
Abstract
In this paper, we propose a novel method for recognizing occluded offline handwritten Chinese characters based on deep convolutional generative adversarial network (DCGAN) and improved GoogLeNet. Different from previous methods, our proposed method is capable of inpainting and recognizing occluded characters without needing to know the concrete positions of corrupted regions. First, the generator and discriminator of DCGAN are combined to generate realistic Chinese characters from corrupted images, and the contextual loss and the content loss are further used to inpaint generated images. Finally, we use the improved GoogLeNet with traditional feature extraction methods to recognize the recovered handwritten Chinese characters. The proposed method is evaluated on the extended CASIA-HWDB1.1 dataset for two challenging inpainting tasks with different portions of blocks or random missing pixels. Experimental results show that our method can achieve higher repair rates and higher recognition accuracies than most of existing methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Handwritten Chinese character recognition (HCCR) has been studied for several decades. According to the type of input data, HCCR can be divided into two types: online and offline. Online HCCR involves the automatic conversion of texts as they are written on a special digitizer or personal digital assistant, and this kind of technology has been widely used for smartphones, writing boards, computer-aided education and so on. Offline HCCR involves the automatic conversion of texts in an image into letter code, and it is used for bank check reading, book and handwritten notes transcription, signature check and so on.
Offline HCCR is considered as a difficult problem owing to a large number of character categories, the variability of writing styles and the complicated structures of texts. Many meaningful theories and algorithms have been proposed for solving the problem. Existing models, such as convolutional neural network (CNN) [18], deep belief network (DBN) [12] and deep recurrent neural network (DRNN) [9], take into account essential structural features of Chinese characters, and these methods are effective when handwritten Chinese characters are uncorrupted. For corrupted characters, it is hard to obtain their structural features, which leads to the difficulty of recognition.
For realizing occluded offline HCCR, the first step is to inpaint the images of occluded handwritten Chinese characters. Many approaches of images inpainting have been proposed. Total variation approaches take into account the smoothness of natural images, which can remove small holes and spurious noises [27]. Certain subsets of images may also contain special properties, such as being planar [15] or having a low-rank structure [14]. Although they are good at seamlessly filling holes with local pixels, they are unable to predict the semantic information in missing regions, especially when the desired content is not contained in corrupted images. To predict missing pixel values, Hays and Efros proposed to cut and paste a semantically similar patch from a huge database [11]. To inpaint a scene, the images of the same scenes were retrieved from the Internet [31]. Results were obtained by registering and blending the retrieved images. Unlike the previous hand-crafted matching and editing, sparse coding was proposed to recover corrupted images from a learned dictionary [24]. Recently, inpainting via convolutional neural networks has shown promising results [25, 33].
After inpainting the images of occluded offline handwritten Chinese characters, the second step is to recognize them. Originally, researchers used the traditional framework of preprocessing, feature extracting and classification to recognize handwritten Chinese characters. The basic principle of this framework is to obtain Chinese characters using image acquisition devices, then extract distinguishing features from characters and finally analyze the features to recognize them. The recognition algorithms include rule-embedded neocognitron [35], support vector machines (SVM) [4], hidden markov model (HMM) [21], fuzzy clustering analysis [22], and so on. Nevertheless, these methods make the process of training more complicated, and traditional small sample machine learning algorithms have almost reached a bottleneck in HCCR.
With the success of deep learning and the availability of better computational hardware, the solution to offline HCCR has been changed from traditional approaches to CNNs [19]. The multi-column deep neural network (MCDNN) [2, 3] is the first reported method, and then, alternately trained relaxation convolutional neural network was proposed in [32] for offline HCCR. Although these approaches perform well, they are based on end-to-end learning, which neglects some valid domain-specific information in HCCR. Recently, traditional feature extraction methods were combined with GoogLeNet [29] to obtain high recognition accuracies in [39]. In [38], Zhang et al. obtained new higher recognition accuracies for both online and offline HCCR through integrating the traditional normalization-cooperated direction-decomposed feature map (directMap) with a deep convolutional neural network (DCNN).
Recently, Zhou et al. [40] proposed an occluded HCCR method based on deep learning. They made use of two deep recurrent neural networks (ReNet) to extract high-level abstract features in uncorrupted images and corrupted characters, respectively. Then they trained a deep belief network (DBN) to convert the corrupted characters feature space to the uncorrupted characters feature space. Finally, Deep Boltzmann Machine (DBM) was utilized to recognize characters based on reconstructed features. This method performs well on some datasets; however, it is exposed to weakness when being lack of enough training examples or facing large corrupted areas in images.
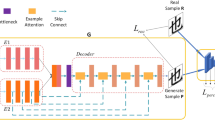
Given occluded handwritten Chinese characters with large corrupted areas, in order to achieve meaningful and visually believable results of recovering and recognizing, we propose to inpaint occluded offline handwritten Chinese characters using deep convolutional generative adversarial network (DCGAN) and then combine improved GoogLeNet with traditional feature extraction methods to recognize the recovered characters. The flowchart of the proposed method is shown in Fig. 1.

The flowchart of the proposed method
The main contributions of this paper include:
We employ two distinct ways of data augmentation. First we use rotation, Gaussian blur and elastic deformation to expand handwritten character datasets and the datasets after being expanded are considered as the ground truth. Then a series of random occlusions are used on the ground truth to obtain corrupted characters that are used as the input data of DCGAN.
We use DCGAN to generate new samples from an unknown probability distribution and then find out pixel values from the samples to inpaint corrupted characters without needing to know the concrete positions of corrupted regions. Contextual loss function and content loss function are used to improve the generative effectiveness.
We combine the improved GoogLeNet with traditional feature extraction methods to recognize the recovered handwritten Chinese characters.
We evaluated our method on expanding datasets with different portions of blocks or random missing pixels. The results demonstrate that our inpainting method can generate more realistic images and our recognition method can achieve higher accuracy than the existing methods on some challenging tasks.
The paper is organized as follows. Section 2 includes the standard GAN, DCGAN, our model structure of generating realistic characters based on DCGAN, and the details of loss functions. Section 3 introduces the architecture of recognizing recovered characters and Gabor transform. Section 4 describes several experiments to show the results of generating realistic characters and recognizing recovered characters and to verify our method to be more effective. The final section concludes this paper and points out our future work.
2 Generating realistic characters via DCGAN
2.1 Generative adversarial network (GAN) and deep convolutional GAN
GAN is a framework for training generative parametric models. It has been shown to generate high-quality natural images [7, 10, 26] and can be adopted to perform image-to-image translation task effectively [16, 37]. This framework trains two networks, including a generative model G and a discriminative model D, as shown in Fig. 2. In the phase of training, the generative model G maps a random vector z, sampled from a prior distribution \(p_z\) , to the real-world data distribution, and the discriminative model D maps an input image to a likelihood. The discriminator D aims to distinguish the real samples \(y \sim p_{\mathrm{data}}\) from the generated samples \(G(z) \sim p_g\) in the training procedure, while the generator G tries to confuse the discriminator D by generating more and more realistic samples.

The structure of GAN
The loss function of the two networks can be described as
where y is a sample from the \(P_{\mathrm{data}}\) distribution, and z is randomly generated from a prior distribution \(p_z\).
GAN provides an attractive alternative to maximum likelihood technique, and a wide variety of functions can be incorporated into the model to generate more realistic images. However, GAN has been proved to be unstable to train and the generator often produces nonsensical outputs.

The architecture of DCGAN. a Generative network, and b discriminative network
In order to solve the problems of GAN, Radford et al. [26] developed a new architecture named Deep Convolutional GAN (DCGAN). On the one hand, DCGAN adopts a series of deconvolution layers to compose the generator and adopts a series of convolution layers to compose the discriminator; on the other hand, DCGAN replaces all pooling layers with fractional-strided convolutions (generator) and strided convolutions (discriminator), and BatchNorm is applied in both generator and discriminator. ReLU activation is used in generator for all layers except for the output, which uses Tanh, LeakyReLU activation is used in discriminator for all layers, and full connected hidden layers are removed. The use of convolutional networks can effectively improve the feature learning ability of the model, and a set of constraints on the architectural topology of GAN can make the training process more stable. Besides, it allows for training deeper generative models to acquire higher resolutions. The structure of DCGAN is shown in Fig. 3.
2.2 The structure of occluded handwritten Chinese characters inpainting based on DCGAN
The basic idea of existing methods for image inpainting is first to obtain the probability density function from images, and then convert the problem of exploring missing pixels to the problem of solving the maximum of a likelihood function. Generally speaking, it is difficult to obtain the likelihood function according to image pixels, which motivated us to use DCGAN to generate new samples from an unknown probability distribution, and then find out pixel values from the samples to inpaint corrupted characters. The structure of our model is shown in Fig. 4.

The structure of inpainting handwritten Chinese characters
The generator G includes two parts. First, the input layer is an image of \(64*64*3\), followed by a series of convolutional layers where the image dimension is halved, and the number of channels is doubled from the previous layer. This part is used to extract image features automatically. Second, we use a series of deconvolutional layers to inpaint corrupted areas and generate realistic images. On the other hand, the discriminator D is designed as a traditional CNN architecture and the output layer is a two-class softmax to distinguish between real images and generated images.
Above all, the basic idea of occluded handwritten Chinese characters inpainting based on DCGAN is that the generator G generates realistic images, and the discriminator D plays an adversarial role in discriminating between the images generated from G and the images sampled from data distribution. The adversarial process is to inpaint Chinese characters iteratively until the discriminator cannot distinguish between generated images and real images. Combining generator and discriminator avoids generating nonsensical results, which neither come from the real data distribution nor come from the generated distribution, and avoids obtaining unreasonable mapping on the generated distribution.
The generative adversarial loss The contextual loss in [34] and the content loss in [20] are combined as the generative loss to inpaint the realistic characters generated by generator G, as shown in Fig. 4. The contextual loss is used to limit the deviation of uncorrupted areas between corrupted images and generated images, which is defined as
where M denotes the binary mask of uncorrupted area, which comes from training set, x is a corrupted image and \(\odot \) denotes the element-wise product operation. And the content loss is used to value the details and structure information and encourage the generator to generate more realistic images to pass the examination of the discriminator, which is defined as
where the VGG [28] is one of convolutional neural networks (CNNs), \({\mathrm{VGG}}(*)\) is the feature map of \(*\) processed by VGG network, \(\Vert *\Vert _F\) is Frobenius norm (F-norm) of matrix, and y and G(x) are ground truth and generated image, respectively.
Thus, the generative loss of inpainting handwritten Chinese characters includes two parts: the contextual loss and the content loss. The total loss is shown in Eq. (4).
The adversarial loss is leveraged to penalize the recovered images that are perceptually unrealistic, which is defined as
Above all, the final loss function can be expressed as
where \(\lambda _1\) and \(\lambda _2\) are hyper-parameters to control their balance.
3 Recognizing recovered characters via improved GoogLeNet
3.1 GoogLeNet
GoogLeNet [29] is designed with computational efficiency and practicality in mind, and the main hallmark of this architecture is the deep convolutional neural network architecture codenamed inception, as shown in Fig. 5. The structure of inception improves utilization of computing resources inside the network and keeps the computational budget unchanged when increasing the depth and width of the network. It is responsible for obtaining good performance in classification and detection.

The structure of inception
GoogLeNet (Fig. 6) includes 100 layers. Besides the inception structure, GoogLeNet uses average pooling instead of fully connected layers at the end of the network and dropout is still used after removing fully connected layers.
With the increasing of network depth, the back-propagation gradients through all layers may be lost. So auxiliary classifiers connected to the intermediate layers are added to increase the gradient signal and provide additional regularization. During training, the losses of auxiliary classifiers are added to the total loss of the network, and during inference phase, these auxiliary networks are discarded.

GoogLeNet network

The structure of the improved GoogLeNet
3.2 The structure of recovered handwritten Chinese character recognition via improved GoogLeNet
In this paper, we use the architecture of the improved GoogLeNet in [39], which uses fewer inception modules, as shown in Fig. 7. Feature extraction is an important step of traditional techniques for HCCR. Considering that CNN is an end-to-end neural network, we do not know what kinds of features the network extracts and learns, and it may neglect some valid domain-specific information. Therefore, we extract directional Gabor features as prior knowledge and add obtained feature maps into the input layer as well as original images to enhance the recognition performance of the improved GoogLeNet.
Gabor features are good candidates for recognizing handwritten Chinese characters [6, 8], and they have also been found to be less sensitive to noises, small range of translation, rotation, and scaling. Equation (7) shows the multi-directional Gabor transform:
where I(x, y) denotes an input image, and \(G(x,y;\kappa , v_k)\) denotes the Gabor filter. The equation of Gabor filter is as follows:
where \(\sigma =\pi , \kappa =\frac{2\pi }{l}\). The parameters l and \(v_k\) are the wavelength and orientation of the plane wave, respectively. M denotes the number of Gabor features we extracted from each sampling point.
In this paper, l = \(4\sqrt{2}\) and \(M=8\). The eight orientations are \(0^\circ \), \(22.5^\circ \) , \(45^\circ \) , \(67.5^\circ \) , \(90^\circ \) , \(112.5^\circ \) , \(135^\circ \) , \(157.5^\circ \), respectively. After extracting the eight directional Gabor features, we add them to the input layer and the original images to construct the input vectors of \(N*N*9\) for CNN, where \(N*N\) denotes the size of input characters. An example of the input layer of the improved GoogLeNet is shown in Fig. 8.

An example of the input layer of improved GoogLeNet
4 Experiments
4.1 Datasets
CASIA-HWDB1.1 handwritten Chinese character library is used, as shown in Fig. 9. The dataset consists of handwritten Chinese characters, containing 3755 GB2312 first-grade Chinese characters and 171 English numerals. Each character in the dataset was written by 300 writers, and each example is represented as an 8-bit grayscale image. Because of the limitation of devices, we randomly chose 60 writers for each character to compose our final dataset.

Isolated offline character samples of CASIA-HWDB1.1
Data preprocessing is as follows.
Randomly choosing 60 writers for each character to compose the initial dataset D0.
Converting the GNT file of D0 into a 64 * 64 pixels PNG file to generate the dataset D1.
Expanding the dataset D1. We chose 80% of the examples in D1 to compose the training set, and the rest to compose the testing set. The training examples in D1, which are denoted as dataset D2, were amplified using rotation, Gaussian blur and elastic deformation to reduce overfitting, as shown in Fig. 10. In this paper, the argument of Fliplr is 0. The sigma of Gaussian blur and elastic transformation are 2.00 and 0.2, respectively, and the alpha of elastic transformation is 3.0.

Different methods of amplification
A series of random occlusions were used to expand the dataset D2.
On each Chinese character image, we randomly added a rectangular block with the area of 5%, 15% and 25% of the original image, respectively. Figure 11a–d shows the examples of the original images and the images with a rectangular block with the area of 5%, 15% and 25%, respectively. The generated datasets are denoted as D3, D4 and D5, respectively.

Examples of the original images and the images with a rectangular block
On each Chinese character image, we randomly added three rectangular blocks with the area of 5%, 15% and 25% of the original image, respectively. Figure 12 shows the examples of the original images and the images with three rectangular blocks with the area of 5%, 15% and 25%, respectively. The generated datasets are denoted as D6, D7 and D8, respectively.

Examples of the original images and the images with three rectangular blocks

Examples of the original images and the images with a round block

Examples of the original images and the images with different numbers of round blocks

Examples of the original images and the images with random pixel removal
On each Chinese character image, we randomly added a round block with the area of 20%, 35% and 50% of the original image, respectively, as shown in Fig. 13. The generated datasets are denoted as D9, D10 and D11, respectively.
On each Chinese character image, we randomly added three round blocks with the area of 10% of the original image, six round blocks with the area of 10% of the original image and eight round blocks with the area of 5% of the original image, respectively, as shown in Fig. 14. The generated datasets are denoted as D12, D13 and D14, respectively.
20%, 50%, 80% pixels were removed from each Chinese character image, respectively, as shown in Fig. 15. The generated datasets are denoted as D15, D16 and D17, respectively.
D3–D17 are the training sets, and the same random occlusions were added onto the rest of D1. That means, 20% of the examples in D1 were used to obtain the final testing set via the same processing as above.
4.2 The results of inpainting via DCGAN
Parameter details Every constructed training set of D3–D17 includes \(3755*(60*0.8)*3=540{,}720\) corrupted Chinese characters, and every testing set of D3–D17 includes \(3755*(60*0.2)=45{,}060\) corrupted Chinese characters. Adam [17] is used as the optimization method. The hyper-parameters of Adam are \(\alpha =0.0004\) and \(\beta =0.9\). The hyper-parameter \(\lambda _1\) and \(\lambda _2\) in Eq. (6) are 0.001 and 0.01, respectively. The batch size is 128. And more details are shown in our code.Footnote 1 In order to evaluate different methods, Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index (SSIM) [30] are used. Compared with SSIM [30] which values the similarity of structure, PSNR takes similarity of pixel seriously. Via using PSNR and SSIM, we can evaluate the inpainting capacity of a network quantitatively.
The inpainting results based on different testing sets The testing sets of D3–D17 are used to verify the performance of our model, and the results after 60,000 iterations are shown in Figs. 16 and 17. The images in the first row are the original images, those in the 2nd, 4th and 6th are the corrupted images, and those in the 3rd, 5th and 7th are the corresponding recovered images. Figures 16 and 17 display that when there exists a small or moderate continuous occluded block, the inpainting performs well and no matter how much the pixels missing of the character, it can be inpainted effectively. Although when the corrupted regions are larger and the results are somewhat disordered, we can also recognize which characters they are visually and the essential parts can be inpainted to a certain extent.

The inpainting results on D3–D8. a The inpainting results of single rectangle occlusion on D3–D5, and b The inpainting results of three rectangles occlusions on D6–D8

The inpainting results on D9–D17. a The inpainting results of single round occlusion on D9–D11, b The inpainting results of different numbers of round occlusions on D12–D14 and c The inpainting results after removing 20%, 50%, and 80% pixels, respectively, on D15–D17
With intent to compare the inpainting results of occluding different regions of the original characters, we added a rectangular block with the area of 25%, at the top, medium and bottom onto the original image, respectively. The results are shown in Fig. 18, which demonstrates that given a fixed size of occluding block, the inpainting effects for the different occluded regions of the same character are different. Therefore, our training dataset should include occluded characters with different occluded regions and the experiments verify that our construction method of dataset is effective enough.

The inpainting results after occluding different regions of the original image
In order to evaluate our model quantitatively, we first calculated PSNR and SSIM between the original images and the corrupted images and then calculated them between the original images and the generated images. The inpainting results on D3–D17 testing sets are shown in Table 1, which demonstrates that with the increasing of the corrupted area, the values of PSNR and SSIM decrease and the way of randomly removing pixels performs better than other ways of occlusion.
The results of different methods We chose the datasets D3, D6, D9, D12 and D15 to compare different inpainting results from different methods quantitatively and qualitatively. We use the default parameters of total variation regularization [1] and nearest neighbor filling [5] to verify their performance. [14, 23] use low-rank minimization to inpaint corrupted images, and we chose the code in [23] to verify its performance. However, we found that the method in [23] is not efficient enough, that is, if we use the default parameters in the original code, it takes about 130 seconds to obtain one recovered image. Therefore, we used small iterations and small max-ranks instead of original code because of a large number of testing sets and the simplicity of Chinese characters compared to other complicated images. And owing to the large amount of training samples, we used small iterations of context encoder [25].
Table 2 displays the inpainting results of different methods quantitatively. When there exists larger corrupted area, our method is more effective than most of other methods. Compared with the recent method in [25], we obtain similar inpainting results and each has its own merits. Compared with other methods in Table 2, our proposed method shows obvious superiority. The reason why the PSNR of [23] on D15 is higher than ours is that the generator of our architecture generates all pixels from a tensor of \(4*4*512\) so that it cannot obtain the pixels of uncorrupted areas that are the same as those of original images exactly, while the proposed method of [23] just inpaints the occluded area and does not modify the pixels of uncorrupted areas. In fact, the SSIM of our method on D15 is higher than that in [23], which means that we generate more similar characters with the original characters.
Qualitatively, the occluding ways in [25] were used to generate some occluded character images and we compare different inpainting results based on those characters. We chose the methods in [5, 23, 25] to evaluate their performance. In Fig. 19, images in the first column are the occluded images and those in the last column are ground truth (GT). The results demonstrate that our proposed method is capable of achieving notable good performance by comparison. More specifically, when there exists a larger corrupted region, the methods of [23, 25] struggle to inpaint them but on some Chinese characters we cannot recognize them visually based on their inpainting results. The method in [5] is capable of inpainting the occluded regions effectively while remaining some noises. Our proposed method can both inpaint the corrupted regions and remain their semantic information.

The results on real occluded images We used some real occluded handwritten Chinese characters to evaluate the performance of the proposed method. The reason why we did not compare our method with other inpainting methods in [1, 5, 23, 25] is that most of these methods need a mask when inpainting the occluded characters, that is, they need to know the concrete locations of the corrupted regions beforehand. However, given any real occluded handwritten character, it is inadvisable to let the user tell the algorithm or network accurately where needs to inpaint. Different from those methods that depend on users’ experiences, our proposed method does not need extra information on occluded positions, and the network is capable of recognizing and inpainting the occluded area automatically.
The inpainting results on real occluded characters are shown in Fig. 20. The images in the top row are the real occluded characters and the images in the bottom row are the corresponding inpainting characters. Even though there is no the same occlusion as the training samples, our model can also inpaint them effectively.

The inpainting results on the real occluded images
4.3 The results of recognition via improved GoogLeNet
The details of training We adopted a series of measures to facilitate the training speed and prevent overfitting. Small random numbers \(0.001*N (0,1)\) were used to initialize weights, where N(0, 1) is a standard normal distribution. The size of input images is \(64*64*1\), and we used small kernel (for example, \(3*3\)), small stride (for example, 1) and padding = 0 to reduce parameters. The pooling size is \(2*2\). The initial learning rate of training is 0.1 and it is halved when the loss is stable. The activation function is ReLU and Dropout regularization [13] is used to prevent overfitting.
The results of recognition We chose the recovered images from D3, D6, D9, D12 and D15 testing sets, respectively, as the input of the recognition network. Nowadays, there are many methods to recognize handwritten Chinese characters. We used those recovered characters to verify their performance and the results are compared in Table 3, which demonstrates that our method performs better than most of other methods. In more details, our proposed method achieves the highest results on D6, D12 and D15, and obtains overwhelming superiority than that in [40]. Wu et al. [32] achieves better recognition results on D3 and D9 but they are only a little higher than ours. The experiments verify that our method is effective for all possible occluding ways mentioned above.
As known to all, the recognition methods based on deep learning need a huge number of data. In order to verify whether our dataset is sufficient or not, we chose the dataset in [32] as DB. Then we used DB, D1 and D2, respectively, to train our recognition network and used the total of the testing sets including D3, D6, D9, D12 and D15 to evaluate their performance. The results are shown in Table 4, illustrating that using the dataset DB can obtain a higher recognition rate than ours owing to their large amount of samples. However, on the other hand, too many training samples mean the sacrifice of efficiency. How to leverage more samples in an effective way to train our model is also a question worthy of consideration.
5 Conclusion
This paper first proposes an architecture based on DCGAN to inpaint occluded offline handwritten Chinese characters. The core of the inpainting method contains two points: traditional convolutional networks are used to extract character features and deconvolutional networks are used to inpaint the corrupted images and generate realistic characters; and the loss function combining the contextual loss and the content loss is designed.
Furthermore, the paper proposes to use the improved GoogLeNet to recognize the recovered characters. Gabor features and less inception modules are used, and directional features are extracted as prior knowledge and are added to input layer and original images.
Rotation, Gaussian blur and elastic deformation are used to expand the training set, which can prevent overfitting and improve robustness. The proposed method for recognizing occluded offline handwritten Chinese characters has never been seen in previous research literatures. And a series of experiments verify the effectiveness of our method.
In the future work, we need to consider the following three problems:
When the larger regions of original characters are occluded and the critical regions are corrupted, the proposed method is hard to inpaint them. And how to preserve more details of uncorrupted areas is also a problem to deal with. We will optimize the architecture and loss functions to find more effective ways to handle this knotty problem.
Owing to the limitations of devices, no more training samples are used in this paper. How to leverage more samples in an efficient way to train our model is also a question worthy of consideration.
We only considered the recognition problem on single occluded offline handwritten Chinese characters, and we will focus more on a series of offline handwritten Chinese characters recognition.
Notes
Code for our models: https://github.com/bitsongge/occluded-offline-HCCR.
References
Afonso MV, Bioucas-Dias JM, Figueiredo MA (2010) An augmented Lagrangian approach to linear inverse problems with compound regularization. In: 2010 17th IEEE international conference on image processing (ICIP), IEEE, pp 4169–4172
Cireşan D, Meier U (2015) Multi-column deep neural networks for offline handwritten Chinese character classification. In: 2015 international joint conference on neural networks (IJCNN), IEEE, pp 1–6
Cireşan D, Meier U, Schmidhuber J (2012) Multi-column deep neural networks for image classification. arXiv preprint arXiv:1202.2745
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20(3):273–297
Criminisi A, Pérez P, Toyama K (2004) Region filling and object removal by exemplar-based image inpainting. IEEE Trans Image Process 13(9):1200–1212
Daugman JG (1988) Complete discrete 2-D Gabor transforms by neural networks for image analysis and compression. IEEE Trans Acoust Speech Signal Process 36(7):1169–1179
Denton EL, Chintala S, Fergus R, et al (2015) Deep generative image models using a Laplacian pyramid of adversarial networks. In: Advances in neural information processing systems, pp 1486–1494
Ge Y, Huo Q, Feng ZD (2002) Offline recognition of handwritten Chinese characters using Gabor features, CDHMM modeling and MCE training. In: 2002 IEEE international conference on acoustics, speech, and signal processing (ICASSP), IEEE, vol 1, pp I–1053
Gers FA, Schmidhuber E (2001) LSTM recurrent networks learn simple context-free and context-sensitive languages. IEEE Trans Neural Netw 12(6):1333–1340
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Advances in neural information processing systems, pp 2672–2680
Hays J, Efros AA (2008) Scene completion using millions of photographs. Commun ACM 51(10):87–94
Hinton GE, Salakhutdinov RR (2006) Reducing the dimensionality of data with neural networks. Science 313(5786):504–507
Hinton GE, Srivastava N, Krizhevsky A, Sutskever I, Salakhutdinov RR (2012) Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580
Hu Y, Zhang D, Ye J, Li X, He X (2013) Fast and accurate matrix completion via truncated nuclear norm regularization. IEEE Trans Pattern Anal Mach Intell 35(9):2117–2130
Huang JB, Kang SB, Ahuja N, Kopf J (2014) Image completion using planar structure guidance. ACM Trans Graph (TOG) 33(4):129
Ji Y, Zhang H, Wu QJ (2018) Saliency detection via conditional adversarial image-to-image network. Neurocomputing 1:18
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980
LeCun Y, Boser BE, Denker JS, Henderson D, Howard RE, Hubbard WE, Jackel LD (1990) Handwritten digit recognition with a back-propagation network. In: Advances in neural information processing systems, pp 396–404
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, Aitken AP, Tejani A, Totz J, Wang Z, et al (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: CVPR, vol 2, p 4
Li H (2007) Offline handwritten character recognition based on multiple hidden Markov model. Ph.D. thesis, Changsha University of Science and Technology
Liu W, Jiang J (2014) A new Chinese character recognition approach based on the fuzzy clustering analysis. Neural Comput Appl 25(2):421–428
Lu C, Tang J, Yan S, Lin Z (2014) Generalized nonconvex nonsmooth low-rank minimization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4130–4137
Mairal J, Elad M, Sapiro G (2008) Sparse representation for color image restoration. IEEE Trans Image Process 17(1):53–69
Pathak D, Krahenbuhl P, Donahue J, Darrell T, Efros AA (2016) Context encoders: Feature learning by inpainting. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2536–2544
Radford A, Metz L, Chintala S (2015) Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434
Shen J, Chan TF (2002) Mathematical models for local nontexture inpaintings. SIAM J Appl Math 62(3):1019–1043
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A (2015) Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1–9
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612
Whyte O, Sivic J, Zisserman A (2009) Get out of my picture! internet-based inpainting. In: BMVC, vol 2, p 5
Wu C, Fan W, He Y, Sun J, Naoi S (2014) Handwritten character recognition by alternately trained relaxation convolutional neural network. In: 2014 14th international conference on frontiers in handwriting recognition (ICFHR), IEEE, pp 291–296
Xie J, Xu L, Chen E (2012) Image denoising and inpainting with deep neural networks. In: Advances in neural information processing systems, pp 341–349
Yeh R, Chen C, Lim TY, Hasegawa-Johnson M, Do MN (2016) Semantic image inpainting with perceptual and contextual losses, vol 2. arXiv preprint arXiv:1607.07539
Yeung DS, Fong HS (1994) Handwritten Chinese character recognition by rule-embedded neocognitron. Neural Comput Appl 2(4):216–226
Yin F, Wang QF, Zhang XY, Liu CL (2013) ICDAR 2013 Chinese handwriting recognition competition. In: 2013 12th international conference on document analysis and recognition (ICDAR), IEEE, pp 1464–1470
Zhang H, Sun Y, Liu L, Wang X, Li L, Liu W (2018) Clothingout: a category-supervised GAN model for clothing segmentation and retrieval. Neural Comput Appl 1:1–12
Zhang XY, Bengio Y, Liu CL (2017) Online and offline handwritten Chinese character recognition: a comprehensive study and new benchmark. Pattern Recogn 61:348–360
Zhong Z, Jin L, Xie Z (2015) High performance offline handwritten Chinese character recognition using GoogleNet and directional feature maps. In: 2015 13th international conference on document analysis and recognition (ICDAR), IEEE, pp 846–850
Zhou X (2016) Deep model based offline handwritten Chinese character recognition. Ph.D. thesis, Zhejiang University
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 61271374). The authors would like to thank the anonymous reviewers for their helpful suggestions which have led to great improvement on this paper, especially on the experiments.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Li, J., Song, G. & Zhang, M. Occluded offline handwritten Chinese character recognition using deep convolutional generative adversarial network and improved GoogLeNet. Neural Comput & Applic 32, 4805–4819 (2020). https://doi.org/10.1007/s00521-018-3854-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-018-3854-x