
Abstract
Age-at-death estimation methods are important in forensic anthropology. However, age assessment is problematic due to inter-individual variation. The subjectivity of visual scoring systems can affect the accuracy and reliability of methods as well. One of the most studied skeletal regions for age assessment is the pubic symphysis. Few studies on Spanish pubic symphysis collections have been conducted, making further research necessary as well as the sampling of more forensic skeletal collections. This study is a preliminary development of an age-at-death estimation method from the pubic symphysis based on a new simple scoring system. A documented late twentieth century skeletal collection (N = 29) and a twenty-first century forensic collection (N = 76) are used. Sixteen traits are evaluated, and a new trait (microgrooves) is described and evaluated for the first time in this study. All traits are scored in a binary manner (present or absent), thus reducing ambiguity and subjectivity. Several data sets are constructed based on different age intervals. Machine learning methods are employed to evaluate the scoring system’s performance. The results show that microgrooves, macroporosity, beveling, lower extremity, ventral and dorsal margin decomposition, and lipping are the best preforming traits. The new microgroove trait proves to be a good age predictor. Reliable classification results are obtained for three age intervals (≤ 29, 30–69, ≥ 70). Older individuals are reliably classified with two age intervals (< 80, ≥ 80). The combination of binary attributes and machine learning algorithms is a promising tool for gaining objectivity in age-at-death assessment.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Age-at-death estimations from skeletal remains are crucial in forensic anthropology. However, age assessment from skeletal remains is problematic as a result of the disparities between biological age and chronological age due to inter-individual variation [1]. Several age estimation methods have been developed and are continuously evaluated to date on many skeletal collections from different populations. These methods depend on the observation of macroscopic morphological changes in skeletal remains which usually leads to a subjectivity problem that affects the accuracy and reliability of the method itself. Therefore, research on methods for age-at-death estimation from skeletal remains is still a developing science [2,3,4,5].
One of the most studied skeletal regions for age assessment is the pubic symphysis [3]. The articular surface change of this skeletal structure, due to maturation and later degenerative processes, is what makes the pubic symphysis an important target for age estimation [6,7,8]. However, most of the methods that are based on the pubic symphysis have been developed on North American collections, made up of African and European descendants. Due to the variability between distinct populations and the consequent age mimicry phenomenon [9,10,11], it is necessary to test these methods for an evaluation of their functionality before proceeding to use them on a population that is different from the one they were developed on.
Another restrictive factor is the limited amount of reference collections with human skeletons of recent origin. Most of them are from twentieth century cemeteries or from ancient cemeteries in which variation could exist not only between human populations but across centuries as well due to environmental changes over time. Therefore, methods developed from older collections may not be very useful when applied to current populations, i.e., forensic cases [12, 13]. Sampling of skeletal remains from different populations, resulting in new forensic collections, is necessary to understand the current diversity and, in this manner, adjust existing methods or create new ones that perform better.
A study on age-at-death estimations from the pubic symphysis and the auricular surface in a Spanish skeletal collection, where three established methods are compared (Suchey-Brooks, Lovejoy, and Buckberry and Chamberlain methods) [14], shows that it may be problematic when these are used on a Spanish population. It suggests that more statistical studies should be carried out before using existing age assessment methods in Spanish populations. However, there are no posterior studies on Spanish pubic symphysis collections, implying that there is still a lack of understanding about the corresponding diversity.
The present study, based on documented twentieth and twenty-first century skeletal collections, constitutes a preliminary development and evaluation of a new method for age-at-death estimation from the pubic symphysis that reduces the observer subjectivity by using a simpler binary scoring system. The objectives are (1) to describe new age-related traits and a new scoring criterion and (2) to evaluate machine learning models for age estimation based on the new method.
Materials and methods
Documented collections
The pubic symphyses of two Spanish documented skeletal collections are used for this study; a documented late twentieth century skeletal collection housed at the Universitat Autònoma de Barcelona (UAB) and a twenty-first century forensic collection from the Institut de Medicina Legal i Ciències Forenses de Catalunya (IMLCFC). The UAB skeletal collection was sampled in the late 1990s from a cemetery at the city of Granollers, Barcelona. It is constituted of people who died between the 1970s and 1990s [15]. The IMLCFC forensic collection is composed only by pubic symphyses collected from medicolegal autopsies between the years 2000 and 2019. Table 1 shows a description of the collections.
Symphyseal traits and scoring system
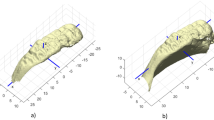
A total of 16 traits or attributes are studied and described (Table 2). Fifteen of these traits are extracted from the traditional methods of Todd [16, 17] and McKern and Stewart [18], and they are modified into binary traits obtaining a score of present or absent. More recent descriptions can be found in an open access laboratory manual of revised osteometric definitions from the University of Tennessee [19]. Furthermore, a new age-related trait named microgrooves is observed and described for the first time in this study (Fig. 1). This trait appears as very small grooves or indentations into the surface of the symphyseal face, forming a type of network that presents a reticular aspect. It differs from microporosity in that it maintains the continuity of the cortical bone; therefore, the spongy bone is not exposed. And it differs from crests in that these do not present a reticular aspect as the microgrooves do, but rather present much larger and well distinct ridges and furrows that extend from the dorsal to the ventral area of the symphyseal surface. Besides the size and reticular aspect, it also differs from crests in that microgrooves do not present elevated ridges. The microgrooves or microindentations can appear across the entire symphyseal face or can be present in segments. It is advisable to observe this feature carefully under a magnifying glass so that it is not missed or confused with microporosity.

The new microgrooves trait (MG). In the image on the right microgrooves are marked to indicate their location. The arrows represent points for visual orientation
A descriptive analysis of each trait is executed elucidating their distribution by age. Additionally, a McNemar test is performed for the interrater agreement assessment considering a significance level of 0.05 (5%). The JAMOVI 0.9.2.3 [20] statistical software is used for this test.
Statistics
For the following statistical experiments, the data set is divided into age intervals, resulting in five different age interval sets (Table 3). In addition, the Wrapper Subset Evaluator method is applied on each age interval set in order to select the best performing traits.
The Wrapper method employs a search algorithm to seek through all the possible trait combinations or subsets and test each one by executing a machine learning algorithm. In this manner, it develops and evaluates a classification model for each possible trait subset and then selects the best performing subset of traits. Since the Wrapper Evaluator selects the subset of traits that best performs for a specific machine learning algorithm, this same specific algorithm has to be used later to develop the classification model from the selected trait subset. In other words, each machine learning algorithm has its own best performing subset of traits for each data set. The Wrapper Subset Evaluator and all the machine learning algorithms in this study are implemented with the Waikato Environment for Knowledge Analysis software (Weka; version 3.8.3) [21]. A total of 5 data sets (each age interval set) are used for the training and evaluation of the machine learning models.
Three different supervised learning algorithms are applied on each one of the age interval sets (S1, S2, S3, S4, S5); these algorithms are the ZeroR classifier which establishes a baseline performance to which the other classification methods are compared, the Naïve Bayes classifier, and the Random Tree classifier [22]. Every model is tested with a 10-fold cross-validation. In addition, we run every algorithm ten times, with a different seed value for randomization on each run, to obtain the average precision and its standard deviation for each model.
Results
Table 4 shows the age distribution for every trait. CR is present at younger ages, and its frequency gradually decreases towards the middle ages. BEV is very confined between ages 20 and 40. PR is almost equally distributed across ages with higher frequencies between 20 and 60 years. UE and LE show a very high frequency across all ages. MG is primarily present at middle ages, increasing from younger and decreasing towards older individual. VW has a wide distribution across all age groups with a higher frequency between 35 and 55 years. VMD and DMD are mainly present in the upper half of the age range, and their frequency increases towards older ages. Specifically, DMD is more confined to older ages than VMD. LIP is generally very frequent, and it is present in almost all age groups except for the younger individual. There is also a slightly higher frequency for individuals older than 65 years. MIC is present in almost all ages, but it presents a much higher frequency for older individual, increasing rapidly from the middle ages towards the greater ages. On the other hand, MAC is slightly more distributed towards older ages. DR, VR, UR, and LR are widely distributed across ages, and in particular UR and LR have low frequencies in general.
The interrater agreement assessment results, for the scoring system, indicate that there is sufficient evidence to consider the existence of agreement between observers (McNemar’s test: all p values are superior to 0.05) (Table 5).
Table 6 shows how MIC, DR, and UR are not selected by the Wrapper Subset Evaluator for any age interval set. The biggest group selection (S2 Naïve Bayes classifier subset) contains 9 traits, and the smallest group selection (S2 Random Tree classifier subset) contains 4 traits.
Within all the resulting models, the S4 Random Tree model (\( \overline{x} \) = 82%; SD = 1.38) and the S5 Naïve Bayes model (\( \overline{x} \) = 91.90%; SD = 0.67) have the best results (Table 7). The average precision results are higher when the age intervals are broader.
On Table 8 the average precision result of each age category or class is presented for the best performing models. In general, the best classified age categories are the younger ones, and the worst classified categories are the oldest. The first age category (≤ 24) does not get any result under a 70%, and age categories from 40 to 65 years get results over an 80%, except for the S2 Naïve Bayes model that gets an average precision of 61.42% (SD = 2.84). Age categories over 60 and 70 years have average precision results under 70% obtaining in some cases a 0%, except for the S5 Naïve Bayes model that presents a result of 71.40% (SD = 0.00) for individuals with 80 years of age and older.
Figures 2 and 3 display the resulting decision trees from the best performing data subsets; these are the S4 Random Tree model (\( \overline{x} \) = 82.00%; SD = 1.38) and the S5 Random Tree model (\( \overline{x} \) = 90.29%; SD = 0.40), respectively.

Decision tree from the S4 Random Tree model. This tree employs seven traits: MG, MAC, BEV, LE, VMD, DMD, and LIP. 0 = absence, 1 = presence. In parentheses, the value on the left is the total number of instances classified in that leaf, and the number on the right represents the incorrectly classified instances in that leaf. Seed value for randomization = 2

Decision tree from the S5 Random Tree model. This tree employs three traits: MG, VR and DMD. 0 = absence, 1 = presence. In parentheses, the value on the left is the total number of instances classified in that leaf, and the number on the right represents the incorrectly classified instances in that leaf. Seed value for randomization = 2
Discussion
Research on age-at-death estimation from skeletal remains is a challenging task. Not only the disparities between chronological and biological age due to variability can contribute to the difficulty of this challenge, but the subjectivity of scoring systems is an important limiting factor as well [1, 23, 24]. In order to develop and evaluate a new method, we studied each trait separately, transforming their traditional scoring criteria into a less ambiguous binary categorization (present or absent).
The present work is based on fifteen traits previously described in traditional age assessment methodologies [16,17,18]. Additionally, we present an all new age-related trait (microgrooves; MG) never described before. It is noticeable how this new trait proves to be a useful indicator for age-at-death estimations in this study, since it is selected by the Wrapper Subset Evaluator for several data subsets including the best performing subsets. Nevertheless, further studies should be developed to test the MG trait on other collections. It is also important that these studies focus on the evaluation of the MG trait’s sensibility to bone preservation; that is whether the preservation of the pubic symphysis affects the visibility of this new trait.
Regarding the general attribute selection, the best performing age-related traits include MG, MAC, BEV, LE, VMD, DMD, and LIP. These binary traits present an acceptable classification capacity (from 70 to 82%) for wide age intervals (≤ 29, 30–69, ≥ 70). However, as the intervals get smaller (20-, 15-, and 10-year age intervals) the traits’ classification power decreases to unreliable precision results (less than 60%). The bad performance of short age intervals can be related to the traits’ natural broad age distribution. Only some traits are very confined to certain age ranges, such as crests for ages under 20 years and the margin decomposition for ages over 70 and 80 years. Another study on age-at-death estimation from pelvic bones (pubic symphysis and sacropelvic surface) obtained similar results [25]. Their method separated the symphyseal surface into three areas, and each area was scored into one of the 2 to 4 stage categories. They were only able to get good results when wide age intervals were considered, with the highest precision results being over 70%. When they used 10-year age intervals, unreliable classification results were obtained. Also, they got the highest class precision results for individuals younger than 29 years of age and elders older than 70 years of age, but with values that did not reach a 50%. Compared with their results, our models did get high reliable class precisions for individuals under 24 years old (from 70 to over 80%) and for individuals between 40 and 65 years of age (from 61 to over 80%).
Concerning the classification of older individuals, with two age intervals, we were able to obtain a model (S5 Naïve Bayes) that presented a high classification capacity of elderly individuals (over 70%) with an overall precision result of 91.9% (SD = 0.67), employing the MG, MAC, VMD, DMD, and LIP traits. This result is interesting taking into account that generally age-at-death estimation methods poorly classify older individuals [26, 27]. A specific classifier model for elders (older than 70 and 80 years) could be used in conjunction with another model that performs well for younger and middle age individuals as a multi-model approach. In other words, we can first identify if an individual is an elder with a specific model for older individuals such as the S5 Naïve Bayes model, and if it classifies the individual in the young category, then another model with reliable class precision results for young and middle age categories could be used for a more precise classification.
As to the limitations of our method, the small size of the skeletal collection and the scarce representation of some age intervals, such as the young individuals and elders, can have their own downside. However, despite the small sample size, the results of our study show that the combination of binary attributes and machine learning algorithms is a promising tool to gain objectivity in forensic anthropology age-at-death assessments. The resulting decision trees from the employment of machine learning methods are simple tools that can facilitate the age classification process and can be easily used in the field. This is an important point to consider since a method’s simplicity is a well valued factor when implementing age-at-death assessment methods.
It is also noteworthy that the reference collection used in this study is unique in the sense that it is constituted by a new Spanish twenty-first century pubic symphysis forensic collection. Its importance relies on the potential it has for the development of future studies. It is a continuously growing tool that will help investigators research new methodologies for age-at-death estimation such as 3D image analysis, computed tomography, or digital image processing [28,29,30,31,32]. It is necessary to stress that more contemporary forensic collections are needed to better understand the diversity of current populations. That is, a continuous sampling must be considered to maintain these collections updated just as populations are dynamic entities that are in continuous change due to the effect of globalization and human migration [33, 34]. In addition, social and lifestyle changes can have an effect through time as well.
This work demonstrates the potential of the proposed methodology to facilitate age-at-death assessments in forensic anthropology. The results of this study are preliminary and further, evaluation of the binary traits must continue in order to better elucidate their relation not only with age but with other factors such as sex or population origin. Future experiments should be designed in order to validate this preliminary method on different collections and on a larger sample size.
References
Kemkes-Grottenthaler A (2002) Aging through the ages: historical perspectives on age indicator methods. Paleodemography 48–72. https://doi.org/10.1017/CBO9780511542428.004
Nikita E, Nikitas P (2019) Skeletal age-at-death estimation: Bayesian versus regression methods. Forensic Sci Int 297:56–64. https://doi.org/10.1016/j.forsciint.2019.01.033
Savall F, Rérolle C, Hérin F et al (2016) Reliability of the Suchey-Brooks method for a French contemporary population. Forensic Sci Int 266:586.e1–586.e5. https://doi.org/10.1016/j.forsciint.2016.04.030
Kim J, Algee-Hewitt BFB, Stoyanova DK, Figueroa-Soto C, Slice DE (2019) Testing reliability of the computational age-at-death estimation methods between five observers using three-dimensional image data of the pubic symphysis. J Forensic Sci 64:507–518. https://doi.org/10.1111/1556-4029.13842
Kotěrová A, Navega D, Štepanovský M, Buk Z, Brůžek J, Cunha E (2018) Age estimation of adult human remains from hip bones using advanced methods. Forensic Sci Int 287:163–175. https://doi.org/10.1016/j.forsciint.2018.03.047
Dubourg O, Faruch-Bilfeld M, Telmon N, Maupoint E, Saint-Martin P, Savall F (2019) Correlation between pubic bone mineral density and age from a computed tomography sample. Forensic Sci Int 298:345–350. https://doi.org/10.1016/j.forsciint.2019.03.018
Kotěrová A, Velemínská J, Cunha E, Brůžek J (2019) A validation study of the Stoyanova et al. method (2017) for age-at-death estimation quantifying the 3D pubic symphyseal surface of adult males of European populations. Int J Legal Med 133:603–612. https://doi.org/10.1007/s00414-018-1934-1
Dudzik B, Langley NR (2015) Estimating age from the pubic symphysis: a new component-based system. Forensic Sci Int 257:98–105. https://doi.org/10.1016/j.forsciint.2015.07.047
Cunha E, Baccino E, Martrille L, Ramsthaler F, Prieto J, Schuliar Y, Lynnerup N, Cattaneo C (2009) The problem of aging human remains and living individuals: a review. Forensic Sci Int 193:1–13. https://doi.org/10.1016/j.forsciint.2009.09.008
Ross AH, Ubelaker DH, Kimmerle EH (2011) Implications of dimorphism, population variation, and secular change in estimating population affinity in the Iberian Peninsula. Forensic Sci Int 206:214.e1–214.e5. https://doi.org/10.1016/j.forsciint.2011.01.003
Katz D, Suchey JM (1989) Race differences in pubic symphyseal aging patterns in the male. Am J Phys Anthropol 80:167–172. https://doi.org/10.1002/ajpa.1330800204
Ferreira MT, Vicente R, Navega D et al (2014) A new forensic collection housed at the University of Coimbra, Portugal: the 21st century identified skeletal collection. Forensic Sci Int 245:202.e1–202.e5. https://doi.org/10.1016/j.forsciint.2014.09.021
Cattaneo C, Mazzarelli D, Cappella A et al (2018) A modern documented Italian identified skeletal collection of 2127 skeletons: the CAL Milano Cemetery Skeletal Collection. Forensic Sci Int 287:219.e1–219.e5. https://doi.org/10.1016/j.forsciint.2018.03.041
Rissech C, Wilson J, Winburn AP, Turbón D, Steadman D (2012) A comparison of three established age estimation methods on an adult Spanish sample. Int J Legal Med 126:145–155. https://doi.org/10.1007/s00414-011-0586-1
Rissech C, Steadman DW (2011) The demographic, socio-economic and temporal contextualisation of the Universitat Autònoma de Barcelona collection of identified human skeletons (UAB collection). Int J Osteoarchaeol 21:313–322. https://doi.org/10.1002/oa.1145
Todd TW (1920) Age changes in the pubic bone I. Am J Phys Anthropol 3:285–334. https://doi.org/10.1002/ajpa.1330030301
Todd TW (1921) Age changes in the pubic bone II-IV. Am J Phys Anthropol 4:1–70. https://doi.org/10.1002/ajpa.1330040102
Brooks ST (1958) Skeletal age changes in Young American Males: analysis from the standpoint of age identification. Thomas W. McKern, T. D. Stewart. Am Anthropol 60:982–982. https://doi.org/10.1525/aa.1958.60.5.02a00490
Langley NR, Meadows Jantz L, Ousley SD et al (2016) Data collection procedures for forensic skeletal material 2.0, 3rd edn. The University of Tennessee Department of Anthropology and Forensic Anthropology Center, Knoxville
The jamovi project (2020) jamovi (Version 1.2) [Computer Software]. Retrieved from https://www.jamovi.org
Frank E, Hall MA, Witten IH (2016) The WEKA workbench. Online Appendix for “Data mining: practical machine learning tools and techniques,” 4th Edn. Morgan Kaufmann, Burlington
Witten IH, Frank E, Hall MA, Pal CJ (2011) Data mining: practical machine learning tools and techniques, 4th edn. Elsevier, Amsterdam
Kimmerle EH, Prince DA, Berg GE (2008) Inter-observer variation in methodologies involving the pubic symphysis, sternal ribs, and teeth. J Forensic Sci 53:594–600. https://doi.org/10.1111/j.1556-4029.2008.00715.x
Shirley NR, Ramirez Montes PA (2015) Age estimation in forensic anthropology: quantification of observer error in phase versus component-based methods. J Forensic Sci 60:107–111. https://doi.org/10.1111/1556-4029.12617
Buk Z, Kordik P, Bruzek J et al (2012) The age at death assessment in a multi-ethnic sample of pelvic bones using nature-inspired data mining methods. Forensic Sci Int 220:294.e1–294.e9. https://doi.org/10.1016/j.forsciint.2012.02.019
Milner GR, Boldsen JL (2012) Transition analysis: a validation study with known-age modern American skeletons. Am J Phys Anthropol 148:98–110. https://doi.org/10.1002/ajpa.22047
Garvin HM, Passalacqua NV, Uhl NM, Gipson DR, Overbury RS, Cabo LL (2012) Developments in forensic anthropology: age-at-death estimation. In: A companion to forensic anthropology. John Wiley & Sons, Ltd, Chichester, pp 202–223
Bakthula R, Agarwal S (2014) Automated human bone age assessment using image processing methods - survey. Int J Comput Appl 104:33–42. https://doi.org/10.5120/18265-9259
Pietka E, Gertych A, Pospiech S, Fei Cao, Huang HK, Gilsanz V (2001) Computer-assisted bone age assessment: image preprocessing and epiphyseal/metaphyseal ROI extraction. IEEE Trans Med Imaging 20:715–729. https://doi.org/10.1109/42.938240
Pinchi V, Pradella F, Buti J, Baldinotti C, Focardi M, Norelli GA (2015) A new age estimation procedure based on the 3D CBCT study of the pulp cavity and hard tissues of the teeth for forensic purposes: a pilot study. J Forensic Legal Med 36:150–157. https://doi.org/10.1016/j.jflm.2015.09.015
Stoyanova DK, Algee-Hewitt BFB, Kim J, Slice DE (2017) A computational framework for age-at-death estimation from the skeleton: surface and outline analysis of 3D laser scans of the adult pubic Symphysis. J Forensic Sci 62:1434–1444. https://doi.org/10.1111/1556-4029.13439
Slice DE, Algee-Hewitt BFB (2015) Modeling bone surface morphology: a fully quantitative method for age-at-death estimation using the pubic symphysis. J Forensic Sci 60:835–843. https://doi.org/10.1111/1556-4029.12778
Pinchi V, Focardi M, Pradella F et al (2017) Day to day issues in the forensic identification practice related to illegal immigration in Italy. J Forensic Odontostomatol 35:157–165
Olivieri L, Mazzarelli D, Bertoglio B, de Angelis D, Previderè C, Grignani P, Cappella A, Presciuttini S, Bertuglia C, di Simone P, Polizzi N, Iadicicco A, Piscitelli V, Cattaneo C (2018) Challenges in the identification of dead migrants in the Mediterranean: the case study of the Lampedusa shipwreck of October 3rd 2013. Forensic Sci Int 285:121–128. https://doi.org/10.1016/j.forsciint.2018.01.029
Acknowledgments
Special thanks to the Master of Biological Anthropology of Autonomous University of Barcelona (UAB) and Research Group in Biological Anthropology (GREAB, AGAUR 2017SGR1630).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
All autopsy samples are stored in private collection at the IMLCFC, registered as a collection at the Instituto de Salud Carlos III (Reference C.0004241) in compliance with the ethical regulations.
Informed consent
Informed consent was not required for this study.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Castillo, A., Galtés, I., Crespo, S. et al. Technical note: preliminary insight into a new method for age-at-death estimation from the pubic symphysis. Int J Legal Med 135, 929–937 (2021). https://doi.org/10.1007/s00414-020-02434-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00414-020-02434-6