
Abstract
This paper is concerned with finite sample approximations to the supremum of a non-degenerate U-process of a general order indexed by a function class. We are primarily interested in situations where the function class as well as the underlying distribution change with the sample size, and the U-process itself is not weakly convergent as a process. Such situations arise in a variety of modern statistical problems. We first consider Gaussian approximations, namely, approximate the U-process supremum by the supremum of a Gaussian process, and derive coupling and Kolmogorov distance bounds. Such Gaussian approximations are, however, not often directly applicable in statistical problems since the covariance function of the approximating Gaussian process is unknown. This motivates us to study bootstrap-type approximations to the U-process supremum. We propose a novel jackknife multiplier bootstrap (JMB) tailored to the U-process, and derive coupling and Kolmogorov distance bounds for the proposed JMB method. All these results are non-asymptotic, and established under fairly general conditions on function classes and underlying distributions. Key technical tools in the proofs are new local maximal inequalities for U-processes, which may be useful in other problems. We also discuss applications of the general approximation results to testing for qualitative features of nonparametric functions based on generalized local U-processes.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
This paper is concerned with finite sample approximations to the supremum of a U-process of a general order indexed by a function class. We begin with describing our setting. Let \(X_1,\ldots ,X_n\) be independent and identically distributed (i.i.d.) random variables defined on a probability space \((\Omega , {\mathcal {A}}, {\mathbb {P}})\) and taking values in a measurable space \((S, {\mathcal {S}})\) with common distribution P. For a given integer \(r \geqslant 2\), let \({\mathcal {H}}\) be a class of jointly measurable functions (kernels) \(h:S^{r} \rightarrow {\mathbb {R}}\) equipped with a measurable envelope H (i.e., H is a nonnegative function on \(S^{r}\) such that \(H \geqslant \sup _{h \in {\mathcal {H}}}|h|)\). Consider the associated U-process
where \(I_{n,r} = \{ (i_{1},\ldots ,i_{r}) : 1 \leqslant i_{1},\ldots ,i_{r} \leqslant n, i_{j} \ne i_{k} \ \text {for} \ j \ne k \}\) and \(| I_{n,r} | = n!/(n-r)!\) denotes the cardinality of \(I_{n,r}\). Without loss of generality, we may assume that each \(h \in {\mathcal {H}}\) is symmetric, i.e., \(h(x_{1},\ldots ,x_{r}) = h(x_{i_{1}},\ldots ,x_{i_{r}})\) for every permutation \(i_{1},\ldots ,i_{r}\) of \(1,\ldots ,r\), and the envelope H is symmetric as well. Consider the normalized U-process
The main focus of this paper is to derive finite sample approximation results for the supremum of the normalized U-process, namely, \(Z_{n} := \sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}(h)/r\), in the case where the U-process is non-degenerate, i.e., \(\mathrm {Var}({\mathbb {E}}[h(X_1,\ldots ,X_{r}) \mid X_1]) > 0\) for all \(h \in {\mathcal {H}}\). The function class \({\mathcal {H}}\) is allowed to depend on n, i.e., \({\mathcal {H}}= {\mathcal {H}}_{n}\), and we are primarily interested in situations where the normalized U-process \({\mathbb {U}}_{n}\) is not weakly convergent as a process (beyond finite dimensional convergence). For example, there are situations where \({\mathcal {H}}_n\) depends on n but \({\mathcal {H}}_{n}\) is further indexed by a parameter set \(\Theta \) independent of n. In such cases, one can think of \({\mathbb {U}}_{n}\) as a U-process indexed by \(\Theta \) and can consider weak convergence of the U-process in the space of bounded functions on \(\Theta \), i.e., \(\ell ^{\infty }(\Theta )\). However, even in such cases, there are a variety of statistical problems where the U-process is not weakly convergent in \(\ell ^{\infty }(\Theta )\), even after a proper normalization. The present paper covers such “difficult” (and in fact yet more general) problems.
U-processes are powerful tools for a broad range of statistical applications such as testing for qualitative features of functions in nonparametric statistics [1, 25, 38], cross-validation for density estimation [43], and establishing limiting distributions of M-estimators (see, e.g., [4, 18, 50, 51]). There are two perspectives on U-processes: (1) they are infinite-dimensional versions of U-statistics (with one kernel); (2) they are stochastic processes that are nonlinear generalizations of empirical processes. Both views are useful in that: (1) statistically, it is of greater interest to consider a rich class of statistics rather than a single statistic; (2) mathematically, we can borrow the insights from empirical process theory to derive limit or approximation theorems for U-processes. Importantly, however, (1) extending U-statistics to U-processes requires substantial efforts and different techniques; and (2) generalization from empirical processes to U-processes is highly nontrivial especially when U-processes are not weakly convergent as processes. In classical settings where indexing function classes are fixed (i.e., independent of n), it is known that Uniform Central Limit Theorems (UCLTs) in the Hoffmann-Jørgensen sense hold for U-processes under metric (or bracketing) entropy conditions, where U-processes are weakly convergent in spaces of bounded functions [4, 8, 18, 44] (these references also cover degenerate U-processes where limiting processes are Gaussian chaoses rather than Gaussian processes). Under such classical settings, [5, 56] study limit theorems for bootstrapping U-processes; see also [3, 6, 9, 19, 32,33,34, 55] as references on bootstraps for U-statistics. Giné and Mason [27] introduce a notion of the local U-process motivated by a density estimator of a function of several variables proposed by [24] and establish a version of UCLTs for local U-processes. More recently, [11] studies Gaussian and bootstrap approximations for high-dimensional (order-two) U-statistics, which can be viewed as U-processes indexed by finite function classes \({\mathcal {H}}_n\) with increasing cardinality in n. To the best of our knowledge, however, no existing work covers the case where the indexing function class \({\mathcal {H}}= {\mathcal {H}}_n\) (1) may change with n; (2) may have infinite cardinality for each n; and (3) need not verify UCLTs. This is indeed the situation for many of nonparametric specification testing problems [1, 25, 38]; see examples in Sect. 4 for details.
In this paper, we develop a general non-asymptotic theory for directly approximating the supremum \(Z_n = \sup _{h \in {\mathcal {H}}} {\mathbb {U}}_n (h)/r\) without referring a weak limit of the underlying U-process \(\{{\mathbb {U}}_n(h) : h \in {\mathcal {H}}\}\). Specifically, we first establish a general Gaussian coupling result to approximate \(Z_n\) by the supremum of a Gaussian process \(W_P\) in Sect. 2. Our Gaussian approximation result builds upon recent development in modern empirical process theory [13,14,15] and high-dimensional U-statistics [11]. As a significant departure from the existing literature [4, 14, 15, 27], our Gaussian approximation for U-processes has a multi-resolution nature, which is neither parallel with the theory of U-processes with fixed function classes nor that of empirical processes. In particular, unlike U-processes with fixed function classes, the higher-order degenerate components are not necessarily negligible compared with the Hájek (empirical) process (in the sense of the Hoeffding projections [31]) and they may impact error bounds of the Gaussian approximation.
However, the covariance function of the Gaussian process \(W_P\) depends on the underlying distribution P which is unknown and hence the Gaussian approximation developed in Sect. 2 is not directly applicable to statistical problems such as computing critical values of a test statistic defined by the supremum of a U-process. On the other hand, the (Gaussian) multiplier bootstrap developed in [13, 15] for empirical processes is not directly applicable to U-processes since the Hájek process also depends on P and hence is unknown. Our second main contribution is to develop a fully data-dependent procedure for approximating the distribution of \(Z_n\). Specifically, we propose a novel jackknife multiplier bootstrap (JMB) tailored to U-processes in Sect. 3. The key insight of the JMB is to replace the (unobserved) Hájek process by its jackknife estimate (cf. [10]). We establish finite sample validity of the JMB (i.e., conditional multiplier CLT) with explicit error bounds. As a distinguished feature, our error bounds involve a delicate interplay among all levels of the Hoeffding projections. In particular, the key innovations are a collection of new powerful local maximal inequalities for level-dependent degenerate components associated with the U-process (see Sect. 5). To the best of our knowledge, there has been no theoretical guarantee on bootstrap consistency for U-processes whose function classes change with n and which do not converge weakly as processes. Our finite sample bootstrap validity results with explicit error bounds fill this important gap in literature, although we only focus on the supremum functional.
It should be emphasized that our approximation problem is different from the problem of approximating the wholeU-process \(\{{\mathbb {U}}_n(h) : h \in {\mathcal {H}}\}\). In testing monotonicity of nonparametric regression functions, [25] consider a test statistic defined by the supremum of a bounded U-process of order-two and derive a Gaussian approximation result for the normalized U-process. Their idea is a two-step approximation procedure: first approximate the U-process by its Hájek process and then apply Rio’s coupling result [47], which is a Komlós–Major–Tusnády (KMT) [36] type strong approximation for empirical processes indexed by Vapnik-Červonenkis (VC) type classes of functions. See also [35, 41] for extensions of the KMT construction to other function classes. It is worth noting that the two-step approximation of U-processes based on KMT type approximations in general requires more restrictive conditions on the function class and the underlying distribution in statistical applications. Our regularity conditions on the function class and the underlying distribution for the Gaussian and bootstrap approximations are easy to verify and are less restrictive than those required for KMT type approximations since we directly approximate the supremum of a U-process rather than the whole U-process; in fact, our approximation results can cover examples of statistical applications for which KMT type approximations are not applicable or difficult to apply; see Sect. 4 for details. In particular, both Gaussian and bootstrap approximation results of the present paper allow classes of functions with unbounded envelopes provided suitable moment conditions are satisfied.
To illustrate the general approximation results for suprema of U-processes, we consider the problem of testing qualitative features of the conditional distribution and regression functions in nonparametric statistics [1, 25, 38]. In Sect. 4, we propose a unified test statistic for specifications (such as monotonicity, linearity, convexity, concavity, etc.) of nonparametric functions based on the generalized local U-process (the name is inspired by [27]). Instead of attempting to establish a Gumbel type limiting distribution for the extreme-value test statistic (which is known to have slow rates of convergence; see [30, 46]), we apply the JMB to approximate the finite sample distribution of the proposed test statistic. Notably, the JMB is valid for a larger spectrum of bandwidths, allows for an unbounded envelope, and the size error of the JMB is decreasing polynomially fast in n, which should be contrasted with the fact that tests based on Gumbel approximations have size errors of order \(1/\log n\). It is worth noting that [38], who develop a test for the stochastic monotonicity based on the supremum of a (second-order) U-process and derive a Gumbel limiting distribution for their test statistic under the null, state a conjecture that a bootstrap resampling method would yield the test whose size error is decreasing polynomially fast in n [38, p. 594]. The results of the present paper formally solve this conjecture for a different version of bootstrap, namely, the JMB, in a more general setting. In addition, our general theory can be used to develop a version of the JMB test that is uniformly valid in compact bandwidth sets. Such “uniform-in-bandwidth” type results allow one to consider tests with data-dependent bandwidth selection procedures, which are not covered in [1, 25, 38].
1.1 Organization
The rest of the paper is organized as follows. In Sect. 2, we derive non-asymptotic Gaussian approximation error bounds for the U-process supremum in the non-degenerate case. In Sect. 3, we develop and study a jackknife multiplier bootstrap (with Gaussian weights) tailored to the U-process to further approximate the distribution of the U-process supremum in a data-dependent manner. In Sect. 4, we discuss applications of the general results developed in Sects. 2 and 3 to testing for qualitative features of nonparametric functions based on generalized local U-processes. In Sect. 5, we prove new multi-resolution and local maximal inequalities for degenerate U-processes with respect to the degeneracy levels of their kernel. These inequalities are key technical tools in the proofs for the results in the previous sections. In Sect. 6, we present the proofs for Sects. 2, 3. Appendix contains additional proofs, discussions, and auxiliary technical results.
1.2 Notation
For a nonempty set T, let \(\ell ^{\infty }(T)\) denote the Banach space of bounded real-valued functions \(f: T \rightarrow {\mathbb {R}}\) equipped with the sup norm \(\Vert f \Vert _{T} := \sup _{t \in T}|f(t)|\). For a pseudometric space (T, d), let \(N(T,d,\varepsilon )\) denote the \(\varepsilon \)-covering number for (T, d), i.e., the minimum number of closed d-balls with radius at most \(\varepsilon \) that cover T. See [53, Section 2.1] or [29, Section 2.3] for details. For a probability space \((T,{\mathcal {T}},Q)\) and a measurable function \(f: T \rightarrow {\mathbb {R}}\), we use the notation \(Q f := \int f dQ\) whenever the integral is defined. For \(q \in [1,\infty ]\), let \(\Vert \cdot \Vert _{Q,q}\) denote the \(L^{q}(Q)\)-seminorm, i.e., \(\Vert f \Vert _{Q,q} := (Q|f|^{q})^{1/q} := (\int |f|^{q} dQ)^{1/q}\) for finite q while \(\Vert f \Vert _{Q,\infty }\) denotes the essential supremum of |f| with respect to Q. For a measurable space \((S,{\mathcal {S}})\) and a positive integer r, \(S^{r} = S \times \cdots \times S\) (r times) denotes the product space equipped with the product \(\sigma \)-field \({\mathcal {S}}^{r}\). For a generic random variable Y (not necessarily real-valued), let \({\mathcal {L}}(Y)\) denote the law (distribution) of Y. For \(a,b \in {\mathbb {R}}\), let \(a \vee b = \max \{ a,b \}\) and \(a \wedge b = \min \{ a,b \}\). Let \(\lfloor a \rfloor \) denote the integer part of \(a \in {\mathbb {R}}\). “Constants” refer to finite, positive, and non-random numbers.
2 Gaussian approximation for suprema of U-processes
In this section, we derive non-asymptotic Gaussian approximation error bounds for the U-process supremum in the non-degenerate case, which is essential for establishing the bootstrap validity in Sect. 3. The goal is to approximate the supremum of the normalized U-process, \(\sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}(h)/r\), by the supremum of a suitable Gaussian process, and derive bounds on such approximations.
We first recall the setting. Let \(X_{1},\ldots ,X_{n}\) be i.i.d. random variables defined on a probability space \((\Omega ,{\mathcal {A}},{\mathbb {P}})\) and taking values in a measurable space \((S,{\mathcal {S}})\) with common distribution P. For a technical reason, we assume that S is a separable metric space and \({\mathcal {S}}\) is its Borel \(\sigma \)-field. For a given integer \(r \geqslant 2\), let \({\mathcal {H}}\) be a class of symmetric measurable functions \(h: S^{r} \rightarrow {\mathbb {R}}\) equipped with a symmetric measurable envelope H. Recall the U-process \(\{ U_{n}(h) : h \in {\mathcal {H}}\}\) defined in (1) and its normalized version \(\{ {\mathbb {U}}_{n}(h) : h \in {\mathcal {H}}\}\) defined in (2). In applications, the function class \({\mathcal {H}}\) may depend on n, i.e., \({\mathcal {H}}= {\mathcal {H}}_{n}\). However, in Sects. 2 and 3, we will derive non-asymptotic results that are valid for each sample size n, and therefore suppress the possible dependence of \({\mathcal {H}}= {\mathcal {H}}_n\) on n for the notational convenience.
We will use the following notation. For a symmetric measurable function \(h: S^{r} \rightarrow {\mathbb {R}}\) and \(k=1,\ldots ,r\), let \(P^{r-k}h\) denote the function on \(S^{k}\) defined by
whenever the latter integral exists and is finite for every \((x_{1},\ldots ,x_{k}) \in S^{k}\) (\(P^{0}h = h\)). Provided that \(P^{r-k}h\) is well-defined, \(P^{r-k}h\) is symmetric and measurable.
In this paper, we focus on the case where the function class \({\mathcal {H}}\) is VC (Vapnik-Červonenkis) type, whose formal definition is stated as follows.
Definition 2.1
(VC type class) A function class \({\mathcal {H}}\) on \(S^{r}\) with envelope H is said to be VC type with characteristics (A, v) if \( \sup _Q N({\mathcal {H}}, \Vert \cdot \Vert _{Q,2}, \varepsilon \Vert H\Vert _{Q,2}) \leqslant (A / \varepsilon )^v\) for all \(0 < \varepsilon \leqslant 1\), where \(\sup _{Q}\) is taken over all finitely discrete distributions on \(S^{r}\).
We make the following assumptions on the function class \({\mathcal {H}}\) and the distribution P.
- (PM)
The function class \({\mathcal {H}}\) is pointwise measurable, i.e., there exists a countable subset \({\mathcal {H}}' \subset {\mathcal {H}}\) such that for every \(h \in {\mathcal {H}}\), there exists a sequence \(h_k \in {\mathcal {H}}'\) with \(h_k \rightarrow h\) pointwise.
- (VC)
The function class \({\mathcal {H}}\) is VC type with characteristics \(A \geqslant (e^{2(r-1)}/16) \vee e\) and \(v \geqslant 1\) for envelope H. The envelope H satisfies that \(H \in L^{q}(P^{r})\) for some \(q \in [4,\infty ]\) and \(P^{r-k}H\) is everywhere finite for every \(k=1,\ldots ,r\).
- (MT)
Let \({\mathcal {G}}:= P^{r-1} {\mathcal {H}}:= \{ P^{r-1} h : h \in {\mathcal {H}}\}\) and \(G:=P^{r-1}H\). There exist (finite) constants
$$\begin{aligned} b_{{\mathfrak {h}}} \geqslant b_{{\mathfrak {g}}} \vee \sigma _{{\mathfrak {h}}} \geqslant b_{{\mathfrak {g}}} \wedge \sigma _{{\mathfrak {h}}} \geqslant {\overline{\sigma }}_{{\mathfrak {g}}} > 0 \end{aligned}$$such that the following hold:
$$\begin{aligned} \begin{aligned}&\Vert G\Vert _{P,q} \leqslant b_{{\mathfrak {g}}}, \qquad \sup _{g \in {\mathcal {G}}} \Vert g \Vert _{P,\ell }^{\ell } \leqslant {\overline{\sigma }}_{{\mathfrak {g}}}^2 b_{{\mathfrak {g}}}^{\ell -2}, \ \ell =2,3,4, \\&\Vert P^{r-2} H \Vert _{P^{2},q} \leqslant b_{{\mathfrak {h}}}, \ \text {and} \ \sup _{h \in {\mathcal {H}}} \Vert P^{r-2}h \Vert _{P^{2},\ell }^{\ell } \leqslant \sigma _{{\mathfrak {h}}}^{2} b_{{\mathfrak {h}}}^{\ell -2}, \ \ell =2,4, \end{aligned} \end{aligned}$$where q appears in Condition (VC).
Some comments on the conditions are in order. Conditions (PM), (VC), and (MT) are inspired by Conditions (A)–(C) in [15]. Condition (PM) is made to avoid measurability difficulties. Our definition of “pointwise measurability” is borrowed from Example 2.3.4 in [53]; [29, p. 262] calls a pointwise measurable function class a function class satisfying the pointwise countable approximation property. Condition (PM) ensures that, e.g., \(\sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}(h) = \sup _{h \in {\mathcal {H}}'} {\mathbb {U}}_{n}(h)\), so that \(\sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}(h)\) is a (proper) random variable. See [53, Section 2.2] for details.
Condition (VC) ensures that \({\mathcal {G}}\) is VC type as well with characteristics \(4\sqrt{A}\) and 2v for envelope \(G=P^{r-1}H\); see Lemma 5.4 ahead. Since \(G \in L^{2}(P)\) by Condition (VC), it is seen from Dudley’s criterion on sample continuity of Gaussian processes (see, e.g., [29, Theorem 2.3.7]) that the function class \({\mathcal {G}}\) is P-pre-Gaussian, i.e., there exists a tight Gaussian random variable \(W_P\) in \(\ell ^\infty ({\mathcal {G}})\) with mean zero and covariance function
Recall that a Gaussian process \(W= \{ W(g) : g \in {\mathcal {G}}\}\) is a tight Gaussian random variable in \(\ell ^{\infty }({\mathcal {G}})\) if and only if \({\mathcal {G}}\) is totally bounded for the intrinsic pseudometric \(d_{W}(g,g') = ({\mathbb {E}}[ (W(g)-W(g'))^{2}])^{1/2}, g,g' \in {\mathcal {G}}\), and W has sample paths almost surely uniformly \(d_{W}\)-continuous [53, Section 1.5]. In applications, \({\mathcal {G}}\) may depend on n and so the Gaussian process \(W_P\) (and its distribution) may depend on n as well, although such dependences are suppressed in Sects. 2 and 3. The VC type assumption made in Condition (VC) covers many statistical applications. However, it is worth noting that in principle, we can derive corresponding results for Gaussian and bootstrap approximations under more general complexity assumptions on the function class beyond the VC type, as our local maximal inequalities for the U-process in Theorem 5.1 ahead, which are key technical results in the proofs of the Gaussian and bootstrap approximation results, can cover more general function classes than VC type classes; but the resulting bounds would be more complicated and may not be clear enough. For the clarity of exposition, we focus on VC type function classes and present a Gaussian coupling bound for general function classes in “Appendix E”.
Condition (MT) imposes suitable moment bounds on the kernel and its Hájek projection. Specifically, this moment condition contains interpolated parameters which control the lower moments (i.e., \(L^{2}, L^{3}\), and \(L^{4}\) sizes) and the envelopes of \({\mathcal {H}}\) and \({\mathcal {G}}\).
Under these conditions on the function class \({\mathcal {H}}\) and the distribution P, we will first construct a random variable, defined on the same probability space as \(X_{1},\ldots ,X_{n}\), which is equal in distribution to \(\sup _{g \in {\mathcal {G}}} W_{P}(g)\) and “close” to \(Z_{n}\) with high-probability. To ensure such constructions, a common assumption is that the probability space is rich enough. For the sake of clarity, we will assume in Sects. 2 and 3 that the probability space \((\Omega ,{\mathcal {A}},{\mathbb {P}})\) is such that
where \(X_{1},\ldots ,X_{n}\) are the coordinate projections of \((S^{n},{\mathcal {S}}^{n},P^{n})\), multiplier random variables \(\xi _{1},\ldots ,\xi _{n}\) to be introduced in Sect. 3 depend only on the “second” coordinate \((\Xi ,{\mathcal {C}},R)\), and U(0, 1) denotes the uniform distribution (Lebesgue measure) on (0, 1) (\({\mathcal {B}}(0,1)\) denotes the Borel \(\sigma \)-field on (0, 1)). The augmentation of the last coordinate is reserved to generate a U(0, 1) random variable independent of \(X_{1},\ldots ,X_{n}\) and \(\xi _{1},\ldots ,\xi _{n}\), which is needed when applying the Strassen–Dudley theorem and its conditional version in the proofs of Proposition 2.1 and Theorem 3.1; see “Appendix B” for the Strassen–Dudley theorem and its conditional version. We will also assume that the Gaussian process \(W_{P}\) is defined on the same probability space (e.g. one can generate \(W_{P}\) by the previous U(0, 1) random variable), but of course \(\sup _{g \in {\mathcal {G}}} W_{P}(g)\) is not what we want since there is no guarantee that \(\sup _{g \in {\mathcal {G}}}W_{P}(g)\) is close to \(Z_{n}\).
Now, we are ready to state the first result of this paper. Recall the notation given in Condition (MT) and define
with the convention that \(\sum _{k=3}^{r} =0\) if \(r=2\). The following proposition derives Gaussian coupling bounds for \(Z_{n} = \sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}(h)/r\).
Proposition 2.1
(Gaussian coupling bounds) Let \(Z_n = \sup _{h \in {\mathcal {H}}} {\mathbb {U}}_n(h)/r\). Suppose that Conditions (PM), (VC), and (MT) hold, and that \(K_{n}^{3} \leqslant n\). Then, for every \(n \geqslant r+1\) and \(\gamma \in (0,1)\), one can construct a random variable \({\widetilde{Z}}_{n,\gamma }\) such that \({\mathcal {L}}({\widetilde{Z}}_{n,\gamma }) = {\mathcal {L}}(\sup _{g \in {\mathcal {G}}} W_P(g))\) and
where \(C,C'\) are constants depending only on r, and
In the case of \(q=\infty \), “1 / q” is interpreted as 0.
In statistical applications, bounds on the Kolmogorov distance are often more useful than coupling bounds. For two real-valued random variables V, Y, let \(\rho (V,Y)\) denote the Kolmogorov distance between the distributions of V and Y, i.e., \(\rho (V,Y) := \sup _{t \in {\mathbb {R}}} | {\mathbb {P}}(V \leqslant t) - {\mathbb {P}}(Y \leqslant t)|\). To derive a Kolomogorov distance bound, we will assume that there exists a constant \({\underline{\sigma }}_{{\mathfrak {g}}} > 0\) such that
Condition (5) implies that the U-process is non-degenerate. For the notational convenience, let \({\widetilde{Z}} = \sup _{g \in {\mathcal {G}}} W_{P}(g)\).
Corollary 2.2
(Bounds on the Kolmogorov distance between \(Z_n\) and \(\sup _{g \in {\mathcal {G}}}W_{P}(g)\)) Assume that all the conditions in Proposition 2.1 and (5) hold. Then, there exists a constant C depending only on \(r, {\overline{\sigma }}_{{\mathfrak {g}}}\) and \({\underline{\sigma }}_{{\mathfrak {g}}}\) such that
In particular, if the function class \({\mathcal {H}}\) and the distribution P are independent of n, then \(\rho (Z_n, {\widetilde{Z}} )= O(\{ (\log n)^{7}/n \}^{1/8} )\).
Condition (5) is used to apply the “anti-concentration” inequality for the Gaussian supremum (see Lemma A.1), which is a key technical ingredient of the proof of Corollary 2.2. The dependence of the constant C on the variance parameters \({\underline{\sigma }}_{{\mathfrak {g}}}\) and \({\overline{\sigma }}_{{\mathfrak {g}}}\) is not a serious restriction in statistical applications. In statistical applications, the function class \({\mathcal {H}}\) is often normalized in such a way that each function \(g \in {\mathcal {G}}\) has (approximately) unit variance. In such cases, we may take \({\underline{\sigma }}_{{\mathfrak {g}}} = {\overline{\sigma }}_{{\mathfrak {g}}} = 1\) or \(({\underline{\sigma }}_{{\mathfrak {g}}},{\overline{\sigma }}_{{\mathfrak {g}}})\) as positive constants independent of n; see Sect. 4 for details.
Remark 2.1
(Comparisons with Gaussian approximations to suprema of empirical processes) Our Gaussian coupling (Proposition 2.1) and approximation (Corollary 2.2) results are level-dependent on the Hoeffding projections of the U-process \({\mathbb {U}}_n\) (cf. (17) and (18) for formal definitions of the Hoeffding projections and decomposition). Specifically, we observe that: (1) \({\underline{\sigma }}_{{\mathfrak {g}}}, {\overline{\sigma }}_{{\mathfrak {g}}}, b_{{\mathfrak {g}}}\) quantify the contribution from the Hájek (empirical) process associated with \({\mathbb {U}}_n\); (2) \(\sigma _{{\mathfrak {h}}}, b_{{\mathfrak {h}}}\) are related to the second-order degenerate component associated with \({\mathbb {U}}_n\); (3) \(\chi _n\) contains the effect from all higher order projection terms of \({\mathbb {U}}_n\). For statistical applications in Sect. 4 where the function class \({\mathcal {H}}= {\mathcal {H}}_n\) changes with n, the second and higher order projections terms are not necessarily negligible and we have to take into account the contributions of all higher order projection terms. Hence, the Gaussian approximation for the U-process supremum of a general order is not parallel with the approximation results for the empirical process supremum [14, 15].
3 Bootstrap approximation for suprema of U-processes
The Gaussian approximation results derived in the previous section are often not directly applicable in statistical applications such as computing critical values of a test statistic defined by the supremum of a U-process. This is because the covariance function of the approximating Gaussian process \(W_{P}(g), g \in {\mathcal {G}}\), is often unknown. In this section, we study a Gaussian multiplier bootstrap, tailored to the U-process, to further approximate the distribution of the random variable \(Z_{n} = \sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}(h)/r\) in a data-dependent manner. The Gaussian approximation results will be used as building blocks for establishing validity of the Gaussian multiplier bootstrap.
We begin with noting that, in contrast to the empirical process case studied in [13, 15], devising (Gaussian) multiplier bootstraps for the U-process is not straightforward. From the Gaussian approximation results, the distribution of \(Z_{n}\) is well approximated by the Gaussian supremum \(\sup _{g \in {\mathcal {G}}} W_{P}(g)\). Hence, one might be tempted to approximate the distribution of \(\sup _{g \in {\mathcal {G}}}W_{P}(g)\) by the conditional distribution of the supremum of the the multiplier process
where \(\xi _{1},\ldots ,\xi _{n}\) are i.i.d. N(0, 1) random variables independent of the data \(X_{1}^{n} := \{ X_{1},\ldots ,X_{n} \}\) and \({\overline{g}} = n^{-1} \sum _{i=1}^{n} g(X_{i})\). However, a major problem of this approach is that, in statistical applications, functions in \({\mathcal {G}}\) are unknown to us since functions in \({\mathcal {G}}\) are of the form \(P^{r-1}h\) for some \(h \in {\mathcal {H}}\) and depend on the (unknown) underlying distribution P. Therefore, we must devise a multiplier bootstrap properly tailored to the U-process.
Motivated by this fundamental challenge, we propose and study the following version of Gaussian multiplier bootstrap. Let \(\xi _1,\ldots ,\xi _n\) be i.i.d. N(0, 1) random variables independent of the data \(X_1^n\) [these multiplier variables will be assumed to depend only on the “second” coordinate in the probability space construction (3)]. We introduce the following multiplier process:
where \(\sum _{(i,i_{2},\ldots ,i_{r})}\) is taken with respect to \((i_{2},\ldots ,i_{r})\) while keeping i fixed. The process \(\{ {\mathbb {U}}_n^\sharp (h) : h \in {\mathcal {H}}\}\) is a centered Gaussian process conditionally on the data \(X_{1}^{n}\) and can be regarded as a version of the (infeasible) multiplier process (6) with each \(g(X_{i})\) replaced by a jackknife estimate. In fact, the multiplier process (6) can be alternatively represented as
where \(\overline{P^{r-1}h} = n^{-1} \sum _{i=1}^{n} P^{r-1}h(X_{i})\). For \(x \in S\), denote by \(\delta _{x}\) the Dirac measure at x and denote by \(\delta _{x} h\) the function on \(S^{r-1}\) defined by \((\delta _{x} h)(x_{2},\ldots ,x_{r}) =h(x,x_{2},\ldots ,x_{r})\) for \((x_{2},\ldots ,x_{r}) \in S^{r-1}\). For each \(i=1,\ldots ,n\) and a function f on \(S^{r-1}\), let \(U_{n-1,-i}^{(r-1)}(f)\) denote the U-statistic with kernel f for the sample without the i-th observation, i.e.,
Then the proposed multiplier process (7) can be alternatively written as
that is, our multiplier process (7) replaces each \((P^{r-1}h)(X_{i})\) in the infeasible multiplier process (8) by its jackknife estimate \(U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}h)\).
In practice, we approximate the distribution of \(Z_{n}\) by the conditional distribution of the supremum of the multiplier process \(Z_{n}^{\sharp }:=\sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}^{\sharp }(h)\) given \(X_{1}^{n}\), which can be further approximated by Monte Carlo simulations on the multiplier variables.
To the best of our knowledge, our multiplier bootstrap method for U-processes is new in the literature, at least in this generality; see Remark 3.1 for comparisons with other bootstraps for U-processes. We call the resulting bootstrap method the jackknife multiplier bootstrap (JMB) for U-processes.
Now, we turn to proving validity of the proposed JMB. We will first construct couplings \(Z_{n}^{\sharp }\) and \({\widetilde{Z}}_{n}^{\sharp } := {\widetilde{Z}}_{n,\gamma }^{\sharp }\) (a real-valued random variable that may depend on the coupling error \(\gamma \in (0,1)\)) such that: 1) \({\mathcal {L}}({\widetilde{Z}}_{n}^{\sharp } \mid X_{1}^{n} ) = {\mathcal {L}} ( {\widetilde{Z}} )\), where \({\mathcal {L}}(\cdot \mid X_{1}^{n})\) denotes the conditional law given \(X_{1}^{n}\) (i.e., \({\widetilde{Z}}_{n}^{\sharp }\) is independent of \(X_{1}^{n}\) and has the same distribution as \({\widetilde{Z}} = \sup _{g \in {\mathcal {G}}}W_{P}(g)\)); and at the same time 2) \(Z_{n}^{\sharp }\) and \({\widetilde{Z}}_{n}^{\sharp }\) are “close” to each other. Construction of such couplings leads to validity of the JMB. To see this, suppose that \(Z_{n}^{\sharp }\) and \({\widetilde{Z}}_{n}^{\sharp }\) are close to each other, namely, \({\mathbb {P}}(|Z_{n}^{\sharp } - {\widetilde{Z}}_{n}^{\sharp }| > r_{1}) \leqslant r_{2}\) for some small \(r_{1},r_{2} > 0\). To ease the notation, denote by \({\mathbb {P}}_{\mid X_{1}^{n}}\) and \({\mathbb {E}}_{\mid X_{1}^{n}}\) the conditional probability and expectation given \(X_{1}^{n}\), respectively (i.e., the notation \({\mathbb {P}}_{\mid X_{1}^{n}}\) corresponds to taking probability with respect to the “latter two” coordinates in (3) while fixing \(X_{1}^{n}\)). Then,
by Markov’s inequality, so that, on the event \(\{ {\mathbb {P}}_{\mid X_{1}^{n}} (|Z_{n}^{\sharp } - {\widetilde{Z}}_{n}^{\sharp }| > r_{1}) \leqslant r_{2}^{1/2} \}\) whose probability is at least \(1-r_{2}^{1/2}\), for every \(t \in {\mathbb {R}}\),
and likewise \({\mathbb {P}}_{\mid X_{1}^{n}} (Z_{n}^{\sharp } \leqslant t) \geqslant {\mathbb {P}}({\widetilde{Z}} \leqslant t-r_{1} ) - r_{2}^{1/2}\). Hence, on that event,
The first term on the right hand side can be bounded by using the anti-concentration inequality for the supremum of a Gaussian process (cf. [14, Lemma A.1] which is stated in Lemma A.1 in “Appendix A”), and combining the Gaussian approximation results, we obtain a bound on the Kolmogorov distance between \({\mathcal {L}}(Z_{n}^{\sharp } \mid X_{1}^{n})\) and \({\mathcal {L}}(Z_{n})\) on an event with probability close to one, which leads to validity of the JMB.
The following theorem is the main result of this paper and derives bounds on such couplings. To state the next theorem, we need the additional notation. For a symmetric measurable function f on \(S^{2}\), define \(f^{\odot 2} = f^{\odot 2}_{P}\) by
Let \(\nu _{{\mathfrak {h}}} := \Vert (P^{r-2}H)^{\odot 2} \Vert _{P^{2},q/2}^{1/2}\).
Theorem 3.1
(Bootstrap coupling bounds) Let \(Z_n^\sharp = \sup _{h \in {\mathcal {H}}} {\mathbb {U}}_n^\sharp (h)\). Suppose that Conditions (PM), (VC), and (MT) hold. Furthermore, suppose that
Then, for every \(n \geqslant r+1\) and \(\gamma \in (0,1)\), one can construct a random variable \({\widetilde{Z}}_{n,\gamma }^\sharp \) such that \({\mathcal {L}}({\widetilde{Z}}_{n,\gamma }^\sharp \mid X_1^n) = {\mathcal {L}}(\sup _{g \in {\mathcal {G}}} W_P(g))\) and
where \(C, C'\) are constants depending only on r, and
In the case of \(q=\infty \), “1 / q” is interpreted as 0.
We note that \(\nu _{{\mathfrak {h}}}^{q} \leqslant \Vert P^{r-2}H\Vert _{P^{2},q}^{q} \leqslant b_{{\mathfrak {h}}}^{q}\), but in our applications \(\nu _{{\mathfrak {h}}} \ll b_{{\mathfrak {h}}}\) and this is why we introduced such a seemingly complicated definition for \(\nu _{{\mathfrak {h}}}\). To see that \(\nu _{{\mathfrak {h}}} \leqslant b_{{\mathfrak {h}}}\), observe that by the Cauchy–Schwarz and Jensen inequalities,
Condition (9) is not restrictive. In applications, the function class \({\mathcal {H}}\) is often normalized in such a way that \({\overline{\sigma }}_{{\mathfrak {g}}}\) is of constant order, and under this normalization, Condition (9) is a merely necessary condition for the coupling bound (10) to tend to zero.
The proof of Theorem 3.1 is lengthy and involved. A delicate part of the proof is to sharply bound the sup-norm distance between the conditional covariance function of the multiplier process \({\mathbb {U}}_{n}^{\sharp }\) and the covariance function of \(W_{P}\), which boils down to bounding the term
To this end, we make use of the following observation: for a \(P^{r-1}\)-integrable function f on \(S^{r-1}\), \(U_{n-1,-i}^{(r-1)}(f)\) is a U-statistic of order \((r-1)\), and denote by \(S_{n-1,-i}(f)\) its first Hoeffding projection term. Conditionally on \(X_{i}\), \(U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}h) - P^{r-1}h(X_{i}) - S_{n-1,-i}(\delta _{X_{i}}h)\) is a degenerate U-process, and we will bound the expectation of the squared supremum of this term conditionally on \(X_{i}\) using “simpler” maximal inequalities (Corollary 5.6 ahead). On the other hand, the term \(n^{-1} \sum _{i=1}^{n} \{ S_{n-1,-i}(\delta _{X_{i}}h) \}^{2}\) is decomposed into
where the order of degeneracy of the latter term is 1, and we will apply “sharper” local maximal inequalities (Corollary 5.5 ahead) to bound the suprema of both terms. Such a delicate combination of different maximal inequalities turns out to be crucial to yield sharper regularity conditions for validity of the JMB in our applications. In particular, if we bound the sup-norm distance between the conditional covariance function of \({\mathbb {U}}_{n}^{\sharp }\) and the covariance function of \(W_{P}\) in a cruder way, then this will lead to more restrictive conditions on bandwidths in our applications, especially for the “uniform-in-bandwidth” results [cf. Condition (T5\('\)) in Theorem 4.4].
The following corollary derives a “high-probability” bound for the Kolmogorov distance between \({\mathcal {L}}( Z_{n}^{\sharp } \mid X_{1}^{n})\) and \({\mathcal {L}}({\widetilde{Z}})\) (here a high-probability bound refers to a bound holding with probability at least \(1 - C n^{-c}\) for some constants C, c).
Corollary 3.2
(Validity of the JMB) Suppose that Conditions (PM), (VC), (MT), and (5) hold. Let
with the convention that \(1/q = 0\) when \(q=\infty \). Then, there exist constants \(C,C'\) depending only on \(r, {\overline{\sigma }}_{{\mathfrak {g}}}\), and \({\underline{\sigma }}_{{\mathfrak {g}}}\) such that, with probability at least \(1-C \eta _{n}^{1/4}\),
If the function class \({\mathcal {H}}\) and the distribution P are independent of n, then \(\eta _{n}^{1/4}\) is of order \(n^{-1/16}\), which is polynomially decreasing in n but appears to be non-sharp. Sharper bounds could be derived by improving on \(\gamma ^{-3/2}\) in front of the \(n^{-1/4}\) term in (10). The proof of Theorem 3.1 consists of constructing a “high-probability” event on which, e.g., the sup-norm distance between the conditional covariance function of \({\mathbb {U}}_{n}^{\sharp }\) and the covariance function of \(W_{P}\) is small. To construct such a high-probability event, the current proof repeatedly relies on Markov’s inequality, which could be replaced by more sophisticated deviation inequalities. However, this is at the cost of more technical difficulties and more restrictive moment conditions. In addition, we derive a conditional UCLT for the JMB in “Appendix D” when \({\mathcal {H}}\) is fixed and P does not depend on n.
Remark 3.1
(Connections to other bootstraps) There are several versions of bootstraps for non-degenerateU-processes. The most celebrated one is the empirical bootstrap
where \(X_1^*,\ldots ,X_n^*\) are i.i.d. draws from the empirical distribution \(P_{n} = n^{-1} \sum _{i=1}^n \delta _{X_i}\) and \(V_n(h) = n^{-r} \sum _{i_{1},\ldots ,i_{r}=1}^{n} h(X_{i_1},\ldots ,X_{i_{r}})\) is the V-statistic associated with kernel h (cf. [5, 6, 11]). A slightly different bootstrap procedure
is proposed in [3]; see Remark 2.7 therein. If \({\mathcal {H}}= \{h\}\) is a singleton and the associated U-statistic \(U_{n}(h)\) is non-degenerate, then \({\mathbb {U}}_{n}^{\natural }(h)\) and \({\mathbb {U}}_n^*(h)\) are asymptotically equivalent in the sense that they have the same weak limit that is given by the centered Gaussian random variable \(W_{P}(P^{r-1}h)\); see Theorem 2.4 and Corollary 2.6 in [3]. Since the bootstrap \({\mathbb {U}}_{n}^{\natural }(h)\) can be viewed as the empirical bootstrap applied to a V-statistic estimate of the Hájek projection, i.e., \({\mathbb {U}}_{n}^{\natural }(h) =n^{-1/2} \sum _{i=1}^{n} (\delta _{X_{i}^{*}} - P_{n}) P_{n}^{r-1} h\), our JMB is connected to (but still different from) \({\mathbb {U}}_{n}^{\natural }(h)\) in the sense that we apply the multiplier bootstrap to a jackknife U-statistic estimate of the Hajek projection. Another example is the Bayesian bootstrap (with Dirichlet weights)
where \(w_{i} = \eta _{i} / (n^{-1} \sum _{j=1}^n \eta _{j})\) for \(i=1,\dots ,n\) and \(\eta _1,\dots ,\eta _n\) are i.i.d. exponential random variables with mean one (i.e., \((w_{1},\dots ,w_{n})\) follows a scaled Dirichlet distribution) independent of \(X_{1}^{n} = \{ X_{1},\dots ,X_{n} \}\) [39, 40, 48, 56]. If \({\mathcal {H}}\) is a fixed VC type function class and the distribution P is independent of n (hence the distribution of the approximating Gaussian process \(W_{P}\) is independent of n), then the conditional distributions (given \(X_1^n\)) of the empirical bootstrap process \(\{{\mathbb {U}}_n^*(h) : h \in {\mathcal {H}}\}\) and the Bayesian bootstrap process \(\{{\mathbb {U}}_n^\flat (h) : h \in {\mathcal {H}}\}\) (with Dirichlet weights) are known to have the same weak limit as the U-process \(\{r^{-1} {\mathbb {U}}_n(h) : h \in {\mathcal {H}}\}\), where the weak limit is the Gaussian process \(W_{P} \circ P^{r-1}\) in the non-degenerate case [5, 56]. The proposed multiplier process in (7) is also connected to the empirical and Baysian bootstraps (or more general randomly reweighted bootstraps) in the sense that the latter two bootstraps also implicitly construct an empirical process whose conditional covariance function is close to that of \(W_P\) under the supremum norm (cf. [11]). Recall that the conditional covariance function of \({\mathbb {U}}_n^\sharp \) can be viewed as a jackknife estimate of the covariance function of \(W_P\). For the special case where \(r = 2\) and \({\mathcal {H}}= {\mathcal {H}}_n\) is such that \(|{\mathcal {H}}_n| < \infty \) and \(|{\mathcal {H}}_n|\) is allowed to increase with n, [11] shows that the Gaussian multiplier, empirical and randomly reweighted bootstraps (\({\mathbb {U}}_n^\flat (h)\) with i.i.d. Gaussian weights \(w_i \sim N(1,1)\)) all achieve similar error bounds. In the U-process setting, it would be possible to establish finite sample validity for the empirical and more general randomly reweighted bootstraps, but this is at the price of a much more involved technical analysis which we do not pursue in the present paper.
4 Applications: testing for qualitative features based on generalized local U-processes
In this section, we discuss applications of the general results in the previous sections to generalized localU-processes, which are motivated from testing for qualitative features of functions in nonparametric statistics (see below for concrete statistical problems).
Let \(m \geqslant 1, r \geqslant 2\) be fixed integers and let \({\mathcal {V}}\) be a separable metric space. Suppose that \(n \geqslant r+1\), and let \(D_{i} = (X_{i},V_{i}), i=1,\dots ,n\) be i.i.d. random variables taking values in \({\mathbb {R}}^m \times {\mathcal {V}}\) with joint distribution P defined on the product \(\sigma \)-field on \({\mathbb {R}}^{m} \times {\mathcal {V}}\) (we equip \({\mathbb {R}}^{m}\) and \({\mathcal {V}}\) with the Borel \(\sigma \)-fields). The variable \(V_{i}\) may include some components of \(X_{i}\). Let \(\Phi \) be a class of symmetric measurable functions \(\varphi :{\mathcal {V}}^r \rightarrow {\mathbb {R}}\), and let \(L: {\mathbb {R}}^{m} \rightarrow {\mathbb {R}}\) be a (fixed) “kernel function”, i.e., an integrable function on \({\mathbb {R}}^{m}\) (with respect to the Lebesgue measure) such that \(\int _{{\mathbb {R}}^{m}} L(x)dx = 1\). For \(b > 0\) (“bandwidth”), we use the notation \(L_{b} (\cdot ) = b^{-m}L(\cdot /b)\). For a given sequence of bandwidths \(b_{n} \rightarrow 0\), let
where \({\mathcal {X}}\subset {\mathbb {R}}^{m}\) is a (nonempty) compact subset. Consider the U-process
which we call, following [27], the generalized localU-process. The indexing function class is \(\{ h_{n,\vartheta } : \vartheta \in \Theta \}\) which depends on the sample size n. The U-process \(U_{n}(h_{n,\vartheta })\) can be seen as a process indexed by \(\Theta \), but in general is not weakly convergent in the space \(\ell ^{\infty }(\Theta )\), even after a suitable normalization (an exception is the case where \({\mathcal {X}}\) and \(\Phi \) are finite sets, and in that case, under regularity conditions, the vector \(\{\sqrt{nb_{n}^{m}} (U_{n}(h_{n,\vartheta }) - P^{r}h_{n,\vartheta }) \}_{\vartheta \in \Theta }\) converges weakly to a multivariate normal distribution). In addition, we will allow the set \(\Theta \) to depend on n.
We are interested in approximating the distribution of the normalized version of this process
where \(c_{n}(\vartheta ) > 0\) is a suitable normalizing constant. The goal of this section is to characterize conditions under which the JMB developed in the previous section is consistent for approximating the distribution of \(S_{n}\) (more generally we will allow the normalizing constant \(c_{n}(\vartheta )\) to be data-dependent). There are a number of statistical applications where we are interested in approximating distributions of such statistics. We provide a couple of examples. All the test statistics discussed in Examples in 4.1 and 4.2 are covered by our general framework. In Examples 4.1 and 4.2, \(\alpha \in (0,1)\) is a nominal level.
Example 4.1
(Testing stochastic monotonicity) Let X, Y be real-valued random variables and denote by \(F_{Y \mid X}(y \mid x)\) the conditional distribution function of Y given X. Consider the problem of testing the stochastic monotonicity
Testing for the stochastic monotonicity is an important topic in a variety of applied fields such as economics [7, 23, 52]. For this problem, [38] consider a test for \(H_0\) based on a local Kendall’s tau statistic, inspired by [25]. Let \((X_{i},Y_{i}), i=1,\dots ,n\) be i.i.d. copies of (X, Y). Lee et al. [38] consider the U-process
where \(b_n \rightarrow 0\) is a sequence of bandwidths and \(\mathrm {sign}(x) = 1(x > 0) - 1(x < 0)\) is the sign function. They propose to reject the null hypothesis if \(S_n = \sup _{(x,y) \in {\mathcal {X}}\times {\mathcal {Y}}} U_n(x, y)/c_n(x)\) is large, where \({\mathcal {X}},{\mathcal {Y}}\) are subsets of the supports of X, Y, respectively and \(c_n(x) > 0\) is a suitable normalizing constant. Lee et al. [38] argue that as far as the size control is concerned, it is enough to choose, as a critical value, the \((1-\alpha )\)-quantile of \(S_{n}\) when X, Y are independent, under which \(U_{n}(x,y)\) is centered. Under independence between X and Y, and under regularity conditions, they derive a Gumbel limiting distribution for a properly scaled version of \(S_{n}\) using techniques from [45], but do not consider bootstrap approximations to \(S_{n}\). It should be noted that [38] consider a slightly more general setup than that described above in the sense that they allow \(X_{i}\) not to be directly observed but assume that estimated \(X_{i}\) are available, and also cover the case where X is multidimensional.
Example 4.2
(Testing curvature and monotonicity of nonparametric regression) Consider the nonparametric regression model \(Y = f(X) + \varepsilon \) with \({\mathbb {E}}[ \varepsilon \mid X] = 0\), where Y is a scalar outcome variable, X is an m-dimensional vector of regressors, \(\varepsilon \) is an error term, and f is the conditional mean function \(f(x) = {\mathbb {E}}[ Y \mid X=x]\). We observe i.i.d. copies \(V_{i} = (X_{i},Y_{i}), i=1,\dots ,n\) of \(V=(X,Y)\). We are interested in testing for qualitative features (e.g., curvature, monotonicity) of the regression function f.
Abrevaya and Jiang [1] consider a simplex statistic to test linearity, concavity, convexity of f under the assumption that the conditional distribution of \(\varepsilon \) given X is symmetric. To define their test statistics, for \(x_{1},\dots ,x_{m+1} \in {\mathbb {R}}^{m}\), let \(\Delta ^{\circ } (x_{1},\dots ,x_{m+1}) = \{ \sum _{i=1}^{m+1} a_{i} x_{i} : 0< a_{j} < 1, j=1,\dots ,m+1, \ \sum _{i=1}^{m+1}a_{i} = 1\}\) denote the interior of the simplex spanned by \(x_{1},\dots ,x_{m+1}\), and define \({\mathcal {D}}= \bigcup _{j=1}^{m+2} {\mathcal {D}}_{j}\), where
The sets \({\mathcal {D}}_{1},\dots ,{\mathcal {D}}_{m+2}\) are disjoint. For given \(v_{i}=(x_{i},y_{i}) \in {\mathbb {R}}^{m} \times {\mathbb {R}}, i=1,\dots ,m+2\), if \((x_{1},\dots ,x_{m+2}) \in {\mathcal {D}}\) then there exist a unique index \(j=1,\dots ,m+2\) and a unique vector \((a_{i})_{1 \leqslant i \leqslant m+2,i \ne j}\) such that \(0< a_{i} < 1\) for all \(i \ne j, \sum _{i \ne j} a_{i}=1\), and \(x_{j}=\sum _{i \ne j} a_{i} x_{i}\); then, define \(w(v_{1},\dots ,v_{m+2}) = \sum _{i \ne j} a_{i} y_{i} - y_{j}\). The index j and vector \((a_{i})_{1 \leqslant i \leqslant m+2,i \ne j}\) are functions of \(x_{i}\)’s. The set \({\mathcal {D}}\) is symmetric (i.e., its indicator function is symmetric) and \(w(v_{1},\dots ,v_{m+2})\) is symmetric in its arguments.
Under this notation, [1] consider the following localized simplex statistic
where \(\varphi (v_1, \dots , v_{m+2}) = 1\{(x_1,\dots ,x_{m+2}) \in {\mathcal {D}}\} \mathrm {sign}(w(v_1,\dots ,v_{m+2}))\), which is a U-process of order \((m+2)\). To test concavity and convexity of f, [1] propose to reject the hypotheses if \({\overline{S}}_n = \sup _{x \in {\mathcal {X}}} U_n(x)/c_n(x)\) and \({\underline{S}}_n = \inf _{x \in {\mathcal {X}}} U_n(x)/c_n(x)\) are large and small, respectively, where \({\mathcal {X}}\) is a subset of the support of X and \(c_n(x) > 0\) is a suitable normalizing constant. The infimum statistic \({\underline{S}}_n\) can be written as the supremum of a U-process by replacing \(\varphi \) with \(-\varphi \), so we will focus on \({\overline{S}}_{n}\). Precisely speaking, they consider to take discrete deign points \(x_{1},\dots ,x_{G}\) with \(G = G_{n} \rightarrow \infty \), and take the supremum or infimum on the discrete grids \(\{ x_{1},\dots ,x_{G} \}\). Abrevaya and Jiang [1] argue that as far as the size control is concerned, it is enough to choose, as a critical value, the \((1-\alpha )\)-quantile of \({\overline{S}}_{n}\) when f is linear, under which \(U_{n}(x)\) is centered due to the symmetry assumption on the distribution of \(\varepsilon \) conditionally on X. Under linearity of f, [1, Theorem 6] claims to derive a Gumbel limiting distribution for a properly scaled version of \({\overline{S}}_{n}\), but the authors think that their proof needs a further justification. The proof of Theorem 6 in [1] proves that, in their notation, the marginal distributions of \({\widetilde{U}}_{n,h}(x_{g}^*)\) converge to N(0, 1) uniformly in \(g =1,\dots ,G\) (see their equation (A.1)), and the covariances between \({\widetilde{U}}_{n,h}(x_{g}^*)\) and \({\widetilde{U}}_{n,h}(x_{g'}^*)\) for \(g \ne g'\) are approaching zero faster than the variances, but what they need to show is that the joint distribution of \(({\widetilde{U}}_{n,h}(x_{1}^*),\dots ,{\widetilde{U}}_{n,h}(x_{G}^*))\) is approximated by \(N(0,I_{G})\) in a suitable sense, which is lacking in their proof. An alternative proof strategy is to apply Rio’s coupling [47] to the Hájek process associated to \(U_{n}\), but it seems non-trivial to apply Rio’s coupling since it is non-trivial to verify that the function \(\varphi \) is of bounded variation.
On the other hand, [25] study testing monotonicity of f when \(m=1\) and \(\varepsilon \) is independent of X. Specifically, they consider testing whether f is increasing, and propose to reject the hypothesis if \(S_{n} = \sup _{x \in {\mathcal {X}}} {\check{U}}_{n}(x)/c_{n}(x)\) is large, where \({\mathcal {X}}\) is a subset of the support of X,
and \(c_{n}(x) > 0\) is a suitable normalizing constant. Ghosal et al. [25] argue that as far as the size control is concerned, it is enough to choose, as a critical value, the \((1-\alpha )\)-quantile of \(S_{n}\) when \(f \equiv 0\), under which \(U_{n}(x)\) is centered. Under \(f \equiv 0\) and under regularity conditions, [25] derive a Gumbel limiting distribution for a properly scaled version of \(S_{n}\) but do not study bootstrap approximations to \(S_{n}\).
In Appendix F, we discuss some alternative tests in the literature for concavity/convexity and monotonicity of regression functions.
Now, we go back to the general case. In applications, a typical choice of the normalizing constant \(c_{n}(\vartheta )\) is \(c_n(\vartheta ) = b_{n}^{m/2} \sqrt{\mathrm {Var}_{P}(P^{r-1}h_{n,\vartheta })}\) where \(\mathrm {Var}_{P}(\cdot )\) denotes the variance under P, so that each \(b_{n}^{m/2} c_{n}(\vartheta )^{-1}P^{r-1}h_{n,\vartheta }\) is normalized to have unit variance, but other choices (such as \(c_{n}(\vartheta ) \equiv 1\)) are also possible. The choice \(c_n(\vartheta ) = b_{n}^{m/2} \sqrt{\mathrm {Var}_{P}(P^{r-1}h_{n,\vartheta })}\) depends on the unknown distribution P and needs to be estimated in practice. Suppose in general (i.e., \(c_n(\vartheta )\) need not to be \(b_{n}^{m/2} \sqrt{\mathrm {Var}_{P}(P^{r-1}h_{n,\vartheta })}\)) that there is an estimator \({\widehat{c}}_{n}(\vartheta ) = {\widehat{c}}_{n}(\vartheta ; D_{1}^{n}) > 0\) for \(c_{n}(\vartheta )\) for each \(\vartheta \in \Theta \), and instead of original \(S_{n}\), consider
We consider to approximate the distribution of \({\widehat{S}}_{n}\) by the conditional distribution of the JMB analogue of \({\widehat{S}}_{n}\): \({\widehat{S}}_{n}^{\sharp } := \sup _{\vartheta \in \Theta } b_{n}^{m/2}{\mathbb {U}}_{n}^{\sharp }(h_{n,\vartheta })/{\widehat{c}}_{n}(\vartheta )\), where
and \(\xi _{1},\dots ,\xi _{n}\) are i.i.d. N(0, 1) random variables independent of \(D_{1}^{n} = \{ D_{i} \}_{i=1}^{n}\). Recall that for a function f on \(({\mathbb {R}}^{m} \times {\mathcal {V}})^{r-1}\), \(U_{n-1,-i}^{(r-1)}(f)\) denotes the U-statistic with kernel f for the sample without the i-th observation, i.e., \(U_{n-1,-i}^{(r-1)} (f) = |I_{n-1,r-1}|^{-1} \sum _{(i,i_{2},\dots ,i_{r}) \in I_{n,r}} f(D_{i_{2}},\dots ,D_{i_{r}})\).
Let \(\zeta , c_{1},c_{2}\), and \(C_{1}\) be given positive constants such that \(C_{1} >1\) and \(c_{2} \in (0,1)\), and let \(q \in [4,\infty ]\). Denote by \({\mathcal {X}}^{\zeta }\) the \(\zeta \)-enlargement of \({\mathcal {X}}\), i.e., \({\mathcal {X}}^{\zeta } := \{ x \in {\mathbb {R}}^{m} : \inf _{x' \in {\mathcal {X}}} | x - x' | \leqslant \zeta \}\) where \(|\cdot |\) denotes the Euclidean norm. Let \(\mathrm {Cov}_{P}(\cdot ,\cdot )\) and \(\mathrm {Var}_{P}(\cdot )\) denote the covariance and variance under P, respectively. For the notational convenience, for arbitrary r variables \(d_{1},\dots ,d_{r}\), we use the notation \(d_{k:\ell } = (d_{k},d_{k+1},\dots ,d_{\ell })\) for \(1 \leqslant k \leqslant \ell \leqslant r\). We make the following assumptions.
- (T1)
Let \({\mathcal {X}}\) be a non-empty compact subset of \({\mathbb {R}}^{m}\) such that its diameter is bounded by \(C_{1}\).
- (T2)
The random vector X has a Lebesgue density \(p(\cdot )\) such that \(\Vert p \Vert _{{\mathcal {X}}^{\zeta }} \leqslant C_{1}\).
- (T3)
Let \(L:{\mathbb {R}}^{m} \rightarrow {\mathbb {R}}\) be a continuous kernel function supported in \([-1,1]^m\) such that the function class \({\mathfrak {L}} := \{ x \mapsto L(ax+b) : a \in {\mathbb {R}}, b \in {\mathbb {R}}^{m} \}\) is VC type for envelope \(\Vert L \Vert _{{\mathbb {R}}^{m}} = \sup _{x \in {\mathbb {R}}^{m}}|L(x)|\).
- (T4)
Let \(\Phi \) be a pointwise measurable class of symmetric functions \({\mathcal {V}}^r \rightarrow {\mathbb {R}}\) that is VC type with characteristics (A, v) for a finite and symmetric envelope \({\overline{\varphi }} \in L^{q}(P^{r})\) such that \(\log A \leqslant C_{1}\log n\) and \(v \leqslant C_{1}\). In addition, the envelope \({\overline{\varphi }}\) satisfies that \(( {\mathbb {E}}[ {\overline{\varphi }}^{q} (V_{1:r}) \mid X_{1:r}=x_{1:r}] )^{1/q} \leqslant C_{1}\) for all \(x_{1:r} \in {\mathcal {X}}^{\zeta } \times \cdots \times {\mathcal {X}}^{\zeta }\) if q is finite, and \(\Vert {\overline{\varphi }} \Vert _{P^{r},\infty } \leqslant C_{1}\) if \(q=\infty \)
- (T5)
\(nb_{n}^{3mq/[2(q-1)]} \geqslant C_{1}n^{c_{2}}\) with the convention that \(q/(q-1) = 1\) when \(q=\infty \), and \(2m(r-1)b_{n} \leqslant \zeta /2\).
- (T6)
\(b_{n}^{m/2}\sqrt{\mathrm {Var}_{P} (P^{r-1}h_{n,\vartheta })} \geqslant c_{1}\) for all n and \(\vartheta \in \Theta \).
- (T7)
\(c_{1} \leqslant c_{n}(\vartheta ) \leqslant C_{1}\) for all n and \(\vartheta \in \Theta \). For each fixed n, if \(x_{k} \rightarrow x\) in \({\mathcal {X}}\) and \(\varphi _{k} \rightarrow \varphi \) pointwise in \(\Phi \), then \(c_{n}(x_{k},\varphi _{k}) \rightarrow c_{n}(x,\varphi )\).
- (T8)
With probability at least \(1-C_{1}n^{-c_{2}}\), \(\sup _{\vartheta \in \Theta } \left| \frac{{\widehat{c}}_n(\vartheta )}{c_n(\vartheta )}- 1\right| \leqslant C_1 n^{-c_2}\).
Some comments on the conditions are in order. Condition (T1) allows the set \({\mathcal {X}}\) to depend on n, i.e., \({\mathcal {X}}= {\mathcal {X}}_{n}\), but its diameter is bounded (by \(C_{1}\)). For example, \({\mathcal {X}}\) can be discrete grids whose cardinality increases with n but its diameter must be bounded (an implicit assumption here is that the dimension m is fixed; in fact the constants appearing in the following results depend on the dimension m, so that m should be considered as fixed). Condition (T2) is a mild restriction on the density of X. It is worth mentioning that V may take values in a generic measurable space, and even if V takes values in a Euclidean space, V need not be absolutely continuous with respect to the Lebesgue measure (we will often omit the qualification “with respect to the Lebesgue measure”). In Examples 4.1 and 4.2, the variable V consists of the pair of regressor vector and outcome variable, i.e., \(V=(X, Y)\) with Y being real-valued, and our conditions allow the distribution of Y to be generic. In contrast, [25, 38] assume that the joint distribution of X and Y have a continuous density (or at least they require the distribution function of Y to be continuous) and thereby ruling out the case where the distribution of Y has a discrete component. This is essentially because they rely on Rio’s coupling [47] when deriving limiting null distributions of their test statistics. Rio’s coupling is a powerful KMT [36] type strong approximation result for general empirical processes, but requires the underlying distribution to be defined on a hyper-cube and to have a density bounded away from zero on the hyper-cube. In contrast, our analysis is conditional on X and we only require some moment conditions and VC type conditions on the function class. Thus our JMB does not require Y to have a density for its validity and thereby having a wider applicability in this respect.
Condition (T3) is a standard regularity condition on kernel functions L. Sufficient conditions under which \({\mathfrak {L}}\) is VC type are found in [28, 29, 43]. Condition (T4) allows the envelope \({\overline{\varphi }}\) to be unbounded. Condition (T4) allows the function class \(\Phi \) to depend on n, as long as the VC characteristics A and v satisfy that \(\log A \leqslant C_{1}\log n\) and \(v \leqslant C_{1}\). For example, \(\Phi \) can be a discrete set whose cardinality is bounded by \(Cn^{c}\) for some constants \(c,C>0\). Condition (T5) relaxes bandwidth requirements in [25, 38] where \(m = 1\) and \(q = \infty \). For example, [25] assume \(n b_n^2 /(\log n)^{4} \rightarrow \infty \) and \(b_n \log n \rightarrow 0\) for size control. For the problem of testing for regression/stochastic monotonicity of univariate functions, our test statistic is of order \(r=2\). If we choose a bounded kernel (such as the sign kernel), then we only need \(n^{-2/3+c} \lesssim b_{n} \lesssim 1\) for some small constant \(c > 0\). Further, our general theory allows us to develop a version of the JMB that is uniformly valid in compact bandwidth sets, which can be used to develop versions of tests that are valid with data-dependent bandwidths in Examples 4.1 and 4.2; see Sect. 4.1 ahead for details.
Condition (T6) is a high-level condition and implies the U-process to be non-degenerate. Let \(\varphi _{[r-1]}(v_{1},x_{2:r}) := {\mathbb {E}}[\varphi (v_{1},V_{2:r}) \mid X_{2:r}=x_{2:r}] \prod _{j=2}^{r} p(x_{j})\), and observe that
for \(\vartheta = (x,\varphi )\), where \(x-b_{n}x_{2:r}= (x-b_{n}x_{2},\dots ,x-b_{n}x_{r})\). From this expression, in applications, it is not difficult to find primitive regularity conditions that guarantee Condition (T6). To keep the presentation concise, however, we assume Condition (T6).
Condition (T7) is concerned with the normalizing constant \(c_{n}(\vartheta )\). For the special case where \(c_n(\vartheta ) = b_{n}^{m/2} \sqrt{\mathrm {Var}_{P}(P^{r-1}h_{n,\vartheta })}\), Condition (T7) is implied by Conditions (T4) and (T6). Condition (T8) is also a high-level condition, which together with (T7) implies that there is a uniformly consistent estimate \({\widehat{c}}_{n}(\vartheta )\) of \(c_{n}(\vartheta )\) in \(\Theta \) with polynomial error rates. Construction of \({\widehat{c}}_{n}(\vartheta )\) is quite flexible: for \(c_{n}(\vartheta ) = b_{n}^{m/2} \sqrt{\mathrm {Var}_{P}(P^{r-1}h_{n,\vartheta })}\), one natural example is the jackknife estimate
The following lemma verifies that the jackknife estimate (13) obeys Condition (T8) for \(c_{n}(\vartheta ) = b_{n}^{m/2} \sqrt{\mathrm {Var}_{P}(P^{r-1}h_{n,\vartheta })}\). However, it should be noted that other estimates for this normalizing constant are possible depending on applications of interest; see [1, 25, 38].
Lemma 4.1
(Estimation error of the normalizing constant) Suppose that Conditions (T1)–(T7) hold. Let \(c_{n}(\vartheta ) = b_{n}^{m/2} \sqrt{\mathrm {Var}_{P}(P^{r-1}h_{n,\vartheta })}, \vartheta \in \Theta \) and \({\widehat{c}}_{n}(\vartheta )\) be defined in (13). Then there exist constants c, C depending only on \(r, m, \zeta , c_{1},c_{2}, C_{1}, L\) such that
Now, we are ready to state finite sample validity of the JMB for approximating the distribution of the supremum of the generalized local U-process.
Theorem 4.2
(JMB validity for the supremum of a generalized local U-process) Suppose that Conditions (T1)–(T8) hold. Then there exist constants c, C depending only on \(r, m, \zeta , c_{1},c_{2}, C_{1}, L\) such that the following holds: for every n, there exists a tight Gaussian random variable \(W_{P,n}(\vartheta ), \vartheta \in \Theta \) in \(\ell ^{\infty }(\Theta )\) with mean zero and covariance function
for \(\vartheta , \vartheta ' \in \Theta \), and it follows that
where \({\widetilde{S}}_{n}:=\sup _{\vartheta \in \Theta }W_{P,n}(\vartheta )\).
Theorem 4.2 leads to the following corollary, which is another form of validity of the JMB. For \(\alpha \in (0,1)\), let \(q_{{\widehat{S}}_{n}^\sharp }(\alpha ) = q_{{\widehat{S}}_{n}^\sharp }(\alpha ; D_{1}^{n})\) denote the conditional \(\alpha \)-quantile of \({\widehat{S}}_{n}^\sharp \) given \(D_{1}^{n}\), i.e., \(q_{{\widehat{S}}_{n}^\sharp } (\alpha ) = \inf \left\{ t \in {\mathbb {R}}: {\mathbb {P}}_{\mid D_{1}^{n}} ({\widehat{S}}_{n}^\sharp \leqslant t) \geqslant \alpha \right\} \).
Corollary 4.3
(Size validity of the JMB test) Suppose that Conditions (T1)–(T8) hold. Then there exist constants c, C depending only on \(r, m, \zeta , c_{1},c_{2}, C_{1}, L\) such that
4.1 Uniformly valid JMB test in bandwidth
A version of Theorem 4.2 continues to hold even if we additionally take the supremum over a set of possible bandwidths. For a given bandwidth \(b \in (0,1)\), let
and for a given candidate set of bandwidths \({\mathcal {B}}_n \subset [{\underline{b}}_n, {\overline{b}}_n]\) with \(0< {\underline{b}}_n \leqslant {\overline{b}}_n < 1\), consider
where \(c_{n}(\vartheta ,b) > 0\) is a suitable normalizing constant and \({\widehat{c}}(\vartheta ,b) > 0\) is an estimate of \(c(\vartheta ,b)\). Following a similar argument used in the proof of Theorem 4.2, we are able to derive a version of the JMB test that is also valid uniformly in bandwidth, which opens new possibilities to develop tests that are valid with data-dependent bandwidths in Examples 4.1 and 4.2. For related discussions, we refer the readers to Remark 3.2 in [38] for testing stochastic monotonicity and [22] for kernel type estimators.
Consider the JMB analogue of \({\widehat{S}}_{n}\):
Let \(\kappa _{n} = {\overline{b}}_n / {\underline{b}}_n\) denote the ratio of the largest and smallest possible values in the bandwidth set \({\mathcal {B}}_{n}\), which intuitively quantifies the size of \({\mathcal {B}}_{n}\). To ease the notation and to facilitate comparisons, we only consider \(q = \infty \). We make the following assumptions instead of Conditions (T5)–(T8).
- (T5\('\)):
\(n {\underline{b}}_{n}^{3m/2} \geqslant C_1 n^{c_2} \kappa _{n}^{m(r-2)}\), \(\kappa _{n} \leqslant C_1 {\underline{b}}_{n}^{-1/(2r)}\), and \(2m(r-1){\overline{b}}_{n} \leqslant \zeta /2\).
- (T6\('\)):
\(b^{m/2}\sqrt{\mathrm {Var}_{P} (P^{r-1}h_{\vartheta ,b})} \geqslant c_{1}\) for all n and \((\vartheta , b) \in \Theta \times {\mathcal {B}}_{n}\).
- (T7\('\)):
\(c_{1} \leqslant c_{n}(\vartheta ,b) \leqslant C_{1}\) for all n and \((\vartheta , b) \in \Theta \times {\mathcal {B}}_{n}\). For each fixed n, if \(x_{k} \rightarrow x\) in \({\mathcal {X}}\), \(\varphi _{k} \rightarrow \varphi \) pointwise in \(\Phi \), and \(b_k \rightarrow b\) in \({\mathcal {B}}_n\), then \(c_{n}(x_{k},\varphi _{k}, b_{k}) \rightarrow c_{n}(x,\varphi ,b)\).
- (T8\('\)):
With probability at least \(1 - C_1 n^{-c_2}\), \(\sup _{(\vartheta , b) \in \Theta \times {\mathcal {B}}_{n}} \left| \frac{{\widehat{c}}_n(\vartheta ,b)}{c_n(\vartheta ,b)} - 1\right| \leqslant C_1 n^{-c_2}\).
Theorem 4.4
(Bootstrap validity for the supremum of a generalized local U-process: uniform-in-bandwidth result) Suppose that Conditions (T1)–(T4) with \(q=\infty \), and Conditions (T5\('\))–(T8\('\)) hold. Then there exist constants c, C depending only on \(r, m, \zeta , c_{1},c_{2}, C_{1}, L\) such that the following holds: for every n, there exists a tight Gaussian random variable \(W_{P,n}(\vartheta ,b), (\vartheta , b) \in \Theta \times {\mathcal {B}}_n\) in \(\ell ^{\infty }(\Theta \times {\mathcal {B}}_n)\) with mean zero and covariance function
for \((\vartheta ,b), (\vartheta ',b') \in \Theta \times {\mathcal {B}}_{n}\), and the result (15) continues to hold with \({\widetilde{S}}_{n}:=\sup _{(\vartheta , b) \in \Theta \times {\mathcal {B}}_n}W_{P,n}(\vartheta ,b)\).
If \({\underline{b}}_{n} = {\overline{b}}_{n} = b_n\) (i.e., \({\mathcal {B}}_{n} = \{b_n\}\) is a singleton set), then Conditions (T5\('\))–(T8\('\)) reduce to (T5)–(T8) and Theorem 4.4 covers Theorem 4.2 with \(q = \infty \) as a special case. Condition (T5\('\)) states that the size of the bandwidth set \({\mathcal {B}}_{n}\) cannot be too large. Conditions (T6\('\))–(T8\('\)) are completely parallel with Conditions (T6)–(T8). Such “uniform-in-bandwidth” type results are not covered in [1, 25, 38].
4.2 A simulation study on testing for monotonicity of regression
We provide a numerical example to verify the size validity of the JMB test for monotonicity of regression in Example 4.2. We generate i.i.d. univariate covariates \(X_{1},\dots ,X_{n}\) from the uniform distribution on [0, 1] and consider the zero regression function \(f \equiv 0\) (which implies that the covariate X and the response Y are stochastically independent). As argued in [25], \(f \equiv 0\) is the hardest case in terms of size control under the null hypothesis \(H_{0} : f \text{ is } \text{ increasing } \text{ on } [0,1]\). We consider two error distributions: (i) Gaussian distribution \(\varepsilon _{i} \sim N(0, 0.1^{2})\); (ii) (scaled) Rademacher distribution \({\mathbb {P}}(\varepsilon _{i} = \pm 0.1) = 1/2\). For both error distributions, the (unnormalized) U-process \({\check{U}}_{n}(x)\) defined in (12) has mean zero (i.e., \({\mathbb {E}}[{\check{U}}_{n}(x)] = 0\) for all \(x \in [0,1]\)). The Rademacher distribution is not covered in [25]. We use the Epanechnikov kernel \(L(x) = 0.75(1-x^{2})\) for \(x \in [-1,1]\) and \(L(x) = 0\) otherwise, together with bandwidth parameter \(b_{n} = n^{-1/5}\). We consider three sample sizes \(n=100,200,500\). For each setup, we generate 2000 bootstrap samples. We consider test of the form
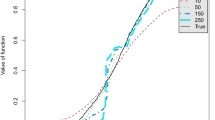
where \({\widehat{c}}_{n}(x)\) is given in (13) and the critical value q is calibrated by the JMB. In particular, for any nominal size \(\alpha \in (0, 1)\), the value of \(q := q(\alpha )\) is chosen as the \((1-\alpha )\)-th conditional quantile of the JBM. Empirical rejection probability of the JMB test is obtained by averaging over 5000 simulations. We observe that the empirical rejection probability is close to the nominal size of the JMB test. Table 1 shows the proportion of rejections at the nominal sizes \(\alpha =0.05, 0.10\), and Fig. 1 shows the JMB approximation of the proportion of rejections uniformly in \(\alpha \in (0, 1)\).

JMB approximation of sizes of the regression monotonicity test. Top row: Gaussian errors. Bottom row: Rademacher errors
5 Local maximal inequalities for U-processes
In this section, we prove local maximal inequalities for U-processes, which are of independent interest and can be useful for other applications. These multi-resolution local maximal inequalities are key technical tools in proving the results stated in the previous sections.
We first review some basic terminologies and facts about U-processes. For a textbook treatment on U-processes, we refer to [18]. Let \(r \geqslant 1\) be a fixed integer and let \(X_{1},\dots ,X_{n}\) be i.i.d. random variables taking values in a measurable space \((S,{\mathcal {S}})\) with common distribution P.
Definition 5.1
(Kernel degeneracy; Definition 3.5.1 in [18]) A symmetric measurable function \(f: S^{r} \rightarrow {\mathbb {R}}\) with \(P^{r}f=0\) is said to be degenerate of order k with respect to P if \(P^{r-k}f(x_{1},\dots ,x_{k}) = 0\) for all \(x_{1},\dots ,x_{k} \in S\). In particular, f is said to be completely degenerate if f is degenerate of order \(r-1\), and f is said to be non-degenerate if f is not degenerate of any positive order.
Let \({\mathcal {F}}\) be a class of symmetric measurable functions \(f: S^{r} \rightarrow {\mathbb {R}}\). We assume that there is a symmetric measurable envelope F for \({\mathcal {F}}\) such that \(P^{r}F^{2} < \infty \). Furthermore, we assume that each \(P^{r-k}F\) is everywhere finite. Consider the associated U-process
For each \(k=1,\dots ,r\), the Hoeffding projection (with respect to P) is defined by
The Hoeffding projection \(\pi _k f\) is a completely degenerate kernel of k variables. Then, the Hoeffding decomposition of \(U_{n}^{(r)}(f)\) is given by
In what follows, let \(\sigma _{k}\) be any positive constant such that \(\sup _{f \in {\mathcal {F}}} \Vert P^{r-k}f \Vert _{P^{k},2} \leqslant \sigma _{k} \leqslant \Vert P^{r-k}F \Vert _{P^{k},2}\) whenever \(\Vert PF^{r-k} \Vert _{P^{k},2} > 0\) (take \(\sigma _{k} = 0\) when \(\Vert P^{r-k} F \Vert _{P^{k},2} = 0\)), and let
where \(X_{(i-1)k+1}^{ik} = (X_{(i-1)k+1},\dots ,X_{ik})\).
We will assume certain uniform covering number conditions for the function class \({\mathcal {F}}\). For \(k=1,\dots ,r\), define the uniform entropy integral
where \(P^{r-k}{\mathcal {F}}= \{ P^{r-k}f : f \in {\mathcal {F}}\}\) and \(\sup _{Q}\) is taken over all finitely discrete distributions on \(S^k\). We note that \(P^{r-k}F\) is an envelope for \(P^{r-k}{\mathcal {F}}\). To avoid measurablity difficulties, we will assume that \({\mathcal {F}}\) is pointwise measurable. If \({\mathcal {F}}\) is pointwise measurable and \(P^{r} F < \infty \) (which we have assumed) then \(\pi _{k}{\mathcal {F}}:= \{ \pi _{k} f : f \in {\mathcal {F}}\}\) and \(P^{r-k}{\mathcal {F}}\) for \(k=1,\dots ,r\) are all pointwise measurable by the dominated convergence theorem.
Let \(\varepsilon _{1},\dots ,\varepsilon _{n}\) be i.i.d. Rademacher random variables such that \({\mathbb {P}}(\varepsilon _{i}=\pm 1)=1/2\). A real-valued Rademacher chaos variable of order k, X, is a polynomial of order k in the Rademacher random variables \(\varepsilon _{i}\) with real coefficients, i.e.,
where \(a, a_{i}, a_{i_{1} i_{2}}, \dots , a_{i_{1} \dots i_{k}} \in {\mathbb {R}}\). If only the monomials of degree k in the variables \(\varepsilon _{i}\) in X are not zero, then X is a homogeneous Rademacher chaos of order k; see Section 3.2 in [18].
Definition 5.2
(Rademacher chaos process of orderk; page 220 in [18]) A stochastic process \(X(t), t \in T\) is said to be a Rademacher chaos process of order k if for all \(s, t \in T\), the joint law of (X(s), X(t)) coincides with the joint law of two (not necessarily homogeneous) Rademacher chaos variables of order k.
In the remainder of this section, the notation \(\lesssim \) signifies that the left hand side is bounded by the right hand side up to a constant that depends only on r. Recall that \(\Vert \cdot \Vert _{{\mathcal {F}}} = \sup _{f \in {\mathcal {F}}} | \cdot |\).
Theorem 5.1
(Local maximal inequalities for U-processes) Suppose that \({\mathcal {F}}\) is poinwise measurable and that \(J_{k}(1) < \infty \) for \(k=1,\dots ,r\). Let \(\delta _{k} =\sigma _{k}/ \Vert P^{r-k} F \Vert _{P^{k},2}\) for \(k=1,\dots ,r\). Then
for every \(k=1,\dots ,r\). If \(\Vert P^{r-k} F \Vert _{P^{k},2} = 0\), then the right hand side is interpreted as 0.
The proof of Theorem 5.1 relies on the following lemma on the uniform entropy integrals.
Lemma 5.2
(Properties of the maps \(\delta \mapsto J_k(\delta )\)) Assume that \(J_{k} (1) < \infty \) for \(k=1,\dots ,r\). Then, the following properties hold for every \(k=1,\dots ,r\). (i) The map \(\delta \mapsto J_k(\delta )\) is non-decreasing and concave. (ii) For \(c \geqslant 1\), \(J_k(c \delta ) \leqslant c J_k(\delta )\). (iii) The map \(\delta \mapsto J_k(\delta ) / \delta \) is non-increasing. (iv) The map \((x,y) \mapsto J_k(\sqrt{x/y}) \sqrt{y}\) is jointly concave in \((x,y) \in [0,\infty ) \times (0,\infty )\).
Proof of Lemma 5.2
The proof is almost identical to [14, Lemma A.2] and hence omitted. \(\square \)
Proof of Theorem 5.1
Pick any \(k=1,\dots ,r\). It suffices to prove (20) when \(\Vert P^{r-k} F \Vert _{P^{k},2} > 0\) since otherwise there is nothing to prove (recall that we have assumed that \(P^{r} F^{2} < \infty \), which ensures that \(\Vert P^{r-k} F\Vert _{P^{k},2} < \infty \)). Let \(\varepsilon _{1},\dots ,\varepsilon _n\) be i.i.d. Rademacher random variables independent of \(X_1^n\). In addition, let \(\{ X_{i}^{j} \}\) and \(\{ \varepsilon _{i}^{j} \}\) be independent copies of \(\{ X_{i} \}\) and \(\{ \varepsilon _{i} \}\). From the randomization theorem for U-processes [18, Theorem 3.5.3] and Jensen’s inequality, we have
Conditionally on \(X_{1}^{n}\),
is a (homogeneous) Rademacher chaos process of order k. Denote by \({\mathbb {P}}_{I_{n,k}} = |I_{n,k}|^{-1} \sum _{(i_1,\dots ,i_k) \in I_{n,k}} \delta _{(X_{i_{1}},\dots ,X_{i_{k}})}\) the empirical distribution on all possible k-tuples of \(X_1^n\); then Corollary 3.2.6 in [18] yields
where \(\Vert \cdot \Vert _{\psi _{2/k} \mid X_{1}^{n}}\) denotes the Orlicz (quasi-)norm associated with \(\psi _{2/k}(u) = e^{u^{2/k}} - 1\) evaluated conditionally on \(X_{1}^{n}\). The \(\Vert \cdot \Vert _{\psi _{2/k} \mid X_{1}^{n}}\)-diameter of the function class \( {\mathcal {F}}\) is at most \(2\sigma _{I_{n,k}}\) with \(\sigma _{I_{n,k}}^{2} := \sup _{f \in {\mathcal {F}}} \Vert P^{r-k} f \Vert _{{\mathbb {P}}_{I_{n,k}},2}^{2}\). So, since the first moment is bounded by the \(\psi _{2/k}\)-(quasi)norm up to a constant that depends only on k (and hence r), by Corollary 5.1.8 in [18] together with Fubini’s theorem and a change of variables, we have
The last inequality follows from the definition of \(J_{k}\). Since \(J_k(\sqrt{x/y}) \sqrt{y}\) is jointly concave in \((x,y) \in [0,\infty ) \times (0,\infty )\) by Lemma 5.2 (iv), Jensen’s inequality yields
We shall bound \({\mathbb {E}}[\sigma _{I_{n,k}}^{2}]\). To this end, we will use Hoeffding’s averaging [49, Section 5.1.6]. Let
Then, the U-statistic \(\Vert P^{r-k} f \Vert _{{\mathbb {P}}_{I_{n,k}},2}^{2} = |I_{n,k}|^{-1} \sum _{I_{n,k}} (P^{r-k}f)^{2}(X_{i_{1}},\dots ,X_{i_{k}})\) is the average of the variables \(S_{f,k}(X_{j_{1}},\dots ,X_{j_{n}})\) taken over all the permutations \(j_{1},\dots ,j_{n}\) of \(1,\dots ,n\). Hence,
by Jensen’s inequality, so that \(z \leqslant {\widetilde{z}} := \sqrt{B_{n,k} / \Vert P^{r-k}F \Vert _{P^{k},2}^2}\). Since the blocks \(X_{(i-1)k+1}^{ik}, i=1,\dots ,m\) are i.i.d.,
where (1) follows from the triangle inequality, (2) follows from the symmetrization inequality [53, Lemma 2.3.1], (3) follows from the contraction principle [29, Corollary 3.2.2], and (4) follows from the Cauchy–Schwarz inequality. By (a version of) the Hoffmann-Jørgensen inequality to the empirical process [53, Proposition A.1.6],
The analysis of the expectation on the right hand side is rather standard. From the first half of the proof of Theorem 5.2 in [14] (or repeating the first half of this proof with \(r=k=1\)), we have
Since the integral on the right hand side is bounded by \(J_{k}({\widetilde{z}})\), we have
Therefore, we conclude that
By Lemma 5.2 (i) and applying [54, Lemma 2.1] with \(J(\cdot )= J_k(\cdot ), r=1, A^2 = \Delta ^2\), and \(B^2 = \Vert M_k\Vert _{{\mathbb {P}},2} / (\sqrt{n} \Vert P^{r-k} F \Vert _{P^{k},2})\), we have
Combining (21) and (22), we arrive at
We note that \(\Delta \geqslant \delta _k\) and recall that \(\delta _{k} =\sigma _{k}/\Vert P^{r-k} F \Vert _{P^{k},2}\). Since the map \(\delta \mapsto J_k(\delta )/\delta \) is non-increasing by Lemma 5.2 (iii), we have
In addition, since \(J_k(\delta _k) / \delta _k \geqslant J_k(1) \geqslant 1\), we have
Finally, since
the desired inequality (20) follows from (23). \(\square \)
When the function class \({\mathcal {F}}\) is VC type, we may derive a more explicit bound on \(n^{k/2}{\mathbb {E}}[ \Vert U_{n}^{(k)} (\pi _{k} f) \Vert _{{\mathcal {F}}}]\).
Corollary 5.3
(Local maximal inequalities for U-processes indexed by VC type classes) If \({\mathcal {F}}\) is pointwise measurable and VC type with characteristics \(A \geqslant (e^{2(r-1)}/16) \vee e\) and \(v \geqslant 1\), then
for every \(k=1,\dots ,r\).
Remark 5.1
(i). Our maximal inequality (20) scales correctly with the order of degeneracy, namely, the bound on \({\mathbb {E}}[\Vert U_{n}^{(k)} (\pi _k f) \Vert _{{\mathcal {F}}}]\) scales as \(n^{-k/2}\) if \({\mathcal {F}}\) is fixed with n; recall that the functions \(\pi _{k} f, f \in {\mathcal {F}}\) are completely degenerate functions of k variables. In addition, our maximal inequality is “local” in the sense that the bound is able take into account the \(L^{2}\)-bound on functions \(P^{r-k}f, f \in {\mathcal {F}}\), namely, the bound will yield a better estimate if we have an additional information that such an \(L^{2}\)-bound is small.
(ii). Giné and Mason [27, Theorem 8] establishes a different local maximal inequality for a U-process indexed by a VC type class with a bounded envelope. To be precise, they prove the following bound under the assumption that the envelope F is bounded by a constant M: there exist constants \(C_1\) and \(C_2\) depending only on r, A, v, and M such that
whenever
where \(\sigma _r\) is a positive constant satisfying \(\sup _{f \in {\mathcal {F}}} \Vert f \Vert _{P^{r},2} \leqslant \sigma _r \leqslant \Vert F \Vert _{P^{r},2}\). Our Corollary 5.3 improves upon the bound (25) in several directions: 1) First, our bound (24) allows for an unbounded envelope while the bound (25) requires the envelope to be bounded. 2) Second, the constants \(C_1\) and \(C_2\) appearing in the bound (25) implicitly depend on the VC characteristics (A, v) and the \(L^{\infty }\)-bound M on the envelope F, in addition to the order r, and so is not applicable to cases where the VC characteristics (A, v) and/or the \(L^{\infty }\)-bound M change with n. On the other hand, the constant involved in our bound (24) depends only on r (recall that the notation \(\lesssim \) in present section signifies that the left hand side is bounded by the right hand side up to a constant that depends only on r), and so is applicable to such cases. 3) Finally, our bound (24) is of the multi-resolution nature in the sense that it depends on the \(L^{2}\)-bound on \(P^{r-k}f\) for \(f \in {\mathcal {F}}\) (i.e., \(\sigma _k\)) for each projection level \(k=1,\dots ,r\) rather than that on \(f \in {\mathcal {F}}\) (i.e., \(\sigma _r\)), which allows us to obtain better rates of convergence for kernel type statistics than (25). In particular, \(\sigma _{k}\) for \(k < r\) can be potentially much smaller than \(\sigma _{r}\), which is indeed the case in the applications considered in Sect. 4. To be precise, for the function class \(\{ b_{n}^{m/2} c_{n}(\vartheta )^{-1} h_{n,\vartheta } : \vartheta \in \Theta \}\) appearing in Sect. 4, \(\sigma _{k}\) would be of order \(b_n^{-m(k-1)/2}\) and so \(\sigma _k \ll \sigma _r\) for \(k < r\); see the proof of Theorem 4.2.
We also note that [2, 26] derive sophisticated moment inequalities for U-statistics in Banach spaces. However, we find that their inequalities are difficult to apply in our setting.
(iii). Theorem 5.1 and Corollary 5.3 generalize Theorem 5.2 and Corollary 5.1 in [14] to U-processes. In fact, Theorem 5.1 and Corollary 5.3 reduce to Theorem 5.2 and Corollary 5.1 in [14] when \(r=k=1\), respectively.
Before proving Corollary 5.3, we first verify the following fact about VC type properties.
Lemma 5.4
If \({\mathcal {F}}\) is VC type with characteristics (A, v), then for every \(k=1,\dots ,r-1\), \(P^{r-k}{\mathcal {F}}\) is also VC type with characteristics \(4\sqrt{A}\) and 2v for envelope \(P^{r-k}F\), i.e.,
Proof of Lemma 5.4
This follows from Lemma A.3 in Appendix A with \(r=s=2\). \(\square \)
Proof of Corollary 5.3
For the notational convenience, put \(A'=4\sqrt{A}\) and \(v'=2v\). Then,
Integration by parts yields that for \(c \geqslant e^{k-1}\),
Since \(A'/\delta \geqslant A' \geqslant e^{r-1} \geqslant e^{k-1}\) for \(0 < \delta \leqslant 1\), we conclude that
Combining Theorem 5.1, we obtain the desired inequality (24). \(\square \)
The appearance of \(\Vert P^{r-k} F \Vert _{P^{k},2}/\sigma _{k}\) inside the log may be annoying in applications but there is a clever way to delete this term. Namely, choose \(\sigma _{k}' = \sigma _{k} \vee (n^{-1/2} \Vert P^{r-k} F \Vert _{P^{k},2})\) and apply Corollary 5.4 with \(\sigma _{k}\) replaced by \(\sigma _{k}'\); then the bound for \(n^{k/2} {\mathbb {E}}[ \Vert U_{n}^{(k)}(\pi _{k}f) \Vert _{{\mathcal {F}}} ]\) is
Since \(v \log (A \vee n) \geqslant 1\) by our assumption, the second term is bounded by the third term. We state the resulting bound as a separate corollary since this form would be most useful in (at least our) applications.
Corollary 5.5
If \({\mathcal {F}}\) is pointwise measurable and VC type with characteristics \(A \geqslant (e^{2(r-1)}/16) \vee e\) and \(v \geqslant 1\), then,
for every \(k=1,\dots ,r\). Furthermore, \(\Vert M_{k} \Vert _{{\mathbb {P}},2} \leqslant n^{1/q} \Vert P^{r-k}F \Vert _{P^{k},q}\) for every \(k=1,\dots ,r\) and \(q \in [2,\infty ]\), where “1 / q” for the \(q=\infty \) case is interpreted as 0.
Proof of Corollary 5.5
The first half of the corollary is already proved. The latter half is trivial. \(\square \)
If one is interested in bounding \({\mathbb {E}}[ \Vert U_{n}^{(r)}(f) - P^{r}f \Vert _{{\mathcal {F}}} ]\), then it suffices to apply (20) or (24) repeatedly for \(k=1,\dots ,r\). However, it is often the case that lower order Hoeffding projection terms are dominant, and for bounding higher order Hoeffding projection terms, it would suffice to apply the following simpler (but less sharp) maximal inequalities.
Corollary 5.6
(Alternative maximal inequalities for U-processes) Let \(p \in [1,\infty )\). Suppose that \({\mathcal {F}}\) is pointwise measurable and that \(J_{k}(1)< \infty \) for \(k=1,\dots ,r\). Then, there exists a constant \(C_{r,p}\) depending only on r, p such that
for every \(k=1,\dots ,r\). If \({\mathcal {F}}\) is VC type with characteristics \(A \geqslant (e^{2(r-1)}/16) \vee e\) and \(v \geqslant 1\), then \(J_{k}(1) \lesssim ( v \log A )^{k/2}\) for every \(k=1,\dots ,r\).
Proof of Corollary 5.6
The last assertion follows from a similar computation to that in the proof of Corollary 5.3. Hence we focus here on the first assertion. The proof is a modification to the proof of Theorem 5.1 and we shall use the notation used in the proof. The randomization theorem and Jensen’s inequality yield that \(n^{pk/2}{\mathbb {E}}[\Vert U_{n}^{(k)}(\pi _{k}f) \Vert _{{\mathcal {F}}}^{p}]\) is bounded by
up to a constant depending only on r, p, where \(\varepsilon _{1},\dots ,\varepsilon _{n}\) are i.i.d. Rademacher random variables independent of \(X_{1}^{n}\). Denote by \({\mathbb {E}}_{\mid X_{1}^{n}}\) the conditional expectation given \(X_{1}^{n}\). Since the \(L^{p}\)-norm is bounded from above by the \(\psi _{2/k}\)-(quasi-)norm up to a constant that depends only on k (and hence r) and p, we have
for some constant C depending only on r and p. The entropy integral bound for Rademacher chaoses (see the proof of Theorem 5.1) yields that the right hand side is bounded by, after changing variables,
up to a constant depending only on r, p. The desired result follows from bounding \(\sigma _{I_{n,k}}/\Vert P^{r-k}F \Vert _{{\mathbb {P}}_{I_{n,k}},2}\) by 1 and observation that \({\mathbb {E}}[\Vert P^{r-k}F \Vert _{{\mathbb {P}}_{I_{n,k}},2}^{p}] \leqslant \Vert P^{r-k} F \Vert _{P^{k},2 \vee p}^{p}\) by Jensen’s inequality. \(\square \)
Remark 5.2
Corollary 5.6 is an extension of Theorem 2.14.1 in [53]. For \(p=1\), Corollary 5.6 is often less sharp than Theorem 5.1 since \(\sigma _{k} \leqslant \Vert P^{r-k}F \Vert _{P^{k},2}\) and in some cases \(\sigma _{k} \ll \Vert P^{r-k} F \Vert _{P^{k},2}\). However, Corollary 5.6 is useful for directly bounding higher order moments of \(\Vert U_{n}^{(k)} (\pi _{k}f) \Vert _{{\mathcal {F}}}\). For the empirical process case (i.e., \(k=1\)), bounding higher order moments of the supremum is essentially reduced to bounding the first moment by the Hoffmann-Jørgensen inequality [53, Proposition A.1.6]. There is an analogous Hoffmann-Jørgensen type inequality for U-processes (see [18, Theorem 4.1.2]), but for \(k \geqslant 2\), bounding higher order moments of \(\Vert U_{n}^{(k)}(\pi _{k}f) \Vert _{{\mathcal {F}}}\) using this Hoffmann-Jørgensen inequality combined with the local maximal inequality in Theorem 5.1 would be more involved.
6 Proofs for Sects. 2 and 3
In what follows, let \({\mathcal {B}}({\mathbb {R}})\) denote the Borel \(\sigma \)-field on \({\mathbb {R}}\). For a set \(B \subset {\mathbb {R}}\) and \(\delta > 0\), let \(B^{\delta }\) denote the \(\delta \)-enlargement of B, i.e., \(B^{\delta } =\{ x \in {\mathbb {R}}: \inf _{y \in B} |x-y| \leqslant \delta \}\).
6.1 Proofs for Sect. 2
We begin with stating the following lemma.
Lemma 6.1
Work with the setup described in Sect. 2. Suppose that Conditions (PM), (VC), and (MT) hold. Let \(L_{n} := \sup _{g \in {\mathcal {G}}} n^{-1/2}\sum _{i=1}^{n} (g(X_{i}) - Pg)\) and \({\widetilde{Z}} := \sup _{g \in {\mathcal {G}}} W_{P}(g)\). Then, there exist universal constants \(C,C'> 0\) such that \({\mathbb {P}}(L_n \in B) \leqslant {\mathbb {P}}({\widetilde{Z}} \in B^{C \delta _n}) + C'(\gamma + n^{-1})\) for every \(B \in {\mathcal {B}}({\mathbb {R}})\), where
In the case of \(q=\infty \), “1 / q” is interpreted as 0.
The proof is a minor modification to that of Theorem 2.1 in [15]. Differences are (1) Lemma 6.1 allows \(q=\infty \), and constants \(C,C'\) to be independent of q; (2) the error bound \(\delta _{n}\) contains \(b_{{\mathfrak {g}}} K_n/ (\gamma n^{1/2-1/q})\) instead of \(b_{{\mathfrak {g}}} K_n/(\gamma ^{1/q} n^{1/2-1/q})\); and (3) our definition of \(K_{n}\) is slightly different from theirs. For completeness, in “Appendix C.1”, we provide a sketch of the proof for Lemma 6.1, which points out required modifications to the proof of Theorem 2.1 in [15].
Proof of Proposition 2.1
In view of the Strassen–Dudley theorem (see Theorem B.1), it suffices to verify that there exist constants \(C,C'\) depending only r such that
for every \(B \in {\mathcal {B}}({\mathbb {R}})\). In what follows, \(C,C'\) denote generic constants that depend only on r; their values may vary from place to place.
We shall follow the notation used in Sect. 5. Consider the Hoeffding decomposition for \(U_{n}(h) = U_{n}^{(r)}(h)\): \( U_{n}^{(r)}(h) - P^{r}h = r U_{n}^{(1)}(\pi _{1} h) + \sum _{k=2}^{r} \left( {\begin{array}{c}r\\ k\end{array}}\right) U_{n}^{(k)}(\pi _{k}h)\), or
where \({\mathbb {G}}_n(P^{r-1}h) := n^{-1/2}\sum _{i=1}^{n} (P^{r-1}h (X_{i}) - P^{r}h)\) is the Hájek (empirical) process associated with \({\mathbb {U}}_n\). Recall that \({\mathcal {G}}= P^{r-1}{\mathcal {H}}= \{ P^{r-1}h : h \in {\mathcal {H}}\}\), and let \(L_n = \sup _{g \in {\mathcal {G}}} {\mathbb {G}}_n(g)\) and \(R_n = \Vert \sqrt{n} \sum _{k=2}^r \left( {\begin{array}{c}r\\ k\end{array}}\right) U_{n}^{(k)}(\pi _{k}h)/r \Vert _{\mathcal {H}}\). Then, since \(|Z_n - L_n| \leqslant R_n\), Markov’s inequality and Lemma 6.1 yield that for every \(B \in {\mathcal {B}}({\mathbb {R}})\),
where \(\delta _{n}\) is given in (26).
It remains to bound \({\mathbb {E}}[R_{n}]\). To this end, we shall separately apply Corollary 5.5 for \(k=2\) and Corollary 5.6 for \(k=3,\dots ,r\). First, applying Corollary 5.5 to \({\mathcal {F}}={\mathcal {H}}\) for \(k=2\) yields
Likewise, applying Corollary 5.6 to \({\mathcal {F}}= {\mathcal {H}}\) for \(k=3,\dots ,r\) yields
Therefore, we conclude that
Combining (27) with (28) leads to the conclusion of the proposition. \(\square \)
Proof of Corollary 2.2
We begin with noting that we may assume that \(b_{{\mathfrak {g}}} \leqslant n^{1/2}\), since otherwise the conclusion is trivial by taking \(C \geqslant 1\). In this proof, the notation \(\lesssim \) signifies that the left hand side is bounded by the right hand side up to a constant that depends only on \(r, {\overline{\sigma }}_{{\mathfrak {g}}}\), and \({\underline{\sigma }}_{{\mathfrak {g}}}\). Let \(\gamma \in (0,1)\) and pick a version \({\widetilde{Z}}_{n,\gamma }\) of \({\widetilde{Z}}\) as in Proposition 2.1 (\({\widetilde{Z}}_{n,\gamma }\) may depend on \(\gamma \)). Proposition 2.1 together with [15, Lemma 2.1] yield that
Now, the anti-concentration inequality (see Lemma A.1 in “Appendix A”) yields
Since \({\mathcal {G}}\) is VC type with characteristics \(4\sqrt{A}\) and 2v for envelope G (Lemma 5.4), by Lemma A.2, we have \(N({\mathcal {G}}, \Vert \cdot \Vert _{P,2}, \tau ) \leqslant (16\sqrt{A} \Vert G \Vert _{P,2}/\tau )^{2v}\) for all \(0 < \varepsilon \leqslant 1\). Hence, Dudley’s entropy integral bound [29, Theorem 2.3.7] yields \({\mathbb {E}}[{\widetilde{Z}}] \lesssim ({\overline{\sigma }}_{{\mathfrak {g}}} \vee (n^{-1/2} b_{{\mathfrak {g}}})) K_n^{1/2} \lesssim K_{n}^{1/2}\)where the last inequality follows from the assumption that \(b_{{\mathfrak {g}}} \leqslant n^{1/2}\). Since \(\sqrt{1 \vee \log ({\underline{\sigma }}_{{\mathfrak {g}}} / (C \varpi _n))} \lesssim (K_n \vee \log (\gamma ^{-1}) )^{1/2}\), we conclude that
The desired result follows from balancing \(K_{n}^{1/2} \varpi _{n}(\gamma )\) and \(\gamma \). \(\square \)
6.2 Proofs for Sect. 3
Proof of Theorem 3.1
In this proof we will assume that each \(h \in {\mathcal {H}}\) is \(P^{r}\)-centered, i.e., \(P^{r}h = 0\) for the rotational convenience. Recall that \({\mathbb {P}}_{\mid X_{1}^{n}}\) and \({\mathbb {E}}_{\mid X_{1}^{n}}\) denote the conditional probability and expectation given \(X_{1}^{n}\), respectively. In view of the conditional version of the Strassen–Dudley theorem (see Theorem B.2), it suffices to find constants \(C,C'\) depending only on r, and an event \(E \in \sigma (X_1^n)\) with \({\mathbb {P}}(E) \geqslant 1- \gamma - n^{-1}\) on which
The proof of Theorem 3.1 is involved and divided into six steps. In what follows, let C denote a generic positive constant depending only on r; the value of C may change from place to place.
Step 1: Discretization For \(0 < \varepsilon \leqslant 1\) to be determined later, let \(N := N(\varepsilon ) := N({\mathcal {G}}, \Vert \cdot \Vert _{P,2}, \varepsilon \Vert G \Vert _{P,2})\). Since \(\Vert G\Vert _{P,2} \leqslant b_{{\mathfrak {g}}}\), there exists an \(\varepsilon b_{{\mathfrak {g}}}\)-net \(\{ g_{k} \}_{k=1}^{N}\) for \(({\mathcal {G}}, \Vert \cdot \Vert _{P,2})\). By the definition of \({\mathcal {G}}\), each \(g_{k}\) corresponds to a kernel \(h_{k} \in {\mathcal {H}}\) such that \(g_{k} = P^{r-1}h_{k}\). The Gaussian process \(W_P\) extends to the linear hull of \({\mathcal {G}}\) in such a way that \(W_{P}\) has linear sample paths (e.g., see [29, Theorem 3.7.28]). Now, observe that
where \({\mathcal {G}}_{\varepsilon } = \{g-g' : g, g' \in {\mathcal {G}}, \Vert g-g'\Vert _{P,2} < 2 \varepsilon b_{{\mathfrak {g}}} \}\) and \({\mathcal {H}}_{\varepsilon } = \{h-h' : h, h' \in {\mathcal {H}}, \Vert P^{r-1} h- P^{r-1} h' \Vert _{P,2} < 2 \varepsilon b_{{\mathfrak {g}}} \}\).
Step 2: Construction of a high-probability event\(E \in \sigma (X_1^n)\) We divide this step into several sub-steps.
(i). For a P-integrable function g on S, we will use the notation
Consider the function class \(\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}} = \{ gg' : g,g' \in \breve{{\mathcal {G}}} \}\) with \(\breve{{\mathcal {G}}} = \{ g, g - Pg : g \in {\mathcal {G}}\}\). Recall that \({\mathcal {G}}\) with envelope G is VC type with characteristics \((4\sqrt{A},2v)\). The function class \(\{ g -Pg : g \in {\mathcal {G}}\}\) with envelope \(\breve{G} := G + PG\) is VC type with characteristics \((4\sqrt{2A},2v+1)\) from a simple calculation. Conclude that \(\breve{{\mathcal {G}}}\) with envelope \(\breve{G}\) is VC type with characteristics \((8\sqrt{2A},2v+1)\), and by Lemma A.5, \(\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}}\) with envelope \(\breve{G}^{2}\) is VC type with characteristics \((16\sqrt{2A},4v+2)\). For \(g,g' \in {\mathcal {G}}\), \(P(gg')^2 \leqslant \sqrt{Pg^4} \sqrt{P(g')^4} \leqslant {\overline{\sigma }}_{{\mathfrak {g}}}^{2}b_{{\mathfrak {g}}}^{2}\) by Condition (MT). Likewise,
We also note that \(\Vert \breve{G} \Vert _{P,q} \leqslant 2 \Vert G \Vert _{P,q} \leqslant 2b_{{\mathfrak {g}}}\). Hence, applying Corollary 5.5 with \({\mathcal {F}}=\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}}, r=k=1\), and \(q= q/2\) yields
so that with probability at least \(1 - \gamma /3\),
by Markov’s inequality.
(ii). Define
We will show that
Together with Markov’s inequality, we have that with probability at least \(1-\gamma /3\),
The proof of the inequality (32) is lengthy and deferred after the proof of the theorem.
(iii). We shall bound \({\mathbb {E}}[ \Vert U_{n}(h) - P^{r}h \Vert _{{\mathcal {H}}}^{2}]\). Applying Corollary 5.6 to \({\mathcal {H}}\) for \(k=2,\dots ,r\) yields
Next, since \(U_{n}^{(1)}(\pi _{1}h), h \in {\mathcal {H}}\) is an empirical process, we may apply the Hoffmann-Jørgensen inequality [53, Proposition A.1.6] to deduce that
where the second inequality follows from Corollary 5.5. Since \({\overline{\sigma }}_{{\mathfrak {g}}} \leqslant \sigma _{{\mathfrak {h}}}\) and \(b_{{\mathfrak {g}}} \leqslant b_{{\mathfrak {h}}}\),
so that by Markov’s inequality, with probability at least \(1-\gamma /3\),
(iv). Let \({\mathbb {P}}_{I_{n,r}} = |I_{n,r}|^{-1} \sum _{(i_1,\dots ,i_r) \in I_{n,r}} \delta _{(X_{i_1},\dots ,X_{i_r})}\) denote the empirical distribution on all possible r-tuples of \(X_1^n\). Then Markov’s inequality yields that with probability at least \(1-n^{-1}\),
Now, define the event E by the the intersection of the events (30), (33), (34), and (35). Then, \(E \in \sigma (X_1^n)\) and \({\mathbb {P}}(E) \geqslant 1 - \gamma - n^{-1}\).
Step 3: Bounding the discretization error for \(W_P\) By the Borell-Sudakov-Tsirel’son inequality (cf. [29, Theorem 2.5.8]), we have
From a standard calculation, \(N({\mathcal {G}}_{\varepsilon }, \Vert \cdot \Vert _{P,2}, \tau ) \leqslant N^2({\mathcal {G}}, \Vert \cdot \Vert _{P,2}, \tau /2)\). Since \({\mathcal {G}}\) is VC type with characteristics \(4\sqrt{A}\) and 2v for envelope G, by Lemma A.2, we have \(N({\mathcal {G}}, \Vert \cdot \Vert _{P,2}, \tau \Vert G\Vert _{P,2}) \leqslant C (16 \sqrt{A} / \tau )^{2v}\), so that \( N({\mathcal {G}}_{\varepsilon }, \Vert \cdot \Vert _{P,2}, \tau ) \leqslant (32 \sqrt{A} b_{{\mathfrak {g}}} / \tau )^{4v}\). Now, Dudley’s entropy integral bound [53, Corollary 2.2.8] yields
Choosing \(\varepsilon = 1/n^{1/2}\), we have
Since \(\log n \leqslant K_n\), we conclude that
Step 4: Bounding the discretization error for \({\mathbb {U}}_n^\sharp \). Since \(\{ {\mathbb {U}}_{n}^{\sharp } (h) : h \in {\mathcal {H}}\}\) is a centered Gaussian process conditionally on \(X_{1}^{n}\), applying the Borell-Sudakov-Tsirel’son inequality conditionally on \(X_1^n\), we have
where \(\Sigma _{n} := \Vert n^{-1} \sum _{i=1}^{n}\{ U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}h) - U_{n}(h) \}^{2} \Vert _{{\mathcal {H}}_{\varepsilon }}\) with \(\varepsilon = 1/n^{1/2}\).
We begin with bounding \(\Sigma _{n}\). For any \(h \in {\mathcal {H}}_{\varepsilon }\), \(n^{-1}\sum _{i=1}^{n}\{ U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}h)- U_{n}(h) \}^{2}\) is bounded by \(n^{-1}\sum _{i=1}^{n}\{ U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}h)\}^{2}\) since the average of \(U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}h), i=1,\dots ,n\) is \(U_{n}(h)\) and the variance is bounded by the second moment. Further, the term \(n^{-1}\sum _{i=1}^{n}\{ U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}h)\}^{2}\) is bounded by
The last term on the right hand side of (36) is bounded by \(8(\varepsilon b_{{\mathfrak {g}}})^{2}\). The supremum of the first term on \({\mathcal {H}}_{\varepsilon }\) is bounded by \(8\Upsilon _{n}\) since \({\mathcal {H}}_{\varepsilon } \subset \{ h-h' : h,h' \in {\mathcal {H}}\}\) [the notation \(\Upsilon _{n}\) is defined in (31)]. For the second term, observe that \(\{ (P^{r-1}h)^{2} : h \in {\mathcal {H}}_{\varepsilon } \} \subset \{ (g-g')^{2} : g,g' \in {\mathcal {G}}\}, (g-g')^{2} - P(g-g')^{2} = (g^{2} - Pg^{2}) + 2(gg' - Pgg') + ((g')^{2} - P(g')^{2})\), and \(\{ g^{2} : g \in {\mathcal {G}}\} \subset \breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}}\), so that the supremum of the second term on the right hand side of (36) is bounded by \(8n^{-1/2} \Vert {\mathbb {G}}_{n} \Vert _{\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}}}\). Therefore, recalling that we have chosen \(\varepsilon =1/n^{1/2}\), we conclude that
on the event E.
Next, we shall bound \({\mathbb {E}}_{\mid X_{1}^{n}} [\Vert {\mathbb {U}}_n^\sharp \Vert _{{\mathcal {H}}_{\varepsilon }}]\) on the event E. Since \({\mathcal {H}}\) is VC type with characteristics (A, v), we have
In addition, since
where the last inequality follows from Jensen’s inequality, and since a weaker pseudometric induces a smaller covering number, we have
Hence, using \(2\left[ (n^{-(r-1)/2}\Vert H \Vert _{P^{r},2}) \vee \Sigma _{n}^{1/2} \right] \) as a bound on the d-diameter of \({\mathcal {H}}_{\varepsilon }\), we have by Dudley’s entropy integral bound
on the event E (we have used \(\Vert H \Vert _{{\mathbb {P}}_{I_{n,k},2}} \leqslant n^{1/2} \Vert H \Vert _{P^{r},2}\) on E). Since \(n^{-(r-1)/2}\Vert H \Vert _{P^{r},2} \leqslant \chi _{n}\), we have
on the event E. Hence, we conclude that
on the event E, where
Step 5: Gaussian comparison Let \(Z_n^{\sharp ,\varepsilon } := \max _{1 \leqslant j \leqslant N} {\mathbb {U}}_n^\sharp (h_j)\) and \({\widetilde{Z}}^{\varepsilon } := \max _{1 \leqslant j \leqslant N} W_P(g_j)\). Observe that the covariance between \({\mathbb {U}}_{n}^{\sharp }(h_{k})\) and \({\mathbb {U}}_{n}^{\sharp }(h_{\ell })\) conditionally on \(X_{1}^{n}\) is
Recall that \(g_{k} = P^{r-1}h_{k}\) for each k. Replacing \(h_{k}\) by \(h_{k} - P^{r}h_{k}\) in the above expansion, we have
where we have used the Cauchy–Schwarz inequality. Since \(n^{-1} \sum _{i=1}^{n} \{ g (X_{i}) - Pg \}^{2}\) is decomposed as \(P(g - Pg)^{2} + n^{-1/2} {\mathbb {G}}_{n}((g-Pg)^{2})\) and the supremum of the latter on \({\mathcal {G}}\) is bounded by \({\overline{\sigma }}_{{\mathfrak {g}}}^{2}+n^{-1/2} \Vert {\mathbb {G}}_{n} \Vert _{\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}}}\), we have
where the second inequality follows from the inequality \(2ab \leqslant a^{2} + b^{2}\) for \(a,b \in {\mathbb {R}}\). Now, Condition (9) ensures that
on the event E, so that
Therefore, the Gaussian comparison inequality of [15, Theorem 3.2] yields that on the event E,
Step 6: Conclusion Let
Then, from Steps 1–5, we have for every \(B \in {\mathcal {B}}({\mathbb {R}})\) and \(\eta > 0\),
Choosing \(\eta = \gamma ^{-1} \delta _{n}^{(2)}\) leads to the conclusion of the theorem. \(\square \)
It remains to prove the inequality (32).
Proof of the inequality (32)
For a \(P^{r-1}\)-integrable symmetric function f on \(S^{r-1}\), \(U_{n-1,-i}^{(r-1)} (f) \) is a U-statistic of order \(r-1\) and its first projection term is
Consider the following decomposition:
Consider the second term. By Corollary A.4, for given \(x \in S\), \(\delta _{x} {\mathcal {H}}= \{ \delta _{x} x : h \in {\mathcal {H}}\}\) is VC type with characteristics (A, v) for envelope \(\delta _{x}H\). Hence, we apply Corollary 5.6 conditionally on \(X_{i}\) and deduce that
Since \(\sum _{k=2}^{r-1} n^{-k} \Vert P^{r-k-1}H \Vert _{P^{k+1},2}^{2} K_{n}^{k} = \sum _{k=3}^{r}n^{-(k-1)} \Vert P^{r-k}H \Vert _{P^{k},2}^{2} K_{n}^{k-1} \leqslant C\chi _{n}^{2}\), the expectation of the supremum on \({\mathcal {H}}\) of the second term on the right hand side of (37) is at most \( C \chi _{n}^{2}\).
For the first term, observe that
Let \({\mathcal {F}}= \{ P^{r-2} h : h \in {\mathcal {H}}\}\) and \(F=P^{r-2}H\), and observe that for \(f \in {\mathcal {F}}\),
Since \(P^{2}f^{2} - P (Pf)^{2} \leqslant \sigma _{{\mathfrak {h}}}^{2}\), we focus on bounding the suprema of the last two terms. The second term is proportional to a non-degenerate U-statistic of order 2, and the third term is proportional to a degenerate U-statistic of order 3. Define the function classes
together with their envelopes
respectively. Lemma 5.4 yields that \({\mathcal {F}}\) is VC type with characteristics \((4\sqrt{A}, 2v)\) for envelope F, and Corollary A.1 (i) in [14] together with Lemma 5.4 yield that \({\mathcal {F}}_{1},{\mathcal {F}}_{2},{\mathcal {F}}_{3}\) are VC type with characteristics bounded by CA, Cv for envelopes \(F_{1},F_{2},F_{3}\), respectively. Functions in \({\mathcal {F}}_{1}\) are not symmetric, but after symmetrization we may apply Corollaries 5.5 and 5.6 for \(k=1\) and \(k=2\), respectively. Together with the Jensen and Cauchy–Schwarz inequalities, we deduce that
where we have used \(\Vert P^{r-2}h \Vert _{P^{2},4}^{4} \leqslant \sigma _{{\mathfrak {h}}}^{2} b_{{\mathfrak {h}}}^{2}\) for \(h \in {\mathcal {H}}\) by Condition (MT).
Next, observe that \(\Vert U_{n}^{(3)}(f) \Vert _{{\mathcal {F}}_{2}^{0}} \leqslant \Vert U_{n}^{(2)}(f) \Vert _{{\mathcal {F}}_{2}} + \Vert U_{n}^{(3)}(f) \Vert _{{\mathcal {F}}_{3}}\). Since for \(f \in {\mathcal {F}}_{2}^{0}\), \({\mathbb {E}}[ f(x_{1},X_{2},X_{3})] = {\mathbb {E}}[ f(X_{1},x_{2},X_{3}) ] = {\mathbb {E}}[f(X_{1},X_{2},x_{3})] ={\mathbb {E}}[ f(x_{1},X_{2},x_{3}) ] = {\mathbb {E}}[ f(x_{1},x_{2},X_{3})] = 0\) for all \(x_{1},x_{2},x_{3} \in S\), both \(U_{n}^{(2)}(f), f \in {\mathcal {F}}_{2}\) and \(U_{n}^{(3)}(f), f \in {\mathcal {F}}_{3}\) are completely degenerate. So, applying Corollary 5.5 to \({\mathcal {F}}_{2}\) and \({\mathcal {F}}_{3}\) after symmetrization, combined with the Jensen and Cauchy–Schwarz inequalities, we deduce that
where recall that \(f^{\odot 2} (x_{1},x_{2}) := f^{\odot 2}_{P}(x_{1},x_{2}) := \int f(x_{1},x) f(x,x_{2}) dP(x)\) for a symmetric measurable function f on \(S^{2}\). For \(f \in {\mathcal {F}}\), observe that by the Cauchy–Schwarz inequality,
On the other hand, \(\Vert F^{\odot 2}\Vert _{P^{2},q/2} = \nu _{{\mathfrak {h}}}^{2}\) by the definition of \(\nu _{{\mathfrak {h}}}\). Therefore, we conclude that
This completes the proof. \(\square \)
Proof of Corollary 3.2
This follows from the discussion before Theorem 3.1 combined with the anti-concentration inequality (Lemma A.1), and optimization with respect to \(\gamma \). It is without loss of generality to assume that \(\eta _{n} \leqslant {\overline{\sigma }}_{{\mathfrak {g}}}^{1/2}\) since otherwise the result is trivial by taking C or \(C'\) large enough, and hence Condition (9) is automatically satisfied. \(\square \)
References
Abrevaya, J., Jiang, W.: A nonparametric approach to measuring and testing curvature. J. Bus. Econ. Stat. 23(1), 1–19 (2005)
Adamczak, R.: Moment inequalities for U-statistics. Ann. Probab. 34(6), 2288–2314 (2006)
Arcones, M., Giné, E.: On the bootstrap of \(U\)- and \(V\)-statistics. Ann. Stat. 20(2), 655–674 (1992)
Arcones, M., Giné, E.: Limit theorems for \(U\)-processes. Ann. Probab. 21(3), 1495–1542 (1993)
Arcones, M., Giné, E.: U-processes indexed by Vapnik–Červonenkis classes of functions with applications to asymptotics and bootstrap of U-statistics with estimated parameters. Stoch. Process. Appl. 52(1), 17–38 (1994)
Bickel, P.J., Freedman, D.A.: Some asymptotic theory for the bootstrap. Ann. Stat. 9(6), 1196–1217 (1981)
Blundell, R., Gosling, A., Ichimura, H., Meghir, C.: Changes in the distribution of male and female wages accounting for employment composition using bounds. Econometrica 75(2), 323–363 (2007)
Borovskikh, Y.V.: U-Statistics in Banach Spaces. V.S.P. Intl Science, Zeist (1996)
Bretagnolle, J.: Lois limits du Bootstrap de certaines functionnelles. Annales de l’Institut Henri Poincaré Section B XIX(3), 281–296 (1983)
Callaert, H., Veraverbeke, N.: The order of the normal approximation for a Studentized \(U\)-statistic. Ann. Stat. 9(1), 360–375 (1981)
Chen, X.: Gaussian and bootstrap approximations for high-dimensional U-statistics and their applications. Ann. Stat. 46(2), 642–678 (2018)
Chernozhukov, V., Chetverikov, D., Kato, K.: Gaussian approximations and multiplier bootstrap for maxima of sums of high-dimensional random vectors. Ann. Stat. 41(6), 2786–2819 (2013)
Chernozhukov, V., Chetverikov, D., Kato, K.: Anti-concentration and honest, adaptive confidence bands. Ann. Stat. 42(5), 1787–1818 (2014)
Chernozhukov, V., Chetverikov, D., Kato, K.: Gaussian approximation of suprema of empirical processes. Ann. Stat. 42(4), 1564–1597 (2014)
Chernozhukov, V., Chetverikov, D., Kato, K.: Empirical and multiplier bootstraps for suprema of empirical processes of increasing complexity, and related gaussian couplings. Stoch. Process. Appl. 126(12), 3632–3651 (2016)
Chetverikov, D.: Testing regression monotonicity in econometric models. arXiv:1212.6757 (2012)
Davydov, Y., Lifshits, M., Smorodina, N.: Local Properties of Distributions of Stochastic Functions (Transaction of Mathematical Monographs, Vol. 173). American Mathematical Society, New York (1998)
de la Peña, V., Giné, E.: Decoupling: From Dependence to Independence. Springer, Berlin (1999)
Dehling, H., Mikosch, T.: Random quadratic forms and the bootstrap for \(U\)-statistics. J. Multivar. Anal. 51(2), 392–413 (1994)
Dudley, R.M.: Real Analysis and Probability. Cambridge University Press, Cambridge (2002)
Dümbgen, L.: Application of local rank tests to nonparametric regression. J. Nonparametric Stat. 14(5), 511–537 (2002)
Einmahl, U., Mason, D.M.: Uniform in bandwidth consistency of kernel-type function estimators. Ann. Stat. 33(3), 1380–1403 (2005)
Ellison, G., Ellison, S.F.: Strategic entry deterrence and the behavior of pharmaceutical incumbents prior to patent expiration. Am. Econ. J. Microecon. 3(1), 1–36 (2011)
Frees, E.W.: Estimating densities of functions of observations. J. Am. Stat. Assoc. 89(426), 517–525 (1994)
Ghosal, S., Sen, A., van der Vaart, A.: Testing monotonicity of regression. Ann. Stat. 28(4), 1054–1082 (2000)
Giné, E., Latała, R., Zinn, J.: Exponential and moment inequalities for \(U\)-statistics. High Dimensional Probability II. Springer, Berlin (2000)
Giné, E., Mason, D.M.: On local \(U\)-statistic processes and the estimation of densities of functions of several sample variables. Ann. Stat. 35(3), 1105–1145 (2007)
Giné, E., Nickl, R.: Uniform limit theorems for wavelet density estimators. Ann. Probab. 37(4), 1605–1646 (2009)
Giné, E., Nickl, R.: Mathematical Foundations of Infinite-Dimensional Statistical Models. Cambridge University Press, Cambridge (2016)
Hall, P.: On convergence rates of suprema. Probab. Theory Relat. Fields 89(4), 447–455 (1991)
Hoeffding, W.: A class of statistics with asymptotically normal distributions. Ann. Math. Stat. 19(3), 293–325 (1948)
Huškova, M., Janssen, P.: Consistency of the generalized bootstrap for degenerate \(U\)-statistics. Ann. Stat. 21(4), 1811–1823 (1993)
Hušková, M., Janssen, P.: Generalized bootstrap for studentized \(U\)-statistics: a rank statistic approach. Stat. Probab. Lett. 16(3), 225–233 (1993)
Janssen, P.: Weighted bootstrapping of \(U\)-statistics. J. Stat. Plann. Inference 38(1), 31–42 (1994)
Koltchinskii, V.I.: Komlos–Major–Tusnády approximation for the general empirical process and Haar expansions of classes of functions. J. Theor. Probab. 7(1), 73–118 (1994)
Komlós, J., Major, P., Tusnády, G.: An approximation of partial sums of independent rv’s and the sample df. I. Z. Wahrscheinlichkeitstheor. Verw. Geb. 32(1–2), 111–131 (1975)
Ledoux, M., Talagrand, M.: Probability in Banach Spaces: Isoperimetry and Processes. Springer, New York (1991)
Lee, S., Linton, O., Whang, Y.-J.: Testing for stochastic monotonicity. Econometrica 77(2), 585–602 (2009)
Albert, Y.L.: A large sample study of the Bayesian bootstrap. Ann. Stat. 15(1), 360–375 (1987)
Mason, D.M., Newton, M.A.: A rank statistics approach to the consistency of a general bootstrap. Ann. Stat. 20(3), 1611–1624 (1992)
Massart, P.: Strong approximation for multivariate empirical and related processes, via KMT constructions. Ann. Probab. 17(1), 266–291 (1989)
Monrad, D., Philipp, W.: Nearby variables with nearby conditional laws and a strong approximation theorem for Hilbert space valued martingales. Probab. Theory Relat. Fields 88(3), 381–404 (1991)
Nolan, D., Pollard, D.: \(U\)-processes: rates of convergence. Ann. Stat. 15(2), 780–799 (1987)
Nolan, D., Pollard, D.: Functional limit theorems for \(U\)-processes. Ann. Probab. 16(3), 1291–1298 (1988)
Piterberg, V.I.: Asymptotic Methods in the Theory of Gaussian Processes and Fields. American Mathematical Society, New York (1996)
Resnick, S.I.: Extreme Values, Regular Variation, and Point Processes. Springer, Berlin (1987)
Rio, E.: Local invariance principles and their application to density estimation. Probab. Theory Relat. Fields 98(1), 21–45 (1994)
Rubin, D.B.: The Bayesian bootstrap. Ann. Stat. 9(1), 130–134 (1981)
Serfling, R.J.: Approximation Theorems of Mathematical Statistics. Wiley, New York (1980)
Sherman, R.P.: Limiting distribution of the maximal rank correlation estimator. Econometrica 61(1), 123–137 (1993)
Sherman, R.P.: Maximal inequalities for degenerate \(U\)-processes with applications to optimization estimators. Ann. Stat. 22(1), 439–459 (1994)
Solon, G.: Intergenerational income mobility in the United States. Am. Econ. Rev. 82(3), 393–408 (1992)
van der Vaart, A., Wellner, J.A.: Weak Convergence and Empirical Processes: With Applications to Statistics. Springer, Berlin (1996)
van der Vaart, A., Wellner, J.A.: A local maximal inequality under uniform entropy. Electron. J. Stat. 5, 192–203 (2011)
Wang, Q., Jing, B.-Y.: Weighted bootstrap for \(U\)-statistics. J. Multivar. Anal. 91(2), 177–198 (2004)
Zhang, D.: Bayesian bootstraps for U-processes, hypothesis tests and convergence of Dirichlet U-processes. Stat. Sin. 11(2), 463–478 (2001)
Acknowledgements
The authors would like to thank the anonymous referees and an Associate Editor for their constructive comments that improve the quality of this paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
X. Chen is supported by NSF DMS-1404891, NSF CAREER Award DMS-1752614, and UIUC Research Board Awards (RB17092, RB18099).
Appendices
Appendix A. Supporting lemmas
This appendix collects some supporting lemmas that are repeatedly used in the main text.
Lemma A.1
(An anti-concentration inequality for the Gaussian supremum) Let \((S,{\mathcal {S}},P)\) be a probability space, and let \({\mathcal {G}}\subset L^{2}( P )\) be a P-pre-Gaussian class of functions. Denote by \(W_{P}\) a tight Gaussian random variable in \(\ell ^{\infty }({\mathcal {G}})\) with mean zero and covariance function \({\mathbb {E}}[ W_{P}(g) W_{P}(g') ] = \mathrm {Cov}_{P}(g,g')\) for all \(g,g' \in {\mathcal {G}}\) where \(\mathrm {Cov}_{P}(\cdot ,\cdot )\) denotes the covariance under P. Suppose that there exist constants \({\underline{\sigma }}, {\overline{\sigma }}>0\) such that \({\underline{\sigma }}^{2} \leqslant \mathrm {Var}_{P}(g) \leqslant {\overline{\sigma }}^{2}\) for all \(g \in {\mathcal {G}}\). Then for every \(\varepsilon > 0\),
where \(C_{\sigma }\) is a constant depending only on \({\underline{\sigma }}\) and \({\overline{\sigma }}\).
Proof
See Lemma A.1 in [14]. \(\square \)
Lemma A.2
Let \({\mathcal {F}}\) be a class of real-valued measurable functions on a measurable space \(({\mathcal {X}},{\mathcal {A}})\) with finite measurable envelope F. Then for any probability measure R on \(({\mathcal {X}},{\mathcal {A}})\) such that \(RF^{2} < \infty \), we have
for every \(0 < \varepsilon \leqslant 1\), where \(\sup _{Q}\) is taken over all finitely discrete distributions on \({\mathcal {X}}\).
Proof
This follows from approximating R by a finitely discrete distribution. See Problem 2.5.1 in [53]. \(\square \)
Lemma A.3
Let \(({\mathcal {X}},{\mathcal {A}}), ({\mathcal {Y}},{\mathcal {C}})\) be measurable spaces and let \({\mathcal {F}}\) be a class of real-valued jointly measurable functions on \({\mathcal {X}}\times {\mathcal {Y}}\) with finite measurable envelope F. Let R be a probability measure on \(({\mathcal {Y}},{\mathcal {C}})\) and for a jointly measurable function \(f: {\mathcal {X}}\times {\mathcal {Y}}\rightarrow {\mathbb {R}}\), define \({\overline{f}}: {\mathcal {X}}\rightarrow {\mathbb {R}}\) by \({\overline{f}}(x) := \int f(x,y) dR(y)\) whenever the latter integral is defined and finite for every \(x \in {\mathcal {X}}\). Suppose that \({\overline{F}}\) is everywhere finite and let \({\overline{{\mathcal {F}}}} = \{ {\overline{f}} : f \in {\mathcal {F}}\}\). Then, for every \(r,s \in [1,\infty )\),
where \(\sup _{Q}\) and \(\sup _{Q'}\) are taken over all finitely discrete distributions on \({\mathcal {X}}\) and \({\mathcal {X}}\times {\mathcal {Y}}\), respectively.
Proof
This follows from Lemma A.2 in [25] combined with Lemma A.2. \(\square \)
If \(R=\delta _{y}\) for some \(y \in {\mathcal {Y}}\), then \(\Vert \delta _{y} f \Vert _{Q,r}^{r} = \Vert f \Vert _{Q \times \delta _{y},r}^{r}\) (with \(\delta _{y} f(x) = f(x,y)\)) and \(Q \times \delta _{y}\) is finitely discrete if Q is so. Hence, we have the following corollary.
Corollary A.4
Under the setting of Lemma A.3, for every \(y \in {\mathcal {Y}}\) and \(r \in [1,\infty )\),
Lemma A.5
Let \({\mathcal {F}}\) and \({\mathcal {G}}\) be function classes on a set \({\mathcal {X}}\) with finite envelopes F and G, respectively. If \({\mathcal {F}}\cdot {\mathcal {G}}\) stands for the class of pointwise products of functions from \({\mathcal {F}}\) and \({\mathcal {G}}\), then for any \(r \in [1,\infty )\),
where \(\sup _{Q}\) is taken over all finitely discrete distributions on \({\mathcal {X}}\).
Proof
See Lemma A.1 in [25] or [53, Section 2.10.3]. \(\square \)
Appendix B. Strassen–Dudley theorem and its conditional version
In this appendix, we state the Strassen–Dudley theorem together with its conditional version due to [42]. These results play fundamental roles in the proofs of Proposition 2.1 and Theorem 3.1. In what follows, let (S, d) be a Polish metric space equipped with its Borel \(\sigma \)-field \({\mathcal {B}}(S)\). For any set \(A \subset S\) and \(\delta > 0\), let \(A^{\delta } = \{ x \in S : \inf _{y \in A} d(x,y) \leqslant \delta \}\). We first state the Strassen–Dudley theorem.
Theorem B.1
(Strassen–Dudley) Let X be an S-valued random variable defined on a probability space \((\Omega ,{\mathcal {A}},{\mathbb {P}})\) which admits a uniform random variable on (0, 1) independent of X. Let \(\alpha , \beta >0\) be given constants, and let G be a Borel probability measure on S such that \({\mathbb {P}}(X \in A) \leqslant G(A^{\alpha })+ \beta \) for all \(A \in {\mathcal {B}}(S)\). Then there exists an S-valued random variable Y such that \({\mathcal {L}}(Y) (:= {\mathbb {P}}\circ Y^{-1}) = G\) and \({\mathbb {P}}(d(X,Y) > \alpha ) \leqslant \beta \).
For a proof of the Strassen–Dudley theorem, we refer to [20]. Next, we state a conditional version of the Strassen–Dudley theorem due to [42, Theorem 4].
Theorem B.2
(Conditional version of Strassen–Dudley) Let X be an S-valued random variable defined on a probability space \((\Omega ,{\mathcal {A}},{\mathbb {P}})\), and let \({\mathcal {G}}\) be a countably generated sub \(\sigma \)-field of \({\mathcal {A}}\). Suppose that there is a uniform random variable on (0, 1) independent of \({\mathcal {G}}\vee \sigma (X)\), and let \(\Omega \times {\mathcal {B}}(S) \ni (\omega ,A) \mapsto G(A \mid {\mathcal {G}}) (\omega )\) be a regular conditional distribution given \({\mathcal {G}}\), i.e., for each fixed \(A \in {\mathcal {B}}(S)\), \(G(A \mid {\mathcal {G}})\) is measurable with respect to \({\mathcal {G}}\) and for each fixed \(\omega \in \Omega \), \(G(\cdot \mid {\mathcal {G}})(\omega )\) is a probability measure on \({\mathcal {B}}(S)\). If
then there exists an S-valued random variable Y such that the conditional distribution of Y given \({\mathcal {G}}\) is identical to \(G(\cdot \mid {\mathcal {G}})\), and \({\mathbb {P}}( d(X,Y) > \alpha ) \leqslant \beta \).
Remark B.1
(i) The map \((\omega ,A) \mapsto {\mathbb {P}}(X \in A \mid {\mathcal {G}})(\omega )\) should be understood as a regular conditional distribution (which is guaranteed to exist since X takes values in a Polish space). (ii) \({\mathbb {E}}^{*}\) denotes the outer expectation.
For completeness, we provide a self-contained proof of Theorem B.2, since [42] do not provide its direct proof.
Proof of Theorem B.2
Since \({\mathcal {G}}\) is countably generated, there exists a real-valued random variable W such that \({\mathcal {G}}= \sigma (W)\). For \(n=1,2,\dots \) and \(k \in {\mathbb {Z}}\), let \(D_{n,k} = \{ k/2^{n} \leqslant W < (k+1)/2^{n} \}\). For each n, \(\{ D_{n,k} : k \in {\mathbb {Z}} \}\) forms a partition of \(\Omega \). Pick any D from \(\{ D_{n,k} : n =1,2,\dots ; k \in {\mathbb {Z}} \}\); let \({\mathbb {P}}_{D} = {\mathbb {P}}(\cdot \mid D)\) and \(G(\cdot \mid D) = \int G(\cdot \mid {\mathcal {G}}) d{\mathbb {P}}_{D}\). Then, the Strassen–Dudley theorem yields that there exists an S-valued random variable \(Y_{D}\) such that \({\mathbb {P}}_{D} \circ Y_{D}^{-1} = G(\cdot \mid D)\) and \({\mathbb {P}}_{D}(d(X,Y_{D}) > \alpha ) \leqslant \varepsilon (D) := \sup _{A \in {\mathcal {B}}(S)} \{ {\mathbb {P}}_{D}(X \in A) - G(A^{\alpha } \mid D) \}\).
For each \(n=1,2,\dots \), let \(Y_{n} = \sum _{k \in {\mathbb {Z}}} Y_{D_{n,k}} 1_{D_{n,k}}\), and observe that
Let M be any (proper) random variable such that \(M \geqslant \sup _{A \in {\mathcal {B}}(S)} \{ {\mathbb {P}}(X \in A \mid {\mathcal {G}}) - G(A^{\alpha } \mid {\mathcal {G}}) \}\), and observe that
where the notation \({\mathbb {E}}^{{\mathbb {P}}_{D}}\) denotes the expectation under \({\mathbb {P}}_{D}\). So,
and taking infimum with respect to M yields that the left hand side is bounded by \(\beta \).
Next, we shall verify that \(\{ {\mathcal {L}}(Y_{n}) : n \geqslant 1 \}\) is uniformly tight. In fact,
and since any Borel probability measure on a Polish space is tight by Ulam’s theorem, \(\{ {\mathcal {L}}(Y_{n}) : n \geqslant 1 \}\) is uniformly tight. This implies that the family of joint laws \(\{ {\mathcal {L}}(X,W,Y_{n}) : n \geqslant 1 \}\) is uniformly tight and hence has a weakly convergent subsequence by Prohorov’s theorem. Let \({\mathcal {L}}(X,W,Y_{n'}) {\mathop {\rightarrow }\limits ^{w}} Q\) (the notation \({\mathop {\rightarrow }\limits ^{w}}\) denotes weak convergence), and observe that the marginal law of Q on the “first two” coordinates, \(S \times {\mathbb {R}}\), is identical to \({\mathcal {L}}(X,W)\).
We shall verify that there exists an S-valued random variable Y such that \({\mathcal {L}}(X,W,Y) =Q\). Since S is polish, there exists a unique regular conditional distribution, \({\mathcal {B}}(S) \times (S \times {\mathbb {R}}) \ni (A,(x,w)) \mapsto Q_{x,w}(A) \in [0,1]\), for Q given the first two coordinates. By the Borel isomorphism theorem [20, Theorem 13.1.1], there exists a bijective map \(\pi \) from S onto a Borel subset of \({\mathbb {R}}\) such that \(\pi \) and \(\pi ^{-1}\) are Borel measurable. Pick and fix any \((x,w) \in S \times {\mathbb {R}}\), and observe that \(Q_{x,w} \circ \pi ^{-1}\) extends to a Borel probability measure on \({\mathbb {R}}\). Denote by \(F_{x,w}\) the distribution function of \(Q_{x,w} \circ \pi ^{-1}\), and let \(F_{x,w}^{-1}\) denotes its quantile function. Let U be a uniform random variable on (0, 1) (defined on \((\Omega ,{\mathcal {A}},{\mathbb {P}})\)) independent of (X, W). Then \(F_{x,w}^{-1} (U)\) has law \(Q_{x,w} \circ \pi ^{-1}\), and hence \(Y = \pi ^{-1} \circ F_{X,W}^{-1} (U)\) is the desired random variable.
Now, for any bounded continuous function f on S, observe that, whenever \(N \geqslant n\), \({\mathbb {E}}[ f(Y_{N})1_{D_{n,k}} ] = \int _{D_{n,k}} \int f(y) G(dy \mid {\mathcal {G}}) d{\mathbb {P}}\), which implies that the conditional distribution of Y given \({\mathcal {G}}\) is identical to \(G( \cdot \mid {\mathcal {G}})\). Finally, the Portmanteau theorem yields \({\mathbb {P}}(d(X,Y)> \alpha ) \leqslant \liminf _{n'} {\mathbb {P}}(d(X,Y_{n'}) > \alpha ) \leqslant \beta \). This completes the proof. \(\square \)
Appendix C. Additional proofs for the main text
1.1 C.1. Proof of Lemma 6.1
We begin with noting that \({\mathcal {G}}\) is VC type with characteristics \(4\sqrt{A}\) and 2v for envelope G. The rest of the proof is almost the same as that of Theorem 2.1 in [15] with \(B(f) \equiv 0\) (up to adjustments of the notation), but we now allow \(q=\infty \). To avoid repetitions, we only point out required modifications. In what follows, we will freely use the notation in the proof of [15, Theorem 2.1], but modify \(K_{n}\) to \(K_{n} = v \log (A \vee n)\), and C refers to a universal constant whose value may vary from place to place. In Step 1, change \(\varepsilon \) to \(\varepsilon =1/n^{1/2}\). For this choice, \(\log N({\mathcal {F}},e_{P},\varepsilon b) \leqslant C \log (Ab/(\varepsilon b)) = C\log (A/\varepsilon ) \leqslant CK_{n}\), and Dudley’s entropy integral bound yields that \({\mathbb {E}}[ \Vert G_{P} \Vert _{{\mathcal {F}}_{\varepsilon }}] \leqslant C\varepsilon b \sqrt{\log (Ab/(\varepsilon b))} \leqslant Cb\sqrt{K_{n}/n}\) (there is a slip in the estimate of \({\mathbb {E}}[\Vert G_{P}\Vert _{{\mathcal {F}}_{\varepsilon }}]\) in [15], namely, “\(Ab/\varepsilon \)” inside the log should read “\(Ab/(\varepsilon b)\)”, which of course does not affect the proof under their definition of \(K_{n}\)). Combining the Borell-Sudakov-Tsirel’son inequality yields that \({\mathbb {P}}\{ \Vert G_{P}\Vert _{{\mathcal {F}}_{\varepsilon }} > C b\sqrt{K_{n}/n} \} \leqslant 2n^{-1}\). In Step 3, Corollary 5.5 in the present paper (with \(r=k=1\)) yields that \({\mathbb {E}}[ \Vert {\mathbb {G}}_{n} \Vert _{{\mathcal {F}}_{\varepsilon }}] \leqslant C(b\sqrt{K_{n}/n} + bK_{n}/n^{1/2-1/q}) \leqslant CbK_{n}/n^{1/2-1/q}\), which is valid even when \(q=\infty \). Then, instead of applying their Lemma 6.1, we apply Markov’s inequality to deduce that
In Step 4, instead of their equation (14), we have
whenever \(\delta \geqslant 2c\sigma ^{-1/2}(\log N)^{3/2} \cdot (\log n)\) for some universal constant c (\(C_{7}\) comes from their Theorem 3.1 and is universal). Finally, in Step 5, take
for some large but universal constant \(C' > 1\). Under the assumption that \(K_{n}^{3} \leqslant n\), this choice ensures that \(\delta \geqslant 2c\sigma ^{-1/2}(\log N)^{3/2} \cdot (\log n)\), and
It remains to bound \(M_{n,X}(\delta )\). For finite q, their Step 4 shows that
Since \(\log N \leqslant C''K_{n}\) for some universal constant \(C''\), the right hand side is bounded by
Since \(K_{n}\) is bounded from below by a universal positive constant (by assumption), and \(\gamma \in (0,1)\), by taking \(C' > C''\), the above term is bounded by \(\gamma \) up to a universal constant.
Now, consider the \(q=\infty \) case. In that case, \(\max _{1 \leqslant j \leqslant N}| {\widetilde{X}}_{1j} | \leqslant 2b\) almost surely and \(\delta \sqrt{n}/\log N \geqslant 2C'b/(C''\gamma ) > 2b\) provided that \(C' > C''\). Hence \(M_{n,X}(\delta ) =0\) in that case. These modifications lead to the desired conclusion. \(\square \)
1.2 C.1. Proofs for Sect. 4
We first prove Theorem 4.2 and Corollary 4.3, and then prove Lemma 4.1 and Theorem 4.4.
Proof of Theorem 4.2
In what follows, the notation \(\lesssim \) signifies that the left hand side is bounded by the right hand side up to a constant that depends only on \(r,m,\zeta ,c_1,c_2,C_1,L\). We also write \(a \simeq b\) if \(a \lesssim b\) and \(b \lesssim a\). In addition, let \(c,C,C'\) denote generic constants depending only on \(r, m,\zeta , c_{1},c_{2}, C_{1}, L\); their values may vary from place to place. We divide the rest of the proof into three steps.
Step 1 Let
In this step, we shall show that the result (15) holds with \({\widehat{S}}_{n}\) and \({\widehat{S}}_{n}^{\sharp }\) replaced by \(S_{n}\) and \(S_{n}^{\sharp }\), respectively.
We first verify Conditions (PM), (VC), (MT), and (5) for the function class
with a symmetric envelope
Condition (PM) follows from our assumption. For Condition (VC), that \({\mathcal {H}}_{n}\) is VC type with characteristics \((A', v')\) satisfying \(\log A' \lesssim \log n\) and \(v' \lesssim 1\) follows from a slight modification of the proof of Lemma 3.1 in [25]. The latter part follows from our assumption. Condition (VC) guarantees the existence of a tight Gaussian random variable \({\mathcal {W}}_{P,n}(g), g \in P^{r-1}{\mathcal {H}}_{n} =: {\mathcal {G}}_{n}\) in \(\ell ^{\infty }({\mathcal {G}}_{n})\) with mean zero and covariance function \({\mathbb {E}}[{\mathcal {W}}_{P,n}(g){\mathcal {W}}_{P,n}(g')] = \mathrm {Cov}_{P}(g,g')\) for \(g,g' \in {\mathcal {G}}_{n}\). Let \(W_{P,n} (\vartheta ) = {\mathcal {W}}_{P,n}(g_{n,\vartheta })\) for \(\vartheta \in \Theta \) where \(g_{n,\vartheta } = b_{n}^{m/2} c_{n}(\vartheta )^{-1} P^{r-1}h_{n,\vartheta }\). It is seen that \(W_{P,n}(\vartheta ), \vartheta \in \Theta \) is a tight Gaussian random variable in \(\ell ^{\infty }(\Theta )\) with mean zero and covariance function (14).
Next, we determine the values of parameters \({\underline{\sigma }}_{{\mathfrak {g}}}, {\overline{\sigma }}_{{\mathfrak {g}}}, b_{{\mathfrak {g}}}, \sigma _{{\mathfrak {h}}}, b_{{\mathfrak {h}}}, \chi _{n},\nu _{{\mathfrak {h}}}\) for the function class \({\mathcal {H}}_n\). We will show in Step 3 that we may choose
and bound \(\nu _{{\mathfrak {h}}}\) and \(\chi _{n}\) as
Given these choices and bounds, Corollaries 2.2 and 3.2 yield that
Step 2 Observe that
We shall bound \(\sup _{\vartheta \in \Theta } | c_{n}(\vartheta )/{\widehat{c}}_{n}(\vartheta ) - 1|, \Vert \sqrt{n}U_{n} \Vert _{{\mathcal {H}}_{n}}\), and \(\Vert {\mathbb {U}}_{n}^{\sharp } \Vert _{{\mathcal {H}}_{n}}\).
Choose \(n_{0}\) by the smallest n such that \(C_{1}n^{-c_{2}} \leqslant 1/2\); it is clear that \(n_{0}\) depends only on \(c_{2}\) and \(C_{1}\). It suffices to prove (15) for \(n \geqslant n_{0}\), since for \(n < n_{0}\), the result (15) becomes trivial by taking C sufficiently large. So let \(n \geqslant n_{0}\). Then Condition (T8) ensures that with probability at least \(1-C_{1}n^{-c_{2}}\), \(\inf _{\vartheta \in \Theta } {\widehat{c}}_{n}(\vartheta )/c_{n}(\vartheta ) \geqslant 1/2\). Since \(| a^{-1} - 1 | \leqslant 2 | a - 1 |\) for \(a \geqslant 1/2\), Condition (T8) also ensures that
Next, we shall bound \(\Vert \sqrt{n}U_{n} \Vert _{{\mathcal {H}}_{n}}\) and \(\Vert {\mathbb {U}}_{n}^{\sharp } \Vert _{{\mathcal {H}}_{n}}\). Given (38) and (39), and in view of the fact that the covering number of \({\mathcal {H}}_{n} \cup (-{\mathcal {H}}_{n}) := \{ h,-h : h \in {\mathcal {H}}_{n} \}\) is at most twice that of \({\mathcal {H}}_{n}\), applying Corollaries 2.2 and 3.2 to the function class \({\mathcal {H}}_{n} \cup (-{\mathcal {H}}_{n})\), we deduce that
(Theorem 3.7.28 in [29] ensures that the Gaussian process \({\mathcal {W}}_{P,n}\) extends to the symmetric convex hull of \({\mathcal {G}}_{n}\) in such a way that \({\mathcal {W}}_{P,n}\) has linear, bounded, and uniformly continuous (with respect to the intrinsic pseudometric) sample paths; in particular, \(\{ {\mathcal {W}}_{P,n}(g) : g \in {\mathcal {G}}_{n} \cup (-{\mathcal {G}}_{n}) \}\) is a tight Gaussian random variable in \(\ell ^{\infty }({\mathcal {G}}_{n} \cup (-{\mathcal {G}}_{n}))\) with mean zero and covariance function \({\mathbb {E}}[{\mathcal {W}}_{P,n}(g){\mathcal {W}}_{P,n}(g')] = \mathrm {Cov}_{P}(g,g')\) for \(g,g' \in {\mathcal {G}}_{n} \cup (-{\mathcal {G}}_{n})\) and \(\sup _{g \in {\mathcal {G}}_{n} \cup (-{\mathcal {G}}_{n})} {\mathcal {W}}_{n}(g) = \Vert {\mathcal {W}}_{P,n} \Vert _{{\mathcal {G}}_{n}}\).) Dudley’s entropy integral bound and the Borell-Sudakov-Tsirel’son inequality yield that \({\mathbb {P}}\{ \Vert {\mathcal {W}}_{P,n} \Vert _{{\mathcal {G}}_{n}} > C(\log n)^{1/2} \} \leqslant 2n^{-1}\), so that
Now, the desired result (15) follows from combining (40)–(43) and the anti-concentration inequality (Lemma A.1). In fact, the anti-concentration inequality yields
Hence, combining the bounds (40)–(44), we have for every \(t \in {\mathbb {R}}\),
and likewise \({\mathbb {P}}({\widehat{S}}_{n} \leqslant t) \geqslant {\mathbb {P}}({\widetilde{S}}_{n} \leqslant t) - Cn^{-c}\). Similarly, we have
Step 3 It remains to verify (38) and (39). First, that we may choose \({\underline{\sigma }}_{{\mathfrak {g}}} \simeq 1\) follows from Conditions (T6) and (T7). For \(\varphi \in \Phi \) and \(k=1,\dots ,r-1\), let
and define \({\overline{\varphi }}_{[r-k]}\) similarly. Then, for \(k=1,\dots ,r\),
where \(x-b_{n}x_{k+1:r} = (x-b_{n}x_{k+1},\dots ,x-b_{n}x_{r})\). Likewise, we have
Suppose first that q is finite and let \(\ell \in [2,q]\). Observe that by Jensen’s inequality,
so that \(\sup _{h \in {\mathcal {H}}_n} \Vert P^{r-k}h \Vert _{P^k,\ell } \lesssim b_n^{-m[(k-1/2)-k/\ell ]}\). Hence, we may choose \({\overline{\sigma }}_{\mathfrak {g}}\simeq 1\) and \(\sigma _{\mathfrak {h}}\simeq b_n^{-m/2}\). Similarly, Jensen’s inequality and the symmetry of \({\overline{\varphi }}\) yield that
so that \(\Vert P^{r-k} H_n \Vert _{P^k,\ell } \lesssim b_n^{-m[(1-1/\ell )k - (1/2-1/\ell )]}\). Hence, we may choose \(b_{\mathfrak {g}}\simeq b_n^{-m/2}\), \(b_{\mathfrak {h}}\simeq b_n^{-3m/2}\), and bound \(\chi _{n}\) as
Similar calculations yield that
Hence, \(\nu _{{\mathfrak {h}}} \lesssim b_n^{-m(1-1/q)}\).
It is not difficult to verify that (38) and (39) hold in the \(q=\infty \) case as well under the convention that \(1/q=0\) for \(q=\infty \). This completes the proof. \(\square \)
Proof of Corollary 4.3
Let \(\eta _{n} := Cn^{-c}\) where the constants c, C are those given in Theorem 4.2. Denote by \(q_{{\widetilde{S}}_{n}}(\alpha )\) the \(\alpha \)-quantile of \({\widetilde{S}}_{n}\). Define the event
whose probability is at least \(1-\eta _{n}\). On this event,
where the second equality follows from the fact that the distribution function of \({\widetilde{S}}_{n}\) is continuous (cf. Lemma A.1). This shows that the inequality \(q_{{\widehat{S}}_{n}^{\sharp }}(\alpha ) \leqslant q_{{\widetilde{S}}_{n}}(\alpha +\eta _{n})\) holds on the event \({\mathcal {E}}_{n}\), so that
The above discussion presumes that \(\alpha + \eta _{n} < 1\), but if \(\alpha + \eta _{n} \geqslant 1\), then the last inequality is trivial. Likewise, we have \({\mathbb {P}}\left\{ {\widehat{S}}_{n} \leqslant q_{{\widehat{S}}_{n}^{\sharp }}(\alpha ) \right\} \geqslant \alpha -3\eta _{n}\). This completes the proof. \(\square \)
Proof of Lemma 4.1
We begin with noting that
where \(\breve{h}_{n,\vartheta } = b_{n}^{m/2}c_{n}(\vartheta )^{-1} h_{n,\vartheta }\). We note that \(\mathrm {Var}_{P}(P^{r-1}\breve{h}_{n,\vartheta }) =1\) by the definition of \(c_{n}(\vartheta )\). Recall from the proof of Theorem 4.2 that the function class \({\mathcal {H}}_{n} =\{ \breve{h}_{n,\vartheta } : \vartheta \in \Theta \}\) is VC type with characteristics \((A', v')\) satisfying \(\log A' \lesssim \log n\) and \(v' \lesssim 1\) for envelope \(H_{n}\). Now, from Step 5 in the proof of Theorem 3.1 applied with \({\mathcal {H}}= {\mathcal {H}}_{n}\), we have for every \(\gamma \in (0,1)\), with probability at least \(1-\gamma -n^{-1}\),
for some constant C depending only on r. The desired result follows from the choices of parameters \({\overline{\sigma }}_{{\mathfrak {g}}}, b_{{\mathfrak {g}}}, \sigma _{{\mathfrak {h}}}, b_{{\mathfrak {h}}}, \chi _{n}\), and \(\nu _{{\mathfrak {h}}}\) given in the proof of Theorem 4.2 together with choosing \(\gamma = n^{-c}\) for some constant c sufficiently small but depending only on \(r, m, \zeta , c_{1},c_{2}, C_{1}, L\). \(\square \)
Proof of Theorem 4.4
The proof follows from similar arguments to those in the proof of Theorem 4.2, so we only highlight the differences. Define the function class
with a symmetric envelope
Recall that we assume \(q=\infty \) in this theorem. In view of the calculations in the proof of Theorem 4.2, we may choose
and bound \(\nu _{{\mathfrak {h}}}\) and \(\chi _{n}\) as
Given these choices and bounds, the conclusion of the theorem follows from repeating the proof of Theorem 4.2. \(\square \)
Appendix D. Conditional UCLT for JMB
In this section we prove the conditional UCLT for the JMB when the function class \({\mathcal {H}}\) and the distribution P are independent of n under a metric entropy condition. We obey the notation used in Sects. 2 and 3 but since we consider a limit theorem we assume that the probability space is \((\Omega ,{\mathcal {A}},{\mathbb {P}}) = (S^{{\mathbb {N}}},{\mathcal {S}}^{{\mathbb {N}}},P^{{\mathbb {N}}}) \times (\Xi , {\mathcal {C}}, R)\) and \(X_{1},X_{2},\dots \) are the coordinate projections of \((S^{{\mathbb {N}}},{\mathcal {S}}^{{\mathbb {N}}},P^{{\mathbb {N}}})\). To formulate the conditional UCLT, recall that weak convergence in \(\ell ^{\infty }({\mathcal {H}})\) is “metrized” by the bounded Lipschitz distance: for arbitrary maps \({\mathbb {X}}_{n}: \Omega \rightarrow \ell ^{\infty }({\mathcal {H}})\) and a tight Borel measurable map \({\mathbb {X}}: \Omega \rightarrow \ell ^{\infty }({\mathcal {H}})\), \({\mathbb {X}}_{n}\) converge weakly to \({\mathbb {X}}\) if and only if
where \(BL_{1} = \{ f : \ell ^{\infty }({\mathcal {H}}) \rightarrow {\mathbb {R}}: |f| \leqslant 1, |f(x)-f(y)| \leqslant \Vert x-y \Vert _{{\mathcal {H}}} \ \forall x,y \in \ell ^{\infty }({\mathcal {H}}) \}\); see [53, p. 73]. If the function class \({\mathcal {G}}= P^{r-1} {\mathcal {H}}= \{ P^{r-1} h : h \in {\mathcal {H}}\}\) is P-pre-Gaussian, then there exists a tight Gaussian random variable \(W_{P}\) in \(\ell ^{\infty }({\mathcal {G}})\) with mean zero and covariance function \({\mathbb {E}}[W_{P}(g)W_{P}(g')] = \mathrm {Cov}_{P} (g,g')\). Set \({\mathbb {W}}_{P} (h) = W_{P} \circ P^{r-1} (h)\), which is a tight Gaussian random variable in \(\ell ^{\infty }({\mathcal {H}})\) with mean zero and covariance function \({\mathbb {E}}[{\mathbb {W}}_{P} (h){\mathbb {W}}_{P}(h')] = \mathrm {Cov}_{P}(P^{r-1}h,P^{r-1}h')\). We will show that conditionally on \(X_{1}^{\infty } = \{ X_{1},X_{2},\dots \}\), \({\mathbb {U}}_{n}^{\sharp }\) converges weakly to \({\mathbb {W}}_{P}\) in probability in the sense that
converges to zero in outer probability under regularity conditions (\({\mathbb {E}}_{\mid X_{1}^{\infty }}\) denotes the conditional expectation given \(X_{1}^{\infty }\)). Since the map \((\xi _{1},\dots ,\xi _{n}) \mapsto n^{-1/2} \sum _{i=1}^n \xi _{i}[ U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}\cdot ) - U_n(\cdot ) ]\) is continuous from \({\mathbb {R}}^{n}\) into \(\ell ^{\infty }({\mathcal {H}})\), the multiplier process \({\mathbb {U}}_{n}^{\sharp }\) induces a Borel measurable map into \(\ell ^{\infty }({\mathcal {H}})\) for fixed \(X_{1}^{\infty }\). For an arbitrary map \(Y: \Omega \rightarrow {\mathbb {R}}\), let \(Y^{*}\) denote the measurable cover [53, lemma 1.2.1].
Theorem D.1
(Conditional UCLT for JMB) Let \({\mathcal {H}}\) be a fixed pointwise measurable class of symmetric measurable functions on \(S^{r}\) with symmetric envelope \(H \in L^{2}(P^{r})\) such that \(\int _{0}^{1} \sqrt{\lambda (\varepsilon )} d\varepsilon < \infty \) with \(\lambda (\varepsilon ) = \sup _{Q} \log N({\mathcal {H}},\Vert \cdot \Vert _{Q,2},\varepsilon \Vert H \Vert _{Q,2})\). Then \({\mathcal {G}}= P^{r-1}{\mathcal {H}}= \{ P^{r-1} h : h \in {\mathcal {H}}\}\) is P-pre-Gaussian, \(d_{BL}({\mathbb {U}}_{n}/r,{\mathbb {W}}_{P}) \rightarrow 0\), and \(d_{BL \mid X_{1}^{\infty }}({\mathbb {U}}_{n}^{\sharp },{\mathbb {W}}_{P})^{*} {\mathop {\rightarrow }\limits ^{{\mathbb {P}}}} 0\) as \(n \rightarrow \infty \).
Theorem D.1 should be compared with Theorem 2.1 in [5] that establishes a conditional UCLT for the empirical bootstrap for a non-degenerate U-process under the same metric entropy condition. Interestingly, however, our moment condition on the envelope H is weaker than their condition (2.3), which, if \(r=2\), requires \({\mathbb {E}}[H(X_1,X_1)]<\infty \) in addition to \({\mathbb {E}}[H^{2}(X_1,X_2)] < \infty \). This comes from the difference in how to estimate the Hajék projection; our JMB estimates the Hajék projection by a jackknife U-statistic, while the empirical bootstrap estimates it by a V-statistic (see Remark 3.1).
If we are interested in \(\sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}(h)/r\), then the result of Theorem D.1 implies that
as long as the distribution function of \(\sup _{g \in {\mathcal {G}}} W_{P}(g)\) is continuous, which is true if \(\inf _{g \in {\mathcal {G}}} \mathrm {Var}_{P}(g) > 0\) (cf. Lemma A.1). When the function class \({\mathcal {H}}\) is centrally symmetric (i.e., \(-h \in {\mathcal {H}}\) whenever \(h \in {\mathcal {H}}\)) so that \(\sup _{h \in {\mathcal {H}}}{\mathbb {U}}_{n}(h) = \Vert {\mathbb {U}}_{n} \Vert _{{\mathcal {H}}}\), \(\sup _{g \in {\mathcal {G}}}W_{P}(g) = \Vert W_{P} \Vert _{{\mathcal {G}}}\), and \(\sup _{h \in {\mathcal {H}}}{\mathbb {U}}_{n}^{\sharp }(h) = \Vert {\mathbb {U}}_{n}^{\sharp } \Vert _{{\mathcal {H}}}\), then the distribution function of \(\Vert W_{P} \Vert _{{\mathcal {G}}}\) is continuous under a much less restrictive assumption that \(\mathrm {Var}_{P}(g) > 0\) for some \(g \in {\mathcal {G}}\). Indeed, from Theorem 11.1 in [17], the distribution of \(\Vert W_{P} \Vert _{{\mathcal {G}}}\) is (absolutely) continuous on \((\ell _{0},\infty )\) with \(\ell _{0} \geqslant 0\) being the left endpoint of the support of \(\Vert W_{P} \Vert _{{\mathcal {G}}}\), but from [37, p. 57–58], \(\ell _{0} = 0\). This implies that, unless \(\Vert W_{P} \Vert _{{\mathcal {G}}} = 0\) almost surely, the distribution function of \(\Vert W_{P} \Vert _{{\mathcal {G}}}\) does not have a jump at \(\ell _{0} = 0\) (as \({\mathbb {P}}(\Vert W_{P} \Vert _{{\mathcal {G}}} = 0) = 0\)) and so is everywhere continuous on \({\mathbb {R}}\).
Proof of Theorem D.1
The first two results are essentially implied by the proof of Theorem 4.9 in [4] but we include their proofs for completeness. By changing H to \(H \vee 1\) if necessary, we may assume \(\Vert G \Vert _{P,2} > 0\) (recall \(G=P^{r-1}H\)), which implies \(\Vert H \Vert _{P,2} > 0\). By Jensen’s inequality, \(\Vert P^{r-1}h \Vert _{P,2} \leqslant \Vert h \Vert _{P^{r},2}\) and so we have
The right hand side is bounded by \(\sup _{Q}N({\mathcal {H}},\Vert \cdot \Vert _{Q,2},\tau \Vert H \Vert _{Q,2}/4)\) by Lemma A.2. Conclude that
which implies by Dudley’s criterion for sample continuity that \({\mathcal {G}}\) is P-pre-Gaussian (to be precise we have to verify \(\int _{0}^{1} \sqrt{\log N(\{ g-Pg : g \in {\mathcal {G}}\},\Vert \cdot \Vert _{P,2},\tau )} d\tau < \infty \) but this is immediate). The convergence of marginals of \({\mathbb {U}}_{n}/r\) to \({\mathbb {W}}_{P}\) follows from the multidimensional CLT for U-statistics. To conclude \(d_{BL}({\mathbb {U}}_{n}/r,{\mathbb {W}}_{P}) \rightarrow 0\), it suffices to show the asymptotic equicontinuity condition
holds for every \(\eta > 0\). We defer the proof of (45) after the proof of the theorem.
To prove the last result of the theorem, let \(e_{P} (h,h') = \Vert P^{r-1}(h-h') \Vert _{P,2}\) and for given \(\delta > 0\) let \(\{ h_{1},\dots ,h_{N(\delta )} \}\) be a \((\delta \Vert G \Vert _{P,2})\)-net of \(({\mathcal {H}},e_{P})\). Let \(\pi _{\delta }: {\mathcal {H}}\rightarrow \{ h_{1},\dots ,h_{N(\delta )} \}\) be a map such that for each \(h \in {\mathcal {H}}\), \(e_{P} (h,\pi _{\delta }(h)) \leqslant \delta \Vert G \Vert _{P,2}\). Define \({\mathbb {U}}_{n,\delta }^{\sharp } := {\mathbb {U}}_{n}^{\sharp } \circ \pi _{\delta }\) and \({\mathbb {W}}_{P,\delta } := {\mathbb {W}}_{P} \circ \pi _{\delta }\). For any \(f \in BL_{1}\), we have
The third term on the right hand side of (46) is bounded by \({\mathbb {E}}[2 \wedge \Vert {\mathbb {W}}_{P,\delta } - {\mathbb {W}}_{P} \Vert _{{\mathcal {H}}}]\) and by construction \({\mathbb {W}}_{P}\) has sample paths almost surely uniformly \(e_{P}\)-continuous, so that \({\mathbb {E}}[2 \wedge \Vert {\mathbb {W}}_{P,\delta } - {\mathbb {W}}_{P} \Vert _{{\mathcal {H}}}] \rightarrow 0\) as \(\delta \downarrow 0\) by the dominated convergence theorem. Since \({\mathbb {U}}_{n,\delta }^{\sharp }\) can be identified with a Gaussian vector of dimension \(N(\delta )\) conditionally on \(X_{1}^{\infty }\), by Lemma 3.7.46 in [29], the second term on the right hand side of (46) is bounded by
for some constant \(c(\delta )\) that depends only on \(\delta \), where
From Step 5 of the proof of Theorem 3.1 and using the notation in the proof, we have
From the UCLT for the U-process established in the first paragraph, the last term on the right hand side is \(o_{{\mathbb {P}}}(1)\). The function class \(\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}}\) is weak P-Glivenko-Cantelli by Lemmas A.3 and A.5 together with Theorem 2.4.3 in [53], which implies that \(n^{-1/2} \Vert {\mathbb {G}}_{n} \Vert _{\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}}} = o_{{\mathbb {P}}}(1)\). From Lemma D.3 below, we also have \(\Upsilon _{n} = o_{{\mathbb {P}}}(1)\).
Finally, the first term on the right hand side of (46) is bounded by
for any \(\varepsilon > 0\), where \({\mathcal {H}}_{\delta } = \{ h-h' : h,h' \in {\mathcal {H}}, e_{P}(h,h') < 2\delta \Vert G \Vert _{P,2} \}\). Let \(\Sigma _{n,\delta } := \Vert n^{-1} \sum _{i=1}^{n}\{ U_{n-1,-i}^{(r-1)} (\delta _{X_{i}}h) - U_{n}(h) \}^{2} \Vert _{{\mathcal {H}}_{\delta }}\). By Markov’s inequality,
From Step 5 of the proof of Theorem 3.1,
with \(d(h,h') = \{ {\mathbb {E}}_{\mid X_{1}^{\infty }} [\{ {\mathbb {U}}_{n}^{\sharp } (h) - {\mathbb {U}}_{n}^{\sharp } (h') \}^{2}]\}^{1/2}\). Hence by Dudley’s entropy integral bound, we have
up to a constant independent of n and \(\delta \), and \(\Vert H \Vert _{{\mathbb {P}}_{I_{n,r},2}}^{2} = |I_{n,r}|^{-1}\sum _{I_{n,r}} H^{2}(X_{i_{1}},\dots ,X_{i_{r}}) = \Vert H \Vert _{P^{r},2}^{2} + o_{{\mathbb {P}}}(1)\) by the law of large numbers for U-statistics [18, Theorem 4.1.4]. From Step 4 of the proof of Theorem 3.1,
and the last two terms on the right hand side are \(o_{{\mathbb {P}}}(1)\) while the first term can be arbitrarily small by taking \(\delta \) sufficiently small. This implies that for any \(\eta > 0\),
Putting everything together, we conclude \(d_{BL \mid X_{1}^{\infty }}({\mathbb {U}}_{n}^{\sharp },{\mathbb {W}}_{P})^{*} {\mathop {\rightarrow }\limits ^{{\mathbb {P}}}} 0\), completing the proof. \(\square \)
Lemma D.2
Under the assumption of Theorem D.1, the asymptotic equicontinuity condition (45) holds.
Proof of Lemma D.2
For \(\delta \in (0,1]\), let \({\mathcal {H}}_{\delta }' = \{ h -h' : \Vert h - h' \Vert _{P^{r},2} < \delta \Vert H \Vert _{P^{r},2} \}\). By Markov’s inequality, it suffices to show that
We use Hoeffding’s averaging [49, Section 5.1.6] to bound the expectation. Let
Then we have
where \(\sum _{j_{1},\dots ,j_{n}}\) are taken over all permutations \(j_{1},\dots ,j_{n}\) of \(1,\dots ,n\). By Jensen’s inequality, \({\mathbb {E}}[ \Vert {\mathbb {U}}_{n} \Vert _{{\mathcal {H}}_{\delta }'}]\) is bounded by \(\sqrt{n}{\mathbb {E}}[\Vert S_{h}(X_{1},\dots ,X_{n}) - P^{r}h \Vert _{{\mathcal {H}}_{\delta }'}]\). Since
and since \((X_{(i-1)r+1},\dots ,X_{ir}) , i=1,\dots ,m\) are i.i.d., we can apply Theorem 5.2 in [14] to conclude that
up to a constant that depends only on r, where \(M_{r} = \max _{1 \leqslant i \leqslant m} H(X_{(i-1)r+1},\dots ,X_{ir})\) and the J function is defined in [14]. From a standard calculation, \(J(\delta ,{\mathcal {H}}_{\delta }', 2H) \lesssim J(\delta ,{\mathcal {H}},H) = \int _{0}^{\delta }\sqrt{1+\lambda (\tau )} d\tau \) up to a universal constant and \(\Vert M_{r} \Vert _{{\mathbb {P}},2} = o(\sqrt{m})\) by \(H \in L^{2}(P^{r})\) [53, Problem 2.3.4]. Hence we conclude
up to a constant that depends only on r, and by the dominated convergence theorem the right hand side is o(1) as \(\delta \downarrow 0\). This completes the proof. \(\square \)
Lemma D.3
Under the assumption of Theorem D.1, we have \({\mathbb {E}}[\Upsilon _{n}]= O(n^{-1})\) where \(\Upsilon _{n}\) is defined in (31).
Proof of Lemma D.3
We begin with noting that
By Hoeffding’s averaging [49, Section 5.1.6],
where \(\sum _{j_{1},\dots ,j_{n-1}}\) is taken over all permutations \(j_{1},\dots ,j_{n-1}\) of \(1,\dots ,n-1\), and
By Jensen’s inequality,
By Corollary A.4 and the condition of Theorem D.1, for given \(x \in S\),
Hence, applying Theorem 2.14.1 in [53] conditionally on \(X_{n}\), we have
up to a constant independent of n. Since \({\mathbb {E}}[\Vert \delta _{X_{n}} H \Vert _{P^{r-1},2}^{2}] = \Vert H \Vert _{P^{r},2}^{2}\), we obtain the desired conclusion by Fubini’s theorem. \(\square \)
Appendix E. Gaussian approximation for suprema of U-processes indexed by general function classes
In this section we derive Gaussian approximation error bounds for the U-process supremum indexed by general function classes. We obey the notation used in Sects. 2, 3 and 5. We make the following assumptions on the function class \({\mathcal {H}}\) and the distribution P.
- (A1)
The function class \({\mathcal {H}}\) is pointwise measurable.
- (A2)
The envelope H satisfies that \(H \in L^{3}(P^{r})\).
- (A3)
The class \({\mathcal {G}}= P^{r-1} {\mathcal {H}}= \{ P^{r-1} h : h \in {\mathcal {H}}\}\) is P-pre-Gaussian, i.e., there exists a tight Gaussian random variable \(W_{p}\) in \(\ell ^{\infty }({\mathcal {G}})\) with mean zero and covariance function \({\mathbb {E}}[W_{P}(g) W_{P}(g')] = \mathrm {Cov}(g(X_{1}), g'(X_{1}))\) for all \(g,g' \in {\mathcal {G}}\).
Conditions (A1)–(A3) are parallel with the corresponding conditions in [14]. Condition (A1) is the same as Condition (PM) in Sect. 2. Condition (A3) is a high-level assumption that is implied by Condition (VC) in Sect. 2.
For \(\varepsilon > 0\), define \({\mathcal {N}}_{n}(\varepsilon ) = \log (N({\mathcal {G}}, \Vert \cdot \Vert _{P,2}, \varepsilon \Vert G \Vert _{P,2}) \vee n)\) with \(G= P^{r-1}H\). Under Condition (A3), \({\mathcal {G}}\) is totally bounded for the intrinsic pseudometric induced by \(\Vert \cdot \Vert _{P,2}\) and \({\mathcal {N}}_{n}(\varepsilon )\) is finite for every \(\varepsilon \in (0,1]\). In addition, the Gaussian process \(W_{P}\) extends to the linear hull of \({\mathcal {G}}\) in such a way that \(W_{P}\) has linear sample paths (see e.g., Theorem 3.7.28 in [29]). For \(\varepsilon \in (0,1], \gamma \in (0,1)\), and \(\kappa > 0\), define
where \({\mathcal {G}}_{\varepsilon } = \{g-g' : g, g' \in {\mathcal {G}}, \Vert g-g'\Vert _{P,2} < 2\varepsilon \Vert G\Vert _{P,2}\}\), \(\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}} = \{gg' : g, g' \in \breve{{\mathcal {G}}}\}\), \(\breve{{\mathcal {G}}} = \{g, g-Pg : g \in {\mathcal {G}}\}\), and \(\breve{G} = G + PG\). Here \(c > 0\) is some universal constant. Below is an abstract (yet general) version of the Gaussian coupling bound.
Proposition E.1
(Abstract Gaussian coupling bound) Let \(Z_{n} = \sup _{h \in {\mathcal {H}}} {\mathbb {U}}_{n}(h)/r\). Suppose that Conditions (A1)–(A3) hold. Let \(\kappa > 0\) be any positive constant such that \(\kappa ^{3} \geqslant {\mathbb {E}}[\Vert n^{-1}\sum _{i=1}^{n}|g(X_{i}) - P g|^{3}\Vert _{{\mathcal {G}}}]\). Then, for every \(n \geqslant r+1\), \(\varepsilon \in (0,1]\), and \(\gamma \in (0,1)\), one can construct a random variable \({\widetilde{Z}}_{n} = {\widetilde{Z}}_{n,\varepsilon ,\gamma ,\kappa }\) such that \({\mathcal {L}}({\widetilde{Z}}_{n}) = {\mathcal {L}}(\sup _{g \in {\mathcal {G}}} W_P(g))\) and
where \(C_{1} = C_{1,r}\) is a constant depending only on r and \(C_{2}\) is a universal constant.
The proposition should be considered as an extension of Theorem 2.1 in [14] to the U-process. To apply the above proposition, we need to derive bounds on
which can be derived under some moment conditions on H and by using the uniform entropy integrals \(J_{k}(\delta ), k=1,\dots ,r\) defined in (19) (cf. Lemma 2.2 in [14] and our Theorem 5.1), where the latter can be simplified in terms of the VC characteristics (A, v) for a VC type function class (cf. the proof of Corollary 5.3).
Proof of Proposition E.1
The proof is based on a modification to that of Theorem 2.1 in [14]. In this proof C denotes a generic universal constant; the value of C may change from place to place. Let \(\{g_{k}\}_{k=1}^{N}\) be a minimal \(\varepsilon \Vert G\Vert _{P,2}\)-net of \(({\mathcal {G}}, \Vert \cdot \Vert _{P,2})\) with \(N := N({\mathcal {G}}, \Vert \cdot \Vert _{P,2}, \varepsilon \Vert G\Vert _{P,2})\). By the definition of \({\mathcal {G}}\), each \(g_{k}\) corresponds to a kernel \(h_{k} \in {\mathcal {H}}\) such that \(g_{k}=P^{r-1}h_{k}\). Recall the Hoeffding decomposition \({\mathbb {U}}_{n}(h) = r {\mathbb {G}}_{n}(P^{r-1}h) + \sqrt{n} \sum _{k=2}^{r} {r \atopwithdelims ()k} U_{n}^{(k)}(\pi _{k}h)\), where \({\mathbb {G}}_{n}(P^{r-1} h) = n^{-1/2} \sum _{i=1}^{n} (P^{r-1}h (X_{i}) - P^{r}h)\). Let \(L_{n}=\sup _{g \in {\mathcal {G}}} {\mathbb {G}}_{n}(g)\) and \(R_{n}=\Vert r^{-1} \sqrt{n} \sum _{k=2}^{r} {r \atopwithdelims ()k} U_{n}^{(k)}(\pi _{k}h)\Vert _{{\mathcal {H}}}\). Then \(|Z_{n}-L_{n}| \leqslant R_{n}\). Define
We note that \(|L_{n}-L_{n}^{\varepsilon }| \leqslant \Vert {\mathbb {G}}_{n}\Vert _{{\mathcal {G}}_{\varepsilon }}\) and \(|{\widetilde{Z}}-{\widetilde{Z}}^{\varepsilon }| \leqslant \Vert W_{P}\Vert _{{\mathcal {G}}_{\varepsilon }}\). By Corollary 4.1 in [14], we have for every \(B \in {\mathcal {B}}({\mathbb {R}})\) and \(\delta > 0\),
where
Observe that \(T_{1} \leqslant n^{-1/2} {\mathbb {E}}[\Vert {\mathbb {G}}_{n}\Vert _{\breve{{\mathcal {G}}} \cdot \breve{{\mathcal {G}}}}]\), \(T_{2} \leqslant n^{-1/2} \kappa ^{3}\), and \(T_{3} \leqslant n^{-1/2} P[\breve{G}^{3} 1(\breve{G}>\delta \sqrt{n} {\mathcal {N}}_{n}(\varepsilon )^{-1})]\). Thus choosing
we have
Since \(\delta \geqslant c \gamma ^{-1/3} n^{-1/6} \kappa {\mathcal {N}}_{n}^{2/3}(\varepsilon )\), we have
Conclude that with \(\eta _{n} = (\gamma / 5) P[(\breve{G}/\kappa )^{3} 1(\breve{G}/\kappa >c \gamma ^{-1/3} n^{1/3} {\mathcal {N}}_{n}(\varepsilon )^{-1/3})]\),
Next, we will bound \(\Vert {\mathbb {G}}_{n}\Vert _{{\mathcal {G}}_{\varepsilon }}\) and \(\Vert W_{P}\Vert _{{\mathcal {G}}_{\varepsilon }}\). By Markov’s inequality, with probability at least \(1-\gamma /5\),
Further, by the Borell–Sudakov–Tsirel’son inequality (see Theorem 2.5.8 in [29]), with probability at least \(1-\gamma /5\), we have
Therefore, for every \(B \in {\mathcal {B}}({\mathbb {R}})\),
The conclusion of the proposition follows from the Strassen–Dudley theorem (see Theorem B.1). \(\square \)
Appendix F. Alternative tests for concavity/convexity and monotonicity of regression functions
We will obey the setting of Example 4.2.
1.1 F.1. Alternative tests for concavity/convexity of regression function f
Instead of the original localized simplex statistic (11) proposed in [1], we may consider the following modified version:
where \({\widetilde{\varphi }} (v_{1},\dots ,v_{m+2}) = 1\{ (x_{1},\dots ,x_{m+2}) \in {\mathcal {D}}\} w(v_{1},\dots ,v_{m+2})\), and test concavity or convexity of f if the scaled supremum or infimum of \({\widetilde{U}}_{n}\) is large or small, respectively. These alternative tests will work without the symmetry assumption on the conditional distribution of \(\varepsilon \), which is maintained in [1]. Our results below also cover these alternative tests.
1.2 F.2. Alternative tests for monotonicity of regression function f
Chetverikov [16] considers testing monotonicity of the regression function f without the assumption that the error term \(\varepsilon \) is independent of X. Chetverikov [16] studies, e.g., U-statistics given by replacing \(\mathrm {sign}(Y_{j}{-}Y_{i})\) in (12) by \(Y_{j}{-}Y_{i}\), and the test statistic defined by taking the maximum of such U-statistics over a discrete set of design points and bandwidths whose cardinality may grow with the sample size (indeed, the cardinality can be much larger than the sample size). His analysis is conditional on \(X_{i}\)’s, and he cleverly avoids U-process machineries and applies directly high-dimensional Gaussian and bootstrap approximation theorems developed in [12]. It should be noted that [16] considers more general test statistics and studies multi-step procedures to improve on powers of his tests.
Another related test for regression monotonicity is based on the local linear rank statistics [21]. Let \(R_{mk}(i) = \sum _{j=m+1}^{k} 1(Y_{j} \leqslant Y_{i})\) be the local rank of \(Y_{i}\) among \(Y_{m+1},\dots ,Y_{k}\). In [21], Dümbgen considers a test for monotone trend of f (with fixed design points \(X_{1},\dots ,X_{n}\)) via the local linear rank statistics
where \(\beta \) and q are functions on (0, 1) such that: 1) \(\beta (1-u)=-\beta (u)\) and \(q(1-u)=-q(u)\) for \(u \in (0,1)\); 2) \(\beta (\cdot )\) and \(q(\cdot )\) are nondecreasing on (0, 1). Then [21] proposes the multiscale test statistic
where \(s_{i}\) and \(c_{i}\) are properly chosen nonnegative numbers. For the special case of the Wilcoxon score function \(q(u) = 2u-1\) and \(\beta (u) = q(u)\), one can write
The statistic \(T_{mk}\) is related to our test statistic \({\check{U}}_{n}(x)\) with \(L(u) = 1(u \in [-1,1])\), namely \(T_{mk}\) and \({\check{U}}_{n}(x)\) are (local) U-statistics with kernels \((j-i) \mathrm {sign}(Y_{j}-Y_{i})\) and \(\mathrm {sign}(X_{i}-X_{j}) \mathrm {sign}(Y_{j}-Y_{i})\), respectively. Thus for a given sequence of bandwidths \(b_{n}\), our monotonicity test based on the U-process \({\check{U}}_{n}(x)\) can be viewed as a single-scale test \(T_{mk}\) with \((k-m)/n = 2 b_{n}\) in Dümbgen’s sense. In particular, both \(T_{0n}\) and \({\check{U}}_{n}(x)\) with \(b_{n} = 1\) quantify the monotonicity on the global scale. In addition, the “uniform-in-bandwidth” type results for our U-process approach in Sect. 4.1 can be viewed as the multiscale analog T of \(T_{mk}\) with the Wilcoxon score function. Nevertheless, since [21] considers the fixed design points, \(T_{mk}\) is a local U-statistic on \(Y_{i}\)’s and \({\check{U}}_{n}(x)\) is a local U-statistic on \((X_{i}, Y_{i})\)’s. Our analysis (which requires a Lebesgue density on X) is not directly applicable for the local linear rank statistics of [21].
Rights and permissions
About this article

Cite this article
Chen, X., Kato, K. Jackknife multiplier bootstrap: finite sample approximations to the U-process supremum with applications. Probab. Theory Relat. Fields 176, 1097–1163 (2020). https://doi.org/10.1007/s00440-019-00936-y
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-019-00936-y