
Abstract
As an effective way to help users find attractive locations and meet their individual needs, point-of-interest (POI) recommendation has become an important application in location-based social networks (LBSNs). Although the geographical influence has been reported as an effective factor for improving POI recommendation accuracy, previous work mainly models it from the user perspective instead of location perspective. Intuitively, neighboring POIs tend to be visited by similar users, which implies that modeling geographical relationships from a location perspective can simulate users’ behavior more reasonably. Moreover, different from traditional recommendation problems, users in LBSNs often express their interests only by checking in different POIs, which is a kind of implicit feedback. In other words, we can easily get the POIs that the users have visited, but it is hard to get the ones that the users do not like. We cannot use a common approach to distinguish these negative values directly. Based on the above observations, this work concentrates on exploiting the geographical relationships among POIs from a location perspective for implicit problem, where a location neighborhood-aware weighted probabilistic matrix factorization is proposed (L-WMF). To be specific, the weighted probabilistic matrix factorization (WMF) that can deal with implicit feedback is first introduced as our basic POI recommendation method. Then, we incorporate the geographical relationships among POIs into the WMF as the regularization terms to exploit the geographical characteristics from a location perspective. Finally, we conduct several experiments to evaluate our L-WMF method on two real-world datasets, and the experimental results indicate that the L-WMF is more effective and can reach better performance than other related methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the development of mobile Internet, the location-based social network (LBSN, e.g., Yelp, Foursquare and Gowalla) as one of the most popular open platforms for information exchanging and sharing has rapidly entered user’s daily life and work. Users in LBSNs can express their interest by checking in different POIs (e.g., cinemas, restaurants and hotels), which provides a reference for other users to select possible visiting places. On the other hand, the huge amount of data makes users fall into the dilemma of information overload and cannot make personalized recommendations effectively. To solve this problem, POI recommendation as an efficient way to help users explore interesting unknown locations has become one of the most hot research topics in social media mining.
Motivated by the observation that people’s mobile behavior is limited by physical constraints, that is, users are more likely to visit adjacent places, more and more researches have considered geographical influences in the design of algorithms to further enhance the performance of traditional recommendation (Ye et al. 2011; Cheng et al. 2012; Guo et al. 2018). For example, Zhang and Chow (2013) leveraged kernel density estimation to model the geographical influence by using a personalized distance distribution for each user rather than a universal distribution for all users. This method mainly focuses on exploring the personalized geographical influence of locations from the users’ check-in behaviors. Inspired by the intuition that user’s check-ins often disperse around several centers, Zhao et al. (2013) proposed a genetic algorithm-based Gaussian mixture model (GA-GMM) to capture geographical influence.
Although the work that explores the influence of geographical factor for POI recommendation has been conducted by these above studies, most of them mainly focused on making recommendations by utilizing explicit feedback-based methods. However, compared with other recommender systems, in POI recommendation the user feedback is implicit rather than explicit, which means only positive user behaviors can be observed (such as the POIs that the users have visited) and the places that users dislike are not recorded in the system. How to infer user interest from implicit feedback data is the main task of this kind of recommendation problem. Lian et al. (2014) developed the GeoMF model based on weighted matrix factorization and regarded POI recommendation as the one-class collaborative filtering problem (OCCF) (Pan et al. 2008). Yang et al. (2017) proposed a semi-supervised learning framework to jointly learn the embeddings of both users and POIs, where a neural network-based method was trained for logistic prediction and POI recommendation. Yu et al. (2016) proposed a ranking-based Poisson matrix factorization model for POI recommendation and took the advantage of the Poisson distribution to model users’ check-in behaviors.
However, the above existing studies mainly investigated the geographical influence from a user perspective, and the approach that exploits it from location perspective has not yet been fully developed. In order to further investigate geographical influence, we conducted an empirical analysis of users’ mobile data and found that neighboring POIs tend to share similar users, i.e., POI pairs that have a short distance show a much higher probability to be visited by common users. This characteristic is independent of individuals and should be beneficial for POI recommendations. Liu et al. (2014) modeled the geographical neighborhood of a location by capturing the geographical characteristics from instance level and region level, where a weighting strategy and a group lasso penalty were introduced. However, this work did not model the geographical distance among neighboring locations, and their influence on recommendations needs to be explored.
Consequently, we propose a new location-based matrix factorization method for POI recommendation, which exploits the geographical characteristics from a location perspective. Specifically, we first treat the check-in data that can reflect the users’ interests on POIs as implicit feedback, and then introduce the WMF method as our basic recommendation framework by assuming that the more a user checks in a POI, the more the user likes this POI. In order to consider the impact of geographical features, we assume the nearest neighbors tend to have similar latent factors and further incorporate these factors into WMF method as regularization terms to model the location relationship explicitly. To evaluate our proposed method, we compare the performance of our method with other related work, and the experimental results on two real-world datasets demonstrate the importance of geographical characteristics and the effectiveness of our proposed approach.
The remainder of this paper is organized as follows. Section 2 describes some preliminaries, which include the recommendation problem that we studied in this work and several related recommendation methods. Section 3 details our proposed location neighborhood-aware weighted matrix factorization method. Section 4 shows the comparison results of our method with other related methods in two real-world datasets. Section 5 outlines some conclusions and directions for future work.
2 Preliminary
In this section, we first describe the recommendation scenario in LBSNs. Then, we review and discuss some related recommendation methods, which include explicit and implicit feedback-based recommendation, POI recommendation with geographical context and other types of contexts.

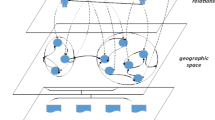
POI recommendation scenario in LBSNs. a The visit frequency matrix of users to POIs. b Overview of a LBSN. c Preference matrix of users to POIs
2.1 Problem statement
Different from traditional recommender systems that mainly utilize explicit feedback for recommendation, in POI recommender systems the check-in feedback is not explicit but implicit, which means only positive user behaviors can be observed, and unobserved POIs are either unattractive or undiscovered, but potentially attractive. Moreover, POIs have geographical information, and the users’ check-in behaviors have clustering phenomenon, which means nearby locations tend to be visited by similar users. Accordingly, we can conclude that there are two factors in LBSNs play an important role in the POI recommendation process: the user preference and the geographical features of POIs, which can be modeled by the visit frequency matrix and the geographical distance, separately (as presented in Fig. 1a, b).
As shown in Fig. 1a, the user check-in behaviors are denoted by the user–POI check-in frequency matrix, with unvisited locations are marked as “?.” Each entry in this matrix shows the visit frequencies of a target user to a place. By assuming observed check-in behaviors as positive samples and unobserved behaviors as negative samples, we can further derive the corresponding user preference matrix (as shown in Fig. 1c), with “1” and “0” denoting the positive and negative samples, respectively. Since the unobserved check-in behaviors are mixed of negative and potentially positive samples, merely treating them as negative ones cannot accurately model user behaviors. Therefore, in this work we will focus on how to solve the implicit feedback problem. Furthermore, as POIs are geographical terms, neighboring locations tend to be visited by similar users. The check-in behaviors and users’ mobile patterns are constrained by location’s geographical characteristics. Therefore, how to effectively exploit geographical features to enhance POI recommendation is our another focus.
2.2 Related work
2.2.1 Explicit feedback and implicit feedback-based recommendation
In many recommender systems (such as movie and book recommendation), users can express their preferences by scoring different items, where we can explicitly know the exact preference of a user to an item. (We refer to the rating score as explicit feedback.) Exploiting the explicit feedback to model users’ behavior has been widely studied in recent years (Wei et al. 2016; Li et al. 2018). However, in many recommender systems, users’ rating data are not always available. In many scenarios, we can only observe the items that the users have purchased, clicked or visited, but the exact rating score is unavailable. (We refer to these kinds of data as implicit feedback.) Since the missing data are mixed of negative and potential positive behaviors, we cannot infer the user preferences from implicit data directly, which makes the recommendation process more complicated (Pan et al. 2008; Guo et al. 2015a, b). To meet this challenge, many effective methods have been proposed. For instance, Pan et al. (2008) regarded the collaborative filtering with only positive samples as one-class collaborative filtering problem and introduced three weighting schemes to measure the extent that they should regard missing information as negative feedback. To avoid assigning the same weight to missing data, He et al. (2016) further weighted the missing data based on item popularity, which is more effective and flexible. In this method, a new MF-based method was developed to improve the learning process.
2.2.2 Geographical influence and preference modeling
To meet user’s urgent needs for information filtering in LBSNs, POI recommendation has become one of the most hot research topics in recent years (Han and Yamana 2017; Liu 2018; Yang et al. 2017). Inspired by the observation that nearby POIs tend to be accessed by similar users, many studies tried to explore geographical features as auxiliary information to assist POI recommendation. Ye et al. (2011) investigated the spatial clustering phenomenon exhibited in user check-in activities and leveraged the power law distribution to model it, and a unified framework was finally derived to make recommendations. As in real world, the users’ visited POIs are usually scattered around several centers, Zhao et al. (2013) employed Gaussian distribution models to approximate users’ check-in behaviors, where they focused on center discovering methods to capture the geographical influence. Different from the above methods, Zhang et al. (2015) argued that the geographical impact on each individual user should be personalized. Therefore, they utilized kernel density estimation to model the geographical influence individually. To deal with the implicit check-in data, Lian et al. (2014) developed the GeoMF model based on weighted matrix factorization, which uses the augmented latent factors to model the users’ clustering phenomenon. Yu et al. (2016) proposed a ranking-based Poisson matrix factorization model to make recommendations, which utilizes the Bayesian personalized ranking metric to optimize the loss function. Li et al. (2017) treated the business circle as a kind of geographical priority; that is, users are usually concerned more about which consumer centers they want to go to rather than the specific POIs. They redefined the user’s activity and POI influence, and thus proposed a new geographical matrix factorization model based on business circles.
2.2.3 Other context-aware POI recommendation
In addition to geographical influence, other types of contexts (such as user comments, social relationships and temporal information) have also been explored in POI recommender systems (Li et al. 2016; Zhang et al. 2018). Yang et al. (2013) developed a sentiment-enhanced location recommendation method, which first utilizes text-based sentiment analysis techniques to explore the user comments, and then fuses it to estimate users’ check-in preferences. Li et al. (2016) proposed a two-step framework to leverage the friend relationships to improve POI recommendation, which incorporates the check-in data from three types of friends into matrix factorization model by using two different loss functions. Inspired by the observation that users’ check-in time and corresponding location have a strong correlation, Gao et al. (2013) presented a time-enhanced MF recommendation framework to investigate temporal properties of check-in behaviors. In this method, temporal slot-based latent vectors are exploited to model user’s behavior preference. Si et al. (2017) further introduced an adaptive POI recommendation method to capture the impact of feature diversity of check-in data, where check-in and temporal features are fused with user-based collaborative filtering method. In addition, there are also many joint models combine these factors with geographical features to improve POI recommendations. Baral et al. (2016) exploited all the major aspects of check-in behaviors (i.e., the categorical, the geographical, the social and the temporal aspects) and incorporated them into a fused model to make recommendations.
Although the above related methods have conducted comprehensive research about how to use geographical factors to improve POI recommendation, most of them mainly focused on analyzing the geographical influence from a user perspective. But in real world, the neighboring locations are more likely to be visited by similar users. The location distance is a major factor in determining whether a user will visit a place. Hence, it is more reasonable to examine the geographical influence from location perspective. Liu et al. (2014) first investigated this problem, and they captured the geographical characteristics from a location perspective, but they did not model the geographical distance directly, and the location relations are not explicitly considered. In our work, we will further investigate how to model the geographical distance and exploit this kind of characteristics explicitly to enhance traditional recommender system.
3 Recommendation methodology
This section will systematically elaborate on how we explore geographical characteristics from a location perspective to improve traditional recommendations. First, we introduce the probabilistic matrix factorization (PMF) method to learn the latent feature factors of users and POIs, which can scale linearly with the number of observations and can be applied to very large datasets (Salakhutdinov and Mnih 2007). Second, we further introduce weighted probabilistic matrix factorization (WMF) method to deal with the implicit check-in data existing in LBSNs. Finally, we introduce how we exploit the geographical features from a location perspective and propose a location neighborhood-aware recommendation method.
3.1 Probabilistic matrix factorization
Suppose in the location-based social network \(\mathscr {G}\), we have a set of users \(\mathscr {U}\)={\(u_1 \ldots u_N\)}, and a set of POIs \(\mathscr {I}\)={\(i_1 \ldots i_M\)}. U and V represent the latent user and POI feature matrices, with column vectors \(U_u\) and \(V_i\) indicate user-specific and POI-specific latent feature vectors, respectively. In POI recommendation scenario (as described in Fig. 1), users often express their favors by visiting different POIs, which is denoted by the user–POI check-in frequency matrix \(F \in \mathbb {R}^{N\times M}\), where each entry \(F_{u,i}\) indicates how many times user u has visited POI i. In order to learn the latent features of users and POIs, the probabilistic matrix factorization (PMF) method is employed to factorize the user–POI check-in matrix F, and the conditional distribution over the observed frequencies is defined as:
where \(\mathscr {N}(x|\mu ,\sigma {^2})\) is the probability density function of the Gaussian distribution with mean \(\mu \) and variance \(\sigma {^2}\), and \(I_{u,i}\) is the indicator function that is equal to 1 if user u has visited POI i and equal to 0 otherwise. In PMF, the zero-mean spherical Gaussian priors are placed on user and POI feature vectors:
Through a Bayesian inference, the posterior probability of the latent variables U and V can be obtained as follows:
Then, the latent factors U and V can be further deduced by maximizing the posterior probability denoted by Eq. (4). U and V are the low-dimensional feature representation of users and items, which denote there are only a small number of factors determining the users’ preferences.
3.2 Weighted probabilistic matrix factorization
PMF is designed for recommender systems with explicit rating values (Wen et al. 2018), which treats POIs with high visit frequencies as positive samples and POIs with low visit frequencies as negative samples. But in POI recommendation, a user’s check-in behavior indicates his/her preference for this location. The visit frequency determines the confidence we can deduce the user like to visit that location. To deal with this kind of implicit feedback, we introduce the weighted probabilistic matrix factorization method to learn the latent factors, which models the check-in data by randomly sampling some negative examples from missing values and giving them smaller weights than positive ones since we have small confidence to treat them as negative examples. The corresponding weighting matrix W is defined as follows:
where \(\alpha F_{u,i}>0\) is a monotonically increasing function with respect to the visit frequency \(F_{u,i}\).
By considering the above weighting matrix of users’ visiting behaviors, the posterior probability of the latent variables U and V (denoted by Eq. 4) can be rewritten as:
Compared with Eq. (4), the check-in frequency matrix F is replaced by the binary preference matrix P (denoted in Fig. 1), and the weighting matrix W is introduced to determine the confidence level of users’ check-in behavior. Each entry \(P_{u,i}\in \{0,1\}\) of matrix P indicates whether user u has visited POI i, and \(P_{u,i}\) is derived by binarizing the \(F_{u,i}\) values:
3.3 Our location neighborhood-aware recommendation method
WMF assumes that for any two POIs i and j, the latent features of i are independent of j. But in real world, location geographical characteristics are important factors of users’ selection process, and neighboring locations are more likely to be accessed by similar users, that is, the latent feature vector of i is close to the latent feature vectors of all its neighboring POIs. To further explore the geographical information to improve recommendations, we propose a regularization-based method from a location perspective.
Let \(T=(T_{i,j})_{M\times M}\) denote the neighborhood relation matrix of POIs. The geographical character of neighboring POIs can be formulated as follows:
where \(T_{i,j}=sim(i,j)/\sum _{j\in \mathscr {L}(i)}sim(i,j)\) is the normalization version of the distance measure. \(\mathscr {L}(i)\) represents the neighboring location set of POI i. sim(i, j) denotes the distance between POI i and j, which can be calculated as follows:
where \(x_i\) and \(x_j\) represents the geographical coordinates (latitude and longitude) of POI i and j, respectively, and \(\sigma \) is a constant which is empirically set as 0.1 in our experiments.
The POI latent feature factor V now has two factors: the zero-mean Gaussian prior and the conditional distribution of V given the latent features of its nearby locations. Therefore,
Similar to Eq. (4), through a Bayesian inference we can achieve the posterior probability of latent feature vectors of U and V given P and T:
The log of the posterior probability can be computed as follows:
where D is the dimension of user-specific and POI-specific latent feature vectors of users u and POI i, and C is a constant. Maximizing Eq. (12) with hyper-parameters kept fixed is equivalent to minimize the following objective function, that is, our location neighborhood-aware weighted matrix factorization method L-WMF:
where \(\lambda _U=\left. {\sigma _P^2}\big /{\sigma _U^2}\right. \), \(\lambda _V=\left. {\sigma _P^2}\big /{\sigma _V^2}\right. \), \(\lambda _T=\left. {\sigma _P^2}\big /{\sigma _T^2}\right. \), and \(\Vert \cdot \Vert _{Fro}^2\) denotes the Frobenius norm. From Eq. (13), we can observe that once the user factor or the POI factor is fixed, the cost function becomes quadratic, so its global minimum can be readily computed. This leads to an alternating least squares optimization process, where each step is guaranteed to lower the value of the cost function. The analytic expression of \(U_u\) and \(V_i\) can be achieved as follows:
Algorithm 1 presents the learning procedure of the latent feature vectors U and V.

4 Experimental results and analysis
In this section, we first compare the performance of our proposed method with other related POI recommendation algorithms on two real-world datasets. Then, to evaluate the effectiveness of our proposed method, we conduct several experiments to explore the impact of different parameter settings to our approach.
4.1 Datasets
In experiments, we utilize two popular location-based social networks Gowalla and Foursquare to evaluate our proposed method.Footnote 1 As a mobile web application, Gowalla was launched in 2007 and closed in 2012, which allowed users to check into locations that they visited. Foursquare was another location-based social network, which was created in 2008 and now is a well-known local search-and-discovery service mobile application. Before August 2014, it mainly provided users check-in and location sharing services. On both Gowalla and Foursquare, the visited locations of registered users can be accurately obtained and the related POIs can be selectively presented to users.
The Gowalla dataset we used was crawled by its API worldwide from February 2009 to October 2010, and in our experiments, those users with less than 15 check-ins and those POIs with less than 10 visitors were removed. The Foursquare data were crawled by its API within USA (except Alaska and Hawaii) from April 2012 to September 2013, and those users with less than 10 check-ins and those POIs with less than 10 visitors were filtered. Both of these two datasets include the users’ check-in frequencies and the locations’ longitude and latitude information. The detailed statistics of these two datasets are summarized in Table 1.
4.2 Evaluation metrics
We evaluate our proposed method by two widely used metrics Precision@k and Recall@k. Precision@k indicates the percentage of locations among the top k recommended POIs that have been visited by the target user. Recall@k denotes the percentage of the visited locations of the top k recommendation list which can hit the test dataset. The formulations of Precision@k and Recall@k are defined as follows (Lian et al. 2014):
where N is the user number and \(L^T(u) \) represents the location set that was visited by user u in the test data. \(L^k(u)\) denotes the top k recommended POIs for user u, where k is the length of the recommendation list. In experiments, we set k as 10 and use Precision@10 and Recall@10 as the corresponding evaluation metrics.
4.3 Performance comparison
To understand the effectiveness of our method for POI recommendation, we compare the recommendation results with the following approaches:
MostPopular This is a simple but effective recommendation method, which selects the POIs that are most visited to make recommendations for each user.
LRT This is a time-aware POI recommendation method (Gao et al. 2013), which explores the influence of temporal factor by modeling users’ preferences at different time slots.
MGMPFM This is a fused model that combines geographical and social influence with MF (Cheng et al. 2012), which assumes a multicenter Gaussian model (MGM) of the probability of a user’s check-in.
iGSLR This is a personalized unified recommendation framework fusing user preference, social influence and geographical influence(Zhang and Chow 2013), where the kernel density estimation approach is leveraged to personalize the geographical influence on users’ check-in behaviors as individual distributions.
BPRMF This is the state-of-the-art method to deal with the implicit feedback (Rendle et al. 2009), which uses a Bayesian criterion to directly optimize for personalized rankings.
WMF This is another state-of-the-art recommendation method (Pan et al. 2008; Hu et al. 2008) proposed for addressing the implicit feedback problem, which assigns smaller weights to sampled negative examples.
L-WMF This is our proposed method that further improves the WMF method by integrating location relationships as regularization terms.

Performance comparison on two datasets (\(k=10 \), training \(=70\%\)). a Precision@k in the Gowalla data. b Recall@k in the Gowalla data. c Precision@k in the Foursquare data. d Recall@k in the Foursquare data
In our experiments, we split each dataset into three separate parts, that is, training set, tuning set and test set. Specifically, we select the most earliest 70% actions (70% user–POI pairs) of each user for training, the most recent 20% check-ins as the test data, and tune the parameter values to achieve optimal result using the remaining 10% actions. The experimental settings of our method are as follows: For Gowalla, we set the geographical regularization parameter \(\lambda _T\) as 0.0001 and parameter \(\alpha \) as 15. For Foursquare, we set \(\lambda _T\) as 0.00002 and \(\alpha \) as 20. For both Gowalla and Foursquare, the dimension of the latent factors U and V is set as D = 10, and regularization parameters of U and V are set as \(\lambda _U=\lambda _{V}=0.005\).
Figure 2 describes the comparison results of the related recommendation methods with respect to top 10 recommendations on Gowalla and Foursquare datasets. Note that as our Foursquare data have no social information, for iGSLR method, we only report its result on Gowalla dataset. From Fig. 2, we can observe that because the MostPopular method only simply selects the most popular locations as its recommendations, it achieves the worst performance in our experiments. LRT achieves a significant improvement than MostPopular, which demonstrates the importance of the temporal information. But in LRT, it needs to divide the user’s check-in matrix according to time points, which makes the check-in data more sparse and obtains relatively worse results than other related work. MGMPFM further explores other kind of factors, such as geography and social relationships, to improve traditional recommendations, and can perform better than LRT, which only utilize time factor for recommendation. However, MGMPFM does not consider the OCCF problem existing in LBSNs and learn the latent feature factors of users and items by directly factorizing the user–POI check-in frequency matrix, which treats locations with low check-in frequencies as negative samples. In LBSNs, the users’ check-in behaviors are not explicit, but implicit, where the missing values are a mixture of negative and potential positive behaviors. Hence, directly factorizing the user–POI check-in frequency matrix for POI recommendation is unreasonable. iGSLR utilizes the idea of collaborative filtering and predicts the preference of a user to a specific POI by finding out the users with similar interests. iGSLR can perform better than MGMPFM but worse than BPRMF and WMF. Both MGMPFM and iGSLR model the geographical information from a user’s perspective and ignore the relationships among locations, which is a unique characteristic, and will be helpful to the recommendation process.
To investigate the importance of the geographical characteristics and the effectiveness of our location-based POI recommendation method, we further compare our method with two state-of-the-art recommendation methods BPRMF and WMF, which are proposed for implicit feedback. From the experimental results, we find that our method is superior to these two methods, and can achieve the best performance on both Gowalla and Foursquare datasets. We also notice that the methods (BPRMF, WMF and L-WMF) that can deal with OCCF problem perform better than traditional rating-based methods, which indicates that modeling user’s check-ins as implicit feedback is more appropriate in the POI recommendation task. This experimental result also indicates that model the geographical feature from a location perspective is more effective, and our method can model users’ behaviors more precisely.
4.4 The impact of parameter \(\lambda _T \)
In our L-WMF method, the parameter \(\lambda _T\) plays an important role, which balances the utilized information from user’s check-in behaviors and neighboring relationships. A large value of \(\lambda _T \) indicates we will make recommendations mainly dependent on the geographical characteristics of locations. In contrast, a small value of \(\lambda _T \) denotes that our method will mainly exploit the user’s check-in behaviors to make recommendations.
Figure 3 shows the experimental results (Precision@k and Recall@k) with \(\lambda _T \) in different values, from which we can observe that the value of \(\lambda _T \) can influence our experimental results significantly, which indicates the geographical features are important factors in modeling user’s check-in behaviors. Specifically, in both Gowalla and Foursquare datasets, with \(\lambda _T\) increases, the recommendation performance of our method increases at first, but when \(\lambda _T \) surpasses a certain value, its performance decreases with further increasing the value of \(\lambda _T\). This result also indicates that only utilizing users’ check-in behaviors or geographical information to make recommendations cannot get better results than fusing them together.

Impact of parameter \(\lambda _T \) on two datasets. a Precision@k in the Gowalla data. b Recall@k in the Gowalla data. c Precision@k in the Foursquare data. d Recall@k in the Foursquare data

Recommendation performance of our method with the changes in the recommended number k on two datasets. a Precision@k in the Gowalla data. b Recall@k in the Gowalla data. c Precision@k in the Foursquare data. d Recall@k in the Foursquare data

Convergence comparison results on two datasets. a Precision@k in the Gowalla data. b Recall@k in the Gowalla data. c Precision@k in the Foursquare data. d Recall@k in the Foursquare data
4.5 The influence of the recommendation number
In location-based social networks, users are more likely to select their favorite POIs from a limited number of recommendations (say top k-related items) to avoid being overwhelmed in unrelated recommendations. The length of the recommendation list determines how well the target user can get along with the system. Hence, we further evaluate our method in top k recommendations with the recommendation number k varies from 1 to 10. The recommendation performance is also measured by Precision@k and Recall@k in both two datasets, and the experimental results are shown in Fig. 4, which only examines the top k relevant POIs returned by our method.
From this result, we can observe that the increase in the recommendation number can result in the decrease in the Precision@k and the increase in Recall@k in both Gowalla and Foursquare datasets. A small value of Precision@k means our method can only find a few number of relevant POIs within the recommendation list, and the ability that our method can find correct POIs from the test set is low. A big value of Recall@k means our method can hit more correct POIs, and the ability that our method can retrieve relevant POIs is high.
4.6 Convergence analysis
To explore the efficiency of our location-based approach, we further conduct several experiments to compare the convergence of our L-WMF method with the state-of-the-art WMF method on two datasets. In comparisons, we use the same number of samples for training, validating and testing, and set the same learning rate for both two methods (both are set as 0.05). The comparison results are shown in Fig. 5, from which we can observe that these methods both converge very fast. They can converge within 3 iterations in Gowalla and 4 iterations in Foursquare. Although our L-WMF method incorporates location information as regularization terms, compared with WMF the convergence speed is not slowed by these fused information, but get better result. This experimental result demonstrates that our method can utilize these geographical characteristics efficiently and effectively.
5 Conclusions and future work
To further explore the geographical information for POI recommendation, this work mainly focuses on how to utilize location-aware matrix factorization method to model the influence of geographical characteristics, and proposes a location regularization-based POI recommendation method L-WMF from a location perspective. This kind of feature is different from users’ latent factors and should be considered differently. To deal with the implicit feedback, we first introduce the WMF method to make up the shortcomings of traditional matrix factorization method. To exploit the geographical features to improve the recommendation process, we further incorporate them as location regularization terms. Experimental results on two real-world datasets demonstrate that our method can effectively utilize the geographical information and can make better recommendations than other related work.
To simplify this problem, this work mainly emphasizes on how to explore the influence of geographical information, and other kind of side information has not been considered, which may also plays an important role in the recommendation process. Moreover, as deep learning-based techniques can handle multi-dimensional information and have been demonstrated in many related tasks (such as network embedding and link prediction), we plan to build deep neural network-based model to incorporate multi-dimensional information for POI recommendation in future work.
References
Baral R, Wang D, Li T, Chen SC (2016) Geotecs: exploiting geographical, temporal, categorical and social aspects for personalized poi recommendation (invited paper). In: IEEE international conference on information reuse and integration, pp 94–101
Cheng C, Yang H, King I, Lyu MR (2012) Fused matrix factorization with geographical and social influence in location-based social networks. AAAI 12:17–23
Gao H, Tang J, Hu X, Liu H (2013) Exploring temporal effects for location recommendation on location-based social networks. In: ACM conference on recommender systems, pp 93–100
Guo L, Ma J, Chen Z, Zhong H (2015a) Learning to recommend with social contextual information from implicit feedback. Soft Comput 19(5):1351–1362
Guo L, Ma J, Jiang HR, Chen ZM, Xing CM (2015b) Social trust aware item recommendation for implicit feedback. J Comput Sci Technol 30(5):1039–1053
Guo L, Wen YF, Wang XH (2018) Exploiting pre-trained network embeddings for recommendations in social networks. J Comput Sci Technol 33(4):682–696
Han J, Yamana H (2017) Geographical diversification in POI recommendation: toward improved coverage on interested areas. In: Proceedings of the eleventh ACM conference on recommender systems, RecSys’17. ACM, pp 224–228
He X, Zhang H, Kan MY, Chua TS (2016) Fast matrix factorization for online recommendation with implicit feedback. In: Proceedings of the 39th international ACM SIGIR conference on research and development in information retrieval, SIGIR’16. ACM, pp 549–558
Hu Y, Koren Y, Volinsky C (2008) Collaborative filtering for implicit feedback datasets. In: 2008 eighth IEEE international conference on data mining. IEEE, pp 263–272
Li H, Ge Y, Hong R, Zhu H (2016) Point-of-interest recommendations: learning potential check-ins from friends. In: KDD, pp 975–984
Li MR, Huang L, Wang CD (2017) Geographical and overlapping community modeling based on business circles for POI recommendation. In: Sun Y, Lu H, Zhang L, Yang J, Huang H (eds) Intelligence science and big data engineering. Springer, Berlin, pp 665–675
Li J, Xu W, Wan W, Sun J (2018) Movie recommendation based on bridging movie feature and user interest. J Comput Sci 26:128–134
Lian D, Zhao C, Xie X, Sun G, Chen E, Rui Y (2014) Geomf: joint geographical modeling and matrix factorization for point-of-interest recommendation. In: Proceedings of the 20th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, pp 831–840
Liu S (2018) User modeling for point-of-interest recommendations in location-based social networks: the state of the art. Mob Inf Syst 2018:1–13
Liu Y, Wei W, Sun A, Miao C (2014) Exploiting geographical neighborhood characteristics for location recommendation. In: Proceedings of the 23rd ACM international conference on conference on information and knowledge management. ACM, pp 739–748
Pan R, Zhou Y, Cao B, Liu NN, Lukose R, Scholz M, Yang Q (2008) One-class collaborative filtering. In: 2008 eighth IEEE international conference on data mining. IEEE, pp 502–511
Rendle S, Freudenthaler C, Gantner Z, Schmidt-Thieme L (2009) BPR: Bayesian personalized ranking from implicit feedback. In: Proceedings of the twenty-fifth conference on uncertainty in artificial intelligence. AUAI Press, pp 452–461
Salakhutdinov R, Mnih A (2007) Probabilistic matrix factorization. In: Proceedings of the 20th NIPS, NIPS’07. Curran Associates Inc., Red Hook, pp 1257–1264
Si Y, Zhang F, Liu W (2017) CTF-ARA: an adaptive method for POI recommendation based on check-in and temporal features. Knowl Based Syst 128:59–70
Wei S, Zheng X, Chen D, Chen C (2016) A hybrid approach for movie recommendation via tags and ratings. Electron Commer Res Appl 18:83–94
Wen Y, Guo L, Chen Z, Ma J (2018) Network embedding based recommendation method in social networks. In: Companion of the the web conference, pp 11–12
Yang D, Zhang D, Yu Z, Wang Z (2013) A sentiment-enhanced personalized location recommendation system. In: Proceedings of the 24th ACM conference on hypertext and social media, HT’13. ACM, pp 119–128
Yang C, Bai L, Zhang C, Yuan Q, Han J (2017) Bridging collaborative filtering and semi-supervised learning: a neural approach for poi recommendation. In: ACM SIGKDD international conference on knowledge discovery and data mining, pp 1245–1254
Ye M, Yin P, Lee WC, Lee DL (2011) Exploiting geographical influence for collaborative point-of-interest recommendation. In: Proceedings of the 34th international ACM SIGIR conference on research and development in information retrieval. ACM, pp 325–334
Yu Y, Yang G, Hao W (2016) A ranking based Poisson matrix factorization model for point-of-interest recommendation. J Comput Res Dev 53(8):1651–1663
Zhang JD, Chow CY (2013) iGSLR: personalized geo-social location recommendation: a kernel density estimation approach. In: Proceedings of the 21st ACM SIGSPATIAL international conference on advances in geographic information systems. ACM, pp 334–343
Zhang JD, Chow CY, Li Y (2015) iGeoRec: a personalized and efficient geographical location recommendation framework. IEEE Trans Serv Comput 8(5):701–714
Zhang Z, Liu Y, Zhang Z, Shen B (2018) Fused matrix factorization with multi-tag, social and geographical influences for poi recommendation. In: World Wide Web-internet and web information systems, pp 1–16
Zhao S, King I, Lyu MR (2013) Capturing geographical influence in POI recommendations. Lect Notes Comput Sci 8227:530–537
Acknowledgements
This study was funded by the National Natural Science Foundation of China (Nos. 61602282, 61772321), the China Postdoctoral Science Foundation (No. 2016M602181) and the Innovation Foundation of Science and Technology Development Center of Ministry of Education and New H3C Group (No. 2017A15047).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Guo, L., Wen, Y. & Liu, F. Location perspective-based neighborhood-aware POI recommendation in location-based social networks. Soft Comput 23, 11935–11945 (2019). https://doi.org/10.1007/s00500-018-03748-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-018-03748-9