
Abstract
Quantum information science is an interdisciplinary subject spanning physics, mathematics, and computer science. It involves finding new ways to apply natural quantum-mechanical effects, particularly superposition and entanglement, to information processing in an attempt to exceed the limits of traditional computing. In addition to promoting its mathematical and physical foundations, scientists and engineers have increasingly begun studying cross-disciplinary fields in quantum information processing, such as quantum machine learning, quantum neural networks, and quantum image processing (QIMP). Herein, we present an overview of QIMP consisting of a succinct review of state-of-the-art techniques along with a critical analysis of several key issues important for advancing the field. These issues include improving current models of quantum image representations, designing quantum algorithms for solving sophisticated operations, and developing physical equipment and software architecture for capturing and manipulating quantum images. The future directions identified in this work will be of interest to researchers working toward the greater realization of QIMP-based technologies.
Similar content being viewed by others
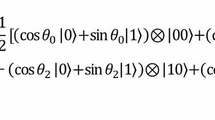
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Physics and computer science share a long history of cross-fertilization. One of the latest outcomes of this mutually beneficial relationship is quantum information science, which comprises the study of information-processing tasks that can be accomplished using quantum-mechanical systems (Nielsen and Chuang 2000). Responding to the growing need to extract information from images and video, image processing is a fundamental task in many branches of science and engineering. Owing to the restricted architecture of classical computers and the computational complexity of state-of-the-art classical algorithms in image processing and its applications, developing efficient algorithms to store and manipulate visual information has become an important and challenging research area (Yan and Venegas-Andraca 2020).
Quantum image processing (QIMP) is an emergent field of quantum information science with the primary goal of strengthening the capacity for storing, processing, and retrieving visual information from images and video, either by transitioning from digital to quantum paradigms or by complementing digital imaging with quantum techniques. The expectation is that harnessing the properties of quantum-mechanical systems in QIMP (e.g., computational parallelism) will result in the realization of advanced technologies that will outperform, enhance, or complement existing and upcoming digital technologies for image and video processing tasks. Specifically, QIMP technologies are anticipated to offer unrivaled capabilities and performance in areas such as computing speed, tamper-proof security, and minimizing storage requirements (Iliyasu 2018).
QIMP has become a popular area of quantum research due to the ubiquity and primacy of digital image and video processing in modern life (Yan and Venegas-Andraca 2020). Digital image processing is a key component of several branches of applied computer science and engineering, including computer vision and pattern recognition. These disciplines have had tremendous scientific, technological, and commercial success due to their widespread applications in many fields, including medicine, military technology, and entertainment (Gonzalez and Woods 2018). The technological and commercial success of digital image processing in contemporary (both civil and military) life is a powerful incentive for research on the development of QIMP.
A key feature of QIMP that is crucial to understanding its current development and challenges, as well as to designing corresponding science and technology roadmaps, is that QIMP is both a scientific discipline and a field of engineering with potential commercial applications. Potential applications of QIMP can be found not only in the development of quantum algorithms for general-purpose quantum computers, but also in specific-purpose technologies, such as quantum radar (Lanzagorta 2011) and smart cameras.
Hence, there are many good reasons to work in QIMP: some are scientific or theoretical in nature, while other reasons involve the commercial benefits of integrating classical and quantum technologies aimed at developing products and services for high-tech markets. Thus, research interests in QIMP are diverse, and some will fall within the traditional scope of quantum-computing scientific research (such as using quantum entanglement for information processing (Venegas-Andraca and Ball 2010), quantum mathematical morphology (Yuan et al. 2015), image segmentation (Caraiman and Manta 2015b), or designing quantum algorithms with provable computational speed-up, this last topic being an important ongoing task in the QIMP community), while other approaches will be oriented toward engineering applications (e.g., El-Latif et al. 2018; Yan et al. 2018b).
Two research contributions in the field of QIMP in the past two decades are noteworthy, in which two co-authors of the present paper played important roles:
(1) In 2003, Venegas-Andraca et al., at the University of Oxford, proposed the foundation of the new field of QIMP (Venegas-Andraca and Bose 2003). They posited that if we assume an apparatus that could detect electromagnetic frequencies and produce a quantum state as output, we could store color in a qubit by translating given frequencies to quantum states. In addition, by updating the indices to specify the pixels in the image, a full image could be stored in a qubit lattice. QIMP has great significance for quantum information research and saw much development at its earliest stage, while most of the subsequent literature has been limited to exploring the physical essence of quantum images.
(2) QIMP began to flourish in 2010 when Hirota et al., at the Tokyo Institute of Technology, proposed a flexible representation of a quantum image (FRQI) (Le et al. 2011a), which is a normalized state that captures the essential information (i.e., its color and position) of every point in an image. FRQI employs the concept of using an angle to communicate the color information of an image, and by using the two-dimensional position information (Y and X axes), the representation is more similar to the pixel representation for images on conventional computers. Following the robust formulation of FRQI, QIMP studies have been focused on its use, modification, extension, or applications (Venegas-Andraca 2015).

a Bar graph and corresponding table data showing number of papers published in the field of QIMP among researchers in China and other countries since 2014 and percentile change in number of papers published each year relative to previous year. b Sunburst chart providing rough summary and classification of available results in the QIMP field, which demonstrates the vigorous and wide-ranging nature of QIMP research over the past several years. It is worth noting that the statistics above considered only publications included in the Web of Science database obtained from a search based on the keywords “quantum image processing.” Moreover, studies that merely cited QIMP but did not contribute to the field were not counted
In the past decade since the initial proposal of FRQI, the volume of research focused on QIMP has steadily increased in terms of the number of papers published each year in China and other countries; its recent development is shown in Fig. 1 (QIMP is of particular interest to Chinese research groups, and hence, China has become the most important contributor to this discipline currently). Figure 1 also presents a succinct analysis of QIMP sub-topics and the corresponding percentages of published papers according to the Web of Science database. We note that the vast majority of QIMP research has been devoted to security issues (41.9%), while the least amount of work has focused on quantum image representation (8.9%). To further show the advances of QIMP in its security areas, several simulation results and formal comparison of these results are provided (in Table 1) regarding steganography and watermarking techniques. Note that the capacity and peak-signal-to-noise-ratio (PSNR) values shown in the table are used for intuitive reference rather than technical comparison. This is because some of their experimental settings are different in the cited studies. For example, regarding watermarking technique, although we consider all of the cover images in these algorithms with the “Lena” image, factors such as their image size and embedding strength are different from each other.
The above analysis of present developments in the field highlights several features and further research topics in QIMP. Several interesting reviews pre-date our effort in the present study. For example, in Yan et al. (2016a), the authors gathered the current mainstream quantum image representations and discussed the advances based on them. Then in Yan et al. (2017a), the authors focused on the progress in QIMP-based security technologies, including watermarking, encryption, and steganography. Recently, the authors of Iliyasu (2018) discussed the roadmap to talking quantum movies by inquiring about the development of quantum image and quantum audio signals. Different from all the previous works, the present paper seeks to arouse the interest of scientific and engineering communities toward the greater realization of QIMP-based technologies by identifying and discussing three primary issues using a few simulation experiments, the development of which will be most helpful for advancing the field of QIMP: improving current models of quantum-image representations, designing quantum algorithms for solving sophisticated operations, and developing physical equipment and software architectures for capturing and manipulating quantum images. Before addressing these issues, we present the following analysis.
(1) The original motivations to create QIMP as presented in Venegas-Andraca and Bose (2003), Venegas-Andraca and Bose (2003), Venegas-Andraca (2005) are similar to those that gave birth to the field of quantum walks (Venegas-Andraca 2012) in the sense that both disciplines were created as quantum counterparts of already existing mathematical and computational tools in the digital world. First steps in QIMP were focused on showing that it was indeed possible to create a set of tools in the quantum domain, somewhat equivalent to those already developed in the digital domain, that would provide basic capacities for storing, manipulating, and retrieving images stored in quantum systems. Indeed, for any classical computation there is a quantum counterpart (i.e., classical computation is a subset of quantum computation), but in order to convince scientists and engineers from fields other than quantum computing, with academic backgrounds that would not necessarily include quantum mechanics, it was compulsory to present solid evidence of the viability of QIMP, as well as evidence written and described in the language and techniques of digital image processing.
Therefore, the QIMP community worked on designing methods that would in principle allow encoding, processing, and recovering images using quantum systems, followed by algorithms that would provide key routines and capacities, e.g., arbitrary rotations, scaling, similarity evaluation, encryption, and steganography. The focus was on ensuring that algorithms were robust rather than efficient (or more efficient than their classical counterparts). A full introduction to QIMP can be found in Yan and Venegas-Andraca (2020) and concise reviews on quantum image representation models and security technologies have been published in Yan et al. (2017a), Yan et al. (2016a).
(2) The historical development of QIMP closely resembles the early evolution of digital image processing in the period 1950–1971 (Rosenfeld 1973) since, for more than two decades, researchers worked on building a theoretical corpus for the storage of and basic operations on digital images (as stated in Rosenfeld (1969), “ Over the past 15 years, much effort has been devoted to developing methods of processing pictorial information by computer.”) Moreover, note that although available computer power at that time was not enough to compute beyond some simple tasks, that did not prevent scientists from working on the algorithms that would eventually be run by the end of the century. To appreciate the advances of QIMP and rightly situate its challenges, an exercise of comparative history is both necessary and helpful (in fact, this exercise of comparative history should also be made for quantum algorithms and other branches of quantum computing).
(3) From its inception, QIMP has benefited from the talent and efforts of a research community vastly composed of computer scientists, mathematicians, and computer engineers. Now, as in all branches of quantum computing, unleashing the power of QIMP depends upon a full interdisciplinary approach in which physicists, chemists, and other professional communities also actively contribute toward solving open problems and challenges in this field (for instance, the development of novel quantum image representation models and applications). This approach is particularly important to QIMP because of the existence of quantum imaging (Lugiato et al. 2002; Shih 2007), a branch of quantum optics and quantum information focused on harnessing quantum correlations and other properties of quantum-mechanical systems in order to surmount imaging limits imposed by classical optics (see, for example, Defienne et al. 2019). Coordinating research efforts from QIMP and quantum imaging communities toward common goals would certainly boost research and investment in scientific research and innovative applications.
Based on the above analysis, we discuss the three aforementioned issues. They can be interpreted and illustrated by focusing on the storage and retrieval of images in quantum systems, algorithm development and algorithmic speed-up in QIMP, and the road ahead—a proposal of future steps for QIMP.
2 Storage and retrieval of images in quantum systems
Digital images are discrete representations of the physical world; they are stored in arrays resembling matrices M of order \(m_1 \times m_2\), and each entry \(a_{i,j} \in M \) is a picture element, that is, pixel, produced via the photoelectric effect (Fiete 2012). Pixels are arrays of bits, usually 8 bits for grayscale images and 24 bits for color images in the RGB model (this is the standard in commercial imaging; cameras designed for scientific research may use more bits, depending on specific needs). Thus, pixels are scalars. The total number of bits required to store a digital image as described in this paragraph is \(8 \times m_1 \times m_2\) for grayscale images and \(24 \times m_1 \times m_2\) for RGB color images, and operations on digital images are usually described as operations on matrices or pixel-wise functions.
In QIMP, the term quantum image was coined to refer to an image stored in a set of qubits, regardless of the classical/quantum nature of the source of information, and operations on quantum images are performed via quantum evolution (Yan and Venegas-Andraca 2020). Several methods for creating quantum images (known as image-representation models and shown in Fig. 2) have been proposed; particularly popular among them are the FRQI (Le et al. 2011a) and novel enhanced quantum representation (NEQR) (Zhang et al. 2013a) models. Several pioneering operations and recent applications based on these two quantum image representations are presented in Table 2.

Simple examples of several popular quantum-image representations, as well as their storage (color encoding) and retrieval strategy. The FRQI and NEQR models share the same method of encoding coordinate information, the main difference being that the NEQR model uses the basis state of a qubit sequence to store the grayscale value of every pixel instead of an angle encoded in a qubit in the FRQI model, which results in probabilistic and deterministic retrieval results. In addition, QUALPI and NAQSS focus on the position information by encoding the image in a log-polar coordinate system and multi-dimensional system, respectively, to pursue more advanced applications (color figure online)
We now analyze the FRQI representation model in order to quantify the amount of resources needed to store and retrieve information contained in quantum images. Suppose we have a spatially ordered array A of \(m^2\) colors (i.e., frequencies) denoted by \(\{\theta _0\), \(\theta _1\), \(\ldots \), and \(\theta _{m^2 -1}\}\). We want to store them using two formats: a digital image and a quantum image. Let us assume, for the sake of convenience (i.e., just to avoid cumbersome calculations) and without loss of generality, that \(m = 2^r\), where \(r \in \mathbb {N}\). It is worth noting that the size of array A, \(m = 2^r\), is not meant to asymptotically grow exponentially large, as m is a fixed number, not a function. Modern digital images produced by professional cameras are of the order of megapixels. For instance, the \(\alpha 9^{\tiny {\textregistered }}\) Sony camera has 24.2-megapixel resolution; that is, \(2.42 \times 10^7\) pixels per digital photograph. Thus, \(m^2 = 2.42 \times 10^7 \Rightarrow m \approx 4920\). Since \(2^{12} = 4096\) and \( 2^{13} = 8192\), we may set \(r= 13\) as an upper bound for modern digital-camera technology.
Hence, to store A as a digital image, we would need \(m^2\) pixels and 8 bits for each grayscale pixel or 24 bits for each color pixel in the RGB model, i.e., \(24m^2\) bits in total at most. Note that we are only counting the number of bits needed to store an \(m^2\) digital RGB color image; we are not taking into account the hardware and processing power required by the Nyquist-Shannon sampling theorem to avoid aliasing and excessive blur.
We now focus on resource consumption on quantum images. A \(2\times 2\) FRQI image is presented in Fig. 2. Equation (1) introduces its general case, i.e., a \(m \times m\) FRQI image model:
where \(\theta _i\in [0, \frac{\pi }{2}]\) is a vector of angles encoding colors, and \(\vert i\rangle \), \(i\in \{0, 1, \cdots , m^2-1\}\), is the computational basis of \(\mathcal{H}^{m^2}\) to store the coordinates of each quantum color pixel. Storing an \(m^2\) pixel image with pixel values taken from \(\{0,1, \ldots , 255\}\) grayscale images on the FRQI model takes \(1 + \log _2 m^2\) qubits: 1 qubit to store the grayscale values of \(m^2\) pixels and \(\log _2 m^2\) qubits as indices.
Therefore, in a digital system, it takes \(24 m^2\) bits to store a color image and \(8 m^2\) bits to store a grayscale image, while \( 1 + \log _2 m^2\) qubits are needed to store a grayscale image in the FRQI model, i.e., in both models we need a polynomial amount of resources to store a color/grayscale image. In this regard, there is room for improvement, as qubits are scarce and it is difficult to justify using quantum states as indices while this is a job that could be done using bits. This criticism points toward the development of hybrid classical-quantum approaches for storing, processing, and retrieving quantum images.
We now address a most important criticism that has been raised about quantum image representation models. In general (except for the NEQR model, in which grayscale values can be deterministically retrieved, as it suffices to individually measure quantum states \(|C_{yx}^i\rangle \) with measurement operators based on the computational basis of \(\mathcal{H}^{q}\), where q is the number of qubits to encode the colors in an NEQR image), retrieving an image stored in a quantum image representation model is a probabilistic process that would require identical preparation of several quantum images. In contrast, retrieving a color image stored in a digital system is a deterministic process that requires only one copy. Thus, the amount of resources required to retrieve images stored in quantum systems is larger than in the digital case (this resource-estimation analysis cannot be forthrightly extended to the full procedure of acquiring, processing, and measuring quantum images because, on one hand, in this paper we have not taken into account the resources needed to implement the Nyquist-Shannon sampling theorem on digital images and, on the other, quantum hardware for QIMP has not yet been designed).
Indeed, under most current quantum image representation models, image retrieval is a probabilistic process. This is also the case with all other branches of quantum computation, including most celebrated quantum algorithms like Shor’s and Grover’s (Nielsen and Chuang 2000): data are extracted from a quantum system via a probabilistic procedure. In this sense, the criticism is correct, but it must be contextualized as this is a feature shared with other fields of quantum computation because it is inherited from quantum mechanics. Thus, a crucial research goal in QIMP must be to design algorithms and measurement strategies that reduce the amount of quantum resources required for data manipulation and extraction. In the following, we elaborate some forward-looking ideas on quantum image retrieval and quantum image representation models.
(1) Quantum image representation models developed so far are mostly inspired by digital image formats and do not fully incorporate quantum-mechanical properties. Current models of quantum image representation require extensive improvement to integrate and take full advantage of quantum-mechanical properties, as well as to design efficient strategies for image retrieval. A good example of the revolutionary potential of quantum image representations lies in the use of quantum entanglement as a resource to natively store depth information in a quantum image, thereby overcoming the geometrical constraints imposed by the \(\mathbb {R}^3\rightarrow \mathbb {P}^2\) transformation that governs the geometry of digital images.
Next generations of quantum image models must be fully fledged (possibly hybrid in the sense described above) methods for storing visual information with quantum-mechanical properties as essential components (for example, Grigoryan and Agaian 2020 proposes a promising approach along these lines). This is key in order to integrate quantum images as a full member of quantum-technology ecosystems like quantum radar technology and other novel applications.
(2) To date, techniques used in QIMP for image retrieval consist of basic projective measurements and straightforward use of statistics, leaving aside the full richness of quantum measurement theory. Next steps in QIMP research programs must include quantum-state tomography techniques (Banaszek et al. 2012–2013) that, possibly combined with advanced computational paradigms such as machine learning (Youssry et al. 2019), would potentially lead to optimized quantum image retrieval processes.
(3) A potential fruitful area for further development of QIMP is to test upcoming quantum image representation models, algorithms, and information retrieval techniques in fields in which images are likely to play a key role. We now give a few examples along this line of thought.
-
The emergence and consolidation of quantum technology as a pervasive field in science, engineering, and other disciplines will come together with a dire necessity to keep data safe, which translates into the creation of encryption and steganography methods for quantum images (some recent examples along these lines include Du et al. 2019; Abd El-Latif et al. 2019). According to Fig. 1, the area of security on quantum images is most popular among QIMP researchers; hence, we would have the human capital needed to design, for example, homomorphic encryption techniques for quantum images that, among other novel methods for encrypting quantum information, could provide novel levels of secrecy (see Acar et al. 2018 for a recent review on homomorphic encryption).
-
Images are a key component in advanced fields of classical computer science and engineering like computer vision, artificial intelligence, pattern recognition, and machine learning. A promising research avenue would be to design quantum image storage and retrieval methods suitable for use as input to algorithms from the emergent fields of quantum machine learning (Biamonte et al. 2017; Venegas-Andraca et al. 2018; Cruz-Santos et al. 2019), quantum computer vision (e.g., Yu et al. 2019), and quantum pattern recognition (Trugenberger 2002). Three concrete examples would be quantum algorithms for reconstructing medical images (Kiani et al. 2004), variational quantum algorithms (McClean et al. 2016; Biamonte 2019) for quantum machine learning and other emergent branches of quantum computing, as well as quantum clustering algorithms (Aïmeur et al. 2007; Horn and Gottlieb 2001), a promising area of unsupervised quantum machine learning, the classical counterparts of which are most useful in pattern recognition.
3 Algorithm development and algorithmic speed-up in QIMP
As shown in Fig. 1, quantum algorithms in QIMP have been developed in six main areas, security being the most popular among them. A review of the papers published in the areas of image representation, operations, multimedia, and understanding reveals that the efforts of the QIMP community have been focused on developing techniques that would replicate or complement existing techniques in the digital image processing domain, the main goal being that of algorithm robustness (that is, that the algorithm does what it is meant and expected to do) rather than speed-up.
As previously stated in this paper, arguments on computational complexity must be contextualized in order to make fair comparisons. To date, just a few cases of algorithmic speed-up are known in the quantum computing domain. Grover’s algorithm is irrefutably faster than its best possible classical counterpart (so, Grover’s is provably faster and optimal). The other most-celebrated quantum algorithm, Shor’s algorithm, is exponentially faster than the best known classical counterparts designed so far (i.e., we know that factorization is in \(\mathsf {NP}\), but we do not know whether factorization is in \(\mathsf {P}\)). A third case is presented in Childs et al. (2003), in which a quantum walk-based algorithm running on glued trees (a very particular family of trees designed specifically for this algorithm) is exponentially faster than its classical random walk-based counterpart \(\mathsf {P}\). A third case is presented in Childs et al. (2003), in which a quantum walk-based algorithm running on glued trees (a very particular family of trees designed specifically for this algorithm) is exponentially faster than its classical random walk-based counterpart. In both classical and quantum computing, achieving exponential speed-up is a very difficult task, and most of the quantum algorithms developed so far that are faster than their classical counterparts exhibit quadratic speed-up.
To date and to the best of our knowledge, there is no QIMP algorithm that exhibits irrefutable exponential speed-up with respect to a classical counterpart, that is, a classical image processing algorithm. In the following, we argue that imposing on QIMP the requirement of exponential speed-up as the main and/or only success criterion is a choice of limited scope that does not take into account the nature and goals of this discipline.

a Color image of the Hubble Telescope; b and c grayscale and black-and-white versions of a, respectively. In addition, d–f are the results of applying a dilation algorithm using three different values for the size of the structuring element (color figure online)
(1) Exponential speed-up is the result of comparing efficient versus inefficient algorithms, and so achieving exponential speed-up on a quantum algorithm requires classical algorithms with exponential complexity as counterparts. In classical image processing, the vast majority of problems can be satisfactorily solved with \(\mathsf {P}\) algorithms or a polynomial number of iterations of \(\mathsf {P}\) algorithms. This is due to the nature of problems faced in image processing, the finite size of data input, and also because success criteria for image processing algorithms are a combination of quantitative outcomes (e.g., a stop criterion as in numerical analysis algorithms) and qualitative results that basically consist of the approval of human beings. Therefore, even for optimization problems in image processing, algorithms do not need to find the global minimum or maximum of the corresponding cost functions, but just need to produce values that make sense to the human eye or that are good enough for machine consumption (like computer vision algorithms, for example).
As an example, we now analyze the behavior of the images and algorithms presented in Fig. 3. The color image presented in Fig. 3a is of the Hubble Telescope, and (b) as well as (c) are grayscale and black-and-white versions of (a), respectively. Producing grayscale and black-and-white digital images is achieved by polynomial-time algorithms. The borders of the image in Fig. 3c are rather weak, i.e., it is difficult for the human eye to quickly identify all borders that correspond to the actual Hubble Telescope and the different objects that are on its surface. To intensify the border contrast in this image, we may use a dilation operator (Serra 1984), which can be implemented by another polynomial-time algorithm. Images in Fig. 3d–f are the results of applying the same dilation algorithm using three different values for one parameter (the size of the structuring element).
Now, the question is the following: From the second row of Fig. 3, which image is best? The answer will ultimately depend on the preferences of the person in charge of choosing the best image. For instance, we may choose (e) because (d) still has weak borders, while borders in (f) are slightly too thick and we lose some details of the objects that are on the surface of the Hubble Telescope. This rationale is found over and over in image processing and related fields: algorithms are likely to be found in the \(\mathsf {P}\) sphere because of the nature of the problem to solve (in this case, sweeping a mask over the digital image and performing some numerics on each step), as well as because running the algorithm just a few times will suffice to produce a result that is satisfactory to the human eye. Indeed, polynomial or exponential algorithmic speed-up must be a goal in QIMP, but, in addition to that aim, we should also consider other quality criteria, like the suitability of quantum images for human or machine consumption.
(2) There are two approaches for estimating the complexity of an algorithm: asymptotic analysis and empirical analysis. Asymptotic analysis provides a definite and analytical answer to the amount of computational resources needed to run an algorithm on inputs of arbitrary size. Unfortunately, following this approach is very challenging to many algorithms because of the mathematical intricacies faced when calculating asymptotic resource consumption. As an alternative, we may follow the empirical analysis approach: algorithms can be run on a portfolio of random inputs different in size so that good estimates for typical resource consumption on finite-size machines can be produced (McGeoch 2012).
Several QIMP papers have presented algorithms with asymptotic analysis results, while some others present numerical results as evidence of algorithmic performance. In both scenarios, quantum algorithms exhibit computational complexities that are roughly of the same order, or polynomially upper-bounded, as those of their classical counterparts.
As an example of asymptotic analysis results, we now present a case study of edge detection in the digital and quantum domains. Edge detection, a most important activity in image processing and computer vision, consists of identifying sharp intensity changes on an image (Gonzalez et al. 2016). The goal of edge detection, in plain human terms, is to identify borders and silhouettes in an image (Gonzalez et al. 2019). There are several methods for detecting edges, and among them are the Sobel operator (Sobel 2014) and Canny operator (Canny 1986) methods.
Figure 4 (a) is a color image of Parque México, a famous park in Mexico City, and (b) is the result of running the MATLAB\(^{\copyright }\) 2019 implementation of the Sobel algorithm on (a). Keeping in mind that the key elementary step in the Sobel operator algorithm is the computation of discrete convolution, results for classical and quantum algorithms for computing Sobel operators are the following.
\(\bullet \) A straightforward implementation of the Sobel operator on an image composed of \(n^2\) pixels using a textbook definition for computing discrete convolution results in an algorithm of order \(O(n^2)\), while a more refined implementation based on the Fast Fourier transform results in an algorithm of order \(O(n\log n)\).
\(\bullet \) In Zhang et al. (2015), a quantum algorithm for computing the Sobel operator on a FRQI image is presented. The complexity of this quantum algorithm, taking into account quantum measurements for extracting the Sobel edge values, is of order \(O(n^2)\) on the number of quantum gates, at best (the complexity comparison made in Zhang et al. (2015), that of number of bits versus number of qubits, misses the fact that computational complexity measures the number of elementary steps that an algorithm runs on inputs of arbitrary size).
Thus, both classical and quantum versions of the Sobel operator algorithm are equivalent in terms of computational complexity. As it was the case with the original formulation of the Sobel operator (Duda and Hart 1973), the next steps for QSobel would likely include using the mathematical machinery of quantum information and quantum mechanics to produce enhanced versions of this algorithm (possibly achieving polynomial speed-up).

a Color image of Parque México, a famous park in Mexico City; b result of running the MATLAB\(^{\copyright }\) 2019 implementation of the Sobel algorithm on (a). In addition, b was previously smoothed using a \(4 \times 4\) mask Gaussian filter and its brightness enhanced by running a dilation operator with a radius-2 disk as the structuring element (color figure online)
Regarding QIMP algorithms written under the empirical analysis approach, some papers based on numerical evidence contain claims of high efficiency and performance, claims that must be further analyzed and tested by the scientific community. A detailed list of these papers can be found in Yan and Venegas-Andraca (2020). Empirical analysis is a powerful tool in contemporary computer science and engineering as well as in software engineering. This is because it is often the case that the calculation of computational complexity for modern algorithms using the tools of asymptotic analysis is very difficult. Moreover, most of the results of computational complexity are based on the notion of standalone computation, and some celebrated modern algorithms either run natively on distributed systems or the amount of elementary steps required to run those algorithms exceed the typical power of standalone computers. A good example of the difficulties faced when estimating computational complexity is Google’s PageRank algorithm.
Suppose that we have a digraph \( {\mathbf{G}}(V,E)\) and are interested in ranking its nodes based on the importance of each node, i.e., we want an ordered list \((v_1, v_2, ... v_n)\), where \(v_i \in V\), \(i \in \{1,2, \ldots , n\}\). PageRank is an algorithm developed to provide a quantitative approach to the qualitative notion of node importance in a digraph. The problem for which PageRank was designed was that of ranking the nodes of the WWW. PageRank was presented in 1999 as a technical report (Page et al. 1999) and the computation of the node rank basically consists of computing an eigenvector of a matrix A, the entries of which are functions of the incoming links and outgoing links of each node (Bryan and Leise 2006; Langville and Meyer 2006).
The computation of eigenvectors has been a very well-known mathematical problem since the XIXth Century. Many seminal texts, methods, and algorithms about this problem have been published since the beginning of the computer era (e.g., Wilkinson 1965; Gobul and Van Loan 1992). Several algorithms for computing the eigenvectors of different families of matrices were presented during those years and abundant numerical evidence of the complex polynomial nature of the eigenproblem presented, but not until 1999 was it definitely known that “the deterministic arithmetic complexity of the eigenproblem for any \(n \times n\) matrix A is bounded by \(O(n^3)\)” (Pan and Chen 1999).
Therefore, the performance of PageRank is linked to the computational complexity of algorithms for solving the matrix eigenproblem, and having only partial theoretical results as well as abundant numerical estimates was enough to provide the scientific grounds and product development of Google’s star product. Furthermore, the tremendous size of the WWW makes the computation of PageRank an interesting challenge for distributed algorithms, and the first provable efficient distributed PageRank algorithm was published as recently as 2015 (Sarma et al. 2015).
Empirical analysis is a tool that was seldom utilized in the beginning of the quantum computing era, but its use is steadily increasing. For example, in Paparo and Martin-Delgado (2012), a quantum algorithm for computing PageRank in a quantum network was presented and Loke et al. (2017) shows a comparison between classical and quantum versions of PageRank. These two papers make extensive use of numerics to estimate the performance of corresponding algorithms. Furthermore, other areas of vigorous research, like quantum machine learning, are also adopting empirical analysis (Biamonte et al. 2017).
The QIMP community should continue presenting results based on both approaches. Regarding asymptotic analysis, procedures and results should be more mathematically rigorous and transparent. With respect to empirical analysis and following current trends in scientific repeatability, testing code and data should be made available to the scientific community. These enhancements will depend on both researchers and the requirements imposed by scientific journals.
4 The road ahead—a proposal of future steps for QIMP
In addition to the proposals presented in this paper, we put forward the following analysis. To efficiently implement the retrieval process in QIMP, the measurement strategy for quantum images must be explored in depth (Yan et al. 2021a). In addition, quantum error correction (QEC) is used to protect quantum information from errors due to decoherence and other quantum noise. In QIMP, most of the current researches are focused on the image manipulation with very little attention given to its physical preparation and retrieval steps. These are stages in which QEC could make or mar the gains made in the area. It is therefore necessary to consider frameworks for integrating QEC into existing QIMP protocols as well as future ones (Yan et al. 2017a).
Although the development of QIMP technologies that are fully competitive with corresponding digital technologies is highly desirable, future research efforts must avoid attempting to realize quantum versions for every digital image processing algorithm, as not all digital image processing algorithms may be appropriate for implementation in the quantum computing realm. We should choose and develop only those algorithms that either have a better performance than classical algorithms or that significantly enhance the overall performance of image processing tasks by complementing classical algorithms (Yan et al. 2016b). In addition, research must be devoted toward ensuring that formal comparisons can be made between digital algorithms and their corresponding quantum algorithms. This requires the development of metrics for evaluating and comparing the computational complexity of quantum and classical algorithms used for encoding, processing, and recovering images, as well as the physical (both quantum and digital) resources employed for these tasks. Furthermore, researchers in the field of QIMP should be critical of published results when the theories or methods employed during analysis are controversial.
QIMP is a component of a greater goal for quantum technology, namely that of creating a complete integrated quantum-technology ecosystem in which data produced by quantum sensors are transmitted via quantum channels. Thus, efforts could be focused on developing quantum algorithms for solving sophisticated operations like image registration, classification, reconstruction, and super-resolution with quantum image representations (Yan et al. 2021a), as well as developing potential applications for solving open problems in science and engineering, e.g., machine vision, remote sensing, and health informatics (Ross 2019). In addition, quantum techniques should be developed that complement classical digital processing algorithms. For example, numerous image processing and computer vision algorithms are of an iterative nature because their mathematical setting requires finding maxima or minima of a cost function. As such, quantum techniques would be highly complementary because quantum computers have been demonstrated to be good candidates for solving optimization problems.
In addition, we must note that the development of physical equipment for capturing and processing quantum images is key for making QIMP as pervasive a field as digital image processing. However, the development of such equipment, such as the physical realization of interfaces connecting digital and quantum images (i.e., preparation and measurement), remains a pending task. A crucial aspect of these efforts involves capitalizing on the interdisciplinary nature of QIMP, which spans through physics, optics, computer science, and electrical engineering, to design dedicated hardware either as standalone units or as part of larger hybrid systems. Furthermore, complete toolkits including loadable quantum modules and packages should be developed that can be employed by scientists and engineers as basic building blocks in designing hybrid quantum-classical image processing algorithms (Li et al. 2020).
The development of specific-purpose hardware is a promising approach that conforms well with the contemporary industry-university cooperative research paradigm. For example, analogous to the conversion of analog signals to digital signals using analog-to-digital converters, a very practical effort would be to devise digital-to-quantum converters to integrate the digital and quantum computing realms seamlessly (Yan et al. 2018a). In addition, we note that most existing QIMP experiments are based on simulations using mathematical software. This can be expected to continue in the future regardless of the availability of hardware owing to the great benefits of computer simulation in the hardware design process. However, such expediencies confuse the implementation of QIMP and digital image processing algorithms, thereby restricting the anticipated power of quantum information technologies. Therefore, quantum computing software must be developed to complement the design of future QIMP hardware and facilitate the objective validation of QIMP algorithms (e.g., Co et al. 2020).
Finally, QIMP is essentially a strategy that uses quantum mechanics to store and process image information. Similar encodings can be considered in several technologies related to image processing, e.g., machine learning, neural networks, and fuzzy logic (Castillo et al. 2017; Melin et al. 2014). The integration of multiple disciplines is bound to promote the development and evolution of each other. For instance, quantum machine learning (Biamonte et al. 2017) can be used to avoid rounding errors caused by data coding, thus improving the accuracy of processing tasks. As such, the quantum image state is likely to be encapsulated into a quantum machine learning module for further analysis and processing, so that key information in the image can be retrieved more efficiently. Further, when we consider the intersection in a more practical manner, research on the realization of quantum radar, quantum sensors, quantum robots, and quantum nanoscale materials should command more attention (Yan et al. 2017a).
5 Concluding remarks
The notion of quantum computation and quantum information holds expectations of fast and secure computing technologies. This is due to the quantum-mechanical properties of superposition, entanglement and interference inherent in information processing on these paradigms. Therefore, extending digital image processing to the quantum-computing realm, that is, QIMP, conjures similar expectations.
QIMP has the potential to become a key component toward making quantum technology a pervasive field with huge impacts on many areas of science and technology, just like digital image processing is currently. To achieve this goal, the research agenda of QIMP must include the development of novel quantum image storage and retrieval techniques and to harness quantum phenomena (e.g., quantum entanglement) as a tool for image processing and analysis. Development of an emerging area needs all of the contributions in the community, in which some controversial comments may arise, such as the nature of quantum imaging; that is, whether it can be interpreted as classical intensity correlations or fundamentally non-local quantum correlations is still debatable (Shih 2012; Shapiro and Boyd 2012). We believe, therefore, in QIMP, either the compliments or criticisms will be an important impetus to promote this area.
Feynman’s famous lecture title, “ There is plenty of room at the bottom,” has been an inspiration for many members of the QIMP community, including ourselves, to work toward the development of a branch of quantum science and engineering focused on storing, processing, and retrieving visual information using quantum systems, with the higher goal of contributing to the development of quantum-technology ecosystems. This perspective paper has been written with that purpose in mind.
Availability of data and material
Not applicable.
Code availability
Not applicable.
References
Abd El-Latif AA, Abd-El-Atty B, Hossain MS, Rahman MA, Alamri A, Gupta BB (2018) Efficient quantum information hiding for remote medical image sharing. IEEE Access 6:21075–21083
Abd El-Latif AA, Abd-El-Atty B, Venegas-Andraca SE (2019) A novel image steganography technique based on quantum substitution boxes. Opt Laser Technol 116:92–102
Acar A, Aksu H, Uluagac AS, Conti M (2018) A survey on homomorphic encryption schemes: theory and implementation. ACM Comput Surv 51(4):1–35
Aïmeur E, Brassard G, Gambs S (2007) Quantum clustering algorithms. In: Proceedings of the 24th international conference on machine learning (ICML), New York, pp 1–8
Banaszek K, Cramer M, Gross D (2012–2013) Focus issue on quantum tomography (31 articles). New J Phys 14–15: 125020
Biamonte J (2019) Universal variational quantum computation. arXiv:1903.04500,
Biamonte J, Wittek P, Pancotti N, Rebentrost P, Wiebe N, Lloyd S (2017) Quantum machine learning. Nature 549:195–202
Bryan K, Leise T (2006) The \$25,000,000,000 eigenvector: the linear algebra behind google. SIAM Rev 48(3):569–581
Canny J (1986) A computational approach to edge detection. IEEE Trans Pattern Anal Mach Intell 8(6):679–698
Caraiman S, Manta VI (2015a) Image segmentation on a quantum computer. Quantum Inf Process 14(5):1693–1715
Caraiman S, Manta V (2015b) Image segmentation on a quantum computer. Quantum Inf Process 14:1693
Castillo O, Sanchez MA, Gonzalez CI, Martinez GE (2017) Review of recent type-2 fuzzy image processing applications. Information 8(3):97
Chen K, Yan F, Hirota K, Zhao J (2019) Quantum implementation of powell’s conjugate direction method. J Adv Comput Intell Intell Inf 23(4):726–734
Childs AM, Cleve R, Deotto E, Farhi E, Gutmann S, Spielman D (2003) Exponential algorithmic speedup by quantum walk. In: Proceedings of the 35th ACM symposium on the theory of computation (STOC), pp 59–68
Co H, Peña Tapia E, Tanetani N, Arias Zapata JP, García Sánchez-Carnerero L. Quantum image processing using QISKIT. https://qiskit.org/experiments/quantum-img-processing/. Retrieved on 10 Feb, 2020
Cruz-Santos W, Venegas-Andraca SE, Lanzagorta M (2019) A QUBO formulation of minimum multicut problem instances in trees for D-Wave quantum annealers. Sci Rep 9:17216
Defienne H, Reichert M, Fleischer JW, Faccio D (2019) Quantum image distillation. Sci Adv 5(10):eaax0307
Du S, Qiu D, Mateus P, Gruska J (2019) Enhanced double random phase encryption of quantum images. Results Phys 13:102161
Duda R, Hart P (1973) Pattern classification and scene analysis. Wiley, London, p 271272
El-Latif AAA, Abd-El-Atty B, Talha M (2018) Robust encryption of quantum medical images. IEEE Access 6:1073–1081
Fiete RD (2012) Formation of a digital image: the imaging chain simplified. SPIE, Bellingham
Gobul GH, Van Loan CF (1992) Matrix computations, 1st edn. Baltimore: Johns Hopkins University Press, 1983 Press WH, Teukolsky SA, Vetterling WT, and Flannery BP. Numerical Recipes in C, 2nd edn. Cambridge University Press, Cambridge
Gonzalez RC, Woods RE (2018) Digital image processing. Pearson, New York
Gonzalez CI, Melin P, Castro JR, Castillo O, Mendoza O (2016) Optimization of interval type-2 fuzzy systems for image edge detection. Appl Soft Comput 47:631–643
Gonzalez CI, Melin P, Castro JR, Castillo O (2019) Edge detection approach based on type-2 fuzzy images. J Multiple Valued Logic Soft Comput 33(4–5):431–458
Grigoryan AM, Agaian SS (2020) New look on quantum representation of images: Fourier transform representation. Quantum Inf Process 19:148
Heidari S, Farzadnia E (2017) A novel quantum LSB-based steganography method using the Gray code for colored quantum images. Quantum Inf Process 16(10):1–28
Heidari S, Naseri M (2016) A novel LSB based quantum watermarking. Int J Theor Phys 55(10):4205–4218
Horn D, Gottlieb A (2001) Algorithm for data clustering in pattern recognition problems based on quantum mechanics. Phys Rev Lett 88(1):018702
Hou C, Liu X, Feng S (2020) Quantum image scrambling algorithm based on discrete baker map. Mod Phys Lett A 35(17):2050145
Hu W, Zhou R, El-Rafei A, Jiang S (2019a) Quantum image watermarking algorithm based on Haar wavelet transform. IEEE Access 7:121303–121320
Hu W, Zhou R, El-Rafei A, Jiang S (2019b) Quantum image watermarking algorithm based on haar wavelet transform. IEEE Access 7:121303–121320
Hu WW, Zhou RG, Liu XA, Luo J, Luo GF (2020) Quantum image steganography algorithm based on modified exploiting modification direction embedding. Quantum Inf Process 19(5):1–28
Iliyasu AM (2018) Roadmap to talking quantum movies: a contingent inquiry. IEEE Access 7:23864–23913
Iliyasu AM, Le PQ, Dong F, Hirota K (2012) Watermarking and authentication of quantum images based on restricted geometric transformations. Inf Sci 186(1):126–149
Jiang N, Wang L (2015) Quantum image scaling using nearest neighbor interpolation. Quantum Inf Process 14(5):1559–1571
Jiang N, Zhao N, Wang L (2016) LSB based quantum image steganography algorithm. Int J Theor Phys 55(1):107–123
Kiani BT, Villanyi A, Lloyd S. Quantum medical imaging algorithms. arXiv:2004.02036v3 [quant-ph]
Langville AN, Meyer CD (2006) Google’s pagerank and beyond: the science of search engine rankings. Princeton University Press, Princeton
Lanzagorta M (2011) Quantum radar. Morgan and Claypool (Synthesis Lectures on Quantum Computing), San Rafael
Le PQ, Iliyasu AM, Dong F, Hirota K (2010) Fast geometric transformations on quantum images. Int J Appl Math 40(3):113–123
Le PQ, Dong F, Hirota K (2011a) A flexible representation of quantum images for polynomial preparation, image compression, and processing operations. Quantum Inf Process 10:63–84
Le PQ, Iliyasu AM, Dong F, Kaoru H (2011b) Efficient color transformations on quantum images. J Adv Comput Intell Intell Inf 15(6):698–706
Le PQ, Iliyasu AM, Dong F, Hirota K (2011c) Strategies for designing geometric transformations on quantum images. Theoret Comput Sci 412(15):1406–1418
Li H, Fan P, Xia H, Peng H, Long G (2020) Efficient quantum arithmetic operation circuits for quantum image processing. Sci China Phys Mech Astron 63:280311
Loke T, Tang JW, Rodriguez J, Small M, Wang JB (2017) Comparing classical and quantum PageRanks. Quantum Inf Process 16:25
Lugiato LA, Gatti A, Brambilla E (2002) Quantum imaging. J Opt B: Quantum Semiclass Opt 4(3):S176–S183
Luo G, Zhou RG, Hu W, Luo J, Liu X, Ian H (2018) Enhanced least significant qubit watermarking scheme for quantum images. Quantum Inf Process 17(11):1–19
Luo J, Zhou RG, Luo G, Li Y, Liu G (2019) Traceable quantum steganography scheme based on pixel value differencing. Sci Rep 9(1):1–12
Ma S, Khalil A, Hajjdiab H, Eleuch H (2020) Quantum dilation and erosion. Appl Sci 10(11):4040
McClean JR, Romero J, Babbush R, Aspuru-Guzik A (2016) The theory of variational hybrid quantum-classical algorithms. New J Phys 18:023023
McGeoch C (2012) A guide to experimental algorithmics. Cambridge University Press, Cambridge
Melin P, Gonzalez CI, Castro JR, Mendoza O, Castillo O (2014) Edge-detection method for image processing based on generalized type-2 fuzzy logic. IEEE Trans Fuzzy Syst 22(6):1515–1525
Miyake S, Nakamae K (2016) A quantum watermarking scheme using simple and small-scale quantum circuits. Quantum Inf Process 15(5):1849–1864
Naseri M, Heidari S, Baghfalaki M, Gheibi R, Batle J, Farouk A, Habibi A et al (2017) A new secure quantum watermarking scheme. Optik 139:77–86
Nielsen MA, Chuang IL (2000) Quantum computatation and quantum information. Cambridge University Press, Cambridge
Page L, Brin S, Motwani R, Winograd T (1999) The pagerank citation ranking: bringing order to the Web. Technical Report 1999-66. Stanford InfoLab
Pan VY, Chen ZQ (1999) The complexity of the matrix eigenproblem. In: Proceedings of the 31st annual ACM symposium on theory of computing, pp 507–516
Paparo GD, Martin-Delgado MA (2012) Google in a quantum network. Sci Rep 2:444
Qu Z, Cheng Z, Liu W, Wang X (2019) A novel quantum image steganography algorithm based on exploiting modification direction. Multimed Tools Appl 78(7):7981–8001
Qu Z, Chen S, Wang X (2020) A secure controlled quantum image steganography algorithm. Quantum Inf Process 19(10):1–25
Rosenfeld A (1969) Picture processing by computer. ACM Comput Surv 1(3):147–174
Rosenfeld A (1973) Progress in picture processing: 1969–1971. ACM Comput Surv 5(2):81–104
Ross OHM (2019) A review of quantum-inspired metaheuristics: going from classical computers to real quantum computers. IEEE Access 8:814–838
Sarma AD, Molla AR, Pandurangan G, Upfal E (2015) Fast distributed PageRank computation. Theoret Comput Sci 561:113–121
Serra J (1984) Image analysis and mathematical morphology, vol 1 and 2. Academic Press, London
Shapiro JH, Boyd RW (2012) Response to the physics of ghost imaging-nonlocal interference or local intensity fluctuation correlation? Quantum Inf Process 11:1003–1011
Shih Y (2007) Quantum imaging. IEEE J Sel Top Quantum Electron 13(4):1016–1030
Shih Y (2012) The physics of ghost imaging-nonlocal interference or local intensity fluctuation correlation? Quantum Inf Process 11:995–1011
Sobel I (2014) An isotropic 3\(\times \) 3 image gradient operator (history and definition of the sobel operator). https://www.researchgate.net/publication/239398674. Retrieved on 07 Feb, 2020
Song X, Wang S, Abd El-Latif AA, Niu X (2014) Dynamic watermarking scheme for quantum images based on Hadamard transform. Multimedia Syst 20(4):379–388
Trugenberger CA (2002) Quantum pattern recognition. Quantum Inf Process 1(6):471–493
Venegas-Andraca SE, Bose S (2003) Quantum computation and image processing: new trends in artificial intelligence. In: Proceedings of the international conference on artificial intelligence (IJCAI), pp 1563–1564
Venegas-Andraca SE (2005) Discrete quantum walks and quantum image processing. DPhil thesis, The University of Oxford, London
Venegas-Andraca SE (2012) Quantum walks: a comprehensive review. Quantum Inf Process 11(5):1015–1106
Venegas-Andraca SE (2015) Introductory words: special issue on quantum image processing published by quantum information processing. Quantum Inf Process 14:1535–1537
Venegas-Andraca SE, Ball JL (2010) Processing images in entangled quantum systems. Quantum Inf Process 9(1):1–11
Venegas-Andraca SE, Bose S (2003) Storing, processing, and retrieving an image using quantum mechanics. SPIE Conf Quantum Inf Comput 5105:137–147
Venegas-Andraca SE, Cruz-Santos W, McGeoch C, Lanzagorta M (2018) A cross-disciplinary introduction to quantum annealing-based algorithms. Contemp Phys 59(2):174–197
Wang J, Jiang N, Wang L (2015) Quantum image translation. Quantum Inf Process 14(5):1589–1604
Wilkinson JH (1965) The algebraic eigenvalue problem, 1st edn. Oxford University Press, Oxford
Xia H, Xiao Y, Song S, Li H (2020) Quantum circuit design of approximate median filtering with noise tolerance threshold. Quantum Inf Process 19:1–23
Xu P, He Z, Qiu T, Ma H (2020) Quantum image processing algorithm using edge extraction based on kirsch operator. Opt Express 28(9):12508–12517
Yan F, Venegas-Andraca SE (2020) Quantum image processing. Springer, Berlin
Yan F, Iliyasu AM, Venegas-Andraca SE (2016a) A survey of quantum image representations. Quantum Inf Process 15:1–35
Yan F, Iliyasu AM, Yang H, Hirota K (2016b) Strategy for quantum image stabilization. Sci China Inf Sci 59:052102
Yan F, Iliyasu AM, Le PQ (2017a) Quantum image processing: a review of advances in its security technologies. Int J Quantum Inf 15(3):1730001
Yan F, Chen K, Venegas-Andraca SE, Zhao J (2017b) Quantum image rotation by an arbitrary angle. Quantum Inf Process 16:282
Yan F, Iliyasu AM, Guo Y, Yang H (2018a) Flexible representation and manipulation of audio signals on quantum computers. Theoret Comput Sci 752:71–85
Yan F, Jiao S, Iliyasu AM, Jiang Z (2018b) Chromatic framework for quantum movies and applications in creating montages. Front Comput Sci 12(4):736–748
Yan F, Li N, Hirota K (2021a) QHSL: a quantum hue, saturation, and lightness color model. Inf Sci 577:196-213
Yan F, Zhao S, Venegas-Andraca SE, Hirota K (2021b) Implementing bilinear interpolation with quantum images. Digital Signal Process 117:103149
Yang Y, Pan Q, Sun S, Xu P (2015) Novel image encryption based on quantum walks. Sci Rep 5:7784
Youssry A, Ferrie C, Tomamichel M (2019) Efficient online quantum state estimation using a matrix-exponentiated gradient method. New J Phys 21:033006
Yu C, Gao F, Liu C, Huynh D, Reynolds M, Wang J (2019) Quantum algorithm for visual tracking. Phys Rev A 99:022301
Yuan S, Mao X, Li T, Xue Y, Chen L, Xiong Q (2015) Quantum morphology operations based on quantum representation model. Quantum Inf Process 14:1625
Zhang Y, Lu K, Gao Y, Wang M (2013a) NEQR: a novel enhanced quantum representation of digital images. Quantum Inf Process 12:2833–2860
Zhang WW, Gao F, Liu B, Wen QY, Chen H (2013b) A watermark strategy for quantum images based on quantum Fourier transform. Quantum Inf Process 12(2):793–803
Zhang Y, Lu K, Gao Y (2015) QSobel: a novel quantum image edge extraction algorithm. Sci China Inf Sci 58:1–13
Zhao S, Yan F, Chen K, Yang H (2021) Interpolation-based high capacity quantum image steganography. Int J Theor Phys 60:3722–3743 (2021). https://doi.org/10.1007/s10773-021-04891-0
Zhou RG, Luo J, Liu X, Zhu C, Wei L, Zhang X (2018) A novel quantum image steganography scheme based on LSB. Int J Theor Phys 57(6):1848–1863
Funding
This work was supported by Tecnologico de Monterrey and CONACyT (SNI No. 41594, Fronteras Ciencia 1007).
Author information
Authors and Affiliations
Contributions
FY Conceptualization, Methodology, Data curation, Visualization, Writing-original draft, Writing-review and editing. SEV-A Funding acquisition, Conceptualization, Formal analysis, Validation, Writing-original draft, Writing-review and editing. Kaoru Hirota: Investigation, Writing-original draft, Writing-review and editing, Supervision.
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Ethics approval
Not applicable.
Consent to participate
All authors read and agreed to participate in the final manuscript.
Consent for publication
All authors agreed to publish this paper, if accepted.
Additional information
Communicated by Oscar Castillo.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yan, F., Venegas-Andraca, S.E. & Hirota, K. Toward implementing efficient image processing algorithms on quantum computers. Soft Comput 27, 13115–13127 (2023). https://doi.org/10.1007/s00500-021-06669-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-021-06669-2