
Abstract
In this study, a risk aversion based interval stochastic programming (RAIS) method is proposed through integrating interval multistage stochastic programming and conditional value at risk (CVaR) measure for tackling uncertainties expressed as probability distributions and intervals within a multistage context. The RAIS method can reflect dynamic features of the system conditions through transactions at discrete points in time over the planning horizon. Using the CVaR measure, RAIS can effectively reflect system risk resulted from random parameters. When random events are occurred, the adjustable alternatives can be achieved by setting desired targets according to the CVaR, which could make the revised decisions to minimize the economic penalties. Then, the RAIS method is applied to planning agricultural water management in the Zhangweinan River Basin that is plagued by drought due to serious water scarcity. A set of decision alternatives with different combinations of risk levels employed to the objective function and constraints are generated for planning water resources allocation. The results can not only help decision makers examine potential interactions between risks under uncertainty, but also help generate desired policies for agricultural water management with a maximized payoff and a minimized loss.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Due to numerous factors such as continuous population growth, economy development, climate change, water quality deterioration, agricultural water shortage has become more and more severe (Cameron and Damowski 2015; Amarasingha et al. 2015). The sustainable development of agricultural system depends on the stable and rational irrigation water management (Davijani et al. 2016). Agricultural water requirements could be met through carrying out effective water resources management schemes. However, it might be impossible with consideration of limited available water resources. Optimizing water-resources allocation is one of the commonly used approaches to increase the quantity of available water and improve water utilization efficiency in agriculture irrigation systems (Melkonyan 2015). For example, two-stage stochastic programming (TSP) is used for planning water allocation to identify the optimal irrigation scheme in agriculture irrigation systems (Hughes and Slaughter 2016). Nevertheless, the dynamic variations of irrigation system conditions, especially for sequential structure of large-scale agriculture problems, could not be adequately reflecting by TSP (Suinyuy et al. 2016).
As a result, many experts and scholars employed multistage stochastic programming (MSP) approach to manage water resource systems (Sirangelo et al. 2015; Agliardi et al. 2016; He 2016; Nematian 2016). Li et al. (2006) formulated an interval-parameter multistage stochastic linear programming method to allocate water resources; through using probability density functions and discrete intervals, the method can effectively express the uncertainties of the systems. Mohammed et al. (2007) developed a coupled hydrologic-economic spreadsheet water-allocation model which was used by both agriculture and environmental sectors for the Murray-Darling Basin (Australia) with various policy scenarios. Chen et al. (2015) developed an inexact multistage fuzzy-stochastic programming to tackle various uncertainties and their interrelationships under different α-cut levels at a plurality of periods; when the promised water allocation targets are violated after random events, recourse decisions can be made to minimize penalties with a maximized system benefit (Kouwenberg 2001; Gulpinar et al. 2002). MSP is effective for water resources management where the analysis of policy scenarios is desired (Casey and Sen 2005; Li et al. 2008a, b). However, MSP couldnot measure the potential economic loss caused by the lack of water resources. Besides, the agricultural systems are surrounded with a number of uncertain factors that would result in system risks, such as random inflow and water demand during growth cycle (Wang et al. 2016). Thus, a sound risk-averse method is desired for analyzing agricultural water management system. Value-at-risk (VaR), a measure of risk, can effectively quantify the potentially system risks within agricultural systems; however, VaR only can represent the average risk of a financial asset or portfolio value without considering the extreme occasion (Josh 2015; Wang et al. 2016). The conditional value at risk (CVaR) taking the impacts of all extreme values in the tail of the distribution into account is more effective in reflecting extreme occasions than that of VaR. It is desired to introduce the CVaR measure into agricultural water management and planning to generate water allocation scheme with a maximum system benefit and a minimum system risk.
Therefore, a risk aversion based interval stochastic programming (RAIS) method is proposed for supporting water resources management through integrating MSP and CVaR into a general framework. RAIS can deal with uncertainties expressed as probability distributions and interval numbers. Besides, it can reflect the dynamic processes of agricultural water management through setting a series of promised water targets with considering the uncertainties of crop water requirement. Dynamic risk analysis avoids the difficult adjustment of static risk analysis and is more realistic (Maryam et al. 2016). Then, the RAIS method will be demonstrated for agricultural water management and planning in Zhangweinan River Basin (China).
2 Methodology
Interval-parameter programming (IPP) can deal with intervals with known lower and upper bounds and one IPP model can be formulated as follows (Huang 1996):
subject to:
where A ± ∊ {R ±}1×n, C ± ∊ {R ±}1×n, B ± ∊ {R ±}m×1, X ± ∊ {R ±}n×1;R ± denotes a set of interval numbers with deterministic lower and upper bounds; “−” and “+” represent the lower and upper bounds of the interval parameters (or variables), respectively. In agricultural water management, because of the spatial–temporal variability and inhomogeneity of natural factors and the uncertainty of human activities, water supplies during the planning horizon would have random features, and the promised water cannot always be satisfied. MSP can reflect dynamic features of water allocation processes. In MSP, recourse can be realized by taking corrective actions after a random event has taken place. The initial action is called the previous stage decision, and the corrective one is named the current stage decision. The previous stage decisions have to be made before further information of initial system uncertainties is revealed, whereas the current stage ones are allowed to adapt to this information (Li et al. 2008a, b). Uncertainties in MSP can be conceptualized into a multilayer scenario tree (as shown Fig. 1), with a one-to-one correspondence between the previous random variable and one of the nodes (states of the system) in each time stage (t). Based on techniques of IPP and MSP, the problem under consideration can be formulated as an interval MSP (IMSP) model:
subject to:

Multilayer scenario tree
CVaR is a measure to deal with system risks caused by water shortage in agricultural water system and it can reflect the impacts of all extreme values in the tail of the distribution (available water resources). The CVaR risk-measure equation can be formulated as:
where Z represents random variable, a (α ∊ (0, 1)) represents the expected value of the tail of the distribution of Z. However, only taking into account the impact of critical scenarios may lead to conservative and expensive policies (Rockafellar and Uryasev 2002). In this sense, the convex combination of expected value and CVaR has been considered in the objective function to express the loss function as shown below:
where Z = C t X t + φ t+1(X t , ξ t+1), C ∊ R, X ∊ R, R represents the real number set, λ ∊ (0, 1). Application of formula (4) leads to a nested CVaR formulation, as illustrated in (5) for a 3-stage problem.
The use of the nested CVaR is necessary in order to ensure time consistency. Through introducing the CVaR measure into model (2), a risk aversion based interval stochastic programming (RAIS) model can be obtained:
subject to:
The amount of water in this case study is the approximate to fall through statistical analysis, as shown Fig. 2, can be seen from the graph, the amount of water resources for data is not completely fall on the approximate normal distribution curve, therefore, compared with the VaR, using the advantage of CVaR can more accurately characterize the uncertainty of the water resources. α is used to calculate the value of CVaR tail risk, and λ represents the importance of risk value to the decision maker.

Statistical analysis of water resources
In this study, an optimized set of target values is identified by having y ijt decision variables. Let IT ± ijt = IT − ijt + ΔIT ijt y ijt , where ΔIT ijt = IT + ijt − IT − ijt and y ijt ∈[0, 1]. When IT ± ijt approach their upper bounds (i.e. when y ijt = 1), a relatively high benefit may be obtained if the water demands are satisfied; however, a high penalty may have to be paid when the promised water is not delivered. Conversely, when IT ± ijt reach their lower bounds (i.e. when y ijt = 0), we may have a lower benefit but, at the same time, a lower risk of violating the promised targets (and thus lower penalty). Then, the RAIS model can be solved through transforming it into two deterministic submodels based on a two-step interactive algorithm to get the lower and upper bounds of f ±. When the system objective is to be maximized, the submodel corresponding to f + can be first formulated; the other submodel (corresponding to f −) can then be formulated based on the solution of the first submodel. The submodel corresponding to f + can be expressed as follows:
subject to
where ISD − ijtk and y ijt are decision variables. Solution for f + provides the extreme upper bound of system benefit under uncertain inputs of water-allocation targets. \( ISD_{ijt \, opt}^{ - } \) and y ijt can be obtained from submodel (7). Then the submodel corresponding to f − can be formulated as follows:
subject to
where ISD + ijtk and y ijt are decision variables. Solution for f − provides the extreme lower bound of system benefit under uncertain inputs of water-allocation targets. Their solutions of ISD + ijt can be obtained through solving sub-model (8). By combining the solutions from sub-models (7) and (8), the final solution of model (6) can be obtained as follows:
The optimized water allocation schemes would be:
where Z ± ijtk opt is the total water allocation to scenario k subarea j planting crop i. Figure 3 presents the framework of the RAIS method.

Framework of the RAIS method
3 Case study
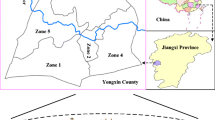
Zhangweinan River Basin is subordinate to Haihe River Basin and accounts for 11% of the total river basin. It stretches through Shanxi, Henan, Hebei, Shandong provinces and the municipality of Tianjin, with a basin area of 37,700 km2 (Xu et al. 2012). The topography of the basin consists of mountainous areas in the west and plain areas in the east. The basin is located in the semi-arid, semi-humid monsoon climate of temperate zone, with an average annual temperature of 14 °C and an average annual precipitation of 608.4 mm. Precipitation varies largely among different seasons. For example, precipitation in winter accounts for only 2% of annual precipitation, while that in summer, especially in July and August, accounts for more than half of annual precipitation (Li and Huang 2011). Zhangweinan River Basin is one of the main food and cotton producing regions in North China, and it faces serious water shortage.
The Yuecheng Reservoir lies in Ci County of Hebei Province and Anyang County of Henan Province. It is the largest reservoir in the Zhangweinan River Basin which is one of the two tributaries of the study river basin. This reservoir is also responsible for the water supply of municipal, industrial and agricultural sectors in two cities (i.e. Anyang and Handan). The total storage capacity of the reservoir is 11.3 billion m3, with a control basin area of 18,100 km2. Most of the area is cropland with cultivated crops, including wheat, maize, cotton, rice, bean, oilseed, and vegetables. Among them, wheat, maize, cotton and vegetable are the main crops and consume the majority of water from the reservoir. Double cropping maize and wheat is the dominating cropping system used on the study area (as shown Fig. 4). In this cropping system, maize is seeded in early June, immediately after the wheat harvest and harvested in the middle September; winter wheat is then seeded in early October and harvested in the following June.

The study area
In agricultural irrigation system, uncertainties in water resources allocation processes may influence the stability of agricultural water management system. For example, the crop water requirement should be considered when the available water is under low level (Allen 2000). Moreover, many factors affect the crop water requirement such as evaporation, transpiration, evapotranspiration, weather parameters, crop factors, management and environmental conditions and so on. The determination of crop water demand has become an important limiting factor in such system. Many researchers tried to tackle these difficulties through reference evapotranspiration (Olivera-Guerra et al. 2014; Vipan et al. 2015; Wherley et al. 2015). Among them, actual crop evapotranspiration and single crop coefficients were considered in crop irrigation system. To better manage irrigation water inputs and improve water use efficiency for crop production, the actual crop evapotranspiration (ET) and the single crop coefficients (k cb ) were taken into account.
In double crop coefficients method, the reference standard crops were cited to reflect the uncertainties of crop water requirement when the types of crops are less than dual crop coefficient method. Evapotranspiration is an important part of the field water cycle and has significant influences on crop growth, development and yield (Alberto et al. 2014). Actual ET reflects the crop’s water need which consists of transpiration (T) and evaporation (E). Determination of k c under local climatic condition is the basis to improve planning and efficient irrigation management in many field crops. The crop coefficient (k c ) can be determined by dividing ET with ET 0 (reference crop evapotranspiration) (Allen 2000). However, previous studies mainly concentrated on Kc, and they paid little attention to its components, k cb (basal crop coefficient). In double crop coefficients approach, the different stages of crops’ growth cycle are taken into account, which is drawing more attention in view of potential future shortages of water needed for agricultural production.
According to the Penmen–Monteith equation, the standard crop evapotranspiration quantity computation formula is as follows:
Figure 5 presents the crop evapotranspiration coefficients of wheat, maize, cotton in the study area.

The crop evapotranspiration coefficient of wheat, maize, cotton
In this study, the irrigation districts supplied by Yuecheng Reservoir are chosen as the study areas, and the districts are divided into fifteen subareas. Since wheat (which is cultivated from early October to early June), maize (which is grown from mid-June to late September) and cotton (which is sown in late April to early May and harvested in late October) are the three main crops that consume the majority of water from the reservoir, they are selected as the study crops. Moreover, five periods are chosen to cover the whole growth stages (which are divided on the basis of the water shortage response) of the three crops. These periods include October through December of last year, January through March, April through May, June through July, and August through September of current year (Liu et al. 2014). Four periods (i.e. winter of last year, spring, summer and autumn of current year) cover the growth stages of the three main crops. Available water for irrigation and water demand from crops both change along with different periods (i.e. growth period). Since the inflow of Yuecheng Reservoir varies significantly during four periods, it is divided into five discrete intervals with probability distributions to approximate the stochastic inflow value in each period. Five inflows are generated in each period with different probabilities, which are named as very-low (VL), low (L), medium (M), high (H) and very-high (VH), respectively. Table 1 provides the available water resources for irrigation under different reservoir inflows in each period. Tables 2, 3 and 4 present the irrigation targets, irrigation benefits, and penalties for different crops, respectively. The actual precipitation in each period is presented in Table 5.
The proposed RAIS method is used for supporting agricultural water management in the study river basin under such uncertainties. The study problem can be formulated as follows:
subject to
4 Result and discussion
Figure 6 compares the system benefits without and with consideration of system risks (λ = 0 and 1) under different α levels. When λ = 0, the system benefit would be [20.39, 245.93] × 106 RMB¥. When λ = 1, the sytem benefit would be [19.01, 244.71] × 106 RMB¥ (α = 0.90), [17.63, 243.50] × 106 RMB¥ (α = 0.95), [13.51, 239.86] × 106 RMB¥ (α = 0.98), which are lower those obtained without consideration of system risk. In addition, when sytem risk was taken into consideration, system benefit would decrease as α level is raised. A higher α level corresponding a higher degree of confidence would result in a lower system benefit but, at the same time, a waste of water available resources when the inflow is high; however, a lower α level related to a lower degree of confidence would lead to a higher system benefit (and thus a higher risk of water shortage when the inflow is low).

System benefits under different α levels (× 106 RMB¥)
Figure 7 presents the system benefits under different λ levels, which shows that different λ levels lead to varied objective-function values. For example, when λ = 0, the system benefit would be [20.39, 245.93] × 106 RMB¥; when λ = 0.6, the system benefit would be [20.35, 245.80] × 106 RMB¥. Obviously, the system benefit would increase with λ level. Higher λ level corresponding higher proportion of risk loss in objective-function values would lead to lower system benefit with lower system risk; conversely, lower λ level corresponding lower proportion of risk loss in objective-function values, would result in higher system benefit with higher system risk.

System benifits under different λ levels
Figure 8 presents the cumulative value of optimal cultivation area for wheat, maize and cotton in fifteen subareas. The inner circular rings present the lower bound of the irrigation areas, the outer circular rings present the upper bound. As shown in Fig. 8a–e, no water would be allocated to argriculture under the very-low (VL) inflow. On the contary, the irrigation area would be distributed the largest water when the availble water is very-high (VH). In comparison, argriculture would get some water even under VL inflow in period 3 (as shown in Fig. 8c).

Total irrigation area in different period
Figure 9 presents the optimal irrigation areas of different crops in different subareas. Deficits would occur if the available water from the reservoir could not meet the irrigation demand. For example, when three crops (wheat, maize and cotton) were cultivated in period 4, the actual irrigated area for maize would be zero due to insufficient of surface water. In addition, due to their high irrigation benefits, wheat and cotton are more competitive than maize for irrigation water. Cotton would be fully irrigated under VL–VL–VL–VL inflow; wheat would be partly irrigated under L–L–L–L, M–M–M–M and H–H–H–H inflows and fully irrigrated under VH–VH–VH–VH inflow. This is mainly because cotton, as an economic crop with high irrigation benefit, can bring higher system benefit than wheat and maize. Figures 9, 10, 11, 12, 13, 14 and 15 present the irrigation areas in different subareas under different inflow scenrios in periods 1–5 (λ = 1). The results also indicate that different inflows correspond to varied available surface water and thus result in different water-allocation plans. For example, under M inflow, the irrigated area for wheat in DM would be [0, 106], [0, 750], [1214, 2277] and [1027.5, 1074.0] ha from period 1 to period 5.

Optimal irrigation area of each crop in different period

Irrigation area in different subarea under t = 1 and λ = 1

Irrigation area in different subarea under t = 2 and λ = 1

Irrigation area in different subarea under t = 3 and λ = 1

Irrigation area in different subarea under t = 4 and λ = 1

Irrigation area in different subarea under t = 5 and λ = 1

Irrigation area in different subarea under VL–VL–VL inflows (t = 3 and λ = 1)
Figure 16 presents the optimal irrigation area of wheat under different λ levels in period 1. The irrigation area of wheat would be changed in different subareas under different λ levels. For example, when λ = 0.2, the irrigation area would be 1730, 2550, 1145 ha in QZ, FX, GP, respectively. In AY, the irrigation area of wheat would be 8420, 8356, 8258, 8245, 8239 ha under λ = 0.2, 0.4, 0.6, 0.8 and 1. Figure 16 presents the total irrigation area of wheat under M, H and VH inflows in period 1. Results indicate that different λ levels correspond to different proportion of risk loss in objective-function values and would result in different total irrigation area of wheat. Generally, the total irrigation area of wheat would increase with level λ increasing, apart from some special points (e.g., λ = 0.7). For example, under M inflow, the total irrigation area of wheat would be [32.23, 34.85] × 103, [33.48, 35.44] × 103, [32.14, 34.83] × 103 ha when λ = 0.7, 0.8, 0.9 respectively. Under H inflow, the total irrigation area would respectively be [33.30, 35.79] × 103, [33.32, 35.34] × 103, [33.42, 35.79] × 103 ha when λ = 0.7, 0.8 and 0.9. The abnormalities at λ = 0.8 demonstrate that values around 0.8 would have significant influence on the total irrigation area (Fig. 17).

Optimal irrigation area of wheat under different λ level when t = 1

The total irrigation areas of wheat under M, H and VH inflows when t = 1 (103 ha)
Figure 18 presents the irrigation area for wheat, maize and cotton of FX under different inflow scenarios. Due to the competition for water of industrial, there is no available for irrigation and irrigation area in FX would be zero under VL, VL–VL, VL–VL–VL and VL–VL–VL–VL–VL inflows. In period 2, irrigation area of wheat would increase with the inflow level changing from VL to VH. The irrigation target of wheat would be satisfied because of increased available water. In other words, the irrigation target of wheat cannot be satisfied under VL to H inflows due to lack of available water. Similarly, because there is no competition of cotton and maize (only wheat is planted in periods 1 and 2), the changing trends for irrigation area of wheat would be the same as that in period 1 (Fig. 18b). In period 3, cotton is cultivated. The irrigation area of wheat is more than those in periods 1 and 2 due to the increased precipitation in this period. In period 4, wheat, maize and cotton would be all planted. However, due to the weak competitive ability, the irrigation area of maize would be zero. In period 5, wheat has been harvested. Maize would be irrigated when the irrigation target of cotton is satisfied under L–L–L–L–L, M–M–M–M–M, H–H–H–H–H and VL–VL–VL–VL–VL inflows. This is mainly because the limited cotton area results in limited water requirement of cotton.

Optimal irrigation area of different crop in FX under λ = 1
5 Conclusions
In this study, a risk aversion based interval stochastic programming (RAIS)method has been developed for planning agricultural water management. RAIS integrates interval-parameter programming (IPP), multistage stochastic programming (MSP), and conditional value-at-risk (CVaR) measure into a general framework. The developed RAIS can not only handle uncertainties expressed as probability distributions and interval numbers, but also reflect the system risk resulted from uncertain parameters within a multistage context. In its solution process, the RAIS model has been solved by a two-step interactive algorithm and transformed into two deterministic submodels that correspond to the lower and upper bounds of the desired objective-function value.
The proposed RAIS method has been applied to agricultural water management in the Zhangweinan River Basin. Through taking irrigation targets and limited available water resources into consideration, water allocation schemes for different crops in different periods under different scenarios have been obtained. Results indicate that a higher α level (corresponding a higher degree of confidence) would result in a lower system benefit; a lower α level (related to a lower degree of confidence) would lead to a higher system benefit (and thus a higher risk of water shortage when the inflow is low). Conversely, higher λ level (corresponding higher proportion of risk loss in objective-function values) would lead to lower system benefit with lower system risk; lower λ level (corresponding lower proportion of risk loss) would result in higher system benefit with higher system risk. Results can help decision-makers generate desired policies for agricultural water management with a maximized system payoff and a minimized risk loss.
Abbreviations
- I :
-
Crop, i = 1, 2, 3, I
- j :
-
Subarea, j = 1, 2,…, 15, J
- t :
-
Planning time period, t = 1, 2,…, 5, T
- k :
-
Scenario of reservoir inflow, k = 1, 2,…, 5 representing very-low, low, medium, high and very-high levels respectively
- f ± :
-
Expected system benefit over the planning horizon (RMB¥)
- IB ± ijt :
-
Irrigation benefit for crop i in subarea j per unit of planting area (RMB¥/ha)
- IT ± ijt :
-
Fixed surface-water irrigation target of crop i in subarea j during period t (ha)
- p tk :
-
Probability level under scenario k during period t
- IP ± ijt :
-
Reduction of benefit (economic penalty) to subarea j planting crop i per unit of area not irrigated during period t (RMB¥/ha)
- ISD ± ijtk :
-
Cropland that cannot be irrigated by the surface water under scenario k (ha)
- W ± ijt :
-
Irrigation quota for crop i in subarea j during period t (m3)
- W ± ij(t−1) :
-
Irrigation quota for crop i in subarea j during period t − 1(m3)
- IQ ± tk :
-
Water available for irrigation in Yuecheng Reservoir under scenario k during period t (m3)
- IQ ±(t−1)k :
-
Water available for irrigation in Yuecheng Reservoir under scenario k during period t − 1 (m3)
- ɛ ±(t−1)k :
-
Surplus flow when water is delivered in period t−1 under scenario k (m3), and assuming no spilling for reservoir
- ɛ ±(t−2)k :
-
Surplus flow when water is delivered in period t − 2 under scenario k (m3), and assuming no spilling for reservoir
- IT ± ijtmax :
-
Maximum area that crop i should be planted in subarea j during period t (ha)
- λ :
-
Weight coefficient between cost and risk
- ξ :
-
The biggest system loss under the given confidence level (RMB¥)
- α :
-
Confidence interval
- v ± tk :
-
Instrumental variables
- CWR ± ijt :
-
Amount of water requirement of crop i in subarea j during period t (m3/ha)
- D ± ijt :
-
Average root depth of crop i in period t (m)
- D ± ij(t+1) :
-
Average root depth of crop i in period t + 1 (m)
- θ ± ijt :
-
Soil moisture content of crop i in subarea j in period t (m3/m)
- θ ± ij(t+1) :
-
Soil moisture content of crop i in subarea j in period t + 1 (m3/m)
- θ ± ijtmax :
-
Maximum soil moisture content of crop i in subarea j (m3/m)
- θ ± ijtmin :
-
Minimum soil moisture content of crop i in subarea j (m3/m)
- Ep ± jt :
-
Amount of effective precipitation of crop i in subarea j in period t (m3/ha)
- Ep ±0jt :
-
Amount of actual precipitation of crop i in subarea j in period t (m3/ha)
- Ec ± jt :
-
Evaporation capacity of crop i in subarea j in period t (m3/ha)
- SR ± jt :
-
Surface runoff of crop i in subarea j in period t (m3/ha)
- UR ± jt :
-
Underground runoff of crop i in subarea j in period t (m3/ha)
- DP ± ijt :
-
Deep percolation for crop i in subarea j during the period t (m)
References
Agliardi E, Pinar M, Stengos T (2016) Air and water pollution over time and industries with stochastic dominance. Stoch Environ Res Risk Assess. https://doi.org/10.1007/s00477-016-1258-y
Alberto MCR, Quilty JR, Buresh RJ, Wassmann R, Haidar S et al (2014) Actual evapotranspiration and dual crop coefficients for dry-seeded rice and hybrid maize grown with overhead sprinkler irrigation. Agric Water Manag 136:1–12
Allen RG (2000) Using the FAO-56 dual crop coefficient method over an irrigated region as part of an evapotranspiration intercomparison study. J Hydrol 229:27–41
Amarasingha RPRK, Suriyagoda LDB, Marambe B et al (2015) Modelling the impact of changes in rainfall distribution on the irrigation water requirement and yield of short and medium duration rice varieties using APSIM during Maha season in the dry zone of Sri Lanka. Trop Agric Res 26(2):274–284
Cameron B, Damowski J (2015) Empowering marginalized communities in water resources management: addressing inequitable practices in Participatory Model Building. J Environ Manag 153:153–162
Casey MS, Sen S (2005) The scenario generation algorithm for multistage stochastic linear programming. Math Oper Res 30(3):615–631
Chen F, Huang GH, Fan YR (2015) Inexact multistage fuzzy-stochastic programming model for water resources management. J Water Resour Plan Manag 141(11):04015027
Davijani MH, Banihabib ME, Anvar A, Nadjafzadeh Hashemi SR (2016) Optimization model for the allocation of water resources based on the maximization of employment in the agriculture and industry sectors. J Hydrol 533:430–438
Gulpinar N, Rustem B, Settergren R (2002) Multistage stochastic programming in computational finance. Computational methods in decision making, economics and finance: optimization models. Kluwer Academic Publishers, Dordrecht, pp 33–45
He J (2016) Probabilistic evaluation of causal relationship between variables for water pollution control. J Environ Inf 28(2):110–119
Huang GH (1996) IPWM: an interval parameter water quality management model. Environ Optim A35 26(2):79–103
Hughes DA, Slaughter AR (2016) Disaggregating the components of a monthly water resources system model to daily values for use with a water quality model. Environ Model Softw 80:122–131
Josh RS (2015) Testing the expectations hypothesis with survey forecasts: the impacts of consumer sentiment and the zero lower bound in an I(2) CVAR. J Int Financ Mark Inst Money 35:85–101
Kouwenberg R (2001) Scenario generation and stochastic programming models for asset liability management. Eur J Oper Res 134(2):279–293
Li YP, Huang GH (2011) Planning agricultural water resources system associated with fuzzy and random features. J Am Water Resour Assoc 47(4):841–860
Li YP, Huang GH, Nie SL (2006) An interval-parameter multi-stage stochastic programming model for water resources management under uncertainty. Adv Water Resour 29:776–789
Li YP, Huang GH, Nie SL, Liu L (2008a) Inexact multistage stochastic integer programming for water resources management under uncertainty. J Environ Manag 88:93–107
Li S, Kang S, Li F, Zhang L (2008b) Evapotranspiration and crop coefficient of spring maize with plastic mulch using eddy covariance in northwest China. Agric Water Manag 95(11):1214–1222
Liu J, Li YP, Huang GH, Zeng XT (2014) A dual-interval fixed-mix stochastic programming method for water resources management under uncertainty. Resour Conserv Recycl 88:50–66
Maryam S, Reza K, Mohammad RN, Hamideh N (2016) A conditional value at risk-based model for planning agricultural water and return flow allocation in river systems. Water Resour Manag 30(1):427–443
Melkonyan A (2015) Climate change impact on water resources and crop production in Armenia. Agric Water Manag 161:86–101
Mohammed M, Mac Kirby M, Qureshi E (2007) Integrated hydrologic-economic modeling for analyzing water acquisition strategies in the Murray River Basin. Agric Water Manag 93(1):123–135
Nematian J (2016) An extended two-stage stochastic programming approach for water resources management under uncertainty. J Environ Inf 27(2):72–84
Olivera-Guerra L, Mattar C, Galleguillos M (2014) Estimation of real evapotranspiration and its variation in Mediterranean landscapes of central-southern Chile. Int J Appl Earth Obs Geoinf 28:160–169
Rockafellar RT, Uryasev S (2002) Conditional value-at-risk for general loss distributions. J Bank Finance 26(7):1443–1471
Sirangelo B, Caloiero T, Coscarelli R, Ferrari E (2015) A stochastic model for the analysis of the temporal change of dry spells. Stoch Environ Res Risk Assess 29(1):143–155
Suinyuy DN, Xiong ZX, Presley K, Wesseh J (2016) Signatures of water resources consumption on sustainable economic growth in sub-Saharan African countries. Int J Sustain Built Environ 112:1375–1385
Vipan K, Theophilus K, Udeigwe EL, Clawson RV, Rohli DK, Miller DK (2015) Crop water use and stage-specific crop coefficients for irrigated cotton in the mid-south, United States. Agric Water Manag 156:63–69
Wang YY, Huang GH, Wang S, Li W, Guan PB (2016) A risk-based interactive multi-stage stochastic programming approach for water resources planning under dual uncertainties. Stoch Envitron Res Risk Assess 94:217–230
Wherley B, Dukes MD, Cathey S, Miller G, Sinclair T (2015) Consumptive water use and crop coefficients for warm-season turfgrass species in the Southeastern United States. Agric Water Manag 156:10–18
Xu XS, Xu ZX, Wu W, Tang FF (2012) Assessment and spatiotemporal variation analysis of water quality in the Zhangweinan River Basin, China. Proced Environ Sci 13:1641–1652
Acknowledgements
This research was supported by the National Key Research Development Program of China (2016YFA0601502), the Natural Science Foundation of China (51779008), and the Interdiscipline Research Funds of Beijing Normal University. The authors are grateful to the editors and the anonymous reviewers for their insightful comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Li, Q.Q., Li, Y.P., Huang, G.H. et al. Risk aversion based interval stochastic programming approach for agricultural water management under uncertainty. Stoch Environ Res Risk Assess 32, 715–732 (2018). https://doi.org/10.1007/s00477-017-1490-0
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-017-1490-0