
Abstract
Evidence in the literature suggests that listening to music can improve cognitive performance. The aim of the present study was to examine whether the short- and long-term gains of a working memory (WM) training in older adults could be enhanced by music listening—the Mozart’s Sonata K448 and the Albinoni’s Adagio in G minor—which differ in tempo and mode. Seventy-two healthy older adults (age range: 65–75 years) participated in the study. They were divided into four groups. At each training session, before starting the WM training activities, one group listened to Mozart (Mozart group, N = 19), one to Albinoni (Albinoni group, N = 19), one to white noise (White noise group, N = 16), while one served as an active control group involved in other activities and was not exposed to any music (active control group, N = 18). Specific training gains on a task like the one used in the training, and transfer effects on visuo-spatial abilities, executive function and reasoning measures were assessed. Irrespective of listening condition (Mozart, Albinoni, White noise), trained groups generally outperformed the control group. The White noise group never differed from the two music groups. However, the Albinoni group showed larger specific training gains in the criterion task at short-term and transfer effects in the reasoning task at both short-and long term compared to the Mozart group. Overall the present findings suggest caution when interpreting the effects of music before a WM training, and are discussed according to aging and music effect literature.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Over the last few decades, studies on aging have focused on developing cognitive interventions to delay age-related cognitive decline and promote healthy aging. Nowadays, these programs are designed to sustain older adults’ cognitive functioning by improving core cognitive mechanisms such as working memory (WM), the ability to retain and manipulate information for use in complex cognitive tasks (Baddeley & Hitch 1974) that are sensitive to aging and play a crucial role in our everyday lives. Studies in aging have clearly shown that WM training promotes large, significant gains on the tasks used in the training and on tasks closely related to them (near transfer effects) (e.g., Karbach & Verhaeghen 2014 for a meta-analysis). Promising (but more debatable) results have also been reported regarding far transfer effects, i.e., benefits on untrained tasks sharing few cognitive processes with the tasks used in the training (see Borella, Carbone, Pastore, De Beni, & Carretti, 2017 for a summary).
Together with cognitive training procedures, literature also shows that listening to music may also modulate cognitive performance. The music listening effects in this literature have generally been investigated using two procedures. In one group of studies, participants perform a cognitive task while listening to music. In this case, music listening is theoretically consuming resources that could be otherwise dedicated to the task and should, therefore, lower performance. However, music listening lowers cognitive performance only when music is both fast and loud (Thompson, Schellenberg, & Letnic 2012). In the second group of studies, the cognitive task is performed after listening to music. In this case, music listening seems to have some positive effects on performance. There are indeed many, although controversial, studies reporting that music listening might enhance cognitive performance, the so-called Mozart effect (Rauscher, Shaw, Ky, 1993). Now, it is generally accepted that the effect of music listening on human cognition is not “Mozart-specific” but can be observed with different excerpts of music (e.g., Hetland 2000). Furthermore, the positive effect of music listening on cognitive performance has been attributed to the impact that music has on the emotional state of the listener, which in turn influences his/her cognitive abilities. The tempo (fast or slow) and mode (major or minor) of a piece of music modulate arousal (the degree of physiological activation) and the mood (the persistence of emotions) of the listener (see Gabrielsson & Lindström 2010 for a review). Specifically, music with a fast tempo in a major mode seems to enhance arousal and induce a positive/happy mood, whereas a slow tempo and minor mode induce less arousal and a more negative or sad mood (Husain, Thompson, & Schellenberg, 2002; Nantais & Shellenberg 1999; Shellenberg, Nakata, Hunter, & Tamoto 2007; Thompson, Schellenberg, & Husain, 2001). Moreover, the effects of these different moods and arousal seem to vary depending on the cognitive abilities considered (Thompson et al. 2001; Husain et al. 2002; Schellenberg et al. 2007). Surprisingly, only a few studies have investigated the influence of music listening on cognitive performance in aging. In terms of age-related and individual differences, one can assume that changes in core aspects of our cognitive functioning (i.e., inhibition and processing speed) along with those in memory (WM, in particular) may affect music processing. For example, inhibition appears to operate at various cerebral levels in normal aging, from lateral inhibition in the visual and auditory cortices that contribute to perceptual acuity to the inhibition required for selective attention (Hampshire & Sharp 2015). Inhibitory processes are necessary during the perception of sound and selective attention towards one sound stream over others. In addition, processing speed has been shown to be sensitive to the tempo and the mode of the music (e.g., Schellenberg et al. 2007) and, thus, may explain the differential effects of positive and negative background music in older adults (see, Bottiroli, Rosi, Russo, Vecchi, & Cavallini, 2014, for a similar hypothesis). It is also worth mentioning that studies concerning pathological aging have also found that older adults with Alzheimer’s dementia show specific deficits in terms of temporal and pitch processing (e.g., Golden, Clark, Nicholas, Cohen, Slattery, & Warren, 2017 for a review), indicating that deficits in core cognitive mechanisms—impaired with dementia—may contribute to difficulties in processing music information.
As for the four studies that addressed the influence of music on cognitive performance in aging, these found that music enhanced cognitive performance, as measured by word fluency (Mammarella, Fairfield, & Cornoldi, 2007; Thompson, Moulin, Hayre, & Jones, 2005), recognition memory (Ferreri, Bigand, Perrey, Muthalib, Bard, & Bugaiska, 2014), WM (Mammarella et al. 2007), processing speed and declarative memory tasks (Bottiroli et al. 2014). The remaining study found no robust evidence of any benefit of music listening on cognitive performance in young or older adults (Borella, Carretti, Grassi, Nucci, & Sciore, 2014b). It is worth mentioning that Ferreri et al. (2014), Mammarella et al. (2007) and Thompson et al. (2005) only presented one musical excerpt characterized by fast tempo and major mode. In contrast, Bottiroli et al. (2014) and Borella et al. (2014b) played excerpts that differed in tempo and mode (i.e., a fast tempo and major mode piece of music vs a low tempo and minor mode piece of music). Other methodological aspects, such as the control condition (silence for Thompson et al. 2005; both silence and white noise for; Mammarella et al. 2007, and; Bottiroli et al. 2014; story for; Borella et al. 2014b), whether participants were exposed to music before (Borella et al. 2014b) or while completing the cognitive tasks (Ferreri et al. 2014; Mammarella et al. 2007; Thompson et al. 2005; Bottiroli et al. 2014); the type of cognitive tasks used to assess the role of music (Shellenberg & Weiss 2013 for a review) may also account for discordant results. It is, therefore, still unclear whether music affects older adults’ cognitive performance and high-level processes such as WM, and, if so, which types of music have such an effect. Further, no studies, to date, have examined the impact of music on contributing to the enhancement of cognitive performance with cognitive—i.e., WM—training activities.
The aim of the present study was to examine whether listening to music in association with a WM training program administered to a sample of healthy older adults could affect/enhance the short- and long-term gains and transfer effects of the training.
As mentioned earlier, the arousal-and-mood hypothesis (Thompson et al. 2001) assumes that music promoting positive mood and heightened arousal produces benefits on attentional processes, and consequently on cognitive performance. This theory also holds that listening to music, or in general to enjoyable musical stimuli, can affect performance in two ways. On the one hand, it widens the focus of attention, so that participants can process (or maintain active) a larger amount of information. On the other, it increases motivation and makes learning tasks more interesting and thereby increasing the learner’s overall resources toward the task (see also Antonietti 2009; Mammarella et al. 2007).
Again, greater arousal and task engagement results in higher levels of attention, so more material would be processed by the learner, leading to a better performance in retention tests. The same may apply during WM training: music may make training sessions more engaging and interesting and thus prompt greater gains and transfer effects compared to control conditions.
To examine this possibility, we formed three experimental groups and exposed them to three different conditions before starting training activities: one group listened to a musical excerpt with a fast tempo and major mode (i.e., the Mozart’s Sonata K 448); another listened to music with a slow tempo and minor mode (i.e., the Albinoni’s Adagio in G minor); and a third listened to white noise, i.e., a non-musical auditory stimulus (including equal amounts of every frequency within the range of human hearing, from 20 Hz to 20 kHz). These three groups were compared to an active control group of participants involved in other activities, who neither attended the WM training nor listened to music.
We adopted the WM training procedure by Borella, Carretti, Riboldi, & De Beni (2010) because, to date, it is one of the few verbal WM training programs used in aging that has shown consistent results in terms of both short- and long-term training gains and transfer effects (see Borella et al. 2017). This program combines an adaptive procedure with systematic changes to the demands of the task, features that promote the engagement of different cognitive processes (encoding, maintaining and inhibiting information, simultaneously managing two tasks, sustaining and shifting attention), and that are believed to favor both learning and transfer effects by making the task constantly novel, challenging and motivating.
Tasks for measuring transfer effects were chosen according to the conceptually based continuum proposed by Noack, övdén, Schmiedek, & Lindenberger (2009).
We assessed specific training gains with a task very similar to those used in the training [the Categorization WM span task (CWMS)]. We used the visuo-spatial backward Corsi blocks task, which taps the same broad ability (memory) but poses different demands and is based on a different type of material and requests from the task used in the training (see Bopp & Verhaegen 2005) to test near transfer effects. We assessed far transfer effects by selecting constructs known to be related to WM process in aging (e.g., de Ribaupierre & Lecerf 2006), measures of fluid intelligence (Cattell test), executive functions (i.e., verbal fluency, see Shao, Janse, Visser, & Meyer, 2014), and higher-order visuo-spatial abilities (spatial visualization—measured with the Minnesota Paper Form Board—and spatial learning using spatial descriptions, see Meneghetti, Borella, Carbone, Martinelli, De Beni, 2016), all necessary for various daily activities.
Except for two tasks (i.e., verbal fluency and Minnesota Paper Form Board), all the other tasks have already been adopted in previous studies using the same, or nearly the same, training procedure (Borella, Carretti, Cantarella, Riboldi, Zavagnin, & De Beni, 2014a, b, Borella, Meneghetti, Ronconi, & De Beni c; Carretti, Borella, Zavagnin, & Beni, 2013). This tasks' selection allowed us also to compare the present results—deriving from the inclusion of music exposure—to those obtained with the original procedure and thus to (i) replicate—or not—its efficacy, and (ii) to stress—or not—the music benefits prior to a cognitive training.
In line with the results obtained with the same training procedure (see Borella et al. 2017), we expected short-term training gains (i.e., in the WM task similar to the trained tasks), as well as maintenance in the three trained groups compared to the active control one. Theoretical background leads us to expect transfer effects too, given that the tasks selected to assess them tap mechanisms that have been shown to be related to WM functioning in older adults. It must be noted, however, that the untrained tasks vary in the degree of processing overlap with the WM practice one, so their magnitude of modifiability was examined. More specifically, near transfer effects in the short-term memory task were expected only immediately after training (e.g., Borella et al. 2010). On the contrary, we expected long lasting effects for the Cattell test and for spatial descriptions, as found in previous studies that used these tasks in association with the same training procedure (see Borella et al. 2017; Carretti et al. 2013). For the verbal fluency task, a measure of executive functions and requiring mechanisms such as shifting, updating and inhibition (see Miyake et al. 2000; Shao et al. 2014) similar to the those trained, we expected to find far transfer and maintenance effects to the verbal fluency task.
Finally, we will explore training gains on the Minnesota Paper Form Boar, as studies have shown its relationship with WM (Borella et al. 2014c).
In line with the literature about the effect of music on cognitive performance, we expect larger benefits in the two music conditions (i.e., Mozart and Albinoni) compared to the White Noise one (i.e., listening to a non-musical auditory stimulus, which served as a control condition). As suggested by the arousal-and-mood hypothesis (Thompson et al. 2001), we also expect to find differences between the two music conditions (Mozart and Albinoni). In particular, in line with the results by Thompson et al. (2001), we expect training benefits to be larger in the group that listened to the Mozart excerpt compared to the Albinoni one since it has been shown that the Mozart excerpt increases arousal and improves mood (see also Nantais and Schellenberg 1999). Indeed, it is well established that positive moods can lead to improved performance on various cognitive and problem-solving tasks (e.g., Ashby, Isen, & Turken 1999; Isen 1999). This improvement should not be for the Albinoni excerpt that induces low arousal and sad mood and, thus, detrimental effects on cognitive performance. It should be noted, however, that these results have been mostly obtained with younger adults. The negative effect of the Albinoni excerpt on cognitive performance was observed for the younger adults, but not for the older adults (see, Borella et al. 2014a, b, c). Thus, given the reportedly variable influence of music on cognitive performance in aging, we expect that both music conditions should produce the same effect in terms of influencing the efficacy of the WM training.
It may also be that listening to music interacts with WM training in diverse ways, leading to different training benefits depending on the nature of the tasks (i.e., verbal, visuo-spatial) used to assess training benefits. On the one hand, in line with the evidence of a link between listening to music and improved performance in visuo-spatial tasks (Hetland 2000), we expect larger benefits in the tasks assessing visuo-spatial skills and in the spatial reasoning task, compared to the verbal ones. On the other hand, the auditory components of the melody of the musical excerpts may provide direct cues to the phonological components of WM and, together with repeated practice with a verbal WM task, may prove to be the right combination to favor benefit in those tasks that rely more heavily on the phonological components of WM (i.e., the WM criterion task, verbal fluency, spatial descriptions) (Mammarella et al. 2007; Wallace 1994). However, as studies on older adults have never investigated whether the impact of the type of music depends on the nature of the task (verbal, visuo-spatial), and mixed findings across the few studies on aging have been found (Borella et al. 2014b; Mammarella et al. 2007), we may not observe any music effect. The white noise condition serves as a control condition.
Finally, since the beneficial effects of music on cognitive performance seem to depend on the complexity of the task in terms of cognitive resources and attentional control required (e.g., Shellenberg and Weiss 2013; Steele, Dalla Bella, Peretz, Dunlop, Dawe, Humphrey, Shannon, Kirby, Jr., & Olmstead, 1999), we also investigated whether music effects on the benefits of the WM training differ in relation to the features of the tasks used to tap them, possibly with larger gains in tasks that were more complex (in terms of the resources required), such as the Cattell test, the verbal fluency or the tasks measuring spatial learning skills, than in tasks demanding fewer cognitive resources, like the short-term memory task or the spatial visualization one.
Method
Participants
Seventy-two older adults (age range: 65–75 years) volunteered for the study. All participants were healthy native Italian speaking community-dwelling individuals recruited through associations in north-western and southern Italy. None of the participants were musicians nor had previous long-lasting experience of music instrument training. Further, they reported being naive regarding classical music since they only listen to it occasionally. None of the participants had ever been involved in other cognitive training programs or had experienced WM tasks like the one proposed in the present study.
Participants were selected based on a physical and a psychological health questionnaire. None met the “exclusion criteria” proposed by Crook, Bartus, Ferris, Whitehouse, Cohen, & Gershon (1986), which include: history of head trauma; neurological or psychiatric illness; history of brain fever; dementia or any other state of altered consciousness; use of benzodiazepines in the previous 3 months; use of illicit drugs; visual, auditory, or motor impairment; and any symptomatic cardiovascular condition, breathing problems, or pathologies possibly causing cognitive impairments. They also performed above cutoff for their age and education in the Categorization Working Memory Span task (see Italian norms, De Beni, Borella, Carretti, Marigo, & Nava, 2008). During a qualitative interview, none of the participants reported to be in a negative mood.
Participants were randomly assigned to four groups, the three experimental groups that attended the WM training after listening to music or white noise and the active one. Nineteen participants (11 women and 8 men) listened to Mozart’s Sonata K 448 (Mozart group), 19 (7 women and 12 men) listened to Albinoni’s Adagio in G minor (Albinoni group), 16 (12 women and 4 men) listened to white noise (White noise group), and 18 participants constituted the active control group (12 women and 6 men). This latter group attended the same number of sessions but was involved in alternative activities that entailed no listening to music of any kind (Control group).
The trained and control groups did not differ in terms of age, F(3,68) = 0.57 p = 0 .63, years of formal education, F(3,68) = 1.10, p = 0.35, or gender, F(3,68) = 2.04 p = 0.16. Demographic characteristics by group are shown in Table 1.
Materials
Criterion task
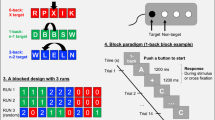
Categorization Working Memory Span (CWMS) task (De Beni et al. 2008). This task consists of 10 sets of word lists, each including 20 lists of words (divided into groups containing from 2 to 6 lists). Participants listen to a set of audio-recorded word lists at a rate of 1 word per second and are instructed to tap the table with their hand whenever an animal noun was heard (processing phase). Word lists are separated by a 2 s interval. At the end of each set, participants recall the last word on each list (maintenance phase)—i.e., they need to remember from 2 to 6 words, depending on the length of the set.
Two parallel versions (A/B, each containing five different sets of word lists) were administered in a counterbalanced fashion across testing sessions (i.e., pre-test, post-test, 6-month follow-up).
Near-transfer effects
Short-term memory
Backward Corsi blocks task (adapted from Corsi 1972). In this task, participants are presented with nine blocks randomly arranged on a wooden tablet and asked to tap the same sequences of blocks as the examiner, but in the reverse order. Participants reproduce increasingly long sequences of blocks (from 2 to 7), with two trials for each sequence length. After two consecutive recall errors, the task is discontinued. The number of the longest sequence reached is considered the dependent variable (maximum score of 7).
Two versions of the task were created, i.e., exchanging the sequences of blocks within each level of difficulty, and administered in a counterbalanced fashion across the testing sessions (i.e., pre-test, post-test, 6-month follow-up).
Far-transfer effects
Executive functions
Verbal fluency (adapted from Novelli 1986). In this task, participants are given 1 min to generate as many words as possible that start with a given letter, excluding proper names (phonemic fluency). The experimenter records the words produced orally by the participant on a blank sheet of paper. The dependent variable is the total number of appropriate words produced by the participant.
Two parallel versions (version A with the letter “F”, version B with the letter “P”) were administered in a counterbalanced fashion across testing sessions (i.e., pre-test, post-test, 6-month follow-up).
Spatial skills
Spatial visualization
Minnesota Paper Form Board (MPFB; adapted from Likert & Quasha, 1948). This task involved piecing together separate objects to make up a complete figure. Participants are given 15 items, each consisting of a 2D target object and five options (i.e., five sets of fragmented parts), and must decide which of the sets made up the target object. There are no time constraints for task completion. The total number of correct items is considered as the dependent variable (maximum score of 15).
Two parallel versions (A and B, each containing 15 different items) were administered in a counterbalanced fashion across testing sessions (i.e., pre-test, post-test, 6-month follow-up).
Spatial learning
Spatial descriptions—map drawing—(De Beni, Pazzaglia, Gyselinck, & Meneghetti, 2005; see also; Carretti et al. 2013). Two audio-recorded texts, describing outdoor environments from a route perspective, i.e., from the individual’s point of view (a farm, and a countryside with a lake), were used. Each spatial description was 10 sentences long (about 220 words) and mentioned 10 landmarks. The two environments had similar layouts in terms of the positions of the landmarks. Participants listened to the recordings twice, then drew a map of the environment. The dependent variables were the sum of the landmarks correctly recalled on the map drawing plus the number of landmarks located in the right position (maximum score 20).
The two audio-recorded descriptions were administered in a counterbalanced fashion across testing sessions (i.e., pre-test, post-test, 6-month follow-up).
Fluid intelligence
Culture Fair test, Scale 3 (Cattell test; Cattell & Cattell, 1973). Scale 3 of the Cattell test consists of two parallel versions (A and B), each containing 4 subtests to be completed in 2.5 to 4 min (depending on the subtest). Participants are asked to: (i) choose from amongst six figures which one best completes a target series of figures; (ii) identify figures or shapes that differ from the others in a series; (iii) choose items that correctly complete matrices of abstract figures and shapes; (iv) assess the relationship linking a series of items. The dependent variable is the number of correctly answered items across the four subtests (maximum score 50).
Two parallel versions (A and B, each containing four different subtests) were administered in a counterbalanced fashion across testing sessions (i.e., pre-test, post-test, 6-month follow-up).
Procedure
All participants attended six individual sessions: the first and fifth sessions were for pre-test and post-test, and the sixth for the follow-up (6 months later). During the other three sessions (sessions 2–3–4), the trained participants attended the WM training program (see Table 2), while the active controls were involved in other activities. For all groups, the activities were completed within a 2-week time frame, with a fixed two-day break between sessions. The duration of the individual sessions (about 60 min each) and the amount of interaction with the experimenter were comparable for all four groups.
During the three assessment sessions (pre–post-test and follow-up sessions), participants completed the following tasks (listed in order of presentation): Health interview (only at pre-test), CWMS, Verbal fluency, MPFB, backward Corsi blocks, spatial description—map drawing—and Cattell test. The order of presentation was fixed for each participant. The CWMS and the spatial description—map drawing—were presented in auditory modality (audio recorded), using a computer and amplifying the sound through speakers. The other tasks were presented in a paper (the MPFB) or paper and pencil (Cattell tests) format. Before starting the pre- post-test and follow-up assessments, the auditory presentation was adjusted to the participant’s hearing level to limit the influence of sensory variables (sight and hearing) on the outcomes. The experimenter set the volume of the musical excerpts so that it would be suitable for that participant to listen to it.
We chose to use speakers instead of headphones, especially during the training sessions, to allow participants to feel as most comfortable as possible while performing the training task across sessions. Headphones, instead, were used to present the musical excerpts during the 6-minute interval preceding the training sessions to allow participants to focus better on the musical excerpts. The experimenter set the volume of the excerpts to account for each participant’s preference. For the paper and pencil tasks, all participants were asked whether they found it easy to read the stimuli.
Before starting the training activities, the three trained groups listened to the first movement without the first refrain of Mozart’s Sonata K 448 (5 min and 57 s), Albinoni’s Adagio in G minor (5 min and 50 s), or white noise synthesized with a sample rate of 44,100 Hz and 16 bits resolution with the Audacity© program (5 min and 57 s) for approximately 6 min. Noise was normalized in amplitude. The onset and offset of the noise (the first/last 20 ms) were modulated in amplitude with a raised cosine ramps to avoid onset and offset clicks. The music pieces (and noise) were presented using headphones (Sennheiser HD 280 pro) to encourage participants to focus on the auditory stimuli. The experimenter set the volume of the excerpts according to participants’ preference. Music and noise were never presented at levels higher than 55 dBA. Successively, participants were presented with lists of audio-recorded words organized in the same way as for the CWMS task. Again, as for the abovementioned criterion task used in the assessment sessions, the audio-recorded word lists were presented through speakers (Sony, SRS-X11) and the experimenter adjusted the volume of the excerpts to account for participants’ preference. Participants were instructed to remember target words while tapping their hand on the table whenever they heard an animal noun. The maintenance demand of the CWMS task was thus manipulated using an adaptive procedure only in session 2: task difficulty increased if a participant was successful at a given level; in the case of failure, the lowest level was presented. The demands of the task also varied and, depending on the session, could involve having to recall: (i) words proceeded by a beep (session 3); or (ii) the last or first word in each list (session 4). The processing demand (tapping on the table when an animal noun was heard) was manipulated by varying the frequency of animal words in the lists (session 3). This kind of training procedure combines an adaptive procedure in session 2 with a standard one (from the easiest to the hardest trials) and is referred to as a “hybrid procedure”. A detailed description of the three training sessions is presented in Table 2.
Participants in the active control group (see also Borella et al. 2017) were asked to complete paper-and-pencil questionnaires: the Autobiographical Memory questionnaire (De Beni et al. 2008) in session 2; the Memory Sensitivity questionnaire (De Beni et al. 2008) and a psychological well-being questionnaire (De Beni et al. 2008) in session 3 (see Table 2). As for the other groups, the sessions were individual.
All participants completed the interest/enjoinment subtest of Text Material section of the Intrinsic Motivation Inventory (McAuley, Duncan, & Tammen, 1989) at the end of each training session. The interest/enjoinment subtest is composed of 4 items rated on a 7-point likert scale (from not at all true to very true). The dependent variables were the mean of the scores obtained across the three training sessions. After the inventory, the two music groups were presented with a short questionnaire (two items) in which they rated the pleasure of listening to music before the training activities using a 6-point scale (from “not at all true” to “very true”), while the White noise group rated two sentences about whether they felt irritated by listening to white noise before the training activities using a 6-point scale (from “not at all true” to “very true”).
This study was approved and conducted in accordance with the recommendations of the local Research Ethics Committee. All participants were provided with information about the study and gave written informed consent in accordance with the Declaration of Helsinki (World Medical Association 2013).
Results
Training gains and transfer effects
The four groups’ baseline performance was compared by means of separate analyses of variance (ANOVAs) with group (Mozart, Albinoni, white noise and active control) as the between-subjects factor on pretest performance in all tasks. The results showed that the four groups did not differ at the pre-test session—CWMS task, F(3,68) = 2.52, p = 0.06; backward Corsi blocks, F(3,68) = 0.53, p = 0.66; verbal fluency, F(3,68) = 1.04, p = 0.37; MPFB, F(3,68) = 1.32, p = 0.27; spatial descriptions—map drawing—: F(3,68) = 0.24, p = 0.87; and Cattell test: F(3,68) = 0.96, p = 0.42.
Descriptive statistics by group are presented in Table 3.
To examine immediate and long-term specific training-related gains and transfer effects, we ran univariate ANCOVAs using the post-test score (for immediate effects) or the follow-up score (for long-term effects) as dependent variables, the pre-test score as a covariate, and group as a between-subjects factorFootnote 1. The purpose of these analyses was: first to compare the performance of the three trained groups with that of the active control group to ascertain whether the WM training was effective; then to compare the three trained groups with one another to examine the effect of the listening condition.
We calculated the Helmert contrast to assess transfer effects on performance at group level, comparing the listening condition (white noise; Mozart; Albinoni) vs the active control group first, then the white noise condition vs the music conditions (Mozart; Albinoni), and finally the two different music conditions (Mozart vs Albinoni).
The critical p value was set at 0.02, since there were 3 main comparisons. Descriptive statistics for each measure of interest by group and by session are given in Table 3, and the results of the ANCOVAs are summarized in Table 4.
The presentation of the analyses first focuses on the comparison between the three trained groups with the active control group, then on the comparison between the white noise condition and the two music conditions, and finally on the comparison between the two music conditions.
In general, the analyses (summarized in Table 4) showed a main effect of the covariate at both post-test and follow-up.
For the criterion task, the main effect of group indicated that the three trained groups performed better than the control group in the CWMS at both post-test and follow-up (ps = 0.001). The white noise group did not differ from the other two trained groups at either post-test or follow-up (p = 0.05, p = 0.03, respectively). The Albinoni group performed better than the Mozart group at post-test (p = 0.005), while these two groups no longer differed at follow-up (p = 0.06).
For the near transfer effect on the backward Corsi blocks task, the effect of group was not significant, neither at post-test (p = 0.06), nor at follow-up (p = 0.28).
In terms of transfer effects on verbal fluency, the main effect of group indicated that all three trained groups performed better than the active control group at both post-test and follow-up (p = 0.001, p = 0.004, respectively), and the trained groups did not differ from one another.
As for far transfer effects on the MPFB, the main effect of group was not significant at post-test or follow-up (p = 0.18, p = 0.16, respectively). As for the spatial description task—map drawing—there was a significant main effect of group with all three trained groups performing better than the active control group (p < 0.001), and the trained groups only differed from one another at post-test. The effect of group was not significant at follow-up (p = 0.89).
Finally, for the Cattell test, the main effect of group was significant at post-test and at follow-up. The three trained groups only performed better than the active control group at post-test (p = 0.015). The White noise group did not differ from the other two trained groups at either post-test or follow-up (p = 0.40, p = 0.39, respectively). The Albinoni group performed better than the Mozart group at post-test (p = 0.001) and follow-up (p = 0.016).
As for the Text Material inventory, the four groups did not differ with respect to the interest/enjoyment subtest (see Table 5).
The Albinoni and Mozart groups also rated the pleasure of listening to music before the training itself in a comparable manner (M = 6.34, DS = 0.74, and M = 6.01, DS = 1.80, respectively). Instead, the White noise group reported having sometimes felt irritated by listening to the white noise before the training activities (M = 4.61, SD = 1.17).
Effect sizes
To ascertain the dimension of the immediate (pre-vs post-test) and long-term (pre-test vs follow-up) gains, Cohen’s d was computed for each of the trained groups (Mozart, Albinoni and White noise), and for each of the outcome measures as follows: {(Post-test or follow-up for each trained group − Pre-test for each trained group) − (Post-test or follow-up for the control group − Pre-test for the control group)}/(Pooled SD of the difference) (Weisz & Hawley 2001). This enabled us to adjust the gains made by each of the trained groups in relation to the gains made by the control group (see Table 6).
In addition, to better understand the effects of the three training conditions, we compared effect sizes (only for those measures for which ANCOVAs yielded a significant group effect, i.e., CWMS, Verbal fluency, Spatial description–map drawing, Cattell test). Cohen’s d was transformed into r indexes, and then compared. The size of the differences, expressed in Cohen’s q, was interpreted according to Cohen’s guidelines: a difference < 0.1: no effect; from 0.1 to 0.3: small effect; from 0.3 to 0.5: medium effect; > 0.5: large effect.
Regarding the effect sizes index computed for immediate gains (pre- vs post-test) (see Table 5), the three trained groups revealed a large effect size (over 0.80) in the criterion task. The Mozart group also showed large effect sizes for the backward Corsi blocks task and for the spatial description—map drawing—a medium effect size was found for all other measures (except for the Cattell test). For the Albinoni group, large effect sizes were found for verbal fluency, the spatial description—map drawing—and the Cattell test, while the effect was medium for other tasks. For the white noise group, the effect sizes were small for the MPFB, the Cattell test as well as for all the other tasks (see Table 6).
Effect size comparisons highlighted that the Cohen’s d for the CWMS was higher for the Albinoni group with respect to both the Mozart group (with a medium effect) and the White noise group (with a small effect); the difference between the latter two was in the range of a small effect (in favor of the White noise group). For Verbal fluency, the Cohen’s d was higher for the Albinoni group with respect to the Mozart and the White noise group (with a large effect in both cases); Effect sizes in the Mozart and White noise group did not differ. The dimension of Cohen’s d was the same in the Spatial description—map drawing—task, with the only small difference between Albinoni and White noise group (in favor of the former). Finally, in the Cattell test, the Cohen’s d was higher for the Albinoni group with respect to the Mozart and the White noise groups (with a medium effect in both cases); the effect sizes of the Mozart and White noise groups did not differ between each other.
When long-term gains (pre-test vs follow-up) were compared, effect size remained large in the criterion task for the three trained groups. However, differences emerged in the dimension of the effect sizes (see Table 6) in the transfer measures. In the Mozart group, the large effect size in the backward Corsi blocks task became medium and the one in the spatial description—map drawing—became small; the effect in the verbal fluency test, however, from medium became large. As for the Albinoni group, there was a reduction of the effect size for backward Corsi blocks task (from medium to small), verbal fluency (from large to medium) and spatial description—map drawing—(from large to small). The effect size of the Cattell test varied too, although it remained qualitatively close to a large effect (0.74). In the White noise group, the overall effect sizes for the transfer measures were small.
Effect size comparisons highlighted that the Cohen’s d for the CWMS did not yield differences, with only a marginal difference between Albinoni and White noise groups (in favor of the former). For Verbal fluency, the Cohen’s d was slightly higher for the Mozart group with respect to the Albinoni and the White noise groups (with a small effect in both cases); the difference between the latter two was in the range of a small effect (in favor of the Albinoni group). No differences emerged in the dimension of Cohen’s d in the map drawing task and in the Cattell test.
Discussion
There is evidence in the literature showing that music listening enhances cognitive performance. Music effects on cognitive skills have been mainly attributed to the influence that music excerpts have on an individual’s emotional state. Indeed, music not only promotes positive mood but can also have a positive influence on attentional processes (Thompson et al. 2001). It is thus plausible to predict that this beneficial effect of music could be applied, as in this study, to a cognitive WM training. That is, music may promote greater gains and transfer effects compared to control conditions by fostering attentional control and a “different” attitude toward training sessions (Antonietti 2009; Mammarella et al. 2007).
Based on this assumption, together with evidence suggesting that WM training benefits aging by sustaining cognitive functioning (see Borella et al. 2017), the aim of the present study was to examine whether listening to music before a WM training program administered to healthy older adults could enhance the short- and long-term gains and transfer effects of the training. To examine this possibility, we exposed three experimental groups to three different music-listening conditions before starting the training activities: one group listened to a musical excerpt with a fast tempo and major mode (Mozart’s Sonata K 448); another listened to a musical excerpt with a slow tempo and minor mode (Albinoni’s Adagio in G minor); and a third listened to white noise, i.e., a non-musical stimulus. These three groups were compared with an active control group comprising participants involved in other activities, who neither attended the WM training nor listened to music.
Accordingly, before analyzing the effect of listening condition and the possible effect of music listening, we first discuss the general pattern of findings due to the training procedure itself. Overall, our results confirmed the efficacy of the verbal WM training procedure proposed by Borella et al. (2010) and recently demonstrated by Borella et al. (2017). Indeed, the three trained groups showed specific training gains. They performed better in the criterion task than the active control group immediately after the training and maintained this benefit at follow-up. This finding is consistent with the literature showing that WM training generally leads to specific benefits in tasks similar to the trained task, which are maintained over time (e.g., Borella et al. 2014a; Karbach and Verhaeghen 2014).
The positive effects of the WM training were generally apparent in terms of transfer effects, at least at short-term (at post-test): the trained groups outperformed the active control group in some of the far transfer measures considered. The trained groups indeed showed larger gains in measures of executive functioning (verbal fluency), spatial learning (spatial description—map drawing), and reasoning (Cattell test) compared to the control one. Such a pattern of findings confirms that the present training regimen, thanks to a flexible and variable procedure (Borella et al. 2017), produces transfer effects to measures that are theoretically related to WM or that share processes with it (e.g., Borella et al. 2010; Buschkuehl, Jaeggi, Hutchison, Perrig-Chiello, Däpp, Müller, & Perrig, 2008). The maintenance of such benefits was limited, but it reiterates that WM training can also lead to long-lasting far transfer effects (Karbach and Verhaegen 2014). Indeed, long-term transfer effects were found only for some of the tasks: verbal fluency, a novel finding, and the Cattell test, in line with previous studies, but in the latter case only for one of the trained groups (the Albinoni one), as discussed below. Contrary to our predictions, no benefit was maintained for the spatial learning task based on spatial descriptions, as instead shown in a previous study (Carretti et al. 2013).
Unexpectedly, we found no transfer effects on the backward Corsi blocks task, the near transfer task used here, nor in the spatial visualization (the MPFB) task, one of the far transfer tasks. Results from Borella et al. (2017) in four studies that used the same procedure as our study, clearly highlighted a lack of maintenance effects for both tasks with a visuo-spatial nature and short-term memory ones as well. Such a pattern of findings, along with those of Borella et al. (2017), highlights the importance of reflecting on the “nature” (verbal-visuo-spatial) of the tasks for which transfer effects were found with the present procedure and on their “stability”—at short vs long term. It could be that both visuo-spatial and short-term memory tasks call upon the use of specific routines or more specific processes and abilities that can hinder training efficacy and «stability» in time. In this case, the nature of the visuo-spatial tasks (spatial) also plays a crucial role (Borella et al. 2010). Further, several studies reported correlations between spatial visualization tasks and the visuo-spatial sub-component of WM (e.g., Borella et al. 2014c; Mitolo et al. 2015), while no studies have verified its relationship with the verbal WM one. It may be, therefore, that since the current training is based on practicing a verbal WM task, not directly sensitizing specific visuo-spatial processes required for the spatial visualization task (the MPFB), it may not produce transfer effects in the visualization task. Performance in spatial tasks, for instance, has been shown to be prone to the use of strategies (e.g., Gluck and Fitting, 2003). Even in the context of training, repeated practice with spatial tasks combined with clear instructions on how to approach the tasks with an effective strategy has been found to improve spatial performance and maintain such a benefit (Meneghetti, Cardillo, Mammarella, Caviola, & Borella, 2017).
A similar reasoning can be applied to the visuo-spatial short-term memory task used here (the backward Corsi blocks task): it relies on practiced skills and strategies, and this may account for such a result. The nature of information (verbal vs visuo-spatial) also explains the short-term effect we found in the spatial description—map drawing: the task requires processing verbal information in order to form a representation that is, however, spatial. Therefore, both verbal and visuo-spatial WM resources are required as Meneghetti et al. (2016) have demonstrated. This modality of conveying information may favor a transient short-term performance improvement since the training is verbal, but not a long-term one. The lack of maintenance for this transfer effect may, thus, be due to the nature of the task and the specific processes a l’oeuvre that cannot be modified. Carretti et al. (2013) also found a long-term effect but that may be due to variations in the training procedures between Carretti et al. (2013)—that added activities on updating text representations—and the “original” one.
It could be, of course, that individual characteristics also account for the present results and the incongruences observed between the present study and previous ones (Borella et al. 2017). Accordingly, a closer look at individual differences must be one of the future aims of training studies to identify the critical factors that determine training effects and, as a consequence, guide the selection of transfer tasks.
The general replication of training efficacy enabled us to further assess whether listening to music before each training session had an influence, or not, on training gain at both short- and long term. Overall our results do not support the enhancement of training efficacy after listening to music: in fact the white noise group did not differ from the two music conditions. Such a result was unexpected. Since the white noise group was conceived as a sort of control condition compared to the other two groups that listened to Mozart and Albinoni, we expected larger gains in the music conditions compared to the white noise one. However, it must be noted that mixed findings on the effect of white noise exposure on cognitive performance have been reported. While some studies indeed found disturbing effects due to competition for cognitive resources (e.g., Boman, Enmarker, & Hygge, 2005), others found that noise exposure was: i) effective in causing a narrowing of attention, thus improving performance in an inhibition task due to a noise-induced increment of emotional arousal (e.g., O’Malley & Poplawsly 1971; O’Malley & Gallas 1977); ii) enhanced connectivity between some brain regions involved in attention modulation and memory processes (e.g., Rausch, Bauch, & Bunzeck, 2014); iii) promoted learning in participants with attentional deficits (e.g., Söderlund, Sikström, & Smart 2007, Sikström, Loftesnes, & Sonuga-Barke, 2010). Such mixed evidence on the influence—disturbing vs stimulating effects—of noise on cognition could be linked to various factors, such as the duration, intensity and type of exposure to noise (i.e., whether intermittent or continuous), the type of noise (i.e., speech or non-speech noise), the type of task (e.g., perceptual, cognitive, motor) (see Szalma & Hancock 2011 for a meta-analysis).
This condition may thus not be the most appropriate control condition. However, we chose it among other possible control conditions, such as sitting in silence for 6 min before starting the training activities, to avoid demotivating participants or to elicit mind wondering. It must be noted that, although our participants sometimes reported being irritated by the white noise, none of them reported being disturbed by the previous white noise exposure when completing the training activities. That is, participants in the white noise condition felt quite comfortable within the context of the training and did not reported any concerns about their motivation and attitude toward the training activities, despite the somewhat irritating and “annoying” experience of being exposed to white noise.
However, future studies should further examine this issue to identify the best control condition. A direction to be investigated could be the inclusion of a brief mindfulness practice before training (Malinowski, Moore, Mead, & Gruber, 2017).
Beyond this general lack of music listening effects, it is noteworthy that when comparing the effect size for the criterion task in this study with that in previous studies using the same training procedure with participants without pre-training exposure to music, effect sizes were larger (2.62 for Albinoni 1.56 for the Mozart and 1.82 for the White noise groups vs 1.48 in Borella et al. 2017). Some minor differences between the two music excerpts were also found.
The Albinoni group outperformed the Mozart group at both short and long term. In particular, the Albinoni group obtained larger improvements in the criterion task and in the Cattell test at short term; those results are supported by the effect sizes and their comparison. It is worth mentioning that compared to the net effect sizes of our previous studies (see Borella et al. 2017) that did not include a pre-training phase, the ones obtained in the present study for both the criterion task (2.62 here vs 1.48 in Borella et al. 2017) and the Cattell test, at least at short-term, are larger (1.15 here vs 0.67 in Borella et al. 2017). Although this is just a qualitative comparison and it was possible only for the few common measures presented here and the previous study, this result might suggest some benefits for the pre-training music exposure advantage, in particular for the Albinoni group.
Furthermore, in the verbal fluency task, even though the three trained groups did not differ, the Albinoni group was the only one to show a large effect size compared to the other two trained groups at short term. Again, the comparison of effect sizes supports the advantage of this music condition with respect to the other two (Mozart and White noise). Overall, these results contrasted with predictions based on the literature with younger adults. In fact, we expected the Mozart group to show larger gains than the Albinoni group. According to the hypothesis proposed by Thompson et al. (2001), the so-called Mozart effect induces a positive mood and heightens the arousal, contrary to the postulated depressive effect on performance of Albinoni music, which induces low arousal and sad mood. However as reviewed in the introduction, the depressive effect of Albinoni was demonstrated in younger adults, but not in older adults (see for example Borella et al. 2014b). This might account for the lack of differences depending on music characteristics on training efficacy reported here. Some speculations could also be drawn by looking at the nature of the tasks (verbal, visuo-spatial) for which the Albinoni group showed improvements compared to the Mozart one. It could be that, at least in our sample of older adults, the repeated exposure to Albinoni’s melody throughout the training sessions additionally “trained” the phonological components of WM. We used an auditory presentation for the CWMS task and performance on this task may be sensitive to perceptual similarities between auditory patterns present in the musical excerpt and in the ongoing task. That is, rhythm congruency effects may arise between the Albinoni adagio excerpt and the auditory presentation of the CWMS task used during training: that is, a repeated practice with a complex verbal WM task requiring participants to listen to word lists presented with an established rhythm. Indeed, there are studies in the literature that show how providing participants with matching rhythmic context primes results in a phoneme detection task (e.g., Cason, Astésano, & Schön 2015). Thus, participants may have been primed by the Albinoni rhythm more than the Mozart group in terms of cadence, favoring greater training gains in the criterion task and transfer effects to the Verbal fluency task as well.
The above effect sizes and transfer effects to a task that relies in part on the verbal components of WM (i.e., verbal fluency) (Mammarella et al. 2007), at least at short-term, support this speculation. In addition, it could be argued that the tasks in which the Albinoni group showed greater benefits—that is a short-term training gain in the WM criterion task, and transfer effects, along with their maintenance, in both the verbal fluency task and Cattell test—compared to the Mozart group were the more complex tasks that required more general resources compared to the others—as the spatial tasks—that rely on more specific—visuo-spatial resources and strategies. This result may partially support the hypothesis that music effects on training efficacy differ according to the complexity of the tasks (in terms of the resources required) to assess training benefits.
It must also be underlined that the musical excerpts were presented before the WM tasks in three different sessions during which participants repeatedly practiced this complex verbal task. Although the Mozart and Albinoni groups did not differ in terms of interest for the training activities and they both reported pleasure in listening to the music piece before the training, it may be that the Albinoni pieces, for its de-activating effects on arousal, allowed older participants to feel at ease in an unfamiliar situation and helped them to focus attention and to regulate their resources better. This, in turn may have led to larger benefits from training activities.
We did not introduce a measure of participants’ mood or a debriefing questionnaire concerning how they felt “thanks” to the music, both in terms of their emotional attitudes and arousal. Such an issue deserves to be examined in future studies. In the same vein, an analysis of the training progress across single sessions may have helped to clarify such an issue. The present training procedure does not allow for such an analysis.
Second, personality has been also shown to be associated with music involvement (e.g., Corrigall, Schellenberg, & Misura, 2013) and the focus of attention on emotional stimuli is often compatible with one’s personality (e.g., amicality/nevroticism). It may be that music has differential impacts on WM performance depending on participants’ individual features. Here again, this is just a speculation and is an issue that needs to be explored and verified in future studies since we did not include any measure to assess personality traits and individual features.
Last, the effect of listening to music has been mainly examined in younger adults, while little is known about its impact on older adults. Therefore, it could be that in aging preferences shift towards melodies that are of lower arousal and slower tempo. Studies have indeed shown that because of the well-known decline of the speed at which information is processed in aging (Craik & Salthouse 2008), older adults have difficulties in processing faster melodies (see Dowling, Bartlett, Halpern, & Andrews, 2008). It is also possible that music preferences are amongst the changes that characterize aging, nullifying the negative effect of the Albinoni condition on cognitive performance as found by Thompson et al. (2001). Negative emotions could thus have narrowed the focus of attention, leading to over focusing on target information (see Mammarella, Borella, Carretti, Leonardi, & Fairfield, 2013). Although this issue needs to be examined in future studies, it seems that in aging, music effects on cognition, in terms of enhancement, are not related to an increase in positive mood and arousal levels; such an interpretation is in line with the results of Borella et al. (2014b) and Bottiroli et al. (2014).
It is worth mentioning that at long term, differences between the Albinoni and Mozart groups did not last, except for the Cattell test which showed an effect size that was close to a large one for the Albinoni group, compared to the small one in the Mozart group (and the White Noise one). This result is quite intriguing and, before concluding about the benefit of music with slow tempo and minor mode on this type of task, also merits to be replicated with other reasoning tasks using verbal stimuli as well.
Despite the originality of the present study, which is the first to combine music listening prior to the training sessions, and the consistency of results with previous findings using the same procedure, we must acknowledge several limitations. First, the sample size, although in line with training studies, precludes running analyses to verify the impact of individual differences in training gains in the three groups, and is linked to the limit of not having rigorously assessed the participants’ music preferences on the one hand, and their mood with a quantitative questionnaire (the experimenter only asked a question concerning how they felt before starting each session) on the other one. Music perception and cognition are subjective and influenced by individual differences in traits and temporary differences in mood states. Future studies would benefit from having participants rate their mood, the arousal properties and emotional dimensions of the music, as well as how much they enjoy listening to it using questionnaire in the assessment sessions.
Second, our participants were relatively young, so results need to be replicated with other groups of older people (i.e., old–old ones) that may benefit more from music listening, to elucidate the role of music. In fact, there is evidence that listening to music appears to more consistently enhance memory in cognitively impaired populations, with positive findings when the music stimulus is presented prior to learning (i.e., Isern 1960; Lord & Garner 1993; Prickett & Moore 1991), and with a range of music types.
In future WM training studies, it would also be interesting to control for longer intervals of music listening prior to session that may result in different and clearer results in favor of music listening. In addition, in light of the present results, the type of control condition used to compare music listening could also be taken into account. Finally, music listening might be more beneficial for other cognitive processes such as processing speed, one of the abilities sensitive to tempo and mode of the music in studies involving students (e.g., Angel, Polzella, & Elvers, 2010; Schellenberg et al. 2007); thus, it could represent a clear probe of the possible different effects of positive and negative listening to music in older adults. This latter issue also merits verification in future studies.
In conclusion, although the mechanisms of music listening influence seem to refer to embedded or ancillary factors (e.g., control of distraction, mood induction, locus of control, and perceptual-cognitive stimulation) and not to music itself, our pattern of results suggests that listening to music before training activities on verbal WM does not have an additive value for training gains. At most, music pre-training promotes a more relaxed approach to training activities, as suggested by the advantage of Albinoni condition.
Notes
For the comparison between post-test and follow-up, a gain score was computed for each outcome measure as follows: follow-up − post-test. Univariate ANCOVAs were run for each outcome measure with the abovementioned index as dependent variable and the gain at short-term—(post-test—pre-test)—as covariate. Helmert contrasts were run to compare first the listening condition (white noise; Mozart; Albinoni) vs the active control group, then the white noise condition vs the music conditions (Mozart; Albinoni), and finally the two different music conditions (Mozart vs Albinoni). The critical p value was set at 0.02, as there were 3 main comparisons. The covariate was significant for all the outcome measures: CWMS, F(1,67) = 18.42, p < .001, ηp2 = 0.22, Backward Corsi blocks, F(1,67) = 10.29, p = 0.002, ηp2 = 0.13, Verbal fluency, F(1,67) = 20.98, p < 0.001, ηp2 = 0.23, MPFB, F(1,67) = 34.65, p < 0.001, ηp2 = 0.34, Spatial descriptions—map drawing, F(1,67) = 29.91, p < 0.001, ηp2 = 0.31, Cattell test, F(1,67) = 52.50, p < 0.001, ηp2 = 0.44, while the main effect of group was not significant for any of them: CWMS, F(3,67) = 0.26, p = 0.85, ηp2 = 0.01, Backward Corsi blocks, F(3,67) = 0.93, p = 0.43, ηp2 = 0.04, Verbal fluency, F(3,67) = 2.04, p = 0.12, ηp2 = 0.08, MPFB, F(3,67) = 0.32, p = 0.81, ηp2 = 0.01, Spatial descriptions—map drawing, F(3,67) = 1.30, p = 0.28, ηp2 = 0.05, Cattell test, F(3,67) = 0.26, p = 0.85, ηp2 = 0.01.
References
Angel, L. A., Polzella, D. J., & Elvers, G. C. (2010). Background music and cognitive performance. Perceptual and Motor Skills, 11, 1059–1064. https://doi.org/10.2466/pms.110.3c.1059-1064.
Antonietti, A. (2009). Why is music effective in rehabilitation? In A. Gaggioli, E. Keshner, P. L. Weiss & G. Riva (Eds.), Advanced Technologies in Neurorehabilitation (pp. 179–194). Amsterdam: IOS Publisher.
Ashby, F. G., Isen, A. M., & Turken, A. U. (1999). A neuropsychologica l theory of positive affect and its influence on cognition. Psychological Review, 106, 529–550. https://doi.org/10.1037/0033-295X.106.3.529.
Baddeley, A. D., & Hitch, G. (1974). Working memory. Psychology of Learning and Motivation, 8, 47–89. https://doi.org/10.1016/S0079-7421(08)60452-1.
Boman, E., Enmarker, I., & Hygge, S. (2005). Strength of noise effects on memory as a function of noise source and age. Noise Health, 7, 11–26. https://doi.org/10.4103/1463-1741.31636.
Bopp, K. L., & Verhaeghen, P. (2005). Aging and verbal memory span: A meta-analysis. Journal of Gerontology: Psychological Sciences, 60, 223–233. https://doi.org/10.1093/geronb/60.5.P223.
Borella, E., Carbone, E., Pastore, M., De Beni, R., & Carretti, B. (2017). Working memory training for healthy older adults: The role of individual characteristics in explaining short-and long-term gains. Frontiers in Human Neuroscience, 11, 1–21. https://doi.org/10.3389/fnhum.2017.00099.
Borella, E., Carretti, B., Cantarella, A., Riboldi, F., Zavagnin, M., & De Beni, R. (2014a). Benefits of training visuospatial working memory in young-old and old-old. Developmental Psychology, 50(924), 714–727. https://doi.org/10.1037/a0034293.
Borella, E., Carretti, B., Grassi, M., Nucci, M., & Sciore, R. (2014b). Are age-related differences between young and older adults in an affective working memory test sensitive to the music effects? Frontiers in Aging Neuroscience, 6, 1–9. https://doi.org/10.3389/fnagi.2014.00298.
Borella, E., Carretti, B., Riboldi, F., & De Beni, R. (2010). Working memory training in older adults: Evidence of transfer and maintenance effects. Psychology and Aging, 25, 767–778. https://doi.org/10.1037/a0020683.
Borella, E., Meneghetti, C., Ronconi, L., & De Beni, R. (2014c). Spatial abilities across the adult life span. Developmental Psychology, 50, 384. https://doi.org/10.1037/a0033818.
Bottiroli, S., Rosi, A., Russo, R., Vecchi, T., & Cavallini, E. (2014). The cognitive effects of listening to background music on older adults: processing speed improves with upbeat music, while memory seems to benefit from both upbeat and downbeat music. Frontiers in Aging Neuroscience, 6, 284, 1–7. https://doi.org/10.3389/fnagi.2014.00284.
Buschkuehl, M., Jaeggi, S. M., Hutchison, S., Perrig-Chiello, P., Däpp, C., Müller, M. & Perrig (2008). Impact of working memory training on memory performance in old-old adults. Psychology and Aging, 23, 743–753. https://doi.org/10.1037/a0014342.
Carretti, B., Borella, E., Zavagnin, M., & Beni, R. (2013). Gains in language comprehension relating to working memory training in healthy older adults. International Journal of Geriatric Psychiatry, 28, 539–546. https://doi.org/10.1002/gps.3859.
Cason, N., Astésano, C., & Schön, D. (2015). Bridging music and speech rhythm: rhythmic priming and audio-motor training affect speech perception. Acta Psychologica, 155, 43–50. https://doi.org/10.1016/j.actpsy.2014.12.002.
Cattell, R. B., & Cattell, A. K. S. (1973). Measuring intelligence with the culture fair tests. Champaign IL: Institute for Personality and Ability Testing.
Corrigall, K. A., Schellenberg, E. G., & Misura, N. M. (2013). Music training, cognition, and personality. Frontiers in Psychology, 4, 1–10. https://doi.org/10.3389/fpsyg.2013.00222.
Corsi, P. M. (1972). Human memory and the medial temporal region of the brain. Unpublished doctoral dissertation. Montreal: McGill University.
Craik, F. I. M., & Salthouse, T. A. (2008). Handbook of cognitive aging (3rd edn.). New York: Psychology Press.
Crook, T., Bartus, R. T., Ferris, S. H., Whitehouse, P., Cohen, G. D., & Gershon, S. (1986). Age associated memory impairment: Proposed diagnostic criteria and measures of clinical change—Report of a National Institute of Mental Health Work Group. Developmental Neuropsychology, 2, 261–276. https://doi.org/10.1080/87565648609540348.
De Beni, R., Borella, E., Carretti, B., Marigo, C., & Nava, L. A. (2008). BAC. Portfolio per la valutazione del benessere e delle abilità cognitive nell’età adulta e avanzata [The assesment of well-being and cognitive abilities in adulthood and aging]. Firenze: Giunti OS.
De Beni, R., Pazzaglia, F., Gyselinck, V., & Meneghetti, C. (2005). Visuospatial working memory and mental representation of spatial descriptions. European Journal of Cognitive Psychology, 17, 77–95. https://doi.org/10.1080/09541440340000529.
de Ribaupierre, A., & Lecerf, T. (2006). Relationships between working memory and intelligence: convergent evidence from a Neo-Piagetian and a Psychometric approach. European Journal of Cognitive Psychology, 18, 109–137. https://doi.org/10.1080/09541440500216127.
Dowling, W. J., Bartlett, J. C., Halpern, A. R., & Andrews, M. W. (2008). Melody recognition at fast and slow tempos: Effects of age, experience, and familiarity. Attention, Perception, & Psychophysics, 70, 496–502. https://doi.org/10.3758/PP.70.3.496.
Ferreri, L., Bigand, E., Perrey, S., Muthalib, M., Bard, P., & Bugaiska, A. (2014). Less effort, better results: How does music act on prefrontal cortex in older adults during verbal encoding? An fNIRS study. Frontiers in Human Neuroscience, 8, 1–11. https://doi.org/10.3389/fnhum.2014.00301.
Gabrielsson, A., & Lindström, E. (2010). The role of structure in the musical expression of emotions. In P. N. Juslin & J. A. Sloboda (Eds.) Handbook of music and emotion: Theory, research, and applications (pp. 367–400). Oxford: Oxford University Press
Gluck, J., & Fitting, S. (2003). Spatial strategy selection: Interesting incremental information. International Journal of Testing, 3, 293–308. https://doi.org/10.1207/S15327574IJT0303_7.
Golden, H. L., Clark, C. N., Nicholas, J. M., Cohen, M. H., Slattery, C. F., … & Warren, J. D. (2017). Music perception in Dementia. Journal of Alzheimer’s Disease, 55, 933–949. https://doi.org/10.3233/JAD-160359.
Hampshire, A., & Sharp, D. J. (2015). Contrasting network and modular perspectives on inhibitory control. Trends in Cognitive Science, 19(8), 445–452. https://doi.org/10.1016/j.tics.2015.06.006.
Hetland, L. (2000). Learning to make music enhances spatial reasoning. Journal of Aesthetic Education, 34(3/4), 179–238. https://doi.org/10.2307/3333643.
Husain, G., Thompson, W. F., & Schellenberg, E. G. (2002). Effects of musical tempo and mode on arousal, mood, and spatial abilities. Music Perception, 20, 151–171. https://doi.org/10.1525/mp.2002.20.2.151.
Isen, A. M. (1999). On the relationship between affect and creative problem solving. In S. Russ (Ed.), Affect, creative experience and psychological adjustment (pp. 3–17). Philadelphia: Brunner/Mazel.
Isern, B. (1960). Summary, conclusions, and implications: The influence of music upon the memory of mentally retarded children. Proceedings of the National Association for Music Therapy, 10, 149–153.
Karbach, J., & Verhaeghen, P. (2014). Making working memory work: A meta-analysis of executive control and working memory training in younger and older adults. Psychological Science, 25, 2027–2037. https://doi.org/10.1177/0956797614548725.
Likert, R., & Quasha, W. (1948). Revised Minnesota paper form board test. New York: Psychological Corporation.
Lord, T. R., & Garner, J. E. (1993). Effects of music on Alzheimer’s patients. Perceptual and Motor Skills, 76, 451–455.
Malinowski, P., Moore, A. W., Mead, B. R., & Gruber, T. (2017). Mindful aging: the effects of regular brief mindfulness practice on electrophysiological markers of cognitive and affective processing in older adults. Mindfulness, 8, 78–94. https://doi.org/10.1007/s12671-015-0482-8.
Mammarella, N., Borella, E., Carretti, B., Leonardi, G., & Fairfield, B. (2013). Examining an emotion enhancement effect in working memory: Evidence from age-related differences. Neuropsychological Rehabilitation, 23, 416–428. https://doi.org/10.1080/09602011.2013.775065.
Mammarella, N., Fairfield, B., & Cornoldi, C. (2007). Does music enhance cognitive performance in healthy older adults? The Vivaldi effect. Aging Clinical and Experimental Research, 19, 394–399. https://doi.org/10.1007/BF03324720.
McAuley, E., Duncan, T., & Tammen, V. V. (1989). Psychometric properties of the intrinsic motivation inventory in a competitive sport setting: A confirmatory factor analysis. Research Quarterly for Exercise and Sport, 60, 48–58. https://doi.org/10.1080/02701367.1989.10607413.
Meneghetti, C., Borella, E., Carbone, E., Martinelli, M., & De Beni, R. (2016). Environment learning using descriptions or navigation: The involvement of working memory in young and older adults. British Journal of Psychology, 107, 259–280. https://doi.org/10.1111/bjop.12145.
Meneghetti, C., Cardillo, R., Mammarella, I. C., Caviola, S., & Borella, E. (2017). The role of practice and strategy in mental rotation training: Transfer and maintenance effects. Psychological Research, 81, 415–431. https://doi.org/10.1007/s00426-016-0749-2.
Mitolo, M., Gardini, S., Caffarra, P., Ronconi, L., Venneri, A., & Pazzaglia, F. (2015). Relationship between spatial ability, visuospatial working memory and self-assessed spatial orientation ability: A study in older adults. Cognitive Processing, 16, 165–176. https://doi.org/10.1007/s10339-015-0647-3.
Miyake, A., Friedman, N. P., Emerson, M. J., Witzki, A. H., Howerter, A., & Wager, T. D. (2000). The unity and diversity of executive functions and their contributions to complex “frontal lobe” tasks: A latent variable analysis. Cognitive Psychology, 41, 49–100. https://doi.org/10.1006/cogp.1999.0734.
Nantais, K. M., & Schellenberg, E. G. (1999). The Mozart effect: An artifact of preference. Psychological Science, 10, 370–373. https://doi.org/10.1111/1467-9280.00170.
Noack, H., Lövdén, M., Schmiedek, F., & Lindenberger, U. (2009). Cognitive plasticity in adulthood and old age: Gauging the generality of cognitive intervention effects. Restorative Neurology and Neuroscience, 27, 435–453. https://doi.org/10.3233/RNN-2009-0496.
Novelli, G., Papagno, C., Capitani, E., & Laiacona, M. (1986). Tre test clinici di memoria verbale a lungo termine: taratura su soggetti normali. Archivio di Psicologia, Neurologia e Psichiatria, 47, 278–296.
O’Malley, J. J., & Gallas, J. (1977). Noise and attention span. Perceptual and Motor Skills, 44, 919–922. https://doi.org/10.2466/pms.1977.44.3.919.
O’Malley, J. J., & Poplawsky, A. (1971). Noise-induced arousal and breadth of attention. Perceptual and Motor Skills, 33, 887–890. https://doi.org/10.2466/pms.1971.33.3.887.
Prickett, C. A., & Moore, R. S. (1991). The use of music to aid memory of Alzheimer’s patients. Journal of Music Therapy, 28, 101–110. https://doi.org/10.1093/jmt/28.2.101.
Rausch, V. H., Bauch, E. M., & Bunzeck, N. (2014). White noise improves learning by modulating activity in dopaminergic midbrain regions and right superior temporal sulcus. Journal of Cognitive Neuroscience, 26, 1469–1480. https://doi.org/10.1162/jocn_a_00537.
Rauscher, F. H., Shaw, G. L., & Ky, K. N. (1993). Music and spatial task performance. Nature, 365. https://doi.org/10.1038/365611a0.
Schellenberg, E. G., Nakata, T., Hunter, P. G., & Tamoto, S. (2007). Exposure to music and cognitive performance: Tests of children and adults. Psychology of Music, 35, 5–19. https://doi.org/10.1177/0305735607068885.
Schellenberg, E. G., & Weiss, M. W. (2013). Music and cognitive abilities psychology of music. In D. Deutsch (Ed.), Music and cognitive abilities (3rd edn., pp. 499–550). Amsterdam: Elsevier. https://doi.org/10.1016/B978-0-12-381460-9.00012-2.
Shao, Z., Janse, E., Visser, K., & Meyer, A. S. (2014). What do verbal fluency tasks measure? Predictors of verbal fluency performance in older adults. Frontiers in Psychology, 5, 1–10. https://doi.org/10.3389/fpsyg.2014.00772.
Söderlund, G. B. W., Sikström, S., Loftesnes, J. M., & Sonuga-Barke, E. (2010). The effects of background white noise on memory performance in inattentive school children. Behavioral and Brain Functions, 6, 55. https://doi.org/10.1186/1744-9081-6-55.
Söderlund, G. B. W., Sikström, S., & Smart, A. (2007). Listen to the noise: Noise is beneficial for cognitive performance in ADHD. Journal of Child Psychology and Psychiatry, 48, 840–847. https://doi.org/10.1111/j.1469-7610.2007.01749.x.
Steele, K. M., Bella, D., Peretz, S., Dunlop, I., Dawe, T., Humphrey, L. A., Shannon, G. K., Kirby, R. A., J.L., Jr., & Olmstead, C. G. (1999). Prelude or requiem for the “Mozart Effect”? Nature, 400, 826–828. https://doi.org/10.1038/23611.
Szalma, J. L., & Hancock, P. A. (2011). Noise effects on human performance: a meta-analytic synthesis. Psychological Bulletin, 137, 682–707. https://doi.org/10.1037/a0023987.
Thompson, R. G., Moulin, C. J. A., Hayre, S., & Jones, R. W. (2005). Music enhances category fluency in healthy older adults and Alzheimer’s disease patients. Experimental Aging Research, 31, 91–99. https://doi.org/10.1080/03610730590882819.
Thompson, W. F., Schellenberg, E. G., & Husain, G. (2001). Arousal, mood, and the Mozart effect. Psychological Science, 12, 248–251. https://doi.org/10.1111/1467-9280.00345.
Thompson, W. F., Schellenberg, E. G., & Letnic, A. K. (2012). Fast and loud background music disrupts reading comprehension. Psychology of Music, 40, 700–708. https://doi.org/10.1177/0305735611400173.
Wallace, W. T. (1994). Memory for music: Effect of melody on recall of text. Journal of Experimental Psychology: Learning, Memory, and Cognition, 20, 1471–1485. https://doi.org/10.1037/0278-7393.20.6.1471.
Weisz, J. R., & Hawley, K. M. (2001). Procedural and coding manual for identification of evidence-based treatments. Unpublished manuscript: University of California.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical standards
The present study was performed in accordance with the ethical standards established by the 1964 Declaration of Helsinki and its later amendments. All participants gave informed consent prior to inclusion in the study. Details that might disclose the identity of the subjects under study should be omitted.
Conflict of interest
The author declares that there is no conflict of interest.
Rights and permissions
About this article

Cite this article
Borella, E., Carretti, B., Meneghetti, C. et al. Is working memory training in older adults sensitive to music?. Psychological Research 83, 1107–1123 (2019). https://doi.org/10.1007/s00426-017-0961-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00426-017-0961-8