
Abstract
We explored by eye-tracking the visual encoding modalities of participants (N = 20) involved in a free-observation task in which three repetitions of ten unfamiliar graspable objects were administered. Then, we analysed the temporal allocation (t = 1500 ms) of visual-spatial attention to objects’ manipulation (i.e., the part aimed at grasping the object) and functional (i.e., the part aimed at recognizing the function and identity of the object) areas. Within the first 750 ms, participants tended to shift their gaze on the functional areas while decreasing their attention on the manipulation areas. Then, participants reversed this trend, decreasing their visual-spatial attention to the functional areas while fixing the manipulation areas relatively more. Crucially, the global amount of visual-spatial attention for objects’ functional areas significantly decreased as an effect of stimuli repetition while remaining stable for the manipulation areas, thus indicating stimulus familiarity effects. These findings support the action reappraisal theoretical approach, which considers object/tool processing as abilities emerging from semantic, technical/mechanical, and sensorimotor knowledge integration.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
We live surrounded by different kinds of objects. Some of them, the graspable ones, particularly capture our attention as their affordances, namely the opportunities that those objects offer for action (Gibson, 1977; see also Osiurak et al., 2017), influence how we visually explore them (e.g., Gomez et al., 2018). As a result of such an action predisposition, observers may concentrate their visual attention toward objects’ action-related areas to prepare themselves for action (e.g., Handy et al., 2003; Riddoch et al., 2003). Indeed, seeing prehensible objects stimulates neural activations in the dorsal and ventral streams, respectively associated with the motor control system and semantic processing (e.g., Grezes & Decety, 2002; Roberts & Humphreys, 2010). Thus, on the one hand, affordances—as high-level associations between object properties and our actions toward them—may trigger visuomotor responses that implicitly modulate observers’ attention and performance (e.g., Humphreys et al., 2013; Masson et al., 2011). On the other hand, an observer can capture specific semantic information from the visual scene to identify objects and recognise their functions (e.g., Federico & Brandimonte, 2019, 2020).
Analysing how we look at objects can be an effective way to study their processing since the most basic assumption of the direct-visual-route-to-action is that vision guides actions (Milner & Goodale, 2008). Consequently, an increasing number of studies have investigated how observers may visually encode objects under a variety of experimental contexts (e.g., Ambrosini & Costantini, 2017; Myachykov et al., 2013; Natraj et al., 2015; Tamaki et al., 2020; Van Der Linden et al., 2015). When looking at and using objects, we need to integrate different kinds of information (i.e., semantic, technical/mechanical, and sensorimotor knowledge) in a recursive way (Osiurak et al., 2020). Then, we may use such integrated information to construct generalisable action representations usable in everyday cognitive contexts (e.g., Federico, et al., 2021c; see also Wurm & Caramazza, 2019; Lambon Ralph et al., 2017). The neurocognitive process at the head of such a multi-modal integration mechanism has been recently named “action reappraisal” and it produces peculiar visual-attentive patterns directed towards different objects’ areas (Federico & Brandimonte, 2019; Federico et al., 2021b). Specifically, action reappraisal has been defined as a multidimensional cognitive process that utilises multiple sources of information and different neurocognitive systems to exploit the environment in terms of action (Federico & Brandimonte, 2020, 2022).
Increasing evidence indicates how, during the initial exploration of familiar graspable objects, observers’ gaze is systematically biased toward objects’ functional areas (e.g., the head of a screwdriver, e.g., Natraj et al., 2015; Tamaki et al., 2020; Van Der Linden et al., 2015). On the one hand, such an area includes the object’s part in contact with other objects when generating mechanical actions (e.g., the head of the hammer striking the nail; Goldenberg & Spatt, 2009; Tamaki et al., 2020). On the other hand, the object’s functional area might be related to the object’s identity, permitting observers to recognise the object by accessing semantic knowledge (Federico & Brandimonte, 2020). Therefore, the concentration of visual-spatial attention toward the object's functional area may signal the interplay of neurocognitive systems involved in both technical reasoning (i.e., reasoning on the physical relations between objects) and semantic processing (Federico et al., 2021a, 2021b, 2021c; Tamaki et al., 2020). Instead, the object’s manipulation area can be associated with the object’s graspability, hence concerning the sensorimotor interface between the observer's hand and the object (Osiurak et al., 2017). Therefore, the allocation of visual-spatial attention to the object’s manipulation area may predict the finalisation of motor programs aimed at preparing the observer for the action (i.e., reaching/grasping the object to use it). Ultimately, we may assume observers’ object visual-exploration patterns as the by-product of the interactions between multiple neurocognitive systems, namely the dorso-dorsal system (i.e., the motor-control system), the dorso-ventral system (i.e., the technical-reasoning system), and the ventral system (i.e., the semantic system; Almeida et al., 2013; Goldenberg & Spatt, 2009; Ishibashi et al., 2016; Lesourd et al., 2021; Reynaud et al., 2016; Rizzolatti & Matelli, 2003).
The debate about how the neurocognitive systems involved in object processing work and interact with one another is extremely lively in the literature (e.g., Osiurak & Federico, 2021; Osiurak et al., 2017; Reynaud et al., 2016). A kind of semantic-to-mechanical-to-motor cascade reiterative mechanism has been recently proposed to describe the set of neurocognitive interactions intervening during the visual exploration and use of objects (Federico & Brandimonte, 2020; see also Osiurak et al., 2020). However, whereas a growing body of research has analysed how these interactions may generate peculiar visual-attentional trade-offs between functional and manipulation areas of familiar objects, much less has been said about how such areas could be visually explored when objects are unfamiliar. Nevertheless, analysing the visual-attentional patterns of observers looking at unfamiliar graspable objects might be very helpful to characterise the involvement of semantic, technical/mechanical, and sensorimotor knowledge during the visual exploration of objects. Indeed, the visual exploration of unfamiliar objects should produce visual-attentional patterns aimed at identifying them (i.e., semantic knowledge) and, subsequently (or simultaneously), at preparing for using/grasping them (i.e., technical/mechanical and motor knowledge). The emergence of distinct forms of knowledge should affect the temporal allocation of visual-spatial attention to the objects’ manipulation and functional areas as an effect of the action reappraisal (e.g., Federico et al., 2021a, 2021b, 2021c; Federico & Brandimonte, 2022).
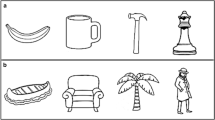
To test the above hypotheses, in this eye-tracking study we presented participants with ten unfamiliar monochromatic objects extracted from the Novel Object and Unusual Name (NOUN) database (Horst & Hout, 2016). We used object novelty (i.e., unfamiliar objects) to manipulate the visual-perceptual context's semantic characterisation indirectly. We balanced the novelty factor across all the stimuli. Indeed, both the objects’ heads and handles differed from each other (see Fig. 1). Additionally, we used greyscale stimuli depicting objects alone to limit the confounding effects given by colours, contexts (e.g., objects placed on a table) and object-to-object relations, thus focusing on the effects given by object novelty (Federico & Brandimonte, 2019). Consistently with the action-reappraisal approach, in this study, object novelty has been conceptualized as a kind of semantic knowledge that an observer may activate earlier than lower-level perceptual information (e.g., Bar et al., 2006). All the objects comprised a manipulation end on the right (i.e., the area of the object where to put the hand to grasp/use it) and a functional end on the left (i.e., the area of the object through which one may infer its function/identity). By choosing such a spatial disposition, we aimed at generating an experimental visual-perceptual context that may effectively prompt action affordances. Indeed, we placed the object’s graspable handle in the participant's right peri-personal space, namely the one that was ipsilateral to the participant’s effector arm. Thus, we manipulated the visual-perceptual context in such a way as to amplify the sensorimotor processing of the scene based on objects’ affordances (e.g., Tucker & Ellis, 1998).Footnote 1 We presented participants with three repetitions of the stimuli to investigate the effects of stimuli familiarization on object visual exploration. Thus, we analysed all the time course (t = 1500 ms) of participants' visual-spatial attention to the two Areas of Interest (AOIs) of the objects (i.e., the manipulation and functional areas). We first assessed overall differences in the participants’ gaze behaviour; then, we devised a growth curve analysis (Mirman, 2014) to study differences in the shape and latency of the participants' gaze curves as a function of time.

Stimuli used in the study. In this study, we used ten monochromatic images of unfamiliar objects extracted from the NOUN database (Horst & Hout, 2016). All the stimuli presented the manipulation area on the right side and the functional area on the left side of the stimulus
Methods
Participants
Twenty (9 females; mean age = 27.45 years, S. = 6.07) right-handed participants were enrolled for the study. Participants’ handedness was assessed using the Edinburgh Handedness Inventory (Oldfield, 1971). When calculating the sample size for the experiment, we first considered previous studies in the field by our and other laboratories (i.e., Federico & Brandimonte, 2019, 2020; Natraj et al., 2015; Tamaki et al., 2020; Van Der Linden et al., 2015). In particular, we calculated the sample size of this study taking into account the results of Van Der Linden and colleagues (2015; N = 18), which involved eye-tracking for single objects that were analysed in terms of three different AOIs (i.e., manipulation area, object centre and functional area). Also, to calculate the expected overall effect size, we considered our previous findings in the context of single-tool visual exploration (Federico & Brandimonte, 2019). Therefore, we implemented the power analysis with G*Power (Faul et al., 2007) to detect a moderate effect size (ηp2 = 0.35) within the context of a within-factors repeated measures analysis of variance, with a power of 0.80 and an alpha level of 0.05 (computed N = 18), as per Cohen (2013)’s effect-size specification procedures. The Institutional Ethics Committee approved the study as being fully compliant with the Helsinki Declaration's ethical standards lied down in 1964. Before starting the experiment, written informed consent was obtained from each participant, and every participant was assessed for right-handedness (Oldfield, 1971), self-reported absence of neurological/psychiatric diseases, and self-reported adequate visual acuity.
Materials
We used ten monochromatic images of unfamiliar objects extracted from the Novel Object and Unusual Name (NOUN) database (Horst & Hout, 2016) that appeared on a screen with a white background. All the images were arranged in such a way as to depict objects having a manipulation part placed on the right and a functional part on the left, according to the object’s centre. Images were assessed by an independent jury (N = 10; 5 females; mean age = 30.2 years; SD = 5.03) regarding the following criteria: (i) right-hand graspability judgement (“How easy to grasp with your right hand this object is?”, with 0 = impossible to grasp and 10 = extremely easy to grasp; Mean Graspability = 9.5/10; SD = 0.5); (ii) familiarity judgement (“How familiar do you think this object is?”, with 0 = never-seen object and 10 = very common object; Mean Familiarity = 1.1/10; SD = 0.8). All images had a resolution of 900 × 900px. All the stimuli used in the experiment are illustrated in Fig. 1.
Procedure
The experiment was performed in the IRCCS Synlab SDN (Naples, Italy). Participants were invited to sit on a chair, placing their chin on a chinrest at approximately 50 cm from a 24-inches monitor. Participants kept their hands motionless on the desk. In this way, both hands were peripherally visible. Then, an eye-tracking calibration procedure was performed. Participants looked at a series of red dots that appeared in different screen areas. The instructions appeared on the screen at the end of the calibration process, and the study started. The task was to "look at the images in the most natural way possible". Three repetitions of ten images, each preceded by a fixation point, were administered. Hence, for each repetition, ten images randomly appeared on the screen, for a total of thirty images. The fixation point was placed in the centre of the visual scene and appeared for 500 ms. Images appeared for 1500 ms, followed by a black screen (3000 ms). A single stimulation (fixation point + image + black screen) lasted 5000 ms. Overall, the stimuli presentation lasted 2.5 min. The experimental visual flow is summarised in Fig. 2. At the end of the experiment, all participants were asked to judge the usability of the objects used as stimuli in the study (“How much is the object usable with your right hand to do something?”, with 0 = unusable object and 10 = very usable object; Mean Usability = 8.3/10; SD = 0.7). The overall duration of the study was approximately 10 min for each participant. All participants were debriefed about the research aim at the end of the study. No participant was excluded from the sample.

Experimental flow. A fixation point appeared for 500 ms; then, the stimulus appeared for 1500 ms, and participants' gaze data were acquired. Finally, a black screen was shown to permit participants’ eyes to relax
Apparatus
Gaze-behaviour data were collected using a Full-HD Webcam (Logitech HD Pro C920) with a sampling rate of 30 Hz and the RealEye.io online eye-tracking platform (RealEye sp. z o.o., Poland). The RealEye.io platform is based on the WebGazer JavaScript library (Papoutsaki et al., 2016). A 24-inch monitor with a resolution of 1920 × 1080px was used to show stimuli. The eye-tracking technologies involved in this study have been used in previous experiments (e.g., Federico & Brandimonte, 2019, 2020; Federico et al. 2021a, 2021b, 2021c) and have been considered a consistent technology for studies that do not require a very detailed spatial resolution, as in the case of the present investigation (Semmelmann & Weigelt, 2018).
Eye-tracking data
Participants' visual-attentional patterns were analysed by considering fixation proportions to two specific AOIs, namely the object manipulation area (i.e., the prehensible area placed on the right of each object) and the object’s functional area (i.e., the area of the object through which one may recognise its identity, placed on the left of each object). To mitigate the standard error produced by the RealEye.io platform (i.e., average accuracy: 113px), the AOIs were comprised in a rectangle expanded by a minimum of 120 pixels in all directions, considering the object’s centre and the left/right borders of the object’s area included in the AOI. The size of the rectangle was kept unchanged for all stimuli. All gaze-behavioural data were extracted using custom PHP/MySQL scripts. An example of AOIs considered in this study is shown in Fig. 3.

The areas of interest (AOIs) analysed in the study. The AOIs analysed in the study were the Function Area (highlighted and labelled in the blue rectangle) and the Manipulation Area (highlighted and labelled in the red rectangle) of the object
Data analyses
In this study, we implemented multiple hypothesis-driven data analyses. As a first-level analysis, we implemented two repeated-measure analyses of variance (RM-ANOVA). In the first RM-ANOVA, we considered the effect of the three-level factor Repetitions (i.e., “R1” vs “R2” vs “R3”) on dwell time (expressed in milliseconds) related to objects’ functional AOIs. With the second RM-ANOVA, we instead explored the effect of Repetitions on dwell time related to objects’ manipulation AOIs. With both the RM-ANOVAs, we considered the entire time window of analysis (i.e., 1500 ms), thus assessing participants’ full visual exploration. As a second-level analysis, we further investigated the temporal allocation of participants’ visual-spatial attention to the visual scene. Therefore, we devised an ad-hoc time-series analysis. We divided gaze-behavioural data into 100-ms time bins and then implemented a growth curve analysis (GCA; Mirman, 2014) by fitting a linear mixed model under REML, modelling the participants’ proportion-looking (i.e., the mean of raw proportion scores) to the objects’ functional and manipulation areas throughout the trials. The model took the form [Prop ~ Repetitions * (ot1 + ot2) + (ot1 + ot2|Participants) + (ot1 + ot2|Trial)], where ot1 and ot2 refer to the linear and quadratic orthogonal polynomials, respectively. The time course of visual exploration was captured with second-order orthogonal polynomials, with fixed effects of Repetitions and random effects of Participants and Trials on all the time terms. We statistically evaluated the bends in the curves by implementing an ANOVA for mixed-effects models using Satterthwaite's method, thus obtaining a p-value for all the effects we considered in the analysis. For all the analyses, an alpha level of 0.05 was used, with Bonferroni correction for post-hoc comparisons.
Results
First-level analysis
Data associated with participants’ dwell time related to objects’ functional AOIs are summarized in Table 1. Instead, participants’ dwell time related to objects’ manipulation AOIs are shown in Table 2. Both the results are sorted by Repetition (i.e., “R1” vs “R2” vs “R3”).
The first RM-ANOVA revealed a main effect of Repetitions on participants’ dwell time related to object’s functional AOIs, F (2, 38) = 6.99, p = 0.003, ηp2 = 0.27 (Fig. 4A). Post-hoc Bonferroni-corrected pair-wise comparisons revealed that dwell time was higher in R3 than both R2 (p = 0.01) and R1 (p = 0.048). No effects of Repetitions on participants’ dwell time related to object’s manipulation AOIs were captured by the second RM-ANOVA, F (2, 38) = 2.97, p = 0.063, ηp2 = 0.13 (Fig. 4B).

The visual encoding of unfamiliar graspable objects. The first-level analysis (A, B) revealed a main effect of stimuli repetitions on participants’ dwell time related to the functional areas of the objects. Indeed, dwell time to functional areas significantly decreased at the third stimuli repetition (A) while remaining stable for manipulation areas (B). Within the second-level growth-curve analysis (C, D), we found a reversed quadratic trend in the way participants explored objects. Within the first 750 ms of visual exploration, participants tended to shift their gaze on the functional areas, while decreasing their attention on the manipulation areas (C). After the 750-ms peak, participants reversed this trend, decreasing their visual-spatial attention to the functional areas and increasing their fixations to the manipulation areas (D). Vertical bars in (A, B) denote 0.95 confidence intervals, computed by adopting a more straightforward solution to Loftus and Masson (1994) provided by Cousineau (2005)
Second-level analysis
Figure 4C shows fixation proportions over time to objects’ functional AOIs for each repetition (i.e., R1 vs R2 vs R3). A Type III ANOVA with Satterthwaite's method for the GCA's effects indicated a main effect of the quadratic time term, F (1, 25,097) = 19.22, p = 0.0002. Congruently with the first-level analysis, a main effect of Repetitions was also found, F (1, 27,006) = 6.87, p = 0.004. No interactions between Repetitions and the first- and second-order orthogonal time-term polynomials were found. A second Type III Satterthwaite's ANOVA has been performed to analyse participants’ fixation proportions over time to objects’ manipulation AOIs as a function of Repetitions (Fig. 4D). A main effect of the quadratic time term was found, F (1, 26,833) = 22.01, p < 0.0001. No main effects of Repetitions or interactions were found. Overall, the model we devised showed a reversed quadratic trend in the participants’ gaze-behavioural data. Specifically, participants exhibited an increasing trend in focusing their visual-spatial attention on the objects’ functional AOIs during the first 750 ms of visual exploration (Fig. 4C). An inverse trend emerged as regards objects’ manipulation AOIs (Fig. 4D). Thus, within the first 750 ms of visual exploration, participants tended to focus their gaze on the functional AOIs, while decreasing their attention on the manipulation AOIs. Afterwards, participants reversed this trend, decreasing their visual-spatial attention to the functional AOIs while increasing their temporal allocation of visual-spatial attention to the manipulation AOIs. Most importantly, the global amount of visual-spatial attention for objects’ manipulation AOIs did not significantly change as an effect of stimuli repetition. Conversely, participants looked at functional AOIs significantly longer during the first and second repetition, as confirmed by the first- and second-level data analysis, indicating a stimulus familiarity effect.
Discussion
In this eye-tracking study, we explored the visual-exploration patterns of participants involved in a free-to-look-at task where ten unfamiliar graspable objects extracted from the NOUN database (Horst & Hout, 2016) were presented. Specifically, we analysed the participants’ temporal allocation of visual-spatial attention to objects’ manipulation (i.e., the area of the object aimed at manipulating it) and functional (i.e., the part of the object through which one may gather its identity and function) AOIs. Also, we administered three stimuli repetitions to investigate how increasing stimulus familiarity impacts the way participants look at unfamiliar objects. Hence, we indirectly manipulated stimuli novelty by modulating stimuli familiarity using time, namely the number of repetitions of the same stimuli, in such a way as to give rise to a progressive increase of semantic/mechanical knowledge associated with the gradually more-familiar objects. Results highlighted peculiar visual-exploration patterns, with participants looking at functional and manipulations AOIs in a reversed-U way. Indeed, we found that unfamiliar-object visual exploration was fully described by quadratic curves, with participants looking at functional AOIs in such a way as to generate an almost-convex parabolic trend. Instead, participants showed an almost-concave parabolic trend of fixations to objects' manipulation AOIs. During the first 750 ms of visual exploration, participants increased their visual-spatial attention to the objects’ functional AOI (Fig. 4C). Conversely, participants' visual-spatial attention to manipulation AOIs (Fig. 4D) decreased during the same time interval. After the 750 ms peak, participants reversed their visual exploration trend, hence reducing their visual-spatial attention to the functional AOIs while relatively increasing their fixations toward the manipulation AOIs. Crucially, we found that familiarization effects related to stimuli repetitions reverberated only in the way participants visually explored functional AOIs. Indeed, during the third stimuli repetition, participants significantly reduced their visual-spatial attention to the functional AOIs (Fig. 4A, C) while maintaining unchanged their fixations to manipulation AOIs (Fig. 4B, D).
According to the findings we report here, the visual exploration of unfamiliar graspable objects seems to be characterised by an explorative gaze behaviour aimed at focusing on the objects’ functional area after about 200 ms of visual exploration, reaching the peak after approximately 750 ms. Intriguingly, the temporal evolution of the central fixation bias in the context of scene viewing produces effects within the first 250 ms of stimuli exploration (Rothkegel et al., 2017). Therefore, by interpreting results starting from the first 250 ms of visual-exploration data to prevent central-fixation biases, we found a visual-attentional pattern aimed at identifying the object's function and identity, i.e., increased fixations to the functional AOIs (e.g., Natraj et al., 2015; Tamaki et al., 2020; Van Der Linden et al., 2015). After such a preliminary semantic-driven visual exploration of the stimulus, we found that participants oriented their visual-spatial attention toward the object’s manipulation areas as if they were to prepare themselves for action (Handy et al., 2003; Riddoch et al., 2003). Such a perspective is in line with the perception-for-action theoretical framework (e.g., Milner & Goodale, 2008) while emphasizing at the same time the relevance of high-level cognitive processes involved in semantic cognition, action understanding and technical reasoning (Federico & Brandimonte, 2020, 2022). Critically, in line with such a hybrid approach, we found that familiarization effects produced by stimuli repetitions did not impact the manipulation-related visual exploration of objects, thus influencing only the functional-related gaze behaviour. Indeed, one may reasonably assume that imagining how to grasp unfamiliar objects should not produce so many fluctuations in visually exploring their manipulation areas over time, whereas identifying and recognizing the function of an object might be a process susceptible to the stimulus’ exposure time (Federico & Brandimonte, 2019). It should be noted that the specific experimental scenario we used in this study may reinforce further such an interpretation of the results. Indeed, we highlighted the effects of semantic-driven processing of objects when they are in a high action/affordance-ready spatial condition (i.e., the graspable handle shown ipsilateral to the observer’s dominant/effector's arm).
Rather than emphasising a competitive approach between semantic, technical/mechanical and sensorimotor knowledge, our results underline how human signification processes may be traced in the interplay among multiple cognitive processes (Federico & Brandimonte, 2022). In fact, the visual exploration of unfamiliar but graspable objects appears to reflect the interactions between affordance-based (e.g., Humphreys et al., 2013; Masson et al., 2011) and higher-level cognitive processing (e.g., Bar et al., 2006; Federico et al., 2021a, 2021b, 2021c; Wurm & Caramazza, 2019). Additionally, as we mentioned above, the exploration of objects’ functional areas might also be associated with technical-knowledge processing through which observers may reason about how objects can be used with other objects mechanically (e.g., looking at the head of a hammer, thus focusing on the action-performing area that will hit a nail; Goldenberg & Spatt, 2009; Tamaki et al., 2020). In this sense, our results align with multiple studies showing how participants may concentrate on the action’s goal component more than on its manipulation component (e.g., Massen & Prinz, 2007; Osiurak & Badets, 2014). These goal-related patterns have also been traced in observational investigations where observers looked at an actor using an object (e.g., Decroix & Kalénine, 2019; Naish et al., 2013; Nicholson et al., 2017; van Elk et al., 2008). Such studies investigated the action’s goal component regarding objects’ functional AOIs, thus implicitly referring to the semantic/technical knowledge retrievable by looking at objects. However, those results are typically interpreted only in terms of manipulation/sensorimotor knowledge (e.g., Thill et al., 2013), possibly because of the absence of alternative theoretical frameworks (Osiurak & Federico, 2020).
The polymorphic interactions between distinct kinds of knowledge we summarised above give space to the idea of a cognitive functioning oriented towards integrating multiple information modalities through which humans may endow reality with meaning and exploit the environment for action. Such a kind of hybrid cognitive mechanism involved in the way humans integrate distinct kinds of information to generate representations that may be used in everyday life has been recently labelled as action reappraisal (Federico & Brandimonte, 2019, 2020, 2022). The results presented here provide further experimental support for the action reappraisal mechanism and interrogate about the possible neurocognitive systems supporting such a multifaceted phenomenon. Indeed, brain areas underlining the identification, recognition and use of objects comprise an extensive and multifunctional fronto-temporo-parietal network (e.g., Almeida et al., 2013; Goldenberg & Spatt, 2009; Ishibashi et al., 2016; Lesourd et al., 2021; Rizzolatti & Matelli, 2003). Consequently, specific hypotheses have been generated about the involvement of such fronto-temporo-parietal areas in the context of the action-reappraisal approach (e.g., Federico & Brandimonte, 2020). Although the scientific debate about the neural correlates of the action reappraisal mechanism is very far from being concluded, increasing and converging support for the action reappraisal idea comes from studies that highlighted the involvement of specific brain networks involved in integrating information about action and objects across different modalities (e.g., Chen et al., 2018; De Bellis et al., 2020; Lambon Ralph et al., 2017; Lesourd et al., 2021; Pupíková et al., 2021; Wurm & Caramazza, 2019). Significantly, a most recent fMRI/tDCS study (Pupíková et al., 2021) demonstrated how stimulating the fronto-parietal network with twenty minutes of 2 mA anodal tDCS increased the recognition performance of participants involved in a yes–no object recognition task which was similar to the one developed by Federico and Brandimonte (2020), hence providing the first solid causal evidence for the action reappraisal mechanism.
By following the tripartite neural-stream division introduced by Rizzolatti and Matelli (2003), the central neurocognitive systems involved in object processing and tool use are those related to the motor-control system (i.e., the dorso-dorsal system), the mechanical/technical-knowledge system (i.e., the dorso-ventral system), and the semantic system (i.e., the ventral system, e.g., Almeida et al., 2013; Goldenberg & Spatt, 2009; Ishibashi et al., 2016; Osiurak et al., 2017). Intriguingly, the recent Three-Action System model (Osiurak et al., 2017) identifies a part of the ventro-dorsal system, namely the left inferior parietal lobe and specifically its related area PF (Caspers et al., 2006), as a kind of bridge between the semantic system related to objects’ identity (i.e., the ventral system), and the motor-control system (i.e., the dorso-dorsal stream). Additionally, most recent neuroscientific and neuropsychological evidence highlighted the inferior parietal and middle temporal brain areas as the ones pertaining to an integrative cognitive layer related to the generation of object-related action multi-modal representations (e.g., Chen et al., 2018; De Bellis et al. 2020; Lambon Ralph et al., 2017; Wurm & Caramazza, 2019; Lesourd et al., 2021; see also Humphreys et al., 2021). Also, when considering the frontal and prefrontal cortex involvement in object processing, it appears that these areas might be easily related to high-level executive functions, motor timing, sequencing and simulation (e.g., Bortoletto & Cunnington, 2010; Koechlin & Summerfield, 2007). However, whereas the above-specified integrated processes involving temporo-parietal brain areas have been increasingly investigated, the frontal and prefrontal areas' involvement did not get the same popularity. Notwithstanding, these areas might actively take part in the action reappraisal mechanism as they may signal a specific cognitive functioning through which an observer, from the multiple environment-available information and action possibilities, may select only those that are consistent with their intentions (for a discussion, see Federico et al., 2021a, 2021b, 2021c).
Conclusion
The results we reported here highlight the effects of both action and signification processing on unfamiliar objects’ visual-encoding modalities. While the effects of the affordance-based processing, namely the time spent by participants looking at the manipulation end of the objects, seems to be invariant to stimuli’s reiteration/learning, we found that objects’ semantic processing emerges as a time-dependent process which may vary according to the object’s novelty. Thus, the less familiar the object, the greater the semantic processing of it. Conversely, as stimulus familiarity increases, semantic processing reduces. All the results discussed in this study appear to fit very well with the action-reappraisal idea introduced by Federico and Brandimonte (2019, 2020, 2022). Within such a hybrid perspective, object processing might be considered an ability that emerges from the integration of distinct kinds of information. Such integration is plausibly achievable through the interoperability of multiple neurocognitive systems. Therefore, we suggest that when processing objects, the human mind may rely on distinct reservoirs of knowledge, namely semantic, mechanical (i.e., technical reasoning) and sensorimotor knowledge. Notably, while the present approach is not aimed at dismissing an embodied-cognition view of cognition (e.g., Shapiro, 2019), it nonetheless reinforces the idea – recently emerged among scholars (e.g., Bar et al., 2006) – that semantic information might be activated earlier than lower-level perceptual information, hence affecting visual perception. However, while increasing evidence supports the action reappraisal idea, further studies are necessary to explore its neural correlates. Also, given the number of possible variables involved in the action reappraisal, future studies with larger samples should confirm our preliminary findings in more ecological contexts.
Notes
The spatial disposition we used in this study represents the worst condition should one wish to emphasize semantic effects in modulating the temporal allocation of visual-spatial attention. Hence, we chose the worst experimental scenario with respect to the action reappraisal (Federico & Brandimonte, 2019).
References
Almeida, J., Fintzi, A. R., & Mahon, B. Z. (2013). Tool manipulation knowledge is retrieved by way of the ventral visual object processing pathway. Cortex, 49(9), 2334–2344.
Ambrosini, E., & Costantini, M. (2017). Body posture differentially impacts on visual attention towards tool, graspable, and non-graspable objects. Journal of Experimental Psychology: Human Perception and Performance, 43(2), 360.
Bar, M., Kassam, K. S., Ghuman, A. S., Boshyan, J., Schmid, A. M., Dale, A. M., Hämäläinen, M. S., Marinkovic, K., Schacter, D. L., Rosen, B. R., & Halgren, E. (2006). Top-down facilitation of visual recognition. Proceedings of the National Academy of Sciences of the United States of America, 103(2), 449–454.
Bortoletto, M., & Cunnington, R. (2010). Motor timing and motor sequencing contribute differently to the preparation for voluntary movement. NeuroImage, 49(4), 3338–3348.
Caspers, S., Geyer, S., Schleicher, A., Mohlberg, H., Amunts, K., & Zilles, K. (2006). The human inferior parietal cortex: Cytoarchitectonic parcellation and interindividual variability. NeuroImage, 33(2), 430–448.
Chen, Q., Garcea, F. E., Jacobs, R. A., & Mahon, B. Z. (2018). Abstract representations of object-directed action in the left inferior parietal lobule. Cerebral Cortex, 28(6), 2162–2174.
Cohen, J. (2013). Statistical power analysis for the behavioral sciences. Routledge.
Cousineau, D. (2005). Confidence intervals in within-subject designs: A simpler solution to Loftus and Masson’s method. Tutorials in Quantitative Methods for Psychology, 1(1), 42–45.
De Bellis, F., Magliacano, A., Sagliano, L., Conson, M., Grossi, D., & Trojano, L. (2020). Left inferior parietal and posterior temporal cortices mediate the effect of action observation on semantic processing of objects: Evidence from rTMS. Psychological Research Psychologische Forschung, 84(4), 1006–1019.
Decroix, J., & Kalénine, S. (2019). What first drives visual attention during the recognition of object-directed actions? The role of kinematics and goal information. Attention, Perception, & Psychophysics, 81(7), 2400–2409.
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G* Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191.
Federico, G., & Brandimonte, M. A. (2019). Tool and object affordances: an ecological eye-tracking study. Brain and Cognition, 135, 103582.
Federico, G., & Brandimonte, M. A. (2020). Looking to recognise: The pre-eminence of semantic over sensorimotor processing in human tool use. Scientific Reports, 10(1), 1–16.
Federico, G., & Brandimonte, M. A. (2022). Il ruolo del ragionamento e dell’elaborazione semantica nell’uso di utensili: La prospettiva integrata dell’action reappraisal. TOPIC-Temi Di Psicologia Dell’ordine Degli Psicologi Della Campania, 1(1), 10–53240.
Federico, G., Ferrante, D., Marcatto, F., & Brandimonte, M. A. (2021a). How the fear of COVID-19 changed the way we look at human faces. PeerJ, 9, e11380.
Federico, G., Osiurak, F., & Brandimonte, M. A. (2021b). Hazardous tools: the emergence of reasoning in human tool use. Psychological Research, 85, 3108–3118. https://doi.org/10.1007/s00426-020-01466-2.
Federico, G., Osiurak, F., Reynaud, E., & Brandimonte, M. A. (2021c). Semantic congruency effects of prime words on tool visual exploration. Brain and Cognition, 152, 105758.
Gibson, J. J. (1977). The theory of affordances. Hilldale, USA, 1(2), 67–82.
Goldenberg, G., & Spatt, J. (2009). The neural basis of tool use. Brain, 132(6), 1645–1655.
Gomez, M. A., Skiba, R. M., & Snow, J. C. (2018). Graspable objects grab attention more than images do. Psychological Science, 29(2), 206–218.
Grezes, J., & Decety, J. (2002). Does visual perception of object afford action? Evidence from a Neuroimaging Study. Neuropsychologia, 40(2), 212–222.
Handy, T. C., Grafton, S. T., Shroff, N. M., Ketay, S., & Gazzaniga, M. S. (2003). Graspable objects grab attention when the potential for action is recognized. Nature Neuroscience, 6(4), 421–427.
Horst, J. S., & Hout, M. C. (2016). The Novel Object and Unusual Name (NOUN) Database: A collection of novel images for use in experimental research. Behavior Research Methods, 48(4), 1393–1409.
Humphreys, G. W., Kumar, S., Yoon, E. Y., Wulff, M., Roberts, K. L., & Riddoch, M. J. (2013). Attending to the possibilities of action. Philosophical Transactions of the Royal Society b: Biological Sciences, 368(1628), 20130059.
Humphreys, G. F., Lambon Ralph, M. A. L., & Simons, J. S. (2021). A unifying account of angular gyrus contributions to episodic and semantic cognition. Trends in Neurosciences., 44, 452–463.
Ishibashi, R., Pobric, G., Saito, S., & Lambon Ralph, M. A. (2016). The neural network for tool-related cognition: An activation likelihood estimation meta-analysis of 70 neuroimaging contrasts. Cognitive Neuropsychology, 33(3–4), 241–256.
Koechlin, E., & Summerfield, C. (2007). An information theoretical approach to prefrontal executive function. Trends in Cognitive Sciences, 11(6), 229–235.
Lambon Ralph, M. A., Jefferies, E., Patterson, K., & Rogers, T. T. (2017). The neural and computational bases of semantic cognition. Nature Reviews Neuroscience, 18(1), 42–55.
Lesourd, M., Servant, M., Baumard, J., Reynaud, E., Ecochard, C., Medjaoui, F. T., Bartolo, A., & Osiurak, F. (2021). Semantic and action tool knowledge in the brain: identifying common and distinct networks. Neuropsychologia, 159, 107918.
Loftus, G. R., & Masson, M. E. (1994). Using confidence intervals in within-subject designs. Psychonomic Bulletin & Review, 1(4), 476–490.
Massen, C., & Prinz, W. (2007). Programming tool-use actions. Journal of Experimental Psychology: Human Perception and Performance, 33(3), 692.
Masson, M. E., Bub, D. N., & Breuer, A. T. (2011). Priming of reach and grasp actions by handled objects. Journal of Experimental Psychology: Human Perception and Performance, 37(5), 1470.
Milner, A. D., & Goodale, M. A. (2008). Two visual systems re-viewed. Neuropsychologia, 46(3), 774–785.
Mirman, D. (2014). Growth curve analysis: A hands-on tutorial on using multilevel regression to analyze time course data. In: Proceedings of the Annual Meeting of the Cognitive Science Society (Vol. 36, No. 36).
Myachykov, A., Ellis, R., Cangelosi, A., & Fischer, M. H. (2013). Visual and linguistic cues to graspable objects. Experimental Brain Research, 229(4), 545–559.
Naish, K. R., Reader, A. T., Houston-Price, C., Bremner, A. J., & Holmes, N. P. (2013). To eat or not to eat? Kinematics and muscle activity of reach-to-grasp movements are influenced by the action goal, but observers do not detect these differences. Experimental Brain Research, 225(2), 261–275.
Natraj, N., Pella, Y. M., Borghi, A. M., & Wheaton, L. A. (2015). The visual encoding of tool–object affordances. Neuroscience, 310, 512–527.
Nicholson, T., Roser, M., & Bach, P. (2017). Understanding the goals of everyday instrumental actions is primarily linked to object, not motor-kinematic, information: Evidence from fMRI. PLoS ONE, 12(1), e0169700.
Osiurak, F., & Badets, A. (2014). Pliers, not fingers: Tool-action effect in a motor intention paradigm. Cognition, 130(1), 66–73.
Oldfield, R. C. (1971). The assessment and analysis of handedness: The Edinburgh inventory. Neuropsychologia, 9, 97–113.
Osiurak, F., & Federico, G. (2021). Four ways of (mis-) conceiving embodiment in tool use. Synthese, 199, 3853–3879. https://doi.org/10.1007/s11229-020-02960-1.
Osiurak, F., Federico, G., Brandimonte, M. A., Reynaud, E., & Lesourd, M. (2020). On the temporal dynamics of tool use. Frontiers in Human Neuroscience, 14. https://doi.org/10.3389/fnhum.2020.579378.
Osiurak, F., Rossetti, Y., & Badets, A. (2017). What is an affordance? 40 years later. Neuroscience & Biobehavioral Reviews, 77, 403–417.
Papoutsaki, A., Sangkloy, P., Laskey, J., Daskalova, N., Huang, J., & Hays, J. (2016). WebGazer: Scalable webcam eye tracking using user interactions. In: Proceedings of the twenty-fifth international joint conference on artificial intelligence-IJCAI 2016.
Pupíková, M., Šimko, P., Gajdoš, M., & Rektorová, I. (2021). Modulation of working memory and resting-state fMRI by tDCS of the right frontoparietal network. Neural Plasticity. https://doi.org/10.1155/2021/5594305
Reynaud, E., Lesourd, M., Navarro, J., & Osiurak, F. (2016). On the neurocognitive origins of human tool use: A critical review of neuroimaging data. Neuroscience & Biobehavioral Reviews, 64, 421–437.
Riddoch, M. J., Humphreys, G. W., Edwards, S., Baker, T., & Willson, K. (2003). Seeing the action: Neuropsychological evidence for action-based effects on object selection. Nature Neuroscience, 6(1), 82–89.
Rizzolatti, G., & Matelli, M. (2003). Two different streams form the dorsal visual system: Anatomy and functions. Experimental Brain Research, 153(2), 146–157.
Roberts, K. L., & Humphreys, G. W. (2010). Action relationships concatenate representations of separate objects in the ventral visual system. NeuroImage, 52(4), 1541–1548.
Rothkegel, L. O., Trukenbrod, H. A., Schütt, H. H., Wichmann, F. A., & Engbert, R. (2017). Temporal evolution of the central fixation bias in scene viewing. Journal of Vision, 17(13), 3–3.
Semmelmann, K., & Weigelt, S. (2018). Online webcam-based eye tracking in cognitive science: A first look. Behavior Research Methods, 50(2), 451–465.
Shapiro, L. (2019). Embodied cognition. Routledge.
Tamaki, Y., Nobusako, S., Takamura, Y., Miyawaki, Y., Terada, M., & Morioka, S. (2020). Effects of tool novelty and action demands on gaze searching during tool observation. Frontiers in Psychology, 11, 3060.
Thill, S., Caligiore, D., Borghi, A. M., Ziemke, T., & Baldassarre, G. (2013). Theories and computational models of affordance and mirror systems: An integrative review. Neuroscience & Biobehavioral Reviews, 37(3), 491–521.
Tucker, M., & Ellis, R. (1998). On the relations between seen objects and components of potential actions. Journal of Experimental Psychology: Human Perception and Performance, 24(3), 830.
Van Der Linden, L., Mathôt, S., & Vitu, F. (2015). The role of object affordances and center of gravity in eye movements toward isolated daily-life objects. Journal of Vision, 15(5), 8–8.
Van Elk, M., Van Schie, H. T., & Bekkering, H. (2008). Conceptual knowledge for understanding other’s actions is organized primarily around action goals. Experimental Brain Research, 189(1), 99–107.
Wurm, M. F., & Caramazza, A. (2019). Distinct roles of temporal and frontoparietal cortex in representing actions across vision and language. Nature Communications, 10(1), 1–10.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Federico, G., Osiurak, F., Brandimonte, M.A. et al. The visual encoding of graspable unfamiliar objects. Psychological Research 87, 452–461 (2023). https://doi.org/10.1007/s00426-022-01673-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00426-022-01673-z