
Abstract
Sufficient rainfall data are required to estimate the probable rainfall for a range of different return periods; however, for various reasons, many areas lack rainfall data. In this study, the Weather Research Forecasting (WRF) model was applied to obtain rainfall information based on varying parameter sets representing physical atmospheric conditions. Generated rainfall data were considered historical rainfall information for a region plagued by insufficient rainfall information. To analyze the applicability of the generated rainfall data, at-site/regional frequency analyses were conducted with various compositions of generated rainfall data. Prior to frequency analysis, comparisons of annual maximum rainfall for specific periods highlighted the need for bias correction when utilizing WRF generated rainfall data (e.g. underestimation of WRF around 22.53–79.12%). For at-site/regional frequency analyses, generated rainfall data after bias correction (GRA) provided a more accurate estimate in terms of relative root mean square error (RRMSE) with the Monte Carlo simulation. The increased accuracy using observations (OBS) with GRA was 87.5% for at-site frequency during the none-exceedance probability at 1. For regional frequency analysis, the estimates of rainfall for higher return periods (> 100 year) from generated rainfall data by WRF without bias correction (GRW) had a similar median to the observation. The maximum of RRMSEs of GRW, GRA, and OBS were 0.218, 0.181, and 0.175, respectively. In terms of possible combinations of regional frequency analysis, the findings show that physical location or diverse parameter set methods are both feasible for use in frequency analysis.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Frequency analysis provides the probable rainfall data required for the hydraulic design of various infrastructure. Historical rainfall observations of annual maximums are required as input data; however, oftentimes there is insufficient rainfall data due to missing data and/or a short record length (Trinh et al. 2016). According to the Flood Estimation Handbook (Handbook 1999), regional frequency analysis (RFA) is recommended if the duration of the observational record is less than or equal to the design frequency (T) at a rainfall station. An at-site frequency analysis is recommended if the data period is more than or equal to two times the design frequency (2 T). Despite these recommendations, lack of data has often led to frequency analysis with short datasets. Frequency analysis for datasets over a short period is unreliable due to the large dispersion and the parameter biases. To compensate for these shortcomings, many studies have been carried out to generate rainfall data.
Daily rainfall was simulated with a stochastic model, the first-order Markov Chain, which was first used by Haan et al. (1976). Estimated transitional probabilities apply historical data and tend to produce similar statistical outputs. Srikanthan et al. (2005) proposed the various transition probabilities matrix model (TPM) based on a first-order Markov Chain. They also compared the model performance by using data from North America, South Africa and Australia. Chandler et al (2002) applied the Gaussian Displacements Spatial–Temporal Model (GDSTM) using radar data that generated stochastic simulations. This process included probabilistic assumptions that were expressed using physical parameters when constituting rainfall structures. Viglione et al. (2012) suggested locally calibrated stochastic rainfall generators to estimate extreme rainfall quantiles. Piantadosi et al. (2009) suggested a stochastically generating model that provides annual totals to assess the effects of rainfall variability. Researchers are also developing models in terms of probabilities such as general circulation models; however, these have been found to provide poor rainfall estimates with low regional accuracy (Guttorp 1996). Although various probabilistic studies have been conducted, stochastic generation does not include the physical rainfall processes affected by meteorological conditions. Therefore, we used models that deviate from this stochastic process to estimate physical rainfall generation. The Weather Research and Forecasting (WRF) model is designed for research and various applications such as mesoscale numerical weather prediction and atmospheric simulation. As WRF is a regional scale model, we used it in an attempt to interpret output for the region; this is advantageous if regional assessment is required. In general, WRF has been used to evaluate and analyze event-centric simulations. Maussion et al. (2011) evaluated the WRF capacity of three domains (30, 10, and 2 km – grid sizes) of the Tibetan Plateau. Caldwell et al. (2009) compared a WRF-based dynamic downscaling experiment at 12 km grids. Kumar et al. (2008) simulated the Mumbai event in 2005 using WRF and interpret approximately four parameters (microphysics parameters: Thompson, Lin, The WRF Single-Moment 6-class (WSM6), and Morrison). Jalowska and Spero (2019) tried to develop precipitation intensity–duration–frequency (PIDF) curves using different grid sizes (e.g. 36, 12 km) of WRF simulation. Most of these have been developed based on a short-term event as opposed to long-term simulations. Unlike previous studies, we used the WRF to generate long-term rainfall data rather than focusing on events.
The main objective of this study was to investigate whether rainfall generation using various physical systems of the WRF may be used as long-term hydrologic input data. Notably, none of the aforementioned approaches have utilized the WRF physical factors other than for estimations and statistical output during the rainfall generation process. The physically based model we used contains parameters with definite physical meanings; these parameters may be measured or determined from prior experimental data. The inputted physical option in the rainfall generation model includes cloud modeling, ice, snow, and graupel processes, and column moisture adjustment schemes (Skamarock et al. 2008; Jung and Lin 2016). In this paper, these physical options were adjusted to generate rainfall without using stochastic and statistical methods. To evaluate the reliability of the generated rainfall data, frequency analysis was conducted between the observations and generated data. By using this approach, we will generate physical rainfall in the Chung-Ju dam (CJD) basin.
2 Study area
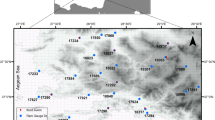
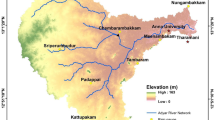
The CJD basin, located in northeastern South Korea, was the selected region for this study, as shown in Fig. 1. This site serves as a representation of the weather in the Korean Peninsula, containing a sufficient amount of hydrologic information. The CJD is one of the largest multi-purpose dams in South Korea; it was built in the south part of the Han river basin and is a source of industrial/domestic water supply, while also contributing to flood control and power supply. The size of CJD basin is 6648 km2, with a total storage of 2.750 × 109 m3 and a flood control capacity of 6.16 × 108 m3. The longest length of river in the CJD is ~ 385 km and its average slope is 0.35 (Kim et al. 2021). The CJD has 32 rainfall gauge stations that are well-distributed in throughout the basin; Table 1 summarizes the characteristics of these rain gauge stations (STN). The highest elevation rain gauge station is the Sabuk station (705 m), while the maximum elevation difference is 558 m; this means this area may be categorized as a mountainous region. The rainfall record length is over 22 year (y) with maximum 31 y by 2017, and approximately 30% of the rain gauge stations contain the statistically required record length (~ 30 y). The rainfall in this region is concentrated in the summer season and follows the mountainous regional rainfall characteristics such as fluctuations with moisture and temperature instability. The CJD basin information and observed rainfall records were obtained at the Water Resources Management Information System (WAMIS: http://www.wamis.go.kr) in Korea.

Location of Chung-Ju dam basin and 32 rainfall stations
3 Methodology
Figure 2 summarizes a procedure to analyze the adaptability of physically generated rainfall data for hydrologic applications. We first selected event periods based on hourly maximum rainfall with rainfall independency (rainfall event interval: 8–10 h) and proper rainfall duration (over 12 h) over the 1999–2017 period; in total, 19 rainfall events were selected that largely occurred during summer in Korea (from July to September). Based on the selected events the WRF version 3.6.1 was utilized to generate rainfall data with a range of diverse parameter combinations. These combinations represent different physical atmospheric conditions that form rainfall droplets; details on these combinations are presented in Sect. 2.1. The generated rainfall was validated with observed rainfall data and modified using a bias correction process. This process provided a statistically similar rainfall pattern to the observed rainfall data. Then, comparative analyses were conducted using at-site and regional frequency analyses to observe the applicability of the physically generated rainfall data after bias correction (GRA).

Flow chart illustrating key steps involved in this study
3.1 Rainfall data generation
3.1.1 Weather research forecasting model
The WRF has been designed for research and various applications such as real-time mesoscale numerical weather prediction and regional climate simulation (Skamarock et al. 2008). Originally, the WRF was developed as next generation of non-hydrostatic numerical weather prediction models based on the Fifth-Generation Penn State/NCAR Mesoscale Model (MM5) and more widely used in a regional weather prediction (Kusaka et al. 2005). For real-time numerical weather predictions (NWP), the WRF model provides a range of options in numerical schemes such as physical representations, parameterizations, and data assimilation. In addition, prognostic equations in the WRF model generate spurious oscillations and numerical smoothing of mass, momentum, and entropy of the atmosphere (Pattanayak and Mohanty 2008). As such, we managed the physical values for atmospheric conditions to generate rainfall estimates based on global weather observations. In particular, atmospheric heat and moisture flux conditions were represented by two substantial physical parameters, cumulus and microphysics parameterizations, for quantitative precipitation forecasts (QPF) (Jung and Lin 2016). The cumulus parameterizations provide atmospheric temperature and humidity, cloud tendency profiles, and surface sub-grid scale (convective) rainfall. Generally, cumulus parameterizations were not adopted when the grid size was smaller than 4 km as a smaller grid size is able to resolve mesoscale dynamics, updrafts and downdrafts, and local sub-grids that also involve other physical functions (Gilliland and Rowe 2007). Some researchers have recommended using cumulus parameterizations concurrently with microphysics parameters in the grey zone (1–10 km) to avoid accumulated energy at grid points (Gerard 2007). For this study, we fixed the Betts-Miller-Janjic (BMJ) scheme (Betts and Miller 1993; Janjić 1994) for cumulus parameterization; this is well developed to adjust column moisture in the relaxation profile for an optional Eta structure.
With respect to microphysics parameterizations, 17 different parameters were applied to provide possible conditions using a range of numerical representations. Cloud properties and structures within the meso and cloud-scale were represented by microphysical parameterizations. These manage the formation processes of precipitation such as generation, growth, decay, and fall using various phases of ice in the cloud. During the microphysical processes, ice phases (i.e., cloud ice, graupel/hail, and snow) hydrometers were appropriately displayed for mid-latitude deep convective clouds and smaller grid simulations (Jung and Lin 2016). Table 2 presents the selected parameter options with acronyms for the different combinations of parameters; in total, there were 17 combinations with diverse microphysics and one cumulus parameterization. To initialize and update the boundary conditions of the WRF model, the National Center for Environmental Prediction (NCEP) and the Final (FNL) operational global analysis data were obtained from the research data archive (www.rda.ucar.edu). These NCEP FNL data were generated by the same model for the Global Forecast System (GFS) data generation with continuously updated observational data from the Global Telecommunications System (GTS). These data have a 1º × 1º grid size, which updates every 6 h for weather predictions. These FNL data include data on surface pressure, sea level pressure, sea surface temperature, geopotential height, temperature, soil moisture, ice cover, relative humidity, and u and v-winds (wind velocities toward the east and north, respectively) at 26 obligatory stretching levels between 10 and 1000 mb (www.rda.ucar.edu). We used FNL data for rainfall data generation to create a rainfall data archive based on the potential physical formation of rainfall.
3.1.2 Bias correction
Generated rainfall data may be directly input into the hydrologic model for flood estimation (Jung and Lin 2016); however, with the generation of the rainfall Intensity–Duration–Frequency (IDF) curve, Kuo et al. (2014) produced rainfall data using the 5th Generation National Center for Atmospheric Research (NCAR)/Penn State Mesoscale Model (MM5). They found that the meteorological model was limited in terms of simulating storm intensity and the potential movement of a storm center which potentially leads to over-estimates in rainfall. In addition, regional climate models (RCMs) also have considerable systematic biases due to conceptualization problems, the erroneous prediction of rainfall intensity, and spatial resolution issues (Caldwell et al. 2009; Teutschbein and Seibert 2012; Requena et al. 2019). To address this systematic bias, the Quantile Mapping (QM) algorithm has been used as one of the well-developed methods for bias correction (Cannon et al. 2015; Lee and Singh 2019). A number of studies have demonstrated that the QM outperforms simple statistical bias correction (Jakob Themeßl et al. 2011). Block et al. (2009) and Piani et al. (2010) also suggested that QM was an adequate method for use in rainfall bias correction. For this study, the QM with a gamma distribution method was applied to correct biased rainfall data from the WRF simulation. The conventional QM is displayed in Eq. (1) with inverse function of the cumulative distribution function (CDF) for OBS (\(F_{0}^{ - 1}\)) and CDF of the model output (\(F_{m,base}\)). The gamma distribution contains two parameters, the shape parameter (α) and scale parameter (β); this includes an independent variable (\(x\)) and gamma function (\({\Gamma }\)) according to Eq. (2). The distribution parameters are obtained from Eqs. (3) and (4) with expectation (\(E\left( x \right) = {\upmu }\)) and variance (\(Var\left( x \right) = \sigma^{2}\)). The shape and scale parameters were related to the profile and dispersion of the distribution:
3.2 Frequency analysis
The aim of frequency analysis is to estimate design flood quantities to appropriately design infrastructure for hydrologic applications. Frequency analysis may be categorized into at-site and regional frequency analyses; the procedures involved with frequency analysis are presented in Fig. 3. Overall, this process is composed of data preparation, the selection of an appropriate probability distribution, and the estimation of quantiles for a range of storm sizes. For this process, a sufficient period of rainfall data is required for frequency analysis, where the input data period is greater than the return period (Hosking and Wallis 2005). In many cases, frequency analysis is carried out using a short data length, potentially providing an incorrect design flood due to the over/under estimation of rainfall with biases (Rahman et al. 2013). For regions with a shortage of rainfall data, at-site frequency analysis is limited in terms of generating the design storms. RFA is another means to overcome this rainfall data shortage; a number of studies have presented the merit of RFA (Lettenmaier and Potter 1985; Lettenmaier et al. 1987; Potter and Lettenmaier 1990; Stedinger and Lu 1995; Hosking and Wallis 2005). RFA utilizes possible rainfall data around a region, despite the region having insufficient observational rainfall data. The homogeneity of regions is a substantial part of RFA because the data dispersion relies on this characteristic. RFA may be categorized into four different methods: the index flood method, regional shape estimation method, hierarchical Bayesian modeling, and the focused rainfall growth extension method (Heo and Kim 2019). One of the well-developed index flood methods is an L-moment based method (Hosking and Wallis 2005); L-moment is the linear combinations of the probability weighted moment (Greenwood et al. 1979). The L-moment was selected for RFA because it is minimally influenced by unusually biased data.

Flow chart of at-site (left)/regional (right) frequency analyses
3.2.1 At-site frequency analysis
Generally, at-site frequency analysis using antecedent hydrologic data requires an estimation of the statistical characteristics of the data. One of the major processes is the selection of a representative statistical distribution for a site; the selected statistical distribution provides a design storm at-site frequency analysis. Prior to selecting a representative distribution, the randomness of data was measured using a range of methods (e.g., Correlogram Test, Run Test, Rank Correlation Coefficient Test, and Turning Point Test). Randomness presents the unbiasedness, independence, and stationarity of rainfall data. During the selection of statistical distribution, parameters with varying distributions were estimated by methods of moment, maximum likelihood, and/or probability weighted moments. The goodness-of-fit tests to select the most optimal distribution include the \(x^{2}\), Kolmogorov–Smirnov, Cramer Von Mises, and/or Probability Plot Correlation Coefficient tests. A representative statistical distribution was selected to operate at-site frequency analysis for selected frequencies.
3.2.2 Regional frequency analysis
For preparation of regional frequency analysis, data discordancy and heterogeneity tests were required to carry out the RFA using L-moment. The data discordancy test identifies discord sites using L-moment ratios based on basic statistical analysis between sites (i.e., t = standard deviation(std)/mean: L-CV, t3 = skewness/std: L-skewness, t4 = kurtosis/std: L-kurtosis) using discordancy (Di). In general, a discord site has a Di value over the criterion based on the given number of sites (e.g., for > 15 sites: Di = 3.0). Following the discordancy tests for each site, the selected region was validated for data homogeneity using a heterogeneity measure (H). A homogeneous region refers to a group of sites with identical statistical characteristics. Data from a homogeneous region can produce more reliable estimates compared to at-site estimations because of the effects of substituting spatial/regional rainfall data for limited temporal rainfall data for a site (Cunnane 1988). The criteria of homogeneous, possibly heterogeneous, and heterogeneous regions are: \(H < 1\), \(1 \le H < 2\), and \(H \ge 2\), respectively. After data preparation, we estimated the rainfall quantiles based on the selected distribution. We obtained five candidate distributions (generalized extreme values (GEV), generalized logistic (GLO), generalized normal (GNO), generalized pareto (GPA), and Pearson type III (PE3)) to represent a homogeneous region using the R package (Hosking 2019). During identification, the goodness of fit, \(Z^{DIST}\), was measured to illustrate similarities between the L-skewness and L-kurtosis of the candidate distribution with the regional average values. For example, the \(\left| {Z^{DIST} } \right| \le 1.64\) means that the fit is reasonable at a confidence level of 90%; the most optimal fit distribution has a \(Z^{DIST}\) that is close to 0.
A growth curve using the index-flood method suggested by Dalrymple (1960) was adopted to produce quantile estimates. In terms of the assumption regarding the homogeneity of a region, the rainfall quantile for each site was produced by multiplying between the average rainfall of the points and the regional growth curve. The values of a growth curve within region were similar/the same, because of regional homogeneity. The ratio of quantile estimate \(Q_{i} \left( F \right)\) and index flood (i.e., average annual rainfall quantiles: \(\mu_{i}\)) for the return period (T) is presented in the regional growth curve. In Eq. (5), \(q\left( f \right)\) is a dimensionless quantile function (i.e., regional growth curve) that is typically applied to every site. For an accurate estimation of the rainfall quantile to compare two or more different data applications for frequency analysis, the Monte Carlo simulation method was applied as shown in Eq. (6). Here, \(\hat{Q}_{i}^{\left[ m \right]} \left( F \right)\) is the site, i, quantile estimate for the non-exceedance probability F in the mth Monte Carlo simulation for a total number of simulations (M). The regional average relative RMSE (\({\text{RRMSE}}:{ }R^{R} \left( F \right)\)) of the estimated quantiles was obtained using Eq. (7):
4 Results and discussion
4.1 WRF simulations
In terms of rainfall data generation, 17 different parameter combinations (i.e., microphysics and cumulus parameterizations) were applied in the WRF model, as discussed in Sect. 2.2. These various combinations rely on the initial scheme, planetary boundary layer (PBL) parameterization, and fixed domain with buffer zones. PBL parameterization calculates the vertical temperature motion, moisture conditions, and the resultant energy; this study selected the Yonsei University (YSU) PBL parameterization (Hong et al. 2006). This parameterization has an eddy coefficient scheme with a definitive entrainment layer and figurative K-profiles in the mixed layers. Figure 4 shows the Korean Peninsula with the Mercator map projection in the WRF simulation domain. For the domain layers, three nested domains including two-way interactions were adopted for a finer resolution. The Nest 1, 2, and 3 in Fig. 4 shows grid sizes of 36, 12, and 4 km, respectively. Nest 1 has a guide point for south-north (SN) and west–east (WE) at 128.058°E, 36.316°N. There were 43 and 49 grids at Nest 2 for SN and WE, respectively, while Nest 3 contained 82 (SN) and 58 (WE) grids; the generated rainfall data were from Nest 3 (4 km resolution). The selected grid points to compare rainfall generation were near to the rainfall observation points based on the longitudinal and latitudinal information.

Three nested domains in WRF simulations
To understand the WRF operations for rainfall generation, two observation stations (STN 11 and STN 13) were selected to identify the most optimal parameter combinations (i.e., microphysics and cumulus parameterization) for each event. Figure 5(a) illustrates the most optimal parameter combinations (P1–P17) based on the Nash Sutcliffe efficiency (NSE) values with horizontal (STN 11) and vertical (STN 13) patterns over 19 y. For STN 13, the P1 parameter combination were selected most frequently (26.3%); P11 was the most optimal combination for STN 11 with 15.8% selection. Based on the Fig. 5, it was difficult to report that one combination is able to represent a location or region for accurate rainfall estimation; however, a number of researchers have focused on identifying the most optimal combinations for rainfall simulations (Giorgi and Mearns 1999; Yerramilli et al. 2010; Nasrollahi et al. 2012). As opposed to identifying the most optimal parameter combinations for a STN, we investigated the potential to adopt this WRF model to generate historical rainfall data for a region for which adequate rainfall data are unavailable. After constructing the hourly rainfall of observed and generated data for selected events, the maximum rainfall of 12 h duration was plotted in (see Fig. 5b). This figure shows the maximum rainfall for observations (OBS) rainfall stations and those generated rainfall data by WRF (GRW). The observed maximum rainfall is denoted as a dark line, while the 17 GRW data from different parameters combinations are represented in a lighter gray color. Figure 5b shows that the rainfall estimations from the GRW sets were underestimated by 22.53–79.12% of the observational data as other applications of regional climate models (Mearns et al. 1999; Teutschbein and Seibert 2012). In the simulations of Kuo et al. (2014) using MM5 for central Alberta, rainfall estimations were over-simulated about 49–77%. Thus, bias correction was required in order to apply GRW for frequency analysis.

a Selected parameter combinations for two observed rainfall stations (1999–2017, vertical pattern: STN 11 and horizontal pattern: STN 13); b maximum rainfall of 12 h duration events for the OBS and GRW at 31 stations
4.2 Frequency analysis
4.2.1 At-site frequency analysis
At-site frequency analysis is preferred if there is sufficient rainfall data with a record length over two times of the return period for a watershed (Handbook 1999). For the CJD basin, the current status of rainfall information is unsatisfactory because of a shortage in rainfall information (Table 1, maximum number of years: 31 y). We selected a grid point near a rainfall observation station. All generated rainfall data following GRA were added into the observed rainfall data and treated the same way as the OBS. The generated rainfall data were 17 times the length of the simulation period (e.g. 10 y × 17 parameters combinations = 170 y data at a point). For frequency analysis, the rainfall data consisted of the annual maximum rainfall for given durations (e.g., 1 to 72 h). At-site frequency analysis was carried out following the preparation of rainfall data. To select the best statistical distribution fit for the rainfall information, a range of distributions were compared. We selected the method of probability weighted moments to estimate parameters; once the parameters were identified, the GEV distribution was selected through the goodness of fit test. Figure 6 (left) shows the IDF curve at STN 1 generated by an estimated rainfall intensity equation. The GRA with observed data were of a sufficient length for at-site frequency analysis because the GRA data at each station compensates for the lack of a decent length of observed rainfall data. Figure 6 (right) displays the relative RMSE (RRMSE) comparison between OBS only and GRA with OBS at STN 1. With respect to RRMSE, the GRA with OBS showed lower values because the larger data set potentially provided more information to generate the probability of rainfall estimation. The GRA may compensate historical rainfall data using various parameter combinations presenting physically possible atmospheric conditions.

At-site IDF (left) and the relative RMSE in Monte Carlo simulation (right)
4.2.2 Regional frequency analysis
Following bias correction for the WRF simulation data (i.e., GRA data), RFA was conducted for the CJD basin. At first, statistics for each site and discordancy measure were calculated for OBS and GRA to identify whether each site differed from the entire region; discordancy measures were obtained from L-CV, L-skewness, and L-kurtosis. A discord region was based on given criterion (i.e., > 3) dependent on the number of sites (i.e., 32 sites for this study) in the region. For each observed event, the WRF generated 17 different events attributed to 17 parameter combinations (i.e., P1–P17, Table 2). The number of total events was 544 from WRF simulations. During discordancy analysis, there were very low discordances (0.92%) from the WRF simulations. Five parameter sets (i.e., P1, P3, P8, P9, and P10) showed only one discordance station of 32 the stations with slightly higher discordancy values. In this study, a small percentage of discordant stations were included in the RFA because more data will minimize the rainfall data variances, despite the data having discrepancies. The heterogeneity measure identified the homogenous region of rainfall data; Table 3 displays the results of heterogeneities for H1, H2, and H3. The OBS and GRA were accepted as homogenous regions. The range of H-values was from -0.35 to -4.28 in which the GRAs showed larger amount of cross-correlation between sites compared to observations (-1.33– -1.60). The WRF simulation may contain some regularities during physical rainfall generation and the potentially short observation location distances produce strong cross-correlation (Hosking and Wallis 2005).
We selected feasible distributions based on the L-moment ratio diagram and the Z value; five different distributions were investigated (i.e., GEV, GLO, GNO, GPA, and PE3) in the goodness of fit test. Figure 7 illustrates the L-moment ratios between L-Skewness and L-Kurtosis for 32 sites in the CJD basin for annual maximums of 12 h rainfall events. In this figure, the cross (black) and triangle (red) points denote the L-moment ratios of 32 sites and the average ratio of 32 sites, respectively. The selection of the most optimal distribution of the data was based on the closeness between the average ratio (i.e. triangle) and representative lines or points of statistical distributions. The confirmation of preferable distributions may be estimated by the Z statistics; a statistical distribution was selected when the number of Z-values is within the criterion and close to the zero (presented as distance in Table 4). The satisfactory criterion was |Z|≤ 1.64, which corresponds to an acceptance of the hypothesized distribution at a confidence level of 90%. PE3 was the most optimal statistical distribution for GRA based on the distance from Fig. 7. The GEV was selected as a representative statistical distribution because of the number of Z-value over the criterion; however, GNO and PE3 showed higher pass ratios where the Z-values were a shorter distance from zero.

L-moment ratio of OBS and selected parameter combinations (i.e., P2, P3, P7, P9, P12)
Figure 8 displays the simple boxplots of averaged probable rainfall for a given return period by OBS, GRA, and GRW. These were generated by multiplying the quantile function of growth curves and averaged rainfall of station as per Eq. (5). The boxplot for each return period was averaged from probable rainfall for each parameter combination (P1–P17). For the probable rainfall for a 2 y return period, the GRW showed a relatively low median as expected in Sect. 4.1. With an increased return period, the variations of probable rainfall for GRW were also elevated with the presence of unusual values. The GRA showed median differences at a lower return period with higher variances. After a 10 y return period, the GRA slightly underestimated the probable rainfall, where the variances were similar to the probable rainfall distribution of a 2 y return period. The GRA and GRW for a higher return period (after 100 y) shared similar median values; the size differences between the 75th and 25th percentiles of GRA and GRW were also similar across all return periods. No substantial quartile skews were observed for the GRW and GRA as OBS. For higher return periods (> 100 y), the bias correction process may not be necessary to generate probable rainfall in terms of the median and interquartile range.

Averaged probable rainfall for specific return periods in the CJD basin
The Monte Carlo simulation was used to compare the accuracy of estimated rainfall quantile results. Figure 9 shows the averaged RRMSEs of GRW and GRA for 17 parameter sets including 32 rainfall stations during the rainfall quantile generation for non-exceedance probabilities. The averaged RRMSE for GRA had a higher accuracy compared to the averaged RRMSE for GRW; the range of RRMSEs for GRW, GRA, and OBS were 0.064–0.218, 0.046–0.181, and 0.031–0.175, respectively. The averaged RRMSEs of GRA and OBS were remarkably lower than GRW. This suggests that the GRA calculated reliable probability hydrologic quantiles. However, the GRA had a higher RRMSE compared to OBS; this differed from the Monte Carlo simulations for at-site frequency analysis. For a selected site, the at-site frequency analysis had more data as all WRF generated rainfall data were included for different parameter combinations (P1–P17) and considered observations. Figure 9 shows the comparison of the same number of rainfall data (32 rainfall data = 32 stations per event) for OBS and GRA generated by WRF for each parameter combination set (i.e., P1, P2, …, or P17). Thus, the same dataset number produced lower accuracy in terms of comparing Monte Carlo simulations. With a higher return period, the accuracies of GRW, GRA and OBS requires consideration to maximize the accuracy in future research. Based on the results, it is recommended that bias correction for WRF simulation rainfall data is carried out for frequency analysis that will estimate the design storm.

RRMSE of observation and average of GRA, GRW
4.2.3 Possible combinations for a regional frequency analysis
Figure 10 displays the possible combinations of a RFA using WRF simulated rainfall data following bias correction. The first combination involved each parameter set having its own rainfall data at 32 rainfall observation stations (method 1) as previously analyzed. Generated rainfall data for each rainfall station were recognized as regional rainfall information. Another combination was where all rainfall data generated for different parameter sets (P1–P17) were added into a station displayed as Fig. 10—method 2. Each parameter set may be considered a different region to carry out a RFA for method 2. The at-site frequency analysis in Sect. 4.2.1 forms one part of this method; however, we did not place different parameter sets as distinct regions.

Possible combinations of regional frequency analysis using GRA. Method 1: rainfall stations based combinations; method 2: parameter set based combinations
Figure 11(a) shows the possible range of the growth curves for the different parameter combinations. The range of method 2 is displayed between dotted lines, showing the larger range of the growth curves. Method 2 contained a range of physical conditions compared to the method 1 based on only one parameter set; this will generate various storm events. Method 1 showed higher growth curves for all stations. The range of growth curves for method 2 were ranged widely, including the growth curves of OBS and Method 1. With a lower return period (< 20 y), the quantiles of the two methods underestimated the regional growth curve compared to OBS (small graphs in Fig. 11a). Figure 11b presents the averaged probable rainfall for specific return periods using two different methods. For the 2 y return period, methods 1 and 2 showed a lower median of possible rainfall with larger variances. When the return period was increased, the medians of possible rainfall were well-matched. Methods 1 and 2 demonstrated higher variances compared to the OBS for all return periods; method 2 showed larger variances for all return period with some outliers. Based on the generated possible rainfall, methods 1 and 2 have potential to provide more rainfall information to generate design storms.

a Growth curves of different methods of rainfall data combinations for regional frequency analysis; b averaged possible rainfall using different rainfall data combination methods for specific return periods in the CJD basin
5 Summary and conclusions
This study applied the WRF model to generate rainfall data using parameters (i.e., microphysics and cumulus parameterization) representing a range of physical conditions in terms of moisture and heat flux in the atmosphere. Simulated rainfall data using 17 parameter combinations were evaluated in terms of at-site/regional frequency analyses; these were then compared with observed data at 32 rainfall stations. The findings from the study are as follows:
-
1.
Direct usage of WRF generated rainfall information using a specific parameter combination is not recommended. In some cases, various parameter combinations may produce the best fit for observations; this means it is difficult to specify one parameter combination that is able to represent a specific region for rainfall simulations. In terms of the averaged maximum rainfall data for a given duration at each rainfall station, WRF underestimated this value for most rainfall stations. For hydrologic applications, a bias correction process was required as other regional climate models;
-
2.
To analyze the applicability of generated rainfall data after bias correction (GRA), at-site and regional frequency analyses were carried out, and compared with the generated rainfall by WRF without bias correction (GRW) and/or observations (OBS). These results showed that:
-
With at-site frequency analysis, the GRA with OBS showed higher accuracy compared to only OBS in terms of RRMSEs using the Monte Carlo simulation method. GRA provided more rainfall data by the various parameter sets based on globally simulated atmospheric conditions (FNL operational global analysis data);
-
With RFA, the GRA, GRW, and/or OBS produced averaged probable rainfall for specific return periods. For a short return period (2 y), the medians of averaged probable rainfall for GRW and GRA were lower than the OBS. The simplicity of the WRF model in complex rainfall phenomena potentially underestimated rainfall. With increased return periods, the median of GRW approached the OBS with larger variances. For higher return periods (> 100 y), a bias correction process for GRW may not be required.
-
-
3.
There were two possible methods for RFA using WRF generated rainfall data: method 1 was based on physical locations; and method 2 was based on a range of parameter sets. With a comparison of averaged possible rainfall, methods 1 and 2 showed similar medians of averaged probable rainfall, although method 2 contained more variances and some outliers.
Consequently, we conclude that 1) the rainfall generation using physical systems (i.e. microphysics and cumulus parameterization) of WRF can be applied to produce long-term hydrologic input data with a bias correction process; 2) different parameter combinations may be applied as different regions for regional frequency analysis. In future studies, physically generated rainfall data may be used to provide runoff data to analyze the spatial characteristics of mid/small watersheds.
References
Betts AK, Miller MJ (1993) The betts-miller scheme. In: The representation of cumulus convection in numerical models. Springer, pp 107–121. https:/doi.org/https://doi.org/10.1007/978-1-935704-13-3_9
Block PJ, Souza Filho FA, Sun L, Kwon H (2009) A streamflow forecasting framework using multiple climate and hydrological models 1. JAWRA J Am Water Resour Assoc 45:828–843. https://doi.org/10.1111/j.1752-1688.2009.00327.x
Caldwell P, Chin H-NS, Bader DC, Bala G (2009) Evaluation of a WRF dynamical downscaling simulation over California. Clim Change 95:499–521. https://doi.org/10.1007/s10584-009-9583-5
Cannon AJ, Sobie SR, Murdock TQ (2015) Bias correction of GCM precipitation by quantile mapping: How well do methods preserve changes in quantiles and extremes? J Clim 28:6938–6959. https://doi.org/10.1175/JCLI-D-14-00754.1
Chandler RE, Wheater HS, Isham V, Onof C (2002) Generation of spatially consistent rainfall data. Contin river flow Simul methods, Appl uncertainties, BHS Occas Pap No 13:59–65. https:/doi.org/https://doi.org/10.13140/RG.2.1.2218.2642
Cunnane C (1988) Methods and merits of regional flood frequency analysis. J Hydrol 100:269–290. https://doi.org/10.1016/0022-1694(88)90188-6
Gerard L (2007) An integrated package for subgrid convection, clouds and precipitation compatible with meso-gamma scales. Q J R Meteorol Soc A J Atmos Sci Appl Meteorol Phys Oceanogr 133:711–730. https://doi.org/10.1002/qj.58
Gilliland EK, Rowe CM (2007) A comparison of cumulus parameterization schemes in the WRF model. In: Proceedings of the 87th AMS Annual Meeting & 21st conference on hydrology
Giorgi F, Mearns LO (1999). Introduction to Special Section: Regional Climate Modeling Revisited. https://doi.org/10.1029/98JD02072
Greenwood JA, Landwehr JM, Matalas NC, Wallis JR (1979) Probability weighted moments: definition and relation to parameters of several distributions expressable in inverse form. Water Resour Res 15:1049–1054. https://doi.org/10.1029/WR015i005p01049
Guttorp P (1996) Stochastic modeling of rainfall. In: Environmental studies. Springer, pp 171–187. https://doi.org/10.1007/978-1-4613-8492-2_7
Haan CT, Allen DM, Street JO (1976) A Markov chain model of daily rainfall. Water Resour Res 12:443–449. https://doi.org/10.1029/WR012i003p00443
Handbook FE (1999) Institute of hydrology. Wallingford, UK
Heo J-H, Kim H (2019) Regional frequency analysis for stationary and nonstationary hydrological data. J Korea Water Resour Assoc 52:657–669. https://doi.org/10.3741/JKWRA.2019.52.10.657
Hong S-Y, Noh Y, Dudhia J (2006) A new vertical diffusion package with an explicit treatment of entrainment processes. Mon Weather Rev 134:2318–2341. https://doi.org/10.1175/MWR3199.1
Hosking JRM, Hosking MJRM (2019) Package ‘lmom’
Hosking JRM, Wallis JR (2005) Regional frequency analysis: an approach based on L-moments. Cambridge University Press. https://doi.org/10.1017/CBO9780511529443
Jakob Themeßl M, Gobiet A, Leuprecht A (2011) Empirical-statistical downscaling and error correction of daily precipitation from regional climate models. Int J Climatol 31:1530–1544. https://doi.org/10.1002/joc.2168
Janjić ZI (1994) The step-mountain eta coordinate model: Further developments of the convection, viscous sublayer, and turbulence closure schemes. Mon Weather Rev 122:927–945. https://doi.org/10.1175/1520-0493(1994)122%3c0927:TSMECM%3e2.0.CO;2
Jalowska AM, Spero TL (2019) Developing PIDF curves from dynamically downscaled WRF model fields to examine extreme precipitation events in three eastern U.S. metropolitan areas. J Geophy Resea Atmophere 124. https://doi.org/10.1029/2019JD031584
Jung Y, Lin Y-L (2016) Assessment of a regional-scale weather model for hydrological applications in South Korea. Environ Nat Resour Res 6:28–41. https://doi.org/10.5539/enrr.v6n2p28
Kim N-W, Kim K-H, Jung Y (2021) Spatial recognition of regional maximum floods in ungauged watersheds and investigations of the influence of rainfall. Atmosphere 12(800):1–14. https://doi.org/10.3390/atmos12070800
Kumar A, Dudhia J, Rotunno R, Niyogi D, Mohanty UC (2008) Analysis of the 26 July 2005 heavy rain event over Mumbai, India using the Weather Research and Forecasting (WRF) model. Q J R Meteorol Soc 134:1897–1910. https://doi.org/10.1002/qj.325
Kuo C-C, Gan TY, Hanrahan JL (2014) Precipitation frequency analysis based on regional climate simulations in Central Alberta. J Hydrol 510:436–446. https://doi.org/10.1016/j.jhydrol.2013.12.051
Kusaka H, Crook A. Dudhia J, Wada K (2005) Comparison of the WRF and MM5 models for simulation of heavy rainfall along the Baiu Front, SOLA, 1:197–200. https://doi.org/10.2151/sola.2005-051
Lee T, Singh VP (2019) Statistical downscaling for hydrological and environmental applications. CRC Press, Boca Raton, USA
Lettenmaier DP, Potter KW (1985) Testing flood frequency estimation methods using a regional flood generation model. Water Resour Res 21:1903–1914. https://doi.org/10.1029/WR021i012p01903
Lettenmaier DP, Wallis JR, Wood EF (1987) Effect of regional heterogeneity on flood frequency estimation. Water Resour Res 23:313–323. https://doi.org/10.1029/WR023i002p00313
Maussion F, Scherer D, Finkelnburg R, Richters J, Yang W, Yao T (2011) WRF simulation of a precipitation event over the Tibetan Plateau, China–an assessment using remote sensing and ground observations. Hydrol Earth Syst Sci 15:1795–1817. https://doi.org/10.5194/hess-15-1795-2011
Mearns LO, Bogardi I, Giorgi F, Matyasovszky I, Palecki M (1999) Comparison of climate change scenarios generated from regional climate model experiments and statistical downscaling. J Geophys Res Atmos 104:6603–6621. https://doi.org/10.1029/1998JD200042
Nasrollahi N, AghaKouchak A, Li J, Gao X, Hsu K, Sorooshian S (2012) Assessing the impacts of different WRF precipitation physics in hurricane simulations. Weather Forecast 27:1003–1016. https://doi.org/10.1175/WAF-D-10-05000.1
Pattanayak S, Mohanty UC (2008) A comparative study on performance of MM5 and WRF models in simulation of tropical cyclones over Indian seas. Curr Sci 923–936
Piani C, Haerter JO, Coppola E (2010) Statistical bias correction for daily precipitation in regional climate models over Europe. Theor Appl Climatol 99:187–192. https://doi.org/10.1007/s00704-009-0134-9
Piantadosi J, Boland J, Howlett P (2009) Generating synthetic rainfall on various timescales—daily, monthly and yearly. Environ Model Assess 14:431–438. https://doi.org/10.1007/s10666-008-9157-3
Potter KW, Lettenmaier DP (1990) A comparison of regional flood frequency estimation methods using a resampling method. Water Resour Res 26:415–424. https://doi.org/10.1029/WR026i003p00415
Rahman AS, Rahman A, Zaman MA, Haddad K, Ahsan A, Imteaz M (2013) A study on selection of probability distributions for at-site flood frequency analysis in Australia. Nat Hazards 69:1803–1813. https://doi.org/10.1007/s11069-013-0775-y
Requena AI, Burn DH, Coulibaly P (2019) Estimates of gridded relative changes in 24-h extreme rainfall intensities based on pooled frequency analysis. J Hydrol 577:123940. https://doi.org/10.1016/j.jhydrol.2019.123940
Skamarock WC, Klemp JB, Dudhia J, Gill DO, Barker D, Duda MG, Huang X-Y, Wang W, Powers JG (2008) A description of the advanced research WRF version 3. NCAR Tech. Note NCAR/TN-475+ STR. Natl Cent Atmos Res Boulder, CO, USA 125:. http://dx.doi.org/https://doi.org/10.5065/D68S4MVH
Srikanthan R, Harrold TI, Sharma A, McMahon TA (2005) Comparison of two approaches for generation of daily rainfall data. Stoch Environ Res Risk Assess 19:215–226. https://doi.org/10.1007/s00477-004-0226-0
Stedinger JR, Lu L-H (1995) Appraisal of regional and index flood quantile estimators. Stoch Hydrol Hydraul 9:49–75. https://doi.org/10.1007/BF01581758
Teutschbein C, Seibert J (2012) Bias correction of regional climate model simulations for hydrological climate-change impact studies: Review and evaluation of different methods. J Hydrol 456:12–29. https://doi.org/10.1016/j.jhydrol.2012.05.052
Trinh T, van den Akker B, Coleman HM, Stuetz RM, Drewes JE, Le-Clech P, Khan SJ (2016) Seasonal variations in fate and removal of trace organic chemical contaminants while operating a full-scale membrane bioreactor. Sci Total Environ 550:176–218. https://doi.org/10.1016/j.scitotenv.2015.12.083
Viglione A, Castellarin A, Rogger M, Merz R, Bl schl G, (2012) Extreme rainstorms: Comparing regional envelope curves to stochastically generated events. Water Resour Res. https://doi.org/10.1029/2011WR010515
Yerramilli A, Challa VS, Dodla VBR, Myles L, Pendergrass WR, Vogel CA, Tuluri F, Baham JM, Hughes R, Patrick C, Young J, Swanier S (2010) Simulation of surface ozone pollution in the central gulf coast region using WRF/Chem Model: Sensitivity to PBL and Land Surface Physics. Adv Meteorol: https://doi.org/10.1155/2010/319138
Acknowledgements
This study was supported by Wonkwang University in 2022.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Choi, G., Jung, Y. Applicability of physically generated rainfall data using a regional weather model. Stoch Environ Res Risk Assess 36, 2979–2994 (2022). https://doi.org/10.1007/s00477-022-02173-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-022-02173-7