
Abstract
The present study evaluates the performance of hybrid machine learning models to predict flood peak due to land cover changes. Performance of feed forward neural network (FNN) and adaptive neuro-fuzzy inference system (ANFIS) was compared and analyzed to select the best model in which different conventional training algorithms and evolutionary algorithms were applied in the training process. The inputs consist of stream flow in previous time step, rainfall and area of each land use class, and output of the model is stream flow in the current time step. The models were trained and tested based on the available data in a river basin located in the Australian tropical region. Based on the results in the case study, invasive weed optimization is the best method to train the machine learning system for simulating flood peak. In contrast, some optimization algorithms such as harmony search algorithm are very weak to train the machine learning model. Furthermore, results corroborated that the performance of FNN and NFIS is the same in terms of generality. The FNN model is more reliable to predict the flood peak in the case study. Moreover, ANFIS-based model is more complex than FNN. However, ANFIS is advantageous in terms of interpretability. The main weakness of ANFIS-based model is underestimation of flood peak in the major and minor floods. Two scenarios of changing land cover were tested which demonstrated reducing natural cover might increase the flood peak more than twice.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Flood damage is serious hazard for the communities. Hence, flood assessment and simulation have been highlighted in the literature (e.g., [31]). Predicting or simulating flood peak or flood hydrograph is one of the critical tasks for the civil engineers who should have an accurate assessment on potential flood events. Hydrological modeling is one of the conventional options to simulate flood hydrograph or stream flow which has extensively been applied in the literature [37]. Event-based models are simple models to simulate flood hydrograph in which a rainfall event could be converted to the runoff [36]. Event-based runoff routing models are able to simulate a rainfall event. However, interactions between rainfall events to generate runoff are complex which means event-based models might not properly simulate actual runoff in the catchment scale. Hence, continuous hydrological simulation has been recommended to improve runoff routing in recent years [13]. Several packages have been developed to simulate runoff in the catchment scale continuously. For example, soil and water assessment tool (SWAT) is one of the known packages that is able to carry out continuous hydrological simulation for a long-term period [10]. Many previous studies corroborated the reliability of this model to simulate stream flow or flood in the river basins (e.g., [1, 3, 34]). However, applying continuous hydrological models such as SWAT might need extensive field data such as soil map, digital elevation model. Hence, using alternative methods has been addressed in recent decades. Artificial intelligence (AI) methods could be a robust alternative for conventional hydrological models [28].
Due to focus of this study on using AI methods, it is necessary to review the concepts and methods briefly. Powerful computers provided ample room to use advanced computational methods. These computational methods are able to generate model for predicting future events using past experiences. Hence, AI methods and machine learning models have broadly recommended for solving engineering problems in which there is a complex relationship between inputs and output(s) [16]. An artificial neural network (ANN) as a known soft computing method generally consists of three sections including input layer, hidden layers and output layer. The hidden layers connect input layer to the output layer to generate a map which is able to predict output for unseen scenarios. Feed forward neural networks are one of the common types of the neural networks which have been utilized in the engineering problems due to high efficiency and robustness [7]. More details regarding the theory and application of the neural networks have been addressed in the literature (e.g., [33]). Putting a fuzzy inference system in the structure of a neural network generates a neuro fuzzy inference system which has some advantages (more details reviewed by Salleh et al. [30]). Predicting or simulating flood peak is a critical problem in the hydrological engineering in which AI methods have been addressed as an applicable solution [27]. For instance, adaptive neuro fuzzy inference system has been applied to simulate inflow of reservoirs (e.g., [32]). Other types of machine learning models have been applied as well. However, changing land cover is not highlighted in previous data-driven models which means improving stream flow machine learning models is still a fresh research field in the hydrology.
Training methods are another challenge in developing the machine learning methods. It is needed to apply a robust and reliable method to train the neural network. Efficiency of training methods is not the same which means each method should be addressed independently in terms of computational complexities. A range of conventional methods has been addressed in the literature to train the neural networks that might have different performance in terms of the optimizing the weights and running time of the training process (a comprehensive review on implementation on ANNs by Ahmad et al. [2]). Due to needs for improving the training algorithms, new methods have been proposed in recent years. Evolutionary algorithms are other types of AI methods applied in the optimization problems. Training process of the neural networks is an optimization problem in which weights of the network for connecting layers should be optimized. Hence, evolutionary algorithms could be used in this regard (reviewed by Janga et al. [18]). Recent studies demonstrated these algorithms are efficient for training neural networks to predict the stream flow (e.g., [32]). As a classification of these algorithms, animal inspired algorithms such as particle swarm optimization (PSO) imitate the social behavior of the animals to find the best solution for the optimization problem [17]. Moreover, some algorithms apply physical laws to find the best solution. Evolutionary algorithms could be classified as the classic and new generation algorithms as well. The classic algorithms such as genetic algorithm have extensively been addressed in the problems. In contrast, new generation algorithms have been developed to improve the efficiency of the optimization process [12].
Changing land use/land cover is critically effective on flood magnitude. Continuous hydrologic models such as SWAT have highlighted land use changes. Previous studies corroborated the considerable impact of land use change on flood magnitude (e.g., [14, 22, 29]). Data acquisition is a serious challenge to assess floods in river basins which might be expensive and arduous task. Hence, an applicable machine learning model should be able to simulate the impact of land cover change on the flood considering minimum data requirement.
One of the current research gaps in the flood assessment is lack of data-driven models which are able to predict flood (especially flood peak) considering land cover changes in which minimum data are needed. Moreover, efficiency and accuracy of hybrid machine learning methods is not tested in the literature. Based on these gaps, we present a novel machine learning model with minimum data requirements in which impact of land cover is integrated in the data-driven model of flood prediction. Moreover, several hybrid machine learning methods are tested to select the best one for simulating flood peaks using data-driven models. Results of this research work are useful for decision-makers to apply machine learning models in the river basin management effectively.
2 Application and methodology
2.1 Framework and architecture of the model
Two types of neural network were considered in the present study. First, a feed forward neural network was applied to develop a model in which different training algorithms were utilized. Some initial assessments were carried out to select the optimal number of hidden layers in the model. The selected number of hidden layers was six in the present study. Figure 1 displays the general architecture of the feed forward neural network. Moreover, Table 1 displays more details regarding the developed FNN in which seven inputs were selected as the main effective inputs on the flood hydrograph at the outflow point of the simulated catchment. Expert opinions and some initial tests were applied to select the best combination of inputs. Seven inputs were considered in the machine learning model including (1) rainfall in time step t, (2) average rainfall in time step t to time step t − 5, (3) average rainfall in time step t to time step t − 3, (4) area of rural/agricultural regions, (5) area of natural areas with low-density vegetation, and (6) area of natural areas with high-density vegetation. We develop a daily model which is appropriate for accurate hydrological prediction. Moreover, high population residential regions or high-density urban areas were not available in the selected catchment. Hence, rural region or residential areas with low population were only considered in the machine learning model.

General architecture of FNNs (more details by Ding et al. [11])
Figure 2 displays the framework of the present study to simulate flood peak by the data-driven model. The architecture of the feed forward neural network was developed based on the Table 1. Then, two types of training algorithms were considered for training the machine learning model. More details regarding the training algorithms have been presented in the next section. In the next step, testing process of the ANN model was carried out to select the best training method. It is helpful to embellish this section by presenting more details on development of the FNN model. First, an optimization model was developed to select the optimal number of hidden layers in which 1 to 100 hidden layers were tested. Number of neuron in each layer was considered seven in the FNN model. A conventional training method (LM) was used in the optimization of number hidden layers. In total, 70% of data were used in the training and 30% was applied in the testing the impact of number hidden layers. Finally, root-mean-square error was utilized as an index to select the optimal number of hidden layers. In other words, the number of hidden layers with minimum RMSE was considered as the optimal number of hidden layers. In the next step, other training methods were applied for the FNN model with the optimal number of hidden layers. All the training methods were applied considering sufficient number of iterations in the training process. In other words, the number of iterations was considered as the termination criterion in the development of the hybrid machine learning models. Based on our tests, 5000 iterations were enough for converging the optimization algorithms. However, we defined 10,000 iterations as the termination criterion.

The workflow of the present study
It is also needed to present more details on the selection process of the inputs in the neural network models. Previous studies indicated that many parameters including rainfall in different time steps, available river flow, land use, slope, and other factors are effective on the flood peak. Some parameters such as land use might include many other effective factors such as area of each land use class. In the present study, 24 parameters were identified initially as the effective factors on the flood flows. However, experts who were involved in this research work selected seven parameters as the key factors displayed in Table 1. Three experts were engaged in the assessment of the inputs including a junior water resources engineer, a regional environmental manager, and supervisor of this study (a principal water resources engineer). It should be noted that technical considerations were also taken into account in the selection of the inputs. For example, no dense urban area was available in the case study. Hence, the area of urban regions was excluded in the simulations.
Then, an adaptive neuro fuzzy inference system was developed for comparing results of the ANN and ANFIS-based model to simulate the impact of land cover change on the flood peak. The inputs of the ANFIS-based model are the same with the ANN model. However, its structure is different in which a fuzzy inference system was utilized in the structure of the neural network. Figure 3 displays the simple structure of an ANFIS-based model in which two inputs could be observed. The training method of the ANFIS-based model was selected based on the result of the simulation by the FNN model. In the next step, developed ANFIS-based model was tested and finally outputs of the FNN and ANFIS-based models were compared. Two scenarios in the case study were tested to show the ability of the proposed model for simulating the impact of changing land cover on the flood peak.

A simple structure of ANFIS with two inputs [5]
Table 2 shows more details regarding the structure of the ANFIS model in which inputs are the same with the FNN model. We applied five linear membership functions (triangular function) for inputs and output. Subtractive clustering method was applied to reduce the complexities of the model including required time and memory in the training and testing processes. More details on clustering methods have been addressed in the literature [5].
2.2 Training methods
Selecting a robust training method is effective on the outputs of the machine learning model. Different methods have been proposed to train the neural networks which are not the same in terms of efficiency. Efficiency of the model was assessed considering two points (1) computational time and memory in the training process, (2) computational time and memory in the testing process. Moreover, the effectiveness of the model was checked by assessing the accuracy of the model to simulate the flood peak in the testing process. We applied two types of training algorithms including conventional methods and evolutionary methods. Four conventional methods were utilized including Levenberg–Marquardt backpropagation (LM), Bayesian regularization backpropagation (BR), scaled conjugate gradient backpropagation (SCG), BFGS quasi-Newton backpropagation (BFG). Table 3 displays more details regarding each method.
Evolutionary algorithms were applied to train the neural networks as well. We selected some algorithms with different origins. The general workflow of the evolutionary algorithms is displayed in Fig. 4. However, they apply different strategies to find the best candidates in the search space of possible solutions. Table 4 shows more details regarding the selected algorithms in the present study.

General flowchart of evolutionary algorithms [6]
2.3 Case study
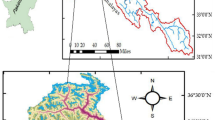
We implemented the proposed method in the Ross River in Queensland, Australia. This river is located in the tropical regions of Australia (Fig. 5). Considerable rainfall in the wet seasons might cause major and minor floods which are remarkably detrimental due to potential damages for the urban and non-urban areas. As displayed in Fig. 6, several land use classes are available in the study area. For example, Fig. 6 displays one of the generated land cover maps in the study area in which three regions are recognizable including rural/agricultural areas, low-density vegetation areas, and high-density vegetation areas. Land cover change due to increasing agricultural areas might affect the floods in the study area. Increasing flood peaks might escalate the vulnerability of the study area. Hence, it would be helpful to simulate the impact of land cover change on the flood peaks as the main motivation of the present study. We selected 10 years for developing the data-driven model. The land cover and outflow of the catchment were recorded in these years. Moreover, rainfall data were available in the daily scale. Hence, 3650 points were available to develop the data-driven model. Furthermore, 100 days in another year were selected to test the developed models. In the testing period, one major flood and one minor flood were occurred. Thus, this period is appropriate to investigate how the machine learning model is able to simulate flood peaks. Figure 7 displays the flood peaks respect to annual exceedance probability (AEP%). When the AEP is less than 20%, it is considered as the major flood. In contrast, when AEP is more than 20% the flood is a minor flood.

Location of the study area in the present study

A sample of land cover maps in the study area

Peak point of floods in different AEP%
Each data-driven model needs an index to measure the robustness of the model. In the present study, the main purpose of the data-driven model is to simulate the peak point of the floods. Hence, if difference between the peak point of the real flood and the generated flood by the model is minimized, it will be a robust model to predict impact of land use/land cover change on the flood. Thus, comparing the generated peak point by the machine learning model and real peak point was simply considered as the criterion to select the best model.
3 Results
In this section, results of developing the machine learning system are presented. In the next section, a full discussion on different aspects of the developed model will be provided. Figure 8 displays the results of testing process for the conventional training methods of the ANN model to simulate the stream flow in the testing period in which two floods have been occurred. According to the recorded data, the first flood which is a major flood could be observed at day 16. Moreover, a minor flood could be observed at day 38. Other floods are not considerable or nuisance. It matters to evaluate how the machine learning model is able to predict peak points of these two floods in the testing period.

Simulated floods by different conventional training methods of FNN
According to Fig. 8, two methods are weak to simulate stream flow in the simulated period including LM and BR methods. BR simulates the stream flow incorrectly in many time steps. Hence, BR is not an appropriate option and accountable method to develop a robust machine learning model for simulating the flood peak in future studies. In other words, it should be excluded from the list of suitable methods. Furthermore, LM is not a proper method to train the machine learning model as well. In fact, this method is unreliable to simulate peak points of the flood in the testing period. Hence, this method should be excluded as well. However, two other methods consisting of BFG and SCG are more reliable compared with other methods. Hence, it might be logical to have further investigation on these methods.
Figure 9 shows the performance of the evolutionary algorithms to train the ANN method for simulating the peak point of the floods. It sounds that some algorithms are not reliable and robust for training the developed machine learning system. For example, some algorithms such as HS and BBO are not able to simulate the changes in the stream flow in the simulated period. Thus, these algorithms should be excluded in the future studies for simulating the peak point of the floods by the proposed machine learning method. Moreover, some methods such as GA predict several incorrect flood events. In other words, GA overestimates the flood events in the simulated period. Based on our analysis, IWO is only able to predict flood events among the EA methods used in this research work. Hence, this method was selected for further assessment. One of the important results is inability of some known evolutionary algorithms such as HS or BBO for training the stream flow model. Many previous studies highlighted the applicability of these algorithms for optimization process. However, they are not able to generate the reliable results in the training of the hydrological data-driven models. In other words, these algorithms are able to simulate neither major floods nor minor floods.

Simulated floods by different evolutionary algorithms associated with FNN
As presented, the main purpose of the developed system is to simulate peak point of two floods in the simulated period including a major flood at day 16 and a minor flood at day 38. Hence, comparing the simulated flood peaks with the observed peak point could be helpful to finalize the machine learning model. Figure 10 displays the performance of three selected training method regarding the simulation of the floods. It seems that the performance of the methods is different in terms of predicting the peak point of the major flood and minor flood. It should be noted that the flood damage in the major floods is more considerable compared with minor floods. Hence, it might be logical to consider the major flood as the criterion to select the best method. According to the results, no method is accurate for simulating the flood peak. In other words, underestimation or overestimation could be seen for all the methods. In the major flood, IWO overestimates the peak point of the flood. However, two other methods including BFG and SCG underestimate the flood peak. It should be noted that underestimation of the peak point of a major flood might be hazardous for managing the possible damages by the flood. In other words, it is highly recommendable to use methods in which underestimation of flood peaks is not potential. Conversely, the result of predicting the peak point of minor flood is totally different compared with the major flood. In fact, IWO underestimates the flood peak. In contrast, two other methods including BFG and SCG overestimate the peak point of the minor flood in the simulated period. It should be noted that all the results are only valid in the case study that means machine learning models should be developed case by case and all the training methods should be applied for selecting the best model. In fact, the proposed machine learning model considers the main effective parameters to simulate the impact of land cover change on the flood peak. In other words, generating runoff in the catchment is a very complex process that means it is necessary to develop machine learning models for flood estimation case by case.

Comparing results of the simulated flood peaks and recorded flood peaks
IWO was applied to train an ANFIS-based model to investigate its robustness compared with the ANN or FNN model. Figure 11 displays three time series including observed data, simulated stream flow by IWO-ANN model, and simulated stream flow by IWO-ANFIS model. It seems that the ANFIS-based model is not adequately robust to simulate the stream flow in the testing period, because the ANFIS-based model remarkably underestimates the flood peaks for either major flood or minor flood. Hence, it is not recommendable to apply the ANFIS-based model in the case study. Some points should be noted regarding the application of ANFIS-based models. First, the output of the present study regarding the robustness of the ANFIS-based model to simulate the impact of land cover on the flood might not be reliable for all the case studies. Hence, we recommend using both ANFIS model and ANN model for developing a robust machine learning model. Furthermore, experiments demonstrated that using ANFIS-based model might need more time for training process. Thus, if the response of the ANN or FNN model is robust enough, it will not be recommendable to apply the ANFIS-based model in terms of efficiency. It should be noted that speed of training process might be highly important in the projects. In fact, it might be needed to repeat the training process for many times that means high required time for training process might increase the computational cost of the machine learning model.

Comparing results of the simulation by FNN and ANFIS-based models
In the final step, two assumed scenarios for land cover change in the study area were tested by the developed model. In other words, we tested how the developed machine learning system is able to simulate the impact of land cover change in the study area. Two scenarios including (1) increasing 30% of the rural/agricultural areas and 40% of the low-density vegetation area and (2) decreasing 30% of the rural/agricultural areas and 40% of the low-density vegetation area were considered for testing the capabilities of the model. Generally, it seems that increasing rural and agricultural lands in the study area might raise the peak point of the floods. In contrast, second scenario might reduce the peak point of the flood. However, it is complex to predict how much the peak point of flood might be increased or reduced. Hence, utilizing a robust model is essential. Figure 12 displays the performance of the developed machine learning model to simulate two selected scenarios for land cover change in the study area. As could be observed, peak point of the major flood due to using scenario 1 (i.e., reducing high-density vegetation areas) is considerably incremented. In other words, more damages might be predictable in the study area due to reducing high-density vegetation areas in the catchment. Due to accurate simulation of the peak point of the major flood by the developed model, it is possible to assess the flood damage by applying hydraulic model such as HEC-RAS. Moreover, it could be observed that reducing the high-density vegetation areas might not have considerable impact on the minor floods in the study area. In fact, the machine learning could simulate the complex relationship between land cover and peak of the floods in the study area. Furthermore, simulating the second scenario of the land cover change in the study area (i.e., increasing high-density vegetation areas in the catchment) indicated that peak point of the major flood might reduce 40% compared with the current condition. This scenario is able to reduce the peak point of the minor flood considerably. The outputs of the present study might be helpful for better management of the catchment in the study area. It sounds that a precise plan for developing the residential areas and agricultural lands is required in the catchment. The results help the engineers to plan appropriate river engineering projects for reducing the potential damages by the floods.

Results of simulating two land cover change scenarios (up: scenario 1, down: scenario 2)
4 Discussion
It is necessary to discuss on the technical and computational aspects of the developed system. In the present study, IWO as one of the known evolutionary algorithms was selected as the best method to train the FNN model to simulate the impact of land over change on the peak point of the flood. Some point should be noticed in the application of evolutionary algorithms to train the machine learning models. First, one of the main drawbacks of this algorithm is inability to guarantee the global optimization that means utilizing different evolutionary algorithms might be essential to get the best results. It is needed to apply many other available algorithms in the future studies for increasing the robustness of the model. In fact, the outputs of the present study indicated that the performance of the evolutionary algorithms might be very different in terms of optimizing the weights of the network. Hence, using other new generation algorithms might be useful to increase the robustness of the model. For example, many new algorithms have been developed in recent years that might be able to improve the model.
The computational complexities are one of the important matters to investigate the efficiency of a machine learning model. As an official definition on this term, it is defined as the given time and memory to the algorithm for finding the optimal solution. In our case, it means allocated time and memory to the model in the training process. The required memory for all models was not very different. Hence, we did not consider it in our analysis. However, the differences of computational times were remarkable. In other words, it is needed to quantify the concept of computational complexities for comparing the models. We applied computational time in minutes for both training and testing processes. Based on Table 5, LM has the lowest computational time among the conventional methods to train and test the neural network. In contrast, BR has the highest computational time. Moreover, either BFG or SCG is not as complex as the BR method. As discussed, these two methods are more reliable compared with other conventional methods to train the machine learning model for simulating the impact of land cover change on the stream flow. Computational time should be noticed regarding the evolutionary algorithms. In the present study, HS was the best algorithm in terms of computational time due to low needed time for training process. However, the results indicated that this algorithm is not a proper algorithm for training developed machine learning model. In contrast, some algorithms such as ABC or ACO need much time for the training process. However, these two algorithms were not able to train the model appropriately. The computational time for the PSO and IWO is the same and less than ABC or ACO. However, complexities of these algorithms are much higher than HS. Hence, it sounds that there is not a direct relationship between the computational time and robustness of the training method. IWO is beneficial in terms of either accuracy or computational time. Computational time for training and testing process in other evolutionary algorithms is not far from PSO which means their performance in terms of computational time is similar. Furthermore, Table 5 indicates that ANFIS-based model is more complex than FNN in terms of computational time.
Some advantages should be noted regarding the proposed method in the present study. The proposed model needs minimum data requirements that might be available easily. Rainfall data are usually recorded in the local weather stations, and it is available in online data banks. Moreover, general land use/land cover maps are generally generated by the department of environment in different years that could be used for developing the proposed machine learning model. Stream flow is recorded in the local hydrometric station that could be used as another input for developing the data-driven model. It should be noted that continuous hydrological models such as SWAT require much more data compared with the developed system that might not be available in all the cases. For example, soil map is one of the requirements for this model that is not available in many river basins in the developing countries. Moreover, this model needs digital elevation model that is another limitation. Furthermore, detailed information regarding the cultivation pattern and agriculture is needed for using continuous hydrological models such as SWAT which are able to simulate the impact of changing land use/land cover on the peak point of the floods in the catchments. Thus, the proposed model might be highly advantageous for engineers who are willing to apply the simple models for hydrological studies in the river basins.
Each model or system might have some limitations which should be discussed in the applications. The proposed method is able to assess the peak point of the floods approximately. This model is not recommendable for simulating all characteristics of the flood hydrograph in the study area. However, practical studies regarding the assessment of the floods demonstrated that the peak point of flood might be enough to have a reliable assessment on the potential damages in the study area. Moreover, the proposed system is not useable for assessing other aspects of the floods such as water pollutants. We recommend using the proposed model for a quick and approximate assessment of the impact of land use on the peak point of the floods in the future periods.
One of the important advantages of this research work is to compare the efficiency and abilities of different machine learning models to simulate the flood peak. Hence, it is needed to compare all the aspects of the developed model extensively. As shown, performance of ANFIS-based model is weaker than FNN model. It is needed how far it can be undervalued and why it underestimates the flood peak. Underestimation of ANFIS-based model is more than 75% in the major floods of the case study which might be a serious threat for modeling purposes. In other words, this significant underestimation might increase flood damages due to lack of preparedness for facing potential disastrous status. It also matters why the ANFIS-based model is not able to assess the flood peak properly. The accuracy of the ANFIS-based models is dependent on the number of fuzzy membership function. Increasing the number of fuzzy membership function improves the accuracy of the model to predict simulated outcome. However, the computational complexities will be increased as well. In other words, considerable time and memory are needed to train and finalize the model. In the present study, we applied five membership functions in the training process of the model for reducing computational complexities. However, using more membership functions might enhance the abilities of the model. We had some limited tests with more membership function which indicated using more membership function is helpful for improving the accuracy of the ANFIS-based model to predict the flood peak. Comparing ANFIS and FNN for predicting flood peak in terms of reliability, complexity and generality is helpful for the readers to select the best one in future practical studies. In terms of the generality, it is necessary to develop computational models with minimum restrictions. In other words, the developed model should not be restricted to the case studies. In the present study, the performance of both models (i.e., ANFIS and FNN) is the same in this regard because the inputs and output of the models are the same. In fact, the architecture of the model is changed which means both models could be applicable in other cases. It should be noted that we developed computational models with minimum number of inputs which is useable in many cases due to availability of needed data. The outputs demonstrated that reliability of the FNN-based models is higher than ANFIS-based models. However, the interpretability of the ANFIS-based model is better than the FNN model because using fuzzy rules provides qualitative assessment regarding impact of inputs on the output. Complexity is another important aspect in development of computational models which is highly effective on further applications. The results demonstrated that ANFIS-based model is more complex than FNN model to predict the flood peak. In other words, ANFIS needs more time and memory in the training and testing processes. However, the outputs were not satisfactory compared with the FNN model.
Selection process of inputs is a crucial step for using the proposed method in future studies. We proposed a combination of inputs which are useable in many cases. However, it might be needed to consider an independent selection process in each river basin. In this selection process, expert opinions considering regional condition could be used to select the combination of inputs. For example, unavailable land use classes should be excluded from the inputs. However, some parameters such as rainfall and stream flow are effective in all cases. Expert panel can discuss on the effect of all the available parameters. It is advantageous to reduce the number of inputs like the present study due to possible unavailability of data and minimizing efforts in data collection. Furthermore, using more inputs will increase the complexity and reduce the accuracy of the computational model.
It should be noted that other types of neural networks such as recurrent neural networks (RNN) are also useable in the simulation of the flood peak. RNNs have some advantages and disadvantages compared with the used models in the present study. Performance of RNN might be better than the FNN and ANFIS especially where different time steps are effective on the output. Hence, it is useful to test the RNN models to assess the flood peak in future studies. However, we did not use RNN in this research work due to following reasons.
-
(1)
Most previous data-driven models of runoff routing have been developed by the FNN or ANFIS methods. Hence, using these methods is helpful to compare the outputs of the present study with previous works.
-
(2)
Water resources engineers who will be the end users of the proposed model are not extensively familiar with the structure of RNN models because robustness and reliability of the FNN and ANFIS-based models have been confirmed in many previous studies. Thus, these models are currently known and popular among the water resources engineers. It should be noted that the purpose of this study was to develop a straight forward approach with minimum data requirement to simulate the flood peak. Thus, applying FNN and ANFIS methods was prioritized.
The proposed model needs to be linked with the forecasting rainfall model. Many previous studies corroborated the impact of climate change on the rainfall in the river basins. Hence, it is necessary to integrate the potential impacts of climate change in the hydrological data-driven model. Hence, it is recommendable to couple the proposed model with the climate change assessment models such as general circulation models and downscaling models to project the impact of the climate change on the rainfall. The, the outputs of the climate change assessment should be inserted as the input to the proposed system. We developed and applied the model in the daily scale. However, it could be modified for the monthly scale as well. Hence, the proposed method is flexible for further applications and required changes. Furthermore, this model could be linked with a flood damage model. For instance, 2D hydraulic models might be a good option to convert the outputs of this model to the flood damage. Many improvements might be possible for the proposed system. For example, using other AI methods such as support vector machine might be useful for increasing the robustness of the system.
5 Conclusions
The present study developed a machine learning model to simulate the impact of the land cover change on the flood peak in the catchment scale. FNN and ANFIS-based models were applied to architect the machine learning model. A wide range of training methods were applied to train the model as well. FNN and ANFIS-based models were compared in terms of generality, reliability, and complexity. Based on the results, the performance of both models is the same in terms of generality. FNN model is more reliable to predict the flood peak in the case study. Moreover, ANFIS-based model is more complex than FNN. Using ANFIS is advantageous in terms of interpretability. However, underestimation of the flood peak is a significant weakness for this type of data-driven model. In the case study, IWO was selected as the best method to train the neural network. However, its performance is not perfect to develop a robust model. Simulating two land cover change scenarios by the model demonstrated that this machine learning system is able to model potential changes of the flood peaks.
Data availability
Some or all data and materials that support the findings of this study are available from the corresponding author upon reasonable request.
References
Aadhar S, Swain S, Rath DR (2019) Application and performance assessment of SWAT hydrological model over Kharun river basin, Chhattisgarh, India. World environmental and water resources congress 2019: watershed management, irrigation and drainage, and water resources planning and management. American Society of Civil Engineers, Reston, VA, pp 272–280
Ahmad A, Ghritlahre HK, Chandrakar P (2020) Implementation of ANN technique for performance prediction of solar thermal systems: a comprehensive review. Trends Renew Energy 6(1):12–36
Almeida RA, Pereira SB, Pinto DB (2018) Calibration and validation of the SWAT hydrological model for the Mucuri river basin. Eng Agríc 38:55–63
Atashpaz-Gargari,E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. In: 2007 IEEE congress on evolutionary computation. IEEE, pp 4661–4667
Awan JA, Bae DH (2014) Improving ANFIS based model for long-term dam inflow prediction by incorporating monthly rainfall forecasts. Water Resour Manag 28(5):1185–1199
Bartz-Beielstein T, Branke J, Mehnen J, Mersmann O (2014) Evolutionary algorithms. Wiley Interdiscip Rev Data Min Knowl Discov 4(3):178–195
Cao W, Wang X, Ming Z, Gao J (2018) A review on neural networks with random weights. Neurocomputing 275:278–287
Cobb S (1982) Practical optimization, by PE Gill, W. Murray and MH Wright. Pp 402.£ 19·20. 1981. ISBN 0-12-283-950-1 (Academic Press). Math Gaz 66(437):252–253
Coello Coello CA, Becerra RL (2004) Efficient evolutionary optimization through the use of a cultural algorithm. Eng Optim 36(2):219–236
Cuceloglu G, Abbaspour KC, Ozturk I (2017) Assessing the water-resources potential of Istanbul by using a soil and water assessment tool (SWAT) hydrological model. Water 9(10):814
Ding S, Li H, Su C, Yu J, Jin F (2013) Evolutionary artificial neural networks: a review. Artif Intell Rev 39(3):251–260
Dokeroglu T, Sevinc E, Kucukyilmaz T, Cosar A (2019) A survey on new generation metaheuristic algorithms. Comput Ind Eng 137:106040
Formetta G, Prosdocimi I, Stewart E, Bell V (2018) Estimating the index flood with continuous hydrological models: an application in Great Britain. Hydrol Res 49(1):123–133
Gao Y, Chen J, Luo H, Wang H (2020) Prediction of hydrological responses to land use change. Sci Total Environ 708:134998
Geem ZW (ed) (2009) Music-inspired harmony search algorithm: theory and applications, vol 191. Springer, New York
Huang Y, Fu J (2019) Review on application of artificial intelligence in civil engineering. Comput Model Eng Sci 121(3):845–875
Jain NK, Nangia U, Jain J (2018) A review of particle swarm optimization. J Inst Eng India Ser B 99(4):407–411
JangaReddy M, NageshKumar D (2021) Evolutionary algorithms, swarm intelligence methods, and their applications in water resources engineering: a state-of-the-art review. H2Open J 3(1):135–188
Karaboga D (2005) An idea based on honey bee swarm for numerical optimization, vol 200. Technical report-tr06, Erciyes University, Engineering Faculty, Computer Engineering Department, pp 1–10
Katiyar S, Ibraheem N, Ansari AQ (2015) Ant colony optimization: a tutorial review. In: National conference on advances in power and control. pp 99–110
Kennedy J, Eberhart R (1995) Particle swarm optimization. In: Proceedings of ICNN'95-international conference on neural networks, Vol 4. IEEE, pp 1942–1948
Lee Y, Brody SD (2018) Examining the impact of land use on flood losses in Seoul, Korea. Land Use Policy 70:500–509
MacKay DJ (1992) Bayesian interpolation. Neural Comput 4(3):415–447
Mardquardt DW (1963) An algorithm for least square estimation of parameters. J Soc Ind Appl Math 11:431–441
Mehrabian AR, Lucas C (2006) A novel numerical optimization algorithm inspired from weed colonization. Eco Inform 1(4):355–366
Møller MF (1993) A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw 6(4):525–533
Mosavi A, Ozturk P, Chau KW (2018) Flood prediction using machine learning models: literature review. Water 10(11):1536
Oyebode O, Stretch D (2019) Neural network modeling of hydrological systems: A review of implementation techniques. Nat Resour Model 32(1):e12189
Rogger M, Agnoletti M, Alaoui A, Bathurst JC, Bodner G, Borga M, Chaplot V, Gallart F, Glatzel G, Hall J, Holden J (2017) Land use change impacts on floods at the catchment scale: challenges and opportunities for future research. Water Resour Res 53(7):5209–5219
Salleh MNM, Talpur N, Hussain K (2017) Adaptive neuro-fuzzy inference system: overview, strengths, limitations, and solutions. International conference on data mining and big data. Springer, Cham, pp 527–535
Salman AM, Li Y (2018) Flood risk assessment, future trend modeling, and risk communication: a review of ongoing research. Nat Hazard Rev 19(3):04018011
Sedighkia M, Datta B (2021) Utilizing evolutionary algorithms for continuous simulation of long-term reservoir inflows. In: Proceedings of the institution of civil engineers-water management. Thomas Telford Ltd, London. pp 1–35
Sharma P, Singh A (2017) Era of deep neural networks: a review. In: 2017 8th international conference on computing, communication and networking technologies (ICCCNT). IEEE, pp 1–5
Simões K, Condé RDCC, Roig HL, Cicerelli RE (2021) Application of the SWAT hydrological model in flow and solid discharge simulation as a management tool of the Indaia River Basin, Alto São Francisco, Minas Gerais. Revista Ambiente & Água, 16.
Simon D (2008) Biogeography-based optimization. IEEE Trans Evol Comput 12(6):702–713
Stephens CM, Johnson FM, Marshall LA (2018) Implications of future climate change for event-based hydrologic models. Adv Water Resour 119:95–110
Towner J, Cloke HL, Zsoter E, Flamig Z, Hoch JM, Bazo J, Coughlan de Perez E, Stephens EM (2019) Assessing the performance of global hydrological models for capturing peak river flows in the Amazon basin. Hydrol Earth Syst Sci 23(7):3057–3080
Whitley D (1994) A genetic algorithm tutorial. Stat Comput 4(2):65–85
Funding
Not applicable.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sedighkia, M., Datta, B. Predicting impact of land cover change on flood peak using hybrid machine learning models. Neural Comput & Applic 35, 6723–6736 (2023). https://doi.org/10.1007/s00521-022-08070-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-08070-y