important LCF in KNN, RF, and XGBoost models (12.5%, 16.9%, and 19.2%, respectively; Fig. 7), while the bare land of LULC (19.35%) in the case of SVM and SO4 (6.55%) in the case of ANN is identified as a most critical factor for landslides, respectively. In the case of KNN, SO4 class of soil texture (12.5%), rainfall (11.48%), slope (8.65%), and GM7 (i.e., highly dissected hills and valleys) of geomorphology (8.44%) are also major contributing factors after distance to the road. Similarly, for RF, the rainfall and slope are the second and third most critical factors, with a relative variable importance value > 9% (Fig. 7). While in XGBoost, SO4 (18.6%), slope (15.9%), and rainfall (9.98%) are the most significant factors after distance to the road (Fig. 7). The SVM model identifies LI6 of lithology (10.44%) and TWI (9.38%) as the second and third most important LCFs.

Relative variable importance of different LCF using a KNN; b RF; c SVM; d XGBoost; and e ANN models
The spatial distribution of susceptibility maps shows that the southern and south-eastern portions of the study area, along with regions near a road, are more susceptible to landslides in all five models (Fig. 6). The steep slope of the southern portion dominated by dissected plateau, hills, and valley (in Jaintia and Khasi hills region) are showing high to very high LS. In the Garo hills region, the majority landscape remains associated with no or low LS except for the tracts along the road network (Fig. 6).
The spatial distribution of LS classes was also compared with landslide density distribution in the region. The landslide density (LD) representing the number of landslides per square km is obtained using the kernel density tool in ArcGIS 10.8, as shown in Fig. 8. The high-density values are concentrated in the Khasi Hills region (central portion) and along the southern and south-eastern tip of the study area (Fig. 8). Thus, produced LSMs are also coherent with the LD distribution in the region (Figs. 6 and 8).

Landslide density distribution in the study area
Accuracy assessment and model validation
The prediction performances of adopted models are evaluated and validated based on the widely used AUC-ROC and other statistical metrics such as sensitivity, specificity, accuracy, F1-score, and kappa using the testing dataset (30% of total landslide inventory). Table 3 shows the results of these statistical metrics for all models. The kappa index for the models varies from 0.87 (ANN) to 0.92 (XGBoost), indicating an excellent agreement between the prediction and the ground truths.
The XGBoost model shows the highest positive predictive probability (precision = 92.62%), highest sensitivity (91.92%), and the highest ability to classify non-landslide pixels correctly, i.e., specificity (92.79%) (Table 3). In terms of precision, the ANN model has the smallest value (87.66%) in this study, whereas the KNN model shows the lowest ability to correctly classify landslide pixels, i.e., sensitivity (87.31%; Table 3). However, regarding overall accuracy, the ANN model has the lowest value (88.22%). The XGBoost model has the highest overall accuracy with a value of 92.36%, followed by RF (91.73%), SVM (91.23%), and KNN (88.35%), respectively (Table 3).
The F1-score statistics, which combine sensitivity and precision into a single measure, also indicate XGBoost as the best model (0.923), followed by RF (0.917), SVM (0.911), KNN (0.883), and ANN (0.881), respectively. The ROC curves, generated using the testing dataset (i.e., prediction curve), are shown in Fig. 9. The highest AUC values are obtained for XGBoost and RF models (0.971 for both). The AUC values for SVM, KNN, and ANN models are 0.958, 0.951, and 0.945, respectively (Fig. 9 and Table 3). Since the AUC values of all five ML models are very high (AUC > 0.9), it suggests excellent performance by the models for spatial prediction of landslide susceptibility in Meghalaya.

Prediction rate curve of five machine learning models. a ANN. b KNN. c RF. d SVM. e XGBoost using testing dataset
Discussion
Landslides are among the frequent geological hazards and are often triggered by earthquakes or rainfalls. The LSS is considered the first step toward landslide hazard and risk assessment. LS studies are helpful in the prior identification of highly susceptible regions for landslides and effective regional land use planning with the objective of disaster risk reduction and mitigation (NDMA 2019). Although several models for LS mapping have been proposed recently, the model selection is still contentious (Yilmaz 2010; Adnan et al. 2020). Therefore, five prevalent and widely used machine learning algorithms for pattern recognition, classification, or regression are adopted in the present study. Since the performance of susceptible models is sensitive to the quality of input data (Tien Bui et al. 2016), the selected 15 LCFs are tested for multicollinearity based on VIF and T values (Chen et al. 2017). The results show no multicollinearity in the dataset, and all 15 factors are adopted for LS assessment.
The XGBoost, RF, and SVM yielded better overall results than KNN and ANN (Table 3). However, the difference in overall accuracy is not very significant and ranges from 92.36% (for XGBoost) to 88.22% (ANN). The relative importance of LCFs changes with the algorithms and affects the model’s outcome. In the present study, in general, the distance from roads, rainfall, slope, and soil texture (SO4) is identified as the most critical factors affecting the LS in the region for all the models except SVM (Pham et al. 2017; Youssef and Pourghasemi 2021; Ghasemian et al. 2022). In the case of SVM, the bare land of LULC (LU6) and quaternary deposits of lithology (LI6) are the two most contributing factors. Similar heterogeneity in variable importance among different models is also reported by several researchers, such as Ali et al. (2021) and Pham et al. (2021).
Furthermore, the prophecy of the developed ML-based LS models is evaluated using the testing dataset, which shows excellent results. The highest prediction performance is shown by RF and XGBoost models with an AUC value of 0.971 for both models, which is consistent with the other reported studies such as Chen et al. (2017), Adnan et al. (2020), Cao et al. (2020), and Pham et al. (2021). Chen et al. (2017) reported the RF model as the best among logistic regression, RF, and CART models. At the same time, Cao et al. (2020) compared XGBoost, SVM, and RF models and reported XGBoost as the best model with AUC = 0.93. Youssef and Poughasemi (2021) also compared ANN, RF, and SVM with other models in their study and reported RF and ANN with higher accuracy than SVM. In the current study, the prediction accuracy of the SVM model is the third best after XGBoost and RF models. The findings of the AUC value are also backed by other statistical metrics, as shown in Table 3. Though the XGBoost model offers the highest accuracy and AUC value, the problem of overestimation cannot be ignored. Therefore, RF can be considered the best model for Meghalaya in the present study.
The spatial distribution of susceptibility classes using all five ML algorithms shows that the south and south-eastern portion of Meghalaya is highly susceptible to landslides other than slopes along the road network and is consistent with the landslide distribution in the region (Fig. 8). The similar trend is also reported by a recent study of Agrawal and Dixit (2022a) using bivariate and MCDA approach with highest AUC of 0.913. However, the present study has shown considerable improvement in prediction accuracy (highest AUC = 0.971) using the ML models over the conventional methods for the same study region and generated LSMs effectively identify the different susceptibility zones with actual landslide zones (Fig. 10). The present study identifies the critical LCFs using ML models for Meghalaya and highlights that the contribution of each can be different in different models. This study is the first attempt to employ a variety of ML algorithms, including relatively new approaches like XGBoost, for landslide susceptibility mapping in Meghalaya.

Comparison of derived LSM with the field images of past landslides obtained using Google Earth over the study region
Conclusion
This study evaluates the effectiveness of several machine learning algorithms, such as ANN, KNN, RF, SVM, and XGBoost, for LS assessment in the Meghalaya, Shillong Plateau region of NER, India. The application of these models is novel in performing susceptibility mapping in the region. The findings demonstrate the potential of these models to accurately predict susceptibility to landslides by utilizing a range of LCFs that are selected based on multicollinearity statistics. Distance from roads is the most critical factor for predicting LS in this region. The present study highlights the importance of model validation using various performance metrics such as sensitivity, specificity, overall accuracy, F1-score, kappa value, and AUC of ROC curves in ensuring reliable results. The findings suggest that the RF and XGBoost models show the most promising results, but the other models also provide satisfactory results (AUC > 0.8) for the considered study area. However, caution should be exercised while interpreting the results and developing mitigation strategies, as the distribution of susceptibility classes suggests the potential overestimation problem for the ANN and XGBoost models. Nevertheless, the application of ML algorithms for susceptibility mapping presents a powerful tool for disaster management and risk reduction in various tectonic and geo-environmental settings, as demonstrated for Meghalaya. By utilizing continuous data (e.g., slope, elevation, distance from roads) and avoiding the need for classification, these models offer a more robust and accurate alternative to MCDA and traditional statistical models. The presented framework can be replicated in other regions facing similar geological hazards, allowing for the development of more accurate and effective LSMs, and can be extended to assess the impacts of change in climate and LULC at a sub-regional scale.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request.
References
Abedi R, Costache R, Shafizadeh-Moghadam H, Pham QB (2021) Flash-flood susceptibility mapping based on XGBoost, random forest and boosted regression trees. Geocarto Intern 1–18
Adnan MSG, Rahman MS, Ahmed N, Ahmed B, Rabbi MF, Rahman RM (2020) Improving spatial agreement in machine learning-based landslide susceptibility mapping. Remote Sensing 12(20):3347
Agrawal N, Dixit J (2022a) Assessment of landslide susceptibility for Meghalaya (India) using bivariate (frequency ratio and Shannon entropy) and multi-criteria decision analysis (AHP and fuzzy-AHP) models. All Earth 34(1):179–201
Agrawal N, Dixit J (2022b) Topographic classification of North Eastern Region of India using geospatial technique and following seismic code provisions. Environmental Earth Sciences 81:436
Agrawal N, Gupta L, Dixit J (2022) Geospatial assessment of active tectonics using SRTM DEM-based morphometric approach for Meghalaya. India All Earth 34(1):39–54
Akgun A (2012) A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: a case study at İzmir. Turkey Landslides 9(1):93–106
Ali SA, Parvin F, Vojteková J, Costache R et al (2021) GIS-based landslide susceptibility modeling: a comparison between fuzzy multi-criteria and machine learning algorithms. Geosci Front 12(2):857–876
Balamurugan G, Ramesh V, Touthang M (2016) Landslide susceptibility zonation mapping using frequency ratio and fuzzy gamma operator models in part of NH-39, Manipur. India Natural Hazards 84(1):465–488
Bilham R, England P (2001) Plateau ‘pop-up’in the great 1897 Assam earthquake. Nature 410(6830):806–809
Bragagnolo L, Da Silva RV, Grzybowski JMV (2020) Artificial neural network ensembles applied to the mapping of landslide susceptibility. CATENA 184:104240
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Cao J, Zhang Z, Du J, Zhang L, Song Y, Sun G (2020) Multi-geohazards susceptibility mapping based on machine learning—a case study in Jiuzhaigou. China Natural Hazards 102(3):851–871
Catani F, Lagomarsino D, Segoni S, Tofani V (2013) Landslide susceptibility estimation by random forests technique: sensitivity and scaling issues. Nat Hazard 13(11):2815–2831
Chacón J, Irigaray C, Fernandez T, El Hamdouni R (2006) Engineering geology maps: landslides and geographical information systems. Bull Eng Geol Env 65(4):341–411
Chanu ML, Bakimchandra O (2022) Landslide susceptibility assessment using AHP model and multi resolution DEMs along a highway in Manipur. India Environmental Earth Sciences 81(5):1–11
Chauhan S, Sharma M, Arora MK, Gupta NK (2010) Landslide susceptibility zonation through ratings derived from artificial neural network. Int J Appl Earth Obs Geoinf 12(5):340–350
Chen T, Guestrin C (2016 August) Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining (pp. 785–794)
Chen T, He T, Benesty M et al (2022) Xgboost: extreme gradient boosting. R package version 1.6.0.1. (https://cran.r-project.org/web/packages/xgboost/xgboost.pdf)
Chen W, Peng J, Hong H et al (2018) Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci Total Environ 626:1121–1135
Chen W, Pourghasemi HR, Panahi M, Kornejady A, Wang J, Xie X, Cao S (2017) Spatial prediction of landslide susceptibility using an adaptive neuro-fuzzy inference system combined with frequency ratio, generalized additive model, and support vector machine techniques. Geomorphology 297:69–85
Chen X, Chen W (2021) GIS-based landslide susceptibility assessment using optimized hybrid machine learning methods. CATENA 196:104833
Chimidi G, Raghuvanshi TK, Suryabhagavan KV (2017) Landslide hazard evaluation and zonation in and around Gimbi town, western Ethiopia—a GIS-based statistical approach. Applied Geomatics 9(4):219–236
CRED (2022) 2021 Disasters in numbers. CRED, Brussels. https://cred.be/sites/default/files/2021_EMDAT_report.pdf
Di Napoli M, Carotenuto F, Cevasco A et al (2020) Machine learning ensemble modelling as a tool to improve landslide susceptibility mapping reliability. Landslides 17:1897–1914. https://doi.org/10.1007/s10346-020-01392-9
Dikshit A, Sarkar R, Pradhan B, Segoni S, Alamri AM (2020) Rainfall induced landslide studies in Indian Himalayan region: a critical review. Appl Sci 10(7):2466
Fritsch S, Guenther F, Guenther MF (2019) Package neuralnet. Training of Neural Networks
Ghasemian B, Shahabi H, Shirzadi A et al (2022) A robust deep-learning model for landslide susceptibility mapping: a case study of Kurdistan Province. Iran Sensors 22(4):1573
Ghosh S, Carranza EJM (2010) Spatial analysis of mutual fault/fracture and slope controls on rocksliding in Darjeeling Himalaya. India Geomorphology 122(1–2):1–24
Glade T (2003) Vulnerability assessment in landslide risk analysis. Erde 134(2):123–146
Guha-Sapir D, Hoyois P, Wallemacq P, Below R (2017) Annual disaster statistical review 2016. The numbers and trends. CRED Brussels
Günther F, Fritsch S (2010) Neuralnet: training of neural networks. The R Journal 2(1):30–38
Gupta L, Agrawal N, Dixit J, Dutta S (2022) A GIS-based assessment of active tectonics from morphometric parameters and geomorphic indices of Assam Region, India. J Asian Earth Sci X:100115
Gupta L, Dixit J (2022) A GIS-based flood risk mapping of Assam, India, using the MCDA-AHP approach at the regional and administrative level. Geocarto Intern 1–33
Guzzetti F, Carrara A, Cardinali M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study. Central Italy Geomorphology 31(1–4):181–216
Huang F, Ye Z, Jiang SH, Huang J, Chang Z, Chen J (2021) Uncertainty study of landslide susceptibility prediction considering the different attribute interval numbers of environmental factors and different data-based models. CATENA 202:105250
Huang W, Ding M, Li Z, Yu J, Ge D, Liu Q, Yang J (2023) Landslide susceptibility mapping and dynamic response along the Sichuan-Tibet transportation corridor using deep learning algorithms. CATENA 222:106866
Hussain MA, Chen Z, Zheng Y, Shoaib M, Shah SU, Ali N, Afzal Z (2022) Landslide susceptibility mapping using machine learning algorithm validated by persistent scatterer In-SAR technique. Sensors 22(9):3119
Jiang Z, Wang M, Liu K (2023) Comparisons of convolutional neural network and other machine learning methods in landslide susceptibility assessment: a case study in Pingwu. Remote Sensing 15(3):798
Kala R (2012) Multi-robot path planning using co-evolutionary genetic programming. Expert Syst Appl 39(3):3817–3831
Kanungo DP, Arora MK, Sarkar S, Gupta RP (2006) A comparative study of conventional, ANN black box, fuzzy and combined neural and fuzzy weighting procedures for landslide susceptibility zonation in Darjeeling Himalayas. Eng Geol 85(3–4):347–366
Karra K, Kontgis C, Statman-Weil Z, Mazzariello JC, Mathis M, Brumby SP (2021) Global land use/land cover with sentinel 2 and deep learning. International Geoscience and Remote Sensing Symposium (IGARSS), 2021-July, 4704–4707. https://doi.org/10.1109/IGARSS47720.2021.9553499
Kavzoglu T, Colkesen I (2009) A kernel functions analysis for support vector machines for land cover classification. Int J Appl Earth Obs Geoinf 11(5):352–359
Kavzoglu T, Sahin EK, Colkesen I (2014) Landslide susceptibility mapping using GIS-based multi-criteria decision analysis, support vector machines, and logistic regression. Landslides 11(3):425–439
Kayal JR, De R (1991) Microseismicity and tectonics in northeast India. Bull Seismol Soc Am 81(1):131–138
Kayastha P, Dhital MR, De Smedt F (2013) Application of the analytical hierarchy process (AHP) for landslide susceptibility mapping: a case study from the Tinau watershed, west Nepal. Comput Geosci 52:398–408
Kim HG, Lee DK, Park C et al (2018) Estimating landslide susceptibility areas considering the uncertainty inherent in modeling methods. Stoch Env Res Risk Assess 32:2987–3019. https://doi.org/10.1007/s00477-018-1609-y
Kumar D, Thakur M, Dubey CS, Shukla DP (2017) Landslide susceptibility mapping & prediction using support vector machine for Mandakini River Basin, Garhwal Himalaya, India. Geomorphology 295:115–125
Lee S, Ryu JH, Kim IS (2007) Landslide susceptibility analysis and its verification using likelihood ratio, logistic regression, and artificial neural network models: case study of Youngin. Korea Landslides 4(4):327–338
Liaw A, Wiener M (2022) randomForest: Breiman and Cutler’s random forests for classification and regression. R package version, 4.7–1.1, 29. https://cran.r-project.org/web/packages/randomForest/randomForest.pdf
Marjanovic M, Bajat B, Kovacevic M (2009, November) Landslide susceptibility assessment with machine learning algorithms. In 2009 International Conference on Intelligent Networking and Collaborative Systems (pp. 273–278). IEEE
McHugh ML (2012) Interrater reliability: the kappa statistic. Biochemia Medica 22(3):276–282
Meena SR, Ghorbanzadeh O, van Westen CJ et al (2021) Rapid mapping of landslides in the Western Ghats (India) triggered by 2018 extreme monsoon rainfall using a deep learning approach. Landslides 18:1937–1950. https://doi.org/10.1007/s10346-020-01602-4
Meyer D, Dimitriadou E, Hornik K, Weingessel A, Leisch F, Chang C-C, Lin C-C (2022) e1071: Misc functions of the Department of Statistics, Probability Theory Group (formerly: E1071), TU Wien. R package version 1.7–11. (https://cran.r-project.org/web/packages/e1071/e1071.pdf)
Midi H, Sarkar SK, Rana S (2010) Collinearity diagnostics of binary logistic regression model. Journal of Interdisciplinary Mathematics 13(3):253–267
Mondal S, Mandal S (2019) Landslide susceptibility mapping of Darjeeling Himalaya, India using index of entropy (IOE) model. Applied Geomatics 11(2):129–146
NDMA (2019) Compendium of task force sub group reports on national landslide risk management strategy. A publication of the National Disaster Management Authority. Government of India, New Delhi
Novellino A, Cesarano M, Cappelletti P et al (2021) Slow-moving landslide risk assessment combining machine learning and InSAR techniques. CATENA 203:105317. https://doi.org/10.1016/j.catena.2021.105317
Oh HJ, Pradhan B (2011) Application of a neuro-fuzzy model to landslide-susceptibility mapping for shallow landslides in a tropical hilly area. Comput Geosci 37(9):1264–1276
Ozdemir A, Altural T (2013) A comparative study of frequency ratio, weights of evidence and logistic regression methods for landslide susceptibility mapping: Sultan Mountains, SW Turkey. J Asian Earth Sci 64:180–197
Pandey A, Dabral PP, Chowdary VM, Yadav NK (2008) Landslide hazard zonation using remote sensing and GIS: a case study of Dikrong river basin, Arunachal Pradesh. India Environmental Geology 54(7):1517–1529
Peethambaran B, Anbalagan R, Shihabudheen KV, Goswami A (2019) Robustness evaluation of fuzzy expert system and extreme learning machine for geographic information system-based landslide susceptibility zonation: a case study from Indian Himalaya. Environmental Earth Sciences 78(6):1–20
Pham BT, Pradhan B, Bui DT, Prakash I, Dholakia MB (2016) A comparative study of different machine learning methods for landslide susceptibility assessment: a case study of Uttarakhand area (India). Environ Model Softw 84:240–250
Pham BT, Prakash I, Dou J et al (2020) A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers. Geocarto Int 35(12):1267–1292
Pham BT, Shirzadi A, Shahabi H et al (2019) Landslide susceptibility assessment by novel hybrid machine learning algorithms. Sustainability 11(16):4386
Pham BT, Tien Bui D, Pourghasemi HR, Indra P, Dholakia MB (2017) Landslide susceptibility assessment in the Uttarakhand area (India) using GIS: a comparison study of prediction capability of naïve bayes, multilayer perceptron neural networks, and functional trees methods. Theoret Appl Climatol 128(1):255–273
Pham QB, Achour Y, Ali SA et al (2021) A comparison among fuzzy multi-criteria decision making, bivariate, multivariate and machine learning models in landslide susceptibility mapping. Geomat Nat Haz Risk 12(1):1741–1777
Pokharel B, Althuwaynee OF, Aydda A, Kim SW, Lim S, Park HJ (2021) Spatial clustering and modelling for landslide susceptibility mapping in the north of the Kathmandu Valley. Nepal Landslides 18(4):1403–1419
Porowal SS, Dey AK (2010) Tunnelling through a highly slide prone area at Meghalaya. India, Geotechnical Challenges in Megacities 3:1099–1106
Pourghasemi HR, Moradi HR, Fatemi Aghda SM, Gokceoglu C, Pradhan B (2014) GIS-based landslide susceptibility mapping with probabilistic likelihood ratio and spatial multi-criteria evaluation models (North of Tehran, Iran). Arab J Geosci 7(5):1857–1878
Pradhan AMS, Kim YT (2020) Rainfall-induced shallow landslide susceptibility mapping at two adjacent catchments using advanced machine learning algorithms. ISPRS Int J Geo Inf 9(10):569
Pradhan B (2013) A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput Geosci 51:350–365
Pradhan B, Lee S (2010) Delineation of landslide hazard areas on Penang Island, Malaysia, by using frequency ratio, logistic regression, and artificial neural network models. Environmental Earth Sciences 60(5):1037–1054
Prasad N, Singh R, Lal SP (2013, September) Comparison of back propagation and resilient propagation algorithm for spam classification. In 2013 Fifth international conference on computational intelligence, modelling and simulation (pp. 29–34). IEEE
Prokop P (2014) The Meghalaya Plateau: landscapes in the abode of the clouds. In Landscapes and landforms of India (pp. 173–180). Springer, Dordrecht
Ramakrishnan D, Singh TN, Verma AK, Gulati A, Tiwari KC (2013) Soft computing and GIS for landslide susceptibility assessment in Tawaghat area, Kumaon Himalaya. India Natural Hazards 65(1):315–330
Selby MJ (1980) A rock mass strength classification for geomorphic purposes: with tests from Antarctica and New Zealand. Zeitschrift für Geomorphologie 31–51
Sengupta S, Krishna AP, Roy I (2018) Slope failure susceptibility zonation using integrated remote sensing and GIS techniques: a case study over Jhingurdah open pit coal mine, Singrauli coalfield. India Journal of Earth System Science 127(6):1–17
Shano L, Raghuvanshi TK, Meten M (2020) Landslide susceptibility evaluation and hazard zonation techniques–a review. Geoenvironmental Disasters 7(1):1–19
Strong CM, Attal M, Mudd SM, Sinclair HD (2019) Lithological control on the geomorphic evolution of the Shillong Plateau in Northeast India. Geomorphology 330:133–150
Tien Bui D, Tuan TA, Klempe H, Pradhan B, Revhaug I (2016) Spatial prediction models for shallow landslide hazards: a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 13(2):361–378
Vapnik V (1999) The nature of statistical learning theory. Springer science & business media
Wang H, Zhang L, Yin K, Luo H, Li J (2021) Landslide identification using machine learning. Geosci Front 12(1):351–364
Wen H, Wu X, Ling S, Sun C, Liu Q, Zhou G (2022) Characteristics and susceptibility assessment of the earthquake-triggered landslides in moderate-minor earthquake prone areas at southern margin of Sichuan Basin, China. Bull Eng Geol Env 81(9):346
Yao X, Tham LG, Dai FC (2008) Landslide susceptibility mapping based on support vector machine: a case study on natural slopes of Hong Kong. China Geomorphology 101(4):572–582
Yilmaz I (2009) Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat—Turkey). Comput Geosci 35(6):1125–1138
Yilmaz I (2010) Comparison of landslide susceptibility mapping methodologies for Koyulhisar, Turkey: conditional probability, logistic regression, artificial neural networks, and support vector machine. Environmental Earth Sciences 61(4):821–836
Youssef AM, Pourghasemi HR (2021) Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region. Saudi Arabia Geoscience Frontiers 12(2):639–655
Zhang Y, Ge T, Tian W, Liou YA (2019) Debris flow susceptibility mapping using machine-learning techniques in Shigatse area. China Remote Sensing 11(23):2801
Zhu AX, Miao Y, Wang R et al (2018) A comparative study of an expert knowledge-based model and two data-driven models for landslide susceptibility mapping. CATENA 166:317–327
Author information
Authors and Affiliations
Contributions
Conceptualization: Jagabandhu Dixit; methodology: Navdeep Agrawal, Jagabandhu Dixit; formal analysis and investigation: Navdeep Agrawal; data curation and software: Navdeep Agrawal; validation: Navdeep Agrawal; visualization: Navdeep Agrawal, Jagabandhu Dixit; writing—original draft: Navdeep Agrawal; writing—review and editing: Jagabandhu Dixit; resources: Jagabandhu Dixit; supervision: Jagabandhu Dixit.
All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Ethics approval
All authors have read, understood, and have complied as applicable with the statement on “Ethical responsibilities of Authors” as found in the Instructions for Authors and are aware that with minor exceptions, no changes can be made to authorship once the paper is submitted.
Competing interests
The authors declare no competing interests.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Agrawal, N., Dixit, J. GIS-based landslide susceptibility mapping of the Meghalaya-Shillong Plateau region using machine learning algorithms. Bull Eng Geol Environ 82, 170 (2023). https://doi.org/10.1007/s10064-023-03188-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10064-023-03188-2