
Abstract
Phenology is an important indicator of ecological response to climate change. Yet, phenological responses are highly variable among species and biogeographic regions. Recent monitoring initiatives have generated large phenological datasets comprised of observations from both professionals and volunteers. Because the observation frequency is often variable, there is uncertainty associated with estimating the timing of phenological activity. “Status monitoring” is an approach that focuses on recording observations throughout the full development of life cycle stages rather than only first dates in order to quantify uncertainty in generating phenological metrics, such as onset dates or duration. However, methods for using status data and calculating phenological metrics are not standardized. To understand how data selection criteria affect onset estimates of springtime leaf-out, we used status-based monitoring data curated by the USA National Phenology Network for 11 deciduous tree species in the eastern USA between 2009 and 2013. We asked, (1) How are estimates of the date of leaf-out onset, at the site and regional levels, influenced by different data selection criteria and methods for calculating onset, and (2) at the regional level, how does the timing of leaf-out relate to springtime minimum temperatures across latitudes and species? Results indicate that, to answer research questions at site to landscape levels, data users may need to apply more restrictive data selection criteria to increase confidence in calculating phenological metrics. However, when answering questions at the regional level, such as when investigating spatiotemporal patterns across a latitudinal gradient, there is low risk of acquiring erroneous results by maximizing sample size when using status-derived phenological data.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Phenology is recognized as an important indicator of ecological response to environmental change, including climate change (EPA 2014; IPCC 2014). Many species are altering their phenology in response to warming temperatures by days to weeks (Parmesan 2007; Thackeray et al. 2010; Anderson et al. 2012; Ellwood et al. 2013). The intensity and direction of phenological responses vary among species, populations, and biogeographic regions (Parmesan 2006; Donnelly et al. 2011; Cleland et al. 2012). However, the nature of regional and species-specific variability in response can be difficult to measure, given the wide range of methods used to characterize phenological behavior (Parmesan 2007; Wolkovich et al. 2012).
Contemporary phenology data, collected recently and over short timeframes, can be used to examine the responsiveness of species to climate to better understand how climatic variability influences phenology (Rafferty et al. 2013). In circumstances where the same individuals at a site are monitored for many years over a range of climatic conditions, these data may inform predictions on how species will respond to ongoing and future changes in climate (Dunne et al. 2004; Iler et al. 2013). Likewise, contemporary data that span ecological and latitudinal gradients may inform predictive models by substituting responses over space for time (e.g., Jochner et al. 2013; Phillimore et al. 2013), although this approach does not account for local genetic adaptation to environmental conditions throughout species ranges. One phenological phenomenon that has received considerable attention is the apparent advancement of the spring season (Parmesan 2006; Thackeray et al. 2010). Numerous studies have documented how organisms are responding to warmer springs by advancing phenophase onset, particularly in temperate regions that experience strong temperature-related seasonal cues that result in phenological transitions (Zhao and Schwartz 2003; Badeck et al. 2004; Marra et al. 2005; Schwartz et al. 2006; Peeters et al. 2007; Cook et al. 2012). One consequence of advancing spring phenology includes a lengthening of the growing season when the cues driving senescence do not result in similar advancements, which has important impacts on carbon and water cycling as well as trophic interactions (Richardson et al. 2013). Eastern temperate deciduous trees are an ideal functional group for examining how climatic variability influences phenological activity due to a strong response to temperature-related drivers and because they tend to exhibit distinct and detectable onset of breaking leaf buds in the spring (Lechowicz 1984; Polgar and Primack 2011; Rollinson and Kaye 2012).
The need for ground-based phenological data has led to the creation of national phenology observation programs (e.g., USA National Phenology Network, Project BudBurst, North American Bird Phenology Program, Swedish National Phenology Network, and the Dutch Phenological Network called Nature’s Calendar). These typically represent broad partnerships across federal and state agencies, tribes, non-governmental organizations, botanical gardens, agricultural extension programs, and individual citizens (Schwartz et al. 2013b). Taken collectively, data derived from these vast networks of observers can help address phenological research questions on broad spatial and temporal scales as well as at site to regional scales that are of particular importance to natural resource managers and decision-makers (Enquist et al. 2014). In fact, numerous recent studies have used datasets from these programs to examine short and long-term phenological responses and to validate phenological model predictions at large spatial scales (Jeong et al. 2011; Hurlbert and Liang 2012; Courter et al. 2013; Jeong et al. 2013; Chapman et al. 2014; Euskirchen et al. 2014; McCormack et al. 2014). These data also provide valuable baseline data for future studies to investigate shifts and patterns in phenology relative to ongoing climate change.
Nonetheless, a major challenge associated with using such large, multi-contributor datasets relates to uneven sampling design, particularly with regards to the frequency of monitoring and the spatial distribution of observation sites within a geographic area of interest. For example, there can be considerable variation in the frequency of records collected by observers at different sites. Further, in the cases where observers are encouraged to record both the presence and absence of phenophases, as in “status monitoring” (Denny et al. 2014), trends may be skewed towards later onset dates when there is a greater timespan between the last observation of absence and the first observation of presence (Miller-Rushing et al. 2008; Keatley and Hudson 2010; Morellato et al. 2010; Moussus et al. 2010). In addition, observers may only record presence of a phenophase and thus fail to capture observations of absence, reducing our ability to quantify precision or uncertainty of phenological metrics such as onset date or duration of phenophase activity (Cole et al. 2012; Ferreira et al. 2014).
As a result of these confounding issues, researchers and practitioners interested in using these data may need to filter raw phenological data sets to reduce uncertainty and improve statistical robustness (Bird et al. 2014). However, concerns regarding the filtering of large phenology datasets and selecting a subset of the data for analysis are often not overtly addressed, and the community lacks a standard approach for calculating phenological metrics using status data (Ferreira et al. 2014). Decisions related to data selection criteria will often constitute a trade-off, where excluding records with low precision could affect statistical power and variance. In contrast, including records with low precision to maintain sample size could skew detected trends. Data users will also need to decide how to estimate the date of phenophase onset and end for individuals and/or populations at site and/or regional scales (Cornelius et al. 2011). For example, onset can be estimated from status monitoring data by using the first observed presence of a phenophase or by calculating the midpoint date between the last observed “no” and the first observed “yes” (e.g., Tierney et al. 2013; Denny et al. 2014).
Given the complexity and size of many phenological data sets, data selection criteria that take into account sampling frequency are paramount to estimating phenological activity across organismal and geographic scales. Ultimately, the need for standardized analytical approaches will be critical to improving future efforts to model and forecast phenology for applications in natural resource management and beyond.
To begin to address these challenges, we used data curated by the USA National Phenology Network to (1) test a suite of data selection criteria to understand trade-offs between resulting datasets across spatial scales and (2) apply estimated phenophase onset dates to explore increasingly common questions about the relationship between climatic and phenological patterns across geographies. To do so, we developed a series of three increasingly restrictive data selection criteria for use with phenophase status data to investigate the effect of uncertainty related to sampling frequency on the estimation of phenophase onset across geographic scales. For the purpose of this study, we focused on the timing of the onset of spring leaf-out because it is well known as an indicator of climate change impacts (Schwartz et al. 2013a; EPA 2014).
We specifically asked:
-
1.
How are estimates of the date of leaf-out onset, at the site and regional levels, influenced by three data selection criteria and methods for calculating onset when using phenological data derived from status monitoring?
-
2.
At the regional level, can each dataset demonstrate how the timing of leaf-out relates to springtime minimum temperatures across latitudes and species?
Materials and methods
The USA National Phenology Network and status monitoring
The USA National Phenology Network (USA-NPN), established in 2007, curates the National Phenology Database (NPDb), which includes a large (>4.5 million records) dataset comprised of plant and animal phenology data collected since 2009 (Schwartz et al. 2012; Rosemartin et al. 2013). Much of the phenological data in the NPDb are input through Nature's Notebook, a comprehensive national plant and animal phenology monitoring program developed by the USA-NPN (Rosemartin et al. 2013). Observations are collected by both professional scientists and volunteer observers using scientifically vetted and standardized protocols (Denny et al. 2014). Participants geolocate and register sites, and one or more individual marked plants to monitor at each site.
USA-NPN standard protocols employ status monitoring, whereby observers are encouraged to make frequent observations (at least twice weekly during periods of phenological transitions) and record both the presence and absence status of phenophases throughout their annual cycle (Denny et al. 2014). This data is gathered by asking observers to answer “yes” or “no” to the question, “Do you see [phenophase]?” on a particular day and individual plant. The status monitoring approach enables quantification of the precision in estimates of phenophase onset dates, which can be high when the timeframe between observations is short (i.e., less than 7 days), low when the timeframe is long (i.e., 30 days), or unknown if no record of absence precedes a report of presence. Ideally, this approach results in datasets that are sufficiently robust to estimate and model the onset, magnitude, and duration of phenophases, across species, populations, and geographies.
Study region and data used
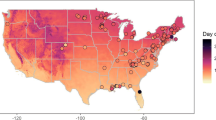
Our study region was comprised of the distribution of 11 species of deciduous trees found in eastern deciduous temperate forests in the USA (Table 1). To capture the onset of spring leaf-out for these species, we selected the phenophase “breaking leaf buds” (Denny et al. 2014). This phenophase is defined as “one or more breaking leaf buds are visible on the plant. A leaf bud is considered ‘breaking’ once a green leaf tip is visible at the end of the bud, but before the first leaf from the bud has unfolded to expose the leaf stalk (petiole) or leaf base.” We downloaded status data for each of the focal tree species using the USA-NPN’s data download tool (www.usanpn.org/results/data) for the years 2009–2013 (USA National Phenology Network, 2013). This resulted in a set of observation dates for a total of 1,177 individual trees across 465 sites over 5 years within the study region (Fig. 1). A site consists of one or more individuals of one or more plant species and is the smallest identifiable geographic unit in the database, represented by the single latitude and longitude of the site center (in decimal degrees). The latitude for each site was used as a covariate in subsequent analyses.

Map of Nature’s Notebook sites used for study
Data selection
We developed three sets of data selection criteria for estimating onset of breaking leaf buds (Fig. 2). Here, we distinguish our datasets by the degree of precision associated with each individual record given the sampling frequency under which it was observed. The application of more restrictive criteria results in decreased sample size but increased precision of onset estimates. Importantly, the estimated dates generated using these sets of criteria are not meant to represent the “true” date of onset for breaking leaf buds, which cannot be known from available existing data on the focal individuals and sites. The first set of criteria included all records of the first recorded presence of the phenophase for an individual plant after a given start date for the study (hereafter termed Y or the first “yes” observation record in a given season), regardless of whether any prior negative observations were recorded. We considered this the most inclusive dataset; it yields the most data points thus the greatest sample size; however, many records may be later than the true onset date and thus potentially inaccurate. The second set of criteria required that there be an absence (or “no”) record at a date prior to the first presence (“yes”) record for each individual plant (hereafter termed NY). Thus, this dataset allowed for the identification of the timeframe during which the true onset occurred. The third most restrictive set of criteria required that the first record of presence be preceded by a record of absence (“no”) within 7 days to further reduce uncertainty in the estimated leaf-out date (hereafter termed NY7). For each of the three datasets, we estimated onset day of year by using the date of the first observed presence of a phenophase.

Hypothetical status-based monitoring dataset illustrating how varying data selection results in three increasingly restrictive yet smaller-sized datasets. The Y dataset (orange) uses the first positive observation (“yes”) for a given individual and phenophase regardless of whether there is a negative observation (“no”) record preceding it; this results from the most inclusive data selection criteria. The NY dataset (blue) uses only first positive observations that are preceded by a negative observation, and the NY7 dataset (green) uses only data that has 7 days or less between the last negative and first positive observation records
Climate Data
To determine how climatic conditions can help predict onset dates, we downloaded March mean monthly minimum temperatures (TMIN) for 2009–2013 in gridded format from the PRISM climate group (PRISM Climate Group, http://www.prism.oregonstate.edu/). We chose this month for our climate analyses because March is often used to represent the beginning of spring in eastern deciduous forests (e.g., Zhang et al. 2004). We extracted mean monthly minimum temperature estimates at each phenology observation point location (site) using the geographic information software ArcMap 10 (ESRI 2011).
Data Analysis
To assess the effect of data selection criteria at the site level, we calculated site-level means of estimated onset dates across years and species to minimize variation in sampling of individuals between sites. We performed a mixed linear model to compare site level means of all deciduous tree species combined, with dataset as a fixed effect in the model and site as a random effect. In addition, we performed this analysis for each species in the dataset.
To compare the three datasets at a regional scale, we used an area encompassing the range of all the 11 species across the eastern USA. We performed an ANCOVA using XLSTAT (Addinsoft Version 2014.1.06) to test for differences between the slopes of the relationships between latitude and the site-level mean estimated onset dates and used Tukey-Kramer pairwise comparisons on the slopes to test for differences between the three models.
To assess the influence of latitude, TMIN, and species on the estimated onset dates of breaking lead buds for individual plants for each of the three datasets, we carried out linear mixed-effect models (JMP, SAS Institute Inc. 2013). TMIN, latitude, species, TMIN × species, and latitude × species were treated as fixed effects with year treated as a random effect and individuals nested within sites treated as a random effect. Pairwise comparisons between species were carried out using Tukey-Kramer tests within each dataset. In addition, using the NY dataset, we performed an ANCOVA analysis to test for species differences in the slope of the relationships between latitude and estimated onset date.
Results
There was a reduction in the number of observation records comprising the datasets by 27 % from the Y to the NY dataset and by another 30 % from the NY to the NY7 dataset (Table 1). We found that the set of criteria applied had a significant effect on the site-level mean estimated onset dates when all species were analyzed together (Table 2, p = 0.031). Although average differences were small in these comparisons, individual site mean differences in estimated onset DOY varied substantially: they ranged between 42 and −73 days for datasets Y and NY, between 51 and −23 days for datasets NY and NY7, and between 49 and −50 days for datasets Y and NY7 (Fig. 3). As the difference between mean onset dates within a site ranged both earlier (positive values) and later (negative values) when two datasets were compared, this indicates no consistent direction that onset estimates are expected to change

Box plot and histogram showing the distribution of differences (number of days) in estimated onset dates of breaking leaf buds when comparing mean values at each site for all species combined. Box plots display the median and quantiles of the distribution; however, boxes are not visually evident in cases when the majority of the distribution is clustered around the mean; in such cases, the remaining visible points are considered outliers
When species were analyzed separately, we detected significant effects of dataset criterion on only one species, Fagus grandifolia and a near significant effect in Acer rubrum (Table 2). However, for all species, we found large variation in the range of values for which the site level means differed when datasets were compared (Supplementary Fig. 1a–k).
At the regional scale, the slopes of the positive relationship between latitude and site-level estimated onset dates did not differ between datasets (Fig. 4, Y slope = 3.11, NY slope = 2.91, NY7 slope = 2.71; p < 0.001 for each dataset).

The positive relationship of site-level mean estimated onset date of breaking leaf buds for deciduous trees in the eastern USA from 2009 to 2013 relative to latitude. Data point and regression line types represent three separate datasets extracted from the National Phenology Database using different criteria: Y (orange), NY (blue), and NY7 (green). Correlation is significant within all three datasets (p < 0.001 for each). The three slopes are not significantly different from one another
For each of the three derived datasets and associated models, estimated onset of breaking leaf buds in deciduous trees was earlier with higher March TMIN and was later with progressively northern latitudes (Table 3). Consistent across the three datasets was a significant interaction between latitude and species, indicating that species-specific responses vary across latitude. Individuals nested within sites accounted for 31–35 % of the variation not explained by the fixed effects in the models, whereas year only accounted for about 1–3 % of the variation not explained by fixed effects (Table 3).
Across datasets, Liriodendron tulipifera consistently had the earliest mean estimated onset dates; Betula papyrifera, Populus tremuloides, and Tilia americana had the latest estimated onset dates (Table 1). Each of the 11 species demonstrated a similar positive trend in their relationship between latitude and estimated site-level mean onset date, although the relationships were not significant for Tilia americana and Robinia pseudoacacia (Fig. 5). Slopes varied from 1.8 days/degrees latitude (Quercus rubra) to 3.3 days/degrees latitude (A. rubrum).

Relationship between estimated onset date and latitude by species, showing the direction and variation of phenological responses across a geographic gradient. Letters represent significant differences between slopes as determined by Tukey-Kramer pairwise comparisons within an ANCOVA analysis (p < 0.05). All linear correlations were significant (p < 0.005) with the exceptions of Robinia pseudoacacia and Tilia americana
Discussion
Considerations for data selection from complex phenological datasets
Our results highlight the fact that the geographic scale of inquiry is an important consideration when applying data selection criteria to data from multi-contributor databases such as the NPDb to estimate phenological metrics. On smaller geographic scales in instances where knowledge of phenological information is desired for a given individual or site, such as in making management decisions for protected areas (Enquist et al. 2014), a more restrictive set of data selection criteria may be preferred in order to reduce uncertainty and ensure more precise estimates. Specifically, we found that site means differed significantly between datasets due to the different composition of individual data points included in analyses, depending on the criteria used to select data, and whether one is looking at patterns within functional groups (e.g., start of growing season for deciduous trees, which would be relevant when comparing results to remote sensing data) or individual species (Table 2 and Fig. 3). Restrictive criteria are also likely appropriate when highly variable phenology is detected, and it is not known whether the variability is inherent to a species or site or a result of low frequency of data collection.
However, it must be noted that phenophase onset estimates resulting from the NY7 dataset do not necessarily reflect the “true” date or accurate calculation of phenophase onset. In order to ensure both an accurate and precise estimate of phenological metrics, managers may want to apply a specific rigorous sampling design to the collection of phenological data that includes consistent sampling throughout the year and consistent sampling throughout the region of interest in order to account for variation over the landscape and between and within populations. Reducing spatial and temporal biases will allow for greater integration with abiotic and climate datasets and help generate more robust regional datasets for decision-making purposes. Additionally, the methods presented in this study do not accurately estimate the uncertainty around mean onset dates because the true date of onset is not known, and only a single date is considered for the observation, rather than the window of time within which the first observation may have occurred. Estimation of the uncertainty of these values for the purposes of predictive modeling may be more accurately calculated using Bayesian hierarchical modeling (e.g., Diez et al. 2014).
These results demonstrate that, for geographically extensive data applications where broad regional or latitudinal variation in phenology is of interest, the reduction of sample size through more restrictive criteria may have minimal influence on the detection of generally robust biogeographic and climatic trends. Specifically, we detected no difference in the nature of the relationship of estimated onset date and latitude, despite relatively large reductions in sample size (Fig. 4). For researchers investigating broad spatial trends, it may be preferable to increase sample size by employing more inclusive data selection criteria. Here, reducing uncertainty at the site level may not be as crucial for elucidating these large-scale patterns; however, results will depend strongly on the spatial and temporal availability of data on the species and phenophases of interest across a focal region. In regions and for species for which data is less abundant compared to a well-sampled group (e.g., eastern deciduous trees), or phenology is expected to be more variable or driven by multiple environmental cues (e.g., flowering in arid and semi-arid regions), we predict that one might find substantially more variability within the data from the NPDb when different methods are applied to estimate phenological metrics.
This work further supports the importance of utilizing standardized methods and protocols to collect and analyze phenology data across species and regions (Parmesan 2007; Cornelius et al. 2011; Ferreira et al. 2014). For instance, efforts that emphasize the importance of once- or twice- weekly monitoring frequency should decrease uncertainty in onset estimates by reducing the time between the last record of absence and the first record of presence for a phenophase. These efforts can potentially reduce unexplained variation in models estimating phenological metrics by ensuring that a greater proportion of data will be included when restrictive data selection criteria are applied. We recommend that users of status-based monitoring databases, such as the NPDb, first explore the impact of data selection criteria on their results in order to determine an optimal process for selecting data for a given science or resource management question.
Relationships between phenology, geography, and climate
Our results highlight the capacity for contemporary datasets generated from status monitoring, such as those in the USA-NPN’s National Phenology Database, to capture spatiotemporal dynamics of phenological variability within and between species relative to geography and climate. Although additional years of data are desirable for more robust trend detection and attribution, we are able to elucidate patterns of geographic and climatic variability on phenological behavior on a regional scale with only 5 years of data. Specifically, we found strong trends relating advanced (earlier) onset of breaking leaf buds with higher minimum temperatures at lower latitudes in the eastern USA, regardless of dataset used. Estimated onset dates varied little across species in the magnitude of their response to mean minimum temperature, with slightly greater interspecific variation in the magnitude of the relationship between onset date and latitude. Remarkably, inter-annual variation contributed very little to models, whereas individual trees explained a much greater proportion of the unexplained variation. Thus, individual micro-habitat and genetic profile are an important component that should be considered when scaling predictions across years and individuals and further emphasizes the importance of a robust temporal and spatial sampling design. Although these species are within the same functional type (temperate deciduous trees), the consistency of the responsiveness patterns between species is somewhat surprising given the degree of interspecific variation in responses to temperature demonstrated by other community level studies (Zhang et al. 2007; Crimmins et al. 2010; Cook et al. 2012).
When estimating phenological metrics such as onset from large complex databases at various geographic scales, we encourage researchers to be mindful of the trade-offs between reducing the uncertainty introduced by low observation frequency and maintaining adequate sample size as it relates to their scientific questions of interest. Our study highlights the importance of these factors for understanding and quantifying biogeographic variation in phenological responses resulting from both local processes and large-scale atmospheric patterns at continental scales (Ault et al. 2013; Schwartz et al. 2013a). Moreover, efforts to continue to strategically increase the breadth and depth of data records comprising status-based phenological databases, such as the NPDb, will enhance our collective capacity to expand and apply our knowledge of these important and complex dynamics, particularly in an era of rapid environmental change. To further develop standard methods for processing status-based phenological data, we plan to broaden this scope of inquiry to better understand how data selection criteria influence analyses across phenological metrics, species, regions, and phenophases.
References
Anderson JT, Inouye DW, McKinney AM, Colautti RI, Mitchell-Olds T (2012) Phenotypic plasticity and adaptive evolution contribute to advancing flowering phenology in response to climate change. Proc R Soc B-Bioll Sci 279(1743):3843–3852. doi:10.1098/rspb.2012.1051
Ault TR, Henebry GM, de Beurs KM, Schwartz MD, Betancourt JL, Moore D (2013) The false spring of 2012, earliest in North American record. Eos, Trans AGU 94(20):181–182. doi:10.1002/2013eo200001
Badeck FW, Bondeau A, Bottcher K, Doktor D, Lucht W, Schaber J, Sitch S (2004) Responses of spring phenology to climate change. New Phytol 162(2):295–309. doi:10.1111/j.1469-8137.2004.01059.x
Bird TJ, Bates AE, Lefcheck JS, Hill N, Thomson R, Edgar GJ, Stuart-Smith RD, Wotherspoon SJ, Krkosek M, Stuart-Smith JF, Pecl GT, Barrett NS, Frusher SD (2014) Statistical solutions for error and bias in global citizen science datasets. Biological Conservation 173 doi: doi:10.1016/j.biocon.2013.07.037
Chapman DS, Haynes T, Beal S, Essl F, Bullock JM (2014) Phenology predicts the native and invasive range limits of common ragweed. Glob Chang Biol 20(1):192–202. doi:10.1111/gcb.12380
Cleland EE, Allen JM, Crimmins TM, Dunne JA, Pau S, Travers SE, Zavaleta ES, Wolkovich EM (2012) Phenological tracking enables positive species responses to climate change. Ecology 93(8):1765–1771
Cole H, Henson S, Martin A, Yool A (2012) Mind the gap: the impact of missing data on the calculation of phytoplankton phenology metrics. J Geophys Res Oceans 117(C8), C08030. doi:10.1029/2012jc008249
Cook BI, Wolkovich EM, Parmesan C (2012) Divergent responses to spring and winter warming drive community level flowering trends. Proc Natl Acad Sci U S A 109(23):9000–9005. doi:10.1073/pnas.1118364109
Cornelius C, Petermeier H, Estrella N, Menzel A (2011) A comparison of methods to estimate seasonal phenological development from BBCH scale recording. Int J Biometeorol 55(6):867–877. doi:10.1007/s00484-011-0421-x
Courter JR, Johnson RJ, Bridges WC, Hubbard KG (2013) Assessing migration of ruby-throated hummingbirds (Archilochus colubris) at broad spatial and temporal scales. Auk 130(1):107–117. doi:10.1525/auk.2012.12058
Crimmins TM, Crimmins MA, Bertelsen CD (2010) Complex responses to climate drivers in onset of spring flowering across a semi-arid elevation gradient. J Ecol 98(5):1042–1051. doi:10.1111/j.1365-2745.2010.01696.x
Denny EG, Gerst KL, Miller-Rushing AJ, Tierney GL, Crimmins TM, Enquist CAF, Guertin P, Rosemartin AH, Schwartz MD, Thomas KA, Weltzin JF (2014) Standardized phenology monitoring methods to track plants and animal activity for science and resource management applications. Int J Biometeorol. doi:10.1007/s00484-014-0789-5
Diez JM, Ibáñez I, Silander JA, Primack R, Higuchi H, Kobori H, Sen A, James TY (2014) Beyond seasonal climate: statistical estimation of phenological responses to weather. Ecol Appl 24(7):1793–1802. doi:10.1890/13-1533.1
Donnelly A, Caffarra A, O'Neill BF (2011) A review of climate-driven mismatches between interdependent phenophases in terrestrial and aquatic ecosystems. Int J Biometeorol 55(6):805–817. doi:10.1007/s00484-011-0426-5
Dunne JA, Saleska SR, Fischer ML, Harte J (2004) Integrating experimental and gradient methods in ecological climate change research. Ecology 85(4):904–916. doi:10.1890/03-8003
Ellwood ER, Temple SA, Primack RB, Bradley NL, Davis CC (2013) Record-breaking early flowering in the eastern United States. Plos One 8 (1). doi:10.1371/journal.pone.0053788
Enquist CAF, Kellermann JL, Gerst KL, Miller-Rushing AJ (2014) Phenology research for natural resource management in the United States. Int J Biometeorol. doi:10.1007/s00484-013-0772-6
EPA US (2014) Climate change indicators in the United States. Environmental Protection Agency www.epa.gov/climatechange/indicators.html
Euskirchen ES, Carman TB, McGuire AD (2014) Changes in the structure and function of northern Alaskan ecosystems when considering variable leaf-out times across groupings of species in a dynamic vegetation model. Glob Chang Biol 20:963–978. doi:10.1111/gcb.1239
Ferreira AS, Visser AW, MacKenzie BR, Payne MR (2014) Accuracy and precision in the calculation of phenology metrics. J Geophys Res Oceans:n/a-n/a. doi:10.1002/2014jc010323
Hurlbert AH, Liang Z (2012) Spatiotemporal variation in avian migration phenology: citizen science reveals effects of climate change. Plos One 7 (2). doi:10.1371/journal.pone.0031662
Iler AM, Hoye TT, Inouye DW, Schmidt NM (2013) Long-term trends mask variation in the direction and magnitude of short-term phenological shifts. Am J Bot 100(7):1398–1406. doi:10.3732/ajb.1200490
IPCC (2014) Climate change 2014: Synthesis Report. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change [Core Writing Team, R.K. Pachauri and L.A. Meyer (eds.)]. IPCC, Geneva, Switzerland, p 151.
Jeong S-J, Ho C-H, Gim H-J, Brown ME (2011) Phenology shifts at start vs. end of growing season in temperate vegetation over the Northern Hemisphere for the period 1982–2008. Glob Chang Biol 17(7):2385–2399. doi:10.1111/j.1365-2486.2011.02397.x
Jeong S-J, Medvigy D, Shevliakova E, Malyshev S (2013) Predicting changes in temperate forest budburst using continental-scale observations and models. Geophys Res Lett 40(2):359–364. doi:10.1029/2012gl054431
Jochner S, Caffarra A, Menzel A (2013) Can spatial data substitute temporal data in phenological modelling? A survey using birch flowering. Tree Physiol 33(12):1256–1268. doi:10.1093/treephys/tpt079
Keatley MR, Hudson IL (2010) Phenological research methods for environmental and climate change analysis: introduction and overview. Phenol Res Methods Environ Climate Change Analysis. doi:10.1007/978-90-481-3335-2_1
Lechowicz MJ (1984) Why do temperate deciduous trees leaf out at different times—adaptation and ecology of forest communities. Am Nat 124(6):821–842. doi:10.1086/284319
Marra PP, Francis CM, Mulvihill RS, Moore FR (2005) The influence of climate on the timing and rate of spring bird migration. Oecologia 142(2):307–315. doi:10.1007/s00442-004-1725-x
McCormack ML, Gaines K, Pastore M, Eissenstat D (2014) Early season root production in relation to leaf production among six diverse temperate tree species. Plant Soil:1–9. doi:10.1007/s11104-014-2347-7
Miller-Rushing AJ, Inouye DW, Primack RB (2008) How well do first flowering dates measure plant responses to climate change? The effects of population size and sampling frequency. J Ecol 96(6):1289–1296. doi:10.1111/j.1365-2745.2008.01436.x
Morellato LPC, Camargo MGG, Neves FFD, Luize BG, Mantovani A, Hudson IL (2010) The influence of sampling method, sample size, and frequency of observations on plant phenological patterns and interpretation in tropical forest trees. Phenol Res Methods Environ Climate Change Analysis. doi:10.1007/978-90-481-3335-2_5
Moussus JP, Julliard R, Jiguet F (2010) Featuring 10 phenological estimators using simulated data. Methods Ecol Evol 1(2):140–150. doi:10.1111/j.2041-210X.2010.00020.x
Parmesan C (2006) Ecological and evolutionary responses to recent climate change. In: Annual Review of Ecology Evolution and Systematics, vol 37. Annual Rev Ecol Evol Syst. pp 637–669. doi:10.1146/annurev.ecolsys.37.091305.110100
Parmesan C (2007) Influences of species, latitudes and methodologies on estimates of phenological response to global warming. Glob Chang Biol 13(9):1860–1872. doi:10.1111/j.1365-2486.2007.01404.x
Peeters F, Straile D, Lorke A, Livingstone DM (2007) Earlier onset of the spring phytoplankton bloom in lakes of the temperate zone in a warmer climate. Glob Chang Biol 13(9):1898–1909. doi:10.1111/j.1365-2486.2007.01412.x
Phillimore AB, Proios K, O'Mahony N, Bernard R, Lord AM, Atkinson S, Smithers RJ (2013) Inferring local processes from macro-scale phenological pattern: a comparison of two methods. J Ecol 101(3):774–783. doi:10.1111/1365-2745.12067
Polgar CA, Primack RB (2011) Leaf-out phenology of temperate woody plants: from trees to ecosystems. New Phytol 191(4):926–941. doi:10.1111/j.1469-8137.2011.03803.x
Rafferty NE, CaraDonna PJ, Burkle LA, Iler AM, Bronstein JL (2013) Phenological overlap of interacting species in a changing climate: an assessment of available approaches. Ecol Evol 3(9):3183–3193. doi:10.1002/ece3.668
Richardson AD, Keenan TF, Migliavacca M, Ryu Y, Sonnentag O, Toomey M (2013) Climate change, phenology, and phenological control of vegetation feedbacks to the climate system. Agric For Meteorol 169:156–173. doi:10.1016/j.agrformet.2012.09.012
Rollinson CR, Kaye MW (2012) Experimental warming alters spring phenology of certain plant functional groups in an early successional forest community. Glob Chang Biol 18(3):1108–1116. doi:10.1111/j.1365-2486.2011.02612.x
Rosemartin AH, Crimmins TM, Enquist CAF, Gerst KL, Kellermann JL, Posthumus EE, Weltzin JF, Denny EG, Guertin P, Marsh LR (2013) Organizing phenological data resources to inform natural resource conservation. biological conservation. doi:10.1016/j.biocon.2013.07.003
Schwartz MD, Ahas R, Aasa A (2006) Onset of spring starting earlier across the northern hemisphere. Glob Chang Biol 12(2):343–351. doi:10.1111/j.1365-2486.2005.01097.x
Schwartz MD, Ault TR, Betancourt JL (2013a) Spring onset variations and trends in the continental United States: past and regional assessment using temperature-based indices. Int J Climatol 33(13):2917–2922. doi:10.1002/joc.3625
Schwartz MD, Beaubien EG, Crimmins TM, Weltzin JF (2013b) North America. In: Schwartz MD (ed) Phenology: an integrative environmental science, 2nd edn. Springer, Netherlands, pp 67–89. doi:10.1007/978-94-007-6925-0_5
Schwartz MD, Betancourt JL, Weltzin JF (2012) From Caprio's lilacs to the USA National Phenology Network. Front Ecol Environ 10(6):324–327. doi:10.1890/110281
Thackeray SJ, Sparks TH, Frederiksen M, Burthe S, Bacon PJ, Bell JR, Botham MS, Brereton TM, Bright PW, Carvalho L, Clutton-Brock T, Dawson A, Edwards M, Elliott JM, Harrington R, Johns D, Jones ID, Jones JT, Leech DI, Roy DB, Scott WA, Smith M, Smithers RJ, Winfield IJ, Wanless S (2010) Trophic level asynchrony in rates of phenological change for marine, freshwater and terrestrial environments. Glob Chang Biol 16(12):3304–3313. doi:10.1111/j.1365-2486.2010.02165.x
Tierney G, Mitchell B, Miller-Rushing A, Katz J, Denny E, Brauer C, Donovan T, Richardson AD, Toomey M, Kozlowski A, Weltzin J, Gerst K, Sharron E, Sonnentag O, Dieffenbach F (2013) Phenology monitoring protocol: Northeast Temperate Network. Natural Resource Report. NPS/NETN/NRR—2013/681. Fort Collins, CO
USA National Phenology Network (2013) Plant phenology data for the United States, 2009–2013. USA-NPN, Tucson, Arizona, USA. Data set accessed 15-08-2013 at http://www.usanpn.org/results/data.
Wolkovich EM, Cook BI, Allen JM, Crimmins TM, Betancourt JL, Travers SE, Pau S, Regetz J, Davies TJ, Kraft NJB, Ault TR, Bolmgren K, Mazer SJ, McCabe GJ, McGill BJ, Parmesan C, Salamin N, Schwartz MD, Cleland EE (2012) Warming experiments underpredict plant phenological responses to climate change. Nature 485(7399):494–497. doi:10.1038/nature11014
Zhang X, Tarpley D, Sullivan JT (2007) Diverse responses of vegetation phenology to a warming climate. Geophys Res Lett 34 (19). doi:10.1029/2007gl031447
Zhang XY, Friedl MA, Schaaf CB, Strahler AH (2004) Climate controls on vegetation phenological patterns in northern mid- and high latitudes inferred from MODIS data. Glob Chang Biol 10(7):1133–1145. doi:10.1111/j.1529-8817.2003.00784.x
Zhao TT, Schwartz MD (2003) Examining the onset of spring in Wisconsin. Clim Res 24(1):59–70. doi:10.3354/cr024059
Acknowledgements
Data were provided by the USA National Phenology Network and the many participants who contribute to its Nature’s Notebook program. Special thanks to Theresa Crimmins and Jake Weltzin for discussions and comments on earlier drafts. The project described in this publication was supported by Grant/Cooperative Agreement Number G14AC00405 from the United States Geological Survey.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Fig. 1a–k
Box plots and histograms showing the distribution of differences (number of days) in estimated onset dates of breaking leaf buds when comparing mean values at each site between each of the three datasets for each species. Box plots display the median and quantiles of the distribution; however boxes are not visually evident in cases when the majority of the distribution is clustered around the mean; in such cases the remaining visible points are considered outliers (GIF 67 kb)
(GIF 65 kb)
(GIF 49 kb)
Rights and permissions
About this article

Cite this article
Gerst, K.L., Kellermann, J.L., Enquist, C.A.F. et al. Estimating the onset of spring from a complex phenology database: trade-offs across geographic scales. Int J Biometeorol 60, 391–400 (2016). https://doi.org/10.1007/s00484-015-1036-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00484-015-1036-4