
Abstract
Self-organized flocking of robotic swarms has been investigated for approximately 20 years. Most studies are based on a computer animation model named Boid. This model reproduces flocking motion by three simple behavioral rules: collision avoidance, velocity matching, and flock centering. However, flocking performance depends on how these rules are configured and no guideline for the configuration exists. This paper investigates real robot flocking where individuals can switch their roles depending on the situations. Robots can move as leaders or followers, and the roles are dynamically allocated using stochastic learning automata. The flocking performance is evaluated, and swarming behavior is analyzed in a scenario where robots consecutively travel between two landmarks.
Similar content being viewed by others

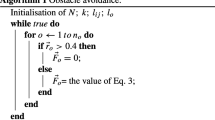

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Self-organized coordinated motion is commonly observed in animal societies. Swarming behaviors increase the survival rate and reduce the energy consumption of individual animals [1]. Similarly, the navigation and sensing performance of artificial systems can be improved by employing a swarm of robots.
This decade has witnessed growing interest in the research field of the collective behavior of large robot groups, known as Swarm Robotics (SR) [2]. Swarm robotic systems (SRSs) consist of many simple autonomous robots that operate without global controllers. SRSs are expected to have several advantages against a single high-performance robot, such as robustness, flexibility, and scalability. Collective behavior in robotic swarms emerges from the self-organization processes as in biological swarms.
SRSs are usually assigned biological swarming tasks such as aggregation [3], foraging [4], and collective transport [5]. In most studies on flock-like motions of SRSs (see for example, [6, 7]), robots are designed based on the well-known computer animation model Boid [8]. Reynolds showed that flocking in the Boid model can be developed using three simple rules: collision avoidance, velocity matching, and flock centering. However, flocking performance depends on how these rules are configured and no guideline for the configuration exists.
This paper thus investigates swarm robot flocking by introducing multiple rule configurations that can be switched depending on situations. The remainder of this paper is organized as follows. Our task allocation approach for flocking behavior in mobile robots is described in Sect. 2. Section 3 shows experimental results. Conclusions and future research directions are presented in Sect. 4.
2 Method
Boid-based flocking has been successfully demonstrated in various computer simulations, but cannot be easily implemented in real robots. The main reason is that accurate neighbor information, especially on the orientations, is difficult to obtain in modern technological systems for mechanical and electrical reasons. To overcome this difficulty, mobile robots are frequently programmed with communication functions that enable flocking behaviors [6, 7]. Explicit communication, however, presents an additional challenge because it requires external computation or communication devices.
Another difficulty in implementing Boid to real robots is that no guideline on how to coordinate collision avoidance, velocity matching, and flock centering does not exist. Trial-and-error based weighting for the rules is typically conducted.
In this paper, the first problem is simply mitigated by providing robots information on their destination. The heading direction of robots tends to be aligned toward the destination. For the second problem, multiple weighting parameter sets are provided, and a learning mechanism for which parameter set to use is implemented.

Rule areas
Figure 1 shows the range of each behavioral rule based on Boid model. The repulsion and attraction rules enable the robot to avoid collisions and remain close to its neighbors, respectively. The repulsion works for robots within the range of \(r_\mathrm{rep}\) from the center of the corresponding robot. The attraction rule is applied if neighboring robots are in the range of \(r_\mathrm{rep}\) to \(r_\mathrm{att}\). The acceleration rule is a biomimetic rule inspired by surf scoter behavior [9]. This rule gives robots a preference for neighbors in the frontal sector with the central angle of \(\theta _f\). The heading direction vector is calculated as
where \(\mathbf {R}\), \(\mathbf {A}\), and \(\mathbf {L}\) denote the repulsion vector, attraction vector, and leader vector (landmark-heading vector), respectively. The leader vector is expected to be utilized as an alignment rule in the original Boid. Constants a, b, and c are set within the range [0.0, 1.0].
In this paper, robots have a mechanism for switching their roles depending on the situations. Robots can move as leaders or followers, and the roles are dynamically allocated using stochastic learning automata (SLA). Leaders have a preference for moving toward their destination (\(b<c\)), and followers for attracting to neighbors ahead (\(b>c\)). Whether outputs of SLA are correct or not is evaluated based on the distribution of neighboring robots. Leaders/followers prefer neighbors behind/ahead rather than those ahead/behind, respectively.
3 Experiments
3.1 Mobile robot
Figure 2 shows the two-wheeled mobile robot used in this paper. The robot is 28 cm tall and 18 cm in diameter. It is equipped with seven distance sensors and an omnidirectional camera. Objects within the sensor range, such as neighboring robots and walls, can be detected. If an object is in the sensing range of a distance sensor, robot i tries to avoid collisions by generating the repulsion force as follows:
where \(d_k\) is the value of the distance sensor k attached at \(\phi _k = \frac{\pi }{6}k\) (\(k \in \{ 0,1,...,6 \}\)). When neighbors are in the acceleration area, robot i moves toward them by generating an attractive vector described in the next section.

Two-wheeled robot with IR sensors and an omni-vision camera
3.2 Heading direction vector
When \(n_{\text {rep}}\) robots are in the repulsion area, the repulsion vector \(\mathbf {r}\) is generated from information obtained by the omnidirectional camera:
where \(\mathbf {x}_i\) denotes the position vector of the ith robot, and \(g(\cdot )\) is a normalizing function. The attraction vector for \(n_{\text {att}}\) robots in the attraction area is calculated as:
Besides, the leader vector is determined as
where \(\mathbf {h}_{\text {l}}\) and \(\mathbf {h}_{\text {c}}\) are the direction for a target landmark and the current heading direction of a robot.
3.3 Robot behavior
The vectors defined in the previous subsection are transformed into signals that actuate the two side-wheels of the mobile robot. The rotation velocities of the left and right wheels, denoted \(N_{\text {L}}\) and \(N_{\text {R}}\), respectively, are calculated as
where \(u_{\text {max}}\) and \(u_{\text {min}}\), respectively, denote the maximum and minimum speed of the robot, \(K_p=0.5\) is a proportional gain, l is the distance between the left and right wheels, and r is the wheel radius.
3.4 Setups
The above flocking approach was evaluated on real robots placed in a 6 m \(\times\) 4 m experimental field surrounded by walls. The initial locations of the 10 deployed robots are shown in Fig. 3. The task for the robots is making round trips between two landmarks located on the both of the shorter walls as many as possible. At the beginning of each experiment, all the robots are oriented in the same direction and start moving toward the landmark ahead. After reaching the target landmark, robots turn around and move toward the other landmark. By repeating this movement, the robots can make round trips.

Environment
Four types of robotic swarms are evaluated: (i) all leaders (\(b<c\)), (ii) all followers (\(b>c\)), (iii) random leader–follower allocation at each time step, and (iv) SLA-based leader–follower switching. Five runs, each of 300-s duration, are executed for each swarm. The fixed parameters are listed in Table 1. SLA-based leader–follower switching in the robotic swarms (iv) is conducted every 10 time steps, approximately 5 s, during the experimental runs online. When a robot selects a leader rule at time t, the probabilities for selecting a leader/follower rule, \(P_l\) and \(P_f\), respectively, are updated as follows:
where \(\alpha\) and \(\beta\) are learning coefficients. \(N_f\) and \(N_b\) denote the numbers of neighbors in front and back at \(t+1\), respectively. The probability update after selecting a follower rule is executed as in Eqs. (12) and (13).
3.5 Results
Flocking behavior was evaluated by two criteria: the number of round trips and largest aggregate. The connectivity of robots i and j is defined if both robots are in the sensing range [10]. The cohesiveness of the flock is ratio of the largest aggregate, \(\phi\), to the whole flock. We evaluated the swarm behavior via movies recorded by a camera on the ceiling of our experimental room.
Figures 4 and 5 present the number of successful round trips and the largest aggregate metrics. A swarm with all leaders made the biggest number of round trips. Judging from the largest aggregate metric, however, robots behave not cooperatively but individually. The largest aggregate performance of the robotic swarms is improved when a learning mechanism is implemented. It can be said that dynamic task allocation in a robotic swarm can improve the coherence of flocking.

Number of round trips

Largest aggregate

Snapshots of flocking behavior

Transition of coverage areas

Flocking behavior of a robotic swarm and its coverage areas as Voronoi diagrams (100–200 s)
Figure 6 shows snapshots of a flocking mobile robotic swarm in a trial. It can be observed that the flock formation dynamically changes during round trips. Figure 7 shows the transitions of the coverage areas represented as Voronoi diagrams, a partitioning of the experimental filed into regions based on distance to robots, in experimental runs where largest aggregates \(\phi\) are low/high. The closest pair of robots corresponds to two adjacent cells in the diagram. Since robots can detect neighbors in their sensing range, \({r}_\mathrm{{att}}\), cell sizes are also restricted. The more coherently the robots perform, the smaller the coverage areas are. Several peaks in the sum of the coverage areas are observed in each experiment. It can be said from this observation that robots repeat the cycle of aggregation and dispersion throughout the experimental runs. When a robotic swarm displays good flocking behavior, peaks tend to be steep. Figure 8 depicts the position and the sensing range of each robot in the middle of experimental runs. As robots separate and turn around individually, the coverage area expands.
4 Conclusions
Self-organized coordinated motion in swarming robots can improve the navigation and sensing performance of the robotic system. This paper investigated a flocking model of SRS that can switch leading/following behavior according to the situations. In this task allocation model, a stochastic learning automaton is used to determine which behavior to be selected. The aggregate and order performances of the model were evaluated in real robot experiments.
As future scope, we plan on introducing more robots into the physical experiments. We are also interested in whether our approach is extendible to flying robots. Flocking behavior of robots that tune weights during the runtime will be investigated.
References
Parrish K, Viscido SV, Grünbaum D (2002) Self-organized fish schools: an examination of emergent properties. Biol Bull 202(3):296–305
Şahin E (2005) Swarm robotics : from source of inspiration to domain of applications, swarm robotics, SAB2004 International Workshop, Santana Monica, CA, USA, July 2004. Revised Selected Papers, LNCS 3342:10–20
O. Soysal, and E. Şahin (2005) Probabilistic aggregation strategies in swarm robotic systems. In: Proc. of the 2005 IEEE Swarm Intelligence Symposium, pp 325–332
Liu W, Winfield AFT, Sa J, Chen J, Dou L (2007) Towards energy optimization: emergent task allocation in a swarm of foraging robots. Adapt Behav 15(3):289–305
Groß R, Dorigo M (2009) Towards group transport by swarms of robot. Int J Bio-Inspired Comput 1(1–2):1–13
Turgut AE, Çelikkant H, Gökçe F, Şahin E (2008) Self-organized flocking in mobile robot swarms. Swarm Intell 2(2–4):97–120
Ferrante E, Turgut AE, Mathews N, Birattari M, Dorigo M (2010) Flocking in stationary and non-stationary environments : a novel communication strategy for heading alignment. Lect Notes Comput Sci 6239:331–340
Reynolds C (1987) Flocks, herds and schools: a distributed behavioral model, computer graphics, vol 21, no.4 (Proceedings of ACM SIGGRAPH ’87). ACM Press, pp 25–34
Lukeman R, Li YX, Edelstein-Keshet L (2010) Inferring individual rules from collective behavior. Proc Natl Acad Sci 107(28):12576–12580
Çelikkanat H, Şahin E (2010) Steering self-organized robot flocks through externally guided individuals. Neural Comput Appl 19(6):849–865
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was presented in part at the 1st International Symposium on Swarm Behavior and Bio-Inspired Robotics, Kyoto, Japan, October 28–30, 2015.
About this article

Cite this article
Toshiyuki, Y., Nakatani, S., Adachi, A. et al. Adaptive role assignment for self-organized flocking of a real robotic swarm. Artif Life Robotics 21, 405–410 (2016). https://doi.org/10.1007/s10015-016-0331-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10015-016-0331-4