
Abstract
When two individuals alternate reaching responses to targets located in a visual display, reaction times are longer when responses are directed to where the co-actor just responded. Although an abundance of work has examined the many characteristics of this phenomenon it is not yet known why the effect occurs. In particular, some authors have argued that action representation mechanisms are central to the effect. However, here we present evidence in support of an account in which the representation of action is not necessary. First, the basic effect occurs even when participants cannot see their co-actor’s movement but, importantly, have their attention shifted to a target side via an attentional cue. Second, its time course is too short-lasting to function effectively as a component of action planning. Finally, unlike other joint action phenomena, the effect is not modulated by higher order mechanisms concerned with the personal attributes of a co-actor. Taken together, these results suggest that this particular joint action phenomenon is due to attentional rather than action mechanisms.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The dominant paradigm in cognitive research is the testing of individuals on tasks performed in isolation. In the archetypal experiment, a lone individual performs a required task in front of a computerised display, from which the experimenter can examine aspects of the individual’s perceptual, attentional, memory, or executive abilities. However, during the past decade or so a number of researchers have begun to examine how cognition operates when a person acts jointly with another individual. One finding is that the presence of others can influence how attention is selectively allocated across a visual display (Böckler, Knoblich, & Sebanz, 2012; Frischen, Loach, & Tipper, 2009; Tversky & Hard, 2009). For example, when participants are asked to respond to a target, whilst ignoring simultaneously appearing distractors, they seem to form a different frame of reference to encode visual information, depending on whether they are executing the task alone or with a partner (Frischen et al., 2009). Thus, if a participant performs the task alone, objects (e.g., in this case distractors; Frischen et al., 2009) appear to be coded with reference to the agent’s own body (i.e., distractors appearing close to the agent’s hand are inhibited more strongly). However, interestingly, when executing the task jointly with another individual, the participants’ reference frame shifts to coding objects in respect to their proximity to the task-partner instead (i.e., distractors occurring close to the other person’s hand are inhibited more strongly; Frischen et al., 2009).
Joint action work is often placed within the context of theories that link mechanisms representing perception and action, one of which being the theory of event coding (TEC; Hommel, Musseler, Ascherschleben, & Prinz, 2001a). In essence, the TEC suggests that perceived events (perception) and intended to-be-executed events (action) share a common representational domain. As such, irrespective of their role, both stimulus and response codes are formed and represented in the same medium as cognitive structures, called ‘event codes’. Event codes are said to prime each other in accordance to an overlap on an abstract distal-coding level, implying these are formed on the basis of goal-directed representations of the events. ‘According to TEC, intentionality renders perception and action planning inherently similar and functionally equivalent’ (Hommel, Pratt, Colzato, & Godjin, 2001b, p. 904). Thus, anticipating a perceptual event, perceiving it, planning the event or executing it, are assumed to result in a similar activation in the motor system.
The theory has been used as an explanation for one of the most notable joint action effects, namely the ‘joint Simon effect’ (or ‘social Simon effect’; Sebanz, Knoblich, & Prinz, 2003). In the basic paradigm, co-actors sit adjacent to one another and each has a single target they are required to respond to. One participant responds with their left hand, the other with their right. For example, co-actor A may respond only to the appearance of a blue stimulus by pressing a left key, whereas co-actor B presses a right key whenever a green stimulus is displayed. Furthermore, targets can appear either to the left or right hand side of a display. Results indicate that although the position of the targets is irrelevant, co-actors are generally quicker to respond to stimuli appearing on the side associated with their response button (e.g., left key press for a blue stimulus appearing to the left) and are slower whenever their target appears on the partner’s side (Sebanz et al., 2003; Hommel, Colzato, & van den Wildenberg, 2009). Importantly, this effect is present only when the task is performed jointly with another individual, or alone where the person makes both responses (i.e., Simon & Rudell, 1967), but not when a lone participant responds to just one of the two stimuli (Hommel, 1996). In the terminology of TEC, the standard (lone) Simon effect occurs because agents automatically form binding codes between the relevant stimulus features (i.e., colour) and the irrelevant but corresponding stimulus features (i.e., location). Consequently, when these coincide a facilitation effect, translated into shorter reaction time (RT), occurs whereas a stimulus–response mismatch results in interference and longer RTs (Hommel et al., 2001b, 2009). Following this logic, Sebanz et al. (2003, Sebanz, Bekkering, & Knoblich, 2006) argued that when acting jointly on a task, co-actors represent each other’s stimulus–response maps and therefore experience interference whenever these are violated. This suggests that co-actors represent and integrate each other’s perspective (Sebanz et al., 2003, 2006; Sebanz & Knoblich, 2009, Obhi & Sebanz, 2011).
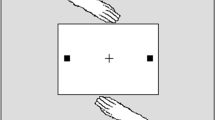
Action representation mechanisms have also been invoked to explain another commonly employed joint action phenomenon first reported by Welsh and colleagues (Atkinson, Simpson, Skarratt, & Cole, 2014; Doneva & Cole, 2014; Cole, Skarratt, & Billing, 2012; Hayes, Hansen, & Elliott, 2010; Ondobaka, de Lange, Newman-Norlund, Wiemers, & Bekkering, 2012; Ondobaka, Newman-Norlund, de Lange, & Bekkering, 2013; Reid, Wong, Pratt, Morgan, & Welsh, 2013; Skarratt, Cole, & Kingstone, 2010; Skarratt, Cole, & Kuhn, 2012; Welsh et al., 2005; Welsh et al., 2007; Welsh, McDougall, & Weeks, 2009a; Welsh, Ray, Weeks, Dewey, & Elliott, 2009b). In the basic paradigm two co-actors sit facing each other and take turns to respond to targets appearing on a flat display located between them. Once a response has been made, the actor is required to return their hand to a resting position in front of them (see Fig. 1). Typical results reveal that RTs to initiate a response are longer when reaching to the same location as the co-actor’s previous response. Or to put it another way, RTs are shorter when reaching to a different location, usually the opposite side of the display. Although an abundance of work has now examined the various characteristics and properties of the effect, it is not yet clear why the phenomenon occurs. Indeed, authors, including ourselves, have assumed that the effect is due to a particular mechanism. This can be seen in the work of Welsh and colleagues and Skarratt et al. (2010) who, in referring to the effect as ‘between-person inhibition of return’ and ‘social inhibition of return’ (IOR) respectively, suggest it reflects the visuomotor inhibition that follows an attention-capturing event. By contrast, Ondobaka et al. (2012, 2013) suggest the effect is due to action imitation, i.e., congruency of observed and performed movements. In the present paper, we describe and test three explanations that have been posited to explain the basic effect. We refer to the three explanations, described below, as the action–location account (Hayes et al., 2010; Welsh et al., 2005, 2007, 2009b), the movement congruency account (Ondobaka et al., 2012, 2013), and the attentional shift hypothesis (Cole et al., 2012). Although fundamentally different from each other, there are similarities amongst the three theories. For instance, both the Welsh et al.’s and Ondobaka et al.’s accounts incorporate the action–perception models described earlier in which an observed action is said to be represented both by perceptual mechanisms and action mechanisms. However, in contrast to Welsh et al.’s explanation, the location of response is not important in the Ondobaka et al. account. Furthermore, the theories of Welsh et al. and Cole et al. are both concerned with inhibitory mechanisms (i.e., IOR) whereas the Ondobaka et al.’s explanation is not.

A schematic representation of the ‘social IOR’ paradigm
Welsh and collaborators (and others, e.g., Sebanz & Knoblich, 2009) argued that the effect is caused by the linking of mechanisms underlying action representation and inhibition. With respect to the former, Welsh et al. (2007, p. 955) suggested that ‘between-person IOR results from an understanding of the other person’s response’. Furthermore, Welsh et al. (2007) posited the mirror neuron system (MNS, Rizzolatti & Craighero, 2004) as a mediating mechanism. The MNS is often referred to as the action observation system of the brain, known to become active both during action execution and when the same action is observed. As Welsh et al. (2007, p. 955) stated, ‘We hypothesize that the activation of the mirror neuron system during the observation of the response mimicked the activity associated with the actual response’. The second and complimentary aspect of their account concerns inhibition and specifically IOR. It is now well-established that humans are slower to act upon a stimulus presented at a recently attended location (i.e., Posner & Cohen, 1984). Thus when an observer sees another individual attend to a location, this initiates IOR in the observer. Put simply, Welsh et al.’s account suggests that when co-actor A reaches to location X, co-actor B’s perceptual mechanisms perceive it as if co-actor B has performed the action themselves which activates an inhibitory response to that location.
The second account, advocated by Ondobaka et al. (2012, 2013), places the effect within the context of mechanisms that represent congruency of movement. In addition to inhibiting an action, observing a biological movement can also facilitate the same movement in the observer. For example, participants are quicker to execute a finger (Brass, Bekkering, & Prinz, 2001) or an arm movement (Kilner, Paulignan, & Blakemore, 2003) compatible with the one observed (Kilner et al., 2003, see also Liepelt, Cramon, & Brass, 2008). With respect to the present phenomenon, Ondobaka et al. argued that when a participant reaches out to, say, their right (because the target appeared on the right) this facilitates a rightward reach in the observer (i.e., co-actor) when she is then required to reach to her right on the next trial. In other words, the action is facilitated when, within an egocentric framework, it is congruent with the one just seen.
The third explanation argues that the effect occurs solely as a result of mechanisms associated with attentional orienting and resultant IOR (Cole et al., 2012). The basic IOR phenomenon is normally studied in paradigms where a peripheral ‘cue’ is presented to a lone observer, followed by a delay longer than approximately 300 ms and a target that appears with equal probability at either the cued or the uncued location (Posner & Cohen, 1984; Rafal, Choate, & Vaughan, 1989). Results typically show that participants are slower to respond to cued targets. In other words, after an initial capture of attention by the cue, inhibition follows. Thus, it is possible that instead of representing an observed action the effect occurs because a co-actor’s arm movement (and/or target onset) shifts the observer’s attention to one side of the display. In effect, the partner’s arm reach serves an identical role to the peripheral cue in Posner and Cohen’s classic study (1984); that is, it provides a transient event that draws an observer’s attention to a region of space. Furthermore, the fact that the phenomenon is still observed when only the initial portion of the arm movement can be seen (see Welsh et al., 2007; Skarratt et al., 2010) does not negate the attentional shift hypothesis; occluding the peripheral ‘transients’ generated by a reaching action renders the initial (seen) movement as a ‘central’ cue, and classical IOR is now known to be induced with central cues (e.g., Cole, Smith, & Atkinson, 2015; Taylor & Klein, 2000; Weger, Abrams, Law, & Pratt, 2008). Indeed, Skarratt et al. (2010) reported that seeing a co-actor’s eye gaze only was sufficient to generate social IOR (Skarratt et al., 2010).Footnote 1 In support, a recent study found that visual access to the partner’s targets seems to be necessary for social IOR to occur, as knowledge alone about the location of the partner’s response, communicated via the presentation of auditory cues (a low- or a high-toned pitch) could not trigger the effect (Welsh, Manzone, & McDougall, 2014). Thus, Welsh et al. (2014) concluded that their results were indicative of the phenomenon being modulated by the sensorimotor, lower order aspects of the task. Moreover, although Welsh et al. (2014) submitted that ‘the sIOR effect is dependent on the observers witnessing and representing the spatial aspects of how the action was executed’ (p. 158) and thus advocate that the observation of action plays a special role in triggering the effect, their findings are in line with this third alternative account of the effect. This is because, as mentioned earlier, Cole et al. suggest that any salient event, including the motion of the partner’s limbs could serve as a cue to shift the observer’s attention and result in social IOR.
The present work examined which of the three theories provides the most parsimonious explanation of the basic joint action effect described above. In Experiment 1 we assess the consequences of having attention shifted to a location in the absence of an observed action to that location, i.e., in which no imitation or action representation can occur. In Experiment 2 we examine whether the time course of the effect concurs with what is known about the time course of action co-representation mechanisms. Experiment 3 assesses whether high-level attributions made about a co-actor can modulate the effect, as has been established for the joint Simon effect (e.g., Hommel et al., 2009).
Experiment 1
Recall that Welsh et al.’s (2005) account of the present joint action effect posits that co-actors inhibit actions via the MNS whilst Ondobaka et al. (2012) suggest that the effect is due to congruency of actions. Thus, action representations are central to both theories. By contrast, Cole et al. (2012) suggest that actions are epiphenomenal: in this context, they merely happen to shift attention. A necessary condition of the attentional shift hypothesis is that a social IOR-like effect should occur if a participant’s attention is shifted to a target location via an attentional cue, even when no action can be seen. In other words, as long as attention orients to a location, an inhibitory effect should occur. Therefore in one block of trials in Experiment 1, all actions performed by the participant’s (confederate) co-actor were occluded by a barrier (the ‘non-visible’ condition). In these trials the participant made a reaching response to a target, i.e., performed the standard task. However, when the co-actor took his turn, he operated a physical arrow that merely pointed to the target rather than reach to it. At the same time a peripheral cue appeared. This ‘transient’ together with the arrow cue should ensure that the participant’s attention will be shifted to the cue. In a second block, both co-actors performed the standard task in which they both reached out to the target. In addition to a social IOR-like effect occurring in the non-visible condition, the attentional account also predicts that the size of a participant’s social IOR effect should be related to the size of their (non-social) IOR effect induced by the attentional cues. This rationale follows Welsh et al. (2009a) who argued that if social IOR is indeed based on IOR mechanisms a correlation should exist between IOR induced by observing another person’s response (‘between-person IOR’) and IOR induced by observing one’s own response (‘within-person IOR’).
Method
Participants
A volunteer sample of 24 (6 male; 18 female) participants aged between 18 and 25 took part in the study. All were undergraduates at the University of Essex, right-handed and naïve to the purposes of the study. Ethical approval from the ethics committee of the University of Essex was obtained prior to commencing of all three experiments.
Stimuli and apparatus
In social IOR experiments co-actors invariably sit in slightly different positions with respect to each other, the workspace, and stimuli. Thus, stimuli size differs in terms of visual angle for each participant, we therefore provide all measurements in millimeter. Stimuli were presented on a 22″ LCD monitor built into a table positioned between the co-actors and had a Keytec touch-screen placed over it. The participants sat opposite each other such that they were facing and the distance between their chests and their ‘home buttons’ was approximately 240 mm. A black square measuring 10 mm in diameter (0.3 cd/m2 measured on-screen) was presented in the centre of the display against a uniform white background (67.3 cd/m2) and acted as a fixation point. Two other squares of the same size and luminance were presented to the left and right of the display area (see Fig. 2). The target was the rapid onset then offset (i.e., a flash) of one of these squares. Participants made a response by moving their hand from the home button and touching the target square. One co-actor served as the naïve participant whilst the other was a confederate. On half of the trials a barrier was located such that it occluded all hand/arm movements made by the confederate co-actor. A wooden arrow was located at the base of this barrier operated by the co-actor. An RM Pentium PC running custom software controlled stimulus generation and the recording of responses.

The equipment used in Experiment 1. The confederate co-actor operates one end of the wooden arrow. No actions can be seen by the participant
Design
We employed a within-participants 2 × 2 design. The first factor manipulated target side, i.e., the side of the display where the target appeared compared with the previous trial. We refer to this factor as ‘target side’ instead of ‘target location’ throughout the paper since although in Experiment 1 participants responded to exactly the same physical location, in Experiments 2 and 3 they responded to either the same or different side, rather than the exact physical location. A same trial was one in which the target occurred on the same side as the previous trial whilst a different trial was one in which that target appeared on the opposite side. The second factor manipulated the visibility of the co-actor’s action. This had two levels. Either the participant had a full view of the co-actor’s action or it was fully occluded. The dependent variable in all experiments was the time that elapsed between target presentation and the screen touch (response time, RT).
Procedure
Participants were asked to alternate responses with their co-actor and that they should reach out and touch the target as soon as it appeared and then return their hand to the ‘home’ button in front of them. The target appeared for 100 ms. Three hundred and fifty milliseconds elapsed between response completion and the next target occurring. Participants were asked to fixate the centre until they were required to make their response, during which they were instructed to fixate the target. They were additionally told that they should respond as quickly and as accurately as possible. Furthermore, they were informed that other than to alternate responses, they should ignore their partner’s responses. In the visible condition the confederate co-actor performed the same task as the participant. That is, he reached out and touched the location of the target. In the non-visible condition by contrast, he moved one end of the wooden arrow such that it pointed directly at the target position. The co-actor then returned the arrow to the mid position immediately after. He also remained fixated on the central point for the entire duration of the trial. A custom program generated a random sequence for the presentation of the targets where no target appeared on the same side more than four times in succession. The target side factor was presented randomly within-block whilst the visibility factor was blocked. Two blocks of trials were presented, each comprising 209 trials (104 participant trials together with 105 co-actor trials).
Results and discussion
Outliers (more than two SDs above or below the mean) were removed from further analysis and accounted for 4.3 % of responses. Figure 3 shows mean RTs for the four conditions. An ANOVA with target side (same or different) and visibility (visible or non-visible) as within-participant factors revealed significant main effects of target side, F(1, 23) = 65.5, p < 0.001, \(\eta_p^2\) = 0.65, and visibility, F(1, 23) = 43.5, p < 0.001, \(\eta_p^2\) = 0.74. The interaction was also significant, F(1, 23) = 6.3, p < 0.05, \(\eta_p^2\) = 0.22. Post-hoc analyses showed that the target side effect (i.e., social IOR) was present in both the visible and non-visible conditions, t(23) = 8.6, p < 0.001, and t(23) = 5.5, p < 0.001, respectively. We also found a significant correlation (r = 0.49, p < 0.05) between the size of a participant’s social IOR effect (i.e., in the visible condition) and the size of their cueing effect (i.e., in the non-visible condition).

Mean RTs for Experiment 1. Error bars represent standard errors of the mean
The first notable aspect of these results is that participants were slower to initiate a response to the same target side that their co-actor had just reached to (in the visible condition). This replicates the basic social IOR findings of Welsh et al. (2005, 2007) and Skarratt et al. (2010). Important, however, was the observation that the effect also occurred in the non-visible condition in which no co-actor movements could be seen (and were different) but attentional cues were presented. As we set out in the “Introduction” to the present experiment, a necessary condition of the attentional shift account (Cole et al., 2012) is that a social IOR-like effect should occur when attention is directed to the target location, by whatever means. This was therefore supported. The attentional account also predicted that the size of a participant’s social IOR effect should be correlated with the size of the effect induced by attentional cues. This was also supported; thus, those participants who showed a particularly large (or small) IOR effect induced the observation of a partner’s response (i.e., social IOR) also showed particularly large (or small) IOR induced by cueing. This, as suggested by Welsh et al. (2009a) supports the notion that social IOR is due to the same mechanisms that give rise to standard IOR.
Although the present results support the attentional shift hypothesis, one aspect of the results is however in line with the imitation account of Ondobaka et al. (2012). The IOR effect was significantly larger (i.e., the target side × visibility interaction) when participants saw their co-actor’s actions compared to when these were occluded. This could also however be due to greater transient signals being induced by the arm movements compared to the cues in the non-visible condition. In Experiment 2 therefore we provided a more direct test of the imitation account.
Experiment 2
In order for action observation to effectively influence one’s own actions, the action representation ought to persist for some duration; time will elapse between the start of an observed action and the moment an observer performs a similar action themselves. Peak activity in motor areas following action observation has been reported to last between 2 and 6 s (e.g., Lestou, Pollick, & Kourtzi, 2008). Additionally, Gangitano, Mottaghy and Pascual-Leone (2004) found mirror neuron activation up to 3.2 s when participants observed videos of hand-grasping movements. Clearly, the use of relatively long delays between action observation and execution (e.g., 6 s in Gangitano et al., 2004; 3–9 s in Gazzola, Rizzolatti, Wicker, & Keysers, 2007) and resultant effects suggests that the MNS remains active for a relatively long period after the inducing stimulus is no longer present. Moreover, mirror neurons have been implicated in delayed imitation performance (Krüger et al., 2014; Paukner, Ferrari, & Suomi, 2011), in which imitation is prevented for a few seconds (Krüger et al., 2014) to several minutes (Rogers, Young, Cook, Giolzetti, & Ozonoff, 2008) or even days (Meltzoff & Moore, 1994; Eskritt, Donald, & Muir, 1998). Furthermore, it has been found to correlate highly with immediate imitation both in terms of behavioural accuracy in humans (Rogers et al., 2008) and rhesus monkeys (Paukner et al., 2011) and in terms of neural activation (Krüger et al., 2014).
The aim of Experiment 2, therefore, was to systematically assess the time course of the present joint action effect. We employed four different stimulus onset asynchronies (SOA); 1000, 2200, 3400, and 4600 ms. Based on the notion that action observation processes need to persist for some time (see above), Welsh et al.’s and Ondobaka et al.’s (action-based) accounts predict that the effect ought to be present in at least the two shortest SOA conditions, and probably in the longest two.
Method
Participants
A volunteer sample of 24 (2 male; 22 female) participants aged between 18 and 22 took part. All were first-year psychology undergraduates at the University of Essex who participated in exchange for course credits. All were right-handed and were naïve to the purposes of the study. None had taken part in Experiment 1.
Stimuli and apparatus
All aspects of the stimuli were as described previously with the following exceptions. As with many other social IOR experiments two physical barriers were placed between co-actors that occlude peripheral transients. These allow a visible central gap of 145 mm to be seen. Employing these barriers may be considered a conservative way of assessing social IOR because the effect relies on central cues rather than peripheral transients. Because of these barriers, co-actors could not respond to the same targets. The targets (same dimensions as described in Experiment 1), were therefore grouped inside two light grey rectangles, each covering 200 mm2 of the screen. Thus, two squares (1 to the left, 1 to the right) were displayed in front of each participant. They were located at a distance of 160 mm from the black fixation cross and were protruding 50 mm to the left and to the right of the screen midline. The distance between the left and the right squares was 320 mm. As in Experiment 1 target illumination represented a removal of one of the black squares for 100 ms.
Design and procedure
The experiment had a 2 (target side) × 4 (SOA) fully within-participants design. To generate different SOAs we varied the interval between the completion of one response and the target onset of the following trial. That is, the inter-trial interval (ITI). These were 350, 1550, 2750, and 3950 ms. Because the SOA includes the time it takes a participant to complete a response, the precise SOA values are not known. However, we know that the mean movement time to contact the target in the standard social IOR paradigm is approximately 325 ms. This, plus the time it takes to return the hand to the home button (325 ms) equates to a total of approximately 650 ms. By then adding the appropriate ITI, an approximate SOA is generated for each ITI. That is, the interval between seeing a co-actor’s hand beginning to move and the participant’s own target. The four SOA conditions were blocked and their presentation order was counterbalanced. Each block consisted of 209 trials. This generated a total of 836 trials. Participants undertook one practice session consisting of 21 trials which had the same SOA as the first experimental condition they completed. Unlike in Experiment 1, both co-actors were participants rather than one being a confederate. As in Experiment 1, the dependent variable was the time that elapsed between target presentation and the screen touch.
Results and discussion
Outliers (more than two SDs above or below the mean) were removed from further analysis. Mean RTs (see Fig. 4) were computed as a function of target side (same, different) and SOA (1000, 2200, 3400 and 4600 ms) and were entered into a 2 × 4 fully within participants ANOVA. The main effect of SOA was significant, F(3, 69) = 58.17, p < 0.001, \(\eta_p^2\) = 0.717, as was the main effect of target side, confirming the presence of social IOR, F(1, 23) = 7.91, p < 0.01, \(\eta_p^2\) = 0.256. Importantly, the SOA × target side interaction was also significant, F(3, 69) = 3.26, p < 0.027, \(\eta_p^2\) = 0.124, indicating that social IOR was modulated by SOA. Planned comparisons showed that social IOR occurred only when the SOA was 1000 ms, t(23) = 2.74, p < 0.012. In all other SOA conditions, the difference between the two target types was non-significant (all ps > 0.498).

Mean RTs as a function of SOA and target side position with respect to a partner’s target. Error bars represent standard errors of the mean
Experiment 2 demonstrates that social IOR is modulated by the interval between action observation and action performance. Specifically, the effect is a short-lived phenomenon which extinguishes somewhere between 1000 and 2200 ms. Although no other studies have systematically examined its duration, the present results support earlier findings using short trial and ITI durations (Atkinson et al., 2014; Doneva & Cole, 2014; Hayes et al., 2010; Welsh et al., 2005). Importantly, the time course of the effect does not concur with the known time course of many other action observation effects (e.g., 6000 ms in Gangitano et al., 2004). These results in turn suggest that the mechanisms giving rise to social IOR are unlikely to be concerned with action observation. These results in turn suggest that the mechanisms giving rise to social IOR are unlikely to be concerned with action observation. It is also worth noting that our observed duration of social IOR and consequent conclusion that it rapidly dissipates is very conservative; the SOA factor manipulated the time between the onset of an observed response and the initiation of an action. However, one could also argue that the critical interval is the one between seeing an action being completed (rather than being started) and initiating the same action oneself. Conceiving the duration in this way leads to the conclusion that social IOR persists for an even shorter duration. That is, between 350 and 1550 ms.
Experiment 3
Experiments 1 and 2 suggested that the present effect is more likely to be due to visuomotor inhibition, rather than action representation. Thus, in Experiment 3 we examined whether the effect is modulated by higher level mechanisms that represent relations between co-actors. As discussed in the “Introduction”, the classic example of shared task representations has been the joint Simon effect. It is known that higher order factors such as the personal relationship between co-actors affect the extent to which they represent the other’s task rules. For instance, Hommel et al. (2009) found that the joint Simon effect was present only when there was a positive relationship between the two partners and disappeared when participants were partnered with a negative confederate. Furthermore, a similar study indicated that the joint Simon effect was influenced by one’s mood (Kuhbandner, Pekrun, & Maier, 2010) such that it was present when a positive mood had been induced in participants but disappeared if the task followed negative affect induction. Indeed, early social psychology research has indicated that individuals are less likely to integrate the perspective and ideas of a person they dislike (Heider, 1958) and that liking another person decreases the self-other distinction (Aron, Aron, Tudor, & Nelson, 1991). In Experiment 3 therefore, we replicated the present joint action procedure under two different conditions: either the co-actor acted in a positive manner towards the participant or a negative manner.
Method
Participants
A volunteer sample of 24 (9 male; 15 female) participants aged between 18 and 28 (M = 20.38 years, SD = 3.87 years) took part in the study. All participants were undergraduates at the University of Essex who participated in exchange for £3.
Stimuli and apparatus
The stimuli and apparatus were as described previously in Experiment 2 including the use of the physical barriers, placed between the two co-actors
Design and procedure
The experiment had a 2 (target side: same, different) × 2 (partner: positive, negative) mixed participants design. The dependent variable was again participants’ RT referring to the interval between target presentation and screen touch.
Participants completed 2 blocks of 209 trials. All other aspects were as described previously. Half of the participants were confronted with an exceptionally nice confederate (positive condition) whereas the other half with amore distant and critical one (negative condition).Footnote 2 The first author (SPD) acted as the confederate in both valence conditions. This began at the start of the experimental session, with the ‘positive’ confederate greeting the participant and initiating a friendly conversation, and smiling throughout the experiment. At the same points in the negative condition, the confederate was more distant, indifferent yet still polite. She also greeted the participant, yet did not smile at them, or initiate an informal conversation before the start of the experiment. Regardless of confederate type, a set of fixed phrases were used as feedback to the participant during the experiment. The confederate gave feedback to the participant on only two occasions—once they had completed the practice session and after the first experimental block. The wording of the phrases used in the positive and negative condition was very similar and the feedback was delivered only while the confederate was looking at the participant’s data. Thus, in the positive condition after the practice block, the confederate used the phrases: ‘You were very quick’ and ‘You didn’t make any mistakes’ and confirmed this after the first experiment block by saying: ‘You were again very quick’ and ‘You didn’t make any mistakes’. By contrast, in the negative condition the confederate used: ‘I’m afraid you were not quick enough’ and ‘You made several mistakes’ and confirmed this with the statements: ‘You were still not very quick’ and ‘You again made some mistakes’ after the end of the first experimental block. Although it was not expected that the negative condition would cause emotional discomfort in participants, their emotional reactions were monitored, so that the experiment could be stopped immediately if any signs of distress were noticed. Based on Hommel et al. (2009), participants’ subjective feelings of happiness, anxiety, nervousness, irritation and insecurity were informally assessed. Participants were also orally debriefed.
Results and discussion
As previously described, outliers (2 SDs) were removed. The data were entered into a 2 × 2 mixed ANOVA with target side (same, different) as a within-participants factor and partner type (positive, negative) as a between-participants factor (see Fig. 5). The main effect of target side was significant, [F(1, 22) = 5.28, p < 0.031, \(\eta_p^2\) = 0.19], confirming the presence of social IOR. However, neither the effect of partner, nor the partner × target side interaction were significant (ps > 0.74). Although the interaction was not significant, planned follow-up comparisons were performed to examine whether social IOR emerged in the two partner conditions. Interestingly, these revealed a significant effect in the negative partner condition [t(11) = 2.74, p < 0.02, Bonferroni adjusted alpha = 0.025] but not in the positive partner condition [t(11) = 0.41, p < 0.687, Bonferroni adjusted alpha = 0.025].

Mean RTs to localise targets as a function of partner type and target side. Error bars represent standard errors of the mean
These results suggest that unlike the joint Simon effect, social IOR is not influenced by higher order factors such as the social affiliation between the two co-actors or the participant’s affect during the task. Indeed, statistically, the effect was comparable in both partner conditions as the target location by partner type interaction did not reach significance. However, even a more conservative interpretation of the results (i.e., exploring the simple main effects) yields the opposite of what would be expected if action representation subserved the present effect—social IOR should have emerged in the positive, rather than the negative partner condition, as individuals are known to normally integrate the perspective of people they like (Heider, 1958; Hommel et al., 2009). Thus, these findings suggest that unlike the joint Simon effect, social IOR is not influenced by higher order factors such as the social affiliation between the two co-actors or the participant’s affect during the task.
Finally, the data revealed that type of partner did not significantly affect participants’ general response speed. This might have been due to both the positive and the negative condition producing comparable effects on general RT performance through different routes. Thus, while participants in the positive partner condition performed well because they presumably experienced increased levels of positive affect (Andersen & Chen, 2002), those in the negative condition probably wanted to improve their performance as they were receiving negative feedback (‘participants took the speed-related comments of the confederate to heart’, Hommel et al., 2009, p. 797). In support, the tendency in general RTs was similar to that reported by Hommel et al. (2009) who found that individuals in the negative condition responded more quickly.
General discussion
When two individuals alternate reaching responses to targets located between them, responses are slower when they are directed to the same location as a co-actor’s previous response. Three different theories have been posited to explain the effect, each of which differs in terms of how important action and attention are in generating the effect. The action–location account of Welsh and colleagues (e.g., Welsh et al., 2007) suggests that observers inhibit an action towards the location just responded to whilst the movement congruency account of Ondobaka et al. (2012, 2013) suggests that observers imitate the action just seen. These two explanations therefore posit action as being centrally or at least peripherally involved in mediating the effect. By contrast, the attentional shift hypothesis of Cole et al. (2012) suggests that the representation of an action per se is not necessary for the effect to occur. Rather, the body movement seen acts as an attention shifting cue, which then induces IOR. Experiment 1 showed that the basic effect still occurs even when a co-actor performed a different action to that of the participant and one that could not be seen. Importantly however, the effect was observed when a participant’s attention was directed to a target side via attentional cues. The notion that social IOR is not due to action representation was supported in Experiment 2 where the duration of the effect was found to be substantially shorter than one that would be expected of an action representation effect. Finally, Experiment 3 found that, unlike the joint Simon effect (see Hommel et al., 2009; Kuhbandner et al., 2010) the mechanisms that subserve social IOR do not appear to represent the personal relationship between the co-actors.
Overall these findings do not support an account of the basic phenomenon based on action representation. Rather, they suggest that the effect is due to IOR induced by an attentional shift. Specifically, when a co-actor reaches to a particular target side, this shifts an observer’s attention to that location (e.g., Cole & Kuhn, 2009, 2010). Attention is then shifted away from this ‘cued’ position to where the co-actor returns their hand. Visuomotor inhibition (i.e., IOR) is subsequently generated in the observer for the processing of stimuli that appear at the target side. In effect, an observed response acts in the same manner as any other visual cue that shifts attention and elicits IOR. The present findings support other work that has challenged the movement congruency account of social IOR. For instance, Doneva and Cole (2014) found that the effect can be induced in response to attention-capturing transients that mimic the movement of an arm reach even when there is no co-actor actually present (see also Welsh et al., 2007). The authors also found the basic effect when a participant’s co-actor used her leg/foot to reach to the target rather than her arm/hand. As with the present Experiment 1, no imitation was permitted in these scenarios.
Although the present work has refuted Ondobaka et al.’s (2012) imitation account, a more conservative assessment of the data suggests that the action–location account of Welsh et al. could still be possible. Welsh et al. (2005) argued that the distal cause of the basic phenomenon could be due to the same reasons that basic (i.e., lone) IOR is sometimes thought to occur. Klein and MacInnes (1999) suggested that IOR is a visual search facilitator that assists in foraging; it is uneconomical to return to a location or object just viewed. Since humans have evolved as social animals, Welsh et al. suggested that IOR might occur for locations where another individual has just searched. Thus simply knowing that another individual has attended to a location, even when they have not reached or acted on it may be enough to induce social IOR. This is precisely the scenario we had in the non-visible condition of Experiment 1; social IOR was observed when the co-actor pointed, and therefore attended to a location, without actually reaching or acting upon it. However, it should be noted that Welsh et al. (2014) recently argued that receiving auditory information alone about where the partner was going to respond (without seeing the person reaching) was not sufficient to activate the inhibitory mechanisms giving rise to IOR. Thus, the authors concluded that ‘some visuospatial information about the co-actor’s action is necessary to activate the processes leading to sIOR’ (Welsh et al., 2014, p. 157). Still, other published studies suggest that the observation of the partner’s reaching is not necessary to produce social IOR (Atkinson et al., 2014; Doneva & Cole, 2014). Thus, in our view, attention to a location could be considered as the critical component of the Welsh et al.’s account rather than the action component.
The present findings also raise the possibility that previous work has underestimated the role that attentional orienting plays in joint action phenomena. This issue has thus far received little consideration. Indeed, it is common for action observation and joint action studies to make no reference to attentional orienting, or ‘attention’ at all (e.g., Atmaca, Sebanz, & Knoblich, 2008; Braun, Ortega, & Wolpert, 2011; Paulus & Moore, 2011; Vesper, van der Wel, Knoblich, & Sebanz, 2011), including articles that review the field (e.g., Galantucci & Sebanz, 2009). One exception was reported by Dolk, Hommel, Prinz and Liepelt (2013). They showed that the joint Simon effect can occur even in the absence of a partner as long as a sufficiently salient event shifts attention to where the partner would normally sit. Although this shift was believed to initiate a different process to the one proposed for the present paradigm, i.e., a spatial coding of event features as opposed to IOR, attentional orienting is central to Dolk et al.’s explanation. Indeed, Dolk, Hommel, Colzato, Schütz-Bosbach, Prinz and Liepelt (2014) have gone on to suggest that ‘neither the integration of another person nor the integration of another person’s action into one’s own action, task, or body representation is necessary for the [Joint Simon Effect] to occur’ (p. 5). This is however, not to say that models advocating shared action representations exclude attentional processes initiated by an action performed by another individual. Nor do attentional models rule out the possibility that attentional attraction leads to co-representation. For instance, attention, along with perception and intention, is very much part of the TEC (Hommel et al., 2001b). The issue however is whether action representation is required at all for some joint action effects. It does appear that it is not necessary for two such effects to occur, i.e., the joint Simon effect, and social IOR.
Furthermore, we are not suggesting that attention plays a role in, and/or explains all action observation effects. A number of studies have shown such effects when attentional orienting has been controlled. For instance, Liepelt et al. (2008) presented photographs of a hand that had a target number placed over the image. Observers were required to discriminate the target and make a response by lifting either their index or middle finger. The important manipulation was that the hand in the photograph had either its index or middle finger raised. Results showed that when the target required the middle finger to be raised responses were faster if the depicted hand also had the middle finger raised. The same facilitation effect occurred for the index finger. Importantly, the authors undertook a control experiment showing that the effect was significantly reduced when the agent’s fingers were moved via small pulleys and wires (in order to examine intention to act). This eliminates attention as an explanation because the visual transients in both ‘active’ and ‘passive’ conditions were virtually identical.
In sum, we have found that a common joint action effect purported to be due to the representation of an observed action can be induced when no actions are seen. We have also found that its time course is too short to be due to action representation mechanisms. We argue that as long as attention is shifted to the relevant location the effect will occur. This in turn suggests that the effect is due to lOR, being induced via attentional cues, rather than being due to action representation. Finally, given that the effect is likely to be due to relatively ‘lower’ mechanisms, we suggest that, in line with Dolk et al. (2013) and their reference to the ‘joint Simon effect’, the term ‘social IOR’ should be replaced with ‘joint IOR’, or even ‘between-person IOR’ as Welsh et al. (2005) originally stated.
Notes
Debate surrounds the degree to which IOR is due to inhibition of attention as opposed to motor processes. However, most authors agree that an initial shift of attention occurs in order to induce IOR.
There is clearly an inherent difficulty in manipulating and operationalising (i.e., acting out) what is essentially a personality variable. We therefore based this aspect of our procedure on Hommel et al. (2009) who partly manipulated positive/negative interaction via a number of set phrases.
References
Andersen, S. M., & Chen, S. (2002). The relational self: An interpersonal social-cognitive theory. Psychological Review, 109, 619–645.
Aron, A., Aron, E. N., Tudor, M., & Nelson, G. (1991). Close relationships as including other in the self. Journal of Personality and Social Psychology, 60, 241–253.
Atkinson, M. A., Simpson, A., Skarratt, P. A., & Cole, G. G. (2014). Is social inhibition of return due to action co-representation? Acta Psychologica, 150(14), 85–93.
Atmaca, S., Sebanz, N., Prinz, W., & Knoblich, G. (2008). Action co-representation: The joint SNARC effect. Social Neuroscience, 3, 410–420.
Böckler, A., Knoblich, G., & Sebanz, N. (2012). Effects of a coactor’s focus of attention on task performance. Journal of Experimental Psychology: Human Perception and Performance, 38(6), 1404–1415.
Brass, M., Bekkering, H., & Prinz, W. (2001). Movement observation affects movement execution in a simple response task. Acta Psychologica, 106(1–2), 3–22.
Braun, D. A., Ortega, P. A., & Wolpert, D. M. (2011). Motor coordination: When two have to act as one. Experimental Brain Research, 211, 631–641.
Cole, G. G., & Kuhn, G. (2009). Appearance matters: Attentional orienting by new objects in the precuing paradigm. Visual Cognition, 17, 755–776.
Cole, G. G., & Kuhn, G. (2010). What the experimenter’s prime tells the observer’s brain. Attention, Perception, & Psychophysics, 72, 1367–1376.
Cole, G., Skarratt, P., & Billing, R. (2012). Do action goals mediate social inhibition of return? Psychological Research, 76(6), 736–746.
Cole, G.G., Smith, D.T. & Atkinson, M.A. (2015). Mental state attribution and the gaze cueing effect. Attention, Perception, & Psychophysics, 77(4), 1105–1115.
Dolk, T., Hommel, B., Colzato, L. S., Schütz-Bosbach, S., Prinz, W., & Liepelt, R. (2014). The joint Simon effect: A review and theoretical integration. Frontiers in Psychology, 5, 974.
Dolk, T., Hommel, B., Prinz, W., & Liepelt, R. (2013). The (not so) social Simon effect: A referential coding account. Journal of Experimental Psychology: Human Perception and Performance, 39(5), 1248–1260.
Doneva, S. P., & Cole, G. G. (2014). The role of attention in a joint-action effect. PLoS One, 9(3), e91336.
Eskritt, M., Donald, M., & Muir, D. (1998). Delayed imitation of complex behavioural sequences by 14- to 16-month olds. Early Development and Parenting, 7(4), 171–180.
Frischen, A., Loach, D., & Tipper, S. (2009). Seeing the world through another person’s eyes: Simulating selective attention via action observation. Cognition, 111(2), 212–218.
Galantucci, B., & Sebanz, N. (2009). Joint action: Current perspectives. Topics in Cognitive Science, 1, 255–259.
Gangitano, M., Mottaghy, F. M., & Pascual-Leone, A. (2004). Modulation of premotor mirror neuron activity during observation of unpredictable grasping movements. European Journal of Neuroscience, 20, 2193–2202.
Gazzola, V. V., Rizzolatti, G. G., Wicker, B. B., & Keysers, C. C. (2007). The anthropomorphic brain: The mirror neuron system responds to human and robotic actions. Neuroimage, 35(4), 1674–1684.
Hayes, S. J., Hansen, S., & Elliott, D. (2010). Between-person effects on attention and action: Joe and Fred revisited. Psychological Research, 74(3), 302–312.
Heider, F. (1958). The psychology of interpersonal relations. New York: Wiley.
Hommel, B. (1996). S-R compatibility effects without response uncertainty. The Quarterly Journal Of Experimental Psychology: Section A, 49(3), 546–571.
Hommel, B., Colzato, L. S., & van den Wildenberg, W. P. M. (2009). How social are task representations? Psychological Science, 20, 794–798.
Hommel, B., Musseler, J., Ascherschleben, G., & Prinz, W. (2001a). The theory of event coding (TEC): A framework for perception and action planning. Behavioral and Brain Sciences, 24, 849–937.
Hommel, B., Pratt, J., Colzato, L., & Godjin, R. (2001b). Symbolic control of visual attention. Psychological Science, 12, 360–365.
Kilner, J., Paulignan, Y., & Blakemore, S. (2003). An interference effect of observed biological movement on action. Current Biology, 13(6), 522–525.
Klein, R. M., & MacInnes, J. (1999). Inhibition of return is a foraging facilitator in visual search. Psychological Science, 10, 346–352.
Krüger, B., Bischoff, M., Blecker, C., Langhanns, C., Kindermann, S., Sauerbier, I., & Pilgramm, S. (2014). Parietal and premotor cortices: Activation reflects imitation accuracy during observation, delayed imitation and concurrent imitation. Neuroimage, 100, 39–50.
Kuhbandner, C., Pekrun, R., & Maier, M. A. (2010). The role of positive and negative affect in the ‘mirroring’ of other persons’ actions. Cognition and Emotion, 24(7), 1182–1190.
Lestou, V., Pollick, F., & Kourtzi, Z. (2008). Neural substrates for action understanding at different description levels in the human brain. Journal of Cognitive Neuroscience, 20(2), 324–341.
Liepelt, R., Cramon, D., & Brass, M. (2008). What is matched in direct matching? Intention attribution modulates motor priming. Journal of Experimental Psychology: Human Perception and Performance, 34(3), 578–591.
Meltzoff, A. N., & Moore, M. K. (1994). Imitation, memory, and the representation of persons. Infant Behavior & Development, 17, 83–99.
Obhi, S., & Sebanz, N. (2011). Moving together: Toward understanding the mechanisms of joint action. Experimental Brain Research, 211(3–4), 329–336.
Ondobaka, S., de Lange, F. P., Newman-Norlund, R. D., Wiemers, M., & Bekkering, H. (2012). Interplay between action and movement intentions during social interaction. Psychological Science, 23(1), 30–35.
Ondobaka, S., Newman-Norlund, R. D., de Lange, F. P., & Bekkering, H. (2013). Action recognition depends on observer’s level of action control and social personality traits. PLoS One, 8(11), e81392.
Paukner, A., Ferrari, P., & Suomi, S. (2011). Delayed imitation of lipsmacking gestures by infant rhesus macaques (Macaca mulatta). PLoS One, 6(12), e28848.
Paulus, M., & Moore, C. (2011). Whom to ask for help? Children’s developing understanding of other people’s action capabilities. Experimental Brain Research, 211, 593–600.
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. Bouwhuis (Eds.), Attention and performance (Vol. X, pp. 531–554). London: Lawrence Erlbaum.
Rafal, R. D., Calabresi, P. A., Brennan, C. W., & Sciolto, T. K. (1989). Saccade preparation inhibits reorienting to recently attended locations. Journal of Experimental Psychology: Human Perception and Performance, 15(4), 673–685.
Reid, C., Wong, L., Pratt, J., Morgan, C., & Welsh, T. N. (2013). IOR effects in a social free-choice task. Journal of Motor Behavior, 45(4), 307–311.
Rizzolatti, G., & Craighero, L. (2004). The mirror neuron system. Annual Review of Neuroscience, 27, 169–192.
Rogers, S. J., Young, G. S., Cook, I., Giolzetti, A., & Ozonoff, S. (2008). Deferred and immediate imitation in regressive and early onset autism. Journal of Child Psychology and Psychiatry, 9, 449–457.
Sebanz, N., Bekkering, H., & Knoblich, G. (2006). Joint action: Bodies and minds moving together. Trends in Cognitive Sciences, 10(2), 70–76.
Sebanz, N., & Knoblich, G. (2009). Prediction in joint action: What, when, and where. Topics in Cognitive Science, 1(2), 353–367.
Sebanz, N., Knoblich, G., & Prinz, W. (2003). Representing others’ actions: Just like one’s own? Cognition, 88, B11–B21.
Simon, J. R., & Rudell, A. P. (1967). Auditory S-R compatibility: The effect of an irrelevant cue on information processing. Journal of Applied Psychology, 51, 300–304.
Skarratt, P. A., Cole, G. G., & Kingstone, A. (2010). Social inhibition of return. Acta Psychologica, 134(1), 48–54.
Skarratt, P. A., Cole, G. G., & Kuhn, G. (2012). Visual cognition during real social interaction. Frontiers in Human Neuroscience, 6, 1–9.
Taylor, T. L., & Klein, R. M. (2000). Visual and motor effects in inhibition of return. Journal of Experimental Psychology: Human Perception and Performance, 26, 1639–1656.
Tversky, B., & Hard, B. M. (2009). Embodied and disembodied cognition: Spatial perspective-taking. Cognition, 110, 124–129.
Vesper, C., van der Wel, R. P. R. D., Sebanz, N., & Knoblich, G. (2011). Making oneself predictable: Reduced temporal variability facilitates joint action coordination. Experimental Brain Research, 211, 517–530.
Weger, U., Abrams, R., Law, M., & Pratt, J. (2008). Attending to objects: Endogenous cues can produce inhibition of return. Visual Cognition, 16(5), 659–674.
Welsh, T. N., Elliot, D., Anson, J. G., Dhillon, V., Weeks, D. J., Lyons, J. L., & Chua, R. (2005). Does Joe influence Freds actions? Inhibition of return across different nervous systems. Neuroscience Letters, 385, 99–104.
Welsh, T. N., Lyons, J., Weeks, D. J., Anson, J. G., Chua, R., Mendoza, J., & Elliott, D. (2007). Within- and between-person inhibition of return: Observation is as good as performance. Psychonomic Bulletin & Review, 14, 950–956.
Welsh, T. N., Manzone, J., & McDougall, L. (2014). Knowledge of response location alone is not sufficient to generate social inhibition of return. Acta Psychologica, 153(1), 153–159.
Welsh, T. N., McDougall, L. M., & Weeks, D. J. (2009a). The performance and observation of action shape future behaviour. Brain and Cognition, 71, 64–71.
Welsh, T. N., Ray, M. C., Weeks, D. J., Dewey, D., & Elliott, D. (2009b). Does Joe influence Fred’s action? Not if Fred has autism spectrum disorder. Brain Research, 1248, 141–148.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Doneva, S.P., Atkinson, M.A., Skarratt, P.A. et al. Action or attention in social inhibition of return?. Psychological Research 81, 43–54 (2017). https://doi.org/10.1007/s00426-015-0738-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00426-015-0738-x