
Abstract
A dominating set \(D \subseteq V\) in a graph \(G=(V,E)\) is a subset of vertices such that every vertex in V belongs to D or has at least one neighbour in D. In this paper we deal with the problem of finding an approximation of the dominating set of minimum size, i.e., the approximation of the minimum dominating set problem (MDS) in a distributed setting. A distributed algorithm that runs in a constant number of rounds, independent of the size of the network, is called local. In research on distributed local algorithms it is commonly assumed that each vertex has an unique identifier. However, as was shown by Göös et al., for certain classes of graphs (for example, lift-closed bounded degree graphs) identifiers are unnecessary and only a port numbering is needed. We confirm that the same remains true for the MDS up to a constant factor in the class of planar graphs. Namely, we present a local deterministic 694-approximation algorithm for the MDS in planar graphs in a model with a port numbering only. Moreover, our algorithm uses only short messages, i.e., in each round each node can send only a \(O(\log {|V|})\)-bit message to each of its neighbours.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction and notation
A distributed algorithm is called local if it terminates in a constant number of synchronised communication rounds. In such algorithm each node makes its decision based only on knowledge about its constant radius neighbourhood. If the structure of the network changes (e.g., when a node is removed), then local algorithms must be re-called to repair its output only for vertices that are at a constant distance from the change.
In recent years, there has been a growing interest in designing distributed local algorithms. This might result from their scalability and fault tolerance. There is a large number of papers referring, more or less closely, to this topic and it is not possible to list them all here. The best way to study local algorithms is to refer to an excellent survey [13] written by Suomela.
Newly proposed algorithms compute solutions that are good approximations of various problems (e.g., minimum edge cover, minimum dominating set [10], semi-matching [1, 2]), in different classes of graphs (e.g., bounded degree graphs, planar graphs). Such algorithms very often assume that vertices have unique identifiers and/or vertices are allowed to send arbitrarily large messages. These assumptions could be too strong in practice, hence we consider a more restrictive model. Our algorithm does not use any additional information besides a port numbering and we assume that in each round each node can send only a short message to any of its neighbours (i.e., a message with \(O(\log n)\)-bits, where n is the size of the network).
A dominating set \(D \subseteq V\) in a graph \(G=(V,E)\) is a subset of vertices such that every vertex in V belongs to D or has at least one neighbour in D. In this paper we are concerned with the problem of finding a constant approximation of the minimum dominating set. The main challenge of this work it to solve the problem in planar graphs without unique identifiers. Note that this limitation makes it impossible to, e.g., detect small cycles in the network or to let each vertex learn the topology of vertices at a distance that is at most two (2-hop neighbourhood).
We will work in a synchronous communication model and as a representation of the network we will use a planar graph \(G=(V ,E)\). The edges in the graph will correspond to communication links and vertices V will correspond to processors. We will assume that each vertex has its own labelling of its incident edges. No additional information is available to the vertices and in particular, vertices do not have unique identifiers.
For a set \(A \subseteq V\), we define the inclusive neighbourhood of A as \(N[A]:=\left\{ v: v\in A \vee \exists _{e=uv \in E(G)} u\in A \right\} \). Furthermore, we denote \(N(A):=N[A]{\setminus } A\). To simplify the notation in the case where \(A=\left\{ a\right\} \) we may omit the braces, i.e., we write N(a) instead of \(N({\{a\}})\). When the considered graph G is not clear from the context, we write \(N_G(A)\). By \(deg_G(v)\) we denote the degree of a vertex \(v\in V\) in G. Moreover, for two subsets of vertices \(X,Y \subseteq V\) by E(X, Y) we denote the set of all X-Y edges in a set E, i.e., \(E(X, Y):=\{\{x,y\} \in E: x \in X \wedge y \in Y\}\).
1.1 Related work
In 1992, Linial showed in [11] that there is no algorithm that, in constant time, finds a maximal independent set (i.e., a set of pairwise non-adjacent nodes, maximal under inclusion) in a cycle with unique identifiers.
Three years later, in 1995, Naor and Stockmeyer in [12] introduced the concept of Locally Checkable Labellings (LCL) and showed that if there exists a local algorithm in the model with unique identifiers then there is also an order-invariant local algorithm which uses only the fact that for each pair of vertices (\(v,u \in V)\) \( id (v)< id (u)\) or \( id (v) > id (u)\). Therefore, from the point of view of the LCL problem both models are almost equivalent. Note that the class of LCL problems contains, among others, maximal independent set or vertex colourings problems. Thus, it is natural to ask the question whether there exists an algorithm which, without information about the order of vertices, is able to solve any non-trivial problem. Recently, Göös et al. in [6] showed that for lift-closed bounded degree graphs, the model with unique identifiers (known as the \(\mathcal {LOCAL}\) [11]) and the model with a port numbering only (known as the PO model [6]) are practically equivalent for local algorithms. However, the techniques used in their work do not allow us to consider the equivalence of these models in planar graphs. The existence of a distributed local algorithm in the port numbering model and/or with short messages that returns a constant-factor approximation to an MDS in planer graphs, is an issue that was raised in [6, 10]. We provide an answer to this question by proposing a local distributed algorithm with an approximation ratio of 694. Recently, Hilke et al. proved in [7] that there is no deterministic local algorithm that finds a \((7-\varepsilon )\)-approximation of a minimum dominating set on planar graphs for any positive constant \(\epsilon \). Using a similar method as in [4], the authors of [7] improve the earlier known lower bound \(5-\varepsilon \).
The distributed complexity of the minimum dominating set problem has been extensively considered in many papers. Kuhn and Wattenhofer in [9] presented the first local but randomised algorithm with short messages for bounded degree graphs. Next, the algorithm in [8] was improved by Kuhn, Wattenhofer and Moscibroda. Both approaches used the method of linear programming. The first deterministic constant approximation local algorithm that finds a minimum dominating set, in planar graphs, was proposed by Lenzen et al. in [10]. However, their algorithm requires that the vertices learn the topology of their neighbourhood at a distance of at least two and it is not clear how to do this without unique identifiers and in a model with short messages.
This is an extended version of the paper that appeared in PODC’13 [14].
1.2 Main results and organisation
Our main result is summarised in the following theorem.
Theorem 1
There is a local algorithm that finds a 694-approximation of a minimum dominating set on planar graphs in the port numbering model with short messages, i.e., each message contains at most \(O(\log {|V|})\) bits.
The rest of this paper is structured as follows. We begin by describing our main technique with an idea how to use it in Sect. 2. Then, in Sect. 3.1, we introduce the principle of our algorithm and its formal pseudocode. Next, in Sects. 3.2 and 3.3, we present the analysis of our algorithm, and prove the constant approximation factor. At the end, in Sect. 4, we summarise our considerations.
2 Main technique
Our main technique which is used in this paper is the partition of a plane graph \(G=(V,E)\) into subgraphs called bunches. For a plane graph we use the definition from [5]: A plane graph is a pair (V, E) of finite sets with the following properties:
-
(i)
\(V \subseteq {\mathbb {R}}^2\);
-
(ii)
every edge is an arc between two vertices;
-
(iii)
different edges have different sets of endpoints;
-
(iv)
the interior of an edge contains no vertex and no point of any other edge.
We use bunches to split the graph into disjoint regions in \({\mathbb {R}}^2\), in such a way that each region contains vertices from the minimum dominating set M and a constant number of vertices returned by our algorithm. Notice, that although our algorithm works in planar graphs, in the analysis we assume that a given graph is plane and we use the properties of its plane drawing.

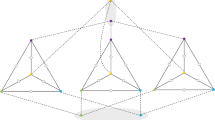
An example of sets \({{\mathrm{Reg}}}[P \cup Q]\) and \({{\mathrm{Reg}}}(P \cup Q)\), where \(P=(v,u,z)\) and \(Q=(v,w,z)\)
First, we introduce some graph theoretical terminology for planar graphs, which is necessary only for analysis of the algorithm. For a plane graph G in \({\mathbb {R}}^2\) we define the face of G as a maximal open set f in \({\mathbb {R}}^2 {\setminus } G\) such that any two points in f can be connected by a curve contained in f. There is exactly one unbounded face \(f_u\), and the other faces are called inner faces. Furthermore, let \({{\mathrm{Reg}}}[G]\) be the set of points in \({\mathbb {R}}^2\) lying outside the unbounded face \(f_u\) (\({{\mathrm{Reg}}}[G]:= {\mathbb {R}}^2 {\setminus } f_u\)). We assume that W is the set of all edges adjacent to the face \(f_u\). Then we set \({{\mathrm{Reg}}}(G):={{\mathrm{Reg}}}[G] {\setminus } W\). If a vertex \(v\in V\) is contained in the set of points \({{\mathrm{Reg}}}[G']\) (or \({{\mathrm{Reg}}}(G')\)), where \(G'\) is a subgraph of G, then we write \(v \in {{\mathrm{Reg}}}[G']\) (or \(v \in {{\mathrm{Reg}}}(G')\)). By \(V \cap {{\mathrm{Reg}}}[G']\) we denote all vertices of V lying inside the set of points \({{\mathrm{Reg}}}[G']\).
In this paper we often use \({{\mathrm{Reg}}}[P \cup Q]\) (or \({{\mathrm{Reg}}}(P \cup Q)\)), where P, Q are two paths with the same endpoints. An example of \({{\mathrm{Reg}}}[P \cup Q]\) and \({{\mathrm{Reg}}}(P \cup Q)\) is illustrated in Fig. 1.
Now we are ready to define the term S-U-W-bunch, which was first introduced in [3].
Definition 1
Let \(G = (V, E)\) be a plane graph, and \(S,U,W \subseteq V\) disjoint subsets of the vertices. A path suw is called an S-U-W-special path if \(s \in S, u \in U\) and \(w \in W\).
Definition 2
Let \(\mathcal {P}\) denote a subset of all S-U-W-special paths in the plane graph G such that every vertex \(u \in U\) belongs to exactly one S-U-W-special path in \({\mathcal {P}}\).
For a fixed pair of vertices \(s \in S, w \in W\) let \({{\mathcal {P}}}_{s,w} \subseteq {\mathcal {P}}\) denote all S-U-W-special paths beginning at s and ending at w. Moreover, for any subset \(P \subseteq {{\mathcal {P}}}_{s,w}\), paths \(P_i, P_j \in P\) (not necessarily distinct) are called the boundary paths of P if all special paths from P are contained inside \({{\mathrm{Reg}}}[P_i \cup P_j]\).
A maximal subset of special paths \(B_{s,w} \subseteq \mathcal {P}_{s,w}\) such that the open region \({{\mathrm{Reg}}}(B_{s,w})\) does not contain any vertex from \(S \cup W\) is called S-U-W-bunch.
We can observe that the set of all S-U-W bunches with respect to \({\mathcal {P}}\) (denoted by \({{\mathcal {B}}}\)) forms a partition of \({\mathcal {P}}\). An example of S-U-W-bunches is illustrated in Fig. 2. To simplify the notation, if sets S, U and W are clear from the context, we simply write special paths instead of S-U-W-special paths and bunches instead of S-U-W-bunches.
In this paper we also consider S-U-X-W-bunches and S-U-X-W-special paths. These definitions are analogous to Definitions 1 and 2. The only difference is that an S-U-X-W-special path \(p:=(s,u,x,w)\) (\(s\in S,u\in U,x\in X,w\in W\)) contains four (instead of three) vertices. Furthermore, we assume that sets S, U, X and W are disjoint. Then, the set \(\mathcal {P}\) denotes a subset of all S-U-X-W-special paths in the plane graph G such that every vertex \(x \in U \cup X\) belongs to exactly one S-U-X-W-special path in \({\mathcal {P}}\).
After defining the concepts, in Lemma 1 we estimate the maximum number of bunches in any plane graph G.

An example of two S-U-W-bunches and the created multigraph H. Paths \((s_1,u_1,w)\) and \((s_1,u_3,w)\) are the boundary paths of bunch \(B_1\)
Lemma 1
Given disjoint sets \(S,U,W \subseteq V\), the number of S-U-W-bunches is at most \(2(|S| + |W|)\).
Proof
Let \({\mathcal {B}}\) be the set of all S-U-W-bunches with respect to \({\mathcal {P}}\), where \({\mathcal {P}}\) is defined according to Definition 2. We define the bipartite multigraph \(H:=(S \cup W, E_{{{\mathcal {B}}}})\) where each bunch \(B \in {{\mathcal {B}}}\) between vertices s and w corresponds to an edge \(\{s,w\}\) in \(E_{{{\mathcal {B}}}}\). Multigraph H is planar since it can be obtained from G by taking the subgraph induced by all bunches in \({{{\mathcal {B}}}}\) and replacing each bunch with an edge contained in its closed region (see Fig. 2). Thus we need to show that \(|E_{{{\mathcal {B}}}}|\le 2(|S|+|W|)\).
Without loss of generality we can assume that multigraph H is connected since otherwise we can show the bound for each component separately and then sum it up. By Euler’s formula [5], \(|\phi |-|E_{{{\mathcal {B}}}}|+|V(H)|=2\), where \(\phi \) is the set of all faces of the embedding of H. Thus, since \(|V(H)| = |S| + |W|\), the statement of the lemma will follow if we can prove that \(|\phi | \le |E_{{{\mathcal {B}}}}|/2+2\).
We say that a face f in \(\phi \) touches an edge \(e \in E_{{{\mathcal {B}}}}\) if e appears in the boundary walk of f. We count multiplicity, i.e., each edge is touched exactly twice, potentially by the same face. We claim that each bounded face touches at least four edges. Since H is bipartite, all closed walks are of even length. Hence, assuming otherwise entails that there is some bounded face \(f \in \phi \) whose boundary walk is of the form (s, w, s), where \(s \in S, w \in W\), and the two traversed edges \(\{s,w\}\) are not identical (this is possible since H is a multigraph). Therefore, these edges correspond to different bunches. Moreover, the maximality of bunches implies that there is a node \(v \in S \cup W\) in the open region enclosed by (s, w, s). However, since H is connected, there must be a path inside the region connecting v to the cycle (s, w, s), which contradicts the assumption that (s, w, s) is the boundary walk of f.

An example of graph G. The edges that do not belong to \({{\mathcal {B}}}\) are dashed grey lines
We conclude that each bounded face indeed touches at least four edges. Since there is exactly one unbounded face, this yields that \(4(|\phi |-1) \le 2|E_{{{\mathcal {B}}}}|\). Hence, \(|\phi | \le |E_{{{\mathcal {B}}}}|/2+1\) and as we observed earlier, this concludes the proof. \(\square \)
The above lemma is used in several proofs in this paper (e.g. in Lemmas 5 and 7). Below, we show how Lemma 1 can be applied to bound the number of vertices added to a dominating set in a graph with some additional assumptions. Let \(G=(V, E)\) be a plane graph and \(U,W \subseteq V\) the disjoint subsets of vertices, such that \(|W| = O(|M|)\), where M is a minimum dominating set in G. We construct a set \(S \subseteq V\) in the following way:
-
(1)
initially, \(S:= \emptyset \);
-
(2)
for every \(v \in U\), we add to S a vertex of the maximum degree from its closed neighbourhood N[v].
An example of graph G and three disjoint sets S, U, W is shown in Fig. 3. Let us observe that the set S is not small for every possible graph G (i.e, it is possible that \(|S| = \omega (|M|\))). Therefore, an additional assumption has to be made on G. In particular, we have to ensure that each S-U-W-bunch contains a small number of special paths (e.g., each bunch \(B\in {{{\mathcal {B}}}}\) contains at most five special paths) and that there is relatively large number of S-U-W-special paths (e.g., \(|{{\mathcal {P}}}| \ge 20|S|\)). It should be pointed out that in the proofs in Sects. 3.2 and 3.3, it is not obvious how to estimate the amount of bunches and special paths and it is essential for the proof. Next, by using Lemma 1 we can upper bound the maximal number of special paths:
Then, by applying the assumption \(|{{\mathcal {P}}}| \ge 20|S|\) we obtain that \(|S| \le |W|\). Hence, \(|S| = O(|M|)\).
A similar reasoning will be applied to estimate the size of a dominating set returned by our algorithm in Lemma 5. In the proof of Lemma 7 we use a slightly different reasoning. We observe there that the value |U| bounds the number of newly selected nodes S. Thus we bound |S| by showing that \(|U| = O(|M|)\).
3 Constant approximation in the port numbering model
3.1 Idea of the algorithm and pseudocode
At the beginning we shortly review the algorithm of Lenzen et al. [10] and indicate why it cannot be simply applied in the port numbering model.
Lenzen et al.’s algorithm consists of two parts. The first phase, called preprocessing, is responsible for adding to the resulting dominating set D, each vertex whose neighborhood cannot be dominated by a small number of other vertices.
Next, in the main phase, each vertex that is not yet dominated chooses a node from its inclusive neighbourhood of maximal residual degree (i.e., one that dominates the most not yet dominated vertices) and adds it to D.
Unfortunately, in the port numbering model, it could be impossible for some vertex \(v \in V\) to check if there exists a small subset of \(N[N(v)] {\setminus } \{v\}\) that dominates all neighbors of v. More precisely, it is not clear how to answer, without unique identifiers the question whether there is a set A such that \(v \notin A, |A| \le c\) (where c is constant) and \(N(v) \subseteq N(A)\).

An example of possible results for a an optimal algorithm and b an algorithm in which each vertex chooses one neighbour of the largest degree. The vertices from the resulting dominating set are marked (black)
Moreover, let us observe why the preprocessing phase, in Lenzen et al.’s algorithm, is necessary. To this end we compare a possible output of the algorithm without the preprocessing phase to an optimal solution. For the graph shown in Fig. 4 the dominating set computed by the modified algorithm can be arbitrarily large, while the optimal solution contains only two vertices. Hence, if we are going to use the idea of the main phase of Lenzen et al.’s algorithm we need to propose an other preprocessing phase.

We observe that most of the vertices from set \(U:=\{u_1, u_2, \ldots , u_k\}\) in Fig. 4 are added to the dominating set D by themselves (or by other vertices from U). Thus, it seemed like a good idea to remove U from the set of nodes that could select themselves in the preprocessing phase. It turns out that we can find a small subset \(A \subseteq V\) that dominates U, i.e., we can find a set A such that \(U \subseteq N[A]\) and \(|A|=O(|M|)\), where M is the minimum dominating set in G.
The above idea is applied in the preprocessing phase of our algorithm which contains double calls of DominateBigVertices. In the first step of DominateBigVertices each not yet dominated vertex v adds to a temporary set X a vertex \(x \in N[v]\) with the largest residual degree (i.e., a vertex that dominates the most not yet dominated vertices). Obviously, at the beginning of the first invocation of DominateBigVertices no vertex is dominated and thus the residual degree of each vertex is equal to its degree plus one. Next, each \(x \in X\) adds to the set \(D_{ new }\) one vertex \(w \in N[x]\) dominating the maximum number of vertices in X. We can show that although the size of X can be arbitrarily large with respect to the size of the optimal solution M, the number of vertices added to \(D_{ new }\) by vertices in X is small (i.e., \(|D_{ new }| = O(|M|)\)).

An example of the preprocessing phase. Vertices in \(D_1\) are marked by a black square and vertices with the currently largest residual degree (set X) are coloured black. a Input graph, b, c first invocation of DominateBigVertices, d, e second call of DominateBigVertices and f the main phase of the algorithm (the black vertex is a vertex with the largest residual degree)
It turns out that a single call of DominateBigVertices may be insufficient to guarantee that the set of vertices added into the dominating set in the main phase of the algorithm is small. This is illustrated by the run of the algorithm as depicted in Fig. 5. Allowing uncovered nodes select a neighbour of the maximal residual degree into D after a single preprocessing step might result in all nodes from U being selected (see Fig. 5d). Only a second call of the function enforces a breaking of the symmetry of degrees of vertices. This is the reason why we invoke DominateBigVertices twice.
Next, in the main phase of the algorithm (steps 7–9), each not yet dominated vertex \(v\in V {\setminus } N[{D_1}]\) adds to \(D_2\) a vertex \(w(v) \in N(v) \cap N({D_1})\) with the largest residual degree. We add only neighbours of \(D_1\) in order to guarantee that each added vertex belongs to a special kind of bunches that is helpful in the analysis. This allows us to build bunches between disjoint subsets of vertices. Furthermore, this way vertices cannot add themselves to the set \(D_2\).

All such properties are needed in the construction of the bunches.
The result of the algorithm is the dominating set \(D:= D_1 \cup D_2\). As can be easily seen, the algorithm can be performed in twelve communication rounds. Indeed, each call of DominateBigVertices takes five communication rounds and we need two additional rounds in the main phase to gather a residual degree and to select the vertices from \(D_2\). Moreover, the algorithm returns a dominating set due to the last round in which each not yet dominated vertex v picks one neighbour in \(N(v) \cap N({D_1})\) and adds it to \(D_2\). Note that since \(D_1\) is the 2-hop dominating set, such a vertex exists. Indeed, since the set X in the first call of DominateBigVertices is a dominating set and each vertex X adds itself or neighbour to \(D_1\), for each \(v \in V {\setminus } D_1\) there is a vertex from \(D_1\) within distance two.
3.2 Preprocessing phase
Our aim in this section is to upper bound the size of the set \(D_1 := D_1' \cup D_1''\). Instead of estimating both sets separately, we estimate the size of the set \(D_{ new }\) returned by one invocation of DominateBigVertices. The result can be applied to both sets: \(D_1'\) and \(D_1''\).
Now we define a subgraph \(G'\) of the graph G. It should be noted that the construction of \(G'\) could be different for each invocation of DominateBigVertices.
Definition 3
Let graph \(G'=(V',E')\) be a subgraph of \(G=(V,E)\) constructed in the following way:
-
(i)
\(V' := X \cup D_{ new }\), where X and \(D_{ new }\) are the sets from a considered call of DominateBigVertices.
-
(ii)
\(E' := \left\{ uv \in E: u,v \in V'\right\} \).
-
(iii)
For each node \(v\in V'\) not dominated by M (i.e., \(v \in V' {\setminus } N_{G'}[{M}]\)) pick a node \(m \in M \cap N_G(v)\). Add node m and edge \(\{v,m\}\) to \(G'\).
-
(iv)
Let \(X_L:= \{ v \in X{\setminus } M: |N_{G'}[d(v)] \cap X| > 33 \}\) and \(Y_L:=\left\{ d(v) : v \in X_L \right\} \). For each \(x \in X_L {\setminus } Y_L\) such that \(N_{G'}[x] \cap Y_L {\setminus } M = \emptyset \) remove x and each edge adjacent to x from \(G'\).

An example of graph \(G'\). If \(d(v)=u\), then edge vu is marked by an arrowhead. Notice, that edge e can not exist since otherwise vertex w would choose v instead of z
The step (iv) is performed to satisfy assumptions to the set U in Lemma 1. Recall that M is the minimum dominating set in G and that X is the set of vertices selected by not yet dominated vertices, i.e., as vertices with the largest residual degree in theirs neighbourhoods. In order to simplify the description of the proofs, we introduce the following sets related to M and X (see Fig. 6):
where d(v) is a vertex chosen in step 8 of the algorithm. Notice that not all of the subsets are disjoint, i.e., it is possible that there is a vertex v that belongs to both sets \(Y_L\) and \(X_L\) (\(v\in Y_L \cap X_L\)). To show that the maximal number of vertices in the set \(D_{ new } = Y_M \cup Y_S \cup Y_L\) is comparable to the size of M, we will estimate the size of each set \(Y_M, Y_S\), and \(Y_L\) separately. This analysis is described in Lemmas 2, 3 and 5. The step (iv) of the definition allow us, in Lemma 4, to consider \(Y_L{\setminus } M\)-\(X_L{\setminus } Y_L\)-M-bunches, which requires that each vertex \(X_L {\setminus } Y_L\) has at least one neighbour in each sets \(Y_L{\setminus } M\) and M. In step (iv) we simply remove vertices that do not satisfy such condition.
At the beginning we will provide a simple but very useful fact.
Fact 1
\( |Y_i| \le |X_i| \text { for each } i \in \left\{ M,S,L\right\} \).
Proof
Note that the vertices from the set \(Y_i\) have been added to \(D_1\) in step 10 of the function by the vertices in \(X_i\). In addition, each vertex \(x \in X_i\) selects at most one vertex into \(Y_i\). Thus the size of the set \(Y_i\) cannot be greater than the size of the set \(X_i\). \(\square \)
Lemma 2
\(|X_M| \le |M |\text { and } |Y_M| \le |M|.\)
Proof
From the definition of \(X_M\), we know that \(X_M \subseteq M\). Hence, the size of \(X_M\) is less or equal to the size of M (\(|X_M| \le |M|\)). Using Fact 1 we obtain that \(|Y_M| \le |X_M| \le |M|\). \(\square \)
Lemma 3
\(|X_S| \le 33|M| \text { and } |Y_S| \le 33|M|.\)
Proof
Note that sets \(X_S\) and M are disjoint and M dominates every vertex in \(X_S\). Let \(A:=N_G(X_S) \cap M\), i.e., by A we denote the set of neighbours of \(X_S\) that also belong to M.
In step 10 of DominateBigVertices for every \(v \in X\) we add a vertex \(w \in N_G[v]\) adjacent to the largest number of vertices in X (i.e., a vertex with the largest \(\delta ^X_w\), where \(\delta ^X_w := |N_G[w] \cap X|\)). The residual degree of every vertex \(u \in Y_S\) is less or equal to 33 (\(\delta ^X_{u} \le 33\)). Thus, every vertex \(m \in A\) dominates at most 33 vertices in \(X_S\). Hence, \(|M| \ge |X_S|/33\). Next, using Fact 1 we obtain that \(33|M| \ge |X_S|\ge |Y_S|\). \(\square \)
Recall that our goal was to show that \(|Y_M \cup Y_S \cup Y_L|=O(| M |)\), so what is left is to prove that the maximal number of vertices in \(Y_L\) is small (i.e., \(|Y_L| = O(|M|)\)). For this purpose we use the technique of splitting graph G into bunches, then we show that an induced region of each bunch contains a small number of vertices in \(X_L {\setminus } Y_L\). Next, we upper bound the number of such bunches, which gives us the desired bound.
Let \({{\mathcal {P}}}_1\) be the set of all \((Y_L {\setminus } M)\)-\((X_L {\setminus } Y_L)\)-M-special paths such that every vertex \(x \in X_L {\setminus } Y_L\) belongs to exactly one special path in \({{\mathcal {P}}}_1\). By \({\mathcal {B}}_1\) we denote the set of all \((Y_L {\setminus } M)\)-\((X_L {\setminus } Y_L)\)-M-bunches with respect to \({{\mathcal {P}}}_1\) and for each \(B \in {\mathcal {B}}_1\) by \(b_B\) we denote the number of special paths contained in B.
Lemma 4
Let \(B \in {\mathcal {B}}_1\). Then B contains at most seven special paths (\(b_B \le 7\)).
Proof
From the definition of \((Y_L {\setminus } M)\)-\((X_L {\setminus } Y_L)\)-M-bunches we know that there is no vertex from \(M \cup Y_L\) inside the open region of bunch B (i.e., \({{\mathrm{Reg}}}(B) \cap (M \cup Y_L) = \emptyset \)). Let \(\{m\}:= M \cap V(B)\) and \(\{v\}:= (Y_L {\setminus } M) \cap V(B)\). Since \({{\mathrm{Reg}}}[B]\) contains exactly one vertex from each of the sets M and \(Y_L {\setminus } M\), such a definition is feasible. Moreover, we assume that vertices \(x_1, x_2, \ldots , x_{b_B} \in (X_L {\setminus } Y_L) \cap V_B\) are numbered according to their relative position in the planar embedding of bunch B (see Fig. 7). For each \(x_i \in \{x_1, x_2,\ldots , x_{b_B}\}\) by \(u_i\) we denote a vertex that adds \(x_i\) to the set \(X_L\) in the considered invocation of DominateBigVertices.
Observe that since M dominates every vertex in V(G) and \({{\mathrm{Reg}}}(B) \,\cap \, M = \emptyset \), every vertex in \(V(G) \,\cap \,{{\mathrm{Reg}}}(B)\) is adjacent to m.
By A we denote the set of all vertices V(G) lying inside the closed region \({{\mathrm{Reg}}}[B]\) and which are not dominated by the current set D, i.e., \(A:= (V(G) {\setminus } N_G[D]) \cap {{\mathrm{Reg}}}[B]\). Since v is the only vertex in A that is possibly not adjacent to m,
Note that if \(b_B \ge 4\), then \(x_2\) belongs to the open region of the cycle \((v,x_1,m,x_3,v)\). Thus, it is not adjacent to any vertex in \(\{x_4,x_5,\ldots ,x_{b_B}\}\) (see Fig. 7). The vertex \(x_2\) is also not adjacent to any vertex in \(\{u_5,u_6,\ldots ,u_{b_B -1}\} {\setminus } \{v\}\). Hence,
Without loss of generality we can assume that vertex \(x_2\) (in Fig. 7) was not added to X by v (i.e., \(u_2 \ne v\)), since otherwise \(b_B \le 3\), or we could reverse the enumeration of the vertices. Then, since in step 4 of DominateBigVertices vertex \(u_2\) chose \(x_2\) and vertex \(u_2 \) is also adjacent to m, we obtain that \(\delta ^V_m \le \delta ^V_{x_2}\). Using (1) and (2), we obtain that \(b_B \le 7\). \(\square \)

An example of the \(Y_L{\setminus } M\)-\(X_L {\setminus } Y_L\)-M bunch with an additional vertex \(u_i \in V(G)\). Vertex \(u_i\) adds \(x_i\) to X. Note that it is possible that \(x_i = u_j\) for \(i \in \{j-1, j, j+1\} \mod b_B\)
Now we are ready to show the following lemma:
Lemma 5
\(|Y_L {\setminus } M| \le 4 |M|.\)
Proof
We start with an outline of the proof. At the beginning we show that there are many edges between \(Y_L{\setminus } M\) and \(X_L\) (i.e., set \(E_L\) defined earlier in Definition 3 is large). Next we prove that almost each edge in \(E_L\) induces a \((Y_L {\setminus } M)\)-\((X_L {\setminus } Y_L)\)-M-special path in \(G'\). Finally, by using Lemmas 1 and 4 we upper bound the size of \(Y_L {\setminus } M\).
Now we are ready to give the proof of the lemma. We assume that \(|Y_L {\setminus } M| > 4|M|\). In the other case the statement of the lemma is proved. To estimate the number of edges in \(E_L\), we firstly upper bound the size of sets \(E_M\) and \(E_S\).
We observe that \(G'\) is planar and sets \(X_M\) and \(Y_L {\setminus } M\) are disjoint (\(X_M \cap (Y_L {\setminus } M) = \emptyset \)). Moreover, since the bipartite planar graphs of n nodes have fewer than 2n edges, \(|E_M| \le 2(|X_M| + |Y_L {\setminus } M|)\). By using Lemma 2 and the assumption that \(|Y_L {\setminus } M| > 4 |M|\), we obtain that
Notice also that the set \(E_S\) is empty (\(E_S = \emptyset \)). Indeed, if there is an edge \(e=\{u,v\}\) such that \(u \in X_S\) and \(v \in Y_L {\setminus } M\) then vertex u would have chosen a vertex \(v \in Y_L {\setminus } M\), so u will not be in the set \(X_S\).
From the definition the set \(E_L\) contains all edges between \(Y_L{\setminus } M\) and \(X_L\). Using the fact that for each vertex \(v \in Y_L {\setminus } M\) the value \(|N_{G'}[v] \cap X|\) is greater or equal to 34 we obtain that each vertex \(Y_L {\setminus } M\) is adjacent to at least 33 vertices in X (since v could also belongs to X). Then, we can estimate the minimum number of edges in set \(E(Y_L{\setminus } M, X)\). However, we have to notice that since \(X_L \cap (Y_L {\setminus } M)\) might not be empty, it is possible that \(e\in E_L\) has both endpoints in \((Y_L {\setminus } M) \cap X_L\) (see edge \(e_1\) in Fig. 8). Hence,
We added the value \(|E(Y_L {\setminus } M, Y_L {\setminus } M)|\) on the right side of the inequality because the edges \(E(Y_L {\setminus } M, Y_L {\setminus } M)\) could be counted twice if both endpoints belongs to \((Y_L {\setminus } M) \cap X_L\). Furthermore, since graph \(G'\) is planar, \(|E(Y_L {\setminus } M, Y_L {\setminus } M)| \le 3|Y_L {\setminus } M|\). Hence,
To sum up, there are many edges \(E_L\), but still not every edge \(E_L\) belongs to \({{\mathcal {P}}}_1\) (see edge \(e_2\) in Fig. 8).

Since \((v_1,x_1,m_1) \in {{\mathcal {P}}}_1\), the marked edge \(\{x_1,v_2\}\in E_L\) does not belong to any special path in \({{\mathcal {P}}}_1\)
By \(E'_L \subseteq E_L\) we denote the subset of edges \(E_L\) which belongs to any special path in \({{\mathcal {P}}}_1\). Let us observe that we could construct set \(E'_L\) by removing from \(E_L\) all edges \(E(Y_L {\setminus } M, X_L {\setminus } Y_L)\) that do not belongs to any special path \({{\mathcal {P}}}_1\) and all edges with both endpoints in \(Y_L {\setminus } M\).
All edges \(E(Y_L {\setminus } M, X_L {\setminus } Y_L)\) that do not belong to any special path \({{\mathcal {P}}}_1\) are edges between \(Y_L {\setminus } M\) and vertices lying on the boundary paths of \({{\mathcal {P}}}_1\). This is due to the fact that the open region \({{\mathrm{Reg}}}(B)\) of any bunch \(B \in B_1\) does not contain vertices from \(Y_L {\setminus } M\). By Z we denote all vertices \(X_L {\setminus } Y_L\) that belongs to some boundary path in \({{\mathcal {P}}}_1\). Using Lemma 1 and the fact that each bunch could contains at most two boundary vertices Z, we obtain that \(|Z| \le 4(|Y_L {\setminus } M| + |M|)\). Furthermore, since the sets \(Y_L {\setminus } M\) and \(X_L {\setminus } Y_L\) are disjoint and each vertex Z belongs to exactly one special path, set \(E_L\) contains less than \(2(|Z| + |M|)+ |Y_L {\setminus } M|)-|Z|\) edges in \(E(Y_L {\setminus } M, X_L {\setminus } Y_L)\) that do not belong to \({{\mathcal {P}}}_1\). Hence, using the assumption that \(|Y_L {\setminus } M| > 4 |M|\) and the inequality \(|E(Y_L {\setminus } M, Y_L {\setminus } M)| \le 3|Y_L {\setminus } M|\), we obtain that
There is a bijection from \(E'_L\) to a set of \((Y_L {\setminus } M)\)-\((X_L {\setminus } Y_L)\)-M-special paths in \(G'\). Thus, graph \(G'\) contains at least \(18|Y_L {\setminus } M|\) of such special paths. From Lemma 4 we know that each bunch contains at most seven special paths. Hence,
Finally, we obtain that
which concludes the proof of the lemma that \(|Y_L {\setminus } M| \le 4|M|\). \(\square \)
Corollary 1
\(|D_1 {\setminus } M| \le 76|M|.\)
Proof
By applying Lemmas 2, 3 and 5 together we obtain that
Since the same reasoning can be applied to upper bound \(|D''_1|\), we have that
\(\square \)
3.3 Main phase
In this section we analyse the main phase of the algorithm PortNumberingMDS. Recall that, in this phase each not yet dominated vertex v adds to \(D_2\) a neighbour \(w(v) \in N_G(v) \cap N_G(D_1)\) with the largest residual degree (i.e., a node that dominates the most not yet dominated vertices). Our goal here is to upper bound the size of the set added to the resulting dominating set D in this phase, i.e., we want to show that \(|D_2|= O(|M|)\). To this end, we partition \(D_2\) into three disjoint subsets: \( D_2 \cap M, \) \( D_2':=\left\{ x \in (D_2 {\setminus } M): \exists u \in N_G(x) {\setminus } M \wedge w(u) = x \right\} \) and \( D_2 {\setminus } (D'_2 \cup M),\) where \(w(\cdot )\) denotes a vertex from step 8 of the algorithm. Next we upper bound the size of each set separately.
Note that \(|D_2 \cap M| \le |M|\). Moreover, since the vertices in \(D_2 {\setminus } (D'_2 \cup M)\) were added to \(D_2\) only by vertices from M, and each vertex can add only one vertex, then \(|D_2 {\setminus } (D'_2 \cup M)| \le |M|\).
What is only left to show is that \(|D'_2| = O(|M|)\). For this purpose, we construct the following subgraph \(G''\) of graph G:
Definition 4
Let graph \(G''=(V'',E'')\) be a subgraph of \(G=(V, E)\) constructed in the following way:
-
(i)
Initially, \(V'' := D_2'\), and \(E'' := \emptyset \).
-
(ii)
For every vertex \(x \in V''\) pick a node \(u \in V {\setminus } M\) such that vertex u adds x to \(D_2\) in step 9 of the algorithm (i.e., \(w(u) = x\)). Add node u and edge \(\{x,u\}\) to graph \(G''\). We denote the set of added vertices as U.
-
(iii)
For every \(x \in D_2'\) pick a vertex \(v \in D_1 \cap N_G(x)\). Add vertex v and edge \(\{x,v\}\) to graph \(G''\).
-
(iv)
For every \(u \in U\) pick a vertex \(m \in (M {\setminus } D_1) \cap N_G(u)\). Add vertex m and edge \(\{x,m\}\) to graph \(G''\).
Note that in step 9 of the algorithm, only the neighbours of \(D_1\) (i.e., \(N_{G}({D_1})\)) are added to \(D_2\). Thus, step (iii) of the construction of \(G''\) is feasible (i.e., each vertex from \(D_2'\) has a neighbour in \(D_1\)). Moreover, since the vertices in U execute steps 7–9 of the algorithm, no vertex in U is adjacent to a vertex in \(D_1\).
We notice that Definition 4 ensures that inner nodes (i.e, \(D_2' \cup U\)) have degree exactly two in \(G''\). Thus the definition of bunches can be applied. By \({\mathcal {B}}_2\) we denote the set of all \(D_1\)-\(D_2'\)-U-\((M {\setminus } D_1)\)-bunches in \(G''\). Before we prove that \(|D'_2|=O(|M|)\), we shortly sketch the idea of the proof. At the beginning, in Lemma 6 we show, by way of contradiction, that each bunch \(B \in B_2\), contains at most four special paths. Then, using Lemma 1 we obtain that \(|{{{\mathcal {B}}}}_2| \le 2(|D_1| + |M {\setminus } D_1|)\) and thus, \(|{{{\mathcal {B}}}}_2|= O(|M|)\). Finally, since each bunch contains at most four special paths and each vertex in \(D'_2\) belongs to one of them we obtain the desired bound.
Now we are ready to formally prove that \(|D'_2| = O(|M|)\). For a given bunch \(B \in {{{\mathcal {B}}}}_2\), we define \(\{v\} := V(B) \cap D_1\) and \(\{m\}:= V(B) \cap (M {\setminus } D_1)\). Moreover, we assume that vertices \(x_1, x_2,\ldots ,x_{b_B} \in V_B \cap D_2'\) are numbered according to their relative position in the planar embedding of the bunch B (see Fig. 9) and for each vertex \(x_i \in V_B \cap D_2'\) by \(u_i\) we denote a vertex from the set U such that \(w(u_i) = x_i\). We remind the reader that \(w(u_i)\) is a vertex chosen in step 8 of the algorithm and the set U is given in Definition 4.

An example of a \(D_1\)-\(D_2'\)-U-\((M {\setminus } D_1)\)-bunch in constructed graph \(G''\). The four vertices lying inside the open region of cycle \({{\mathrm{Reg}}}(v,x_3,u_3,m,u_4,x_4,v)\) do not belong to a \(D_1\)-\(D_2'\)-U-\((M {\setminus } D_1)\)-bunch
Lemma 6
Let \(B \in {\mathcal {B}}_2\). Then, B contains at most four special paths (\(b_{B} \le 4\)).
Proof
Let A be the set of all vertices inside the closed region of B which are not dominated by \(D_1:=D_1' \cup D_1''\), i.e., \(A:= (V(G) {\setminus } N_G[D_1]) \cap Reg[B]\).
By way of contradiction we assume that \(b_B \ge 5\). We show a contradiction by the following statements (a), (b) and (c):
-
(a)
Every vertex in A is adjacent to m and \(\delta ^{V {\setminus } N(D_1)}_{m} \ge |A|\).
-
(b)
\(\delta ^{V{\setminus } N(D_1)}_{x_3} \le |A|-(b_B-3)\).
-
(c)
\(\delta ^{V {\setminus } N(D_1)}_{m} \le \delta ^{V {\setminus } N(D_1)}_{x_3}\).
Note that from the definition of bunches, vertices m and v are the only possible nodes from M lying in the closed region \({{\mathrm{Reg}}}[B]\). Since all vertices are dominated by M and vertices from A are not adjacent to v, we have proved statement (a). Moreover, \(x_3\) is contained inside the open region of cycle \((v,x_2,u_2,m, u_4,x_4,v)\). Thus, \(x_3\) is not adjacent to any vertex in the outer face of this the cycle, in particular, \(u_1,u_5,\ldots ,u_{b_B} \notin N_G(x_3)\) (see Fig. 9). This shows statement (b).
Let us notice that vertex \(u_3\) is also contained in the open region of the cycle \((v,x_2,u_2,m, u_4,x_4,v)\), i.e., \(u_3 \in {{\mathrm{Reg}}}(v,x_2,u_2,m, u_4,x_4,v)\). Furthermore, since \(u_3\) is not dominated by \(D_1\), it performs both invocations of DominateBigVertices. Hence, there are two possibilities:
-
(1)
\(u_3\) adds to X a vertex from the open region of the bunch (i.e., \(x(u_3) \in {{\mathrm{Reg}}}(B)\)) during the first invocation of DominateBigVertices, and so \(v \in D_1'\) or
-
(2)
\(u_3\) adds vertex m to X in the first call of DominateBigVertices, and so m has a neighbour in \(D_1\).
We claim that if case (1) occurs then m belongs to X in the second call of DominateBigVertices. Indeed, after the first invocation of DominateBigVertices all not yet dominated vertices inside \({{\mathrm{Reg}}}[B]\) are adjacent to m but not all such vertices are adjacent to \(x_3\). Thus, in the second call of DominateBigVertices vertex \(u_3\) adds vertex m to the set X. So, either way \(m \in N_G(D_1)\). Furthermore, since \(m \in N_G(D_1)\) and vertex \(u_3\) adds \(x_3\) in the main phase of the algorithm, \(\delta ^{V {\setminus } D_1}_{m} \le \delta ^{V {\setminus } D_1}_{x_3}\). This proves statement (c).
Hence, using (a), (b) and (c) we obtain that \(b_B \le 3\). This is a contradiction to the assumption that \(b_B \ge 5\). \(\square \)
Lemma 7
\(|D_2'| \le 616|M|.\)
Proof
Observe that the sets \(D_1, D_2', U\), and \(M {\setminus } D_1\) are disjoint. Moreover, a vertex \(x_i \in D'_2\) is adjacent to exactly one vertex \(u_i \in U\) in \(G''\). Let \(H''\) be the graph constructed from \(G''\) by contracting each edge \(\{x_i,u_i\} \in E(G'')\). Then, from Lemma 1 and Corollary 1, we obtain that \(|{\mathcal {B}}_2| \le 2(|D_1 \cup M|) \le 154|M|.\)
For each vertex \(x \in D'_2\) there exists a bunch \(B \in {{{\mathcal {B}}}}_2\) such that x belongs to a special path in B. Since, from Lemma 6 each bunch contains at most four special paths, we obtain that
\(\square \)
3.4 Final result
In this section we summarise the analysis of the algorithm’s approximation factor.
Theorem 1
There is a local algorithm that finds a 694-approximation of a minimum dominating set on planar graphs in the port numbering model with short messages, i.e., each message contains at most \(O(\log {|V|})\) bits.
Proof
The size of the set D returned by our algorithm satisfies the following inequality:
From Corollary 1 we know that \(|D_1{\setminus } M| \le 74\). The set \(D_2\) is a partition into three sets \(D_2 \cap M, D_2'\) and \(D_2 {\setminus } (D'_2 \cup M)\). Let us note that the set \(D_2 {\setminus } (D'_2 \cup M)\) contains only vertices from \(D_2\) added by vertices M. Hence
Next, using Lemma 7 we obtain that
Hence,
\(\square \)
4 Conclusion
In this paper we presented a local deterministic algorithm that finds a constant-factor approximation for the minimum dominating set problem in planar graphs. Our algorithm does not use any additional information besides a port numbering and assumes that in each round each node can send only short messages (i.e., messages with \(O(\log n)\)-bit) to each neighbour.
Recently, Göös et al. [6] showed that for lift-closed bounded degree graphs the models PO and ID are practically equivalent. In this paper we show that this is partially true for planar graphs and the MDS (up to constant factors). We hope that this work will be helpful as a hint for further comparisons of these models in other classes of graphs.
The approximation factor of the proposed algorithm is 694. Thus there is a large gap between the result and the known lower bound of (\(7-\epsilon \)). Recently, it has been shown in [15] that Lenzen et al.’s algorithm [10] yields a 52-approximation of the optimal solution in the model with unique identifiers on the vertices. An interesting issue might be a reduction of this gap in a PO and/or ID model.
References
Czygrinow, A., Hanćkowiak, M., Krzywdziński, K., Szymańska, E., Wawrzyniak, W.: Brief announcement: distributed approximations for the semi-matching problem. In: Proceedings of 25th International Symposium on Distributed Computing (DISC, Rome, Italy, September 2011), volume 6950 of Lecture Notes in Computer Science, pp. 200–201. Springer, Berlin, Germany (2011)
Czygrinow, A., Hanćkowiak, M., Szymanska, E., Wawrzyniak, W.: Distributed 2-approximation algorithm for the semi-matching problem. In: Proceedings of 26th International Symposium on Distributed Computing (DISC, Salvador, Brazil, October 2012), volume 7611 of Lecture Notes in Computer Science, pp. 210–222. Springer, Berlin, Germany (2012)
Czygrinow, A., Hanćkowiak, M., Wawrzyniak, W.: Distributed packing in planar graphs. In: The Twentieth ACM Symposium on Parallel Algorithms and Architectures, pp. 55–61 (2008)
Czygrinow, A., Hanćkowiak, M., Wawrzyniak, W.: Fast distributed approximations in planar graphs. In Proceedings of 22nd International Symposium on Distributed Computing (DISC, Arcachon, France, September 2008), volume 5218 of Lecture Notes in Computer Science, pp. 78–92. Springer, Berlin, Germany (2008)
Diestel, R.: Graph Theory, 4th Edition. Graduate Texts in Mathematics 173, Springer 2012, pp. 1–436. ISBN 978-3-642-14278-9, pp. I–XVIII (2012)
Göös, M., Hirvonen, J., Suomela, J.: Lower bounds for local approximation. JACM 60(5), October 2013, Article No. 39 (2013)
Hilke, M., Lenzen, C., Suomela, J.: Brief announcement: Local approximability of minimum dominating set on planar graphs. In: PODC 2014, 33rd ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing, Paris, France (2014)
Kuhn, F., Moscibroda, T., Wattenhofer, R.: The price of being near-sighted. In: Proceedings of 17th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA, Miami, FL, USA, January 2006), pp. 980–989. ACM Press, New York, NY, USA (2006)
Kuhn, F., Wattenhofer, R.: Constant-time distributed dominating set approximation. Distrib. Comput. 17(4), 303–310 (2005)
Lenzen, C., Pignolet, Y.-A., Wattenhofer, R.: Distributed minimum dominating set approximations in restricted families of graphs. Distrib. Comput. 26(2), 119–137 (2013)
Linial, N.: Locality in distributed graph algorithms. SIAM J. Comput. 21(1), 193–201 (1992)
Naor, M., Stockmeyer, L.: What can be computed locally? SIAM J. Comput. 24(6), 1259–1277 (1995)
Suomela, J.: Survey of local algorithms. ACM Comput. Surv. (CSUR) 45(2), 1–40 (2013)
Wawrzyniak, W.: Brief announcement: a local approximation algorithm for MDS problem in anonymous planar networks. In: ACM Symposium on Principles of Distributed Computing, PODC’13, Montreal, QC, Canada, July 22–24 (2013)
Wawrzyniak, W.: A strengthened analysis of a local algorithm for the minimum dominating set problem in planar graphs. Inf. Process. Lett. 114(3), 94–98 (2014)
Acknowledgments
We would like to thank the anonymous reviewers of the manuscript and Edyta Szymańska for providing us with constructive comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Additional information
A preliminary version of this work [14] appeared in PODC’13.
The research has been supported by Grant No. N206 565740.
Rights and permissions
About this article

Cite this article
Wawrzyniak, W. A local approximation algorithm for minimum dominating set problem in anonymous planar networks. Distrib. Comput. 28, 321–331 (2015). https://doi.org/10.1007/s00446-015-0247-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00446-015-0247-6