
Abstract
The paper contributes to the debate on how to measure regions’ innovation performance. On the basis of the concept of regional innovation efficiency, we propose a new measure that eases the issue of choosing between industry-specific or global measures. We argue for the use of a robust shared-input DEA-model to compute regions’ innovation efficiency in a global manner, while it can be disaggregated into industry-specific measures.
We illustrate the use of the method by investigating the innovation efficiency as well as its change in time of German labor market regions. It is shown that the method treats regions that have industry structures skewed towards industries with high and low innovation intensities more fairly than traditional approaches.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The innovation performance of spatial units, regions, is frequently measured quantitatively (Jaffe 1989; Audretsch 1998). The EU Regional Innovation Scoreboard is a good example of such an endeavor. However, many of the available measures can be criticized for mixing inputs and outputs of innovation processes, instead of evaluating the output based on the used inputs (Edquist and Zabala-Iturriagagoitia 2015). While characterized by severe uncertainty, innovation generation processes involve the utilization of valuable resources such as human and financial capital. Hence, from an economic standpoint it is interesting to evaluate regions’ innovation success considering the invested resources (Fritsch 2000; Fritsch and Slavtchev 2011; Brenner and Broekel 2012; Chen and Guan 2012; Bonaccorsi and Daraio 2006).
A raft of empirical approaches has been put forward aiming at capturing this relation between invested resources and innovative outcomes. Popular approaches are, for instance, patents per capita (Audretsch 1998) or patents per employee (Deyle and Grupp 2005). Fritsch (2000) refines these approaches arguing in favor of measuring regional innovation efficiency whereby regions are compared with respect to their organizations’ abilities to transform knowledge input factors into innovative output. The term efficiency is used to highlight that the observed innovation output is compared to the maximal output achievable given the available inputs. Other regions serve as benchmarks in determining the maximal achievable output. While the efficiency approach can be seen as a logical extension of the widely-accepted knowledge production function approach by Griliches (1979), Brenner and Broekel (2011) argue that the empirical computation of meaningful regional innovation efficiency measures is far from being easy. The literatures on regional innovation performance and innovation efficiencies are dominated by two approaches. Most studies compare the total innovation output (usually patents) of regional economies to the total inputs, leading to an all-industries measure of innovation efficiency (e. g., Fritsch 2000; Fritsch and Slavtchev 2011). Some studies use data on one industry and compare its regional innovation output with the regional inputs related to this industry (e. g., Broekel 2012, 2015). These studies obtain an industry-specific regional innovation efficiency measure. While both approaches have their merits and problems, the latter approach might be more informative for industry representatives. In contrast, the former approach considers all regional innovation activities and therefore presents a more complete view of regions. However, considering all inputs and outputs in a region, independent of their industrial origin, implies the innovation performance becoming a measure strongly shaped by the regions’ industrial structure.
The intention of this paper is to tackle this issue and provide an all-industry measure of innovation efficiency controlling for regions’ industrial structures. Innovation indicators are used in policy discussion to detect best practices for other regions to learn from. However, if innovation indicators are strongly influenced by the regions’ industry structures, those regions are chosen for orientation that happen to contain the most innovative industries, and not necessarily those facilitating innovation processes best.
Of course, existing indicators and measures approximate what is politically intended: measuring how well regional institutions and circumstances support innovation activities. However, we think that there is quite some space for improvement and that the measure developed here represents a good step into this direction. It allows for a fairer – in the sense of correcting for the regional industry structure – and, thus, more adequate, identification of those regions in which the innovation process is especially efficient, so that they can be used as best practice cases. Moreover, our approach can also be applied to any level of industry aggregation to identify industries that are most efficient in a region.
Our approach consists of three steps. First, we discuss the differences between all-industry and industry-specific innovation efficiency measures. Second, we propose the robust shared-input DEA-model as a new method to construct an all-industry regional innovation efficiency measure that explicitly considers inter-regional variations in regions’ industrial structures. In addition, this method also provides industry-specific innovation efficiency measures for the assessed regions. Third, we apply this method to 150 German labor market regions for which we compute innovation efficiency measures for multiple years.
The paper is structured as follows. The subsequent section discusses the empirical measurement of regional innovation efficiency with a focus on all-industry and industry-specific approaches. The third section presents the used empirical data on German labor market regions, which represents data commonly used in such approaches. Section four introduces the robust shared-input DEA-model as a new method to compute regions’ innovation efficiency. The empirical results of its illustrative application to German labor market regions are presented and discussed in section five. The sixth section concludes the paper.
2 Towards regional innovation efficiency
2.1 The concept of innovation efficiency
Conceptualizing regional innovation performance as regional innovation efficiency has gained in popularity in recent years (Fritsch 2003; Fritsch and Slavtchev 2011; Broekel 2012, 2015; Chen and Guan 2012). This approach originates from production theory and implies that performance is defined as the achievements (output) in comparison to the involved costs (input). This production allegory became famous through the knowledge production function approach by Griliches (1979). As this allegory is not unproblematic, we will highlight the differences between production and innovation creation and rather speak of input factors instead of inputs and innovative output instead of output (see on this Broekel and Brenner 2011).
Relating innovative output to input factors on a regional level implies that both are known and can be meaningfully measured in the context of regions. A wide range of approaches and definitions is applied in the literature. The variation on the output side is relatively small, as data availability leaves patents as dominant approximation of innovative output.Footnote 1 In contrast, a wide range of variables have been considered as input factors including the number of inhabitants (Stern et al. 2002), the number of employees (Deyle and Grupp 2005), the number of R&D employees (Fritsch 2003; Broekel 2015), R&D employees in combination with the level of highly qualified employees in a region (Broekel 2012), and a wide set of regional factors including R&D employees (Chen and Guan 2012).
While there is no consensus about which of these input factor sets is most appropriate (Brenner and Broekel 2011), using the number of R&D employees as input factor has become the most frequent approach. The rationale is that R&D employees provide the most accurate approximation (given the availability of data) to the true level of resources invested in innovation processes by organizations. This also highlights, that regions are not innovative – the R&D generators (organizations) located within a region are the creative actors. Their aggregated productivity/efficiency constitutes a region’s innovation efficiency.
In the measurement of regions’ innovation efficiency, we follow the approach labeled by Brenner and Broekel (2011) as the “R&D employees’ innovation efficiency”.Footnote 2 We do not simply use the ratio between innovative output (patents) and the number of R&D employees, as this neglect regional variations in industrial structures. Here, innovation efficiency is defined as a measure benchmarking the relation between innovative output (patents) in a region to the potential innovative output, which is calculated based on a region’s industrial R&D employment and the relation between innovative output and R&D employment input in other (comparable) regions. The mathematical details of our approach are given in Sect. 3.2.
2.2 All-industry vs. industry-specific measures
In the literature, innovation efficiency is measured in different ways. Most importantly, this concerns the choice of the measure’s industrial dimension: shall it cover the entire regional economy (all-industry approach) or is it computed with respect to a specific sector/industry (industry-specific approach)? This is not just a theoretical question but also matters in terms of empirical results and potential political conclusions.
Differences in results of the two approaches are mainly due to two reasons. First, the number of innovations generated by a certain number of R&D employees or a certain amount of R&D expenditures differs (innovation productivity) (Cohen and Klepper 1996). Second, since regions’ innovative output is primarily approximated by patent data, it also matters that industries differ in the share of their innovations that are patented (patent propensity) (Arundel and Kabla 1998; Malerba et al. 2000). While industrial variations in innovation productivity and patent intensity impact the variance of all-industry efficiency measures, industry-specific regional innovation efficiency measures take this explicitly into account by establishing the relation between input factors and innovative output separately for each industry (see Broekel 2012 and Broekel 2015 for such an approach).
This advantage comes at some costs. First, they usually require a higher quality of data, with respect to the matching of innovative output to considered input factors that are frequently differently organized (e. g., NACE for employment and IPC for patents). Secondly, the researcher must decide about what the appropriate level of industrial aggregation is, i. e. how can industries be defined in a meaningful way? The decision usually involves many trade-offs implying that it can rarely be answered in a completely satisfactory way. Thirdly, estimating innovation efficiency in an industry-specific manner naturally results in an innovation efficiency index that applies only to one industry. So far all-industry measures have dominated the literature (e. g. the European Innovation Scoreboard). Such measures are also widely used in policy discussion. However, especially in the context of smart specialization (Foray 2015) the interest in industry-specific indicators has increased. To get a picture of an entire region’s situation when using industry-specific measures one must look at multiple measures, with the number of measures being determined by the number of industries separately investigated. Policy makers often prefer simple indices and, hence, indices with a low number of dimensions, preferable only one dimension. To evaluate the global innovation efficiency of a region with one measure, the industry-specific measures would need to be aggregated into a single index, which again involves trade-offs and information losses.
Despite these theoretical and practical differences, it is often data availability that determines what kind of measure is used. This implies that if industry-specific data are available, an industry-specific approach is chosen because of its higher scientific precision (cf. Brenner and Broekel 2011).
3 Empirical approach
This paper aims at presenting a methodology that provides a convenient and scientifically sound way of estimating an all-industry regional innovation efficiency measure, which minimizes the potential bias induced by variations in regions’ industrial structures. At the same time, it is decomposable into industry-specific measures that are little influenced by matching procedures between input factors and innovative output data. Accordingly, this methodology combines the advantages of both approaches that have been used in the literature so far.
3.1 Empirical challenge and proposed solution
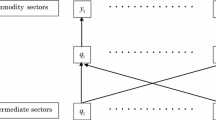
Before we go into the mathematical details of our approach, a simple example is used to present the problems we tackle and the solutions that we offer. Let us assume a world with three regions and two industries. Regional R&D employment are known for each industry. Moreover, innovation activities are known and can be classified in two technological fields that reasonably but not completely match the industries. Fig. 1 exemplarily depicts the situation and size of the activities. Let us further assume that in Industry 1 the same R&D input generates more innovative output than in Industry 2. Industry 1 generates mainly innovative output in Technology 1 but also some output in Technology 2, while Industry 2 generates only innovative output in Technology 2.

Exemplary structure of regional innovation activities (size of boxes signal the respective activity)
Fig. 1 shows the problems of the all-industry and industry-specific approaches. The exemplary size of the activities is chosen such that the same R&D input of each industry generates the same output in each region. Nevertheless, in an all-industry measure the output-input-ratio is highest in Region 1, because this region is dominated by Industry 1.
Let us assume an industry-technology matching that assigns Industry 1 to Technology 1 and Industry 2 to Technology 2. Then, an industry-specific measure will find the highest output-input-ratio for Industry 2 in Region 1, while the output-input-ratio is the same in all regions for Industry 1.
The above problem can be easily solved when the percentage of each industries’ contribution to each technology are known. However, this is usually not the case. Frequently, even firms themselves do not exactly know how much R&D resources, e. g. laboratories, R&D staff, etc., are utilized in R&D activities related to an innovation. In the context of regional innovation efficiency, this implies that even if data are available for industry-specific input-factors (R&D employment) and innovative output (patents). these numbers are (even at the firm and plant level) rough approximations. Moreover, at the regional level usually only regions’ (aggregated) patent and R&D employment portfolios are observed. While the former is organized according to technologies, i. e. patents are classified by the international patent classification (IPC), some sort of economic sector classification organizes employment data (in Europe this is the NACE).Footnote 3 Approximated matching concordances can be used, but introduce (usually unknown) biases into the computations.
Hence, we are dealing with two empirical problems. The first is the unobserved resource allocation: it is unknown to what extent regional innovation generators of a specific industry (e. g., NACE-code) allocate their R&D resources to a technology (e. g., patent IPC-code). Second, and this is what we are interested in, the efficiency is not observed with which these resources are then transformed into innovative output (unknown efficiency). Therefore, the unobserved resource allocation blurs industry-specific and all-industry efficiency estimates.
As we pointed out above, innovations (and patents for that matter) in different technologies vary considerably in their structure and in the resources needed for their realization (cf. Malerba and Orsenigo 1993). When this differentiation is applied to the innovative output (e. g., patents per IPC-code), we are facing a so-called shared-resource, or shared-input factor problem because we do not know the exact allocation of industries’ R&D employees among technologies. For instance, an R&D employee working in the electronics industry might file for two patents, however, for various reasons the two patents might be classified into two different IPC classes (e. g. electronics and machine tool engineering). The two patent classes might be assigned to different industries in the above-mentioned matching concordances implying that the R&D employee of the electronics industry contributes to the output of the machine tool industry. Put differently, this R&D employee is an innovation input shared by two technologies. While matching concordances aims at minimizing such problems, significant (and by and large unknown) biases are more than likely to remain. In particular, general-purpose industries and technologies (i. e. electronics, machine tool engineering, etc.) are subject to this problem (see for an excellent discussion on this issue Lybbert and Zolas 2013).
In the following section, we will propose an empirical approach designed to overcome this problem.
3.2 Data envelopment analysis
The basic idea is to calculate the potential innovation (patent) output profile of a region based on its R&D resources and the outputs that regions with similar R&D resources generate in other regions. This potential output quantity is compared to the output observed for this region. This relation represents an efficiency measure based on multidimensional inputs and output vectors.
Empirically, the suggested approach builds upon the Data Envelopment Analysis (DEA) methodology, which is very popular in the Operations Research and Management Science literature where it was originally developed by Farrell (1957) and further popularized by Charnes et al. (1978). In the context of regional performance similar approaches have already been applied e. g. by Zabala-Iturriagagoitia et al. (2007); Guan and Chen (2010); Chen and Guan (2012); Broekel (2012); Broekel (2015). In essence, DEA is a non-parametric efficiency measurement technique that computes the efficiency of \(n\) (j = 1, …, n) units, which use certain levels of p different inputs \(x_{j,i}\) (i = 1, …, p) to produce \(q\) different outputs \(y_{j,r}\) (r = 1, …, q) outputs typically characterized by no reliable information on the prices (weights) of inputs and outputs and/or no (exact) knowledge about the ‘functional form’ of the production function. The DEA-model computes for each unit the efficiency measure \(e_{k}^{a}\) as a ratio of a weighted sum of outputs over a weighted sum of inputs. DEA computes this efficiency score in relation to the efficiencies of the other units in the sample. The computation of the innovation efficiency for the evaluated region k can be made with linear programming:Footnote 4
Whereby, the input weights and output weights are \(v_{k,i}\left (i=1,...,p\right )\) and \(w_{k,r}\left (r=1,...,q\right )\), respectively. The key feature of the DEA-model is that input and output weights are endogenously computed (hence, the non-parametric nature of DEA). As information on the true values of input and output weights is usually lacking, DEA looks for plausible weights by letting the data speak for themselves. In the context of our paper, this means that in the evaluation of regions’ innovation efficiencies, DEA looks (for each region) for input factor and innovative output weights such that the region is evaluated optimally (i. e., the highest possible global innovation efficiency score \(e_{k}^{a}\)) relative to the other regions in the sample set.Footnote 5
This data-driven weighting approach of the DEA-model is more appropriate than, for instance, an equal weighting or fixed weighting approach. Contrary to such simplistic weighting approaches, the DEA-weighting method does not penalize a region for a successful pursuit of an objective, at the acknowledged expense of another conflicting objective. Basically, this implies that some heterogeneity among regions is allowed in the sense that regions can specialize on different outputs (innovative industries).
By the normalization constraint, it holds that the global efficiency score \(e_{k}^{a}\) is situated between 0 and 1. An efficiency score for the evaluated region \(k\) below one implies that there is at least one region (in most cases multiple regions) in the dataset, which realize a better level of global innovation efficiency. Note that in the interpretation of this global innovation efficiency score \(e_{k}^{a}\), the difference \(1-e_{k}^{a}\) can be perceived as a measure of the overall inefficiency in a region’s innovation performance, which quantifies its room for innovation efficiency improvements. Hence, the model represents the so-called ‘output-orientation’, which identifies the necessary increase in output for regions to become efficient. One may also ask for the necessary reduction in inputs (‘input-orientation’). We argue that the output-orientation is more appropriate because from a social, political and economic perspective innovations are desirable and hence it should be the aim to ‘maximize’ innovation output instead of minimizing R&D input.Footnote 6
The DEA-model implicitly assumes constant returns to scale (CRS) in the generation of innovations. Whether this CRS assumption holds is an important question. Whereas we didn’t formally test for the existence of scale economies, there is the important indication of the regional innovation efficiency being uncorrelated to region size.Footnote 7 In a sense, this result can be interpreted as saying that, in the aggregate, regions are operating at a more or less efficient scale level. Note, however, that the shared input DEA-model as presented in the paper can be easily adjusted such as to allow for variable returns to scale (VRS). In that case, an additional variable \(u_{k}\)(free in sign) must be added to the objective and the normalization constraint (1a).
Before concluding this section, note that we argued for disaggregating the innovative output into multiple technologies to take the technology-specificity of regional innovation efficiency into account. In contrast, for the R&D employment we do not know the exact distribution across technologies, so that we use only a single, shared input ‘R&D employment’. This implies that in our set-up the traditional DEA-score will mix the unknown allocation of R&D employment with the unknown efficiency distribution.
3.3 Shared input DEA-analysis
The standard DEA-model can be adapted so that the focus will be on the computation of partial innovation efficiency scores. The basic question to be addressed is: “how should one split the shared input factor ‘R&D employment’ among the several technologies in the DEA model?”.
The solution proposed is to determine the distribution of the shared factor input among different technologies (output dimensions) endogenously, which is similar to the definition of the input factor and innovative output weights in the traditional DEA-model. For this we make use of the shared input DEA-model, which is based on the contributions of, among others, Beasley (1995) and Cook and Green (2004).Footnote 8 In essence, it adapts the basic DEA-model so that the key DEA-feature of endogenously determining the unknowns is not only applied in the definition of the input and output weights but also in the definition of the distribution of the shared-input. The shared input DEA-model thus determines for each evaluated unit the input and output weights as well as the distribution of the shared input from a relative perspective to the other regions in the sample. Formally,
In the context of the paper, \(e_{k}^{a}\) is the global innovation efficiency score for the evaluated region k;\(\alpha _{k,r}\) the DEA-computed input factor shares, that is to say, the DEA-computed shares of R&D employment across all technologies for the evaluated region \(k\). The assumption is that all R&D employment is accounted for by the considered technologies: \(\sum _{r=1}^{q}\alpha _{k,r}=1\) (constraint (2f)). As with the input factor and innovative output weights, the shared input DEA-model determines the R&D employment shares for the evaluated region such that the global innovation efficiency score \(e_{k}^{a}\) is optimal. As noted by Beasley (1995) in a different context, the advantage of letting the DEA-model decide on the input factor shares is that there is no need to determine an a priori distribution of the shared-input factor across the technologies. Clearly, in the context of ambiguity concerning the true R&D employment distribution, this feature is an advantage (or at least, an appealing second-best route).
The partial innovation efficiency scores for all empirically observed industries are computed as the ratio \(e_{k,r}^{a}=w_{k,r}y_{k,r}/\alpha _{k,r}v_{k,i}x_{k,i}\).Footnote 9 In the interpretation of the partial efficiency scores of the industries \(e_{k,r}^{a}\), the same reasoning applies as for the global efficiency score for the region. In particular, it holds that the partial efficiency scores for the underlying industries, as computed by the non-robust version of the shared input DEA-model, are situated between 0 and 1, with higher values indicating higher innovation efficiency for the focal industry. The difference 1 − \(e_{k,r}^{a}\) can be perceived as a measure of industries’ innovation inefficiency, which quantifies the room for efficiency improvements.
3.4 Restricting the employment shares
The shared input DEA-model as in (2)–(2f) is very flexible in the definition of the optimal employment shares. As with the input and output weights, only a normalization and non-negativity constraint applies to the optimal \(\alpha _{k,r}\)-values (i. e., \(\alpha _{k,r}\geq \varepsilon \)). The non-negativity constraint (2e) imposes that at least a very small fraction (\(\varepsilon =0.0001\) or 0.01%) of the shared-input should be allocated to each technology in each region. The advantage of this flexibility is that the employment shares are optimally chosen for each evaluated region. This implies that eventual poor innovation efficiency scores cannot be blamed on the computed \(\alpha _{k,r}\)-values because any shares, other than the ones computed, will (by definition) lower a region’s innovation efficiency. However, this flexibility also has disadvantages: in the attempt to maximize the region’s innovation efficiency, it is perfectly allowable for the model to assign employment shares that are unrealistically low or high as the non-negativity constraint only imposes that \(\alpha _{k,r}\) ≥ 0.01%.
This potential problem can be overcome by fine-tuning the model so that (1) unrealistic shared input fraction shares are less probable and (2) DEA-based shared input fraction shares are in conformity with some general beliefs and opinions on what are appropriate values for the shared input shares or at least more in line with what practicable observation shows. One way of doing so is limiting the freedom in the DEA-model by means of restrictions on the shared input fraction shares \(\alpha _{k,r}\). More precisely, restrictions of the type \(a_{r}\leq \alpha _{k,r}\leq b_{r}\) can be added to the model, which ensure that optimal employment shares are fitted within the boundaries \(a_{r}\) and \(b_{r}\). Such requires information about the potential magnitude and range of those shares. Ideally, these restrictions should be specified based on expert and stakeholder information and/or practical observation. In the current application, we estimate for each region the shares of industry-specific R&D employment. Subsequently, the minimum level of employment shares observed among all regions and industries are used as global lower bounds \(a_{r}\)in the shared-input DEA-computations. Note that by using the minimum levels of employment shares observed among all regions and industries, we take a minimalist position, which reflects the idea that at least a minimal fraction of the shared input is allocated to each of the outputs (innovation industries). The DEA-estimated shared input fraction shares \(\alpha _{k,r}\) estimated in this paper are displayed in Appendix, Tables 6 and 7.
3.5 Measuring innovation efficiency change
To measure change in innovation efficiency, we employ the Malmquist Productivity Index (MPI, hereafter). This frontier method was originally introduced by Malmquist (1953) and further popularized by, among others, Färe et al. (1994). The MPI measures the change in innovation efficiency between a period t and a subsequent t + 1, denoted as \(IC_{k}\), by calculating the ratio of innovation efficiency scores computed at each time relative to a common transformation technology.
Each of the innovation efficiency scoresFootnote 10 in \(\left (3\right )\) is measured by the shared input version of the DEA-model as described above. In the interpretation of the MPI-scores, \(IC_{k}\)-values above one indicate an improvement and \(IC_{k}\)-values below one show a decrease in the global innovation efficiency of the assessed region k during the observed period.
The MPI can be disaggregated into an “environmental change”-component (\(EC_{k}\)) and a “catching-up”-component (\(CU_{k}\)). The catching-up component reflects a region’s idiosyncratic improvement and helps answering the question of how much closer it got to its ‘contemporaneous’ benchmark region(s). The environmental change component represents the change in the general innovation environment in which a region operates. This component focuses on the conduct of the benchmark region(s) (i. e., the change of the best practice region(s) between two periods). Mathematically, this disaggregation boils down to the following (for more on the decomposition, see Färe et al. 1994):
A CU-value above one indicates progress in a region’s innovation efficiency relative to the benchmark regions between the two periods due to own effort, while the opposite interpretation holds for \(CU_{k}\)-values below one. In the same vein, environmental change-component values above (below) one imply that the general innovation environment has improved (worsened), i. e. it generally takes fewer input factors to create the same quantity of innovative output.
3.6 Robust efficiency analysis
An important drawback of the non-parametric DEA-model and MPI-approach is their sensitivity to the influences of outliers and measurement errors (or other data irregularities). This dependency results from two features: the deterministic nature of the DEA-model by which efficiency scores are taken to be perfect reflections of actual efficiency without considering the potential for any noise or other irregularities in the data. In addition, in the basic (non-robust) DEA-model, the input-output combinations of all regions are considered in the computation of each region’s efficiency. This implies that the presence of just one region with outlying, atypical and/or mismeasured innovation data can downwardly bias the innovation efficiency scores of all other regions.
To overcome this drawback, the DEA-model and the MPI-analysis are adjusted to the insights of the robust order-m efficiency model by Cazals et al. (2002).Footnote 11 Without going into detail, this approach models the transformation of inputs into outputs as a stochastic process and evaluates a region’s output level (output-orientation) against the expected maximal value of output achieved by regions with equal or lower input levels. This considerably minimizes a single region’s impact on the evaluations of other regions and hence the potential influence of statistical noise. In practice, Cazals et al. (2002) propose a Monte Carlo simulation approach in which each region’s efficiency is computed in a large number of DEA-based computation rounds (in casu, 1000 rounds) in each of which its innovation efficiency is evaluated relative to a subsample of \(m\) randomly selected regions with equal or fewer input levels.Footnote 12 , Footnote 13 The robust innovation efficiency score is then computed as the average innovation efficiency score defined over the rounds.Footnote 14
As pointed out by Cazals et al. (2002) and Daraio and Simar (2007), in the robust order-m DEA-framework, the parameter m has a dual nature. On the one hand, m is a ‘trimming parameter’ that determines the analysis’ level of robustness. On the other hand, the parameter m can be interpreted as the benchmark level one wants to carry out over the efficiency evaluations. There is no standard methodology, which allows computing the most appropriate value for the parameter m. However, an important guideline is that too high and too low values of m should be avoided. For a more detailed discussion on robust efficiency analyses and the role of the parameter m, we refer the interested reader to Daraio and Simar (2007). In the present analysis, after a careful study of different m-values, we set m = 50. Contrary to the non-robust efficiency scores, the global innovation efficiency scores, as computed by the robust order-m version of the shared-input DEA-model, can be larger than one. A region with a global innovation efficiency score \(e_{k}^{a}\) higher (lower) than one implies that this region is evaluated as being more (less) innovation efficient than the average identified order-m benchmark.
3.7 Data on regional input factors and innovative output
We apply the above measure to 150 German labor market regions defined by Eckey et al. (2006) on daily commuting behavior. The use of labor market units instead of administrative regions is advantageous for two reasons: First, labor market units are defined such that most people live and work within the same region, which is important because we use the private addresses of inventors to assign patents to regions. Second, in the case of the labor market regions defined by Eckey et al. (2006), there is little economic interaction between neighboring regions, so that spatial effects, which we do not explicitly consider here, play a minor role.
In a common manner, regions’ innovative outputs are approximated by patent applications.Footnote 15 The data are taken from the German Patent and Trademark Office (DPMA) for the period 1999 to 2008. Patents are organized into a multi-digit classification, the International Patent Classification (IPC). The inventor principle is applied to regionalize the patent data, i. e. each patent is assigned to the labor market region where its inventor is located. If a patent is developed by multiple inventors located in different regions, it is partially assigned to each region.
We obtain data on R&D employees from the German labor market statistics. The employees are available on an industry-specific basis as they are classified according to the NACE-classification. The R&D personnel are defined as the sum of the occupational groups agrarian engineers (032), engineers (60), physicists, chemists, mathematicians (61), and other natural scientists (883) (Bade 1987, pp. 194 ff.). The descriptive statistics for all input and output variables can be found in Appendix, Tables 4 and 5.
The shared-input DEA-model implies that it is sufficient to consider the technology-specificity exclusively in the definition of the innovative output. On the input side, we treat total R&D employment as shared-input, i. e. a single variable. We nevertheless make the two data sources comparable for three reasons. First, the IPC captures the technological dimension of patented inventions, while we are more interested in industry-specificities (i. e. the differentiation on the input side). Second, to evaluate the shared-input DEA-model, it is useful to construct some industry-specific measures that require a matching of patent and employment data. Third, we argued above that the quality of the shared-input DEA-based results greatly improves when bounds are specified for R&D employment shares (respectively the \(a_{r}\)- and \(b_{r}\)-values as described in Sect. 3.3) for each technology (i. e. each dimension of the output variable). This is easily possible when total R&D employment is disaggregated according to the same dimensions as the innovative output.
We therefore employ the “standard” concordance developed by Schmoch et al. (2003) that relates 3‑digit employment NACE-classes to IPC patent classes. Note that by making the input and output dimensions comparable in this way, we transform our original technology-specific innovation efficiency measure into an industry-specific measure. We therefore use the latter in the remainder of the paper.
The conversion results in 43 industriesFootnote 16 with corresponding R&D employment and patent data for 150 German labor market regions. This means that we have 43 different innovative outputs, which correspond to the patent counts of regional organizations in 43 industries. These are related to the total R&D employment numbers.
4 Empirical results
4.1 Evaluating the efficiency measure
4.1.1 Correlation analysis
To put the results of the shared-input DEA-model, which are denoted with EFF in the following, into perspective, they are compared to the simplest type of “innovation efficiency measure”, namely the ratio between a region’s total patent output and the total number of regional R&D employees. The ratio measure represents the weighted average of the 43 industry-specific ratios of patent counts and R&D employment numbers.Footnote 17 The implicit weights correspond to industries’ employment shares of total employment (relative input) and it hence strongly relates to regions’ industrial structures.
EFF and the ratio measure strongly rank correlate at R = 0.847*** (1999–2003) and R = 0.837*** (2004–2008). In Fig. 2 it can also be seen that the two measures are relatively similar, which seemingly signals a relatively weak impact of regions’ industry structures on their global innovation efficiencies.Footnote 18 It is, however, important to keep in mind that there are two scenarios in which the measures can be expected to yield very large differences. In the first one, the ratio measure will underestimate regions’ global innovation efficiency if they are dominated by industries with low patent intensities, but which are (relatively) highly innovation efficient (underestimation scenario). In the second scenario, regions’ innovation efficiency will be overestimated by the ratio if they are dominated by patent intensive industries that are (relatively) innovation inefficient in comparison to other regions (overestimation scenario).

Ratio measure vs. efficiency
In any other than these two scenarios, the two measures are likely to produce similar efficiency rankings. While these two scenarios are not very common, they represent a considerable number of cases, which is indicated by the two measures’ (rank) correlation remaining well below one. In this respect, it is also important to point out that the likelihood of observing one of the two scenarios is subject to the disaggregation of the input and output dimension. It is generally less likely that one will observe regions being dominated by an industry when the industrial dimension is strongly disaggregated, i. e. when the average relative size of industries is small. Reducing the dimensionality on the innovative output side, i. e. disaggregating the patents into fewer industries, tends to decrease the correlation between ratio and efficiency measure. This is related to the general tendency of weighting schemes to lose their importance when the number of weighted items increases (Wang and Stanley 1970).
The disaggregation of the innovative output (and innovation input) also relates to a problem, which in its extreme is known as “sparsity bias” (Pedraja-Chaparro et al. 1999, p. 638). A growing dimensionality of the input-output space tends to decrease the number of regions that are comparable with another region, i. e. that may serve as benchmarks. This in turn will increase the regions’ efficiency levels. A lower input-output dimensionality will accordingly allow the efficiency analysis to be more discriminating, which is likely to further reduce the correlation with the ratio measure. When applying the presented method, researchers therefore face a trade-off between the degree of industrial disaggregation and the extent with which the industrial structure influences the empirical results.
In summary, the relatively large correlation between the efficiency estimates and the ratio measure are explained by the chosen disaggregation of the innovative output (43 industries), the comparatively small sample size (150 regions), and the relative rareness of regions being highly specialized in industries with high (low) patent intensities but regionally low (high) innovation efficiencies.
The correlation in the levels of innovation efficiency translates into a significant, however comparatively smaller, correlation in their rates of change. The rank-correlation between the relative change in the ratio measure and the change of EFF between the two periods is RS = 0.71***.Footnote 19 Hence, the average difference between the two approaches’ results is more severe in the dynamic perspective than when looking at one particular time period.
To get an idea on the impact of the DEA-weighting method, we examine the rank correlation between the region innovation efficiency ranks as computed in the present analysis and the regional innovation efficiency ranks as computed using the equal weighting method (i. e., using equal weights for the innovation outputs and equal shared input fraction shares across all regions and their underlying industries). The rank correlation yields RS = 0.774***. Similarly, to see how the use of the robust order-m version of the shared-input DEA-model impacts the resulting innovation efficiency scores and ranks of the German regions, we compute the rank correlation between the innovation efficiency ranks as computed using the robust order-m and the non-robust DEA-model. The rank correlation yields RS = 0.885***. Both rank correlations are high, which suggest that in general the innovation efficiency ranks computed using the different approaches largely correspond. However, note that high correlations don’t imply that the region innovation efficiency scores (ranks) are completely equivalent. Quite the contrary, for several regions the resulting efficiency scores (ranks) clearly depend on the weighting method and/or on whether or not the robust order-m version of the shared input DEA-model was used. Therefore, the norm should be differential (DEA-) weighting using a robust order-m version of the shared input DEA-model.
4.1.2 Comparison of individual cases
The considerable differences between the two measures are highlighted in the following based on particularly illustrative cases.
An illustrative example is the region Rottweil in the period 1999–2003. In terms of R&D employment and patent output Rottweil is of average size. It ranks 72th in patent output (1046.34 patents) and 60th in R&D employment (18,690 employees). According to the ratio of patent output and R&D employment (0.056) it has the 105th highest ratio among the 150 regions. However, its innovation efficiency value is 177.7%, which ranks 10th. In other words, we find a discrepancy of 95 ranks between the two measures. Hence, Rottweil seems be characterized by an industrial structure that generates less patents per R&D employee. This is confirmed by the data. The three industries with the largest patent output in Rottweil are I19 (fabricated metal products), I23 (machine tools), and I25 (weapons and ammunition). They account for about 81% of the region’s total patent output. The three industries’ industry-specific ratios of patent output to R&D employees are 0.057 (I19), 0.067 (I23), and 0.006 (I25). They rank 25th, 21st, and 42th among the 43 industries. Hence, Rottweil is strongly specialized in industries with low patent to R&D employment ratios. It is therefore strongly discriminated against when measured according to the simple ratio analysis. Our innovation efficiency measure reveals, moreover, that the region does outstandingly well in industry I25 (efficiency of 469%), while it is relatively inefficient in industries I19 (35%) and I23 (33%).
Another similarly illustrative example is Darmstadt, a region in the south of Hessia, in the period 2004–2008. The region ranks much higher than Rottweil in terms of patent output (17th) and R&D employment (50th). With a ratio of 0.169 it is among the top-ten German regions (rank 8). However, when taking its industrial structure into account it drops to rank 30 in the innovation efficiency ranking with a value of 97.04%. Hence, the difference is again marked with 22 ranks. However, in contrast to Rottweil, Darmstadt benefits from its industrial structure in the ratio computation. About 43% of its patent outputs are attributed to industries I12 (pharmaceuticals) with 29% and I9 (basic chemicals) with 13%. These are the top-two industries in terms of patents to R&D employment ratios (I12: 0.545 and I9: 0.326).
These examples and the mean difference between regions’ ranks according to the two measures, which amounts to approximately 16 positions in both periods, highlight the fact that ignoring the industrial structure can be very misleading when measuring regions’ innovation efficiency.
4.1.3 Regions’ size and innovation efficiency
Another important quality aspect of a measure of regional innovation efficiency is its uncorrelatedness to regions’ size. Tables 1 and 2 report the rank of a region in terms of total patent output. While it suggests that regions with low patent output tend to be more innovation efficient (e. g. Rügen, Nordfriesland, Prignitz), the rank correlations between the innovation output and efficiency measure underlines the size-independence of the latter with values of RS = 0.33*** (1999–2003) and RS = 0.30*** (2004–2008). The efficiency measure is also doing a much better job of controlling for regions’ size than the ratio measure for which the corresponding correlations amount to RS = 0.52*** in 1999–2003 and 2004–2008.
4.2 The innovation efficiency of German regions
After the discussion of the measures characteristics, we now want to look at the results. The mean efficiency is 71.43% in 1999–2003 and 70.89% in 2004–2008. The median is 52.9% and 51.09% in 1999–2003 and 2004–2008, respectively, illustrating a left–skewed distribution, which is visualized in Fig. 3.

Distribution of efficiency values
Our analysis identifies 29 regions (19% of regions) as being significantly efficient in generating patentable innovation in the period 1999–2003, and 27 (18% of regions) in 2004–2008. Their median efficiency score is 146.7% (1999–2003) and 141.89% (2004–2008), respectively. The comparison with the median scores of the inefficient regions (1999–2003: 48.61%; 2003–2008: 46.44%) highlights that there is substantial potential for increasing regions’ innovation efficiency in Germany.
We report the top (bottom) fifteen innovation efficient regions in Table 1 (Table 2). Garmisch-Partenkirchen holds the top spot in both periods. The region is highly efficient in several industries (11) with industries I4 (wearing apparel) and I6 (wood production) obtaining dominating weights in the computation. The region’s outstanding performance is explained by the fact that it has the largest number of efficient industries (EFF ≥ 100) in both periods (1999–2003: 9; 2004–2008: 16).
In 1999–2003, just 24 regions (23 in 2004–2008) are characterized by more than one innovation efficient industry, with the mean number of efficient industries per region being 3.5 (3.8 in 2004–2008). These figures underline the fact that outstanding innovation efficiency is by and large related to regions being highly efficient in a small number of industries.
Aachen and Jena, which hold the top spots for the most innovation efficient regions among regions with more than average patent output, are interesting cases. Both regions’ good innovation efficiencies come from being efficient in multiple industries. Aachen particularly profits from excellent innovation efficiencies in industry I27 (office machinery and computers), I30 (accumulators, battery), I34 (signal transmission, telecommunications). In Jena, industries I36 (medical equipment), I37 (measuring instruments), and particularly I39 (optical instruments) explain its outstanding performance. All these industries represent well-known strengths of these regions, as exemplified by the relevance of the optical instruments industry in Jena with the headquarters of ZEISS and Jenoptik being located there.
The three cases of Garmisch-Partenkirchen, Aachen, and Jena confirm the idea that excellence in just one industry is not enough to achieve outstanding innovation efficiency. It takes a number of (potentially related) industries to boost a regions’ performance (cf. Cooke et al. 1997; Frenken et al. 2007).
Among the top-performance are several “surprising” regions: like Rügen, Nordfriesland, and Prignitz. However, their high levels of efficiency are primarily explained by their very low input and output values. We therefore refrain from discussing these cases.
The maps in Fig. 4 show the spatial distribution of regional innovation efficiency. While the visual inspection does not suggest the generally lower innovation efficiency of East German regions as reported in Fritsch and Slavtchev (2011) and Broekel (2012), East German regions have a mean efficiency of 56.2% in contrast to West German regions’ 76.4% in 1999–2003. The difference drops somewhat in the following period (West: 74.7%, East: 59.34%). Both differences are significant at the 0.01 level.Footnote 20 We therefore confirm previous findings in the literature concerning the existence of an innovativeness gap between the two parts of Germany, which not only shows in absolute patent numbers but also in terms of efficient innovation generation. We also show that the inefficiency of East German regions cannot be attributed solely to the presence of unfavorable industrial structures.

Geographic distribution of regional innovation efficiency
The second impression derived from the maps in Fig. 3 is that regional innovation efficiency appears to be geographically clustered. While the Moran’s I test on the efficiency scores (1999–2003 I = 0.064*; 2004–2008 I = 0.025) provides little support, the same test applied to the ranks of the efficiency values is confirmative (1999–2003 I = 0.18***; 2004–2008 I = 0.22***).Footnote 21 We thus find regional innovation efficiency to be significantly spatially (rank-) autocorrelated.
4.3 Temporal dynamics of regional innovation efficiency
The two regional innovation efficiency measures computed for the periods 1999–2003 and 2004–2008 show similar patterns. Their correlation is, however, just 0.87***, which suggests that some regions improved and others declined in innovation efficiency.
We argued above that temporal change in innovation efficiency can be disaggregated into two components representing different types of change. The first type of dynamic concerns the “environmental change”-component (EC), i. e. how does the overall (region external) environment for generating innovations develop between two time periods. The mean value of the EC-component is 0.76 and thereby well below one. Accordingly, the overall conditions for innovation generation deteriorated between the two periods. In other words, in 2004–2008 it takes on average significantly more R&D workers to generate the same number of patentable innovation than in 1999–2003. A possible explanation might be the “.com” bubble in 2000–2001 that boosted patent numbers in the earlier period. This clearly deserves more attention in future research.
The second component of innovation efficiency change reflects whether a region can catch up to its contemporaneous comparison regions (period 1999–2008). Table 3 lists the top fifteen regions that could catch up. The region of Prignitz holds the top spot with a CU-value of 23.67. It clearly represents an extreme value caused by its very low level of output making extreme growth rates more likely (output rank: 148 in 1999–2003). This pattern of regions with low levels of output growing more in terms of efficiency than regions with large output values dominates Table 3. However, it is surprisingly more or less restricted to the listed regions. The correlation between patent output in 1999–2003 and efficiency growth is just about R = −0.05 (rank correlation: RS = 0.01). Stuttgart, the number one region in terms of patent output in both periods, is an example in this respect. While it ranks at an average place 82 in 1999–2003, its rank in 2004–2008 is 121. Its efficiency dropped from 50.9 to 29.58%, which corresponds to a decline in the CU-component efficiency of 0.58%. The decline is caused by a decrease in patentable output by 28% from 35,871 patents to 25,713. The input, i. e. the number of R&D employees, remained more or less the same.
In addition to the regions’ level of innovative output, the level of innovation efficiency is another factor that does not predict growth in innovation efficiency well. The relevant correlation is R = −0.09 (rank correlation: RS = −0.14*). Other factors than regions’ initial output and innovation efficiency level are accordingly driving the development of regional innovation efficiency.
In Fig. 5, we show the geographic distribution of innovation efficiency change (i. e. the extent to which regions are catching up). No specific neighborhood patterns are visible, something that is confirmed by a very small Moran’s I: 0.01 (Moran’s I of ranks: 0.03). Innovation efficiency growth processes of neighboring labor market regions are more or less unrelated, a fact that can be interpreted to mean that the chosen delineation of the spatial units captures the (outer) spatial dimension of innovation processes well.

Geographic distribution of innovation efficiency change
Lastly, we look at the development of innovation efficiency in the two parts of Germany. It appears to be the case that the average level of innovation efficiency has decreased: The mean innovation efficiency of East German is 56.2% in 1999–2003 and increases to 59.34% in 2004–2008. The relevant levels are 76.4% in 1999–2003 and 74.7% in 2004–2008 for West German regions. However, a shrinking difference between the two parts of Germany cannot be statistically backed. While there is a difference in mean innovation efficiency growth of West and East German regions (West: 0.99%; East: 1.58%) it is not significant in any test set-up (t-Test, Wilcoxon test, log-transformed growth rates). Accordingly, we do not find statistically robust signs for a convergence between the two parts of Germany in terms of regional innovation efficiency.
5 Discussion and conclusion
We propose the use of a recently developed method to compute regions’ innovation efficiency: namely the robust shared-input Data Envelopment Analysis. We argue that this method is particularly advantageous when analyzing regional innovation efficiency using employment data to approximate input factors and patent numbers, as proxies for innovative output, i. e. in the scenario most common in this type of literature.
Amongst the more obvious advantages of the method are the sparsity of theoretical and empirical assumptions and the requirement of using only publicly available data, while it still allows for considering differences in regions’ industrial structures in the computation. As shown in the paper, the latter are biasing traditional measures leading to the overestimation or underestimation of regions’ innovation efficiency when being dominated by industries with very low or very high patent intensities. By means of a comparison with the number of patented innovations per R&D employee, it has been shown that the new measure yields similar ranking structures but significantly reduces the bias induced by these over- and underestimation scenarios. This is particularly important for the identification of best practice regions. The policy intention is frequently not to identify regions with the most innovative industries but to identify regions that given their industry structures are most innovative. Hence, our approach provides helpful information for policy makers on which regions are the ones to be copied. Moreover, it allows to zoom in on the performance of each industry in a region while still considering regions’ overall performance. A respective analysis on the European level would be an extension of great interest.
In addition, a measure of regions’ innovation efficiency, controlling for their industrial structures, is a valuable starting point for further studies. The natural next step is based on a major advantage of our approach: the possibility to differentiate between innovation efficient and inefficient regions. This allows for studying in detail what makes regions efficient in innovation generation. The high ranks of Aachen and Jena suggest that universities with a good connection to firms are major assets. Collaborative networks may also play crucial roles. Comparison case studies on regions that are ranked in our analysis very high and very low would be very helpful for understanding the underlying processes in more detail. Moreover, when studying the dynamics of the measure by means of a Malmquist-index approach, different components of innovation efficiency changes can be identified.
We illustrated the usefulness of the method by investigating the innovation efficiency of German labor market regions in two periods, 1999–2003 and 2004–2008. Summarizing the empirical findings of our analysis, we showed that there is considerable variance in regional innovation efficiencies among German regions, which cannot exclusively be explained by the location of innovation intensive industries. Garmisch-Partenkirchen was identified as Germany’s most innovation efficient region. Aachen and Jena represent the top performers among regions with more than average absolute patent output. All these regions are characterized by being innovation efficient in multiple industries. Moreover, we confirmed the existence of a gap in innovation efficiency between East and West German regions in both periods. The comparison of the two time periods did not provide significant signs of convergence in terms of innovation efficiency.
Despite the method’s advantages and interesting empirical findings, a number of issues need to be put into perspective. Most importantly, to construct an innovation efficiency measure considering regions’ industrial structures, the method principally is applicable when information on industry (or technology) structures is exclusively available for the innovative output and not for the input factors. In the case of patent data, such information is publicly available. It is the matching of these industry/technology-specific patent numbers to the relevant industry/technology-specific employment numbers that is either unavailable or comes in the form of approximate associations. In both cases, the matching introduces significant inaccuracies into the empirical results obtained by traditional approaches designed to assess regions’ innovation performance.
We showed that such matching procedures become almost obsolete when using the shared-input DEA-model. However, while the method requires very limited information on the matching of patents and employment, it cannot do entirely without it. To obtain useful results, we employed information on the maximum and minimum regional share of R&D employees in each industry observed across all regions to specify restrictions on the employment shares in the DEA-computations. Alternative approaches designed to define restrictions when lacking such information are yet to be explored.
We conclude our paper with two limitations to the present analysis that form interesting topics for further research. A first limitation is that the present analysis does not correct for background characteristics (e. g., public versus private R&D or the presence of international companies) potentially influencing regions’ innovation input and output levels, the fraction shares of the shared input and, hence, regions’ innovation efficiencies. An extension to the present paper consists in adjusting the robust shared input DEA-model such that it enables accounting for such influences in the computation of regions’ innovation efficiency scores. Daraio and Simar (2007) and De Witte and Kortelainen (2013) discussed how the exogenous environment (represented by background characteristics) can be incorporated into the robust order-m DEA-model used in the present paper. The essence of this conditional approach is to incorporate the background variables directly in the efficiency evaluations by comparing only like with likes. The result is a regional innovation efficiency score that corrects for differences in exogenous innovation conditions.
A second limitation to the present analysis is its static stance in the sense that a regions’ innovation output is assumed to depend on R&D employment in the same period. However, one could argue in favour of a more dynamic version of the analysis in which the regional knowledge stock (measured by past patents or R&D expenditures) is considered as determinant of current innovation output. In the shared-input DEA-model, as discussed in the present paper, this would imply that the model should be adjusted to allow input-output levels to be inter-temporally dependent. Emrouznejad and Thanassoulis (2005) propose such an approach, which surely would be an interesting extension of the present paper.
Notes
However, there are also alternative measures based on the community innovation survey.
A similar definition is put forward by Fritsch (2000) on page 415.
Nomenclature Generale des Activites Economiques dans I’Union Europeenne (NACE).
For a more elaborate introduction see Daraio and Simar (2007).
The assumption inherent in the DEA-model is that the observations are sufficiently homogeneous to be compared in a benchmarking analysis.
Note however that regions identified as being output-inefficient are also input-inefficient and vice versa.
To address the point of whether CRS or VRS actually holds in a statistically robust fashion, one could also resort to the test procedure of Simar and Wilson (2002).
The program code (written in R) is available from the authors upon request. The codes can be easily customized to the specifities of other settings.
Note that zero values may characterize innovative outputs, which may lead to problematic results. As the DEA-model considers outputs with zero values as outputs of relative weakness, the endogenous weighting procedure of the basic DEA-model will automatically assign a zero output weight to such outputs. As such these industries will receive a (partial) efficiency score of zero.
Note that, for instance, \(w_{k,r}^{t+1}y_{k,r}^{t}\) represents the efficiency estimate of region k in t benchmarked against the transformation technology (best-practice) in t+1.
The idea of using the order-m method to identify outlying and/or atypical regions and exclude them from the subsequent analysis (as raised by an anonymous referee) was not pursued in this paper. The reason is that, as was noted by Wilson (1995), one should in general be careful with using the term outlier too loosely. In particular, a region with very high innovation efficiency may at first sight appear to be an outlier, but may simply represent a region that is actually highly efficient in terms of generating innovation and, thus, be a valid benchmark in the innovation efficiency evaluations.
As to the number of computation rounds in the Monte Carlo simulation of the order-m DEA-approach, Daraio and Simar (2007) argued that, in most applications, any number higher than 200 is reasonable.
Sensitivity analysis points out that the resulting innovation efficiency ranks of the regions are relatively robust with respect to alternative choices of value of m (i. e., we also considered m-values of 20, 30, 40, 60, 70, 80, 90, and 100). The outcomes of the DEA-models and the MPI-analysis based on other values of m are available upon request.
We acknowledge that patents capture inventions rather than innovation. However, to stay consistent with the literature, we will use the term ‘innovation’.
Schmoch et al. (2003) identify 44 sectors, however, no patents are recorded for one sector.
The ratio measure strongly rank correlates to the residuals of a linear regression of logarithmized R&D employment and logarithmized innovation output (Rs = 0.99***). This method is frequently used when assessing the impact of regional factors on regions’ innovation performance.
Note that we do not seek a measure with little correlation to the ratio. We present a methodology allowing to reduce the potential influence of industrial structures on regions’ innovation efficiency. The ratio serves as an orientation how regions’ efficiency would be based when ignoring industries’ variance in patent propensity when constructing an efficiency measure.
Here, we only consider the catching-up component of this change, denoted as CU.
Wilcoxon rank sum test 1999–2003: W = 2788, p-value = 0.002376; Wilcoxon rank sum test 2004–2008: W = 2696, p-value = 0.008348.
For the computation of Moran’s I, we used direct neighborhood as basis for the spatial weight matrix.
References
Arundel A, Kabla I (1998) What percentage of innovations are patented? Empirical estimates for European firms. Res Policy 27(3):127–141
Audretsch D (1998) Agglomeration and the location of innovative activity. Oxf Rev Econ Policy 14(2):18–29
Bade F‑J (1987) Regionale Beschäftigungsentwicklung und produktionsorientierte Dienstleistungen. Sonderheft, vol. 143. Deutsches Institut für Wirtschaftsforschung, Berlin
Beasley JE (1995) Determining teaching and research efficiencies. J Oper Res Soc 46:441–452
Bonaccorsi A, Daraio C (2006) Econometric approaches to the analysis of productivity of R&D systems. Handbook of quantitative science and technology research handbook of quantitative science and technology research – the use of publication and patent statistics in studies of S&T systems. Springer, Dordrecht, pp 51–74
Brenner T, Broekel T (2011) Methodological issues in measuring innovation performance of spatial units. Ind Innov 18(1):7–37
Broekel T (2012) Collaboration intensity and regional innovation efficiency in Germany – a conditional efficiency approach. Ind Innov 19(3):155–179
Broekel T (2015) Do cooperative R&D subsidies stimulate regional innovation efficiency? Evidence from Germany. Reg Stud 49(7):1087–1110
Cazals C, Florens JP, Simar L (2002) Nonparametric frontier estimation: a robust approach. J Econom 106:1–25
Charnes A, Cooper WW, Rhodes E (1978) Measuring the efficiency of decision making units. Eur J Oper Res 2:429–444
Chen K, Guan J (2012) Measuring the efficiency of China’s regional innovation systems: application of network data envelopment analysis (DEA). Reg Stud 46(3):355–377
Chen KH, Guan JC (2010) Modeling macro-R&D production frontier performance: an application to Chinese province-level R&D. Scientometrics 82(1):165–173
Cohen WM, Klepper S (1996) A reprise of size and R&D. Econ J 106:925–951
Cook WD, Green RH (2004) Multicomponent efficiency measurement and core business identification in multiplant forms: a DEA model. Eur J Oper Res 157:540–551
Cooke P, Uranga MG, Etxebarria G (1997) Regional innovation systems: Institutional and organisational dimensions. Res Policy 26(4–5):475–491
Daraio C, Simar L (2007) Advanced robust and nonparametric methods in efficiency analysis: methodology and applications. Series: Studies in Productivity and Efficiency. Springer, New York
Deyle H, Grupp H (2005) Commuters and the regional assignment of innovative activities: a methodological patent study of German districts. Res Policy 34(2):221–234
De Witte K, Kortelainen M (2013) What explains the performance of students in a heterogeneous environment? Conditional efficiency estimation with continuous and discrete environmental variables. Appl Econ 45(17):2401–2412
Eckey HF, Kosfeld R, Türck M (2006) Abgrenzung deutscher Arbeitsmarktregionen. Volkswirtschaftliche Diskussionsbeiträge. Universität Kassel, Kassel
Edquist C, Zabala-Iturriagagoitia JM (2015) The Innovation Union Scoreboard is flawed: The case of Sweden – not the innovation leader of the EU – updated version. Papers in Innovation Studies, Paper no. 2015/27. CIRCLE, Lund
Emrouznejad A, Thanassoulis E (2005) A mathematical model for dynamic efficiency using data envelopment analysis. Appl Math Comput 160(2):363–378
Färe R, Grosskopf S, Norris M, Zhang Z (1994) Productivity growth, technical progress, and efficiency change in industrialized countries. Am Econ Rev 81(1):66–83
Farrell MJ (1957) The measurement of productive efficiency. J Royal Stat Soc Ser A 120(3):253–290
Foray D (2015) Smart specialisation. Opportunities and challenges for innovation policy. Routledge, Regional Studies Association, Abingdon
Frenken K, van Oort FG, Verburg T (2007) Related variety, unrelated variety and regional economic growth. Reg Stud 41(5):685–697
Fritsch M (2000) Interregional differences in R&D activities – an empirical investigation. Eur Plan Stud 8(4):409–427
Fritsch M (2003) How and why does the efficiency of regional innovation systems differ. In: Bröcker J, Dohse D, Soltwedel R (eds) Innovation clusters and interregional competition. Springer, Berlin
Fritsch M, Slavtchev V (2011) Determinants of the efficiency of regional innovation systems. Reg Stud 45(7):905–918
Griliches Z (1979) Issues in assessing the contribution of research and development to productivity growth. Bell J Econ 10(1):92. doi:10.2307/3003321
Jaffe A (1989) Real effects of academic research. Am Econ Rev 79(5):957–970
Jeong SO, Park BU, Simar L (2010) Nonparametric conditional efficiency measures: asymptotic properties. Ann Oper Res 173(1):105–122
Lybbert T, Zolas N (2013) Getting patents and economic data to speak to each other: an ‘algorithmic links with probabilities’ approach for joint analyses of patenting and economic activity. Res Policy 43(3):530–542
Malerba F, Orsenigo L (1993) Technological regimes and firm behavior. Ind Corp Change 2(1):45–74
Malerba F, Orsenigo L, Breschi S (2000) Technological regimes and Schumpeterian patterns of innovation. Econ J 110(463):388–410
Malmquist S (1953) Index numbers and indifference surfaces. Trabajos de estadística 4(2):209–242
Pedraja-Chaparro F, Salinas-Jiménez J, Smith P (1999) On the quality of the data envelopment analysis model. J Oper Res Soc 50(6):636–644
Schmoch U, Laville F, Patel P, Frietsch R (2003) Linking technology areas to industrial sectors. Final report to the European Commission. DG Research, Karlsruhe, Paris, Brighton
Simar L, Wilson PW (2002) Non-parametric tests of returns to scale. Eur J Oper Res 139(1):115–132
Stern S, Porter ME, Furman JL (2002) The determinants of national innovative capacity. Res Policy 31(6):899–933
Wang MW, Stanley JC (1970) Differential weighting: a review of methods and empirical studies. Rev Educ Res 40:663–705
Wilson PW (1995) Detecting influential observations in data envelopment analysis. J Prod Analysis 6(1):27–45
Zabala-Iturriagagoitia JM, Voigt P, Gutiérrez-Gracia A, Jiménez-Sáez F (2007) Regional Innovation Systems: How to Assess Performance. Reg Stud 41(5):661–672
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Rights and permissions
About this article

Cite this article
Broekel, T., Rogge, N. & Brenner, T. The innovation efficiency of German regions – a shared-input DEA approach. Rev Reg Res 38, 77–109 (2018). https://doi.org/10.1007/s10037-017-0112-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10037-017-0112-0