
Abstract
With the increased use of social network sites, such as Twitter, attackers exploit these platforms to spread counterfeit content. Such content can be fake advertisements or illegal content. Classifying such content is a challenging task, especially in Arabic. The Arabic language has a complex structure and makes classification tasks more difficult. This paper presents an approach to classifying Arabic tweets using classical machine learning (non-deep machine learning) and deep learning techniques. Tweets corpus were collected through Twitter API and labelled manually to get a reliable dataset. For an efficient classifier, feature extraction is applied to the corpus dataset. Then, two learning techniques are used for each feature extraction technique on the created dataset using N-gram models (uni-gram, bi-gram, and char-gram). The applied classical machine learning algorithms are support vector machines, neural networks, logistics regression, and naïve Bayes. Global vector (GloVe) and fastText learning models are utilised for the deep learning approaches. The Precision, Recall, and F1-score are the suggested performance measures calculated in this paper. Afterwards, the dataset is increased using the synthetic minority oversampling technique class to create a balanced dataset. After applying the classical machine learning models, the experimental results show that the neural network algorithm outperforms the other algorithms. Moreover, the GloVe outperforms the fastText model for the deep learning approach.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The number of users on social media is significantly increasing. Different platforms attract users of other interests in almost all human activities. The significant number of users makes them prune to marketing campaigns and cyber-attacks. One of the illegitimate interactions that online users struggle with is spamming. Spam content ranges from marketing campaigns to malicious links that may cause harm to data and devices.
Because Twitter is a popular social platform through which people and organisations interact by posting tweets, it produces many advertisements that reach its users [1]. However, it is hard for users to distinguish between benign and malicious advertisements. Thus, many researchers have worked on a procedure to detect and deny fake tweets on Twitter [2,3,4,5,6]. Detecting malicious behaviours using Artificial Intelligence, such as machine learning algorithms, is highly effective. Classical machine learning and deep learning were used for different purposes in classification problems in cybersecurity. In [7], classical machine learning was applied to classify malicious and benign websites, whereas in [8], it was used for intrusion detection systems to classify network attacks. Also, it was used in healthcare to classify diseases such as Parkinson's [9]. However, it is remarkable that most spam detection achieved in the literature detects spam in English [6].
Because the Arabic language is complex, much attention is given to detecting abnormal behaviour, fake accounts, and malicious advertisements on Twitter for tweets written in the Arabic language [10, 11]. Some special techniques are used to analyse the meaning behind words in Arabic tweets: stemming and lemmatisation. Lemmatization is the base form of all inflectional forms of an expression, whereas a stem is not. These techniques are parts of the Arabic natural language processing (NLP) that uses artificial Intelligence to understand Arabic dialects. This technique has recently attracted research scholars due to some challenges the Arabic language confronts [12, 13].
Stemming and lemmatisation are two approaches used in search engines to analyse a word's meaning. Stemming retrieves the root words from text content by eliminating the word's prefixes and suffixes, known as a stem. For example, the term "playing" has a suffix "ing," which is removed to obtain the stem word "play." However, according to stemming, the words "studies" and "studying" are stem as "studi" and "study", respectively.
Lemmatization considers the context and converts the word to its meaningful base form, called a lemma. It assesses the morphological analysis of the words in a context. Accordingly, there is a detailed dictionary through which the lemmatisation algorithm links the form to its lemma. For example, the terms "studies" and "studying" within their context are both lemmatised to "study" because the morphological information of "studies" tells that it is the third person, singular number, present tense of the verb "study" and "studying" is the gerund of the verb "study."
Another approach used to measure the similarity between a "term" input and each of the different terms in a database is N-grams. An n-gram is a set of n consecutive characters extracted from a specific word [14]. Two words are similar if they have a high proportion of n-grams in common. This research illustrates three types of N-grams: uni-gram, bi-gram, and char-gram. For instance, a word containing n characters has (n + 1) bi-grams. The term "computer" generates the following bi-grams: {*c, co, om, mp, pu, ut, te, er, r*}. This technique is commonly used in text categorisation, sentiment analysis, and text generation [15] because it successfully converts text from an unstructured format to a structured layout. Moreover, it is widely used because it is language-free and needs no additional effort to be implemented.
This research studies how classical machine learning and deep learning algorithms can detect spam on the Twitter platform. The particular interest of this work consists of studying tweets written in Modern Standard Arabic (MSA). The first classical approach uses four machine learning classifiers, including Naïve Bayes (NB), Support Vector Machine (SVM), Neural Networks (NN), and Logistic Regression (LR). The methodology setups include nine scenarios for two sampling methods: without sampling and oversampling using Synthetic Minority Oversampling Technique (SMOTE). Different preprocessing techniques are used for each sampling setup. The deep learning approach utilised modern deep learning models for text representation, including GloVe and fastText. The output of these models is fed into a long short-term memory (LSTM) model to perform the final classification. The dataset consists of almost 22,000 tweets used in fivefold cross-validation.
The rest of the paper is organised as follows: A literature review of spam detection in social networks using different artificial intelligence techniques is illustrated in Sect. 2. Afterwards, the methodology followed in this paper is explored in Sect. 3, including the data collection for ham and spam tweets, the data cleaning and feature extraction, and the machine learning and deep learning classification. Later the experimental results for classification performance are later explored in Sect. 4, followed by a comparison with an existing dataset. Finally, the study is concluded in Sect. 5.
2 Literature review
The popularity of social media made their main targets for spammers. Most accounts on social media, especially business accounts, have administrators that manually check spam content and remove it. The authors in [19] analysed the reasons behind social spam and proposed an approach that automatically detects spammers. The authors highlight and discuss six different properties that address distinct features of social spam and explain how each property gives the insight to differentiate between legitimate users and spammers. Various machine learning classification models then exploit these properties (or features). The accuracy reported by the authors was 98% in detecting spamming, with 2% false positives.
Many spams have infiltrated the rapidly growing online social networking sites. In [20, 21], the authors focused on Twitter to study its spam content. The proposed approach starts by creating a directed social graph model to identify "friend" and "follower" relationships among different accounts. The proposed method considers Twitter's spam policy and uses graph-based and content-based features. A crawler is created using Twitter's API. The spam detection system uses classical machine learning models like the Naïve Bayes model. Afterwards, different evaluation criteria are used to analyse the system's efficiency. The author reported that the betting model among the ones used in terms of F1-measure was the Bayesian model achieving 89% precision.
Social networking sites have become very popular in recent years. Users use them to find new friends and update their existing friends with their latest thoughts and activities. Twitter's popularity made it a natural target for spammers among these sites. The social media platform used to connect to friends and follow the updates of others is also being used by spammers to spread spam content, whether it is harmful data or marketing content. The authors in [22] discussed content-based and user-based features to distinguish between legitimate users and spammers. Four different classifiers use the same features to detect spam content. The approach starts by using Twitter's API methods and crawler to collect tweets. The authors studied a group of users' activity and returned to the latest hundred tweets. Upon evaluating the classification result of the four chosen classifiers, the best results reported were 98.7% for the F1-score of 98.7% using the Random Forest classifier.
The significant growth in many mobile phones resulted in the development of the Short Message Service (SMS) industry. However, the relatively cheap cost of this messaging service has increased the spam content sent to mobile phone users. In some countries, the spam content reached 30% of the total received SMS. The lack of resources (such as databases), their linguistic nature, and their short size made it hard for classical filtering algorithms to detect SMS spam. The authors in [23] used a database of real SMS spam from the UCI Machine Learning repository. The data were preprocessed, and features were extracted to create vectors suitable for machine learning models. Different models were used, and tenfold cross-validation was adopted. The results show that multinomial naive Bayes with Laplace smoothing and SVM with linear kernel have the best performance in detecting SMS spam. The authors used features such as the length of messages in the number of characters, ran the experiment under different SMS sizes, and analysed the incorrectly classified records.
Moreover, the authors in [6] classified linkless emails as benign and phishing using deep neural networks. Deep neural networks can process data through multiple hidden layers before the data reach the output layer. According to the author's study, the email classification was effective after applying this machine learning approach over different settings on the data. The experimental results showed high performance in terms of precision, recall, and accuracy values.
The popularity of social media and the significant increase in users provided a natural habitat for cybercrime to prosper. Although many legitimate services accompany social media, these users are targets for marketing campaigns. The authors in [24] proposed an inductive-learning approach to detect spamming on Twitter and apply a Random Forest classifier to a few features extracted from tweets. Authors claim. Classification results show that the proposed method outperformed other classifiers with an F1-score of 92% for spammers and 82% for non-spammers.
Spammers post illegitimate tweets to the Twitter platform in order to advertise services or attack users. A detection mechanism should be to label tweets as spam to limit dangerous spammers. Tweets are collected in real-time via streaming using Twitter's API, allowing researchers to collect public tweets. However, classical machine-learning models detect spam in real time as the tweets go live. The authors in [25] try to fill this gap by conducting a performance evaluation focusing on three different aspects: features, models, and data. The authors build a corpus of 600 million public tweets. They further extracted 12 lightweight features for tweet representation to detect spam in a real-time spam fashion. Spam detection was then transformed into a binary classification problem in the feature space and solved by classical machine learning algorithms. They evaluated the impact of different factors on spam detection performance, including spam-to-non-spam ratio, feature discretisation, training data size, data sampling, time-related data, and classical machine learning algorithms. The results show that streaming spam tweet detection is still a big challenge, and a robust detection technique should consider the three aspects of data, feature, and model.
Twitter currently uses Google's SafeBrowsing to detect and block harmful links. Although adopted block lists can block dangerous links embedded in tweets, the detection and blocking delay time hinders the ability to protect users instantly. One obvious solution was to exploit machine learning models to detect and block spam. The authors in [26] conducted a comparative study on six classical machine learning models using a dataset of 600 million tweets. The authors also annotated almost 6.5 million spam tweets and identified 12 features used to classify tweets. The authors ran their experiments on six machine learning models using different setups to analyse the strength and weaknesses points.
The research presented in [27] focuses on detecting spam in emails. The authors provide a classification model that differentiates between spam and legitimate emails using greedy stepwise feature selection and applying their model to the Enron email dataset. Different classifiers such as Naïve Bayes, SVM, and decision trees were used. The classifiers were evaluated (such as F1-measure. The authors reported that SVM gave the best results, achieving SVM with the highest accuracy and the lowest false positive values. However, SVM's training time is higher than the other classifies.
The authors in [28] argue that adopting classical machine learning classifiers that use statistical features to detect Twitter's spam tweets is unreliable as these features may vary with time. The variation in the used annotated dataset of tweets affected the classification performance. This variation is referred to as "Twitter Spam Drift." The authors first analysed the statistical features of one million legitimate and one million spam tweets to override this issue. Afterwards, a scheme called Lfun was proposed to discover the changes in spam tweets and feed them to the classifier to train them on new instances. Results show that continuous classifier training with different spam tweet versions significantly improved classification accuracy.
According to the authors in [29], existing classical machine-learning techniques used to detect spam on Twitter have reached an accuracy of around 80%. However, as spamming techniques become more complex, classical machine learning approaches decline in efficiency in detecting malicious content. The problem becomes complex if the detection is done in real-time. In addition, existing block listing methods cannot catch the increasingly spreading variants of spam content and, therefore, cannot be used as a standalone solution to spam. Since manual spamming detection is infeasible, the authors propose a technique that exploits deep learning to resolve spam detection. Created vectors represent tweets to be input into the classifier. Afterwards, a binary classifier was applied to 10-day actual tweets datasets. The authors compared the performance of other classifiers with that of their classifier and reported higher accuracy when using their classifier.
The authors in [30] proposed a hybrid approach that exploits graph-based and content-based features to identify spammers in social media platforms, namely, Twitter. They tested the proposed technique on a dataset of 400,000 tweets and 11,000 users. The authors reported 97% accuracy and argued that adding a more diverse feature improves the classification accuracy.
Authors in [31, 32] argue that most research is done on spam detection on unbalanced social media datasets. They experimentally illustrate how the imbalanced distribution between legitimate and spam content significantly impacts the spam detection rate. The authors propose a fuzzy-based oversampling called the FOS scheme, a fuzzy-based oversampling method that creates synthetic data records from limited, accurate descriptions based on the intuition of fuzzy-based information decomposition. Afterwards, they propose an ensemble learning technique that improves the classification accuracy of imbalanced data following a three-step process: (1) the imbalanced dataset is fixed using different techniques, such as random under-sampling, random oversampling, and FOS; (2) a classifier is built using the new datasets; (3) a majority voting technique is used to merge the classification results from all the classification models. The authors tried their approach to real-world tweets. The results show that the suggested learning technique can significantly enhance spam detection efficiency when applied to imbalanced datasets.
The authors in [4] surveyed existing approaches to detect spam on Twitter. This survey has three components: a literature review of state-of-art techniques covering thorough analysis and discussion on existing processes; a comparative study that compares compare the efficiency of different classical methods on a universal benchmark to present a quantitative measure of existing methods; open issues and summarises the unsolved problem in existing processes. Solutions to the unsolved problem are essential to both industries and academic institutions.
In [33], the authors argue that although Twitter's BotMaker tool and Google's SafeBrowsing detect and block spam tweets, they do not do this in real-time. The authors claimed that none of the tweet-based and user-based classifiers could detect and block spammers completely. In their proposed solution, they build a user- and tweet-based classifier and also considers the body of the tweet to do the classification. They tested their proposed framework on four distinct classical machine learning classifiers: SVM, Gradient Boosting, Neural Network, and Random Forest. The highest reported accuracy was using Neural Networks, achieving 91.65%.
In [34], the authors argued that classical spammers detection techniques do not prevent a spammer from creating new accounts and sending spam content. They highlighted the need to detect spam at the tweet and user levels. Specifically, they discuss how deep learning approaches may be used in several natural language processing issues, including spam detection. The authors propose a solution based on neural networks that use different lexicons to detect spam. They used five neural network models and one feature-based model. Their proposed framework combines deep learning and classical feature-based techniques using a multi-neural network that serves as a meta-classifier. The framework operates on two datasets, one is balanced, and the other is not. Results show that the proposed classifier outperforms classical ones.
The authors in [35] studied the sentiment of Facebook posts submitted in dialectal Arabic. They examined five classes: positive, negative, neutral, dual, and spam. Their results show that different spam variants were detected using a limited set of spam lexicons and regular expressions. However, their approach uses content-based features and not user-based features.
Many other papers in the literature discuss spam tweet classification using machine learning [36]. The research work [34, 51,52,53,54,55,56,57] will be discussed later and compared with this work.
3 Methodology
This work uses classical machine learning and deep learning approaches for spam detection. In the classical machine learning approach, four machine learning classifiers are studied, including Naïve Bayes (NB), Support Vector Machine (SVM), Neural Networks (NN), and Logistic Regression (LR). Modern deep learning models for text representation, including GloVe and fastText, are used in the deep learning approach.
GloVe is a methodology for extracting word vector representations from words using an unsupervised machine learning algorithm [16]. The training stage is done on aggregated global word-word co-occurrence statistics from a corpus. The main idea is to derive the relationship between words by finding the frequency of two words appearing together.
FastText [17] is an open-source library developed by the Facebook AI Research lab. The main goal of this library is to find scalable, accurate and fast solutions for text classification and representation tasks for large datasets. FastText assumes that a word is composed of n-grams that range from 1 to the length of the word. This helps find rare words that can share n-grams with other common words. Imbalanced data is a dataset with few sample records of the minority class. This is a problem in classification and affects the evaluation of results. The accuracy metric will not indicate results if the data is unbalanced [18]. There are two solutions to this problem. One solution is to be achieved by duplicating the records of the minority class before the model fitting stage. Applying this methodology will not add any additional information to the model but will balance the classes. An improvement of this technique is synthesising more examples of the minority class. This way can be effective for tabular data. Synthetic Minority Oversampling Technique (SMOTE) is the most widely used technique for data synthesis [18]. SMOTE selects a random example a from the minority class. Then, the k nearest neighbours are located, and one neighbour, b is selected randomly. Then, a line is created in the feature space between the two points a and b. The new instances are synthesised as a convex combination of instances a and b. for more effectiveness of this process, it can be associated with random under-sampling of the majority class to trim the number of examples.
Nine scenarios for two sampling methods are investigated for the classical machine learning approach, without sampling and oversampling using SMOTE. Three preprocessing techniques are applied in the sampling methods. In the first technique, features without text preprocessing are extracted. In the other two scenarios, text stemming and lemmatisation are performed. For each preprocessing design, three N-gram methods are used for feature extraction (uni-gram, bi-gram, and char-gram).
For the deep learning techniques, the output of these models is fed into an LSTM model to perform the final classification. A fivefold cross-validation split for the dataset, ending with 17,654 training samples and 4414 testing samples, was applied to validate the different scenarios. Three performance metrics (Precision, Recall, and F1-score) are calculated to validate the accuracy of the models applied. Then, the best model's performance is represented. A detailed description of this research methodology's steps is shown. In addition, the settings parameters that are used in the experiments for all algorithms used are also described.
3.1 Data collection
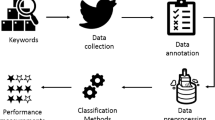
The data are collected from Twitter using Twitter API between January 27, 2021, and March 10, 2021. A Twitter developer's account is needed to access the data using credentials: consumer key, consumer secret, OAuth access token, and OAuth access token secret. Using these keys in the python program allows us to collect user data by querying Twitter using search terms and extracting the tweets. Afterwards, tweets are preprocessed to remove unwanted characters/words/data. Figure 1 shows the flowchart with the sequential steps of the data collection and preprocessing process followed in this work.

Data collection and preprocessing stages
The download tweet information is Tweet ID, Date-Time, URL, Tweet Text, User Name, Location, Replied Tweet ID, Replied Tweet User ID, Replied Tweet User name, Retweet Count, Favorite Count, and Favorited.
Our methodology to construct the dataset to collect the data from both ham and spam Twitter accounts in the Arabic language is as follows:
-
1.
Ham Tweets Collection: In this phase, Twitter is queried using famous verified accounts (e.g., Arabiya, emaratalyoum, and skynewsarabia). The timeline tweets of these accounts were obtained. After removing the duplicates, 11,299 Unique Raw Ham tweets are collected. Since the selected accounts are trusted and verified, the assumption was set that there are no spam tweets in these accounts as they are monitored by the company owning them. Thus, all tweets collected from these accounts were considered ham.
-
2.
Spam Tweets Collection: The strategy to collect spam tweets is as follows:
-
•
Querying Twitter and extracting the tweets using specific Arabic spam keywords as Search Terms. These keywords have been selected from [10]. They listed spam topics, their percentages, and examples. Afterwards, find the top ten spam Twitter accounts to collect tweets from their timelines.
-
•
Removing duplicated tweets
-
•
Inspecting tweets to remove non-spam tweets manually
-
•
Merging all spam tweets files in one file (Unique Raw Spam Tweets – 1030 tweets)
3.2 Preprocessing stage
Cleaning up the collected textual data is essential for any natural language processing. Many preprocessing steps have been applied in the data cleaning phase to remove all unwanted characters or words listed below:
-
Characters (@ $ ?: !. etc.).
-
Retweets.
-
URLs.
-
Media (images, videos, and others).
-
Links, hash-tags, numbers, English letters.
-
Punctuation marks, diacritical marks.
-
Line tap from the tweet text and spaces.
-
All tweets that contain characters other than the Arabic language characters.
-
Remove all stop words collected from many sources, then remove the duplicated ones.
-
The missing stop words are added to the final list manually.
Emojis were also cleaned from the text. Emojis can be very helpful in problems such as sentiment analysis or hate speech classification. However, few emojis can be meaningful in spam content. Usually, spammers may use emojis to attract the reader without having meaningful emojis. So, in this research, the focus was on textual data.
There is always a possibility to have spam tweets not being detected by this data collection method. Some spam tweets may have spam context written using non-spam words. For example, the approach above may not detect a tweet with a sense of urgency. However, such tweets can be easily detected in the English language. However, for the Arabic language, there is still a lack of resources that can assist in collecting such paragraphs from their context in this accurate way.
3.3 Classical machine learning approach
Data in this approach pass through various stages: data sampling, data preprocessing, feature extraction, and model implementation. These stages are explained as follows:
-
Data Sampling. The dataset in this research is unbalanced (add a percentage of imbalance). Therefore, the minor class (spam tweets) was duplicated in the training dataset to achieve a balanced dataset. Synthetic Minority Oversampling Technique (SMOTE) was used for data balancing, a data growth technique to generate more data samples. After SMOTE, we had a dataset of 11,034 samples for each of the two classes. We experimented with two scenarios: with and without SMOTE.
-
Data Preprocessing. Two Arabic text preprocessing techniques (stemming and lemmatisation) are used. For text stemming, the UTF8—Python ISRIStemmer from the Python Natural Language Toolkit NLTK package for Arabic text removes some characters from the Arabic word. The word الحل, which means "solution" in English, is حل after stemming. On the other hand, lemmatisation converts the word into its base format. For example, the word تعاني, which means "suffering" in the English language, is transformed into أعان after lemmatisation. The qalsadi lemmatiser from the qalsadi tool for text lemmatisation is used in this work. The experiments with stemming, lemmatisation, and text in its original format (no preprocessing) are conducted.
-
Feature Extraction. After the text is cleaned and preprocessed, the features for model training are extracted, noting that different text feature extraction methods exist
-
Model Implementation. This work tests the performance of four main classifiers, NB, SVM, NN, and LR, for spam detection. The experiment was conducted with different parameter combinations considering the dataset's high dimensionality to determine the optimal set of parameters that effectively detect spam tweets. Therefore, the selected parameters are the most optimal for our dataset. A multinomial NB classifier was used in the experiment by setting the alpha to 1.0 and fit before valid.
Meanwhile, the SVM parameters were set as follows: kernel is set to rbf, C to 1, and gamma to scale. The kernel was selected as rbf because it more efficiently captures nonlinear relationships between features and labels for high-dimensional datasets. The performance of the SVM model was evaluated with a linear kernel but achieved lower accuracy. On the other hand, the NN model had three hidden layers with eight neurons in each; Adam optimiser is used as a solver; relu is the activation function, and the model had a constant learning rate equal to 0.001. Finally, the LR model was implemented with l2 penalty and lbfgs solver, and Tolerance for stopping criteria equals 0.0001. Table 1 summarises the chosen values and references from the literature supporting the choices.
3.4 Deep learning approach
In this approach, we tested the performance of GloVe and fastText for feature extraction and fed the output of each of the two models into an LSTM model to perform the final classification. This section describes the implementation of deep learning models. Table 2 displays the optimal values from the literature that match this research's choices.
-
Feature Extraction. To convert the text into numeric values that the model can understand, we experimented with GloVe and fastText. GloVe is one of the most popular word vector models, and the Multilingual GloVe that supports the Arabic language is used in this work. Similarly, fastText is implemented for 157 languages, including Arabic fastText.
-
Model Implementation. The output vector of the word vector models is fed into an LSTM model. A deeper LSTM model with more neurons in each layer is more effective for learning relationships between the features and labels for a high-dimensional space. Therefore, the number of layers was carefully fine-tuned to achieve acceptable accuracy while mitigating model complexity and overfitting. After multiple experiments, the best results were obtained with a model having five bidirectional LSTM layers (Bi-LSTM) followed by a dense layer that outputs the probability that an input belongs to one of the two classes. The first 4 LSTM layers consist of 64 neurons, and the last layer consists of 32 neurons.
Figure 2 summarises this research's steps in classifying the Arabic tweets from Twitter API using classical machine learning and deep learning techniques after cleaning data and extracting the features.

The flowchart showing the classification steps for the Arabic tweets from Twitter API
4 Results and discussion
This section covers the performance of the proposed system in various experiments conducted on the datasets. This research used sampling and pre-trained word representation models with deep learning. The performance of classical machine learning models to detect spam Arabic tweets from non-spam Arabic tweets with SMOTE is discussed. Moreover, the performance of classical machine learning models on spam tweet classification with SMOTE and preprocessing methods is offered. Later, the SMOTE-based deep learning model for Arabic tweet classification is explained.
The performance metrics precision, recall, and F1-score are determined for imbalanced tweet classification. F1-score measures the machine learning model's performance. It combines the precision and recall scores of the model. The accuracy metric computes how often a model made a correct prediction across the entire dataset. F1 score is usually more helpful than accuracy when the dataset has uneven class distribution. Accuracy works best if false positives and false negatives have similar costs. If the cost of false positives and false negatives differ, it is better to look at precision and recall and get an F1-score measure. In the first experiment, for instance, the results in Table 4 show the performance of the models before applying SMOTE, which means that the dataset is unbalanced. In order to be able to compare the results in Table 4 with other results after applying SMOTE, F1-score was chosen as a performance metric across the paper.
4.1 SMOTE-level models performance
This section addresses a sampling method for handling imbalanced Arabic tweets classification by evaluating classical machine learning and deep learning models on the RawHamTweets dataset and online datasets. It also discusses the SMOTE-level model's accuracy and execution time for Arabic tweet classification.
Baseline classical machine learning models such as Naïve Bayes, Support Vector Machine, Neural Network, and Logistic Regression are chosen along with SMOTE for imbalanced tweets classification. SMOTE was implemented using the library imbalanced-learn in Python.
As shown in Table 3, the initial RawHamTweets dataset consists of 1817 spam tweets and 11,299 non-spam tweets. The number of samples in both datasets is balanced by the synthetic tweet samples generated by SMOTE. Hence, labels "spam tweet" and "non-spam tweet" were equalised to 11299 samples. The balanced dataset is divided into training and testing datasets based on fivefold cross-validation.
The Naïve Bayes model is chosen because of its simplicity. The model is built from the training dataset by finding the probability of spam and non-spam tweets over other samples. The precision, recall, and F1-score for the test samples were 98.38%, 99.44%, and 98.91%, respectively. Since Support Vector Machine is suitable for binary classification on high dimensional input, the model was built from a balanced training dataset. During testing, the precision, recall, and F1-score were 99.87%, 99.12%, and 99.49%, respectively. The results show that SMOTE-based SVM is better than SMOTE-based Naïve Bayes classifier.
Logistic regression is chosen next for comparison when the input is a large dataset and the output is binary (either 0 or 1). The logistic regression model results for precision, recall, and F1-score were 99.43%, 99.43%, and 99.43%. Another classification method is Neural Network which is a complex model to learn nonlinearity in the data, which was also used. After oversampling, a single hidden layer Multilayer Perceptron was built on training data and tested with their test data. The precision, recall, and F1-score results were 99.96%, 99.49%, and 99.73%, respectively. The neural network achieved better results than the remaining models for the Arabic tweets classification. The corresponding results are shown in Table 4.
4.2 Combination of SMOTE and pre-processing-level classification performance
This section focuses on combining Up-sampling and preprocessing concepts that better imbalanced Arabic tweet classification without biased classification results. Stemming is the first preprocessing approach to be performed after SMOTE, in which stemmers produce the word's stem. The word's stem signifies the semantics of the word as per Arabic sound structure. N-gram-based stemmer is used in this work. After oversampling, the training dataset is preprocessed by stemming. The Arabic stemming is implemented in Python using nltk.stem.isri library. It removes morphological affixes from words and returns the word stem. The classical machine learning models are trained with these balanced and preprocessed training data. The precision, recall, and F1-score for the Naïve Bayes, Support Vector Machine, Logistic Regression, and Neural Network models are shown in Table 5, indicating that the Neural Network achieves better results than the other classical machine learning models of nonlinear activation functions.
Another approach to preprocess the words in a tweet was lemmatisation. It converts the word to a lemma and is performed after SMOTE. The lemmatisation is implemented in Python using an Arabic morphological analyser Library called qalsadi lemmatiser. Afterwards, the classification quality of various machine learning models is analysed. The precision, recall, and F1-score for the different ML models are shown in Table 6. The results in Tables 3 and 4 are the same. This means that both stemming and lemmatisation performed the same on the dataset. Lemmatisation is more accurate than stemming because it performs word analysis based on the word's part-of-speech, which considers the context while producing the lemma, so it does not cut words off. However, lemmatisation is considered more time-consuming. During lemmatisation, the morphological analysis will be performed to derive the meaning of words from the dictionary. Thus, the process consumes time. Usually, the results of stemming and lemmatisation are not the same, especially in the English language. It is always preferred to use lemmatisation over stemming. Nevertheless, the Arabic language is considered a low-resource language that still needs a lot of research to reach the computer processing efficiency of the English language.
4.3 SMOTE-based deep learning-level classification performance
The deep learning model is used in this work to improve the performance of Arabic tweet classification. This research selected pre-trained models such as fastText and GloVe for word representation because they are better than Word2Vec. FastText and GloVe could handle rare words; FastText adopts a term formed by n-grams of character, and n could range from 1 to the length of the word. In this work, the SMOTE has been applied first on the RawHamTweets and Online datasets for oversampling the minority samples. After balancing minority to majority samples, a combination of LSTM and neural network embedding models such as fastText and GloVe is implemented. The fastText model is incorporated inside an LSTM Keras network.
Among deep learning models, LSTM is popular in Natural Language Processing applications. In addition, it is fast and learns spatial and temporal features from the input data. In the first case, after SMOTE, the Long Short-Term Memory (LSTM) deep learning model with the fastText model learns features and remembers the previous vectors; the F1-score of fastText was 95.1%. As for LSTM with GloVe, the F1-score was 97%. The sampling and word embedding pre-trained models perform well in the Arabic tweet classification (see Table 7).
4.4 Discussion
Table 8 displays the F1-score of the different models applied in this paper. Almost all algorithms performed well on this dataset. Neural network shows high performance with and without SMOTE. The highest performance was for the neural network model. Deep learning usually performs better in other languages, but the reason that it did not reach the same performance as classical machine learning models is referred to as the Arabic language. The language still needs much research from the natural language processing perspective. This limitation will always affect all application-based research for the Arabic language.
Table 9 presents various works from the literature that apply machine learning to Twitter spam tweet classification. The selected papers are the ones that mention their detailed work and use F1-score as a performance measure so that their work can be fairly compared to this work. Some of the selected works are in English, and others are in Arabic. In future work, the language specifications will be taken into consideration. For this work, the comparison is based on the results. The best performance in this work was for the neural network model. This research performs better than [34], which also used NN. In addition, this research's deep learning models performed better than [57], where they used a deep learning approach to reach a best F1-score of 93%, whereas this work could reach 97% with GloVe. Compared to [51], where the dataset language was Arabic, all the results of this research outperformed their work. The reason may be referred to the process of collecting data in addition to the feature extraction method. They used TF-IDF as an extraction method for their data. In comparison to [52], this work also outperformed their algorithm. The dataset was collected online from several websites of the world wide web (WWW) in Arabic. Their work achieved a best F1-score of 87.33% on SVM algorithm. They applied word embeddings to extract the features from the text.
5 Conclusions and future work
Cyber-attacks have increased due to the enormous increase in social network activities, including the Twitter platform. Attackers manipulate these platforms to spread fake content, including phoney advertisements or illicit content. The Arabic language is challenging for many researchers who aim to detect and deny harmful content on social media platforms. Content classification as benign or malicious is complicated in Arabic due to its complex structure. This paper presented a model to classify Arabic tweets using two artificial intelligent techniques: classical machine learning and deep learning. Tweets were collected into a dataset using Twitter API and labelled manually. Feature extraction is applied to the dataset. Then, using N-gram models, two learning techniques are used for each feature extraction technique on the created dataset. Precision, Recall, and F1-score are the suggested performance measures calculated in this paper for classical machine learning and deep learning techniques. Afterwards, the dataset is increased using the SMOTE class for a balanced dataset. After applying the classical machine learning models, the experimental results show that the neural network algorithm outperforms the other algorithms with an F1-score of 99.73% for classification without SMOTE, with SMOTE + stemming. Lemmatisation did not perform better than stemming. The reason behind this is referred to in language specifications. Moreover, GloVe outperforms fastText for the deep learning approach with a difference of 0.5%.
This approach will be compared to other languages in future work, especially for preprocessing. For this work, both stemming and lemmatisation were applied. However, lemmatisation was tested, but it had no big impact on the results compared to stemming. This can be addressed in future work. The space and time complexity of stemming and lemmatisation can be measured to save computer resources, given that the results are the same.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Alharbi AR, Aljaedi A (2019) Predicting rogue content and arabic spammers on twitter. Future Internet 11(11):229
Benevenuto F, Magno G, Rodrigues T and Almeida V (2010) Detecting spammers on twitter. In: Collaboration, electronic messaging, anti-abuse and spam conference (CEAS) (Vol. 6, No. 2010, p. 12)
Wang AH (2010) Don't follow me: Spam detection in twitter. In: 2010 international conference on security and cryptography (SECRYPT), pp 1–10. IEEE
Wu T, Wen S, Xiang Y, Zhou W (2018) Twitter spam detection: survey of new approaches and comparative study. Comput Secur 76:265–284
Kaddoura S, Chandrasekaran G, Elena Popescu D, Duraisamy JH (2022) A systematic literature review on spam content detection and classification. PeerJ Comput Sci 8:830. https://doi.org/10.7717/peerj-cs.830
Kaddoura S, Alfandi O and Dahmani N (2020) A spam email detection mechanism for english language text emails using deep learning approach. In: 2020 IEEE 29th international conference on enabling technologies: infrastructure for collaborative enterprises (WETICE). IEEE, pp 193–198. https://doi.org/10.1109/WETICE49692.2020.00045
Kaddoura S (2021) Classification of malicious and benign websites by network features using supervised machine learning algorithms. In: 2021 5th Cyber security in networking conference (CSNet). IEEE, pp 36–40. https://doi.org/10.1109/CSNet52717.2021.9614273
Kaddoura S, Arid AE and Moukhtar M (2021) Evaluation of supervised machine learning algorithms for multi-class intrusion detection systems. In: Proceedings of the future technologies conference. Springer, Cham, pp 1–16. https://doi.org/10.1007/978-3-030-89912-7_1
Ahmed I, Aljahdali S, Khan MS, Kaddoura S (2022) Classification of parkinson disease based on patient’s voice signal using machine learning. Intell Autom Soft Comput 32(2):705–722. https://doi.org/10.32604/iasc.2022.022037
Mubarak, H., Abdelali, A., Hassan, S. and Darwish, K., 2020, October. Spam detection on arabic twitter. In International Conference on Social Informatics (pp. 237–251). Springer, Cham.
Saeed RM, Rady S, Gharib TF (2022) An ensemble approach for spam detection in Arabic opinion texts. J King Saud University-Comput Inf Sci 34(1):1407–1416
Kaddoura S, Itani M, Roast C (2021) Analyzing the effect of negation in sentiment polarity of facebook dialectal arabic text. Appl Sci 11(11):4768. https://doi.org/10.3390/app11114768
Kaddoura S, Ahmed DR (2022) A comprehensive review on Arabic word sense disambiguation for natural language processing applications. Wiley Interdisciplinary Rev Data Mining Knowl Discov 12:e1447. https://doi.org/10.1002/widm.1447
Ekmekcioglu FC, Lynch MF, Willett P (1996) Stemming and n-gram matching for term conflation in Turkish texts. Inf Res 2(2):2–2
Daneshvar S and Inkpen D (2018) Gender identification in twitter using n-grams and lsa. In: Proceedings of the Ninth international conference of the CLEF association (CLEF 2018).
Pennington J, Socher R, Manning CD (2014) Glove: global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp 1532–1543
Bojanowski P, Grave E, Joulin A, Mikolov T (2017) Enriching word vectors with subword information. Trans Assoc Comput Linguist 5:135–146
Ma Y, He H (Eds.). (2013) Imbalanced learning: foundations, algorithms, and applications
Markines B, Cattuto C, Menczer F (2009) Social spam detection. In: Proceedings of the 5th international workshop on adversarial information retrieval on the web, pp 41–48)
Wang AH (2010) Machine learning for the detection of spam in twitter networks. In: International conference on e-business and telecommunications, pp 319–333. Springer, Berlin, Heidelberg
Wang AH (2010) Don't follow me: Spam detection in twitter. In: 2010 international conference on security and cryptography (SECRYPT), pp 1–10. IEEE
Mccord M, Chuah M (2011) Spam detection on twitter using traditional classifiers. In: international conference on Autonomic and trusted computing, pp 175–186. Springer, Berlin, Heidelberg
Shirani-Mehr H (2013) SMS spam detection using machine learning approach. unpublished) http://cs229stanford.edu/proj2013/ShiraniMehr-SMSSpamDetectionUsingMachineLearningApproach.pdf
Meda C, Bisio F, Gastaldo P, Zunino R (2014) A machine learning approach for Twitter spammers detection. In: 2014 international carnahan conference on security technology (iccst), pp 1–6. IEEE
Chen C, Zhang J, Xie Y, Xiang Y, Zhou W, Hassan MM, Alrubaian M (2015) A performance evaluation of machine learning-based streaming spam tweets detection. IEEE Trans Comput Soc Syst 2(3):65–76
Chen C, Zhang J, Chen X, Xiang Y, Zhou W (2015) 6 million spam tweets: a large ground truth for timely Twitter spam detection. In: 2015 IEEE international conference on communications (ICC), pp 7065–7070. IEEE
Trivedi SK (2016) A study of machine learning classifiers for spam detection. In: 2016 4th international symposium on computational and business Intelligence (ISCBI), pp 176–180. IEEE
Chen C, Wang Y, Zhang J, Xiang Y, Zhou W, Min G (2016) Statistical features-based real-time detection of drifted twitter spam. IEEE Trans Inf Forens Secur 12(4):914–925
Wu T, Liu S, Zhang J, Xiang Y (2017) Twitter spam detection based on deep learning. In: Proceedings of the australasian computer science week multiconference, pp 1–8
Mateen M, Iqbal MA, Aleem M, Islam MA (2017) A hybrid approach for spam detection for Twitter. In: 2017 14th international bhurban conference on applied sciences and technology (IBCAST), pp 466–471. IEEE
Liu S, Wang Y, Zhang J, Chen C, Xiang Y (2017) Addressing the class imbalance problem in twitter spam detection using ensemble learning. Comput Secur 69:35–49
Li C, Liu S (2018) A comparative study of the class imbalance problem in Twitter spam detection. Concurr Comput Pract Exp 30(5):e4281
Gupta H, Jamal MS, Madisetty S, Desarkar MS (2018) A framework for real-time spam detection in Twitter. In: 2018 10th international conference on communication systems & networks (COMSNETS), pp 380–383. IEEE
Madisetty S, Desarkar MS (2018) A neural network-based ensemble approach for spam detection in Twitter. IEEE Trans Comput Soc Syst 5(4):973–984
Itani M (2018) Sentiment analysis and resources for informal Arabic text on social media, Doctoral dissertation, Sheffield Hallam University.
Falak A, Ghous H, Malik M (2021) Twitter spam detection using machine learning. Int J Sci Eng Res, 12(2)
Ding Z, Xia R, Yu J, Li X, Yang J (2018) Densely connected bidirectional lstm with applications to sentence classification. In: Natural language processing and chinese computing: 7th CCF international conference, NLPCC 2018, Hohhot, China, August 26–30, 2018, Proceedings, Part II 7, pp 278–287. Springer International Publishing.
Rojas RF, Romero J, Lopez-Aparicio J, Ou KL (2021) Pain assessment based on fnirs using bi-lstm rnns. In: 2021 10th international IEEE/EMBS conference on neural engineering (NER, pp 399–402). IEEE
Jaihuni M, Basak JK, Khan F, Okyere FG, Sihalath T, Bhujel A, Kim HT (2022) A novel recurrent neural network approach in forecasting short term solar irradiance. ISA transactions 121:63–74
Sunny MAI, Maswood MMS, Alharbi AG (2020) Deep learning-based stock price prediction using LSTM and bi-directional LSTM model. In: 2020 2nd novel intelligent and leading emerging sciences conference (NILES), pp 87–92. IEEE
Hegde A, Coelho S, Shashirekha H (2022) MUCS@ DravidianLangTech@ ACL2022: ensemble of logistic regression penalties to identify Emotions in Tamil Text. In: Proceedings of the second workshop on speech and language technologies for Dravidian languages, (pp 145–150
Liu J, Rong Y, Takáč M, Huang J (2019) Accelerating distributed stochastic L-BFGS by sampled 2nd Order Information. Beyond first order methods in ML@ NeurIPS.
Koh K, Kim SJ, Boyd S (2007) A Method for large-scale l~ 1-regularized logistic regression. In: AAAI, pp 565–571
Zhang P, Shen C (2019) Choice of the number of hidden layers for back propagation neural network driven by stock price data and application to price prediction. In: Journal of physics: conference series (Vol. 1302, No. 2, p. 022017). IOP Publishing
Zhang C, Woodland PC (2015) Parameterised sigmoid and ReLU hidden activation functions for DNN acoustic modelling. In: Sixteenth annual conference of the international speech communication association
Huda NS, Mubarok MS (2019) A multi-label classification on topics of quranic verses (english translation) using backpropagation neural network with stochastic gradient descent and adam optimiser. In: 2019 7th International conference on information and communication technology (ICoICT), pp 1–5. IEEE
Goel A, and Srivastava SK (2016) Role of kernel parameters in performance evaluation of SVM. In: 2016 Second international conference on computational Intelligence & communication technology (CICT), pp 166–169. IEEE
Xu PF, Cheng C, Cheng HX, Shen YL, Ding YX (2020) Identification-based 3 DOF model of unmanned surface vehicle using support vector machines enhanced by cuckoo search algorithm. Ocean Eng 197:106898
Wang H, and Hu D (2005) Comparison of SVM and LS-SVM for regression. In: 2005 International conference on neural networks and brain (Vol. 1, pp. 279–283). IEEE
Vergara D, Hernández S, Jorquera F (2016) Multinomial Naive Bayes for real-time gender recognition. In: 2016 XXI Symposium on signal processing, images and artificial vision (STSIVA), pp 1–6. IEEE
Alkadri AM, Elkorany A, Ahmed C (2022) Enhancing detection of arabic social spam using data augmentation and machine learning. Appl Sci 12(22):11388
Al-Azani S, El-Alfy ESM (2018) Detection of arabic spam tweets using word embedding and machine learning. In: 2018 international conference on innovation and intelligence for informatics, computing, and technologies (3ICT), pp 1–5. IEEE
Kardaş Berk et al. (2021) Detecting spam tweets using machine learning and effective preprocessing. In: Proceedings of the 2021 IEEE/ACM international conference on advances in social networks analysis and mining
Alom Z, Carminati B, Ferrari E (2018) Detecting spam accounts on Twitter. In: 2018 IEEE/ACM international conference on advances in social networks analysis and mining (ASONAM), pp 1191–1198. IEEE
Mostafa M, Abdelwahab A, Sayed HM (2020) Detecting spam campaign in twitter with semantic similarity. In: Journal of physics: conference series (Vol. 1447, No. 1, p. 012044). IOP Publishing
Ahmad SBS, Rafie M, Ghorabie SM (2021) Spam detection on Twitter using a support vector machine and users’ features by identifying their interactions. Multimed Tools Appl 80(8):11583–11605
Ban X, Chen C, Liu S, Wang Y, Zhang J (2018) Deep-learnt features for Twitter spam detection. In: 2018 International symposium on security and privacy in social networks and big data (SocialSec), pp 208–212. IEEE.
Funding
This work was funded by Zayed University—Start-up research grant [Grant Number R20081].
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kaddoura, S., Alex, S.A., Itani, M. et al. Arabic spam tweets classification using deep learning. Neural Comput & Applic 35, 17233–17246 (2023). https://doi.org/10.1007/s00521-023-08614-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08614-w