
Abstract
Writing sequences play an important role in handwriting of Chinese characters. However, little is known regarding the integral brain patterns and network mechanisms of processing Chinese character writing sequences. The present study decoded brain patterns during observing Chinese characters in motion by using multi-voxel pattern analysis, meta-analytic decoding analysis, and extended unified structural equation model. We found that perception of Chinese character writing sequence recruited brain regions not only for general motor schema processing, i.e., the right inferior frontal gyrus, shifting, and inhibition functions, i.e., the right postcentral gyrus and bilateral pre-SMA/dACC, but also for sensorimotor functions specific for writing sequences. More importantly, these brain regions formed a cooperatively top-down brain network where information was transmitted from brain regions for general motor schema processing to those specific for writing sequences. These findings not only shed light on the neural mechanisms of Chinese character writing sequences, but also extend the hierarchical control model on motor schema processing.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Human civilization is recorded and spread by written words. For different writing systems across culture, one universal feature is that they all have fixed gesture rules, which are not innate but education-dependent (Nakamura et al. 2012). Chinese characters are one widely used logographic script and remarkable culture icon. They are composed of basic strokes that are mandatorily stipulated to be written in certain rules of sequences in fixed two-dimensional squares (Huang and Wang 1992). As such, writing sequences of Chinese characters are varied and complicated. These rules of writing sequences are incumbent knowledge and skills for students to learn from formal elementary school education for the purpose of spatial planning for writing reasonably and economizing cognitive resources for processing Chinese characters (Lo et al. 2016). It has been shown that students who are better at mastering writing sequences are faster in processing Chinese characters (Giovanni 1994; Law et al. 1998a). The process of organizing basic strokes into a complete character sheds light on the retrieval and integration from fragmented orthographic mental representation, i.e., writing strokes (Lo et al. 2016). However, little is known about the neural organization of writing sequences of Chinese characters.
Some previous functional magnetic resonance imaging (fMRI) studies have investigated separate functions of each brain region involved in processing Chinese character writing sequences (e.g., Yu et al. 2011). For example, Yu et al. (2011) found that bilateral premotor areas and adjacent parietal regions, which are often found to be activated in processing general sequences (Thomas et al. 2018), were less activated for processing scrambled writing sequences than for processing intact ones. In addition, the SMA and pre-SMA related to general sequence processing functions were also found to be involved in writing sequence processing (Yang et al. 2019). In contrast, some other studies revealed several other brain regions specific to processing writing sequences. For example, by utilizing the writing sequence priming paradigm and comparing writing sequences in different languages, some fMRI studies revealed that the left precentral gyrus and left superior parietal lobule (SPL) played consequential roles in Chinese character writing sequence processing (Chen et al. 2016; Nakamura et al. 2012; Yu et al. 2011). These two brain areas are also involved in Chinese handwriting, indicating their specific role in retrieving writing sequences (Cao et al. 2013; Lagarrigue et al. 2017). Some lesion studies have found support for these findings (Hodges 1991; Keller and Meister 2014; Maeda and Ogawa 2014; Otsuki et al. 1999). For example, Otsuki et al. (1999) found that patients with a hemorrhage in the left SPL (BA7) would only fail to produce a Chinese character in correct sequences, but they still managed to report the sequence rules.
It should be noted that as an exemplar of motor schema, a template based on prior knowledge to direct executing simple or complex sequences of motion (Schmidt 1975), writing sequences may be decoded in a complex process. This process might induce a change in multiplex brain activation pattern representing distinctive external stimuli, which either follow or violate the embedded motor schema, instead of univariate increase or decrease of brain activation levels (Baldassano et al. 2018). However, the neural mechanism of writing sequence processing has only been examined from the perspective of brain activation levels (e.g., Yu et al. 2011). It has been shown that multi-voxel pattern analysis (MVPA) is practical to analyze fMRI data presenting naturalistic stimuli (Chow et al. 2018; Spiers and Maguire 2007). Besides, the spatial patterns across voxels of brain regions can be examined using MVPA with whole-brain searchlight to decode the brain activation (Davis et al. 2014; Kriegeskorte and Kievit 2013; Kriegeskorte 2011; Norman et al. 2006). Furthermore, information loss can be significantly reduced because there is no averaging of voxel intensities, and the analysis is done before smoothing (Ma et al. 2018). Therefore, it is worth further examining brain patterns associated with processing writing sequences of Chinese characters using MVPA.
Another relevant important issue is that how these brain regions work in collaboration given that writing a Chinese character in a stipulated and well-learned sequence can be classified as a typical kind of motor schema with rules. Badre and Nee (2018) has concluded that behavioral goals and motor schema are processed by human beings hierarchically. It has also been found that bilateral prefrontal cortex, pre-SMA, SMA, primary motor area, and subcortical areas like the putamen and caudate form a network for executing or imaging sequences of motion (Kim et al. 2018; Sepulveda et al. 2016). A Chinese character, as the highest level of a goal, was cut into ‘strokes’ and written separately in a sequence, reflecting the basic skeleton of a motor schema. Therefore, in the present study, it is reasonable to speculate that brain regions revealed by MVPA will work in collaboration as a network to process writing sequences of Chinese characters.
To summarize, the purpose of the present study was to decode brain patterns involved in processing Chinese character writing sequences using MVPA and to model an information transmission network of these relevant brain regions using extended unified structural equation (euSEM) (Gates et al. 2011; Kim et al. 2007). The potential findings will also shed light on the neural mechanism of motor schema with Chinese character writing sequences as an exemplar.
During the experiment, participants were presented with a series of animations for intact or scrambled writing sequences of Chinese characters and instructed to judge whether the writing sequences were correct or not while being scanned with MRI. Previous studies have suggested that action execution and observation share fundamental and cognitive processes and representations (Cooper 2019) based on mirror neuron systems in the parietal-premotor circuitry. In addition, studies on complex action sequences (Cross et al. 2011), motor schema in producing series of motions (Calvo-Merino et al. 2006), and event schema in daily life (Baldassano et al. 2018) have implemented a similar observation paradigm, and provided evidence that the observation paradigm is able to induce the retrieval of correct motor schema and the processing of the presented motion sequences. Since processing Chinese character writing sequence may involve switching between multiple rules (Law et al. 1998b), e.g., right after left, bottom after the top, it may recruit mechanisms similar to planning and executing general actions (Koechlin and Jubault 2006).
We first detected brain regions activated with significantly different patterns by whole-brain searchlight when participants processed intact and scrambled Chinese character writing sequences. Then, we modeled the effective connectivity among these brain regions. Based on previous studies (e.g., Baldassano et al. 2018; Thomas et al. 2018; Yu et al. 2011), we predicted that activation patterns in brain regions associated with both general motor schema and those specifically involved in writing sequences processing would both be recruited for decoding writing sequences of Chinese characters. More importantly, these brain areas would form a brain network for the purpose of retrieving correct motor schema and monitoring conflicts from incorrect external stimuli.
Method
Participants
Twenty-seven participants were recruited in this study. They were all right-handed native Chinese college students with normal or corrected-to-normal vision. None of them reported any neurological disorders. Data from two participants were excluded due to falling asleep or exhibiting a significantly low accuracy rate (less than 50%) in the writing sequence processing task during MRI scanning. This left data of 25 participants (14 females, mean age = 23.04 years, SD = 2.93) for the final analyses.
Materials
Forty-two Chinese characters: 14 single-component structured (e.g., “车”), 14 left–right structured (e.g., “阳”), and 14 top–bottom structured (e.g., “拿”) were selected as the experimental stimuli. Single-component characters refer to those written by inner writing sequences of strokes, for example, horizontal strokes before vertical. Similarly, left–right structured and the top–bottom structured characters refer to those written by typical rules between strokes, left before right and top before bottom, respectively, as shown in Fig. 1. They were further divided into two subsets that were well-matched on character frequencies and stroke numbers.

Exemplars for single-component, left–right and top-down constructions of Chinese characters
To simulate a real writing process, mini videos were made to animate the intact and scrambled writing process of each Chinese character. In the intact writing process, the order of each stroke complied with the sequences stipulated by the State Language Commission (2000). In the scrambled writing sequence, the order of each stroke was rearranged except the first and the last strokes, deliberately breaking its original integral writing rules (left before right, top before bottom, middle before surrounding, etc.) to violate the highest schematic information of writing sequences, as shown in Fig. 2b.

The procedure used in the present study. a Timing parameters of the Chinese character writing sequence judgment task. b A sample stimulus, “车”, shows how the writing sequence was violated in the experiment. In the scrambled writing sequence, the order of each stroke was rearranged except the first and the last strokes, deliberately breaking its original integral writing rules (left before right, top before bottom, middle before surrounding, etc.)
Procedure
The study was approved by the Institutional Review Board of Beijing Normal University. All participants signed a consent form before the experiment and received a debriefing form afterward. Before the formal experiment, participants performed a practice session of 12 trials. In each trial, a fixation cross was presented for 600 ms followed by a blank screen for 600 ms. Each static character was presented for 400 ms in gray allowing participants to retrieve its orthographic and semantic information so that activation associated with lexical processing that we were not interested in would remain similar across two experimental conditions (Yu et al. 2011). Then, the animation of the writing sequence was presented, in which the duration of each stroke mimicked writing progress by turning from gray to black, was 400 ms, and the integrated Chinese character was also presented in black for 400 ms at the end of each animation.
Participants were instructed to judge whether the writing sequence was correct or not when the blank screen was presented. A randomized inter-trial interval of 2–5 s was applied after presenting the entire writing process of each character. They were required to press a button with either their left or right index finger. The response fingers for correct or incorrect writing sequences were counterbalanced. The experimental procedure is shown in Fig. 2a.
The formal experiment lasted approximately 60 min with 6 runs. In each run, participants watched 42 animations in a randomized order with 21 intact and 21 scrambled writing sequences. The stimuli for all six runs were identical but presented in different orders. After each run, participants could take a break as long as necessary. The functional scanning took about 50 min in total, followed by a 6-min anatomical scanning for each participant.
Previous studies have found that processing Chinese character writing sequences might recruit executive functions as top-down modulation (Yu et al. 2011). Therefore, based on our meta-analytic decoding of the fMRI results, after MRI scanning, participants were called back to perform a task switching task (Kang et al. 2020) to verify the role of executive functions in processing of Chinese character writing sequences. Specifically, participants were required to judge the parity (odd or even) or the magnitude (larger or smaller than 5) of a digit presented in either a square frame or a rhombus frame, which served as a cue. Participants were told to judge the parity (odd or even) of the number following a square frame and to judge the magnitude (larger or smaller than 5) following a rhombus frame as quickly and accurately as possible. The mappings of cues and task requirements were counterbalanced across participants. During the task, each trial began with a fixation in the center of the screen (“+”) for 300 ms, followed by a blank screen for 200 ms. The geometric frame cue would then appear at the center for 500 ms, after which a single digit (1–4 and 6–9) would be presented in the middle of the cue. The digit and the cue would disappear together when any response was made. Then, a blank screen for 1000 ms would appear before the next trial.
The two types of cues were pseudo-randomized, resulting in switch and nonswitch conditions. The cue-task and the response-key mapping were counterbalanced among participants. Participants did a practice session to familiarize themselves with switching between tasks. We calculated switch cost in both accuracy and response times, i.e., difference between switch and nonswitch trials.
Data acquisition
Functional images were acquired by a Siemens Prisma 3-T MRI scanner with an interleaved multiband EPI sequence with the following parameters: multi-slice factor = 2, TR = 1000 ms, TE = 29 ms, flip angle = 70°, FOV = 200 × 200 mm2, matrix size = 64 × 64, resolution within slices = 3.1 × 3.1 mm2, and slice thickness/gap = 4 mm/0.6 mm. There were 378 TRs for each experimental session in total for all conditions. High-resolution T1-weighted anatomical images were also obtained using the following scan parameters: TR = 2530 ms, TE = 2.27 ms, flip angle = 7°, FOV = 256 × 256 mm2, matrix size = 256 × 256, resolution within slices = 1.0 × 1.0 mm2, slice thickness = 1 mm, and number of slices = 207.
Data analysis
Data preprocessing
The fMRI data pre-processing was conducted by the SPM 12 (Wellcome Department of Cognitive Neurology, London, UK, http://www.fil.ion.ucl.ac.uk/spm) based on MATLAB 2018b (The MathWorks Inc). The first eight functional images (corresponding to the first filler trial) were removed due to the instability of the magnetic field. The data preprocessing procedure included the following steps: first, the slice timing corrections were performed. Next, head motion corrections were applied to exclude participants with translational head motion greater than 2 mm or 2°, and no participants were excluded. Besides, we coregisterered all anatomical images to the mean EPI image obtained during realignment. Then, all images were normalized to the EPI template on the basis of Montreal Neurological Institute (MNI) space template and resampled into 3-mm cubic voxels. Finally, 184 TRs (184 s) of data were approximately involved in the formal analysis averaged for each session of each condition.
Multivoxel pattern analysis
First, unsmoothed images were put into a general linear model (GLM) to conduct an individual first-level analysis for each participant to estimate the beta images for correct or incorrect writing sequences. Therefore, for each participant, there were 2 beta images for two experimental conditions, respectively. We generated a mask with voxels of higher than 30% probability based on the SPM original gray matter probability template. Within that mask, a whole-brain searchlight analysis (Kriegeskorte et al. 2006) was conducted by taking these voxels as centers of spheres with a 6-mm radius and calculated their beta values in 6 runs of all participants.
For each searchlight sphere, we applied the support vector machine (SVM, the binary linear vector algorithm in the fitcsvm function of the MATLAB Statistics and Machine Learning Toolbox, https://www.mathworks.com/help/stats/fitcsvm.html) to extract unique brain discrepancy maps (Wang et al. 2007). SVM has been proven to be valid in analyzing high dimensional data even if the sample size is small (LaConte et al. 2005). We used the beta images for 24 participants in two experimental conditions to train the classifier and test it on data from the last participant based on leave-one-out cross-validation, where the data from 24 participants were used for training and the remaining one participant’s data for testing (Alink et al. 2012; Haynes and Rees 2006). The same process was repeated for each participant so that the SVM assigned a weight to each voxel indicating its testing accuracy and an accuracy image could be obtained for each participant.
Finally, we spatially smoothed all images using an isotropic Gaussian kernel with a 6-mm full width at half-maximum. We executed the nonparametric one-sample t-test by the statistical nonparametric mapping toolbox (SnPM, https://warwick.ac.uk/snpm) to identify if the classification accuracy of each voxel is higher than the chance rate (50%) on the group level. The criteria were set to FWE corrected p < 0.05 on the voxel level and the variance smoothing was set to 0. We set the permutation to occur 5000 times.
Meta-analytic functional decoding
To explore the relationship between the brain mechanism of Chinese character writing sequences and specific psychological components of executive functions, we used the online Neurosynth Image Decoder (http://www.neurosynth.org, Rubin et al. 2017) to decode the MVPA filtered image. Based on our assumption, we chose nine terms (including rule, sequence, spatial attention, action observation, motor imagery, expectation, executive function, shifting, inhibition, and updating) covering the writing sequence stimuli features and executive functions. The criteria were set to FDR corrected p < 0.01 automatically by the platform.
Effective connectivity analysis
To get the connectivity network of writing sequence perception, ten nodes were defined by drawing spheres with the coordinates of the brain regions found in the MVPA as centers and radius of 6 mm. We extracted time-series of spheres by the Resting-State fMRI Data Analysis Toolkit (REST, https://www.nitrc.org/projects/rest/ (Song et al. 2011) and defined them as nodes in connectivity analysis. The node centers were the peak voxel in clusters with significantly higher than 50% classifying accuracy values for intact and scrambled writing sequences in the MVPA results.
We employed the extended unified structural equation model (euSEM) to construct an effective connectivity model (Gates et al. 2011). Group iterative multiple model estimation (GIMME) was used to automatically conduct model selection and fitting in practice. The SEM was only qualified to build relationships without time-series order between regions of interest (ROIs) with the assumption that the activation of ROIs was independent. However, the BOLD signals detected by fMRI had a sequential relationship with the time series. Therefore, Kim et al. (2007) developed a unified SEM (uSEM) for block-designed fMRI experiments that combine some lagged relationships with time series and that was also the basis of the euSEM along with its consideration of the task effects and bilinear effects. Therefore, it also fits for ER-designed fMRI studies (Gates et al. 2011).
For our study, Lagrange multiplier equivalents were used to carry out the model selection to free each path, after which we decided if the particular freed connection could improve the holistic model fitting of at least 75% of the participants. Afterward, the model was strictly pruned on the group level. In this step, the connections that did not exist in 75% of participants after being freed were removed. The paths that passed the group level pruning were then freed on the individual level based on the semi-confirmatory manner of freeing. Eventually, those connections that were no longer significant after other connections were freed were trimmed and tested if they fit the confirmatory model.
For model convergence, one participant was removed. Based on prior selected model fitting parameters describing reliability, two norms were fit in the final model: confirmatory fit index (CFI) > 0.90 and nonnormed fit index (NNFI) > 0.90 (Gates et al. 2011).
We separated the network into subdivisions by the Louvain community detection algorithm with added fine tuning so that the network would be easier to read and evaluate (Rubinov and Sporns 2011). This algorithm was built to maximize the number of within-group edges and to minimize the number of between-group edges.
We then applied the optimal core–periphery subdivision algorithm to divide the connectivity network into a core and a periphery group. This approach maximized the edges in the core group and minimized the edges in the peripheral group (Rubinov and Sporns 2010). The cores were named as hubs of the brain network (Braun et al. 2015).
Subsequently, for the core hubs, we calculated their local efficiency, i.e., the inverse of the average shortest path connecting all neighbors of a particular vertex \({E}_{\mathrm{loc}}^{w}= \frac{1}{2}\sum i\in N\frac{{\sum }_{j, h\in N, j\ne i}{({{w}_{ij}{w}_{jh}[{d}_{jh}^{w}({N}_{i})]}^{-1})}^{1/3}}{{k}_{i}({k}_{i}-1)}\)(Rubinov and Sporns 2010), also defined as a measure of how efficiently the node exchanges information in the network system (Latora and Marchiori 2001). To clarify, in the aforementioned formula, \({E}_{\mathrm{loc}}^{w}\) was the weighted local efficiency of the current node; \({k}_{i}\) represented the degree of node i, known as the number of links connected to node i; the connection weights, i.e., how strong the connection between node i and j, was shown by \({w}_{ij}\); \({d}_{jh}^{w}\) stood for the shortest weighted path length between node i and j; N was the set of all nodes in the network (Rubinov and Sporns 2010).
Pearson correlation between the local efficiency and the switching cost of the task-switching task was calculated to examine whether there is any potential relationship between neural correlates for processing Chinese character writing sequences and the shifting component of executive functions.
Data and code availability statement
Data and codes are available and can be currently previewed on Mendeley (https://data.mendeley.com/datasets/8k2857yrch/draft?a=542beca1-a9fd-4cb1-8110-c9408d25f941). The dataset and codes will be open and accessible to readers online.
Results
Behavioral results
Trials with incorrect responses or without a response were identified as incorrect and excluded from data analysis. Trials in which participants made a response before the animation ended were removed from the analysis for response times but not from the accuracy analysis.
The mean accuracy for intact writing sequences was 90.67% ± 8.56% and that for scrambled writing sequences was 94.89% ± 3.99%. There was a significant difference between two conditions, t(24) = 2.42, p = 0.023. The mean reaction time (RT) for intact writing sequences was 510 ± 188 ms and that for scrambled writing sequences was 504 ± 166 ms. No significant difference was observed between two conditions, t(24) < 1.
MVPA results
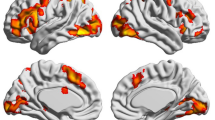
MVPA results showed brain activation patterns in the bilateral supplementary motor area (SMA)/dorsal anterior cingulate gyrus (dACC), left precentral gyrus, left superior parietal lobule (SPL), left putamen, right inferior frontal gyrus (IFG), right postcentral gyrus/right supramarginal gyrus, right inferior parietal lobule (IPL)/right supramarginal gyrus, right middle temporal gyrus, right middle occipital gyrus, and right parahippocampal gyrus (PHG). The results are shown in Table 1 and Fig. 3a.

a Brain regions with a decoding accuracy significantly higher than 50% in the MVPA results (FWE corrected p < 0.05); b the radar image of Pearson correlation coefficients in the functional decoding meta-analysis (FDR corrected p < 0.01)
Meta-analytic functional decoding results
The results of the meta-analytic functional decoding showed that brain patterns associated with Chinese character writing sequences were correlated with rules (r = 0.023), sequence (r = 0.086), spatial attention (r = 0.114), action observation (r = 0.076), motor imagery (r = 0.15), expectation (r = 0.007), executive functions (r = 0.01), shifting (r = 0.047), inhibition (r = 0.038), and updating (r = -0.01). Although the correlations were relatively low, they were on the same level with previous studies using this approach (Gao et al. 2018; Bellucci et al. 2019). The results are shown in Fig. 3b.
Effective connectivity results
The effective connectivity network is shown in Fig. 4a. The core hubs of the network were identified as the right IFG and right postcentral gyrus by the core-periphery subdivision algorithm (q = 0.745).

a The effective connectivity map. b The Pearson correlation between local efficiency of right postcentral gyrus and the switching cost in the task-switching task
We also calculated the local efficiency of the hubs (right postcentral gyrus and right IFG) with functions in the brain connectivity toolbox (BCT, http://www.brain-connectivity-toolbox.net). The local efficiency of the right IFG was 0.067 ± 0.032, and the local efficiency of the right postcentral gyrus was 0.056 ± 0.031.
Furthermore, we found that the local efficiency of the right postcentral gyrus was significantly correlated with the switching cost of RT for the task switching task, indicating that the higher the local efficiency of the right postcentral gyrus, the smaller the switching cost of RT (r = − 0.551, p = 0.030). The local efficiency of the right postcentral gyrus could marginally predict the accuracy switching cost, indicating that the higher the local efficiency of the right postcentral gyrus, the smaller the switching cost of accuracy (r = − 0.521, p = 0.054). However, the local efficiency of the right IFG could not predict the switching cost of RT (r = − 0.301, p = 0.912) or the switching cost of accuracy (r = − 0.361, p = 0.498). The results are shown in Fig. 4b.
To further describe and parse the network distinctively, the Louvain algorithm (Rubinov and Sporns 2011) was used to divide the network into subdivisions: the right PHG and right middle temporal gyrus were identified as components of Module 1; Module 2 included the left precentral gyrus, left putamen, right IFG, right postcentral gyrus, and right IPL; Module 3 consisted of the bilateral SMA/dACC, left SPL and right middle occipital gyrus.
In Module 1, there was a unidirectional information path from the right middle temporal gyrus to the right PHG. In Module 2, information flowed from the right IFG to the right postcentral gyrus. The activation of the right postcentral gyrus modulated that in the right IPL, and the right IPL was responsible for the feedback to the right IFG; thereby, a circuit was constituted. The right postcentral gyrus was also the intermediary hub of information transfer from the right IFG to the left precentral gyrus, and the right IFG also regulated the activity of the left putamen. In Module 3, the bilateral SMA/dACC indirectly modulated the activation of the left SPL with the right middle occipital gyrus as the intermediating region.
In addition, information was transmitted between modules. Information was transmitted from Module 2 to Module 3 through one path from the left putamen and right IFG to the bilateral SMA/dACC and the other from the right postcentral gyrus to the left SPL. Module 2 also transferred information to Module 1 by using the path from the right postcentral gyrus to the right middle temporal gyrus, and the right IFG in Module 2 received feedback information from the right middle temporal gyrus from Module 1. Information flowed from the middle occipital gyrus of Module 3 to the middle temporal gyrus of Module 1.
Discussion
The present study investigated brain activation patterns and the network associated with processing writing sequences of Chinese characters by using MVPA and euSEM. The underlying cognitive mechanism of writing sequence processing was also revealed by decoding the brain activity patterns with meta-analytic functional decoding.
The results of the MVPA showed that both the cortical and subcortical brain regions were engaged in decoding writing sequences of Chinese characters, including the bilateral SMA (including the bilateral pre-SMA/dACC, SMA, right superior frontal gyrus, right middle frontal gyrus and right middle cingulum), left precentral gyrus, left SPL, left putamen, right IFG, right postcentral/supramarginal gyrus, right IPL/supramarginal gyrus, right middle temporal gyrus, right middle occipital gyrus, and right parahippocampal gyrus. Further meta-analytic functional decoding showed that these brain activity patterns were related to rules, sequence, spatial attention, action observation, motor imagery, shifting, and inhibition, and also weakly related to expectation, executive functions, and updating.
Consistent with previous neuroimaging studies, which have found that both the left precentral gyrus and left SPL (the Exner’s area) specifically contribute to processing Chinese character writing sequence (Chen et al. 2016; Nakamura et al. 2012; Yu et al. 2011), we also observed activation pattern divergence of these two brain areas. Although previous studies have found that the VWFA is usually involved in processing Chinese character input information (Yu et al. 2011), the Exner’s area serves as the role of output for motor-orthographic information (Keller and Meister 2014; Linke et al. 2018), analogous to the role of the VWFA in processing visual-orthographic information of Chinese characters (e.g., Cao et al. 2013). Since each character was presented as a whole for participants to retrieve orthographic and semantic information in advance, it was reasonable that the VWFA could not differentiate correct and incorrect writing sequences. This result was also consistent with those from Nakamura et al. (2012) that the VWFA was only found to be activated more strongly with static word priming than moving trajectory priming, while the Exner’s area was found activated significantly differently between forward trajectories and backward trajectories. In addition, VWFA was also not found in a more recent study by Chen et al. (2016), which conceptualized writing sequences as orthographic buffer.
Our MVPA results also showed significant discriminative activation patterns of other brain regions, which were found involved in action organization [e.g., right IPL Desmurget and Sirigu 2012; Rozzi et al. 2008], general cognitive control (e.g., pre-SMA/dACC, Botvinick et al. 2004); right IFG (Badre 2008) and memory retention and retrieval for schematic representation or detailed information [e.g., right middle temporal gyrus and right parahippocampal gyrus (Robin and Moscovitch 2017)]. Therefore, the current findings indicate that the processing involved in discriminating incorrect from correct writing sequences is not only language-specific but also engages in multiple levels of domain-general cognitive control.
The meta-analytic functional decoding results provided further support for our speculation. Despite the terms related to the basic visual characteristics of experimental materials and task demands (e.g., rules, sequence, spatial attention, action observation, motor imagery), brain activity patterns in processing of Chinese character writing sequence was also correlated to the shifting component of executive functions. This is probably due to the fact that multiple rules applied to even one Chinese character (Law et al. 1998a), so participants needed to switch among different rules when processing every animated Chinese character. For example, to write the character “树 (tree)”, both rules of “left before right” and “top before bottom” are used. This is not a unique characteristic of writing Chinese characters. Rather, most motor schemas in everyday life also need to switch between rules, e.g., adjusting gestures to catch balls from different angles and strengths. Furthermore, inhibition function also plays a relatively important role in the process of writing sequences. One possible reason is that both the SMA (Gehring and Knight 2000) and right inferior frontal gyrus (Aron et al. 2014) are recruited for error detection and conflict inhibition to complete the task.
To further determine the univariate indexes of brain activity and, more importantly, to ascertain information interactions among different brain regions, we chose the ten ROIs discovered in the MVPA results and constructed the effective connectivity network for processing Chinese character writing sequences using the euSEM (Gates et al. 2011). The core hubs of the network were identified as the right IFG and right postcentral gyrus, suggesting their multiple crucial functions in processing writing sequences.
The right IFG has been found to be involved in inhibitory control associated with the Go/Nogo task and stop-signal task (Aron et al. 2014; Botvinick et al. 2004; Chatham et al. 2012; Erika-Florence et al. 2014; Hampshire et al. 2010). According to the hierarchical control hypothesis of motor schema, the right IFG may also proceed with abstract contextual information (Badre and Wagner 2004; Badre et al. 2010; Badre 2008), which would be the well-learned rules of Chinese character writing sequences in the present study. Additionally, the right IFG also plans (Grafton and Hamilton 2007) and rehearses (Ashe et al. 2006) the action before an event starts, as well as processes information of general motor sequences (Bubic et al. 2009; Wang et al. 2015). Taken together, we infer that the right IFG guides participants to make a correct or incorrect judgment through a top–down process based on existing motor schema of writing sequences.
In addition, a significant positive correlation was also found between the local efficiency of the right postcentral gyrus and the shifting function revealed by the task-switching task. That is, participants with higher shifting function showed better local efficiency of the right postcentral gyrus. This finding is consistent with one previous resting-state connectivity study that showed the local efficiency of the right postcentral gyrus could predict the shifting ability of participants (Reineberg and Banich 2016), and further suggests that the right postcentral gyrus may be in charge of shifting component of executive functions. Therefore, it is reasonable to speculate that the right postcentral gyrus is the communication and shifting hub of different kinds of sequence rules in the writing of Chinese characters.
To specify the cognitive function of the network associated with writing sequence processing, we further segmented the network into three submodules based on their connectivity patterns among brain regions by the Louvain algorithm (Rubinov and Sporns 2011).
The first module included the connectivity between the right middle temporal gyrus and the right parahippocampal gyrus. These two brain regions were both highly related to information encoding, maintenance and retrieval in memory (Eichenbaum and Lipton 2008; Eichenbaum et al. 2007; Luck et al. 2010; Takahashi et al. 2002; Ward et al. 2014) and interactions of information between long-term memory and working memory (Jeneson and Squire 2012; Squire et al. 2007).
After visual information was processed by the right middle occipital gyrus (Pitzalis et al. 2015, 2013), which has been also found in visual processing and recognizing Chinese characters (Bolger et al. 2005; Wu et al. 2012), intact or scrambled writing sequences were then temporarily organized in working memory before formally being processed. Since our results showed that the right middle temporal gyrus also formed a circuit with the right IFG and right postcentral gyrus, we speculated that prior knowledge of rules for Chinese character writing sequence was retrieved from long-term memory. Meanwhile, the stimulus information temporarily stored working memory was retrieved in order to monitor correct or incorrect writing sequences before making a judgment (Bergmann et al. 2012). Brain regions for memory, i.e., the temporal and parahippocampal gyri, served as information storage for motor schema of writing sequences in the current brain network, and motor schema was directly invoked and retrieved by brain regions for general cognitive control, like SMA and right IFG, for generating comprehensive writing sequence regulations and detecting conflicts from errors. This memory retrieval process provided evidence that domain general processing such as memory retrieval was also involved in the processing of Chinese character writing sequences.
To go further, we found that a top–down mechanism was recruited for both generating correct sequence rules and error monitoring. Specifically, in the second module, the right IFG handled the processing of integral rules of writing sequences and delivered guidelines directly to the right postcentral gyrus, which efficiently utilized multiple rules by invoking shifting functions, then to the left precentral gyrus and the left SPL (Exner's area; Keller and Meister 2014) processing specific writing sequence information, as suggested in our MVPA results. Overall, information flow in the second module confirms the top-down control of abstract contextual information of motor schema to output in low-level motor perception (Badre and Nee 2018). The connectivity modes of the brain regions mentioned above are also similar to the system of frontal-parietal mirror neurons involvement in knotty motor sequence processing (see details in Molnar-Szakacs et al. 2006).
A similar top-down mechanism also fits the connectivity from the right IFG to the third module with straight-down information flow from the bilateral SMAs to the right middle occipital gyrus and the left SPL, with left putamen as the intermediary between two modules. In the present study, the bilateral SMAs included both the bilateral pre-SMA/dACC, which have been found to be involved in involved in conflict detection for an unexpected response (Duque et al. 2013). Connectivity between the right IFG and the pre-SMA has also been discovered for both reactive and proactive inhibition (Obeso et al. 2013). The left putamen also plays a role in motor control (Padmala and Pessoa 2010), and it has been found coactivated with the bilateral inferior frontal gyrus in the cognitive control network (Sundermann and Pfleiderer 2012). Considering the interaction between the right IFG, left putamen, bilateral SMA and pre-SMA/dACC, it is likely that these three brain regions are engaged in top-down control and impart information to the sensory and motor area, i.e., the right middle occipital gyrus and left SPL observed in the present study. As a result, participants were able to determine whether a writing sequence was correct or not.
Furthermore, there was a circuit formed by the right IFG, right postcentral gyrus, and right IPL with both feedforward and feedback mechanisms. The right IPL, somehow similar to the left precentral gyrus and left SPL, is specifically involved in handwriting (Planton et al. 2013; Yang et al. 2020). Therefore, it is reasonable to speculate that a similar top-down model to the connection among the right IFG, right postcentral gyrus and left precentral gyrus or left SPL is also observed for the right IPL, while there is also a feedback pathway from the right IPL to the right IFG, which can be regarded as bottom-up attentional reorienting and inhibition when unexpected or invalid stimuli is observed (Igelstrom and Graziano 2017). It may be inferred that when participants observe the writing animations with unknown sequences, the feedback is sent to the headquarters of the network to acclimate the expectation to the next stroke and make a judgment of true or false.
Taken together, our findings have important theoretical implications. First, we found that brain regions associated with domain-general cognitive functions such as the right IFG and bilateral pre-SMA/dACC, rather than orthographic-specific brain regions such as the VWFA, were highly involved in processing writing sequences. These findings suggest that perception of writing sequences is not a simple processing but a well-established exemplar of a sophisticated motor schema processing. Practically, this implicates that Chinese character writing sequences can be used as superb materials for investigating motor schema and rules. Second, it has been found that motor schema processing depends on the frontal-parietal hierarchical control mechanism (Ashe et al. 2006; Badre and Nee 2018; Badre et al. 2010; Badre 2008). Our results supported and extended the hierarchical control model by revealing that the temporal and occipital cortex, and some subcortical regions like the putamen, were also involved in motor schema processing, especially the right IFG and the right postcentral gyrus as hubs. Specifically, the right IFG processes theoretical contextual information, while the right postcentral gyrus, with shifting functions, regulates all brain regions processing first-order policy specific writing sequences of each Chinese character. Both hubs work as crucial intermediary links in the network and keep the balance between the top–down process for action planning and selection and the bottom–up excitation generated by the environment (Cooper 2019).
However, it should be noted that we did not find any valid activity pattern to differentiate the rostral prefrontal cortex, which has been identified as a classical brain region for high-level schema processing (Badre and Nee 2018; Badre et al. 2010; Badre 2008). One possible reason is that activation of specific regions in the frontal cortex is related to the difficulty of the schema. It has been shown that if the motor schema is difficult to process, it would be more likely for the rostral prefrontal cortex to get involved (Badre and Nee 2018). In contrast, participants in the present study have learned sequence rules for writing Chinese characters proficiently in elementary education, so perception of these writing sequences is probably relatively easy and automatic (Ashe et al. 2006), resulting in no involvement of the rostral prefrontal cortex. Future studies may recruit more beginners or children who have not systematically learned Chinese character writing sequences in order to examine the neural plasticity of motor schema in terms of writing sequences from a developmental perspective.
To summarize, for the first time, the present study examined the neural mechanism of Chinese character writing sequence processing by using both MVPA and euSEM. We found that, as an exemplar of motor schema, Chinese character writing sequence processing recruits neural networks for both domain-general and writing-specific functions. Specifically, the top-down information communication network from the right IFG to brain regions related to sensorimotor and memory implies that motor schema of writing sequences recruits visual sensory processing (i.e., occipital gyrus), specific motor-orthographic processing (i.e., the Exner’s area), and memory retrieval (i.e., temporal and parahippocampal gyrus) modulated by general executive functions of shifting and inhibition (e.g., right postcentral gyrus and IFG).
References
Alink A, Euler F, Kriegeskorte N, Singer W, Kohler A (2012) Auditory motion direction encoding in auditory cortex and high-level visual cortex. Hum Brain Mapp 33(4):969–978. https://doi.org/10.1002/hbm.21263
Aron AR, Robbins TW, Poldrack RA (2014) Inhibition and the right inferior frontal cortex: one decade on. Trends Cogn Sci 18(4):177–185. https://doi.org/10.1016/j.tics.2013.12.003
Ashe J, Lungu OV, Basford AT, Lu X (2006) Cortical control of motor sequences. Current Opinions in Neurobiology 16(2):213–221. https://doi.org/10.1016/j.conb.2006.03.008
Badre D (2008) Cognitive control, hierarchy, and the rostro-caudal organization of the frontal lobes. Trends Cogn Sci 12(5):193–200. https://doi.org/10.1016/j.tics.2008.02.004
Badre D, Nee DE (2018) Frontal cortex and the hierarchical control of behavior. Trends Cogn Sci 22(2):170–188. https://doi.org/10.1016/j.tics.2017.11.005
Badre D, Wagner AD (2004) Selection, integration, and conflict monitoring: assessing the nature and generality of prefrontal cognitive control mechanisms. Neuron 41:473–487
Badre D, Kayser AS, D’Esposito M (2010) Frontal cortex and the discovery of abstract action rules. Neuron 66(2):315–326. https://doi.org/10.1016/j.neuron.2010.03.025
Baldassano C, Hasson U, Norman KA (2018) Representation of real-world event schemas during narrative perception. J Neurosci 38(45):9689–9699. https://doi.org/10.1523/JNEUROSCI.0251-18.2018
Bellucci G, Molter F, Park SQ (2019) Neural representations of honesty predict future trust behavior. Nat Commun 10(1):5184. https://doi.org/10.1038/s41467-019-13261-8
Bergmann HC, Rijpkema M, Fernandez G, Kessels RP (2012) Distinct neural correlates of associative working memory and long-term memory encoding in the medial temporal lobe. Neuroimage 63(2):989–997. https://doi.org/10.1016/j.neuroimage.2012.03.047
Bolger DJ, Perfetti CA, Schneider W (2005) Cross-cultural effect on the brain revisited: universal structures plus writing system variation. Hum Brain Mapp 25(1):92–104. https://doi.org/10.1002/hbm.20124
Botvinick MM, Cohen JD, Carter CS (2004) Conflict monitoring and anterior cingulate cortex: an update. Trends Cogn Sci 8(12):539–546. https://doi.org/10.1016/j.tics.2004.10.003
Braun U, Schafer A, Walter H, Erk S, Romanczuk-Seiferth N, Haddad L, Schweiger JI, Grimm O, Heinz A, Tost H, Meyer-Lindenberg A, Bassett DS (2015) Dynamic reconfiguration of frontal brain networks during executive cognition in humans. Proc Natl Acad Sci USA 112(37):11678–11683. https://doi.org/10.1073/pnas.1422487112
Bubic A, von Cramon DY, Schubotz RI (2009) Motor foundations of higher cognition: similarities and differences in processing regular and violated perceptual sequences of different specificity. Eur J Neurosci 30(12):2407–2414. https://doi.org/10.1111/j.1460-9568.2009.07030.x
Calvo-Merino B, Grezes J, Glaser DE, Passingham RE, Haggard P (2006) Seeing or doing? Influence of visual and motor familiarity in action observation. Curr Biol 16(19):1905–1910. https://doi.org/10.1016/j.cub.2006.07.065
Cao F, Vu M, Chan DH, Lawrence JM, Harris LN, Guan Q, Xu Y, Perfetti CA (2013) Writing affects the brain network of reading in Chinese: a functional magnetic resonance imaging study. Hum Brain Mapp 34(7):1670–1684. https://doi.org/10.1002/hbm.22017
Chatham CH, Claus ED, Kim A, Curran T, Banich MT, Munakata Y (2012) Cognitive control reflects context monitoring, not motoric stopping, in response inhibition. PLoS ONE 7(2):e31546. https://doi.org/10.1371/journal.pone.0031546
Chen HY, Chang EC, Chen SHY, Lin YC, Wu DH (2016) Functional and anatomical dissociation between the orthographic lexicon and the orthographic buffer revealed in reading and writing Chinese characters by fMRI. Neuroimage 129:105–116. https://doi.org/10.1016/j.neuroimage.2016.01.009
Chow TE, Westphal AJ, Rissman J (2018) Multi-voxel pattern classification differentiates personally experienced event memories from secondhand event knowledge. Neuroimage 176:110–123. https://doi.org/10.1016/j.neuroimage.2018.04.024
Cooper RP (2019) Action production and event perception as routine sequential behaviors. Top Cogn Sci. https://doi.org/10.1111/tops.12462
Cross ES, Stadler W, Parkinson J, Schutz-Bosbach S, Prinz W (2011) The influence of visual training on predicting complex action sequences. Hum Brain Mapp 34(2):467–486. https://doi.org/10.1002/hbm.21450
Davis T, LaRocque KF, Mumford JA, Norman KA, Wagner AD, Poldrack RA (2014) What do differences between multi-voxel and univariate analysis mean? How subject-, voxel-, and trial-level variance impact fMRI analysis. Neuroimage 97:271–283. https://doi.org/10.1016/j.neuroimage.2014.04.037
Desmurget M, Sirigu A (2012) Conscious motor intention emerges in the inferior parietal lobule. Curr Opin Neurobiol 22(6):1004–1011. https://doi.org/10.1016/j.conb.2012.06.006
Duque J, Olivier E, Rushworth M (2013) Top-down inhibitory control exerted by the medial frontal cortex during action selection under conflict. J Cogn Neurosci 25(10):1634–1648. https://doi.org/10.1162/jocn_a_00421
Eichenbaum H, Lipton PA (2008) Towards a functional organization of the medial temporal lobe memory system: role of the parahippocampal and medial entorhinal cortical areas. Hippocampus 18(12):1314–1324. https://doi.org/10.1002/hipo.20500
Eichenbaum H, Yonelinas AP, Ranganath C (2007) The medial temporal lobe and recognition memory. Annu Rev Neurosci 30:123–152. https://doi.org/10.1146/annurev.neuro.30.051606.094328
Erika-Florence M, Leech R, Hampshire A (2014) A functional network perspective on response inhibition and attentional control. Nat Commun 5:4073. https://doi.org/10.1038/ncomms5073
Gao X, Yu H, Saez I, Blue PR, Zhu L, Hsu M, Zhou X (2018) Distinguishing neural correlates of context-dependent advantageous- and disadvantageous-inequity aversion. Proc Natl Acad Sci USA 115(33):E7680–E7689. https://doi.org/10.1073/pnas.1802523115
Gates KM, Molenaar PC, Hillary FG, Slobounov S (2011) Extended unified SEM approach for modeling event-related fMRI data. Neuroimage 54(2):1151–1158. https://doi.org/10.1016/j.neuroimage.2010.08.051
Gehring WJ, Knight RT (2000) Prefrontal–cingulate interactions in action monitoring. Nat Neurosci 3(5):516–520
Giovanni FBdA (1994) Order of strokes writing as a cue for retrieval in reading Chinese characters. Eur J Cogn Psychol 6(4):337–355. https://doi.org/10.1080/09541449408406519
Grafton ST, Hamilton AF (2007) Evidence for a distributed hierarchy of action representation in the brain. Hum Mov Sci 26(4):590–616. https://doi.org/10.1016/j.humov.2007.05.009
Hampshire A, Chamberlain SR, Monti MM, Duncan J, Owen AM (2010) The role of the right inferior frontal gyrus: inhibition and attentional control. Neuroimage 50(3):1313–1319. https://doi.org/10.1016/j.neuroimage.2009.12.109
Haynes JD, Rees G (2006) Decoding mental states from brain activity in humans. Nat Rev Neurosci 7(7):523–534. https://doi.org/10.1038/nrn1931
Hodges JR (1991) Pure apraxic agraphia with recovery after drainage of a left frontal cyst. Cortex 27(3):469–473. https://doi.org/10.1016/s0010-9452(13)80043-3
Huang J-T, Wang M-Y (1992) From unit to gestalt: perceptual dynamics in recognizing chinese characters. In: Chen H-C, Tzeng OJL (eds) Language processing in Chinese. Advances in psychology. Elsevier, pp 3–35. https://doi.org/10.1016/s0166-4115(08)61885-3
Igelstrom KM, Graziano MSA (2017) The inferior parietal lobule and temporoparietal junction: a network perspective. Neuropsychologia 105:70–83. https://doi.org/10.1016/j.neuropsychologia.2017.01.001
Jeneson A, Squire LR (2012) Working memory, long-term memory, and medial temporal lobe function. Learn Mem 19(1):15–25. https://doi.org/10.1101/lm.024018.111
Kang C, Ma F, Li S, Kroll JF, Guo T (2020) Domain-general inhibition ability predicts the intensity of inhibition on non-target language in bilingual word production: an ERP study. Biling Lang Cogn. https://doi.org/10.1017/s1366728920000085
Keller C, Meister IG (2014) Agraphia caused by an infarction in Exner’s area. J Clin Neurosci 21(1):172–173. https://doi.org/10.1016/j.jocn.2013.01.014
Kim J, Zhu W, Chang L, Bentler PM, Ernst T (2007) Unified structural equation modeling approach for the analysis of multisubject, multivariate functional MRI data. Hum Brain Mapp 28(2):85–93. https://doi.org/10.1002/hbm.20259
Kim YK, Park E, Lee A, Im CH, Kim YH (2018) Changes in network connectivity during motor imagery and execution. PLoS ONE 13(1):e0190715. https://doi.org/10.1371/journal.pone.0190715
Koechlin E, Jubault T (2006) Broca’s area and the hierarchical organization of human behavior. Neuron 50(6):963–974. https://doi.org/10.1016/j.neuron.2006.05.017
Kriegeskorte N (2011) Pattern-information analysis: from stimulus decoding to computational-model testing. Neuroimage 56(2):411–421. https://doi.org/10.1016/j.neuroimage.2011.01.061
Kriegeskorte N, Kievit RA (2013) Representational geometry: integrating cognition, computation, and the brain. Trends Cogn Sci 17(8):401–412. https://doi.org/10.1016/j.tics.2013.06.007
Kriegeskorte N, Goebel R, Bandettini P (2006) Information-based functional brain mapping. Proc Natl Acad Sci USA 103(10):3863–3868
LaConte S, Strother S, Cherkassky V, Anderson J, Hu X (2005) Support vector machines for temporal classification of block design fMRI data. Neuroimage 26(2):317–329. https://doi.org/10.1016/j.neuroimage.2005.01.048
Lagarrigue A, Longcamp M, Anton JL, Nazarian B, Prevot L, Velay JL, Cao F, Frenck-Mestre C (2017) Activation of writing-specific brain regions when reading Chinese as a second language. Effects of training modality and transfer to novel characters. Neuropsychologia 97:83–97. https://doi.org/10.1016/j.neuropsychologia.2017.01.026
Latora V, Marchiori M (2001) Efficient behavior of small-world networks. Phys Rev Lett 87(19):198701. https://doi.org/10.1103/PhysRevLett.87.198701
Law N, Ki WW, Chung ALS, Ko PY, Lam HC (1998a) Children’s stroke sequence errors in writing Chinese characters. Read Writ 10:267–292
Law N, Ki WW, Chung ALS, Ko PY, Lam HC (1998b) Children’s stroke sequence errors in writing Chinese characters. Read Writ Interdiscip J 10:267–292
Linke A, Roach-Fox E, Vriezen E, Prasad AN, Cusack R (2018) Altered activation and functional asymmetry of exner’s area but not the visual word form area in a child with sudden-onset, persistent mirror writing. Neuropsychologia 117:322–331. https://doi.org/10.1016/j.neuropsychologia.2018.05.022
Lo L-Y, Yeung P-S, Ho CS-H, ChanChung DW-OK (2016) The role of stroke knowledge in reading and spelling in Chinese. J Res Read 39(4):367–388. https://doi.org/10.1111/1467-9817.12058
Luck D, Danion JM, Marrer C, Pham BT, Gounot D, Foucher J (2010) The right parahippocampal gyrus contributes to the formation and maintenance of bound information in working memory. Brain Cogn 72(2):255–263. https://doi.org/10.1016/j.bandc.2009.09.009
Ma F, Xu J, Li X, Wang P, Wang B, Liu B (2018) Investigating the neural basis of basic human movement perception using multi-voxel pattern analysis. Exp Brain Res 236(3):907–918. https://doi.org/10.1007/s00221-018-5175-9
Maeda K, Ogawa N (2014) Agraphia for Kana predominance induced by a cerebral infarction involving the left middle frontal gyrus (Exner’s Area). Austin J Cerebrovasc Dis Stroke 1(4):1016
Molnar-Szakacs I, Kaplan J, Greenfield PM, Iacoboni M (2006) Observing complex action sequences: the role of the fronto-parietal mirror neuron system. Neuroimage 33(3):923–935. https://doi.org/10.1016/j.neuroimage.2006.07.035
Nakamura K, Kuo WJ, Pegado F, Cohen L, Tzeng OJ, Dehaene S (2012) Universal brain systems for recognizing word shapes and handwriting gestures during reading. Proc Natl Acad Sci USA 109(50):20762–20767. https://doi.org/10.1073/pnas.1217749109
Norman KA, Polyn SM, Detre GJ, Haxby JV (2006) Beyond mind-reading: multi-voxel pattern analysis of fMRI data. Trends Cogn Sci 10(9):424–430. https://doi.org/10.1016/j.tics.2006.07.005
Obeso I, Robles N, Marron EM, Redolar-Ripoll D (2013) Dissociating the role of the pre-SMA in response inhibition and switching: a combined online and offline TMS approach. Front Hum Neurosci 7:150. https://doi.org/10.3389/fnhum.2013.00150
Otsuki M, Soma Y, Arai T, Otsuka A, Tsuji S (1999) Pure apraxic agraphia with abnormal writing stroke sequences: report of a Japanese patient with a left superior parietal haemorrhage. J Neurol Neurosurg Psychiatry 66(2):233–237
Padmala S, Pessoa L (2010) Interactions between cognition and motivation during response inhibition. Neuropsychologia 48(2):558–565. https://doi.org/10.1016/j.neuropsychologia.2009.10.017
Pitzalis S, Sereno MI, Committeri G, Fattori P, Galati G, Tosoni A, Galletti C (2013) The human homologue of macaque area V6A. Neuroimage 82:517–530. https://doi.org/10.1016/j.neuroimage.2013.06.026
Pitzalis S, Fattori P, Galletti C (2015) The human cortical areas V6 and V6A. Vis Neurosci 32:E007. https://doi.org/10.1017/S0952523815000048
Planton S, Jucla M, Roux FE, Demonet JF (2013) The “handwriting brain”: a meta-analysis of neuroimaging studies of motor versus orthographic processes. Cortex 49(10):2772–2787. https://doi.org/10.1016/j.cortex.2013.05.011
Reineberg AE, Banich MT (2016) Functional connectivity at rest is sensitive to individual differences in executive function: a network analysis. Hum Brain Mapp 37(8):2959–2975. https://doi.org/10.1002/hbm.23219
Robin J, Moscovitch M (2017) Details, gist and schema: hippocampal–neocortical interactions underlying recent and remote episodic and spatial memory. Curr Opin Behav Sci 17:114–123. https://doi.org/10.1016/j.cobeha.2017.07.016
Rozzi S, Ferrari PF, Bonini L, Rizzolatti G, Fogassi L (2008) Functional organization of inferior parietal lobule convexity in the macaque monkey: electrophysiological characterization of motor, sensory and mirror responses and their correlation with cytoarchitectonic areas. Eur J Neurosci 28(8):1569–1588. https://doi.org/10.1111/j.1460-9568.2008.06395.x
Rubin TN, Koyejo O, Gorgolewski KJ, Jones MN, Poldrack RA, Yarkoni T (2017) Decoding brain activity using a large-scale probabilistic functional-anatomical atlas of human cognition. PLoS Comput Biol 13(10):e1005649. https://doi.org/10.1371/journal.pcbi.1005649
Rubinov M, Sporns O (2010) Complex network measures of brain connectivity: uses and interpretations. Neuroimage 52(3):1059–1069. https://doi.org/10.1016/j.neuroimage.2009.10.003
Rubinov M, Sporns O (2011) Weight-conserving characterization of complex functional brain networks. Neuroimage 56(4):2068–2079. https://doi.org/10.1016/j.neuroimage.2011.03.069
Schmidt R (1975) A schema theory of discrete motor sckill learning. Psychol Rev 82(4):225–260
Sepulveda P, Sitaram R, Rana M, Montalba C, Tejos C, Ruiz S (2016) How feedback, motor imagery, and reward influence brain self-regulation using real-time fMRI. Hum Brain Mapp 37(9):3153–3171. https://doi.org/10.1002/hbm.23228
Song XW, Dong ZY, Long XY, Li SF, Zuo XN, Zhu CZ, He Y, Yan CG, Zang YF (2011) REST: a toolkit for resting-state functional magnetic resonance imaging data processing. PLoS ONE 6(9):e25031. https://doi.org/10.1371/journal.pone.0025031
Spiers HJ, Maguire EA (2007) Decoding human brain activity during real-world experiences. Trends Cogn Sci 11(8):356–365. https://doi.org/10.1016/j.tics.2007.06.002
Squire LR, Wixted JT, Clark RE (2007) Recognition memory and the medial temporal lobe: a new perspective. Nat Rev Neurosci 8(11):872–883. https://doi.org/10.1038/nrn2154
Sundermann B, Pfleiderer B (2012) Functional connectivity profile of the human inferior frontal junction: involvement in a cognitive control network. BMC Neurosci 13(1):119
Takahashi E, Ohki K, Miyashita Y (2002) The role of the parahippocampal gyrus in source memory for external and internal events. NeuroReport 13(15):1951–1956
Thomas RM, De Sanctis T, Gazzola V, Keysers C (2018) Where and how our brain represents the temporal structure of observed action. Neuroimage 183:677–697. https://doi.org/10.1016/j.neuroimage.2018.08.056
Wang Z, Childress AR, Wang J, Detre JA (2007) Support vector machine learning-based fMRI data group analysis. Neuroimage 36(4):1139–1151. https://doi.org/10.1016/j.neuroimage.2007.03.072
Wang L, Uhrig L, Jarraya B, Dehaene S (2015) Representation of numerical and sequential patterns in macaque and human brains. Curr Biol 25(15):1966–1974. https://doi.org/10.1016/j.cub.2015.06.035
Ward AM, Schultz AP, Huijbers W, Van Dijk KR, Hedden T, Sperling RA (2014) The parahippocampal gyrus links the default-mode cortical network with the medial temporal lobe memory system. Hum Brain Mapp 35(3):1061–1073. https://doi.org/10.1002/hbm.22234
Wu CY, Ho MH, Chen SH (2012) A meta-analysis of fMRI studies on Chinese orthographic, phonological, and semantic processing. Neuroimage 63(1):381–391. https://doi.org/10.1016/j.neuroimage.2012.06.047
Yang Y, Zuo Z, Tam F, Graham SJ, Tao R, Wang N, Bi H-Y (2019) Brain activation and functional connectivity during Chinese writing: an fMRI study. J Neurolinguistics 51:199–211. https://doi.org/10.1016/j.jneuroling.2019.03.002
Yang Y, Tam F, Graham SJ, Sun G, Li J, Gu C, Tao R, Wang N, Bi HY, Zuo Z (2020) Men and women differ in the neural basis of handwriting. Hum Brain Mapp 41(10):2642–2655. https://doi.org/10.1002/hbm.24968
Yu H, Gong L, Qiu Y, Zhou X (2011) Seeing Chinese characters in action: an fMRI study of the perception of writing sequences. Brain Lang 119(2):60–67. https://doi.org/10.1016/j.bandl.2010.11.007
Acknowledgements
The study was supported by the National Natural Science Foundation of China (31871097) to Taomei Guo, the National Key Basic Research Program of China (2014CB846102), the Interdiscipline Research Funds of Beijing Normal University, and the Fundamental Research Funds for the Central Universities (2017XTCX04). We thank Leshan Chen for inspiring the research idea, Alex Titus for proofreading the manuscript, and three anonymous reviewers for their valuable comments. All the authors declare no conflict of interest.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Zhang, Z., Yuan, Q., Liu, Z. et al. The cortical organization of writing sequence: evidence from observing Chinese characters in motion. Brain Struct Funct 226, 1627–1639 (2021). https://doi.org/10.1007/s00429-021-02276-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00429-021-02276-x