
Abstract
Clustering is considered to be the most significant method for resolving conflicts of data transmission and maximizing the life span of the network in Wireless Sensor Networks (WSNs). The sensor nodes are densely deployed to satisfy the coverage requirement; this causes some nodes to lazy mode. Some algorithms of cluster heads (CHs) selection were already proposed for sufficient energy management. However, it remains as a challenging task in WSN due to network scalability, protocol characteristics, and data transfer rate. This paper aims to propose a novel clustering model is proposed by this research work for cluster head selection (CHS) that considers four primary constraints: namely energy consumption, delay, distance, and security. In addition, for optimal selection of CH, a novel algorithm, which is the hybridization of the Dragon Fly (DA) algorithm and firefly algorithm, is proposed. The proposed hybrid algorithm is named as FireFly replaced Position Update in Dragonfly (FPU-DA). The performance of the proposed work is compared with conventional algorithms. Subsequently, a parametric analysis is performed by varying the weight factor of the proposed FPU-DA model to investigate its impact on the performance of the CHS problem. The proposed FPU-DA model at round 2000 shows 9%, better than KNN and SOM. Thus, the analysis results proved that the proposed model attains a better life span when compared to that of other conventional models.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In a WSN, numerous sensor nodes get distributed over the networks in a geographical area. These distributed sensor nodes are grouped as clusters to save energy and increase the lifetime of the network. This is termed as the clustering technique in WSN. Moreover, in every cluster, one sensor node will behave as CH (Mazinani et al. 2018; Wang et al. 2018; Muthukumaran et al. 2018), and the other sensor nodes will act as member nodes. In WSN, the CH selection process preserves the energy of each node by designing novel energy management algorithms. While the clusters are separated based on the CH, the CH acts as the coordinator of sensor nodes and BS. CHS can be performed in two ways, namely (1) distance-based selection system (Kang and Nguyen 2012; Lee et al. 2010), all nodes in the cluster have to be located at a specific distance from the CH that is nearest to it, and (2) size-constrained selection (Hao et al. 2010), in which every cluster in a network is restricted to definite number of members. Accordingly, in a cluster, three kinds of nodes are found. The initial one is the CH (Sabet and Naji 2015; An et al. 2017), which makes co-ordination between nodes and compresses the data received from its nodes and the subsequent one is the cluster member, which transfers information to their CH. The third one is the cluster gateway, which links one cluster with another. The main aim of this is to pass the information between clusters (An et al. 2017). The developed FPU-DA algorithm is proposed for optimal selection of CH which is the combination of FF and DA algorithm. The advantage of FPU-DA includes, high accuracy, remarkable stability, increasing population diversity, accelerating the convergence, strong robustness, powerful optimizing ability, and higher precision. The drawbacks of the existing methods include, a high initial set up cost, and not well at exploring the search space. When combining two features (FF and DA), the convergence rate can be further minimized. So that the FPU-DA considers the neighborhood relationship of dragonfly algorithm. If the dragonfly succeeds in finding a better neighborhood solution, then it is considered for further updating, on the other hand if the dragonfly fails to enter the neighborhood solution, the levy-based FF update is imposed.
On the other hand, routing protocols are of two types, i.e., hierarchical-based routing protocol and location-based routing protocol. Every protocol has unique structure and protocol operation. The location-based routing protocol should be aware of its nodes’ position using node positioning devices like GPS, acoustic signals, radio signals or infrared signals. It is very efficient and scalable only when location is known. The location sensing precision differs based on the network range, granularity, cost, and deployment complexity. However, it is undesirable for large scale WSN (Intanagonwiwat et al. 2000). The hierarchical-based routing protocols are deployed for increasing robustness, scalability and reducing data retransmission (Ahmad et al. 2014). The hierarchical routing protocols necessitate cluster-based WSNs. The core elements of the cluster-based WSNs are sensor nodes, clusters, CHs, BS and end-users. The controlling of every cluster is carried out by the CH (Liaqat et al. 2016) that has direct communication with the BS. To preserve the energy and lifetime of the network, each node in the cluster transfers the data to its CH and the CH forwards them to the BS. It avoids every node to transfer the data directly to the BS, because it consumes more energy than transferring to CH. The challenge is determining optimal CH, so that it can coordinate well with the nodes as well as the BS. Since the data rate and node characteristics are dynamic over time period, CHs need to be dynamic to the environment. Hence, it has become a challenging task to the network administrators to determine the optimal CH over a varying time period. The conventional clustering algorithms such as k-means algorithm can be suitable methodology to select CH, it has own limitations such as biased towards initial parameters. This paper intends to develop advanced CH selection algorithm by incorporating advancements in a popular meta-heuristics, which are proven in the literature for its best replacement over traditional clustering algorithms. Moreover, meta-heuristics (Bansal et al. 2017; Bansal 2019, 2020) are high evolving computational intelligence and they are subjected to many challenging multi-objective problems, where trade-off is essential. Accordingly, the CH selection problem remains challenging and it will become more complicated if additional objectives are incorporated. So, this paper made such an attempt to propose a novel variant to address the present challenge of the CH selection problem.
The significant contributions are listed below.
-
1.
We formulate a multi-objective model in which the security objective is incorporated along with the traditional CH selection requirements such as energy consumption, delay and distance minimization objectives with adequate trade-off.
-
2.
We develop a hybrid optimization algorithm called as FPU-DA algorithm, which is the combination of FF and DA algorithm, for optimal selection of CH.
FF has levy-based update function, which attracts towards the best firefly or target. There is no provision of evading from the poor solution, which can be called as enemy in biological inspiration. This feature has been incorporated in the DA. Since FF has been reported in the literature for its good performance, we have intended to enhance its performance further by incorporating the DA characteristics to develop the novel variant FPU-DA.
The paper is arranged as: Sect. 2 reviews various CHS models that are reported in the literature. Section 3 provides a short description on conventional DA and FF algorithm. Section 4 describes the cluster head selection model along with the proposed FPU-DA algorithm. Section 5 presents the constraints for optimal CHS: energy, distance, delay, and security. Section 6 infers the results and Sect. 7 concludes the paper.
2 Literature review
Mazinani et al. (2018) have developed a new scheme known as Fuzzy Multi Cluster-Based Routing with Constant Threshold (FMCR-CT) that intended to improve the life span of WSN by minimizing the transmitted messages and CHS in every round. The distance of every node, count of nodes, and residual energy was considered as a fuzzy criterion (FCM) for choosing the CH. Furthermore, the presented method was distinguished from other approaches concerning various constraints of the node. Finally, the execution outcomes show the enhancement of the presented model.
Wang et al. (2018) have developed a genetic algorithm (GA)-based approach, where the routing and clustering methods were united into a particular chromosome for computing the total energy utilization. Depending on the total energy utilization, fitness function was formulated. Therefore, energy utilization between the nodes could be regulated.
Muthukumaran et al. (2018) have suggested a hierarchical routing energy efficiency model for raising the network life span by adopting the Energy-Efficient Clustering (ENEFC) scheme. The implemented model has offered three varied models, such as Hierarchical Routing Using Multi-Hop (HRMH), HR Using Multilevel (HRML), and HRCI. Here, the HRML has allocated a level to every CH over the whole network, and when the route misbehaves, a new level was introduced for the route among the BS and CH’s. The analysis outcomes demonstrated that the HRML was more effectual with respect to energy efficiency over other models.
Sabet and Naji (2015) have intended a scheme, where multi-hop routing and clustering algorithms were performed at equal levels to reduce control packets. Based on non-uniform energy utilization between nodes, clusters were modeled such that CHs should have the capability in forwarding the transmission tree. The three major modification constraints in CHS were exact distance, adjustment degree, and energy utilization. At last, the outcomes illustrated that the established method provides better minimization of nodes, energy utilization, and it further extends the network life span.
An et al. (2017) have established a system that integrates the issues of network components as the overall decision for increasing the network life span. The development of the planning and decision processes was examined using comprehensive examples in both real and simulated surroundings. Accordingly, the execution outcomes demonstrate that the introduced joint model has admirable allocation and deployment for sensor nodes and CH’s that was much nearer to the desired solution.
Bhatti et al. (2016) have developed a novel model for clustering based on fuzzy c-means (FCM) clustering also the cluster head (CH) was selected using the location of the sensor nodes with respect to its signal-to-noise ratio (SNR), fusion center (FC), and its residual energy. The single sensor’s sensing information was not reliable due to fading and shadowing. To tackle these issues, cooperative spectrum sensing schemes were proposed. For cooperative spectrum sensing, all sensors sense the spectrum and report the sensed energy to FC for the final decision.
Enami and Moghadam (2010), have proposed a centralized adaptive energy-based clustering protocol through the application of self-organizing map neural networks (called EBC-S) which can cluster sensor nodes, based on coordinates of sensor nodes, multi constraints; and energy level. They have applied maximum energy nodes as weights of SOM map units. And hence the nodes with higher energy attract the nearest nodes with lower energy levels. Therefore, formed clusters may not necessarily contain adjacent nodes. The proposed algorithm enables energy balanced clusters. Simulation results proved that new algorithm was able to extend the lifetime of the network.
Fakhet et al. (2017) have proposed a new method for optimal clustering that accurately localizes sensors while minimizing their power consumption. It splits the task of CH between sensor nodes to send data to the base station (BS). The proposed work was based on K-means method to selected cluster head. The selection of CH starts with the closest nodes to the centroid point. Then, the selected nodes with high power were compared to its neighbors, till energy gets ruined. Simulation results prove effectiveness in network lifetime.
Bansal (2018), has proposed multi-objective optimization algorithms (MOAs) to find the optimal Golomb rulers (OGRs) in a reasonable time. The OGRs can be used as a channel allocation algorithm that allows suppression of the four-wave mixing crosstalk in optical wavelength division multiplexing systems. The MOAs outperforms the existing conventional classical and nature-inspired-based algorithms to find near-OGRs in terms of ruler length, total occupied optical bandwidth, and bandwidth expansion factor (Table 1).
3 DA and FF algorithm: a short description
Since the proposed algorithm is the hybridization of DA and FF, a short description of both algorithms is provided as follows:
3.1 Dragonfly algorithm
The Dragonfly algorithm (DA) model (Jafari and Chaleshtari 2017) is associated with the two foremost stages, such as (1) exploration and (2) exploitation. These two phases are designed as follows: Hi denotes the separation of ith DA as represented in Eq. (1), in which Yj signifies the jth position of neighboring individual, Y indicates the position of the current individual, and N shows the number of neighboring individuals
Alignment Bi is measured, as given in Eq. (2), in which Qj signifies the velocity of the jth neighboring individual. Further, the cohesion Gi is formulated as per Eq. (3), in which Yj signifies the position of jth neighboring individual, Ne shows the neighbor count, and Y indicates the position of the current individual.
Equation (4) shows the attraction to a food resource, in which Y+ indicates the food source position.
Distraction towards an enemy is indicated by Eq. (5), in which Y− indicates the enemy’s position and Y specifies the present position of individuals.
In addition, two vectors are evaluated for updating the position of dragonflies; they are a step (ΔY) and position (Y).
Equation (6) shows the step vector that portrays the moving direction of the dragonfly. Accordingly, Hi signifies the separation of ith individual, p denotes the separation weight, a denotes the alignment weight, G indicates the ith individual cohesion, c points to the cohesion weight, B refers to alignment of the ith individual, Fi symbolizes the food resource of ith individual, f indicates the food factor, e corresponds to the enemy factor, wei shows the inertia weight, Ei denotes the enemy’s position of the ith individual and t symbolizes the iteration counter.
Accordingly, the position vectors are shown by Eq. (7), in which t denotes the current iteration.
When there are no other neighboring solutions, the dragonfly’s position gets modified by Eq. (8), in which z signifies the dimension of the position vectors, and t stands for the current iteration.
The Levy flight is evaluated by Eq. (9), in which β is a constant factor and r1r2 denotes the random numbers that range among [0,1]. Further, δ is evaluated using Eq. (10), in which Γ(x) = (x − 1).
3.2 Conventional firefly algorithm
Fireflies (Baskaran and Sadagopan 2015) are the most charismatic insects when compared with others. In FF, the distance u rises with the decrease in light intensity, I as revealed in Eq. (11).
Two significant issues, such as attraction and light intensity variation, must be resolved for designing the FF model. Here, light intensity I representing the solution S is proportional to the fitness value. Here, according to Eq. (12), there will be variation in light intensity I(u), where I0 indicates the light intensity achieved from source, and light absorption is evaluated by deploying the light absorption coefficient γ.
Therefore Eq. (13) can be represented to depict the attractiveness, β, in which β0 symbolize the attraction level at u = 0.
In Eq. (14), uij reveals the distance among two fireflies Si and Sj, where n signifies the dimensionality issues.
Equation (15) is deployed in this manner, in which ɛi denotes a random number.
4 Cluster head selection model with proposed FPU-DA algorithm
4.1 Network model
Wireless Sensor Network (WSN) consists of several nodes denoted by M. These nodes transmit the sensed data to the sink node Bs. The transmission pattern of the entire sink nodes follows uniform distribution, in which the data is distributed with Mn and Mm dimensions in meters. A sensor node group becomes a cluster, which is denoted by Cn. In all the clusters, the corresponding CH is indicated by D nc . Since the method of data transmission from sensor nodes to BS is through the CH, it is termed as CH-oriented routing. Here, dHB denotes the distance between BS and CH, whereas, the distance between the ith node to jth CH is indicated by dij. The protocols define how nodes will communicate with each other and how the information will be disseminated through the network. There are many ways to classify the protocols of WSN namely Node centric protocol, data centric protocol, source-initiated protocol, destination-initiated protocol. In node centric protocols the destination node is specified with some numeric identifiers. For example, low-energy adaptive clustering hierarchy (LEACH).In most of the WSN, the sensed data or information is more valuable than the actual node itself. Therefore, data centric protocol focus on the transmission of information specified by certain attributes rather than collecting data from certain nodes. In source-initiated protocols the source node advertises the data to share and then the route is generated from the source side to the destination. Protocols are called destination-initiated protocols when the path setup generation originates from the destination node. This paper is limited to focus on node centric protocol, which is responsible for administrating the network in acquiring and transmitting the data to the BS energy efficiently. Accordingly, the traditional LEACH protocol is considered for which the CH selection process is effectuated by the proposed algorithm. As mentioned above, this work introduces a new FPU-DA algorithm for selecting the CH, which is given below:
4.2 Proposed FPU-DA algorithm
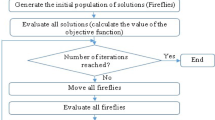
Even though the conventional DA algorithm poses various advantages, it also includes certain disadvantages like minimal internal memory and slow convergence. Hence, it is planned to merge both the concepts such that the optimization problems could be solved with better convergence. The novelty of the hybridization is that the FPU-DA is an ideal combination of FF and DA. FF has levy-based update function, while the DA has an interesting feature of evading from the enemy. By combining these two features, the convergence rate can be further minimized. Hence, the FPU-DA considers the neighborhood relationship of dragonfly algorithm. If the dragonfly succeeds in finding a better neighborhood solution, it is considered for further updating and so the updated solution is away from poor solution. In any case, if the dragonfly-based solution fails to enter the neighborhood, the levy-based FF update is imposed using Eq. (9) to determine the updated solution. The flowchart of the proposed FPU-DA Algorithm is shown in Fig. 1.

Flowchart of the proposed FPU-DA algorithm
Algorithm 1 depicts pseudocode of the proposed FPU-DA algorithm. Moreover, the separation weight, alignment weight, cohesion weight, food attraction weight and enemy distraction weight of proposed algorithm are determined as shown in Eqs. (16)–(20), where w denotes the weighting factor and b is given by Eq. (21). In Eq. (21), tmax denotes the maximum iteration.

5 Constraints for optimal CH selection: energy, distance, delay, and security
5.1 Objective function and energy awareness
Based upon these constraints on cluster head selection, Eq. (23) demonstrates the minimized objective function for CHS. Here, the constant parameters of energy, distance, risk factor, and delay, are denoted by ψ1, ψ2, ψ3 and ψ4 correspondingly. Accordingly, the parameters in Eq. (24) should attain the state given by Eq. (22).
5.2 Distance function and energy awareness
The distance function and energy awareness that are given in Eq. (24) are detailed in Eqs. (26) and (29), respectively.
Equation (26) illustrates the fitness function in terms of distance, in which, g (m)distance indicates the distance among the nodes that ranges between 0 and 1, and g (n)(distance) indicates the packet distance that is transmitted from the normal node to CH and from CH to BS. When the distance among normal node and CH is high, it creates high values of gdistance.
Equation (29) shows the fitness function in terms of energy. If g (m)energy and g (n)energy in Eq. (29) attains several CH and more energy, then the genergy value will be above one. Equation (30) shows the variations of node energy and unit value, which is considered as the condition for achieving the energy constraint. Here, the enhanced CHS process offers minimal nE(q) value. In Eq. (31), E(L normp ) and E(L normq ) denotes the energy of pth the normal node and qth normal node, correspondingly.
5.3 Delay function
The delay function is ratio of maximum number of nodes in a cluster to the number of clusters. The fitness function for the delay is given in Eq. (33). So as to minimize the delay, the count of nodes in the cluster must be reduced.
The fdelay value should range between 0 and 1. In Eq. (33), \( {\text{Max}}\left( {D_{c}^{q} } \right)_{q = 1}^{{D_{c}^{n} }} \) shows the highest CH count and L denotes the entire count of clusters in the network.
5.4 Security awareness
The security awareness in the CHS process can be handled by three security modes, called as γ-risky mode, risky mode, and security mode.
Security mode The CH that satisfies the needs of security is chosen by this mode. In Eq. (34), sd and sr specifies the security demand and security rank associated with the CH, correspondingly. A node is considered as the optimal CH when it satisfies the criterion, sd ≤ sr.
γ-risky mode The CH that holds the higher γ-risk is chosen based on γ-risky mode. Accordingly, γ specifies the probability measure with values, γ = 1 and γ = 0 (i.e., 100%).
Risky mode This mode elects an existing CH that overcomes all the risks for enabling the optimal CHS. Therefore, the risky mode is said to be an insistent mode throughout the CHS processing.
Of all the above mentioned 3 modes, the secure mode is known as the challenging and inexpensive mode, but the most exploited one is the γ-risky mode. Equation (34) shows the probability of security constraint modeling.
Here, if the chosen CH attains the state, sd > sr the risk is lesser than 50%. If the state is 0 < sd − sr ≤ 1, the selection process is performed, and if the state is 1 < sd − sr ≤ 2, the selection process gets delayed. However, the CHS process could not be completed, and it has to be discontinued for the state 2 < sd − sr ≤ 5, because it exhibits 100% risk. The block diagram for optimal CH selection: Energy, Distance, delay, and security awareness is shown in Fig. 2.

Block diagram for optimal CH selection: energy, distance, delay, and security
6 Results and discussion
6.1 Simulation procedure
The implementation for optimal CHS in WSN using FPU-DA was carried out in MATLAB 2018a, and the results were attained. The number of sensor nodes was distributed in the network with an area of 100 m × 100 m centralized BS (Zhao et al. 2016; Zhou et al. 2016; Zhou et al. 2017). Here, EF was the energy requirement of a free space model that was set at 10 nJ/bits/m2 and EI was the initial energy set at 0.5. In addition, ET denotes the energy of transmitter set at 50 nJ/bits/m2 and Ep denotes the energy of power amplifier set at 0.0013 nJ/bits/m2. ED Signifies the energy of data aggregation set at 5 nJ/bits/signal. In the presented work, the experiments were performed by executing the CHS for 2000 rounds. The performance analysis of proposed model is evaluated by (B) Varying the parameter of weighting factor w to 0.2, 04, 06, 08 and 1.0 (C) comparing with the renowned conventional algorithms.
6.2 Parametric analysis
-
(i)
Convergence Analysis
Figure 3 shows the convergence analysis of the adopted FPU-DA scheme by varying the weighting factor w. From the experimental results, the cost function of the proposed model for all values of w gets reduced. More particularly at fifth iteration, minimization of the cost function is 25%, 20%, 30%, and 55% better than the settings, w = 0.2, w = 0.4, w = 0.8 and w = 1.0, respectively. Therefore, the superiority of the presented FPU-DA approach has been validated effectively.

Convergence analysis of proposed model with respect to varying iterations
-
(ii)
Alive nodes Analysis
The Number of Alive Nodes (NAN) and the log of NAN with respect to the number of rounds and distance is shown in Fig. 4. From the examination, the NAN is found to be higher at w = 1.0 over the other values of w. From Fig. 4a, the NAN for the proposed FPU-DA model at w = 1.0 is 15% higher than w = 0.2, w = 0.4, w = 0.6 and w = 0.8 at 2000th round. Moreover, from Fig. 4b, the log of NAN for the presented scheme at a distance of 55 m at w = 1.0 is 9.3%, 2.33%, 2.33% and 4.65% superior to w = 0.2, w = 0.4, w = 0.6 and w = 0.8, respectively.

Analysis on number of alive nodes and log of the number of alive nodes for the proposed scheme with respect to a number of rounds b distance
-
(iii)
Analysis on the Normalized Network Energy
The Normalized Network Energy (NNE) analysis for the implemented FPU-DA scheme by varying values of w is illustrated in Fig. 5. From Fig. 5a, better NNE can be observed at w = 0.8 when compared to other values of w. Accordingly, from Fig. 5b, improved energy is achieved by the presented system in terms of the energy difference.

Analysis on normalized energy of the proposed model a number of rounds and b energy difference
-
(iv)
Analysis on Delay
The delay analysis for optimal CHS using the presented FPU-DA model for varying rounds is specified in Table 2. From the analysis, the presented model at w = 0.2 is 38.1%, 6.49%, 20.98% and 24.44% superior to w = 0.4, w = 0.6, w = 0.8 and w = 1.0, respectively (at 225th round). Thus, the supremacy of the adopted FPU-DA model with respect to w in terms of the delay was confirmed in an effectual way. Moreover, the delay analysis of proposed and conventional models is illustrated in Table 3. On observing the attained results, the delay of the presented algorithm is found to be lesser than the conventional algorithms.
-
(v)
Analysis on Risk probability
Table 4 shows the analysis on risk probability of the selected CH through the FPU-DA at varying weight factors. From the
analysis, the presented model at w = 0.2 is 40.01%, 38.87%, 20% and 9.45% better than when w = 0.4, w = 0.6, w = 0.8 and w = 1.0 at 100th round.
6.3 Comparative analysis
-
(i)
Alive node analysis
Figure 6 illustrates the analysis of proposed and renowned models with respect to varying number of rounds. Figure 6a illustrates the alive node analysis. At round 1500, the proposed model is 6%, 4%, and 24% better than K-means algorithm, FCM, and SOM models. Further, the proposed model at round 2000 is 73.68%, 46.05%, and 17.64% better than K-means algorithm, FCM and SOM model. In addition, Fig. 6b portrays the proposed and conventional CH selection algorithms for different rounds. At round 1500, the proposed model is 23.68%, better than FF algorithm. Similarly, the proposed model is 2% better than GWO and WOA algorithm, 33.33% better than DA algorithm. Moreover, at round 2000, the proposed model is found to be 80.95%, 35.71%, 44%, 46.15%, better than FF, GWO, WOA and DA, respectively. Hence from the comparative analysis in terms of number of alive nodes, the proposed algorithm is better than renowned clustering algorithm and CHS algorithms.

Alive node analysis by varying the number of rounds interms of a state-of-art models and b conventional models
-
(ii)
Normalized energy analysis
Figure 7 illustrates the normalized energy analysis of the proposed and conventional models. Figure 7b demonstrates the normalized energy level for all renowned clustering algorithms. The proposed FPU-DA model at round 2000 shows 9%, better than KNN and SOM. Consequently, the proposed model is 2% superior to FCM. Similar, while analyzing the proposed model with the conventional optimization algorithms, Fig. 7b infers the normalized energy level of the sensor nodes are 52.63%, 9%, 52.61% higher than FF, GWO, and WOA at round 1500, respectively. Likewise, the proposed model also shows its superiority over other conventional algorithms till the final data transmission round. Thus, the analysis results proved that the proposed model attains better life span when compared to that of other conventional models.

Analysis on proposed and conventional models varying the number of rounds interms of a Alive nodes and b Normalized energy
6.4 Statistical Analysis
The statistical analysis of the proposed FPU-DA is compared with the existing FF (Baskaran and Sadagopan 2015), GWO, WOA, and DA (Jafari and Chaleshtari 2017), which is shown in Tables 5, 6 and 7 respectively. All the algorithms should be executed five times, and the statistic of entire execution in terms of best performance, worst performance, mean, median and standard deviations are computed for Alive Nodes, Normalized Energy, and Convergence graph. Here, mean performance is the average of best and worst performance, the median is the centre point of best and worst performance, and the standard deviation provides the degree of alterations happened among 5 executions. In Table 5 for Alive Nodes analysis, the best cases of the proposed FPU-DA is 45.71% better than FF, 20% better than GWO, 22.85% better than WOA, and 25.71% better than DA. For mean cases the proposed FPU-DA is 7.35% better than FF, 7.61% better than GWO, 5.84% better than WOA, and 8.65% better than DA. In Table 6 for normalized network energy, the mean cases of the proposed FPU-DA is 18.63%, 13.95%, 16.66%, 14.88% superior to FF, GWO, WOA, and DA. For median cases the proposed FPU-DA is 33.54% upgraded than FF, 33.42% upgraded than GWO, 31.38% upgraded than WOA, and 33.93% upgraded than DA. In Table 7 for convergence analysis, the worst cases of the proposed FPU-DA is 26.81% advanced than FF, 1.08% advanced than GWO, 15.78% advanced than WOA, and 40.68% advanced than DA. For standard deviation the proposed FPU-DA is 8.11% better than FF, 54.60% better than GWO, 57.44% better than WOA, and 7.26% better than DA.
6.5 Analysis of computational time
The primary intent is to understand the computational complexity of the algorithm, but the theoretical complexity is almost similar to population-based meta-heuristics. Accordingly, the FPU-DA also has a computational complexity of O(nt log (n)) where n denotes the population size and t is the iteration. However, the real computing time varies based on the updating strategies. Hence, the execution time of each algorithm is observed and listed in Table 8 as computational time. On considering the computational time, the proposed algorithm is better than the existing methods, such as FF, GWO, WOA, and DA. The computational time of the proposed FPU-DAis 13.30% better than FF, 24.24% better than GWO, 22.67% better than WOA, and 55.82% better than DA, respectively.
7 Conclusion
This paper has presented a new clustering approach with optimal CHS that considers the foremost constraints namely, energy, delay, distance, and security. Here, in the presented work, a novel FPU-DA scheme for optimal selection of CHS has been proposed. The performance of the adopted technique was examined by carrying out an algorithmic analysis by varying the weight factor of the proposed FPU-DA model. From the analysis, the NAN for the proposed model at 2000th round was 45.95%, 18.92%, 24.32%, and 24.32% better than the FF, GWO, WOA and DA algorithms. On considering the convergence analysis, the NAN for the proposed model at 2000th round is 45.95%, 18.92%, 24.32%, and 24.32% better than the FF, GWO, WOA and DA algorithms. Also, the delay at 0th round, the implemented FPU-DA model was 16.93%, 26.64%, 27.7%, and 27.1% better than the FF, GWO, WOA and DA algorithms. From the analysis, the presented model in terms of risk probability at 0th round was 77.27%, 8.97%, 8.09%, and 49.26% better than the FF, GWO, WOA and DA algorithms. Also, at 1500th round, the implemented FPU-DA scheme was 74.98%, 23.45%, 31.05%, and 45.06% better than the FF, GWO, WOA and DA algorithms. Subsequently, the lifetime and the normalized energy comparison of the state-of-art models and the existing algorithms are also analyzed. For lifetime analysis, the simulation results show 6%, 4%, and 24% better than K-means algorithm, FCM and SOM of the state-of-art models in round 1500. Also, at round 2000, the proposed model was found to be 80.95%, 35.71%, 44%, 46.15%, better than FF, GWO, WOA and DA conventional models. Similar, the normalized energy of the proposed was also shown better results in terms of state-of-the-art models and conventional models. Thus, the improved performance of the implemented FPU-DA-based CHS in WSN was proved in a better way.
Abbreviations
- WSN:
-
Wireless sensor networks
- CH:
-
Cluster head
- CHS:
-
Cluster head selection
- DA:
-
Dragon fly
- FF:
-
Firefly algorithm
- BS:
-
Base station
- FPU-DA:
-
FF replaced position update in DA
- FMCR-CT:
-
Fuzzy multi cluster-based routing with constant threshold
- GA:
-
Genetic algorithm
- ENEFC:
-
Energy-efficient clustering
- HRMH:
-
Hierarchical routing using multi-hop
- HRML:
-
HR using multilevel
- NAN:
-
Number of alive nodes
- NNE:
-
Normalized network energy
References
Ahmad A, Javaid N, Qasim U, Ishfaq M, Khan ZA, Alghamdi TA (2014) RE-ATTEMPT: a new energy-efficient routing protocol for wireless body area sensor networks. Int J Distrib Sens Netw 10(4):464010
An J, Qi L, Gui X, Peng Z (2017) Joint design of hierarchical topology control and routing design for heterogeneous wireless sensor networks. Comput Stand Interfaces 51:63–70
Bansal S (2018) Nature-inspired-based multi-objective hybrid algorithms to find near-OGRs for optical WDM systems and their comparison. Biomimicry Inf Retri Knowl Manag. https://doi.org/10.4018/978-1-5225-3004-6
Bansal S (2019) A comparative study of nature-inspired metaheuristic algorithms in search of near-to-optimal Golomb rulers for the FWM crosstalk elimination in WDM systems. Appl Artif Intell 33(14):1199–1265
Bansal S (2020) Performance comparison of five metaheuristic nature-inspired algorithms to find near-OGRs for WDM systems. Artif Intell Rev. https://doi.org/10.1007/s10462-020-09829-2
Bansal S, Singh AK, Gupta N (2017) Optimal golomb ruler sequences generation for optical WDM systems: a novel parallel hybrid multi-objective bat algorithm. J Inst Eng India Ser B 98(1):43–64
Baskaran M, Sadagopan C (2015) Synchronous firefly algorithm for cluster head selection in WSN. Sci World J 2015:1–7. https://doi.org/10.1155/2015/780879
Bhatti DMS, Saeed N, Nam H (2016) Fuzzy C-means clustering and energy efficient cluster head selection for cooperative sensor network. Sensors 16(9):1–17
Enami N, Moghadam R (2010) Energy based clustering self organizing map protocol for extending wireless sensor networks lifetime and coverage. Can J Multimed Wirel Netw 1(4):42–53
Fakhet W, Khediri SE, Dallali A, Kachouri A (2017) New K-means algorithm for clustering in wireless sensor networks. In: International conference on internet of things, embedded systems and communications (IINTEC), Gafsa, Tunisia, pp 1–5
Hao P, Qiu W, Evans R (2010) An energy-efficient cluster-head selection protocol for energy-constrained wireless sensor networks. In: Zheng J, Mao S, Midkiff SF, Zhu H (eds) Ad Hoc networks. ADHOCNETS 2009. Lecture notes of the institute for computer sciences, social informatics and telecommunications engineering, vol 28. Springer, Berlin
Intanagonwiwat C, Govindan R, Estrin D (2000) Directed diffusion: a scalable and robust communication paradigm for sensor networks. In: Proceedings of the 6th annual international conference on mobile computing and networking, Boston, pp 56–67
Jafari M, Chaleshtari MHB (2017) Using dragonfly algorithm for optimization of orthotropic infiniteplates with a quasi-triangular cut-out. Eur J Mech A Solids 66:1–14
Kang SH, Nguyen T (2012) Distance based thresholds for cluster head selection in wireless sensor networks. IEEE Commun Lett 16(9):1396–1399
Lee K, Lee J, Lee H, Shin Y (2010) A density and distance based cluster head selection algorithm in sensor networks. In: 2010 the 12th international conference on advanced communication technology (ICACT), Phoenix Park, pp 162–165
Liaqat T, Akbar M, Javaid N, Qasim U, Khan Z, Javaid Q, Alghamdi T (2016) On reliable and efficient data gathering based routing in underwater wireless sensor networks. Sensors 16(9):1391
Mazinani A, Mazinani SM, Mirzaie M (2018) FMCR-CT: an energy-efficient fuzzy multi cluster-based routing with a constant threshold in wireless sensor network. Alex Eng J, corrected proof, Available online 26 December (in press)
Muthukumaran K, Chitra K, Selvakumar C (2018) An energy efficient clustering scheme using multilevel routing for wireless sensor network. Comput Electr Eng 69:642–652
Sabet M, Naji HR (2015) A decentralized energy efficient hierarchical cluster-based routing algorithm for wireless sensor networks. AEU Int J Electron Commun 69(5):790–799
Wang T, Zhang G, Yang X, Vajdi A (2018) Genetic algorithm for energy-efficient clustering and routing in wireless sensor networks. J Syst Softw 146:196–214
Zhao Z, Peng M, Ding Z, Wang W, Poor HV (2016) Cluster content caching: an energy-efficient approach to improve quality of service in cloud radio access networks. IEEE J Sel Areas Commun 34(5):1207–1221
Zhou Z, Dong M, Ota K, Wang G, Yang LT (2016) Energy-efficient resource allocation for D2D communications underlaying cloud-RAN-based LTE-a networks. IEEE Internet Things J 3(3):428–438
Zhou Z, Gong J, He Y, Zhang Y (2017) Software defined machine-to-machine communication for smart energy management. IEEE Commun Mag 55(10):52–60
Funding
The author would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 19-COM-1-01-0002.
Author information
Authors and Affiliations
Contributions
The author has come out with the proposed idea; he had make sole contribution for the development and carried out all the research work.
Corresponding author
Ethics declarations
Conflict of interest
Not applicable.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Alghamdi, T.A. Parametric analysis on optimized energy-efficient protocol in wireless sensor network. Soft Comput 25, 4409–4421 (2021). https://doi.org/10.1007/s00500-020-05449-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-020-05449-8